
Abstract
Starting from an ontology of a targeted financial domain corresponding to transaction, performance and management change news, relevant segments of text containing at least a domain keyword are extracted. The linguistic pattern of each segment is automatically generated to serve initially as a learning model. Each pattern is composed of named entities, keywords and articulation words. Some generic named entities like organizations, persons, locations, dates and grammatical annotations are generated by an automatic tool. During the learning step, each relevant segment is manually annotated with respect to the targeted entities (roles) structuring an event of the ontology. Information extraction is processed by associating a role with a specific entity. By alignment of generic entities to specific entities, some strings of a text are automatically annotated. An original learning approach is presented. Experiments with the management change event showed how recognition rates are improved by using different generalization tools.
Keywords
1. Introduction
Information extraction (IE) is the identification of structured information from unstructured text. This task usually covers the automatic recognition of given entities, relations or targeted events in texts. Its purpose is to help the human reader deal with huge amount of text available in electronic format and find the specific information they are looking for efficiently. Even if IE is closely related to a given domain, the current approach to information extraction is general. Starting from a targeted events domain, like transaction, performance, management change (to cite a few), linguistic patterns associated with each one of them can be automatically generated with a well-selected sample of news stories. The extraction process can be ‘the same’ for different domains. However, each pattern is composed by domain’s specific information (i.e. specific named entities, keywords and articulation words). Some of this specific information should be provided by experts as a system input in order to produce adequate patterns for each domain. In the current research we propose a new approach for automatic annotation based on patterns extraction and we show some case application scenarios for a management change event domain followed by experimental result in terms of recognition rates.
This paper is organized as follows. In Section 2 we present the state-of-the-art for the IE domain and recall the different levels concerned with the IE task, namely the entity, relation and event levels. In Section 3 we present our new approach for IE, particularly concerned with the event level. The general architecture is presented as a generic framework that can be applied to different domain types. In fact, specific domain knowledge is embedded within the system in terms of keywords and cue words as input parameters. Our proposed algorithms for learning, as well as pattern alignment, are presented and illustrative examples given. Section 4 reports the results of the carried out experiments and shows the efficiency of our approach in terms of recognition rates, for both roles and event recognition. Section 5 concludes and indicates potential avenues for future work.
2. State of the art in information extraction
In this section we present an overview of the IE domain and explain its different levels.
2.1. Overview
The IE field developed in the late 1980s and 1990s with the Message Understanding Conferences (MUC) [1], in which a set of evaluation campaigns were suggested. These campaigns have defined the various tasks of IE systems and set up the protocols and metrics for the evaluations of these tasks. Other evaluation campaigns on IE have followed, including the Automatic Content Extraction (ACE) evaluation and, more recently, the Text Analysis Conference. For an overview of the domain of IE we refer the reader to the literature [2–5].
2.2. Different levels of information extraction
According to the type of information extracted, different tasks are defined in the domain of IE. In this section we give a general overview of these tasks and elaborate further in subsequent sections.
Named Entity Recognition (NER) – NER consists of identifying some specific entities with their types in texts. More advanced NER includes a co-reference task, which corresponds to the association of different occurrences of entities that actually refer to the same entity. It includes the matching of entity name variations and the matching of pronouns with corresponding entities (anaphora resolution). Co-reference resolution is also called Entity Tracking (for instance in the ACE campaigns).
Relation identification – this consists of the identification of relation existing between two entities. These relations can be of an attributive nature (for instance, the date-of-birth is a relation between a person and a date) or of an event-related nature (for instance, ‘acquisition’ is a relation between two companies). In MUC campaigns, attributive relations are part of the Template Element construction task whereas event relations are part of the Scenario Template production task.
Event identification – the identification of a given set of relations tied by a template structure (for instance, an acquisition event is a structure combining two companies, a date, an amount of money, etc.) [6]. An event template can also be seen as an n-ary relation between several entities. In MUC campaigns, event detection is called Scenario Template production.

Text describing a management change event (http://www.minelco.com/en/News/Bob-Boulton-has-been-appointed-President-of-Minelco/; access date 30 April 2012).
