
Abstract
The current study evaluated the effectiveness of two video modeling programs, one using discrete video modeling and another using standard video modeling, to teach expressive vocabulary words to individuals with autism and other disorders. The researchers collected data across four classrooms in a school district in Inglewood, California, in a double-blind study across three weeks. During Week 1, baseline data were collected across two sets of targets presented in each video modeling program. During Week 2, the instructors showed the standard video modeling program to half of the classrooms, while instructors for the other half of the classes showed the discrete video modeling program. During Week 3, the instructors switched the video modeling programs with the two groups to compare the language acquisition outcomes. The researchers collected data on all targets at the end of each week’s viewings. Comparing the two programs using chi-square tests of independence, the research showed a significant increase in expressive words with the discrete video modeling program.
Keywords
Introduction
The current research compares two video modeling programs used to teach expressive words in group settings to students with disabilities in public, special education classrooms. Additionally, the article provides implications for further research on teaching practices with video modeling in classrooms. As federal policy mandates the use of “scientifically based research” practices for students attending public schools, the current study focuses on features of the most effective teaching tools in order to achieve better educational outcomes in students with autism and other disabilities (U.S. Department of Education, 2002).
Focus on Language Interventions
The increasing number of children with developmental disabilities each year, many of whom have characteristics of delay in language development, has a direct correlation with the need for education and specialized programs (Boyle et al., 2011). As the incidences of autism spectrum disorders (ASDs) and other disabilities increase each year (Hussar & Bailey, 2013), evidence on teaching methods is rapidly growing in the literature to determine the most effective programs. The methods for teaching students expressive words range in teaching modalities (e.g., one-to-one instruction with a behavior specialist or speech-language pathologist, teacher-directed group instruction, or technology such as video modeling programs used individually or as a group). As teachers instruct their students in small or large groups, there is a continued need for further exploration on the most effective programs to teach fundamental skills to students with autism and other disabilities.
The U.S. Department of Education’s reevaluation of the development of programs that have evidence of successful outcomes is a current focus of the push by the federal government to promote innovation and continuous improvement in educational practices (U.S. Department of Education, 2010). Hundreds of research studies support the efficacy of video modeling for individuals with ASD as well as individuals with or without disabilities (Delano, 2007; Hitchcock, Dowrick, & Prater, 2003).
Researchers have contributed evidence on video modeling in the peer-reviewed literature for over three decades. Dr. Charlop-Christy and others have concluded that video modeling can be even more effective than in vivo modeling in children with autism (Charlop & Milstein, 1989; Charlop-Christy & Daneshvar, 2003; Charlop-Christy, Le, & Freeman, 2000). The results indicate overall increases in social engagement and decreases in challenging behaviors (Buggey, 2005; Coyle & Cole, 2004). Research also suggests that video modeling promotes the development of play skills in children with ASD such as complex play sequences, sociodramatic, and pretend play skills (D’Ateno, Mangiapanello, & Taylor, 2003; Dauphin, Kinney, & Stromer, 2004; MacDonald, Clark, Garrigan, & Vangala, 2005). These studies are testament to the success of video modeling as an effective means to teach social and academic skills to most all individuals, whether they possess an exceptionality or not. Finally, researchers have pointed out that technological advances have made video modeling a readily accessible intervention that is easy to use and has minimal costs (Charlop & Milstein, 1989; Charlop-Christy et al., 2000; Goldsmith & LeBlanc, 2004).
Given the real-world constraints of the time and budgetary pressures facing teachers and administrators, effective, evidence-based interventions that are easy to use and systemically sustainable are the most likely to be widely adopted (Strain, Schwartz, & Barton, 2011). Furthermore, clinicians may model skills through the use of video as opposed to modeling skills live because videotaped models are not as labor intensive as an instructional tool (Biederman, Stepaniuk, Davey, Raven, & Ahn, 1999). These analyses of cost and ease of use in regard to video modeling interventions may contribute to the reasons why several researchers advocate for the use of video modeling as opposed to in vivo modeling (Charlop-Christy et al., 2000; Corbett & Abdullah, 2005; Dowrick, 1999).
Discrete Video Modeling
Discrete Video Modeling (DVM) contends to teach expressive language through a sequence of evidenced-based tactics in the applied behavior analytic and speech literature including tactics of repetition and massed trials, stimulus differences, generalization, multiple cues, peer models, and focusing on salient features of speech such as a close-up video presentation of the hyperarticulated words presented. The specific DVM program used in this study contained a library of targets presented in a sequence. The DVM sequence includes repetitive exposure of the targets (e.g., names of animals) articulated in a close-up video on the mouth, while the peer model says the word. Pictures of different examples of the target are presented to promote generalization of the label. The present research compared the DVM program defined earlier to a standard video modeling (SVM) program used to teach language to individuals with autism spectrum disorder.
Method
Purpose
With the validity of video modeling being accepted as an effective mechanism to teach, other studies suggest that particular features in different video modeling programs may promote different types of skills as well as different acquisition rates of the same skills. Bellini and Akullian (2007) and Hitchcock, Dowrick, and Prater (2003) supported the use of video modeling to teach a variety of skills. Moreover, their work highlighted the need for continued research evaluating functional relationships between specific features in video modeling and the acquisition of specific skills.
While the corpus of literature supporting the use of video modeling has developed, to date, there exists no peer-reviewed research comparing two different video modeling programs in the classroom that contend to teach the same skills. The current study compares the results of two video modeling programs that employ different tactics to teach expressive words to children enrolled in a special education program. The teachers in all classrooms who participated in the study presented the video modeling interventions to classes as a group.
