
Abstract
Most research in Arabic roots extraction focuses on removing affixes from Arabic words. This process adds processing overhead and may remove non-affix letters, which leads to the extraction of incorrect roots. This paper advises a new approach to dealing with this issue by introducing a new algorithm for extracting Arabic words’ roots. The proposed algorithm, which is called the Word Substring Stemming Algorithm, does not remove affixes during the extraction process. Rather, it is based on producing the set of all substrings of an Arabic word, and uses the Arabic roots file, the Arabic patterns file and a concrete set of rules to extract correct roots from substrings. The experiments have shown that the proposed approach is competitive and its accuracy is 83.9%, Furthermore, its accuracy can be enhanced more in the sense that, for about 9.9% of the tested words, the WSS algorithm retrieves two candidates (in most cases) for the correct root.
1. Introduction
In this era of the internet and with the extensive number of documents that are posted every single minute, extracting relevant documents is getting more difficult. Therefore, extracting the roots of words (or stemming), which is used to facilitate retrieving relevant documents, has become an important issue. Stemming is a major part of many applications, such as data compression, spelling checkers, text summarization and machine translation. Moreover, word-roots are used to extend queries to retrieve the most relevant information with higher recall and precision.
In some languages, such as English, stemming is an easy process since it can be performed by removing suffixes. In Arabic, however, extracting roots is a difficult and a complicated issue owing to the fact that Arabic has a rich and complex morphology. An Arabic word may have prefixes, infixes and suffixes. Furthermore, some Arabic words may consist of only one or two letters, such as the words (
Arabic words have a sophisticated morphology; they can be built using roots and patterns, where patterns can be described as templates with grammatical rules. A template can be represented as a combination of the root (
Most researchers have focused on reversing the process discussed in the previous paragraph by removing affixes to obtain the correct root. However, the aforementioned process is not easy and may remove original letters (non-affix letters) during the filtering process, which may produce incorrect roots. This paper deals with the problem from a different angle by extracting word roots without removing affixes. The paper introduces a new algorithm called Word Substring Stemming (WSS), which works based on the fact that an Arabic word consists of its root’s letters separated by affixes (with some exceptions discussed in Section 3.2.2). The algorithm extracts all substrings of a given word and uses Arabic roots file and patterns file
The rest of the paper is organized as follows. The next section introduces some related work. Section 3 demonstrates the WSS algorithm. The experiments and results are discussed in Section 4. Finally, Section 5 presents the conclusion and future work.
2. Related work
The retrieval of documents in Arabic language has become a significant issue owing to the continuous evolution of the Internet and the huge spread of Arabic documents. Extensive work has been performed to enhance the precision of retrieving relevant documents by constructing good Arabic stemmers. Some researchers developed stemmers by removing some prefixes and/or suffixes without dealing with infixes [2–4]. Taghva et al. [3] developed a stemmer that is based on matching patterns and removing prefixes and suffixes to extract the root. To enhance the matching process, they used a set of diacritical marks, affixes and patterns. Similarly, Momani and Faraj [4] developed a stemmer based on prefix and suffix removal. The proposed stemmer sorts the term letters and removes double letters that belong to the set of extra characters, which consists of the following letters {
Word-pattern matching techniques were used in extracting Arabic roots [7–9]. Based on this idea, a root is extracted after removing the affixes attached to the given word. The root extraction is performed by matching the positions of the word letters with the corresponding pattern. Al-Fedaghi and A1-Anzi [9] developed a stemmer that matches each word with all possible patterns that have the same length of letters. Then, the stemmer extracts the trilateral substring in the positions (
N-gram systems [10] and clustering methods [11] are also used to extract Arabic roots. Rogati et al. [12] presented an unsupervised learning approach to build an Arabic stemmer. They used a statistical machine translation approach that learns to retrieve the prefix, stem and suffix of a word using a training set. Harmanani et al. [13] proposed a rule-based stemmer for Arabic information retrieval. Their algorithm uses a rule engine that extracts stems based on a set of language-dependent rules. Chen and Gey [14] clustered Arabic words into stem classes using their mappings to English stem classes. They performed this process based on a parallel English–Arabic corpus and an English stemmer. Kadri et al. [15] developed a stemmer that extract roots according to linguistic rules.
