
Abstract
Increasing use of the Internet for health information delivery has created considerable discussion among digital divide scholars (i.e. how online information delivery benefits those individuals in higher socioeconomic brackets more than their counterparts). Because it is health information, we need to integrate how patients seek out online information. This study included patients’ information-seeking behaviour along with digital divide scholars’ constructs (i.e. literacy and computer skills). Using 1617 observations from the 2010 Pew Internet and American Life Project, this study found that individuals with a significant number of health problems, who are likely to be in a lower income bracket, are proactive online health information seekers; however, they are less likely to search general information. This finding adds value to existing research revealing that usefulness, which has been overlooked in online health information seeking, is important and should be a part of the research model.
Keywords
1. Introduction
The Internet has become a major health information source for a growing number of people [1–4] and the most widely searched for information on the Internet is health-related [5, 6]. In spite of the increasing reliance on the Internet for health information, we have not systematically investigated consumers of online health information. More specifically, following digital scholars’ research, health information scholars claim that online health information seeking or non-seeking is the outcome of the social divide. They also claim that the Internet has further reinforced such a divide by adding technology, which usually favours a higher bracket of socioeconomic groups [7–9]. This logic dictates us to conclude that, since poor people are likely to have a higher quantity of health problems [10], individuals with multiple ailments are less likely to seek out health-related information online. While digital scholars’ research has considerably enhanced our understanding of online health information-seeking behaviour (i.e. higher socioeconomic groups are likely to seek out information online), little research has investigated whether patients’ online information-seeking behaviour is different across the subjects, such as the case of health-related versus general information. Answering this question will enable us to develop a model appropriate for online health information seeking and help managers to develop training modules [11]. In order to understand patients’ online health information seeking, this study included patients as an independent construct in addition to digital scholars’ two focal constructs (i.e. literacy and computer skills). Also, this study included general online information seeking in order to compare online health information seeking. Furthermore, owing to the emerging power of social network sites for patients in the healthcare industry, the use of social network sites is also included in the research model.
This introduction is proceeded by the following four sections: Section 2 offers a review of how patients seek out online information and how literacy and computer skills impact online information seeking; Section 3 explicates the research methods; Section 4 reports the finding of this study as well as interpretation; lastly this paper concludes with the implications of the findings and recommendations for instructional designs for online health information seeking.
2. Literature review and hypothesis development
The purpose of this section is to review literature pertinent to seeking online information drawn from information science, medical and health literature, and then to propose hypotheses based on the review. Although there is no doubt that income will impact online information-seeking behaviour, owing to the purpose of this paper, the focus will be on how patients’ information seeking is different when considering health-related and general online information seeking. Also taken into account is how traditional digital divide scholars’ constructs (i.e. literacy and computer skills) are different across health-related and general online information seeking. A graphical presentation of the proposed research model is provided in Figure 1.
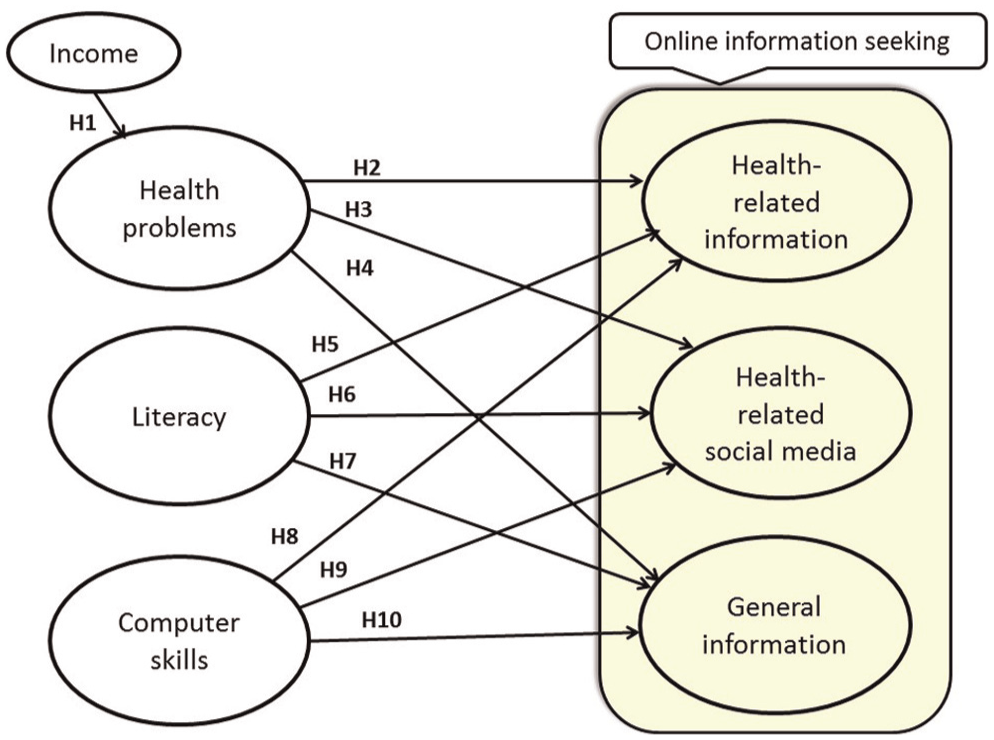
Proposed online information-seeking model.
