
Abstract
Repeated exposure to information increases receptivity to it, even when prior knowledge is present, according to the illusory truth effect. Fazio et al. provided empirical support for this phenomenon and proposed a model that posited dominance of fluency cues, relative to knowledge utilization. This model better elucidated participants’ behaviors than an alternative model assuming precedence of knowledge processes over fluency-related mechanisms. The present research builds on this by refining models and testing them with new and existing data. While reanalysis of existing data revealed comparable performance of both models, new data from two experiments (N = 324), introducing conditions conducive to discerning between the two models, uncovered compelling evidence in support of the model that assumes knowledge processes’ precedence. The discrepancy between Fazio et al. and our findings is discussed, and we encourage future research to explore avenues for resolving the relative roles of knowledge and fluency.
Introduction
The illusory truth effect (ITE) denotes a psychological phenomenon characterized by the enhanced acceptance of information following its repeated presentation—a phenomenon that is robust across various experimental conditions and manipulations (see Dechêne et al., 2010 for a review). In studies investigating the ITE, participants are typically subjected to a dual-phase procedure: an initial exposure phase, in which they encounter a subset of true and false statements and are prompted to engage with them, often by rating how interesting each item is. Subsequently, in the test phase, participants are presented with the complete set of stimuli, comprising both previously encountered (i.e., “old”) statements from the exposure phase and entirely new statements. Participants are then tasked with discerning the veracity of each statement. Consistently documented in ITE research, statements encountered in the exposure phase tend to be more frequently classified as true during the test phase, irrespective of their factual accuracy, thus illustrating the pervasiveness of the ITE.
Despite ongoing debate regarding the precise underlying mechanism of the ITE, there exists a broad consensus attributing its occurrence primarily to processes of fluency (Reber & Schwarz, 1999; Unkelbach, 2007). Specifically, this perspective posits that the perceived ease of processing statements previously encountered is positively correlated with their perceived accuracy. An entrenched assumption within the literature claimed that the ITE manifests exclusively in contexts characterized by ambiguity regarding the veracity of presented information, with participants purportedly relying on their own knowledge when such ambiguity is absent (Dechêne et al., 2010). However, empirical validation of this assumption was notably absent until recent inquiries. In a seminal investigation, Fazio et al. (2015) tested this assumption through two distinct methodological approaches. The first method included introducing known items to the conventional ITE paradigm. Specifically, half of the items, both in the exposure phase as well as in the test phase, were items that were known to participants. 1 Surprisingly, Fazio et al. observed a consistent ITE pattern across both unknown and known items. Second, Fazio et al. employed multinomial processing tree (MPT) models to scrutinize the ambiguity assumption more rigorously.
MPT models represent a class of analytical frameworks occasionally employed within various psychological contexts to elucidate the underlying cognitive mechanisms governing diverse psychological phenomena (Klauer, 2024). In the context of the ITE, Fazio et al. used MPT models to assess the assumption that individuals would primarily resort to processes of knowledge retrieval in the presence of unequivocal information regarding the truth value of presented information. This involved contrasting a model in which a cognitive process of knowledge retrieval is subsequently influenced by fluency processes (termed the knowledge-conditional model) against an alternative model asserting the precedence of fluency processes over knowledge retrieval processes (termed the fluency-conditional model). 2 Comparative analysis of these models yielded the finding that the fluency-conditional model exhibited superior fit to the empirical data. Consequently, the MPT modeling approach adopted by Fazio et al. supported the contention that knowledge does not serve as a protective factor against the ITE and underscored the pivotal role of fluency processes in shaping judgments, even in the presence of accessible knowledge regarding the veracity of information.
The seminal findings of Fazio et al. (2015) have been subjected to conceptual replication across diverse experimental settings. This replication was evidenced in subsequent studies conducted with distinct participant populations, as exemplified by the work of Fazio and Sherry (2020) in children. Furthermore, methodological variations, such as the timing of knowledge assessment relative to the experimental manipulation, as demonstrated by Fazio (2020), have been employed to probe the robustness of the observed effects. Additionally, investigations using alternative paradigms to assess pre-existing knowledge, exemplified by Fazio et al. (2019), have contributed to the replication endeavor. Notably, Fazio et al. (2019) implemented a paradigm involving the presentation of highly trivial information, universally presumed to be known based on common knowledge, and still observed a repetition effect under these conditions. This collective body of research underscores the surprisingly pervasive influence of repetition on truth judgments across varying levels of plausibility, thereby affirming the overarching conclusion that the ITE extends its impact indiscriminately across the spectrum of information plausibility.
Despite advancements in empirical research, commensurate progress has not been made in the area of theoretical modeling pertaining to the role of knowledge in the ITE. The principal objective of the present research was to reassess the issue of information ambiguity by contrasting two distinct theoretical frameworks: a knowledge-conditional model versus a fluency-conditional model. To accomplish this objective, we initiated our inquiry by proposing several refinements to the original models proposed by Fazio et al. (2015) and subsequently subjected these modified models to rigorous evaluation across multiple available data sets. Subsequently, given that both process models demonstrated comparable explanatory efficacy with respect to existing empirical data, we proceeded to embark on the collection of new empirical data aimed at furnishing conditions conducive to adjudicating between these competing models.
Modeling Approach
We constructed MPT models delineated through branching tree diagrams, wherein parameters are designated to encapsulate latent cognitive processes. Specifically, we devised two distinct models: one corresponding to Fazio et al.’s (2015) fluency-conditional model and another corresponding to Fazio et al.’s knowledge-conditional model. Within each model, individual parameters were assigned to denote the likelihood that a given cognitive process contributes to the manifestation of observed behavioral outcomes, with values constrained within the interval of 0 to 1 to reflect probabilities.
In the framework proposed by Fazio et al. (2015), the knowledge-conditional model posits a cognitive process whereby individuals, when tasked with assessing the veracity of a statement, engage in a retrieval process from memory to ascertain pertinent evidence (illustrated in Figure 1). Should this retrieval process yield success (probability = K), all subsequent cognitive operations become inconsequential, leading to a correct response. Conversely, if the retrieval endeavor fails (probability = 1–K) due to lack of relevant knowledge, individuals resort to fluency-based mechanisms to inform their judgment. In the event that fluency serves as a determinant factor (probability = F), individuals endorse statements as “true”; however, in the absence of a fluency cue (probability = 1–F), individuals resort to guessing, wherein the likelihood of responding “true” is represented by the parameter G, while the likelihood of responding “false” is represented by (1–G). To maintain statistical parsimony, Fazio et al. imposed constraints on the model’s parameters. Specifically, the knowledge parameter (K) was permitted to vary between known and unknown statements, but neither as a function of truth status (true vs. false) nor as a function of repetition (new vs. repeated). Similarly, the fluency parameter (F) was allowed to vary between new and reiterated statements while being held constant across known and unknown statements as well as between truths and falsehoods. Finally, the guessing parameter (G) remained invariant across all experimental conditions.
