
Abstract
Multidimensional computerized adaptive testing (MCAT) has been developed over the past decades, and most of them can only deal with dichotomously scored items. However, polytomously scored items have been broadly used in a variety of tests for their advantages of providing more information and testing complicated abilities and skills. The purpose of this study is to discuss the item selection algorithms used in MCAT with polytomously scored items (PMCAT). Several promising item selection algorithms used in MCAT are extended to PMCAT, and two new item selection methods are proposed to improve the existing selection strategies. Two simulation studies are conducted to demonstrate the feasibility of the extended and proposed methods. The simulation results show that most of the extended item selection methods for PMCAT are feasible and the new proposed item selection methods perform well. Combined with the security of the pool, when two dimensions are considered (Study 1), the proposed modified continuous entropy method (MCEM) is the ideal of all in that it gains the lowest item exposure rate and has a relatively high accuracy. As for high dimensions (Study 2), results show that mutual information (MUI) and MCEM keep relatively high estimation accuracy, and the item exposure rates decrease as the correlation increases.
Keywords
Introduction
Multidimensional computerized adaptive testing (MCAT) is based on the multidimensional item response theory (MIRT) and computerized adaptive testing (CAT). It can not only assess the examinees’ multidimensional ability synchronously but also improve the measurement accuracy and test efficiency of the assessment (Luecht, 1996; Segall, 1996). Currently, almost all of the MCAT studies only focus on the dichotomously scored data assessment (e.g., Mulder & van der Linden, 2009; Reckase, 2009; Segall, 1996; van der Linden, 1999; Wang & Chang, 2011; Wang, Chang, & Boughton, 2011). However, polytomously scored items have been broadly used in a variety of tests. In psychological inventories, it is common to use the Likert-type items which are usually scored according to the number of response categories allowed. Polytomous items are also highly applied in the achievement context, which could include some special item types, such as performance tasks, selected responses, and fill-in-the-blank. It is believed that polytomously scored items provide more information than dichotomously scored items ( Donoghue, 1994; Samejima, 1976). It could not only measure concepts and skills in greater depth than dichotomous items but also reduce the test length while achieving the same effects, particularly under the CAT context (De Ayala, 1992).
Item selection strategy constitutes the key component of CAT, which not only makes tests adaptive but also exerts a direct impact on the quality of test. The algorithms of the item selection methods derived for multidimensional three-parameter logistic (M3PL) or two-parameter logistic (M2PL) model focuses on multidimensional dichotomous items other than multidimensional polytomous items. Lin (2012) compared D-optimality, Kullback–Leibler information index (KI), mutual information (MUI), and continuous entropy method (CEM) in MCAT adopting polytomously scored items under multidimensional generalized partial credit model (MGPCM; Yao & Schwarz, 2006). According to Lin (2012), test format completely delivering polytomous items yields the best estimation accuracy and D-optimality, MUI, and CEM have similar estimation and item selection pattern, while KI differs from them. Based on the work of Lin (2012), this article will further focus on the item selection strategy of the polytomously scored MCAT (PMCAT), attempting to (a) explore the proper means to extend more conventionally dichotomous MCAT selection algorithms to polytomous MCAT (PMCAT) and (b) propose two new item selection methods to improve the existing selection strategies for PMCAT.
The remainder of this paper is organized as follows: Firstly, the employed polytomously-scored model, the multidimensional graded response model (MGRM) are described. Secondly, some item selection methods of PMCAT extended from the methods of MCAT are introduced. Next, two new item selection methods of PMCAT considering the posterior distribution are proposed, followed by two Monte Carlo simulation studies, to explore the statistical properties of each strategy and the feasibility of PMCAT, and how the correlation among attributes affects the accuracy of high dimensional PMCAT. At last, the full paper is summarized, and the future research are discussed, which would lay foundations for the further research.
MGRM
In psychological inventories, it is common to use the Likert-type items which assume that the difficulty parameters increase or decrease sequentially. The graded response model (GRM) is suitable for the analysis of this kind of Likert-type data and easier for the user to understand, especially in CAT. There are many instances of CAT system for personality scale by using the GRM (Flens et al., 2017; Gardner et al., 2004; Smits, Cuijpers, & van Straten, 2011). Therefore, the two-parameter MGRM (Muraki & Carlson, 1995) is employed under the PMCAT in this study, which is generalized from the GRM. The logistic form of MGRM can be defined as,
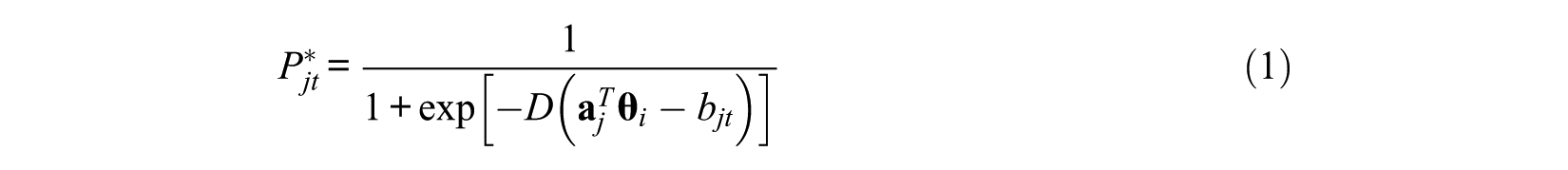
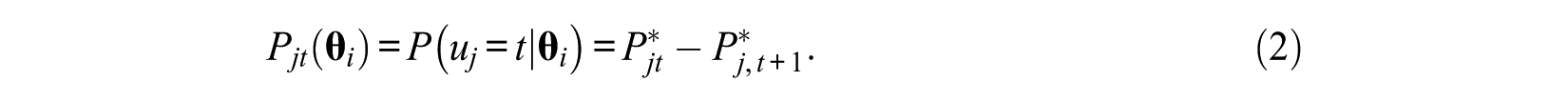
wherein
For the convenience of presentation, the following notations will be used throughout this article. Assume there are
The Extension of Item Selection Methods of MCAT to PMCAT
Under the framework of MCAT, some popular item section methods have been proposed (e.g., Chang & Ying, 1996; Mulder & van der Linden, 2009, 2010; Segall, 1996; Veldkamp & van der Linden, 2002). From the profile of the information statistics, these methods could be classified into three types: One is the method based on Fisher information (FI), and the other two are based on Kullback–Leibler information (KL-based methods), which are the methods based on traditional KL information and the methods based on KL information between posteriors. As there are similarities and differences between MCAT and PMCAT, it attempts to investigate the feasibility of some of these methods under the framework of PMCAT. The details are discussed in the following.
The Extension of FI-Based Methods
Comparison of methods based on FI under MCAT can be found in Appendix A in the online supporting information. Under the framework of PMCAT, with MGRM model employed, the FI matrix for item j is defined as,
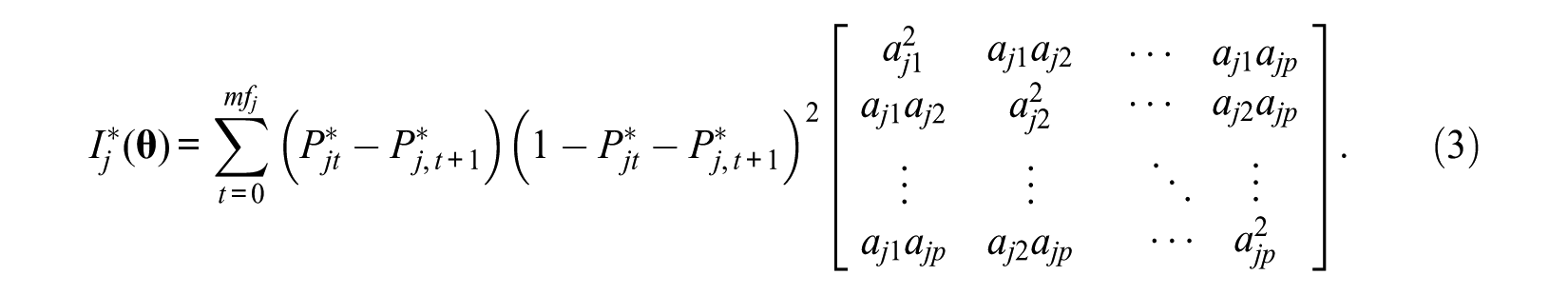
where

According to (4), the six methods could be expressed as follows.
