
Abstract
Many organisations are re-creating the ‘Google-like’ experience behind their firewall to exploit their information. However, surveys show dissatisfaction with enterprise search is commonplace. No prior study has investigated unsolicited user feedback from an enterprise search user interface to understand the underlying reasons for dissatisfaction. A mixed-methods longitudinal study was undertaken analysing feedback from over 1000 users and interviewing search service staff in a multinational corporation. Results show that 62% of dissatisfaction events were due to human (information and search literacy) rather than technology factors. Cognitive biases and the ‘Google Habitus’ influence expectations and information behaviour and are postulated as deep underlying generative mechanisms. The current literature focuses on ‘structure’ (technology and information quality) as the reason for enterprise search satisfaction, agency (search literacy) appears downplayed. Organisations which emphasise ‘systems thinking’ and bimodal approaches towards search strategy and information behaviour may improve capabilities.
Keywords
1. Background
Digital information volumes are increasing exponentially inside organisations [1–3]. This offers the potential for overwhelming information overload, unprecedented levels of information access and serendipitous information discovery [4], which may help or hinder decision making.
In response to this need, many organisations have invested in Enterprise Search and Discovery information retrieval (IR) technologies to allow staff to search their organisation’s distributed information repositories (such as documents, web pages, images and databases) for information. These Enterprise Search engines facilitate the re-use and exploitation of organisational information to share and create new knowledge, saving time and supporting decision making. As such, they are a key part of the digital workspace [5–7].
There is a general dearth of academic socio-technical empirical studies on Enterprise Search environments. This is most likely caused by the difficulties for researchers in gaining access to corporate environments, spending time with staff, accessing information and releasing results [8,9]. The existing literature tends to focus on three areas. First, the generic challenges of enterprise search compared with Internet search [10,11]. Second, numerous studies focusing on evaluating IR [12] applied to the enterprise [13]. Third, practitioner suggestions for the formal organisation, from the perspective of someone managing a search service [5–7].
However, there have been few holistic (transdisciplinary) academic empirical research studies on Enterprise Search from a socio-organisational perspective [14,15]. This is important because the problems faced in organisations can be complex, multi-disciplinary and often resistant to change. Existing enterprise search studies tend to be reductionist, focusing on the ‘parts’ or single disciplines, not the interconnected transdisciplinary ‘whole’ of Enterprise Search and Discovery capability, which could be described as a system. The emergent nature of outcomes and how they change over time means in an open system, it is likely they will be poorly understood by simply studying constituent parts; it is the interaction between all the parts that may determine search task outcomes.
It has been stated (pp. 1–2) that ‘Enterprise Search is an area of increasing importance that has not received the attention it deserves. Not much work if any, has looked at searching from the point of view of the organization, or applied a strategic perspective on search’ [16], emphasising the lack of effective research into this phenomenon. One of the pre-requisites to removing barriers to effective search is identifying the factors that cause them [17]. The aim and objectives of this study are to re-examine the factors and generative mechanisms that give rise to user satisfaction with enterprise search tasks. Taking a holistic approach, an underlying factor is defined for this study as any observable (therefore measurable) entity, process or structure which can influence search user satisfaction [18]. Causes are typically multi-factorial, ‘assemblies’ of the presence (and absence) of multiple factors [19]. A generative mechanism is defined for this study as an unobserved entity, process or structure that acts as an ultimate cause [20] that led to the situation of ‘factor assemblies’ and subsequent search user satisfaction. Generative mechanisms are context dependent, so explanations are concerned with tendencies (rather than laws); they are hypothetical, postulated ‘if they existed’ would have led to the phenomena observed (see Figure 1).
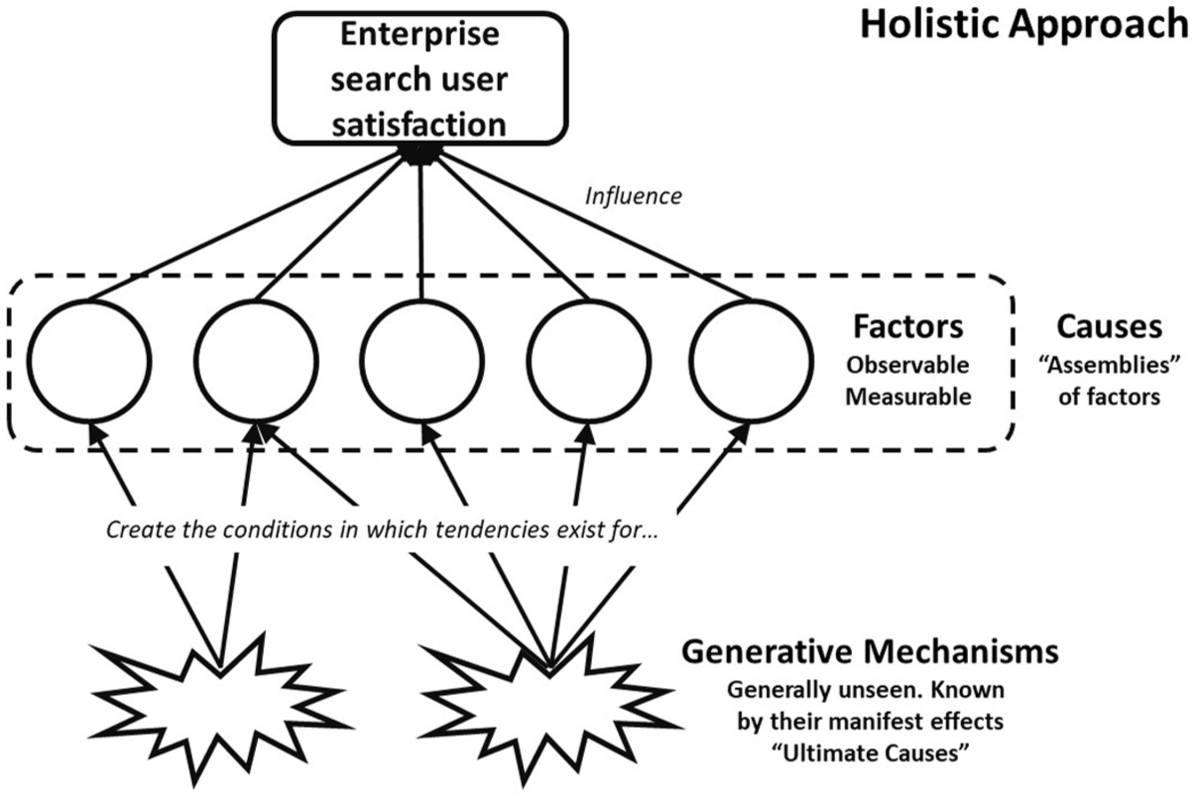
Relationship between the study aims and objectives and enterprise search user satisfaction.
The next section reviews the literature related to enterprise search socio-technical studies. The review then focuses on user satisfaction, moving to the factors deemed to influence satisfaction and underlying potential generative mechanisms, highlighting similarities, contradictions and gaps in the body of research that highlights the need for this study.
2. Literature review
The most recent and to the authors’ knowledge, only, peer-reviewed socio-technical empirical study in an Enterprise Search environment was titled ‘Exploring barriers of Enterprise Search implementation’ [9]. Five barriers to successful enterprise search implementation were identified. These were finding suitable keywords to formulate a successful query, judging relevance, poor metadata, lack of perceived benefits of enterprise search and overall usefulness. While insightful, critically assessing the study, it investigated a tool (Microsoft SharePoint) that was only deployed to search documents (not web pages or other media), for a small number of projects, to a small sample (10 staff) who only had a need to access their own project information that was already stored in a well understood folder structure. The focus was only on lookup/known item search tasks. The study may ultimately be closer to ‘project documentation search in an enterprise’, rather than ‘enterprise search capability’.
2.1. User satisfaction
Business professionals spend an average 23% of their time searching for information [21,22] with higher levels in some industry sectors [23]. Satisfaction with searching and finding information within organisations using search engines has fallen behind the experience using Internet search [11], Enterprise Search appearing more problematic [24]. Satisfaction with Internet search engines appears far higher than Enterprise Search, at 80% [25]. Surveys show that users found the information they were seeking 77% of the time on the Internet in 1999 [26], rising to 90% over the past decade [27,28].
