
Abstract
Choosing suitable estimation methods for cognitive diagnostic models (CDMs) is critical. However, practitioners often face issues like non-convergence, boundary estimates, extreme values, and unstable suboptimal solutions, which affect the accuracy and reliability of parameter estimates. In this study, we compared expectation–maximization (EM), Bayesian modal estimation (BM), their monotonic constraint variants (EMM and BMM), and variational Bayes (VB) methods. A simulation study was conducted, manipulating factors such as sample size (50, 200, 1000), test length (15, 30), item quality (high, low), and attribute distribution (uniform and multivariate normal). The performance was assessed based on the empirical frequency of each issue, the recovery accuracy of the parameters, and the sensitivity to algorithm initialization. The results, analyzed using the generalized deterministic inputs noisy “and” gate model, reveal three main findings. First, an insufficient sample size was identified as a key factor in problems related to parameter estimation. Second, methods that incorporate prior information (BM and VB) exhibited fewer cases of non-convergence and extreme estimates than EM. Third, the sensitivity analysis showed that the stability of solutions was affected by the choice of initial values, emphasizing the need for proper initialization to reduce the risk of becoming trapped in local suboptimal solutions. This systematic comparison demonstrates that no single estimator is universally superior, and the choice depends on practical constraints. Our findings offer evidence-based guidance for selecting context-sensitive methods, thereby improving the validity of CDMs in real-world applications.
Keywords
Introduction
Cognitive diagnostic models (CDMs), or diagnostic classification models (DCMs), provide a statistical framework for evaluating examinees’ detailed latent attributes such as knowledge, strategies, skills, and psychological disorders. These models are commonly used in education, psychology, and psychiatry (Paulsen & Valdivia, 2021; Rupp et al., 2010). Accurate parameter estimation is crucial not only for diagnosing students’ strengths and weaknesses to guide personalized interventions but also for supporting statistical applications, such as item-level model comparison (Buse, 1982; de la Torre & Lee, 2013) and the detection of differential item functioning (Hou et al., 2014; Milewski & Baron, 2002).
Marginalized maximum likelihood estimation using the expectation-maximization algorithm (MLE-EM or EM; de la Torre, 2009, 2011) is an important method for estimating the parameters of CDMs. Packages in R, such as CDM (George et al., 2016) and GDINA (Ma & de la Torre, 2020), as well as software like flexMIRT, Latent GOLD, mdltm, and Mplus (Sen & Terzi, 2020; Templin & Hoffman, 2013), implement MLE-EM for estimating parameters of CDMs. Several extensions have been developed to enhance MLE-EM, including monotonic constraint EM (EMM), Bayes modal estimation (BM), monotonic constraint BM (BMM), and variational Bayes inference (VB; Ma & Jiang, 2021; Yamaguchi & Okada, 2020).
Despite its widespread use, MLE-EM is very sensitive to sample characteristics (Paulsen & Valdivia, 2021; Sessoms & Henson, 2018; Wang et al., 2024). In addition to concerns about general accuracy, practitioners often face several undesirable outcomes, including non-convergence (Templin & Bradshaw, 2014), boundary or extreme parameter estimates (DeCarlo, 2011; Mislevy, 1986), and a tendency to converge to local rather than global optima. These issues can significantly undermine the validity and interpretability of CDMs. In the following sections, we discuss each of these issues in turn.
Boundary Estimates
For DCMs, boundary estimates may occur when parameter values approach the limits of the parameter space (e.g., near 0 or 1) (DeCarlo, 2011; Garre & Vermunt, 2006; Maris, 1999; Yamaguchi, 2023). The sample size requirements are always influenced by the number of attributes involved and their distribution across the items. When test items require many attributes, especially all or most, insufficient sample sizes can result in sparse data for certain attribute profiles, pushing estimates toward the boundaries. This problem is particularly severe when a large number of attributes are combined with a complex Q-matrix (Yamaguchi, 2023). When parameters are close to boundary values, the Fisher matrix can become unstable, causing standard errors (SEs) to be inaccurate. Although Bayesian methods with informative priors have been proposed to address this issue (Harwell & Janosky, 1991; Ma & Jiang, 2021; Mislevy, 1986; Swaminathan & Gifford, 1986), most current approaches overlook structural parameters, which represent the proportions of attribute mastery profiles (Liu et al., 2022). Additionally, choosing appropriate priors in practice is challenging, and misspecified priors can introduce significant bias into parameter estimates (DeMars & Satkus, 2024).
Extreme Parameter Values
Extreme parameter estimates—abnormally high or low values—occur when the observed data lack sufficient power to distinguish among specific parameters (e.g., main effects and interaction effects) (Mislevy, 1986). Consequently, estimation algorithms often fail to converge on a unique optimal solution, leading to unreliable estimates. This issue is especially critical for item parameters (e.g., those representing main and interaction effects), as extreme values can reduce model interpretability. Although Bayesian regularization can help by limiting extreme estimates, its success depends heavily on the proper specification of prior distributions.
Convergence to Local Optima
When the log-likelihood function is convex, it has a single peak and will converge to the global optimum regardless of the starting point (Balakrishnan et al., 2017). However, the multimodal nature of log-likelihood functions, which is common in discrete latent variable models, often causes the EM algorithm to converge to local optima (Shireman et al., 2017). This issue worsens as more latent components are added (Brusa et al., 2024). In CDMs, the discrete latent structure and model complexity worsen this non-convexity problem. As a result, MLE-EM may get trapped in local optima, which are influenced by the choice of initial values. This leads to suboptimal solutions and slow convergence (Gupta & Chen, 2010; Kang et al., 2023; Kuroda & Geng, 2023; Schepers, 2015). R packages like GDINA typically use a single starting value for EM iterations. The algorithm is sensitive to initial values. Different starting points can produce varying results, which affects the stability and reliability of parameter estimation.
Non-Convergence
The convergence rate is a crucial indicator for assessing the performance of an estimation method (Gupta & Chen, 2010; Philipps et al., 2021; Schepers, 2015). When an iterative parameter estimation method fails to converge during later stages, it produces no usable estimates—not even approximate ones, after extensive computation. The MLE-EM iterates between the E-step and M-step until it meets a convergence criterion or reaches the maximum number of iterations (George et al., 2016; Ma & de la Torre, 2020). Convergence failure is a common problem in parameter estimation for CDMs, especially when the sample size is small. Templin and Bradshaw (2014) reported that only 66% to 89% of replications converged in their simulations. Additionally, an overly lenient (i.e., not sufficiently stringent) tolerance can cause the algorithm to halt prematurely, which can result in an inaccurate solution (Karlis & Xekalaki, 2003; Philipps et al., 2021).
