
Abstract
Objectives
Using dyadic genetic information on older couples, this study queried associations of a polygenic score for well-being with one’s own as well as a partner’s relationship experiences.
Method
Data were from the 2010 wave of the U.S. Health and Retirement Study. Analysis was through structural equation modeling.
Results
Especially among women, the genetic score was associated with individuals’ own relationship experiences. Genetic externalities—linkages of one’s genes with a partner’s experiences—were also observed. No significant gender variations emerged.
Discussion
Contrary to conceptions implicit in much of existing genetics literature—which focuses on individuals’ own gene–trait associations—the interpersonal environments most crucial to life course and health outcomes are shaped by the genes of all involved actors. Genetic externalities are a central component. Implications for the life course and gene–environment literatures are discussed.
A growing “gene–environment correlation” (rGE) literature indicates a person’s proximal environment may be linked to their own genes (Avinun & Knafo, 2014; Krapohl et al., 2017). In turn, life-course theory suggests many of the most crucial contexts shaping a person’s life trajectory are interpersonal. Such environments may arguably be structured by genes of all involved individuals—patterns largely unexamined in extant rGE studies. In later life, perhaps the most important interpersonal context is the dyadic one jointly created with a spouse or partner. The quality of that relationship, for instance, has been linked to a range of health outcomes, physical and mental (Waite & Das, 2010). If that critical environment has a genetic basis, then the exogeneity of its health effects becomes questionable. Moreover, given the highly gendered nature of marriage and partnership among older cohorts, genetic influences may be different for women and men.
Studies of rGE using direct genetic measures have largely focused on morbidity-linked genes, such as those for depressive symptoms or major depressive disorder (Avinun & Knafo, 2014; Krapohl et al., 2017; Visscher & Yang, 2016). Positive affect, however, is a distinct set of traits that has known psychosocial implications over and above morbidity (Pressman & Cohen, 2005; Stone et al., 2010). Genetic roots of these traits are only now being understood, and their environmental effects remain unexplored.
The recent availability of polygenic scores (PGSs) for subjective well-being as well as of validated relationship quality indicators from both partners of a relationship in the Health and Retirement Study (HRS)—nationally representative of U.S. adults over age 50—provides an unprecedented opportunity to address these gaps.
Well-Being, Genes, and the Life Trajectory
An established literature in “positive psychology” proposes that well-being is more than just the absence of negative affect and is a key aspect of individual health (Pressman & Cohen, 2005; Stone et al., 2010). Thus, for instance, the World Health Organization (1958) defines health as “a state of complete physical, mental and social well-being and not merely the absence of disease or infirmity.” Theories of “successful aging” similarly propose a central role for positive affect (Bass & Caro, 2001; Rowe & Kahn, 1997). Apart from its intrinsic importance, such an orientation may mitigate unhealthy behaviors, promote healthy ones, and thereby enhance older adults’ physical status (Lindau et al., 2003). With increasing longevity, these “lifestyle” underpinnings of preventive health are becoming increasingly important—both to optimizing individual-level aging trajectories and to reducing health care expenditures at the population scale.
Evidence suggests that while well-being is partly modifiable—and hence amenable to policy interventions—it also has a stable “trait” component or individual-specific set points around which transient states fluctuate (Diener et al., 2006; Probst-Hensch, 2017). Such “trait well-being” has specifically been linked to lower morbidity and increased longevity (Diener et al., 2006). At least part of this stable component is genetically rooted (Bartels, 2015). A recent large-scale twin study, for instance, finds that genetic factors explain 31%–47% of the variance in well-being across the life span (Baselmans et al., 2018). A smaller proportion seems specifically influenced by common genetic variants—single nucleotide polymorphisms (SNPs) that can be captured in genome-wide associations studies (GWAS). In a 2016 GWAS conducted by the Social Science Genetic Association Consortium, PGSs constructed from all measured SNPs explained about 0.9% of the variance in well-being in independent samples (Okbay et al., 2016). As explained below, the score used in the present study was based on this GWAS.
Apart from its health influence, genetically rooted trait well-being may conceivably influence the interpersonal environments through which a person’s life trajectory wends (Antonucci et al., 2011). A large rGE literature examines such genetic linkages—although, as noted, few studies have focused on genetic substrates of positive affect. Much of the available evidence comes from studies of childhood environments and parent–child relationships and suggests four separate but overlapping mechanisms (Avinun & Knafo, 2014; Krapohl et al., 2017). First, many observed associations between offspring genotype and environment-providing parental traits are outside the offspring’s influence (e.g., parental age and education level at childbirth), and hence likely to reflect “passive rGE.” Specifically, parental genetic propensities that were passed down to offspring are also associated with their own environment-providing behavior. This mechanism, however, does not extrapolate to nonkin environments in adulthood such as the marital one. Second, some environments may also reflect “active rGE”—individuals selecting their social environment based on their genetic tendencies. The childhood literature has focused on choice of compatible friends or other social alters (Avinun & Knafo, 2014; Barnes et al., 2014; Krapohl et al., 2017). However, the mechanism can plausibly be extrapolated to choice of careers, spouses and partners, communities of residence, and perhaps entire life ecologies. An obvious extension to partnership is through genetic assortative mating—choice of partners with similar genetic endowments (Robinson et al., 2017). Third, behaviors of social alters could partially be “evoked” by a focal individual’s genetic propensities (McGuire et al., 2012). Childhood studies using PGSs have found linkages of adolescents’ genetic risk for aggression with low family cohesion (Elam et al., 2018), for behavioral undercontrol with poorer parental monitoring (Elam et al., 2017), and for poor response inhibition with mothers’ inconsistent parenting (Wang et al., 2017). Analogous patterns in partnerships remain unexplored. Fourth, rGE could be induced by environmentally mediated genetic effects. For instance, if education-associated genetic variation influenced mothers’ predisposition to smoke during pregnancy—and prenatal nicotine exposure had an environmental effect on offspring attention problems—this could induce associations of the offspring’s own education-associated polygenic variation with maternal smoking as well as capture part of its correlation with offspring attention problems (Krapohl et al., 2017).
