
Abstract
The Doubly Correlated Topic Model is a generative probabilistic topic model for automatically identifying topics from the corpus of the text documents. It is a mixed membership model, based on the fact that a document exhibits a number of topics. We used word co-occurrence statistical information for identifying an initial set of topics as posterior information for the model. Posterior inference methods utilized by the existing models are intractable and therefore provide an approximate solution. Consideration of co-occurred words as initial topics provides a tighter bound on the topic coherence. The proposed model is motivated by the Latent Dirichlet Allocation Model. The Doubly Correlated Topic Model differs from the Latent Dirichlet Allocation Model in its posterior inference; it uses the highest ranked co-occurred words as initial topics rather than obtaining from Dirichlet priors. The results of the proposed model suggest some improved performance on entropy and topical coherence over different datasets.
Keywords
1. Introduction
With the huge amount of information available online and wide usage by users and communities, a more complicated method is required to identify a user need. This has led to the need to automatically organize documents in a meaningful way to understand, search and visualize information from the collection. Categorizing documents according to their topic can improve the precision of search results.
Topic models are well-accepted approaches to analysing texts [1]. Topic modelling involves getting more relevant results for the user’s search from the enormous amount of information available. The basic idea behind the topic model is:
To identify the hidden topical patterns that exist in the corpus of documents. A document can exhibit multiple topics, for example, a document of ‘Zoology’ may also contain information about ‘Biology’, ‘Charles’, ‘Darwin’, ‘Animals’, ‘Evolution’, etc., to some extent. According to the definition of topic models, one can understand a ‘Zoology’ document as a mixture of various topics such as ‘Zoology’, ‘Biology’, ‘Charles’, ‘Darwin’, ‘Animals’, ‘Evolution’, etc.
After identifying topics, these documents are organized according to the topics identified by the topic models.
Topic models are generative models for collections of documents [2], in which each document is considered as a random mixture of corpus-wide topics and each word is drawn from those topics. They examine the document and infer the underlying topical pattern.
Topic models operate on three matrices: a non-negative topic matrix T of dimension 1×k, a non-negative vocabulary matrix V of dimension v×1, and a matrix P of dimension v×k. Every entry of the matrix is the probability distribution of N number of V words from the corpus. Topic models consist of two steps: inference and parameter estimation. In the inference step, the topic matrix is furnished by topic proportion over documents using various inference algorithms, whereas in the parameter estimation step, matrix P is populated with term distribution over topics.
Various topic models are available for organizing, summarizing, searching and understanding the text. Probabilistic Latent Semantic Analyses (PLSA) [3] and Latent Dirichlet Allocation (LDA) [4] are the most popular [5] and are often used as the basis [1] for a number of topic models.
In this study, we proposed an unsupervised probabilistic model, which observes concepts from the set of the highest ranked co-occurring words in the document. These concepts are then assigned to initial topic proportions. The term distribution over these topics is calculated to identify a topical mixture over the document/corpus. The proposed model is a generative probabilistic model for documents, which identifies hidden topical patterns in the document with more approximate inference by identifying correlated terms. Our model is based on LDA [4] with fewer assumptions. The hyper-parameters (two smoothening parameters) play a vital role in the topic models, and assigning appropriate values of hyper-parameters results in performance variation of topic models. In LDA, the value of α governs the smoothing effect of θ, and a higher value of α results in more smoothed topics, while α < 1 results in sparse topics. Here, sparseness of topics indicates the number of atoms that tend to have positive probabilities or higher probability. A higher value of α signifies that the document exhibits a mixture of higher number of topics, whereas a lower value of α signifies that the document is stuck to fewer topics, even only one [6]. On the other hand, the value of β signifies the height of relatedness of words in a topic. If the value of β is higher, more similar words may occur in the topic. Nevertheless, we have ruled out these assumptions, and have not considered any hyper-parameters in the proposed model. The proposed model has only one input that is a corpus.
The paper is organized as follows. Section 2 includes the related work carried out in this area; in addition, topic modelling with PLSA and LDA is briefly described with some improvements suggested by different authors in the posterior inference for LDA. Section 3 describes the proposed model with its generative process. Lastly, Section 4 describes the evaluation of the proposed model.
2. Related work
This study is related to the topic modelling and inference algorithm.
2.1. Topic modelling with PLSA
PLSA is a statistical model for co-occurrence data [3]. It derives the observed variables with respect to their co-occurrence with latent variables (Figure 1). In PLSA, the likelihood of the document is calculated as

where t denotes topics and w indicates words.

Graphical model representation of PLSA [3].
p(t|d) and p(w|t) can be obtained by applying expectation maximization [7] algorithm on the likelihood of a document collection; p(t|d) indicates per document topic proportions and p(w|t) denotes per word topic proportions. The words wi and documents dn conditionally depend on the latent topics; as a result, word wi is generated through latent topics. A problem associated with this model is that it learns topic mixtures only from those documents on which it is trained [4].
