
Abstract
A wide variety of methodological choices and situations can affect the quality of peer nomination measurements but have not received adequate study. This article begins by focusing on systematic nominator missingness as an example of one such situation. We reanalyzed findings from a recent study by Bukowski, Dirks, Commisso, Velàsquez, and Lopez in the year 2019 and compared the results to recent findings of Babcock, Marks, van den Berg, and Cillessen published in the year 2018 to show that systematic nominator missingness can, indeed, have an impact on nomination measures. From there, we discuss the importance of considering sources of error and the ways that sources of error are analyzed. Ultimately, we argue that systematic nominator missingness is one of several potential sources of error that have largely been ignored in the literature, and that analyzing and reporting these sources of error would strengthen the foundations of peer nomination research.
Although peer nomination methodologies have been used in psychological research for nearly a century, there are still a wide variety of uninvestigated or under-investigated methodological issues that may impact the reliability and validity of peer nomination measurements. One of these issues is nominator missingness. In a recent study, Bukowski et al. (2019; herein referred to as Bukowski et al.) addressed the effects of systematic nominator missingness in peer nomination data. The authors post hoc simulated missingness in a real-data set which included nominations of care, withdrawal, popularity, and aggression. They then calculated several correlations, comparing the correlations from a complete group with a missing group. The article is framed largely as a reply to a paper written by us (Babcock et al., 2018; herein referred to as Babcock et al.).
In their investigation, Bukowski et al. drew attention to an important topic. Peer nomination data are an essential measurement tool in research on peer relationships and in social developmental research more generally. Because peer nomination methods are often used to determine the associations between important constructs (e.g., popularity, acceptance, aggression, prosocial behavior, leadership), research that aims to optimize their statistical properties continues to be important. Bukowski et al. conducted a new study using slightly different analysis methods and data from a different part of the world compared to past research (e.g., Babcock et al.). New studies like Bukowski et al. are vital to the field.
Both Babcock et al. and Bukowski et al. used a method centering on real-data simulation. A real-data simulation approach begins with an existing data set and post hoc removes, adds, or resamples key data in order to investigate “what if” scenarios. One then looks at the statistical and measurement quality effects of the simulated change to outline the potential range of effects of phenomena such as random participant dropout or the missing of certain types of participants from a study. Such techniques are a common methodological investigation tool in the field of psychometrics (see Babcock & Hodge, 2020 for an example). However, as Bukowski et al. noted at length and as discussed below, the nature of simulation research necessarily limits its generalizability.
The current investigation addresses several points that were investigated by Bukowski et al. This study starts by pointing out four major differences between the Bukowski et al. and Babcock et al. studies that may affect the comparison of the two. Next, this study applies additional analyses to the correlations provided by Bukowski et al. and examines to what degree the correlational patterns agree with the main conclusions of Babcock et al., thus contributing to the study’s generalizability and the field of peer nomination measurement. Finally, moving beyond the specific contents of Babcock et al. and Bukowski et al., we argue that some sources of error are commonly ignored in peer nomination research, but that analysis, reporting, and study of these sources of error are necessary for the field to move forward.
Differences Between Bukowski et al. and Babcock et al.
Before we compare Bukowski et al.’s findings and conclusions to Babcock et al., it is important to note four key differences between Bukowski et al. and Babcock et al.
The most fundamental difference between the two studies in terms of methodology was the variation among the correlations before missingness was introduced. The correlations in Bukowski et al. for the complete group ranged from −.27 to .37 with a standard deviation of .22. The correlations from Babcock et al. for the complete group ranged from −.70 to .89 with a standard deviation of .47. Given that Babcock et al. expected the absolute value of correlations to be reduced in most cases of systematic missingness (though not all; see Babcock et al., Figure 1), the smaller sized full-sample correlations observed in Bukowski et al. limited the possible significant differences between full-sample and partial-sample correlations. If two things are not very strongly correlated in the first place, then removing nomination data is unlikely to substantially alter that near zero relationship. This issue may have been exacerbated in Bukowski et al. because they investigated the combined effects of random and systematic missingness. Random missingness alone should consistently reduce the magnitude of correlations (Babcock et al.; Marks et al., 2013). Babcock et al. isolated the effects of systematic missingness by using completely random missingness as a basis of comparison.
