
Abstract
This study investigates the effects of research data identifiers specified in data availability statements (DASs) on citations, with altmetrics serving as mediating indicators, as part of broader efforts to analyse the impact of open science policies on the diffusion of scholarly outputs. For this purpose, the study examined DAS from articles published in PLOS ONE over the past 11 years and collected data on the characteristics of research data identifiers, altmetrics and citations. Using a structural equation model to analyse the relationships among these variables, the results revealed that ID diversity affected citations indirectly through saves, URLs through saves and usages, and Digital Object Identifiers (DOIs) through saves, views and usages, although the effects were positive yet weak. This study is significant in demonstrating that DAS, as one of the institutional mechanisms for research data disclosure, can positively contribute to the diffusion of scholarly outputs.
Keywords
1. Introduction
Since 2004, the Organisation for Economic Cooperation and Development (OECD) has initiated discussions on open science with the goal of improving access to research outputs. In 2006, it adopted the OECD Recommendation on Access to Research Data from Public Funding, which was revised and approved in 2021 [1,2]. Similarly, the United Nations Educational, Scientific and Cultural Organization (UNESCO) has advanced policies to enhance the accessibility and reusability of research outputs under the principle that scientific knowledge should be openly available to all [3]. Over the past two decades, interest in open science has steadily increased, with research data produced during the research process at the centre of these discussions. The disclosure and sharing of research data are critical not only for ensuring transparency and reproducibility but also for preventing the social waste that results when different researchers collect the same data redundantly.
With the growing emphasis on the importance of research data, various stakeholders have proposed a range of open science policies to facilitate the collection and management of research data. In the United States, the Office of Science and Technology Policy (OSTP) announced the Year of Open Science to enhance public trust by ensuring access to research outputs funded by national resources [4]. In the European Union (EU), large-scale research funding programmes such as Horizon 2020 and Horizon Europe require the submission of a Data Management Plan (DMP), which outlines how research data will be produced, preserved, managed and shared [5,6].
Publishers have also begun to require the disclosure of research data associated with submitted manuscripts. Since 2014, PLOS has implemented a policy mandating that authors make the research data used in their articles publicly available, accompanied by a Data Availability Statement (DAS) [7]. The DAS policy, which specifies the availability of data and software code as well as practical methods of access, was subsequently adopted by other major publishers, including Springer Nature, the International Committee of Medical Journal Editors (ICMJE) and BMJ [8–10]. Publishers that encourage data sharing also recommend depositing research data in trusted repositories and including repository information in the DAS to ensure actual accessibility. Beyond its role in linking research data to publications, the DAS is also meaningful as a form of data curation authored directly by the researchers who generated the data.
While various stakeholders have proposed policies and systems to promote research data sharing, scepticism also exists. Preparing and documenting data for sharing require substantial time and effort [11,12], leading to questions about whether such data-sharing mandates actually contribute to effective data use and the diffusion of research [10,13]. In this context, this study focuses on DAS and analyses whether such mechanisms for data sharing positively influence the diffusion of scholarly outputs.
Although some studies have shown that data sharing mandates positively influence the diffusion of research outputs [14–16], few have specifically examined whether the access information specified in DAS affects research diffusion. Therefore, this study focuses on how research data identifiers presented in DAS influence the diffusion of research. While citations can be considered the ultimate indicator of research diffusion, considerable time is required for a paper to accumulate citations. As an alternative, this study also analyses short-term diffusion indicators, namely altmetrics [17,18]. By doing so, it seeks to determine how research data identifiers specified in DAS affect short-term diffusion indicators and, ultimately, how they influence citations. The research questions and the hypotheses of this study are as follows:
• RQ1. Do the characteristics of research data identifiers specified in DAS affect short-term diffusion indicators?
H1. The characteristics of research data IDs have a significant effect on altmetric indicators.
• RQ2. Do the characteristics of research data identifiers specified in DAS affect citations through short-term diffusion indicators?
H2. Altmetric indicators have a significant effect on citations.
H3. The characteristics of research data IDs have a direct effect on citations.
H4. The characteristics of research data IDs have an indirect effect on citations through altmetric indicators.
2. Literature review
2.1. Previous studies on identifiers for research data
Brower and Narlock [19] stated that persistent identifiers (PIDs) enable the identification, citation and usage tracking of research data and therefore play a central role in research practices across all academic disciplines. While identifiers such as ORCID, RoR and Digital Object Identifier (DOI) are used to identify various entities within the scholarly community, the study argues that improvements in identifier systems are required as the scope of research data to be managed expands and the complexity of management increases. The study further emphasises that when considering the introduction of new identifier systems, it is necessary to comprehensively evaluate aspects such as the ability to represent hierarchical structures, an open governance model and minimum metadata standards.
Liu [20] focused specifically on DOIs among various PIDs. The study describes the DOI as a PID that plays an important role in the discovery and access of scholarly information and explains the characteristics and structure of the DOI, as well as its use in research data. In particular, the study provides a detailed explanation of the way DOI services operate in the field of research data management, noting that libraries serve as registration agencies offering DOI services and provide related services through Research Data Management (RDM). The study also explains that DOIs have a high degree of interoperability with ORCID and that various intellectual entities will be identified by DOIs in the future, while emphasising the role and importance of DOIs as PIDs for research data in the current research environment where citable data sets are becoming increasingly common.
While Liu [20] emphasised the role of DOIs as PIDs for research data, Wimalaratne et al. [21] pointed out that DOIs are not well suited for application to biomedical data. Wimalaratne et al. [21] focus on the technical implementation of identifiers with the aim of enabling the citation of biomedical data. The study points out that biomedical data repositories present only their own unique accession numbers rather than providing PIDs and, at the same time, highlights the limitations of applying DOIs, which are generally used as identifiers, to biomedical data. As a solution, the study introduces the concept of ‘compact identifiers’, in which a namespace identifier is prefixed to enable the accession numbers of individual repositories to function as identifiers and argues that the broader adoption of this approach will be necessary in the future.