Level 1 in information extraction (Named Entity)

Level 2 in information extraction (Relation between Entities)

Level 3 in information extraction (Management Change Event Detection)

2.3. Named Entity Recognition
Named Entity Recognition has benefitted from the attention of many researchers and has produced the most successful results. The accuracy of entity recognition for standard entities reaches 95% [7], very close to human annotation results. The methods used for NER can be classified according to different dimensions. One of these dimensions is the manual vs automatic opposition: some techniques use manually developed resources, whereas others use learning algorithms to automatically build a model from annotated training data. Another dimension is the nature of the model for the entity identification: some models are symbolic (the resources are explicit and understandable, such as rule-based systems), whereas others are numerical (statistical models).
The hand-coded systems use rules that represent the form or the context of a specific entity. For instance, for the recognition of a person’s name, we can encode the fact that person names can be found after a specific title by a rule like ‘Mr. + capitalized_word’. These rules are developed manually by experts who have the responsibility to organize and maintain the rule set in such a way that it is the most compact and efficient possible.
Even though they were developed in the early years of research in IE [8], rule-based systems are still efficient for real-world systems dealing with controlled domains and entities. In particular, such rules are usually compiled into finite-state automatons that are very efficient.
On the other hand, learning-based methods use annotated data to learn models that will recognize the entities. Annotated data correspond to documents in which the entities, with their types, are indicated. The models learned can be symbolic or statistical. The symbolic models use a rule-learning algorithm to automatically build a set of rules for the recognition of named entities that will work similarly to the manual systems.
The statistical models are standard statistical machine learning algorithms that are based on various features to represent the context or the nature of the entities. For these models, the NER task is generally seen as a classification task that is token-based, not entity-based. The annotated data take the form of annotations associated with each token of the text (words and symbols), to indicate if the token is part of an entity or not. The annotation model is actually defined by three classes: B (for Begin), indicating that the token is the first token of an entity; I (for Inside), indicating that the token is part of the entity; and O (for Outside), indicating that the token is not part of an entity. This redefinition of the NER task into a classification task allows using all kinds of classification learning algorithms to perform the task, based on features extracted from the text.
Several learning algorithms have been tested for NER. Some of these algorithms are based on the classification of words like Decision trees [9], Boosting [10], Support Vector Models [11, 12] or Maximum Entropy Models (MaxEnt) [13, 14].
Since token sequence (words and punctuation) in the text is particularly meaningful, models based on sequence classification, such as Hidden Markov Models [15], Maximum Entropy Markov Models [16] and, more recently, Conditional Random Fields [17, 18], have also been intensively tested.
To give a more precise idea of what elements are used in the text to detect the entities, we present some of the different features generally used in these models:
Word features – the words themselves can be used as a feature. They are useful both to compose internal name dictionaries from the training corpus and mostly to capture the property of certain words to trigger a named entity (e.g. M. generally precedes a person name).
Orthographic features – orthographic properties of the word can be used as features, such as its capitalization pattern (e.g. begins with a capital letter), the presence of special symbols and alphanumeric characters in the token (e.g. composed with numbers).
Morpho-syntactic features – if a linguistic analysis is available, morpho-syntactic information associated with the words can be useful features, such as the grammatical category of the word.
Dictionary lookup features – additional knowledge can be added in the learning systems when an existing database of entities is available by adding, as a feature, the matching of a word to a dictionary entry.
These methods give good results; however, they require massive annotated data. Some techniques have been tested to limit the amount of annotated data using bootstrapping. This method uses only a few examples to learn a system that will be used to annotate more data, from which a new system will be learned, and the process can be iterative. Bootstrapping usually leads to NER systems that achieve relatively good performance with less training data [19, 20].
Another recent trend for named entity recognition is the use of external resources, such as Wikipedia, that provide encyclopaedic information about entities in a semi-structured framework, and can be used to automatically build structured databases or gazetteers [21, 22]. Another interest for these kinds of resources is the multilingual aspect, since a resource like Wikipedia provides cross-lingual links [23]. Such approaches are particularly suited for the disambiguation of named entities and the co-reference resolution (encyclopaedic knowledge often proposes alternative names for one entity).
2.4. Relation identification
The objective of the relation identification task is to find the mention of a binary relation between two entities in a text. For instance, we could consider the relations is-acquired-by for two organizations or is-appointed-CEO-of for a person and an organization.