Today, it has been reported that half of private and public sector organisations face significant difficulties to find internal information [29–32]. In an experimental study of a web catalogue, no association was found between the self-selected participant’s user satisfaction and search task performance [33]. Users may have had inflated views of how well they had completed the search task and some scholars have urged caution on using user satisfaction to measure performance [34]. Despite this, Enterprise Search success continues to be predominantly measured using user satisfaction [32,35] with few other key performance indicators for Enterprise Search capability [36]. In the academic literature, the main reasons why users may be dissatisfied with enterprise search tasks appear to focus on search results ranking (how well the item matched the query compared with competing items), whether the item is in the index and whether permissions enable it to be seen by the user [37].
The dominant way to measure user satisfaction with enterprise search appears to be survey based [31], with opinions sought related to an ‘overall’ perception. While some studies gather feedback after a specific task [38], these are small scale in nature. No known studies exist that examine large-scale user feedback after specific enterprise search tasks.
Personality traits such as negative affectivity have been associated with higher level of dissatisfaction with search tasks [39]. It has also been reported that task type can play a role, with users more likely to be dissatisfied with exploratory search tasks rather than lookup/known item search tasks [40].
Three product requirements have been identified that influence satisfaction. Must-be requirements (if these are not present users will be dissatisfied), one-dimensional and attractive qualities. For the latter, users will not be dissatisfied if these are not present, but may be delighted if they are [41]. The expectation (as anticipation) user satisfaction model proposes that expectations have a direct influence on satisfaction independent of perceived performance [42]. For example, the amount of relevant results users think they need may play a crucial role in their judgement of task success [43].
Expectations/disconfirmation theory posits that people arrive at customer satisfaction through a process of comparison [44], comparing perceived performance against their expectations. A positive disconfirmation leads to satisfaction, a negative disconfirmation leads to dissatisfaction. Users may be pre-disposed to their levels of satisfaction with search tools, with expectations of what they should find [39,40,45]. The mass adoption of Internet search engines may have set high expectations for Enterprise Search engines in organisations [46] and is an area which is explored in this study.
The Perceived Performance model posits that if a product or service performs so well in meeting (or exceeding) needs, expectation is discounted and plays a less significant role [47]. Conversely, equity [48] models (net benefits) are based on the perceived value derived from using the product/service to the effort (cost) of using it [49].
Attributions occur when an individual or team infer causes based on outcomes and is suggested as the mechanism for how we make sense of the world [50]. Attribution Theories [51,52] consider three factors: (1) locus of causality (internal/external), (2) stability and (3) controllability in determining satisfaction. In the locus of causality factor, there may be a tendency for people to attribute causes external to themselves (fundamental attribution bias) attributing cause and effect close in space and time (post hoc fallacy). In the stability factor, a consumer may be more forgiving in a product if poor perceived performance is considered a rare event. For example, in a study of health information, many participants were unable to locate the information they needed on the Internet but despite this held health IR on the Internet in a positive light [53]. This may reveal aspects of the longer term ‘loyalty’ aspect of satisfaction [54].
The multiple (combination) process model [55] suggests consumer’s satisfaction is formed from a multidimensional perspective using all (or some) of the previous models. Equity and disconfirmation have been strongly correlated to customer satisfaction [56]; however, there are studies that report expectancy plays little/no role in satisfaction judgements [57].
Within e-commerce, user satisfaction feedback shows tendencies for a ‘j-curve’ distribution skewed to the positive. Where it is suggested that consumers exhibit ‘purchasing bias’, with tendencies to rate the product they invest their time and money in to purchase, more positively [58].
The next section focuses on the factors commonly raised which influence enterprise search satisfaction.
2.2. Factors
2.2.1. Technology factors
Activity feeds, cybersecurity, Question and Answer (Q&A) conversational interfaces, sentiment analysis, word co-occurrence, OpenSource, graph databases, cloud services [59] and combining structured and unstructured data [11] are gaining in importance and have the potential to disrupt existing enterprise search practices.
The increasing volumes of information (big data), increasing use of natural language processing (NLP) for meaning and machine deep learning (for prediction) has led to some commentators to coin new phrases (related to weak artificial intelligence (AI)) for search task-specific applications in the enterprise that attempt to mimic human thought processes. These phrases include ‘insight engines’ and ‘cognitive search’ [60]. Many of these techniques have yet to make their way into mainstream enterprise search deployments [59]. For example, knowledge workers may ask a question like ‘Did we handle such a case before?’, scholars claim that traditional IR systems are not effective in addressing the aims of case workers [61]. For example, NLP and machine learning techniques were applied to documents related to repetitive events, to surface contradictions between the risks an organisation thought existed in its operations and what actually happened [62]. The resulting search-based application was used to help mitigate both the bias of personal experiences and guidance for people lacking experience of assessing risk. Conversely, despite major breakthroughs, some commentators feel we are ‘at the end of the beginning’ with respect to AI technology, where some technology vendor marketing departments and press may have run amok with quixotic hyperbole, setting unrealistic timelines and promises as well as underestimating access to training data and curation issues [63].
Technology quality has been widely cited in the Information Systems (IS) literature as an antecedent to user satisfaction, system success and adoption [64–66]. There have been numerous studies on improving the precision and recall of Enterprise Search results through corpus statistical techniques [67,68], corpus independent statistical approaches [13], taxonomies/thesauri [69,70] and ontologies/the semantic web [71,72].
Statistical vector space techniques and their derivatives such as latent semantic indexing (LSI) and distributional semantics [73] address some aspects of the vocabulary problem and lack of context, using the latent structure within corpus text. This can be used to automatically infer synonyms and synsets for search retrieval and latent topics for discovery [74]. These techniques have also been applied to the user’s search log, to create community profiles based on usage for navigation support rather than query suggestion [75]. With respect to search result ranking, it has been found that precision was associated with user satisfaction but recall was not (p. 193) ‘For users, precision seems to be the king’ [76]. It may be easier for users to judge and comment on what they find, as opposed to make judgements (forecast) what they may be missing. Users in the enterprise may have a greater need for precision than on the Internet [10].
A survey of the Enterprise Search deployment at the Johnson Space Centre at NASA found that the majority (n = 71, 75%) of the responses were below good [35]. When asked to give reasons, 40% of users attributed it to inadequate search results. Whether the cause relates to just technology (ranking) is unclear at this superficial level. An unintuitive interface (8%) was the next most critical issue as attributed by users.
A synthesis of the common functions that may lead to user satisfaction in the user interface (UI) is shown in Table 1.
Functions in enterprise search and discovery technology UIs that are suggested to lead to positive user satisfaction.

UI: user interface; NLP: natural language processing.
Modern Internet search engines are designed to deliver search results with very fast response times and may have set the benchmark for Enterprise Search technology. There is evidence that users will interact more and have higher perceptions of quality towards results delivered faster, compared with results delivered in slow response times [88]. Very small delays in search result response time (100 ms) of Internet search engines affected user’s search behaviour (made less searches) which continued after the delay had been removed [89]. When Google experimented with delivering 30 results on a search page instead of 10, taking an extra half a second to deliver, usage dropped significantly [90]. It has been suggested that most of the hard problems with Enterprise Search infrastructure, scalability and speed have been solved, with the current direction of travel concerned with relevance and the science of understanding user intent [74].
2.2.2. Information factors
The importance of meaningful titles (of documents or web pages), avoiding duplicate documents [91] and the value of user added metadata [32,92] are cited as information quality factors which tend to lead to more successful Enterprise Search user satisfaction [91]. However, enterprise users may often ‘deposit’ rather than ‘publish’ information, giving little thought to its future use or intended audience [59].
It has been suggested that improving the way information is organised and published may, in some cases, be more advantageous than trying to modify search technology [93]. Information culture [94] has also been positively correlated with successful business performance [95]. In a study of Electronic Records Management (ERM) in organisations [96], findings included (1) emphasising how people issues are fundamental and challenging, (2) success/failure can be contingent on presence/absence of small or accidental factors (supporting a complexity theory perspective) and (3) records professions may be part of the problem as well as the solution, such as overzealous metadata capture forms leading to non-adoption of information practices.
Evidence from Enterprise Search deployments indicate lack of tags (and a lack of culture for metadata tagging by staff) is a factor for dissatisfaction [9,32,92]. Tagging is often considered challenging (p. 4), ‘Any capture of metadata that took more than ten seconds to saving a file was considered problematic’ [97].
