
Abstract
The growing volume of scientific literature makes it difficult for researchers to identify the key contributions of a research paper. Automating this process would facilitate efficient understanding, faster literature surveys and comparisons. The automated process may help researchers to identify relevant and impactful information in less time and effort. In this article, we address the challenge of identifying the contributions in research articles. We propose a method that infuses factual knowledge from a scientific knowledge graph into a pre-trained model. We divide the knowledge graph into mutually exclusive subgroups and infuse the knowledge in the pre-trained model using adapters. We also construct a scientific knowledge graph consisting of 3,600 Natural Language Processing (NLP) papers to acquire factual knowledge. In addition, we annotate a new test set to evaluate the model’s ability to identify sentences that make significant contributions to the papers. Our model achieves the best performance in comparison to previous methods with a relative improvement of 40.06% and 25.28% in terms of F1 score for identifying contributing sentences in the NLPContributionGraph (NCG) test set and the newly annotated test set, respectively.
1. Introduction
A large amount of scientific articles are continuously published online on a daily basis [1–3]. Keeping up-to-date with the new literature and managing information is quite challenging for the researcher. Sifting through the vast amount of data can be difficult, making it hard to extract the most relevant and useful information from the database. Illustratively, in the Natural Language Processing (NLP) domain, a substantial volume of fresh research articles is generated annually [4]. These articles cover a variety of techniques, architectures and evaluation metrics. Researchers are working on developing deep learning models [5] for various tasks, such as text summarisation [6], data mining [7,8], dialogue generation [9], question answering [10], information extraction [11–14] and keyphrase annotation [15]. In order to progress in the field of science, it is essential that researchers stay informed of significant progress and advancements in their respective fields. However, finding the most recent and relevant work in this massive amount of data can be very time-consuming and overwhelming. As a result, researchers need an automatic system to help them identify the most relevant information from the research articles. This can help to reduce the burden on the researcher and make it easier for them to stay informed of new developments.
With the advances in deep learning, the area of NLP [16] has seen significant growth in recent years, as researchers work to develop methods for extracting scholarly information from scientific publications [17,18]. However, research articles are often available in Portable Document Format (PDFs), which can make it difficult to extract information from them. To address this problem, various efforts have been made to develop automatic methods for extracting information from PDFs [19,20]. One such effort is NLPContributionGraph (NCG) [21], a corpus that has been annotated using an information extraction annotation method and an annotation strategy for documenting the scientific contributions in NLP papers. The primary goal of this corpus is to create a scientific knowledge graph, which aims to make scholarly knowledge algorithmically searchable and computable. A scientific contribution knowledge graph would make it possible for machines to understand the contribution of articles, connect through existing methods and techniques in the literature automatically, and create meaningful comparisons of the results. Three layers of annotations are included in the NCG dataset annotation to construct the scientific knowledge graph: (1) identification of contribution sentences, (2) phrase extraction from the contribution sentences and (3) triplets extraction.
The knowledge graph of contributions can make it easier for researchers to extract relevant information from research articles and stay abreast of the newest developments in their field. In our article, we discuss a solution for identifying sentences that describe the contributions of scientific articles. However, existing methods for identification of contribution sentences face limitations in accurately classifying long sentences and the sentences contain less contextual information [22]. To overcome this issue, infusing domain-specific knowledge into a pre-trained model improves the classification of long sentences. It enhances contextual understanding, handles ambiguity and recognises specialised vocabulary. By infusing the domain-specific data, it adapts to the intricacies of the domain, resulting in accurate and effective classification. To effectively classify sentences that have limited contextual information, domain knowledge is important because it provides a foundation for understanding the concepts and skills within a particular domain. This can be achieved by infusing domain-specific knowledge into the deep learning model, which can improve the model’s performance for sentence identification.
In our work, we infuse NLP knowledge of the knowledge graph into the pre-trained model for identifying contribution sentences. To achieve this goal, we begin by partitioning a knowledge graph into mutually exclusive subgraphs and infusing it into a pre-trained model, specifically, SciBERT [23]. To divide the knowledge graph, we use the METIS [24] algorithm, which allows us to partition the graph into manageable subgroups. Once we have divided the knowledge graph, we apply the adapter [25] module to learn the knowledge parameters of each subgroup. The adapter is particularly useful in this context as it is efficient in avoiding the catastrophic forgetting issue [26]. After training the adapter module on each subgroup, we combine the trained adapters to make a mixture layer. The mixture layer uses the knowledge from the adapter to identify contribution sentences. To infuse knowledge into the model, we build an NLP knowledge graph. We collect approximately 3,600 NLP papers from the Association for Computational Linguistics (ACL) anthology and build a factual knowledge graph (FKG). Our knowledge graph comprises a total number of 503,122 entities and 55,077 relations. It encompasses 1,048,574 triplets in total. The goal of incorporating this factual knowledge is to enhance the pre-trained model’s domain-specific understanding, allowing it to make more accurate predictions and inferences. In this work, we develop a new test set for evaluating the performance of our model. The main goal of building a new test set is to identify any biases or weaknesses in the model’s performance and to provide insights on where further improvements may be needed. To achieve this, we collect 160 papers that were published in the year 2022 and cover different domains that are not present in the NCG training, testing, and trial sets of the NCG. Initially, we utilise the existing state-of-the-art model for contribution sentence identification, named ContriSci [22], as bootstrapping for our annotations. However, after the initial annotation process, we recognise that the ContriSci model may contain errors. Therefore, we decide to manually verify the complete test set to ensure the accuracy and integrity of the data. This process involves going through each annotation and making any necessary corrections or adjustments to ensure that the data are as accurate as possible. The methods we implement and use in our research show the best performance compared with all current state-of-the-art models on the NCG test set as well as on a newly proposed test set, with a significant margin of 25.72% and 16.19%, respectively. In the current work, we make several key contributions:
We develop a robust system for the identification of contribution sentences by infusing factual knowledge from a domain-specific knowledge graph into a pre-trained model. It improves the accuracy and effectiveness of sentence identification and provides a valuable tool for researchers in the field.
In addition to this, we build a scientific knowledge graph 1 specifically for the NLP domain. This knowledge graph offers a comprehensive and structured representation of the concepts, relations and information relevant to the field and will serve as a vital resource for future research.
We create a new test set for the identification of contribution sentences, which will be used to evaluate the robustness and weaknesses of our model on unseen texts. This test set is carefully designed to challenge the model and provides valuable insights into its performance and capabilities. Overall, these contributions represent a significant advance in the field of NLP and will be of great benefit to researchers and practitioners alike.
The following sections of this article are structured as follows: we provide a thorough review of relevant prior work in the ‘Related work’ section. Next, in the ‘Problem definition’ section, we clearly define the problem we aim to address. Our chosen methodology for tackling the problem is explained in detail in the ‘Methodology’ section. In the ‘Evaluation’ section, we discuss the dataset, baseline, experimental setup, results and analysis. Furthermore, we explore the dataset, knowledge graph used in our research and the result analysis in more depth in the ‘Discussion’ section. Finally, we summarise the key findings of our work and discuss avenues for future research in the ‘Conclusion and future work’ section.
2. Related work
In this section, we will discuss the existing research on contribution sentence identification, scientific knowledge graph and adapter-based learning, which are closely related to the work.
2.1. Contributing sentences identification
Contributing sentence identification refers to the process of classifying sentences in a scientific document into two categories: contribution sentences and non-contribution sentences. Contribution sentences are those that explicitly state or provide information about the contributions made in the scientific article, highlighting the novel findings, discoveries or advancements presented. Non-contribution sentences, on the contrary, include sentences that do not directly relate to the contributions or may provide background information, methodology details or other supporting context.
In their work, Brack et al. [27] extracted domain-independent scientific concepts from the scientific publication. They used a systematic annotation process to identify the concepts. These sets of concepts are from Science, Medicine and Technology at the phrase level and present a baseline method for this task. Furthermore, they provided the active learning approach for an optimal selection of samples from the proposed dataset in different domains. The D’Souza et al. [21] system contributed to identifying contribution sentences. Several participants worked on diverse approaches to improve accuracy and efficiency in this task, enhancing their understanding of scientific literature. The summary of their works follows. The research reported in Shailabh et al. [28] tackled the NCG challenge by utilising a pre-trained model. They used the SciBERT model to extract contribution sentences from publications, in order to solve the NCG challenge. They developed a method that involves using a bidirectional long short-term memory (BiLSTM) [29] network, which is built on top of the SciBERT model. BiLSTM network allows for improved performance, as it is able to effectively capture the context and dependencies between words in sentences. By combining the SciBERT model with the BiLSTM network, the authors were able to extract the contribution sentences with effective results, making a significant contribution to the field of NCG and the broader field of NLP.
Furthermore, Liu et al. [30] initially approached the problem at hand by utilising a convolutional neural network (CNN) [31] on top of the SciBERT model. However, they found that the CNN-based model is incapable of capturing the long semantic dependencies among tokens in sentences, which resulted in an inability to classify longer sentences accurately. In light of this, the authors decided to employ a different approach and used a SciBERT-based classifier that incorporated positional features. This allowed for improved performance, as the model is now able to effectively capture the semantic dependencies and relation between tokens in longer sentences. The author’s use of a SciBERT-based classifier with positional features demonstrates their commitment to finding the best possible solution for the problem. Ma et al. [32] and Arora et al. [33] developed a simple BERT-based model for the identification of contribution sentences. By using a simple BERT-based model, the authors aim to provide a straightforward and effective solution for the problem. Martin and Pedersen [34] developed a deBERTa [35] based on a multiclass classifier utilised for identifying contribution sentences. The authors raised concerns about the limitations of the system and highlighted a major weakness in the proposed model. They pointed out that the model misses crucial contextual information, which can greatly affect the accuracy of the sentence identification process. The authors claimed that this missing information can negatively impact the overall performance of the system. They conducted an analysis and came to the conclusion that the proposed model fails to take into account important contextual information, which results in missed opportunities for improved accuracy and effectiveness.
Zhang et al. [36] used a BERT-based model for sentence identification. The authors take a multipronged approach to improve the model’s performance, which includes incorporating both sampling and adversarial training techniques. The inclusion of these techniques enhances the overall performance of the system and leads to more accurate results in identifying sentences within a given text. According to the authors, the integration of these techniques is a critical factor that contributes to the model’s success by resolving certain limitations of conventional sentence identification systems. Lin et al. [37] developed a novel approach to sentence classification by constructing an ensemble of three popular models, BERT [38], SciBERT [23] and RoBERTa [39], to create a more robust classification system. The authors utilised a retraining strategy in which the classification ensemble is trained with a silver-labelled test set. This involves first training the classifier using the normal procedure with an actual training dataset, then applying the test set and retraining the classifier. This approach allows for the fine-tuning and improvement of the model, leading to more accurate results in sentence classification. The authors showed that their proposed method significantly outperforms traditional sentence classification methods, highlighting the effectiveness of their approach. Gupta and Manning [40] developed a method for categorising a research work into three distinct categories, namely focus, techniques used and domain of application. This categorisation is accomplished through the use of a matching semantic extraction pattern. The pattern is learned by means of a process called bootstrapping, which involves the use of dependency trees of sentences found in the abstract of research articles. Through this method, the authors were able to extract the relevant characteristics of research work and categorise it accordingly.