In this model, based on the findings from existing studies, income is used as a direct cause for an individual’s health problems. This is because income is closely related to the availability of health insurance [12]. Furthermore, day-to-day living, such as paying bills, becomes the top priority over taking care of one’s health when a person’s income is low [10]. As a result, low-income individuals do not get timely or proper treatments, which is the basis for multiple health problems [13, 14]. Literacy and computer skills have been consistently reported as strong predictors for information seeking online, including health-related information [8, 9, 15–20]. Social media have recently been reported to have a significant impact on patients’ health information seeking and their well-being [21–25]. The use of social media sites is expected to grow rapidly in the healthcare industry and exercise an important role in patients’ information seeking. As such, it is integrated into the model.
2.1. Impact of income on health problems
People with low income are likely to have a higher rate of health problems. This is because they tend to lack health insurance and their primary concern may not be their health but their day-to-day lives [10, 12]. Income largely determines individuals’ health through health insurance and the available financial resources to take care of health. Individuals can access health insurance through their employer, private insurance or other means, which are all closely related to income [12]. In 2012, about three-quarters of working-age adults with low incomes (less than $14,856 a year for an individual or $30,657 for a family of four) — an estimated 40 million people — were uninsured or underinsured. Fifty-nine per cent of adults with moderate incomes (between $14,856 and $27,925 for an individual or between $30,657 and $57,625 for a family of four) — or 21 million people — were uninsured or underinsured [26]. In 2012, because of medical costs without health insurance, 84 million people — nearly half of all working-age US adults — reported that they did not seek medical help. The Commonwealth Fund 2012 Biennial Health Insurance Survey also reported that people are skipping needed healthcare because they cannot afford to pay the cost [26]. As a consequence, patients with low income, who usually lack health insurance, tend to delay seeking or do not seek health screening or treatment. Therefore, they miss the opportunities to detect health problems early, to receive preventive treatments and to get basic and regular clinical services [10].
Empirical studies reporting high correlations between an absence of health insurance and medical problems are not difficult to find. For example, a study based on a health coverage program designed for undocumented and uninsured children who do not have health coverage showed that those in poor or fair health condition considerably improved their health after obtaining health coverage [27]. Another empirical study, based on the two groups with and without health insurance, showed that health problems of the two groups decreased after age 65, because uninsured people with lower incomes can receive access to Medicare services [27–29]. McWilliams and colleagues further reported that control of blood pressure, glucose and cholesterol levels improved for adults with cardiovascular disease and diabetes after acquiring Medicare, while racial, ethnic or other socioeconomic differences did not narrow significantly [28]. Because of the health insurance problem, even if the poor learn about their medical problems, they are less likely to seek medical treatments, which can lead to multiple complications [14, 30]. To explicate, those patients under the poverty level devote resources to their day-to-day survival as opposed to promoting their health through regular screenings or preventive measures. By the time they begin to show symptoms, the health problem is usually beyond a localized stage [10]. Hence, it is not surprising to find numerous reports about high correlations between income and health problems [13–15, 29, 31–33]. Therefore, Hypothesis 1 is proposed as follows:
2.2. Impact of health problems on online information seeking
Online information seeking is categorized into three groups (i.e. health-related information, health-related social media use and general information). There are three groups of prevalent reasons supporting the inverse relationships between health problems and online information seeking. First, as noted in the previous section, income and health problems are highly correlated. People belonging to the lower income group tend to be less health conscious than their counterparts and have a different mind-set on health [34, 35]. A group of problem ‘patients’ tend to have attitudes and conceptions about the importance of health-related issues that differ from those attitudes and conceptions that are held by ‘non-problem’ medical patients [35]. This may be because they have other pressing issues that take precedence over taking care of their health [10, 34]. Digital divide scholars claim that it is not because poor individuals purposely avoid health information, but those individuals are just more likely to have high debt and have to devote their time and efforts to taking care of urgent issues, such as employment and financial concerns [36, 37]. Therefore, it is not surprising to observe dominant health information non-seeking behaviours among those individuals [38, 39]. As a result, although their health conditions call for more health information, people with multiple health problems become health information non-seekers [40]. Second, owing to the lack of resources, when they acquire information about possible treatments for their health problems, the knowledge may elevate their mental discomfort and anxiety [8, 9, 19, 20, 38, 40–43]. The individuals in this group tend to exhibit lower self-efficacy in controlling their health, which in turn prompts them to avoid or dismiss health information [40, 44, 45]. Third, individuals who fall within a lower income group seek out information from different sources. More specifically, they prefer information seeking offline such as through friends, family members, TV or radio [46–48]. Such differences are more pronounced in health information seeking than in general information seeking [48]. Studies further report that individuals experiencing higher levels of health problems are likely to seek health advice from family members or close friends in their neighbourhood, but not from the Internet [46, 47]. A study based on French consumers supports the finding that individuals with lower income are less likely to utilize the Internet for health information [34]. Although they have more health problems, such as diverticular disease, they are not proactive online health information seekers [1, 14, 49]. Scholars speculate that this could be due to their lack of computer skills [34] and/or their lack of trust of the Internet [39]. For example, about 32% of the non-seeker patients reported that they have ‘a lot or some’ trust in cancer information on the Internet, compared with almost 77% of online information seekers [39]. As digital scholars noted earlier, individuals in the lower socioeconomic brackets, who are likely to have a more pronounced quantity of health problems, are less likely to seek out information online. Thus Hypotheses 2–4 are proposed as follows:
2.3. Impact of literacy on online information seeking
Literacy is understood as an ability to read, write and understand information. Literacy impacts Web search behaviour. This is particularly true when traditional education has been an important determinant of online search behaviour [50], and thus individuals with higher educational levels are more likely to use the Internet to obtain information than their less educated counterparts. Education is primarily responsible for literacy and online health information-seeking behaviours, and therefore existing studies have used educational levels to measure health literacy [4, 31, 51]. Following that practice, this study also adopts educational levels to measure literacy.