In fact, barring the unlikely possibility of a substantial increase in the magnitude of coefficients after missingness was introduced, a full third of Bukowski et al.’s partial-sample correlations could not have statistically differed from the full-sample correlations because the correlations were not significantly different from zero in the complete nominator group. Even using one-tailed analyses (as they did), the full-sample correlations would need to be greater than .13 in order for any lower magnitude correlations to differ significantly. Unsurprisingly, Babcock et al. found numerous cases of near zero correlations that did not change due to missingness.
Other differences between Babcock et al. and Bukowski et al. include the following: Babcock et al. looked at 19 levels of missingness ranging from 5% to 95%. Bukowski et al. looked at 20% missingness. Babcock et al. looked at twice as many variables (and more than 3 times as many bivariate relations) compared to Bukowski et al. Bukowski et al. analyzed each of their nine correlations with four potential corrections (outlier corrected, etc.). This is an important line of methodological research that is beyond the bounds of what Babcock et al. tried to analyze.
These differences indicate that, although the research questions of the two studies were similar and both used real-world data as a starting point for simulating missingness, Bukowski et al. was not a close replication of Babcock et al.
Additional Analyses of the Correlations
Given the differences between the two studies, the reported correlations provided by Bukowski et al. are worth examining in detail. Bukowski et al. provided sufficient information to conduct additional analyses of their findings. Bukowski et al. calculated z-tests for independent correlations between the complete and missing groups, which yielded valuable insights. In addition, there are several other calculations that one could conduct to determine if the missingness affected the correlations. We conducted three additional calculations, one of which concerned statistical significance and two of which concerned effect size.
With respect to statistical significance, we examined the correlation groups (full versus missing) for an effect on the p-value for a statistical significance test from zero. We examined this by examining the change in log 10 p-value. A raw difference in p-value is not a very good metric for examination, as relatively large raw differences in p-value have very little effect at the high end of the scale (e.g., p of .90 vs. .60), but small raw differences in p-value can have a substantial effect on the low end of the scale (e.g., p of .10 vs. .02). For the purposes of this study, we flagged a difference in log 10 p-value with an absolute value of 1 or greater as substantial. In other words, the p-value had to change in magnitude by 10 times or more to be flagged. As a further analysis, we looked at pairs of correlations that had one or both correlations between .10 and .19 to see what proportions of those pairs of correlations were flagged by this criterion. This is roughly the range of correlations corresponding to a p range of .10 to .001 for a statistical significance test from zero (assuming a sample size of 285 for both correlations in the pair). That is generally the range where experimenters select a critical p-value, so a log 10 change of 1 or greater could have a substantially greater impact on a study’s conclusions for correlations in this range.
With respect to effect size, we took two steps. First, we examined whether the missingness changed the absolute value of the correlation by .10 or more. While this is somewhat arbitrary, a change in correlation of that size or larger seemed worthy of attention. Second, we examined relative change in R 2, that is, whether the change in correlation had a 50% or larger effect on R 2. A large relative change in R 2 would indicate that the missingness may have had an effect on the data. This is important in the current context, given that the absolute R 2 changes to be expected were limited (as noted above) by the low initial magnitudes of the correlations.
Table 1 contains the correlations from Bukowski et al. for which the authors conducted statistical tests. When examining the change in log 10 p-value, 21 out of 36 (58%) of the correlation pairs had a log 10 p-value change larger than one as indicated by the L flag. Of the 36 pairs, 14 correlation pairs had at least one correlation in the pair with a value between .10 and .19. A total of 13 out of these 14 correlations (93%) had changes in the log 10 p-value of 1 or greater. These changes in the more targeted correlation group, which the introduced missingness appeared to cause, could alter a study’s conclusions about correlational findings.
Correlations From Bukowski et al.’s Three Tables.