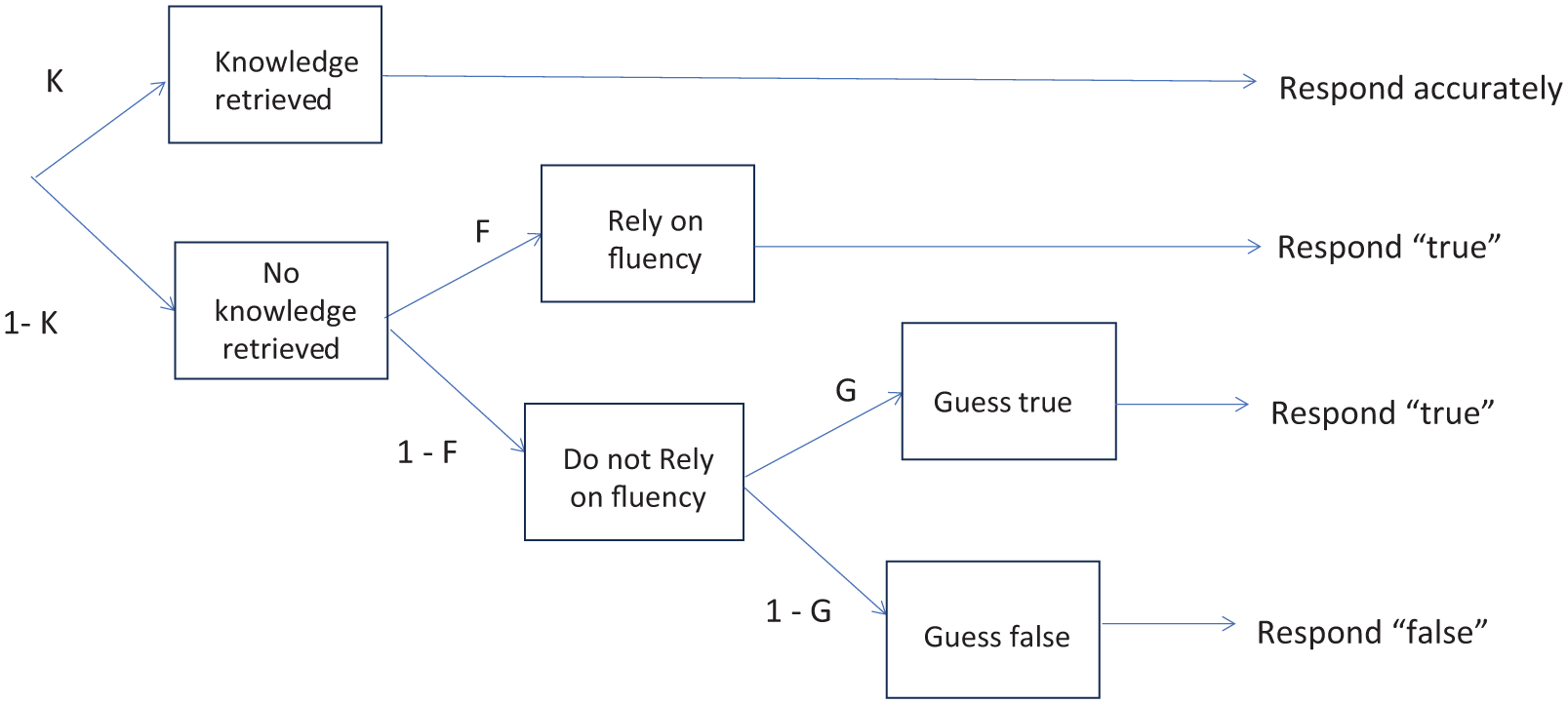
The knowledge-conditional model per Fazio et al. (2015).
In the present research, we propose a new variant of the knowledge-conditional model (illustrated in Figure 2) for two main reasons. First, we found that Fazio et al.’s knowledge-conditional model was unidentified—that is, it contains more parameters than can be uniquely estimated from the available data (for a general discussion of model identifiability, see Bamber & van Santen, 1985). In practical terms, unidentifiability means that different combinations of parameter values can yield identical model predictions, making it impossible to determine unique estimates from the data alone. For example, if a model includes two parameters, a and b, that only appear as a product (a × b) in the model equations, then many pairs of values (e.g., 2 × 6 = 12, 3 × 4 = 12) would fit the data equally well. Because such cases prevent unique estimation of the parameters, the model is considered unidentified.
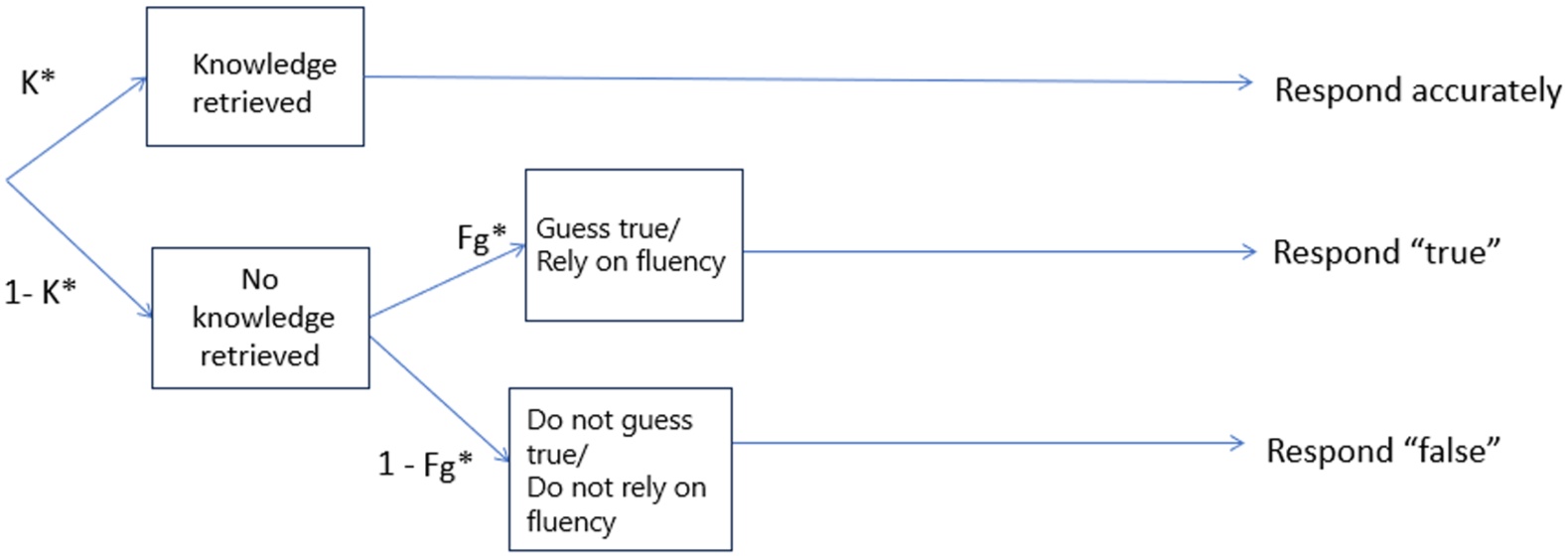
A modified knowledge-conditional model of illusory truth.
Second, we were not convinced that the decision to use the same knowledge parameter for truths and falsehoods is justified. Thus, our knowledge-conditional model variant is different than Fazio et al.’s in two main ways; First, due to the redundant structure of the original knowledge model, where both F/1-F and G/1-G paths lead to the same pattern of responding, and neither parameter F nor G are identified, we removed the paths related to fluency effects and stuck only with a combined fluency-guessing parameter, Fg, which captures the effects of baseline fluency for new and repeated statements and guessing. However, we did incorporate a fluency effect of repetition (Fxr) that was only present for repeated statements, modeling the boost in fluency due to repetition. Specifically, parameter Fg is used for new statements, but the term Fg + (1–Fg) × Fxr is used as a fluency-guessing parameter for repeated statements. In line with Fazio et al. (2015), the combined parameter Fg for baseline fluency and guessing is constant across all conditions. Note that the resulting model is a mathematically identified model that accounts for the same range of data as Fazio et al.’s (2015) original knowledge-conditional model with the theoretically motivated order constraint that the fluency parameter for new statements in Fazio et al.’s model is equal to or smaller than their fluency parameter for repeated statements. In the modified model, this increase in fluency due to repetition is captured by parameter Fxr.
Second, unlike Fazio et al., we separated between knowledge for true and false statements. We reasoned that retrieving the relevant verifying knowledge for true statements should be easier than retrieving the relevant falsifying knowledge for determining falsehoods. Our reasoning is based on the encoding specificity principle (Tulving & Thomson, 1973), according to which the effectiveness of a retrieval cue is contingent upon the degree of overlap it shares with the memory trace. Applied within the framework of distinguishing between truths and falsehoods, the retrieval cue for relevant verifying or falsifying knowledge content in memory is the true or false statement, respectively, presented to participants. The memory trace encoding the relevant knowledge should exhibit a greater degree of overlap when the retrieval cue is the true statement consistent with and supported by the relevant verifying knowledge in memory than when the retrieval cue is the false statement which is not consistent with the relevant falsifying knowledge in memory, thus rendering the retrieval process comparatively more efficient for true than for false statement. For example, the knowledge relevant for assessing the truth of the true statement, “Animals in the desert are often nocturnal, which means they sleep during the day,” is represented in memory by a memory trace that encodes as propositional content an ascription of day sleeping to desert animals. Obviously, there is much overlap between the semantic representation that is formed of the true statement in reading and comprehending it and the propositional content of the relevant memory trace. In contrast, there is less overlap between the false statement, “Animals in the desert are often nocturnal, which means they sleep during the night” and the relevant memory trace that ascribes day rather than night sleeping to desert animals.
Moreover, in the case of falsehoods, even if the relevant memory trace is retrieved, making available the correct proposition (e.g., nocturnal animals sleep during the day), an additional processing step is implied in which participants have to reason that this knowledge mismatches and is in fact inconsistent with the presented false statement (e.g., nocturnal animals sleep during the night)—a processing step that is arguably more difficult and error-prone than determining a match between the true statement and the retrieved relevant memory trace.
For these reasons, we propose a modified knowledge-conditional model in which we permit the knowledge parameter K to be smaller for false than for true statements. We did this by introducing a parameter Pf that signifies the decrease in relying on knowledge with false statements relative to true statements. Specifically, parameter K is used as the knowledge parameter for true statements as before, but the product K * Pf is used as the knowledge parameter for false statements. Note that K * Pf is equal to or smaller than K for true statements, because Pf is smaller or at best equal to one.