2.2. Scientific knowledge graph
A scientific knowledge graph refers to a structured and interconnected representation of scientific knowledge, which encompasses various entities, concepts, relations and attributes in a specific domain or across multiple domains. It is a comprehensive knowledge repository that organises and represents scientific information in a graph-like structure, where entities are represented as nodes and relations between entities as edges.
Recently, knowledge graphs have been employed in multiple NLP applications [41]. In a study by Luan et al. [42], a model is proposed for identifying scientific entities, relations and coreference resolution. The model utilises a multitask approach that shares parameters between low-level tasks, allowing for predictions to be made by utilising context throughout the document via a conference link. Fathalla et al. [43] described how a knowledge graph can be utilised to represent research fields in a structured, systematic and comparable manner. To accomplish this, they introduce a comprehensive ontology that captures the various components of survey articles, such as the research problem, methodology, implementation and results. The authors also demonstrated the practical application of their proposed methodology by analysing a retrospective example of a survey. In Mondal et al. [44], a knowledge graph is constructed specifically for NLP research articles. The knowledge graph has four types of relations: (1) evaluatedOn between datasets and tasks, (2) evaluatedBy between evaluation metrics and tasks, (3) coreferent and (4) related between similar entities. A new method was proposed for these relations and applied to 30,000 NLP papers from the ACL anthology to build a knowledge graph that can assist in automatically creating scientific leaderboards for the NLP community. Tosi and dos Reis [45] introduced a method for organising knowledge in a scientific field.
The method considers the semantics of concepts retrieved from textual documents within the field. The aim is to identify a brief overview of subareas within the field and provide a summary of the identified subareas. The authors also aim to evaluate the system’s performance across various datasets and knowledge domains. Ammar et al. [46] in their work focused on extracting structured data from scientific documents to enhance the ranking of results in academic searches. The authors investigate the techniques used in a production system of considerable scale. This system is designed to extract structured data from scientific articles and create a literature graph. Utilising a directed property graph, the literature graph serves as a condensed representation of important information found in the literature. It has the ability to address both simple and complex queries. Jiang et al. [47] proposed a three-layer representation of a scientific knowledge graph, with attribute nodes and concepts in the first layer, fact and condition tuples in the second layer and statement sentences in the third layer. The authors have created a semi-supervised model for sequence labelling. This model features multi-input and multi-output capabilities and is designed to learn tag dependencies within sequences, ultimately generating output sequences for tuples.
The above literature highlights the absence of existing knowledge graphs that can be developed to understand domain-specific terminologies within deep learning models. Therefore, there is a need for a knowledge graph that facilitates comprehension of NLP terminologies and aids in the development of deep learning models. Motivated by this, we create a knowledge graph as a part of the proposed framework. The proposed framework aims to address this gap and contribute to the field of NLP by leveraging KGs for improved explainability and a better understanding of NLP terminology within the context of deep learning models. Our methodology encompasses the utilisation of various cutting-edge technologies and models, including deep neural networks, specifically the BERT CRF model. The BERT CRF model is developed to extract meaningful phrases from the text, developing a BERT-CRF-based phrase extraction model. To train our model, we utilised the NCG phrase extraction dataset, which encompasses a diverse range of text samples. By leveraging this dataset, we effectively trained our BERT CRF model to accurately extract relevant phrases from the given text. Once the phrases are extracted, we proceed to organise them into triplets. This organisation is accomplished through the implementation of a BERT-based model, which facilitated the creation of semantically meaningful triplets from the extracted phrases. By integrating these advanced technologies and models, namely deep neural networks, the BERT CRF model and the BERT-based model, we successfully constructed a knowledge graph. Using the Neo4j tool, we leveraged its visualisation capabilities to create visual representations of the triplets within our knowledge graph.
2.3. Adapter-based learning
To incorporate the knowledge stored in the knowledge graph into a pre-trained model, we use a neural network component known as adapters [25]. Adapters serve as an alternative approach to fine-tuning and have demonstrated similar performance across a diverse set of applications. These adapters act as additional modules within the model, allowing it to selectively incorporate the knowledge from the knowledge graph without extensively modifying the pre-existing parameters. By leveraging adapters, we can effectively integrate the domain-specific knowledge from the knowledge graph into the model, enhancing its capabilities and enabling it to make more informed and context-aware predictions. This integration is further facilitated by the framework introduced by Pfeiffer et al. [48] called adapterhub. This framework offers a simple and efficient means of transfer learning through community sharing and training of adapters. Adapters are neural network modules that can be integrated into pre-trained models to accelerate the transfer learning of various languages and tasks. He et al. [49] demonstrated that adapter-based tuning, which produces representations that deviate less from those produced by the initial pre-trained language model, mitigates forgetting issues more effectively than fine-tuning. Through their experimentation, the authors demonstrate that adapter-based fine-tuning yields superior results for low-resource and cross-lingual tasks. In addition, this method is less susceptible to fluctuations in learning rates. Ansell et al. [50] developed a Multilingual ADapter Generation (MAD-G) model, which generates language adapters from the language representation. By constructing language adapters for novel languages, the proposed model enables the sharing of linguistic knowledge across languages and facilitates zero-shot inference. Le et al. [51] analysed adapters in the context of multilingual speech translation (ST). The authors discuss the use of adapters for transferring from automatic speech recognition to multilingual speech translation using the pre-trained mBART model. This approach enables the efficient specialisation of speech translation for specific language pairs while using fewer parameters.
Ribeiro et al. [52] developed a method called Structadapt that uses adapters to incorporate the graph structure into pre-trained language models. By using Structadapt, they are able to maintain the topological structure of the graph and integrate task-specific knowledge, and they also explore the advantages of incorporating graph structure into a pre-trained language model. Houlsby et al. [25] used transfer learning with an adapter module. Adapter modules produce a compact and extensible model, add a few trainable parameters for each task and add new tasks without revisiting existing tasks. To show the adapter’s effectiveness, they used the BERT model for various classification tasks. Adapters outperform in these tasks only adding a few parameters. Rebuffi et al. [53] developed an adapter-based residual module that allows compressing many visual domains in small residual networks with parameter sharing between them. They address forgetting problems using the proposed model. Meng et al. [54] developed a framework, Mixture of Partition (MoP), an infusion approach to infuse the knowledge of the large knowledge graph into the pre-trained model using lightweight adapters. These subgraph adapters are further fine-tuned along with the BERT through the mixture layer. Dalle Lucca Tosi and dos Reis [55] proposed a method for monitoring the development of a scientific field at the concept level. The method begins by organising the field into two distinct knowledge graphs, each representing a separate time period of the field being studied. The next step involves clustering these knowledge graphs in order to identify corresponding clusters between them. These correspondences are established by comparing the knowledge graphs and identifying subareas within the field that are present in both time periods. Through this process, the authors are able to track the evolution of the scientific field at a concept level and gain a deeper understanding of how it has progressed over time. The proposed method provides a systematic approach for analysing the development of a scientific field and provides valuable insights for researchers and practitioners alike.
Our research differs from prior studies in that we focus on specific problem settings. Specifically, we construct a knowledge graph that contains factual information about the NLP domain. This knowledge graph is used to enhance the performance of a pre-trained model. Our aim is to extract contribution sentences, those sentences that convey the main contribution of a research paper. The knowledge graph serves as a valuable source of information that can be used to improve the result of the model by providing context. We use the adapter to incorporate the knowledge into the pre-trained model.
3. Problem definition
The problem is to identify a set of contribution sentences, denoted as C, from a given research article R in plain text format. It is assumed that the research article R contains a total of n number of sentences. The objective is to identify a subset of sentences from R, defined as
Example: This article proposes a pre-trained language model called SciBERT for parsing academic texts relating to the social sciences.
The above sentence shows the contribution of the article by proposing a new pre-trained language model called SciBERT, specifically designed for parsing academic texts in the field of social sciences. This proposal of a new tool can potentially aid and improve the efficiency of research and analysis in the social science field.
4. Methodology
In this section, we will provide a detailed discussion of constructing the knowledge graph. Specifically, we will cover the methodologies used for partitioning the knowledge graph as well as the process of incorporating the knowledge graph into a pre-trained model for the identification of contribution sentences from the research articles.
4.1. Building the knowledge graph
The primary purpose of this knowledge graph is to provide our pre-trained model with a more comprehensive understanding of various scientific terms. In order to achieve this goal, we undertake the task of gathering and analysing approximately 3,600 articles from various events in the ACL anthology. These events include but are not limited to the Workshop on Statistical Machine Translation (WMT), Empirical Methods in Natural Language Processing (EMNLP) and North American Chapter of the Association for Computational Linguistics (NAACL) conferences. The goal of gathering these articles is to extract triplets which can be used to construct the knowledge graph. A triplet is a set of three elements, where the first phrase is a subject, the second phrase is a predicate and the third phrase is an object. These triplets will be used to create a graph structure where the subjects and objects are represented as nodes, and the predicates are represented as edges. This will allow us to represent complex relations between scientific concepts in a way that is intuitive and easy to understand.
In order to convert articles into a format that can be understood by machines, we utilise a machine learning library known as Grobid [56], which is specifically designed to extract, analyse and reorganise unstructured documents, such as technical and scientific publications that are typically in PDF format, into structured documents that are encoded in XML/TEI. This allows for more efficient and accurate processing of the document by the machine. In addition to using Grobid for document extraction and analysis, we also utilise a natural language analysis tool called Stanza [57]. Stanza is a package that converts text into lists of sentences and words. However, due to the nature of the documents being processed, some sentences may be split over symbols, such as ‘;’, ‘?:’ and ‘:’. There is some sentence break with the citations, which can cause complications in the analysis process. We manually check the dataset and combine these types of sentences.
After performing natural language analysis on the raw dataset using the Stanza tool, we proceed to extract the phrases using the BERT-CRF-based phrase extraction model. We train the model using the NCG phrase extraction dataset, and then we organise extracted phrases into triplets using a BERT-based model. As shown in Figure 1, the comprehensive architecture of the triplet extraction model is presented, illustrating the interconnected components and the flow of data within the model. The phrase extraction model takes scientific article sentences as input. Subsequently, the predicate classification model utilises both non-predicate and predicate phrases with the predicate highlighter. The information unit (IU) classification model operates by inputting sentences along with their corresponding main heading and subheadings. Finally, the triplet extraction model receives sentences with both predicate and non-predicate markers as input. We will explain the phrase extraction and triplets extraction model in detail.