The analysis of previous studies shows that the importance of research data identifiers is expanding, and that discussions on research data identifiers have mainly centred on PIDs, particularly DOIs. The prominence of DOIs as the principal identifier for research data can be attributed to their stability and interoperability. Unlike URLs, which remain valid only as long as the site operators maintain their websites, DOIs are managed by authorised registration agencies with clearly defined operational policies. Even when a URL changes, the DOI remains valid through the simple update of its target URL. Moreover, the widespread use of DOIs not only for research data but also for a variety of scholarly objects – such as journal articles, images and other research materials – has increased researchers’ familiarity with DOIs.
2.2. Previous studies on DAS
Colavizza et al. [15] analysed the DAS of articles published in BMC and PLOS to examine whether they were adopted in accordance with publisher policies and to assess the correlation between DAS types and citations. The study classified DAS into four categories (access restricted, upon request, in paper and SI, repository) and developed an algorithm for their categorisation. The findings revealed that the distribution of DAS varied across individual journals and that DAS including a URL or a PID linking to a repository showed a statistically significant citation advantage over other types.
Federer [22] shared the same view as Colavizza et al. [15] in that DAS policies help improve the availability of research data but pointed out the limitation that DAS does not necessarily guarantee actual access to the data. To examine the accessibility of data specified in DAS, the study extracted DOIs and URLs of research data from a corpus of 50,000 PLOS ONE articles, tested the automatic link connectivity of 8503 links and reviewed the actual accessibility of 700 links. The results indicated that both DOIs and URLs can serve as effective means of ensuring long-term access to data, and the study argued that DAS should include DOIs and URLs.
While Colavizza et al. [15] and Federer [22] examined general aspects of DAS, An and Byun [23] focused on a specific region and investigated the concrete status of DAS implementation. The study analysed the DAS of articles authored by Korean corresponding authors and published in PLOS ONE between 2014 and 2022 to investigate the data-sharing types of Korean researchers and the major repositories they use. Building on the framework proposed by Federer et al. [24], which served as the foundation for Federer [22], the study categorised data sharing in DAS into 10 types (in paper, in SI, in paper and SI, repository, upon request, location not stated, N/A, other, access restricted, combination). In addition, research data identifiers specified in DAS were classified into DOIs, URLs and accession codes for analysis. Through this analysis, the study identified changes in data-sharing types over time and revealed that the DAS patterns in Korea follow global trends.
A comprehensive review of previous studies analysing DAS revealed that DAS can be categorised into several types, and that the inclusion of research data identifiers may vary depending on the type. It was also confirmed that in the actual process of data sharing, not only PIDs such as DOIs or accession codes but also URLs are presented as research data identifiers.
2.3. Previous studies on the dissemination of research outputs
Brody et al. [25] conducted a study to examine whether short-term web usage, such as the number of downloads and views of research articles, could predict medium-term citation impact. For this purpose, the study collected download and citation data for articles stored in arXiv.org between 2000 and 2002 using Citebase, covering data up to March 2005. The analysis revealed a substantial correlation between downloads and citations in physics articles and confirmed that similar correlations were also observed in other fields of arXiv, including mathematics, astrophysics and condensed matter physics.
While Brody et al. [25] focused on downloads and reads, Kumar et al. [26] and Huang et al. [27] introduced altmetrics as alternative indicators and analysed their correlations with citations. Kumar et al. [26] provided a detailed explanation of altmetrics as online measures of scholarly articles derived from social media platforms. The study noted that altmetrics can be used to assess research impact more rapidly than traditional metrics within social media environments and that they are applicable to a wide range of research outputs. Furthermore, it explained that altmetrics can be categorised into five types – viewed, discussed, saved, cited and recommended – and introduced representative services that provide altmetric data. Huang et al. [27] analysed articles published in six PLOS journals in 2012 to examine whether the impact of altmetrics varies across academic disciplines. The study grouped the indicators of major altmetrics into four categories – social media, usage, citation and saves – and normalised the articles into percentile ranks to analyse correlations. The results confirmed that for journals publishing a substantial number of articles, there was a positive correlation between higher altmetric scores and greater citation counts.
Haustein et al. [28] focused on social media among various types of altmetrics. The study analysed 1.4 million PubMed-indexed articles over a 3-year period to examine how frequently Twitter was used for the dissemination of biomedical research. The study analysed Twitter mentions at the article, journal and disciplinary levels and found that, although there were differences across subfields, the overall proportion of articles mentioned on Twitter remained low. It also found that Twitter mentions showed little correlation with citations, indicating that they do not necessarily reflect the intellectual impact of research.
The review of previous studies revealed that there have been continuous efforts to develop alternative indicators of research impact beyond citations, particularly early diffusion indicators that can capture the spread of research more quickly than citations. Altmetrics exhibit platform bias, as they account for reference managers such as Mendeley but exclude research data platforms like Zenodo and Figshare. Moreover, because their collection depends on application programming interfaces (APIs), they are inherently unstable. Nevertheless, numerous studies have acknowledged altmetrics as a valuable indicator of scholarly influence that can serve as an alternative or complement to traditional citation metrics. Altmetrics are generally categorised as viewed, discussed, saved, cited, recommended and usage, and it was found that studies on the correlation between altmetrics and citation indicators have been conducted from multiple perspectives.
2.4. Previous studies on research data and the dissemination of research outputs
Piwowar et al. [29] conducted a study exploring the relationship between data sharing and citation rates in the field of cancer microarray clinical research. For this purpose, they analysed 85 articles in the field, of which 41 made their research data publicly available through various platforms such as institutional websites and public databases. An analysis of citation counts during the first 24 months after publication revealed that, regardless of journal prestige, articles that shared data were cited approximately 70% more frequently than those that did not. This study is significant in that it was conducted in the 2000s, prior to the introduction of the DAS concept, and it highlights the interesting point that the barriers to research data sharing identified in the study remain persistent issues today.
Since the study by Piwowar et al. [29], research has continued to examine the impact of data sharing on the citation rates of scholarly articles. Henneken and Accomazzi [30] confirmed that articles in the field of microarray-based gene expression profiling that included links to research data had higher citation rates. Similarly, Sears [31] analysed articles published in the journal Paleoceanography over an 18-year period and found that, in 14 of those 18 years, articles with openly available data consistently received more citations. Piwowar and Vision [32] conducted a multivariate regression analysis, taking into account external variables that could influence citations in addition to data sharing, and confirmed that articles with shared data were cited significantly more often. Dorch et al. [33] reconfirmed that in the field of astrophysics, articles providing data links received higher citation counts than those without.