We can distinguish two cases for relation identification. The first one concerns the identification of a relation when the two entities are pre-identified in the text; the second one concerns the identification of all existing relations between all entities that can be found in an open corpus (this case can be referred to as unsupervised information extraction or open information extraction). For the current research, we are interested in the first case.
In this case, the task can be defined as follows: in a text where two entities E1 and E2 are identified, and for a set of possible relations between these two types of entities, the question is: are E1 and E2 in a relation of this set in this text? As for the named entity recognition task, techniques used to identify relations may be grouped in two sets: rule-based methods that use manually developed rules that take into account the structure of the context of the entities, and feature-based methods that use several features as criteria for the identification of the relation.
Here are some of the features used for relation extraction [24]:
Entity features – the value and type of the entities that are candidates for the relation have been shown to be important features.
Word features – the words between the entities and around the entities are also often used as features, either alone (in a bag-of-words representation) or in sequences (as n-grams of words). Other features can be associated with the words, such as morpho-syntactic categories.
Syntactic features – the association of the two entities in a sentence generally relies on the syntactic analysis of the sentence. Syntactic features are then useful to detect a relation between two entities, such as the syntactic path between the entities. If a dependency grammar model is used for the analysis, the syntactic path is formed by the set of syntactic dependency relations between the entities, along with the grammatical categories of the words along the path (if a tree grammar model is used, the feature will be the minimal sub-tree covering the two entities).
Another set of methods is kernel-based and uses a kernel function between two contexts that captures the similarity between the two contexts and then uses a Support Vector Machine to classify the considered example according to its similarity with the different contexts in the training corpus. The kernel function is generally based on the syntactic analysis of the text (for example on the dependency graph [25]).
2.5. Event detection
The event detection task is intended to extract from the text a characterization of an event, defined by a set of entities associated with a specific role in the event. For instance, in the event management change, these entities will be the organization (company), the name of the person joining the organization, their new position, date of the managerial change, etc. The event detection task may be considered as a generalization of the relation identification task, by considering the event as a set of binary relations between the event itself and the entities involved, or by a generic n-ary relation involving all the entities.
Therefore, the techniques for event extraction are similar to the one used for relation extraction. They generally rely on the first step of NER and possible syntactic analysis. Then, some techniques use rule-based approaches, where the patterns in the rules are associated with a sub-set of the event template. For instance, such a rule is presented in Figure 2.
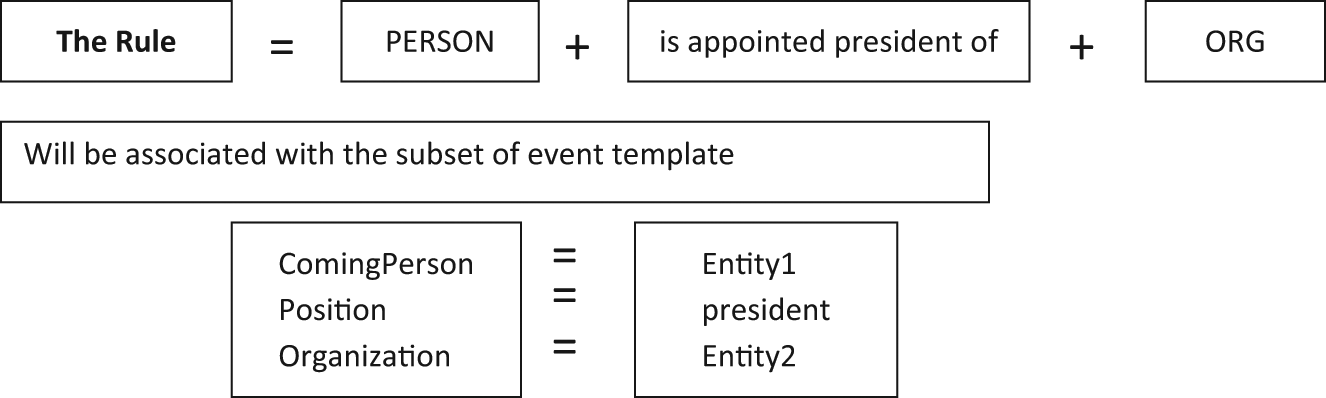
A sample of using a rule-based approach for IE.
