
Abstract
Abdominal trauma with bleeding is a leading cause of post-traumatic death, and detecting free fluid in the abdomen or hemoperitoneum can provide critical guidance for clinical management. Rapid and accurate diagnosis of abdominal bleeding using ultrasound is significant for making decisions regarding the need for surgical intervention. This study introduces a multi-task network for the segmentation and classification of ascites in ultrasound images. The network utilizes a U-Net backbone with a ResNext encoder as the basic architecture for the segmentation and classification models. The segmentation network includes a Frequency Channel Attention (FCA) attention module, which effectively broadens the range of captured information and enhances the robustness of channel representation. Furthermore, an Enhanced Channel Attention Multi Feature Fusion (EMFF) was used to extract the interdependencies between feature channels by combining high-order and low-order feature mappings, thereby improving segmentation accuracy. Lastly, a classification branch was created to classify ascites by sharing encoder features. Experiments on the collected ascites ultrasound dataset demonstrated that the proposed method achieved a segmentation Dice of 85.28% and a classification accuracy of 86.18%. It outperformed the leading multi-task SOTA method by 0.7% in Dice and 2.03% in accuracy, establishing a new benchmark for simultaneous ascites assessment. This study showed that the proposed network is valuable for the preliminary diagnosis of ascites in ultrasound and can serve as a potential auxiliary tool for clinical ascites examination in emergency situations.
Introduction
Abdominal trauma is a prevalent injury that is frequently complicated by active bleeding due to liver or spleen damage, constituting a main cause of death following trauma. 1 As a key indicator of abdominal diseases and organ injuries, ascites is critical for the early diagnosis and grading of abdominal trauma. Its detection enables rapid triage and timely identification of life-threatening cases, leading to lower mortality rates. Rapid and accurate diagnosis of ascites in the abdominal region is significant for making accurate decisions on the need for surgery. 2 Ultrasound imaging is important in the initial assessment of patients suspected of abdominal injury. 3 The non-invasive, rapid, and repeatable nature of ultrasound makes it a valuable tool in emergency situations. 4
Ultrasound-based grading of ascites per clinical guidelines comprises three levels (Figure 1). 5 Grade 1 ascites (<3 cm) is defined by its sonographic detection alone, absent clinical signs like distension or shifting dullness. Grade 2 (3–10 cm) manifests as moderate symmetrical distension, with shifting dullness being variable. Grade 3 (>10 cm) demonstrates overt distension, positive shifting dullness, and possible protuberance or umbilical hernia. 5 The diagnosis of ascites by ultrasound may be affected by the subjectivity of expert diagnosis and the experience of ultrasound technicians. Moreover, for small or occult ascites, it is often difficult to observe with the naked eye, leading to a high rate of missed diagnoses. The aforementioned issues have prompted the exploration of using computer-aided diagnosis (CAD) to improve the accuracy and efficiency for the diagnosis of ascites or abdominal bleeding. 6
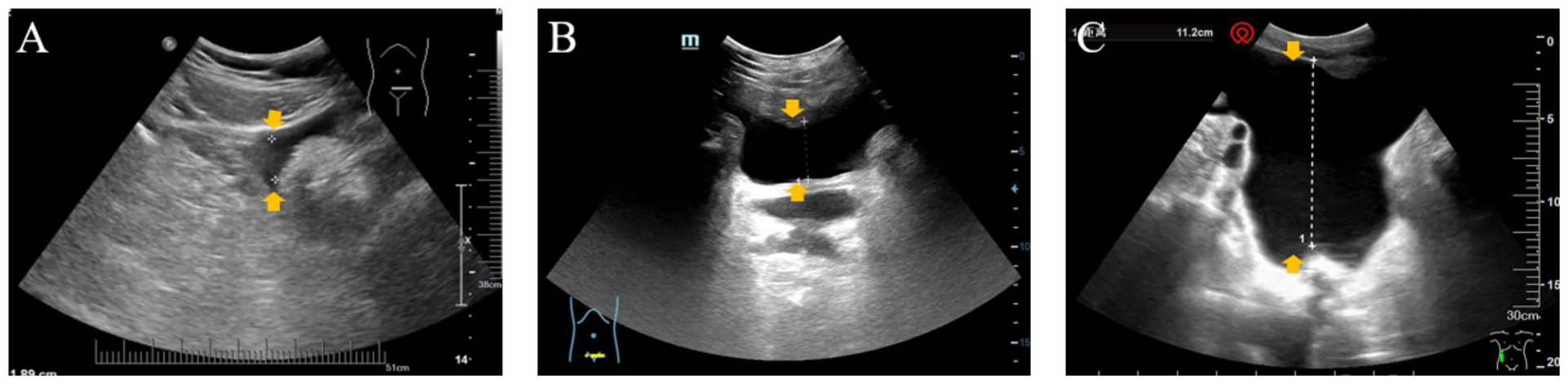
Typical ultrasound images of ascites samples with different degree of ascites. (a) Grade 1 ascites, (b) Grade 2 ascites and (C) Grade 3 ascites.
Deep learning applications offer promising solutions for automating and enhancing the interpretation of medical images.7,8 Leveraging its capacity to discern complex data patterns, deep learning could be used as a powerful tool for improving diagnostic accuracy, thus showing great potential in CAD of abdominal bleeding.6,9 -11 The main tasks of deep learning in the diagnosis of abdominal bleeding are segmentation and classification. Segmentation can accurately identify bleeding sources and detects free fluid in targeted abdominal regions. The free fluid typically accumulated in regions such as the hepatorenal fossa, splenorenal fossa, and pelvic cavity. The occurrence of free fluid or ascites strongly suggest the possibility of severe intra-abdominal injury and bleeding, potentially necessitating emergency laparotomy, blood transfusion, and other life-saving measures. 12 Classification provides accurate grading of ascites. Classification thereby reflect the extent of fluid accumulation in the abdominal cavity and assist physicians in assessing the severity of the patient’s condition. Grading of ascites provides an important basis for clinicians to formulate personalized treatment plans. For example, a small amount of ascites (Grade 1) may only require observation or conservative treatment, while moderate or large amounts of ascites (Grade 2 or 3) may require more aggressive treatment measures, such as diuretics, abdominal paracentesis, and drainage. 13 Grading of ascites can also predict the prognosis of patients to some extent. Generally, patients with persistently increasing or uncontrollable ascites have a poorer prognosis and require closer observation and treatment. 14 Winkel, David J. et al. 15 constructed CNN-based a machine learning model for predicting abdominal bleeding to differentiate free-gas, free-fluid, or fat-stranding based on CT images, with 85% sensitivity and 95% specificity. Ko et al. 9 developed an AI segmentation algorithm for the quantification of ascites based on abdominal CT, achieving an mIOU of 0.87. Lin et al. 6 applied the U-Net to automatic segmentation of ascites in portable ultrasound, yielding Dice coefficients of 0.65 to 0.79 and confirming the viability of deep learning for this application. However, their work just analyzed the segmentation of ascites and did not include the automatic classification of abdominal bleeding. In addition, the classification of ascites necessitates further manual diagnosis and was just binary classification as positive or negative.
In this work, a U-Net-based model for the multi-task segmentation and classification of ascites using ultrasound images was developed. To the best of our knowledge, this is the first study utilizing deep learning for simultaneously segmenting and classifying ascites using ultrasound images. The contributions of this work are as follows: (1) A shared-encoder multi-task framework that jointly optimizes lesion localization and grading via synergistic segmentation and classification branches. (2) Frequency-domain Channel Attention (FCA) block that amplifies salient encoder features to suppress complex ultrasound backgrounds. (3) Enhanced Multi-scale Feature Fusion (EMFF) module with channel-wise attention, aggregating skip-connected details for accurate segmentation.