With the emergence of data journals as a new means of data publication, Fu et al. [34] analysed how data papers published in a data journal influence the citations of related research articles. Specifically, the study examined the citation relationship between articles published in the data journal Data in Brief and their corresponding research papers. A total of 618 articles published in Data in Brief between 2014 and 2021 that had related research articles were selected as the sample, and regression analysis was conducted including a control group of articles unrelated to data publication. In addition, a survey of corresponding authors who had shared data was also conducted. The results confirmed that research articles accompanied by data papers published in data journals were cited more frequently than those without, and that researchers who published data in data journals had more experience in sharing data, had reused data from others and expressed a stronger willingness to share.
3. Research methods
3.1. Research model
This study developed a research model by identifying variables corresponding to the hypotheses based on previous studies. Variables related to the characteristics of research data identifiers specified in DAS were determined with reference to prior studies on research data identifiers and DAS. In general, DOIs and accession codes are recognised as the primary PIDs for research data identification, as they possess the uniqueness required of identifiers and exhibit far greater persistence than URLs. However, the analysis of DAS revealed that URLs are still widely used alongside DOIs, and in some cases, URLs were presented even by repositories that issue DOIs. In addition, no identifiers other than DOIs, accession codes or URLs were observed in the DAS. Accordingly, this study regarded DOI, accession code and URL as the representative identifiers for research data and set both the number of each identifier present and the number of identifier types included in a single DAS as variables. Furthermore, as discussions on the accessibility of research data have continued, and previous studies have noted that identifiers specified in DAS do not necessarily guarantee actual data access [22], the number of accessible identifiers and the number of inaccessible identifiers per article were also included as variables.
Based on the studies of Kumar et al. [26] and Huang et al. [27], the initial diffusion indicators were selected as save, view, share and usage. View refers to the total number of HTML page views and PDF/XML downloads, while save indicates the number of times an article was stored in or bookmarked on reference managers such as Mendeley and CiteULike. Share refers to the number of times an article was disseminated through social media platforms such as Twitter, Wikipedia and Reddit, which is equivalent to discussed. Usage refers to the number of accesses or exports, and in this study, the usage count during the most recent 180 days was selected as a variable. The values for save, view and share were converted into annual averages using the formula n/(2024 − year + 1) and used as variables. The number of citations was derived through a comprehensive consideration of the citation counts reported by Dimensions and Web of Science. Finally, the year of publication was included as a control variable, as it was considered a potential confounding factor that could influence altmetrics and citation performance. The variables established for this study are summarised in Table 1.
Variables included in the research model.
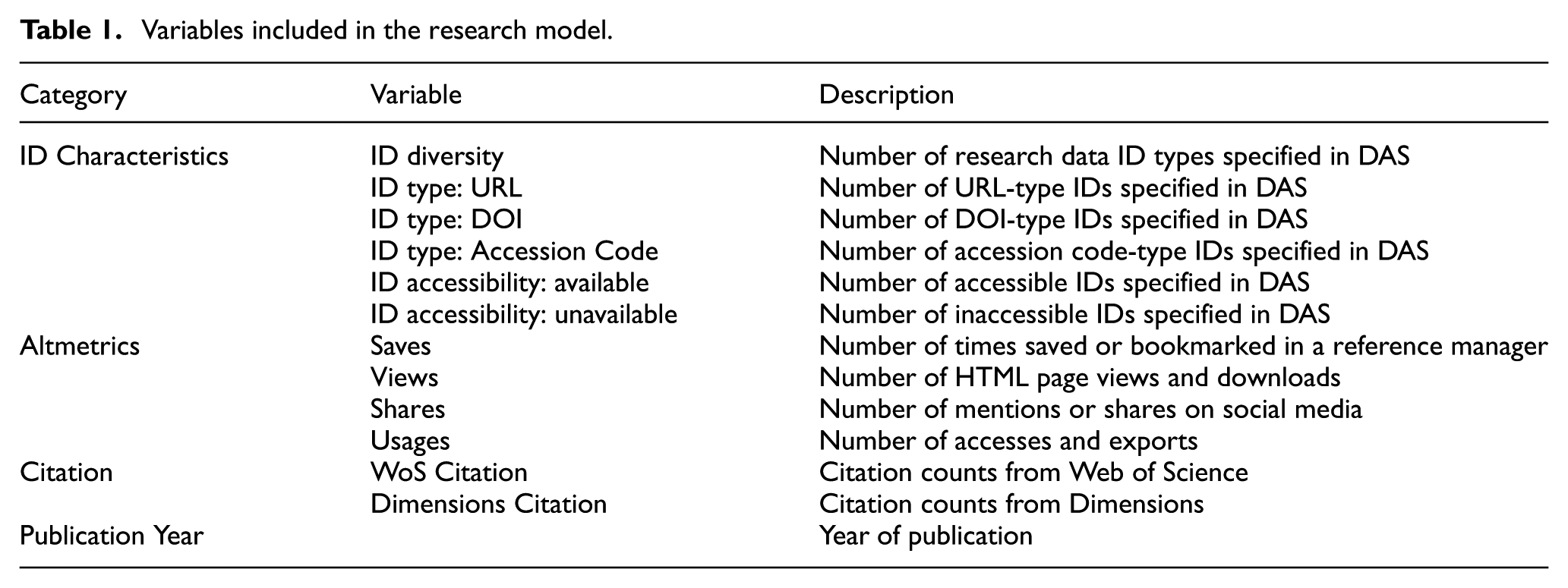
The variables corresponding to the characteristics of research data identifiers were intended to examine their impact on citations. Since each variable represented an independent unit of interpretation, the observed variables were not integrated into a single latent variable. Regarding altmetrics indicators, because each reflects different research behaviours, the study aimed to analyse them individually rather than combining them into a single latent construct in order to identify more specifically how the characteristics of IDs influence citations through different altmetric indicators. For citations, it was confirmed that citation counts from Dimensions and those from Web of Science–indexed journals did not present multicollinearity issues. As this study seeks to assess the overall impact on citations, rather than distinguishing between sources, the two citation counts were combined as observed variables under a single latent variable labelled ‘citation’.