Although new methods (e.g., BMM, VB) have been developed to improve parameter estimation in CDMs, existing research focuses primarily on estimation accuracy. This focus leaves important practical issues inadequately addressed, such as algorithmic convergence, boundary and extreme solutions, and sensitivity to initial values. Therefore, this study systematically compares the estimation accuracy and the prevalence of estimation anomalies (non-convergence, boundary values, extreme estimates, and suboptimal solutions) across estimation methods under varying data conditions. This targeted comparison provides a more comprehensive and practical evaluation, filling a gap not sufficiently explored in prior research. We believe this comparison provides valuable practical insights, providing evidence-based guidance to practitioners in choosing suitable estimation methods for CDMs.
The remainder of this paper is organized as follows. First, we introduce the process of estimating the parameters of CDMs using MLE-EM and its variant methods (EMM, BM, BMM, and VB). Next, we present a simulation study to compare the performance of these methods. Finally, in the “Summary and Discussion” section, we summarize the findings and discuss implications for future research.
Method
An Overview of CDMs
Examinees’ test performances reflect their latent general abilities. Cognitive diagnostic assessment decomposes this abstract ability into specific attributes or skills, where mastery of an attribute indicates possession of the corresponding ability (Paulsen & Valdivia, 2021). CDMs demonstrate the relationship between these latent attributes and item responses (Sen & Terzi, 2020). Based on the theoretical assumptions, CDMs can be categorized as constrained or general models. Popular constrained models include the deterministic input, noisy “and” gate (Haertel, 1989); deterministic input, noisy “or” gate (Templin & Henson, 2006); noisy input, deterministic “and” gate model (Junker & Sijtsma, 2001); and noisy input, deterministic “or” gate (Junker & Sijtsma, 2001). General models, such as the general diagnostic model (von Davier, 2005), the log-linear cognitive diagnostic model (LCDM; Henson et al., 2009), and the generalized deterministic inputs, noisy “and” gate model (G-DINA; de la Torre, 2011), provide more flexible parameterizations. Due to its flexibility and comprehensive implementation in the R package, we focus on the G-DINA model in the next section.
G-DINA Model
Suppose N examinees take a test with J items and K attributes. The response matrix
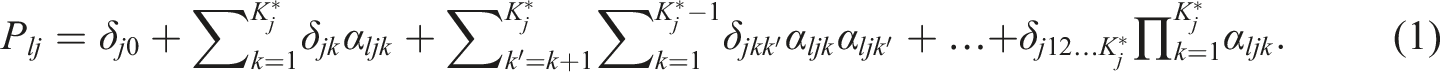
The saturated model has
MLE-EM and Variant Methods for Estimating the Parameters of CDMs
MLE-EM for the G-DINA Model
We use the G-DINA model as an example to illustrate parameter estimation using the MLE-EM. The algorithm starts with an initial set of values, denoted as
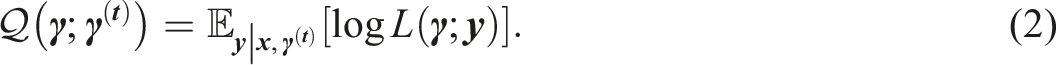
Then, the algorithm calculates the expected posterior probabilities as follows
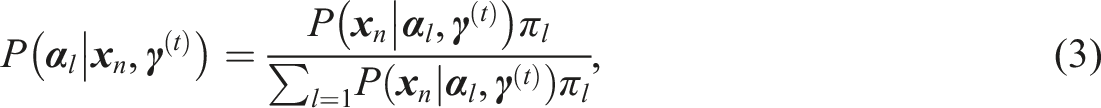


In the maximization step (M-step), these expectations are used to update the parameters to


The updated parameters replace
Bayesian Modal Estimation and Monotonic Constraints
Ma and Jiang (2021) proposed the use of informative priors to improve the MLE-EM estimation in CDMs, and introduced BM estimation for small samples. They demonstrated that when a Beta distribution,
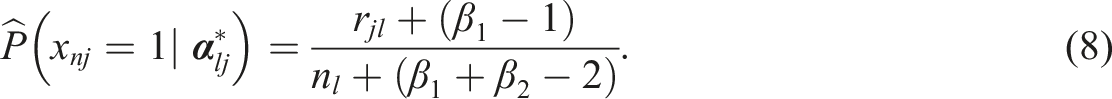
For items measuring multiple attributes, latent groups mastering more attributes should have equal or higher correct-answer probabilities than those mastering fewer. Violations of the monotonicity (e.g.,

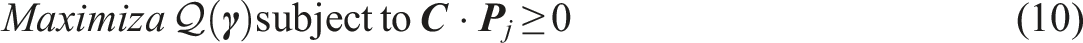
Here,
Variational Bayes Inference Algorithm
Yamaguchi and Okada (2020) developed a VB inference algorithm for parameter estimation in saturated CDMs. In VB, the prior for the correct response probability parameter
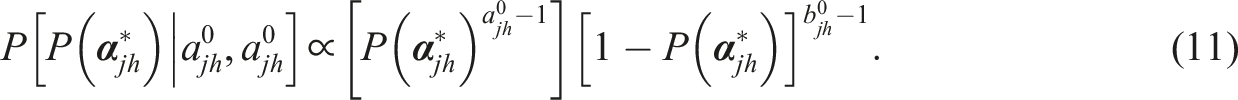
The prior for

The prior for the latent class indicator variable is a categorical distribution

Simulation Study
Design
We manipulated four factors: (1) Sample size (
This simulation study systematically compares the performance of various CDM parameter estimation methods—EM, EMM, BM, BMM, and VB—in addressing common issues such as non-convergence, boundary estimates, extreme values, and local optima. Figure S2 (Appendix) presents the Q-matrices used in the simulation study.
Data Generation
We employed G-DINA as the model for data generation in the simulation study. Data were generated using the simGDINA function from the GDINA package in R. For the high item quality conditions, the true guessing and slipping parameters were set to 0.1. For the low item quality conditions, both parameters were set to 0.2. Under the multivariate normal assumption, the latent abilities of respondents, denoted as
The dichotomous response data were generated by first creating a matrix of correct response probabilities, denoted as
To generate the initial structural parameters
Methods for Comparison
The methods compared in the simulation study included the original EM method (de la Torre, 2011), EMM (Ma & Jiang, 2021), BM (Ma & Jiang, 2021), BMM (Ma & Jiang, 2021), and VB (Yamaguchi & Okada, 2020).
