
Abstract
With the prevalence of research social networks, determining effective methods for recommending scientific articles to online scholars has become a challenging and complex task. Current studies on article recommendation works are focused on digital libraries and reference sharing websites while studies on research social networking websites have seldom been conducted. Existing content-based approaches or collaborative filtering approaches suffer from the problem of data sparsity. The quality information of articles has been largely ignored in previous studies, thus raising the need for a unified recommendation framework. We propose a hybrid approach to combine relevance, connectivity and quality to recommend scientific articles. The effectiveness of the proposed framework and methods is verified using a user study on a real research social network website. The results demonstrate that our proposed methods outperform baseline methods.
Keywords
1. Introduction
The rapid development of information technology, especially Web 2.0, has led to a tremendous growth in online content. The presence of massive amounts of information has posed significant challenges to the discovery of new information, particularly in academia. The number of scientific articles has experienced explosive growth. Over 66 million digital object identifiers (DOIs) have been registered, with each DOI linked to one distinct scientific item; these DOIs include more than 65 million journal articles. 1 Researchers complain of information overload and are frustrated by the search for relevant scientific information. Such an environment urgently requires an efficient and effective information acquisition technology that can help researchers to quickly find relevant articles of interest.
The methods that researchers use for information acquisition have dramatically transformed with the development of information technologies. Researchers in the print age traditionally searched for relevant articles by using library catalogues. This method was ineffective because of the limited number of journal articles and books available in libraries. Online access services, such as Google Scholar 2 and Web of Science database, 3 provide a powerful search tool for finding relevant articles. Digital libraries make academic resources available online and provide a variety of convenient functions for effective information retrieval. For instance, keyword-based search is a convenient and efficient approach to retrieve information. However, forming queries for finding new research articles can be difficult when researchers are uncertain about what they are looking for.
With the spread of social sharing websites (such as CiteULike 4 ) and social networking services (such as Researchgate 5 and Scholarmate 6 ), researchers can now easily share references of interest and promote their own publications. Social networking applications facilitate information search and provide online users with freedom while creating new challenges related to information overload. In this article, we attempt to provide an automatic process of recommending the most relevant articles to scholars in research social networks.
Article recommendation is a hot research topic that has been intensively studied in different contexts [1]. Earlier studies proposed content-based (CB) methods to leverage textual information related to the target user’s interest in recommendation and employed keyword weighting techniques to retrieve relevant articles in digital libraries [2–5]. However, keywords generated through a researcher’s query often have semantic ambiguities. Such semantic relationships may also exist in the documents. Therefore, traditional CB approaches suffer from a mismatch problem, that is, relevant documents that do not exactly match the researcher’s query are discarded. In several studies, collaborative filtering (CF) approaches were employed to leverage the preferences of like-minded users in recommending interesting articles in social computing contexts [6–9]. However, these approaches cannot achieve the expected performance as in taste-related domains (movies, videos and online purchases) because of the data sparsity of the preference matrix, in which the number of scholars (users) is too small and the number of articles (items) is large. Hence, current studies have focused on hybrid recommendation approaches to leverage the advantages of CB and CF approaches and to alleviate their disadvantages [10–14]. Current hybrid methods combine relevance and connectivity features to build recommendation models while ignoring information quality.
In this article, a hybrid approach is proposed to tackle the key challenges highlighted above. The proposed approach leverages relevance, connectivity and quality features in research-oriented social networks to profile online users. Three analysis modules are employed to model the recommendation process and to ensure that a satisfactory recommendation list is provided. An experiment is conducted in a Chinese research social network website to verify the effectiveness of proposed method. The results show that the proposed approach outperforms the baseline methods in terms of recommendation accuracy metrics.