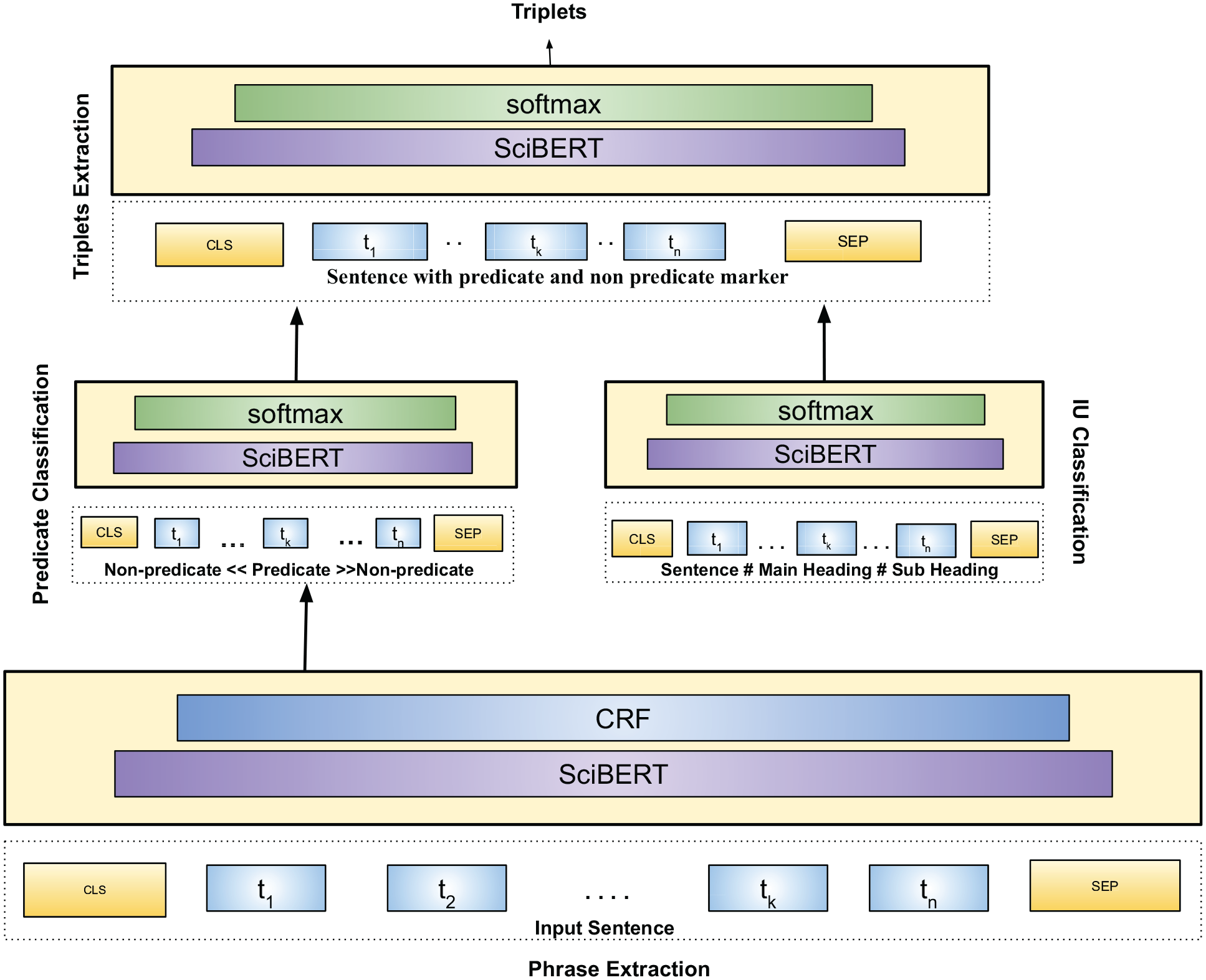
Complete pipeline architecture of the triplet extraction model.
4.1.1. Phrase extraction
For phrase extraction, we use the BERT-CRF [58] model to extract important phrases from sentences in a scientific context. The BERT model is well-suited for understanding the context of the sentences and is able to effectively capture the semantic meaning of the text. The CRF layer, on the contrary, is used to identify specific scientific terms that are relevant to the task at hand. To train the model, we use the NCG phrase extraction dataset. However, this dataset alone is not sufficient to effectively train a neural network model. Therefore, we also use two additional datasets called SciERC [42] and SciClaim [59]. The SciERC dataset, which is based on 500 scientific abstracts, contains annotations for scientific entities, their relations and coreference clusters. This dataset provides additional information about the entities and relations mentioned in the text which can be used to improve the performance of the model. The SciClaim dataset includes 12,738 labels, including entities, relations and attributes/corefs. These labels are extracted from 901 sentences in expert-identified claims, causal language in PubMed papers and heuristically discovered claims and causal language from CORD-19 abstracts. This dataset provides further information about the specific claims and causal language used in the scientific domain which can be used to improve the performance of the model. The combination of the NCG phrase extraction dataset and the additional datasets (SciERC and Sciclaim) provide more comprehensive training data for the model.
4.1.2. Triplet extraction
After obtaining discrete phrases from the phrase extraction model, we organise them into triplets consisting of a subject, predicate and object. These triplets provide a structured representation of the information contained in the text which can be used for various downstream tasks, such as information extraction, question answering and more. To generate these triplets, we classify the article sentences into 1 of 12 categories (IU) such as ablation analysis, approach, baselines, experimental setup, experiments, hyperparameters, model, research problem, results, task, dataset and code. This classification is performed in accordance with the NCG triplets extraction annotation. This helps us to understand the context of the sentences and identify the relevant phrases that should be used to generate the triplets. We enhance the context of the sentence by inputting the relevant section and subsection information into the IU classification model. To separate the predicate from the subject and object, we use a BERT-based binary classifier. This classifier is used to classify the relation (predicate) and entities (subject and object) by labelling the relation as one and the entities as zero. This is a crucial step as it helps us to understand the relation between the entities mentioned in the text and to generate accurate triplets. We generate all possible combinations using the extracted phrases and then use BERT-based classifiers and rules to validate the triplets. This is an important step as it ensures that the triplets generated are semantically correct and accurately represent the information contained in the text. The BERT-based classifiers and rules used in this step help to improve the accuracy and reliability of the triplets generated. The process of generating triplets consisting of a subject, predicate and object, using the phrase extraction model, sentence classification, BERT-based binary classifier and validation step, allows us to represent the information contained in the text in a structured and meaningful way.
As shown in Table 1, the factual knowledge graph comprises 503,122 entities, 55,074 relations and 10,48,574 triplets. These entities, relations and triples are interconnected and are used to represent the knowledge in the NLP domain. The triplets forming the factual knowledge graph are stored in CSV format. In addition, visualising the knowledge graph enhances interpretability and facilitates the communication of complex information. Graphs are inherently visual structures, and presenting the knowledge graph in a visual format makes it easier for researchers, domain experts and stakeholders to grasp the underlying concepts and draw meaningful conclusions. To visualise the knowledge graph, we use the Neo4j [60] tool. To import the data into Neo4j, we transformed it into a triplet form, which allowed us to represent entities and their relationships in a structured manner within the graph. The Neo4j is an open-source graph database that is implemented in Java [61]. It is specifically designed to handle large amounts of data and provide efficient data retrieval and manipulation. The tool is optimised for storing graph nodes, attributes and edges, making it an ideal choice for visualising the knowledge graph. The visualisation of the clusters in the factual knowledge graph is shown in Figure 2.
Statistics of the used FKG and medical domain knowledge graph (S20Rel).

FKG: factual knowledge graph.
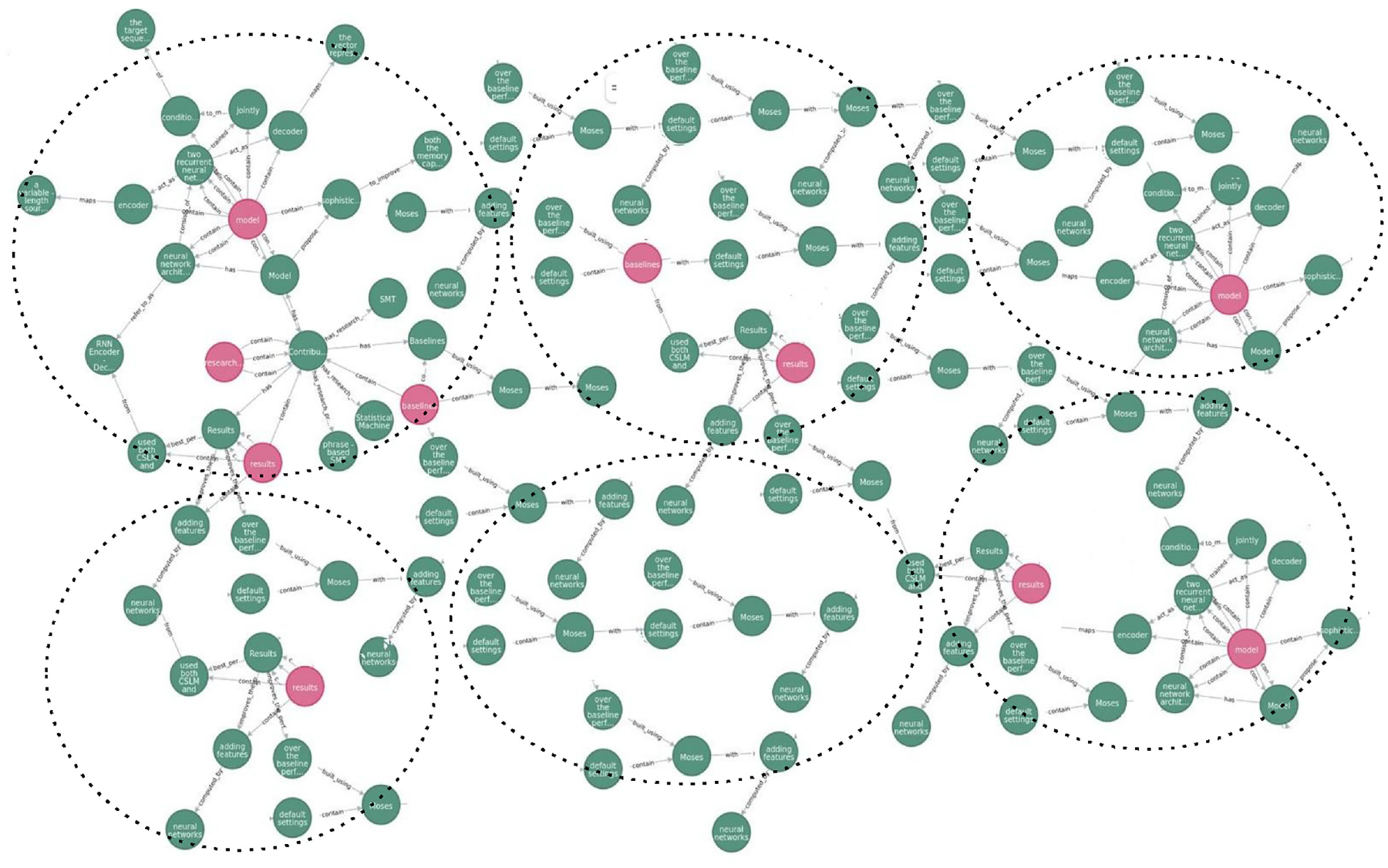
Visualisation of the clusters in the factual NLP knowledge graph.
4.2. Knowledge infusion into pre-trained model
In order to infuse the knowledge into a pre-trained model, such as SciBERT [23], we must first partition the graph nodes into mutually exclusive groups and infuse the cluster into the pre-trained model as shown in Figure 3. Figure 3(a) illustrates the graphical representation of the cluster to visually convey the idea of grouping related entities within the knowledge graph. This allows us to use the adapter [25] module to learn the knowledge parameters from the subgraph. Once this is done, we can gather the knowledge from the various adapters, similar to Meng et al. [54], and use it to identify the contribution sentences from research articles. This process allows us to effectively and efficiently incorporate the knowledge from the knowledge graph into the pre-trained model, making it more powerful and useful for a wide range of applications.
