
Abstract
In the domain of Galleries, Libraries, Archives and Museums (GLAM) institutions, creative and innovative tools and methodologies for content delivery and user engagement have recently gained international attention. New methods have been proposed to publish digital collections as datasets amenable to computational use. Standardised benchmarks can be useful to broaden the scope of machine-actionable collections and to promote cultural and linguistic diversity. In this article, we propose a methodology to select datasets for computationally driven research applied to Spanish text corpora. This work seeks to encourage Spanish and Latin American institutions to publish machine-actionable collections based on best practices and avoiding common mistakes.
1. Introduction
Cultural heritage institutions have traditionally provided access to digital collections. They are an excellent example of public engagement, bringing together materials, people and services with a multidisciplinary perspective. The materials represent rich sources of information that include text, maps, images, metadata, video and audio, among others. Digital collections differ in several ways: for example, in terms of copyright, the number of formats available and the accessing method, that is, using an application programming interface (API) or bulk downloads.
Meanwhile, Labs have emerged in Galleries, Libraries, Archives and Museums (GLAM) institutions that work on the reuse of digital collections in inspiring and creative ways [1]. New scholarship programmes encompassing all disciplines, such as Computer Science and Digital Humanities, are being adopted by GLAM institutions with the goal of improving their services by involving researchers and understanding how they use the data [2]. In addition, institutions are producing innovative models for supporting cloud-based research computing based on their digital collections and identifying requirements as well as possibilities. Examples include the Library of Congress (LC), the National Library of the Netherlands and the National Library of Scotland. In this way, Labs can reinforce and maintain the relevance of GLAM institutions and their digital collections by engaging researchers.
GLAM institutions are starting to explore the benefits of new approaches to the publication of their digital collections to encourage computational use. Most of the documentation and examples of machine-actionable collections, however, are in English, including the text data [3]. In this sense, Spanish and Latin American institutions such as the Biblioteca Digital del Patrimonio Iberoamericano (BDPI) [4], and Mexicana, as well as project-based initiatives are taking a step forward by making digital materials openly available. To foster machine-actionable collections in Spanish and Latin American institutions, best practices and guidelines are required to make their content available and reusable by researchers. Some efforts have recently been made regarding the translation of documentation into Spanish to encourage the use and publication of machine-actionable collections [5], as well as several research projects based on Spanish literature. Examples include Mnemosine and Unlocking the Colonial Archive [6,7].
Digital collections often come in the form of hard-to-access data silos and this impedes their reuse by researchers. In addition, identifying a dataset for reuse is not an easy task for various reasons, such as copyright restrictions, coverage or quality.
In this regard, benchmarks provide an experimental process for comparing and assessing the performance of processes, services, databases and many other technologies with those regarded as the best. Benchmarking allows the identification of opportunities for improvement as well as the replication of the results. In this way, benchmarking can be adapted to datasets to identify the best datasets amenable to computationally driven research [8,9].
The purpose of this study was to introduce an extensible methodology to create a benchmark of digital collections amenable to computationally driven research. The methodology was applied to several Spanish language datasets to encourage Spanish and Latin American institutions to publish machine-actionable collections based on best practices and avoiding common mistakes.
The main contributions of this article are as follows: (a) a methodology for selecting datasets for computationally driven research, (b) a benchmark of Spanish language datasets for computationally driven research and (c) the description of a practical and reproducible example of how to reuse the benchmark.
The article is organised as described next. After a brief review of the state of the art in section 2, section 2.1 describes the methodology to create a benchmark of datasets. Section 3 introduces the benchmark of datasets for computationally driven research and gives an example of reuse based on a collection of Jupyter Notebooks and discusses the results. The article concludes with an outline of the results and general guidelines on how to use the results and future work.
2. Background
For preservation purposes and to improve ease of access, cultural heritage institutions have digitised the vast and rich collections that represent cultural diversity. Digital technologies and the Internet have unleashed unprecedented and unique opportunities to access the rich materials hosted by institutions as well as to create engaging programmes to reuse the contents [10,11].