The rest of the article is organised as follows. In section 2, we survey the related work on article recommendation. The details of the social-network-empowered article recommendation method are introduced in section 3, while section 4 presents the design and methodology used in the experiments. The results are analysed and discussed in section 5. We conclude the work and present the future work in section 6.
2. Related work
Personalisation techniques enable the tailoring of content and services to individuals based on their preferences and tastes. As a primary personalisation tool, a recommender system matches potentially interesting content with user expectations [15]. Recommender systems have gained increased popularity, resulting in huge profits for the industry. They are designed to recommend microblogs [16], news [17], stories [18], movies [19] and so forth. These systems show great prospect and potential to serve scientific communities. In academic contexts, such systems are often used to recommend relevant scientific information to researchers and to consequently reduce search efforts. Several researchers have focused on article recommendation from various perspectives. The related work is reviewed in terms of application domains and recommendation techniques.
2.1. Application domains
Application domains on article recommendation have three main categories: digital libraries, reference sharing websites and academic social networking websites.
2.1.1. Digital libraries (D1)
With the prevalence of the Internet, digital libraries have been frequently used by diverse communities of users and have thus become a source of scientific information for scholars [20]. Digital libraries can be informally defined as collections of information with associated services that are delivered to user communities using a variety of technologies [21]. Digital libraries have evolved rapidly over the past several decades but are still limited to providing only basic search functions. As the volume of information managed by digital libraries increases, the needs of users have also become increasingly complex. Furthermore, users have become frustrated with the limitations of basic facilities. Currently, several digital libraries have begun to offer personalisation functionalities. These functionalities include personalised alert services that notify users with a list of new and relevant documents. Recommender systems are also incorporated into these libraries to meet information needs. Bollacker et al. [22] developed several recommendation strategies to aid researchers in quickly discovering relevant scientific literature.
2.1.2. Reference sharing websites (D2)
Resource sharing systems have become increasingly widespread with the development of Web 2.0 technologies. These systems allow users to upload various types of resources and select objects of interest with personalised tags. Mainstream reference sharing websites include CiteULike, Bibsonomy, 7 Zotero 8 and Mendeley. A myriad of studies have proposed different kinds of paper recommendation methods based on these websites. CiteULike is a social tagging website that offers free service to aid researchers in storing, organising and sharing scholarly papers they are reading. Articles are often stored with their metadata (e.g. title, author and year) and include links to the pages of publishers. Bibsonomy is another social bookmarking and publication sharing system that is focused on bookmarking references and team-oriented publication management. The Bibsonomy system has gained much attention in the academia because it has provided its open application programming interface from the beginning [23]. Zotero and Mendeley focused on the reference management function that assists researchers in organising bibliographic documents.
2.1.3. Academic social network websites (D3)
Reference sharing websites help readers share and find relevant papers, whereas academic social networking websites (e.g. Researchgate, Academia.edu 9 and Scholarmate) focus on the producers of these papers. Researchgate is a typical social networking site for researchers and is often described as a mixture of ‘Facebook, Twitter, and LinkedIn’ because of similar social features. 10 Madisch [24] noted that Researchgate as a social network is the first step towards Science 2.0. This social network has also been distinguished for its academic discussion functions. Academia.edu is an academic social networking site founded by an Oxford University philosopher. The primary rationale of the site is to connect readers to authors to facilitate the raising of queries on recently read articles [25]. Previous studies investigated the two academic social networking websites in terms of their facilities and the implications of their use. However, research that explores recommender systems in these websites is scarce.
2.2. Recommendation techniques
Three types of recommendation techniques mentioned have been employed in the recommendation of scientific articles to researchers. The choice of recommendation techniques often depend on the type of feature used. CB techniques commonly use relevance features to search for relevant articles, whereas CF techniques focus on connectivity features. Hybrid techniques often combine two or more features to build recommendation models.
2.2.1. CB methods
