
Abstract
Web page classification is an important research direction on web mining. The abundant amount of data available on the web makes it essential to develop efficient and robust models for web mining tasks. Web page classification is the process of assigning a web page to a particular predefined category based on labelled data. It serves for several other web mining tasks, such as focused web crawling, web link analysis and contextual advertising. Machine learning and data mining methods have been successfully applied for several web mining tasks, including web page classification. Multiple classifier systems are a promising research direction in machine learning, which aims to combine several classifiers by differentiating base classifiers and/or dataset distributions so that more robust classification models can be built. This paper presents a comparative analysis of four different feature selections (correlation, consistency, information gain and chi-square-based feature selection) and four different ensemble learning methods (Boosting, Bagging, Dagging and Random Subspace) based on four different base learners (naive Bayes, K-nearest neighbour algorithm, C4.5 algorithm and FURIA algorithm). The article examines the predictive performance of ensemble methods for web page classification. The experimental results indicate that feature selection and ensemble learning can enhance the predictive performance of classifiers in web page classification. For the DMOZ-50 dataset, the highest average predictive performance (88.1%) is obtained with the combination of consistency-based feature selection with AdaBoost and naive Bayes algorithms, which is a promising result for web page classification. Experimental results indicate that Bagging and Random Subspace ensemble methods and correlation-based and consistency-based feature selection methods obtain better results in terms of accuracy rates.
1. Introduction
The World Wide Web is one of the richest sources of information with its progressively expanding and changing characteristics. The web enables access to many web pages with several forms of multimedia, such as text, video, etc. The number of web sites and online multimedia has been continually increasing. This makes the field of web mining an essential research direction.
Web mining is the application of data mining and machine learning methods to web contents to discover potentially useful patterns. Web mining brings several research fields, such as information retrieval, natural language processing, data mining, etc., together. Web has a heterogeneous and ill-structured domain with lots of irrelevant and insignificant contents [1, 2], which makes web mining a challenging task.
Web mining can be broadly classified into three different subfields: web content mining, web structure mining and web usage mining [3]. Web content mining aims to discover useful information from online contents, data or documents to enhance information finding, filtering and search [3]. Web structure mining aims to extract useful knowledge from link structures in the web and web usage mining aims to discover useful patterns from server logs [4].
Web page classification is the process of assigning predefined category labels to the web pages. The volume of information available on the web is excessive, so it is infeasible to classify web pages manually. The web provides a dynamic and regularly changing environment, which makes it difficult to build a classification model that can fit to classify many different web pages [5]. The automated classification of web pages is hence essential. In addition, web page classification is required for many information management and retrieval tasks on the web, such as the construction, development and maintenance of Web directories, improvement of search quality results, enhancement of quality in question answering systems, development of focused web crawling, web content filtering, assisted web browsing and contextual advertising [6]. As emphasized above, web mining has several characteristics that make it a more difficult task compared with conventional text mining. Machine learning methods, such as naive Bayes classifier, support vector machine and decision trees, instance-based learning methods have been successfully applied for conventional text mining and web mining.
Research efforts on the automated classification of web pages can be either coarse-grained or fine-grained classification. Coarse-grained web page classification aims to extract the purpose of a web site so that the quality of search results can be enhanced, whereas fine-grained classification aims to obtain automatic categorization of web pages so that Web directories can be obtained [7]. Whether fine-grained or coarse-grained, web page classification, which deals with extracting useful information for establishing web structure, is a current and promising research field of web mining. There are many studies on web page classification. The related work is briefly introduced here.
Lee et al. [8] utilized a fair feature subset selection algorithm in conjunction with an adaptive fuzzy learning network for web page classification. The feature subset selection algorithm was used to handle data dimensionality problems encountered in the domain and an adaptive fuzzy learning network model was selected owing to its fast training time and learning ability. The experimental results indicated that the proposed classification model not only reduces data dimensionality properly, but also provides a high accuracy rate of 86% in testing.
Sun et al. [9] proposed using support vector machines with text and context features for web page classification. In order to examine the efficiency of features on support vector machines, title and hyperlink features were used as context features. The experimental results indicated that the support vector machine performs well in web page classification, especially when anchor words are used as context based features.
Haruechaiyasak et al. [10] proposed a fuzzy association method-based approach to handle properly the ambiguous use of the same word/vocabulary to refer to different entities. The experimental results were conducted on datasets collected from two different web portals and the proposed approach was compared with the vector space model with cosine coefficient. The experimental results indicated that fuzzy approach yields better results for web page classification with an average accuracy of 81.5%.
Wang et al. [11] presented a classification system for automated web document classification based on the naive Bayes algorithm. In the model, two different versions of the algorithm were implemented with four different feature selection methods. The experimental results indicated that the multinomial event model classifier obtains better classification accuracies than the multivariate Bernoulli event model. In addition, the examined feature selection methods fail to achieve performance improvement for web page classification.
Kwon and Lee [12] developed a web site classification system consisting of three stages. The connectivity analysis was used for web page selection and the K-nearest neighbour classifier was utilized for web page classification. In addition, feature selection and a term weighting scheme were utilized in conjunction with the classification algorithm to enhance the performance. The experimental results indicated that the proposed classification model using the home page and its linked pages achieves better performance.
Ribeiro et al. [13] presented a fuzzy logic based approach for web page classification. Web pages were represented via fuzzy representation. A fuzzy-rule-based algorithm was used with a genetic algorithm for classification. The genetic algorithm determines the minimal set that covers properly the instances of the training set. The experimental results indicated the suitability of fuzzy logic for representing the ambiguity within the web mining domain.
Qi and Sun [14] developed a K-means and genetic algorithm-based method for web page classification. The weights of keywords used to refer to categories were adjusted using a genetic algorithm. The proposed model was implemented as a hierarchical web page classification method and the experimental results on a Yahoo dataset were promising.
Selamat and Omatu [15] presented a classification model for web page classification that integrates artificial neural networks, principal component analysis and class profile-based features. Web pages were represented by term-weighting and principal component analysis was used for dimensionality reduction. The experimental results indicated that the proposed classification scheme produces high predictive performance for the sports news domain.
An et al. [16] examined the effectiveness of the rough set-based feature reduction for the web page classification domain. Web pages were represented by frequent words and the words with lower discriminating power were eliminated with the use of rough set-based feature selection. The experimental results indicated that rough set-based feature selection is effective in terms of predictive performance when the number of features is large, whereas the feature selection method degrades the performance for small number of features.