Boudlal et al. [16] used an approach based on hidden Markov models and claimed that this model can achieve very good precision in extracting Arabic roots. Al-Nashashibi et al. [17] introduced some corrections or enhancements such as replacing long vowels and handling specific cases of hamzated words, which can be used in existing algorithms to improve their performance. They showed that using the corrections in the light stemmer proposed by Al-Ameed [18] can improve its performance by about 14%. Hmeidi et al. [19] proposed an algorithm that is based on bigrams. They used two similarity measures – Manhatten distance and Dice’s measure – to test the algorithm’s accuracy, which was claimed to be 86% for trilateral roots.
Al-Kabi and Al-Mustafa [20] proposed an algorithm that is based on affixes removal and the knowledge extracted from structural linguistics. However, the level of complexity of the algorithm is high, and its accuracy depends on the arranging of root patterns. Similarly, Al-Sarhan et al. [21] introduced a new algorithm that is based on Arabic root patterns. Nonetheless, their algorithm assigns numeric values to listed letters and uses those values in roots extraction. Ghawanmeh et al. [22] suggested an algorithm based on Arabic root patterns; however, they used only 81 patterns in the extraction process, which reduces the time needed for extracting Arabic roots.
Most of the aforementioned approaches focused on removing the affixes of a word to extract its root. However, these approaches suffer from the problem of distinguishing between the letters of affixes and the letters of roots. Moreover, they add processing overhead that may not be acceptable in some systems. This paper introduces a new approach that deals with the stemming problem from a different angle by eliminating the need to remove affixes in root extraction. This has an advantage of the elimination of the uncertainty resulting from the distinction between the affix letters and the root letters. It also does not add any processing and computations overhead.
3. The WSS-based algorithm
The proposed approach consists of two phases, which are the pre-processing of words and extracting roots. This section introduces the WSS algorithm and explains its phases in details.
3.1. Preparing the word (pre-processing)
Before using the WSS algorithm to extract a word’s root, the word is prepared by removing letters that are highly probably not the root’s letters. We should mention here that this phase is simple and does not aim to remove affixes. Strictly speaking, it aims to reduce the number of substrings of a word used in the WSS algorithm, and to enhance the probability of finding the correct root. In this phase, the following letters are removed before using the algorithm:
The letters (
The letter (
The letters (
One of the doubled letters at the beginning of a word, such as the letter (
The second weak letter when there are two successive weak letters in a word, such as the letter (
In addition, the preparation process converts some letters to their original forms, such as converting
3.2. The WSS algorithm
The WSS algorithm is used to extract both trilateral and quadric roots. Basically, the algorithm extracts all syntactically correct substrings from the given word, where a substring is defined as follows:
The algorithm assumes that the correct root of a word is highly probably found among the retrieved substrings. Therefore, it uses the roots file, the patterns file (

3.2.1. Analysis
The algorithm starts by preparing the given word as discussed in Section 3.1. Next, in step 2, it extracts all quadric and trilateral substrings of the word. In steps 3–6, the algorithm keeps valid (syntactically correct) substrings only. After this step, it searches for a quadric root. The algorithm searches for valid quadric substrings that have no extra letters as shown in steps 8–9. It assumes that, if such a substring exists, it is most probably a root candidate; therefore, the algorithm adds the substring to the set of root candidates (CR). If there is no substring with all letters original (has no extra letters), the algorithm searches for a substring that has the minimum number of extra letters and adds it to the set of root candidates (as shown in steps 10–17). The algorithm assumes that original letters in a word have very high probability of being root letters. This process is logical since other letters could be extra as it is purposely called ‘extra letters’, which are letters (affixes) that are added to roots to form various Arabic language words. Extra letters may exist as root letters too; meanwhile, original letters do not exist in a word as extra letters. After finishing this phase, the algorithm checks the set of retrieved root candidates (CR). If the algorithm fails to find a four-letter root candidate (step 18), the algorithm jumps to step 33 to search for a trilateral root. If there are quadric root candidates, the algorithm checks CR and searches for a root candidate that exists in the file of four-letter roots, and its letters are contiguous in the given word (W). If such candidate exists, it retrieves it as the root of W (steps 20–23). The algorithm assumes that the letters of the root of a word are highly probably contiguous in the word or separated by weak letters. Thus, if there is no candidate contiguous in W, the algorithm searches for a candidate that is separated by weak letters (as infixes) (steps 24–25). Notice that the algorithm checks the retrieved root candidate against the quadric roots file to ensure that it is a root.