The purpose of this study is to examine the impact of research data IDs specified in DAS on the dissemination of scholarly outputs. Specifically, it analyses how the characteristics of research data IDs influence final citation counts through altmetrics, which serve as short-term indicators of impact. The structural equation model of this study is presented in Figure 1.
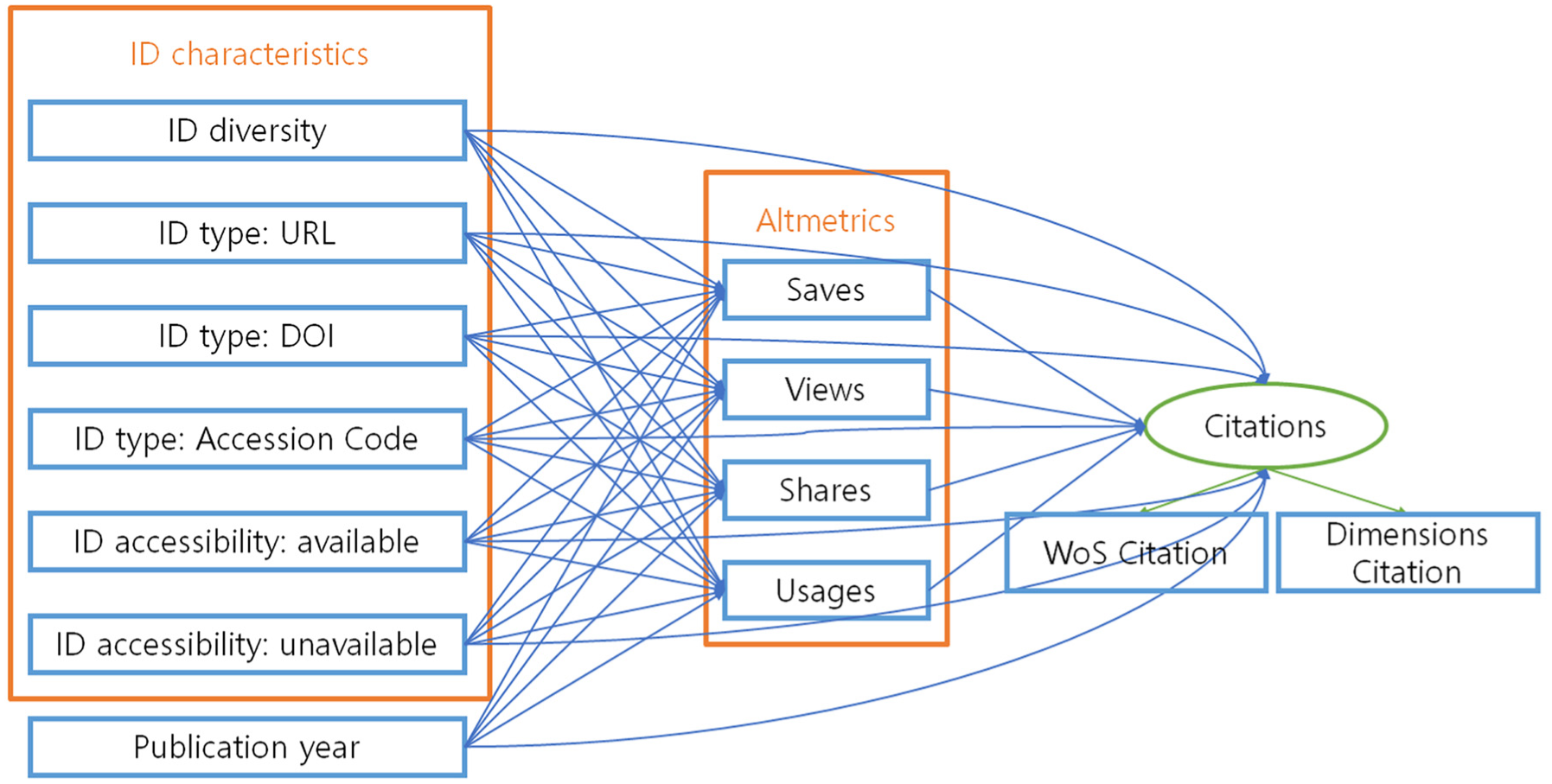
Proposed research model.
3.2. Data collection and preprocessing
Selection of the study sample: This study analysed all articles of the ‘Article’ type published in PLOS ONE over an 11-year period from 2014 to 2024. PLOS ONE is a multidisciplinary journal that has mandated the inclusion of DAS since 2014 and has maintained this policy for more than a decade. Therefore, PLOS ONE and the study period of 2014 to 2024 were deemed appropriate for this research, as they allow for the collection of a large volume of DAS over a long period without being limited to a specific academic discipline:
Collection of target article metadata: To collect information on articles published in PLOS ONE, the Web of Science database (webofscience.com) was utilised. The data set included all records indexed in the Web of Science, encompassing the Core Collection. The search was filtered by Publication Title: PLOS ONE, Document Type: Article and Publication Years: 2014–2024, and the resulting list of articles was downloaded in full. As a result, a total of 207,888 articles were collected.
Collection of DAS: Since DAS cannot be downloaded directly from the Web of Science, they had to be collected from individual article pages. As PLOS ONE is an open access journal, all metadata, including DAS, as well as the full text of articles, are publicly available. Accordingly, DAS information was crawled from each article’s page based on the DOI list collected in the previous step. Web crawling was conducted in accordance with the permissions specified in the robots.txt file of the PLOS ONE website. The file disallows access to specific paths such as /article/metrics, /search and /user but does not restrict access to individual article pages. Therefore, only publicly accessible article pages containing DASs were collected. The web crawling was conducted using Python 3 in a Google Colab environment. The libraries requests and BeautifulSoup were used to retrieve and parse DASs from PLOS ONE articles, while pandas and openpyxl were employed for data cleaning and storage. After excluding 28,005 cases due to DOI duplication, missing data, or the absence of DAS, a total of 179,883 DAS were collected.
