
Abstract
In this article, a new initial centroid selection for a K-means document clustering algorithm, namely, Dissimilarity-based Initial Centroid selection for DOCument clustering using K-means (DIC-DOC-K-means), to improve the performance of text document clustering is proposed. The first centroid is the document having the minimum standard deviation of its term frequency. Each of the other subsequent centroids is selected based on the dissimilarities of the previously selected centroids. For comparing the performance of the proposed DIC-DOC-K-means algorithm, the results of the K-means, K-means++ and weighted average of terms-based initial centroid selection + K-means (Weight_Avg_Initials + K-means) clustering algorithms are considered. The results show that the proposed DIC-DOC-K-means algorithm performs significantly better than the K-means, K-means++ and Weight_Avg_Initials+ K-means clustering algorithms for Reuters-21578 and WebKB with respect to purity, entropy and F-measure for most of the cluster sizes. The cluster sizes used for Reuters-8 are 8, 16, 24 and 32 and those for WebKB are 4, 8, 12 and 16. The results of the proposed DIC-DOC-K-means give a better performance for the number of clusters that are equal to the number of classes in the data set.
1. Introduction
The categorisation of text documents for a large document collection is a major problem in the areas of information retrieval and text mining [1,2]. Text document clustering and classification are among the most important techniques for organising text documents effectively [1,2]. Many clustering and classification approaches are used to organise text documents. The clustering algorithms that are unsupervised learning methodologies partition a document collection into many clusters, such that the documents within the same cluster are almost alike and dissimilar to each of the other clusters [1,3,4]. Partitioning and hierarchical clustering are the two major clustering techniques in information retrieval, data mining and text mining [1]. In recent years, it has been recognised that the partitional clustering approach is well adopted for a large-sized document collection due to its simplicity and low computational complexity [1–3].
The best known partitioning clustering algorithm is the K-means algorithm. The K-means algorithm [2] starts with random initial cluster centroids and keeps reassigning the documents in the document collection to cluster centroids based on the similarity, or distance, between the documents and cluster centroids. The reassignment procedure will not stop until a convergence criterion is met. The procedure for choosing initial cluster centroids in the K-means clustering is very important as it has a direct impact on the formation of final clusters [1–3,5,6]. Since clusters are separated groups, it is desirable to choose initial centroids which are well separated. It is dangerous to pick out outliers as initial centroids, since they are separate from normal samples.
In order to improve the performance of the K-means clustering algorithm, a variety of approaches have been proposed for choosing the initial centroids (seeds). Arthur and Vassilvitskii [7] proposed the K-means++ clustering method in 2007. It consists of randomly selecting only the first centroid from the data set. Each subsequent initial centroid is chosen with a probability proportional to the distance with respect to the previously selected set of centroids. The drawback of this approach refers to its sequential nature and the actual fact that it needs scans of the complete data set. Kang and Cho [8] have a proposed the seeds initialisation algorithm based on three parameters: centrality, sparsity and isotropy. Khan [9] has proposed an approach to choose the initial seeds for the K-means algorithm. This approach arranges the data based on their magnitude and then selects the seeds based on the higher distance between the consecutive arranged data. Karteeka et al. [10] have proposed a method, namely, single pass seed selection (SPSS) algorithm, to initialise the first centroid (seed) and the minimum distance that separates the centroids for K-means++ based on the point which is close to the additional range of alternative points within the knowledge set.
Improper initial centroids (seeds) may produce bad clusters which will directly affect the organisation of the documents [3,5,11]. Aytug Onan et al. [12] have proposed an improved ant clustering algorithm to overcome the sensitivity of initial seed selection. Jaya Mabel Rani and Latha [13] proposed an improved particle swarm optimisation (IPSO) for solving the problem of random initial selection using the K-means clustering algorithm for documents and avoid trapping in a local optimal solution. Sampath Premkumar and Hari Ganesh [14] proposed median-based initial centroid selection for K-means. The authors used a very simple data set, remarking that the technique is not suitable for large high-dimensional data sets. Sohrab Mahmud et al. [15] proposed weighted average of terms-based initial centroid selection for K-means clustering. It performs significantly better than the traditional K-means and K-means++ clustering algorithms.
Various initial centroid (seed) selection methods are used to select the initial centroids for K-means clustering [11,16–26]. Most of them have focused on only one-dimensional data set. Thus, it is necessary to introduce some other novel ideas for generating initial centroids for text document clustering while using the K-means algorithm.
The main objective of this work is to develop high-quality text document clusters using the K-means clustering algorithm, with the help of the proposed new initial centroid selection algorithm. The proposed algorithm considers the document having a minimum standard deviation of term frequency as the first initial centroid. The remaining subsequent initial centroids are selected based on their dissimilarity of previously selected centroids. In the proposed method, every initial centroid of clusters is distinct and dissimilar to each of the other centroids. The remainder of this article is organised as follows: the preliminaries are outlined in section 2, the proposed algorithm is introduced and discussed in section 3, the experimental results are presented in section 4 and the conclusion is presented in section 5.
2. Preliminaries
2.1. Document representation
Most of the text document categorisation is adopted for the vector space model [27–30] to represent the documents, that is to say, each unique term in vocabulary represents one dimension in the future vector space. Therefore, the text document data sets can be represented as a document-by-term matrix
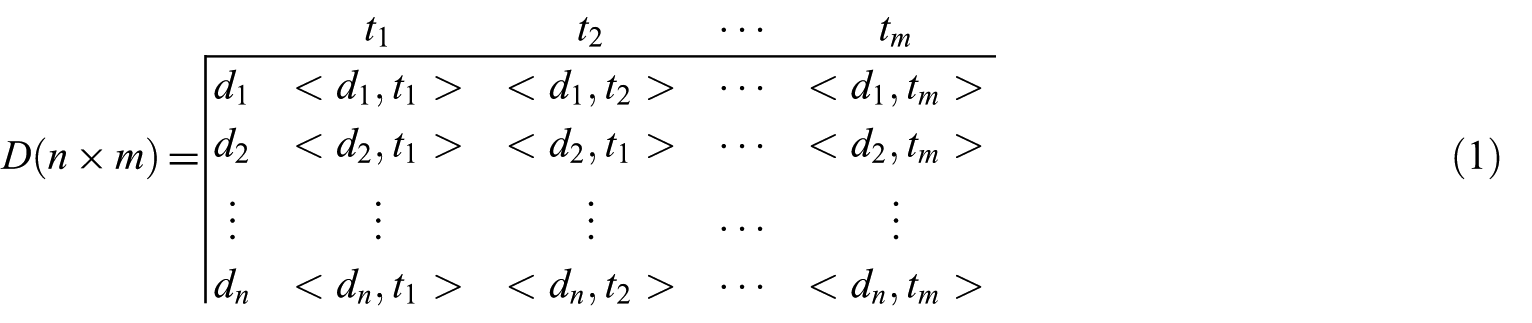
The value of every member of this matrix depends on the degree of relationship between its associated terms and the respective document. There are many methods for measuring this relationship, very often the used word count method, or the term frequency–inverse document frequency (TF-IDF) [31] method. In this article, every member of this matrix is calculated by any of these two methods. In the word count method,
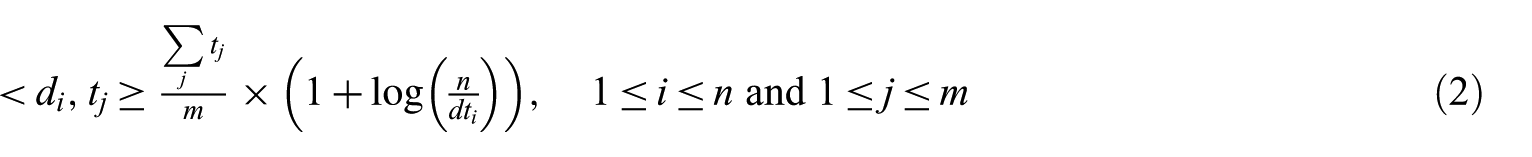
where
2.2. Similarity measure between two documents
Cosine similarity is one of the most popular similarity measures for searching similar documents in text document processing [27,28,31–34]. The cosine measure computes the cosine of the angle between two feature vectors and is used frequently in information retrieval, where the vectors are very large but sparse [35]. For two documents
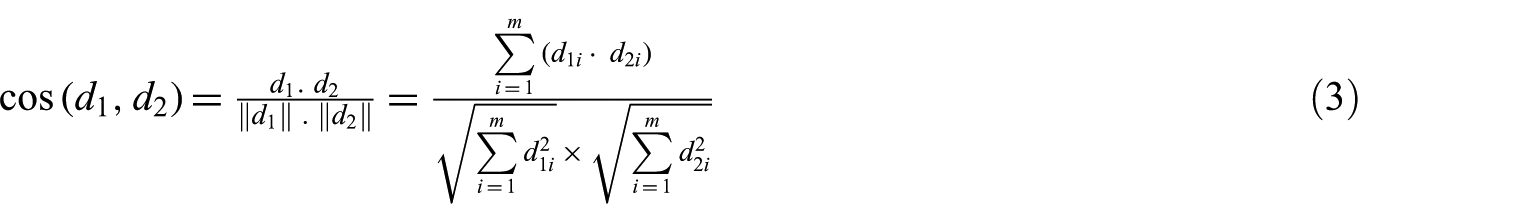
where m is the number of unique terms in both documents. When the cosine similarity is 1, the two documents are identical, and if it is 0, there is nothing common between these two documents.