In contrast to the knowledge-conditional models, Fazio’s fluency-conditional model delineates a distinct configuration of conditional probabilities premised on the notion that fluency can override the retrieval of knowledge, as depicted in Figure 3. Within this framework, the participant initiates a memory search that can determine the true/false response solely in instances where fluency is absent (probability = 1–F). Under such circumstances, a successful retrieval process results in an accurate response (probability = K) or, in the event of failed retrieval (probability = 1-K), resorts to guessing whereby the likelihood of endorsing “true” is represented by the parameter G, while the likelihood of endorsing “false” is denoted by (1–G). Conversely, when participants experience fluent processing and do not discount the influence of fluency, a predisposition toward responding “true” is manifested (probability = F). It is noteworthy that this model adheres to the same constraints on parameters as those applied in the original knowledge-conditional model.
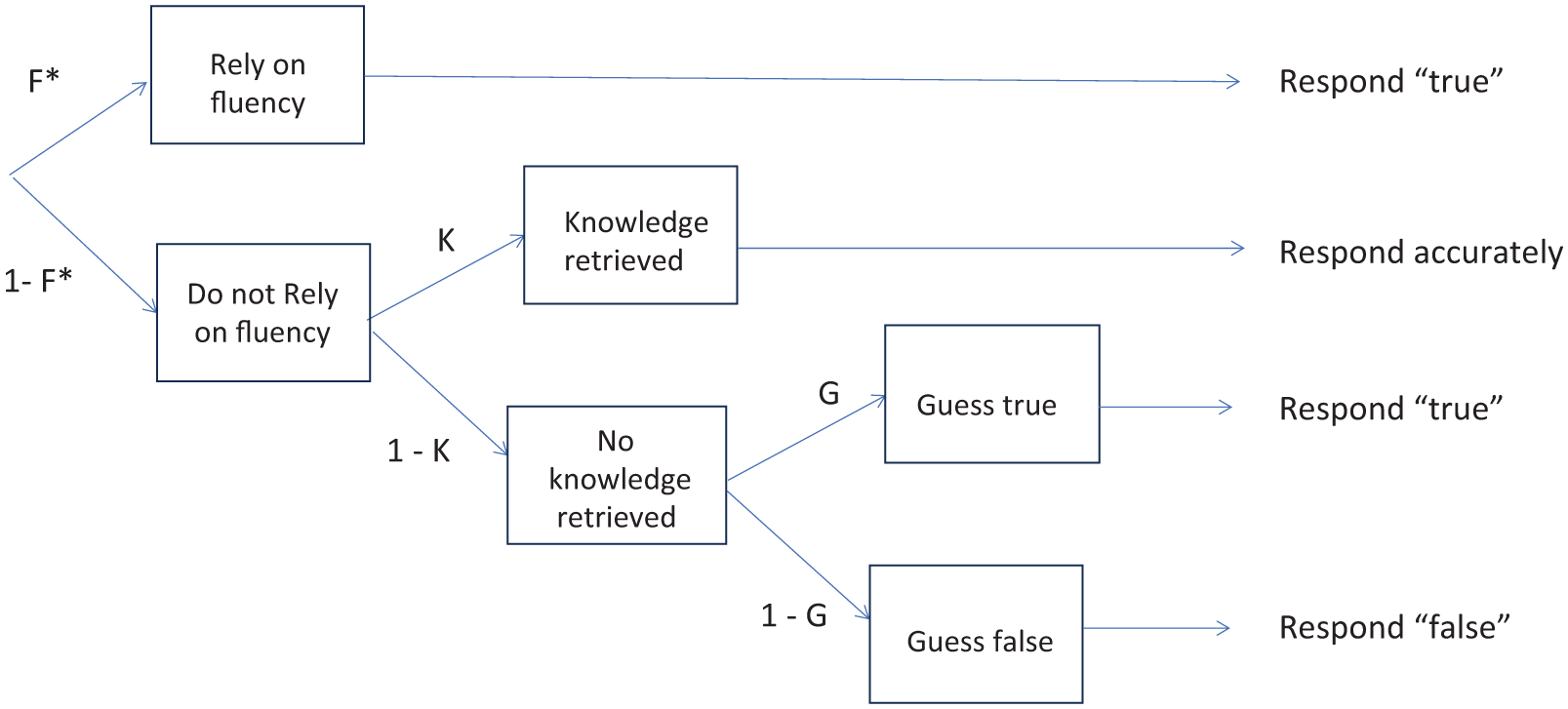
Fluency-conditional model of illusory truth.
In addition to evaluating the fluency-conditional model proposed by Fazio et al. (2015), we investigated an alternative of this model. This model integrated a baseline fluency parameter applicable to both new and repeated statements (F), alongside a fluency boost (Fxr) specific to repeated trials. Other than that, the model is the same as Fazio et al., original fluency-conditional model, the only difference being that the modified model constraints the fluency for repeated statements to be no less than the fluency for new statements. 3
Data sets
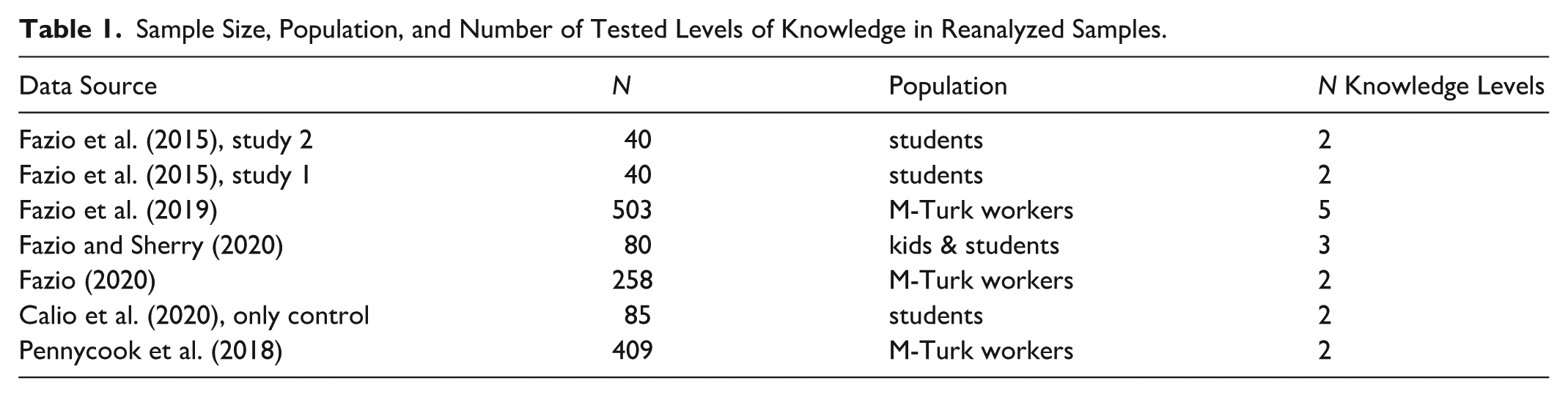
We searched for available data sets that include the conventional ITE paradigm but with a separation between known and unknown statements. We identified the following studies from the following papers: Experiments 1 and 2 from Fazio et al. (2015) 4 ; Experiment 1 in Fazio et al. (2019); Fazio and Sherry (2020); Fazio (2020) 5 ; Calio et al. (2020) [only data from the control condition]; and Pennycook et al. (2018), Study 1. 6 Fazio et al. (2019) used five levels of knowledge, Fazio and Sherry (2020) used three levels of knowledge, and all other studies used two levels. Thus, across all data sets, we separated each of m levels of knowledge (e.g., m = 2 for Fazio et al., 2015, m = 5 for Fazio et al., 2019) and ordered them such that 1 is the highest and m the lowest. Table 1 provides further information on these data sets.
Sample Size, Population, and Number of Tested Levels of Knowledge in Reanalyzed Samples.
Model Testing
We tested the fit of our MPT models using the MPTinR package (Singmann & Kellen, 2013), on frequencies aggregated across persons as traditionally used in the literature on the ITE, which minimizes a G2 statistic (see Appendix for equations); lower G2 values indicate better model fit. The null hypothesis states that the model fits, so significant p values indicate poor fit. In addition, we tested Hierarchical Bayesian MPT models (Klauer, 2010) on the (non-aggregated) judgments (true/false) of the statements under the different conditions. We present the results of the analyses based on the non-aggregated data in the Supplementary Online Material (SOM). Note that the results of these analyses were not qualitatively different from the results based on the aggregated frequencies.