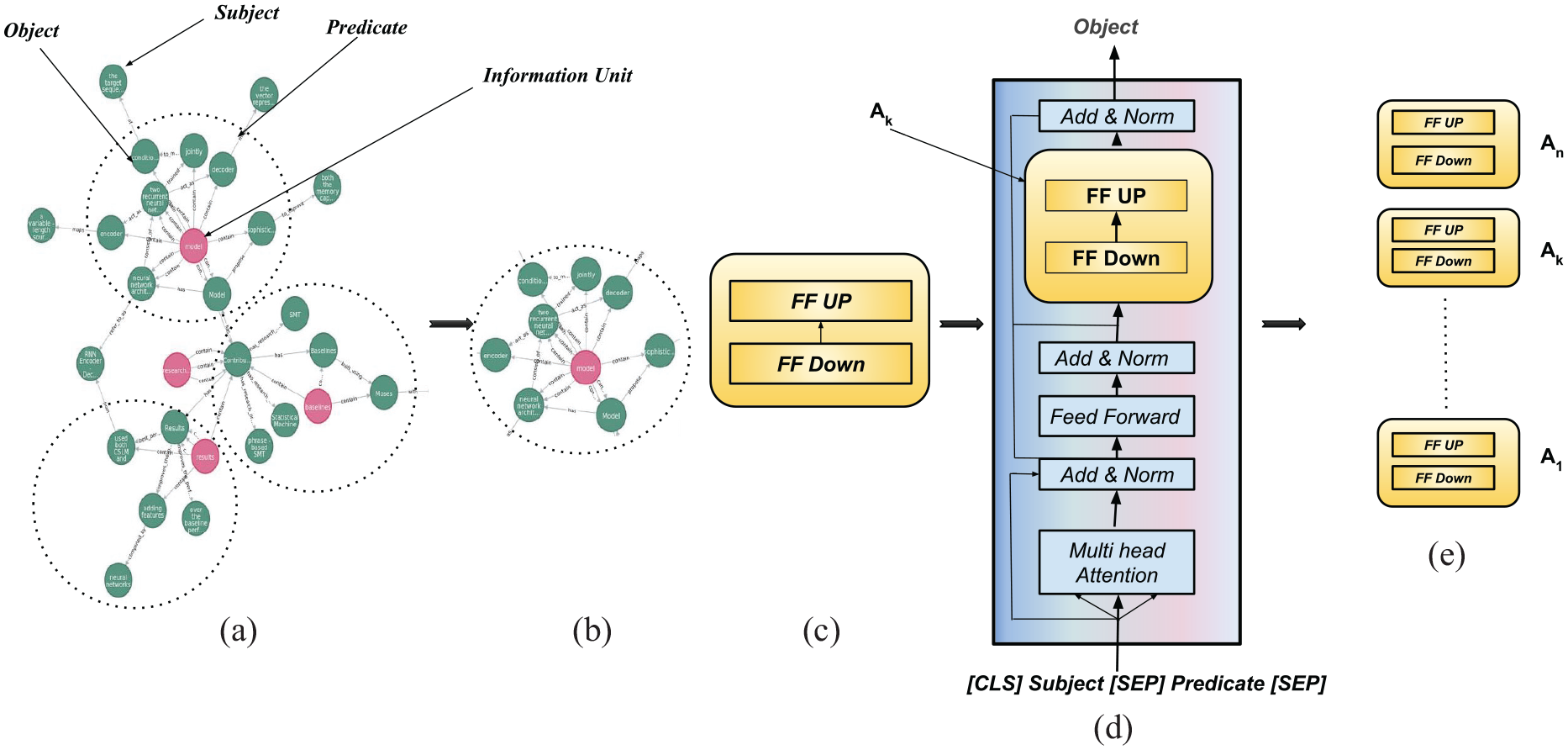
(a) Division of the knowledge graph into mutually exclusive groups. (b) The sub-graph. (c) The adapter architecture. (d) The infusion of knowledge into the pre-trained model using adapters. (e) The trained adapters.
4.2.1. Graph partition
Clustering the knowledge graph’s node is a vital step in the process of infusing its knowledge into a pre-trained model. The goal of this step is to split the graph into mutually exclusive groups, or clusters, in order to better manage and analyse the data. It is important to ensure that the nodes are balanced in all of the subgroups, as this allows for more efficient data parallelism and computation. To accomplish this, an appropriate and automatic clustering algorithm must be used. This algorithm should have the ability to handle large-scale graphs, as well as satisfy certain goals. One of the most important goals is to maintain the maximum number of resulting triplets, as this ensures that the true information is preserved. In addition, the algorithm should be efficient for handling large-scale graphs, as this allows for more efficient computation. One algorithm that is commonly used for this task is the METIS [24] algorithm. The METIS algorithm is utilised to partition the graph. This algorithm is an efficient method for processing large graphs with billions of nodes by breaking down the large graph into smaller ones, processing them efficiently and then applying the partitions to the original larger graph. This allows for efficient and effective clustering of the knowledge graph’s nodes. The METIS algorithm is also used for a wide range of other tasks, making it a versatile and powerful tool for knowledge graph clustering. The METIS algorithm has three phases.
Coarsening Phase: The coarsening phase is a key step in the process of graph partitioning. The goal of the coarsening phase is to reduce the size of the input graph while preserving its essential structural properties. Contract pairs of adjacent nodes in KG to create a coarser representation:
● Let
● For each pair of adjacent nodes
- Contract
- Update the connectivity between contracted nodes in
Partitioning: Initial partitioning refers to the process of dividing a graph into subgraphs or partitions as an initial step before performing subsequent graph partitioning operations. The goal of initial partitioning is to provide a starting point for further refinement and optimisation steps. Let
Refinement Phase: The refinement phase refers to a stage in the algorithm where the initial partitioning solution iteratively improves the partition quality. (a) Uncoarsen the knowledge graph representation by gradually expanding the contracted nodes: ● Let ● Update the connectivity between expanded nodes in (b) We iteratively improve the each partition quality (c) Update the partitioning
By utilising the METIS algorithm, we initially partition a Knowledge Graph into multiple subgraphs, with each sub-graph containing a distinct subset of entities that are disjoint from one another.
4.2.2. Adapter fusion mixture layers
In order to infuse the knowledge from the knowledge graph into a pre-trained model, we utilise a neural network module called adapters. Adapters are developed as an alternative to fine-tuning and are shown to provide comparable performance on a wide range of applications [53,55]. The adapter is a small neural layer that is inserted into the pre-trained model and can be used to learn specific knowledge parameters from the graph. In this case, we use adapters to train each subgraph for entity prediction. The input to the model is the subject and predicate of the triplets, and the goal is to predict the object of each triplet. The input is provided to the model in the form of ‘[CLS] subject [SEP] predicate [SEP]’, which allows the model to effectively learn the knowledge parameters from the subgraph. To optimise the parameters of the adapters, we use the cross-entropy loss [62]. This loss function is commonly used in machine learning and allows us to effectively train the adapters to make accurate predictions. By using adapters, we are able to infuse the knowledge into the SciBERT model, making it more powerful and useful for a wide range of applications.
After infusing the knowledge of the subgraph into adapters, the next step is to combine the different adapters. This is done using adapter fusion [63], a learning algorithm that allows for the combination of knowledge from multiple sources. This technique involves the two-stage process, which includes knowledge extraction and knowledge composition. In the knowledge extraction stage, the task-specific parameters that contain information with the respective task are learned. The goal of this stage is to extract the relevant knowledge from the adapters that will be useful for the specific task at hand. In the knowledge composition stage, the adapters that contain task-specific knowledge are combined by using softmax attention layers shown in Figure 4. Attention mechanisms allow the model to focus on the most important information, and softmax weights are used to assign importance to each adapter. This results in a two-stage contextual mixture weight over adapters at layer l, which allows the model to effectively combine the knowledge from multiple adapters. Overall, adapter fusion is a powerful technique that allows for the effective combination of knowledge from multiple sources. By using this technique, we are able to infuse the knowledge from the knowledge graph into the pre-trained model, making it more powerful and useful for a wide range of applications. In equation (1),

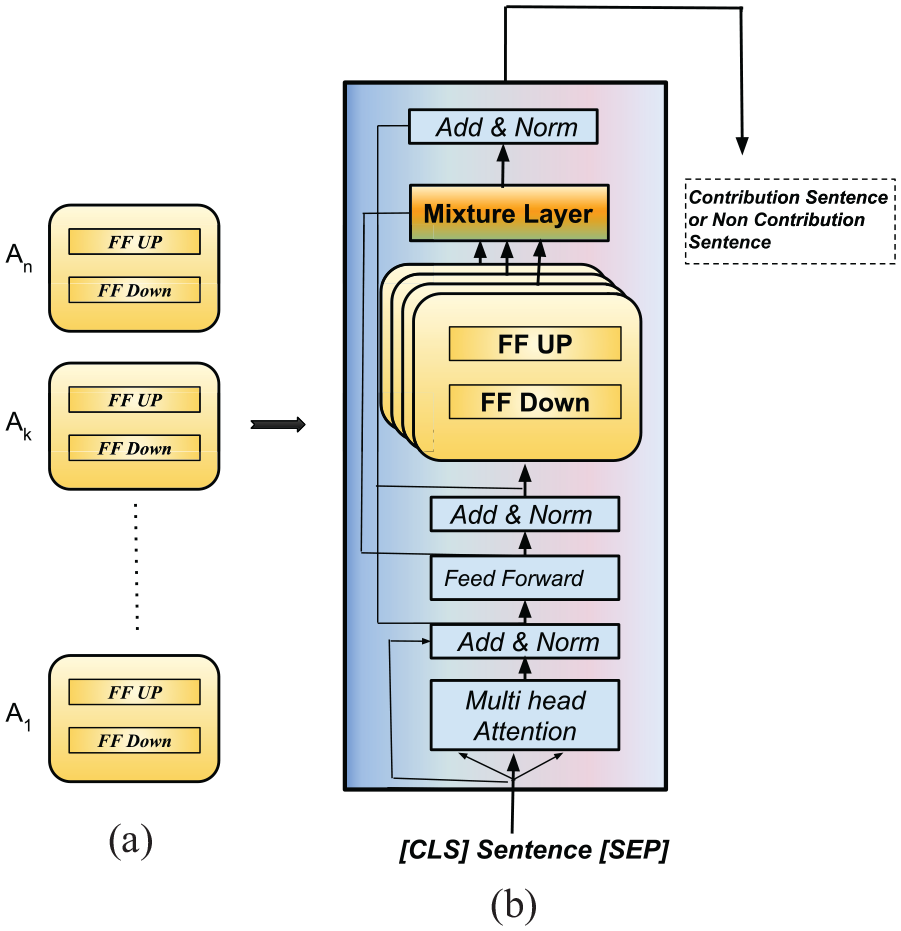
(a) Trained adapters. (b) The mixture layer into the pre-trained model.
In addition, A represents the subgraph-specific parameters, which are specific to a particular subgraph.