Cultural heritage institutions have recently started to explore research applied to digital collections based on computationally driven methods. They are investigating the feasibility of data analytics approaches to improve the access to their digital collections [12]. New approaches such as Collections as Data provide a framework to create machine-actionable collections ready for reuse [13]. The LC recommends creating digital collections usable for computation as well as building institutional capacity for digital scholarship and for expanding user services [14]. The Online Computer Library Centre (OCLC) recently published a study on community engagement with data science, machine learning and artificial intelligence [3].
Nevertheless, designing a sustainable data extraction workflow to publish machine-actionable collections is a challenging task [15]. The National Library of Scotland is exploring the opportunities and challenges of publishing datasets that support computational access including data management, rights and required skills [16]. Other approaches are based on datasets published by several relevant GLAM institutions including a detailed step-by-step guide [17]. KU Leuven Libraries are exploring new ways of creating, sharing and using the libraries’ digitised collections as data [18,19].
While the number of machine-actionable collections for computation has increased, most of them are hosted and published by large western institutions, where the use of English predominates [3]. Standardised benchmarks can be useful to broaden the scope of machine-actionable collections and to promote cultural and linguistic diversity. They can also help practitioners select, reuse and improve the right datasets, and provide objective feedback to the research community [20].
The identification of a dataset for reuse is not an easy task for various reasons, including vague copyright and terms of use, coverage, completeness, or ease of understanding. Even if the dataset is available, in some cases, it may require some preprocessing and cleaning to be ready for computational purposes. In addition, when working with large datasets, researchers can obtain manageable slices of the data.
In this sense, the LC Selected Datasets Collection provides an initial series of 20 datasets to support emerging styles of data-driven research, such as text mining and machine learning [21]. Chronicling America provides access to information about historic newspapers and a selection of digitised newspaper pages in the United States [22]. The publication of text of a collection of books in computer readable format was funded by the Faculty of Arts and Social Sciences and the Digital Humanities Hub of Lancaster University (UK) [23–25]. A collection of datasets released by the British Library includes several openly available repositories [26]. In 2017, the Bibliothèque nationale de France (BnF) published Bnf API et jeux de données, including datasets and the API documentation. Mexicana is an open platform that provides access to available digital collections of the Ministry of Culture in Mexico [27]. GLAM Labs usually publish data openly and in reuseable data ready for computational use. Examples include the National Library of Scotland data [28], the Austrian National Library [29] and the Dutch National Library [30]. Other approaches are based on Linked Open Data (LOD) using standard vocabularies and providing SPARQL [31] endpoints to access the data [32–34]. However, LOD repositories published by libraries are mainly dedicated to publishing metadata retrieved from their main catalogues using several controlled vocabularies. Moreover, additional examples are based on international aggregators including BDPI, Europeana [35] and the Atlas of Digitised Newspapers and Metadata [36].
Organisations, publishers and the community promote the sharing and reuse of datasets for research to encourage scientific progress. In this sense, several factors, such as sustainability, availability and discoverability have become crucial to support a collaborative research environment [37]. As a result, several platforms enable researchers to cite, locate and identify datasets, such as DataCite and Zenodo.
The final report of Collections as Data [38] recommends that institutions share prototypes and examples of use of their collections with the research community. The popularity of Jupyter Notebooks [39] has significantly increased in recent years. A notebook combines software code, multimedia resources, narrative text, visualisations and results in a single document that researchers can use and share. The combination of Jupyter Notebooks and machine-actionable collections provide an innovative and interactive environment for collaborative, transparent and reproducible data analyses [17,40,41].
Although some approaches reuse datasets published by GLAM institutions, to the best our of knowledge, no benchmark of datasets for computationally driven research exists based on Spanish text corpora. Benchmarks based on machine-actionable datasets are relevant because (a) they help to compare the available datasets and to meet the needs of the users; (b) researchers can address new challenges, improving the features and including new datasets; and (c) organisations can benefit from shared best practices when publishing their datasets [20].