There were three main goals driving the research. The primary goal was to determine whether either video modeling program could elicit gains in expressive words when used with groups of children and not in an individualized setting. The second, if gains were seen, was to identify the video modeling program that produced the most significant gains in expressive words skills across students. A third goal was to identify further variables to research in order to determine best practices with video modeling procedures that facilitate the most successful development of expressive words for students with disabilities.
Although the efficacy of video modeling in individual viewing sessions has been proven beyond doubt, there is no previous research on the effectiveness of viewing video modeling sessions in groups. The implications for this group tactic being proven in research are vast as schools’ budgetary concerns and staffing shortages across the nation may cause pressure for administrators to decrease the time for one-to-one instruction or therapy (Baker & Ramsey, 2010). Despite these pressures, if teacher time could be freed up by such group tactics, this could allow more time for one-to-one instruction.
Participants and Setting
The participants in this study were 31 students in preschool, kindergarten, first-, second-, third-, and fourth-grade classes at an inner-city elementary school in the Inglewood Unified School District. Inglewood is a city in southwestern Los Angeles County California. The primary researcher obtained permission from the Inglewood School Board to conduct the study. All classes that participated in the study were assigned in a standard manner by the school district without regard to this trial or this trial’s objectives. A majority of the students came from middle–lower to lower socioeconomic status families, and all students who participated in the study received special education services. All participants held individualized education plans (IEPs) and attended the summer school program while data were collected for the study. A majority of students were diagnosed with autism (58% of the population), and the other disabilities in the population consisted of other health impaired (16.1%), Down’s syndrome (9.7%), specific learning disability (9.7%), and emotional disorder (6.5%). Table 1 presents the demographic data for the participants in this study.
Demographic Data for Participants.

Note. N = 31.
Procedures
The study took place during 3 weeks of summer school. This was a double-blind study, and neither the assessors nor the students were aware of what video modeling intervention they received each week. Seven behavior therapists from a local, nonpublic agency were the assessors who collected primary and reliability data on the preselected expressive word targets that consisted of different animals, clothing items, and body parts. The assessors collected data on the 31 participants during the first week for baseline measures and at the end of the second and third weeks after exposure to one or both video modeling programs. The tests were administered in the back of the classrooms or a space outside the classroom with a desk and chairs provided on the school campus. Each individually administered session ranged from 10 to 40 minutes. The primary investigator organized appropriate times with all teachers to pull students from their classes.
Video Modeling Interventions
The two commercially available video modeling interventions compared in this study were DVM and SVM procedures.
DVM
The DVM program used in this study is a product titled GemIIni©. The DVM program combines several evidence-based tactics to present expressive words (e.g., crab). The DVM curriculum presents each label from its library in a predetermined, controlled sequence including repetition of the item labels by peer models, different examples of the label through a series of pictures and videos, and an intentional removal of all extraneous sensory distractions. No music or sound effects are part of the DVM program.
More specifically, there are five parts of the DVM filming sequence. All of the shots are filmed on white background with the intention of removing all possible distractions and presenting only the salient information. In the first portion of the sequence, the label is presented in a single-object depiction, like a flash card, next to a mid-shot of a peer model articulating the specific label being taught. This is done on white screen, and the only audio is the label itself. Second, there is a close up of the speaker’s mouth, which slowly hyperarticulates the specific label such as “c … r … a … b.” Third, there is a generalization of the word which presents photos and videos of many types, sizes, and colors of the object. Fourth, the close-up of the mouth of the speaker slowly hyperarticulating the word is repeated. Last, the first presentation of the word is repeated with a mid-shot of the peer saying the word next to a picture of the word.
SVM
The SVM program used in this study is a product titled Teach2talk™. This SVM program contends to teach language by presenting the text of the expressive word such as “face,” then showing videos of the words along with the auditory label in a random sequence. Peer models and adults in the video present the targets along with dancing and music playing as well as sound effects to accompany the labels of the words.
More specifically, there are approximately three to five parts of the SVM filming sequence. First the title of the content is presented on the screen and animated with background music playing such as “nouns and body parts.” Second, the text of the word such as “face” is presented on the screen and a child’s voice says the word “face.”. Third, the child appears on the screen and smiles at the camera saying “face.” Peer models are presented individually smiling at the camera and saying the word “face” with sound effects in the background as the peer models appear. Last, the text of the word “face” appears on the screen with the child’s voiceover saying “face.” Each noun is presented a bit differently such as with the word “eye” a child dressed as a pirate lifts up an eye patch with his squinted eye underneath and says “eye.” At the end of the all the nouns presented a man plays a song on the guitar such as “I love all my body parts and it shows” with video clips of kids and adults dancing and laughing.
The teachers conducted the viewings in the same way for both video modeling interventions. They gathered their individual classes as a group around a television monitor to view the videos 3 times a day for 10 minutes of each viewing. The teacher collected fidelity data by indicating the time she had students view the videos each day and the names of any students who were absent from the viewing session. Teachers and teaching assistants encouraged the students to watch the videos by directing them to the television screen. They did not prompt the students to talk during the videos nor did they reinforce any of the content during and after viewings of the videos. Finally, teachers collected observational data on any behavior challenges that occurred during the viewing of the videos.