We tested the original models as proposed by Fazio et al. (2015), as well as our variations on the fluency-conditional and the knowledge-conditional models. Table 2 shows the fit statistics for each of the original Fazio et al. models (columns) per data set (rows), whereas Table 3 shows the fit statistics for each of our models (columns) per data set (rows). Note that the original knowledge-conditional model is not identified because it does not allow one to differentiate between fluency and guessing. This means that the model imposes fewer constraints on the data than suggested by the number of parameters in the model. We corrected for this fact in the degrees of freedom in Table 2.
Fit Statistics for Fazio’s Original Fluency-Conditional Model and Knowledge-Conditional Model.
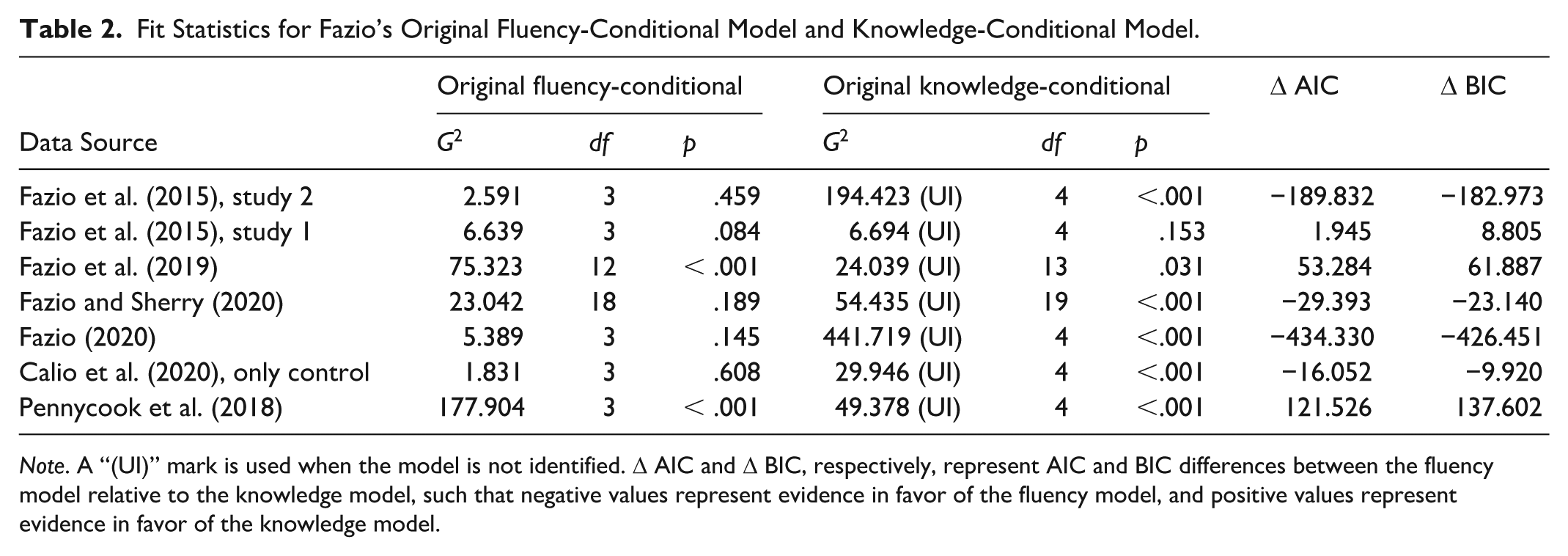
Note. A “(UI)” mark is used when the model is not identified. Δ AIC and Δ BIC, respectively, represent AIC and BIC differences between the fluency model relative to the knowledge model, such that negative values represent evidence in favor of the fluency model, and positive values represent evidence in favor of the knowledge model.
Fit Statistics for the Modified Fluency-conditional and the Modified Knowledge-conditional Models.
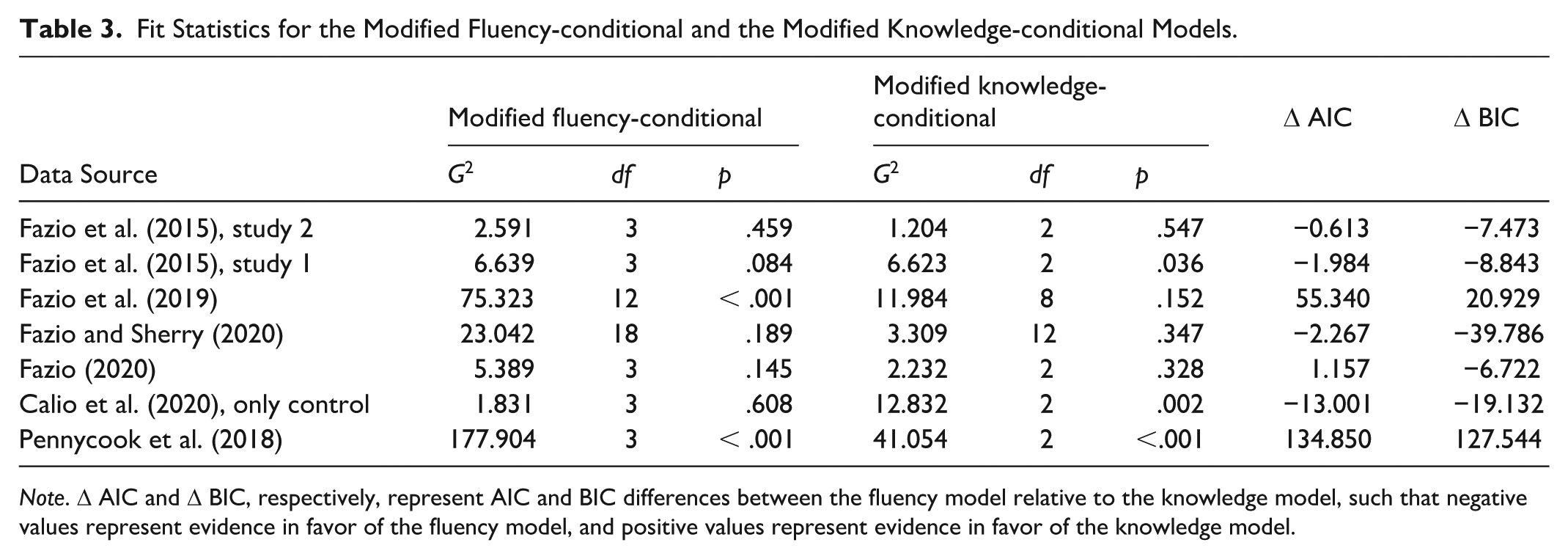
Note. Δ AIC and Δ BIC, respectively, represent AIC and BIC differences between the fluency model relative to the knowledge model, such that negative values represent evidence in favor of the fluency model, and positive values represent evidence in favor of the knowledge model.
As seen in Table 1, across all data sets, Fazio et al.’s (2015) original fluency-conditional model usually had a better fit than the knowledge-conditional model. However, considering the modified knowledge-conditional model (Table 2), the differences in absolute (G2) and relative (Δ AIC/Δ BIC) fit are not as pronounced. For example, looking at Δ BIC, there is substantial evidence in favor of the fluency model in Fazio and Sherry (2020), while in Fazio et al. (2019), there is substantial evidence in favor of the knowledge model.
Discussion
As can be seen by the comparison of Tables 2 and 3, the modifications we have implemented did not change the fluency-conditional model, whereas they had improved the Knowledge-Conditional model substantially. Considering the modified models, the reanalyses suggest that the knowledge-conditional model and its claim that knowledge trumps fluency remains a viable contender relative to the fluency-conditional model and its claim that fluency trumps knowledge. But neither model emerged as a clear winner. Under these circumstances, we wanted to design conditions to best distinguish between these two theoretical models.
For our critical testing we follow the tradition of Fazio et al. (2015) in using a strong manipulation of knowledge. Indeed, the major difference between the fluency-conditional and the knowledge-conditional model occurs when knowledge is clear-cut: Under the knowledge-conditional model, fluency (and hence, repetition) then should have little effect. In contrast, under the fluency-conditional model, fluency as manipulated by repetition should continue to exert a strong effect. There is, however, an asymmetry to consider: Fluency-based judgments invariably result in the response “true,” whereas knowledge-based responses can lead to both the “true” and the “false” response depending upon the statement’s truth status. In consequence, for strongly known true statements, the rate of “true” responses will approach a ceiling effect so that little effect of repetition is to be expected simply because the size of any boost in “true” responses due to repetition is limited by the ceiling. In this situation, both the fluency-conditional and the knowledge-conditional model will predict small effects of repetition.