2.1. A methodology for selecting datasets for computationally driven research
The main goal of this study was to provide the research community with a benchmark to compare and evaluate machine-actionable datasets in cultural heritage institutions. Since the publication of digital collections has become popular and the number of datasets has increased, identifying candidates for the assessment, known as subjects, is an essential factor in a benchmark’s success and performance. Other approaches propose methodologies to identify subjects that consider a variety of attributes ranging from more advanced technical issues to general cultural aspects [42,43].
We defined our benchmark’s criteria based on previous works [20,44–46]. Each feature can be given a score according to a criterion that consists of a function, with values ranging from 1 to 0. The definition of each criterion is described below.
2.1.1. Licencing
In general, licences range from very permissive with none or few obligations and known as open, to very restrictive or closed that include restrictions for reuse. The most permissive open licences are Creative Commons CC0 1.0 Universal Public Domain Dedication, 1 and Public Domain Mark (PDM). Open licences such as CC BY (Creative Commons Attribution Licence), CC BY-SA (Creative Commons Attribution-Share Alike) and other types require attribution and appropriate credit, as well as the indication of whether changes were made. Close licences are less permissive and limit the usage. Other approaches are based on national policies regarding the publication of open data. 2 This criterion is defined as follows

2.1.2. Accuracy
Based on the literature [47], this criterion determines the extent to which data are correct, reliable and certified free of error.
Optical character recognition (OCR) is an automated process that transforms an image into computer-readable text. However, OCR is not 100% accurate, and may contain errors for various reasons, for example, the use of small fonts [48]. Many institutions, such as the LC and Europeana are considering crowdsourcing approaches, thus allowing volunteers to create and review transcriptions to improve search and discovery [49–52]. As a result, this criterion is defined as shown in Table 1.
Possible scores according to the accuracy criterion.
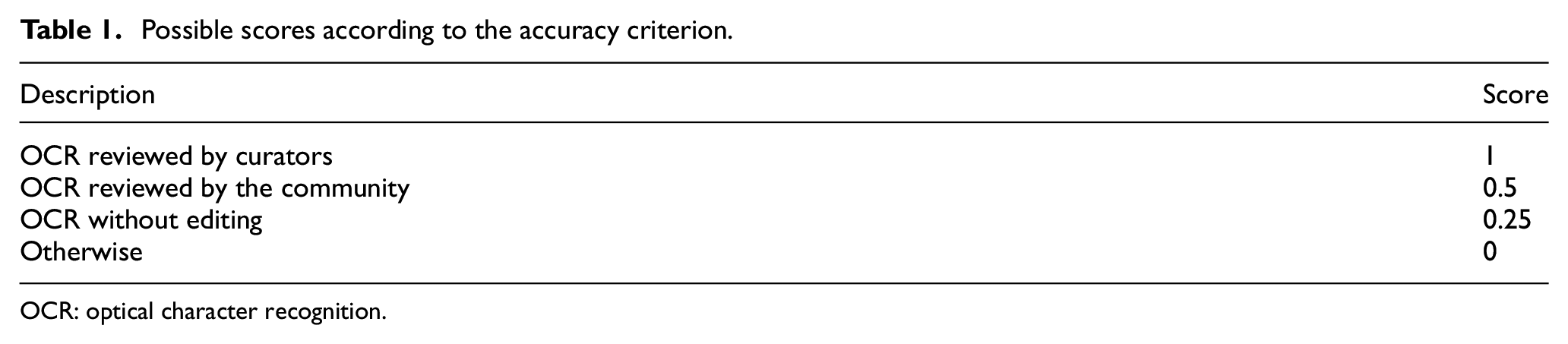
OCR: optical character recognition.
2.1.3. Provenance
The fulfilment of this criterion means that provenance is used to describe the creation process and the derived data. For instance, provenance information can be encoded by using the dcterms: provenance and dcterms: source properties in Dublin Core. This criterion is defined as follows

2.1.4. Language
Datasets are usually provided in the organisation’s original language. However, sometimes the text is provided in several languages such as in the case of an international aggregator. Let

2.1.5. Permanent identifier
Regarding the identification of the datasets, several methodologies and platforms can be used. For instance, when using Zenodo, each dataset is assigned a digital object identifier (DOI). This criterion is defined as follows

2.1.6. Prototypes and documentation
Providing prototypes and examples of use in addition to documentation can facilitate the reuse of the datasets by potential researchers [38,53]. In this sense, Jupyter Notebooks has become very popular in the community and has helped to lower barriers and include reproducible code as well as documentation [17]. This criterion is defined as follows

2.1.7. Formats
It is relevant to providing datasets in a variety of formats because it allows compatibility with commonly used methods and tools [54,55]. Machine-readable formats can be automatically read and processed by a computer, such as CSV and TXT. However, organisations often provide PDF files that are not machine-readable, or that use proprietary formats, such as Microsoft Word (.doc).