CB filtering methods have been proposed to discover interesting articles. Some studies [5,26–29] have suggested that CB approaches are effective in locating textual documents that are relevant to a topic. These methods often require the extraction of personal preferences to build user profiles from document content. User profiles can be constructed through either explicit declaration by users or observation of users’ actions. A successful digital library system, CiteSeer [22], was designed to perform information-filtering and knowledge-discovery functions for online users. CiteSeer uses the personal profiles of researchers to track and recommend relevant research articles. In the study, the different information sources on papers and reviewers were combined for recommendation with the help of a word-based information representation language system. The CB approach used in the work of Soo Kim [30] calculated keyword scores based on locations and frequencies within the text. The semantic expansion method [26] and concept-based method [5,31] have been proposed to address the problem of inadequate information as well as to enhance user profiling and achieve highly relevant recommendations. Most of these methods face the problem of generalisability because they use existing dictionaries and taxonomies, such as WordNet and ACM Taxonomy. In this study, we construct a keyword similarity matrix for semantic expansion to address the mismatch problem.
2.2.2. CF methods
CF methods have attracted increasing attention in recent years because of the prevalence of social bookmarking and social networking websites. Bogers and Van den Bosch [32] applied the traditional CF approach in recommending scientific publications in the CiteULike database and found that a user-based approach is better than an item-based approach because of data distribution factors. Parra and Brusilovsky [33] proposed and evaluated three variants of user-based CF article recommendation algorithms. In their study, BM25-boosted CF achieved better performance compared with the other two CF methods (classic CF and neighbour-weighted CF) because of tag contribution. To overcome the data sparsity problem, Vellino [34] proposed usage-based and citation-based methods for recommending research articles. In addition to collective relations involved in user–item pairs, other social relations have also been analysed and incorporated into CF methods to improve performance. The literature shows that social relations can be used to improve recommendation quality. Guan et al. [35] mined tagging data (user–tag–item assignments) and proposed a graph-based learning algorithm for document recommendation.
2.2.3. Hybrid methods
CF and CB approaches have unique advantages and disadvantages. Several researchers have attempted to combine both techniques and generate hybrid ones to improve performance [11,12,14,36]. The main assumption for hybrid methods is that fusing the algorithms could provide more accurate recommendations than a single algorithm could and that the disadvantages of each algorithm could be overcome by other algorithms. Bogers and van den Bosch [37] considered tagging information and content metadata information, and proposed different fusion strategies for different algorithms. They found that fusing methods significantly improves recommendation accuracy. To incorporate relevance and connectivity features into a unified model, Wang and Blei [8] proposed a hybrid method that combines the merits of traditional CF and probabilistic topic modelling and is capable of providing recommendations on both existing and newly published articles. By contrast, Li et al. [12] proposed a topic regression MF (tr-MF) model based on the assumption that users share similar preferences when they bookmark similar articles. In Lee et al. [14], a hybrid method, combining the CB and the graph-based approaches, was proposed suitable for paper recommendation in DBpia.
Table 1 shows the selected major works on article recommendation, from which general conclusions can be drawn. For application domains, traditional article recommendation studies have focused on digital libraries while recent works have paid attention to reference sharing websites (or social tagging sites). However, few studies have investigated article recommendation in research-oriented social networking websites. Such studies are low in number because of the absence of a public dataset for article recommendation in research-oriented social networks and the high cost of conducting user studies on research-oriented social networks. For recommendation techniques, three types of recommendation approaches in E-commerce contexts have been borrowed for use in academic contexts. CB approaches often provide recommendations based on relevance features, and direct keyword weighting methods have been widely employed in previous studies. CF approaches usually build recommendation models based on connectivity features, especially behaviour connections. Hybrid approaches combine two types of features and often outperform basic CB and CF approaches.
Taxonomy of article recommendation studies.
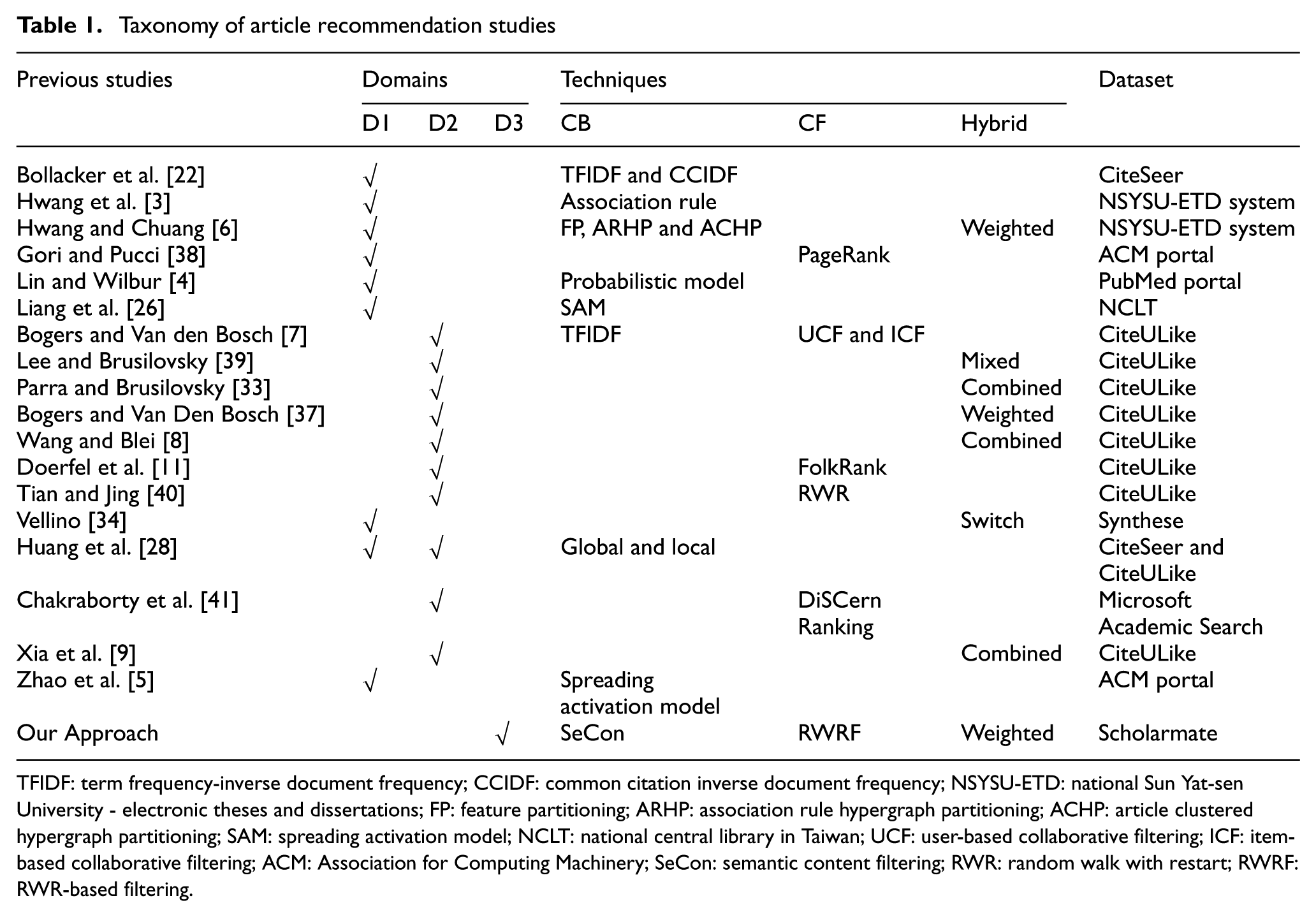