The combination of the adapter’s output and subgraph-specific parameters allows the model to make accurate predictions and infuse the knowledge from the knowledge graph into the pre-trained model. This process makes the model more powerful and useful for identifying contribution sentences from the research articles.
4.3. Construction of test set
We create a new test set that will be used to evaluate the performance of our contribution sentence identification model. In order to acquire data for this test set, we obtain approximately 160 papers from the ACL anthology website. 2 When constructing a new test set, it is crucial to consider various aspects in order to improve its quality and performance compared with the existing NCG test set. By taking into account factors such as class distribution, data diversity and potential biases. In particular, the following considerations should be taken into account in order to create a robust and comprehensive test set:
The new test set should include a diverse range of examples to test the classifier’s ability to handle different types of input. We consider the domains in the new test set which are not included in the NCG dataset.
The new test set should be independent of the training data and should not contain any examples that the classifier has seen before. We include the NLP paper, which was published in 2022.
The new test set should have a balanced distribution of classes, meaning that each class should be represented roughly equally as much as possible. We analyse the NCG dataset and found that the majority of the contribution sentences belong to certain sections of the papers. These sections included the Experimental Setup, Abstract, Introduction, Methodology and Results, as illustrated in Figure 5. We select the sections which contain the maximum number of contribution sentences using rules. We discuss these rules in the ‘Discussion’ section. This helps to ensure that the performance measures are not biased towards one class or another.
We discovered that the NCG dataset had a significant bias towards negative samples. Out of all the sentences in the dataset, only about 10.10% of them are contribution sentences (positive samples), while the rest are non-contribution sentences (negative samples). To address this imbalance and reduce the bias in the new test set, we make a strategic decision to only select the Experimental Setup, Abstract, Introduction and Results sections of the paper for the new test set. This would help to ensure that the new test set is more representative and balanced, taking into account the distribution of contribution sentences throughout the entire dataset.
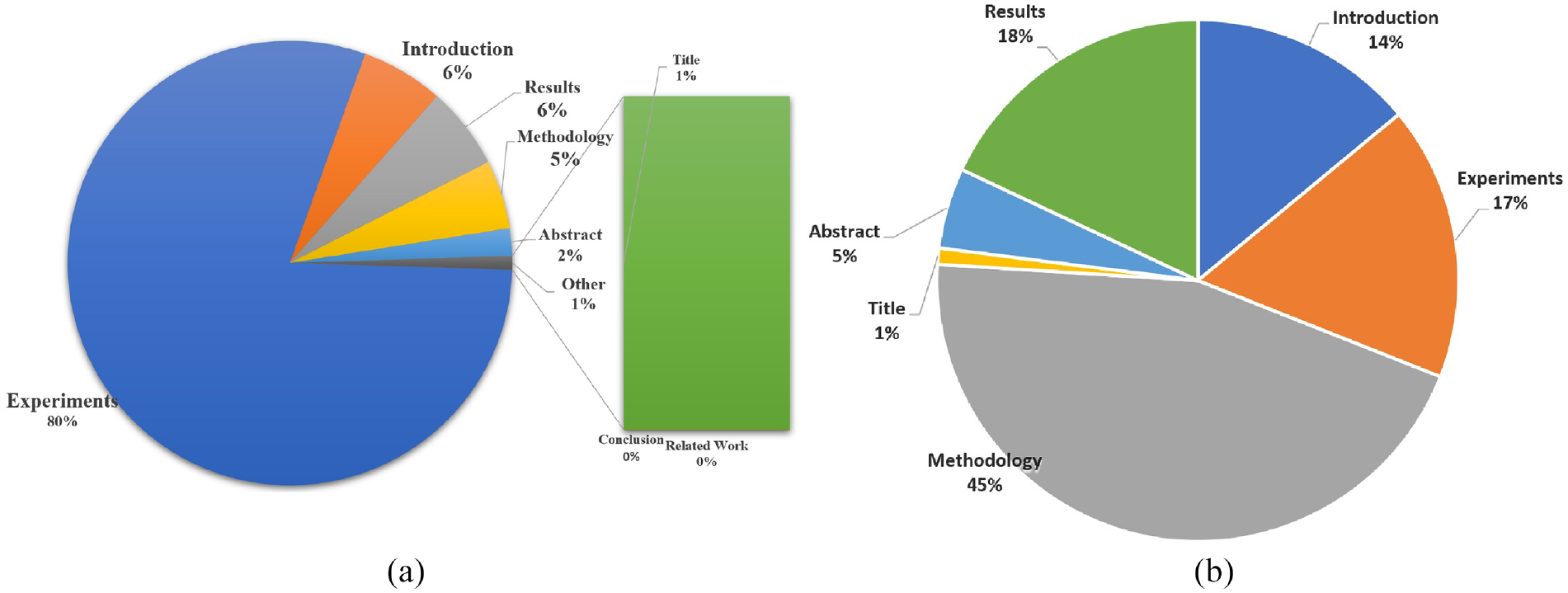
Analysis contribution and non-contribution sentences in sections of NCG dataset. (a) Distribution of contribution sentence in sections. (b) Distribution of training sentence in the sections.
By considering these qualities, one can ensure that the new test set is appropriate for evaluating the classifier and that the performance measures are accurate and meaningful. By doing so, we aim to achieve a more accurate representation of the data and a more robust evaluation of the results.
4.3.1. Prepossessing
The process of analysing PDF documents begins by converting them into a machine-readable format using the Grobid [19] tool. Once the PDFs are in this format, we use the Stanza [57] to analyse them. The annotation of the paper is two-fold: (1) bootstrapping using deep learning model and then (2) manual annotation. In the first phase, we use deep learning ContriSci [22] model to identify the contribution sentences. In the second phase, manual annotation is done to refine and verify the results obtained from the deep learning model.
4.3.2. Annotation
Deep Learning Model: At the initial stage, bootstrapping is performed using the ContriSci [22] model. The ContriSci model is a multitasking model with two scaffold tasks: section identification and citation classification. ContriSci is trained on a dataset called NCG, as well as two additional datasets: the ACL Anthology Sentence Corpus (AASC) 3 and the Scicite [64] dataset. As discussed in Gupta et al. [22], the Contrisci model has the capacity to effectively identify and categorise sentences that convey a contribution. Despite its accuracy, it has been observed that the model is prone to making errors in its classifications. As a result, it was decided that a manual review of the sentences would be conducted in order to ensure that the results produced by the Contrisci model are accurate and reliable.
Manual Annotation: The model may struggle with classifying longer sentences, headings, and subheadings, as well as sentences that have less contextual meaning. To address this, a manual classification process is done, in which sentences that are not accurately classified by the ContriSci model are reviewed and manually labelled by the first author of the paper. It is important to note that the results obtained from the ContriSci model should not be fully relied upon, and therefore, the manual review process is necessary to ensure the accuracy and reliability of the annotation. This manual review process helps to ensure that any errors or inaccuracies introduced by the ContriSci model are corrected and that the final annotation is as accurate and informative as possible. The combination of the deep learning model and the manual review process allows for a more efficient and effective annotation process, while still maintaining a high level of accuracy and reliability.
5. Evaluation
In this section, we thoroughly discuss the dataset utilised for the experiment and the dataset that is used to construct the knowledge graph model. The experimental set-up and baseline are explained to provide a clear understanding of the methods and procedures followed in the work. A detailed comparison of the various models utilised is presented. The experiment also conducts an ablation analysis to investigate the impact of removing specific components of the model on the overall performance. Furthermore, an error analysis is performed to identify the sources of any inaccuracies or errors that may have arisen during the experiment. These findings provide valuable insight into the effectiveness of the knowledge graph model and the impact of different factors on its performance, contributing to the advancement of the field of knowledge representation.
5.1. Dataset used
For the experiment, we utilise the NCG dataset [21]. The NCG dataset is publicly accessible in three distinct sets, namely the training, trial and test sets, which are annotated with three distinct layers of information. These layers include the identification of contribution sentences, the extraction of phrases and the extraction of triplets. The NCG dataset is carefully annotated to provide a comprehensive representation of the data. .
5.1.1. Dataset for contribution sentence identification
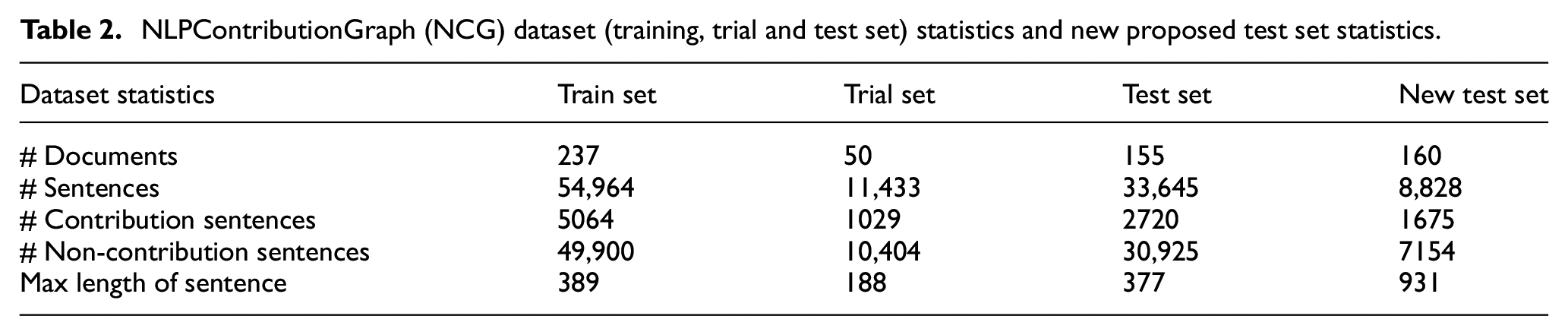
The NCG corpus is used in this experiment consists of approximately 442 NLP research articles from 24 different areas within the field of NLP. The statistics of the raw dataset for the contribution sentence identification task can be seen in Table 2. In order to train the deep learning model for sentence identification, we have opted to combine the training and trial sets. This decision was based on the need to maximise the amount of data available for training and to create a more representative sample of the information in the NCG dataset. By combining the two sets, we increase the overall size of the training data, allowing the deep learning model to better understand the patterns and relations within the data. In the dataset, each article is organised into three separate files, each serving a unique purpose in representing the research article. The first file is the Grobid-out.txt file, which contains the research article in plain text format and is machine-readable. This allows for easy processing and manipulation of text data. The second file is the Stanza-out.txt file, which tokenizes each sentence of the paper. This tokenization helps in breaking down the sentence into its constituent parts, making it easier for machine processing. The final component, sentence.txt file, contains the number index of the contribution sentences. This index helps in tracking and locating specific sentences within the Stanza-out.txt file, allowing for more precise analysis and interpretation. Overall, the structure of the dataset is designed to support the efficient processing and analysis of the research article, while also ensuring that the information is well-organised and easily accessible.
NLPContributionGraph (NCG) dataset (training, trial and test set) statistics and new proposed test set statistics.