The number of formats provided can be computed by exploring their websites as well as open science repositories such as Zenodo and FigShare. This criterion is defined as follows

2.1.8. Terms of use and code of conduct
Adding terms of use to the datasets is crucial to facilitate their reuse [38]. A code of conduct aims at ensuring a respectful and productive environment for reuse and research based on the datasets. These policies are applicable to all users and they may cover several aspects, such as the conditions of use, rules, responsibilities and proper practices. 3 This criterion is defined as follows

2.1.9. Technical aspects
Several technical aspects need to be considered including the use of an API such as a public endpoint SPARQL or the protocol OAI-PMH. This criterion is defined as follows

The list of potential subjects can be evaluated using diverse techniques and methods. For instance, the alternatives to alternatives scorecard consists of a matrix in which candidates for benchmarking (known as alternatives) are shown in rows and attributes based on criteria are shown in columns. Another example is that of polar charts, which are circular graphs where rays associated to attributes are drawn from the centre of a circle and their length is proportional to the rating. The best choice would be the subject that covers the largest area [45].
3. Benchmarking Spanish language datasets
This section introduces the datasets that will serve as benchmark. This approach is based on the methodology proposed in section 2.1 to extend the research value of the digital collections, encourage GLAM institutions to embrace Collections as Data as a core activity and to promote greater linguistic diversity in terms of the texts provided.
There is a wide range of means of publication of datasets that provides a machine-actionable collection ready for reuse. Approaches based on APIs enable reuse of data by multiple applications for different purposes (e.g. embedding images in hypertext markup language (HTML) or enhancing images with transcriptions) [56]. In addition, by using APIs the user is able to identify and download a slice of the dataset according to the requirements of the research to be conducted. Nevertheless, general API users may face the challenge of a steep learning curve. In addition, APIs can be vulnerable to attacks and additional resources are necessary to adopt security protocols and maintenance. Other approaches are based on conventional websites, as well as open and free platforms, such as GitHub and Zenodo. The latter provide a link to the dataset, including OCR text.
In the present case, we were interested in the Spanish language for the criterion
Moreover, there is variety of reasons to exclude a dataset: full text lacking, the language of the text or copyrighted material.
A collection of Jupyter Notebooks based on the datasets provided by the benchmarking was created. The project is openly available in GitHub 4 as a collection of interactive notebooks and the code is runnable and reproducible in a cloud environment such as Binder [59]. The notebook collection was assigned a DOI with the data archiving platform Zenodo. 5 Table 2 shows the main features of the datasets used in the Jupyter Notebooks collection. In addition, Figures 2–4 show the results obtained after reusing the datasets.
Main features of the datasets used and methods applied in the collection of Jupyter Notebooks.