2.2. Topic modelling with LDA
LDA models each document as a mixture over topics. The documents are distributed over topics, and topics generate words. Each vector of mixture proportions is assumed to be drawn from a Dirichlet distribution. The joint distribution of hidden and observed random variables is given by
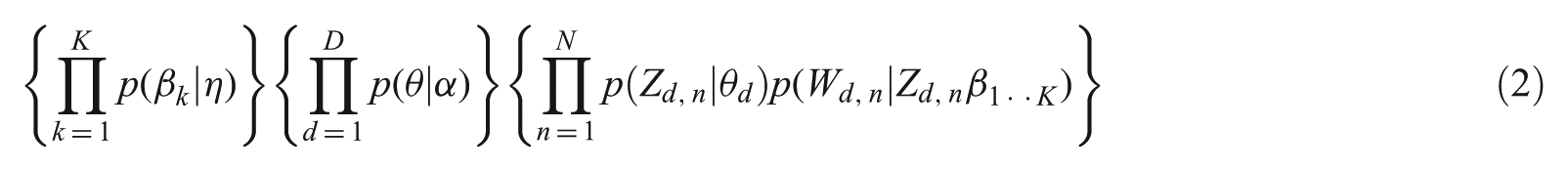
where α is the Dirichlet parameter, sampled once for each corpus; each β is distribution over terms, and we have K of them; βK is the space of all possible distribution and is derived from Dirichlet; θd is the per-document topic proportion, sampled once for each document; Wd,n is the nth word in the dth document; and Zd,n is the per word topic assignment, sampled for every word of a document (Figure 2).
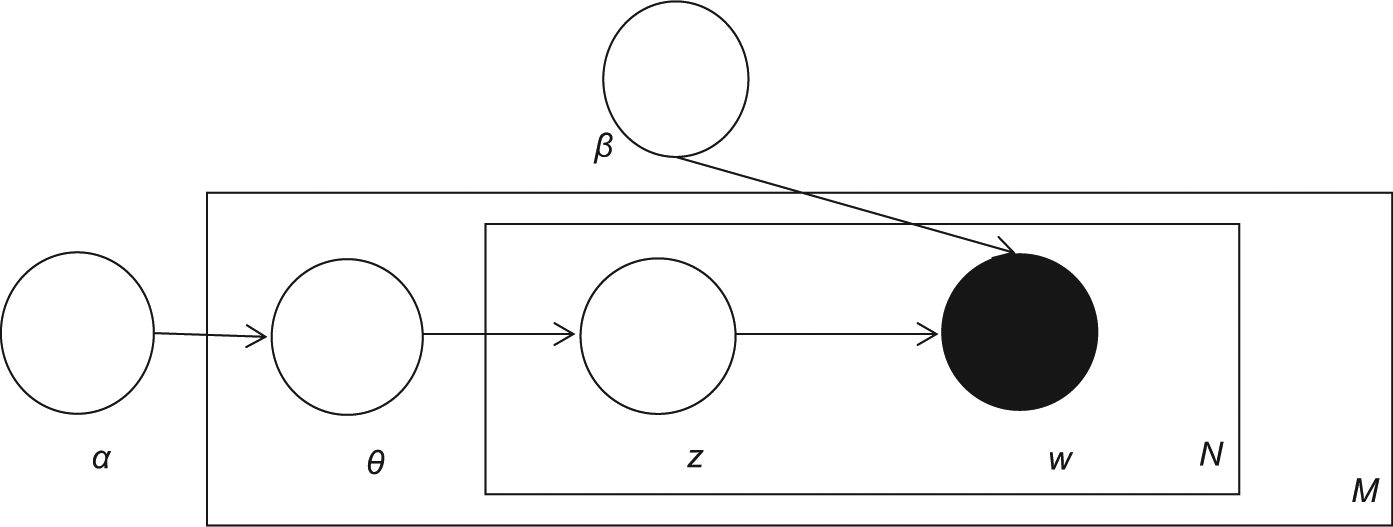
Graphical model representation of LDA [4].
Almost all the uses of topic models require probabilistic inference [8] to determine the topical patterns that exist in each document. The inference task is to solve [9] per document topic proportions θ, per word topic assignment z, and per corpus topic distribution β. The topic proportions are calculated from the posterior, which allows the inclusion of some a priori confidence on the parameters of a prior distribution. A posterior distribution is the conditional distribution of the hidden variables given the observations. For one document, the posterior is the topic assignment and topic proportions [10]. Hence, the per document posterior p(θ|W1…N), when the topics are fixed (LDA works with fixed K topics), will be:
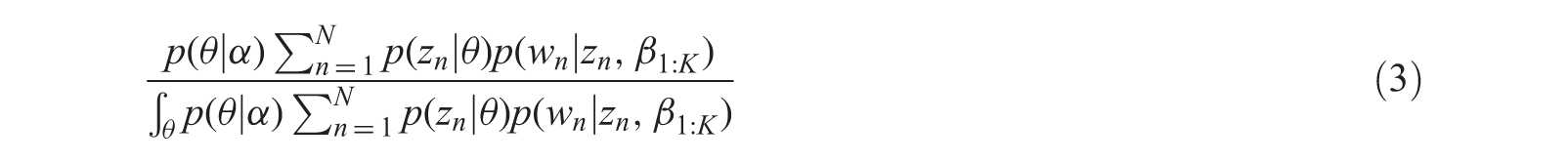
The denominator in Equation (3) is intractable, and hence, we cannot evaluate the exact posterior distribution. Consequently, we have to work with approximate posterior inference, which can be carried out in two ways, either by Gibbs sampling [11] or by variational inference [4, 12, 13]. Gibbs sampling is a special case of Monte Carlo Markov Chain (MCMC) [11]. For sample space (θ, z1:N), the Gibbs sampler initially computes the conditional distribution of the current states of other hidden variables and observations, that is, p(θ | z1:N, w1:N). Given the values of z, θ is independent of w, but dependent on z. The posterior distribution of θ given n draws from θ is just a Dirichlet distribution, and thus, the conditional distribution will be:

Subsequently, we have to sample it again for each z as follows:
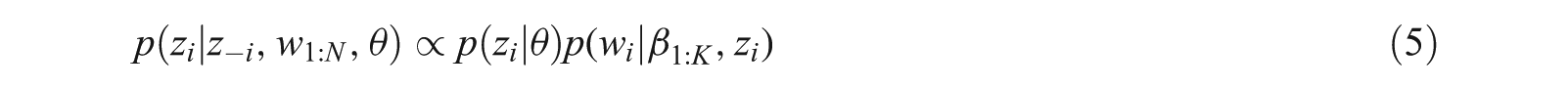
This sampler converges very slowly. However, if sample space (θ, Z1:N) is reduced, then it will converge faster. The collapsed Gibbs Sampler [11, 14] integrates this topic proportion from the sampler. Here, the state of the sample space is the collection of topic assignments. Therefore, we can iteratively sample topic assignments, giving the remaining topic assignments, for integrating out topic proportions and obtain the probability of a word of a given topic with a number of times topic assignment in another topic assignments, that is,
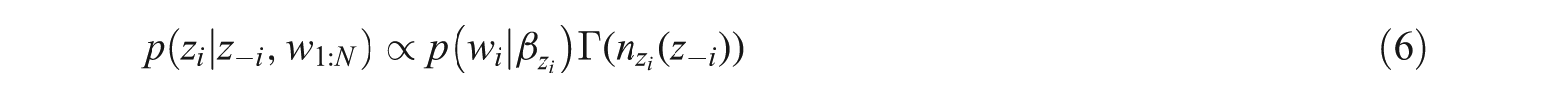
A modified Gibbs sampler is the o-LDA [15], an online algorithm, which samples the next topic by training topics from the words of the document, instead of all preceding words. The algorithm achieves more accurate results with slightly slower performance. Furthermore, although scalable MCMC requires parallel hardware, the computational complexity still scales linearly with the data, which is not sufficient for a large number of data [16].
The variational inference is an alternative to Gibbs sampling, which replaces sampling with optimization to achieve the tightest lower bound [4]. The variational distribution is computed as:
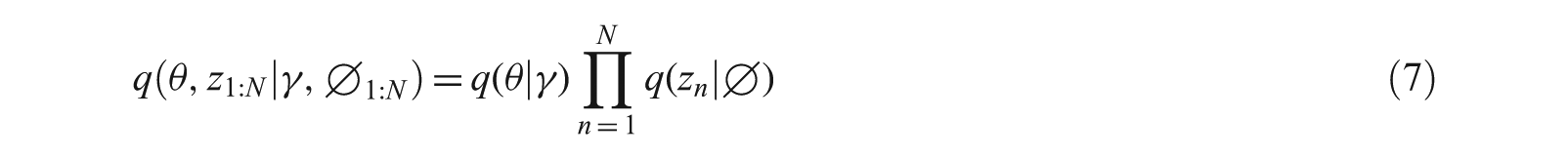
where γ and