Missing in these individual-focused conceptions is the notion of interpersonal environments as “systems” influenced by the attributes of all involved actors. Thus, for instance, genetic externalities—influences of a person’s genes on a social alter’s psychosocial and health outcomes—remain underexplored. Especially if a subject is a dominant partner in a dyad, or the one more responsible relationship maintenance, these “collateral” effects may comprise a large proportion of the overall influence of their genes on the partnership. In larger social systems, the same may be true of those with high “network centrality”—that is, structurally important positions in the web of relationships (Bonacich, 1987). In contexts that may involve genetic concordance with those alters—whether “passively” (when the alter is a consanguineal or blood kin) or through assortative matching (with spouses, partners, or friends)—accurately characterizing these secondary effects requires controlling the alters’ own genes. Moreover, the two may interact, such that a person’s genetic propensities “evoke” a stronger response when an alter also has similar dispositions. High data requirements have thus been a major impediment to genetic analysis of interpersonal systems—especially those involving alters who are not consanguineal kin.
A growing literature on human “social genetics” or “metagenomics” is beginning to examine such patterns (Das, 2019). Two nonkin network studies—both based on the National Longitudinal Study of Adolescent to Adult Health—stand out. The first uses data from 5,500 adolescents to demonstrate that PGSs of an individual’s friends and schoolmates predict their own educational attainment and obesity (Domingue et al., 2018). A second finds that peers’ genetic propensity to smoke predicts one’s own smoking behavior, net of one’s genotype (Sotoudeh et al., 2019). This emerging body of work borrows from a long tradition of social genetics research in animals (Baud et al., 2017; Domingue & Belsky, 2017). In later life, perhaps the most important such environment is the dyadic one constructed with a spouse or intimate partner. The next section addresses its potential genetic linkages.
Late Life Relationship Quality and Its Genetic Correlations
At older ages, individuals experience fundamental changes in the structure of both their families and their broader social network. Children leave home, retirement uproots individuals from their workplace relationships, parents and elders pass away, and health problems begin impeding interaction. During this period, one’s most important social environment is the one formed with the spouse or partner (Lindau et al., 2003). In turn, dyadic theory increasingly suggests that couples form “systems” wherein members are critically interdependent in a range of ways. This symbiosis occurs through repeated small exchanges and specialization of roles within the relationship and serves to maximize efficiency and efficacy, thereby becoming self-perpetuating (Waite & Das, 2010). Such interdependency is particularly strong in late life when the process has had time to cumulate and become entrenched. The quality of this critical relationship may thus influence a range of health dimensions at this life stage (Choi et al., 2016; Waite & Das, 2010). Accordingly, an influential “interactive biopsychosocial model” posits an intricate interweaving of older couples’ lives, such that successful aging becomes a jointly produced outcome, dependent on each partner’s characteristics and on the nature of the partnership itself (Lindau et al., 2003). Loss of dyadic assets due to widowhood, in turn, seems to induce multiple forms of morbidity and mortality (Robards et al., 2012).
In such closely coupled systems, genetic effects can clearly be transpersonal. In a recent study of older HRS dyads, for instance, Das (2019) demonstrates transpersonal linkages of an education-related PGS with not just one’s own but also a partner’s health. Similarly, each partner’s genetically rooted trait well-being may influence their own experience with the partnership, through more positive responses to social situations and lower reactivity to stressors (Diener, 2006). In addition, it may influence the partner’s experiences, through the focal individual’s supportive or conflictual actions toward them. No dyadic studies on these patterns exist.
A sparse literature on the heritability of individuals’ own relationship experiences offers a starting point. In a series of papers, Spotts and colleagues use twin designs to examine the heritability of various dimensions of marital quality, including satisfaction, conflict, and warmth (Horwitz et al., 2010; Spotts et al., 2004, 2006). Overall, they find modest genetic and substantial nonshared environmental influences. None of these investigations use genetic information from both members of a dyad. As noted above, absent such information, overall genetic influence on the system cannot accurately be characterized. Effects of partners’ genes generally come out as environmental (Kendler & Baker, 2007), nor can specific genetic externalities be assessed.