Other approaches use learning-based models. These models can be directly targeted to fill the template or can use a two-step approach. In the direct models, each word or entity in the sentence is associated with its role in the event, and a classifier model is built from annotated data to reproduce this association in new texts. In the two-step approach, a first step of relation extraction is performed in order to build the binary relations between all entities in the text and then, in a second step, these relations are gathered in the more structured template describing the event. For instance, consider a system for the extraction of the binary relations has-position(PERSON,POSITION) and position-in(POSITION,ORG) and a second step to associate these relations in a single Management Change event.
In the sequel, we present the different steps related to development of a new direct model learning-based approach that extracts annotations rules (or patterns) after a learning phase. This new approach integrates the parameters’ entities, words and syntactic features as sets of keywords and articulation words (or cue-words) provided by an expert. Furthermore, a segmentation step is applied on the new document annotation phase. A relaxed alignment process is performed until meaningful annotations are obtained.
3. Our approach: towards a generic learning model
3.1. General architecture
As a direct model learning-based approach, we consider both learning and annotation phases as reported in Figure 6. The main objective of the learning phase is to build a set of patterns describing the possible occurrences of the event. A pattern contains the required information, in a given sequence, describing an event, as for example:

Pattern 1.

Pattern 2.
Each pattern can be considered as a rule that reflects a possible occurrence of an event. It can contain keywords, cue words, Named Entities and ROLES Tags.

Interpretation of elements in Pattern 1.
Figure 6 outlines several steps for learning to occur. First, an expert defines the set of keywords as well as the cue words for the chosen domain. The definition of these words is based on his expertise and well-selected documents. The cue words represent the most important word features that can be found between the entities, or around them, and may inform the possible annotation. As for example, the cue word ‘<With_effect_FROM>’ specifically informs that the following entity is a Date.
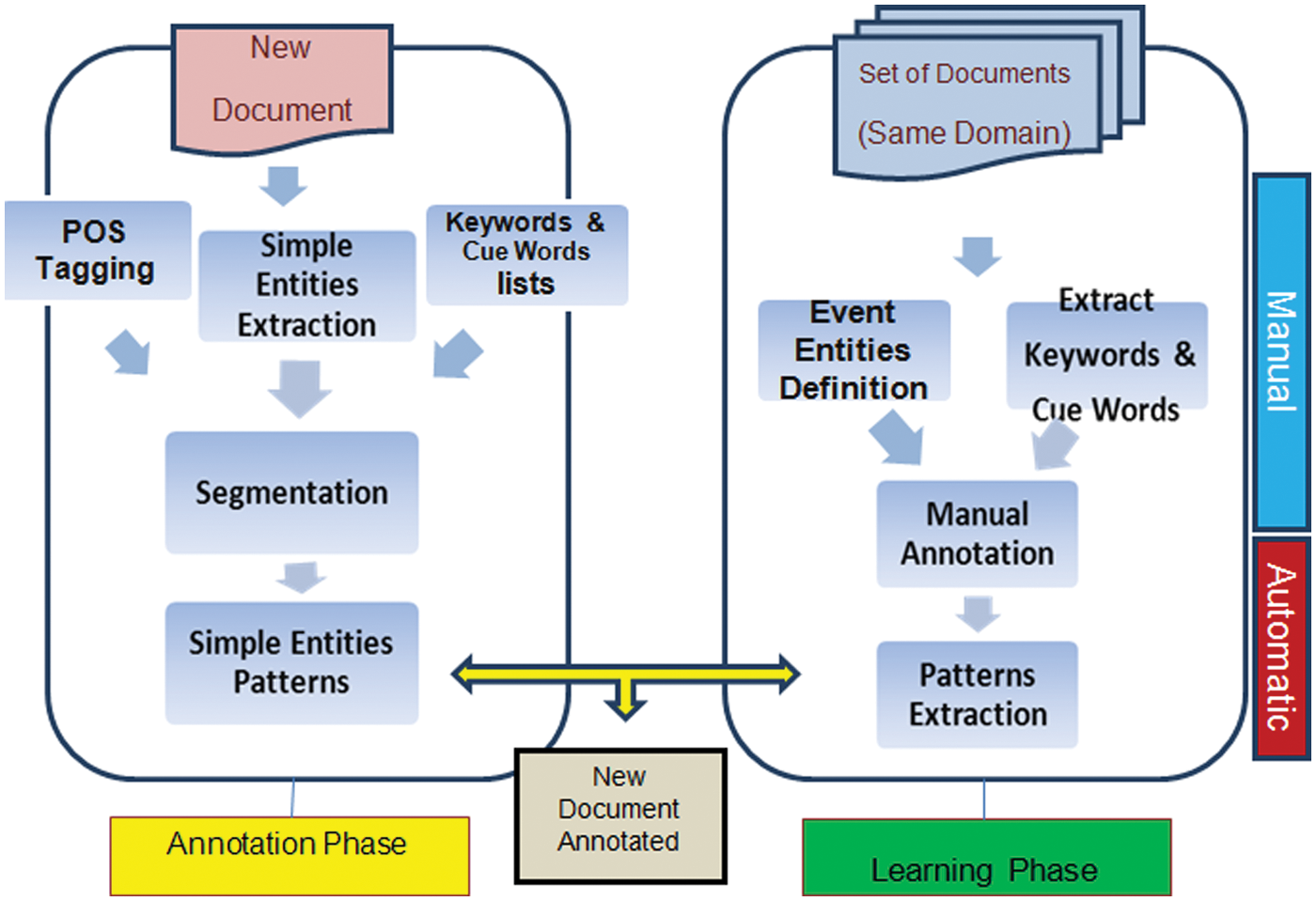
General architecture.
Keywords play a crucial role in the identification of information in an Event. In fact, they represent the event’s bag-of-words or the event’s detector. Therefore, no information could be extracted if any of these words is detected in the text. For instance, in management change event, we should find words like ‘appoints’, ‘names’, ‘resign’, etc., in order to realize the extraction of existing ROLES, for example, ‘Coming_Person_Name’, ‘Leaving_Person_Name’, ‘Date_of_ Leaving’.