At the O&G Company Statoil, it was found that the cleaning and deletion of information was not prioritised, important documents were stored in personal file folders and emails, despite the espoused policy to use the company’s Electronic Document Management System (EDMS) [98]. Information simply not being in the enterprise search index may often be a cause for dissatisfaction [54] as well as increasing information volumes ‘the needle is harder to find in a bigger haystack’ [99].
One of the most cited issues in search is the vocabulary problem [100,101] where two people will not choose the same name for the same concept 80% of the time [102], causing a mismatch between the search terms used and the information sought unless semantic information is exploited by the search tool. This leads to challenges for Enterprise Search technology in finding precise information where even the same word can have different meanings [36] and recalling all relevant information [103]. In a case study of the Spanish O&G company RepsolYPF, it was found that after thousands of documents had been added to the company’s EDMS many documents could not be retrieved [104]. The attributed cause was vocabulary mismatches (synonyms and Spanish terms) between the search queries made by users and the keywords attached to documents.
2.2.3. Search service factors
Practitioners have advocated the rooting of an Enterprise Search strategy within an overall Enterprise Information Management (EIM) Strategy as a critical success factor for Enterprise Search implementations with control of information quality of critical importance [5–7]. Treating search engine deployments as a project rather than a proactive ongoing service has been cited as a factor for poor Enterprise Search experiences [6]. The theory is that Enterprise Search technology needs constant maintenance and tuning to give good results, a proposition supported by other practitioners [74]. Practitioners advocate a Search Service Centre of Excellence (CoE) where, (p. 259) ‘feedback is the bedrock of the relevance-centered enterprise’ [74] where the best approach is trial and error ‘iterate and fail fast’. Their role is to ensure user requirements are clearly identified, search logs continuously analysed to tune the search engine application, regular testing to improve ranking and training of users on the search tool functionality [5–7,74,105].
This is evidenced in practice within several large management consultancy and accounting organisations [106,107]. Focusing on the most frequent searches (top 10% or top 20–50) is advocated [6,107]. Looking at the number of searches that deliver no results is also advised, with some reports of Intranets giving no results for 16% of all queries [108]. Accenture’s Enterprise Search Service CoE had a core team of six people servicing millions of queries a month in their global business [91]. A key part of this Search Service CoE was measuring performance of the system using test queries for relevancy and analysing the search logs for usage patterns in order to identify opportunities for improvement. However, most organisations only have one full time staff or less to proactively improve enterprise search tools [31].
2.2.4. Information literacy factors
Information literacy is divided into three areas: acquisition of information age skills, cultivation of habits of the mind and engagement in information-rich social practices – making context-specific critical judgements about information [109]. One such ‘habit of the mind’ and ‘information age skill’ is described (p. 5), ‘Users need to respond to search results – possibly because there are too few or too many – and know when to stop searching’ [110]. This may be particularly relevant in workplace environments where people need to identify and use accurate and complete information under tight deadlines. Training users on how Enterprise Search works, rather than just how to use the actual search tool [6], may have a dramatic effect on improving search task outcomes [111].
However, Enterprise Search queries can be general, ambiguous and short [112]. Information literacy is not included as a factor in the widely used (but structure dominated) system success or technology acceptance models [64,65] for user satisfaction. Despite this, studies have shown that users who are less ‘search literate’ can display higher levels of satisfaction for exploratory search tasks than users who deliver higher levels of objective performance [38].
2.3. Generative mechanisms
2.3.1. Business case
The literature points to the Chief Information Officer (CIO) role as one mainly focused on risk reduction [113,114] although some feel it should be innovation [115]. Information security and downtime appear to be the two main concerns of the CIO/IT function that ‘keep them awake at night’, not adding (financial) wealth to the organisation [113]. Information Management (IM) and governance culture in organisations may be one also dominated by compliance/risk as opposed to value [116,117].
The business case has been identified as problematic for general purpose enterprise search [6]. This might suggest a penchant for ‘loss aversion bias’ [118] embedded in management roles towards search capability. This may be supported by research that shows decision makers are twice as likely to try to avoid ‘losses’ than to make ‘gains’ [119]. There is also evidence that cost and risk are easier to measure than value (which can be intangible) in IT [120,121].
2.3.2. Technological solutionism
Avoiding technological determinism, the importance of human insight, ‘data does not speak for itself’ and the problems and opportunities presented by big data may effectively be ones of brainpower rather than computational power [99]. This hints at the criticality of human agency for enterprise search and discovery capability in a landscape which may be dominated by technology marketing.
Globalisation has created an increasingly competitive environment for organisations, with Information Technology (IT) a powerful technique to help meet this challenge [120]. At the same time, there is a body of research which suggests IT only improves business performance when considered as part of a system of capability, consisting of formal (such as organisational processes and roles), informal cultures and information literacy [122,123]. Despite this, ‘enterprise search’ terminology tends to have a technology bias [124].
It has been argued (p. 7) that ‘Participant dissatisfaction with current Enterprise Search is a complicated problem that likely has a complicated solution’ [111]. However, it has been reported that there is a tendency for many organisations to go through repeated cycles of ‘fixes that fail’ changing their Enterprise Search technology in pursuit of improved search outcomes [125].
Some organisations appear to make interventions in enterprise search deployments without a robust underlying theory of change, ‘The biggest roadblock is not the technology … it’s the mindset, approach, and naivety of people deploying search’ [125]. Technology while necessary may not be sufficient to develop an effective Enterprise Search and Discovery capability. For example, NASA deployed Google’s version of Enterprise Search inside their organisation, concluding, (p. 6) ‘To make search results relevant can be difficult’ [126]. It has been reported that even Google executives have complained about their own in-house Enterprise Search ‘it’s not that good’ [127].
This may evidence technological solutionism bias [128] a lack of systems thinking [129]. A belief that the answer to complex real-world problems is technology. This is an instance of simplicity bias [130] which proposes that people need disproportionate evidence to accept a complex causal explanation over a simpler alternative.
2.3.3. Google habitus
Despite all the benefits associated with increased access to information, Internet search engines may have influenced our expectations and the way we learn, the ‘Google effect’, towards a more surface type of learning, (p. 5) ‘Once I was a scuba diver in the sea of words. Now I zip along the surface like a guy on a Jet Ski’ [131]. Studies also show that people may have got used to advertising and where it appears on the search page [132], with 72%–79% of users never looking at the top parts of the search results page [133]. The mass adoption of Internet search engines may have set high expectations for Enterprise Search engines in organisations.
The literature review has identified the lack of a holistic study of enterprise search and discovery capability in the academic literature. It has also highlighted the role emerging AI techniques are playing in re-defining what questions can be asked of search technologies in the enterprise. The formal structures of information quality, technology quality and (search) service quality have been explicated as the key factors reported for enterprise search user satisfaction and success. However, the informal factors of agency (information literacy) and structures (cultural biases) appear to be less well understood, developed and integrated into models. These findings inform the development of the study aims and objectives – to re-examine the factors and generative mechanisms that give rise to user satisfaction with enterprise search tasks.
3. Methodology
3.1. Philosophy, approach and strategy
A mixed-methods critical realist [134] philosophy was adopted for this study, well suited to deriving causal explanations of chains of events in complex phenomena. This enabled the identification of demi-regularities along with explanations for why those may be occurring. The adoption of a stratified ontology enables the hypothesis of hidden mechanisms inferred through their manifest effects. Explanations are therefore grounded in the data but not constrained by empiricism so unlike pragmatism it is a philosophy that may be capable of transformational explanations.
Enterprise Search has been deemed as more problematical in large dispersed organisations [32]. The O&G industry has provided six of the ten largest companies in the world by revenue [135], including multinationals operating in different locations. A single large O&G company was therefore purposefully chosen, deemed an appropriate research scope for a case study, so may be an ‘extreme case’ [136] well suited to studying causal mechanisms [137]. A longitudinal case study would allow the full range of links, contextual issues, motivations and behaviours to be observed.
