
Abstract
With the exponential growth of social media, that is, blogs and social networks, organizations and individual persons are increasingly using the number of reviews of these media for decision-making about a product or service. Opinion mining detects whether the emotions of an opinion expressed by a user on Web platforms in natural language are positive or negative. This paper presents extensive experiments to study the effectiveness of the classification of Spanish opinions in five categories: highly positive, highly negative, positive, negative and neutral, using the combination of the psychological and linguistic features of LIWC (Linguistic Inquiry and Word Count). LIWC is a text analysis software that enables the extraction of different psychological and linguistic features from natural language text. For this study, two corpora have been used, one about movies and one about technological products. Furthermore, we conducted a comparative assessment of the performance of various classification techniques, J48, SMO and BayesNet, using precision, recall and F-measure metrics. The findings revealed that the positive and negative categories provide better results than the other categories. Finally, experiments on both corpora indicated that SMO produces better results than BayesNet and J48 algorithms, obtaining an F-measure of 90.4 and 87.2% in each domain.
1. Introduction
The dramatic spread of the Internet in society has substantially changed the forms of communication, entertainment, knowledge acquisition and consumption. There is a constant increase in the number of people who consider the Internet as a medium for answering their queries [1], in addition to using it as a powerful means of communication. Indeed, on the one hand, the reviews expressed in forums, blogs and social networks are achieving greater importance in the decision to buy a product, hire a service or vote for a political party, for example. On the other hand, for providers, this information is also important to obtain feedback about their clients’ expectations, needs and feelings about their products or services and then to improve them. However, the number of reviews has increased exponentially on the Web; therefore, reading all of the opinions is impossible for the users. Various technologies to automatically process these reviews have recently arisen. These technologies are usually known as opinion mining tools.
Sentiment analysis or opinion mining is a type of subjectivity analysis, which aims at identifying opinions, emotions and evaluations expressed in natural language. The main goal is to predict the sentiment orientation (i.e. positive, negative or neutral) of an evaluation by analysing sentiment or opinion words and expressions in sentences and documents. Three fundamental problems have to be solved which require at least linguistic (lexical and syntactical) language analysis, or a richer and formal text characterization: aspect detection, opinion word detection and sentiment orientation identification [2]. The opinion mining task can be transformed into a classification task, so different supervised classification algorithms such as Support Vector Machines (SVM), Bayes Networks and Decision Trees can be used to solve this task.
Thanks to these techniques, several attempts at sentiment classification have been made. However, one of the main issues is that there are many conceptual rules that govern the linguistic expression of sentiments. Human psychology, which relates to social, cultural and other aspects, can be an important feature in sentiment analysis. For this reason, the sentiment mining process requires a rich and diverse text analysis as input. The LIWC (Linguistic Inquiry and Word Count) text analysis software is a good candidate that enables the extraction of psychological and linguistic features from natural language text. We propose to evaluate how LIWC features can be used to classify reviews. It is worth noting that most of the studies on opinion mining deal exclusively with English and Chinese documents, perhaps owing to the lack of resources in other languages. Since the Spanish language has a much more complex syntax than many other languages, and is currently the third most spoken language in the world, we firmly elieve that the computerization of Internet domains in this language is of utmost importance.
The aim of our work is to evaluate how the LIWC features can be used to classify Spanish reviews into five categories – positive, negative, neutral, highly positive or highly negative – using different classifiers. For this purpose, two corpora of Spanish product reviews were first compiled. The first one is a corpus of movies, which has already been used in other studies. The second one is a corpus of technological products, which has been built from online selling websites. Second, the corpora were processed by LIWC to extract linguistic features. Then, three different classifying algorithms were evaluated on the processed corpora with the WEKA tool [3].
This paper is structured as follows: Section 2 presents the state of the art on opinion mining and sentiment analysis. Section 3 describes and discusses text analysis dimensions using LIWC. Section 4 presents the three classifiers used in WEKA for the experiment. Section 5 presents the evaluation of the classifiers based on LIWC text features and the classification of reviews into positive, negative, neutral, highly positive and highly negative. Also, a comparison of the results with related work is presented. Finally, Section 6 describes conclusions and future work.
2. Related work
In recent years, several pieces of research have been conducted in order to improve sentiment classification. Many approaches [4–11] have proposed methods for the sentiment classification of English reviews.
For example, in Rushdi Saleh et al. [4], three corpora available for scientific research into opinion mining are analysed. Two of them are used in several studies, and the last one has been built ad-hoc from Amazon reviews of digital cameras. Finally, an SVM algorithm with different features is applied, in order to test how the sentiment classification is affected. The study presented in Moraes et al. [5] proposes an empirical comparison between a neural network approach and an SVM-based method for classifying positive vs negative reviews. The experiments evaluate both methods as regards the function of selected terms in a bag-of-words (unigrams) approach. In Xia et al. [6] a comparative study of the effectiveness of ensemble methods for sentiment classification is presented. The authors consider two schemes of feature sets, three types of ensemble methods, and three ensemble strategies to conduct a range of comparative experiments on five widely used datasets, with an emphasis on the evaluation of the effects of three ensemble strategies and the comparison of different ensemble methods. The results demonstrate that using an ensemble method is an effective way to combine different feature sets and classification algorithms for better classification performance. In this line of research, He and Zhou [7] propose a novel framework where prior knowledge from a generic sentiment lexicon is used to build a classifier. The documents tagged by this classifier are used to automatically acquire domain-specific feature words, the word-class distributions of which are estimated and are subsequently used to train another classifier by constraining the model’s predictions on unlabelled instances. The experiments, the movie-review data and the multidomain sentiment dataset show that the approach attains comparable or better performance rates than existing hardly supervised sentiment classification methods despite using no labelled documents. In Peñalver Martínez et al. [8] the authors propose an innovative methodology for opinion mining that brings together traditional natural language processing techniques with sentiment analysis processes and Semantic Web technologies. The aim of this work is to improve feature-based opinion mining by employing ontologies in the selection of features and to provide a new method for sentiment analysis based on vector analysis. In Basari et al. [9], a comparative study among n-gram (unigram, bigram and trigram) methods and feature weighting (TF and TF-IDF) is presented. In this piece of research, messages on Twitter to review a movie are used for opinion mining. Also, this work is only related to sentiment classification into two classes (binary classification), that is, a positive class and negative class. The positive class shows good message opinion; otherwise, the negative class shows the bad message opinion of certain movies. The study presented in Montejo Ráez et al. [10] proposes a new unsupervised approach to the problem of polarity classification in Twitter posts. The polarity classification problem is resolved by combining SentiWordNet scores with a random walk analysis of the concepts found in the text over the WordNet graph. In order to validate their unsupervised approach, several experiments were performed in order to analyse major issues in the method and to compare it with other approaches like plain SentiWordNet scoring or machine learning solutions such as Support Vector Machines in a supervised approach. Chen et al. [11] propose a neural-network based approach. It uses semantic orientation indexes as input for the neural networks to determine the sentiments of the bloggers quickly and effectively. Several blogs are used to evaluate the effectiveness of the approach. The results indicate that the proposed approach outperforms traditional ones, including other neural networks and several semantic orientation indexes.