If no quadric roots exist (step 33), the algorithm searches for a trilateral root. As performed in the searching process for a quadric root, the algorithm searches for a trilateral substring(s) that has the least extra letters (36–43) and adds it to the set of root candidates (CR). After these steps, if there is one three-letter root candidate only, the algorithm retrieves it as the root of the given word (steps 44–45). However, if there is more than one trilateral root candidate, the algorithm uses the trilateral roots file (TRF) to filter CR and removes any root candidate that does not exist in the TRF (steps 46–49). After the filtering process, if only one root candidate remains in CR, the algorithm retrieves it as the root of the given word (W) (steps 50-51). Otherwise, the algorithm uses the patterns file PF (
After finishing the process of converting root candidates to patterns, if there is one root candidate in RR, the algorithm retrieves it as the root of W (steps 58–59). Otherwise, the algorithm prefers the root candidate that is contiguous in W and retrieves it as the root (61–62). If there is no contiguous root candidate in W, the algorithm prefers the one that is separated by weak letters (as infixes) (64–65). If the previous steps fail, the algorithm retrieves all root candidates in RR as potential roots for W (65–66). This behaviour is based on the fact that Arabic words may have no infixes such as the word
Figure 1 shows how the algorithm extracts the root of the word
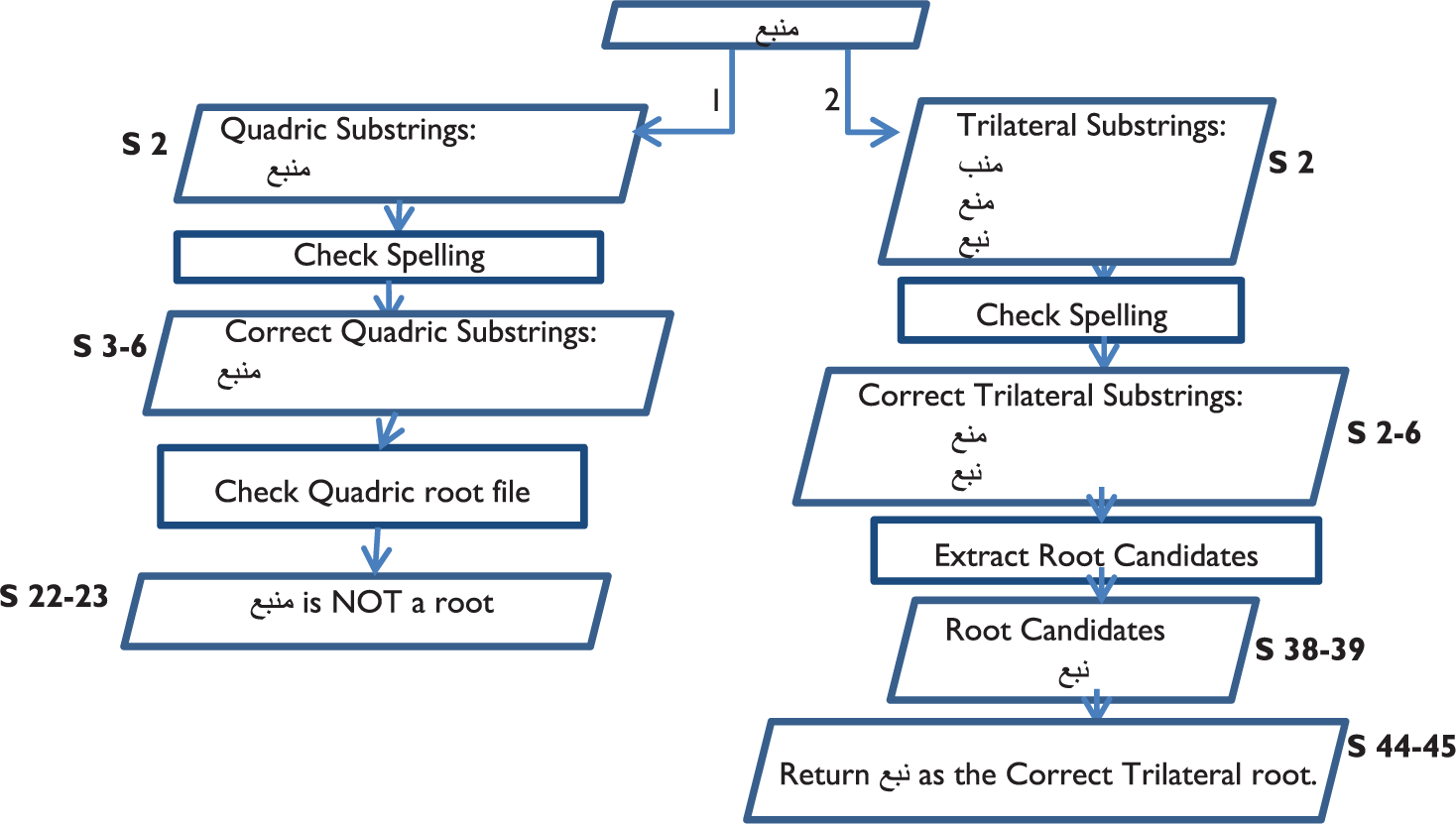
Extracting the root of
More examples are demonstrated in Figure 2, which shows how to use the algorithm to extract the roots of the words
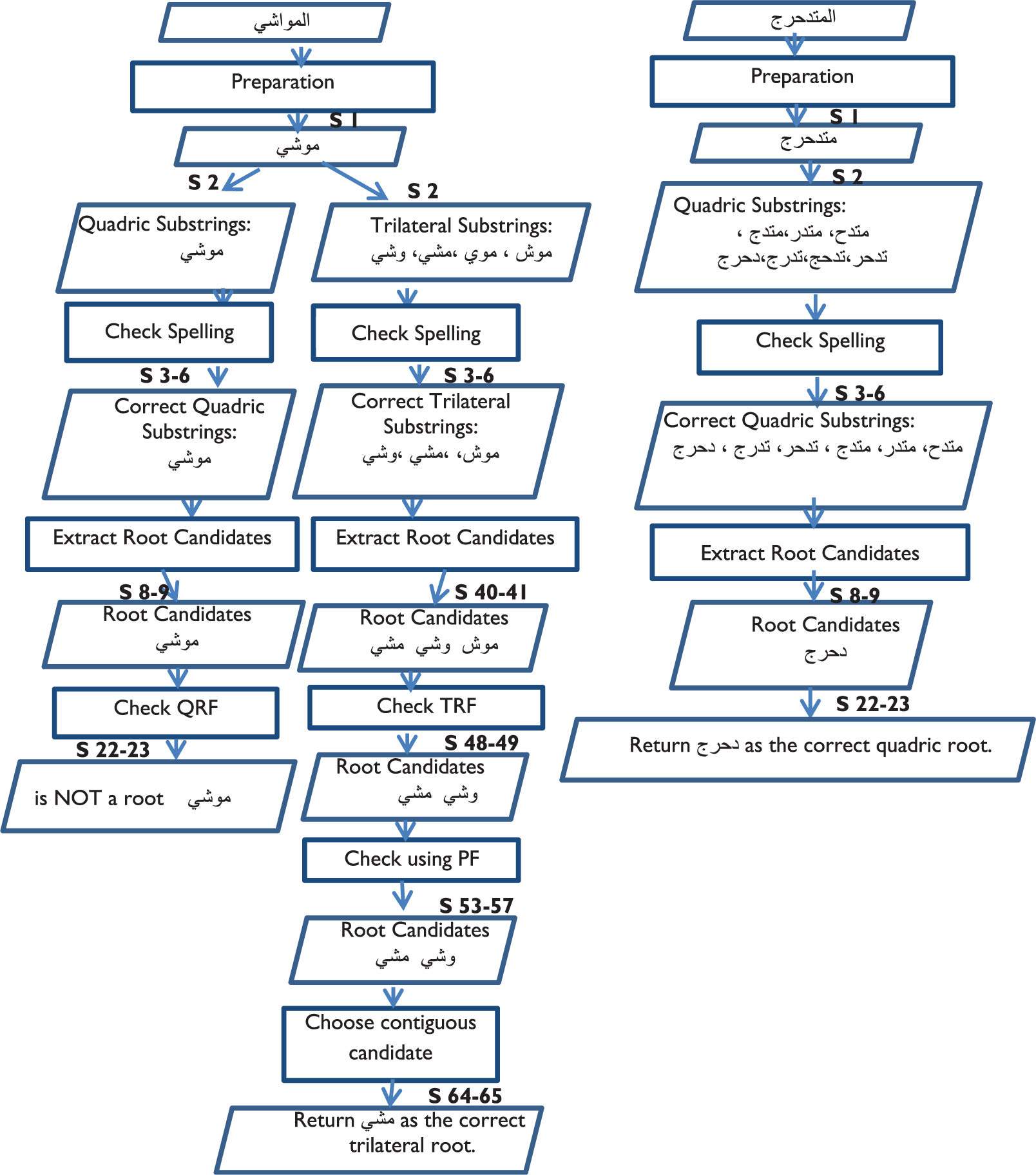
Extracting the root of the words
3.2.2. Special cases
Some Arabic words cannot be manipulated using the mentioned rules in the algorithm such as the words that do not contain one of their root’s letters like