Methods
Overview of Multi-Task Ascites Segmentation and Classification Network (MTASCNet)
MTASCNet takes abdominal ultrasound images as input and produces ascites segmentation and the probability of ascites grading. By leveraging a feature sharing mechanism, MTASCNet enhances the model’s analytical and processing capabilities for ascites regions. As shown in Figure 2, the network is composed of a segmentation branch and a classification branch. The segmentation branch employs a UNet architecture, with its encoder consisting of a series of ResNeXt blocks. 16 The Frequency Channel Attention (FCA) 17 is utilized to assign weights to different channel features output by the encoder, thereby amplifying the salience of informative features. An Enhanced Channel Attention Multi Feature Fusion (EMFF) module was designed to capture channel dependencies across feature maps by merging multi-scale information, thereby enhancing spatial representations of lesions throughout decoder stages. The decoder output stage ultimately enables ascites region segmentation in ultrasound images. Additionally, a classification branch attached to the UNet encoder final layer—processed through a Fully Connected layer and Softmax—predicts ascites severity for each input.
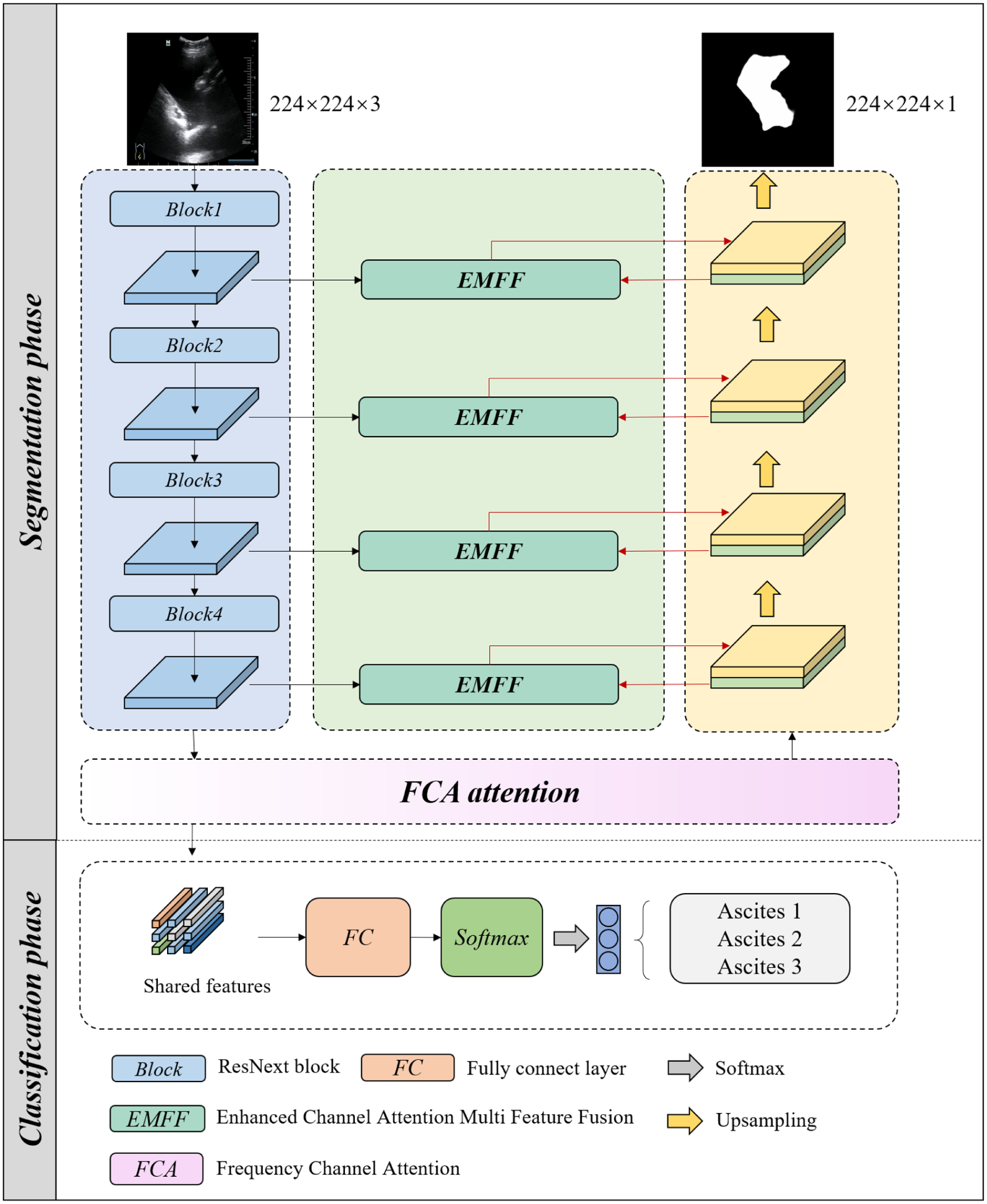
Overview of MTASCNet.
Design of Encoder
ResNeXt extends ResNet by aggregating diverse feature representations through multi-path cardinality. Figure 3 illustrates the structural differences between these architectures. The ResNeXt backbone comprises stacked Bottleneck layers—specialized residual units for complex pattern extraction. Each Bottleneck implements three sequential convolutions: 1 × 1 convolution for reducing the size of the input data. Subsequently, 3 × 3 grouped convolution for capturing detailed patterns, and 1 × 1 convolution for restoring the original size of the data. Batch normalization and ReLU activation follow each convolutional operation for feature stabilization.
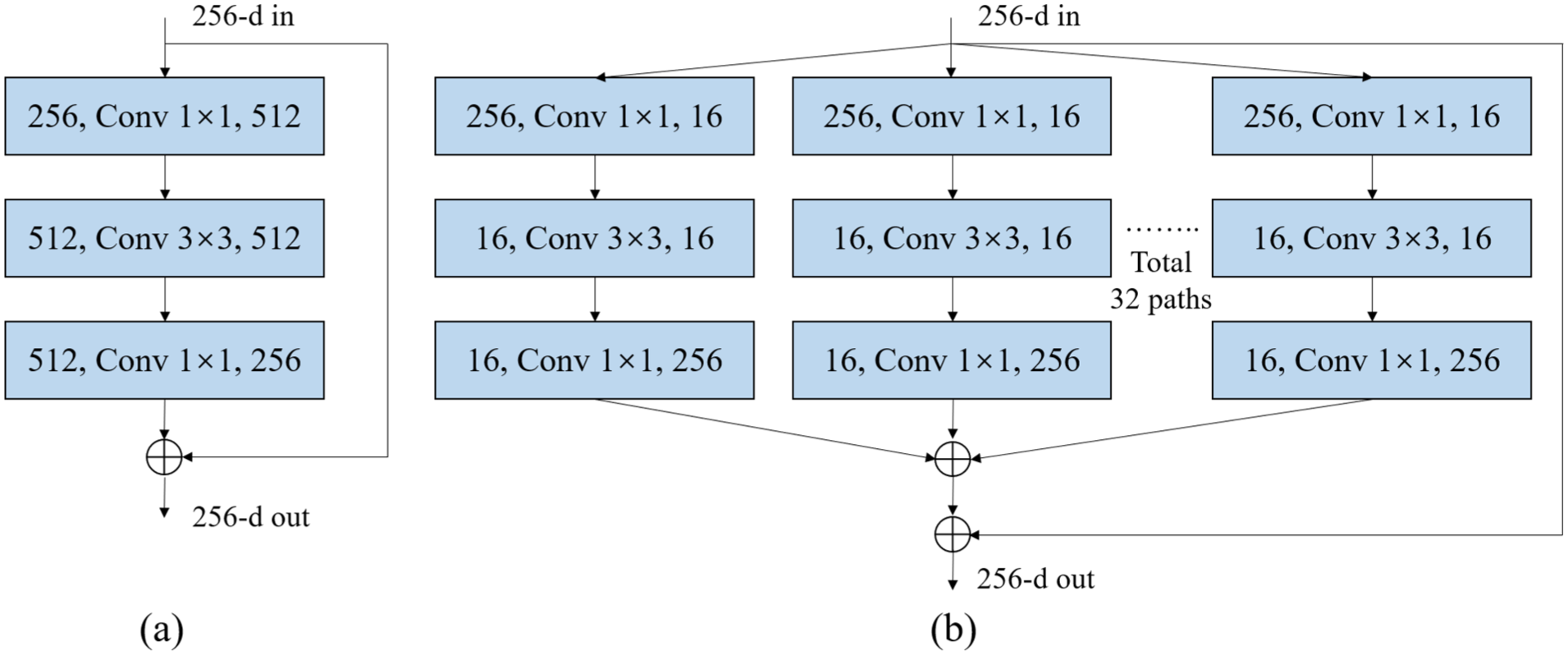
Architecture comparison of ResNet and ResNeXt building blocks, with each layer denoting input channels, kernel size, and output channels: (a) ResNet structure and (b) ResNeXt structure.