2.3. K-means, K-means++ and Weight_Avg_Initials + K-means clustering algorithms
2.3.1. K-means clustering algorithm
K-means is the most important flat clustering algorithm [1,2,32,36], which is one of the top 10 algorithms in data mining. This algorithm is used to cluster n documents into K partitions. The standard K-means clustering algorithm is given in Algorithm 1.

Disadvantages. Due to random selection of the initial centroids, it leads to local optimal solution and takes more number of iterations to reach convergence.
2.3.2. K-means++ clustering algorithm
The K-means++ algorithm [6, 37, 38] provides a way to choose initial centroids for the K-means algorithm. Let D be a set of document collection and K be the number of specified seeds for the cluster. Let

Disadvantage. After selecting the first initial centroid, it takes
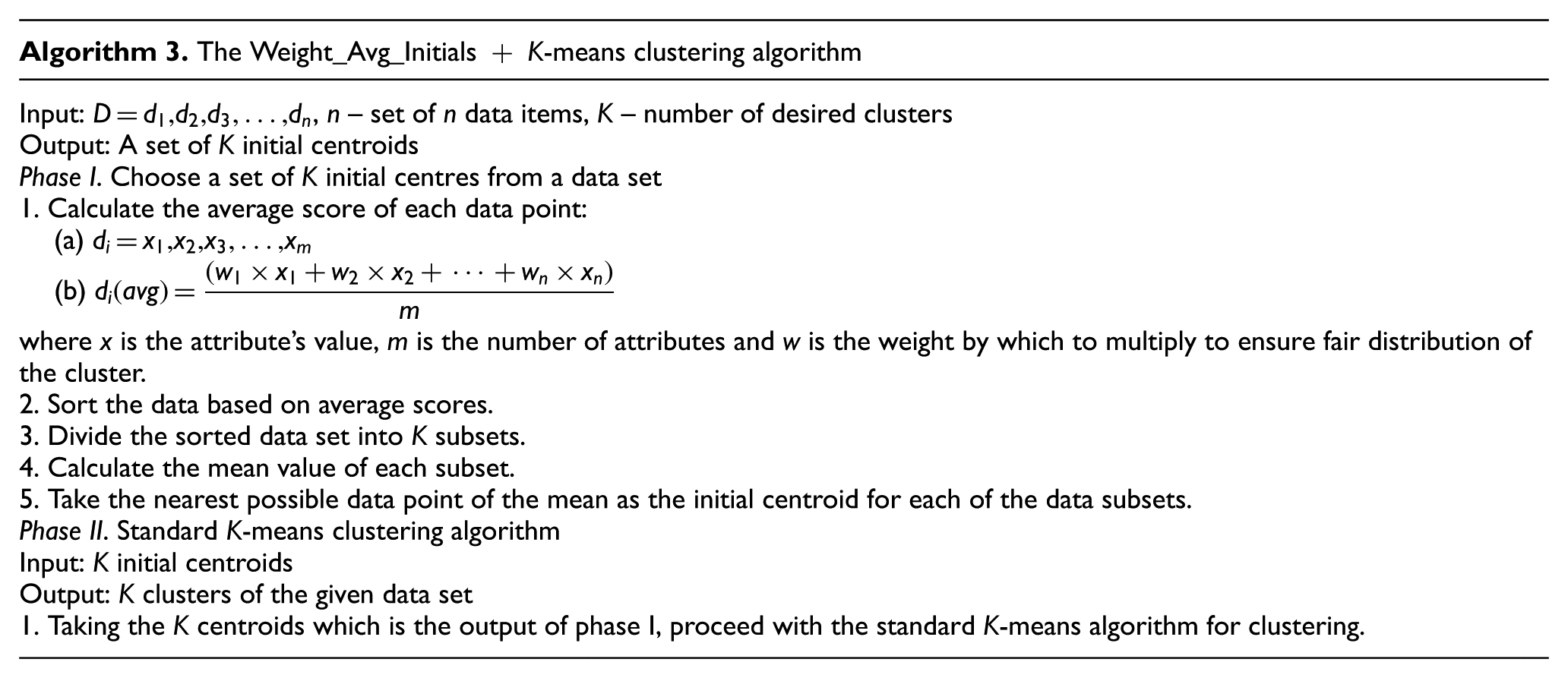
2.3.3. Weighted average of terms-based initial centroids for the K-means clustering algorithm
Sohrab Mahmud et al. [15] proposed weighted average of terms-based initial centroid selection for K-means. Let D be a data set, and it consists of n elements of data, such as
The average values of the entire set of data points are then sorted using merge sort. The sorted list of data points is then divided into K subsets. The nearest possible value of mean from each data set becomes the initial centroid of the cluster to be constructed. This algorithm is applied in n set of document collection. The unique terms are considered as m attributes.
This algorithm is described in Algorithm 3 as follows.