After the preparation process, if the length of a word is less than three letters, the algorithm assumes that the word is a special case, and uses additional rules to extract the root of the word. In the case of the word that does not contain one of its root letters, the word letters are doubled one by one. After doubling a letter, the spelling of the produced word is checked. If it is syntactically correct, the algorithm is used to extract its root. If there is no valid root or there is no valid new word after doubling a letter of the given word, a letter
4. Experiments and results
The implementation was performed using Visual Basic for Applications (VBA) in Microsoft Word. The spelling checker in VBA in MS Word was used to check the correctness of the substrings of a word. The paper used the Holy Quran, which is the holy book in the Islamic religion, as the dataset to test the precision of the WSS algorithm. The Quran is written in Arabic language, and it contains 87,025 words, including stop words. The Quran text was filtered prior the testing process by removing all diacritics and stop words such as
Figure 3 shows the accuracy of the WSS algorithm. To calculate the accuracy, a file that contains Arabic words and their correct roots was created. The file was prepared using an Arabic dictionary (Lesan Alarab

The accuracy of the WSS algorithm.
Figure 4 shows the comparison between the accuracy of the WSS algorithm and five algorithms for Arabic roots extraction, which are Al-kabi [20] algorithm, Al-Sarhan [21] algorithm, Ghawanmeh algorithm [22], Taghva algorithm [3] and Hmeidi Algorithm [19]. A short description of these algorithms has been given in Section 2. The algorithms were tested using the words of the Quran as a dataset. As shown in Figure 4, the WSS approach has a competitive accuracy as it occupies rank 