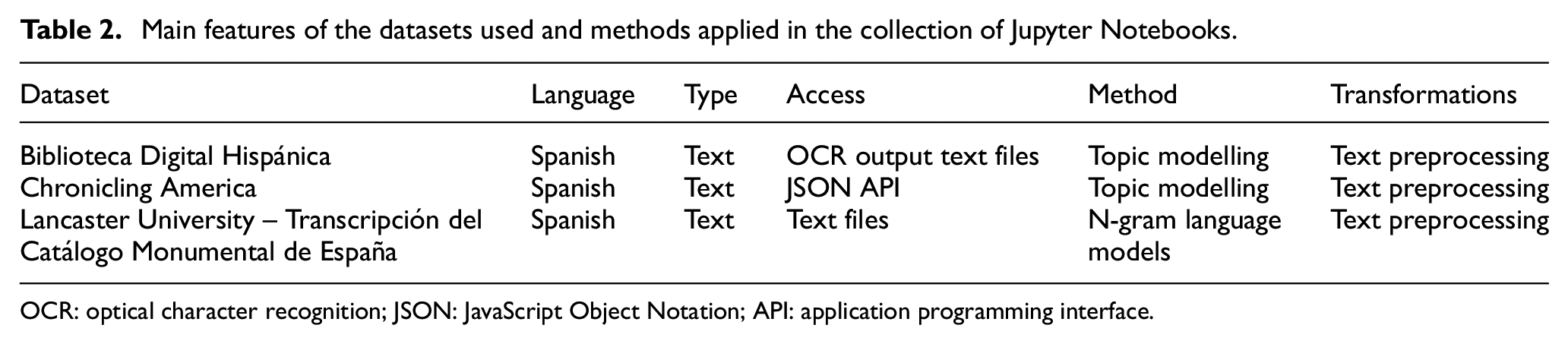
OCR: optical character recognition; JSON: JavaScript Object Notation; API: application programming interface.
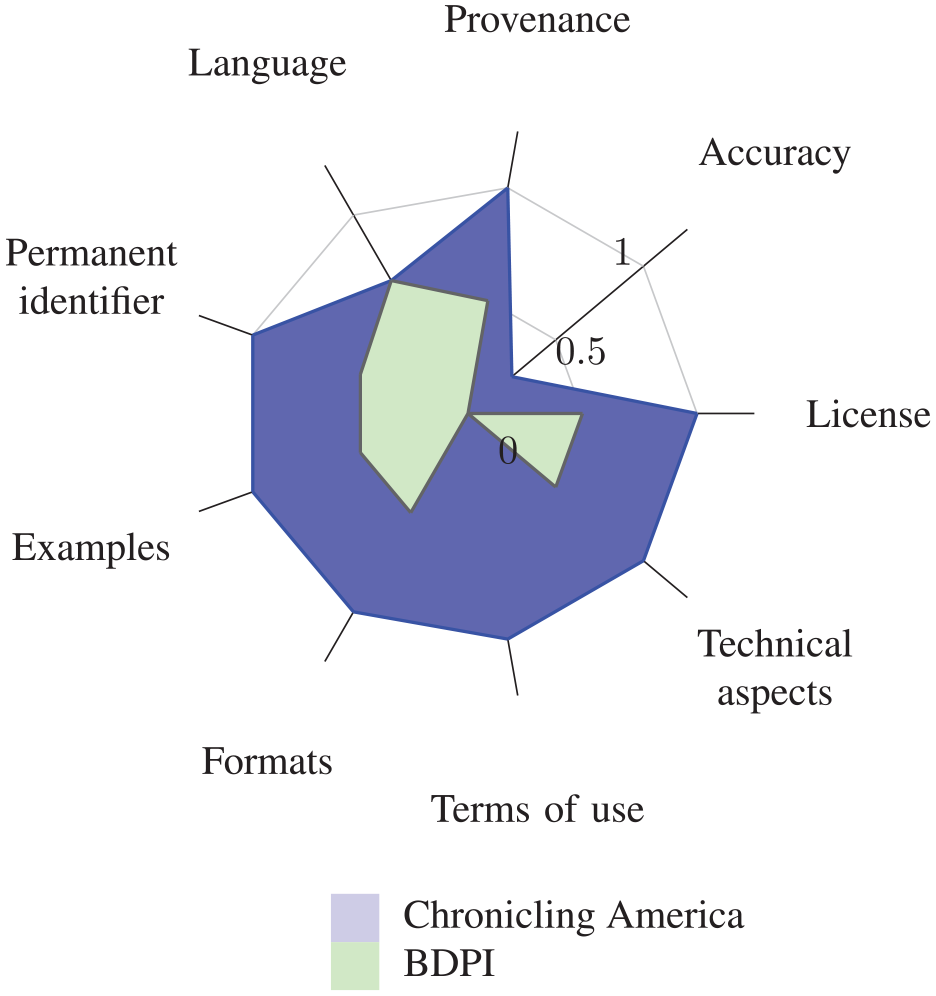
Polar chart that shows Chronicling America and Biblioteca Digital del Patrimonio Iberoamericano that obtained the highest (20.92) and lowest (5.03) scores, respectively.