Various kinds of extensions have been proposed for PLSA and LDA, including more contextual information such as time [13, 14, 17], authorship [18, 19], ranks [20] and links [1, 21–25]. Dirichlet distribution randomly draws topic proportions, which reveal a near-independent structure [26]. Hence, LDA neglects the correlations in document-specific topic usage [5]. When normalizing γ-independent variables, it tends to exhibit a negative correlation. The Doubly Correlated Nonparametric Topic [5] model models topic and document correlations influenced by metadata for an unbounded set of potential topics. It uses MCMC techniques for learning and inference. The Logistic–Normal distribution [27] better captures the inter-component correlations. The Correlated Topic Model (CTM) [28] differs from LDA only in its first step. It draws topic proportion from a Logistic–Normal distribution. As Logistic–Normal distribution is not conjugated to multinomial [29], it complicates exact inference, and hence, it is also intractable in CTM. A fast variational inference [29] algorithm for CTM optimizes the log probability of the document with respect to variation parameters, which results in narrowing of the limits of the marginal probability of observations. Collapsed variational inference [16, 30] integrates the β values to achieve an improved approximation of the posterior variance. However, optimization, zi depends on z-I; hence, its application to a large number of data is difficult [31]. Wang et al. [31] modified collapsed variational inference by considering a single data point xi with its topical patterns zi. A data-driven split-merge algorithm [32] for the hierarchical Dirichlet process dynamically expands and contracts the number of topics. The split step creates new topics and the merge step removes redundant topics. In addition, Wang et al. [33] modified the optimization process by iteratively taking a random subset of data and updating the variational parameter. The variational objective function was optimized by stochastic optimization [34]. Furthermore, Blei et al., in supervised Latent Dirichlet Allocation [35], derived a maximum likelihood procedure to handle intractable posterior by maximizing the evidence lower bound. For a single document response, the vocational objective function was maximized with respect to
The latent mixed-membership model [39], in its generative process, considers the adjacency matrix as a collection of Bernoulli random variables. It uses variational inference for log-likelihood and approximate posterior of the multiple group membership of objects. The nested Chinese restaurant process [40, 41] is a generative probabilistic model that describes a priori distribution over a tree-structured hierarchy with infinitely many paths. The tree hierarchy is used to capture topical patterns in the document. The nested Chinese restaurant process is extended to design a nonparametric topic model tree [41]. The change-point stick-breaking process, together with a product of γ and Poisson construction, is used to represent time-evolving topics deeper in the tree. The L-LDA [42] extends the LDA model for multilabelled corpora by laying ‘topics’ in 1–1 correspondence with labels. Prior-LDA [43] extends LDA by including a two-stage generative process for each document. Initially, it samples a set of observed topics from a corpus-wide multinomial distribution, and then generates the words of the document. However, prior-LDA does not include dependencies between topics, and hence, cannot be used for estimating topics for new documents. The dependency LDA [43] is an extension of prior-LDA, in which the dependency between the topics is computed by T-corpus-wide probability distribution. In the present study, we have proposed a generative probabilistic model for documents, which identifies hidden topical patterns under the document with more approximate inference by identifying correlated terms.