Furthermore, other proposals [12–15] introduce methods for sentiment classification of Chinese reviews. Zhai et al. [12] analyse sentiment-word, substring, substring-group and key-substring-group features, and the commonly used n-gram features. To explore general language, two authoritative Chinese datasets in different domains are used. The statistical analysis of the results indicates that different types of features possess different discriminative capabilities in Chinese sentiment classification. Xu et al. [13] propose a new method for identifying the semantic orientation of subjective terms to perform sentiment analysis. The method takes a classification approach that is based on a novel semantic orientation representation model called S-HAL (Sentiment Hyperspace Analogue to Language). The results indicate that this method has outperformed the SO-PMI method and several other published methods. In Wu and Tan [14] a two-stage framework for cross-domain sentiment classification is proposed. A bridge between the source domain and the target domain is built with the aim of getting some of the most reliably labelled documents in the target domain. The results indicate that the proposed approach could improve the performance of cross-domain sentiment classification dramatically. In Jian et al. [15] a study presents the standpoint that uses individual model (i-model) based on artificial neural networks to determine text sentiment classification. The individual model comprises sentimental features, feature weight and prior knowledge base. The results of the experiment show that the accuracy of the individual model is higher than that of SVMs and hidden Markov model classifiers on the movie review corpus.
Finally, it is worth noting that only a few proposals, such as the one presented here [16], are focused on sentiment classification of Spanish reviews. In this work, two lexicons are used to classify the opinions using a simple approach based on counting the number of words included in the lexicons that occur in each evaluation. Specifically, an opinion is positive if the number of positive words is greater than or equal to the number of negative ones, and is negative in the opposite case.
In order to fully analyse the studies described above and compare them with our proposal, a comparative table is provided below (see Table 1) that summarizes relevant properties of these pieces of research. For this comparison, four features have been used: (1) computational learning; (2) linguistic resources; (3) domain; and (4) language.
Comparison of proposals for sentiment classification.

Several machine learning techniques are used: SVM and Naive Bayes, among others. Almost all the proposals use computational learning. Specifically, the SVM technique is the most frequently used [4–7, 9, 10, 12, 13, 15]. In addition, the techniques of Naive Bayes [6, 7, 10] and neural networks [11] are also used. On the other hand, other pieces of research do not use any machine learning technique [8, 14, 16].
The techniques used for polarity detection in these approaches are n-grams [4, 6, 9, 12, 15], term frequency [4, 6, 9, 12] and semantic orientation indexes [11]. Alternative approaches only use lexical resources [16].
Almost all of the corpora used in the proposals mentioned above include reviews on movies [4–6, 8, 11, 15, 16]. Other proposals use corpora that include reviews on topics such as music [11], hotels [4, 12], products [12, 14], news [13], DVDs [6, 7] and electronics [7]. The English language is the most used in these studies [4–11]. However, other languages are used in some proposals, such as Chinese [12–15] and Spanish [16].
On the basis of the results obtained from the comparative analysis summarized in Table 1, the present study seeks to evaluate the performance of three different classifying algorithms in the classification of Spanish opinions through the combination of psychological and linguistic features extracted using the LIWC text analyser.
3. LIWC
LIWC is a software application that provides an effective tool for studying the emotional, cognitive and structural components contained in language on a word-by-word basis. Early approaches to psycholinguistic concerns involved almost exclusively qualitative philosophical analyses. More modern research in this field provides empirical evidence on the relation between language and the state of mind of subjects, or even their mental health [17]. In this regard, further studies such as Pennebaker et al. [18] have dealt with the therapeutic effect of verbally expressing emotional experiences and memories. LIWC was developed precisely for providing an efficient method for studying these psycholinguistic concerns thanks to corpus analysis, and has been considerably improved since its first version [19]. An updated revision of the original application was presented in Pennebaker et al. [20], namely LIWC2001.
LIWC provides a Spanish dictionary composed of 7515 words and word stems. Each word can be classified into one or more of the 72 categories included by default in LIWC. Also, the categories are classified into four dimensions: (1) standard linguistic processes; (2) psychological processes; (3) relativity; and (4) personal concerns. Next, Table 2 shows some examples of the LIWC categories. The full list of categories is presented in Ramírez Esparza et al. [21].
LIWC categories.

As can be seen in Table 2, the first dimension, standard linguistic processes, involves function words and grammatical information, whereas the second and fourth dimensions are more subjective, especially those denoting emotional processes within the second dimension. Within this dimension, the emotion or affective processes are using subdictionaries that gather words selected from several sources such as the PANAS [22] and Roget’s Thesaurus, being subsequently rated by groups of three judges working independently. Similar to the first dimension, the third dimension, ‘relativity’, is composed of a category concerning time, which is quite clear: past, present and future tense verbs. Within the same dimension, the space category includes spatial prepositions and adverbs. Finally, the fourth dimension involves word categories related to personal concerns intrinsic to the human condition. This is important because it can affect the voicing of a feeling in an opinion.