We implemented the EM, EMM, BM, and BMM based on the original code provided by Ma and Jiang (2021). For the EM algorithm, initial values were generated using the procedures described above. Convergence was assessed using a tolerance of 10-8 on the absolute difference in
Criteria
We Evaluated the Following Rates of Problematic Estimates
a. The rate of boundary estimates, defined as parameter values less than 10-5 or greater than 1–10-5. b. The rate of non-convergence, defined as replications where the algorithm failed to converge. c. The rate of extreme parameter estimates, defined as item parameters less than −1 or greater than 1.
The Accuracy of Parameter Estimates Was Evaluated Using Two Metrics
a. The accuracy of correct response parameters (the probabilities of correct answer) was assessed by calculating the mean bias b. The recovery of the attribute profiles was measured by the pattern correct classification rate (PCCR)

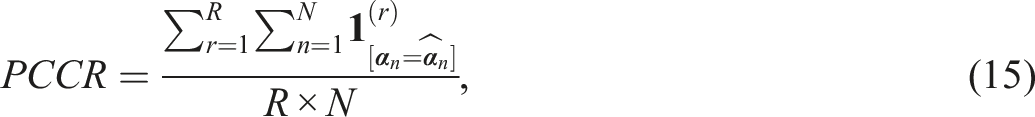
To ensure fair comparisons, criteria (14) and (15) were averaged only over replications in which all compared algorithms converged. This approach ensures that comparisons are based on identical replication sets, thereby avoiding confounding due to convergence proportions. To examine sensitivity to initialization, we performed a separate simulation using a multiple-initialization framework. In this setup, each method was fitted 200 times per replication, with a different set of starting values used for each fitting. This design enables us to isolate and quantify the variability in parameter estimates caused by the choice of initial values.
Sensitivity to Initialization: Unstable Parameter Estimates
Because directly verifying convergence to a global maximum is challenging, we use the stability of parameter estimates across different initializations as a substitute. The basic idea is that if a unique global maximum exists, estimates should be similar regardless of starting points. On the other hand, large differences in estimates from different initializations suggest convergence to different local optima. Therefore, we compared the coefficient of variation (CV) across initializations to empirically evaluate each method’s sensitivity to initialization.
We quantified the stability of each parameter estimate using its CV, calculated from 200 different sets of initial values in each replication. The CV for parameter

Results
Non-Convergence Replications Across all Methods
The Non-Convergence Replications of All Methods
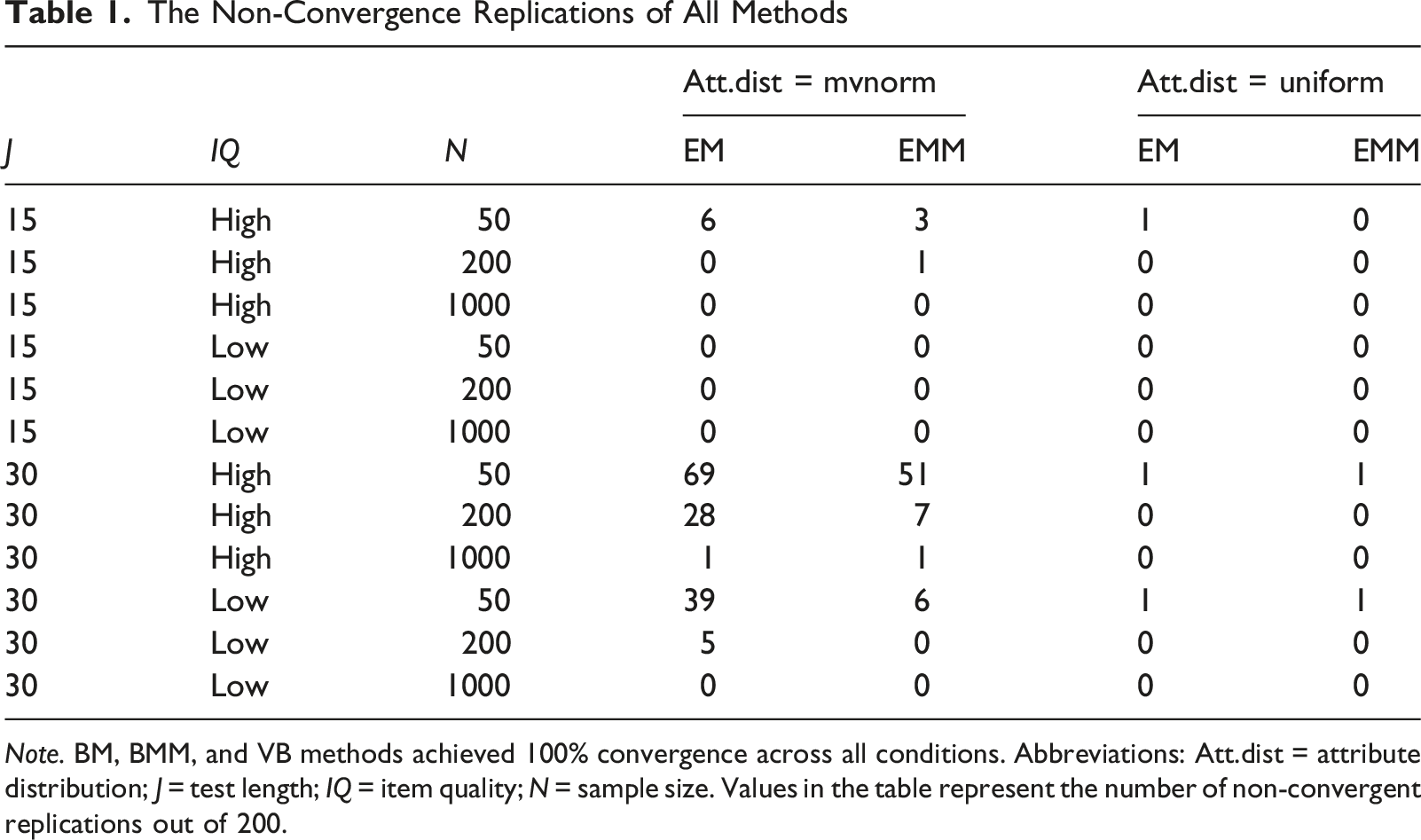
Note. BM, BMM, and VB methods achieved 100% convergence across all conditions. Abbreviations: Att.dist = attribute distribution; J = test length; IQ = item quality; N = sample size. Values in the table represent the number of non-convergent replications out of 200.