3. The proposed Dissimilarity-based Initial Centroid selection for DOCument clustering using K-means algorithm
Many algorithms have been introduced to select initial centroids for improving the performance of the K-means clustering algorithm. Many of them focus only on the random selection of initial centroids for clustering the given data set. Document clustering is a crucial and important application in information retrieval. Characteristics of this type of data such as high dimensionality and sparseness introduce new challenges to the clustering problem and make it harder compared with other types of data [1]. The proposed Dissimilarity-based Initial Centroid selection for DOCument clustering using K-means (DIC-DOC-K-means) algorithm focuses on the clustering of the multidimensional data sets, such as large document collections, using dissimilarity-based centroid selection rather than the random selection of centroids. The K-means algorithm starts with allocating cluster centroids randomly and then looks for the ‘better’ solutions. The K-means++ algorithm starts with the random allocation of one cluster centroid and then searches for other centroids based on the first one. Thus, both the K-means and K-means++ algorithms use the random initialisation method for the starting centroid.
The proposed DIC-DOC-K-means uses the document having the minimum standard deviation of term frequency from the document collection as the first initial centroid. A low standard deviation means that all the term frequencies in a document are close to the mean of its term frequencies. That is, a document for which the term frequencies are almost close is selected as the first initial centroid. This idea completely avoids the random selection of the first centroid, which is used in both K-means and K-means++. The remaining
The algorithm discussed in this article consists of two phases: in phase I, a new dissimilarity-based initial centroid selection algorithm is used to determine the initial centroids; in phase II, the final clusters are formed using the standard K-means algorithm with the help of the initial centroids arrived from phase I.
The proposed DIC-DOC-K-means algorithm is described as follows.

The proposed algorithm aims to identify K completely dissimilar initial centroids from a data collection. In order to attain this, a single control parameter
The main reason for introducing the control parameter is to identify completely dissimilar K initial centroids from a data collection. In some data collections, there are no instances of having K completely dissimilar documents for identifying the K initial centroids. In such cases, increasing the similarity score by a small factor will aid in identifying the K centroids in judicious time without compromising the quality of the centroids to a large extent. Also, selecting a small number of centroids from a highly dissimilar data collection can be done easily using a very small similarity score (0). However, when a large number of centroids need to be identified, having a zero similarity score will result in heavy computational burden. Hence, the control parameter
The proposed technique is computationally better without compromising the quality of the centroids as compared with the other methods. The K-means++ algorithm identifies K – 1 centroids except the first one, using K – 1 scans of the entire document set. This becomes computationally unreasonable when the number of initial centroids is large, or when the data collection has a large number of documents. The proposed algorithm will be able to identify the K centroids in a reasonable time for any value of K and for any type of data collection. This property of the proposed algorithm makes it robust and versatile in different application domains. The pseudocode for the proposed DIC-DOC-K-means is described as follows.

4. Experiments
The proposed algorithm is evaluated and compared with the three other clustering algorithms, namely, K-means, K-means++ and Weight_Avg_Initials + K-means, on two different document data sets.
4.1. Data sets
In this work, two data sets, namely, Reuters-8 and WebKB, are used to validate the quality of the cluster, as they are currently the most widely used benchmark in document clustering research. In both data sets, the documents are clearly classified in the separate classes. Hence, this classification of documents is used to evaluate and validate the clustering results of the proposed algorithm.
4.1.1. Reuters-8
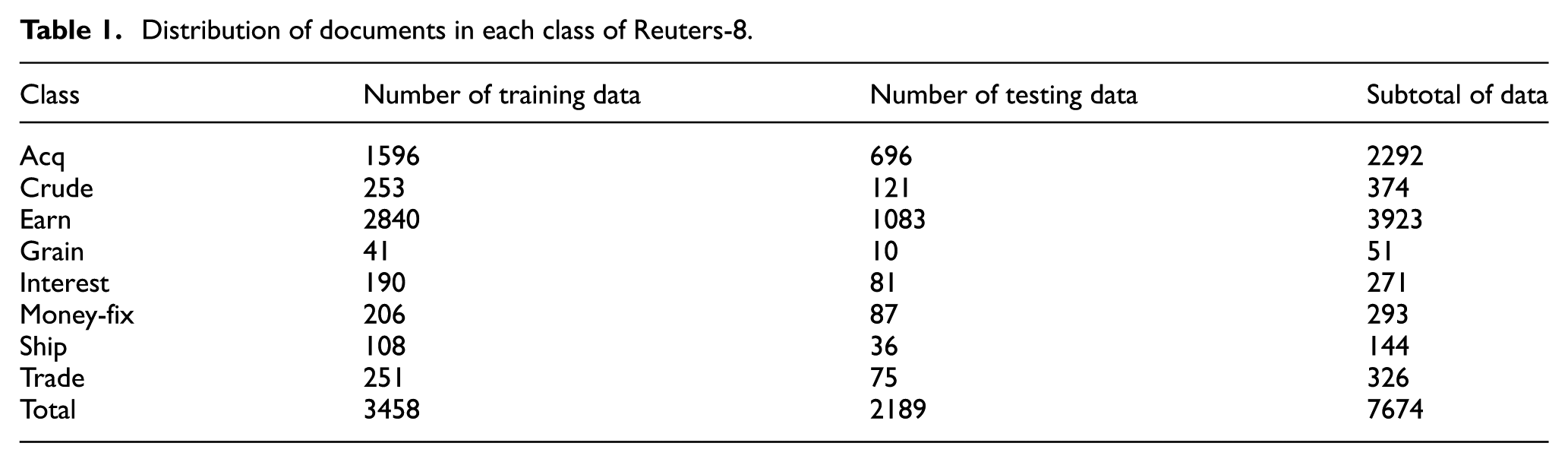
Reuters-21578 document collection [39] is employed to judge the effectiveness of cluster performance. The Reuters-21578 ModeApt’e Split Text Categorization Test Collection contains thousands of documents collected from Reuters newswire in 1987. It comprises 90 categories and 12,902 documents. In this work, the 8 most frequent categories among the 90 categories and only 1 topic document are considered for this work. Table 1 shows the distribution of the training and testing documents of Reuters-8 in every class for training and testing.
Distribution of documents in each class of Reuters-8.
4.1.2. WebKB
The WebKB data sets [40] contain web pages collected from computer science departments of various universities by the World Wide Knowledge Base (Web → Kb) project of the CMU Text Learning Group. The documents of this data set are not predestinated as training or testing patterns. They are divided randomly into training and testing subsets. Table 2 shows the distribution of the documents in every category randomly selected for training and testing.
Distribution of documents in each class of WebKB.