In contrast, for false statements that are known to be false, the differences between the two ideas represented by the knowledge-conditional and the fluency-conditional model should be accentuated: Under the knowledge-conditional model, the “true” response rate should be very low for such statements whether repeated or not; the fluency-conditional model is also consistent with a low “true” response rate for such statements when presented for the first time, but we should see a boost in the “true” response rate as an effect of repetition that is as large as the one usually found for true and false statement with less extreme knowledge levels. For this reason, in Experiment 1, we focus on false statements that are strongly known to be false, that is, unambiguously implausible statements, along with true and false statements with less extreme knowledge levels. The latter allows one to gauge the size of the predicted repetition effect; the former then permit a crucial test of the predictions of the fluency-conditional versus the knowledge-conditional model: Will the repetition effect occur unmitigated even in the presence of strong knowledge as predicted by the fluency-conditional model or will it be depressed as predicted by the knowledge-conditional model? To address this empirical question, we started by creating a list of implausible alternatives to a pool of true and false statements used in prior research and pre-tested them on a sample of 96 English-speaking Prolific workers. 7 Based on the pre-test results, we were able to identify 120 statements that adhere to our pre-determined criteria, namely that implausible false statements were rated lowest in plausibility, followed by plausible false statements, and finally true statements. All the information on Pre-test 1 can be found in the SOM.
Experiment 1
Method
Participants
For pragmatic reasons, we chose to recruit a sample of 200 participants. Of the 200 participants, we did not get complete data from two participants. Thus, our sample included 198 English-speaking Prolific workers who participated in the 25-minutes web experiment in exchange for £3.75. Based on a sensitivity analysis conducted with G*Power (α = .05, power = 0.80, N = 198, and a correlation among repeated measures of 0.3), the study was sufficiently powered to detect effects as small as ηp2 = .0076 in the 2 × 3 within-subjects design. The mean age in the sample was 41.227 (SD = 13.433), 123 participants identified as male, 73 participants identified as female, 1 participant identified as “other” and 1 participant preferred not to say. The pre-registered details of the experiment can be found online at https://osf.io/cf9ha/?view_only=ae7edb4c59a34c9095b9089d6bf94ae8.
Materials
Statements
We used 120 triplets of statements that included true and (plausible) false statements from previous research (i.e., Fazio, 2020; Fazio & Sherry, 2020; Nelson & Narens, 1980; Corneille et al., 2020), along with 120 implausible false statements that were identified as such in the pre-test study. Statements were organized in triplets of one true, one plausible false, and one implausible false statement sharing a common thematical content and differing in as few words as possible.
Cognitive Reflection Test (CRT)
We used a six-item version of the CRT measure (Newton et al., 2021). We presented each of the questions in an open-ended format and coded correct responses as 1 and incorrect responses as 0. As an exploratory analysis, we planned to examine the correlation between our modified models’ parameters and the CRT score; we present these correlations in Table S10 in the SOM.
Procedure
Participants completed the experiment online. Participants first read the instructions, stating that they would complete two statement evaluation tasks. Participants were told that in the first evaluation task, they will be presented with 60 statements and will be asked to rate how interesting each statement is, on a scale from 1 (highly interesting) to 6 (highly non-interesting). Participants were further told that some of the statements were going to be true and some to be false. This exposure phase was meant to acquaint participants with half of the statements. Before embarking on this task, participants responded to two comprehension questions, with two opportunities afforded for accurate answers. Failure to provide correct responses resulted in termination of their participation in the experiment.
Following the exposure phase, participants were informed about the second evaluation task which asked them to evaluate the truth status of 120 statements. Participants were told that some true and some false statements were to be presented, and that they would be asked to judge for each statement whether it is true or false. Participants were also told that some statements would be familiar to them based on the first evaluation task, while other statements would be new. As before, participants were instructed to respond to two comprehension questions prior to engaging with the task, with two opportunities afforded for accurate answers. Failure to provide correct responses resulted in termination of their participation in the experiment. Next, participants completed a six-item open answer CRT measure. Finally, participants were asked to indicate their age, gender, race, and education level, as well as a question about their dedication during the experiment with the following response options: “Yes, I answered all questions seriously and attentively.” “No, I just wanted to “take a look” or do not believe my data to be meaningful for other reasons.” No participants were excluded based on this criterion.
Design
Our design included 2 within-participant factors in a 2 (repetition: repeated/new) × 3 (truth status: true, false plausible, false implausible) design. Participants were exposed to a total of 20 statements in each of the six conditions: true—new, true—repeated, false plausible—new, false plausible—repeated, false implausible—new, and false implausible–repeated. The triplets of statements were randomly assigned to the six conditions, with the appropriate statement of each triplet (true/false plausible/false implausible) presented in the assigned statement status condition. Note in particular that no participant ever saw more than one statement from a given triplet.
Planned Analyses
To examine the ITE, we used a 2 × 3 repeated measures ANOVA with both independent variables as within-participants factors.
To examine the question of model fit, we fitted MPT models on frequencies aggregated across persons as traditionally used in the literature on the ITE as well as hierarchical Bayesian MPT models on the (non-aggregated) judgments (true/false) of the statements under the different conditions. We analyzed our data using R with the package MPTinR (Singmann & Kellen, 2013) for the non-hierarchical models and TreeBugs (Heck et al., 2013) for the hierarchical models. The results of the hierarchical models are detailed in the SOM. Note that for each significant effect, we provide a post hoc power analysis, which we term “achieved power.”
Results
Illusory Truth Effect
Table 4 shows the mean and standard deviation of the frequency of “true” responses in the different conditions. The analysis of variance (ANOVA) revealed the expected main effect of repetition, F(1, 197) = 39.24, p < .001, ηp2 = .166, CI [0.082, 0.260], and achieved power = .93, showing that repeated statements (i.e., statements that appeared in the exposure as well as in the test phase) were more frequently judged as true relative to statements that appeared for the first time in the test phase. Not surprisingly, the results also revealed a main effect of truth status, F(1.57, 308.67) = 1895.34, p < .001, ηp2 = .906, CI [0.889, 0.919], and achieved power > .99. Importantly, the model revealed a significant interaction effect between truth status and repetition, F(1.79, 352.24) = 4.07, p = .022, ηp2 = .02, 95% CI [0.000, 0.056], and achieved power > .99. Follow-up analyses revealed that, as expected, there was a smaller repetition effect for implausible false statements, t(197) = 2.319, p = .021, d = 0.165, 95% CI [0.024, 0.306], and achieved power = .64, than for false plausible statements, t(197) = 3.447, p < .001, d = 0.246, 95% CI [0.104, 0.387], and achieved power = .93, and for true statements t(197) = 5.155, p < .001, d = 0.367, 95% CI [0.223, 0.511], and achieved power > .99. This pattern can be seen in Figure 4.
Mean Frequency and SD of Truth Ratings per Experimental Condition.

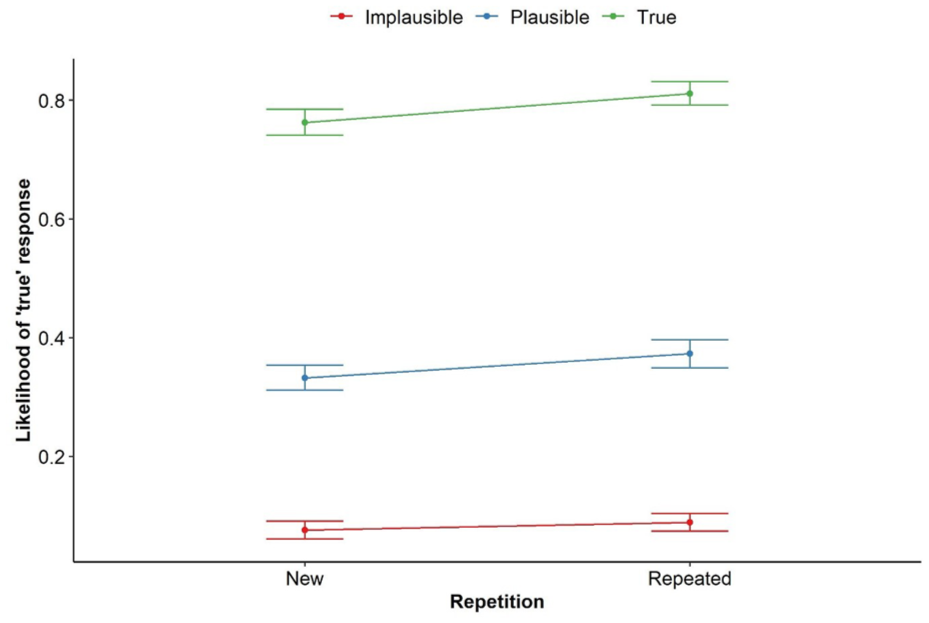
The effect of repetition and statement truth status on the mean frequency of truth ratings.