Holden and Freitas [17] utilized an ant colony optimization-based algorithm (Ant Miner) for web page classification. The comparative study of the Ant Miner algorithm was conducted with a C5.0 decision tree algorithm and the experimental results indicated that the ant colony-based approach can generally yield better results than the decision tree algorithm for the examined web mining datasets.
Yi et al. [18] presented a vector space model based on a tolerance rough set for web document classification. A vector space model with terms was used for representing web documents. The value of term co-occurrence was used for enhancing the description of documents. The documents were classified by tolerance class-based document similarity. The experimental results were conducted on the datasets collected from two web portals and indicated that the proposed representation model achieves better performance compared with conventional vector space representation.
Chen and Hsieh [19] presented a model based on latent semantic analysis, text features and support vector machines for automated classification of web pages. In this model, semantic relations between keywords and between documents were revealed with the use of latent semantic analysis. In addition, text features were extracted from web page content and these features were used for grouping the pages into appropriate categories. The support vector machine classifier was trained with features of semantic relations and was tested with extracted text features. The final category of web pages was determined by a voting schema.
Devi et al. [20] utilized a model that combines feature selection and lazy learning-based classifiers for web page classification. In order to obtain an appropriate subset of features, a number of feature selection methods, such as correlation-based feature selection, ReliefF attribute evaluation and information gain-based attribute evaluation were applied. Then, two lazy learning-based classification methods (lazy Bayesian rules and local weighted learning) were evaluated. The experimental results indicated that lazy learning methods can be used as viable tools for web page classification.
Materna [21] examined the performance of four classification algorithms with several term representations, term clustering and feature selection methods for web page classification. The best (highest) predictive performance among the examined algorithms was achieved with the combination of support vector machine classifier with term frequency representation and mutual information based feature selection.
Zhang et al. [22] utilized fuzzy K-nearest neighbour classifier for web document classification. In order to represent the dataset, a TF/IDF measure was adopted. In addition, membership grade was used to enhance predictive performance. The experimental results indicated that the fuzzy K-nearest neighbour classifier obtains better performance compared with the support vector machine and K-nearest neighbour classifier for web document classification.
Chen et al. [23] developed a fuzzy ranking-based feature selection method for web page classification. The input dimensionality was reduced by fuzzy ranking method and discriminating power measure. The experimental results indicated that discriminating power measure can successfully reduce redundancy and noise inherent in features.
Özel [24] developed a genetic algorithm-based method for web page classification. The proposed method uses both HTML tags and tags of terms as features for classification. Genetic algorithms were used to determine appropriate weight values for each feature. The experimental results indicated that, in the case of there being enough negative documents available in the training set, high predictive accuracy rates can be obtained for web page classification.
Saha et al. [25] presented an ensemble classification model that combines rough set attribute reduction and rule generation for web page classification. The ensemble classification model consists of two stages. In the first stage, the outputs of individual base learners are taken to construct a decision table. In the second stage, rough set theory was applied on the decision table to construct a meta-classifier from multiple base learners.
Zhong and Zou [26] presented an ensemble classification model that combines support vector machine classifiers, principal component analysis and independent component analysis methods for web page classification. Principal component analysis was utilized for feature reduction and independent component analysis was utilized for feature selection.
Choudhary and Raikwal [27] developed a web page classification model that consists of naive Bayes and K-nearest neighbour. After pre-processing, the feature vector of a web page was classified by naive Bayes classifier and the K-nearest neighbour algorithm was utilized to measure the similarity between documents of training and test sets.
In order to solve the high-dimensionality problem, feature selection has been extensively studied in machine learning research. Feature selection can eliminate redundant or irrelevant features from the dataset so that a robust classification model can be achieved. Feature selection is a promising research direction for several fields with large numbers of features, such as text mining and bioinformatics [28]. For instance, Chan et al. [29] presented an ensemble feature selection model for biomarker discovery. The proposed method aims to find an appropriate feature subset by combining different feature alternatives obtained at the different stages of data mining process.
Xia et al. [30] provided an extensive empirical analysis of ensemble methods in sentiment classification. In the experimental study, two different feature selection methods (the part of speech-based and the world-relation-based feature sets) were utilized to represent the data. Naive Bayes, maximum entropy and support vector machines were applied as base learners and the fixed combination, weighted combination and meta-classifier combination methods were selected to examine the effectiveness of the ensemble learning.
Wang et al. [31] examined the efficacy of ensemble learning in sentiment classification. In this study, Bagging, Boosting and Random Subspace ensemble methods were used in conjunction with five base learners, namely naive Bayes, maximum entropy, decision tree, K-nearest neighbour and support vector machine methods. The experimental results indicated that the ensemble learning methods can enhance the predictive performance of base learners in sentiment classification.
Günal [32] presented a hybrid feature selection scheme for text classification. The feature selection scheme consists of filter and wrapper-based feature selection methods. The scheme examined the effectiveness of varying sizes of feature subsets, different dataset characteristics and classification algorithms.
One of the main challenges encountered in web page classification is the high-dimensional feature space [33]. In order to deal with the feature space properly, datasets containing web page information should be represented by a suitable subset of features so that a robust and efficient classification model can be obtained. Feature selection improves the understanding of data, decreases the computational costs incurred and the curse of dimensionality and improves the performance of the classification algorithm [34]. In addition, web mining domain is a field where high predictive performance is desired. Recently, ensemble methods, which is the field of study concerning the use of multiple base learners to obtain better predictive performance, are a promising research direction.
Hence, taking these issues into account, this paper examines the application of feature selection, ensemble method and classification algorithm combinations for web page classification domain. Ensemble learning methods can generally enhance the predictive performance of base learners in several domains [35], yet the empirical analysis of ensemble learning methods for web page classification is very limited. To the best of our knowledge, this is the first attempt that provides an extensive empirical analysis of ensemble of feature sets and classifiers for web page classification. In comparative study, four popular ensemble methods, namely Boosting, Bagging, Dagging and Random Subspace, with four different feature selection methods, namely correlation, consistency, information gain and chi-square-based feature selection are evaluated on four different base learners. In the comparative experimental study, we seek answers to the following research questions:
Which feature selection method selects the optimal feature subset for web page classification?