4.2. Validation of performance
The performance of the proposed algorithm is compared with the other clustering algorithms, namely, K-means and K-means++ clustering algorithms, based on the external measures such as purity, entropy and F-measure [41]. In general, the better clustering results have larger values of purity and F-measure and a lower value of entropy. If
Purity. Purity or accuracy is commonly used for measuring quality of clustering. It measures the largest class of documents for each cluster. The purity of cluster j is the majority number of documents with identical class labels in the jth cluster and is mathematically defined in equation (4)

The overall purity of clustering is a weighted sum of the cluster purities. It can be defined in equation (5)

Entropy. Entropy for clustering of documents is mathematically defined in equation (6)

F-measure. In information retrieval, precision is a measure of result relevancy, while recall is a measure of how many truly relevant results are returned. Precision is the ratio of the number of relevant documents to the total number of documents retrieved. Recall is the ratio of the number of relevant documents retrieved to the total number of relevant documents in the entire collection. The precision and recall can be defined, respectively, as
F-measure is the harmonic mean of precision and recall [1,33,42] and is mathematically defined in equation (7)

The final F-measure for all of the clusters is calculated using equation (8)
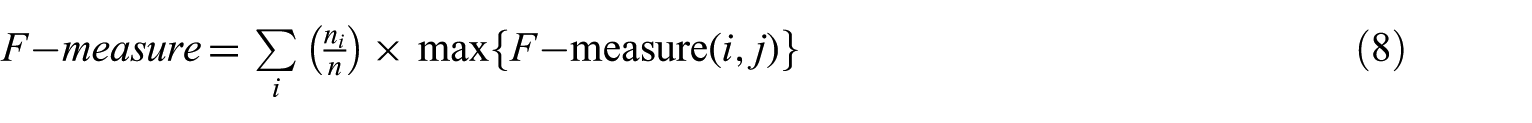
4.3. Results and discussion
The K-means, K-means++ and the proposed DIC-DOC-K-means algorithms are individually implemented in MATLAB 7.10. These three algorithms were run on the Reuters-21578 and WebKB data sets with cosine similarity measure. The results shown below are the average of 10 independent runs by each of K-means and K-means++. The Weight_Avg_Initials + K-means produced the result in a single run because of the fixed initial centroids for all runs. The existing standard K-means, K-means++, Weight_Avg_Initials + K-means and the proposed DIC-DOC-K-means were run under different K values (K = 8, 16, 24, 32) for Reuters-8 and (K = 4, 8, 12, 16) for WebKB for measuring the purity (Pu), entropy (En), F-measure (F-M) and recall (Re) of clusters.
4.3.1. Results for word count representation of documents
The word count representation of the document set produced the better result than the TF-IDF document representation for document clustering. The results for word count representation of documents on the testing data of Reuters-8 and WebKB are shown in Tables 3 and 4 and the same are represented from Figures 1–8.
Purity and entropy values for word count representation of documents.
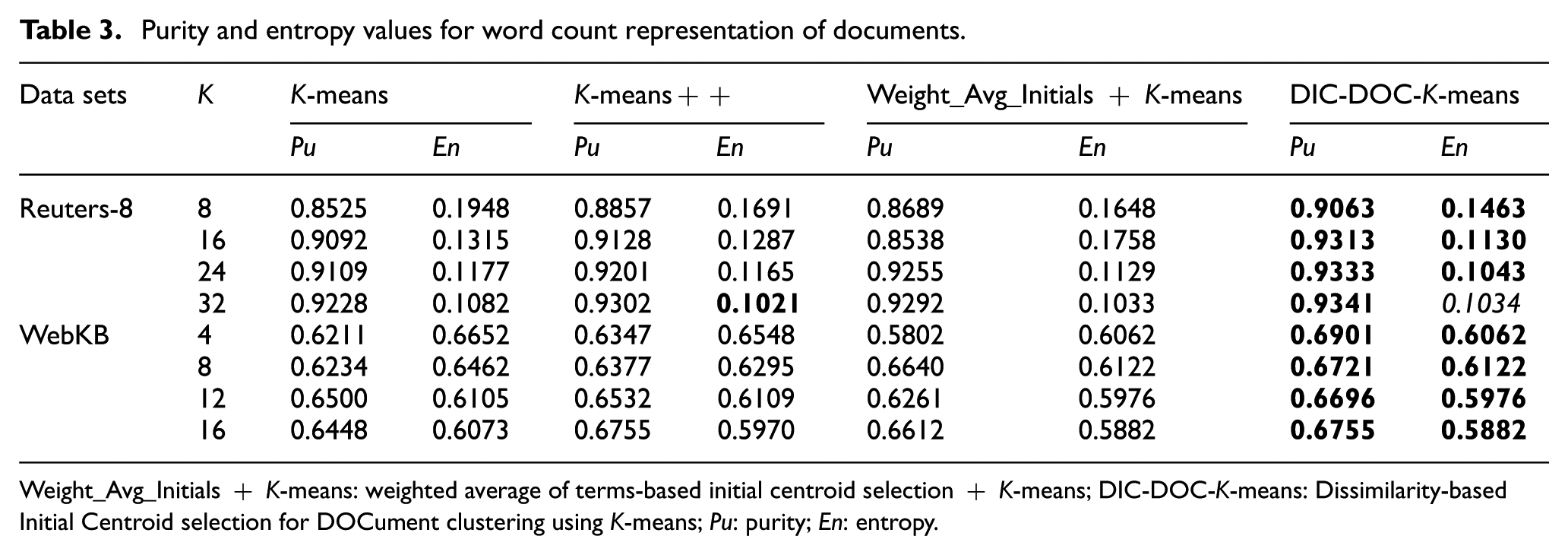
Weight_Avg_Initials + K-means: weighted average of terms-based initial centroid selection + K-means; DIC-DOC-K-means: Dissimilarity-based Initial Centroid selection for DOCument clustering using K-means; Pu: purity; En: entropy.
F-measure and recall values for word count representation of documents.
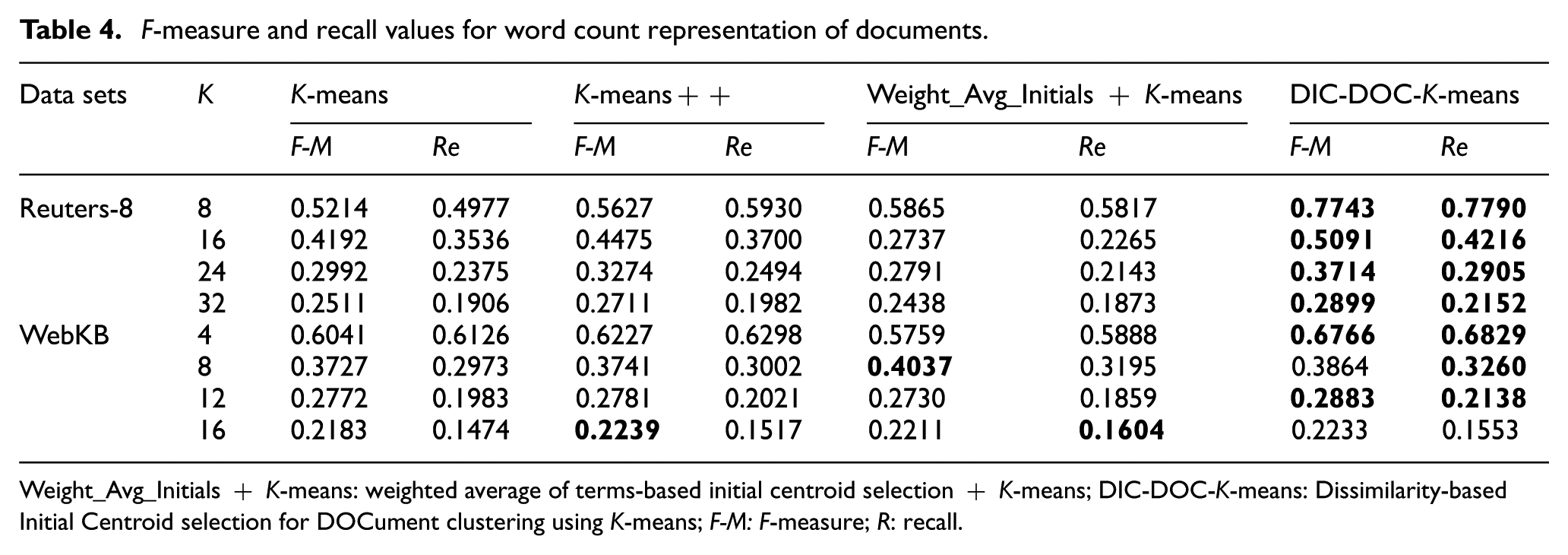
Weight_Avg_Initials + K-means: weighted average of terms-based initial centroid selection + K-means; DIC-DOC-K-means: Dissimilarity-based Initial Centroid selection for DOCument clustering using K-means; F-M: F-measure; R: recall.