Health information literacy in the USA is low as ‘nearly half of all American adults—90 million people—have difficulty understanding and acting upon health information’ [30]. Other research reported that only 12% of adults have proficient health literacy, while the percentage among older adults is a mere 3% [52]. Accordingly, the Institute of Medicine has recommended that health information be written for the sixth-grade reading level [53], and the US Department of Education has proposed an eighth-grade level [54]. Nonetheless, the reading level required in order to understand information published on the Internet is much higher than these suggested guidelines [16, 17, 55, 56]. More specifically, only 3% of epilepsy.com information is written for a sixth-grade level or below, and 15% is eighth-grade or lower [17]. In general, the literacy rate is targeted to both college undergraduate or graduate education levels [17, 57]. Other websites with this problem contain subject matter essential to patients, such as cancer, paediatric patient education materials and asthma [54, 55, 58]. Therefore, digital divide scholars posit that individuals with low health literacy are involuntarily excluded from information access [59]. A study based on cancer patients shows that the probability of information avoidance behaviour increases when patients have difficulty understanding cancer-related information [36]. On top of educated individuals’ capability to understand online health information, these individuals tend to have high self-efficacy in controlling their health and reducing uncertainty through information [38, 60, 61]. While it is expected that literacy will equally impact the relationship between seeking general information and health information, the majority of health information seekers have expressed their difficulty with understanding the health information that is available online [2, 62]. As a consequence, individuals of high literacy are more likely to search for health-related information online than their counterparts. Hypotheses 5–7 are proposed as follows:
2.4. Impact of computer skills on seeking information online
Computer skills are obtained through frequent use [63, 64]. Through repeated use of the Internet, individuals develop the capability to use it for the purposes they choose and to acquire additional skills to search [65]. Because of the rapidly changing nature of technology, if one does not keep up with emerging techniques of online information searching, even if a person has high levels of literacy, online information searching may pose a challenge for them. Although computer skills and health literacy are related, they are two different constructs. For example, older adults, who may have high health literacy, are likely to possess lower computer skills and have more difficulty when it comes to learning computer skills than younger people [66]. Computer skills are critical for online health information seeking. This is especially true for healthcare websites as their design is not usually easy to browse or search [2, 57]. While reliance on the Internet for health information searching is rapidly increasing, healthcare websites pose a problem for a considerable number of patients trying to access information. More specifically, around 30% of those who had an Internet connection at home stated that they did not use the Internet for health information searches because of the difficulties in using a computer [67]. As a result, individuals with computer skills more frequently use health-related websites and are better able to control their health than their unskilled counterparts after controlling for domain knowledge and expertise [68–70]. Computer skills further enable patients to have confidence in their searches and motivate them to rely more on the Internet for health information [71, 72]. As such, computer skills are essential for online health information seeking and can serve as an agent to widen the gap between online information seekers and non-seekers.
When online health information searching is related to social media, computer skill problems will further separate individuals with those skills from those without them. Because online information search skills are built through frequent computer use, those who have not had the opportunities to learn basic computer search skills are likely to further lag behind in keeping up with emerging technologies, such as social media [21–25]. Research findings show that only 10.8% of patients searched online rating websites to find a primary care doctor, and 6.8% of patients utilized social media to find a specialist [73]. Another study reported that only 14% read other patients’ evaluations of medical services before making a medical-related decision [74]. Nonetheless, a majority (76%) of these individuals indicated that online medical reviews had a significant influence on their decision [74]. The statistics above demonstrate that only a few individuals make use of the publicly reported information available through social media to guide their decisions [75]. In alignment with the argument of digital divide scholars, individuals with adequate online search skills are likely to exploit a wide range of online health information sources, including health-related social media sites. Therefore, Hypotheses 8–10 are proposed as follows:
3. Research methods
In order to achieve the main research goal of this paper, which is to determine whether patients’ health-related and general information-seeking behaviours are different, the proposed theoretical model was tested using the 2010 Pew Internet and American Life Project [76]. The dataset is a good candidate for this research because the dataset includes health-related and general online information seeking questions. Second, the sample includes a wide range of participants (e.g. varying levels of computer skills, education, income and health conditions), which enhances the ability to generalize the research findings. Third, the dataset includes good operationalization (Table 1). More specifically, educational levels are categorized into an ordinal measure of seven groups, which is a better measure than a dichotomous measure (e.g. high school vs non-high school degrees) that has been used in existing studies. Income is also measured with a continuous variable, which is superior to a dichotomous measure, such as below or above the poverty level.