3. Doubly correlated topic model
3.1. Terminology
Starting with basic terminologies, we define the following:
Word is the basic entity of the data having its literal and/or practical meaning. It is the sequence of non-space alphanumeric characters and special characters. A standard list of stop words is removed and then normalized by lowercase and stemmed by Porter stemmer.
The topic is a subset of set Word.
The document is a collection of sequence of N words, that is, [w1, w2, …., wN].
3.2. Model
The Doubly Correlated Topic Model (DCTM) is an unsupervised generative probabilistic model for identifying topics from the corpus of the documents. The basic intuition behind the model is the mixed membership model [44], which describes a document as mixtures of multiple topics, where topics are distributed over a fixed vocabulary of words (see Figure 3). Our aim is to evaluate semantically related information from the documents. The DCTM does not consider any document as ‘Bag of words’, and words positioning is important for the model. For example, in the sentence ‘zoology is a part of biology’, we can consider that the words ‘zoology’ and ‘biology’ may be related. The DCTM’s emphasis is on calculating probability words from the vocabulary over concepts generated from co-occurrence; as a result, it computes correlation over correlated words. Our goal is to identify the underlying hidden topical structure of each document from the available thousands of documents in the corpus.
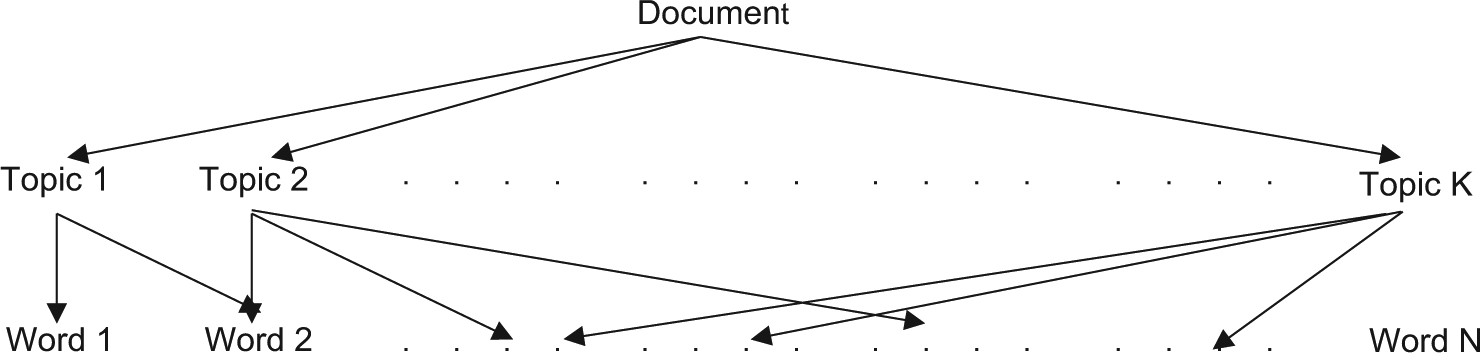
Document as mixture of topics.
3.2.1. The generative process
The DCTM follows a generative process for each document of a corpus (see Figure 4). In the generative process, the DCTM observes topics from the highest-ranked co-occurred words of the documents. Then, it computes the word probability with respect to the observed topics. Initially, we have K number of topics that reside outside the documents, and each topic is the distribution of terms over a fixed vocabulary. These topics come from the concepts that are computed from word co-occurrence statistical information [45]. From these topics, the word topic proportions for every word are calculated for every document of the corpus.

Generative process of DCTM.
3.2.2. Algorithm
The algorithm of DCTM for each document is as follows:
Create a vocabulary V {V1, V2, …., Vv} of words.
For each word in V:
(2.1) Calculate rank R with word co-occurrence statistical information.
Select concept C of K words with highest rank.
Topics z≈ Unigram K (C).
For a matrix P of dimension v×K:
(5.1) Compute p(wi|zj, Pi,j).
For each column of P:
(6.1) Select T words with highest probability;
(6.2) Compute sum of T words.
Select column Y with largest sum.
End.