Identification of research data IDs and examination of ID characteristics: Not all DAS include research data IDs; therefore, it was essential to select only those DAS containing IDs. For this purpose, classification criteria established in previous studies were applied. A DAS was considered to include research data IDs only if it belonged to the repository type or the combination type (repository combined with other types); thus, DAS belonging to other categories were excluded. In addition, PLOS ONE provides an ‘Accessible Data’ icon feature for some articles, which directs readers to the corresponding research data pages. This can also be regarded as a mechanism linking research articles with their associated data. However, since the identifiers were not directly entered by the authors into the DAS, this feature was deemed outside the analytical scope of the present study. Therefore, the presence or absence of the ‘Accessible Data’ icon was not considered. After filtering DAS based on these criteria, the individual statements of each article were analysed. As a result, 92,789 identifiers were identified across 52,379 articles. Subsequently, the number of identifiers of each type per article and the diversity of identifier types contained in each article were organised.
Assessment of data accessibility through the IDs in the DAS: To examine the actual accessibility of research data IDs, the validity of URLs, DOIs and accession codes specified in the DAS was assessed. For URLs and DOIs, the status codes of the linked webpages were collected, and accessibility was determined based on whether the page was successfully displayed. In cases where temporary errors (e.g. 408, 429) prevented access, up to five repeated attempts were made to access the same link; if all five attempts failed, the link was classified as inaccessible. Since accession codes are not directly associated with hyperlinks, the websites through which the accession codes could be queried were identified and searched directly. However, when accession codes originated from the National Centre for Biotechnology Information (NCBI), corresponding links were available, and webpage status codes were collected through them. For all cases in which accession codes were found to be inaccessible or temporarily inaccessible through the links, manual searches were performed in NCBI. Based on these procedures, the number of accessible and inaccessible identifiers was summarised for each article.
Random extraction of articles without IDs: After collecting and preprocessing data for articles whose DAS included research data IDs, a comparison group of articles without research data IDs was added. This was done to test differences in citation effects depending on whether research data identifiers were provided. From the 127,504 articles without research data IDs, 52,379 were randomly extracted, matching the number of articles with research data IDs for each publication year.
Collection of altmetrics, usage and citation data: After finalising the set of articles for analysis, altmetrics usage and citation information was collected. WoS citation and usage data were obtained by downloading all PLOS ONE article records from the Web of Science and matching them to DOIs. The altmetric indicators used in this study – save, view and share – as well as Dimensions citation counts were collected by crawling the information displayed on individual article pages. While the metrics endpoint is disallowed according to the robots.txt file, this study did not access that endpoint directly. Instead, Altmetric information embedded within the publicly accessible article pages was collected as part of the HTML content. Therefore, all data collection remained within the permitted scope of the site’s crawling policy. Since the altmetrics were crawled from the individual article pages rather than from separate altmetrics pages, the same method used for crawling the DAS was applied. To avoid overloading the system, data collection was conducted over a 10-day period from 2 August to 11 August 2025. Although some fluctuations in altmetric indicators may have occurred during the crawling period, the influence of such variation is considered limited, as the analysis focuses on relative differences across groups rather than absolute values at a specific point in time. The collected values for save, view, share and both WoS and Dimensions citation counts were converted into annual averages to minimise the effect of publication year. Figure 2 illustrates the procedures for data collection and preprocessing in this study.
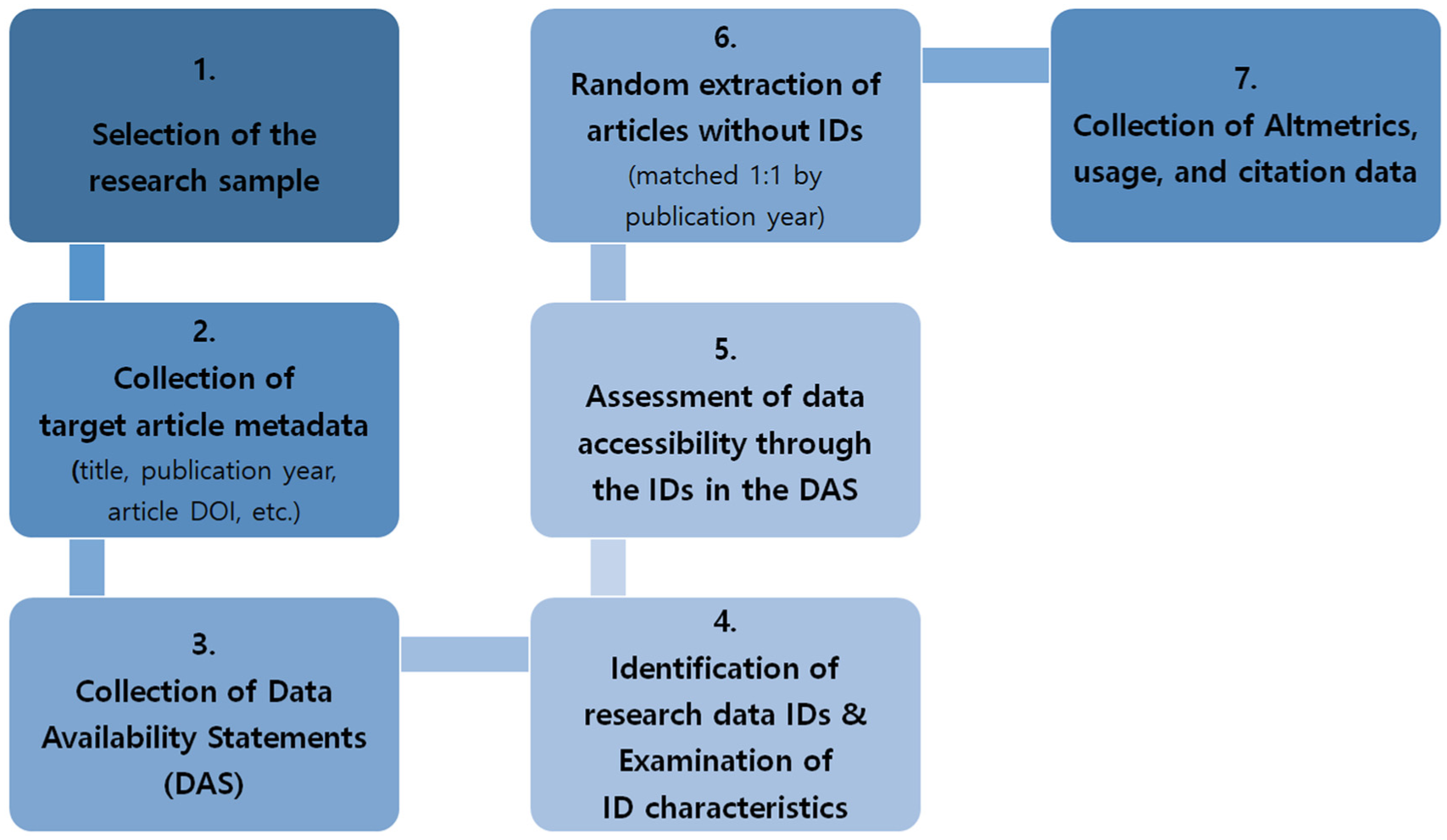
Data collection and preprocessing procedure.