Assuming

The grouped convolution operation in the ResNeXt architecture can be represented as:
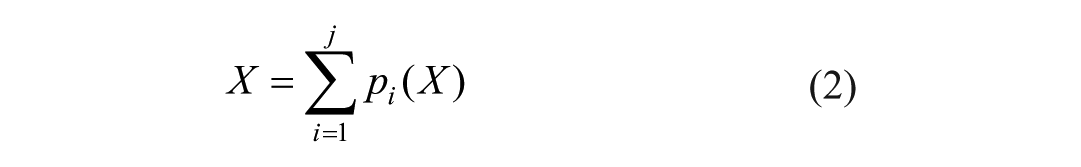
where
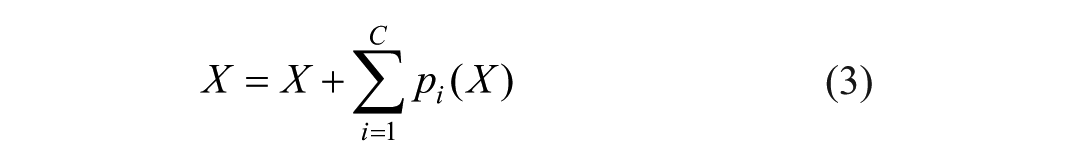
These Bottleneck layers are arranged in stages, each progressively down sampling spatial resolution while expanding feature depth.
FCA Attention Block
Ultrasound imaging typically exhibits marked speckle noise and poor contrast, often causing informative features such as ascitic regions to be submerged in background clutter. Traditional convolution may lead to misclassification of objects due to the capture of local feature information. The Squeeze-and-Excitation (SE) 18 attention mechanism enhances local feature representation by assigning different weights to various channels. However, the SE attention mechanism primarily uses Global Average Pooling (GAP), which retains information mainly from the lowest frequency components, neglecting other frequency components. These other frequency components potentially contain crucial channel weights and comprehensive information patterns. A more potent mechanism is therefore required to accentuate the feature channels that carry rich diagnostic information. To holistically model contextual dependencies across the frequency spectrum, the Frequency Channel Attention (FCA) mechanism was adopted. The FCA attention extends GAP to include multiple frequency components of the Discrete Cosine Transform (DCT), thus integrating a broader spectrum of frequency components. This approach effectively broadens the range of captured information and enhances the robustness of channel representation. Thus, FCA attention was employed to model spatial relationships across channel feature maps. The framework of FCA attention is depicted in Figure 4.
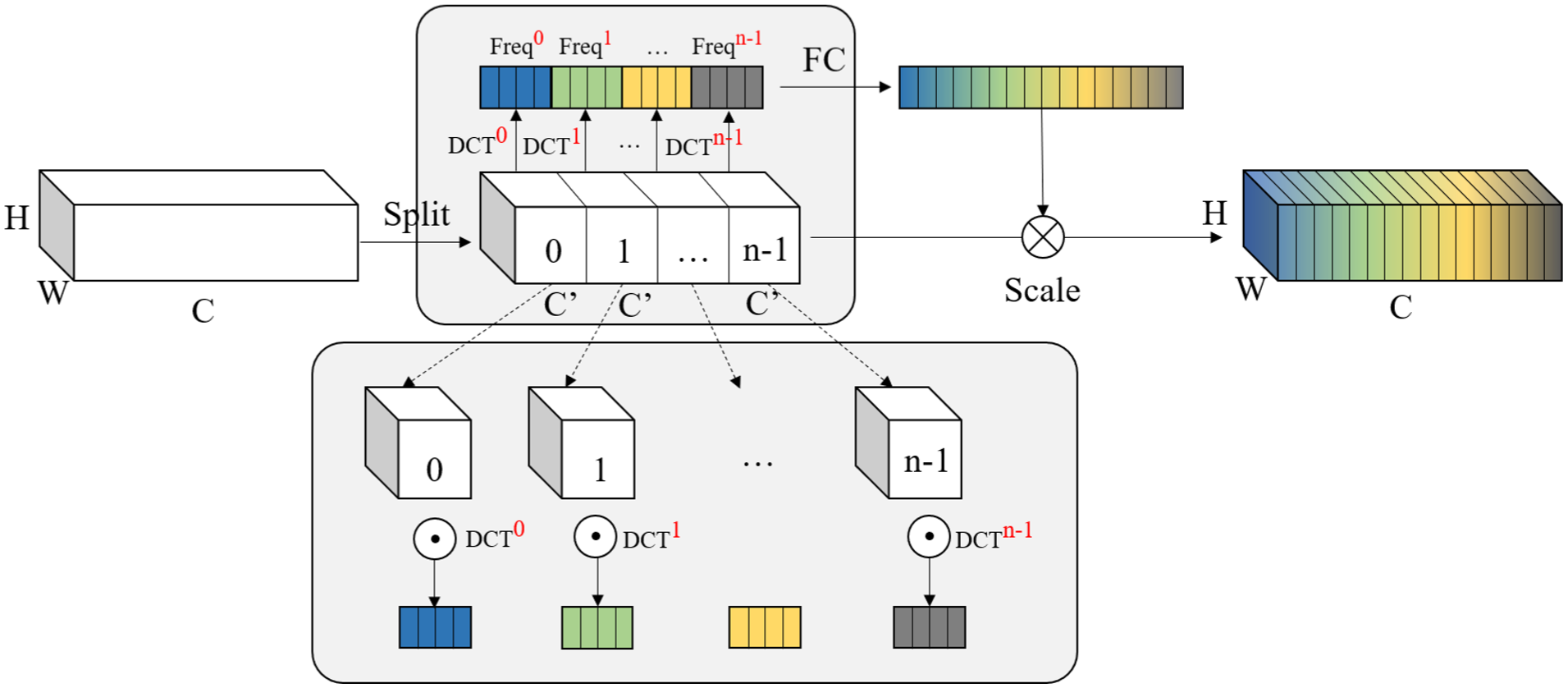
Frequency channel attention module.
Assuming the last layer of the Resnext Encoder outputs a feature map denoted as
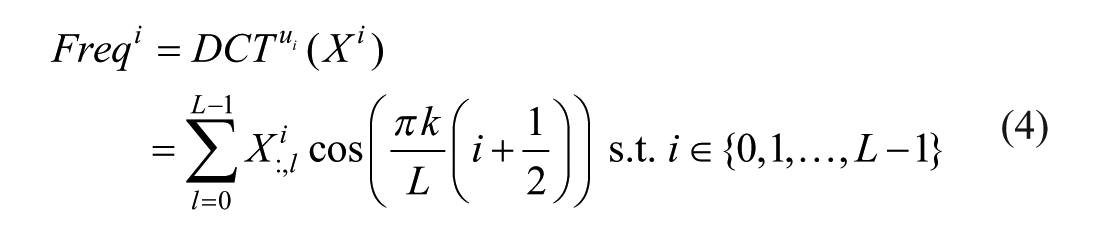
where
Subsequently, the full frequency descriptor
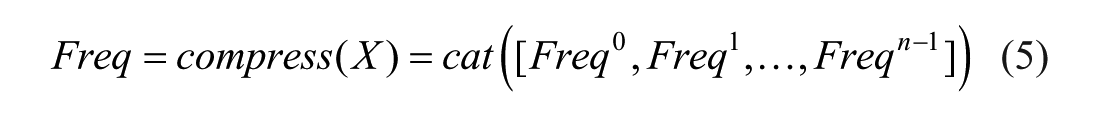
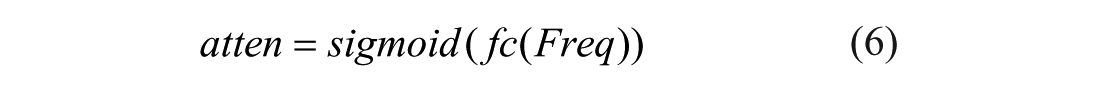
FCA extends the original GAP operation of the SE attention mechanism to a framework that includes multiple frequency components, enriching the compressed channel information and capturing spatial dependencies between arbitrary channel feature maps. Following filtering and weight recalibration, frequency-domain signals are converted back to the spatial domain through inverse transformation. This procedure effectively assigns more precise weights to the feature maps of different channels output by the encoder, thereby amplifying information-rich channels and enhancing the model’s sensitivity to ascitic-region features.