3.2.3. Graphical representation
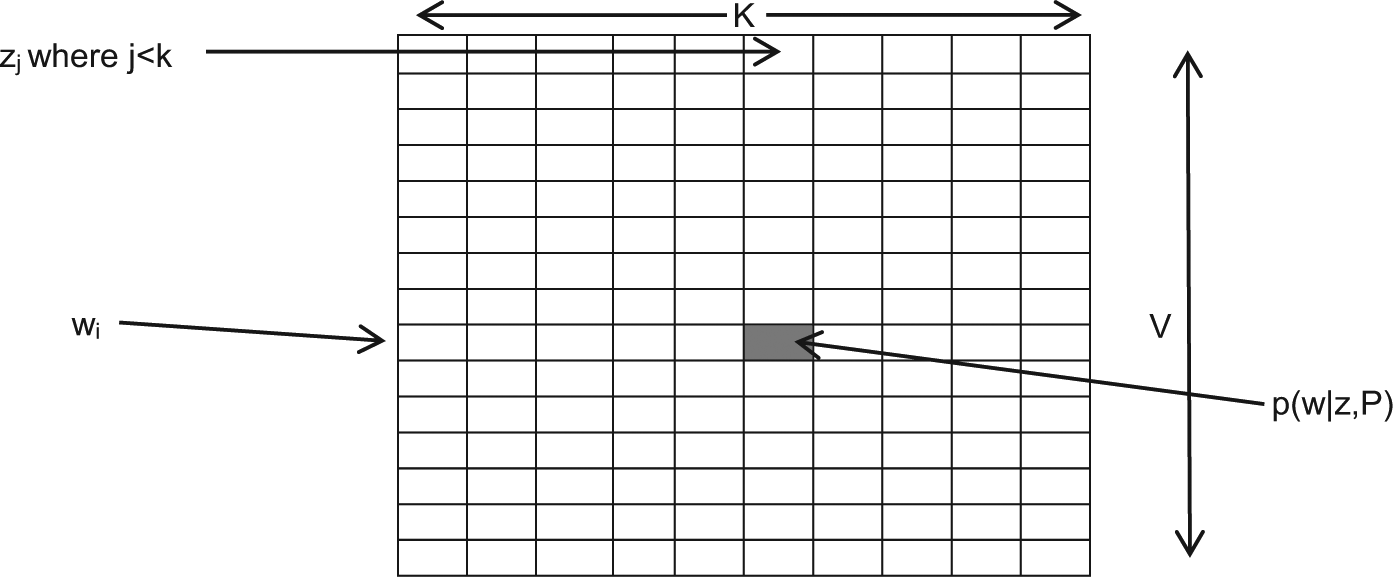
The graphical representation of the DCTM is indicated in plate notation (see Figure 5). As shown in the figure, C is the list of K concepts that arise from the word co-occurrence statistical information [45]. It is sampled once for every M number of documents. The DCTM takes K concepts from each document where each concept may be a combination of one, two or a maximum of three words, and z is the topic proportions over the document, which are being prepared from the concept list. The distribution of word over topic assignment is computed by p(w|z), which is the proportion of assignments to topic t over all documents that come from the word w. It is sampled for every N number of words of every document with K topics, and is calculated over a matrix P of order K and V, where V is the size of the vocabulary.
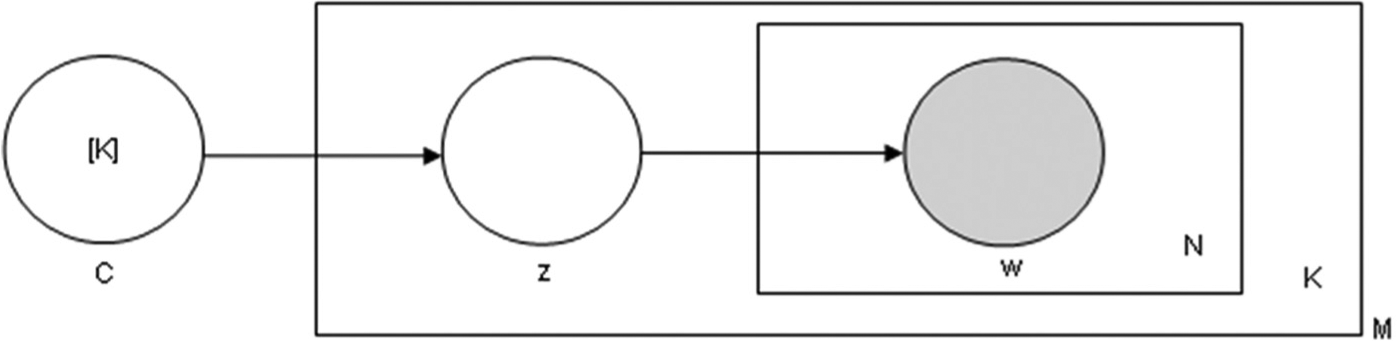
Graphical representation of DCTM.
With the concept list computed from word co-occurrence statistical information, the joint probability of the N words and K topics z is calculated as:

where
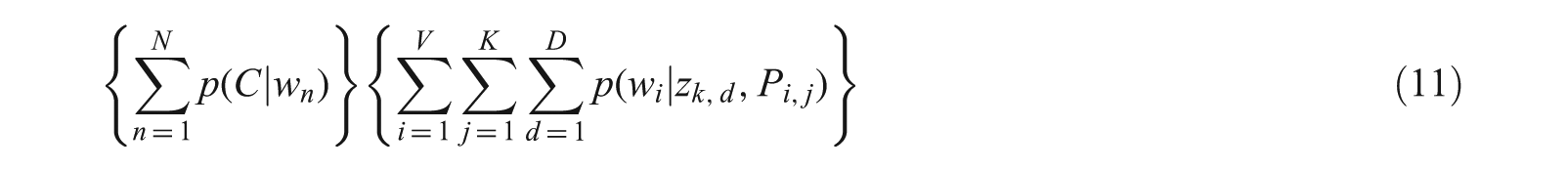
Computation of p(w|z, P).
In Equation (11), the last term represents the likelihood terms of the document. When these likelihood terms are assigned to the topics, it results in co-occurred words of the document. When reducing the sample space, it will tighten the bound on the co-occurred words and this is can be achieved by splitting the document into D parts; that is, instead of considering a document as a whole, the model iterates on data paragraph-wise.