Can the ensemble learning method enhance the predictive performance of base learners in web page classification?
For web page classification, which combination of feature selection, base learner and ensemble method obtains the highest predictive performance?
2. Feature selection methods
Feature selection (attribute evaluation, variable elimination) is one of the integral parts of data mining and machine learning tasks. It requires the selection of an appropriate subset of variables so that noise, irrelevant and redundant variables can be eliminated while maintaining high predictive performance. The main reasons for the application of feature selection methods in classification include avoiding over-fitting and enhancing the predictive performance of the classifier, building a fast and efficient classification model and obtaining better understanding regarding the underlying procedure [28, 34]. The feature selection methods eliminate irrelevant/redundant features based on a certain criterion or measure that evaluates the relevance of a particular feature to the class label. For a dataset with n features, determining the best subset of features requires the enumeration of 2 n different cases. In order to get rid of this computational burden, heuristic methods are widely adopted for feature subset selection [36]. Feature selection methods may be broadly classified into two distinct categories: filter methods and wrapper methods. In filter methods, the feature subsets of datasets are ranked by means of statistical measures and those features with high ranks are used for the features of a classification algorithm. In filter methods, a threshold value is used for eliminating features below this value. In wrapper methods, the usefulness of feature subsets is determined based on the performance of the classification algorithm [28]. Since feature subsets are determined based on optimization of the performance of classification algorithms, wrapper methods are expected to obtain better performance over filter methods. However, wrapper based methods need to run recursively a particular classification algorithm and are generally slower than filter-based methods [37]. This section briefly reviews the feature selection methods utilized in the comparative study.
2.1. Correlation-based feature selection
Correlation-based feature selection (CFS) [37] is a filter-based feature selection method that utilizes correlation based heuristic function to evaluate the merit of feature subsets. Correlation-based feature selection takes into account both the usefulness of individual features for predicting the class label and inter-correlation levels of features. The heuristic evaluation function [37] is defined as given by equation (1):

where Ms is the heuristic merit of a feature subset S containing k features,
2.2. Consistency-based feature selection
Consistency-based feature selection [38] is a probabilistic feature selection method that utilizes the level of consistency in the class values to evaluate the merit of a subset of attributes. The consistency metric used to evaluate subsets of features in the consistency-based feature selection method is defined as given by equation (2):

where s denotes an attribute subset, J represents the number of distinct combinations of attribute values for s, |Di| represents the number of occurrences of ith attribute value combination, |Mi| represents the cardinality of the majority class for ith attribute value combination and N denotes total number of instances in the dataset [39]. The consistency-based feature selection method starts with a subset containing all features. Then, a random subset from the feature subset space is generated. When the generated random subset consists of fewer or an equal number of features than the current subset, the inconsistency rates of data in both feature subsets are compared. If a newly generated subset has a better consistency rate, it has been selected as the best subset. This procedure is repeated a selected number of times.
2.3. Information gain-based feature selection
Information gain-based feature selection is a feature-ranking method that utilizes an information gain metric for ranking features. In information gain-based feature selection, a ranking of the attributes based on relevance is obtained. The entropy of the class C before and after observing a particular feature A is determined as given by equations (3) and (4) [39]:

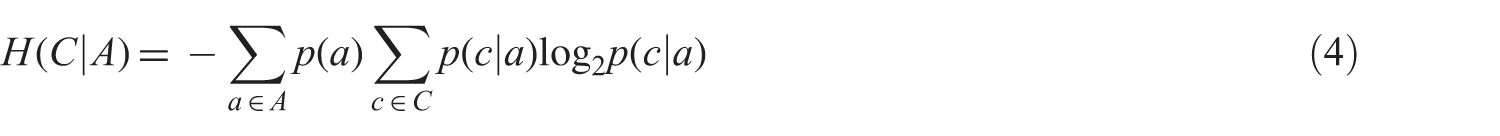
Information gain is a metric that indicates the additional information revealed by observing a particular feature A and the information gain between each feature Ai and the class is determined as given by equation (5) [39]:

Information gain-based feature selection computes the information gain values for each feature and class so that a ranking of the features based on information gain values can be obtained. After a ranking of the features is reached, the most informative (the highest ranked in terms of information gain value) N features are kept as feature subset, while eliminating the rest of the features.
2.4. Chi-square-based feature selection
Chi-square is a common statistical measure that measures the absence of independence between a term t and a category c [40]. The chi-square measure can be calculated as given by equations (6) and (7) [40]:
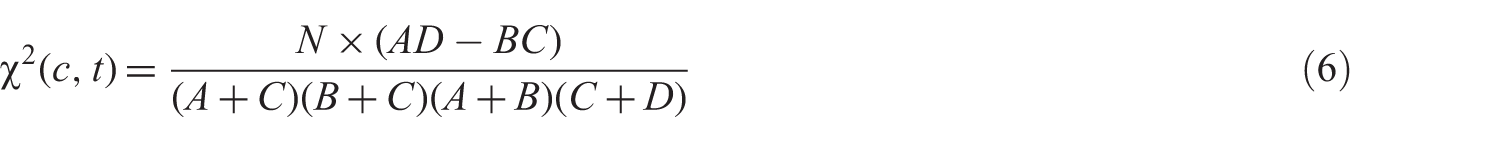

where A is the number of times term t and category c occur simultaneously, N denotes the total number of documents, B denotes the number of times term t occurs without belonging to category c, C represents the number of times c occurs without t, and D denotes the number of documents that do not contain the term t and do not belonging to c [40]. The chi-square statistic is computed for each category and term.
3. Classification algorithms
Machine learning methods have been successfully applied for text and web mining. Statistical/probabilistic classifiers, such as naive Bayes classifier, decision tree/rule based classifiers, such as ID3, C4.5 and C5, regression methods, neural networks, radial basis function networks, support vector machines and instance-based classifiers, such as the K-nearest neighbour algorithm, are widely utilized for text classification [41]. The mentioned machine learning methods can obtain promising results for text classification. However, text and web mining applications generally require large set to be trained, which may be costly for several methods, such as support vector machines and neural networks [42, 43]. Moreover, K-nearest neighbour, naive Bayes and support vector machines obtain similar predictive performance with suitable parameter settings. Regarding the classification tasks, K-nearest neighbour and naive Bayes classifier are good alternatives to support vector machines, owing to their speed and simplicity [44]. Taking these issues into account, this study considers four base learners in the experimental analysis. This section briefly describes the classification algorithms used in the experimental study, namely naive Bayes classifier, K-nearest neighbour algorithm, C4.5 algorithm and FURIA (Fuzzy Unordered Rule Induction Algorithm) algorithms.