We further examined these non-converged cases and observed two patterns. (1) Structural collapse due to empty latent classes. The algorithm terminated with the warning “Nj contains 0.” When there are many latent classes relative to the sample size, some classes receive almost no observations. These cases reflect numerical degeneracy caused by sparse data. (2) The algorithm reaches the maximum number of iterations without meeting the convergence criterion. Examination of the log-likelihood trajectories shows that after an initial phase of rapid improvement, the log-likelihood stabilizes and stays nearly constant over many iterations. However, the maximum parameter change (maxchg) continues to oscillate and does not drop below the convergence tolerance (see Supplemental Figure S3). We tentatively attribute this to flat or weakly identified regions in the later stages of iteration, where local oscillations occur in the parameter space without meaningful improvement in the objective function.
Proportion of Problematic Parameter Estimates
Figures 1 and 2 show the rate of boundary problems for correct response probabilities and structural parameters. Boundary values for response probabilities occurred more often in EM and EMM. This problem was reduced with larger samples and longer tests, and was more frequent under multivariate normal attribute distributions than under uniform distributions. The rate of boundary solutions for structural parameters was much higher than for response probabilities. Except for VB, all estimation methods showed a high rate of boundary solutions in structural parameter estimates. This issue was also reduced by increasing the sample size and test length. The rate of boundary problem for correct response probabilities The rate of boundary problem for structural parameters. Note. Abbreviations: Att. dist = attribute distribution; J = test length; IQ = item quality (1: high, 2: low); N = sample size. Values in the figure represent the rates of boundary problems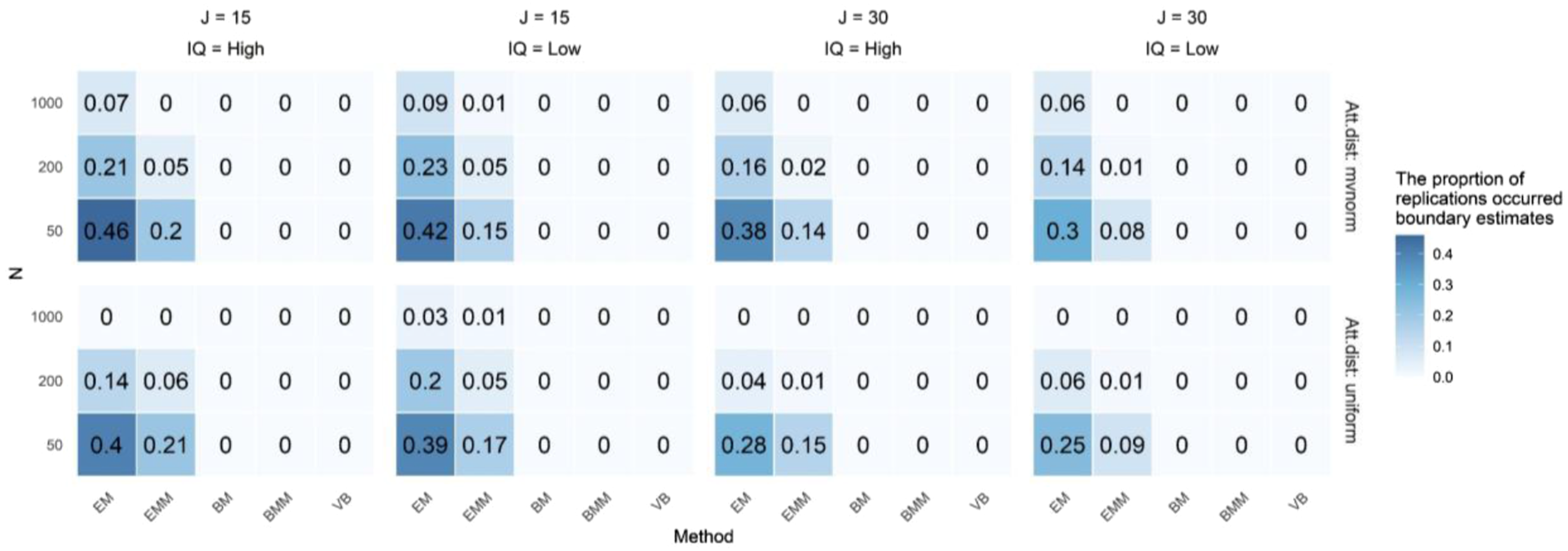
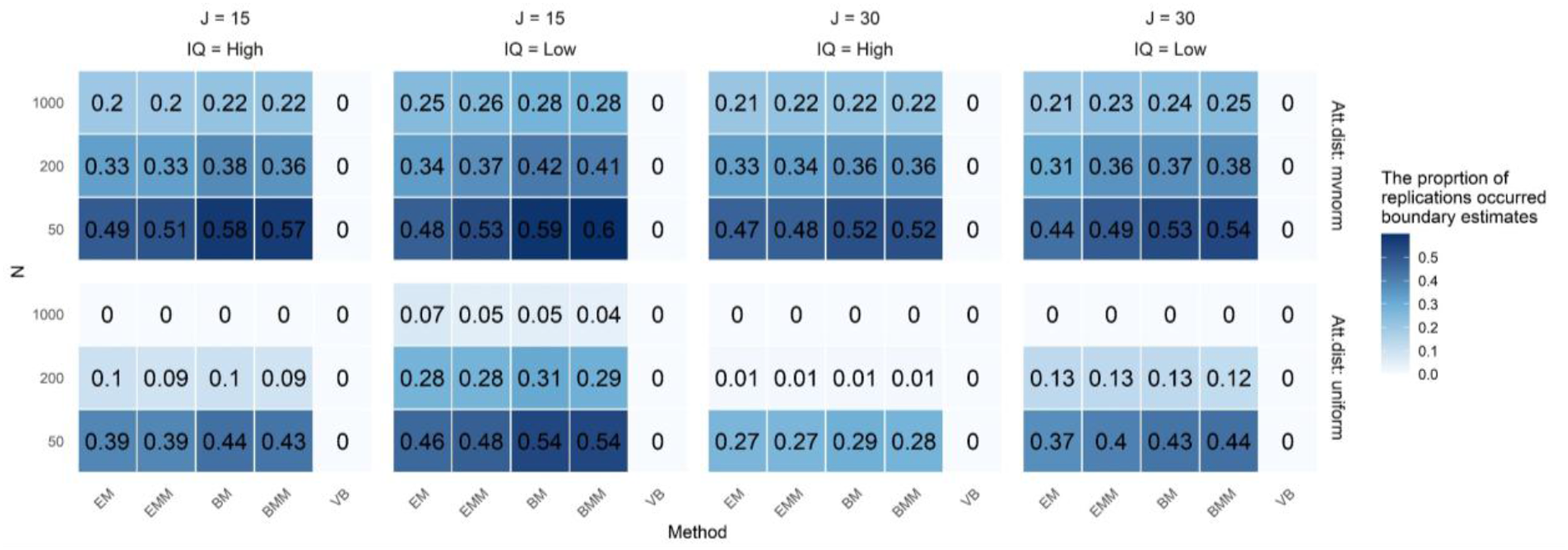
VB showed no boundary estimates for the structural parameters, and this is largely because it uses prior information. While the BM and BMM apply priors solely for the correct response probabilities, VB employs priors for both response probabilities and the structural parameters. This helps regularize estimates and prevents boundary solutions. Further analysis showed that, under the multivariate normal distribution, some attribute mastery patterns appeared infrequently or were missing in the generated data due to sampling error. This scarcity of response data for these rare patterns probably led structural parameter estimates to converge near zero. In real-world applications, such boundary estimates should trigger an examination of the sample and consideration of possible attribute hierarchies. Notably, at a sample size of N = 1000, the occurrence rate decreased significantly, indicating that N = 1000 might serve as a practical benchmark for addressing this issue.