3.3. Learning
Dataset D =

where OF is the observed frequency and EF is the expected frequency. For feature selection, Equation (12) is modified as follows:
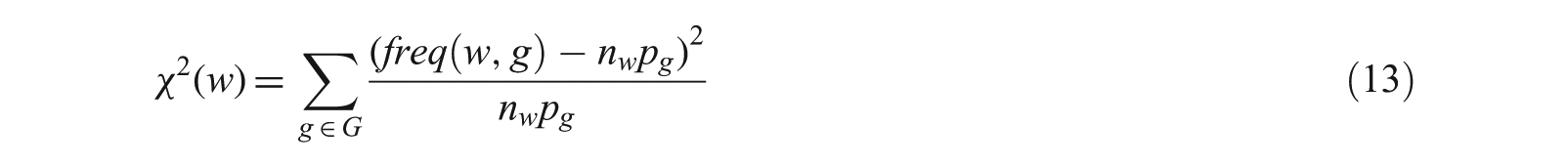
where pg is the sum of the total number of terms in sentences where the term ‘g’ appears, divided by the total number of terms in the document, and nw is the total number of terms in the sentences where w appears.
Word intrusions [46, 47] indicate words that are out of place or are not semantically related with the other, that is, intruders. For example, let us consider a set of words {‘zoology,’‘biology,’‘Darwin,’‘evolution,’‘bike’}. The words except ‘bike’ are semantically related to each other, and hence, ‘bike’ is considered as an intruder. Therefore, the word ‘bike’ should be removed. In order to measure the robustness to bias values, the maximal values are subtracted as:
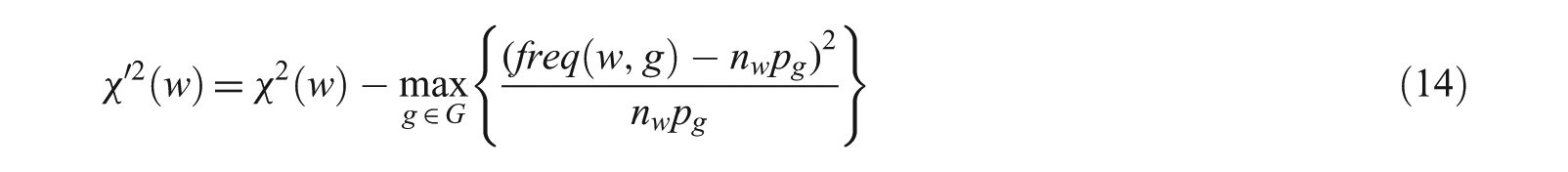
3.4. Topic coherence
Almost all topics models learn the topics by a multinomial distribution over words [48], and the outcome will be the most probable words. Sometimes, these words may co-occur, but the resultant topic may have a very general and specific terms. Therefore, the quality of the topics plays an important role while selecting a topic model. In brief, the resultant topics should be trustworthy. The words of the topic mixture should be related. The topic coherence is a degree of relatedness between words of topic mixture. Initially, topic coherence is improved by applying likelihood terms in Equation (11). These likelihood terms result in the set of co-occurrence words. Computation of co-occurrence over a set of co-occurred terms generated by the algorithm given in Matsuo and Ishizuka [45] results in more semantically related words. The likelihood terms are calculated over each column of the matrix P. More likelihood terms reflect higher probability resulting in more related words.
The concepts (lists of co-occurrence words) may be unigram, bigram or trigram; however, with regard to assignment of these concepts to initial topic proportions, unigram is preferred. If the concepts are bigram or trigram, then they are converted to unigram. On the other hand, computation of the resultant topics from the joint distribution of the topic proportions of the same concept tightens the related words in the resultant topics. Furthermore, the appropriate number of topic limits the topic coherence. Instead of having a fixed number of most probable words in the resultant topic (e.g. top 10 or 20), selection of some threshold percentage, such as 60 or 50% of the maximum rank of the probable term, could result in more semantically related words.
4. Results and analysis
This section describes the evaluation of the proposed DCTM. For the comparison of the results with those of LDA, we used the C# implementation of LDA developed by Shusen Wang. 1 Three different datasets of different domains were used in our experiment. Our data contained 15,000 randomly crawled documents from Wikipedia [49, 50], 1760 documents from NIPS 2 [5, 32, 38, 51] collections and 10,000 documents from the PubMed 3 [51] dataset. The selection of different datasets of different domains helped us to show improved performance of our model irrespective of any prior knowledge. Wikipedia documents contain different types of structured information, categorization information and links to other pages, whereas PubMed and NIPS comprise the text of datasets. All these three documents are freely available in the public domain. The web pages crawled from Wikipedia were converted to text files. A standard list of stop words, HTML tags and images were removed from the HTML documents. Similarly, NXML files of PubMed dataset were converted to text files by removing xml tags along with a standard list of stop words from the documents.
A vocabulary of words was generated as per the definition in Section 3.1. Sometimes, the large size of the vocabulary generated from the corpus of documents may cause problems [4] because some words may occur in a few documents only and some words have a very low frequency. Therefore, instead of creating one big vocabulary for a corpus, an individual vocabulary was generated for each document, and consequently, the proposed model did not suffer from the large vocabulary problem.