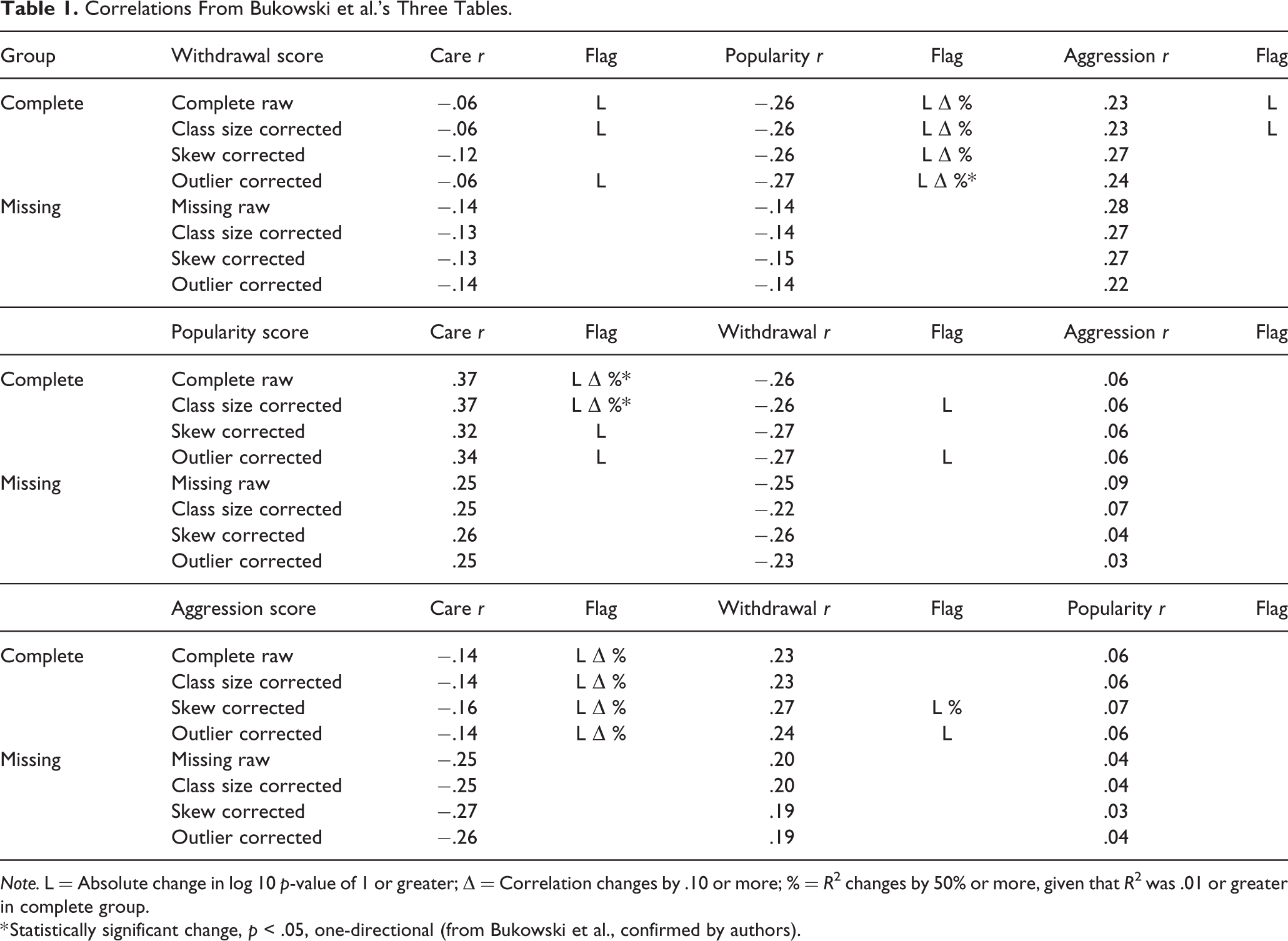
Note. L = Absolute change in log 10 p-value of 1 or greater; Δ = Correlation changes by .10 or more; % = R 2 changes by 50% or more, given that R 2 was .01 or greater in complete group.
* Statistically significant change, p < .05, one-directional (from Bukowski et al., confirmed by authors).
Looking at absolute change, selected correlations between withdrawal and popularity, popularity and care, and aggression and care changed by .10 or more. These same correlations had R 2 values that changed by 50% or more. Additionally, the skew-corrected correlation between aggression and withdrawal had an R 2 change of more than 50%. As discussed above, it was unlikely at the outset that complete sample correlations below .13 would significantly differ from partial-sample correlations. Excluding correlations with an absolute value below .13 in the complete group (and including all corrections), there were 24 calculated correlations. Of those 24, 18 showed at least one effect concerning statistical significance or effect size (75% of those correlations). This high percentage of differences in the reported correlations is consistent with the findings of Babcock et al., namely that systematic nominator missingness can potentially have an impact on the associations between peer nomination measures.