Two of the four classes were randomly assigned to either the DVM program or the SVM program during the first week. After the first week of intervention, the assessors tested the same expressive words that were tested during baseline. The teachers played the second video modeling program during the second week of intervention and the assessors tested the same words at the end of Week 2 of intervention. Refer to Table 2 for the intervention and testing schedule.
Intervention and Testing Schedule.

Note. DVM = discrete video modeling; SVM = standard video modeling.
Assessors conducted baseline probes Monday through Thursday the first week. During Weeks 1 and 2 of intervention, all four classrooms viewed videos for 10 min/session, three sessions per day, on Mondays, Tuesdays, and Wednesdays for each week of intervention (e.g., 30 min total each day). Teachers presented both DVM and SVM videos in the same manner, and all students were exposed to a total of 90 min viewing either DVM or SVM programs each week. Assessors conducted probes on the same words tested during baseline on two consecutive Thursdays after the 3 days of intervention each week.
Reliability and Fidelity
The assessors were randomly assigned as observers to gather interobserver agreement across baseline and intervention conditions. The reliability observer recorded correct and incorrect responses while observing the assessment within 5 feet of the table where the students were assessed. Interobserver agreement was calculated by dividing the total number of agreements between primary and reliability observers by the total number of agreements plus disagreements and multiplying by 100 to get the percentage of reliability.
The primary investigator reviewed fidelity data sheets with each teacher individually prior to intervention. The fidelity sheet included the time teachers played the videos throughout the day, the students who were absent during each viewing period, and notes for any observed behavior changes or use of language throughout the videos.
Criteria for Evaluating Results
The assessors presented a flashcard with a picture of the expressive word to the participant and asked, “What is this?” If the participant emitted an accurate expressive word, the assessor affirmed the correct answer (e.g., “Yes! That is a nose!”) and counted the response as correct (+). If the participant emitted an approximation of the expressive word, an inaccurate expressive word, or no response, the assessor counted the response as incorrect (−). The assessors did not give any corrections nor any response to incorrect answers. For body parts (the SVM targets), the assessors gave participants a second opportunity to respond correctly, as the data collector would point to his own body part and repeat, “What is this?” For animals (the DVM targets) the assessors used only flashcards and no alternate method of questioning.
Target Selection
In a human subject study, the teaching effect is always a concern. It was not possible to test the same group of participants on the exact same expressive words from both DVM and SVM, as once participants have potentially learned an expressive word within the first week, they cannot “unlearn” that word within the second week. This is the reason why the researcher chose two different categories of words to compare across the two different interventions (e.g., DVM words and SVM words). The DVM expressive words were a variety of animals, and the SVM expressive words were a variety of body parts and clothing. As animals, body parts, and clothing are some of the very first labels taught to children, they were considered to be developmentally appropriate expressive words to use for the evaluation of both video modeling programs. Table 3 presents the targets presented through both the DVM and the SVM programs in the order they were presented by the assessors as they conducted the probes.
Expressive Word Targets Presented.
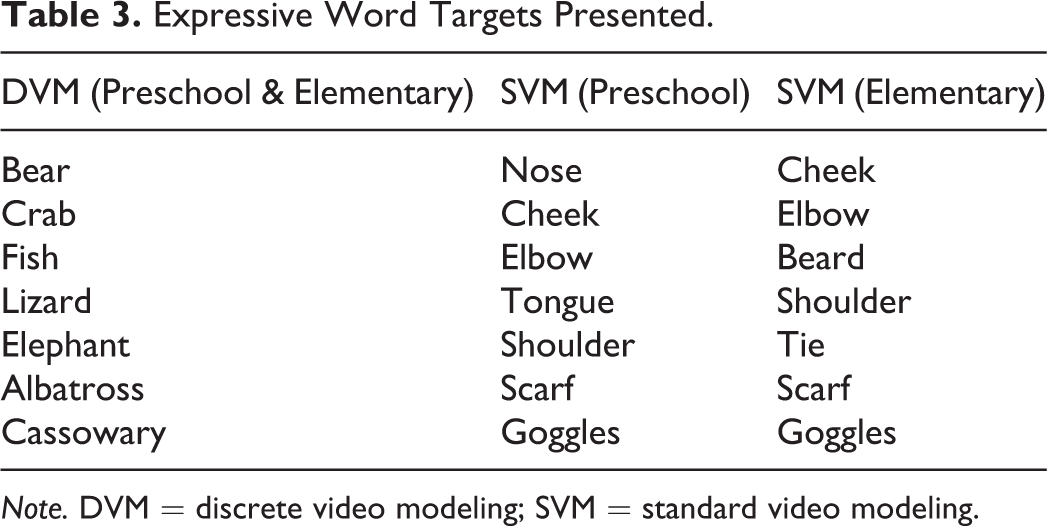
Note. DVM = discrete video modeling; SVM = standard video modeling.
As it was necessary to determine whether the child knew the expressive word for a specific body part or piece of clothing in SVM, targets were chosen that most unambiguously represented these items. The SVM video modeling program did not have discrete enough images throughout the video for this purpose. For example, the assessors presented a flashcard with a picture of a person’s nose in order to determine whether the child knew what “nose” actually meant and not that the actor in the SVM was called “nose.” If the child could not say the expressive word for the target first presented on a flashcard, the data collector would reinforce the query by asking the child to point to his own body part. If the child was still unable to respond, it was counted as a negative. For the clothing, a generic representation of the item was chosen. The clothing targets had the potential to be more problematic as clothing items differ more than body parts. This proved not to be a detriment as the children learned clothing and body parts in equal proportions.