In the probability distribution of training and test datasets, Entropy is used as a direct evaluation technique for comparing our proposed model. Entropy [52] is a measure to evaluate the distance between two probability distributions. Thus, we could evaluate how well DCTM models the random variables (data). Entropy H(x) is calculated as:

While comparing two different probability distributions, Entropy is calculated as Cross Entropy for two distributions p and q on random variable x, defined as:

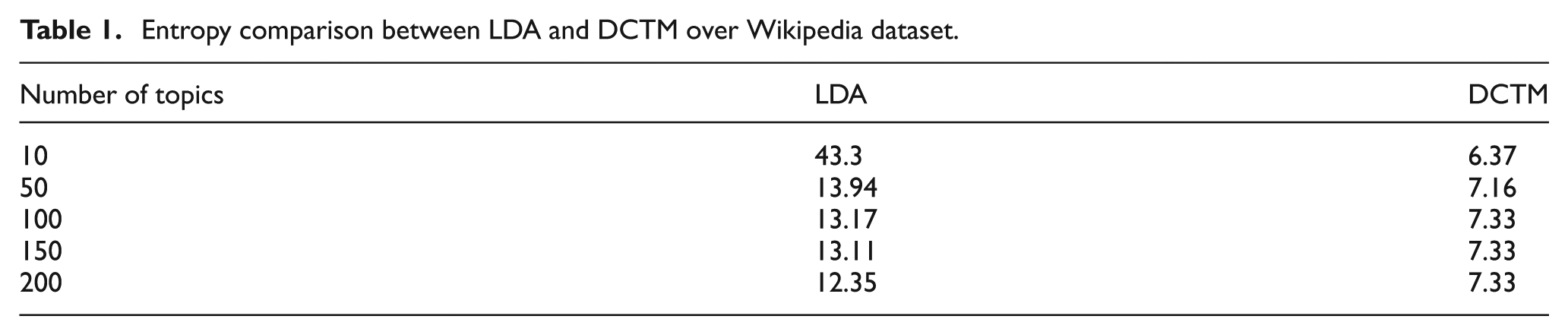
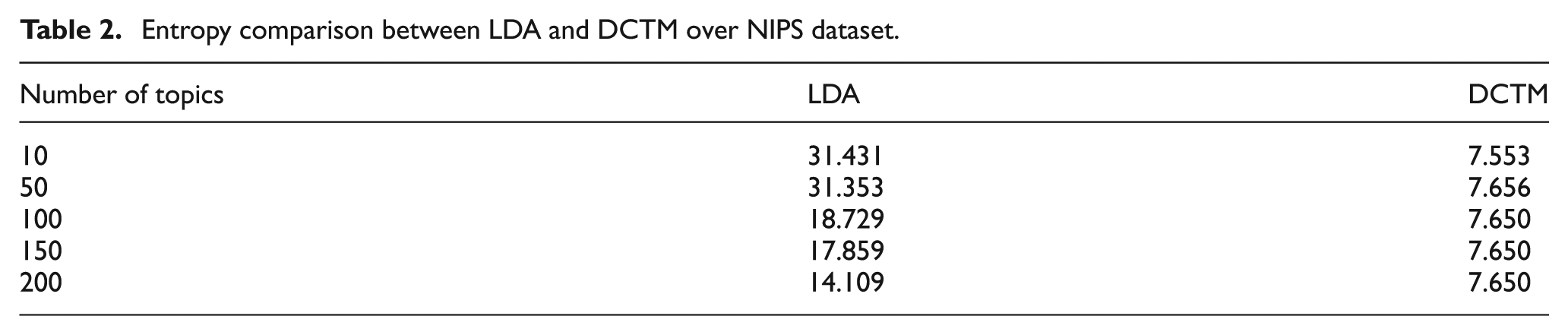
When comparing two different models with entropy, the model with lower entropy is assumed to be more approximate than the other. The datasets were divided into 90:10 ratio for training and testing purposes. Entropy comparison of LDA and DCTM over Wikipedia, NIPS, and Pubmed dataset suggested improved performance of DCTM over LDA (see Tables 1–3, respectively). The entropy of the LDA steadily decreased from topic value 10 to topic value 200, and subsequently remained constant, whereas the entropy of the DCTM increased from topic value 10 to topic value 100, and subsequently remained constant. The entropy of the DCTM suggested that the models perform better with low topic values; this is due to the fact that DCTM processes each document of the corpus separately and a document can be better explained by a topic mixture of 20–30 words, rather than having a topic mixture of 100 words. As DCTM processes each document separately, new documents can easily be added to the model for topic identification purpose.
Entropy comparison between LDA and DCTM over Wikipedia dataset.
Entropy comparison between LDA and DCTM over NIPS dataset.
Entropy comparison between LDA and DCTM over PubMed dataset.