3.1. Naive Bayes classifier
The naive Bayes algorithm is a statistical based on Bayes’s theorem. The algorithm is based on the assumption of class conditional independence, which states the independence of the value of an attribute on a particular class compared with the values of other attributes. The assumption simplifies the required computational cost [2]. Owing to its simple structure, computational efficiency and relatively high predictive performance, the naive Bayes algorithm is widely employed for a wide variety of classification tasks, including text mining applications. In classification tasks, the algorithm achieves comparable results with other popular classification techniques, such as decision tree and artificial neural networks.
3.2. K-nearest neighbour algorithm
The K-nearest neighbour algorithm is an instance based learning algorithm which classifies instances based on their similarity to the k closest training instances [45]. In the method, training instances are represented by n-dimensional features. Each instance represents a single point in n-dimensional space. In this way, each training instance is kept in an n-dimensional instance space. The algorithm determines the class label for an unseen instance based on the majority voting of its k nearest neighbours. In the method, distance metrics such as Euclidean distance and Hamming distance are utilized in order to measure the similarity. The use of feature values directly in the computation of distance metrics may be problematic. Hence, normalization methods, such as min–max normalization and z-score normalization, are generally applied to the data in advance [2]. The K-nearest neighbour algorithm has a simple structure and requires a limited number of parameters. With large enough training sets, the algorithm obtains efficient predictive performance. A drawback of the algorithm is the determination of the k nearest neighbours in extremely large training sets. In order to cope with this issue, principal component analysis-based dimension reduction and/or the use of more sophisticated data structures, such as search trees, may be utilized [46].
3.3. C4.5 algorithm
The C4.5 algorithm [48] is a popular decision tree induction algorithm. Decision tree algorithms can be used as viable tools for classification owing to the main features of the algorithms, such as having a simple and non-parametric structure, generating an easily understandable model and performing relatively rapidly [48]. In the C4.5 algorithm, information gain is used as the test attribute selection criterion. This criterion aims to get rid of the attribute bias problem of ID3 algorithm [47]. The algorithm selects an attribute with the highest information gain to make the decision and the process recurs on the remaining part. The algorithm can deal with both continuous and discrete attributes properly, since it uses a threshold value for splitting the list into groups based on this value [49]. It can handle training data missing attribute values by neglecting those attribute values in the computation of information gain and entropy. After obtaining the tree structure, the algorithm uses pruning so that redundant branches can be eliminated by replacing them with leaf nodes. This process enables over-fitting, exceptions and the noise of the training set to be eliminated [50].
3.4. FURIA algorithm
FURIA (Fuzzy Unordered Rule Induction Algorithm) is a fuzzy rule-based classification algorithm, which extends a rule-based classifier (Ripper algorithm) by learning fuzzy rules and unordered rule sets, instead of conventional rules and rule lists [51]. The algorithm employs an unordered rule sets scheme, so rules are not learned for each class by starting with the selection of one class as a default prediction as in the case of decision list-based approaches. Instead, a set of rules are obtained for each class by following one-versus-another classes approach. However, this scheme may generate incomplete lists. Hence, the algorithm incorporates an efficient rule-stretching approach, which extends minimal generalization-based rule stretching methods by taking the order of when the antecedents have been learned [52]. In addition, the pruning mechanism was not utilized in the method since it degrades performance.
4. Ensemble methods
Ensemble methods are machine learning approaches that aim to combine predictions made by several base learners so that an enhanced generalization ability and robustness can be achieved. Ensemble learning is a promising research direction in machine learning owing to statistical, computational and representational characteristics [52]. Statistically, with the existence of enough data, different classifiers can be obtained via sampling distributions. Hence, the risks, such as taking a wrong decision, locally optimal results and the parameter dependency of algorithms, may be reduced via ensemble learning. Based on the structure used in ensemble generation from base-learning algorithms, ensemble methods are broadly classified into two distinct categories, as dependent and independent methods. In dependent methods, the output of a base learner can be influential in the generation of subsequent classifiers, whereas base learners are obtained separately and their results are amalgamated by a particular method [53]. Boosting and AdaBoost algorithms are typical examples of dependent ensemble methods and Bagging and Random Subspace methods are typical examples of independent ensemble methods.
4.1. AdaBoost algorithm
A boosting algorithm is used for enhancing the predictive performance of weak learning algorithms. The method trains a weak learning algorithm recursively on different sampling distributions so that with the combination of weak learning algorithms a strong/robust classification model can be achieved. The AdaBoost algorithm [54] is a widely used boosting algorithm which aims to improve the predictive performance by focusing on difficult data points. The method assigns a weight value to each instance in the training set. In each iteration of the algorithm, the weight values for misclassified instances are increased, whereas the values for correctly classified instances are decreased so that the weak learning algorithm dedicates more iteration and more classifiers for difficult instances [53]. The classification algorithms of the ensemble are also given weight values to reflect the predictive performance of classifiers. The general structure of AdaBoost algorithm is summarized in Figure 1, where Z denotes the training dataset and βk denotes the combination weights.

The general structure for the AdaBoost algorithm [55].
4.2. Bagging algorithm
Bagging (Boostrap aggregating) [56] is an ensemble learning algorithm that combines classifiers trained on new training sets obtained by sampling from the training set with replacement. The diversity required for efficiency of ensemble methods is achieved by this sampling scheme. The training sets are generally obtained by simple random sampling with replacement method. The bagging algorithm utilizes majority voting or weighted majority voting to combine the results of base models. The bagging algorithm requires having an unstable classification algorithm as the base learning model so that different results can be achieved by training the base learner on different sampled training sets [55]. The general structure of bagging algorithm is outlined in Figure 2, where Z denotes the dataset.

The general structure for the Bagging algorithm [55].
4.3. Dagging algorithm
The Dagging algorithm [57] is an ensemble learning algorithm which trains classifiers on different samples of the training set as in the case of the Bagging algorithm. The general structure outlined for the Bagging algorithm is also valid for the Dagging algorithm, but the method uses disjoint, stratified samples instead of boostrapping. The Dagging algorithm combines the output of individual base learners via majority voting.