D-optimality and Bayesian D-optimality methods
D-optimality method is to select the next item that maximizes the determinant of (4), which is to yield the smallest confidence region for the ability parameters, and its expression is
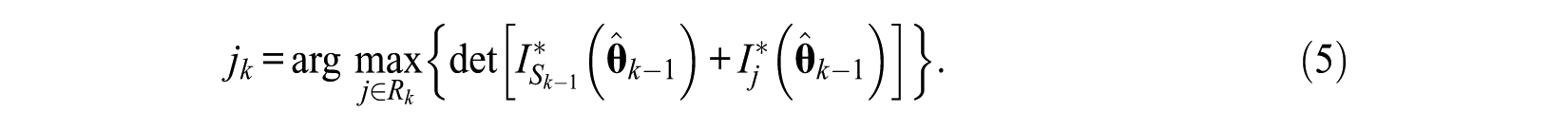
With the consideration of the prior distribution of
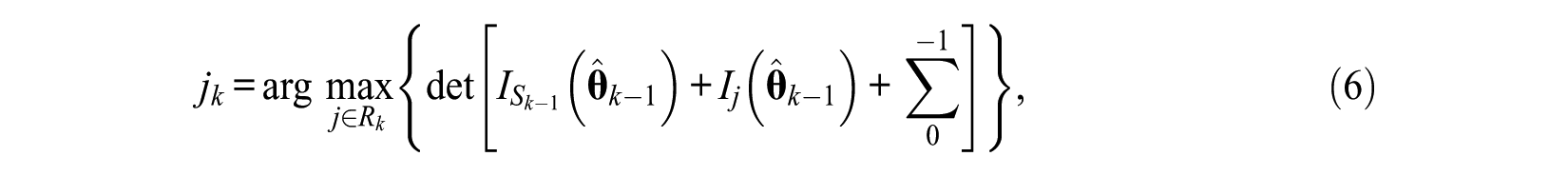
where
A-optimality and bayesian A-optimality methods
A-optimality method is to select the item that minimizes the trace of the inverse of (4), which is to minimize the sum of the (asymptotic) sampling variances of the MLEs of the abilities. Its expression is
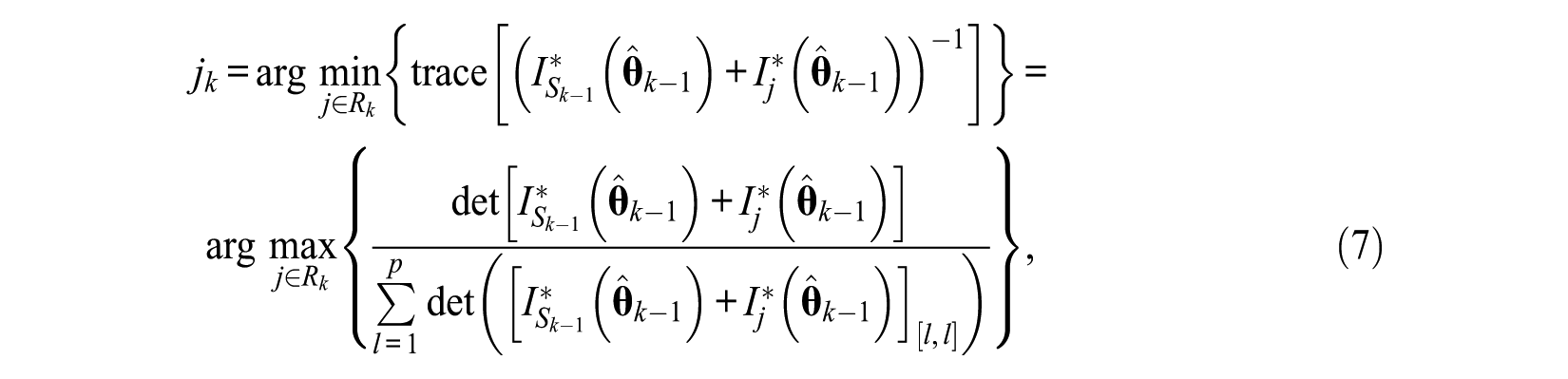
where
E-optimality and bayesian E-optimality methods
The E-optimality method is to maximize the smallest eigenvalue of (4), which is equivalent to minimize the generalized variance of the ability estimators along their largest dimension; its expression is
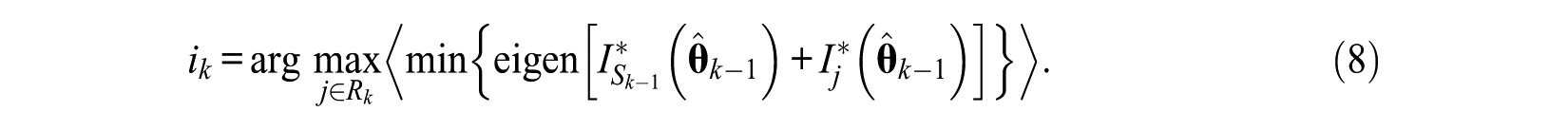
By adding
The Extension of KL-Based Methods
Four popular methods of MCAT based on KL information are discussed here (Chang & Ying, 1996; Mulder & van der Linden, 2010; Veldkamp & van der Linden, 2002; Wang & Chang, 2011), that is, KL index (KI) method, posterior expected KL information method (KB), method of KL information between subsequent posteriors (KLP), and MUI. To be available in PMCAT, these methods will be modified.
Methods based on traditional KL information
For item j, the KL information under MGRM model is defnined as
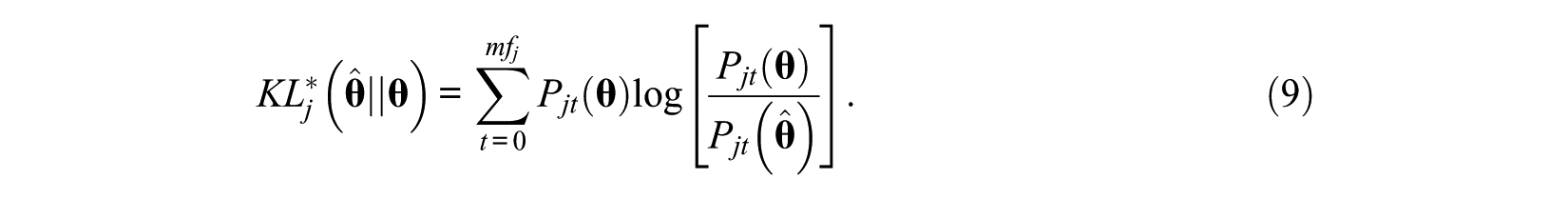
where
Thus, the KI and KB method are expressed as Equations 10 and 11, respectively.