3 among the algorithms. Ghawanmeh’s stemmer occupies rank 1 as it achieves an accuracy of 95%, while Taghva’s stemmer has the least accuracy, about 38%. We should mention here that as there exist special cases that do not follow the rules of stemmers; a stemmer can be enhanced by addressing extra rules that deal with special cases similar to those handled in this paper in Section 3.2.2. That is, the accuracy of the aforementioned stemmers can be increased by dealing with special cases that cannot be dealt with using the stated rules. As a matter of fact, some strong stemmers fail to find the correct roots of words which are extracted correctly by some weak stemmers. Therefore, an enhanced stemmer can be built by combining the strength of two or more strong stemmers [23].
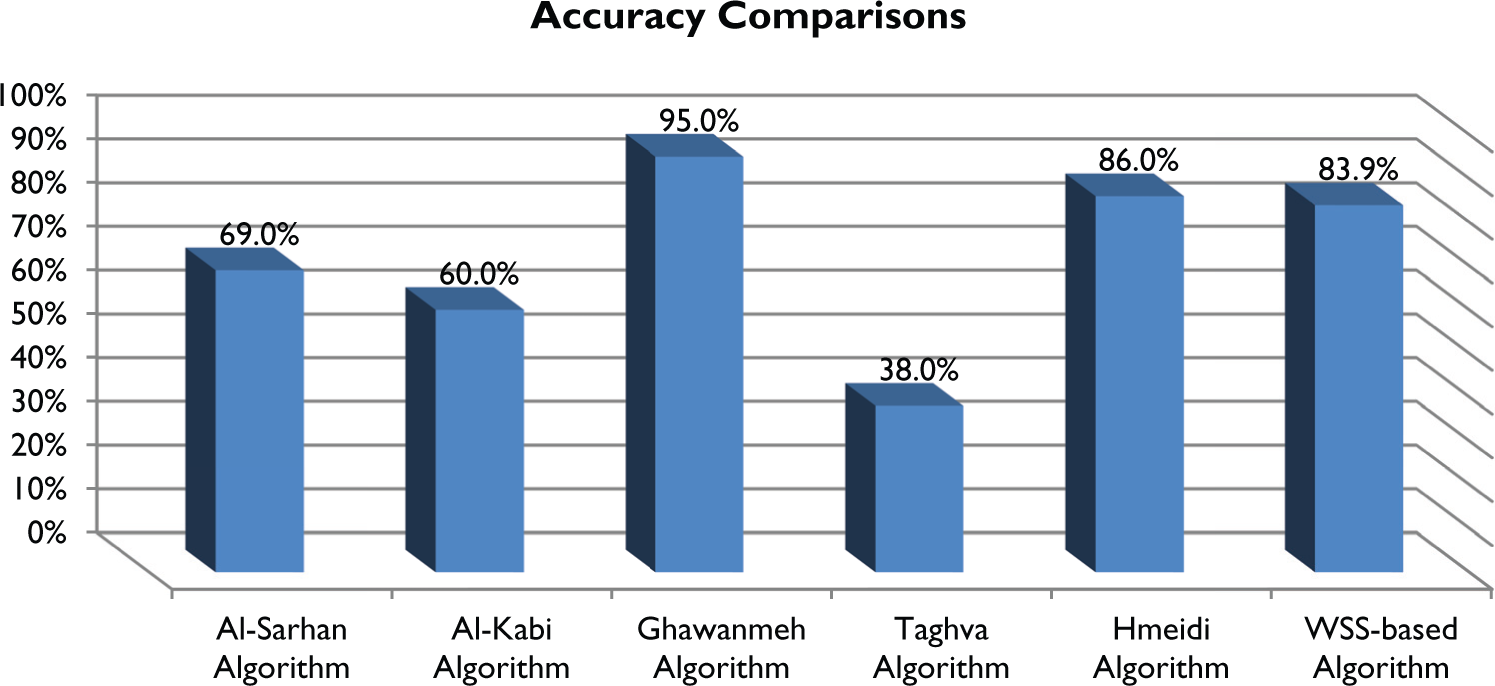
A comparison between the accuracy of the WSS stemmer and the stemmers of Al-Kabi, Al-Sarhan, Ghawanmeh, Taghva and Hmeidi.
The Al-Kabi, Ghawanmeh, Taghva and Hmeidi algorithms are all based on affix removal. Normalizing words by removing affixes has a major flaw, which is the inability to differentiate between root and non-root (extra) letters in some cases; therefore, incorrect roots may be produced. For example, Ghawanmeh’s approach extracts the root
Removing affixes is not performed in Al-Sarhan’s approach. It is based on assigning weights and ranks to the letters of words. Weights are real numbers in the range 0–5, which were determined by some experimentation on an Arabic text. After determining the weights of letters, the approach multiplies the rank of a letter (the order of a letter in a word) by its weight. Then, the three letters with the least product value are chosen as the three-letter root. Obviously, the efficiency of this approach depends on the correctness of the weights of letters and the formula it uses, which can be tested by running