Figure 3 shows the rate of extreme item parameters. Overall, the EM algorithm was most susceptible to this issue, producing the highest rates of extreme problems, especially under conditions of lower item quality, smaller sample sizes, and shorter test lengths. A uniform attribute distribution, compared to a multivariate normal distribution, generally resulted in fewer extreme estimates. The rate of extreme problem. Note. Abbreviations: Att. dist = attribute distribution; J = test length; IQ = item quality (1: High, 2: Low); N = sample size. Values in the figure represent the rates of extreme problems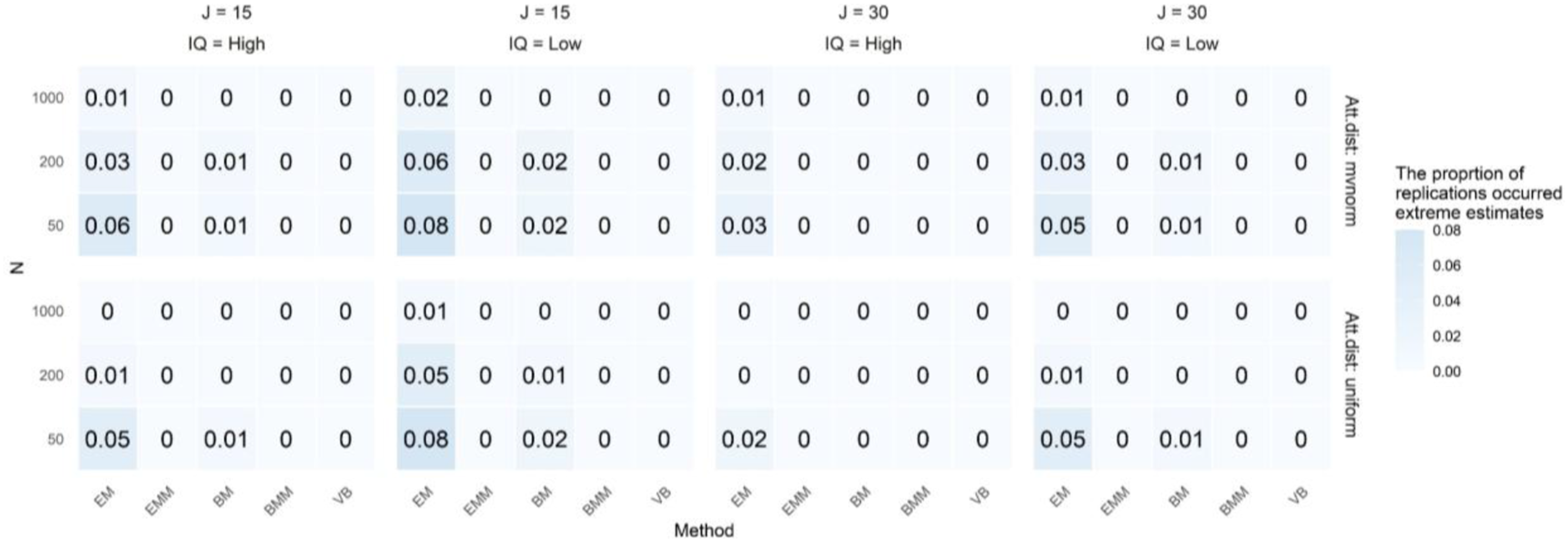
In summary, VB showed better performance in addressing all three issues: non-convergence, boundary estimates, and extreme parameter values. It was the most reliable method in handling non-convergence, which is a clear weakness of the EM method, as well as boundary estimates and extreme parameter values.
These findings support previous research showing that small sample sizes and too many attributes can cause estimation issues (Akbay & de la Torre, 2020; Balakrishnan et al., 2017; Templin & Bradshaw, 2014; Yamaguchi, 2023). VB’s strength comes from its use of informative priors for both item and structural parameters. Proper prior specification is vital in practice because real-world data may involve large sampling errors or hierarchical attribute structures (Akbay & de la Torre, 2020; Balakrishnan et al., 2017; Templin & Bradshaw, 2014).
It is worth noting that the high rates of non-convergence, boundary estimates, and extreme values observed under the N = 50 conditions can be partly attributed to empirical under-identification. In these conditions, the ratio of sample size to freely estimated parameters in the saturated G-DINA model (K = 5) is very low. As this ratio improves at N = 200 and N = 1000, model identifiability increases, and these estimation anomalies decline substantially across all algorithms.