Data operationalization
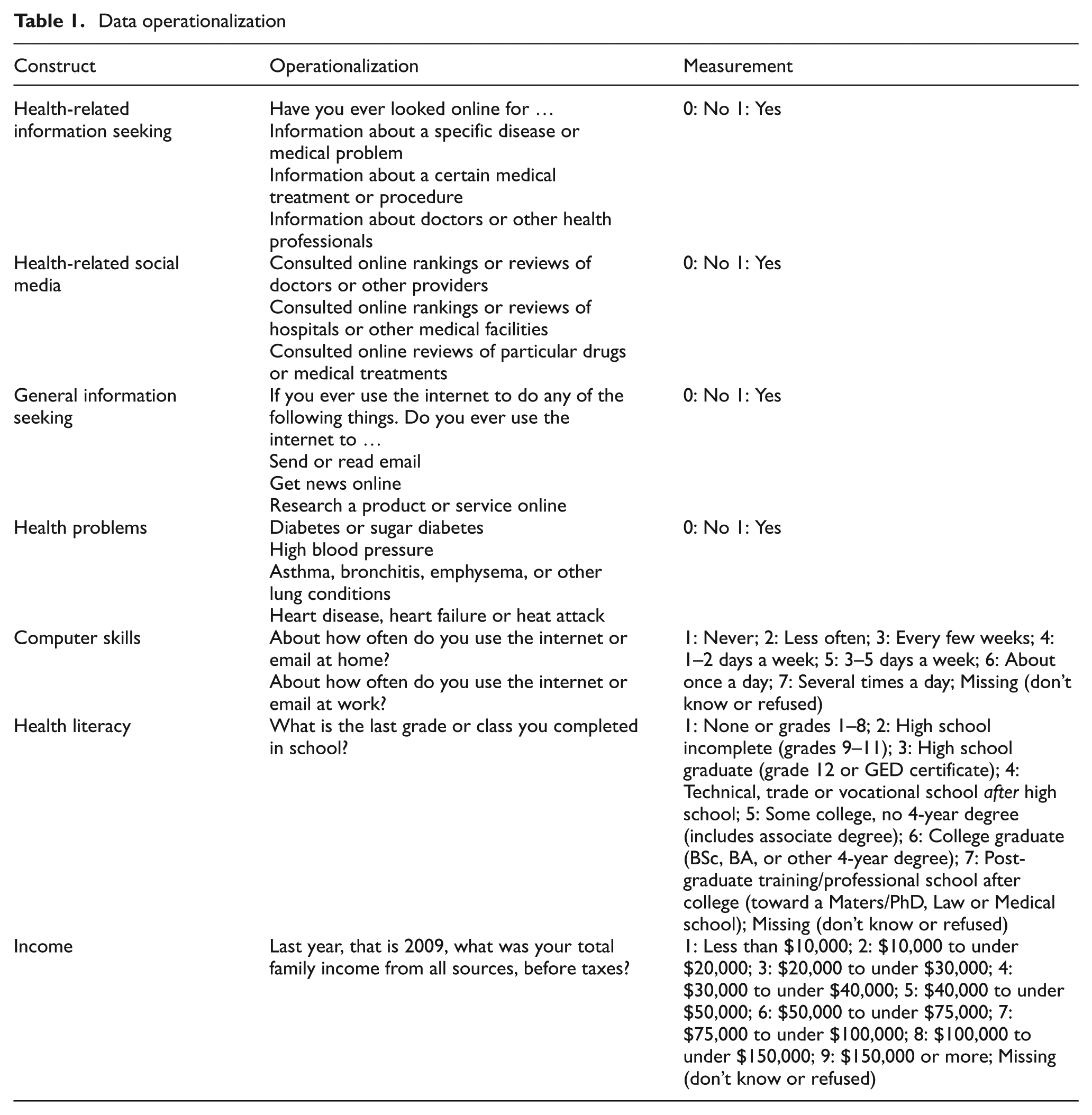
Data operationalizations are made based on existing studies. Because education is not only used for the measure of literacy but also for literacy recommendations in existing studies [17, 30, 31, 68, 77], education is used to measure literacy in this research. Consistent with existing studies, computer skills are measured as the frequency of computer use. Health-related information seeking is measured by each respondent’s online information-seeking behaviour when it comes to medical problems, medical treatments and information on doctors. The use of health-related social media is measured by whether respondents use social media to search for reviews of doctors, hospitals and particular drugs. The use of general information seeking online is measured by checking emails, reading newspapers and researching products. The measure of health problems is measured by asking whether respondents have diabetes, high blood pressure, asthma, heart diseases and/or cancer. This model contains some dichotomous variables. However, if there are enough indicators (e.g. three to five items per construct), or if a sample size is over 500, it is considered acceptable [78, 79]. Each construct has a minimum of three items, and the sample size is 1617 as shown in Table 1.
With regard to construct measurements, the constructs in this proposed model are formative. This means that the items of a construct are hypothesized to cause changes to the construct, and therefore the direction of causality is from the items to the construct [80]. In this case, unlike reflective measures where a construct influences the items and the items co-vary with each other, there is no reason to believe that items in a construct co-vary with other items in the construct. Therefore, a reliability test is not necessary [81, 82].
The original dataset has a considerable number of missing variables. Although the original dataset had 3001 observations, many respondents reported that they did not use the Internet for information seeking, and so they did not answer any questions relating to Internet use. Some respondents answered only a few questions, such as gender. After removing all of these unusable observations, the sample size decreased to 1617. The mean and standard deviation of the variables in the analysis are provided in Table 2, and the correlation table appears in Table 3.