4. Datasets
For the present study, a set of reviews in Spanish that include positive, negative, neutral, highly positive and highly negative reviews was necessary. Each review text is assigned to a single category, meaning that the review as a whole is either positive, negative, etc. Therefore, two corpora were collected, one within the domain of product reviews and the other one within the domain of movie reviews. The first one contains 600 reviews of technological products such as mobile devices, specifically 100 highly negative reviews, 150 negative reviews, 100 neutral reviews, 150 positive reviews and 100 highly positive reviews, obtained from online selling websites e.g. moviles.com [23]. Also, each review was examined and classified manually to ensure its quality. The second corpus was obtained from the corpus presented in [24] related to movie reviews. The original corpus contains 3,878 opinions, which are already classified into five categories (351 highly negative reviews, 923 negative reviews, 1,253 neutral reviews, 890 positive reviews and 461 highly positive reviews). For this experiment, a corpus of 1,000 opinions was compiled by selecting 200 random opinions for each category.
Once the corpora have been built, they are analysed through all the possible combinations of LIWC dimensions and taking into account three possible sets of opinion classes (positive-negative, positive-neutral-negative and highly positive-positive-neutral-negative-highly negative). LIWC searches for target words or word stems from the dictionary, categorizes them into one of its linguistic dimensions, and then converts the raw counts to percentages of total words. The values obtained for the categories were used for the subsequent training of the machine learning classifier.
This analysis aims to evaluate the classifying potential of these dimensions, both individually and collectively.
It is worth noting that the results obtained by LIWC were manually evaluated by experts to confirm that LIWC produces correct results when analysing a set of reviews.
5. Machine learning and classification
In the present work, WEKA [3] has been used to evaluate the classification success of reviews (positive, negative, neutral, highly positive or highly negative) based on LIWC categories. WEKA provides several classifiers, which allows the creation of models according to the data and purpose of analysis. Classifiers are categorized into seven groups: Bayesian (Naive Bayes, Bayesian nets, etc.), functions (linear regression, SMO, logistic, etc.), lazy (IBk, LWL, etc.), meta-classifiers (Bagging, Vote, etc.), miscellaneous (SerializedClassifier and InputMappedClassifier), rules (DecisionTable, OneR, etc.) and trees (J48, RandomTree, etc.). The classification process involves the building of a model based on the analysis of the instances. This model is represented through classification rules, decision trees or mathematical formulae. The model is used to generate the classification of unknown data, calculating the percentage of instances that were correctly classified.
The experiment was performed using three different algorithms: the C4.5 decision tree (J48), the Bayes Network learning algorithm (BayesNet) and the SMO algorithm for SVM classifiers [28]. These algorithms were selected because they have been used in several experiments obtaining good results in data classification [29, 30]. A brief description of the machine learning methods chosen for evaluation is presented in Table 3.
Machine learning methods.

6. Evaluation and results
6.1. Results and figures for the technological corpus
In order to evaluate the results of the classifiers, we used three metrics: precision, recall and F-measure. Recall is the proportion of actual positive cases that were correctly predicted as such. On the other hand, precision represents the proportion of predicted positive cases that are real positives. Finally, F-measure is the harmonic mean of precision and recall.
For each classifier, a 10-fold cross-validation was done. This technique is used to evaluate how the results obtained would generalize to an independent dataset. Since the aim of this experiment is the prediction of the positive, negative, neutral, highly positive and highly negative condition of the texts, a cross-validation is applied in order to estimate the accuracy of the predictive models. It involves partitioning a sample of data into complementary subsets, performing an analysis on the training set and validating the analysis on the testing or validation set.
Next, the results of precision (P), recall (R) and the F-measure for each algorithm are reported (Tables 4–9). The first column indicates which LIWC dimensions are used, that is, (a) standard linguistic processes, (b) psychological processes, (c) relativity, and (d) personal concerns.
Products with two categories (positive and negative).
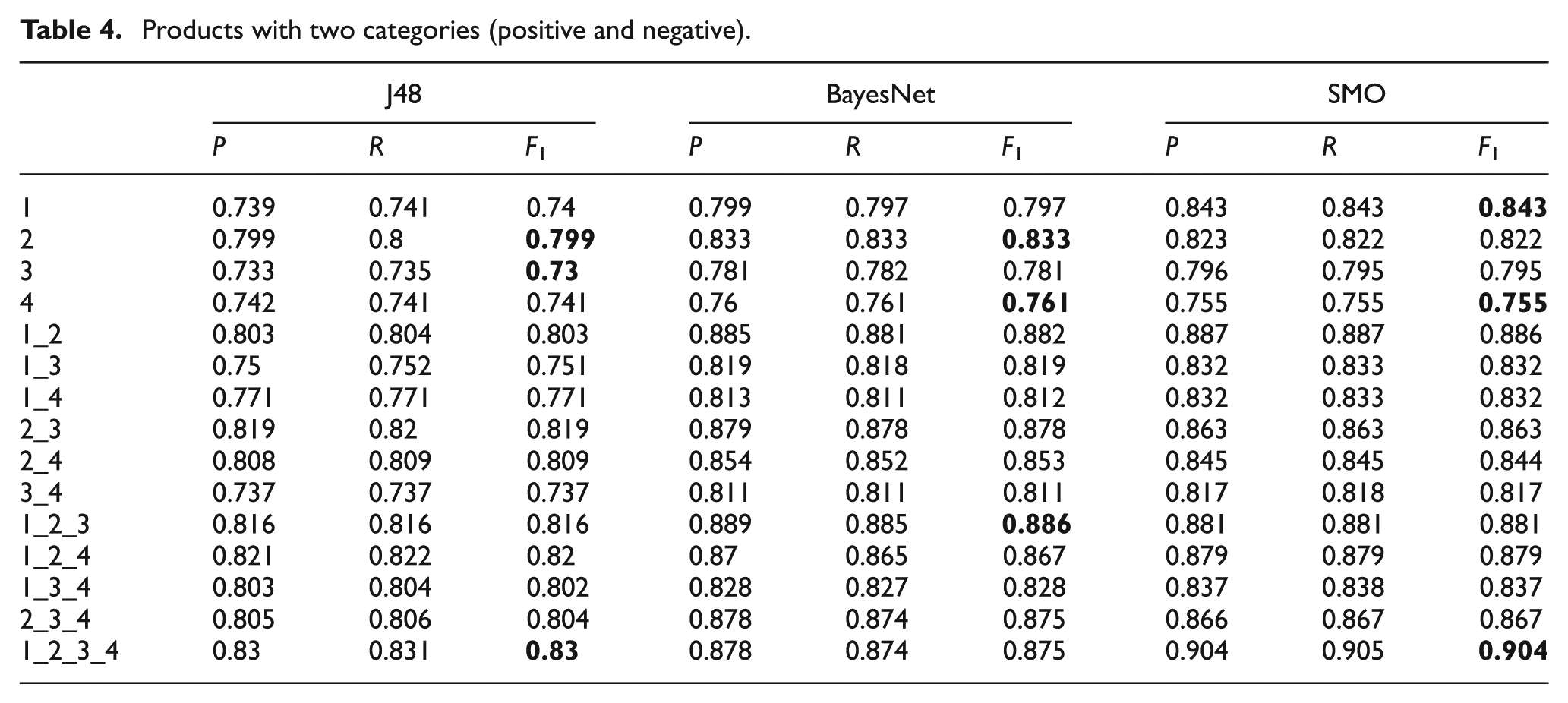
Products with three categories (positive–neutral–negative).
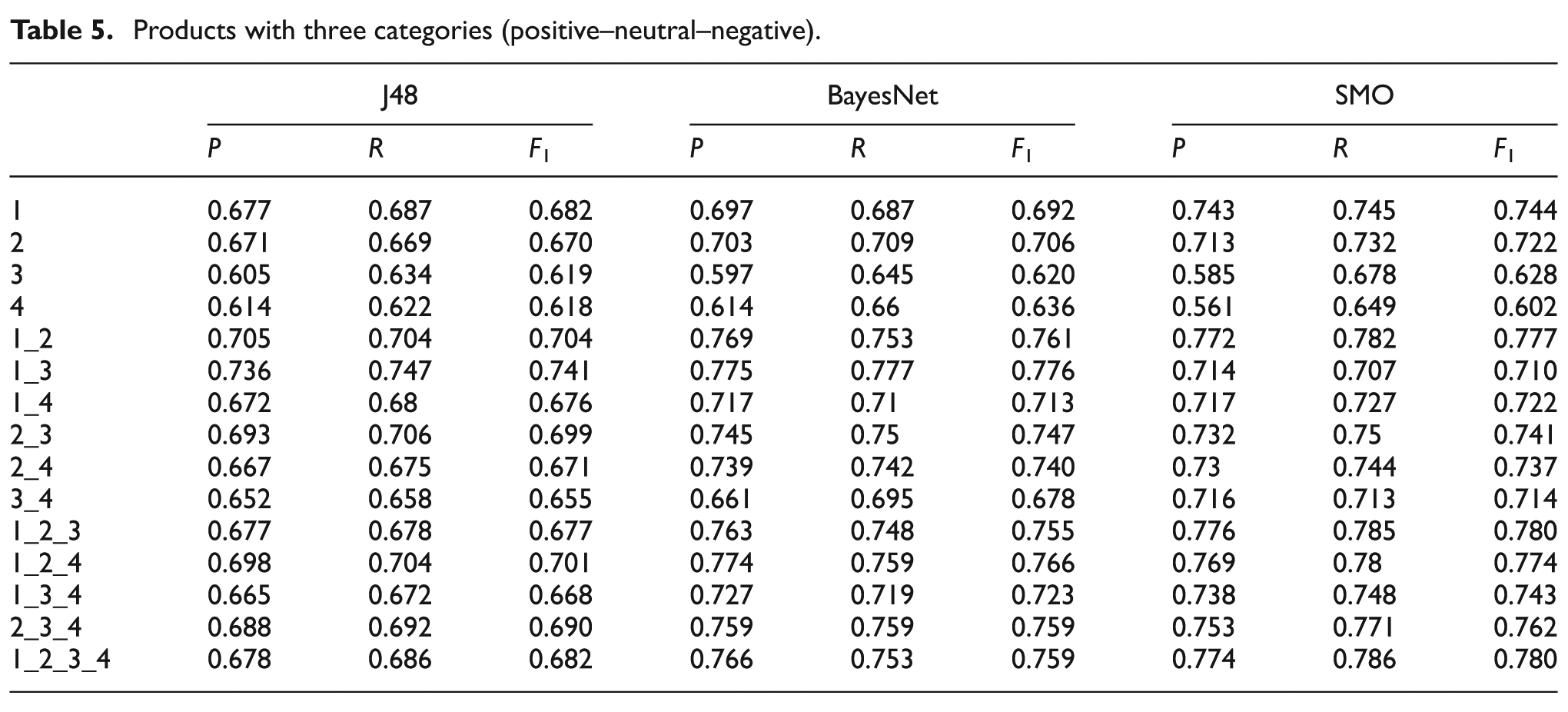
Products with five categories (highly positive–positive–neutral–negative–highly negative).