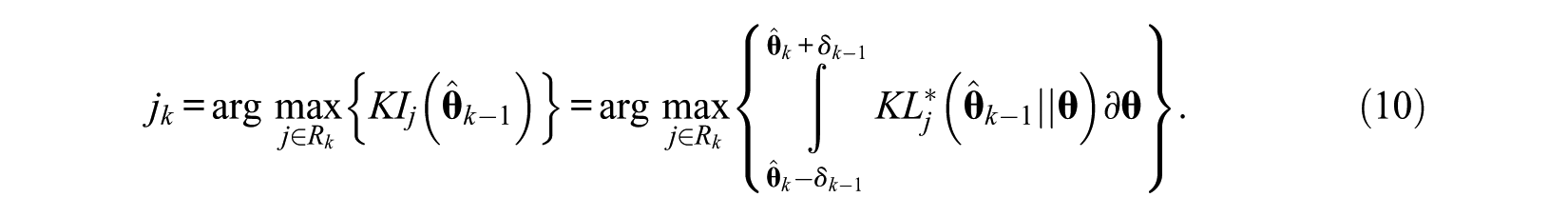
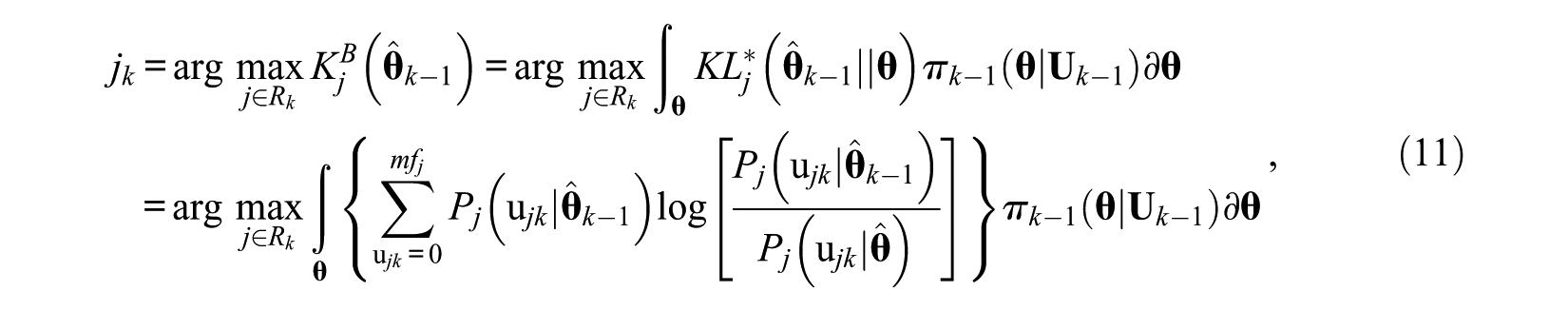
wherein
Methods based on KL information between posteriors
In CAT, the items which yield the largest change of the posterior distribution should been selected. The KL information can be used to formalize this argument. These methods differ profoundly from the traditional KL methods in that the former uses KL information to measure the divergences between the two consecutive posteriors of
Method of KL information between subsequent posterior distributions
The KL information between subsequent posterior distributions
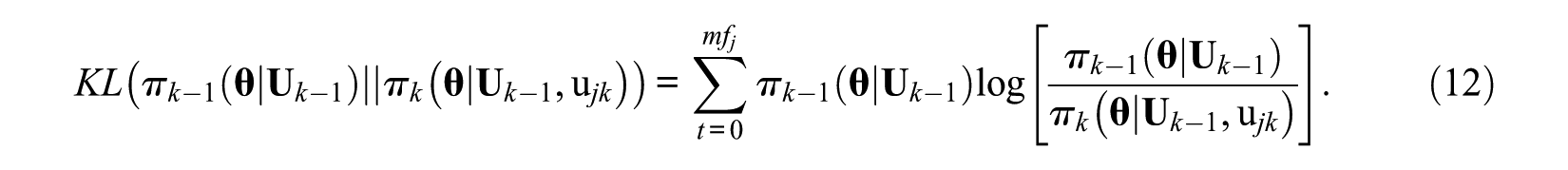
Then, the KLP method, noted as KP, is to select the next item by
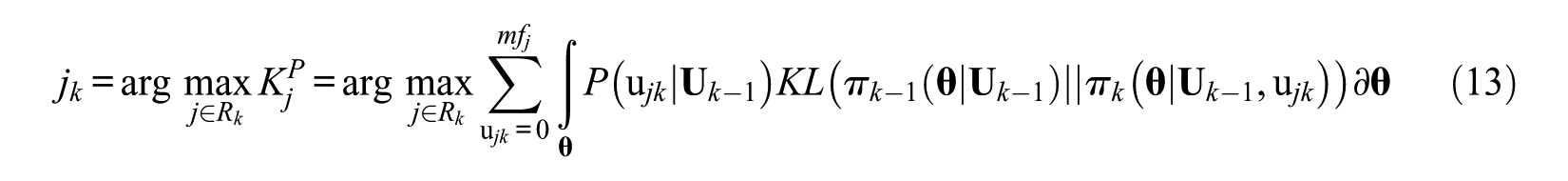
MUI method
In PMCAT, with the analogy to the work of Mulder and van der Linden (2010) in MCAT, the MUI is defined as the KL information between the joint distribution and the product of the marginal distribution. Thus, the polytomous MUI method could be expressed as
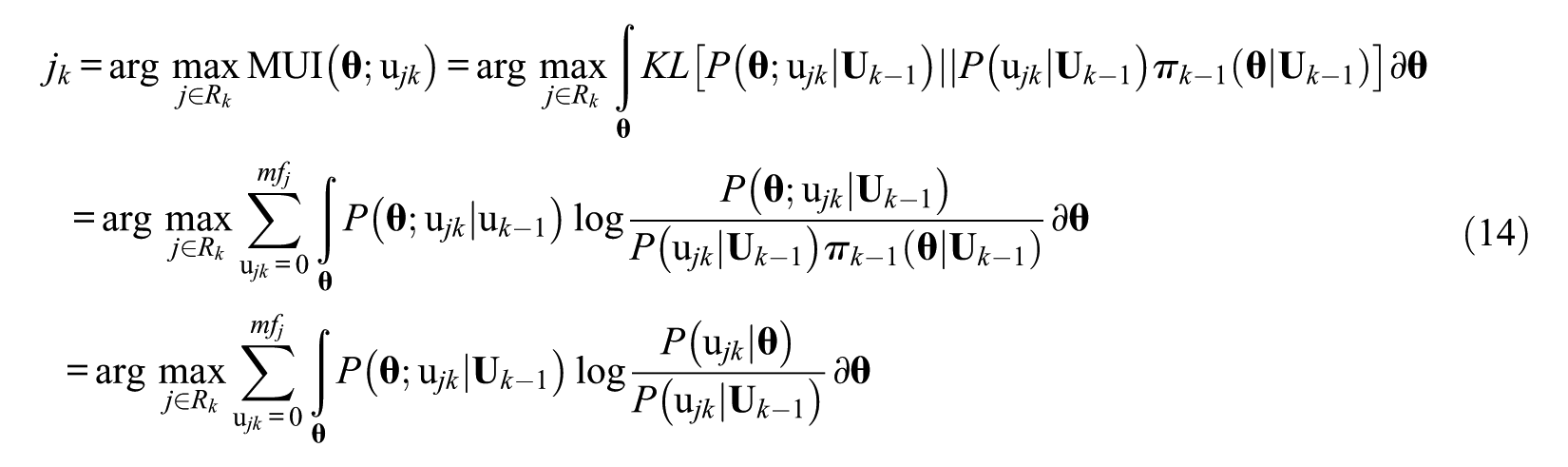
Furthermore, MUI is equivalent to the average KL information between the new and current posteriors
Two New Item Selection Methods of PMCAT
In the section “The Extension of Item Selection Methods of MCAT to PMCAT” based on the similarity between MCAT and PMCAT, some selection methods of MCAT to PMCAT have been extended. However, during the work of extension, some information could be incorporated into some of the former methods. Hence, two new methods are proposed in this segment, that is, the modified method of posterior expected KL information (simplified as MKB method) and the modified method of CEM (simplified as modified continuous entropy method [MCEM] method), and the details are presented in the following.
MKB Method
In KB method, the criterion is computed based on the current estimate
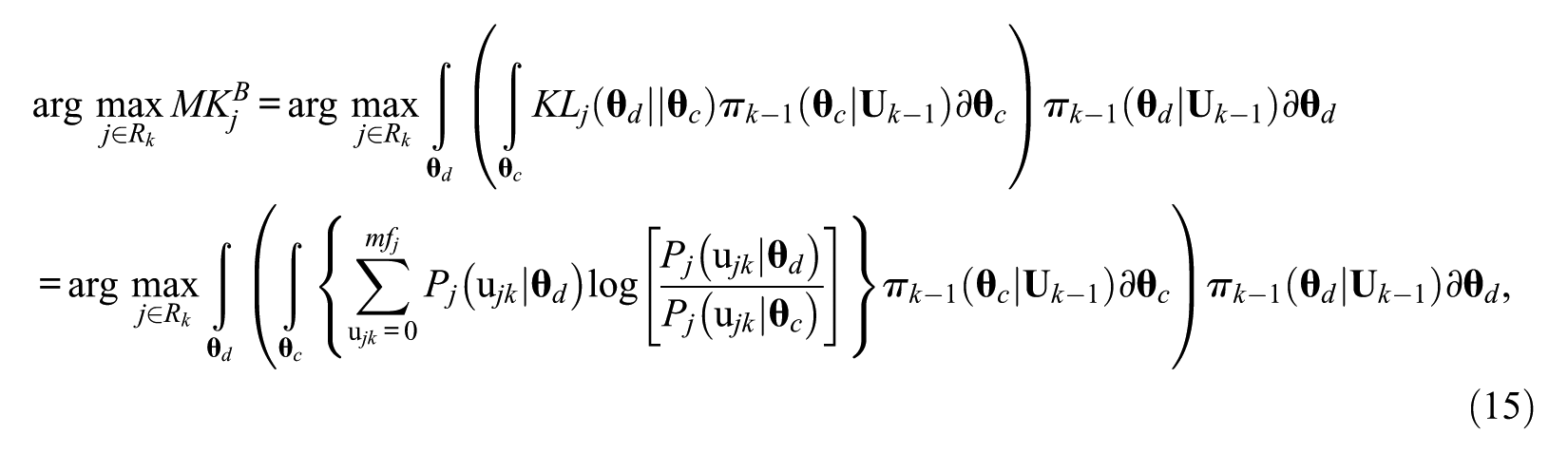
where
Compared with the KB method, the numerator in Equation 14 considers all the possible ability vectors, and weights them accordingly. Because it does not require estimating the ability vector
MCEM Method
Suppose the random variable X follows a continuous distribution, the continuous entropy is defined as the Shannon entropy

Then, the posterior continuous entropy after
