
Abstract
This study introduces a novel structure-based classification (SBC) framework that leverages pairwise distance representations of rating data to enhance classification performance while mitigating individual differences in scale usage. Unlike conventional feature-based approaches that rely on absolute rating scores, SBC transforms rating data into structured representations by computing pairwise distances between rating dimensions. This transformation captures the relational structure of ratings, ensuring consistency between training and test datasets and enhancing model robustness. To evaluate the effectiveness of this approach, we conducted a simulation study in which participants rated stimuli across multiple affective dimensions, with systematic individual differences in scale usage. The results demonstrated that SBC successfully classified affective stimuli despite these variations, performing comparably to traditional classification methods. The findings suggest that relational structures among rating dimensions contain meaningful information for affective classification, akin to functional connectivity approaches in cognitive neuroscience. By focusing on rating interdependencies as well as absolute values, SBC provides a robust and generalizable method for analyzing subjective responses, with implications for psychological research.
Introduction
This study employs a novel structure-based classification (SBC) framework that utilizes pairwise distance representations of rating data. Unlike conventional classification approaches that directly use rating scores as features, our method transforms the data into a structured form by computing pairwise distances between rating dimensions. This transformation ensures consistency between training and test datasets while capturing higher-order relationships between ratings. Similar approaches have been explored in the context of network-based analyses, where relationships among data points reveal deeper insights than absolute values alone (Diedrichsen & Kriegeskorte, 2017; Kriegeskorte et al., 2008).
A key advantage of this method is its focus on the structural patterns of ratings rather than their absolute values. Traditional approaches rely on raw scores assigned to each rating dimension, but these scores can be highly susceptible to individual differences in scale usage (Heine et al., 2002; Schwarz, 1999). In self-report studies, participants often exhibit idiosyncratic tendencies, such as response style biases or scale contraction and expansion effects, which complicate direct score-based analyses (Friedman & Amoo, 1999). Moreover, when class differences are manifested in the inter-item correlation structure rather than in mean levels, for example, when two groups yield identical average ratings but differ in how ratings co-vary, traditional score-based classifiers fail to distinguish them, whereas SBC can exploit those relational differences to achieve reliable separation. Our approach mitigates this issue by emphasizing the relationships between ratings rather than their absolute magnitudes. This is particularly beneficial in psychological research, where individual variations in scale usage pose a challenge to data comparability across participants.
Furthermore, this approach aligns with functional connectivity analyses in cognitive neuroscience, where the emphasis is on interactions between brain regions rather than their absolute activation values (Friston, 2011; Smith et al., 2013). Analogously, our method examines interdependencies between rating dimensions, offering a novel perspective on affective and cognitive structures. If successful, this method will suggest that the structural organization of ratings, rather than their magnitudes, plays a crucial role in classification tasks, much like network-based models of cognition and emotion (Barrett et al., 2019).
By leveraging pairwise distance representations, this study aims to provide a robust and theoretically grounded classification method applicable to psychological and affect research. The success of this approach would highlight the importance of rating structures in emotion classification, potentially leading to new insights into affective processing and measurement strategies.
Data Representation
Let
For training, we construct the feature representations as follows. For each stimulus
Suppose |R| = 4 (ratings A,B,C,D) and |P|-1 = 3 participants. Computing Euclidean distances between each pair of columns yields a 4 × 4
For the test fold, the transformation follows the same procedure. For each stimulus
With the training and test representations constructed, the classification procedure applies to a chosen classification algorithm (e.g., support vector machines, SVM) using the feature vectors
Simulation Study
To demonstrate the clear advantage of SBC when class differences reside in inter-scale relationships rather than in marginal score distributions, we conducted a focused simulation using two stimulus classes (A, B) and four rating dimensions (R = 4). In this scenario, both classes share identical per-dimension means and variances, yet exhibit opposing covariance structures. We show that a traditional SVM on raw scores remains at chance, whereas SBC exploiting pairwise distance features achieves successful discrimination.
Data Generation
We generated synthetic datasets for Classes A and B, each comprising 100 observations on four rating dimensions. To eliminate marginal differences, both classes were assigned the same mean vector μ = [5,5,5,5] and unit variance on each dimension. Class-specific structure was introduced via covariance matrices whose off-diagonal entries were set to ±ρ. Specifically, we systematically varied the correlation magnitude ρ across nine levels from 0.1 to 0.9 in 0.1 increments, so that dimensions one and two and dimensions three and four were positively correlated (+ρ) in Class A and negatively correlated (−ρ) in Class B, with the sign inverted for Class B. Multivariate normal samples were drawn as XsA∼N(μ, ΣA) and XsB∼N(μ,ΣB), yielding a combined dataset of size 200 × 4 with binary labels. To obtain stable performance estimates, we repeated the entire procedure 100 times with newly generated data.