For the DVM target words (e.g., animals), the pictures on the flashcards were the most representative images presented in the DVM program for each word. These pictures were used as they clearly represented the word. For example, in the DVM video for “bear,” several pictures of a bear are presented. The assessors had a screen shot picture from the bear video with the one image that clearly represented a bear. No other distractor such as the peer model holding the card in the video was on the flashcard, only a discrete picture of the animal.
Results
Results of the study indicated that students learned some novel, expressive words from both video modeling programs. Comparing the two programs, students emitted significantly more expressive novel words after exposure to the DVM program when compared to the number of expressive novel words students emitted after exposure to the SVM program.
The results of the study included chi-square tests of independence to show comparisons between the DVM and the SVM groups. The number of novel expressive words attempted in the DVM program for all children inclusive were 132; the participants achieved mastery of 36 expressive words (27.3%). Meanwhile, the number of novel expressive words attempted in the SVM modeling program for all children inclusive were 135. The SVM participants mastered 17 expressive words (12.5%; Figure 1).

Bar graph of the percent of expressive novel words mastered across DVM and SVM programs for all participants.
A chi-square test of independence was performed to test the independent variable group of modeling program (DVM vs. SVM) and the dependent variable group of mastery (yes vs. no) as relates to the proportions of mastered and nonmastered expressive words. Table 4 presents a chi-square test to show the compared novel expressive words attempted to the novel words mastered according to the two groups of (a) DVM vs. (b) SVM for all 31 students. Results were statistically significant, χ2(1) = 9.04, p = .003, with DVM outperforming SVM.
Cross-Tabulation of Correct (“Yes”) and Incorrect (“No”) Expressive Word Components Mastered and Intervention Groups (DVM and SVM).
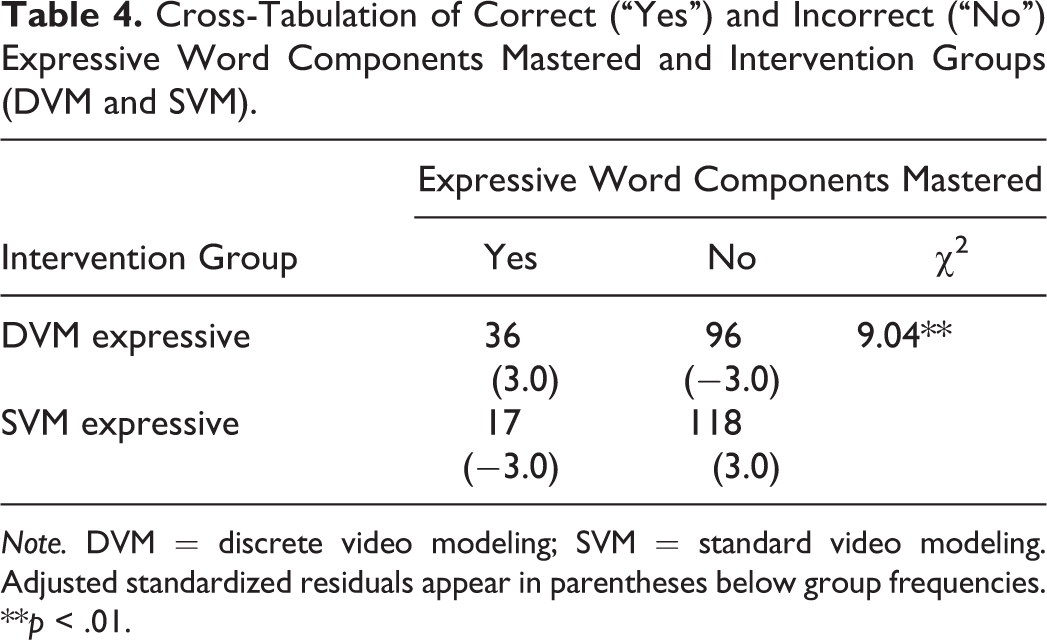
Note. DVM = discrete video modeling; SVM = standard video modeling. Adjusted standardized residuals appear in parentheses below group frequencies.
**p < .01.
Results for Subset of Children With Autism Diagnoses (n = 18)
The researcher also analyzed for subsets of children with autism diagnoses (n = 18; Figure 2). The results in the number of novel expressive words attempted in the DVM modeling program for the children with autism were 65, with mastery of 27 expressive words (41.5%). The number of novel expressive words attempted in the SVM modeling program for the children with autism were 68, with mastery of 9 expressive words (13.2%).