TFIDF: term frequency-inverse document frequency; CCIDF: common citation inverse document frequency; NSYSU-ETD: national Sun Yat-sen University - electronic theses and dissertations; FP: feature partitioning; ARHP: association rule hypergraph partitioning; ACHP: article clustered hypergraph partitioning; SAM: spreading activation model; NCLT: national central library in Taiwan; UCF: user-based collaborative filtering; ICF: item-based collaborative filtering; ACM: Association for Computing Machinery; SeCon: semantic content filtering; RWR: random walk with restart; RWRF: RWR-based filtering.
From Table 1, several important research gaps are identified. First, discovering scientific information from research-oriented social networks has become increasingly common with the prevalence of social networking sites. However, the issues of article recommendation in research-oriented social networking websites have seldom been addressed. To our knowledge, only one work has conducted document recommendation in social trust networks, with the proposed method evaluated in simulation studies. Second, direct keyword weighting methods dominate previous CB approaches, although keyword mismatch problems often emerge. Thus, a semantic content filtering method is needed to address these issues. Third, behaviour connections have been widely used, but additional information has not been mined. Fourth, the quality of information in articles has largely been ignored in previous studies, thereby raising the need for a unified recommendation framework that combines relevance, connectivity and quality features.
3. Hybrid article recommendation
3.1. Overview of recommendation framework
In this study, an integrated approach is proposed in building the article recommender system. Figure 1 shows the main components and procedures of the proposed article recommendation approach.
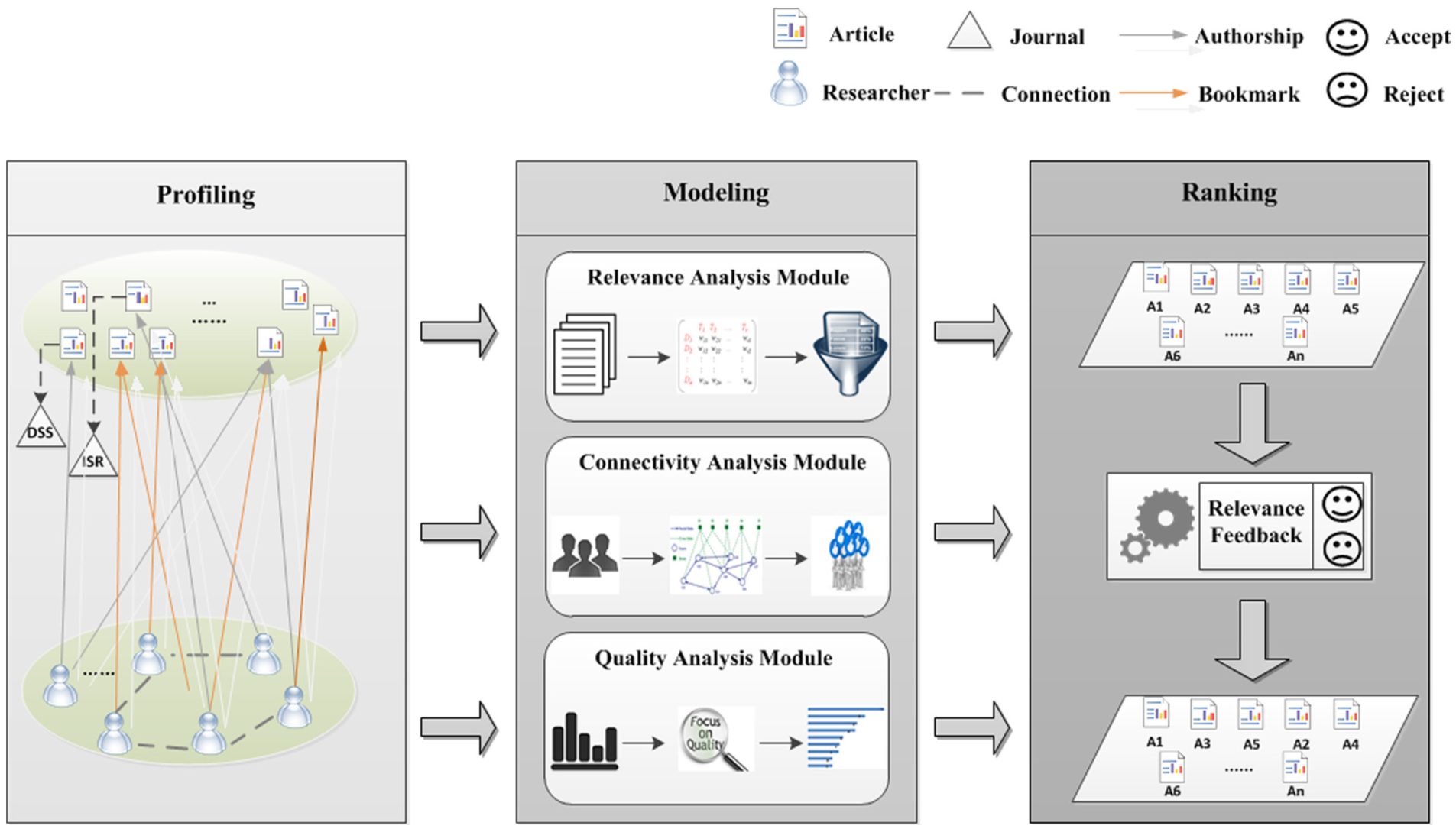
Overview of unified framework for article recommendation.
For the target user, the proposed recommender system outputs a list of relevant articles. A two-stage recommendation strategy is employed to provide article recommendation effectively and efficiently. In the first stage, initial results are output by matching the user profile with profiles of candidate articles such that irrelevant articles are filtered out. In the second stage, the relevance, connectivity score and quality score derived from the former analysis modules are further aggregated with the appropriate weighting distribution. The final article ranking list becomes appropriate and accurate after aggregation.
3.2. Profiling
In general, profiling is the process of identifying and determining relevant information and attributes that can be used to characterise a given object. In the article recommendation context, we focus on the means of collecting the necessary data to construct a comprehensive researcher profile. According to Vivacqua et al. [42], researcher profiles can be constructed in two ways: declaration and inference based on observation of research activities. Declared profiles are reflected by subjective information that often contains self-claimed interests, expertise and skills. The subjective information is often represented by structured keywords. However, obtaining this information imposes extra work on the researcher. Thus, this information is often incomplete and difficult to update. The observation and interpretation of research activities has the potential to build accurate profiles that can be constructed automatically and objectively. In research-oriented social networks, users promote their own publications and bookmark articles of interest for reading. These user activities allow service providers to design recommender systems that can assist users in discovering relevant scientific information. Online users often create their homepages and claim areas of expertise and research interest to easily communicate with other scholars. Researchers connect with others or participate in social groups to promote outputs, share experience and ultimately expand their academic influence. Scientific articles are usually collected from standard academic databases by service providers or from those imported by users. The content (such as title and abstract) and metadata (such as published journal and year) of these articles are often collected to provide users with an overview. The graph representation of the data on research-oriented social networks is presented in Figure 2. These data are utilised in building recommendation models, as described in the next section. In our context, researchers represent users. The terms researchers and users are used interchangeably in this study.
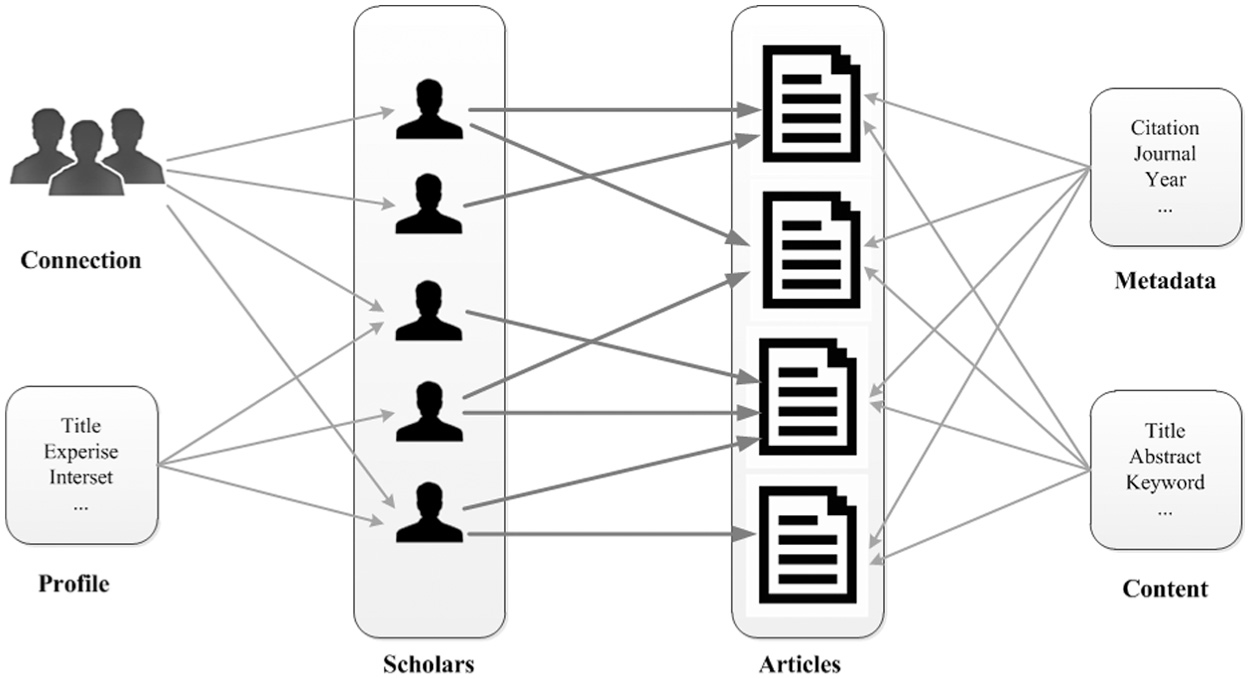
Graph representation of data on research social networks.
3.3. Modelling
3.3.1. Relevance analysis module
This module proposes a semantic keyword weighting method to determine the content relevance of candidate articles. Natural language processing (NLP) procedures are initially used to preprocess articles and construct a keyword–article (KA) matrix, in which matrix elements represent weighted term frequencies. The similarities of keywords are then calculated to build a keyword correlation matrix. In this study, we consider the frequency of keywords in the title, abstract and keyword list as well as social tags to address the keyword sparsity problem. The elements in the KA matrix denote weighted frequency scores (FSs). FS can be calculated as
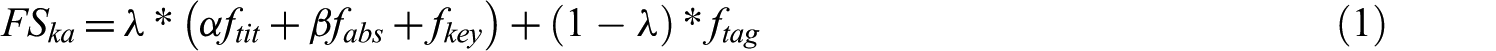
where
In the initial step