3.3. Sample characteristics
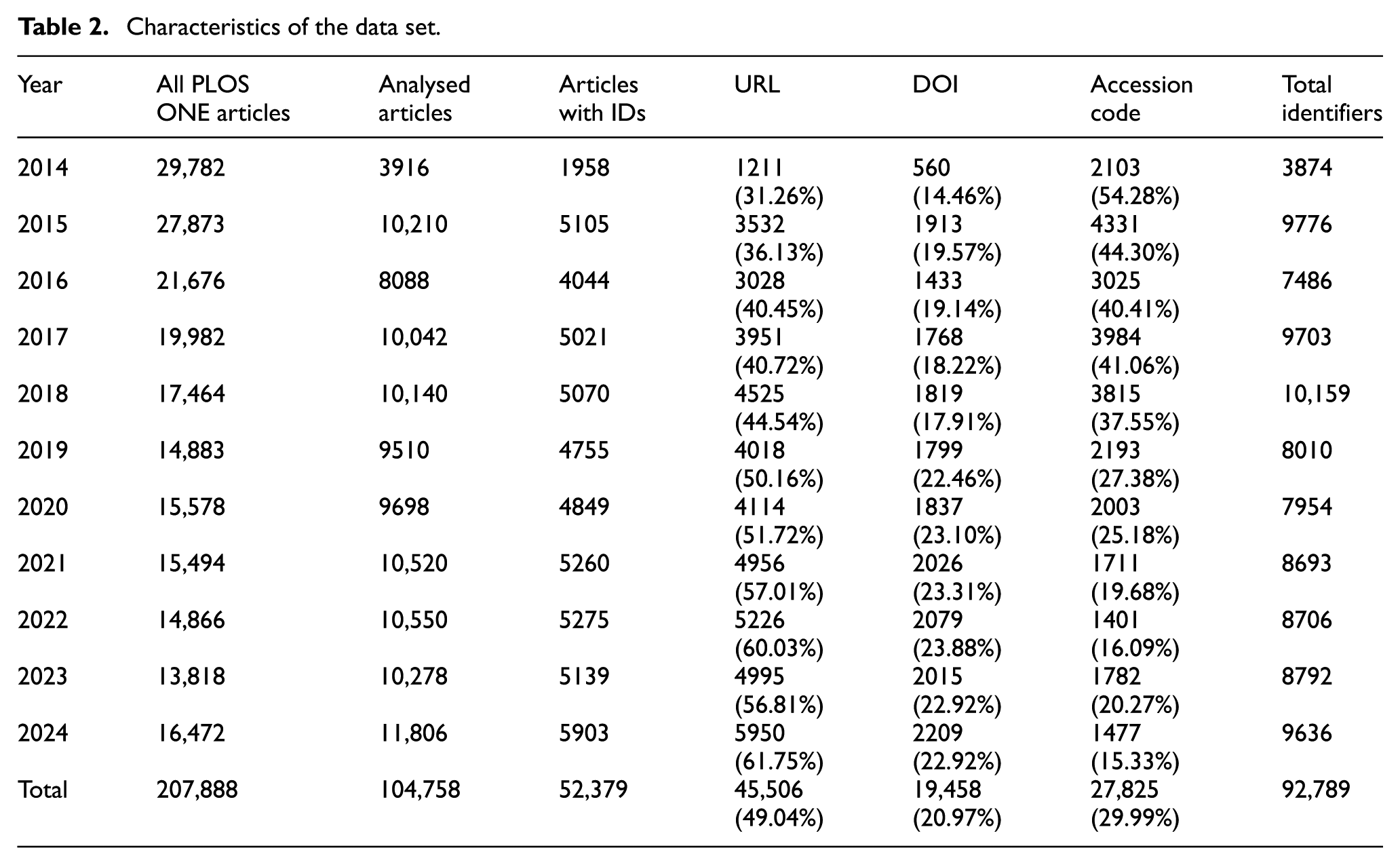
Through the procedures described in section 3.2, a total of 104,758 articles were finalised as the sample for analysis, representing 58.24% of the overall data set. Table 2 presents the characteristics of the analysed articles and their identifiers. Although the number of articles with identifiers fluctuated slightly from year to year, it has shown a continuous increase since 2019. Considering that the total number of PLOS ONE articles has declined annually, the proportion of articles including IDs can be regarded as increasing.
Characteristics of the data set.
3.4. Analytical procedures and methods
This study employed structural equation modelling (SEM) to examine the structural relationships between the characteristics of research data IDs and the dissemination of scholarly outputs. SEM has the advantage of enabling simultaneous analysis of the relationships between independent and dependent variables, as well as mediating effects, direct paths and indirect paths. Since this study aimed to analyse both the indirect effects of research data IDs on citations through altmetric indicators and their direct effects on citations, SEM was considered more suitable than simple regression analysis.
SEM analysis in this study was conducted in a Python environment on Google Colab, using syntax similar to that of the lavaan package in R. Data preprocessing and descriptive statistics were performed with pandas, and variable standardisation was carried out using StandardScaler in scikit-learn. Confirmatory factor analysis (CFA) and structural model estimation were conducted with the semopy package, and bootstrapping was performed through row resampling based on semopy.
First, a CFA was conducted. In this study, citation was the only latent variable, while the characteristics of research data IDs and altmetric indicators were each treated as single observed variables; therefore, no separate CFA was performed for them. The criteria for convergent validity in the CFA were set as standardised factor loadings (λ) ≥ .90, composite reliability (CR) ≥ .90 and average variance extracted (AVE) ≥ .80. As citation was the sole latent variable in the model, the assessment of discriminant validity was omitted.