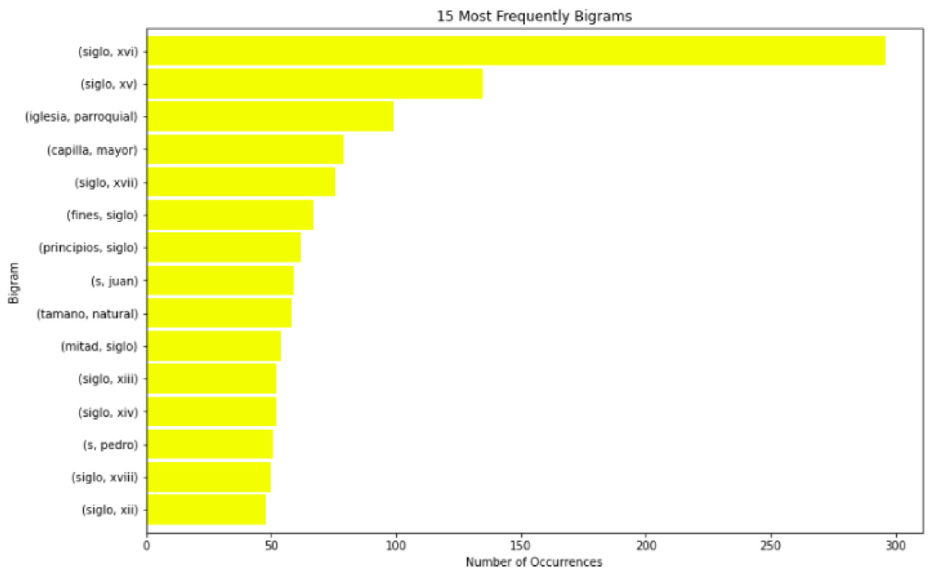
Overview of the most frequent bigrams for the Lancaster University dataset.

Topics and words obtained after applying the LDA model to the dataset from Biblioteca Digital Hispánica. Each topic and their corresponding words are related to a common theme (e.g., topic 3 is related to franceses and cortes).

Topics and words obtained after applying the LDA model to the journal About Hispano América from Chronicling America collection. Each topic and their corresponding words are related to a common theme (e.g., topic 3 is related to independencia and trabajadores).
3.1. Results
To find suitable subject datasets, we applied the methodology described in section 2.1. We identified datasets provided by GLAM Labs, Google Public Datasets and Zenodo whose descriptions contained terms such as library or were included in section 2. Some subjects were removed because they were out of date or because their URLs were invalid. International aggregators sometimes include items that are out of date. 6 Table 3 presents a preliminary list of candidates.
Benchmark of datasets for computationally driven research.