In addition, twin-based estimates may be vulnerable to selection issues. Twins may systematically differ from the rest of the population in particular traits (Schwabe et al., 2017). Moreover, participation in twin registries—upon which many such studies are based—is voluntary (Joseph, 2014). In other words, collider bias may be widespread in such investigations (Munafò et al., 2018). Briefly, a collider is a variable that is itself caused by two other variables, one that is (or is associated with) the treatment and another that is (or is associated with) the outcome. If study participation and retention can be represented by such a measure, investigating associations in the resulting sample is equivalent to conditioning on the collider. The availability of genetic information from both partners in the nationally representative HRS provides an opportunity to move beyond these limitations. Accordingly, the current study used these data to test the following hypotheses:
Gender Differences
As argued above, a person’s genes may influence the relationship more if he or she is either the dominant partner or the one more responsible for relationship maintenance. Occupancy and influence of these roles may be culturally specific. Sociologists and anthropologists working in the “functionalist” tradition have long argued that nominally identical roles may play different functions in particular societal settings (Parsons, 1951). Among older U.S. cohorts, the literature yields two contradictory possibilities. First, due to gender socialization and prevalent norms, women in these cohorts have generally been more responsible for relationship maintenance and “emotion work” (Thomeer et al., 2015). Their caregiving burdens have also been higher than men’s (Allen, 1994). This is especially true given age hypergamy—the tendency of women to be partnered with men several years older than themselves (Drefahl, 2010). Thus, their genetically rooted propensities may carry greater externalities for the relationship and the other partner. Second, however, men in these cohorts tend to have greater power and control in the relationship (Johnson, 2006). In addition, women may tend more to incorporate close others and their attributes into their own self-schemas—and hence be more vulnerable to spousal affective influence (Joiner & Katz, 1999). If so, men’s genes may influence the partnership more. To adjudicate between these possibilities, the following hypotheses were included.
Data
HRS is an ongoing longitudinal survey of older U.S. adults conducted every 2 years since 1992. Overall response rate is about 87%. The survey uses multistage sampling of households with an oversample of Blacks and Hispanics (Sonnega et al., 2014). Measures of relationship quality are modularized. Specifically, a random half sample is assigned every alternate wave to an enhanced face-to-face interview that includes a leave-behind questionnaire on psychosocial topics. Due to the addition of a large “refreshment sample,” Wave 10 (fielded in 2010) has the largest sample size for genetic data and the greatest overlap with psychosocial measures. Models in this study were limited to couples with both members over 50 in that wave since HRS is only population representative for these ages.
HRS genetic data were only available for African and (separately) European ancestry groups. In the 2010 wave, only 0.3% of couples with available genetic data were interracial (Black–White). Same-sex dyads were also sparse (0.5%). Accordingly, analysis was restricted to same-race White or Black heterosexual couples.
Measures
Summary statistics are presented in the e-supplement—for White (Online Supplemental Table S1) and Black (Online Supplemental Table S2) couples. A short introduction to genetic terms and concepts is also provided there.
Relationship quality
Two dimensions of relationship quality were examined. Positive relationship quality, or social support from a partner, was indicated by 3 Likert items. Participants were asked how much (1) their spouse or partner understood the way they felt about things, (2) they could rely on the partner if they had a serious problem, and (3) they could open up to the partner if they needed to talk about their worries. Four other Likert items queried negative relationship quality, or strain: (1) how often the partner made too many demands on them, as well as how much the partner, (2) criticized them, (3) let the participant down when they were counting on them, and (4) got on their nerves. Each item ranged from 1 (a lot) to 4 (not at all) and was reverse coded prior to analysis. These are established and widely used measures (Birditt et al., 2015; Walen & Lachman, 2000) and have been validated within the HRS (Smith et al., 2017).
PGS for subjective well-being
DNA data collection in HRS was through the Oragene DNA Collection Kit (Ware et al., 2018). Genotyping was conducted by the Center for Inherited Disease Research in 2011, 2012, and 2015. Construction of genetic measures followed current best practices. For each phenotype, the PGS was based on a replicated and externally validated GWAS. Scores were calculated using the PRSice and PLINK software packages. Each such measure was standardized within the relevant ancestry group—European or African—to a standard normal curve (mean = 0, standard deviation = 1).
As noted, SNP weights for the well-being PGS came from a 2016 study by the Social Science Genetic Association Consortium (Okbay et al., 2016). These are available on request. To elaborate, the GWAS meta-analysis included 298,420 individuals in the discovery sample and 288,478 in the replication sample. The corresponding European ancestry PGS contained 710,288 SNPs that overlapped between the HRS genetic database and the meta-analysis. The PGS for the African ancestry group was comprised of 707,989 SNPs (Ware et al., 2018). It is acknowledged that these scores include many SNPs with trivial contributions. Moreover, their large size restricts potential future applications to data sets with a similarly large set of SNPs and precludes replication in older data based on different platforms. The literature consistently suggests, however, that more limited PGSs—such as those aggregating “top SNPs”—also explain less trait variation (Ware et al., 2017). In general, in any GWAS sample, there are many more signals that improve prediction accuracy than meet genome-wide significance (Martin et al., 2017).