some evaluations on a good dataset. As shown in Figure 4, the accuracy of this approach is only 69%. However, Figure 4 shows that the accuracy of WSS-based algorithm is better than that of the Al-Sarhan algorithm. In addition, it was observed during the testing that Al-Sarhan’s approach failed to extract the correct root for simple words. For example, it extracted the root
In light of the previous discussion, WSS-based algorithm is a competitive approach with new features that avoid possible flaws that may be produced by affix removal, which exist in traditional stemmers. However, WSS-based algorithm retrieves more than one candidate roots for about 9.9% of tested words, which reduces its efficiency against some traditional stemmers. Therefore, improving WSS-based by adding new rules that decrease the aforementioned percentage will greatly boost its efficiency.
5. Conclusions and future work
This paper has introduced a new approach, which is called WSS Algorithm, for extracting both three- and four-letter roots of Arabic words. The WSS algorithm does not remove affixes when extracting roots except some rendering in the preparation process to reduce the computations needed later. The algorithm was tested using the Holy Quran. The experiments showed that the accuracy of the WSS algorithm is 83.9%, and the percentage of words with more than one root candidate retrieved is 9.9% of the tested words. A comparison between the WSS stemmer and five popular Arabic stemmers showed that it achieves a competitive accuracy as it has occupied rank 3 among them. The WSS algorithm represents a promising approach for dealing with Arabic root extraction. Therefore, as future work, we plan to add more rules to reduce the percentage of words with more than one retrieved root candidate and enhance the accuracy of the algorithm.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.