Enhanced Channel Attention Multi Feature Fusion Module
In U-Net skip connections, concatenating high-level encoder features with up-sampled decoder maps fails to exploit the intrinsic relationships across scales. High-level features capture strong semantic meaning with coarse spatial precision, while low-level features retain fine-grained spatial details but carry weaker semantic information. An intelligent fusion mechanism is therefore required to establish channel-wise dependencies between them, so as to enrich spatial details during decoding. Multi-scale feature fusion is crucial for accurate segmentation, as high-level features encode semantic context while low-level features preserve spatial detail.
Drawing inspiration from the Efficient Channel Attention (ECA) mechanism 19 and multi-scale feature fusion strategies, 20 we designed the Enhanced Multi-scale Feature Fusion (EMFF) module to address a critical challenge in ultrasound imaging: speckle noise significantly compromises boundary delineation. The core insight behind EMFF lies in symmetrically applying 1D convolution-based channel attention to both high-level semantic and low-level spatial feature maps before their integration. This adaptive recalibration of channel weights serves a dual purpose—attenuating noise interference while amplifying anatomical boundary signals. The rationale for this hierarchical processing stems from the complementary nature of features at different scales. High-level features encode rich semantic context essential for global understanding, whereas low-level features preserve fine-grained edge information crucial for detail restoration. By leveraging ECA to learn channel-wise importance from these multi-level representations, EMFF selectively enhances task-relevant feature maps and suppresses those contributing minimally to ascites segmentation. This dynamic weighting mechanism ensures that informative channels are emphasized, enabling more precise boundary localization despite the inherent artifacts of ultrasound imaging.
The EMFF is illustrated in Figure 5. The enhanced channel attention mechanism was applied to both high-order and low-order features. The aim is to increase the weight of significant information in each feature channel for the segmentation task and to disregard useless feature information.
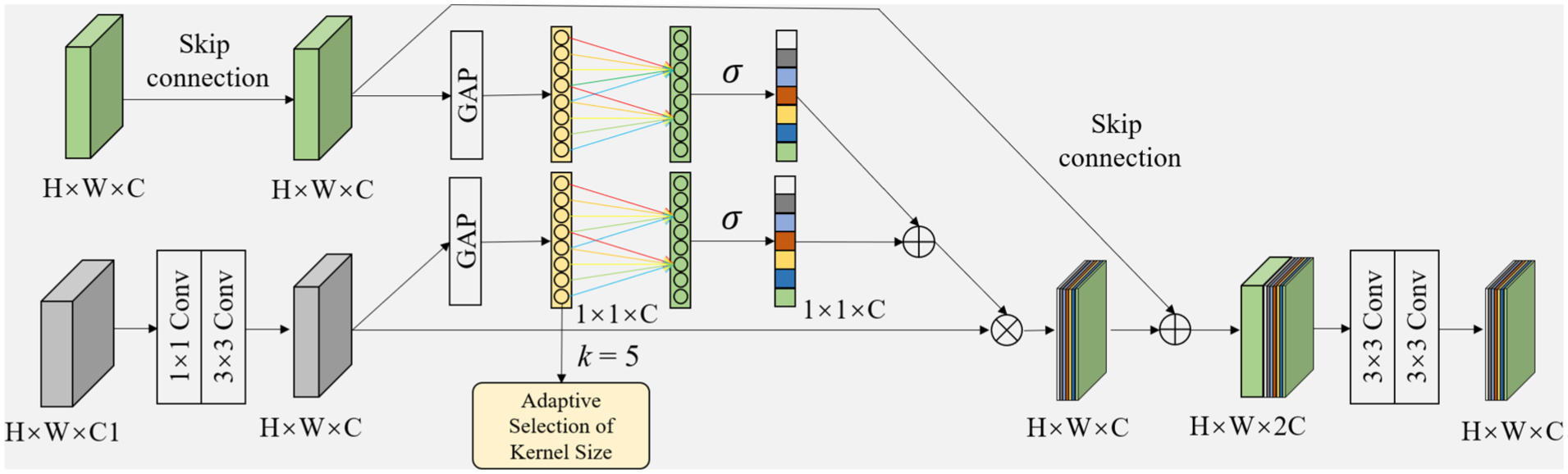
Enhanced channel attention multi feature fusion module.
Firstly, the high-level features
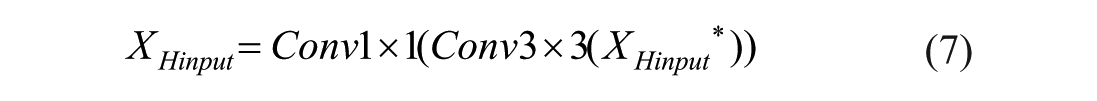
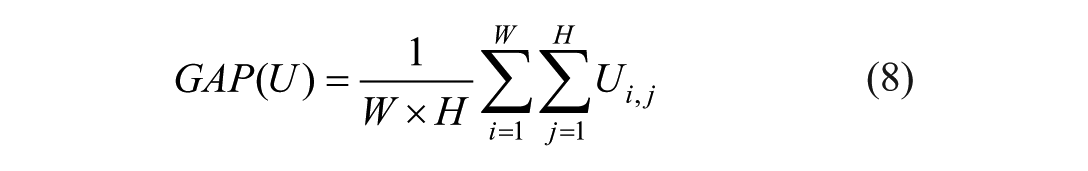
Following the GAP, a one-dimensional convolution with a kernel size of K is applied to GAP(U) to rapidly extract the local feature relationships across the K channels. The activation values of the one-dimensional convolutional output are computed using the sigmoid function, yielding weights
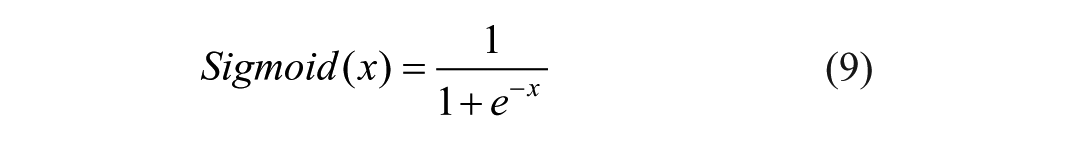
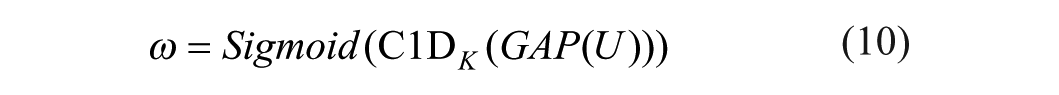
Based on equation (10), low-dimensional and high-dimensional attention weights are obtained to enhance important channel features by assigning them higher values and to autonomously suppress ineffective channel features by assigning them lower values:
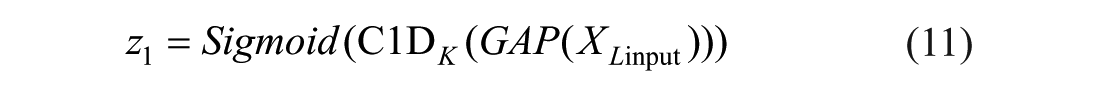
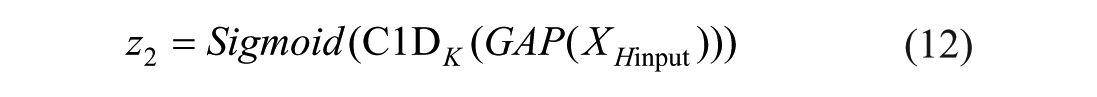

The
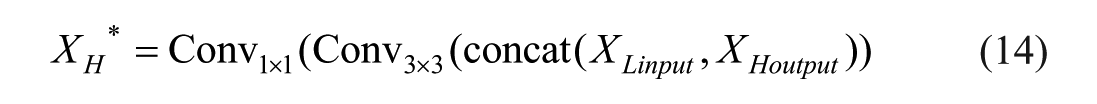
To enhance feature representation and enrich semantic information, the
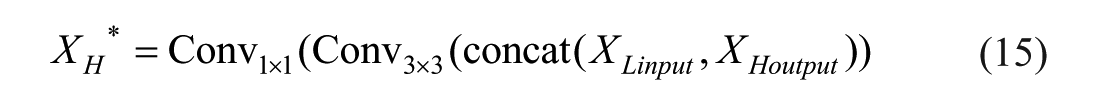
Datasets and Preprocessing