In order to explicate user satisfaction factors and generative mechanism, two data collection methods were used. First, feedback comments gathered directly from the enterprise search UI gauging user satisfaction. Second, interviews with staff (informants) in the enterprise search service team to gather deeper evidence on why satisfaction was or was not occurring. Although targeting different areas, these data were integrated and triangulated, highlighting areas of agreement and dissonance between themes emerging from the user search feedback logs with those from interview accounts with search service staff. The overall approach is shown in Figure 2 linked to the study aims and objectives.
Each of these data collection and analysis methods will be discussed in the following sections.
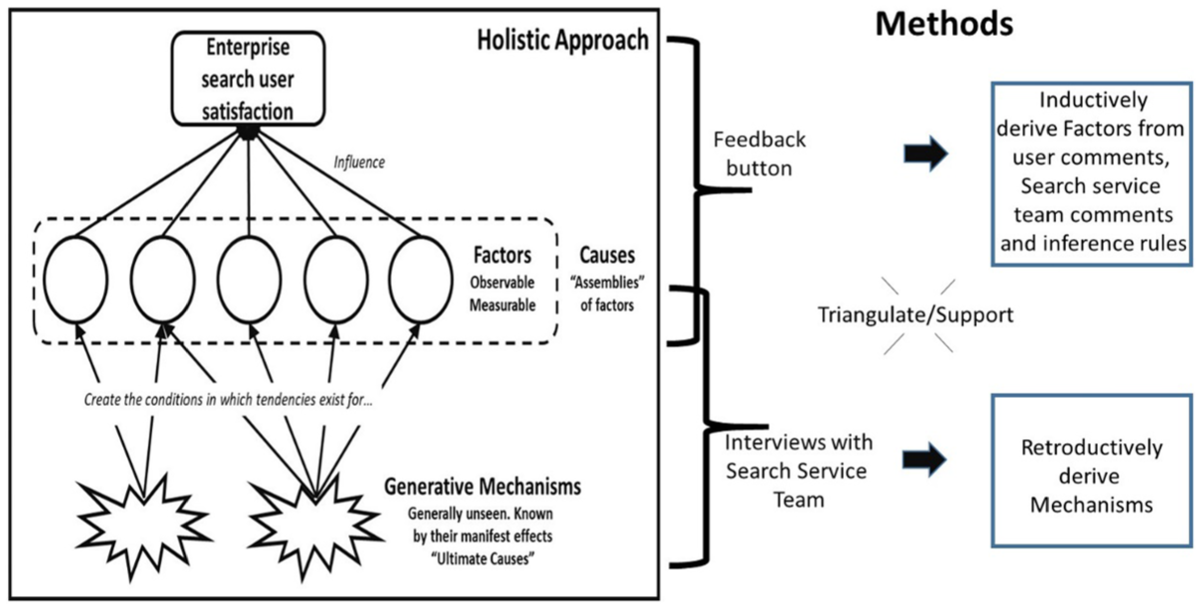
The approach used to explicate user satisfaction factors and generative mechanisms towards an explanation.
3.2. Feedback comments
The Enterprise Search tool chosen was used by approximately 70,000 staff each month (75.2% of total staff count), generating over 450,000 search queries each month. Users of the system range from managers to administration support staff; sales and marketing to engineers and scientists. The Enterprise Search UI is shown in Figure 3.
Blurred/pixelated screenshot (for confidentiality) to illustrate the enterprise search UI used.
This image is not intended to be read (to protect anonymity), but taken as a whole to convey the assumption of the relatively standard (therefore generalisable) nature of the enterprise search UI, similar to other deployments [138]. The search box is along the top, faceted filters on the left, search results in the middle and people on the right. The feedback button icons (enabling the user to convey satisfaction or dissatisfaction) are to the right of the search box. Any mouse click on a ‘smiley’ or ‘unhappy’ face would bring up a small window asking the users to comment. So in addition to counting the frequency of satisfaction/dissatisfaction immediately after events, users could also choose whether to leave qualitative feedback after a query or session, such as what they were looking for or what they felt about the experience in their own words. The Enterprise Search feedback log represents a list of comments collected over a 2-year period (2013–2015) where a user had clicked on the icon (Figure 3) in the Enterprise Search UI in the case study organisation. It includes their comments, system generated information on what a priori search queries the person used and follow-up interactions and explanatory notes from the Enterprise Search Service CoE where an interaction had taken place.
This record was deemed a good source to obtain unsolicited data on why a user is satisfied or not after a search task and infer what may lie at the cause of that satisfaction or dissatisfaction. There are no known published studies on Enterprise Search user feedback logs so it would also provide a useful addition to the body of knowledge. Permission was sought and given to use the Enterprise Search feedback log in the case study organisation under conditions of confidentiality and anonymity.
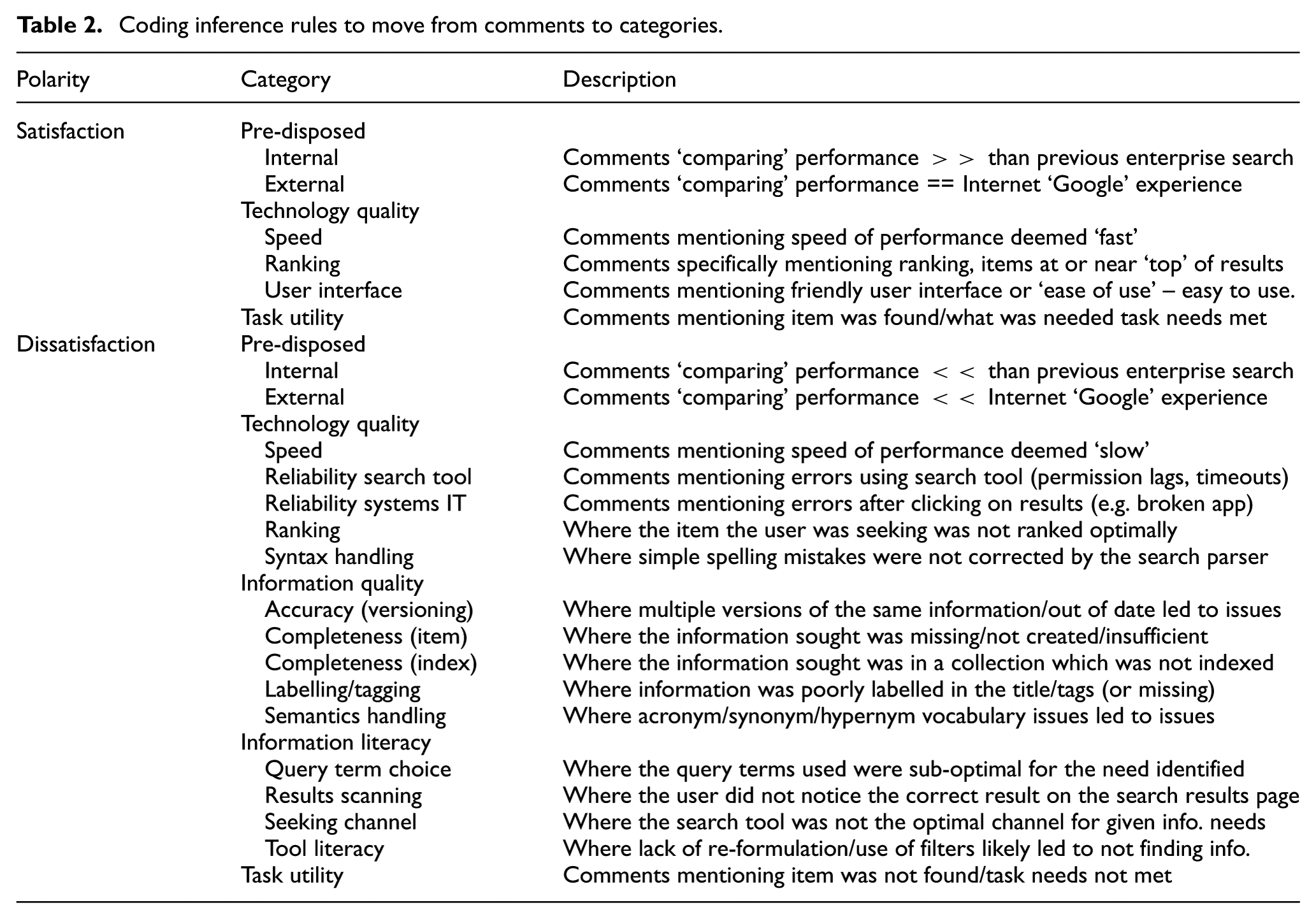
An approach based on content analysis [139] was used to code each instance from the Enterprise Search feedback log into themes which were combined into ‘factors’ to explain why that event had occurred. These themes were generated from the data inductively, so were not created a priori. Section 4 (Table 2) describes the categories that emerged from these data and the criteria for assigning events to categories. Further information was sought from the Search Service CoE and user where required and in some cases the researcher re-created the search event to understand what the user would likely have seen with their query.