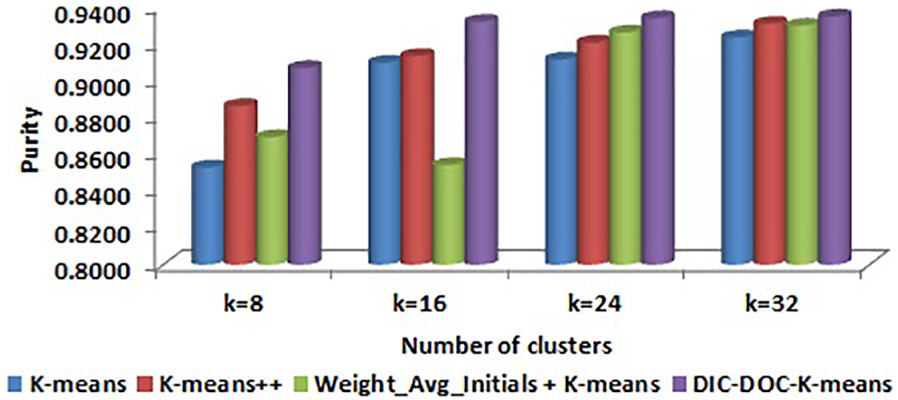
Comparison of purity values for Reuters-8 by word count representation.
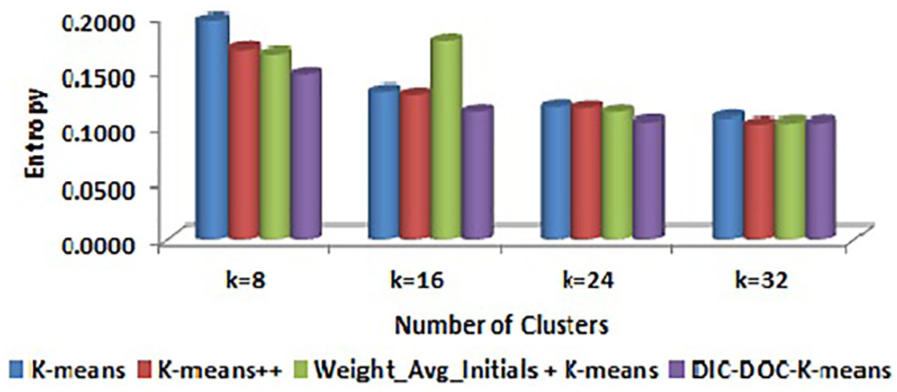
Comparison of entropy values for Reuters-8 by word count representation.
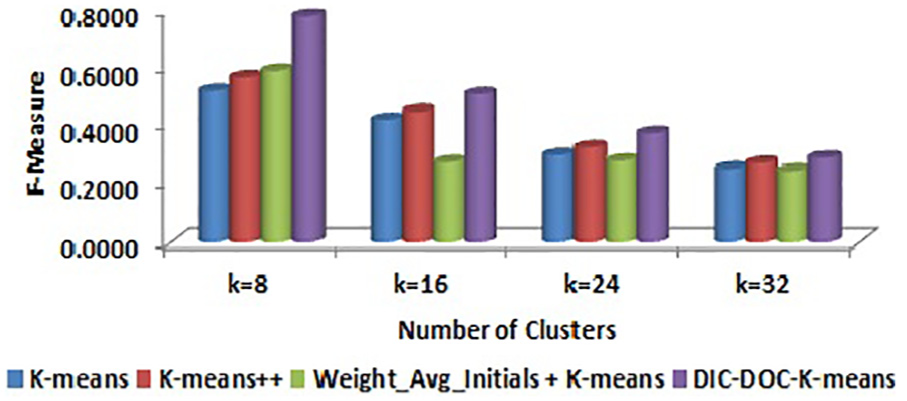
Comparison of F-measure values for Reuters-8 by word count representation.
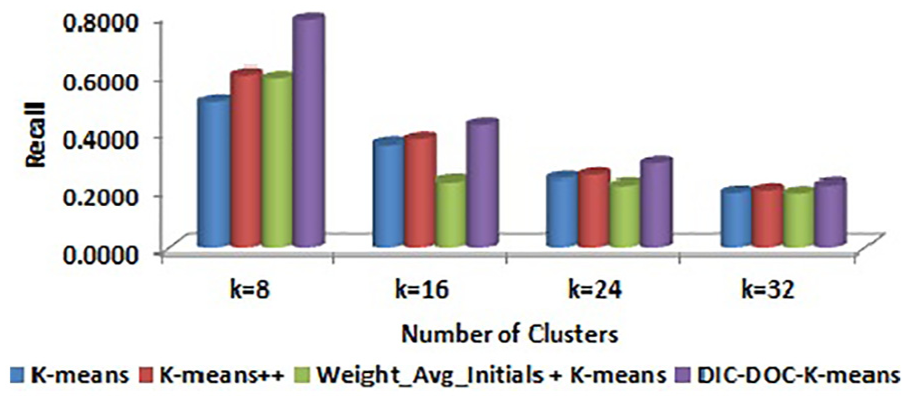
Comparison of recall values for Reuters-8 by word count representation.
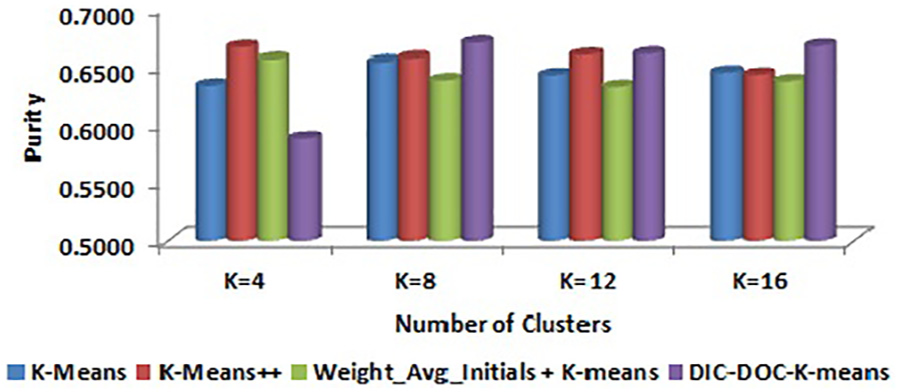
Comparison of purity values for WebKB by word count representation.
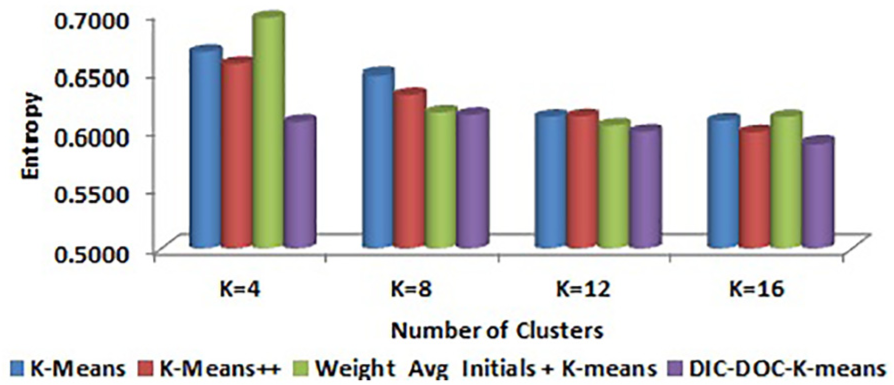
Comparison of entropy values for WebKB by word count representation.