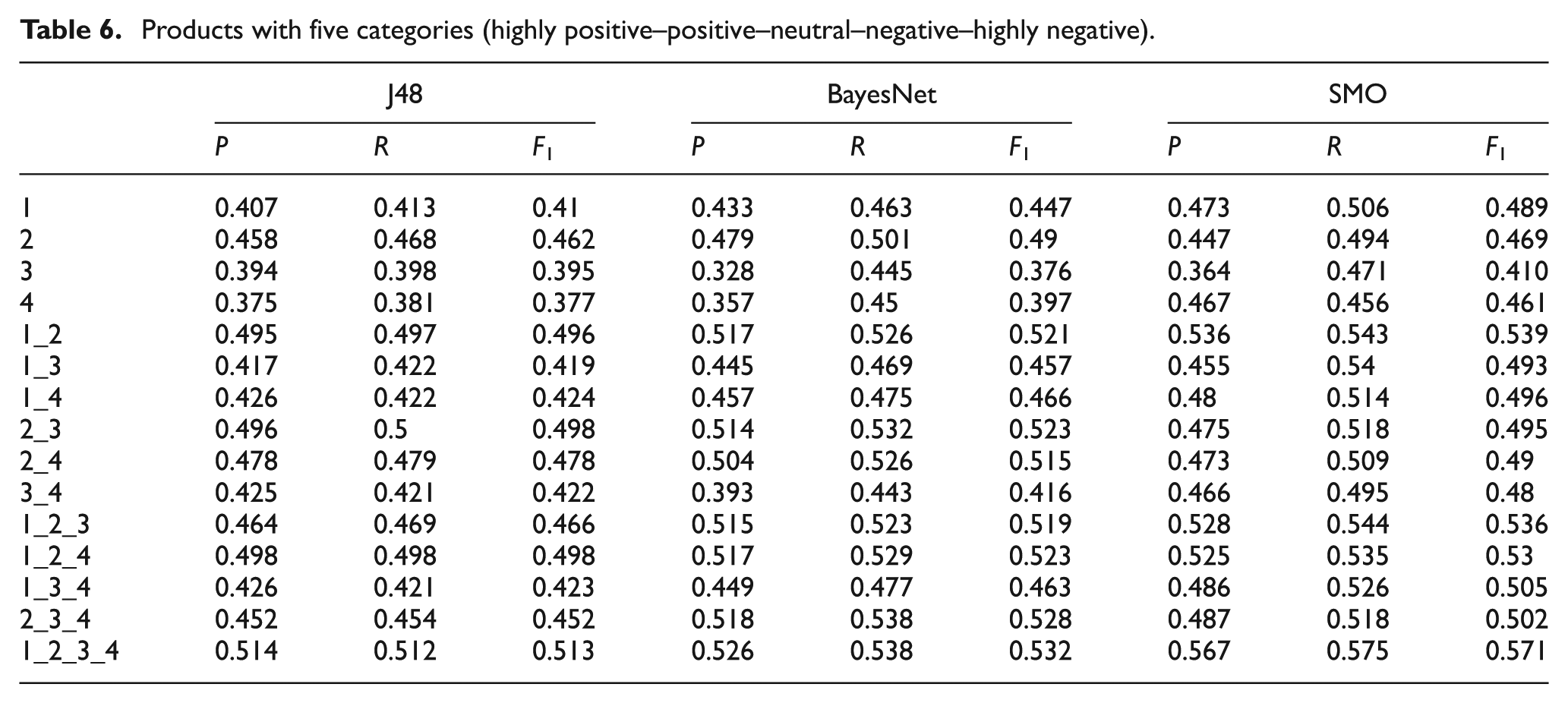
Movies with opinion classification (positive and negative).
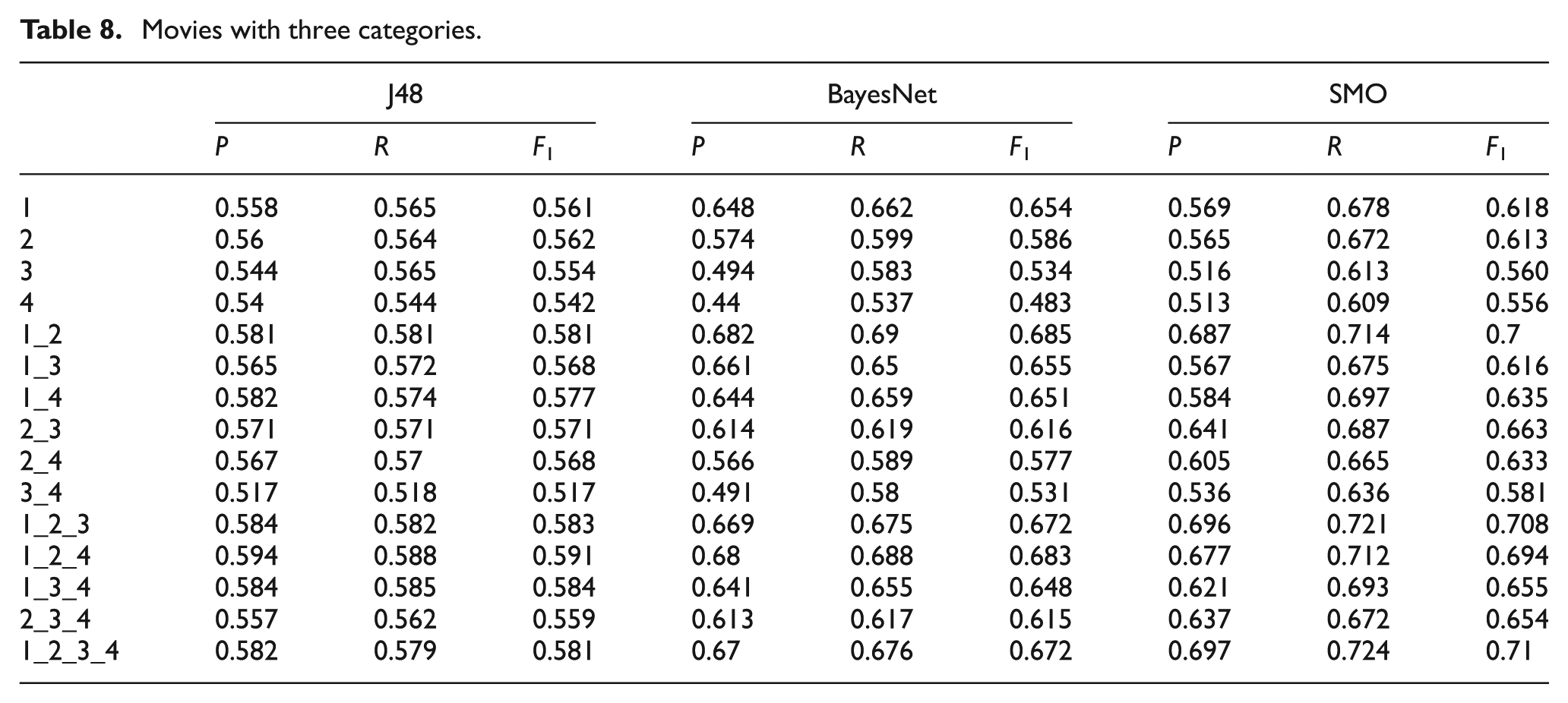
Movies with three categories.