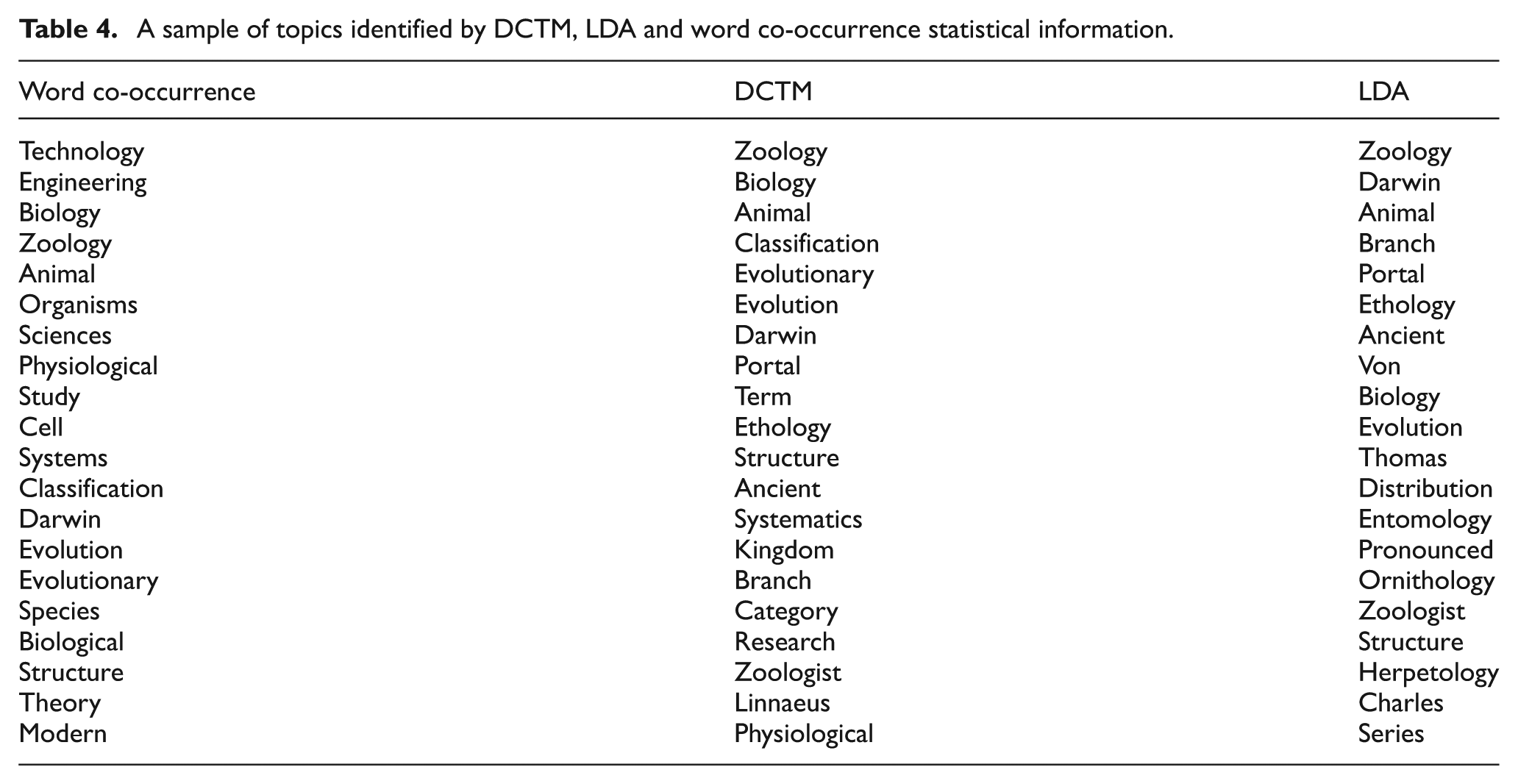
Topic coherence is a semantic relatedness between the words of the topic mixture. In addition, it can also be used to evaluate the quality of topic mixtures of the documents identified by topic models. We compared the top 20 topic words identified by DCTM, LDA and Word co-occurrence statistical information on the Wikipedia-Zoology 4 web page (see Table 4). Table 4 suggests that DCTM offers tighter bound on the topic coherence because words generated from the DCTM are more semantically related than LDA and Word co-occurrence statistical information. A question may arise regarding why we are finding the correspondences between the most co-occurred words and words from vocabulary. The top 20 unigram keywords observed from Word co-occurrence statistical information [45] are shown in column 1 of Table 4. For our model, we used these unigram words as initial topics, and then the correspondence between these topics and vocabulary was calculated for each document, and the results are shown in column 2 of Table 4, whereas the LDA results are shown in column 3 of Table 4. The first most probable word identified by both LDA and DCTM was ‘zoology’, followed by ‘biology’, ‘animal’, ‘classification’ and so on by DCTM (see column 2 of Table 4). This suggested that DCTM could identify the document related to the topic ‘zoology’. Furthermore, the document may be related to topics such as ‘biology’, ‘animal’, ‘classification’, ‘evolutionary’, ‘evolution’, and so on with gradually decreasing probabilities. On the other hand, LDA could identify the document related to ‘zoology’ and then ‘Darwin’, ‘animal’, ‘branch’, and so on with gradually decreasing probabilities.
A sample of topics identified by DCTM, LDA and word co-occurrence statistical information.
5. Conclusion
The web is usually an unstructured or a semi-structured collection of documents. Structuring the web can help to improve the search results. To structure the web, it is necessary to understand the content of the document. Knowing the topics of the document can help in understanding the content of the document, and can consequently help to organize documents in a meaningful way. Topic modelling is one of the ways to identify topics of the document.
In this study, we proposed DCTM, a simple generative probabilistic model. As the exact inference was intractable, we employed a more approximate inference algorithm by reducing the assumptions in our model compared with those in the existing topic models. A feature selection algorithm based on co-occurrence of words in a document was used for posterior inference. Our assumption started from fixing topic assignment that was generated from an inference. Later, this assumption was backtracked, which produced more accurate results than having assumed the values for different hyper-parameters. Our emphasis was to find correspondence between data and topics, and variation of the values of hyper-parameter affected the smoothing and sparseness of topics, which was not used in the model. This made our inference method simpler and gave more accurate results. DCTM is a two-stage generative process model for each document. First, it samples a set of observed topics from the document, and then generates the topical words from the document. It differs from the LDA in its first step, and draws topic proportions from word co-occurrences. As the proposed model is an unsupervised model, it does not need to have any prior knowledge of the corpus. Furthermore, the vocabulary for each document is generated individually; therefore, it does not include any type of dependency between the documents and new documents can be added, and hence, it is a scalable model. The second assumption for DCTM is choosing the appropriate number of topics K. The concepts are initialized by the K most co-occurred words observed from the document. These concepts may be unigram, bigram or trigram, and when converted into unigram words, its size is ≥K. We considered only the K concepts as topics from the set of concepts because of the fact that a document can be better explained by topic mixture of 20–30 words.
The results of the proposed model suggested some performance improvement over the existing unsupervised topic models. Furthermore, the proposed model yielded better results on low number of topics between 10 and 50, and can be used for automatic document categorization and organization of documents.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.