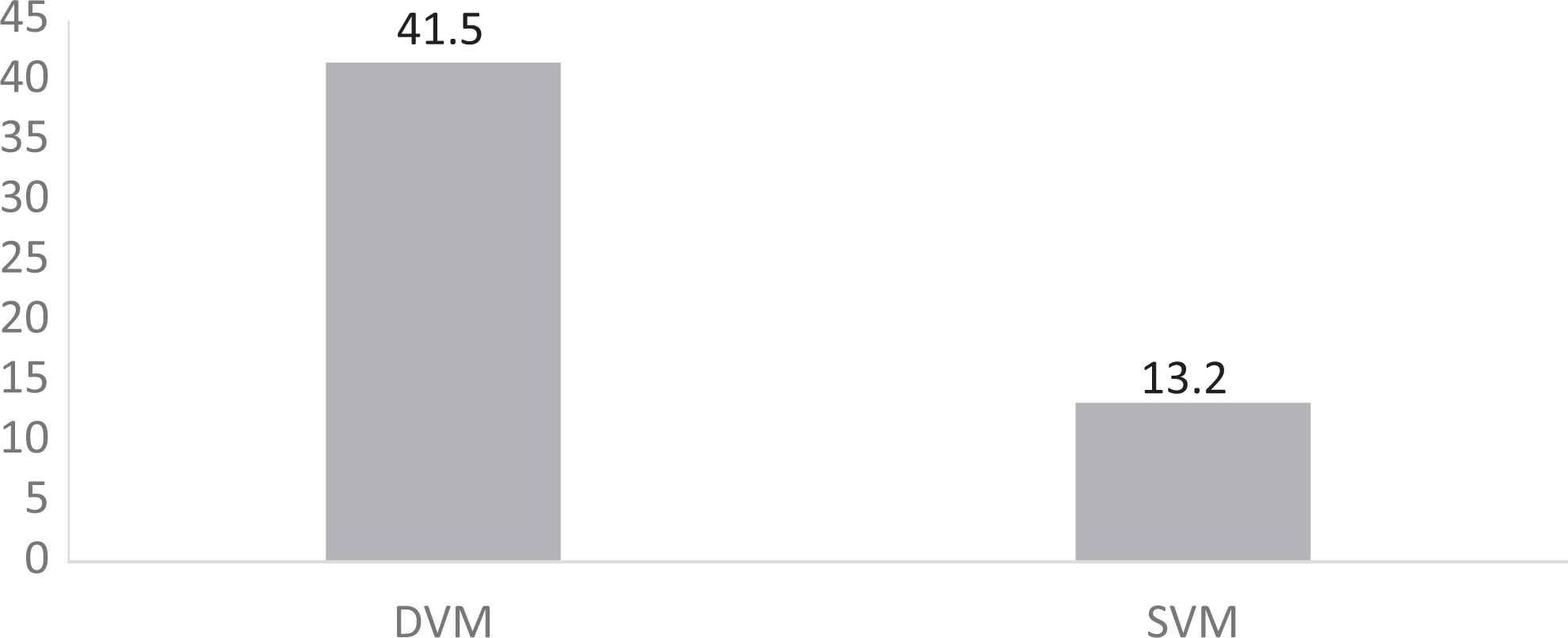
Bar graph of the percentage of expressive novel words mastered across DVM and SVM programs for participants with autism.
A chi-square test of independence was performed to test the independent variable group of modeling program (DVM vs. SVM) and the dependent variable group of mastery (yes vs. no) as relates to the proportions of mastered and nonmastered expressive words for the students with a diagnosis of autism (Table 5). Results were statistically significant, χ2(1) = 13.49, p < .0005. The population with autism significantly outperformed the overall population in mastered novel expressive words when using the DVM intervention as compared with the SVM intervention.
Cross-Tabulation of Correct (“Yes”) and Incorrect (“No”) Expressive Word Components Mastered and Intervention Groups (DVM and SVM) for Students With Autism.

Note. DVM = discrete video modeling; SVM = standard video modeling. Adjusted standardized residuals appear in parentheses below group frequencies.
**p < .01.
Reliability and Fidelity
Assessors collected reliability data on 30.8% of all expressive word probes conducted. Interobserver agreement was calculated by dividing the total number of agreements between primary and reliability observers by the total number of agreements plus disagreements and multiplying by 100 to get the percentage of reliability. Interobserver agreement was at 96.5% across all conditions. Additionally, each teacher collected fidelity data across the 2 weeks of intervention, and there was 100% accuracy of procedural fidelity with all teachers.
Discussion
A growing body of empirically based research in refereed journals supports the efficacy of video modeling to teach expressive words. This study featured a group design model and statistically evaluated the expressive word gains of students exposed to two different video modeling tactics among 31 special education students in grades pre-k through fourth in a public elementary school. Both video modeling tactics were shown to increase the language acquisition skills of participating students. However, there was a statistically significant difference in the rate of acquisition with expressive words between the two programs. The responses to DVM resulted in substantially greater gains (e.g., statistical significance at p < .01 level) when compared to an SVM program.
Strengths and Major Findings
This study supports the effectiveness of video modeling in general to teach expressive words to students with disabilities. Furthermore, in practical settings such as group instructional time in special education classrooms, the study supports the idea that video modeling can effectively be used to teach expressive words within group settings of children and not only as an individual intervention.
The results of the current study indicate that students emitted some novel expressive words presented in both programs after viewing the videos. Comparing DVM words to SVM words mastered across groups, the chi-square data show that the proportion of novel expressive words mastered for the DVM group was significantly greater than the proportion of novel expressive words mastered for the SVM group. These data were evaluated further with the students who were diagnosed with autism showing greater gains with DVM, as the proportion of novel expressive words mastered with the DVM group was significantly greater than the proportion of novel expressive words mastered with the SVM group.
The current research also supports the idea that video modeling as a teaching strategy has treatment utility. It can be utilized in many settings: classrooms, clinics, or in home. Additionally, the research shows that exposure to DVM, when compared to SVM, resulted in more rapid acquisition of expressive words. Students’ gains in novel expressive words after viewing DVM videos were statistically significant when compared to gains in novel expressive words after viewing SVM videos. Other skills such as increased compliance to testing were also noted in behavior observations associated with DVM exposure.