Movies with five categories.
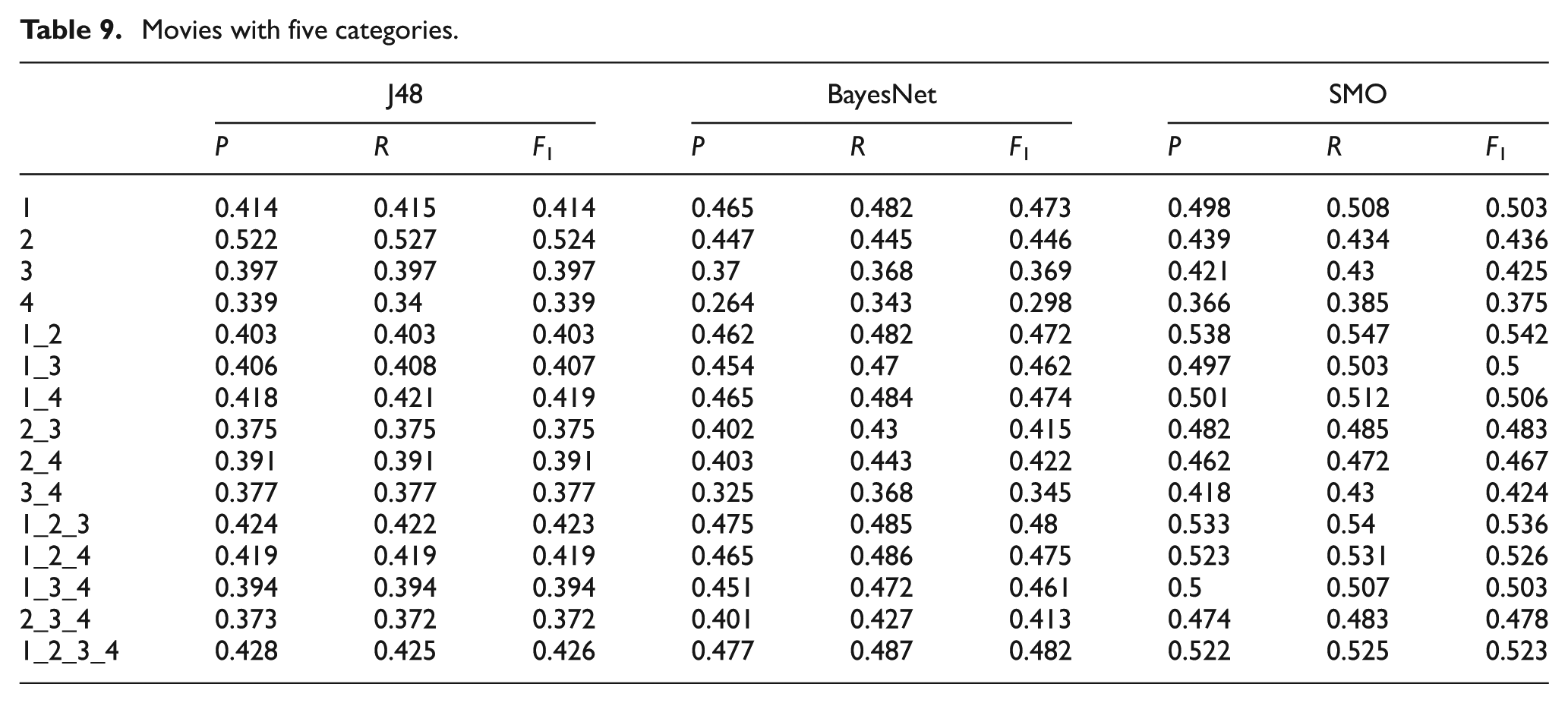
Tables 4–6 show the results obtained for the classification of technological product reviews using two, three and five categories: positive–negative (see Table 4), positive–neutral–negative (see Table 5) and highly positive–positive–neutral–negative–highly negative (see Table 6). In the first column, the number of LIWC dimensions used for each classifier is indicated. For example, 1_2_3_4 indicates that all the dimensions have been used in the experiment, and 1_2 indicates that only the categories of dimensions 1 and 2 have been used to train the classifier.
Considering Tables 4–6, the different classification algorithms generally show similar results, although SVM obtains better results. The best classification results were obtained using two categories, positive–negative (see Table 4). Also, the results from the J48 algorithm show that, individually, the second dimension, ‘psychological processes’, provides the best results, with an F-measure of 79.9%. Conversely, the third dimension, ‘relativity’, provides the worst results, with an F-measure of 73.0%. On the other hand, the combination of all LIWC dimensions provides the best classification result with an F-measure of 83.0%.
The results from the BayesNet algorithm are similar to those obtained by the J48 algorithm, although this experiment provides better classification results. The results show that the second dimension, ‘psychological processes’, provides the best results on its own as well, with an F-measure of 83.3%. In contrast, the fourth dimension, ‘personal concerns’, provides the worst results with an F-measure of 76.1%. Furthermore, the combination of 1_2_3 LIWC dimensions provides the best classification result, with an F-measure of 88.6%. The results obtained by means of the use of the four dimensions are also good, with an overall F-measure of 87.5%.