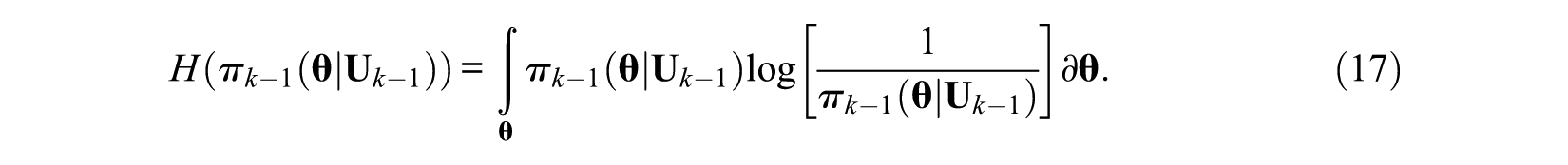
For MCAT, Wang and Chang (2011) suggested a CEM to select the next item that has the smallest expected posterior continuous entropy; the criterion could be expressed as
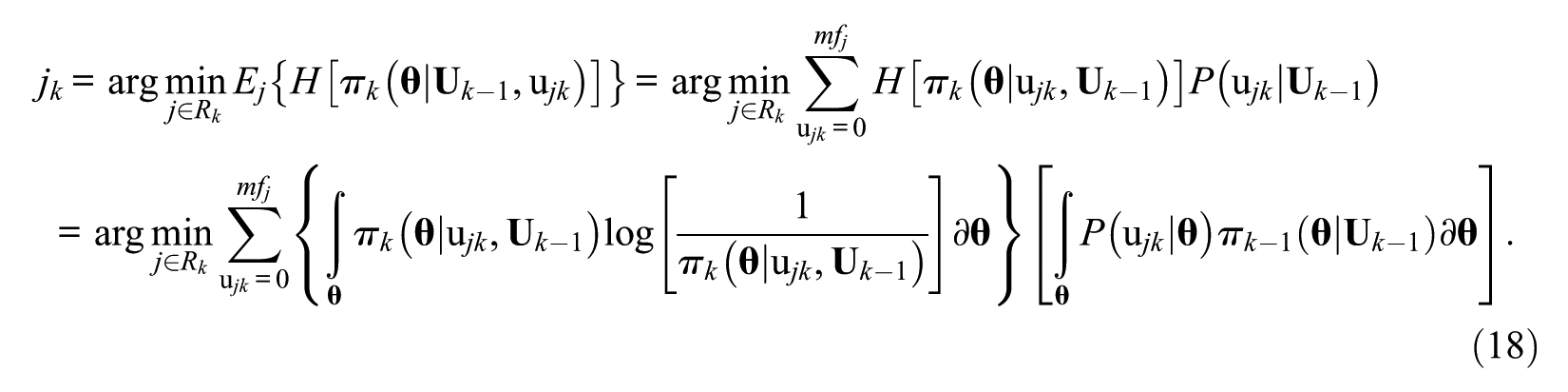
When polytomous data are analyzed, and the MGRM model is used in Equation 18, the CEM method for PMCAT is obtained. In the method, the posterior distribution of
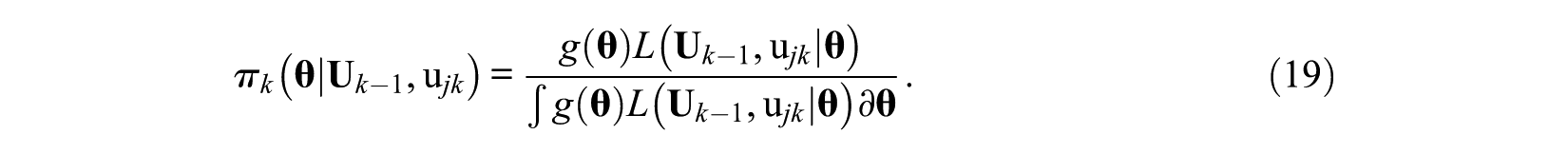
In standard Bayesian methods, the prior distribution
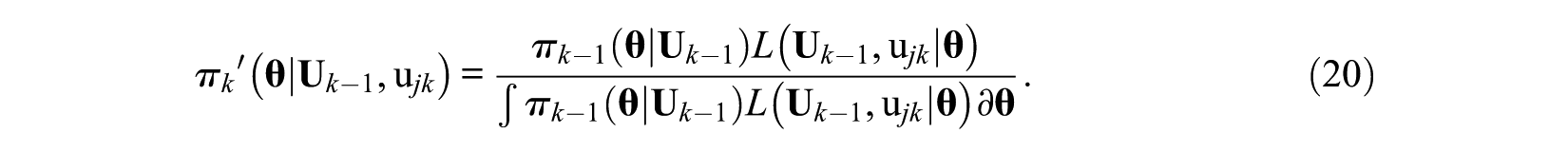
When
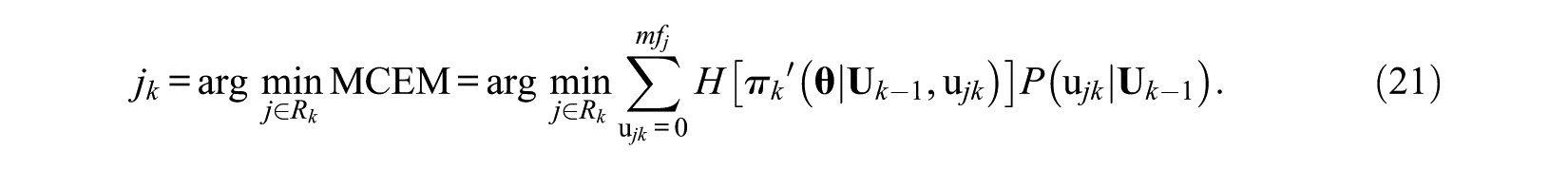
By using the updated prior distribution, the MCEM method could extract more information from the responses; therefore, it can be expected to lead a more accurate estimate than CEM at least in the early stage of PMCAT intuitively.
In addition, according to Wang and Chang (2011), the item selection rule of MUI could be rewritten as the difference between two entropy measures:
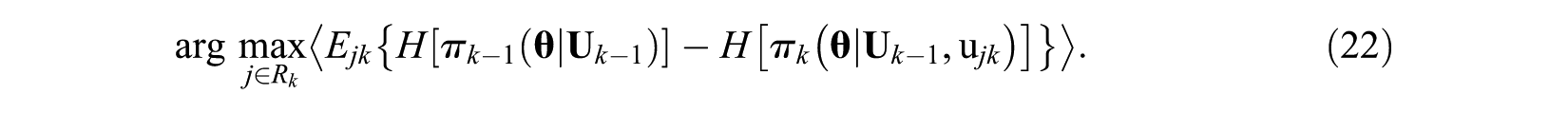
It should be noticed that the first part of this equation
Simulation Studies
Simulation studies are carried out in this research for two important purposes: (a) to detect the statistical properties of the methods proposed in sections “The Extension of Item Selection Methods of MCAT to PMCAT” and “Two New Item Selection Methods of PMCAT” and to demonstrate the feasibility of PMCAT; (b) to verify the performance of the polytomous item selection methods in high dimensional context, and to find out the influence of correlation among multiple abilities on the accuracy and security of PMCAT. To show support to both of these purposes, two separate simulation studies would be implemented.
Simulation Study 1
Simulation conditions
A Monte Carlo simulation study is conducted to compare the performance of the 12 selection strategies, that is, D-optimality, A-optimality, E-optimality, and their Bayesian versions, KI, KB, KLP, MUI, MKB, and MCEM method. Among these criteria, MKB and MCEM method are first introduced in this study.
In the first simulation study, the item pool consists of 450 items following MGRM. Suggested Wang and Chang (2011) and van der Linden (1999) and Lin (2012), the item discrimination parameters
Descriptive Statistics of the Item Banks (M = 450) for Study 1.