4.4. Random Subspace algorithm
Random Subspace [58] is an ensemble learning method where multiple classifiers trained on modified feature space are combined. Like the Bagging algorithm, classifiers are trained on different samples of the training set. As indicated in advance, the Random Subspace method takes different samples on feature space instead of instance space. For a training set X={X1, X2, …, Xn} with n instances, each instance is assigned to a particular class. Each instance Xi in the training set is represented via a p-dimensional vector, Xi={xi1, xi2, …, xip}(i=1, …, n). The method selects randomly p*<p features from the original p-dimensional feature space. Hence, this scheme achieves modified samples from the original training set, each of which is represented by p*-dimensional vector [59]. The method avoids overfitting while preserving high predictive performance. The Random Subspace method achieves efficient results for datasets with many redundant features. The general structure of the Random Subspace method is outlined in Figure 3.

The general structure for the Random Subspace algorithm [60].
5. Experimental design and results
5.1. DMOZ Open Directory Project dataset
To evaluate the predictive performance of feature selection methods, classification algorithms and ensemble learning methods, 50 datasets of DMOZ (Open Directory Project) are used [61]. The minimum number of documents among the queries is 104 and maximum number of documents is 164. The number of topics among the dataset ranges from 3 to 10. The minimum number of attributes is 495, whereas the maximum number of attributes is 822. The dataset is available in a pre-processed format, where special character removal, lower case filtering, stop words removal and Porter stemming are applied. The datasets are available at http://artemisa.unicauca.edu.co/~ccobos/wdc/wdc.htm. Since the datasets are given in a pre-processed format, any pre-processing techniques are not applied here.
5.2. Evaluation measure
To evaluate the predictive performance of feature selection methods, classification algorithms and ensemble learning methods, classification accuracy is selected as evaluation criterion. Classification accuracy (ACC) is the proportion of correctly classified instances obtained by the classification algorithm over the total number of instances as given by the following equation:

5.3. Experimental procedure
In experimental analysis, a 10-fold cross-validation method is utilized. By this scheme, the original dataset is divided into 10 randomly partitioned mutually exclusive folds. Then, the training and testing process is repeated 10 times so that testing uses one fold each time for validation, whereas the rest of the folds are dedicated to training. At the end of the process, average results for 10-fold testing are determined. As indicated above, this paper aims to examine the effectiveness of ensemble learning and feature selection methods for web page classification. In order to do so, each of the 50 datasets in DMOZ directory is configured into five different forms: dataset without feature selection (without FS); dataset with correlation-based feature selection (CorFS); dataset with consistency-based feature selection (ConsFS); dataset with information gain based feature selection (InfoFS); and dataset with chi-square based feature selection (ChiFS). In correlation-based and consistency-based feature selection methods, the best-first search method was selected as the heuristic search strategy. Since information gain-based and chi-square-based feature selection methods provide a ranking of attributes in terms of merit, the 15 most informative features are kept for each dataset when ranking methods are utilized. Ensemble learning methods are obtained by combining several base learning algorithms. In order to compare the effectiveness of different classification approaches in ensemble methods, we chose representatives of four different classification approaches. Hence, a statistical classifier (naive Bayes algorithm), an instance-based classifier (K-nearest neighbour algorithm), a decision tree classifier (C4.5 algorithm) and a rule-based classification algorithm (FURIA algorithm) were utilized for our experiments. In ensemble generation, four widely used ensemble learning methods, namely AdaBoost, Bagging, Dagging and Random Subspace methods, were chosen. In order to minimize the side effect of variability of the training set, all experimental results reported in this section were repeated 100 times. We conducted a set of experiments on a PC with an Intel Core i7 CPU 3.40 GHz with 8.00 GB RAM. The experiments were performed with the machine learning toolkit WEKA (Waikato Environment for Knowledge Analysis) version 3.7.11. It is an open-source platform that contains many machine learning algorithms implemented in JAVA.
The default parameters of WEKA were assigned based on the empirically obtained values, which tend to perform well [62]. Hence, for algorithms and ensemble learning methods, default parameters of WEKA are used. These parameters are summarized in Table 1, where LNorm indicates document length normalization parameter, minimum word frequency denotes the number of words to be ignored with less than the threshold value, K denotes the number of nearest neighbours, confidence factor denotes the parameter used for tree pruning, minimum number of objects denotes the minimum number of instances per leaf, number of folds denotes the parameter that determines the amount of data for reduced-error pruning, seed denotes the parameter used for randomizing the data, and T-norm indicates the parameter that is used as a fuzzy AND-operator.
Parameters of algorithms used in experimental study.

5.4. Results and discussion
As mentioned above, the experimental procedure was repeated for 50 datasets of the DMOZ directory. In Table 2, average (mean) classification accuracies and standard error of the mean for each algorithm and dataset configuration are presented. For each configuration, mean accuracy rates of 50 datasets in one significant figure are used to calculate average classification accuracy and standard error of the mean in Minitab statistical program. The standard error of the mean values indicated by (±) after accuracy rates indicates an estimation of the variability between sample means of 50 accuracy rates obtained from the datasets. In the table, the best results achieved by a particular algorithm on five different dataset configurations are indicated bold–italic type, whereas the highest predictive performance among all the compared results is indicated in bold type. The first question of this study is to examine the effectiveness of feature selection methods.
Classification accuracies obtained by different algorithm/feature selection configurations.