Coding inference rules to move from comments to categories.
3.3. Interviews with the search service team
In order to identify generative mechanisms, interviews were conducted with the Enterprise Search Service Team (Centre of Excellence (CoE)). This team comprised seven full-time staff, consisting of a project manager from the case study organisation and six full-time consultants from a third-party organisation who operated the service as part of an outsourced contract. Permission was sought and granted to interview five staff over the period of 2 years. Participants are coded as [ESM_1] for the Search project manager (from 2006), the current Search Service CoE Manager [ESM_2], the IT manager responsible for business requirements and budgeting for search and unstructured IM [ESM_3] and two consultants within the Search CoE from the outsourced provider [ESM_4-5]. Interviews took place via telephone and were approximately 30 min to 1 h in duration. Interviews were transcribed and also analysed through content analysis. Semi-structured interviews used a critical realist framework, focusing on history and specific events; explanations beliefs and theories; puzzles and contradictions; challenging adequacy of accounts on offer and rehearsing provisional analyses with informants. The three key question areas were as follows:
What previous attempts has the organisation undertaken towards enterprise search? How successful were these perceived by various stakeholders and what were the reasons?
Why do you think it appears difficult to deliver enterprise search user satisfaction?
What do you think is needed in order to deliver a successful enterprise search deployment? Which conditions do you think are missing or are sub-optimal in the current deployment and why?
A causal network diagram [140] was created from the resulting categories.
3.4. Validation
The themes from both the enterprise search feedback log and interviews with the Search Service CoE were triangulated to ascertain areas of agreement and dissonance, with the literature providing the third form of comparative analysis [141].
In order to validate the coding categories generated inductively from the feedback log, initial categories were sent to the Enterprise Search CoE in the case study organisation along with the developed rules and rationale for the classifications. The Search Service CoE and the researcher independently coded the following month’s feedback using the categories developed by the researcher. The differences between the resulting classifications were discussed in a short 15-min interview and further iterations made in order to improve the accuracy of coding than if only performed by an individual [142].
3.5. Limitations
The feedback log is from a self-selecting group so may be subject to bias; however, the data have been collected in a natural setting without any researcher intervention eliminating the possibility of observer bias. A sample of an enterprise search feedback log and Search Service CoE in one company means statistical generalisation of findings is not possible. However, generalisation of theoretical propositions can be proposed as areas for further research.
4. Results
An analysis of 2 years of Enterprise Search feedback comments yielded 1183 comments in total from 1076 unique individuals. Of these, 239 were positive, 53 were questions/requests and 891 (79%) were negative. During this time, over 4.5 million queries were made using the Enterprise Search UI, user feedback represented just 0.003% of all search queries. In addition, the corpus size doubled to over 150 million items, average search query length was 1.89 words and the top 30 most frequent searches fell from representing 14% of all search queries to just 8% by the end of the 2-year period. The percentage of all queries that gave ‘no results’ decreased from approximately 0.4% to 0.3% over the 2-year period.
The feedback icons were initially at the bottom of the search results page; however, moving the icons up next to the search box led to a 456% increase in the number of feedback comments captured each month. The categories identified from the comments and inference rules for their identification are shown in Table 2.
There appeared to be significantly more areas for dissatisfaction than for satisfaction.
4.1. Satisfaction factors from feedback log
The categories of technology expectations being met, technology quality and task (goals) needs being met were given as satisfaction factors (Table 2). The majority of positive comments contained no comments or the word ‘no’ (simply indicating that users of the system had clicked on the smiley face in the search UI). There is therefore limited qualitative data to analyse for positive comments and insufficient data volumes to report percentage-based data. Of the 25 comments that were made, themes were couched in terms of the following (number of mentions in brackets): utility-task needs met (11), search result ranking (4), expectations from previous experiences (3), ease of use-usability/UI (3), speed (2) and works like Google (2). Example comments include the following: Lightning fast today! Found what I wanted Love the new system Very useful I was looking for … it came at the top of the list, great Good, works like Google Search now works great. I use search instead of having a million book marks, good work ⌣ Anything is just ok ⌣ Easy user friendly Happy I found what I was looking for Grateful we can search so easily now!!
These data provide evidence that a by-product of satisfaction for some was hedonic system enjoyment.
4.2. Dissatisfaction factors from feedback log
The vast majority of events where a user clicked on the ‘unhappy face’ icon included user comments. The distribution of the reasons for search dissatisfaction were split between (1) technology factors (38%), (2) information factors (36%) and (3) literacy factors (26%). These were further analysed and subdivided into sub-categories, presented in Table 3.
Typology of dissatisfaction factors inferred from Enterprise Search user feedback log (n = 1183).

The typologies (Tables 2 and 3) for satisfaction/dissatisfaction factors were provided to the Enterprise Search CoE. The agreement between researcher and CoE when independently classifying a new month of feedback comments (n = 138) was 72%. An area of ambiguity is related to whether content a user is trying to find exists within the corpus. It is not always possible to reach a level of confidence that the information is present (or is not present) in the search index [I2] so attributing to only one category (such as search ranking or missing information) can be problematic.
Technology quality factors were spread between reliability of search tool (56%), search ranking issues (32%), search query syntax handling (7%) and IT issues not related to the search technology (5%). Complaints were couched in various forms such as describing the problem, labelling the technology negatively, venting disappointment and solution suggestion. Example comments include the following: Majority of the links is dead. Search function on this site way below standard System is not responding ‘something went wrong’. This is happening too often!! In a world where everyone is used to finding exactly what they want via a Google – the [company] website is very difficult The search engine is just worse than nothing Employ Google NOT PLEASED
Evidence of sarcasm was also encountered as a way to communicate displeasure, By telling a bit more than just ‘something went wrong’. I figured that. Awesome the first organic link for [xxx] goes to a page that says ‘this page cannot be found’ AWESOME ⌣
Tracing changes over time, a new version (from the same technology vendor) of the Enterprise Search engine was deployed during the study period which caused issues in the search ranking because of the way web content was indexed. Specifically, web pages in the new ranking model appeared to have a lower rank than documents in the EDMS. These search ranking issues caused dissatisfaction and regret. For example, It only ever finds me documents Put it back like it was, can’t get to anything needed It would be nice if ‘websites’ would be easy to find Make search actually work. I get 5 year old PDF documents as a primary result instead of actual intranet pages. The entire thing is broken. I want websites not links to PowerPoints This search engine is useless. Make search webpages (not document repositories) the default search option
Some complaints where searchers could not find information appeared to be related to query syntax or spelling issues by the user, for example, the following queries were spelt incorrectly: ‘clasification of records’ and ‘mandotory training’. For this study, these were classified as technology (rather than search literacy) issues by the researcher, as it was assumed that a modern-day search engine (Table 1) should be able to cope with minor spelling mistakes and syntax issues of non-technical terms. As put by one respondent, What about some suggestions for when we might have had some typo?
The feedback log also included IT issues that were not related to the search technology, but underlying systems or general IT issues evidenced by: My favourite tool bar is missing The room booking website gives a Page 404 error.
Technology factors showed the most deviation in frequency. In month #10 and #17 technology quality comments accounted for 79% and 64% of all comments, the two highest monthly percentages for any single category over the 2 years studied.
Information quality issues included poorly tagged (or not tagged at all), missing or insufficient information. This was the largest sub-category within the information factor (35%, Table 2). This was evidenced by user comments requesting information (that did not exist in the corpus) or asking questions to which there was not an answer in the corpus: How do I … Need some kind of information page, maybe wiki on [Topic X] How to contact the IT help desk and get loads of detailed results that do not come close to answering my simple question. Spent 15 mins trying to locate MAKE ROOM RESERVATION without any success
The communication problem between the search terms used and the information sought, along with semantics (acronyms, synonyms, hypernyms) was observed, for example: I can’t find information on flu shots Can we when someone types CO2 into the search box, search on both CO2 and Carbon Dioxide?