Mean and standard deviation

Correlation
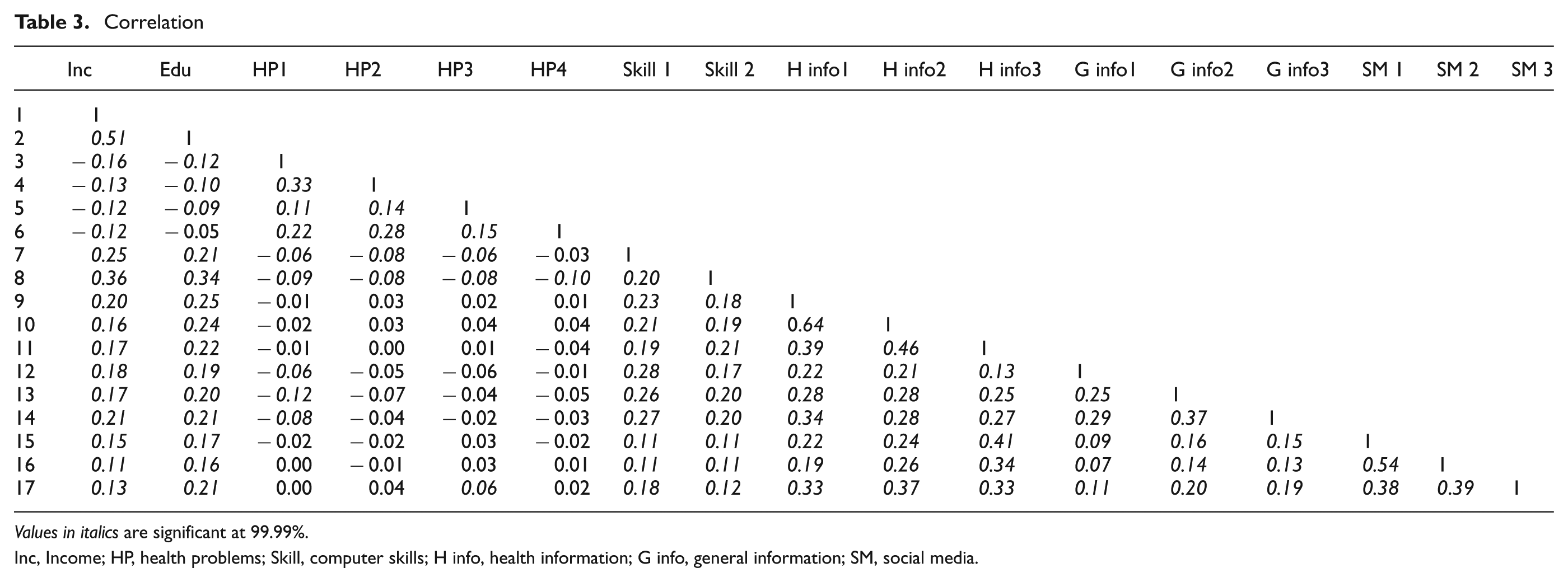
Values in italics are significant at 99.99%.
Inc, Income; HP, health problems; Skill, computer skills; H info, health information; G info, general information; SM, social media.
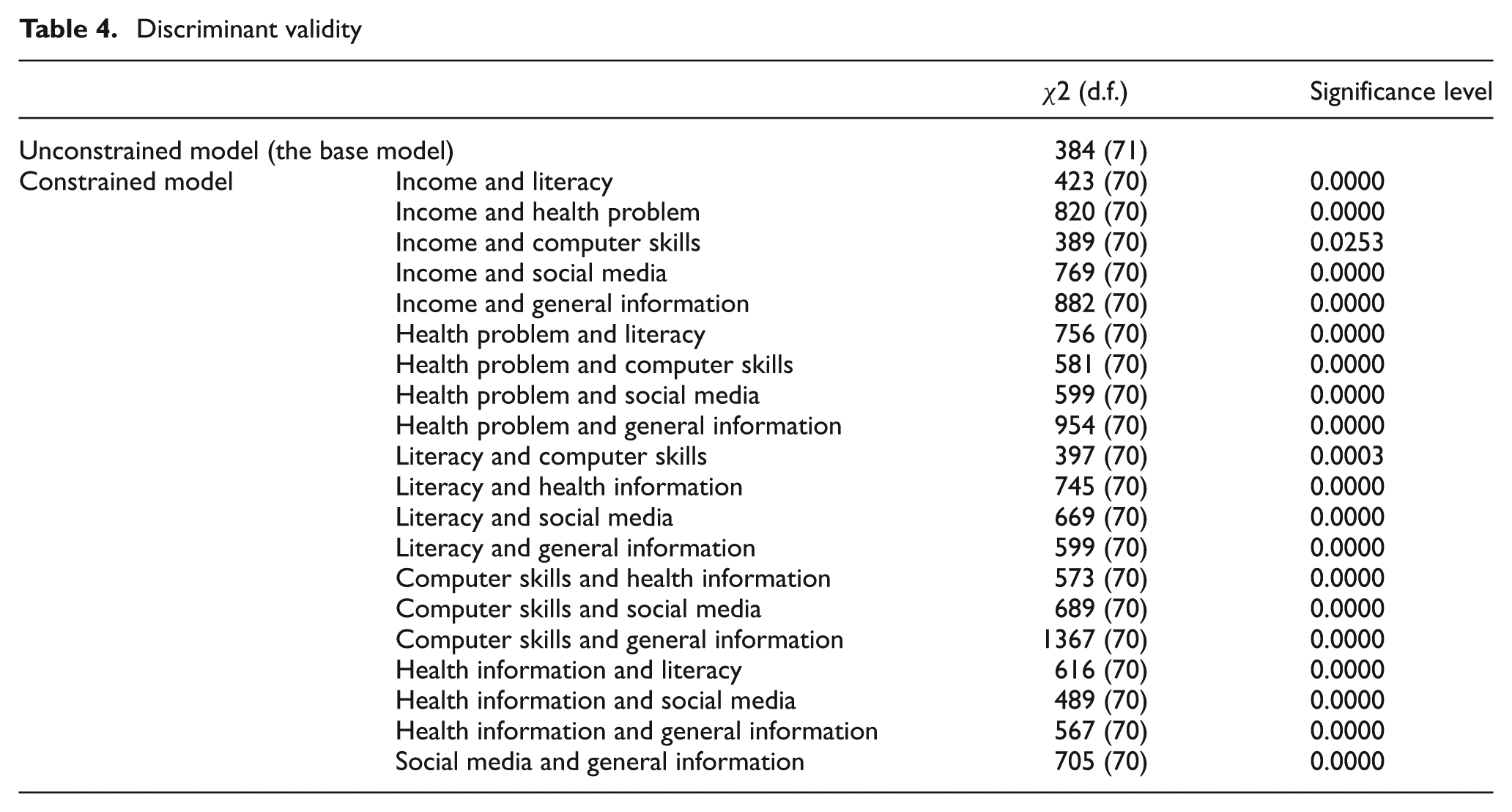
The next step is to investigate confirmatory factor analysis (CFA), which tests convergent and discriminant validity. Convergent validity is achieved when indicators are loaded according to the purported constructs and are statistically significant. The dataset achieved convergent validity at p < 0.001 (Figure 2). Discriminant validity can be assessed by constraining the estimated correlation parameters (e.g. health problems and literacy) to 1.0 and then performing a χ2 difference test on the values obtained for the constrained and unconstrained models [83–85]. Discriminant validity is achieved when two constrained and two unconstrained constructs are statistically and significantly different [81, 86]. The entire sample of the proposed model demonstrated discriminant validity for all items at p < 0.001, except for income and computer efficacy, which were statistically significant at 0.0253 (Table 4).