In the SOM, we provide details of an exploratory analysis we conducted on participants RT. Overall, these analyses provided evidence that our manipulations affected participants responses in the desired way.
Model Testing
To discriminate between the two theoretical accounts (i.e., the fluency first vs. the knowledge first), we tested our modified fluency-conditional and knowledge-conditional models. Furthermore, beyond our base fluency model (hereafter referred to as M1), we evaluated an alternative model, M2, wherein we relaxed the constraint mandating equivalence in baseline fluency between known and unknown statements. This adjustment aimed to address potential critiques regarding discrepancies in fluency levels between the types of statements, such that implausible falsehoods might be argued to be less fluent, or more “disfluent,” relative to the other type of statements. In addition, we examined a further refined fluency model based on M2 and M3, in which we introduced separate parameters for the boost in fluency due to repetition for implausible false statements (Fxri) and for the other statements (Fxr). This particular model was devised to address potential criticisms concerning differences in repetition effects between known and unknown statements, namely that the small fluency or high “disfluency” of the implausible statements might also give rise to a smaller repetition effect on fluency.
Fluency-conditional Model
Unlike the knowledge-conditional model, the fluency-conditional model is not identified for our data, but it does impose two constraints on the data. 8 Testing these two restrictions, it is seen that the original fluency-conditional model M1 by Fazio et al. (2015) fits the data poorly, G2(2) = 30.043, p < .001. The same is true of our modification M1 of it, which gives exactly the same results. Departing from the modified model, we next tested M2 in which we relaxed the constraint that baseline fluency is equal for plausible and implausible statements. M2 in fact imposes the same two restrictions on the data as M1, implying that relaxing the assumption about baseline fluency does not increase the explanatory power of the model and was in fact already consistent with M19. Next, we tested M3 in which baseline fluency as well as the repetition effect on fluency was free to vary between known and unknown items. This relaxation actually increases the range of predictions of the model which now only imposes one constraint on the data. Nevertheless, model fit remained poor, G2(1) = 12.933, p < .001.
Knowledge-conditional Model
Unlike the fluency-conditional model, the modified knowledge-conditional model showed good fit, G2(1) = 0.493, p = .438. The parameter estimates of this model can be seen in Table S5 in the SOM. Comparing the fit of the knowledge-conditional model and the fluency-conditional model, it is clear that the knowledge-conditional model has a higher ability to account for the pattern of behaviors observed in Experiment 1.
Discussion
The findings from Experiment 1 indicate a potential restriction of the ITE to contexts characterized by reduced ambiguity regarding the veracity of presented information. Our empirical analysis demonstrates that heightened certainty levels, specifically when encountering implausible statements, significantly reduce the impact of repetition on participants’ inclination to perceive statements as true. Furthermore, our computational models substantiate this observation by revealing that the data are much better accounted for by a model that implements the idea that knowledge trumps fluency than by a model that implements the idea that fluency trumps knowledge in truth judgments. The findings of this experiment align with the framework recently advanced to elucidate the phenomenon of ITE, specifically the Referential Theory of Repetition-Induced ITE, as proposed by Unkelbach and Rom (2017). According to the referential theory, truth judgments are predicated upon the state of a localized network that mirrors corresponding references in memory and their coherence. In this context, “references” pertain to pre-existing information stored in memory, while “coherence” denotes the relationships among these memory traces, whether excitatory or inhibitory.
The theory posits that information is more likely to be perceived as true if it has a greater number of references in memory and if these references are coherent with one another. The theory further postulates that the repetition induced ITE can be attributed to the proliferation of memory references that are coherently linked. However, it maintains that the sheer number of references (achieved through repetition manipulation) does not enhance the likelihood of a truth judgment if the connections among the nodes are incoherent. This theoretical perspective implies that implausible falsehoods would not gain credibility merely through repetition manipulations, a notion that concurs with the results of the present experiment.
Building on these insights, Experiment 2 aimed to further investigate how the structure and accessibility of the memory network modulate the impact of fluency on truth judgments. While Experiment 1 demonstrated that knowledge can override fluency when the information is implausible or unambiguous, we hypothesized that the accessibility of relevant knowledge may play a similarly critical role in attenuating the ITE. In line with the referential theory, enhancing access to coherent memory references should reduce reliance on fluency cues by reinforcing the truth judgment network. To test this, we manipulated knowledge accessibility by providing participants with cues that either facilitated or did not facilitate retrieval of the relevant knowledge prior to their truth judgments.
We created a pool of 173 helpful as well as 173 irrelevant cues, to match the content of the 173 true and false statements that were used in Pretest 1, and pretested them on a sample of 95 English-speaking Prolific workers. Based on the results, we chose 120 statements that best matched the expected pattern where items following the relevant cue were judged more accurately than when following an irrelevant cue. Full details on Pretest 2 can be found in the SOM.
Experiment 2
Method
Participants
A power analysis (MorePower v. 6.0.1; Kelley, 2007) revealed that a sample of 126 participants would provide us with 80% power to detect a medium-sized effect (partial eta squared = .06). For reasons of experimental control, we chose to run this study in the lab. Thus, our sample included German-speaking students of the University of Freiburg who participated in the 30-minutes study in exchange for course credit or £5. The mean age in the sample was 23.183 (SD = 5.056), 31 participants identified as male, 92 participants identified as female, and 3 participants identified as “other.” The pre-registered details of the experiment can be found online at https://osf.io/bmezs.
Materials
Statements
We used the 120 items chosen in Pretest2. For example, for the true and false statements (respectively) “Glider is an airplane without an engine” and “Helicopter is an airplane without an engine” we used the high accessibility cue “Helicopters require fuel while gliders do not” and the low accessibility cue “The first successful type of engine for performing mechanical work, the steam engine, was invented by Thomas Savery in 1698.” Furthermore, to assure that even irrelevant cues do not facilitate relevant knowledge simply by increasing the accessibility of the topic, we mixed the pairing of the low accessibility cues so that they never matched the topic of the to-be-judged statement.
Procedure
Participants completed the study in the lab. The procedure of Experiment 2 was similar to that of Experiment 1 but with two changes; first, participants were exposed to a cue before each statement, first on a separate screen and then together with the statement. Second, we removed CRT measures as these proved uninformative in Experiment 1.
Design
Our study included 3 within-participant factors in a 2 (repetition: repeated/new) × 2 (truth status: true, false) × 2 (cue condition: high knowledge accessibility/ low knowledge accessibility) design. Participants were exposed to a total of 15 statements in each of the eight conditions. The pairs of statements were randomly assigned to the eight conditions, with the appropriate statement of each pair (true/false) presented in the assigned status condition. Note in particular that no participant ever saw more than one statement or one cue from a given topic.
Planned Analyses
We followed the same analysis plan as in Experiment 1. As before, in the main text, we provide the results of the ANOVA along with the results of the MPT analyses that are based on aggregated data, while the results of the hierarchical MPT models are detailed only in the SOM. Note, however, that the pattern of results was consistent across the two modeling approaches.
Results
Illusory Truth Effect
Table 5 shows the mean and standard deviation of the frequency of “true” responses in the different conditions. The ANOVA revealed the expected main effect of repetition, F(1, 125) = 19.52, p < .001, ηp2 = 0.135, 95% CI [0.043, 0.249], and achieved power > .99, showing that repeated statements (i.e., statements that appeared in the exposure as well as in the test phase) were more frequently judged as true relative to new statements. The results also revealed a main effect of truth status, F(1, 125) = 1878.37, p < .001, ηp2 = .94, 95% CI [0.92, 0.95], and achieved power > .99. Moreover, the effect of cue was also significant, F(1, 125) = 38.79, p < .001, ηp2 = .24, 95% CI [0.12, 0.36], and achieved power > .99, showing that statements preceded by a low knowledge accessibility cue were more likely judged as true relative to statements that were preceded by a high knowledge accessibility cue. Importantly, the model revealed a significant interaction effect between truth status and repetition, F(1, 125) = 4.57, p = .034, ηp2 = .04, 95% CI [0, 0.12], and achieved power > .99, and a significant interaction between truth status and cue, F(1, 125) = 355.89, p < .001, ηp2 = .74, 95% CI [0.67, 0.79], and achieved power > .99. Follow-up analyses revealed that the effect of repetition was larger for true statements, t(125) = 5.550, p < .001, d = 0.50, 95% CI [0.31, 0.68], than for false statements, t(125) = 1.586, p = .115, d = 0.14, 95% CI [−0.03, 0.32] and that participants were better able to distinguish between true and false statements following the high knowledge accessibility cue t(125) = 46.205, p < .001, d = 4.13, 95% CI [3.58, 4.67], relative to the low knowledge accessibility cue t(125) = 24.745, p < .001, d = 2.21, 95% CI [1.89, 2.54]. The overall pattern of the results can be seen in Figure 5. No other effects were significant.