With the ‘flu shots’ query, the Search CoE were able to find the correct information if they searched on the more formal term, ‘influenza vaccination’. This was classed as an information factor, the assumption being that modern search technologies can handle thesauri/taxonomy lookups; however, the organisation needs to embed its domain information into the tool.
Of the information quality–related issues, 28% (Table 2) were related to people trying to find information that was not in the index because it was part of a collection/system that was not currently indexed. From interviews with the Search Service CoE, it appeared that the majority of these were related to content in the previous EDMS system that was currently being migrated to a new EDMS.
There were many queries found in the feedback log where a user used a term or acronym (typically three/four letters) often followed by the word ‘portal’ looking for the company tool/system/site for an activity or technology. These were sometimes domain/discipline specific, on other occasions administration based such as: If I type ‘timewriting’ into the search, why is the timewriting portal not displayed as a result?
The search literacy of users was the third category of factors. These were postulated, as no user stated in the comments that their problems were caused by their own skill or knowledge levels. Literacy issues were inferred through several rules that were constructed from the comments. First was a rule where the queries entered by the user were judged to be quite different in nature to what they were actually seeking. For example, the comment: I was looking for any Health documents related to [country x]
However, the user had only made a search query using the name of Country x and did not include any terms related to health. Another example was a search query ‘decision guides’ when the user explained their information need was: I am looking for Decision Guidelines related to Antitrust Training
The user became dissatisfied and made a complaint after only one search query was made and no further query reformulations were undertaken. So in this case a judgement was made that the literate searcher may have included the word ‘antitrust’ (which is a quite specific word) in their query. When the researcher used this query, they found the relevant information immediately, which was confirmed with the user.
Second were cases where the user only searched on an unusual acronym and not the full term name, or without trying synonyms, but only made a single query, with no reformulation before issuing negative feedback. The Search CoE were able to help people find what they were looking for in several cases using the same queries the user had made, but also using refiners (restricting searching to the corporate Wiki or logical formats such as Microsoft PowerPoint). These issues were attributed to IR Technology literacy (knowing how to use the search tool functionality).
The Search CoE found a relevant result for some queries as a promoted query at the top of the page. When following up this thread with the users, it appeared that they had not noticed (or had subconsciously ignored) the promoted results because it looked different to the ‘organic’ search results. Comments in this category were particularly emotive: For #$%^’s sake, hire Google to make our own internal search, this is rubbish! This search function is a new level of useless
4.3. Interviews with the search service CoE
The Enterprise Search Service CoE formed part of the unstructured data programme, which recognised information was an asset to be managed. Several informants noted the conflict between value and cost as drivers for change. The challenge for making a business case and the lack of executive buy-in was raised: Awareness and importance of IM (search being consumption side of IM) among our senior executives is quite low. They seem to understand CRM [Customer Relationship Management] and ERP [Enterprise Resource Planning] systems, easier to justify and put a cost benefit. When it comes to search, much, much harder, still not been able to articulate the value of doing IM well. Typically so bad [manage information], end up having customers saying just put a search engine over it all so we can find stuff. [ESM_1]
Cost appeared to dominate the business case: Cost is what has been driving search, search should reduce cost elsewhere in the organization but it is difficult to get those type of business cases to resonate with people … They look at one thing, one purpose, cost X per month, steered on that. [ESM_5] The organization is so big, dealing with so many things, search is probably a very small part, low down list compared to saving $100M or information security breaches. Executives do not see it as something worth ‘air time’. [ESM_2]
The challenge of knowledge management (KM) and positioning search within that process was highlighted: What do they [executives] believe the value search provides? Do not have that level of engagement, or ownership at CIO level, gap in our organization. To drive search goes hand in hand with knowledge organization, the knowledge worker. There is an eagerness for KM in some functions, gaps in other parts of the business, challenge to promote KM as a strategy for search. [ESM_3]
One informant described how for some high value parts of the business, it was easier to articulate the value of ‘niche’ search tools to support their business: O&G Exploration has history of experimentation and innovation because investing in alternative ‘search’ could be justified. When you are spending millions of dollars drilling wells, spending $100K that might make a difference easier to justify. [ESM_1] Departmental size can do all sorts of clever stuff. Scale up to all departments globally and you have to make compromises, these clever things are almost always performance hogs, probably don’t scale linearly, but in a power law. [ESM_1] Can either please some of the people all of the time, or all of the people some of the time. Lowest common denominator. [ESM_1]
In 2000 the case study organisation was driving its business towards regional and global models, with more teams working virtually. The goal attractor of effective IR from central and local repositories was identified as a key success factor to an enabling IM environment. The first Enterprise Search technology was stated as working well initially, but started to breakdown over time as the server infrastructure struggled to cope with increasing volumes of content. This led to the search technology not indexing new content or giving partial search results, eventually reaching a tipping point and not working at all: [First generation search engine] (1999–2006) – indexed as much as they could, ran out of space. If you don’t scale the infrastructure for volume of content, sooner or later search will fail, perform badly, will stop indexing content, or it will give partial results, this ultimately happened to [second generation as well] … search starts to fail. [ESM_1]
The failing search led the organisation to conduct a market review and select a new Enterprise Search technology on technical and economic criteria. However, it was deployed in an environment of severe cost pressures, so it was deployed as a technology project (like the first generation), without ongoing proactive support/services. This choice therefore may have immediately conflicted with a more strategic choice: [Second generation 2006–2011] – Central office looked at number of technology vendors, then CIO office got involved and had chosen third generation tool, before we rolled out second generation that undermined it. The world had changed, asked to do it as cheaply as possible, no service team, and at that time server costs were ridiculously high … starved of additional servers. [ESM_1]
The role of IT was criticised for driving a technology-dominated agenda: CIO office always driven technology choices from the point of view of technology, not from business need. As a result still implementing EDMS ten years after decision made, driven by technology not from a business perspective. [ESM_1]
This [second generation] search used statistical conceptual searching, so could return results that may not have included exactly the keywords used by the user. Some users were ‘blown away’ [ESM_1] by this, others left ‘bewildered’ [ESM_1]. The point was also made how disappointing satisfaction with search results provides plenty of ammunition to justify investments in new search technology: Although conceptual search getting a lot of currency now, the problem then was most people think in terms of keywords, bewildered when the [search engine] found other things, caused confusion. A lack of metadata tagged to documents and web pages also did not help. [Second generation search engine] was not as bad as many people made it out to be. More recently people have slagged it off because helps justify why we are not using it anymore. [ESM_1]
As a result of strategic decisions made by IT, a third-generation Enterprise Search (back to a keyword search) was deployed allowing a search ‘like the web’ and filtering ‘like a spreadsheet’. This time a choice was made for a baseload proactive service in the form of a Search CoE outsourced to a large IT service provider. Informants stated that the role of the Enterprise Search CoE was about enterprise search technology capability, rather than enterprise search capability: It’s [Search CoE] the maintenance and development of the
A drawback of an outsourced IT-focused Enterprise Search CoE was identified, creating a gap to other parts of the organisation that impact upon search: Gap at the moment, disconnect of what is going on and feedback into it. Downside of not being part of the company. [ESM_5]
The case study organisation is in the process of moving to a fourth-generation Enterprise Search deployment by moving to a cloud service. The advantages of this approach were discussed: Depends on vendor and product, but generally with large vendors and cloud, they won’t be able to deliver niche requirements, they deliver standardized services. From a cost perspective we have got a much cheaper solution. May look at other vendor (smaller in size) more willing to invest more to deliver specific niche requirements. [ESM_3]
As well as the disadvantages: What I see happening moving to cloud based services. Standardized, standardized, standardized. Stuck with generic solutions that would apply to common themes, opportunities to do more, what we are starting to lose? In Enterprise Search you are processing all of your data, you don’t want it to be a black box and the only thing you can get out of it are lists. [ESM_5]
Informants discussed the ranking model and criticality of IM practices such as adding good titles and tags (even though social voting (clickthrough) and currency (freshness) of information was used to boost ranking). The failure of people to author, upload or publish content ‘with search in mind’ and governance/incentives was highlighted: Are they thinking about search when they upload their content? [ESM_5] If you want search to work properly you need to author content with search in mind. The Title text has the highest weight (in the ranking score model), some web pages don’t have title filled in, so search does not promote web as well as it should. Make site templates require titles. Sometimes people added graphics in as titles, pretty but do not influence search ranking. Make sure you have a title, not rocket science but may go some way to improve search dramatically. Nobody ever got promoted for filing, why the state of IM is precisely for that reason. Disk is cheap, why I am being told to delete stuff, why can’t we keep buying storage – what they don’t get is when you scale that up to 100,000 people … filled up content so much full of crap, can’t find the good stuff. [ESM_1]
Using the Enterprise Search tool to improve transparency and organisational politics was raised: I don’t see technology as major problem, we can get content in, politics of whether we would want to get something indexed, hold things back. [ESM_5] Noticed in past 6 months, search treated less as place to find things, more as a place to find out what we have, more reporting from search index, what type of documents do we have, where are we storing things, are we storing things we should not be storing. [ESM_5]
Many of the informants discussed how users wanted a search experience like Google and some questioned why Google as a technology product or vendor was not deployed. The differences between Enterprise Search and Internet search were raised from a literacy standpoint: Most people searching with one word, with the best will in the world, unless it’s a specialist word, one word will produce millions of hits, unrealistic that you will get results you wanted. Add more words to get specificity. Have to teach people to use ‘your search’ (e.g. 2/3 words rather than one). [ESM_1]
As well as from an expectation and ‘Google’ technology viewpoint: People start out thinking Enterprise Search is just a version of Google. People clearly have expectation it should be used like Google. When they find out it does not work that way, they go through a frustration phase. Once we start talking about why it’s different, they start to understand (security trimming, cannot find everything out there, people don’t normally think about that) but also billions of user statistics/compared to Enterprise Search. People that don’t talk to us, don’t make that connection. [ESM_5] I see a huge diversity in way in which people use these things, lack of interest from people what they put in, they are interested in what they get out. A lot of groups are ‘get out there close that deal’ just want damn things to work without putting in any effort. We have to cater for average employee, for them it’s like using Facebook/Google, want it to be intuitive. 85% of people would not be interested in training, think they know about search – want things to be where they expect them, functions they are used to, are driven by Google/Facebook culture. [ESM_2]
The themes that emerged during the informant interviews were analysed and used to construct a causal network diagram (Figure 4) to explain patterns of unfolding events that led to the current situation.