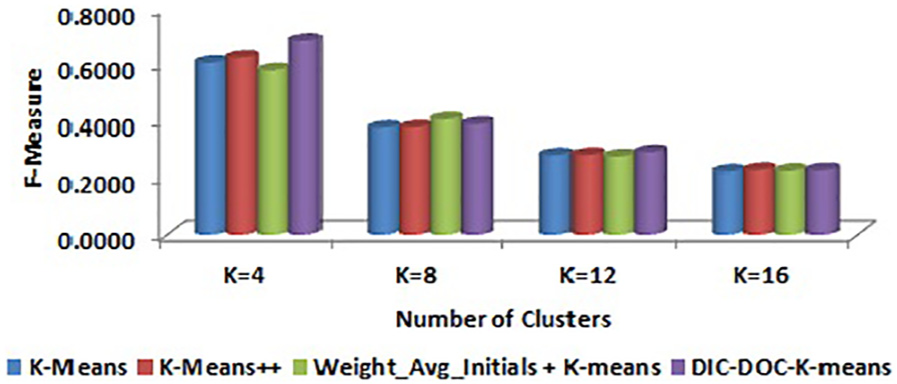
Comparison of F-measure values for WebKB by word count representation.
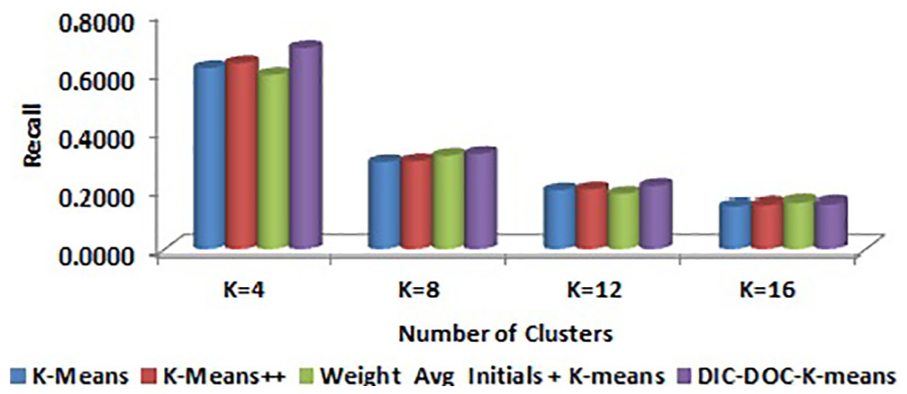
Comparison of recall values for WebKB by word count representation.
In word count representation, the proposed DIC-DOC-K-means shows a significantly better result than the K-means, K-means++ and Weight_Avg_Initials + K-means clustering algorithms.
4.3.2. Results for the TF-IDF representation of documents
The TF-IDF method is the most common document representation in the area of text mining and information retrieval. The results for the TF-IDF representation of documents on testing data of Reuters-8 and WebKB are shown in Tables 5 and 6 and the same are represented in Figures 9–16.
Accuracy and entropy values for TF-IDF representation of documents.
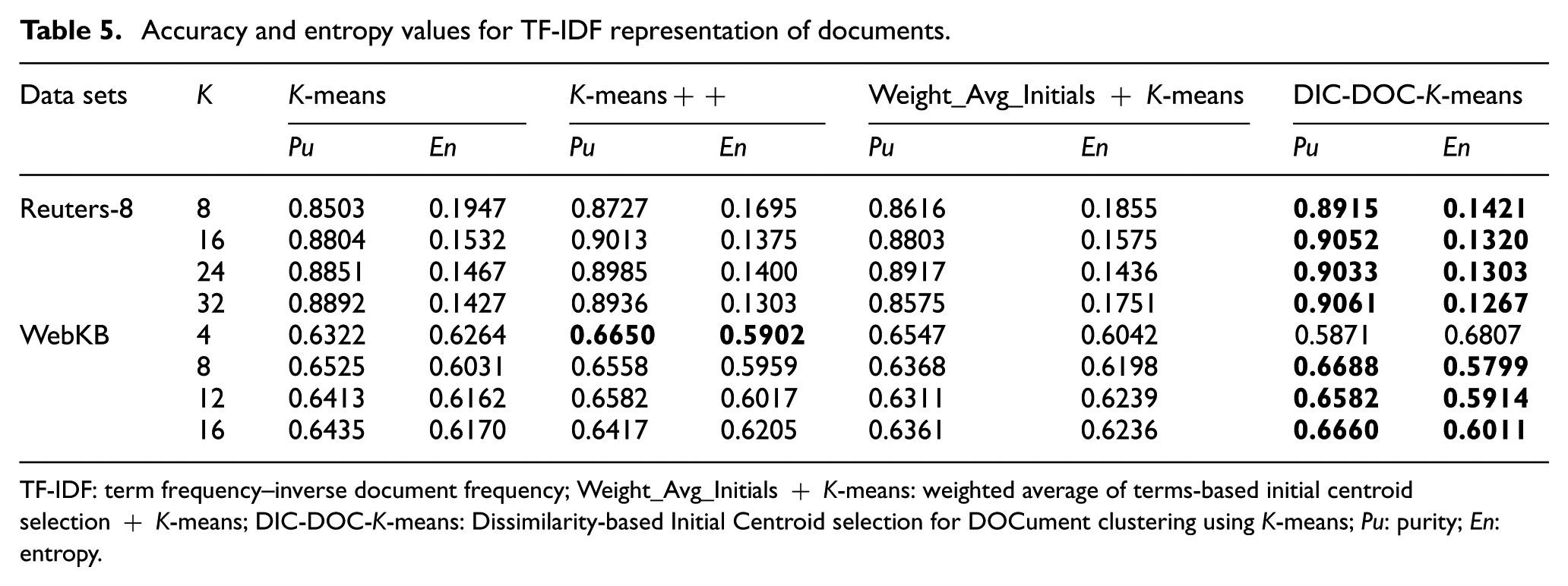
TF-IDF: term frequency–inverse document frequency; Weight_Avg_Initials + K-means: weighted average of terms-based initial centroid selection + K-means; DIC-DOC-K-means: Dissimilarity-based Initial Centroid selection for DOCument clustering using K-means; Pu: purity; En: entropy.
F-measure and recall values for TF-IDF representation of documents.