This is a fixed-length MCAT and the test length is set to 25. The first item is chosen by random. It is expected that a posteriori (EAP) is used as the latent trait estimation approach when the test is ongoing. The prior distribution is to use the standard bivariate normal distribution. In our examples, the Gauss–Hermite numerical integration formulas from Glas (1992) will be used and the integration is taken over the range of ability
Evaluation criteria
Euclidean distance is taken as a global index of psychometric precision when the number of dimension is 2 (Finkelman et al., 2009; Segall, 1996; Wang & Chang, 2011),
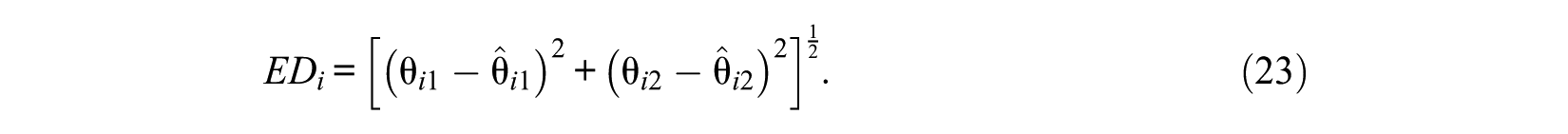
To measure the estimation accuracy of item selection methods at each ability point, the average Euclidean distance (AED) is calculated. And a prior weighted AED (PAED, Finkelman et al., 2009; Wang & Chang, 2011) is adopted as the evaluation criterion of the overall performance of each item selection method under different test lengths
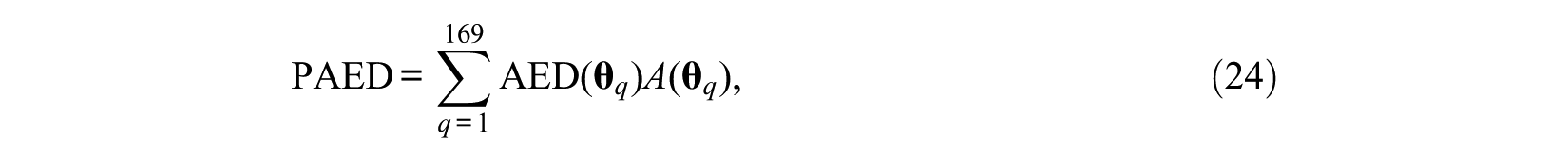
wherein
The exposure rate (ER) and test overlap ration (TOR) index are used to measure the security of the item pool.
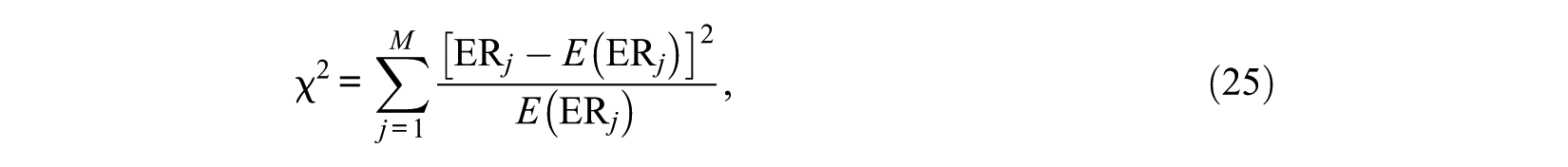
wherein
The test overlap ration (TOR) represents average between-test overlap, which is the arithmetic mean of the between-test overlaps across all possible pairwise comparisons. Therefore, the calculation of TOR is related to the item exposure rate, test length, and number of subjects. Chen, Ankenmann, and Spray (2003) gave its calculation formula as follows:
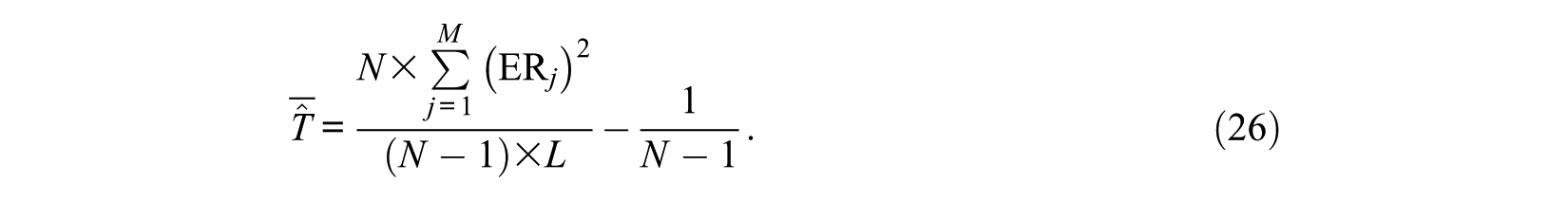
To compare the item selection pattern among item selection methods, the item discriminations throughout the test progression will also be recorded.
Results of Study 1
Ability estimation accuracy
Table 2 shows the overall estimation accuracy (PAED) of each method against test length. As anticipated, the PAED decreases as the test length increases. Except KI method, all the proposed methods achieve relatively high estimate accuracy, which demonstrates their applicability for PMCAT. In details: (1) For the FI-based methods, A-optimality method earns the smallest PAED. (2) There are great differences between the KI method and the other two traditional KL-information-based methods. The KI method obviously performs the worst, while it is hard to distinguish the PAED between KB and MKB method, with the former being slightly better than the latter. (3) As to the methods based on KL information between posteriors, MCEM method generates a little smaller PAED than the other two.
Estimation Accuracy (PAED) of Each Method Against Test Length for Study 1.
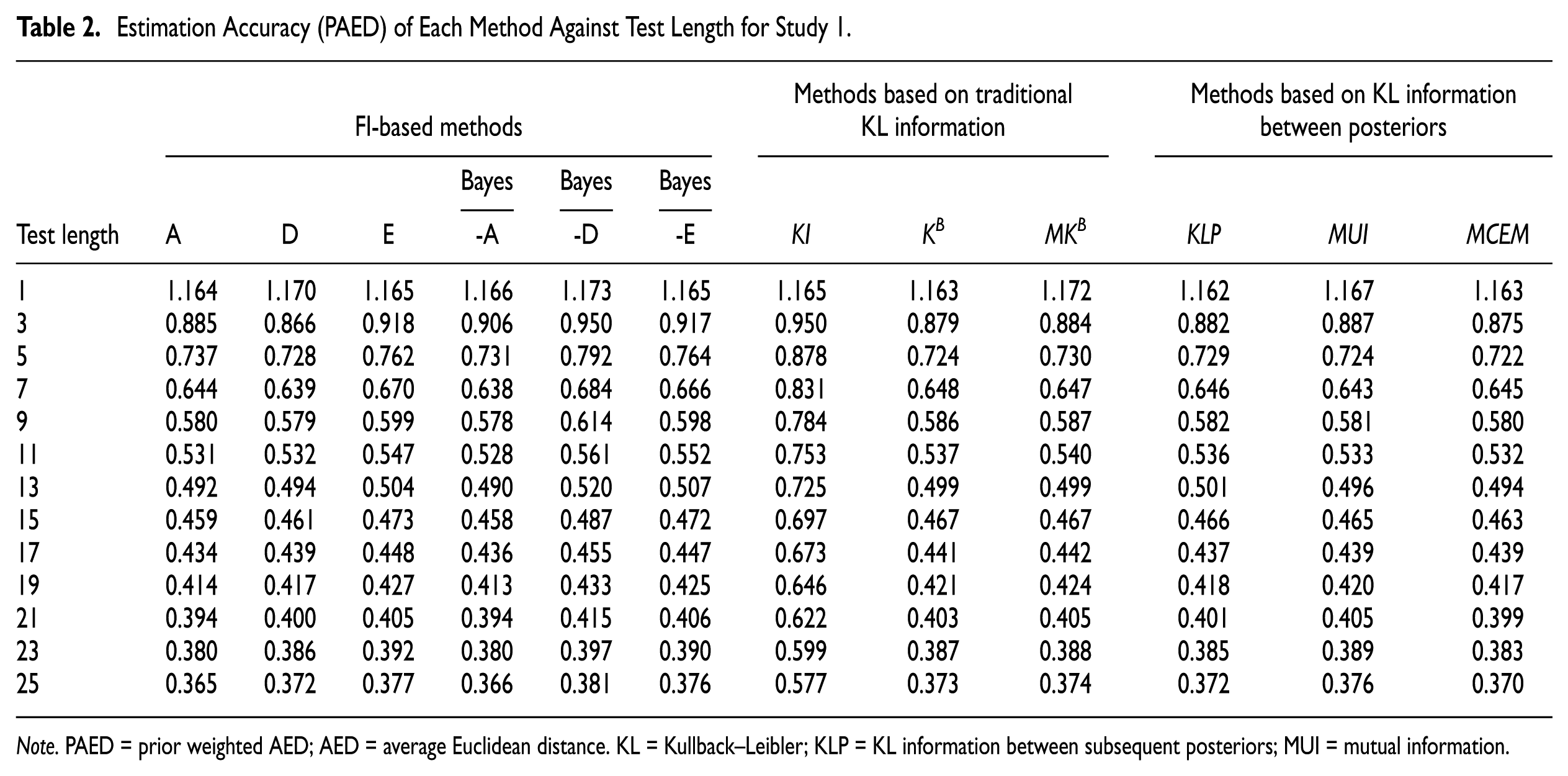
Note. PAED = prior weighted AED; AED = average Euclidean distance. KL = Kullback–Leibler; KLP = KL information between subsequent posteriors; MUI = mutual information.