Control variables
Controls were limited to factors likely not to be “posttreatment”—that is, influenced by the genetic scores and on causal pathways to relationship experiences (Pearl, 2009). As such, partners’ life course or recent incidents were excluded. Among viable controls, each partner’s age was entered linearly in all analyses. Next, a fundamental problem in statistical genetics is population stratification—systematic differences in both trait prevalence and allele frequencies in the subpopulation sampled (see e-supplement for more detailed explanation). Such stratification, which can arise from varying demographic histories and geographic origins, may lead to false-positive associations of genetic signals—that is, “genomic inflation” (Conley, 2016; Peterson et al., 2017). Recent findings suggest such unobserved structure exists even within supposedly homogenous groups, such as White participants in a sample (Haworth et al., 2019). To adjust for this factor, models included 10 genetic principal components—5 from each partner—provided by HRS (Ware et al., 2018).
Analytic Strategy
Analysis was through structural equation models (SEMs) run separately among White and Black same-race couples (Figure 1). The measurement part of each model used ordered logit to regress each partner’s observed relationship quality indicators on a continuous latent factor (e-supplement, Tables S3 and S4). In turn, the structural submodel used ordinary least squares (OLS) to test associations of these factors with both partners’ PGSs. Correlations among factor residuals were specified to control for additional sources of nonindependence such as family effects (Cook & Kenny, 2005). Table 1 presents standardized results for positive relationship quality (or support from the partner), and Table 2 for negative relationship quality (or experience of strain). In each case, Wald tests were used to examine theoretically relevant gender variations. These analyses compared effects of each gender-specific PGS on the other partner’s relationship experiences (to test Hypothesis 3)—as well as “total” effects of each genetic score on both partners combined (Hypothesis 4). To be clear, total effects were additive combinations of the corresponding individual effects, estimated as part of the SEM. Since standardized coefficients were unavailable for these aggregate estimates, unstandardized ones are presented. For completeness, race differences in estimates for each gender were also tested. Given the race-specific nature of the models above, these last checks involved separate multiple-group analysis.
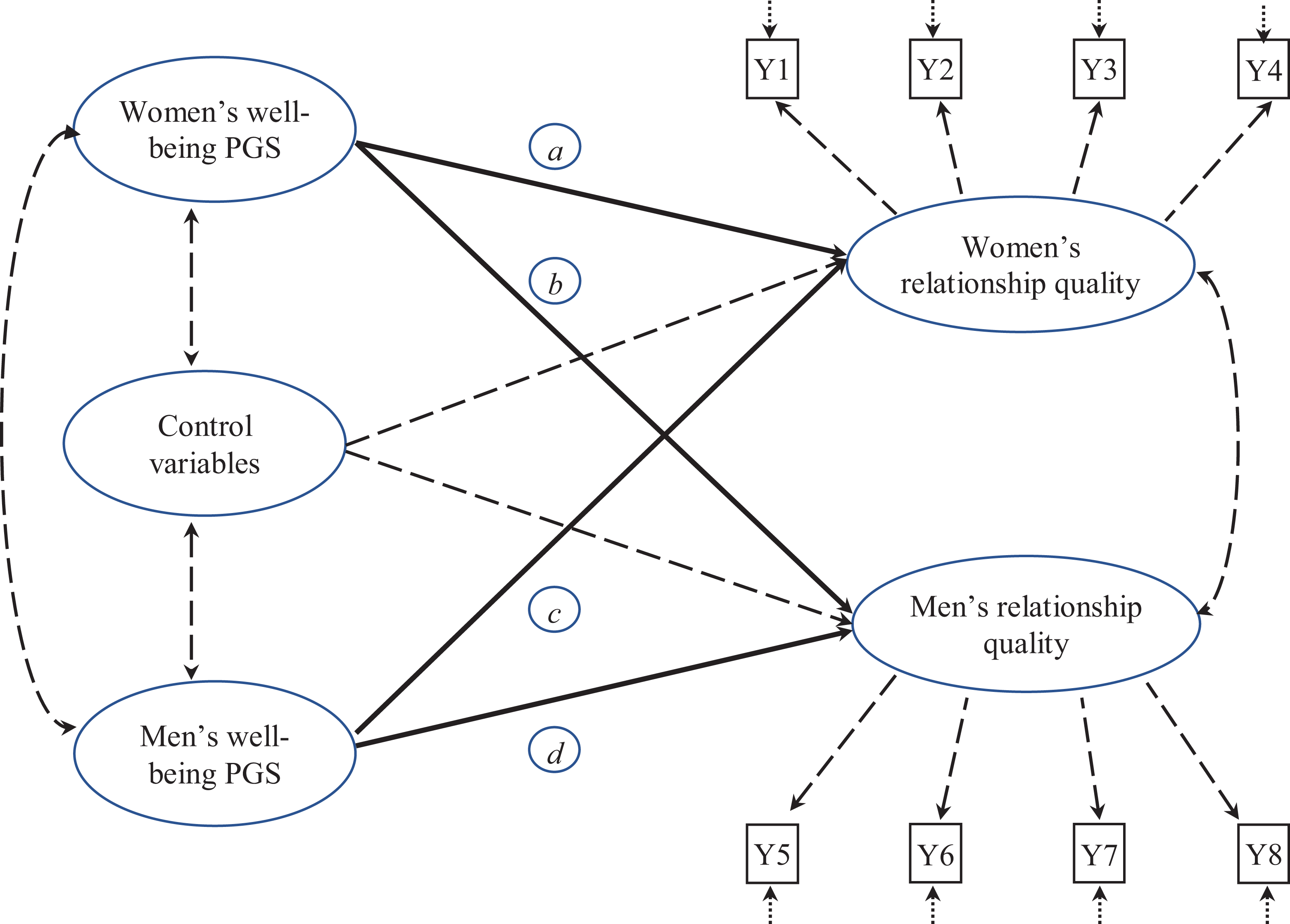
Simplified illustration of structure of proposed linkages. Note. Thick solid lines represent theoretically important paths (a–d) in the structural submodel. The “Ys” represent observed indicators for women (Y1–Y4) and men (Y5–Y8), respectively. These were Likert-type scales and linked to the continuous latent factors for relationship quality through ordered logit models. These measurement submodel results are presented in the Online e-supplement (Tables S3 and S4). PGS = polygenic score.