Accuracy of Parameter Estimates
Figure 4 shows a comparison of estimation accuracy based on PCCR and Bias. Recovery metrics were computed using only converged replications. Overall, performance improved consistently with larger sample sizes, longer tests, and higher item quality. In terms of PCCR, the EM method consistently demonstrated the poorest performance, whereas the EMM method slightly outperformed it. Both EM and EMM exhibited more bias in the correct-response parameters than the BM and BMM methods. BMM and BM presented the best overall performance, achieving higher PCCR values and near-zero bias. In contrast, VB exhibited a notable trade-off: it delivered competitive PCCR values, often similar to BMM and BM, but consistently had the worst Bias. For example, under the challenging mvnorm condition (J = 15, IQ = High, N = 50), VB’s PCCR was only surpassed by BM and BMM, but it exhibited significant bias in estimating response probabilities. The parameter recovery of all methods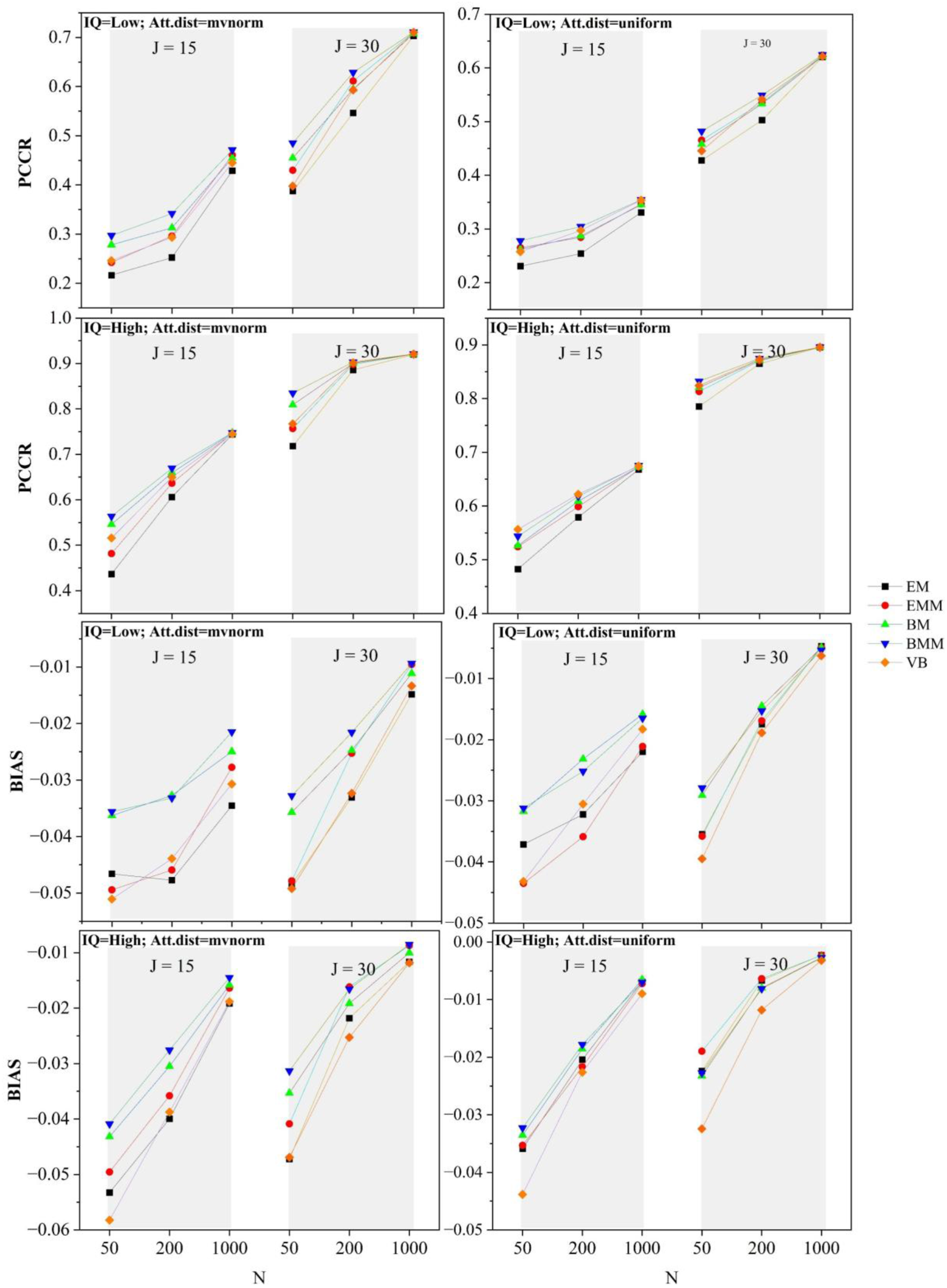
Instances of Monotonicity Constraint Violations
An Example of Noncompliance with Monotonicity Constraints
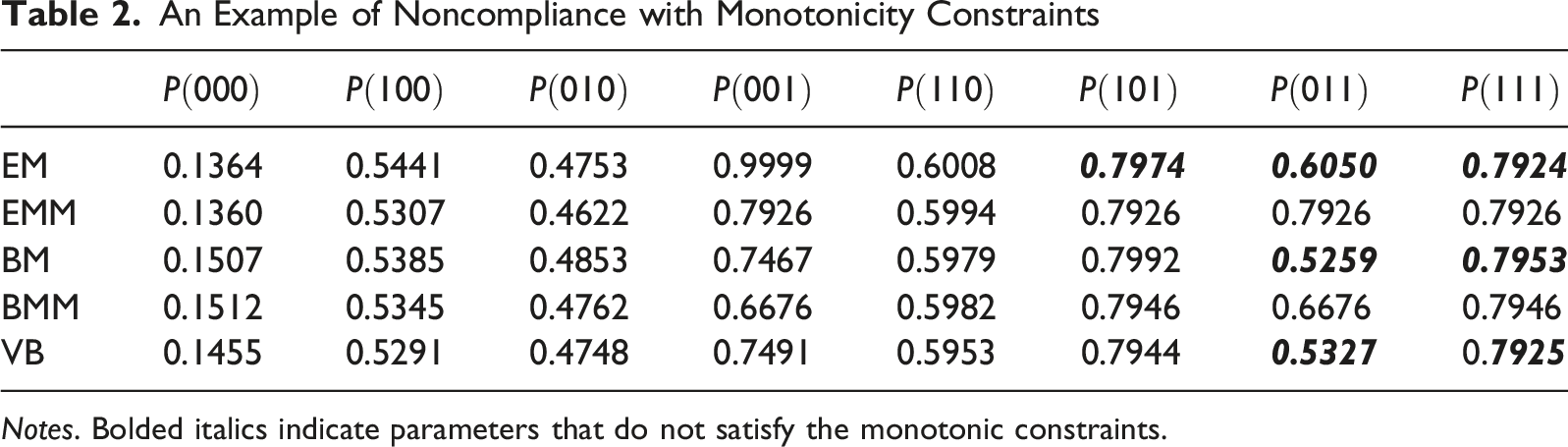
Notes. Bolded italics indicate parameters that do not satisfy the monotonic constraints.