Some keywords can be verbs. If the tense of the verb is considered, then the extracted patterns can be more precise since morpho-syntactic features were considered. For example, we differentiate between patterns reporting ‘appoints’ and ‘has been appointed’. Even though these verbs are ‘equivalent’, they imply two different patterns. Hence, we obtain:
As a first pattern: P1 = (ORG + appoints PERSON) As a second pattern: P2 = ( PERSON + has been appointed + ORG).
The annotation process depends on the entity positions, which clearly depend on the tense of the verb. To improve the matching efficiency between a new segment (from a new text) and the learning set, a reduced format of the latter is generated. This reduction consists of eliminating all tags of the segment except the keywords and the cue words. Hence an initial matching between reduced formats is performed before the complete matching.
3.2. Algorithms
Pattern learning can be considered as a general framework for IE. The whole process is not necessarily specific to a given domain. Once the experts perform their task with high accuracy (as mentioned in Algorithm ‘PatternLearning’), phase 2 integrates the set of keywords, cue words or articulation words and produces patterns related to the specified input. As a first step in phase 2, the procedure ‘Extract simple pattern’ makes a call to a POS tagger [7] and gives out the different tokens in a text annotated by linguistic tags. During this learning step, each relevant segment (containing at least one keyword) is manually annotated with respect to the targeted entities structuring an event as provided in the input.
In step 2, the IE from a new text is processed by associating a string to a specific entity by making a call to the ‘Alignment’ procedure. In fact, by alignment of generic entities to specific entities, some strings of a text are automatically annotated. In some cases, initial complete matching can fail. In that case, a reduced format of the pattern is generated, by eliminating cue tags of the segment except the keywords. Hence a soft matching between reduced formats is performed for efficiency improvement.
3.2.1. Step 1: Pattern generation, using a sample of training set of documents


Selection of the initial sample is based on a cycle of crawling and keyword selection. From the current sample, relevant keywords were extracted. Starting from decided keywords, we continue crawling with general search engines and news providers. Then, automatic pattern generation based on keywords and articulation words was initiated. Descending to stop the crawling process should be done with caution. A decision element (hypothesis) is to compare new generated patterns with existing ones. If no new significant patterns are generated then the process is stopped.
3.2.2. Step 2: Patterns generation and automatic annotation of a new document


3.3. Illustrations
In this sub-section we illustrate our new approach. We consider samples of parameters used in the different steps for the algorithms PatternLearning and AnnotateNewText.