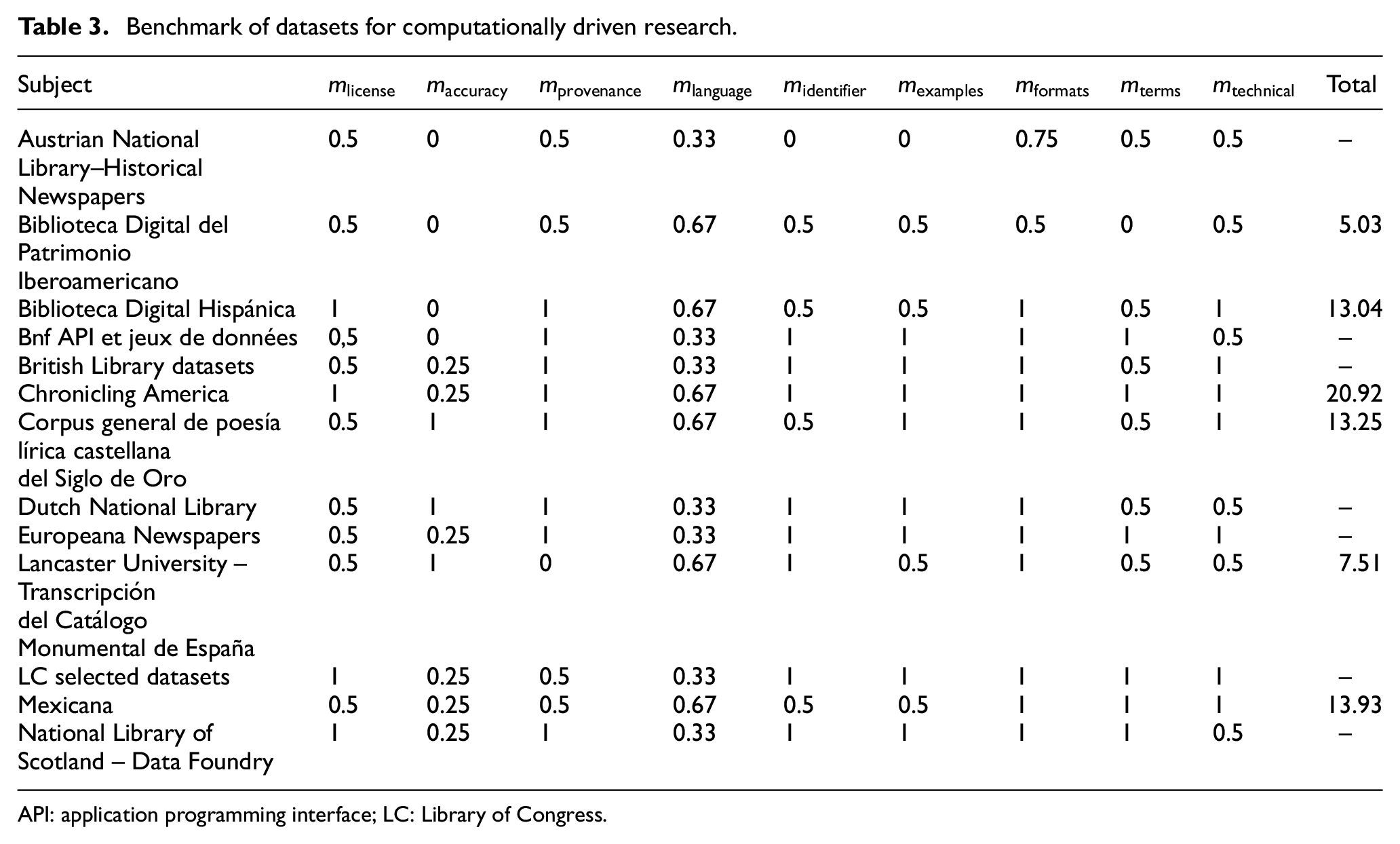
API: application programming interface; LC: Library of Congress.
We then used polar charts to identify which machine-actionable datasets were most suitable for the study. Every axis on the polar chart corresponds to one criterion. The global score is computed as the area of the polar chart – as shown in Figure 1 for Chronicling America. If the subject does not provide content in Spanish, the area is not computed.
As a result of the evaluation, six datasets (see grey cells in Table 3) were selected, which support computationally driven research and their contents are based on text in Spanish. Although the dataset features vary considerably among the datasets, these datasets all mainly publish metadata, images and full text.
The highest value was obtained by Chronicling America because this latter repository provides its content in several languages, including Spanish; uses a permanent identifier; includes machine-readable text; and provides its data under the CC0 licence. Mexicana, Corpus general de poesía lírica castellana del Siglo de Oro and Biblioteca Digital Hispánica obtained a very similar value, above 13. The three of them present their contents in Spanish and provide a URL to download the text. However, regarding licences, Biblioteca Digital Hispánica offers its data under the CC0 licence, while the other two provide the contents under a CC-BY licence. The BDPI obtained the lowest value.
According to the evaluation results, only two datasets achieved the maximum criterion accuracy score. The reason may be that it is time-consuming for institutions to edit large text corpora.