This retrospective study was approved by the Ethics Committee of the Second Affiliated Hospital of Naval Medical University (2024SL024). A comprehensive dataset of 542 images from 315 unique patients (Male/Female: [163/152]) was constructed. Images were acquired using four systems: Mindray DC-70Pro (297 images), Siemens Acuson Sequoia (129 images), GE LOGIQ E9 (55 images), and Philips LU22 (61 images). The dataset includes three clinically stratified categories with 103 cases of mild ascites (Ascites-1), 394 cases of moderate ascites (Ascites-2), and 45 cases of severe ascites (Ascites-3). The dataset focuses on Grades 1 to 3, as the study aims to assist in grading severity for rapid surgical triage in trauma patients where free fluid presence is already suspected, rather than healthy screening (Grade 0). All annotations were performed using ITK-SNAP. In cases of disagreement between the two primary radiologists, a consensus was reached via discussion, the senior radiologist corrected approximately 15% of the initial annotations. The dataset was partitioned into training (80%) and testing (20%) sets at the patient-level using stratified sampling to maintain class distribution, with fivefold cross-validation implemented to maximize data utilization. During preprocessing, all DICOM images were converted to PNG format. Original resolutions were preserved during annotation, with resizing to 224 × 224 performed only at network input stage.
Loss Function
The Cross-Entropy loss (CELoss) 21 function is employed to constrain the training process of the classification model, with the calculation formula given by:
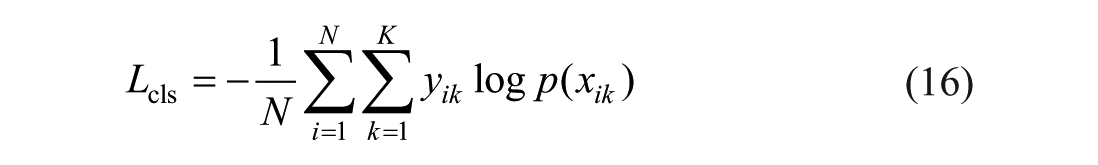
where
In segmentation tasks, a Dice coefficient-based segmentation loss 22 was utilized to address the class imbalance issue between the foreground and background in images. The segmentation loss is defined as:
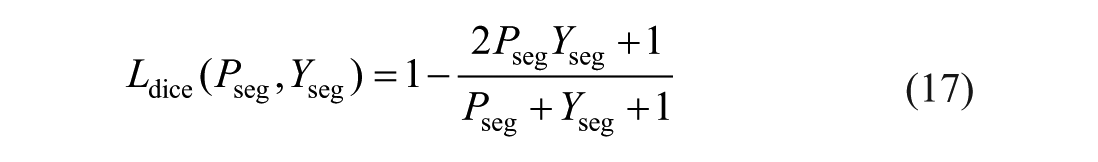
where
The classification loss
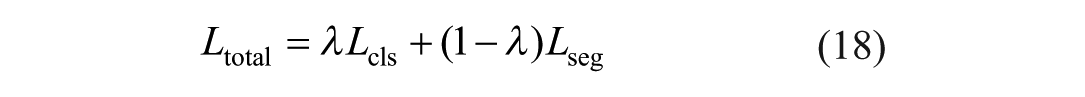
Where
Experiment Details
To address the limited sample size in severe ascites cases, an adaptive augmentation approach was implemented involving random rotation within ± 15 °, horizontal and vertical flipping with 50% probability. Given the class imbalance, severe ascites cases received three times more augmentations than other categories.
Training employed the Adam optimizer with a warmup period of five epochs, starting with an initial learning rate of 1e-4 that decayed by 0.1 at 50 and 75 epochs. Momentum parameters were set at β1 = .9 and β2 = .99 with L2 regularization through 0.0001 weight decay. Hyperparameters were empirically optimized using the validation folds during the cross-validation process. Batch processing utilized a size of 8, running for a maximum of 100 epochs. An early stopping mechanism was implemented, which monitored the combined multi-task validation loss (equation (18)); training was explicitly halted if this validation loss failed to decrease for 15 consecutive epochs to prevent overfitting. All experiments were conducted on an NVIDIA V100-SXM2 to 16 GB GPU with Xeon Gold 6248 R CPU using PyTorch 1.13.0 framework. The implementation leveraged Python 3.9 as primary programming language under Windows 10 Professional operating system.
Evaluation Metrics
Four commonly used metrics were employed to evaluate the effectiveness of ascites segmentation: Dice similarity coefficient (Dice), Jaccard index (Jaccard), 95% asymmetric Hausdorff distance (95HD), and average surface distance (ASD). 21 The calculation methods for these indices are as follows:
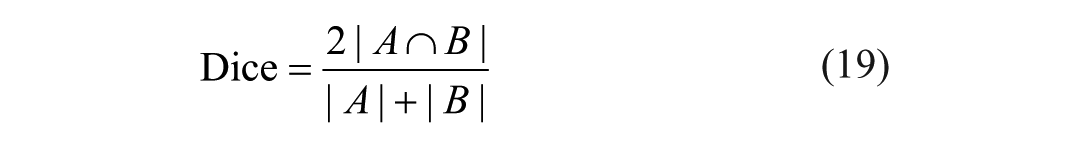
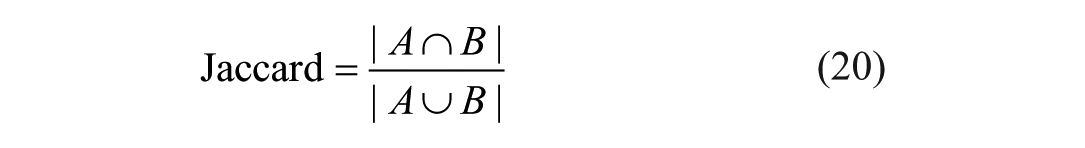
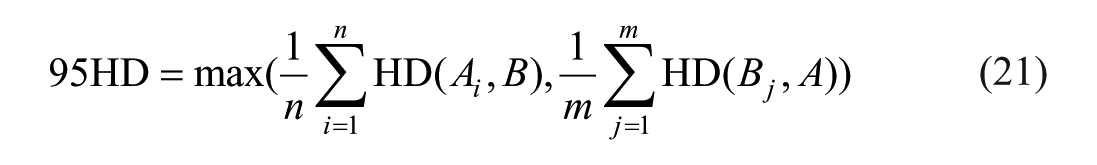
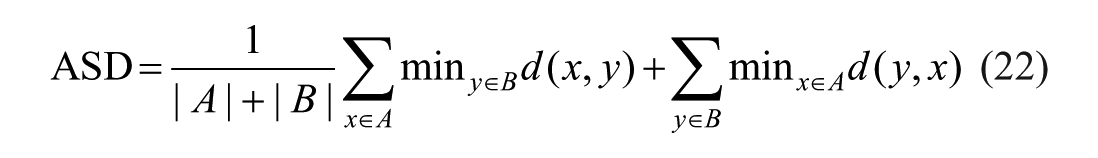
Where
For the ascites classification task, recall (REC), precision (PRE), and accuracy (ACC) 21 were used for quantitative evaluation:
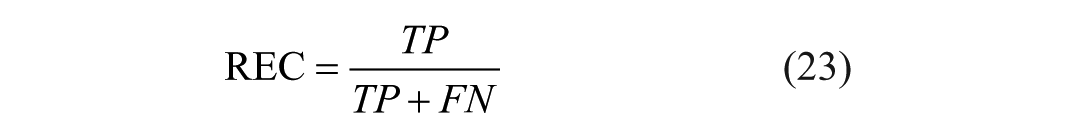
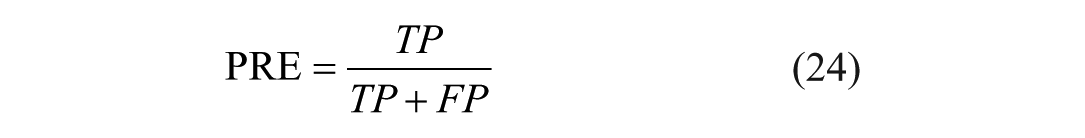
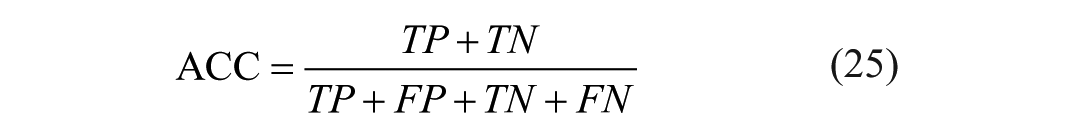
Where TP, FP, TN, and FN represent the counts of true positives, false positives, true negatives, and false negatives, respectively.