In the structural modelling stage, the indicators confirmed in the measurement model were retained to estimate path coefficients, and model fit indices were reassessed. Maximum likelihood (ML) estimation was applied for model estimation, and model fit was evaluated using χ2 statistics, the Comparative Fit Index (CFI), Tucker–Lewis Index (TLI) and Root Mean Square Error of Approximation (RMSEA). Following the thresholds suggested by Hu and Bentler [35], values of CFI and TLI above 0.90 and RMSEA below 0.08 were considered acceptable.
Since the data analysed in this study were not normally distributed, the bootstrap method was employed to ensure the stability and reliability of the path coefficients. Using 5000 replications, standard errors and 95% confidence intervals (CIs) for the path coefficients were estimated, and the direct, indirect and total effects were separated to test the significance of each hypothesis (H1–H4). To assess the overall validity of the model, Bollen–Stine bootstrap χ2 p-values were calculated. During the analysis, some variables were modified or removed from the model if their path coefficients were not statistically significant or if they reduced model fit; to maintain transparency, changes in model fit indices before and after variable inclusion/exclusion were compared.
4. Results
4.1. Descriptive statistics
Table 3 presents the descriptive statistics of the ‘ID characteristics’ variables for the entire dataset (n = 104,758). Since the data set includes an equal number of articles with and without IDs, half of the cases have values of zero for all ID-related variables. As a result, the overall distribution exhibits a long-tail pattern.
Descriptive statistics of ID characteristics across all articles (N = 104,758).
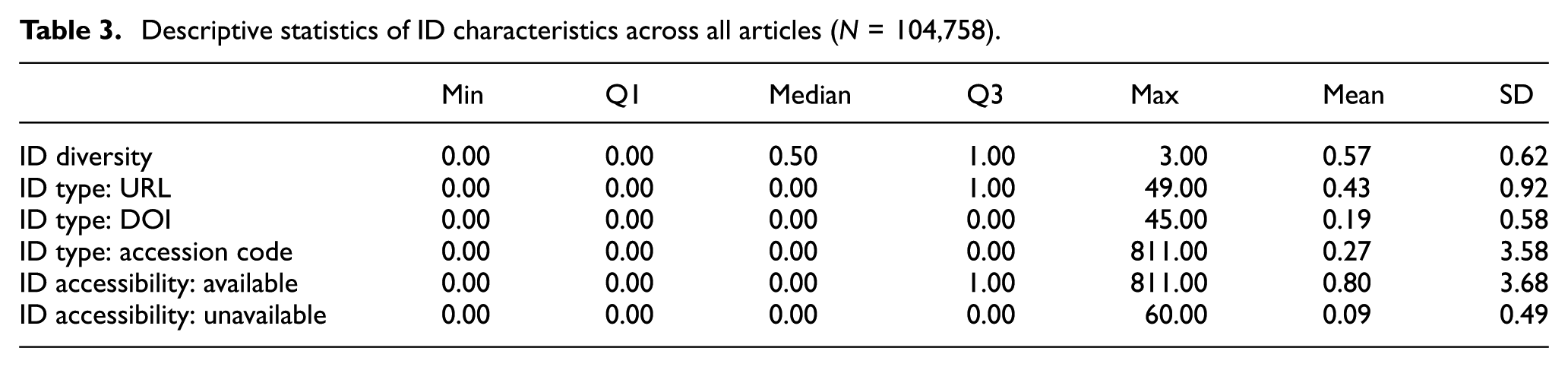
Table 4 reports the results for the 52,379 articles that contained at least one ID, which is more suitable for examining patterns of ID characteristics. The average value of ID diversity was 1.13, with Q1, the median and Q3 all equal to 1, indicating that only a small number of articles contained more than two types of IDs. Regarding ID types, each article contained on average 0.87 URLs, 0.53 accession codes and 0.37 DOIs. The URL type had not only the highest mean but also a median of 1, meaning that more than half of the articles included at least one URL identifier. In contrast, DOIs had a median of 0, showing that more than half of the articles did not include a DOI. Accession codes had a higher mean than DOIs but also had a median of 0. Notably, there was a case in which a single article included 811 accession codes, resulting in a very high standard deviation of 5.05. With respect to ID accessibility, the mean was 1.60, the median was 1, and the third quartile (Q3) was 2, indicating that most articles provided at least one accessible identifier. However, the standard deviation was large because accessibility was influenced by an outlier. The mean value for unavailable identifiers was 0.17, which is relatively low, suggesting that most of the IDs specified in DAS were accessible.
Descriptive statistics of ID characteristics for articles with at least one ID (N = 52,379).