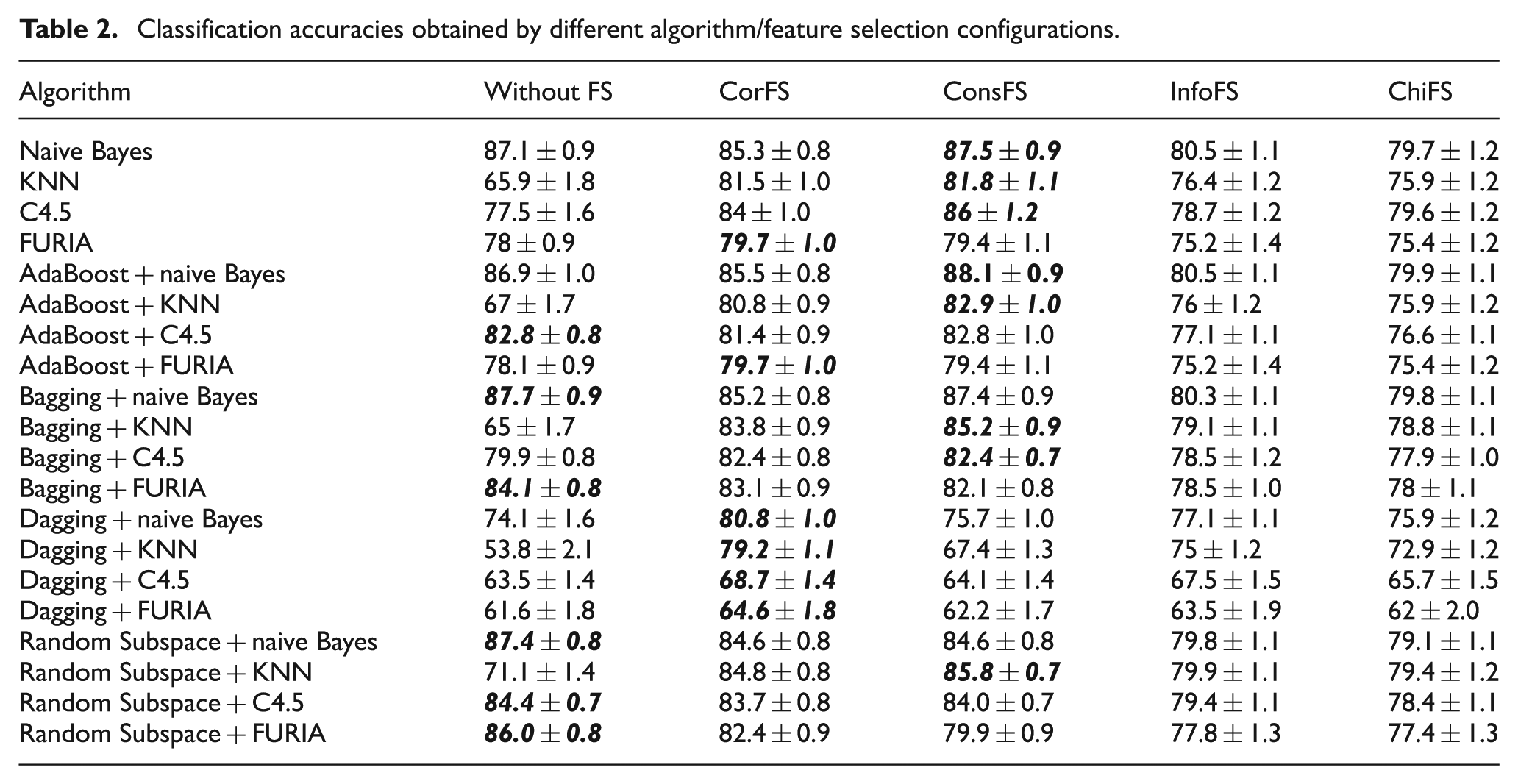
We first consider the results of datasets based on different feature selection configurations. There are 20 different algorithm configurations. Eight of the best results over these configurations are achieved by consistency-based feature selection, six of the best results are obtained by correlation-based feature selection and six of the best results are achieved when no feature selection is applied. Information-based and chi-square-based feature selection methods receive generally worse predictive performance than the other feature selection methods. This may be explained by the number of features kept constant. Although the best results are not achieved by these ranking-based feature selection methods, they still enhance the predictive performance, as indicated by Figure 2. The second question addressed in the study is the effectiveness of ensemble methods to enhance predictive performance. For naive Bayes algorithm on dataset without feature selection, Bagging and Random Subspace methods obtain better performances, for datasets with correlation-based, consistency-based feature selection, AdaBoost algorithm yields better results. For the datasets with ranking-based feature selection methods, Bagging outperforms the base learner.
For the K-nearest neighbour algorithm, the Random Subspace ensemble method has brought a substantial improvement over the base learning algorithm, KNN (65.9, 81.5, 81.8, 76.4, and 75.9) and the Random Subspace ensemble of KNN classifier (71.1, 84.8, 85.8, 79.9 and 79.4), in terms of different dataset configurations, respectively. Bagging also yields good performance compared with the K-nearest neighbour algorithm except for the dataset without feature selection.
For the C4.5 decision tree classifier, the predictive performance improvement by ensemble learning methods is restricted to a small number of cases. For datasets without feature selection, AdaBoost, Bagging and Random Subspace methods yield better performance and the Random Subspace ensemble of C4.5 classifier for dataset with information gain-based feature selection obtains the highest result. For the FURIA algorithm, Random Subspace and Bagging ensemble methods obtain substantial improvement over base learning algorithm.
For comparison purposes, classification accuracies obtained from DMOZ Open Directory Project dataset with other classification and clustering algorithms from the literature are presented in Table 3.
Comparison of accuracy rates.

To further evaluate the results obtained in this study, we performed one parametric test (one-way ANOVA test) and two non-parametric tests (Mood’s Median test and Kruskal–Wallis test) in the Minitab statistical program. Each statistical test is performed based on two different aspects: algorithm-based evaluation and dataset configuration-based evaluation. In the algorithm-based evaluation, five different algorithm configurations (the use of base learner alone, base learner with AdaBoost, base learner with Bagging, base learner with Dagging and base learner with Random Subspace) are taken into consideration, whereas the dataset configuration-based evaluation examines the results based on five different dataset configurations (dataset without feature selection, dataset with correlation-based feature selection, dataset with consistency based feature selection, dataset with information gain-based feature selection and dataset with chi-square based feature selection). The results for one-way ANOVA test of overall results are given in Table 4, where SS, MS, F and P denote sum of squares, mean square, F-statistic and probability value, respectively. According to the analysis results reported in Table 4, probability values for compared algorithm results and for compared dataset configuration results are 0.000. This indicates a meaningful difference among the comparison results for confidence interval 99%.
One-Way ANOVA test results.