Count of Parameters With High Instability (CV >0.3) Across Initializations
To evaluate the influence of initial values, we examined the coefficient of variation (CV) for each model parameter across 200 different initializations. A parameter was deemed unstable if its CV exceeded 0.3. Figures 5 and 6 display the number of such unstable parameters. The G-DINA model with K = 5 and no hierarchical structure has 32 possible attribute mastery patterns, corresponding to 32 structural parameters. For J = 30 items, the G-DINA model included a total of 172 parameters (32 structural and 140 response probabilities). For J = 15, it had 102 parameters. The number of unstable correct response probabilities. Note. Under the G-DINA model, there are 70 correct-response parameters for J = 15 and 140 for J = 30. The numbers in the figures indicate the count of parameters with CV >0.3 The number of unstable structural parameters. Note. Under the G-DINA model with K = 5, there are 32 structural parameters. The numbers in the figures indicate the count of parameters with CV >0.3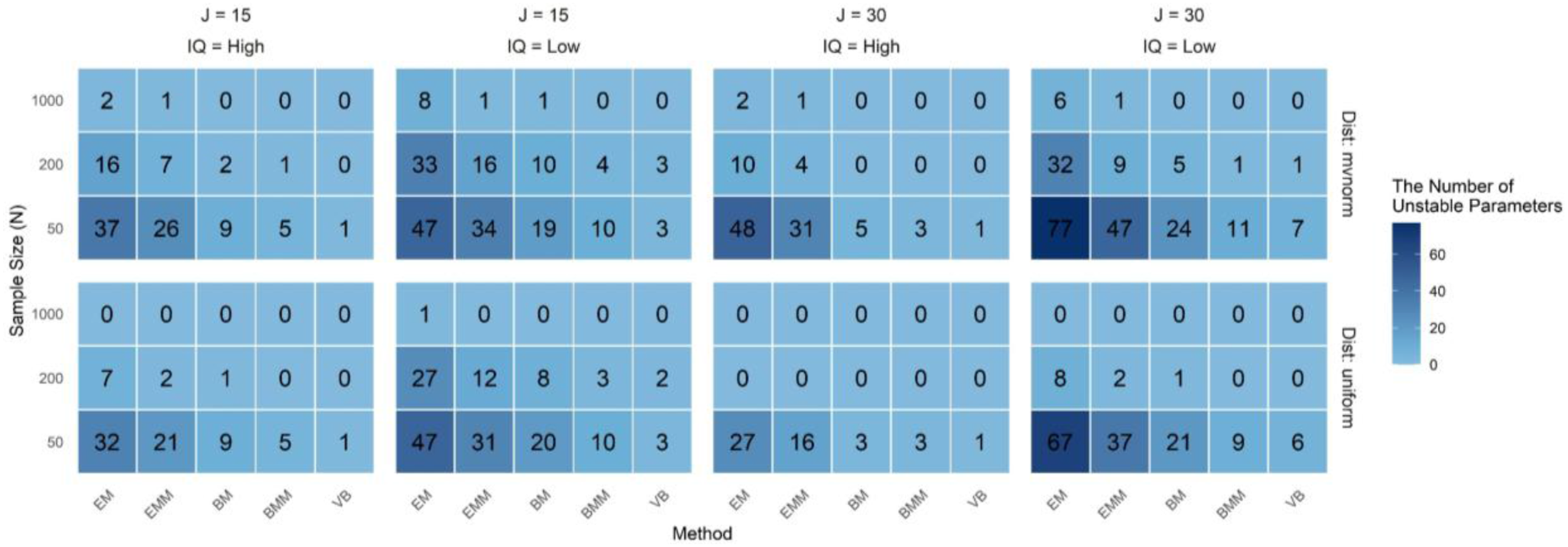
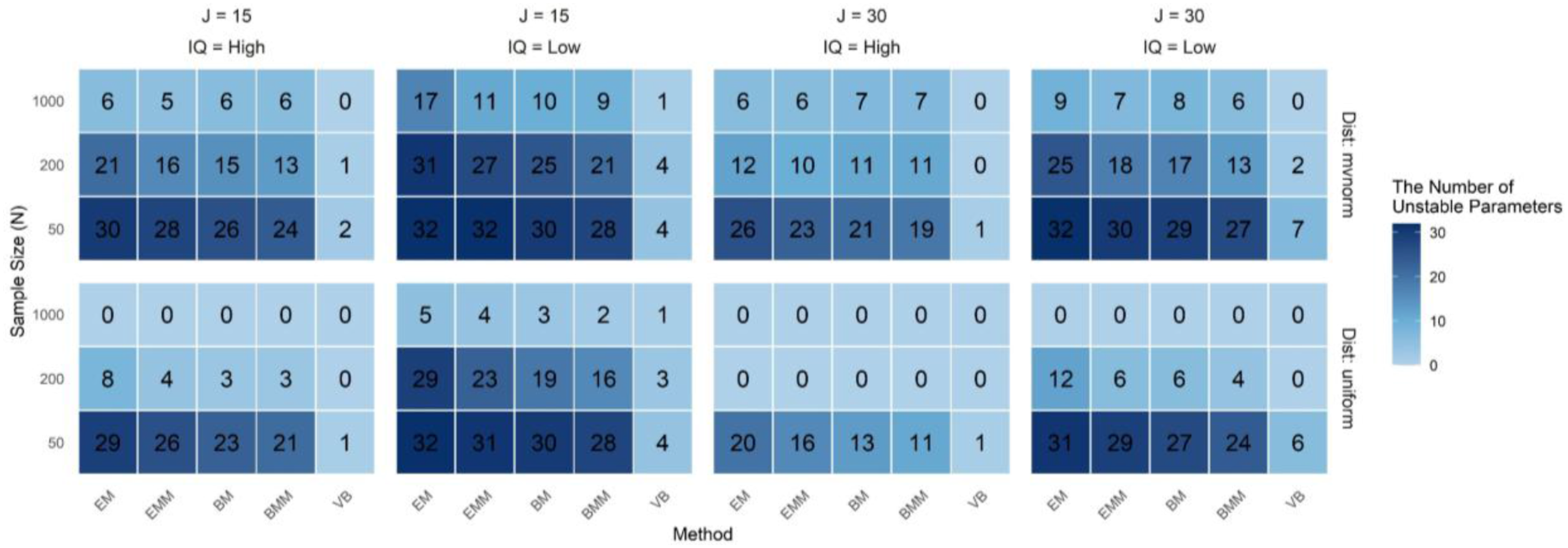
Figure 5 displays the number of unstable response parameters across different conditions. The EM method performed the worst overall. For example, under the conditions of J = 15, N = 50, high item quality, and multivariate normal attribute distribution, 37 out of 70 parameters (about 53%) had CV values higher than 0.3. In comparison, VB demonstrated the best performance, with only 1 unstable parameter under these conditions.