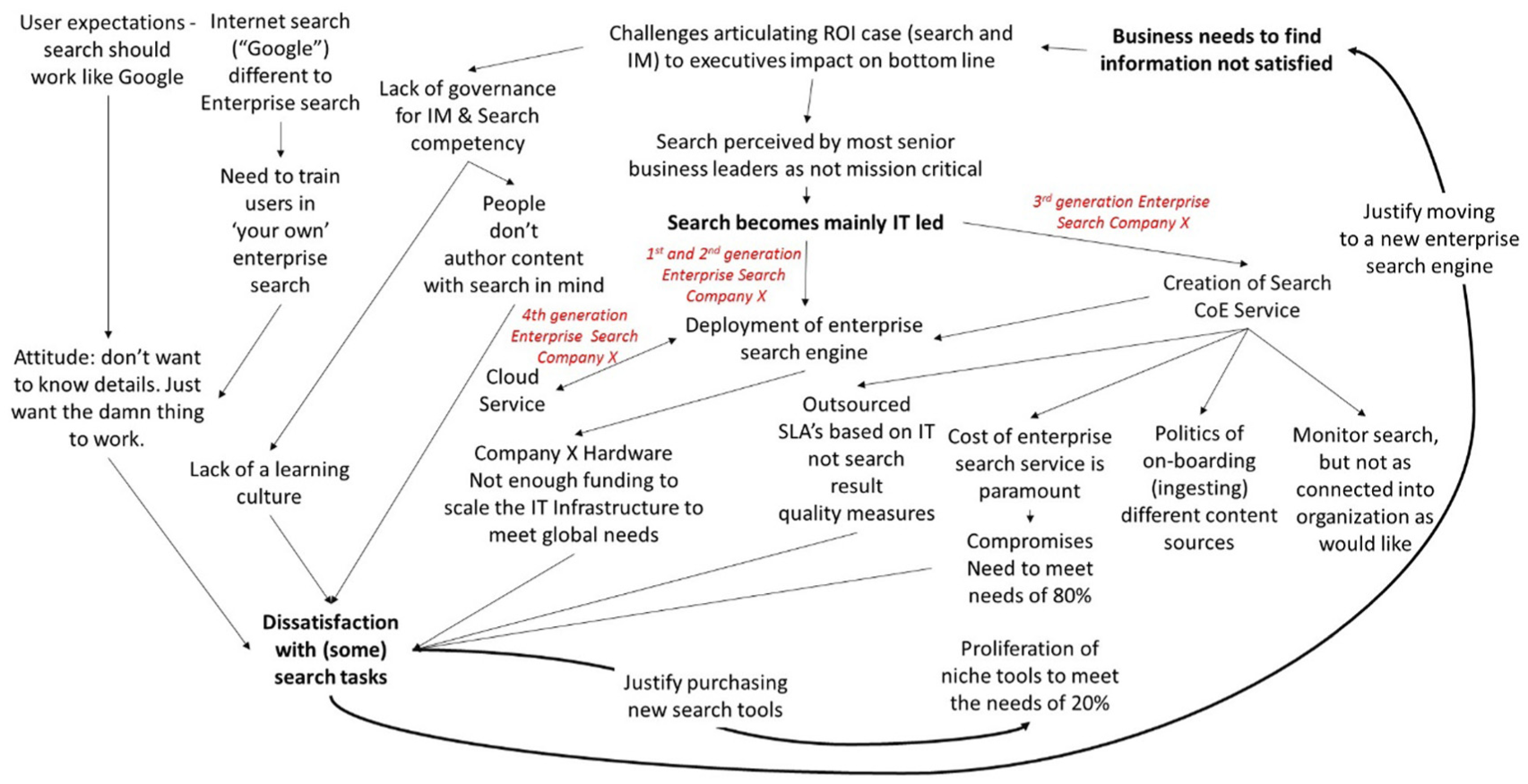
Themes that emerged from interviews with the Enterprise Search Service CoE. Arrows represent lines of influence.
Two cycles are shown in bold loops (Figure 4). First is where dissatisfaction with search may be used to justify the deployment of another Enterprise Search technology. Second is where it is recognised that an existing Enterprise Search deployment cannot meet the niche needs of specialist communities, driving the bottom-up emergence and proliferation of departmental search tools. The root of these events appears to stem from an executive mind-set that ‘search capability’ equates to ‘technology capability’ and ‘search capability’ is not a business critical component to operations.
4.4. Triangulation
The themes from the two data collection methods were triangulated and are shown in a matrix in Table 4.
Enterprise search and discovery themes convergence matrix.

The next section will compare results to the extant literature, highlighting similarities and differences.
5. Discussion
The majority (79%) of user satisfaction feedback comments provided were negative, in contrast with research on e-commerce sites which tends to show ‘j-curve’ distributions skewed to the positive [58]. The factors for enterprise user satisfaction were as follows: technology quality, technology expectations being met in the sense it worked like ‘Google’ or was better than their previous experience of enterprise search tools (sections 4.1–4.3), and task needs being met. Utility, Technology, Information and Literacy were the factors identified from the feedback log as leading to dissatisfaction (for a full breakdown see Table 2). This may imply a combination model [55] for user satisfaction, with the disconfirmation model of performance comparison with pre-disposed expectations (‘like Google’) combining with net benefits (equity) models. User satisfaction may therefore be mediated in part by expectations pre-disposed a priori to the search task, supporting existing web search research [39,45]. The findings (sections 4.1–4.3) also support existing studies that enterprise search satisfaction/dissatisfaction is multi-factorial in nature [111].
The most common category for dissatisfaction was related to technology factors (38%), with over half of these related to IT infrastructure elements. This may contradict existing literature [74] which suggests that most of the hard problems with Enterprise Search infrastructure, scalability and speed have been solved. This may be the case in theory; however, evidence from this study implies difficulties and challenges may still exist in practice, even for large organisations who have significant resources at their disposal.