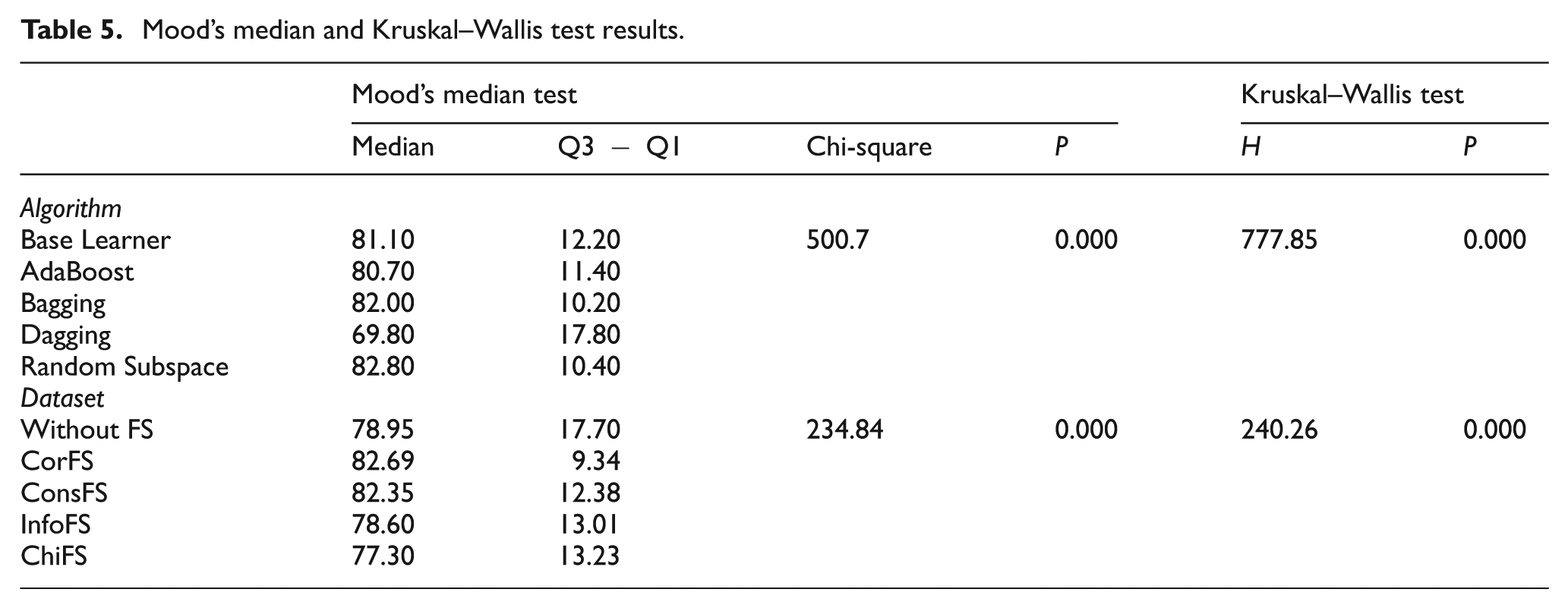
In Table 5, non-parametric test results for algorithms and datasets are summarized, where median, chi-square, inter-quartile range (Q3 − Q1) and probability value for Mood’s median test and H-statistic and probability value for Kruskal–Wallis test are presented. The non-parametric results obtain P=0.000 for both algorithm-based evaluation and dataset configuration-based evaluation. Hence, we conclude that parametric test (one-way ANOVA) results are followed by non-parametric tests and the meaningful differences among compared results are still valid.
Mood’s median and Kruskal–Wallis test results.
In Figure 4, average accuracy rates obtained by the use of only base learner and the use of base learner with AdaBoost, Bagging, Dagging and Random Subspace are summarized. Similarly, Figure 5 denotes the average accuracy rates obtained for five different dataset configurations. These figures emphasize that, in particular, two ensemble learning methods (Bagging and Random Subspace) yield better predictive performance for web page classification domain. As depicted in Figure 4, the average classification accuracy obtained by the base learners is 79.76, accuracy obtained by AdaBoost is 79.60, accuracy obtained by Bagging is 80.97, accuracy obtained by Dagging is 68.76 and accuracy obtained by the Random Subspace method is 81.50. The results obtained by the base learners and AdaBoost are very close to each other and Dagging method obtains lower predictive performance from these two methods. Feature configuration-based analysis of Table 2 does not clearly depict whether feature selection improves predictive performance or not. The average classification accuracy obtained without applying feature selection is 76.08, whereas the correlation-based feature selection method achieves a classification accuracy of 81.06. The classification accuracy obtained by consistency-based feature selection method is 80.44, the accuracy obtained by information gain based feature selection is 76.8 and the accuracy obtained by chi-square feature selection method is 76.19. Figure 5 strongly indicates that feature selection contributes to the performance of classifiers for web page classification. Among the results compared, correlation-based and consistency-based feature selection methods yield better results compared with ranking-based feature selection methods. Correlation-based and consistency-based feature selection methods do not require determining the size of feature subsets. In feature ranking methods, the size of feature subsets should be determined. The size of feature subsets can be taken based on a predefined threshold can be taken as a constant number or a proportional number. In the experimental results, the feature subset sizes in feature ranking methods are kept constant. In addition, correlation-based and consistency-based feature selection methods can be used in conjunction with heuristic search strategies, such as ant colony optimization, particle swarm optimization and genetic algorithms. In this study, the performance of correlation-based and consistency-based feature selection methods on a single heuristic search strategy is examined. As reported in Table 3, the average classification results obtained with feature selection and ensemble learning reported in this study are not the best results for the DMOZ directory dataset. However, taking these variations in feature selection process, future research can improve the predictive performance of classifiers via an ensemble of feature selection and classifiers.