3.3.1. Algorithm PatternLearning
Keywords, cue words and entities encoding
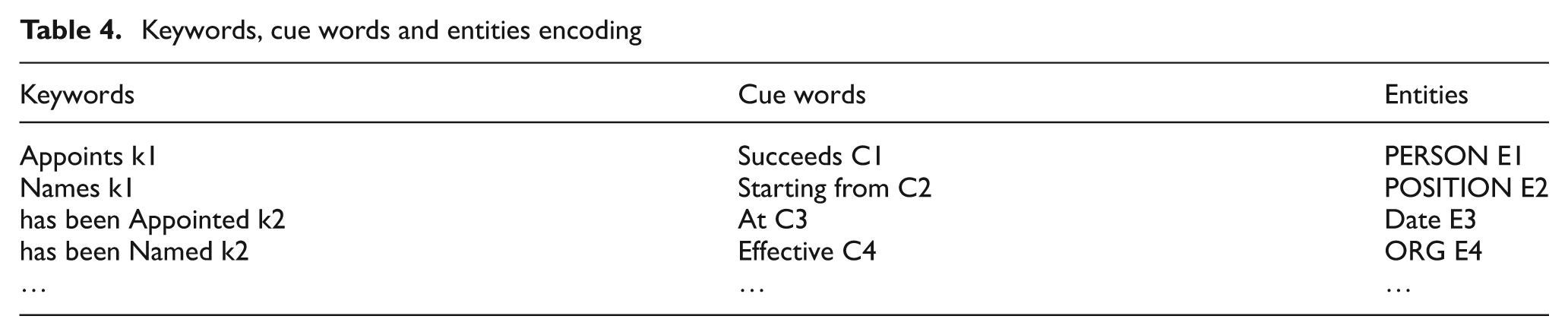
Note that the same code can be related to different elements, specifically in the case of synonyms (i.e. the keywords ‘appoint’ and ‘names’ have the same code k1). This contributes towards avoiding pattern redundancy.
For example, if we consider the text T1 in Figure 7 and its corresponding manual annotation, we can produce the pattern as depicted in Figure 8.
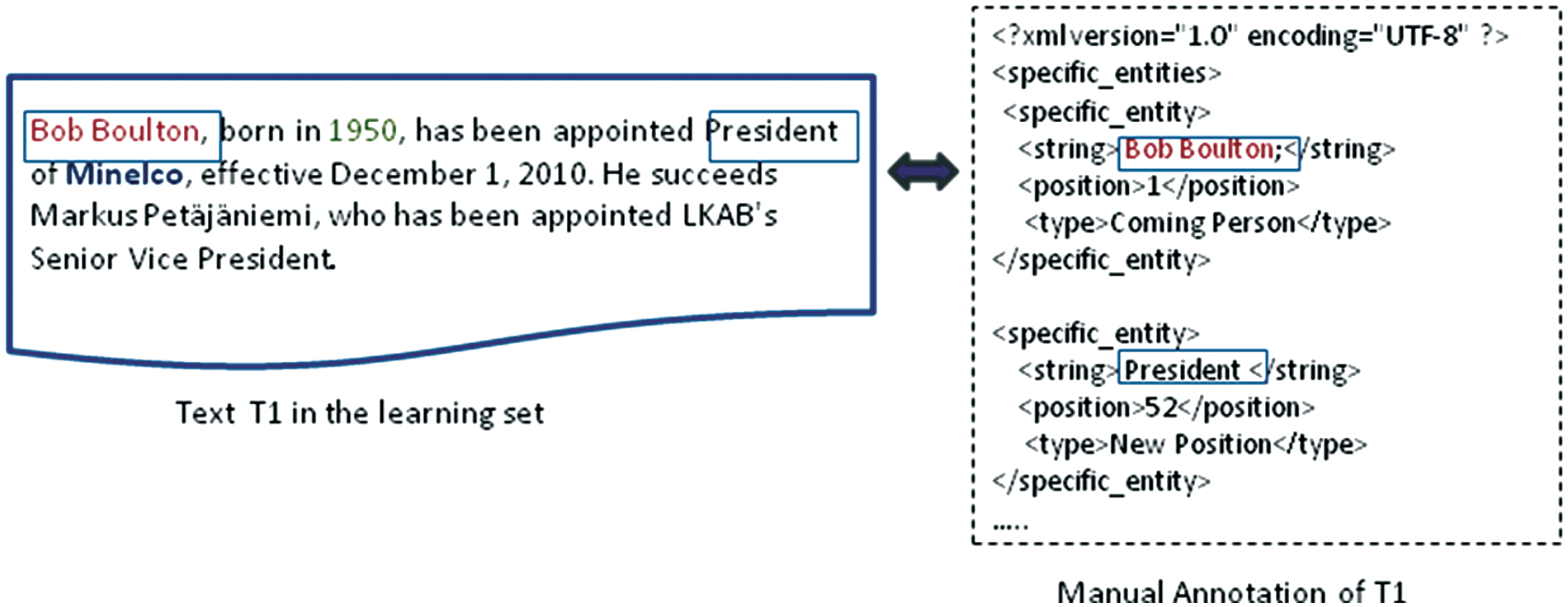
Sample of a learning text and its associated manual annotation.