Associations of Positive Relationship Quality With a Polygenic Score for Well-Being Among White and Black U.S. Couples: Standardized Coefficients [95% Confidence Intervals].

Note. Figures in boldface represent estimates significant at least p < .05. Estimates were weighted to adjust for differential probabilities of selection and nonresponse. Models controlled age and five genetic principal components for each partner. Estimates from the measurement model linking latent factors to observed indicators are provided in e-supplement (Online Supplemental Table S3). Supplementary figures also visually represent key results—for White (Figure S1) and Black (S2) couples. As described in the text, Wald tests were used to examine gender variations in theoretically relevant estimates within each ethnic group and race differences for each gender. Since none of these reached significance, they do not appear in the table. PGS = polygenic score; CFI = comparative fit index; TLI = Tucker–Lewis index; SRMR = standardized root mean square residual.
a Continuous latent factor indicating positive experienced relationship quality among women. b Continuous latent factor indicating positive experienced relationship quality among men. c Sum of Paths a and b (Figure 1). d Sum of Paths c and d (Figure 1). e Sum of Paths a and c (Figure 1). f Sum of Paths b and d (Figure 1). g Sum of Paths a–d (Figure 1).
*p < .05. **p < .01. ***p < .001.
Associations of Negative Relationship Quality With a Polygenic Score for Well-Being Among White and Black U.S. Couples: Standardized Coefficients [95% Confidence Intervals].
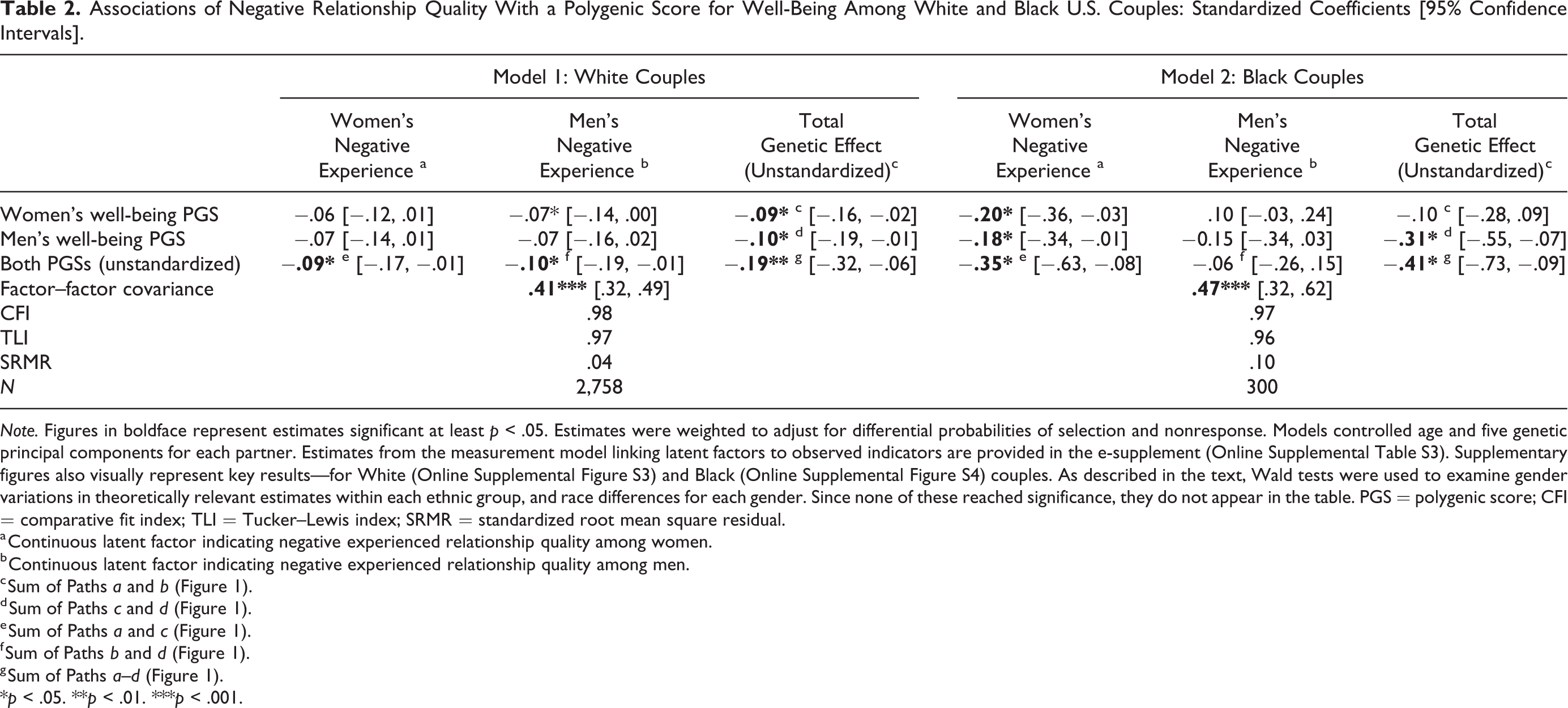
Note. Figures in boldface represent estimates significant at least p < .05. Estimates were weighted to adjust for differential probabilities of selection and nonresponse. Models controlled age and five genetic principal components for each partner. Estimates from the measurement model linking latent factors to observed indicators are provided in the e-supplement (Online Supplemental Table S3). Supplementary figures also visually represent key results—for White (Online Supplemental Figure S3) and Black (Online Supplemental Figure S4) couples. As described in the text, Wald tests were used to examine gender variations in theoretically relevant estimates within each ethnic group, and race differences for each gender. Since none of these reached significance, they do not appear in the table. PGS = polygenic score; CFI = comparative fit index; TLI = Tucker–Lewis index; SRMR = standardized root mean square residual.
a Continuous latent factor indicating negative experienced relationship quality among women. b Continuous latent factor indicating negative experienced relationship quality among men. c Sum of Paths a and b (Figure 1). d Sum of Paths c and d (Figure 1). e Sum of Paths a and c (Figure 1). f Sum of Paths b and d (Figure 1). g Sum of Paths a–d (Figure 1).
*p < .05. **p < .01. ***p < .001.