Results
Selection of Feature Extraction Backbone
The backbone selection process involved three-phase evaluation: (1) architectural suitability for medical imaging, (2) computational efficiency, and (3) feature extraction capability. Systematic comparisons of eight modern architectures (ResNet50, 23 VGG16, 24 Xception, 25 EfficientNetB4, 26 DenseNet, 27 MobileNet, 28 MiT, 29 and ResNeXt 16 ) using fivefold cross-validation were conducted. The reported metrics represent the average performance on the strictly patient-isolated test sets across all fivefolds. To ensure a fair comparison, while the general data augmentation and epoch scheduling remained consistent, the specific hyperparameters (e.g., initial learning rate and weight decay) for each baseline model were independently optimized via grid search on the validation folds to guarantee optimal convergence for each respective architecture. Each model was evaluated without additional modules to isolate backbone performance. The comparative segmentation and classification outcomes are detailed in Table 1. Among these, the ResNeXt-based model demonstrated superior performance across four key segmentation metrics—Dice (84.16%), Jaccard (77.68%), 95HD (10.40), and ASD (1.87)—as well as four classification metrics—ACC (85.07%), PRE (85.58%), REC (73.31%), and F1 score (84.62%). ResNeXt50 emerged as optimal due to its unique combination of: (1) grouped convolutions (32 × 4d template) that efficiently capture ultrasound speckle patterns, (2) higher parameter efficiency reducing overfitting risk. These findings suggest that the ResNeXt architecture is particularly well-suited for the analysis of the ultrasound abdominal dataset.
The Ascites Segmentation Results of Different Comparison Methods.
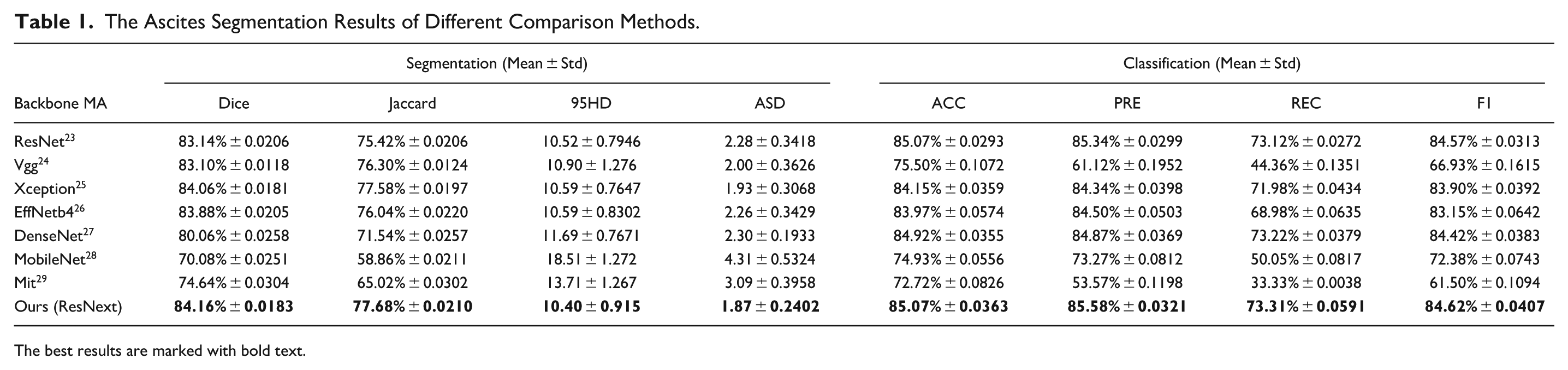
The best results are marked with bold text.
Ablation Experiment
In this section, the effectiveness of the ResNeXt backbone, FCA, and EMFF modules within proposed network are verified. The baseline was constructed as follows: (1) replacing the MTASCNet ResNeXt backbone with the ResNet backbone, (2) removing the FCA from MTASCNet, and (3) removing the EMFF from MTASCNet. Table 2 compares the full model with all ablated variants. Figure 6 intuitively illustrates the segmentation results generated by different components. In terms of segmentation, the baseline achieved Dice, Jaccard, 95HD, and ASD scores of 83.14%, 75.42%, 10.52, and 2.28, respectively. In classification, the baseline achieved ACC, PRE, REC, and F1 score of 85.07%, 85.34%, 74.12%, and 84.97%, respectively. Compared to the baseline, the baseline + ResNeXt model showed an improvement of 1.02% in Dice. By comparing columns 2, 3, and 4 of Figure 6, it can be observed that the addition of ResNeXt helps the network to better focus on the location of the lesions, reducing the interference from complex backgrounds, which allows for the detection of smaller lesions and a reduction in false positives and false negatives. Secondly, the performance of the FCA module was evaluated. The FCA module was further added to the baseline and denoted this model as ResNextUNet + FCA. Compared to the baseline, the ResNextUNet + FCA model improved in Dice and Acc by 1.46% and 0.75%, respectively. Figure 6, particularly columns 2, 3, and 5, indicates that the inclusion of FCA enables the network to better understand the edge integrity of the target area, demonstrating that FCA effectively broadens the range of captured information. Thirdly, the EMFF module was added to the baseline, referred to as ResNextUNet + EMFF, and assessed its performance. The results showed that after adding the EMFF module, Dice and Acc were improved by 2.16% and 1.02%, respectively. The comparison between columns 2, 3, and 6 of Figure 6 indicates that the addition of the EMFF module allows the network to better preserve the structural integrity of the effusion area. Due to the complex mixture and similar contrast of foreground and background information, basic skip connections struggle to accurately extract useful information. To overcome this limitation, the EMFF module enhances the skip connections by integrating a multi-scale enhanced channel attention module, thereby capturing more accurate and detailed edge and structural information in US images. Ablation analysis confirms that each module of MTASCNet contributes to improving the segmentation and classification performance of US images.
The Ablation Study of Each Component of the MTASCNet.

The best results are marked with bold text.