Systematic Missingness in Peer Nominations: It Can Be a Problem
A further examination of the results from Bukowski et al. demonstrated that, even when correlations are relatively small, systematic nominator missingness can make a difference in peer nomination data. Exploring these effects was the purpose of the Babcock et al. study in the first place. Bukowski et al. suggested that the conditions from Babcock et al. were unrealistic, questioned whether the study’s conditions “are representative of what would ever happen in actual studies,” and noted that Babcock et al. contained “contrived comparisons” (p. 5). We agree with those statements. The conditions simulated in Babcock et al. were not what one would see in a field study. Simulations of missingness are inherently contrived, and simulated missingness was deliberately extreme in Babcock et al.; we clearly outlined these limitations in that study’s Discussion section.
Although our comparisons were contrived, we believe that our analyses and conclusions were in line with experimental research conducted throughout the field of psychology. The nature of research is that increased control nearly always costs external validity, and countless experiments in psychology and human development have not corresponded particularly well to everyday life. Despite that fact, there were still things to be learned from many of these experiments.
Beyond the aforementioned comments on their study, we believe that the main limitation of Bukowski et al. lies in the ambiguity of the article’s conclusions. The authors clearly argue that they found our methods and analyses (and their own) to be contrived, but the central question—whether systematic missingness affects correlations between peer nomination variables—was not directly answered. The authors seemed to imply that systematic missingness is not a problem, but they neither explicitly said so nor considered the implications of this conclusion. It was not clear, for example, whether they meant that researchers should not be concerned about systematic missingness among nominators.
The results of Babcock et al. found that systematic missingness can change the correlations between peer nomination variables. When changes occurred, the correlations were most often decreasing in size, though there were occasional examples in which correlations increased. Combining this with the new analyses from the correlations in Bukowski et al., one can see that systematic missingness indeed can affect the validity of peer nominations. Bukowski et al. do not seem to directly agree or disagree with this point. Rather, they appeared to conclude (a) that their own (very different) analyses failed to find an effect of systematic missingness and (b) that the artificiality of the simulations renders the results of both studies essentially meaningless. In line with Bukowski et al.’s argument, we concur that our simulations are limited in terms of generalizability; however, we argue that we appropriately matched our methods to our research question, which was not about whether systematic missingness generally affects the validity of peer nominations, but whether it can.
Implications of the Problem of Systematic Missingness
With all of these potential effects occurring, one may be left asking why systematic missingness has an effect on the correlations. Is it due to simple attenuation of the size of the correlations, or does the removal of the participants have an effect on the nomination process? We believe that it is a combination of both. The missing nominators’ nominations indeed attenuated the size of the correlations. Babcock et al. observed and reported on cases where the effects of systematic removal were quite similar to that of random removal. Such cases would be akin to simple attenuation of correlations due to fewer nominators (and, therefore, less reliable overall scores). There are also cases, however, where we witnessed increases or major decreases in correlations when removing selected individuals that seemed to go well beyond attenuation. For example, when we removed the least popular participants, the correlation between popularity and social preference increased. It is not difficult to think of how this could happen: the least popular participants sometimes nominate friends (also probably not very popular) as being socially preferable where few other people would. When one takes those participants out, no other classmates nominate them as socially preferable. That change increases the correlation. This is one example (one could think of others, too) where the removal affects the process above and beyond the simple attenuation that one would expect from random removal and less reliable nomination scores.
It is important to consider the implications of our conclusions (based on Babcock et al. and our reanalysis of Bukowski et al.’s findings) that systematic missingness can be problematic for peer nomination data. We ended Babcock et al. with two recommendations: first, researchers should maximize their sample sizes and participation rates; second, researchers should assess and (regardless of statistical significance) report differences between nominators and non-nominators. Bukowski et al. seem to agree with the first recommendation (insofar as they say that “…no one thinks that having missing data is desirable.” p. 573), but we are unsure of whether they would agree with the second. Indeed, it seems that their doubts about the artificiality of this simulation research would be addressed by being able to analyze effects of real-world systematic missingness across a variety of peer nomination samples. Unfortunately, researchers generally do not analyze or do not report comparisons between nominators and non-nominators. 1 It is the very absence of this real-world information that makes our simulation research necessary and (to the extent that we are asking a question about whether systematic missingness effects are possible) valid.