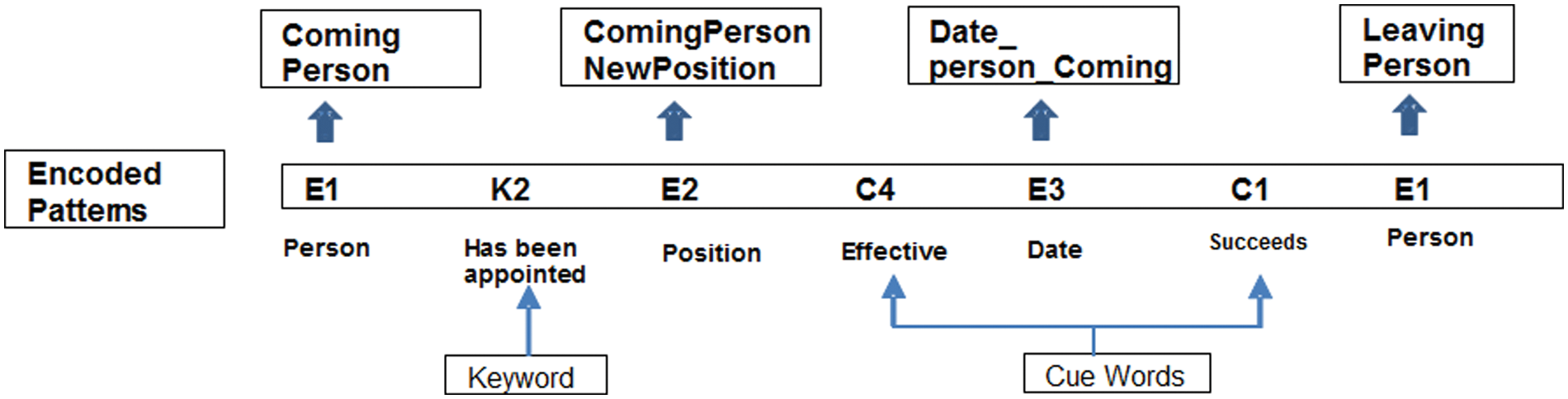
Encoded pattern extracted from phase 2 of Pattern Learning algorithm.
3.3.2. Algorithm AnnotateNewText
In order to annotate the new text as depicted in Figure 9, phase 1 of algorithm AnnotateNewText allows us to extract an encoded segment that contains the most important information cited in the text in terms of entities, keywords and cue words. The objective of the alignment process (phase 2) is to identify the possible roles of some entities as event description. For instance, the alignment between the pattern of Figure 8 and a new text is depicted in Figure 9.