5.1.2. Dataset for building knowledge graph
The process of training a deep learning model for building a knowledge graph involves use of two key datasets: the NCG phrase extraction and the NCG triplet extraction [21] dataset. These datasets are used to train the model to accurately identify entities and relations in text and to build a comprehensive and accurate knowledge graph. The NCG phrase extraction model is designed to annotate a total of 35,262 phrases, while the NCG triplet extraction model is designed to annotate a total of 21,603 triplets. In the NCG phrase extraction dataset, each paper is associated with an entities.txt file that contains important information about the entities in the paper. This file includes the sentence number of the Stanza-out.txt file, as well as the starting and ending index of the entities. The NCG triplet extraction dataset is organised into two well-organised folders info-unit and the triples folder. The info-unit folder contains a JavaScript Object Notation (JSON) [66] file for each information unit in the article, while the triples folder contains triplets for each information unit. The annotated triplets in the NCG triplet extraction dataset provide the model with a better understanding of the relations between entities in a given text, allowing it to build a more accurate knowledge graph. The annotated phrases and triplets in these datasets provide the model with the necessary information to accurately identify and extract entities and relations from text, leading to the creation of a comprehensive and accurate knowledge graph. We combine the training, trial sets to create a training dataset. The decision to use a large sample of data in the NCG dataset was made to improve the model’s understanding of patterns and relationships.
5.2. Experimental set-up
We divide the knowledge graph into smaller subgraphs, specifically 5, 10, 20, 40, 60. For each subgraph, we employ a pre-trained model called SciBERT, with Adapter modules added to it. We utilise a compression rate of 8 and aim to minimise the error using cross-entropy [62] loss during the training process. The AdamW [67] optimizer is used for training and the learning rate for all subgraphs is set to 1e-4. The reported performance results are based on the 20 subgraph partition.
5.3. Baseline
In our study, we compare our model with three baseline models, those of Lin et al. [37] and Shailabh et al. [28]. In particular, Lin et al. [37] developed two models for the identification of contribution sentences. In the first model, they utilised SciBERT and achieved an F1 score of 0.3856. In their second model, they ensemble multiple SciBERT models, and as a result, an improvement was observed with an F1 score of 0.3978. The third baseline, as developed by Shailabh et al. [28], utilises SciBERT with a bidirectional long short-term memory (BiLSTM) network. SciBERT is a transformer-based model that has been fine-tuned for scientific text, and BiLSTM is a type of recurrent neural network that can process input in both directions. The input for the SciBERT model is fed into a stack of BiLSTM layers, and both models are used as binary classifiers for classifying sentences. These models are effective in representing and understanding the scientific text and achieved an F1 score of 0.4680 for identifying contribution sentences, as shown in Table 3. Overall, these results demonstrate that the proposed baselines effectively identify contribution sentences in scientific text, and our model aims to improve upon these results.
Results on NLPContributionGraph (NCG) test set and new test set.
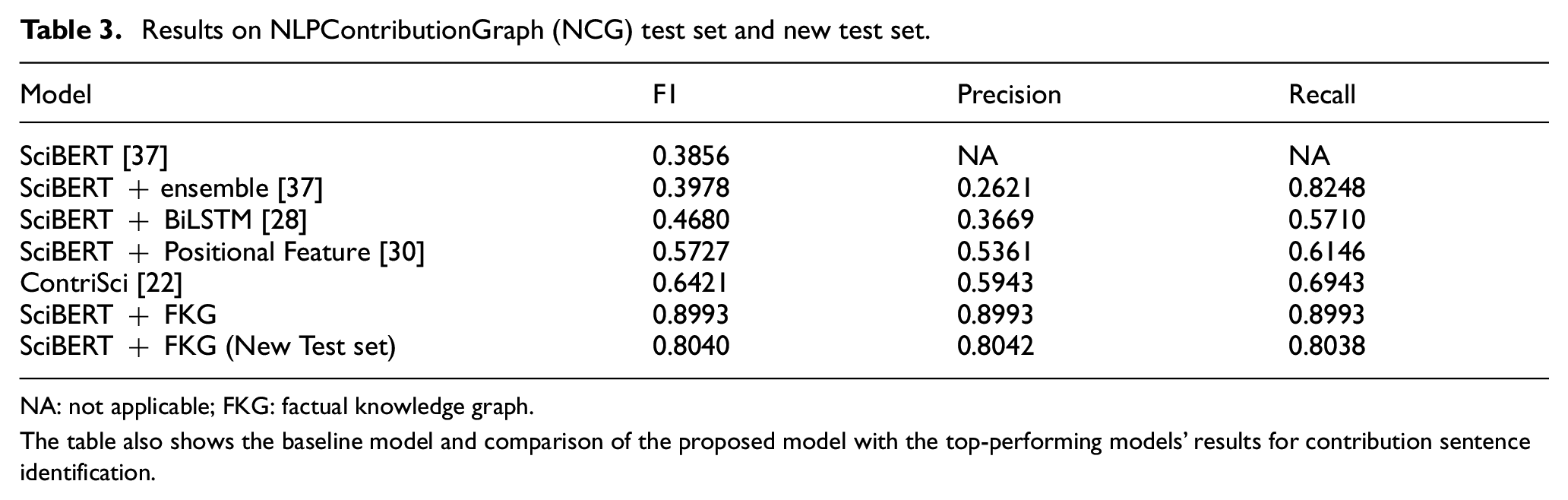
NA: not applicable; FKG: factual knowledge graph.
The table also shows the baseline model and comparison of the proposed model with the top-performing models’ results for contribution sentence identification.
6. Results
In this work, we compare our results with two previous models that demonstrate outstanding performance in the task of identifying contribution sentences. The first model, proposed by Liu et al. [30], uses a combination of SciBERT and positional features. Positional features are used to calculate the relative distance of sentences in articles, which allows for a better understanding of the text. They achieved an F1 score of 0.5727 for identifying contribution sentences, as shown in Table 3. The second model, proposed by Gupta et al. [22], is known as ContriSci. This model proposes a multitask approach, with two scaffold tasks being utilised: section identification and citance classification. In the shared layer of the model, the authors use the SciBERT model. The ContriSci model is the previous state-of-the-art model in this task, achieving an F1 score of 0.6421. In our work, we take a different approach by infusing factual NLP knowledge into the SciBERT model. We show the results on two different test sets: the NCG test set and a new test set. Using the NCG test set, we achieve an F1 score of 0.8993, which is 25.72% ahead of the previous state-of-the-art model. Using new test set, we achieve an F1 score of 0.8040, which is 16.19% ahead of the previous state-of-the-art model. However, it should be noted that the new test set performed lower than the NCG test set due to the different annotations used in the two test sets. The decision is to use a large sample of data in the NCG dataset to improve the model’s understanding of patterns and relations. In conclusion, our study infuses factual NLP knowledge into the SciBERT model and shows that it outperforms the previous state-of-the-art models. The results achieved on the NCG test set were particularly noteworthy, with an F1 score of 89.93%. This demonstrates the potential of incorporating factual domain-specific knowledge into models for natural language understanding tasks.
6.1. Analysis
In the following section, we will discuss the ablation analysis and examine the errors present in the model.
6.1.1. Ablation analysis
We analyse the performance of the sentence identification model. We utilise a partitioning of the knowledge graph in the various number of subgroups as 5, 10, 20, 40, 60 depicted in Figures 6 and 7. Through examination of the results depicted in the figures, it is evident that the performance of the model is affected by the number of partitions in the knowledge graph. Specifically, when there are too many partitions or too few partitions, the performance of the model is degraded. However, it has been determined that the optimal performance of the model is achieved when the knowledge graph is divided into 20 parts. This is because, in this configuration, many of the important relations between nodes are preserved, allowing for a proper infusion of knowledge. On the contrary, when the knowledge graph is divided into 60 parts, the performance of the model is significantly worse as many important node relations are disconnected, resulting in a lack of proper infusion of knowledge. Therefore, it can be concluded that for the identification of contribution sentences, the best partition of the knowledge graph is achieved by infusing it into 20 groups.
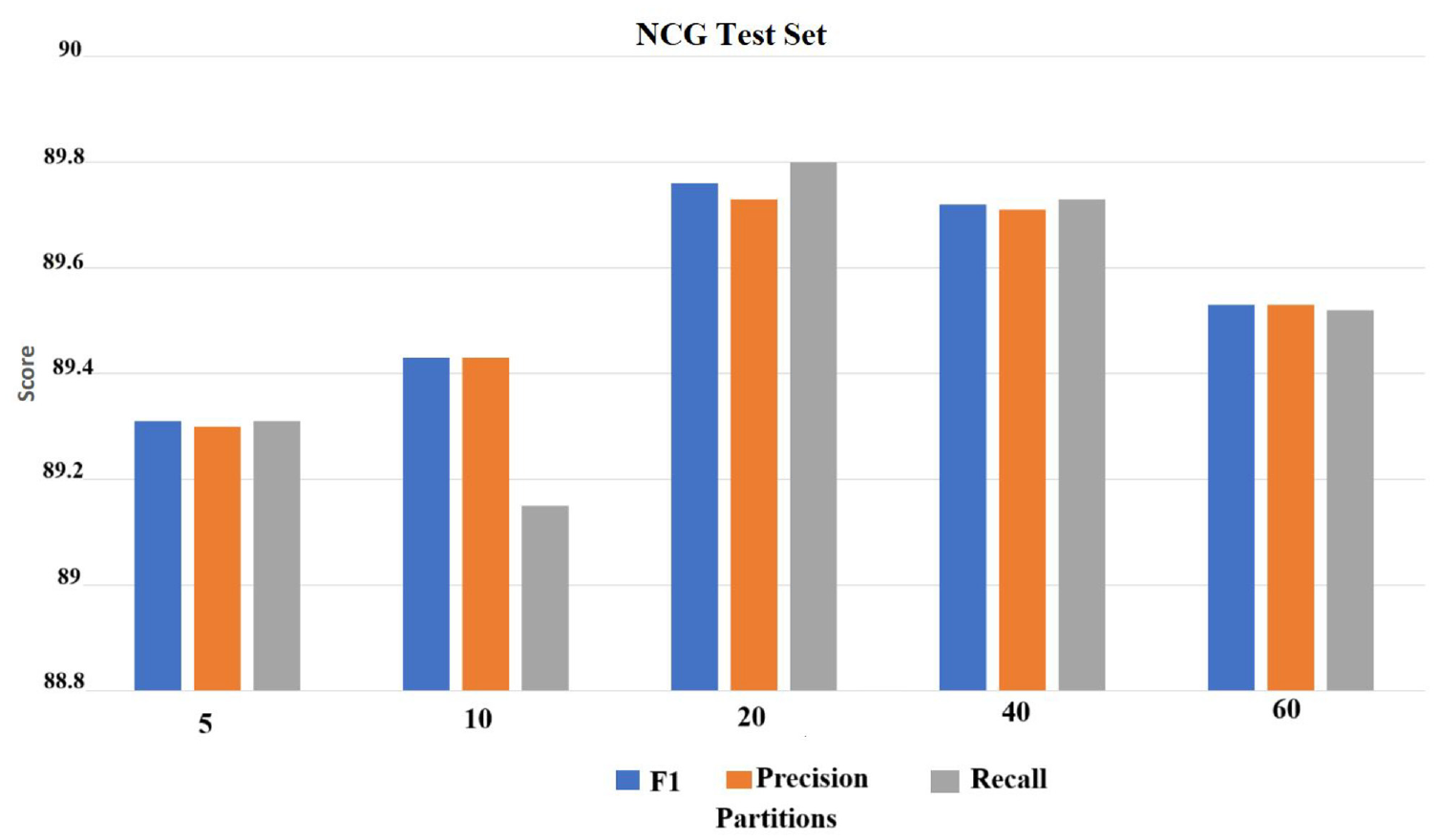
The results of the NCG test set on different partitions of the factual knowledge graph.