Teachers, teaching assistants, and assessors gave frequent anecdotal reports regarding significant changes in behavior during testing after students were exposed to the DVM program. A majority of the teachers commented on the improvement in the students’ overall attending and readiness to learn skills while watching the DVM program. Assessors who tested the DVM group after Week 1 and then again after Week 2 commented that children had fewer behavior issues and could attend to the probes better after treatment. The increase in appropriate attending skills and reduction in adverse behaviors appear to be an ancillary benefit to exposure to DVM which merits future research. These qualitative findings suggest that DVM may constitute a positive behavior change intervention worthy of consideration for individuals with disabilities.
In addition to the observed behavior changes, the week-by-week comparisons with those groups of students who were exposed only to DVM and only to SVM, support the difference between gains in novel DVM expressive words and gains in novel SVM expressive words. Regarding the results of the study, the researcher evaluated the overall gains in expressive words by the two groups and concluded that DVM’s overall gains in expressive words were statistically significant compared to the SVM’s overall gains in expressive words for the 2-week period. In further analysis of the data, a week-by-week comparison of novel expressive word gains showed a startling differential in performance of each group. DVM’s success in teaching expressive words did not change meaningfully from week to week, but there was a marked difference between the 2 weeks for SVM. Refer to Table 6 for the observed number of expressive novel word gains across each week with only DVM or only SVM exposure.
Gains in Novel Expressive Words by Week.
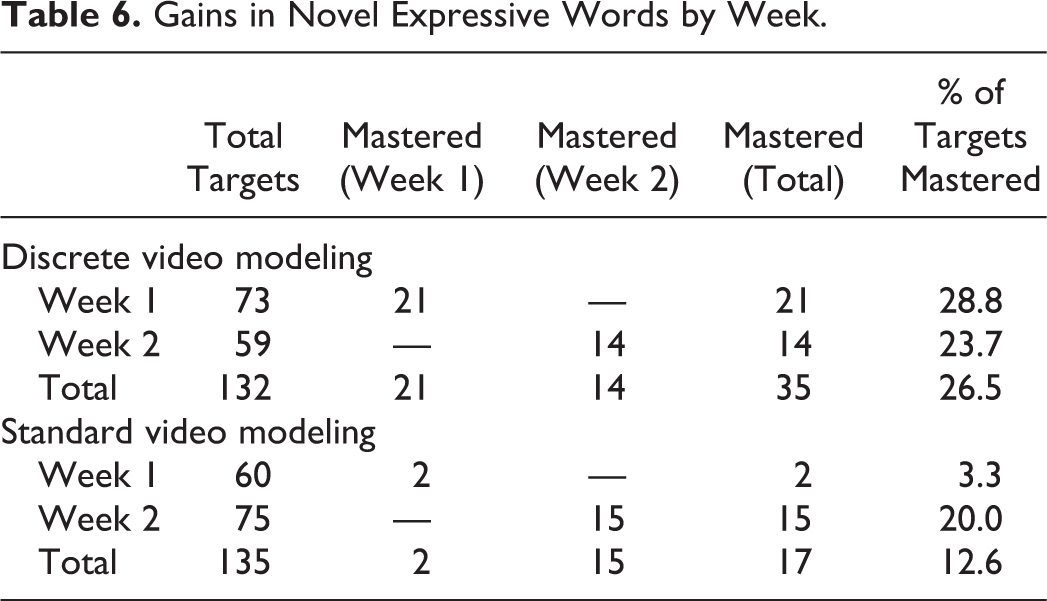
The group of students who viewed only the DVM videos mastered 28.8% of the expressive words at the end of the first week. The students who viewed only the SVM videos mastered 3.3% of the expressive words. When the groups were given the intervention they had not yet been exposed to (e.g., Week 1 DVM group became the Week 2 SVM group and vice versa), the DVM results were similar to the first week. However, the SVM group’s performance increased from 3.3% to 20% mastery of expressive words with the children who had first viewed the DVM program. This result implies that exposure to DVM may have had a substantive accelerative effect on learning the expressive words for those receiving SVM in the second week. Further research should evaluate this potential carryover effect from the DVM program.
Results for Subset of Children With Autism Diagnoses (n = 18)
The students with autism showed more robust gains in expressive words compared to the whole multidisability group expressive word gains. As a group, the students with an autism diagnosis mastered over 200% more target words after exposure to DVM than they did after exposure to SVM. These students varied in their language abilities with 13 of the 18 participants with autism having one- to two-word requests and labels. These students had some conversational skills such as simple questions and answers pertaining to personal information (e.g., “what is your name?”, “how old are you?”) These 13 students also were able to attend to stimuli and follow one-step directions without prompting such as giving the teacher a pen when she says the directive, “give me the pen.” The remaining five students in the autism group fell into a minimally verbal group known as “nonresponders.”
Results With Minimally Verbal Students (n = 5)
Although receptive gains from DVM were greater than receptive gains in SVM during the study, the current research does not present these results, as the analyses on receptive language will be presented in a future study for a more thorough discussion. In that future study, the researcher will expand upon the following discussion on minimally verbal students or nonresponders.
The data show an increasing trend for specific students seen as nonresponders, or students who did not emit any correct responses, including no responses to stimuli presented. Although this particular group represents a rather small sample size, the data are noteworthy. These children can be seen as a very difficult subtype to teach skills that require both receptive and expressive responses from stimuli presented.