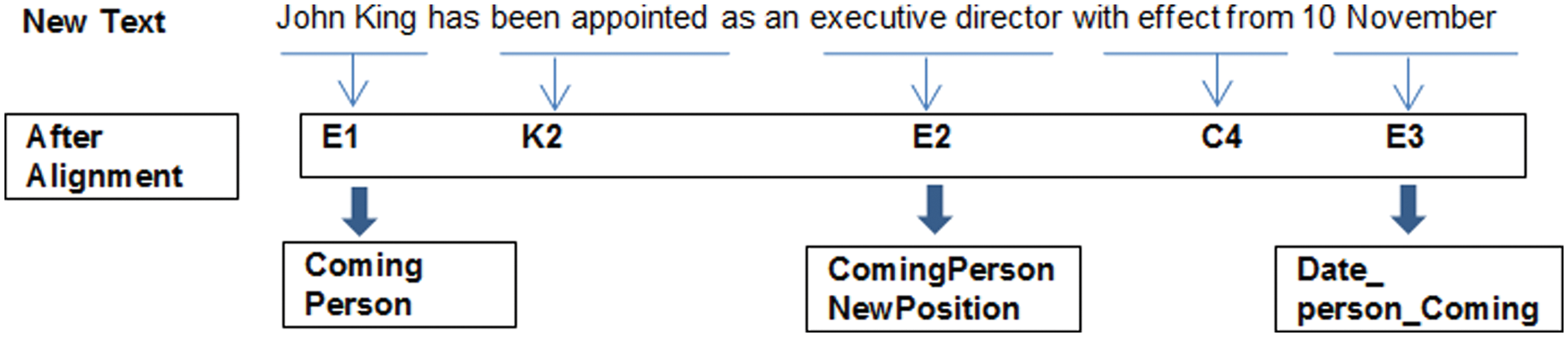
Event extraction for a new text after alignment step.

Event Extraction for a new text.
4. Evaluation
In the evaluation we consider the management change event, as requested by potential end-users. Table 5 presents detailed event role descriptions.
Management change event description

Correct answers by role

Financial experts have participated in defining the different input parameters for the system. For the management change event, a set of 138 keywords and a set of 89 cue words were defined. News stories about management change events were collected by RSS-feeds during the period 15 August 2010 until 30 November 2011. As management change is usually a strategic decision for corporation, therefore these event occurrences are limited. For the current setting, 50 files for the learning phase are collected and 40 others for the testing phase. We automatically extracted 102 patterns corresponding to management change. Redundancy between patterns is included in the count.
The average recognition rate for the 40 new files is 76.90%, which is a very promising result. It is important to note that an accurate definition of input parameters is an extremely important factor for system efficiency. In fact, these parameters play roles in both precision and generalization aspects. Also, the algorithm for pattern alignment is another decisive factor. The alignment between patterns and a new text is not often guaranteed because of the diversity of writing styles that we may find in the news. For this reason, we have proposed soft matching between reduced formats with the objective of maximal utilization of the pattern expressiveness. In several cases, this reduced format successfully allows the assignment of the same role to similar entities cited on the same side, with respect to some keywords or cue words. However, in other cases it fails to make a distinction between opposite roles (i.e. CP_name, LP_name), yielding a weak recognition rate (33.33%). Obviously, this low rate concerns only the event level recognition. This system succeeds in correctly identifying persons, organizations and positions, since appropriate gazetteers have been already integrated.
5. Conclusion and perspectives
Automated IE is a challenging and difficult task, requiring the resources of both expert skills and natural language processing tools. Moreover, for the purpose of this study IE is domain-dependent and context-sensitive. For instance, the information extracted for describing a management change event is completely different from that describing transaction or performance events.
Despite all these considerations, we defend, in this paper, the idea of building a general learning approach that may be applied for different types of events. In fact, we observed that, even if a natural language text appears unstructured, it may be seen as structured if we replace instances by their types. From one text to another, when dealing with the same event, there are some fixed parts as well as varying ones. The keywords and the cue words are the same, but the person’s names or the organizations may be different. Based on these observations, we have proposed a new generic approach for information extraction, including a manual preparation of inputs and automatic pattern generation built on a pre-prepared learning set. We applied our approach to a management change event and obtained around 80% recognition.
Further developments will focus on:
The domain data preparation – including the application of sampling techniques in order to select an adequate learning set for a given domain. The better the quality of this learning set is, the better the extracted patterns are able to cover the domain. Consequently, covering a domain is very important in writing styles recognition.
The patterns representation and reasoning – in order to increase the efficiency of the system, formal representation (i.e. formal context and formal concept) of the pattern sets can be considered for two reasons: first, to avoid the redundancy between patterns; and second, to enhance the support mismatching between patterns in cases of semantically possible alignment.
Footnotes
Acknowledgements
This publication was made possible by a grant from the Qatar National Research Fund NPRP 08-583-1-101. Its contents are solely the responsibility of the authors and do not necessarily represent the official views of the QNRF. Also, the authors would like to thank Dr Christopher J. Leonard for proofreading the paper.