In the pth step
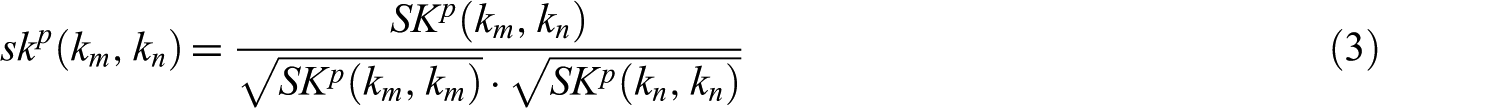
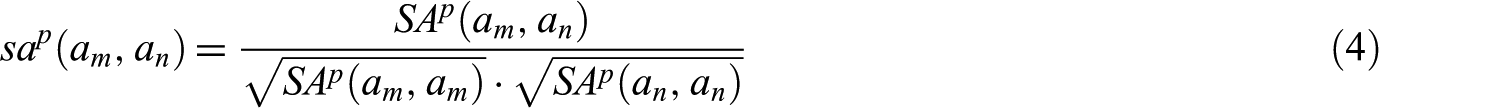
where
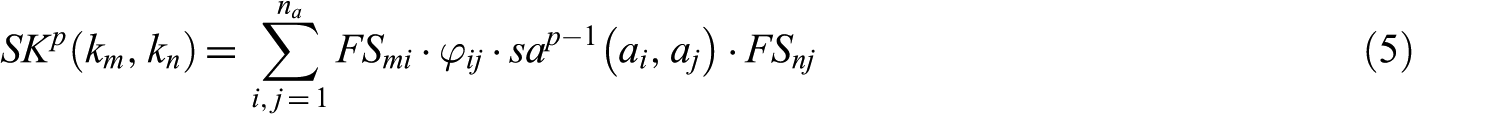
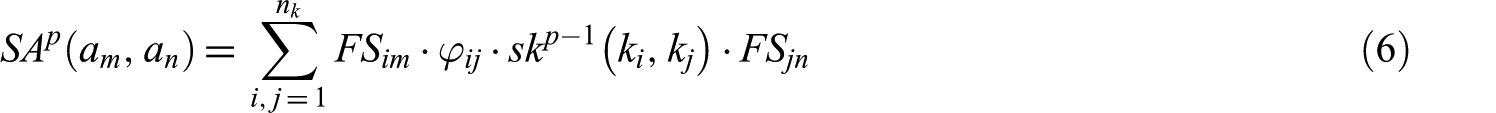
Keyword similarity
The relevance score between the researcher profile and the article profile is calculated as follows
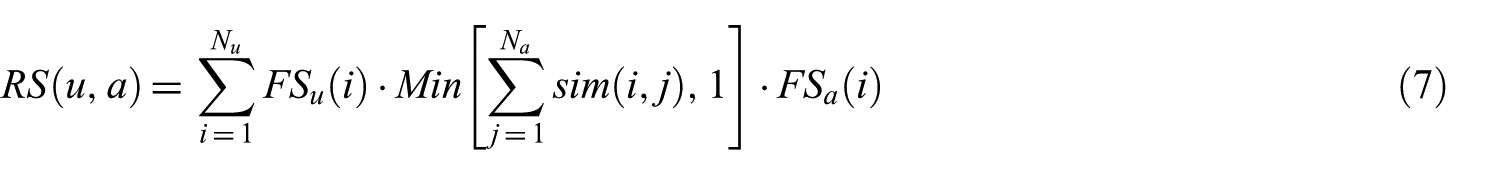
where
3.3.2. Connectivity analysis module
In this study, three types of connectivity features (behavioural, social and semantic features) are utilised to improve article recommendation performance. We represent behavioural, social and semantic connectivity as user–article (
We can derive an undirected tripartite graph