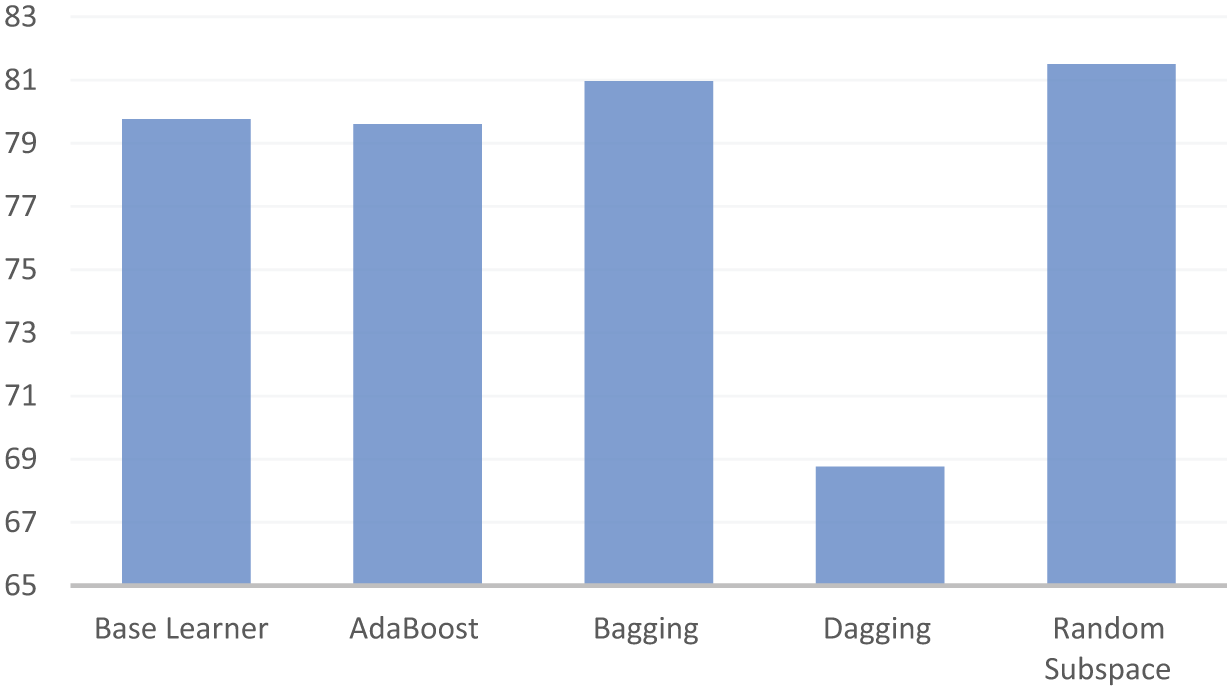
Average accuracy rate comparisons for algorithms.
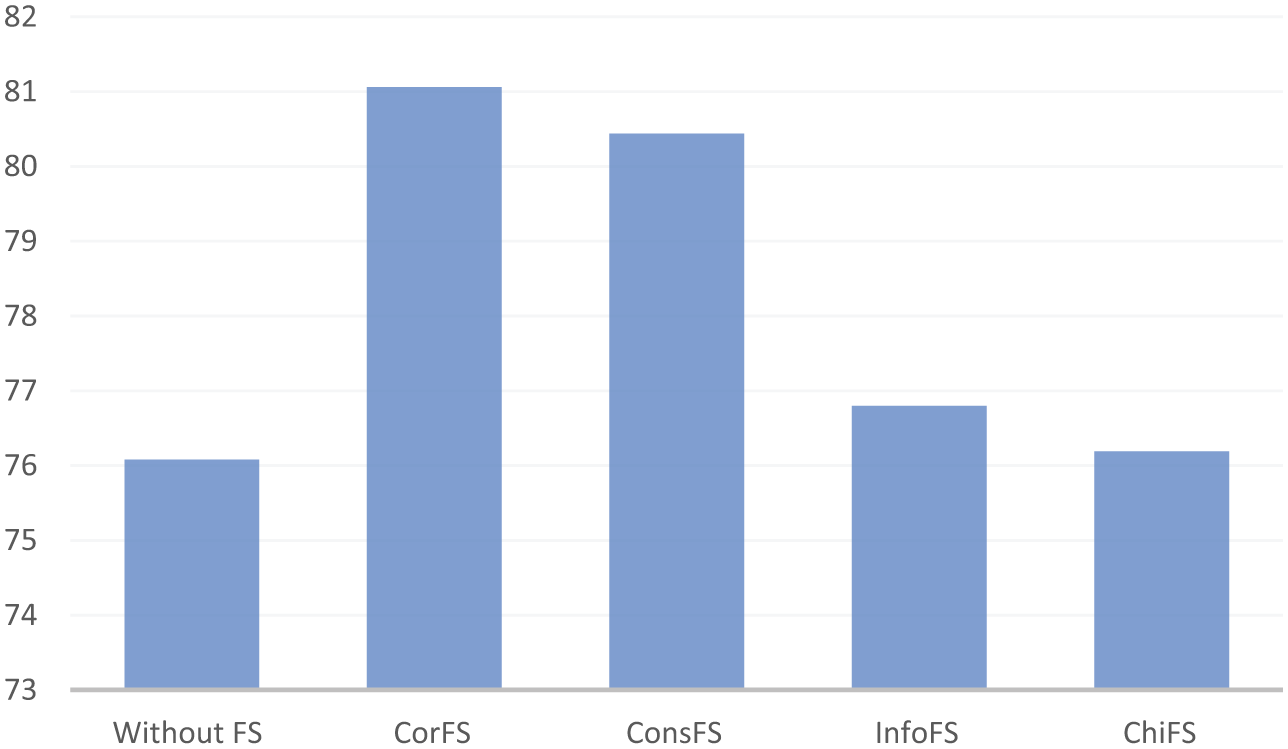
Average accuracy rate comparisons for dataset configurations.
6. Conclusion
Web page classification is one of the main challenges of web mining. With the huge amount of data available, the development of efficient classifiers with high predictive performance is required for web mining applications. Web page classification is an essential task in web mining that aims to categorize Web pages into a predefined particular category based on labelled data. Two major issues that should be handled properly for efficient and robust web mining applications are dealing with high-dimensional feature space and achieving high predictive performance. Hence, this paper examines the effectiveness of four popular feature selection methods (correlation-based feature selection, consistency-based feature selection, information gain-based feature selection and chi-square-based feature selection methods), and the effectiveness of four different ensemble learning algorithms (Boosting, Bagging, Dagging and Random Subspace) is evaluated on four classification algorithms (naive Bayes, K-nearest neighbour algorithm, C4.5 algorithm and FURIA algorithm). The experimental results indicate that feature selection and ensemble method combination can be useful for achieving better predictive performance. In our experiments, the best (highest) average predictive performance on the DMOZ dataset directory is 88.1%, which is achieved with the use of consistency-based feature selection with AdaBoost and naive Bayes algorithms. In addition, among all the compared results, Bagging and Random Subspace yielded better performances than base learning algorithms and correlation-based and consistency-based feature selection methods achieved higher performance compared with other configurations.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.