It is possible that technology factors are over-represented in general in the user feedback log, as IT failure may be sufficient to elicit widespread complaints, in a way events caused by other factors may not. This is supported by the observations that technology factors seemed to ‘burst’ in frequency, in a way that the background information and literacy factors did not, evidenced by month #10 where 79% of all comments were technology related, the highest proportion of any category.
With over a third (36%) of dissatisfaction events related to information factors, the findings support the assertion that in many cases, improving the organisation of information is more advantageous than modifying search technology to improve the search experience [93]. This may be significant for organisations that cannot afford a Search CoE.
Information quality was not explicitly mentioned as a reason for satisfaction (Table 2), probably because it is a ‘must-be’ (tacit) requirement [41] for search – not generally expressed as a reason for satisfaction, but given as a cause for dissatisfaction when not present. The importance of good titles and metadata for information items and the absence of information in the search index (Table 3) supports existing practitioner comments on factors for dissatisfaction [91]. The statement made by informants that users often do not publish or upload content ‘with search in mind’ supports existing views [59]. This emphasises the criticality of non-technological EIM strategies, practices and governance in order to deliver effective search task outcomes. Comparing to existing models in the literature, from Table 3 [T2, T3, I1, I2, I3 and I4] largely map to existing dissatisfaction models although user literacy [L] factors are generally absent [37,64].
Increasing information volumes were identified as a factor for increasing dissatisfaction (section 4.3) supporting existing studies [38,97] although models for information system success only mention the quality property of information, which provides widespread opportunities to revise models in the literature (such as DeLone and McLean [64]).
However, paradoxically, the issue of ‘no results’ for a search query was not found to be a factor for dissatisfaction. In this situation, large information volumes (only 0.3% of queries in the case study found no results) may actually be beneficial because of coverage, whereas enterprise search deployments with much smaller information volumes may be more likely to lead to scores as high as 16% for ‘no results’ from queries [108].
Of all complaints, 55% were made after a single query – no query reformulation had taken place. Investigation of the query made and the users comments suggests these were probably not made by ‘expert searchers’. This may contradict existing reported models [81] which imply novices spend more time reformulating queries than experts. These differences could be explained by task type, motivation and expectations. A novice searcher who is looking for a specific item with a right answer may ‘expect’ the search engine to find it instantly ‘like Google’, attributing search failures as external to their own agency (fundamental attribution bias).
Examples of the vocabulary problem were evidenced supporting existing literature [101–103]. However, synonym/acronym/hypernym factors only accounted for 5% of all dissatisfaction events. This conflicts with assertions that the vocabulary problem is the dominant reason for search task dissatisfaction in the enterprise [101,104]. One explanation may be related to the large scale and longitudinal nature of this study compared with previous narrower studies. A competing explanation could be that the feedback log represents a self-selective sample which is not representative of the proportion of factors for dissatisfaction. Approximately 5% of complaints appeared to be related to people looking for software tools, portals or systems to undertake tasks. Adopting a good practice of building comprehensive A-Z pages that include links to services and software tools and intelligently indexing those pages as part of an information architecture (IA) may improve outcomes and provide opportunities for further research.
Some users appeared to ‘miss’ promoted results at the top of the search results page, even if the items were the information being sought (section 4.2). One explanation is that people may have subconsciously programmed themselves, through extended use of Internet search engines like Google, to avoid gazing at results that look slightly different at the top of the search results page. This is an information behaviour reported when people search using Google to avoid advertised links [132,133] an aspect of the ‘Google Habitus’ – how people think, feel and act, where Internet search engines may have enabled a reconfiguration of human searching habits. To the authors’ knowledge, this is the first time evidence from enterprise search deployments has been reported for this phenomena and has implications for the design and ‘look and feel’ of promoted results in the Enterprise Search UI.
Over a quarter of all dissatisfaction events were attributed to search literacy (Table 2). This factor appears to be downplayed in the enterprise search practitioner and academic literature where deterministic structuralist factors (information and technology quality) predominate: the implication being that when technology and information quality is optimal, search outcomes will ‘take care of themselves’. Where user training is advocated, it tends to be technology-functionality based [7]. This study provides some evidence against structuralism, supported by other recent studies in the enterprise [38,111] and other environments [17]. Furthermore, with increasingly sophisticated possibilities for which questions can be asked through technology [61,62,73], in increasing volumes of information (big data) [1–3], it is likely that information and search literacy will become more nuanced and crucial to enterprise search and discovery capabilities.
The importance of configuration in enterprise search was evident, where an unintentional change biasing documents over web pages led to sub-optimal results. With average query lengths of approximately two words, made by users to dynamic growing corpus sizes, it is unlikely that many information needs will be met without constant configuration, promotion of authoritative (trusted) corporate information and monitoring of performance, supporting the existing literature [5–7,74,106,107].
From the interviews with search service staff, users and business management appear to exhibit a range of cognitive biases which may exist as generative mechanisms, creating the conditions in which many of the factors for dissatisfaction may endure. Simplicity bias (including technological solutionism) may exist, which has strong agreement with the feedback comments ‘Employ Google’. This may influence the strategies taken to improve enterprise search user satisfaction, despite the reasons why enterprise search is different to Internet search being well documented [10,11] although it requires a more complicated explanation. Loss aversion bias within business management (‘Cost is what has been driving search’ [ESM_5]) may steer the strategies and investments in a general purpose search, supporting the existing literature [9,120,121]. Structurally, the ‘Google Habitus’ (‘users are … driven by Google/Facebook culture’ [ESM_2]) may have created widespread mind-sets which view search as a capability which starts and ends with technology; a single way of doing things to locate predominantly the ‘right answer’.
In order to improve enterprise search and discovery capability, it may be useful to revise the existing orthodoxy stated in the literature and ensure informal-social factors are included in the underlying theory and framework. The findings from this study (bold underlined) combined with the existing literature and deeper assumptions [143] are shown in a framework which splits assumptions from strategies and governing variables [144] in Figure 5.

The findings from this study (bold underlined) combined with existing literature and deep assumptions (italics) towards developing effective enterprise search capability.
This framework may offer opportunities to change mind-sets towards enterprise search and discovery capability; away from reductionism, technological solutionism and structuralist determinism, towards a more holistic, fluid and system-centric view of enterprise search capability driven by re-invention through feedback at all levels.
6. Conclusion
The aim of this study was to re-examine the factors and generative mechanisms that give rise to user satisfaction with enterprise search tasks. Grounded in empirical data, the study confirmed the existence of the factors which are commonly stated and advocated in academia and practice (such as information and technology quality). Informal-social factors were also identified, such as information literacy. Generative mechanisms were postulated, such as the role of cognitive biases and the ‘Google Habitus’ that drive expectations and behaviours. These informal factors are largely ignored in the current literature with a tendency to focus on the formal and technical aspects of the enterprise search and discovery environment.
The study finding that 62% of user dissatisfaction events were likely due to non-technological factors may provide the first empirical support for what some enterprise search practitioners have been saying for some time: effective search capability in the enterprise requires more than technology. Validating and refining the multi-factorial model in other areas is a potential area for further research, including interviewing people who choose not to use enterprise search technologies.
Despite having the latest technology and an enterprise Search Service CoE with significant resources, this study provides evidence of the difficulties that exist to make general purpose search results relevant when people do not publish information with ‘search in mind’. Meeting the expectations people have for enterprise search engines due to the ‘Google Habitus’ culture is also challenging. One way to change a culture is to change behaviours and to change behaviours involves changing what people believe. One theory is that it may be inevitable that for some search queries, staff will simply need to be more search literate, aware, persistent and creative using enterprise search tools than when using their Internet search counterparts, effectively adopting bimodal search behaviours.
Bimodal (and multi-modal) enterprise search and discovery technology strategies may further develop within organisations to support work tasks. Technological advances are likely to improve the large-scale general purpose ‘corporate Google’ enterprise search. These advances are also likely to enable staff to ask questions beyond the capabilities of their current search deployments, through a variety of rapidly developed subject domain search–based applications servicing specific work tasks. If enterprise search capability is seen as an intellectual capital item to an organisation, saving time, mitigating risk and generating wealth closer to specific work tasks, the business case may be easier to articulate.
Aspects of information culture and information literacy, however, could be among the key competitive advantages in enterprise search and discovery capability.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.