RWR method is employed in the graph

where
The algorithm of Neighbour Selection with RWR

3.3.3. Quality analysis module
Quality-based retrieval has been paid more attention in recent information retrieval research [44]. The quality of documents has great influence on satisfying a user’s information needs. In this study, three measures are proposed for evaluating the quality of a scientific article: recency, citation and journal impact factor (JIF).
Users often want to read recent papers that are related to their own research interests. The recency measure reflects the freshness of an article and is an important factor in evaluating the quality of articles. It is defined as follows

where

Most search engines consider links of webpages and employ PageRank to present the authority of a webpage. Thus, the network of article citations can be inspected to evaluate the quality of an article. In this study, citation count is employed to represent the authority of an article. The citation measure is defined as

where

The quality of an article is often evaluated by its published venue, such as a journal. The JIF is a tool for ranking journals and is marketed as a tool for evaluating single articles. Although the impact factor is not a perfect tool for measuring the quality of articles, it is the only one deemed effective and has the advantage of already being in existence; therefore, it is a good technique for scientific evaluation [45]. The use of impact factor as a measure of quality is widespread because it fits well with the opinion we have in each field of the best journals in our specialty. The JIF measure

where

Finally, all three measures are aggregated into a scoring function that ranks the retrieved articles. The score function is essentially a weighted sum of quality measures

where
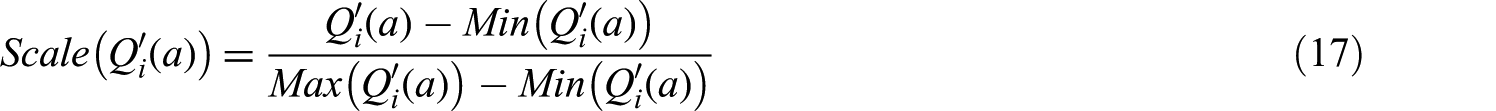
where the subscript i represents different types of quality measures, and
The weights of measures (

where

3.4. Ranking
As the number of articles in research-oriented social networks can be very large, comparing each article with the profile of a target user would be inefficient, and the computation could significantly prolong the recommendation process. To reduce the processing time and to increase the efficiency of the computation, we apply a pre-filtering strategy in the articles within the collections to generate a subset of candidate articles for recommendation in the next stage. If an article contains at least one keyword that exactly matches or is highly similar to one of the keywords in the target user profile, it can be considered as a candidate. We employ a reduced version of the keyword correlation matrix that contains 30% of the most frequently occurring keywords to identify highly similar keywords. After filtering out irrelevant articles, we compute recommendations by aggregating the relevance, connectivity and quality scores of the candidate articles with appropriate weights. The aggregated score is defined as follows
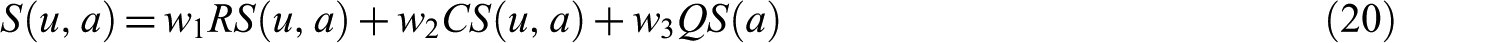
where