Conditional ability estimation accuracy
To show the estimation accuracy of the methods at each ability point, the Euclidean distance defined in Equation 23 is averaged over the 100 repeat subjects.
Estimation patterns of 12 item selection methods could be roughly concluded based on the surface and contour plots of the AED, seen in Figure 1 and Figure 1 of Appendix B in the online supporting information. For the surface plot, the lowest height refers to the smallest estimation error. Figure 1 shows that all methods yield lower height on the diagonal
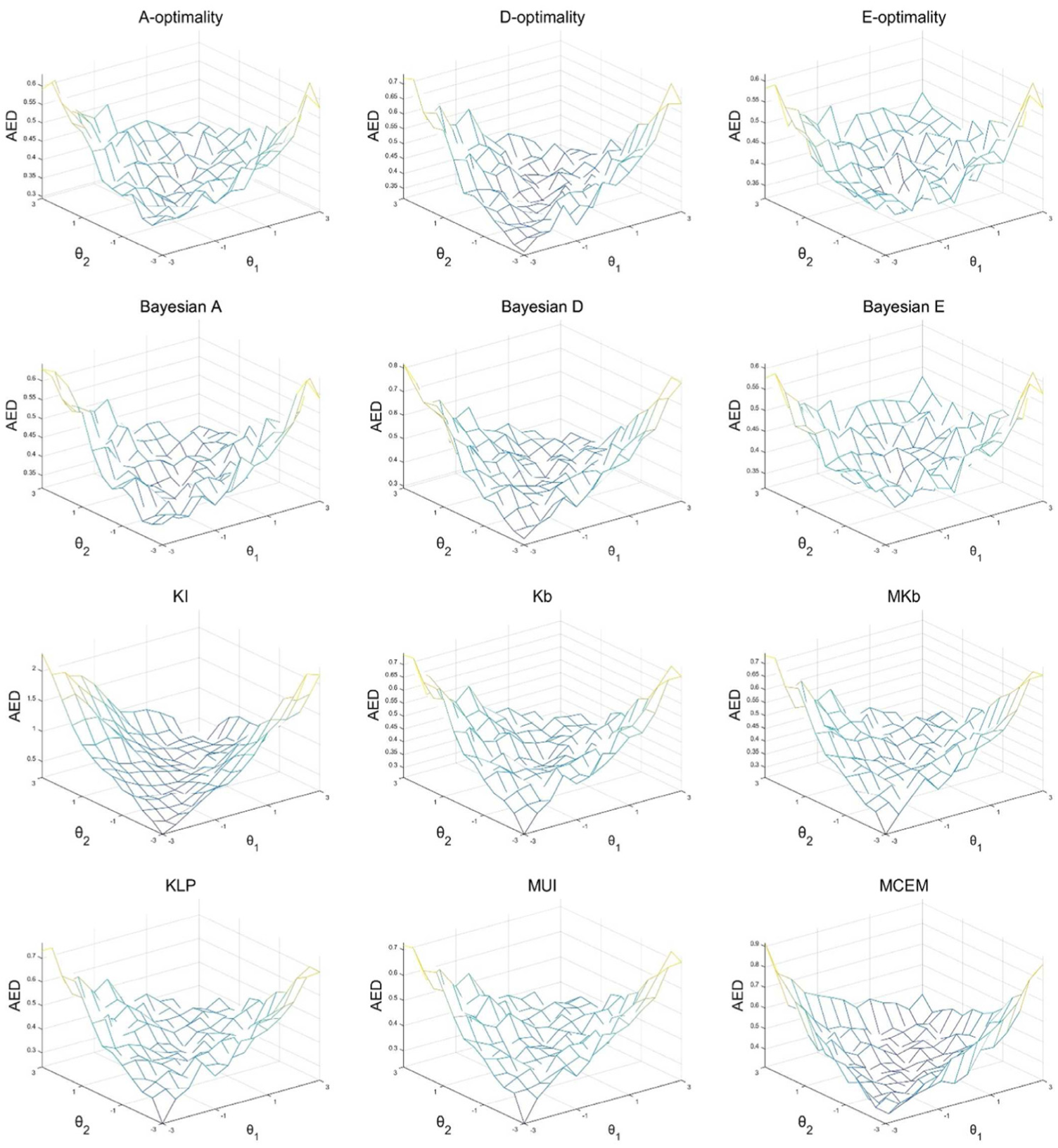
Conditional AED for each method with surface plot for Study 1.
It could be found from the contour plot (Figure 1 of Appendix B) that all methods provide lower AED values in the middle of the theta coordinates. Furthermore, the regions of the lower AED level of E-optimality and Bayesian E-optimality methods are more concentrated in the center, while the shapes of other methods tend to have an angle on the
The exposure rate
Exposure control is an important aspect of adaptive tests, especially for high-stake tests. The following indices are summarized in Table 3 to quantify the equalization of exposure rates: (a) the quartiles of the item exposure rates; (b) the number of overexposed items, which have exposure rates larger than 0.2; (c) the
Exposure rate (L = 25) for Study 1.
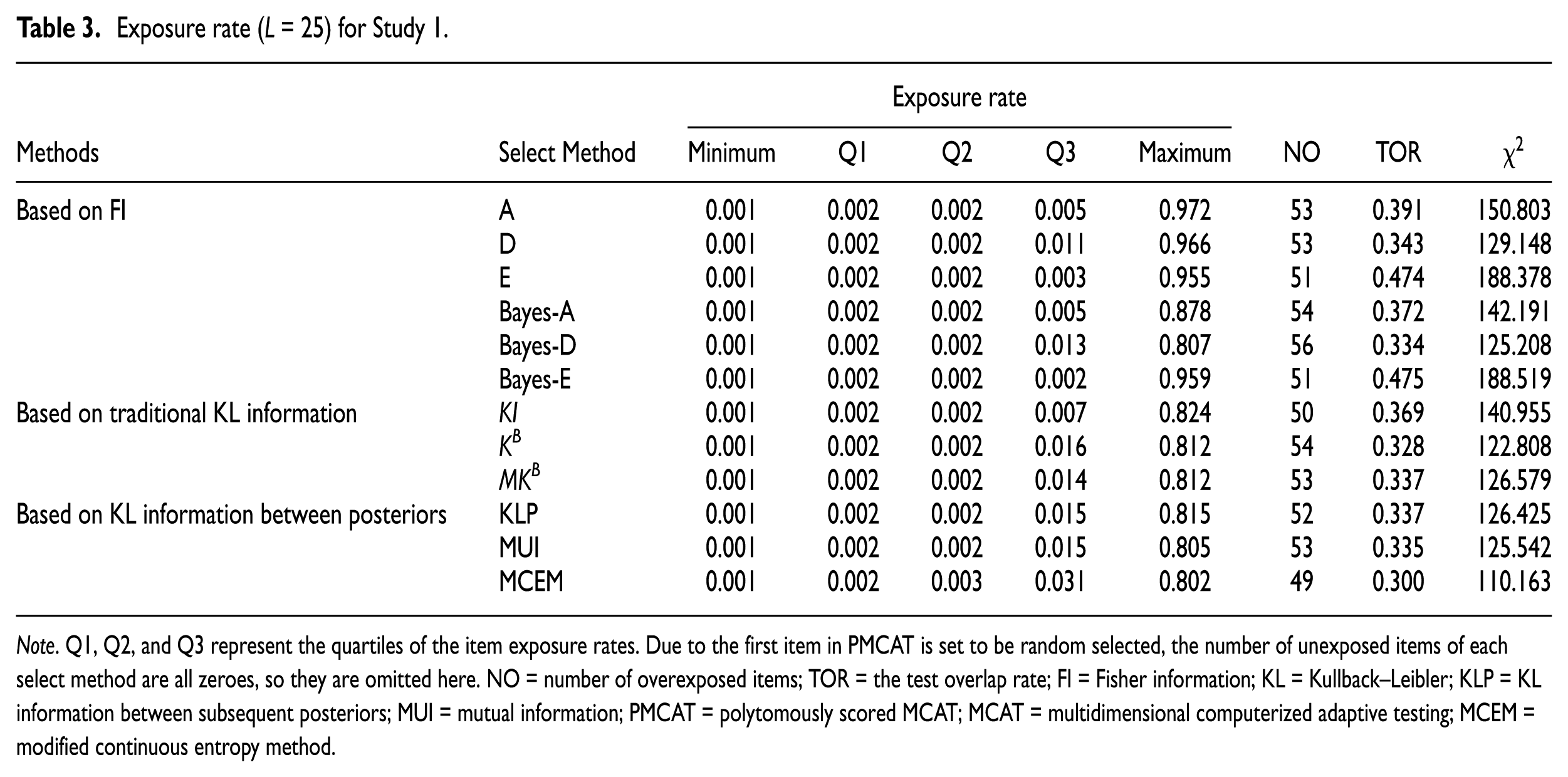
Note. Q1, Q2, and Q3 represent the quartiles of the item exposure rates. Due to the first item in PMCAT is set to be random selected, the number of unexposed items of each select method are all zeroes, so they are omitted here. NO = number of overexposed items; TOR = the test overlap rate; FI = Fisher information; KL = Kullback–Leibler; KLP = KL information between subsequent posteriors; MUI = mutual information; PMCAT = polytomously scored MCAT; MCAT = multidimensional computerized adaptive testing; MCEM = modified continuous entropy method.