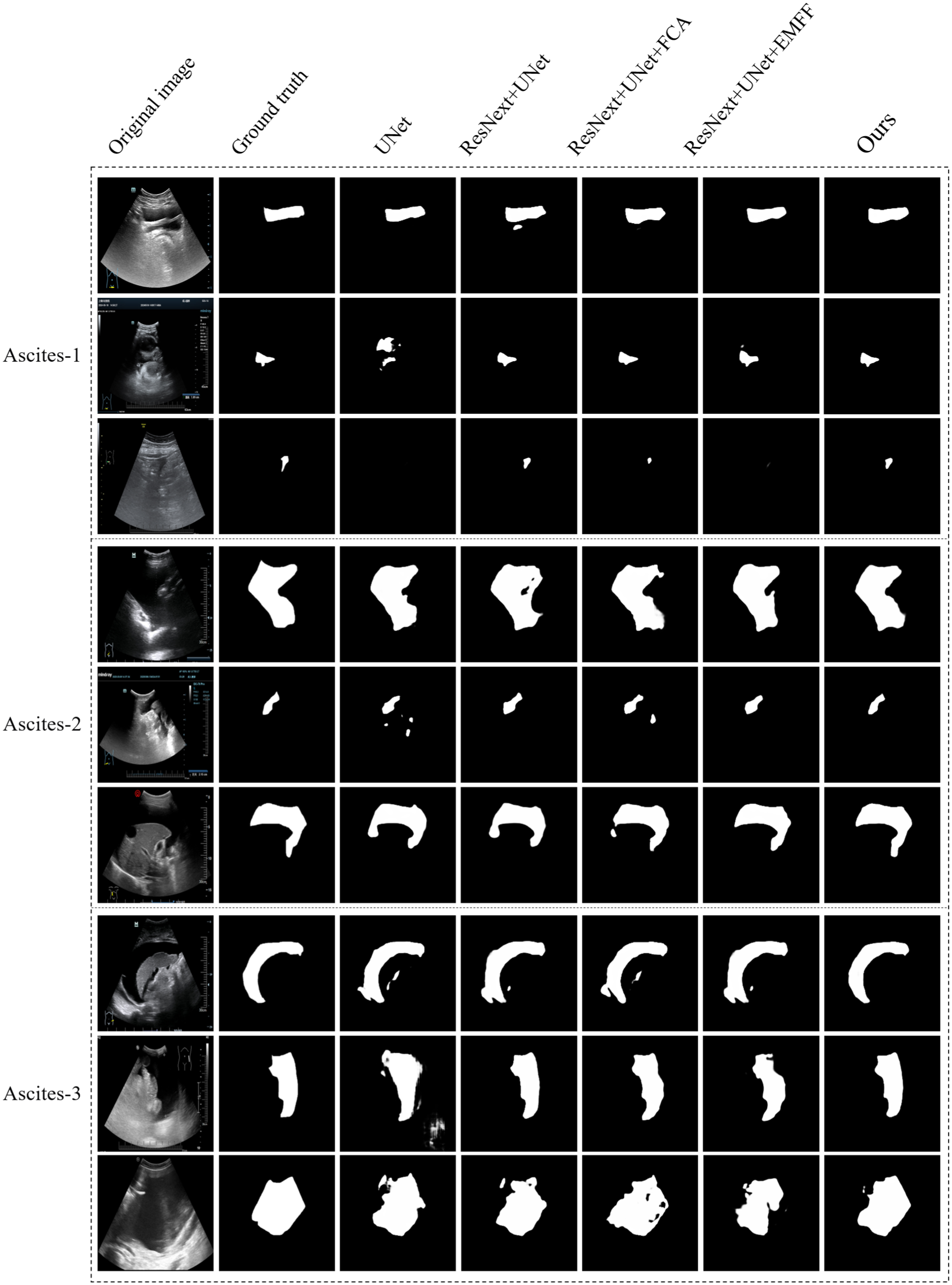
Visual results of segmentation with ablation experiments. From left to right are images of Input, Ground truth, UNet, ResNextUNet, ResNextUNet + FCA, ResNextUNet + EMFF and MTASCNet.
Grouped Test Results
Ultrasound images of ascites vary significantly across different grades. Comparative experiments were conducted on Ascites-1, Ascites-2, and Ascites-3 images to assess the network’s robustness in segmenting ascites of varying severities. To mitigate the influence of the notable differences in ultrasound images that display peritoneal effusion across different regions, the dataset was grouped by grade and tests. Three sets of models were trained using 103 Ascites-1, 394 Ascites-2, and 45 Ascites-3 images, respectively, and reported the final average segmentation results using fivefold cross-validation. As shown in Table 3, the results indicated that the average Dice coefficients for ascites grades 1, 2, and 3 were 59.26%, 86.46%, and 84.88%, respectively. The segmentation accuracy for Ascites-1 and Ascites-3 was lower than that for Ascites-2.
Comparative Segmentation Results on Ascites-1, Ascites-2, and Ascites-3 Ultrasound Images.

Comparison With State-of-the-Art (SOTA)
Table 4 compares the proposed MTASCNet with 16 advanced methods, including six of the latest single-task classification methods (Vgg16, 24 ResNet18, 23 ResNet50, 23 DenseNet, 27 EfficientNetB4, 26 ViT, 30 and Swin Transformer 31 ), six of the latest single-task segmentation methods (Unet, 32 UNet ++, 33 FPN, 34 MANet, 20 MDANet, 35 and MFMSNet 36 ), and three state-of-the-art multi-task learning methods (ASCNet, 37 LogoNet, 38 and Aumente-Maestro et al. 37 ). All models were trained and tested using the same data partitioning and the results of fivefold cross-validation are reported. To establish a rigorous baseline, we implemented a structured radiomics-based pipeline. This approach involved extracting a comprehensive set of 107 hand-crafted features—including 2D shape, first-order statistics, and high-order texture matrices (GLCM, GLRLM, GLSZM, GLDM, and NGTDM)—via the PyRadiomics library. To handle the high-dimensionality of the feature space, we used a Lasso-based feature selection (using an L1 Logistic Regression) to identify the most discriminative radiomic signatures. Classification was performed using a Random Forest model. As shown in Table 4, the Radiomics-based pipeline achieved a high mean accuracy of 83.57%, outperforming several deep learning architectures such as VGG 77.49%, ResNet50 76.76%, and even Transformer-based models like ViT 73.06%. Among the baseline models, only EfficientNet-b4 84.14% ± 0.0240 slightly surpassed the Radiomics approach. Our proposed model achieved the best overall performance with an accuracy of 86.18%, representing a 2.61% improvement over the Radiomics baseline.
Quantitative Performance Against State-of-the-Art Methods.
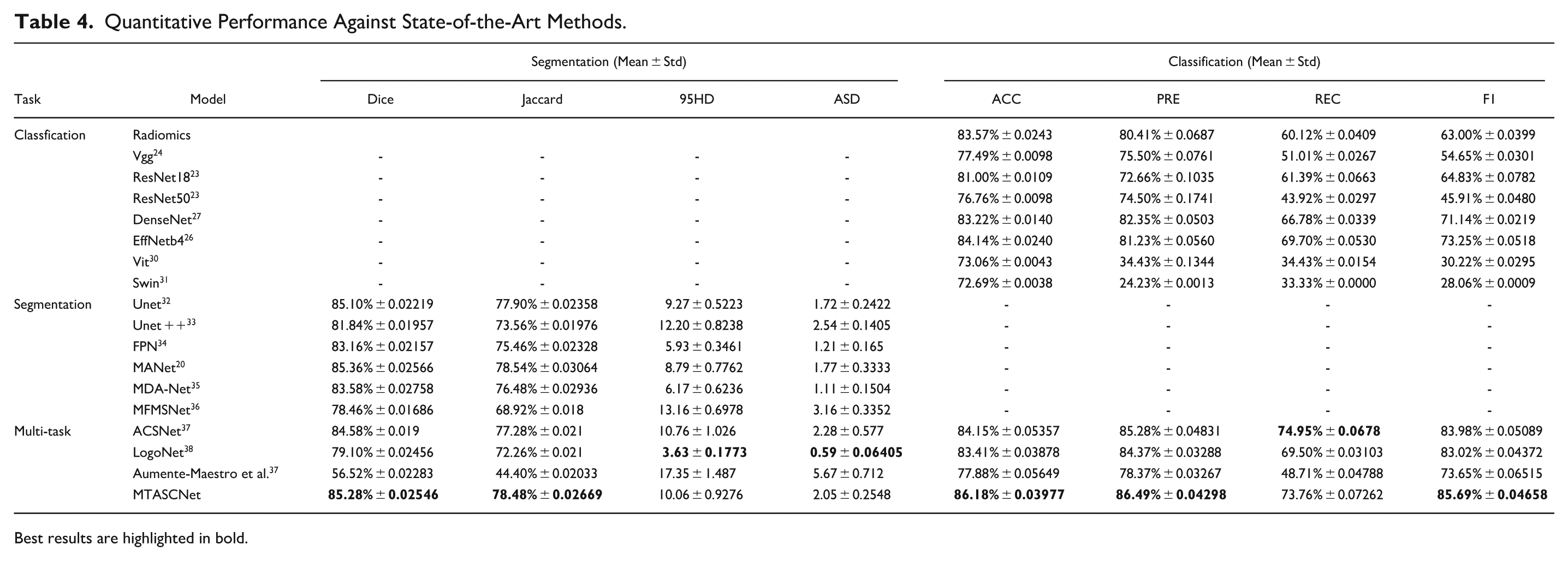
Best results are highlighted in bold.