The results from the experiment with SMO are better than those obtained with the previous algorithms. The results show that, once again, the first dimension provides the best results by itself, with an F-measure of 84.3%. In contrast, the fourth dimension, ‘personal concerns’, provides the worst results with a score of 75.5%. Moreover, the combination of all LIWC dimensions provides the best classification result, with an F-measure of 90.4%.
6.2. Results and figures for the movies corpus
Table 7–9 show the results obtained for the classification of movie reviews using two, three and five categories: positive–negative (see Table 7), positive–neutral–negative (see Table 8) and highly positive–positive–neutral–negative–highly negative(see Table 9). In the classification results for the corpus of movies (Tables 7–9), we found that the SMO algorithm (Table 7) obtains the best results using two categories (positive–negative). When considering the results from the J48 algorithm, individually, the first dimension, ‘standard linguistic processes’, provides the best results, with an F-measure of 77.3%. In contrast, the fourth dimension, ‘personal concern’, provides the worst results, with an F-measure of 68.2%. In addition, the combination of 1_2_3 LIWC dimensions provides the best classification result with an F-measure of 79.6%.
The results from the experiment with the BayesNet algorithm provides better classification results than the J48 algorithm. The results show that the first dimension, ‘standard linguistic processes’, provides the best results on its own as well, with an F-measure of 81.3%. Conversely, the fourth dimension, ‘personal concerns’, provides the worst results with an F-measure of 68.2%. In addition, the combination of 1_2 LIWC dimensions provides the best classification result, with an F-measure of 82.8%.
The results of the SMO algorithm are even better than the ones obtained with the two previous algorithms. The results show that, once again, the first dimension, ‘standard linguistic processes’, provides the best results by itself, with an F-measure of 81.1%. In contrast, the fourth dimension, ‘personal concerns’, provides the worst results with a score of 73.8%. Furthermore, the combination of 1_2_4 LIWC dimensions provides the best classification result with an F-measure of 87.2%.
6.3. Discussion of the results
General results show that the combination of different LIWC dimensions provides better results than individual dimensions. Individually, the first one and the second one provide the best results, probably owing to the large number of grammatical words that are part of the standard linguistic dimension and the fact that written opinions frequently contain words related to the emotional state of the author containing word stems classified into categories such as anxiety, sadness, positive and negative emotions, optimism and energy, and discrepancies, among others. All of these categories are included in the second dimension, confirming its discriminatory potential in classification experiments. Furthermore, the high performance of the first dimension is natural, bearing in mind the considerable potential of function words, which constitute a substantial part of standard linguistic dimensions. The prime importance of these grammatical elements has been widely explored, not only in computational linguistics, but also in psychology. As Chung and Pennebaker [31] have it, these words ‘can provide powerful insight into the human psyche’. Variations in their usage have been associated to sex, age, mental disorders such as depression, status and deception [31]. On the other hand, the fourth dimension provides the worst results, owing to the fact that the topics selected for this study, ‘technological products’ and ‘movies’, bear little relation to the vocabulary corresponding to ‘personal concerns’ categories. It can be stated that this dimension is the most content-dependent, and thus the least revealing.
As regards the classification with two categories (positive–negative), it provides better results than the classification with three (positive–neutral–negative) and five (highly positive–positive–neutral–negative–highly negative) categories. Thus, it is by virtue of the combination of fewer categories that the classification algorithm performs a better classification, probably because in a bipolar system there is less space for the classification of slippery cases. It also means that additional criteria and features are required to get a fine-grained classification into five categories, for instance.
The results obtained for different classifiers are similar. However, SMO provides better results than J48 and BayesNet. These results can be justified by the analysis of different algorithms present in Bhavsar and Amit [32], where it is clearly shown how SVM models are more robust and accurate compared with other classifiers, including the ones used in this piece of research. Furthermore, SVMs have been successfully applied to many text classification tasks owing to their main advantages: first, they are robust in high-dimensional spaces; second, any feature is relevant; third, they are robust when there is a sparse set of samples; and finally, most text categorization problems are linearly separable [4]. Unlike other classifiers such as decision trees or logistic regressions, SVM assumes no linearity, and it can be difficult to interpret its results outside its accuracy values [33].
Finally, with regard to the classification results for the corpus of movie reviews, they are worse than those for the corpus of technological products. From our point of view, the classification results through the LIWC dimensions are strongly dependent on the topic. Thus, for example, the combination of 1_2_3_4 (90.4%) LIWC dimensions achieves the best results for the corpus of ‘technological products’. In contrast, 1_2_4 (87.2%) LIWC dimensions show the best result for the corpus of ‘movies’. There is no doubt that the factor loadings of the four dimensions play a considerable part here.
6.4. Comparison with related work
As stated earlier, many different approaches exist for sentiment classification, and opinion analysis in English and Chinese. Moreover, the results from most of the approaches in these languages present better results than other proposals for Spanish language. We considered that the interest in the English language arises from the fact that it is an official language in a large number of countries, and most of the content on the Internet is written in this language. As regards Chinese, it is becoming one of the most important languages for international business. As commented on in Section 2, extensive research has been carried out for these languages, but not all of them have been evaluated using the standard measures. Thus, Table 10 shows the results from those studies that have been evaluated in terms of precision, recall and F1.
Comparison of related work with our proposal.