It can be easily inferred from Table 3 that the MCEM method has the lowest item exposure rates and gains the least number of overexposed items without sacrificing estimation accuracy. In addition, the distribution of item utilization rates produced by the MCEM method is a little more even, compared with the distribution of item utilization rates generated by other methods. The largest item exposure rate when the A-optimally method is applied is as high as 0.972 compared with the largest item exposure rate of 0.802 when the MCEM is applied. In short, the item exposure rates are relatively less evenly distributed when the methods based on FI matrix are applied compared with that when the methods based on traditional KL information and methods based on the KL information between posteriors are applied.
Item selection pattern
The bubble plot to investigate the item selection patterns can be found in Figure 2 of Appendix B in the online supporting information. In general, the items with low discrimination parameters in both dimensions are barely selected. E-optimality and Bayes E-optimality methods intend to select the items with large discrimination parameter in one dimension while the discrimination parameter in the other dimension is relatively small (see the green shadow). A-optimality and Bayes A-optimality also have this intendancy. KI method prefers the items with high discrimination parameters in both dimensions (see the red shadow); however, it cannot guarantee the best estimate accuracy. The other item selection methods favor the items with high discrimination parameters in either dimension or one of two dimensions. The investigation of item selection patterns can help us generate more simplified item selection methods based on item parameters. Ensuring a high degree of discrimination parameters in one dimension, and selecting the items with large difference between the discrimination parameters in the two dimensions may get good estimation accuracy. Combined with Figure 1, the items with high discrimination parameters in both dimensions, seen in KI method and E-optimality, might influence the conditional ability estimation accuracy at the
Simulation Study 2
To verify the performance of the polytomous item selection methods in high dimensional context, we conducted the second study with a four-dimensional model. Study 2 also intends to investigate the influence of correlation among multiple abilities on the accuracy and security of PMCAT in high dimension.
Simulation conditions of Study 2
Eight target methods are considered in the simulation: A-optimality, Bayes-A, D-optimality, Bayes-D, KI, KB, MUI, and MCEM. E-optimality, Bayes-E, MKB, and KLP are not considered here in that (a) E-optimality is in lack of robustness in applications with sparse data and its use is not recommended (Mulder & van der Linden, 2009); (b) MKB is very time-consuming when being applied to high dimensional data; and (c) MUI is more robust than KLP with respect to error in ability estimation (Mulder & van der Linden, 2010).
The correlations among multiple measured traits are set to three levels: 0.2, 0.5, and 0.8, which represent low, moderate, and high correlation among abilities, respectively. The examinees are generated by following a common multivariate normal distribution. Because three levels of trait correlation are involved in this study, three populations are used for sampling. They share the same mean vector
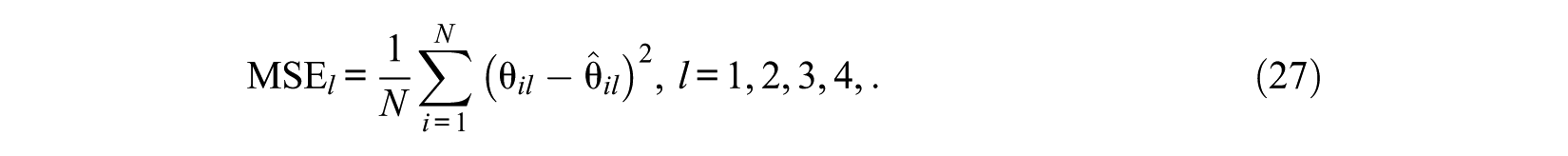
Results of Study 2
The ability estimation accuracy and item exposure rate in the high dimensional case under each correlation levels are reported in Table 4, which indicate that (a) in the multidimensional situation, the estimation accuracy of KI method is still the worst. (b) The estimation accuracy of MUI and MCEM method remains relatively high, and the exposure rate of MCEM is lower than MCEM. (c) Except for KI method, the estimation accuracy of A-optimality is relatively poor, and the exposure rate is relatively low, which is contrary to the performance of A-optimality in the two-dimensional case. Figure 2 shows the influence of correlation on estimation accuracy and item pool security. From the figure, we can clearly see that (a) for most strategies, the conditions of r = 0.2 and r = 0.5 have very similar results, while r = 0.8 yields lower MSE than the former two conditions. For the KI method, the MSE and AED decrease significantly with the increase of correlation. (b) The item exposure rates decrease as the correlation increases.
MSE AED and Exposure Rate of PMCAT With Different Correlation Levels.
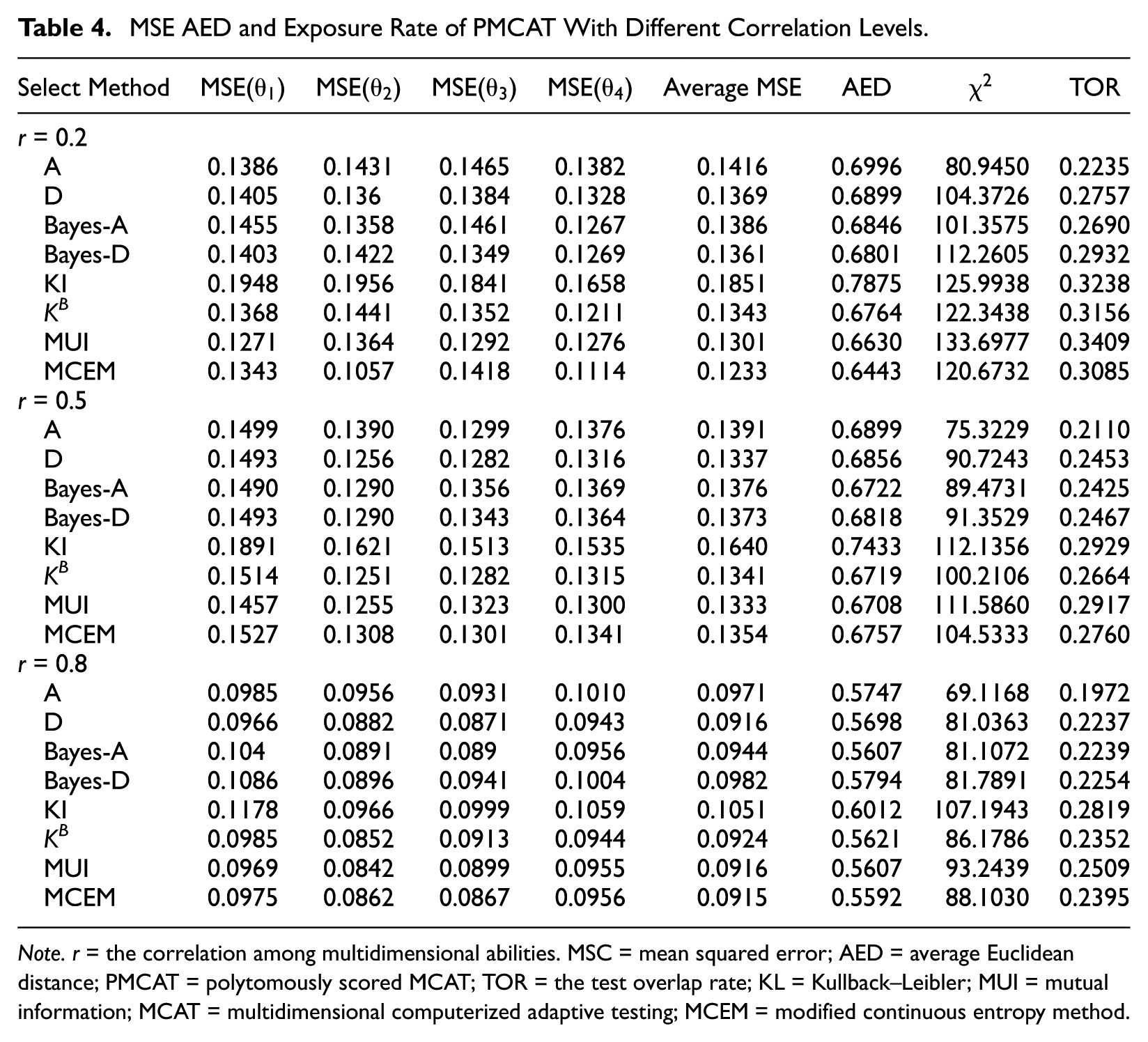
Note. r = the correlation among multidimensional abilities. MSC = mean squared error; AED = average Euclidean distance; PMCAT = polytomously scored MCAT; TOR = the test overlap rate; KL = Kullback–Leibler; MUI = mutual information; MCAT = multidimensional computerized adaptive testing; MCEM = modified continuous entropy method.