Classification Procedure
We trained a linear support vector machine on the raw four-dimensional rating vectors within each training fold and evaluated its accuracy on the corresponding test fold. The SBC method, by contrast, first computed the 4 × 4 matrix of pairwise Euclidean distances among the four dimensions in the training set and extracted its six off-diagonal entries as a six-dimensional feature vector for each observation. A linear SVM was then trained on these distance-based features. During testing, we computed the distances from each test observation to the training dimensions, again producing six-dimensional feature vectors, and applied the trained SVM to obtain predictions. We applied ten-fold cross-validation to each of traditional and SBC classifications.
Results
Figure 1 depicts the ten-fold cross-validation accuracies (averaged over 100 replications) for the traditional classification and the SBC approach method across nine levels of inter-dimension correlation ρ∈{0.1,0.2,…,0.9}. As expected, when ρ = 0.1, both methods perform at chance and a paired-sample t-test yields t = −0.0375, p = 0.9701, indicating no significant difference. However, starting at ρ = 0.2, SBC rapidly outperforms the traditional approach. The t-statistics become increasingly negative (t = −6.28 at ρ = 0.2, t = −13.37 at ρ = 0.3, up to t = −68.28 at ρ = 0.9), with all corresponding p-values falling below 0.001. This pattern demonstrates that as the true covariance structure between dimensions grows stronger, SBC achieves substantially higher accuracy than the raw-score classification with the performance gap widening monotonically with ρ. Importantly, these differences are highly robust across replications, reflecting SBC’s unique ability to leverage inter-item relationships when marginal distributions alone are uninformative. Ten‐Fold Cross‐Validation Accuracies for the Traditional Raw‐Score SVM (dotted red) and the Structure‐Based Classification (SBC; solid blue) as a Function of Inter-Dimension Correlation ρ. Each boxplot summarizes accuracy over 100 replications, with the white circle indicating the mean across replications. Outliers are shown as + symbols. Vertical whiskers represent the 5th to 95th percentile range across replications. When ρ is low (0.1–0.3), both methods perform near chance (∼50 %), but as ρ increases, SBC accuracy rises linearly to over 90 % while traditional accuracy remains near 50–60 %, demonstrating SBC’s ability to exploit covariance structure for robust classification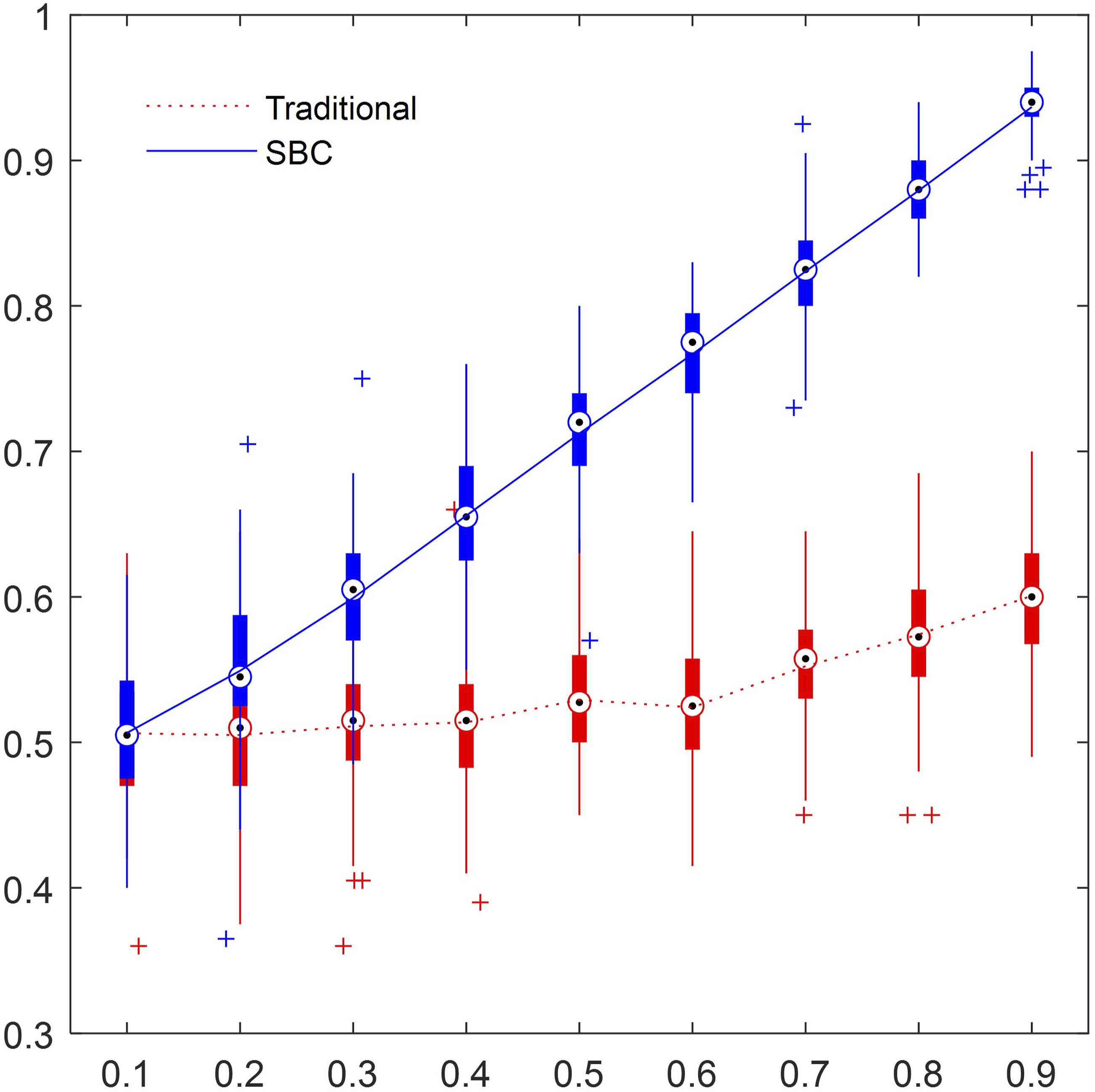
In an independent empirical evaluation using taste- and music-induced affect ratings (Park & Kim, 2024), SBC and traditional SVM achieved comparable four-way classification accuracies (taste: 0.7634 vs. 0.7902; music: 0.7098 vs. 0.7768), confirming that SBC’s relational features generalize to real data (see Supplemental).
Discussion