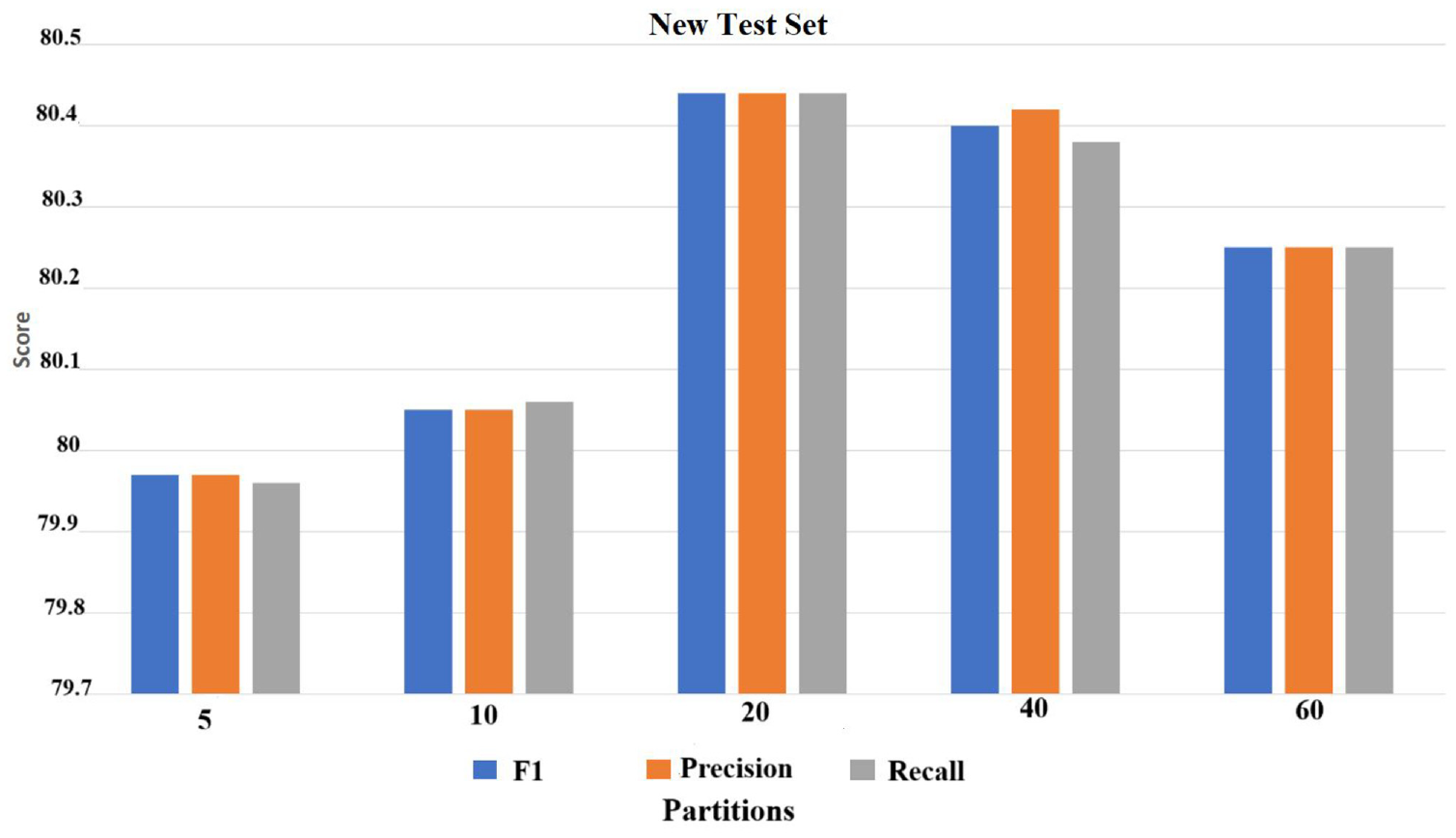
The results of the new test set on different partitions of the factual knowledge graph.
In Figure 8, we aim to show the performance of the model when it is applied to two different domain knowledge graphs: the factual knowledge graph from the NLP domain and the S20Rel [65] knowledge graph from the biomedical domain. In order to compare the model’s performance between the two knowledge graphs, we have partitioned the knowledge graph into 20 groups. The S20Rel knowledge graph has been extracted from the large biomedical knowledge graph UMLS and is based on the SNOMED CT [68], US Edition vocabulary. As shown in Figure 8, incorporating domain-specific knowledge significantly improves the performance of the model. The infusion of factual knowledge provides the model with a deeper understanding of basic domain-specific terms, resulting in enhanced performance. This is evident in the noticeable improvement seen in the performance on both test sets. By including this type of knowledge, the model is better able to make predictions and understand the data being processed. In conclusion, this graph demonstrates the importance of incorporating domain-specific knowledge in improving the performance of deep learning models. It highlights the positive impact that the use of factual knowledge can have on the model’s understanding and predictions. We see a noticeable improvement in performance on both test sets.
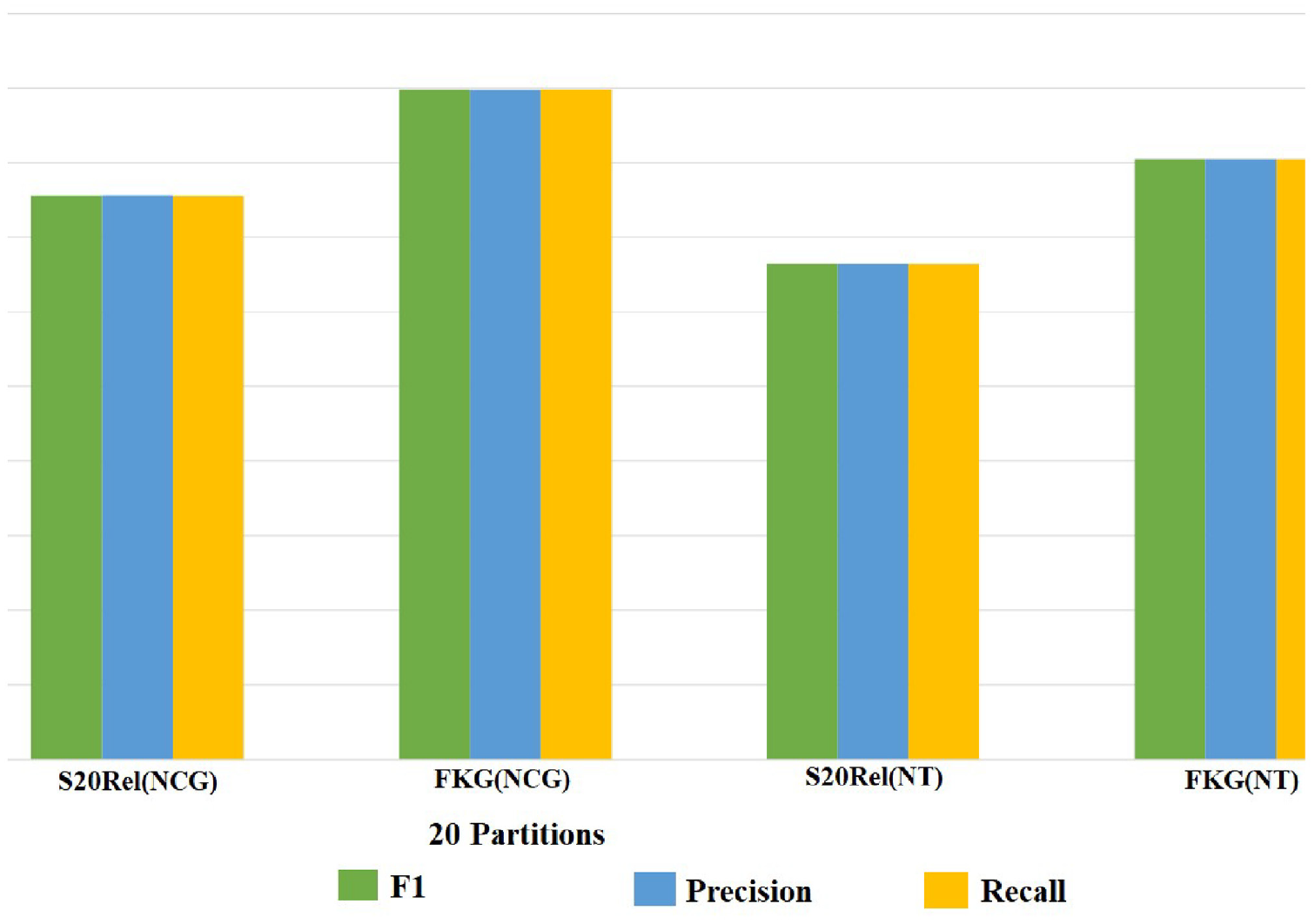
Show the performance of the model from sentence identification infusing knowledge from different domains knowledge graph.