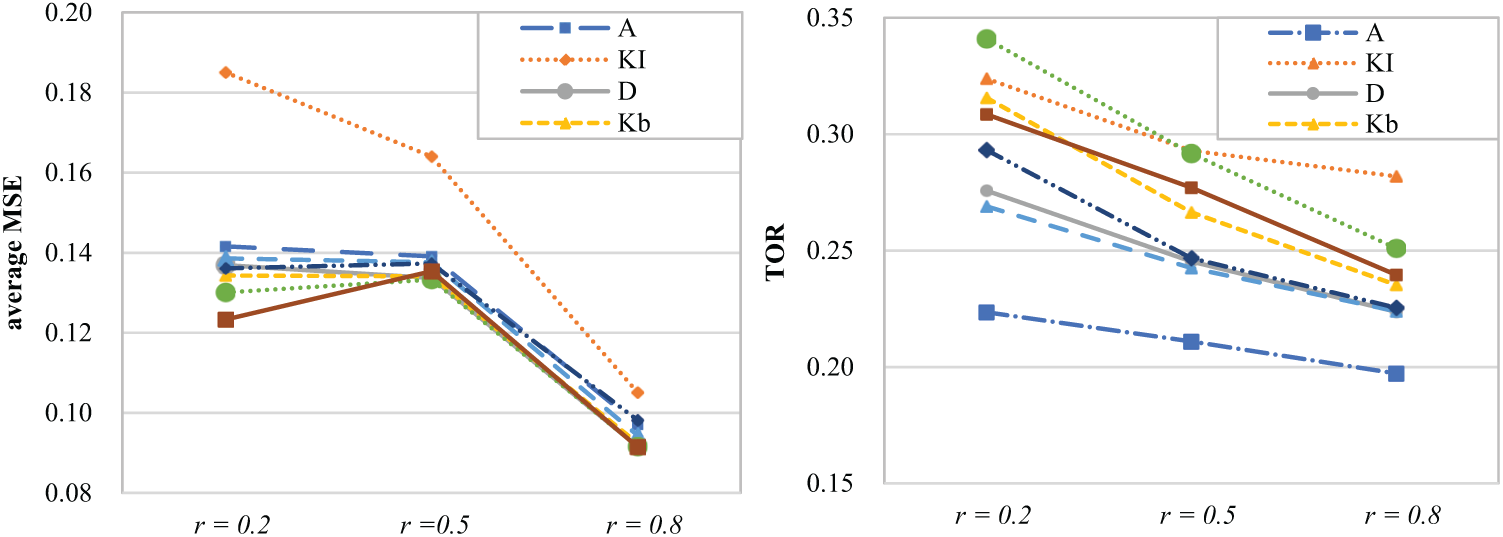
Average MSE and TOR of PMCAT with different correlation levels for Study 2.
Summary and Discussion
The research of MCAT delivering polytomous items has both theoretical and practical significance. Several selection criteria in PMCAT were extended to fit polytomous MIRT model in this study, and two new item selection methods had been proposed. Two simulation studies were carried out to compare the performance of the PMCAT under different conditions. The PMCAT of two dimensional and higher dimensional would be discussed separately in the following.
When only two dimensions are considered, the proposed
From the profile of estimate accuracy, most of the extended selection criteria for PMCAT are feasible except KI method which shows relatively lower estimation precision. It is consistent with the previous study on dichotomous item selection methods (Wang & Chang, 2011) and polytomous item selection methods (Lin, 2012), compared with D-optimal, MUI, CEM, and KI method. It may be because that items with larger KI do not necessarily provide higher power for discriminating
Mulder and van der Linden (2009) assumed that E-optimality was unfavorable for MCAT because of its instability. However, E-optimality and Bayes E-optimality performed well in simulation study 1. It may be because E-optimality is in lack of robustness in applications with sparse data (Mulder & van der Linden, 2009), but the FI matrix under two-dimensional case in this study is not a sparse one.
Furthermore, some conclusions can also be obtained under some given conditions. First, A-optimality,
Last, by utilizing high dimension matrix and parallel computing technique instead of loop statement in the programming of using MATLAB software, this research also achieved high computing speed. (When calculating the selection index, the remaining items are represented by a number of items × number of response categories × number of integral node matrix, and the loop between items is replaced by matrix multiplication. So, the item selection index of each remaining items can be calculated simultaneously). When the two dimensional study was implemented, under the operating environment of using an ordinary laptop computer (i5-3320M CPU@2.6GHz, RAM 4.00G), except the MKB method (needs about 2 s), all the criteria cost less than 0.4 s of each replication finishing 25 items, which meets the time requirements of CAT.
Above all, Simulation Study 1 reflects that the polytomous methods in the study are all feasible to the two-dimensional PMCAT, except for KI method.
The findings of high-dimensional PMCAT with different correlation levels suggest that the multivariate KI method is not recommended in PMCAT for it could not satisfy the accuracy requirement in the four-dimensional case either. Compared with other methods, A-optimality method earns the relativity poor estimation accuracy in the four-dimensional case rather than the highest estimation accuracy in the two-dimensional case, which might indicate the unstable performance of A-optimality in high-dimensional context. Despite of the popularity of the optimality-based criteria in this study, they may behave unfavorably when being used for item selection in high-dimensional MCAT, because they involve taking the inverse or calculating the determinant of the FI matrix, which may run into numerical difficulty if the information matrix is singular or near singular. Besides, MUI and MCEM keep relatively high estimation accuracy, especially when r = 0.2 and r = 0.8, MCEM earns the highest estimation accuracy of all. Although their exposure rates are higher than the optimality-based criteria, the exposure rate of MCEM is still less than the MUI (the same to original CEM) method.
In addition, except for KI method, the correlativity has an impact on estimation accuracy only when the correlation among ability dimensions is higher than medium. And the estimation error of KI method drops dramatically while the correlation becomes larger. This suggests that the effect of attribute correlation is not linear. Moreover, the greater the correlation among ability dimensions is, the lower the item exposure rate would be.
Last, the time of computing in four-dimensional case gets longer than that in two-dimensional case, especially for the algorithms using integrals. The FI-based criteria cost about 0.5 s of each replication finishing 20 items, while the KI-based criteria (all contain integral operations) cost about half a minute. It is practical to identify simpler and equally efficient methods that can reduce the computational intensity in higher dimensional structure.
This represents an initial step in the study of item selection strategies for PMCAT. Based on the research, as a next step, it would be interesting to investigate item selection under various conditions. To make the PMCAT become applicable in real work, it is necessary to discuss the nonstatistical factors, such as item exposure control, content constraints, and so on. Moreover, the practical precondition of PMCAT is the item pool consisting of considerable number of items that have been well calibrated. The item parameter equating, item online calibration, and other issues, which may be faced in the building of item pool, must be further discussed. MCAT will become one of main test delivery approaches in the future testing thanks to its diagnostic feature. Furthermore, polytomous items should be applied into the test for their strength in providing more information and testing the complicated abilities and skills. Research in MCAT test using polytomous items should be investigated profoundly from both theoretical perspective and practical application. To facilitate information, the simulation study seems promising in how researchers and actual users could potentially choose item selection method when dealing with polytomous items in MCAT in the studied context, particularly when the MGRM is considered.
Supplementary Material
Supplementary Material, Online_Appendix – Item Selection Methods in Multidimensional Computerized Adaptive Testing With Polytomously Scored Items
Supplementary Material, Online_Appendix for Item Selection Methods in Multidimensional Computerized Adaptive Testing With Polytomously Scored Items by Dongbo Tu, Yuting Han, Yan Cai and Xuliang Gao in Applied Psychological Measurement
Footnotes
Acknowledgements
Useful suggestions given by the anonymous reviewers are acknowledged.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article is supported by National Natural Science Foundation of China (31660278 and 31760288).
Supplemental Material
Supplemental material is available for this article online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.