On a logistical level, we recognize that we are recommending high participation rates and low systematic nonparticipation during a time when it is becoming increasingly difficult to collect data from large proportions of students in a given class or grade. In fact, this increasing difficulty is precisely the reason that we began to study participant missingness in the first place (Marks et al., 2013). In terms of practical recommendations, we would direct concerned researchers to Mayeux and Kraft (2017), which considers logistical challenges to peer nomination data collection and suggests concrete solutions for overcoming these challenges.
Beyond avoiding systematic missingness in the first place, recent advances in multiple imputation techniques may allow researchers to compensate for systematic missingness in their data. Multiple imputation is the process of building a statistical model to predict which peers a given participant will nominate given the nominations that they have received by other people. Studies have shown multiple imputation to have considerable promise in filling missing data gaps in ways that help to make final analyses less biased. One builds a statistical model using existing data; the model can then probabilistically fill in nominations for those whose nominations are missing. One conducts these imputations multiple times, conducts the relevant overall data set analyses multiple times, and averages the coefficients of the multiple analyses in order to (hopefully) decrease the bias in the analyses. Many approaches for the statistical model could help describe nomination behavior. Although we briefly mentioned this multiple imputation in Babcock et al., one approach that appears to be quite promising in more recent research is social network analysis using methods like exponential random graph models (Krause et al., 2020).
On a related note, researchers who are trying to mitigate the impact of random participant missingness should try to increase the amount of valid nomination data collected from each nominator. Simple strategies for doing so include unlimited nomination procedures; the use of multiple nomination items to assess each variable; and processes that reduce fatigue in the peer nomination process itself, such as allowing students to circle names on paper rosters (rather than writing out names or code numbers by hand) or using a computerized nomination procedure (van den Berg & Gommans, 2017).
Recommendations for Peer Nomination Research: Considering Sources of Error
Beyond the issue of systematic missingness specifically, our research program as a whole has been based on the idea that many potential sources of error in peer nomination research are ignored. We would argue that the long history of the use of sociometric/nomination methods and the difficulty of conducting methodological research have, together, resulted in a lack of recent attention for the effects of methodological choices. Many open questions regarding “best practices” in peer nomination methodology remain, yet (with very notable and welcome exceptions) the recent literature on these issues is sparse. We have three particular recommendations for addressing this issue.
First, it is important that researchers and reviewers consider small sources of error, even if the effect an individual source of error is likely to be trivial. Small sources of systematic error introduced by methodological choices can accumulate, given the number of choices that must be made. Our recent investigations of peer nomination rosters (i.e., effects of name order; Marks et al., 2016; and effects of including versus excluding nonparticipants; Marks et al., 2019) demonstrated small systematic effects on average, but ignoring a dozen such small effects may be just as bad as making a glaring methodological error. Recent and future investigations of these types of effects in peer nomination methods will allow researchers to determine which methodological conventions and recommendations are necessary, which are unnecessary, and which are “best practices.”
Second, we recommend that sources of error that affect findings infrequently, but substantially, should not be ignored. In both Marks et al. (2016) and (2019), a small number of results were strongly affected by methodological decisions. In Babcock et al., although the average effects of systematic missingness at 20% missingness levels were minor, the range of effects was large. Outlining the range of effects, as well as when and where they can happen, is a fruitful line of research for the field. Beginning with “extreme” samples (e.g., samples with high levels of missingness, high levels of skew, etc.) or simulating extreme situations may be the best way to show the true potential range of effects in different scenarios; such research can then be followed up using more generalizable real-world data.
Third, when conducting methodological research, we recommend that researchers look beyond null hypothesis significance testing. Indeed, part of the reason that some sources of error have not been considered in peer nomination research is because null hypothesis significance testing is not possible in many cases (e.g., when statistical dependency is extremely high). Rather than abandoning a research question entirely, a wide variety of indicators can be considered. In our research, we have interpreted findings using simple graphical comparisons (Marks et al., 2013), analyzed effect sizes (Marks et al., 2016), and simulated significance tests using confidence intervals constructed using resampling techniques (Babcock et al.). In some studies, including Babcock et al., we additionally reported cases in which findings would have changed from significantly different from zero to not (or vice versa) as a result of a methodological decision. It is certainly the case that the difference between significance and nonsignificance may be accounted for by small changes in the data. For analyses of data near the cutoff for statistical significance (as several of Bukowski et al.’s correlations were), small changes should not be ignored, because they can make the difference between an effect being either dismissed or entered into the corpus of psychological knowledge. 2 Ideally, small methodological changes that meaningfully affect results should be identified as part of the scientific process (through replication, meta-analysis, etc.). This is only viable if researchers are reporting key methodological and statistical issues that may affect significance in the first place (e.g., the extent to which participant missingness is systematic).