There is a growing urgency in the literature to find new interventions and tactics for nonverbal children, or children seen as nonresponders. Strain, Schwartz, and Barton (2011) indicate the need for interventions with individuals having autism, noting that the authors were “keenly and painfully aware of the lingering issue of the ‘non-responders’ to otherwise evidence-based practices … [T]he vast majority of discrete, evidence-based tactics were developed 10, 20, 30, even 40 years ago. We desperately need innovation to expand the range of intervention options” (p. 330).
Prior nonclinical trials with DVM have shown increases in nonresponders and minimally verbal children. To further evaluate whether these trends held within the Inglewood population, the researcher of the current study looked specifically at the population of nonresponders within the group. The researcher evaluated gains in receptive and expressive words and if there were differences between the interventions, specifically with the nonresponder group.
The students who did not respond to any of the 14 target words used in the study during baseline probes were considered to be nonresponders (see Table 7). As the targets contained some of the very first few words that a child learns (“nose” and “bear”), it was surmised for the sake of this discussion that their lack of receptive and expressive words put them into the group of nonresponders generally. There were five such students who scored zero in both receptive and expressive word probes during baseline.
Gains in Language by “Nonresponder” Students With Zero Mastery of Target Language Prior to Each Intervention.
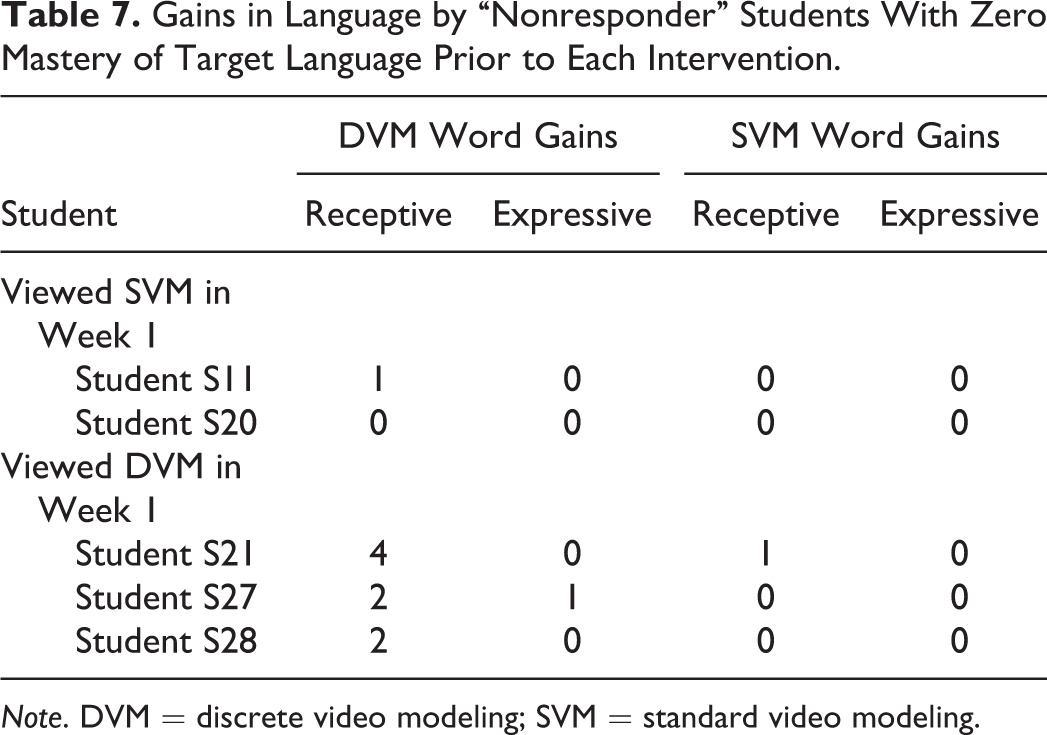
Note. DVM = discrete video modeling; SVM = standard video modeling.
Shifting Definition of Nonresponders
The investigator did encounter one difficulty in defining a nonresponder during the trial, as children who responded to the first week’s intervention might not be considered nonresponders for the second week’s intervention. The scenario arose for the children receiving DVM in Week 1.
Three of the baseline nonresponders (S21, S27, and S28) received DVM as their first intervention. All three of those children had receptive word gains in the first week, and S27 spoke his first-ever expressive word. Although the group had gained nine novel words in the first week of intervention, they were still considered nonresponders for the second week. Of these nonresponders, one student gained one receptive word after exposure to SVM in the second week.
Two of the baseline nonresponders (S11 and S20) received SVM as their first intervention. SVM produced no novel word gains, so even in the strictest interpretation of the definition they remained nonresponders. Of the two children who did not respond to SVM, one child gained a receptive word after exposure to DVM in Week 2.
Characteristics of Nonresponders in General
Nonresponders varied in their attending behavior and use of receptive and expressive words. All five nonresponding students were diagnosed with autism. Three of the nonresponders had similar profiles: S11 (one receptive word gained), S28 (two receptive words gained), and S20 (nonresponsive to both interventions) were all students who, according to teachers, did not emit any vocal verbal words throughout the day, including no echolalia. These three students would emit sounds; however, any attempts for expressive words were not intelligible by teachers. Their receptive language was limited. They were unable to follow one-step directions such as “sit down” and were fully prompted by their teacher to follow the one-step direction asked of them.