The SBC method prioritizes inter-item relationships over absolute scores, offering clear advantages when class distinctions are encoded in covariance patterns rather than in mean levels. In many psychological contexts, such as symptom-network analysis in clinical populations (Borsboom & Cramer, 2013), personality facet interdependencies (Schmitt et al., 2007), or latent profile shifts in cognitive skill sets (Mayer et al., 2008), individuals may endorse similar overall levels on each scale but differ markedly in how those ratings co-vary. For example, two patients might both report moderate levels of anxiety, sleep disturbance, and irritability, yet for one patient those symptoms co-occur tightly (high positive covariance), while for the other they oscillate independently or even inversely. Traditional classifiers, which see only identical marginal means and variances, will fail to distinguish these profiles, whereas SBC leverages the divergent covariance structure to achieve reliable classification.
Our simulation clearly demonstrated this phenomenon. Standard classification on raw scores lingered at chance when class differences were purely relational, while SBC accuracy rose above 90 % as covariance magnitude increased. Such scenarios are common in psychological measurement. In affective neuroscience, emotional network dynamics often manifest as shifting co-activation patterns rather than amplitude changes (Koban et al., 2019). In organizational psychology, employee engagement and burnout factors may present identical average scores yet differ in their inter-factor coupling (Schaufeli et al., 2009). Even in cross-cultural survey research, reference-group effects can equalize item means while altering response correlations (Heine et al., 2002).
Beyond these examples, SBC is naturally aligned with network psychometrics, which conceptualizes psychological constructs as systems of interacting components rather than latent entities (Epskamp et al., 2018). By transforming rating data into distance matrices, SBC operationalizes these interactions directly for classification tasks.
Several limitations and future directions warrant mention. First, applying SBC to categorical or ordinal scales (e.g., Likert with unequal intervals) may require alternative distance metrics or embedding techniques (Gollan et al., 2016). Second, as the number of rating dimensions grows, the pairwise computations may become burdensome. Approximate methods or pre-processing (e.g., principal components analysis) could mitigate this. Finally, SBC could be extended to longitudinal data, capturing dynamic covariance shifts over time, or integrated with graph-based features to enrich classification in complex psychological phenomena.
In sum, SBC provides a robust framework for contexts where relational structure rather than absolute ratings drives meaningful distinctions. Its conceptual harmony with network models and demonstrated empirical effectiveness suggest broad applicability across psychological and affective sciences.
Supplemental Material
Supplemental Material - Structure-Based Classification Approach
Supplemental Material for Structure-Based Classification Approach by Jongwan Kim in Applied Psychological Measurement
Footnotes
Funding
The research received funding from the Brain Korea 21 fourth project of the National Research Foundation of Korea (Jeonbuk National University, Psychology Department no. 4199990714213).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.