Mean frequency and SD of truth ratings per experimental condition, Experiment 2.

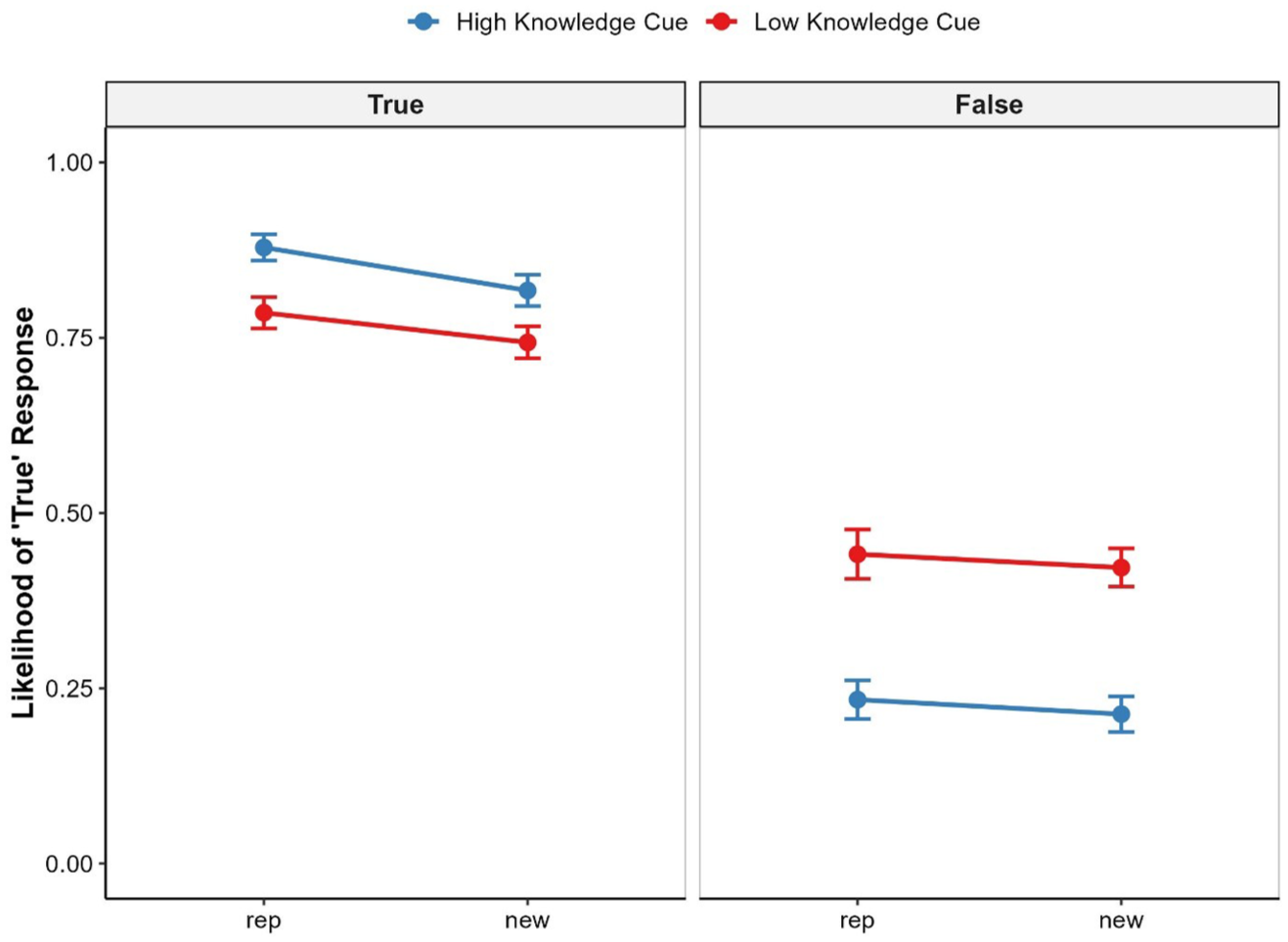
The effect of statement repetition, truth status, and knowledge accessibility cue on the mean frequency of truth ratings.
Model testing
We used the same models as in Experiment 1, but modified them to include our now eight instead of six conditions.
Fluency-conditional Model
The modified fluency-conditional (model M1) fits the data poorly, G2(3) = 47.091, p < .001. Unlike Experiment 1, where the implausible statements might have differed from the plausible ones in fluency or in how repetition affected fluency, Experiment 2 varied only a preceding cue rather than the statements themselves. Thus, models M2 and M3 are less relevant here. However, for completeness, we fitted these models and report the results in the SOM. While both improved on M1, they still fit considerably worse than the knowledge-conditional model.
Knowledge-conditional Model
Relative to the fluency-conditional model, the modified knowledge-conditional model showed better fit, G2(2) = 13.131, p = .001. The parameter estimates of this model can be seen in Table S6 in the SOM. Comparing the fit of the knowledge-conditional and the fluency-conditional model, it is clear that the knowledge-conditional model has a higher ability to account for the pattern of behaviors observed in Experiment 2. The difference between the two models in model-selection indices amount to Δ AIC = 31.960 and Δ BIC = 24.336, indicating a clear preference for the knowledge-conditional model.
Discussion
The findings of Experiment 2 are generally consistent with those of Experiment 1, indicating that in information environments where certainty varies, knowledge is the primary cognitive process driving truth judgments. However, the behavioral data from Experiment 2 show some differences. In Experiment 1, the truth effect—the difference in truth judgments between new and repeated statements—was significantly reduced when certainty in knowledge was high (i.e., when implausible false statements were used). In contrast, this pattern did not emerge in Experiment 2. When certainty in knowledge was high in Experiment 2 (i.e., when statements were preceded by a helpful cue that increased knowledge accessibility), the magnitude of the ITE remained unchanged.
General Discussion
The present research examines the interaction of knowledge and fluency in the making of the ITE, a well-researched psychological phenomenon, wherein information is more likely to be judged as true if it was repeatedly presented. Specifically, we ask whether the effect is robust even in situations where people have existing knowledge. Our results provide evidence showing that this is not necessarily the case. Based on reanalyses of existing data, we show that models representing the idea that knowledge trumps fluency perform on par with models representing the idea that fluency trumps knowledge in accounting for the data. Moreover, our experiments were designed to permit a diagnostic test in the debate as to whether knowledge or fluency takes priority in truth judgments. In this debate, we provide ample evidence in support of the notion that knowledge retrieval processes rather than more heuristic, fluency-based processes take priority when they compete for control over overt responses.
One of the staple assumptions in the early literature about the ITE was that the ITE happens when information is ambiguous about its truth status (Dechêne et al., 2010; Hasher et al., 1977). It was believed that if ambiguity did not exist, knowledge retrieval processes would control this decision-making process, thereby eliminating ITE. This assumption was then brought to the forefront and empirically tested by Fazio and colleagues in 2015. To examine the assumption that knowledge protects against the ITE, Fazio et al. took two approaches. As one approach, the ITE was examined for items on which participants had prior knowledge, while the other approach compared models of cognitive mechanisms involved in an ITE task. The authors found that an ITE persisted even for items for which participants had prior knowledge. Moreover, the authors found that a model that assumes that fluency processes take precedence (i.e., a fluency-conditional model) when judging the truth value of statements better explained that behavioral data than a model that assumes that knowledge retrieval processes take precedence (i.e., a knowledge-conditional model).
The goal of this research was to reexamine this question by proposing improvements to the original models and providing data that could be used to help differentiate between them. Initially, we implemented some improvements to the original knowledge-conditional model, which we thought might explain the poor fit found in the original Fazio et al. (2015) study. We modified the model by combining redundant parameters and by separating knowledge parameters of truths and falsehoods based on theoretical arguments (i.e., the encoding specificity principle), permitting knowledge retrieval for true statements to occur with higher (or at best equal) likelihood than for false statements. Similarly, we somewhat modified the fluency-conditional model such that instead of using a fluency parameter for new and repeated statements, we used one baseline fluency parameter and a fluency effect of repetition (present only in repetition trials). We then tested the fit of these modified models as well as the original fluency and knowledge-conditional models on seven data sets taken from six different published papers. Overall, we found that the two refined models did equally well in explaining existing ITE data. Thus, our first main finding is that existing data, believed to demonstrate a priority of fluency-based over knowledge-based processes in the ITE, is in fact non-diagnostic with respect to this question.