3.2. Discussion
Regarding the use of open licences, there is still room for improvement, since institutions tend to publish digital collections under CC-BY and other types of licences. In some cases, the licences were not clear, and were difficult to find or interpret. In this sense, Creative Commons and platforms such as FigShare and Zenodo facilitate an environment for the adoption of open licences when publishing datasets.
Many institutions and aggregators (e.g. BDPI) include platforms that offer metadata and links, but in some cases, the OCR text is not available. Other institutions provide the original OCR output, but in a non-edited format, because editing is a difficult task that requires considerable resources. Crowdsourcing approaches could thus allow engaging with the public while improving the quality of the contents. Smaller-scale approaches based on a particular work or author are more affordable.
Generally, all benchmark subjects provide documentation about the production process. In some examples, aggregators consist of websites that provide content retrieved from several institutions. Locally generated DOIs are used in some subjects while in others, the DOI is provided by publication platforms.
According to Collections as Data, the datasets should include documentation and examples of use to demonstrate how they can be used for research. Documentation is usually provided, but there is still room for improvement regarding the inclusion of prototypes and examples of use as part of the datasets.
OCR quality is a crucial factor when reusing a dataset. Poor quality OCR requires preprocessing tasks (e.g. removing OCR errors based on non-existent words) and the latter can generate unexpected results. The texts provided by the subjects in the benchmark are different in terms of how they have been created and made available to the public (e.g. OCR output or manually reviewed). In general, the errors generated by OCR tools increase with the age of the documents. There are multiple reasons for this, such as the state of the print medium, the quality of the paper and the scan [60,61]. In this way, OCR software can help to improve quality regarding the use of machine learning–based neural networks, as well as the adoption of post-correction tools [62,63].
In some cases, there is no option to retrieve the datasets by means of an API, hindering the reuse of the digital collections locked inside siloed repositories. In addition, institutions publish the information as PDF files instead of plain text files amenable to computational use. In this sense, tools such as the International Image Interoperability Framework (IIIF) provides an environment to facilitate the publication and reuse of the digital collections by means of APIs.
Datasets based on LOD principles provide rich metadata described using standard vocabularies. In these cases, the content is often provided as PDF files by means of uniform resource indentifiers (URIs) and using properties of the vocabularies such as Functional Requirements for Bibliographic Records (FRBR) [64] and Resource Description and Access (RDA) [65]. As a result, users are required to understand the vocabularies. Moreover, this is sometimes a complex task for beginners. Documentation and examples can be useful in this case.
Regarding the language, and in the particular case of Spain, the contents provided by a digital collection can be expressed in the co-official languages spoken in different geographical areas of the country, such as Catalan, Basque or Galician. Although this work focused on Spanish, the methodology to design the benchmark is flexible and can be adapted to language requirements, allowing the use of one or more languages.
Criteria regarding technical aspects can be improved by means of additional features, such as the use of an API key or the size of the collection. For example, some repositories require registration to be accessed and reused, such as the Rijksmuseum API. 7 In addition, the benchmarking can be improved through additional criteria adapted to assess datasets such as completeness, representativeness or timeliness [45,66].
4. Conclusion
Cultural heritage institutions are starting to adopt Collections as Data to publish machine-actionable datasets that can be reused in innovative and creative ways.
The methodology described in section 2.1 describes a series of steps to create a benchmark of machine-actionable datasets in the Spanish language that can be extended and adapted to other scenarios. In addition, recommendations and best practices are provided based on the results obtained for the benchmark. These examples encourage the adoption of Collections as Data within cultural heritage institutions. They also help to promote greater linguistic diversity regarding the texts provided.
The figures in Table 3 help select the machine-actionable collection that best fits a specific purpose. For instance, if the most relevant feature for an institution is accuracy, using a permanent identifier and providing machine-readable text, the University of Lancaster dataset may be the best choice regarding reuse.
Future work could focus on further generalising and automating the creation of the benchmark and the inclusion of additional features to compare datasets. In addition, the results of the benchmark and recommendations will be used to improve OCR tools and methods currently being used at the Biblioteca Virtual Miguel de Cervantes digital library to publish machine-actionable collections.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been funded by the AETHER-UA (PID2020-112540RB-C43) Project from the Spanish Ministry of Science and Innovation.