Behaviorally, S11 and S28 would often elope to an opposite side of the classroom or to outside the classroom door in response to demands asked of them. During the assessment sessions, the assessors positioned the testing area to keep the student sitting in the same spot and the assessor prompted the student to look at the flashcards.
Student S20 (nonresponsive to both interventions), who was the most severely impacted by characteristics of autism, had difficulty tracking stimuli in front of his face and would sit at the desk but have difficulty looking at where the assessor pointed for more than a half a second.
The remaining two students, S21 (four receptive words gained) and S27 (two receptive words and one expressive word gained), exhibited echolalia on a consistent basis during and outside testing. Additionally, both students were compliant when seated.
The sample size of nonresponders was relatively small which may affect a test of statistical significance; however, the increasing trend in responses after DVM is highly encouraging and warrants further investigation. As video modeling is known to be a low-cost, evidence-based practice, further research should be done on its use as a tactic to initiate the use of receptive and expressive words in nonresponders and all students who receive intensive speech services for severe language delays.
Limitations
All human subject studies are exposed to limitations. Studies conducted with children who have special needs can pose a particular challenge due to issues with behavior management and noncompliance. It is the aim of the research to mitigate as many of these limitations as possible as research in this area is essential for furthering the science.
There were some limitations to the current study. As teachers and assessors reported gains in compliance skills during testing after viewing of initial videos, baseline measures may have had some false-negative values indicating that students knew some of the words expressively during baseline but were not able to be tested effectively due to behavior challenges (e.g., students running away from the assessor or falling to the ground out of their chair when the assessor asked for a response). After the study, the researcher interviewed the assessors on their experience. The assessors reported that with some students who exhibited behavior issues during baseline probes, those same students received higher scores across both DVM and SVM words after exposure to DVM.
Some variables throughout the study could have affected student responses. Since the assessor administered all measures by vocally presenting stimuli, differences in speech patterns, dialects, or language could have affected reliability of the test administration. Also, at times assessors had to pull students out of their classroom without any forewarning which may have affected their responses. For example, some children were engaging in preferred activities in the classroom and during testing they were expected to attend and emit responses to the questions asked by the assessors. These children may have lacked focus during testing because they were interrupted in their preferred activities. The researcher is conducting further studies to control for these potential confounding variables.
Selection of Targets
It is important to note that the DVM-selected targets contained some uncommon animals, whereas the SVM targets (e.g., body parts and clothing) were considered more common items. This is a limitation as the words presented were more difficult in the DVM category when compared to the SVM categories, giving SVM an overall advantage over DVM when evaluating difficulty of both the word names with the way they are pronounced, such as single syllables versus multisyllabic words, as well as the comprehension of the label, such as the word “albatross” compared to “goggles”. Despite the fact that assessors presented multisyllabic words (e.g., cassowary and albatross) in the DVM probes, the children still learned significantly more of the DVM words as compared to SVM.
Recommendations for Future Research
The results of this study are promising because they imply that minimally invasive, low-cost interventions can significantly improve expressive word gains of children with autism and other disabilities in special education classrooms. Additional research could further refine tactics in the implementation of DVM to improve expressive word acquisition. There are several ways in which researchers could improve the quality of evidence on video modeling interventions.
Buggey (2005) examined the use of video modeling interventions to reduce challenging behavior. Assessors in this study commented on the improvement in the students’ overall attending and readiness-to-learn skills while watching the DVM program as well as during testing after exposure to the DVM curriculum. More research is necessary to determine whether viewing DVM in groups facilitates the acquisition of more complex social skills, the attainment of higher level academic skills, and the reduction of inappropriate behaviors in children with disabilities.
The statistical significance of the data in the present study leads the researcher to inquire about what specific components of the DVM approach led to higher expressive word acquisition rates. The researcher shared the data in the current study with speech pathologists, neurologists, and psychologists to gain multidisciplinary insight as to what may be happening. The neurologists who consulted with the researcher suggested that with DVM the simplicity of the delivery, the predictability of videos and the repetition of the concepts could all allow the information to be processed by parts of the brain that bypasses the frontal cortex, teaching specifically to a part of the brain that maintains neuroplasticity throughout life; all hypotheses which need further investigations and the current researcher is presently pursuing this research. Neurologists have stated that the specific part of the brain that has proven to have more neuroplasticity than other regions and may also help with initiation and generalization of inputs as well as an increase in motor skills. These hypotheses clearly show the need for further interdisciplinary research on how the use of DVM could affect the brain to teach expressive words quicker than other video modeling approaches. The present researcher is in agreement with prior researchers that as the field of the education of individuals with special needs moves forward, future evidence needs to be multidisciplinary, since researchers have the ability to control for more behavioral variables that may attribute to the variation seen in responses to intervention (Strain et al., 2011). With that guiding principle the present researcher is currently seeking institutional research partners to perform functional MRI studies in order to evaluate these hypotheses.
As indicated throughout this study, the information presented on effective programs contributes to the mandated use of evidenced-based interventions for students with autism and other exceptionalities. The current paper represents the first documented comparison of video modeling programs used to teach expressive words to students with disabilities. Systematic replications are crucial to support this research on the most effective video modeling programs to teach individuals language skills.
Footnotes
Acknowledgments
The principal researcher would like to acknowledge Inglewood School District staff and students for their participation in the study. Additionally, the researcher would like to acknowledge mathematician Kristina Gilmour from Los Angeles Southwest College and Glendale Community College and statistician Elaine Eisenbeisz from Omega Statistics for their support with the statistical analyses in the present manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.