Departing from this finding, in Experiment 1, we created propitious conditions for distinguishing between the two models. This experiment included implausible falsehoods along with the usual true statements and plausible falsehoods. The rationale for this was, as explained above, is that combining these categories of statements and comparing repetition effects for them should make for an especially diagnostic test so that strongly different predictions arise from the idea that knowledge trumps fluency and from the idea that fluency trumps knowledge. Indeed, based on this data we found that the knowledge-conditional model provided an adequate description of the data in terms of model fit and outperformed the fluency-conditional model, which did not fit the data.
Continuing the same line of reasoning, in Experiment 2, we tested the effect of knowledge accessibility on truth judgments by providing participants with either helpful or irrelevant cues prior to making their judgments. While we did not find knowledge accessibility to moderate the repetition-based truth effect, we again found evidence in favor of the knowledge conditional model, thus lending more credence to the conclusion that truth judgments are dominated more by knowledge retrieval than by reliance on fluency.
One difference between Experiments 1 and 2 deserves note. In Experiment 1, the knowledge manipulation both affected the truth effect (repetition’s effect significantly decreased for implausible statements relative to other statements) and yielded data better predicted by the KCM. In Experiment 2, however, the manipulation did not affect the truth effect, yet the data were still better explained by the KCM. What accounts for this discrepancy?
One potential explanation lies in how the models differ in their predictions regarding repetition effects for true versus false statements. Both models predict a larger repetition effect (higher proportion of “true” responses for repeated vs. new statements) for false statements relative to true statements. However, assuming a large K parameter, the fluency-conditional model predicts this difference to be greater than the KCM does. As shown in Table 5, the truth effect was actually substantially larger for true statements—contrary to both models’ predictions. Because the FCM’s prediction is more extreme, its misfit is correspondingly greater.
Furthermore, the dependence of this pattern on large K suggests that knowledge levels in previous studies may not have been sufficiently high to reveal the KCM’s advantages. Why do our results differ from those by Fazio et al. (2015)? Note first that our reanalyses using the modified knowledge model show that the Fazio et al. (2015) data turn out to be nondiagnostic with respect to the question whether knowledge or fluency takes priority. Both ideas provide comparably adequate accounts of existing data. Although Fazio et al. (2015) used stimuli with high levels of prior knowledge, we also argued above that true statements for which strong knowledge is available do not allow one to discriminate between the two hypotheses. In regards to false statements, we would argue that there is still considerable ambiguity and lack of knowledge in the statements used by Fazio et al. (2015). This is certainly seen in the normative criterion used in that study according to which false statements needed to be responded to correctly by only 60% of the norming participants to qualify as “known” falsehoods.
Fazio et al. (2015) also used a classification of statements as known versus unknown based on individual, participant-wise knowledge checks. Here participants were exposed to the true and the false version of the statement and had to decide which one is correct. We argued, however, that due to the encoding specificity principle and additional processing, knowledge retrieval is easier for true than for false statements. The reanalyses of existing data and the new data support this argument in that they were consistent with and in some cases revealed reliably smaller K parameters for knowledge retrieval for false than for true statements (see Tables S1–S7 and S11, in the SOM). This means that knowledge retrieval is depressed for falsehoods in the evaluation phase of the ITE paradigm in which falsehoods are presented in isolation, but not in the individual knowledge check because here memory can be probed with the true and the false version of the statement as retrieval cues. In other words, the individual knowledge check may be easier than the evaluation task in the ITE paradigm, and it may suggest higher levels of knowledge than operate in the evaluation phase of the ITE paradigm, especially for false statements.
One major question is whether the present results represent the rule, or rather, an exception to the rule. Although we provide evidence that shows that in the face of existing knowledge the truth effect can be highly reduced, it could be argued that in real life, one hardly has to judge the truth value of such trivially incorrect statement. Although the results we presented still stand, they might only represent an extreme case, or a boundary condition in this line of argumentation. This argument, however, confounds the requirements and constraints imposed by the scientific goal of realizing critical diagnostic tests on the one hand and the scope of scientific theories tested thereby on the other hand. It is frequently the case that to provide diagnostic tests, unusual situations have to be implemented that rarely occur in real life. One does not have to think of the extreme conditions that reign in the bowels of the Large Hadron Collider in Geneva to make this point. Even in psychology, it is often the case that two theories largely overlap in their predictions in real-life situations whereas divergent results and hence critical tests are achieved only in unusual settings with uncommon procedures (see, for example, the debate on the validity of threshold models of recognition memory versus models assuming continuous memory signals; see Klauer & Kellen, 2018, for a summary).
Note that in the present case, a clear discrimination between the fluency-conditional and the knowledge-conditional ideas required experiments that incorporate high knowledge certainty like implausibly false statements or helpful cues for theoretical and methodological reasons, whereas both ideas provided comparably adequate accounts of existing data obtained with less focused materials. This means in particular that models assuming a priority of knowledge do account for existing data obtained under conditions that may be more representative of those encountered in real life to the same extent as models assuming a priority of fluency. And the former models prevail in situations tailored to accentuate the differences with the latter models.
Moreover, the claim can be made that implausible falsehoods have particularly poor fluency, and any increment in fluency caused by repetition has in consequence little effect on them. However, some of the models we tested show that this is unlikely to be the case. Namely, none of the fluency-conditional models were able to account for the data, including models that allowed baseline fluency and effects of repetition on fluency to differ between implausible falsehoods and other statements. Although we attempted to model and control for potential differences between implausible statements and other statements, this remained a concern. For this reason, we conducted Experiment 2, in which we manipulated knowledge level through knowledge accessibility rather than content plausibility.
Another major limitation that pertains to most of this research, and is also common to much of the ITE literature, including the studies reanalyzed here, is that the research is typically conducted in English and on English-speaking populations. These populations often consist of students, M-Turk, or Prolific workers, who are predominantly from Western, individualistic societies. This convenience-based approach restricts the research’s applicability to understanding the behavior of these specific populations and does not ensure the findings are generalizable to more diverse groups. While the ITE might affect people from different cultures similarly, this is not necessarily guaranteed. The present research included reanalysis and one new data set from western English-speaking online participants, alongside one lab-based study on a population of German students. While including German participants broadens our ability to generalize a bit, there is still a long way to go for a true generalization across different cultural contexts. For example, considering collectivistic cultures, repetitions—representing the opinions of many people in natural settings—might have a stronger effect, potentially outweighing personal knowledge more than in individualistic cultures. Therefore, we encourage future research to include samples from more diverse cultural backgrounds.
Furthermore, the ITE is often studied using the same sequential two-phase paradigm. In the first phase, participants are typically asked to rate the interest level of statements or categorize them into knowledge domains. The present research used this same procedure to maintain comparability with existing data sets while testing new conditions; we chose not to deviate substantially from the classic design to ensure our results could be meaningfully compared with prior work. Nevertheless, past research shows that the truth effect is sensitive to the tasks participants receive at the encoding stage (see e.g., Calvillo & Harris, 2022; Brashier & Marsh, 2020; Riesthuis & Woods, 2023). Thus, we recommend that future research reexamine the role of knowledge in the truth effect using different designs, particularly by employing different tasks at encoding.
In addition, while this research employed experimental designs in controlled settings to test the role of knowledge in the ITE, such approaches may not fully capture how people are exposed to information and make truth judgments in everyday life. Moreover, controlled studies can introduce demand effects that may influence participant responses. This concern is particularly salient in Experiment 1, where participants evaluated highly implausible statements, compared to Experiment 2, where such demand characteristics are less likely to have played a role. We, therefore, encourage future research to balance rigorous theoretical inquiry—including modeling approaches—with investigations conducted in more ecologically valid settings that minimize potential demand effects.
Overall, the present findings suggest that knowledge retrieval processes shape behavior in situations requiring truth judgments with fluency experiences operating to the extent to which knowledge is not given. This idea was already the working hypothesis in early ITE research, but the present work is one of the few in-depth investigations of this assumption. While the present results are straightforward, they provide only two critical tests of whether knowledge versus fluency takes priority in such judgments. Thus, we encourage future research to add to this topic by devising yet other ways to examine and test for the role of knowledge in protecting against the ITE.
Limits on Generality
The present research investigates how having knowledge influences individuals’ tendency to rely on heuristics—such as familiarity—when making truth judgments. As is common in studies on the ITE, we manipulated the repetition of trivia statements. Our sample consisted of Prolific workers from Western English-speaking countries and university students from Germany. Consequently, the findings may not generalize to other types of knowledge, different manipulations, or cultural contexts beyond those represented in our sample.
Supplemental Material
sj-docx-1-psp-10.1177_01461672251403392 – Supplemental material for Rethinking Knowledge’s Impact on the Illusory Truth Effect
Supplemental material, sj-docx-1-psp-10.1177_01461672251403392 for Rethinking Knowledge’s Impact on the Illusory Truth Effect by Anat Shechter and Karl Christoph Klauer in Personality and Social Psychology Bulletin
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material is available online with this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.