Let
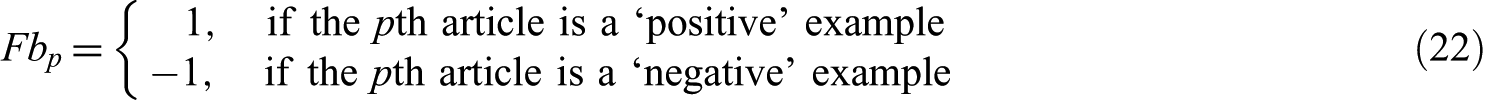
Then, let

In calculating weight

where

Obviously, a great overlap of relevant objects between
4. Experimental design
4.1. Implemented system in Scholarmate
Scholarmate is an online professional social networking community platform in China. The platform aims to foster a knowledge-sharing cyberspace for researchers to allow them to collect and share different resources [48,49]. The proposed approach is implemented as one of the application services in Scholarmate. The system provides main interfaces to extract article-related data, including titles, keywords and abstracts. Once the system has gathered the required information, matching degrees between article and researcher profiles are calculated. The system also extracts different relationships among online researchers to support social-network-empowered recommendation. Figure 3 presents the interface of the article recommendation application with descriptive features (content and social features). As shown in the right panel of Figure 3, additional details about article quality are also provided by the system. The decision button (accept or reject) is displayed in the last column.
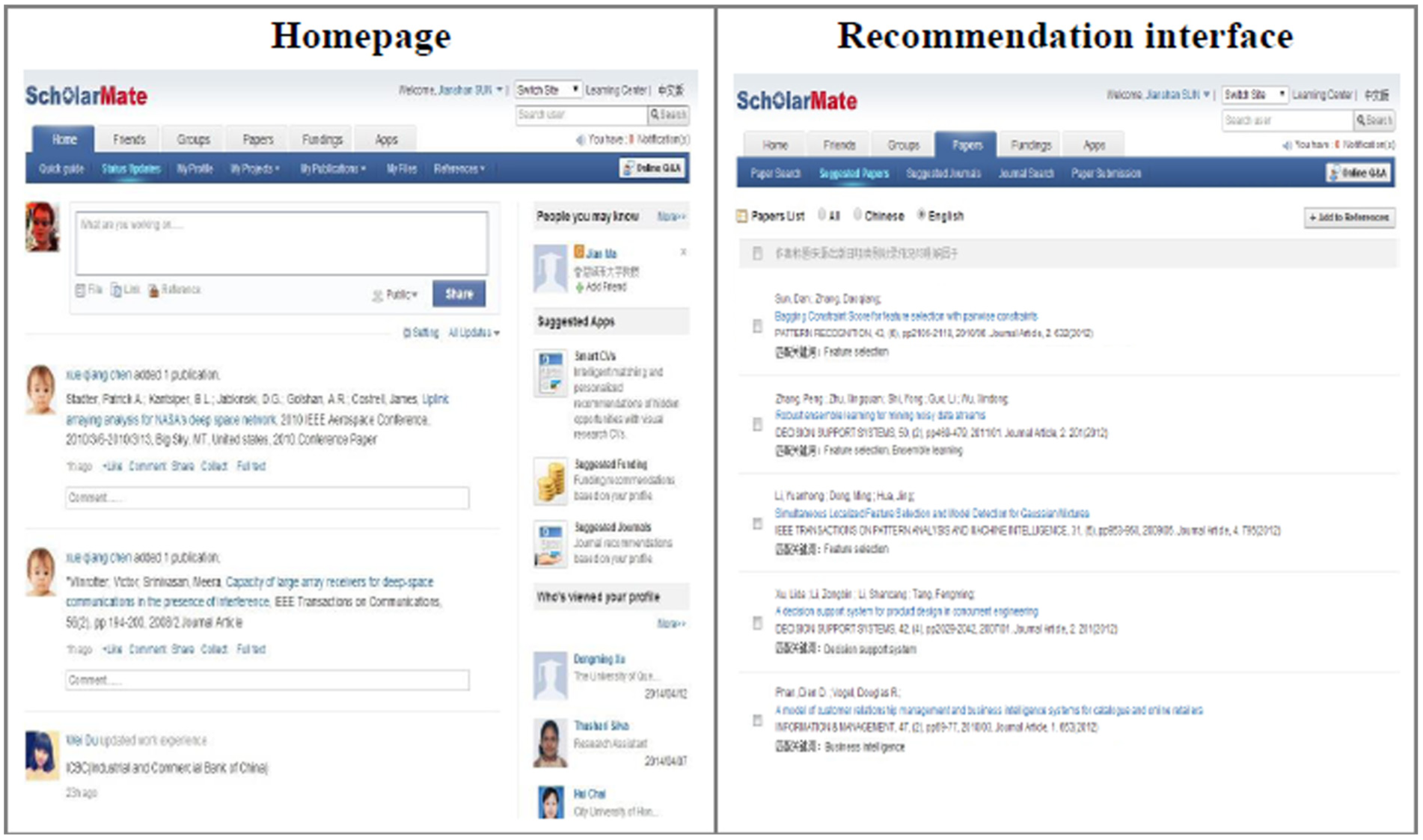
Homepage and article recommendation interface in Scholarmate.
4.2. Data and methodology
A user study is run in Scholarmate to verify the effectiveness of proposed method. For the performance comparison of recommendation methods, we implemented our methods and baselines. They are listed as follows:
Semantic content (SeCon) filtering method: This method has been presented in section 3.3.1.
RWR-based filtering (RWRF) method: This type of model-based CF approach employs RWR to combine connectivity features. This method has been presented in section 3.3.2.
RCQ_SUM recommendation method: This integrated method employs CombSUM strategy [50] to combine the results from the relevance analysis, connectivity analysis and quality analysis modules. It is a type of weighted hybrid recommendation method that sums the results of the three separate analysis modules with equal weights.
RCQ_MNZ recommendation method: This integrated method employs CombMNZ strategy [50] to combine the results from the relevance analysis, connectivity analysis and quality analysis modules. This method regards not only the scores in each of the ranked list but also the number of supported evidence (non-zero scores in each list).
RCQ_RF recommendation method: The RCQ_RF method is our proposed hybrid recommendation method that determines weights by leveraging the user’s relevance feedback. This method has been presented in section 3.4.
All the recommendation methods mentioned were evaluated in the user study. The user study consisted of two main stages (Figure 4). In the first stage, we collected the publications and social activity data of users to compute the scores in the three analysis modules. Using the calculated scores, we provided three recommendation lists (SeCon1, RWRF1 and RCQ_SUM1) to users and investigated their levels of satisfaction with the recommendation lists. We then conducted a comparison analysis on the results of the three methods. In the second stage, we collected relevance feedback on the recommendations in the first stage and computed new recommendations based on adaptive weights. We conducted the second-round survey by providing recommendation lists based on the three hybrid methods (RCQ_SUM2, RCQ_MNZ2 and RCQ_RF2) and conducted another comparison analysis on the results of the three hybrid methods.
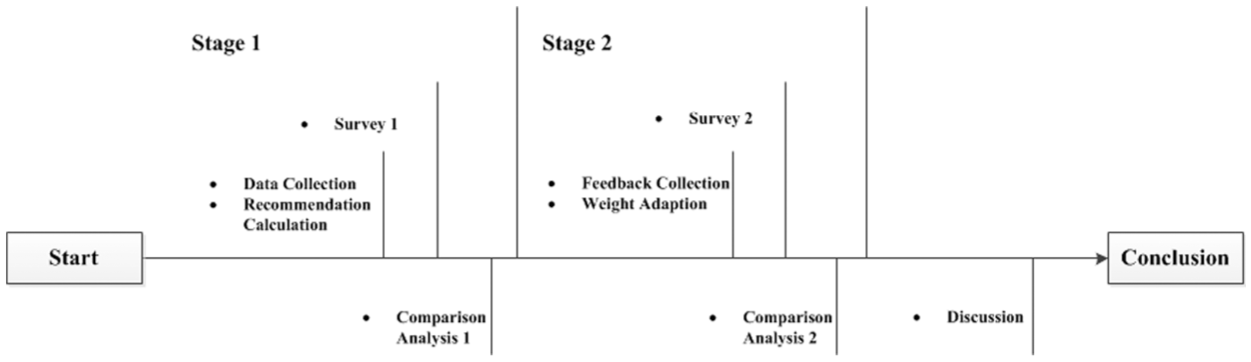
The user study process in Scholarmate.
Our aim is to validate the proposed recommendation method by having online users assess the accuracy of the issued recommendations. Hence, users taking part in the evaluation are referred to as subjects. At each stage, recommendation lists from the three methods were computed, and the top 10 recommendations from each method were presented. Then, each subject assessed the randomised combined recommendation list (not more than 30 articles) to ensure that the rank of a recommendation did not influence the subject’s perception. The subject rated each recommended article on a five-point Likert scale ranging from 1 to 5. Notice that one mark means the subject is not at all interested in the recommended opportunity: this recommendation is not relevant. On the contrary, a high mark by a subject indicates the great relevance of a recommendation. We could thus use the obtained feedback data to evaluate the effectiveness and accuracy of our proposed approach.
We considered active registered users in Scholarmate as subjects from 12 distinct disciplines, such as information systems and management science (refer to the National Natural Science Foundation of China discipline tree 11 ). A total of 100 active users were randomly selected and subjected to the condition that each should have at least three publications in Scholarmate. In the first-round survey, we conducted an online survey of their perceptions on the quality of the recommendation results obtained by the integrated recommendation method and by the other two alternatives. We collected 76 valid responses. The response rate was 76%, which is an acceptable rate. Among the subjects, 14% held the title of professor, 38% held the title of associate professor and 48% held the title of lecturer. In the second-round survey, personal weights were adjusted separately for each user using the relevance feedback adaption mechanism. Then, recommendation lists were recomputed and again presented to users 1 month later. The articles recommended during the first stage were excluded from this stage. In total, 45 users completed our second-round survey.
4.3. Evaluation metrics
Similar to that in traditional recommendation and search systems, we recommended a list of relevant articles to users and asked them to rate the recommendations. The average rating (AR) score and the normalised discounted cumulative gain (NDCG) were selected as performance metrics [51]. These metrics were computed over the top 5 and 10 recommended articles. AR was computed based on the ratings from all the users and indicated the AR of all the recommendations. The NDCG is a commonly adopted metric for evaluating a search engine’s performance and is used for gradual judgments (i.e. documents are non-relevant or more or less relevant to the query). The metrics used are defined as follows


where
5. Result analysis and discussion
In this section, we present the detailed comparison of the results from the online user study. According to Buckley and Voorhees [52], evaluating a search engine should guarantee at least n = 25 queries to ensure the robustness of the retrieval practice. We have 76 valid responses in the first stage and 45 valid responses in the second stage. These numbers are robust for statistical analyses. The performance results of the three methods are shown in Tables 3 and 4.
Performance of three methods in terms of AR.