Beyond these general recommendations, we also argue that methodological research may benefit from erring on the side of caution, especially in areas in which methodological issues are understudied. For example, researchers may conclude from Bukowski et al. that there is no reason to test for systematic differences between participants and nonparticipants because such differences are unlikely to be impactful. Given the difficulty of collecting peer nomination data, there is incentive for researchers to selectively attend to the least demanding methodological recommendations available. We have experienced a similar tendency first hand in the use of our results and conclusions published in Marks et al. (2013), which considered the effects of random missingness on the internal reliability of peer nominations. Several (at least half a dozen) studies have cited this research to justify particular participation rates in their samples, despite the fact that we concluded “that it is impossible to recommend a context-free ‘cutoff’ or ‘target’ participation rate” (p. 619). Not only have our cautions and recommendations (e.g., that researchers report internal reliability) been ignored, some articles have inaccurately claimed that we provided “recommended” or “suggested” response rates. In general, it may be better to establish conventions that are overly strict than to establish conventions that are overly lenient. The former may lead to focusing on potential sample limitations; the latter could lead to reporting results that may not be replicable.
Where Do We Go From Here?
It may seem presumptuous, if not downright pretentious, to be arguing that researchers should avoid sources of error. Surely the recommendations listed above could not possibly be controversial! However, we would argue that many potential (and even likely) sources of error are not being regularly reported by peer nomination researchers and that many reviewers are not requiring that this information be reported. In the context of the current study, we do not believe that it should at all be controversial to suggest that systematic nonparticipation might skew results, which is a fairly basic principle of research methods that we teach to every undergraduate. In fact, there is every reason to believe that systematic nonparticipation should be more problematic in peer nomination research, given that nominators are providing data on each other (see Marks et al., 2013, for a discussion). Systematic missingness of nominators is akin to systematically removing certain types of items from a survey. Yet, researchers very rarely provide any descriptions of their missingness, even when such data are available.
Other common omissions from articles reporting on peer nomination research include estimates of reliability, the ways that novel peer nomination items (and especially items measuring novel constructs) are validated, and information regarding the distribution of nomination data, including the presence of outliers and whether data are being truncated or transformed prior to analyses. Professors rightfully teach their undergraduate research methods students the importance of reporting reliability and validity of measures and the distributional properties of data, yet many researchers fail to include this information. Reviewers then fail to demand it. Thus, published research is underreporting sources of error, and researchers are not being required to report relevant implications of error when reporting their conclusions. And if researchers are taking methodologically appropriate steps (e.g., establishing reliability and validity, truncating outliers, transforming skewed variables) but not reporting them, this both undermines the accuracy of their reported results and indicates to other researchers that these steps are not necessary or not worth considering.
Although we believe that most researchers would agree with our recommendations for methodological research, it is necessary to list and explain them because of how often they are often ignored in practice. Many aspects of peer nomination methodology go uninvestigated, and researchers often fail to analyze and/or report small sources of error. Our ultimate message is not that we should reject all data that includes systematic missingness (or outliers, imperfect reliability, novel questions, etc.). Our message is instead that we should analyze relevant data, report the findings, and appropriately consider factors that may limit the quality of our data or the surety of our conclusions. Doing so may make data collection more difficult in some cases and may require that our “limitations” paragraphs be a bit longer, but it will also (a) improve the accuracy of reporting in peer nomination studies, (b) allow us to compare results from different studies more effectively, (c) allow reviewers to ensure that all peer nomination researchers are equally adhering to basic principles of research methodology, and (d) provide us with data that can later be used to analyze the effects of methodological choices across studies. All of these changes would strengthen the field. In contrast, ignorance benefits only error.
Footnotes
Authors’ Note
Please send all correspondence concerning this manuscript to Ben Babcock (ben.babcock [at] AMPP.org). Any opinions, findings, conclusions, or recommendations expressed in this article are those of the authors and are not necessarily the official position of AMPP.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.