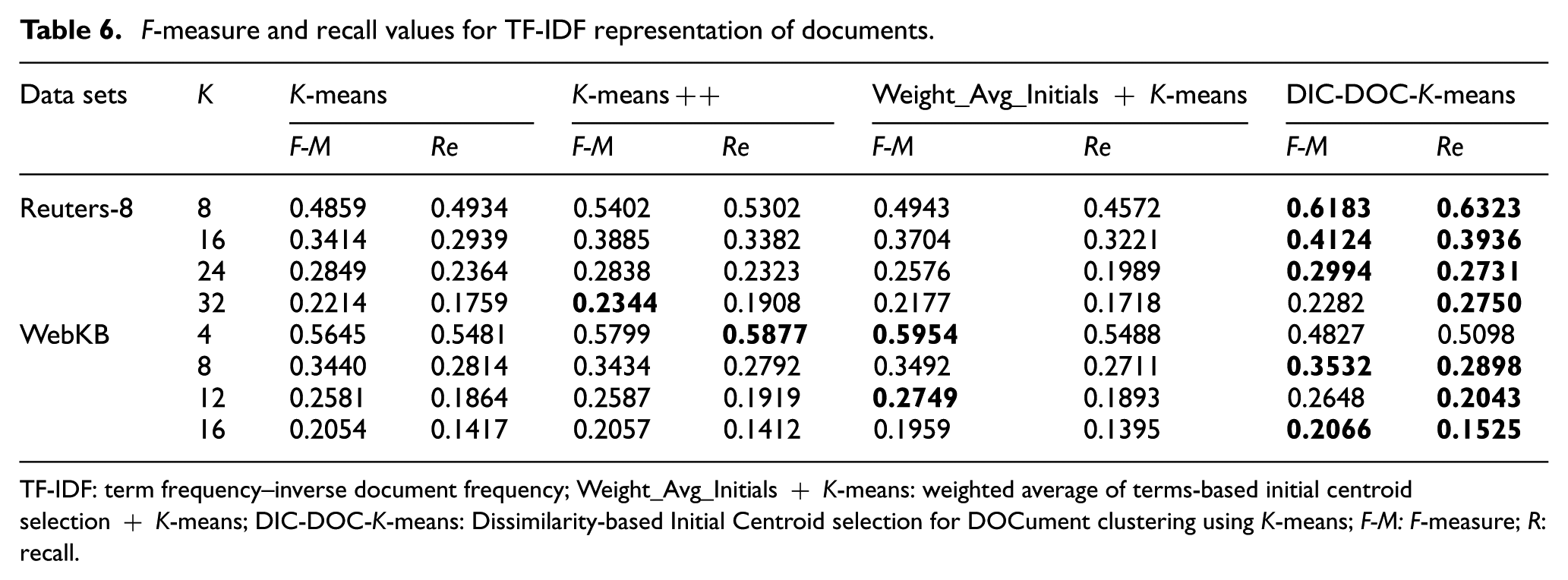
TF-IDF: term frequency–inverse document frequency; Weight_Avg_Initials + K-means: weighted average of terms-based initial centroid selection + K-means; DIC-DOC-K-means: Dissimilarity-based Initial Centroid selection for DOCument clustering using K-means; F-M: F-measure; R: recall.
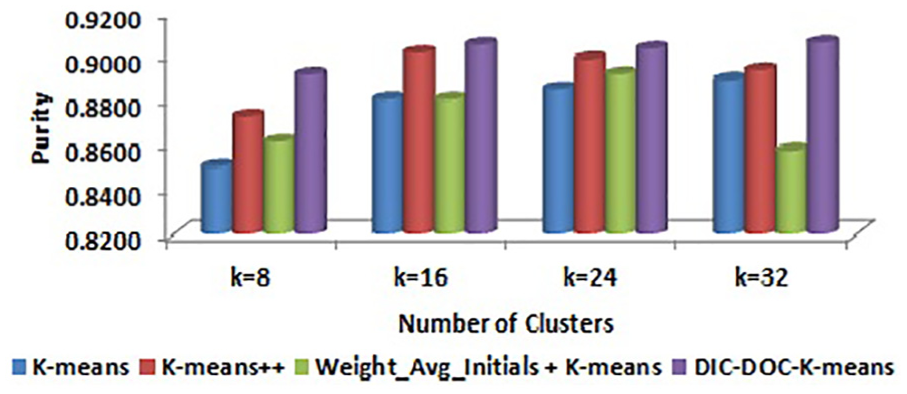
Comparison of purity values for Reuters-8 by TF-IDF representation.
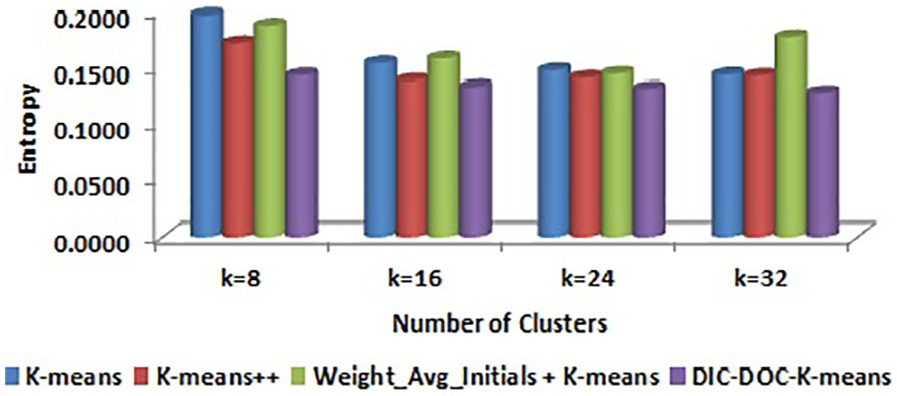
Comparison of entropy values for Reuters-8 by TF-IDF representation.
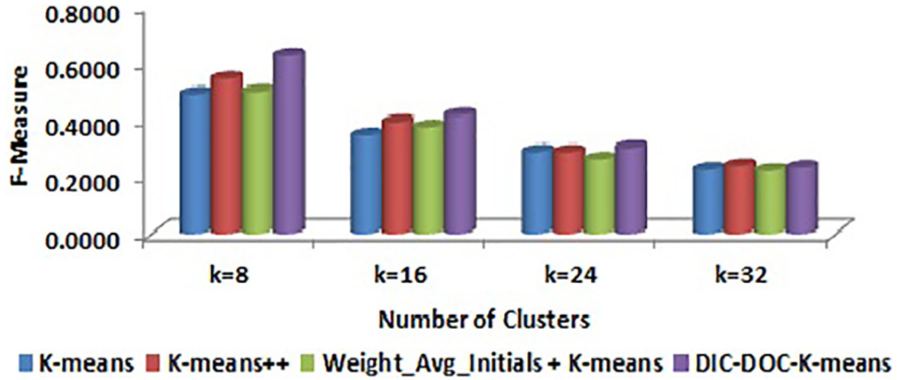
Comparison of F-measure values for Reuters-8 by TF-IDF representation.
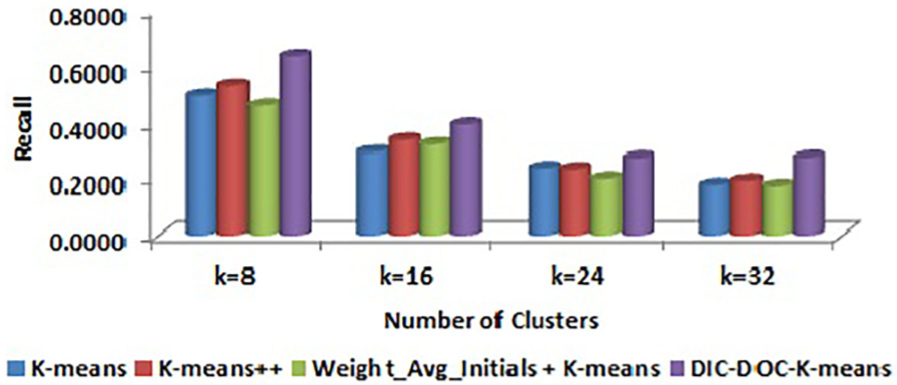
Comparison of recall values for Reuters-8 by TF-IDF representation.