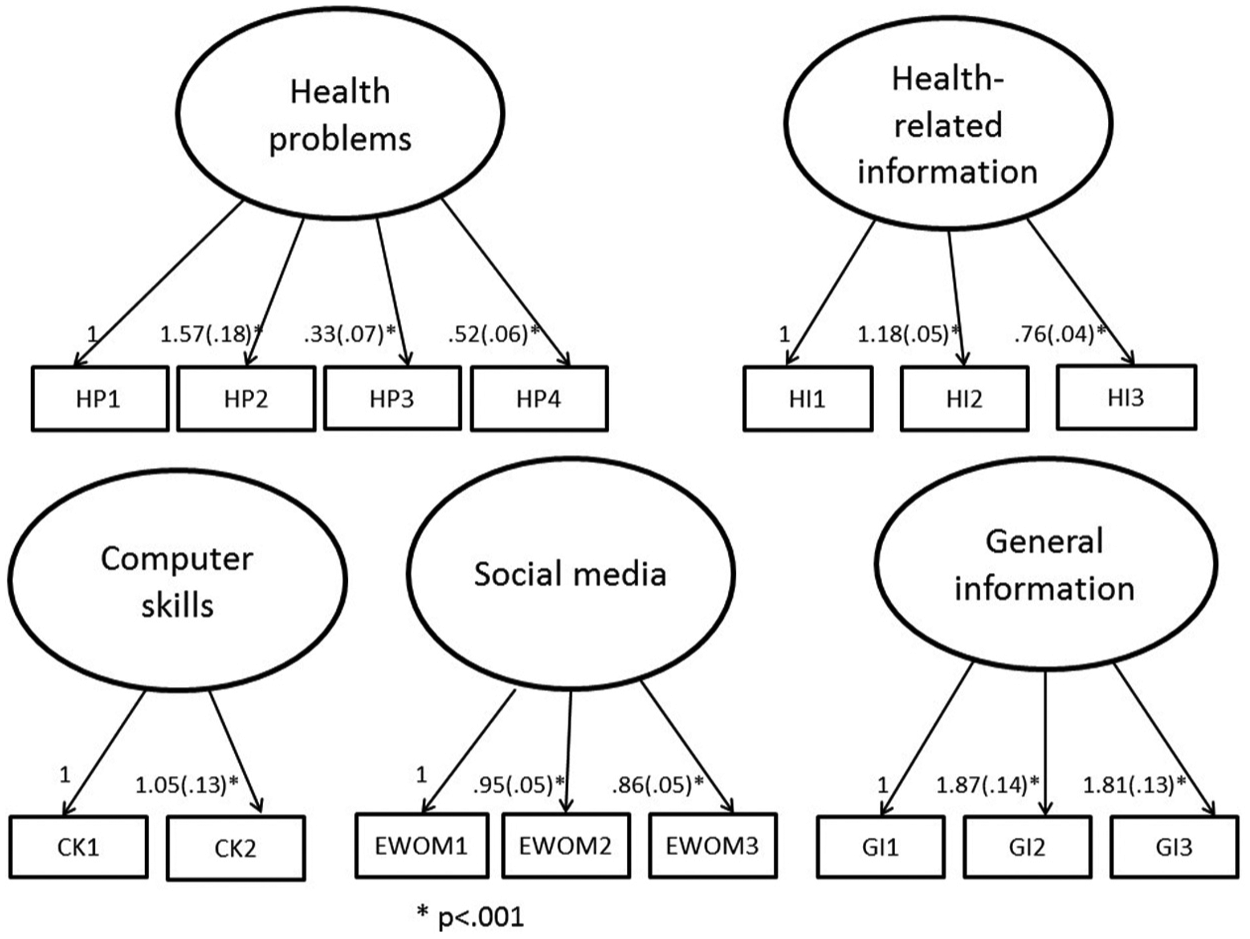
Convergent validity.
Discriminant validity
Maximum likelihood (ML) or generalized least square (GLS) of the common factor analysis is proposed to be used as an extraction method [85, 87, 88]. Unlike the principal component of the common factor analysis that maximizes the explanation of variances, the primary focus of ML or GLS is the observed covariance’s underlying pattern [85]. As a result, it is appropriate for use when a researcher tests pre-existing patterns. AMOS 17.0 offers options of ML and GLS. This article used the ML method.