Two types of selection could have biased results—starting with membership in the Wave 10 dyadic pool. Specifically, 34.19% of participants in this wave had no partners. Preliminary investigation indicated that they were likely to be older, female, non-White, less educated, and with a range of health conditions. Second, nonparticipation in genetic data collection (33.08%) may have been heterogeneous. Indeed, analysis suggested that those not participating were likely to be less educated and with specific morbidity profiles, although they were also younger. As noted above, such selection can cause “collider bias,” such that estimates of associations are incorrect (Elwert & Winship, 2014; Munafò et al., 2018). Inverse probability weighting (IPW) is now a recommended solution to this problem. The approach separates the model of substantive interest from the one used to account for missingness. Assumptions underlying the two are therefore not conflated, and model compatibility problems or other types of misspecification are avoided (Sun et al., 2018).
Accordingly, for each of the two selection types, logistic regression was first used to fit separate predictive models of participation. Based on predicted probabilities from these analyses, stabilized IPWs were created. To elaborate, let Mi indicate whether individual i is missing from the relevant Wave 10 subsample (dyadic or genetic). To specify the predictive model, a set of covariates C thought likely to influence such missingness was defined. This included a participant’s contemporaneous demographic and health attributes (age, ethnicity, gender, years of education, depressive symptoms, and lifetime diagnoses of eight separate conditions). Weights were then defined as:
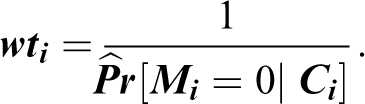
These were unstabilized weights because, as the reciprocal of a probability, they were guaranteed to be greater than 1 for contributing observations and may potentially have been very large for an individual with a small probability of being nonmissing. Accordingly, stabilized IPWs were then computed by multiplying the individual’s unstabilized weight by the conditional probability of being nonmissing, given a smaller set of Wave 10 covariates V (a subset of C )—consisting solely of the individual’s age, gender, and race.
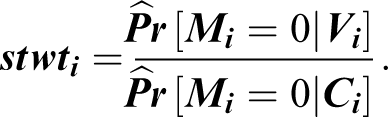
As the ratio of two probabilities, this stabilization was expected to reduce the undue influence of a highly variable unstabilized weight, and therefore to result in narrower confidence intervals (Weuve et al., 2012). Substantive models were then weighted by the cumulative product of the female and the male partner’s stabilized IPWs, and HRS-provided household-level cross-sectional weights. Standard errors were adjusted for sample stratification (sampling strata independently) and clustering (sampling households within primary sampling units).
Results
To condense exposition, the focus below is on conceptually important estimates. Except for total effects, all coefficients are standardized. The e-supplement provides visual representations of key results—for White (Figures S1 and S3) and Black (Figures S2 and S4) couples.
Contrary to speculations above on assortative matching, preliminary analysis did not suggest dyadic concordance in the PGSs. Net of the genetic principal components—and adjusting for sample stratification and clustering—women’s and men’s PGSs were not associated among either White (standardized coefficient = −.05, p = .17) or Black (coefficient = .10, p = .34) couples.