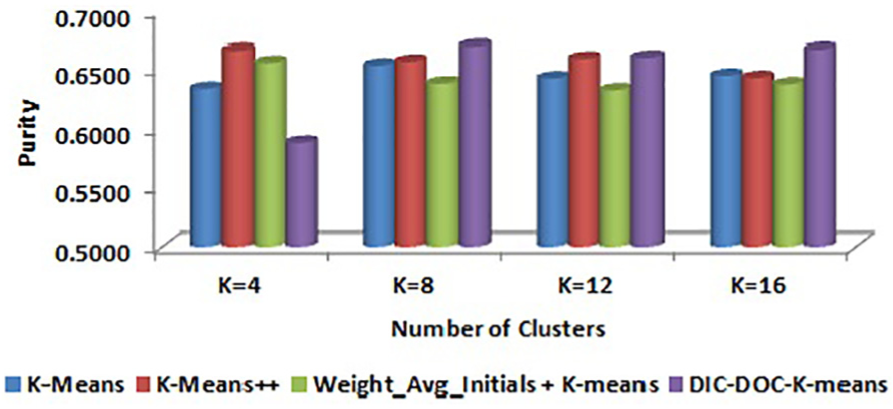
Comparison of purity values for WebKB by TF-IDF representation.
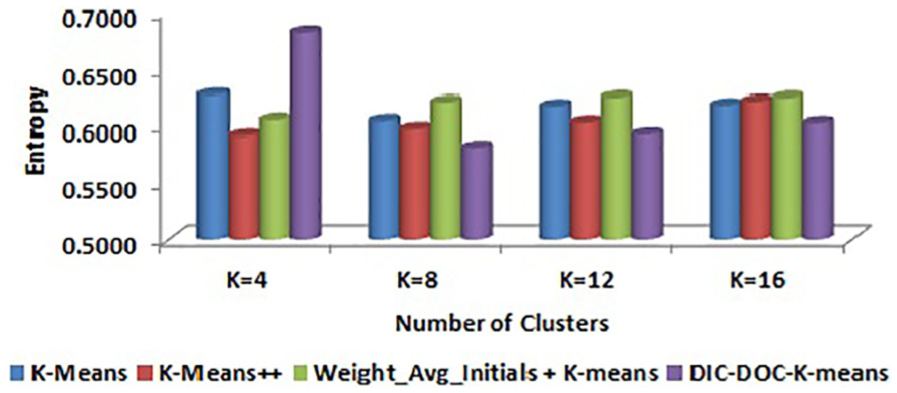
Comparison of entropy values for WebKB by TF-IDF representation.
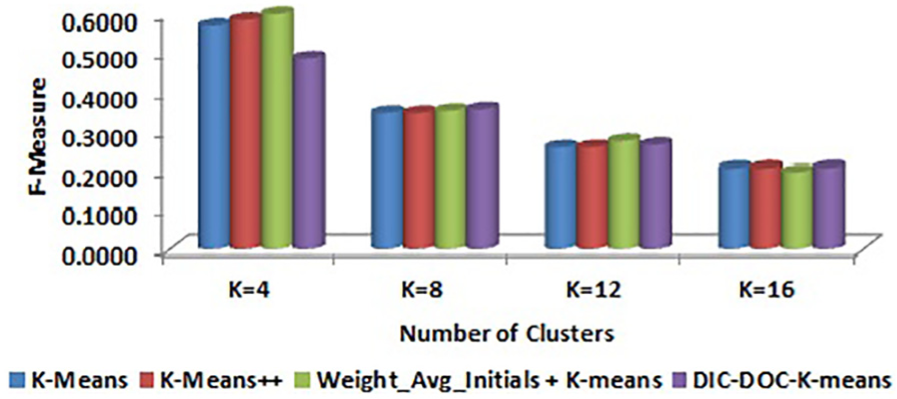
Comparison of F-measure values for WebKB by TF-IDF representation.
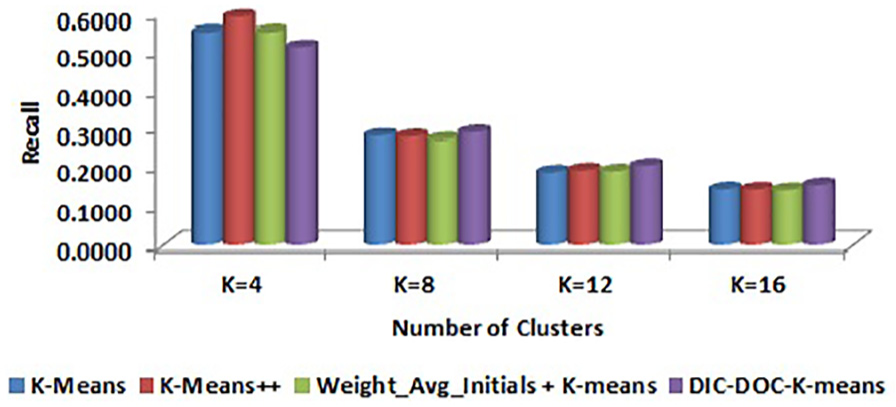
Comparison of recall values for WebKB by TF-IDF representation.
It is observed that the proposed DIC-DOC-K-means provides better results for Reuters-8 for all cluster sizes. For the WebKB data set, the proposed algorithm produced the significantly better result in all cases except K = 4. When the cluster size K = 4, the K-means++ and Weight_Avg_Initials + K-means give better results than the proposed DIC-DOC-K-means algorithm. When the cluster size K = 12, the Weight_Avg_Initials + K-means gives better F-measure values than the proposed as well as K-means and K-means++ algorithms.
It is observed that the proposed DIC-DOC-K-means algorithm produces better results compared with the standard K-means, K-means++ and Weight_Avg_Initials + K-means clustering algorithms for most of the cluster sizes used in this work. In particular, when the number of clusters is equal to the number of classes of the given data set, the proposed algorithm performs significantly better compared with the existing K-means, K-means++ and Weight_Avg_Initials + K-means document clustering algorithms. In addition, the word count representation of documents gives better performance than the TF-IDF representation of documents while using the proposed DIC-DOC-K-means.
5. Conclusion
A new DIC-DOC-K-means algorithm is presented. The proposed DIC-DOC-K-means algorithm uses the cosine similarity measure for calculating the similarity between the previously selected centroids and the other remaining documents for selecting subsequent centroids in phase I. The cosine similarity is used in phase II for calculating the similarity between centroids and documents, for assigning documents to its similar centroids. The performance is validated on testing data sets of Reuters-8 and WebKB, and compared with the performances of the K-means, K-means++ and Weight_Avg_Initials + K-means clustering algorithms. The performance in terms of purity, entropy and F-measure is calculated with the K values of 8, 16, 24 and 32 for Reuters-8 and with the K values of 4, 8, 12 and 16 for WebKB. The proposed DIC-DOC-K-means algorithm improves the performance of text document clustering for any type of text document data sets. Phase I of the proposed DIC-DOC-K-means, which is used for selecting initial centroids, is not only suitable for K-means document clustering, but also for any initial centroid-based document clustering and classification algorithms.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.