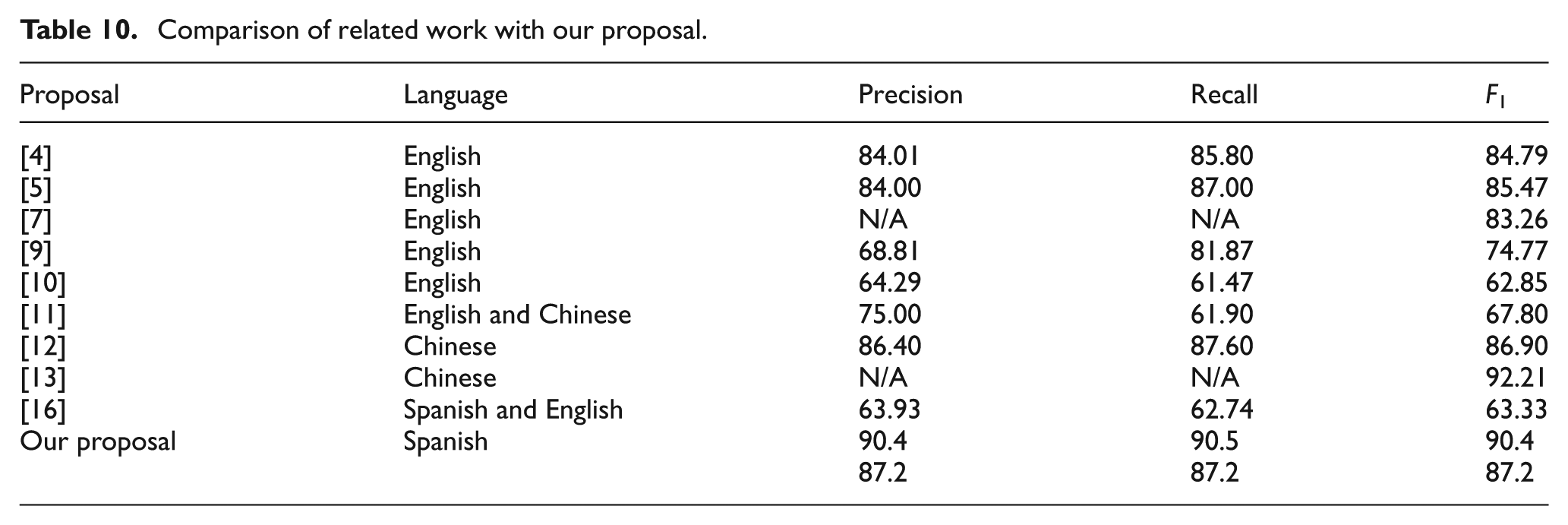
Table 10 shows that our proposal obtained similar results to other approaches, with a high F-measure of 90.4% and 87.2%. However, it is difficult to compare the different opinion mining approaches described in the literature, because none of the software applications is available. Indeed, the corpora used for each experiment differ significantly in content and size, topics and language. A fair comparison of two opinion mining methods would require the usage of the same testing corpus. In spite of this, Table 10 shows that, in Molina González et al. [16], the system obtains an F-measure of 63.33% for the Spanish language, which is considerably lower than the value obtained by our approach.
The studies for the English and Chinese language obtained similar F-measures to the ones obtained here. For example, proposals in English [4, 5] obtained F-measures of 84.79 and 85.47%, and proposals in Chinese [12, 13] obtained F-measures of 86.90 and 92.91%, respectively. However, it is important to mention the lower level of grammatical complexity of the English and Chinese languages as compared with Spanish, which seems to have a strong impact on the final results. For example, in Chinese, there are no tenses and conjugations for every verb.
7. Conclusions and future work
In this piece of research, we have presented an experiment based on sentiment classification with the aim of evaluating the classifying potential of LIWC dimensions. In order to conduct a comprehensive study, we have considered two, three and five categories: positive–negative, positive–neutral–negative and highly positive–positive–neutral–negative–highly negative for the classification of reviews in Spanish. Subsequently, in an attempt to evaluate the efficacy of LIWC features, J48, BayesNet and SMO Weka classifiers were used. The results show that the classification of reviews with two categories, ‘positive–negative’, provides better results than with other categories. Also, SMO obtained the best classification results. Finally, regarding the comparison with the related work, our proposal has obtained encouraging results with a high F-measure score of 90.4% for the corpus of technological product reviews and 87.2% for the corpus of movie reviews.
Despite all the advantages and possibilities of the proposed approach, it has several limitations that could be improved in future work. First, our approach lacks robustness because all of the input to LIWC must be grammatically correct. Furthermore, LIWC presents limitations of disambiguation and ignores context, irony, sarcasm and idioms [34]. Second, our approach does not make use of other sentiment analysis techniques based on sentiment lexicons such as SentiWordNet [35]. Finally, our approach obtains the global polarity of a review. This is a drawback, because an entire document or a single sentence could contain different opinions about different features of the same product or service [36]. In fact, classifying opinions at the document or sentence level does not indicate what the user likes and dislikes. A positive report on an object does not mean that the user has positive opinions on all aspects or features of that object. Likewise, it would be inaccurate to state that a negative document entails that the user dislikes everything about the object. In a document (e.g. a product review), the user typically writes about both the positive and negative aspects of the object, although the general sentiment toward that object may be positive or negative [37]. To obtain such detailed aspects, it is necessary to perform feature-based opinion mining in an attempt to identify the features in the opinion and to classify the sentiments of the opinion for each of these features [38].
As regards further research, the authors are considering a new corpus where the vocabulary is better aligned with the ‘personal concerns’ dimension, as well as other new corpora comprising different domains of the Spanish language, since research into sentiment classification in this language is needed. Furthermore, we will use LIWC features in English and French to verify whether this technique can be applied to different languages. On the other hand, we also attempt to apply the Probabilistic Latent Semantic Indexing to automated document indexing. Finally, it is also intended to adapt this approach to a feature-based opinion mining guided by ontologies, as in the study presented in Peñalver Martínez et al. [8].
Footnotes
Funding
This work was partially supported by the Spanish Ministry of Economy and Competitiveness and the European Commission (FEDER/ERDF) through project SeCloud (TIN2010-18650). María del Pilar Salas-Zárate is supported by the National Council of Science and Technology, the Public Education Secretary and the Mexican Government. Additionally, this work was supported by the University Paul Sabatier under its visiting professors programme.