Genetic Associations With Positive Relationship Quality
White women’s well-being PGS was positively linked to their own perceived support from their male partner (coefficient = .14, p < .01) as well as to the latter’s perceptions of support from them (coefficient = .11, p < .01). Not surprisingly, the total effect of this PGS on both partners’ relationship outcomes was also significant (coefficient = .22, p < .001). Men’s genetic score, in contrast, did not have significant associations with partner-specific outcomes, although confidence intervals overlapped with those for women’s PGS. Moreover, the total effect of men’s score did reach significance (coefficient = .12, p < .05). Separate Wald tests indicated no gender differences relevant to Hypothesis 3 or 4. Effects of women’s PGS on men’s perceived support did not differ significantly from those of men’s genetic score on women’s experience, nor were any differences in the two total effects found.
Genetic linkages did not emerge among Black couples. As above, Wald tests did not indicate any relevant gender variations. Comparisons of gender-specific estimates across race groups also yielded null results—possibly due to the small sample size for Black dyads.
Genetic Associations With Negative Relationship Quality
Consistent with its effect on support, White women’s well-being PGS was negatively linked to their male partner’s perceptions of relationship strain (coefficient = −.07, p < .05). Its total effect on both partners’ outcomes also reached significance (coefficient = −.09, p < .05). Associations of men’s genetic score with partner-specific experiences were similar in magnitude but nonsignificant, while its total effect was about the same as for women’s PGS (coefficient = .10, p < .05).
Among Black couples, women’s experience of relationship strain was negatively and significantly associated with their own (coefficient = −.20, p < .05) as well as the man’s (coefficient = –.18, p < .05) PGS. The latter score also had a modest total effect (coefficient = −.31, p < .05). As in Table 1, Wald tests indicated no significant gender variations among either White or Black couples, nor did gender-specific estimates differ significantly across race groups.
Discussion
This study began by noting that many of the most crucial contexts shaping a person’s life trajectory are interpersonal—emerging from one’s “convoy of social relations” (Antonucci et al., 2011). The genetic underpinnings of such environments—especially those involving alters who are not consanguineal kin—are underexplored in the growing rGE literature. The few available studies are essentially monadic, examining the heritability of a person’s own relationship experiences. Obstacles to genuine multifactor studies have been not so much theoretical but data-related. At least with marriage or partnership—perhaps the most important context in late life—the availability of genetic data from both partners in the nationally representative HRS provides an opportunity to move beyond such limitations. Accordingly, this study examined effects of each partner’s PGS for well-being on experienced relationship quality among both.
At least for women, findings were consistent with effects of these genes on one’s own relationship experiences (Hypothesis 1). While such effects were modest and not fully consistent, it is noted that null estimates among Black couples may well have been due to their small sample size. In addition, the PGS utilized was not for relationship quality per se. As of this writing, externally validated genetic scores for this trait do not exist. Moreover, such scores would have yielded weaker insights into mechanisms than a genetic aggregate already known to predict positive affect. In turn, the fact that genetically rooted trait well-being may have pleiotropic effects on one’s perceptions of relational contexts in later life was perhaps not surprising. These influences could help explain linkages of this trait with lower morbidity and increased longevity (Diener et al., 2006), especially given established effects of partner support on these same outcomes among older adults (Choi et al., 2016; Waite & Das, 2010). Conversely, the latter may partly be artifacts of genetic confounding—patterns that remain unexplored.
More central to this study were the findings of “genetic externalities”—that is, effects of a person’s genes on the partner’s relationship experiences (Hypothesis 2). While it seems intuitive to expect such effects in any closely coupled interpersonal system, they are neither emphasized nor properly operationalized in available genetics literature. Moreover, in shaping the partner’s behaviors and relationship investment, such effects may trigger “downstream” feedback to one’s own experiences. In other words, the states of the two partners’ outcomes at measurement time likely reflect joint equilibria shaped by all four sets of genetic effects in Figure 1 (Paths a–d). As the tables show, associations of a person’s genes with their own relationship experiences (Path a or d) constitute only a small part of this overall genetic influence. The insight is not new. As Kendler and Baker (2007) acknowledged in their influential review of twin studies, the quality of an interpersonal relationship is impacted on by at least two genotypes—that of the informant and that of the other individual. Our assessments only measure the former, while the latter typically comes out in the analyses as “environment (p. 621).”
Indeed, such externalities may be especially strong among older couples. As argued above, dyadic interdependency is likely to be particularly strong in later life, when the process has had time to cumulate and become entrenched. Comparisons of nationally representative studies across the life span, for instance, suggest later life relationships tend to be of the long-term monogamous kind—more so than at younger ages (Das et al., 2012). If so, they may entail more extended exposure to a partner’s genetic predispositions and to the behaviors that flow from them. Older adult data sets such as the HRS are critical to capturing such long-term influences. Moreover, these relational factors may be more consequential to health at older ages, when both individual- and couple-level pressures rise sharply (Waite & Das, 2010).