Figure 6 presents the results for structural parameters, showing an even stronger pattern. Under the challenging setting of J = 15, N = 50, high item quality, and multivariate normal distribution, 30 out of 32 structural parameters (94%) were unstable with EM, compared to only 2 with VB. Together with the results in Figure 5, this indicates that 67 out of the total 102 model parameters were unstable under EM initialization, while only 3 were unstable under VB.
These findings strongly indicate that parameter estimation in EM and related methods is highly sensitive to initial values, raising concerns about their reproducibility and reliability in practical applications. EM and EMM exhibited the greatest sensitivity to initialization, followed by BM and BMM, with VB showing better robustness. Moreover, as the sample size increased to N = 1000 and the quality of items improved, parameter stability improved significantly. While increasing sample size improves stability, it is not a complete solution. A robust application also requires careful method selection to mitigate initialization dependence.
In the Supplemental Material, we additionally selected six sets of initial values to illustrate the impact of initialization on the algorithm (see Table S2). The result shows that a different set of initial values may yield a superior value of the objective function. Notably, combined evidence from Figure S3 and Table S2 suggests that the likelihood surface in CDMs is characterized by complex geometry. The likelihood surface is multimodal, with multiple local optima associated with different starting points (Table S2). Within local regions, however, the algorithm may exhibit oscillatory behavior near stationary points where the surface is relatively flat or weakly identified (Figure S3).
Conclusion
Summary and Discussion
Comparative Summary of Methods: Strengths and Weaknesses

Overall, the findings can be understood along three interrelated dimensions: data conditions, model complexity, and algorithmic characteristics. We observed a strong co-occurrence of empirical under-identification, flat likelihood surfaces, and estimation anomalies. First, consistent with prior research, small sample sizes substantially increase the occurrence of estimation anomalies (Oka & Okada, 2022; Sorrel et al., 2023). One plausible explanation is empirical under-identification, particularly under the G-DINA model, where the number of parameters may be large relative to the available sample size, leading to unstable estimation, non-convergence, and boundary solutions.
Second, differences across estimation methods can be interpreted in light of their algorithmic properties. The EM algorithm showed greater sensitivity to initialization and a higher tendency to yield suboptimal solutions, whereas methods incorporating prior information (e.g., BM and VB) demonstrated greater stability. This pattern is consistent with the regularization effect of priors, which constrain the parameter space and reduce the occurrence of extreme or implausible estimates, particularly under sparse data conditions. Similarly, monotonicity constraints (EMM and BMM) may further restrict the parameter space and improve stability in some scenarios. In practice, priors should be specified not only for item parameters but also for structural parameters. Although priors can mitigate extreme and boundary estimates, choosing appropriate priors remains a nontrivial task (DeMars & Satkus, 2024). We recommend the use of weakly informative priors, as overly strong priors may introduce bias. At the same time, boundary values are not always artifacts. For example, when certain attribute profiles are absent in the population, true parameters may legitimately be near zero. Therefore, careful contextual interpretation is required.
It is important to note that these interpretations are based on observed occurrence patterns rather than formal theoretical analysis. Estimation difficulties in CDMs likely arise from multiple sources, including complex likelihood surfaces with potential local optima, sparse data structures, and model specification. A more rigorous analysis of likelihood geometry and identifiability remains an important direction for future work.
Beyond these general mechanisms, two practical determinants of estimation performance are convergence behavior and initialization. Convergence is critical for valid inference. In this study, non-convergence in EM was typically associated with failure to meet the convergence criterion within the maximum number of iterations, while in EMM it was sometimes related to constrained optimization issues (e.g., zero observed counts or boundary solutions). Although relaxing convergence criteria may increase the number of converged replications (Nader et al., 2011), such solutions may reflect premature convergence and should be interpreted cautiously (Philipps et al., 2021). Therefore, relatively strict convergence criteria are recommended in practice, and more systematic validation of convergence warrants further investigation.
Initialization was a key determinant of both solution quality and reproducibility. Using 200 different starting values, we observed substantial variability in outcomes, indicating that estimates can depend on initialization and may be unstable under single-start practices. This has direct implications for reproducibility, which requires consistent results across repeated analyses (National Academies of Sciences, Engineering, and Medicine, 2019). Accordingly, the routine use of multiple random starts is recommended to reduce the risk of converging to suboptimal solutions. Future work should develop more systematic strategies for selecting or screening starting values, as well as more effective global optimization approaches.
Several practical recommendations follow from these findings. First, under limited sample sizes or short tests, methods incorporating prior information (e.g., BM and BMM) are generally preferable due to their greater robustness. Second, maintaining adequate item quality remains essential, as poor item quality negatively affects all estimation methods, particularly EM. In this study, the number of attributes was fixed at
In addition, beyond parametric estimation methods, nonparametric methods may serve as useful alternatives in specific contexts. In small-sample settings (e.g., N = 50; Sessoms & Henson, 2018; Sen & Cohen, 2021), nonparametric methods have been shown to perform well for attribute classification (Chiu et al., 2018). Practitioners may therefore consider combining or selecting methods based on their goals—for instance, using nonparametric methods when accurate classification is prioritized (Ma et al., 2023).
Several limitations should be noted. First, this study focused on the occurrence and prevalence of estimation anomalies rather than a formal analytical characterization of their underlying causes. Although we discussed potential explanations, such as empirical under-identification and regularization effects, these interpretations are based on simulation evidence and should not be viewed as definitive causal conclusions.
Second, the use of the G-DINA model should be interpreted as a stress-test scenario. While it enables evaluation of estimation methods under challenging conditions, it may overstate the level of difficulty relative to typical applications. In practice, especially under conditions such as small sample sizes and a moderate number of attributes, more reduced models and formal model selection procedures should be considered.
Future research may extend this work by (1) developing estimation methods that explicitly address sparse data conditions, (2) improving global optimization and initialization strategies, (3) examining a wider range of CDMs and model complexities, and (4) conducting more rigorous theoretical analyses to better understand the structural mechanisms underlying estimation anomalies.
Supplemental Material
Supplemental material—The EM Algorithm and Its Variants in Cognitive Diagnostic Models: Comparing Their Propensity for Boundaries, Extremes, Convergence, and Suboptimal Solutions
Supplemental material for The EM Algorithm and Its Variants in Cognitive Diagnostic Models: Comparing Their Propensity for Boundaries, Extremes, Convergence, and Suboptimal Solutions by Yue Zhao, Tao Xin, Yanlou Liu, and Yiming Wang in Applied Psychological Measurement
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China (31900794), the Natural Science Foundation of Shandong Province in China (ZR2019BC084), and the National Key R&D Program of China (2021YFC3340801).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and publication of this article.
Data Availability Statement
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.