Next, it is necessary to determine whether or not the data fit the proposed model. In order to determine the soundness of the proposed model, various indices of model fit are employed. The most commonly used indices are χ2, comparative fit index (CFI), and root mean square error of approximation (RMSEA) [83]. Statistically insignificant χ2 values indicate a good fit between the data in the analysis and the proposed theoretical model, prompting researchers to look for statistically insignificant values. Its p-value is 0.001 (CMIN=342.77; d.f.=100; sample=1617), which is statistically significant. However, this measure is sensitive to the number of observations, meaning that, if the number of observations is larger than 250, it is likely to have a statistically significant value [83]. In this sample, the number of observations is 1617. For this study, therefore, the author chose other indices less sensitive to the number of observations. CFI is an improved version of the χ2 value; consequently, it is the most widely used model index [83]. Its cut-off value is 0.90, and the CFI value of this analysis is 0.966. RMSEA is another widely used model fit for how well a model fits the population. A low value represents a good model fit, and the recommended cut-off value is between 0.03 and 0.08 [83]. The value of RMSEA is 0.028, which is considerably lower than the proposed cut-off value. Considering all these model fit indices, the fit of the proposed model is satisfactory, and the data is sound enough to test the proposed model. In order to answer the research questions, the data analysis was accomplished using structural equation modelling (SEM). AMOS 17.0 was used for the statistical analysis.
4. Reports and interpretation of findings
Figure 3 graphically presents the findings of the analysis. In general, the findings support the proposed theoretical model with a few exceptions.
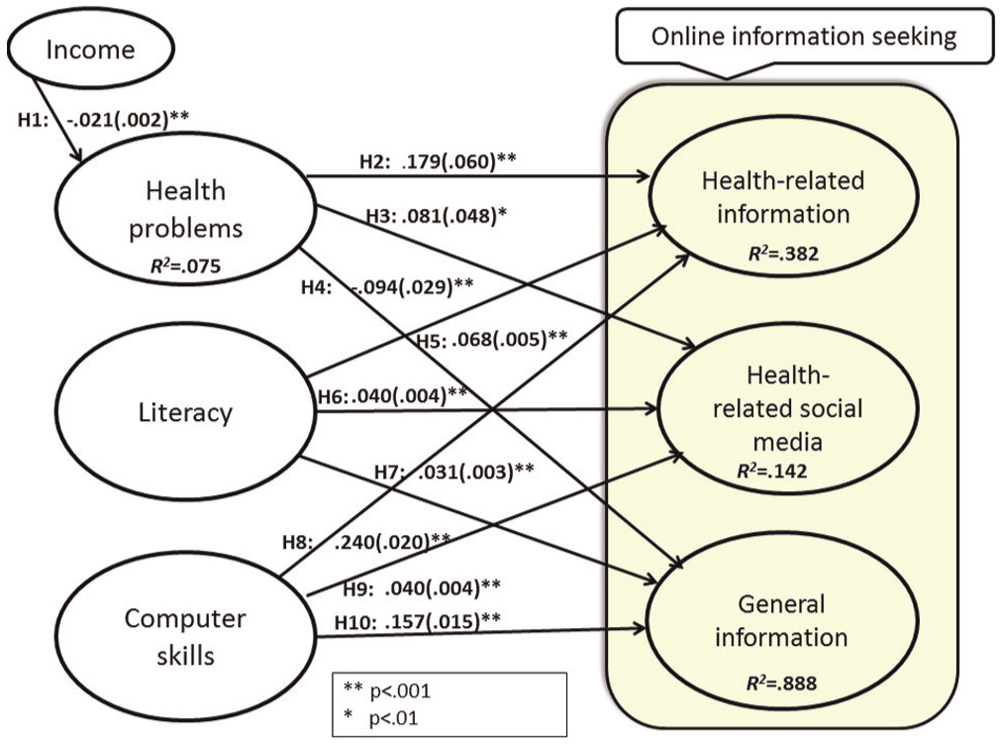
Report of findings.
Hypothesis 1 was proposed to test the impact of income on health problems. As noted, because income impacts the possession of health insurance and financial resources to take care of medical issues, this paper hypothesized a statistically significant and inverse relationship between income and health problems. The finding shows that, as income gets lower, medical problems become greater. The statistical significance level is over 99%. Because of the statistically significant level, one can safely rule out the possibility of such a relationship occuring by chance; however, the effect size is relatively small (−0.021). The author inferred that this might be attributed to the measurement of health problems (i.e. five health problems). To put it in a different way, a decrease of a small income level will not dramatically increase the measured health problems, but certainly a lower income is likely to add health problems such as diabetes, high blood pressure, heart disease, asthma and/or cancer. Based on existing literature, one can speculate that individuals with a lower income are much less likely to have access to health insurance, which inhibits possible prevention and early treatment services, thereby delaying treatment while fostering multiple complications. The second set of hypotheses deals with the relationship between health problems and information-seeking behaviours. More specifically, Hypotheses 2 and 3 attempt to examine the extent to which individuals with health problems seek out online health information, and Hypothesis 4 was designed to test the relationship between individuals with higher levels of health problems and general information seeking online. It was hypothesized that individuals with a larger array of health problems are less likely to pay attention to their health because of resource problems and other pressing issues to take care of; however, the findings of this set of hypotheses show unanticipated results. These results are very interesting and promising. Individuals with health problems sought out health-related information through websites and social media. Although the use of social media is only statistically marginally significant, these findings are also unexpected based on existing studies and yet these are very promising findings. Thus, the statistical findings of Hypotheses 2 and 3 are significant, but the directions are reversed, meaning that patients actively seek out health information from online and social media. On the other hand, the relationship between individuals with health problems and seeking general information online is inversely associated and statistically significant, meaning that individuals with health problems are much less likely to seek out general information such as news. Therefore, Hypothesis 5 is supported. This set of hypotheses implies that the usefulness of online health information plays an important role in online health information seeking, which has been overlooked in studies of online health information-seeking behaviour. One study shows that, once low-income people gain access to the Internet, their behaviour patterns on the web are similar to those of people who are in the high-income population [89]. The author surmises that this finding might have contributed to the fact that health organizations and local libraries provide health-related training, computer use and Internet access, which makes patients better able to search for health-related information online.