Theory also suggests dyads themselves are nested within broader networks comprised of both partners’ family members (Lindau et al., 2003). Consanguineal kin, in turn, may share genes with a focal partner (see Figure S5 in the e-supplement). To take the simplest example, each partner’s parents share transmitted alleles with them (Kong et al., 2018). The same is true to a lesser extent of siblings and other close relatives. In addition, homophily—the tendency to form ties with others like oneself—may produce genetic concordance in each partner’s friendship ties (Christakis & Fowler, 2014). Such shared genes may potentially influence relationship quality through “nurture” effects (Kong et al., 2018)—especially if the alters in question still interact with the couple. In other words, the genetic effects examined in this study may pass both through biological pathways specific to the focal partnerand through behaviors and dispositions of environment-providing kin or friends. To the extent that theoretical interest is solely in the first mechanism, such “secondary” factors may be seen as confounders. If the interest is in genetic effects per se—regardless of pathways—then the genes in question remain causally prior to the environments they induce. Genetic information on close kin and friends is needed to distinguish between these sets of effects in direct genetic studies. While such information is available in some population-based biobanks, such data have known vulnerabilities to collider bias, such that estimates based on them are questionable (Munafò et al., 2018).
Next, it was speculated that effects of one’s genes on the other partner and on the relationship would depend on one’s role. Specifically, it was argued that these influences would be stronger if a subject is either a dominant partner in a dyad or the one more responsible for relationship maintenance. Occupancy and influence of these roles, in turn, may be culturally specific. Among older U.S. cohorts, the literature yields contradictory indications on whether these “central” roles are occupied by women or men. Hypotheses 3 and 4 were included to adjudicate between these possibilities. Contrary to conjectures, however, no gender variations emerged. It is possible that these null results simply reflected the weakness of biological sex as a proxy for relationship roles. More direct measures of these dyad attributes may yield different results.
More generally, a fundamental insight of life-course theory is that a person is never not embedded in relationships. As such, at any given point, one’s proximal interpersonal environment—which a huge literature links to morbidity and mortality (Holt-Lunstad et al., 2010; Link & Phelan, 1995)—is coproduced with close social alters. This study was a first attempt at examining genetic influences on the simplest type of context—the dyadic one. Genetic underpinnings of the array of middle-range environments formed with one’s “convoy of social relations” remain unexplored (Antonucci et al., 2011).
Limitations
This study had several limitations. As noted, the PGS used was for well-being and not for experienced relationship quality per se. No such validated scores currently exist. Moreover, SNP weights for the PGS were derived from an external GWAS of European ancestry individuals, such that the score may not have the same predictive power among other groups (Ware et al., 2018). Next, genetic effects on late life change in relationship quality were not explored since theory did not suggest mechanisms that could mediate such influences. Future studies may wish to test these linkages. Genetic data were unavailable for Hispanic or other ethnicities. Patterns may well be different among these groups. Variations across other axes of social difference—such as religion and class—were also left unexamined in this limited study. Among White and Black dyads, inverse probability weights were used to address selection issues. However, models for these weights may have excluded important predictors of missingness. Moreover, IPWs do not adjust for “missingness not at random.” Next, controls were limited to factors likely not to be posttreatment (Pearl, 2009). Adjustments were avoided for factors that could have been influenced by the genetic scores and on causal pathways to relationship experiences. Omitted variable bias remained a concern, especially given the scarcity of valid “pretreatment” controls in HRS. Standard methods to control for biases due to population structure and environmental heterogeneity, such as principal component analysis (used in this study), work well in simulations but may be insufficient in practice (Barton et al., 2019). Next, the polygenic measures were additive indexes. Empirical genetic influences, however, may also involve interactions between SNPs—both within (dominance) and across loci (epistasis). These interactions may be a major reason “SNP heritability” is uniformly and substantially lower than “twin heritability” (Cheesman et al., 2017). Moreover, GWAS-based scores are currently limited to common alleles and do not incorporate rare genetic variants with potentially large influences. Most importantly, this was a one-sample analysis. A previous generation of “candidate gene” studies lost credibility due to nonreplication of findings (Conley, 2016). While PGSs are promoted partly as a solution to this issue, cross-sample consistency in their effects remains poorly explored. Pending replication in independent samples, then, inferences above remain tentative. Finally, life-course speculations could not directly be tested with this older adult sample. Such patterns await exploration.
Conclusion
Data from a national sample of older U.S. couples indicated that a person’s relationship experiences are in part a function of their genetic propensity for positive affect. More surprisingly, they are also influenced by a partner’s genetic endowments—a component missing in previous genetic studies of interpersonal environments. A large literature suggests that such jointly produced contexts play a crucial role in shaping individuals’ life trajectories and health outcomes. Properly characterizing their genetic foundations is thus important for both scientific and public health reasons. Expanded conceptual templates and analytic strategies to capture these effects are suggested.
Supplemental Material
Supplemental Material, e-supplement - Genes-in-Dyads: A Study of Relationship Quality
Supplemental Material, e-supplement for Genes-in-Dyads: A Study of Relationship Quality by Aniruddha Das in Research on Aging
Footnotes
Acknowledgments
The Health and Retirement Study is sponsored by the National Institute on Aging (Grant NIA U01AG009740) and is conducted by the University of Michigan. The author thanks the editor and three anonymous reviewers for their thorough and insightful comments.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.