AR: average rating.
p-value significant at alpha = 0.05; **p-value significant at alpha = 0.01.
Performance of three methods in terms of NDCG.

NDCG: normalised discounted cumulative gain.
p-value significant at alpha = 0.05; **p-value significant at alpha = 0.01.
5.1. Evaluation of the integrated recommendation framework
The proposed integrated method, RCQ_SUM1, achieves the best performance in terms of both the AR metric and the NDCG metric. The AR scores obtained by using the SeCon method and the RWRF1 method are 3.68 and 3.52, respectively, when recommending the top five articles to users. Although these results are acceptable, the integrated method achieves an improvement of more than 8.4% over the best baselines (SeCon1) because it also considers the additional article quality factors. The improvements of AR for the top 10 recommendations also indicate that the integrated method can recommend more relevant scientific articles compared with the two other methods. We further evaluate the rank performance of the three methods. The NDCG scores reflect the browsing efforts of the users before locating the relevant scientific articles. In terms of the NDCG values, the RCQ_SUM1 method achieves over 12.8% improvement for the top 5 recommendations and over 8.7% improvement for the top 5 recommendations. The improvements in the NDCG value clearly show that the RCQ_SUM1 method is more effective than the SeCon and RWRF methods, as it provides a higher ranking for the relevant articles in the recommendation list.
We also test the significance of the improvement of the results of the integrated method over baseline methods by means of paired t-tests. Tables 3 and 4 show that improvements of the integrated method over the best baseline method in terms of AR and NDCG are all statistically significant.
5.2. Evaluation of relevance feedback fusion
The analysis above indicates that the RCQ_SUM1 method outperforms the other two non-hybrid recommendation methods (SeCon1 and RWRF1). We further investigate the performance of the hybrid method that employs the fusion strategy of relevance feedback. The three hybrid methods (RCQ_SUM2, RCQ_MNZ2 and RCQ_RF2) are compared, and the results are listed in Tables 5 and 6. The RCQ_RF2 method clearly outperforms the other two hybrid methods. The performance improves significantly in terms of AR and NDCG for the top 5 and 10 recommendation lists when relevance feedback weight adaption is used. Therefore, we can conclude that employing users’ feedback can help improve recommendation accuracy.
Performance of three hybrid methods in terms of AR.

AR: average rating.
p-value significant at alpha = 0.05; **p-value significant at alpha = 0.01.
Performance of three hybrid methods in terms of NDCG.
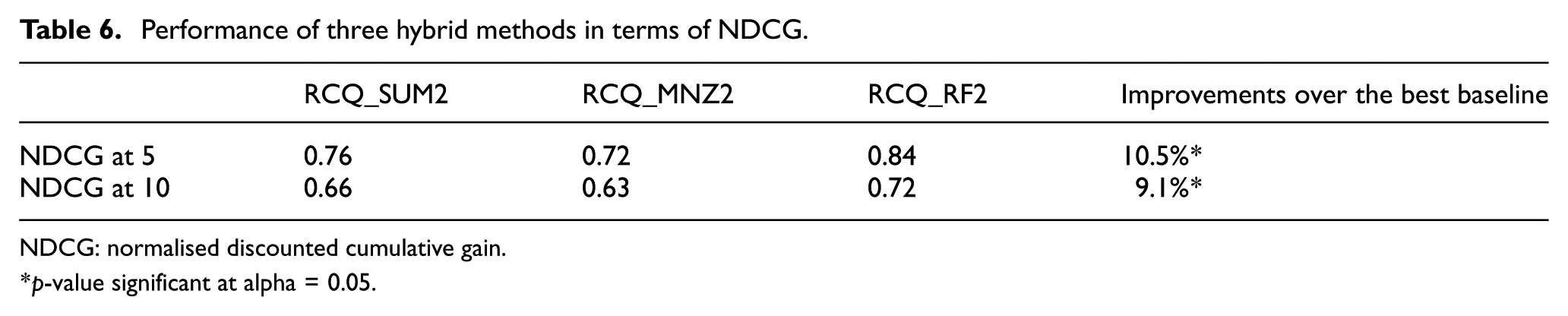
NDCG: normalised discounted cumulative gain.
p-value significant at alpha = 0.05.
6. Conclusion
Personalisation has become a major trend in the industry and the academia, and the recommender systems have become the mainstream in academic communities. In this research, we propose an integrated recommendation framework to help scholars discover relevant articles. The designed recommender system was implemented in a real social networking website. To overcome the shortcomings of the traditional CB- and CF-based methods, we propose a three-dimensional recommendation framework and relevance feedback techniques to fuse the results. The proposed framework and methods were evaluated in a user study. The results show their promising performance in terms of accuracy metrics.
This research has several limitations. The first limitation is related to the semantic content filtering method in the relevance analysis module. In this study, we employed keyword similarity to expand the user profile. The use of domain ontology will help to resolve the semantic ambiguity in keyword matching. In the future, research domain ontology can thus be constructed to support extended profile matching. The second limitation is related to the evaluation part. The number of active subjects in the user study was limited. With the prevalence of Scholarmate, an increasing number of researchers will be actively involved in the website to connect with other scholars for intelligent research. Thus, we will expand the size of the experiment to obtain truthful results.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This work is supported by the National Natural Science Foundation of China (71501057, 71490725, 91546114 and 71371062), the National Key Technology Support Program (2015BAH26F00), Innovative Research Groups of the National Natural Science Foundation of China (71521001), the Humanity and Social Science Foundation of Ministry of Education (15YJC630111), Anhui Provincial Natural Science Foundation (1608085QG166) and Hefei University of Technology (JZ2014HGBZ0368 and JZ2017HGTB0185).