The third set of hypotheses centres on the relationship between literacy and seeking information online. Regardless of health-related and general information, literacy positively impacted individuals’ seeking of online information, and thus Hypotheses 5–7 are all supported. Noticeably, individuals with higher literacy are much more likely to search for health-related online information than general information, which shows a heightened interest in the public’s health-related information. This finding confirms digital divide scholars’ concerns that online health information delivery will favour the higher brackets of socioeconomic groups more so than general information will.
The fourth set of hypotheses relates to the relationship between computer skills and online information seeking. Hypotheses 8–10 are supported. Because this research deals with online information seeking, computer skills were expected to show a strong correlation to online information seeking. Indeed, computer skills were found to be essential. As with the previous set of hypotheses, individuals with a higher level of computer skills were much more likely to seek out online health-related information than general information. The use of social media for this construct was very small.
Overall, the act of seeking health-related information is more prominent than seeking general information for the three constructs. In other words, individuals with health problems are highly interested in seeking out health information online, but they are not quite as interested in searching other information, such as news. This finding is somewhat surprising and unexpected, but at the same time it is a contribution to the field. Because usefulness played an important role in online information searching and a contribution of this study to the field, it is recommended to include this construct in future research.
Consistent with findings of existing studies, individuals with higher literacy and computer skills are much more likely to utilize online health information. However, the extent to which these two constructs make an impact on health-related and general information searching online differ. In other words, these two traditional digital divide constructs each have a higher impact on health-related information searching than they do when it comes to general information. As such, the digital divide issue should be of great concern with reference to online healthcare information searching.
Social media, an emerging technology, are used with much less frequency than health-related and general online information seeking for all three constructs. This implies that only a handful of individuals utilize health-related social media sites. Certainly, computer skills can serve as an agent to widen the gap between online health information seekers and non-seekers, more so than general information seekers. Because online health information seekers enjoy high health benefits [89], they are more likely to further seek out online information from multiple sources, including social media. This inference again supports the concern of digital divide scholars. One noticeable finding is that the strength of social media is not yet as strong of a separator as traditional websites. The traditional health information website produced a much more pronounced online health information digital divide than social media, at least for now. Although health information through social media is from laypeople or non-medical experts, the act of sharing an experience with other people is a considerable health benefit for some patients. However, owing to the nature of needing such a high level of computer skills to utilize these websites, only those individuals with very high levels of computer skills can utilize information from those websites effectively. Emerging communication technologies, such as social media, have the potential to pose a threat while adding another dimension to the online health information divide.
5. Conclusion and recommendations
The purpose of this study was to compare online health-related and general information seeking. It also explored whether patients’ information seeking is different and whether literacy and computer skills play out differently across health-related and general information seeking. This is an important issue because the findings can lead to a better understanding of patients’ online health information-seeking behaviour and be instrumental in the design of training. The most important finding in the research is that patients actively sought out online health-related information. It was an unexpected finding as those individuals were likely to be in the lower income group. Based on existing findings, these individuals are less likely to seek out health information. Certainly, usefulness is an important factor for seeking out online health information, and it should be included in future online health research and factored into the design of training modules. More specifically, trainers should emphasize how helpful and beneficial online health information is with regards to making healthcare decisions. They should also motivate their trainees to actively seek out health information online in order to improve their health. This recommendation should not be taken lightly as this group of individuals has a higher level of health problems. Because the Pew dataset is based on Internet users only, this recommendation is directly applicable to online health information seekers.
Next, because online health information is delivered via the Internet, it is critical to regularly train online health information seekers. The delivery of online information rapidly changes, and thus users can be overwhelmed by a new delivery method. Since computer skills are the most important element for online health information seeking, they can be an agent for health information disparity. Because the use of social network sites is not widespread over the general population, this emerging technology does not pose a serious threat to health information disparity at this time. However, as the use of social network sites rapidly increases, this emerging technology could potentially emerge as an agent for health information inequality. As such, it is recommended to include emerging technologies in online health information training modules.
While this study offered insights into patients’ information-seeking behaviour, the findings do not include all patients as there are those who do not have an Internet connection at home or do not use the Internet for health information seeking. More specifically, this study’s analysis excluded 976 observations from the analysis or 32.5% of the sample. That percentage was comprised of patients who did not use the Internet at all. In that case, one cannot generalize these findings to non-Internet users. Another limitation of this study is that the Pew Research Centre recently released a newer version of the survey (http://www.pewinternet.org/datasets/), and thus this study’s findings do not reflect the most current online information-seeking behaviour.
Footnotes
Acknowledgements
The author greatly appreciates the help of research assistant Melissa Kunz for editing.
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.