6.1.2. Error analysis
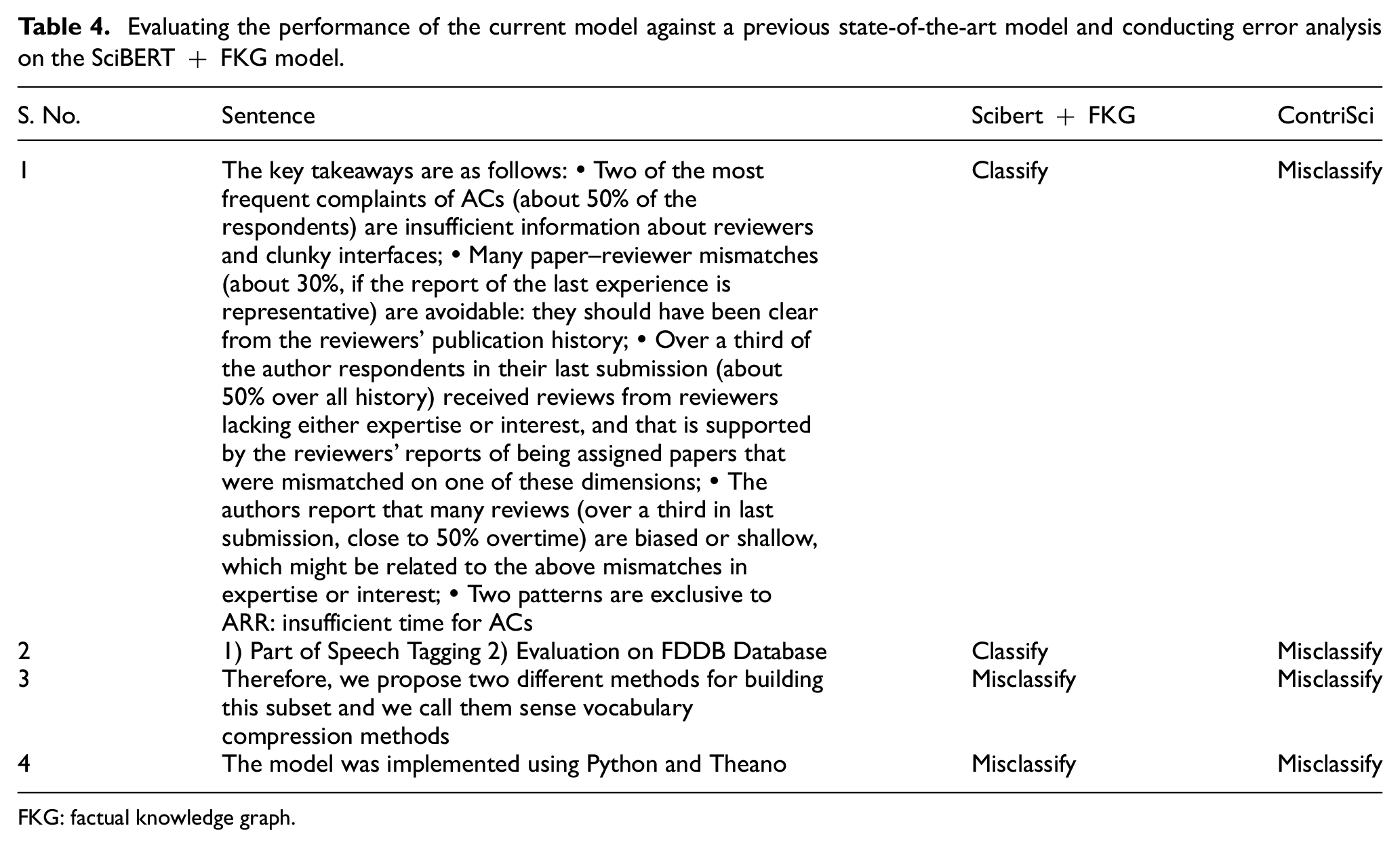
We evaluate the performance of our current model by comparing it to a previous state-of-the-art model and conducting the error analysis on the proposed model, as shown in Table 4. We find that the ContriSci model is unable to correctly classify long sentences due to a lack of semantic knowledge. To address this issue, we incorporate factual knowledge into the model to enable deeper semantic analysis. As demonstrated by Example 1 in Table 4, our improved model is now able to correctly classify long sentences. The Contrisci model may struggle to correctly classify headings and subheadings due to the small size of these sentences and the lack of contextual information they provide. However, our model is able to accurately classify these elements as shown in Table 4, Example 2. In the NCG dataset, there are sentences that contain phrases such as ‘we proposed’, ‘we developed’ and ‘we implemented’. Some of these sentences are labelled as contribution sentences, while others are labelled as non-contribution sentences. Our model is having difficulty in properly classifying these sentences, leading to a high number of false positives and false negatives, as demonstrated in Example 3. The sentence in Example 4 has limited impact on the overall article. To properly categorise sentences like this, models need a more comprehensive understanding of the paper. However, our model is unable to classify these types of sentences.
Evaluating the performance of the current model against a previous state-of-the-art model and conducting error analysis on the SciBERT + FKG model.
FKG: factual knowledge graph.
7. Discussion
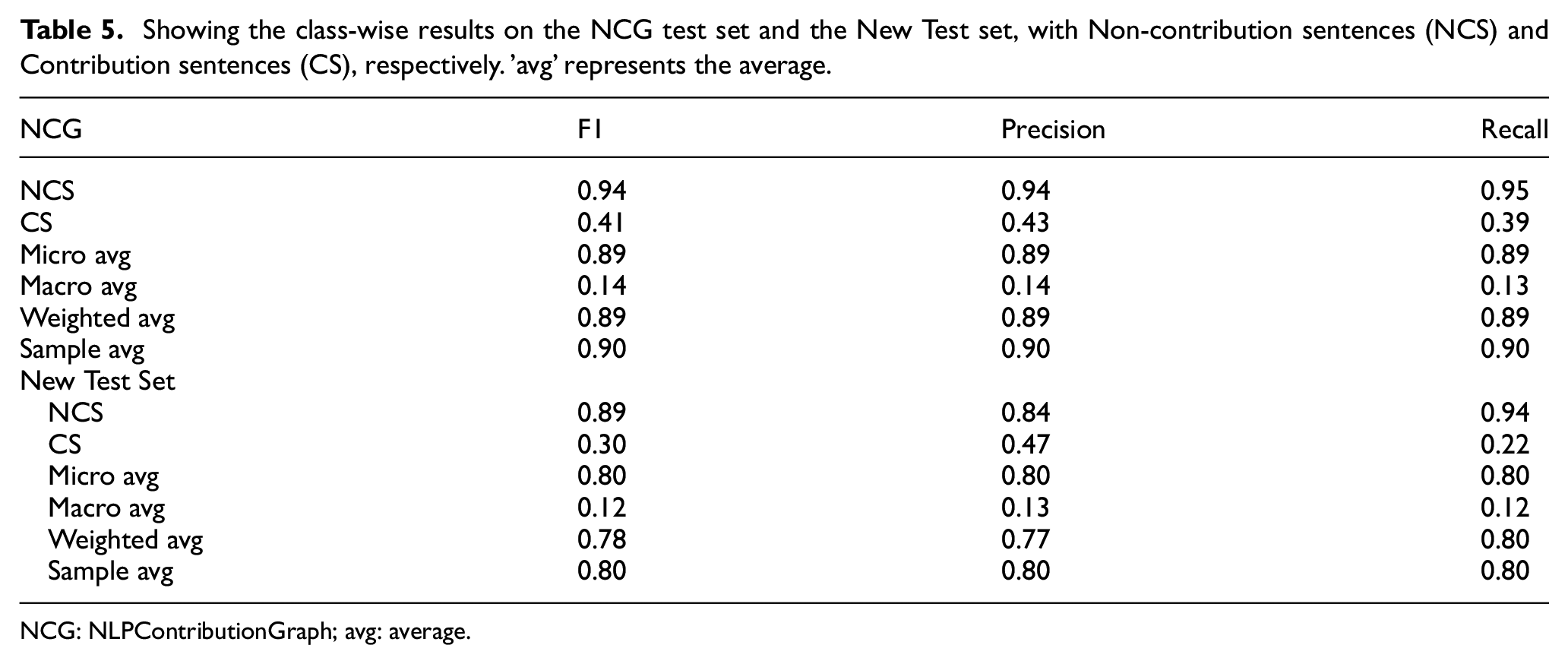
We are conducting additional analysis for both test sets in Table 5. The precision of class NCS is 0.84 for the new test set, which indicates that when the model predicts non-contribution sentences, it is correct 84% of the time. The recall of class NCS is 0.94, which indicates that the model can identify 94% of all samples in class 0. Similarly, the precision of class CS is 0.47, which means that when the model predicts class CS, it is correct 47% of the time. The recall of class CS is 0.22, which means that the model can identify 22% of all samples in class CS. The micro F1-score is 0.80, which means that the model has an overall balanced performance in both classes. However, the macro F1-score is very low at 0.12, which indicates that the model is not performing well in either of the classes. Model is not performing well for the CS class as shown in Table 5. The weighted F1-score is 0.78, which is slightly lower than the micro F1-score, indicating that the model is not performing well on both classes equally. We have also performed the same analysis for the NCG test set. One positive aspect of this result is that the micro F1-score is relatively high, suggesting that the model can make accurate predictions overall. However, the low macro F1-score indicates that the model is not performing well in either class. Therefore, further investigation is needed to improve the performance of the model.
Showing the class-wise results on the NCG test set and the New Test set, with Non-contribution sentences (NCS) and Contribution sentences (CS), respectively. ‘avg’ represents the average.
NCG: NLPContributionGraph; avg: average.
In the latest NLP knowledge graph, the information units are represented in red colour. In the NCG dataset, contribution sentences are divided into a total of 12 distinct information units, including ablation analysis, code, approach, baseline, dataset, experimental setup, experiments, hyperparameters, model, research problem and results. The subjects and objects are represented by a node in the graph, with the green colour and the relations between them being represented by predicates. This allows for clear and organised visualisation of the various components of the dataset and their connections, making it easier to understand and analyse the information contained within.
In order to ensure that our analysis is as accurate as possible, we filter some sections from the research article. Our decision is based on the findings mentioned in Gupta et al. [22]. As indicated, the majority of contribution sentences are found in the Experiment section, followed by the Result and Introduction sections. Specifically, they observe that approximately 20% of sentences in the Experiment section contained contribution sentences, while less than 5% of sentences in the Method section are classified as contribution sentences in the NCG dataset. Given these observations, after preprocessing the scientific article for the new test set, we found that contribution sentences are primarily concentrated in these sections, while the remaining sections did not contain substantial relevant information. As a result, we make the decision to remove these sections during the preprocessing stage to ensure our analysis and evaluation focused on the sections that contribute to the main findings and objectives of the study. To accomplish this, we convert the articles into plain text Grobid and Stanza file formats. We then filter out the sections that do not contain relevant information in each paper. Initially, we extract the section along with its corresponding sentence. We use the following rules to extract the section of the sentence:
1. A sentence with a length of ≤ 4 and containing substrings like Abstract, Introduction, Related Work, Background, Experiment, Implementation and so on is considered as a section heading.
2. We detect potential sections by examining the sentences that appear after blank lines in the Grobid files. These sentences are then evaluated based on the following conditions.
• A sentence is classified as a section named method if its length is < 10 and it contains a substring (with a length ≥ 2) that matches the title of the paper, excluding sentences that end with English stopwords.
Later, we apply a filtering process to select only the sentences that are relevant to the specific section being considered. In the NCG dataset, the title sentences always represent contribution sentences [22]. Therefore, we include all the titles as contribution sentences in our new test set. The filter content is stored in a file named stanza2.txt. After the initial filtering process, we proceed to preprocess the sentences from the stanza2.txt file using a set of predefined preprocessing methods, as described in the Preprocessing section of our manuscript. This preprocessing resulted in a final dataset comprising 8,828 sentences.
8. Conclusion and future work
In this article, we propose a method for infusing scientific knowledge from a knowledge graph into a BERT-based model to identify contribution sentences. To accomplish this, we construct a NLP knowledge graph by collecting data from the ACL anthology, which is a compilation of various NLP conferences. Then we divide the knowledge graph into mutually exclusive groups and use the adapter, a method for infusing knowledge into pre-trained models, to infuse the knowledge into the BERT-based model. With the proposed approach, we observe a significant increment in the model’s understanding of semantic and scientific terms. To evaluate the performance of our model, we test it on two test sets: (1) NCG dataset, a publicly available dataset and (2) a new in-house annotated test set which is a collection of NLP papers published in 2022.
We initially used an existing model (ContriSci) to bootstrap the dataset, then manually annotate the sentences that are misclassified by the ContriSci model. Finally, we verify the complete dataset. Our partition-based model demonstrates the best performance compared with existing models, achieving a significant improvement of + 25.72, + 16.17 in terms of F1 score over NCG and in-house test sets, respectively. We also observe that the model performed particularly well when the knowledge graph was divided into 20 parts. However, there are still some limitations present in the model, such as the misclassification of sentences with less contribution information. In the future, we aim to enhance our model’s semantic intelligence by incorporating real-world knowledge. By doing so, our model will have a deeper understanding of the context and will be able to more accurately identify key sentences and their contributions within a given text.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.