Discussion
In this study, a multi-task deep network was developed for the analysis of ascites in ultrasound images. The proposed model achieved satisfied segmentation and classification performance compared with the state-of-the-art networks. The segmentation Dice of the proposed network for ultrasound ascites reaches 85.28%, and the classification accuracy reaches 86.18%. The results indicate that the proposed network may be useful in detecting and grading ascites in ultrasound imaging.
Ascites segmentation and classification in ultrasound imaging confront substantial challenges, including variable lesion size, indistinct and irregular boundaries, and poor image signal-to-noise ratios. 39 A multi-task learning model was designed specifically for the segmentation and classification of ascites in abdominal ultrasound images. The effectiveness of the components and parameters of MTASCNet was evaluated through ablation studies. The feature extraction capability of ResNext was explored. Based on the strong feature extraction ability of ResNext, MTASCNet gradually extracts basic patterns from the shallow layers and then identifies complex high-level semantic features. It can perform accurate feature analysis of the ascites region and effectively ignore background information from normal tissue areas, using contextual information to improve accuracy. Subsequently, the extracted deep features are optimized through the FCA module. FCA broadens the range of captured information and enhances the robustness of channel representation by extending traditional attention’s GAP to include multiple frequency components with DCT, thereby capturing spatial dependencies between arbitrary channel feature maps and enhancing the model’s ability to accurately recognize and utilize contextual information. At the same time, EMFF integrates contextual information from multiple resolutions to adapt to the morphological changes of ascites, further improving the model’s accuracy in the segmentation of ultrasound ascites. Ablation experiments proved the effectiveness of the components and parameters of MTASCNet. Interestingly, although incorporating additional modules typically elevates overfitting risk in small datasets, the integration of FCA and EMFF enhanced generalization performance. This outcome arises because these attention mechanisms function as structural regularizers rather than simple capacity augmentations. Through adaptive suppression of irrelevant background speckle noise and enforced focus on salient frequency components and morphological boundaries, they effectively constrain the hypothesis space. This prevents the network from memorizing noisy artifacts, thereby mitigating overfitting despite increased model complexity. The performance of MTASCNet was further explored in diagnosing Ascites-1, Ascites-2, and Ascites-3 ultrasound images. Test results showed that MTASCNet achieved a Dice of 59.26% in segmenting Ascites-1 type US images, 86.46% in segmenting Ascites-2 type US images, and 84.88% in segmenting Ascites-3 type US images. After visualizing the segmentation results, we found that the segmentation of images with large ascites regions was more accurate, whereas for small ascites regions, the image segmentation accuracy was lower and more prone to recognition errors. Ascites-1 images contain comparatively small lesions, whereas Ascites-2 images exhibit larger fluid collections, which may explain why MTASCNet’s segmentation of Ascites-2 is superior to Ascites-1. As for Ascites-3, due to the limited training data, the model’s fitting ability is relatively poor.
In classification tasks, the MTASCNet can accurately segment ascites regions and provide classification of ascites. Deep Learning has previously been applied to the automatic classification of ascites to assess the prognosis of advanced schistosomiasis. 40 Studies has proposed deep learning models for the classification of ascites using the CT images.9,15 However, CT imaging is a time-consuming and radiation-emitting examination method, and not usually the clinical first choice for ascites examination. Lin et al. 6 used Unet to segment ascites regions in ultrasound images, followed by binary classification necessitating further manual diagnosis. To the best of our knowledge, this study represents the first application of deep learning for the simultaneous segmentation and classification of ascites using ultrasound images. The comparison analysis showed that the CNN-based single-task classification networks had high accuracy, while transformer-based networks suffered from severe collapse. The Radiomics baseline achieved a remarkable 83.57% accuracy, outperforming several deep models (e.g., VGG, ViT). This success stems from the task’s reliance on geometric dimensions (area, diameter), which Radiomics calculates directly and precisely. While complex architectures like Transformers struggle with ultrasound speckle noise, the Radiomics pipeline—refined by Lasso selection—remains robust. Our proposed model achieved the peak accuracy of 86.18% by combining this geometric sensitivity with deep learning’s superior noise suppression. It effectively transcends manual feature engineering by capturing complex non-linear information while maintaining clinical interpretability. Since single-task classification networks take global abdominal images as input, the CNN’s ability to convolve local features may better distinguish ascites regions from normal tissues. 41 Moreover, multi-task networks, by sharing features from segmentation networks, can better focus on ascites regions, thus producing accurate classification results.21,37 Similarly, in segmentation tasks, proposed network outperformed the segmentation results of single-task and other multi-task segmentation networks. This is due to multi-task network’s incorporation of attention mechanisms, which help the model more accurately detect salient features, especially in detecting small ascites regions in ultrasound images, enhancing the sensitivity to small target segmentation.
In most urgent and emergency situations, clinicians are expected to make diagnosis in real-time during ultrasound scanning, which is usually time-consuming and labor-intensive. There is a potential for missed diagnoses in cases with minimal effusion. 42 Artificial intelligence algorithms can help maintain real-time ultrasound diagnostic support with high diagnostic accuracy. Currently, we are incorporating the MTASCNet algorithm into portable ultrasound for the real-time diagnosis of ascites.
This study may have some limitations. Firstly, there may be a classification bias due to the dataset imbalance between ascites samples of grades 1 to 3. In the future, more data of ascites grades 1 and 3 will be included in the training to mitigate the impact of sample imbalance. Secondly, a reliable clinical evaluation requires a larger number of ascites samples to prevent overfitting that leads to an overestimation of performance. In future studies, we will collect ultrasound images from different centers for external validation to demonstrate the generalizability of MTASCNet.
Conclusion
In this work introduces the MTASCNet, a multi-task framework for simultaneous ascites segmentation and grading in abdominal ultrasound imaging. To suppress noise from redundant or ambiguous features, the FCA and EMFF modules were applied to propagate salient contextual information from the encoder to the decoder through attention mechanisms and multi-scale feature enhancement mechanisms. The effectiveness of MTASCNet was evaluated using a collected dataset of abdominal ultrasound.
Experimental results demonstrate that the proposed MTASCNet outperforms mainstream multi-task learning methods, yielding a segmentation Dice of 85.28% and classification accuracy of 86.18%, effectively overcoming traditional challenges of speckle noise and poor boundary contrast in ultrasound imaging. The results suggest that the proposed framework may serve as a preliminary computer-aided tool for ascites assessment. Future work will explore prospective clinical validation to assess real-world diagnostic utility.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Second Affiliated Hospital of Naval Medical University. The computations in this research were performed using the CFFF platform of Fudan University.
Data Availability Statement
The datasets collected and/or analyzed during this study are available from the corresponding authors upon reasonable request.*