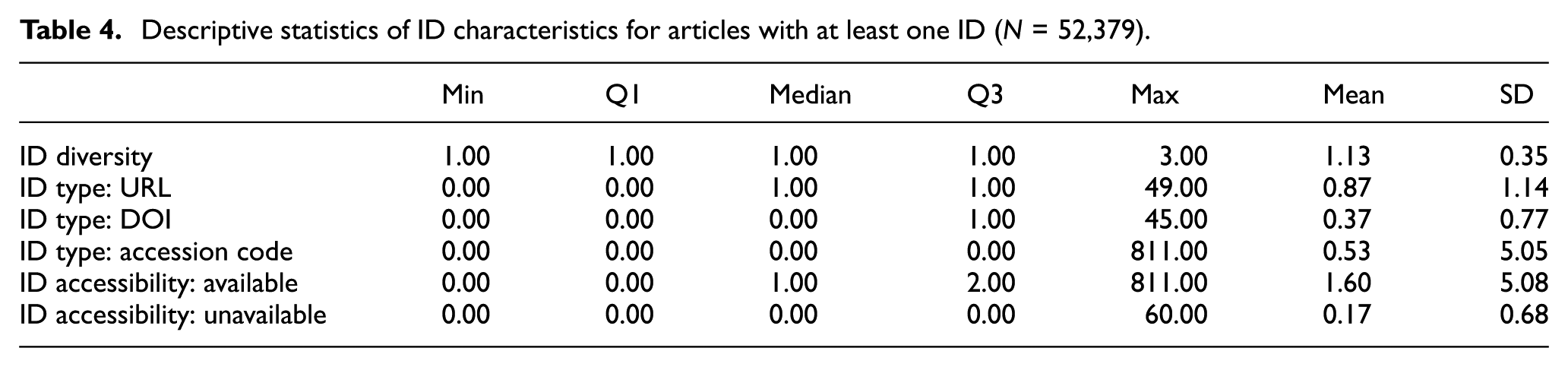
Table 5 presents the descriptive statistics for save, share, view, usage, Dimensions citations and WoS citations. For saves, most articles were saved 5–10 times per year, and there was little difference between the mean and the median. For shares, the median was 0.33 and the third quartile was 1.00, indicating that annual shares were rare, although there was an extreme outlier with 2404.33 shares. Usage exhibited a pattern similar to shares, with most articles recording no usage within 6 months, but a small number of articles showing substantial activity, demonstrating a typical long-tail distribution. For views, articles generally received 500–900 views, but a very small number of articles recorded extremely high view counts. The median and Q3 of Dimensions citations indicated that the majority of articles were cited approximately two to four times per year, while the distribution showed a concentration of citations among a small number of articles, with the median lower than the mean. WoS citations, as expected, were lower in absolute values compared with Dimensions citation counts but exhibited a similar distribution pattern. Overall, the altmetric and citation indicators used in this study followed a long-tail distribution, with a small number of articles recording very high usage and citation values, while the majority showed low values. Since these distributional characteristics may affect the normality assumption of SEM, all variables were standardised (z-scores) before analysis. In addition, to ensure the stability of parameter estimation, Bollen–Stine bootstrap χ2 tests of model fit and effect estimation were conducted concurrently.
Descriptive statistics of altmetrics and citation indicators (N = 104,758).
4.2. Measurement and structural model analysis results
4.2.1. CFA of the latent variable
Prior to the model analysis, a CFA was conducted for Citation, the only latent variable in this study, and no assessment of discriminant validity was performed since no additional latent variables were present. The latent variable Citation was composed of Dimensions citations and WoS citations. The standardised factor loading was 1.000 for Dimensions citations and 0.928 for WoS citations, with both values exceeding the threshold of 0.90, thereby confirming convergent validity. In addition, the CR was 0.964 and the AVE was 0.931, both exceeding the cutoff values of 0.90 and 0.80, respectively, thus satisfying the criteria for construct reliability and AVE.
4.2.2. Verification of structural model fit
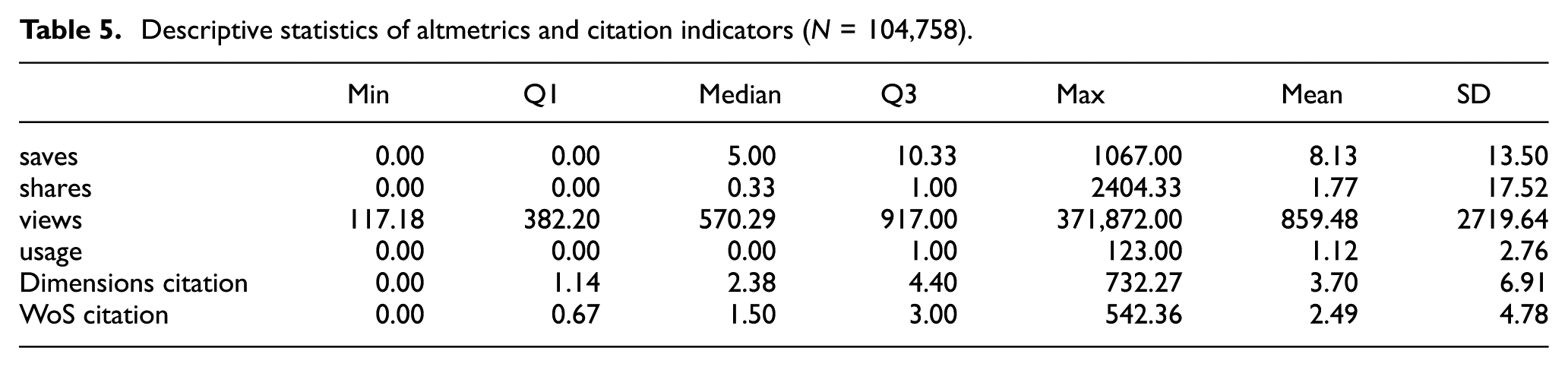
After confirming the CFA results for the latent variable, the fit of the structural model was evaluated. The major fit indices indicated an overall acceptable level (CFI = 0.957, TLI = 0.917, RMSEA = 0.085), although the RMSEA exceeded the conventional threshold (≤ 0.08). Accordingly, a modified model was tested by excluding the share variable from the altmetric indicators. Share refers to the number of times an article was disseminated via social media. Although it was included in the initial model as a typical altmetric indicator, in this data set, the share variable showed low statistical contribution and reduced model fit. Moreover, prior studies have reported that social media mentions exhibit no significant correlations with citations [28,36]. For these reasons, the share indicator was excluded from the model. After removing share, the fit indices improved slightly (CFI = 0.967, TLI = 0.940), and the RMSEA decreased to 0.078, meeting the threshold. Therefore, the model excluding the share indicator was considered the appropriate model for this study. Table 6 presents the results of structural model fit before and after removing the share variable.
Model fit indices of the original model, revised model and recommended cutoff values.
Lower values indicate better fit.
Complemented with alternative indices.
4.2.3. Path coefficient analysis
Based on the proposed SEM, the magnitude and statistical significance of each path coefficient were examined (Table 7). First, the effects of ID characteristics on altmetric indicators were tested. The results showed that ID diversity had a positive effect on saves (β = 0.017, p < 0.001); the number of DOI identifiers positively affected views (β = 0.010, p < 0.05) and usages (β = 0.014, p < 0.01); and the number of URL identifiers positively affected saves (β = 0.015, p < 0.05) and usages (β = 0.017, p < 0.01). Although some ID characteristics had positive effects on altmetric indicators, all of these effects were relatively weak. In contrast, the number of accession codes and the number of accessible IDs did not have significant effects on altmetric indicators.
Standardised path coefficients (β_std) from the SEM (ML estimation).
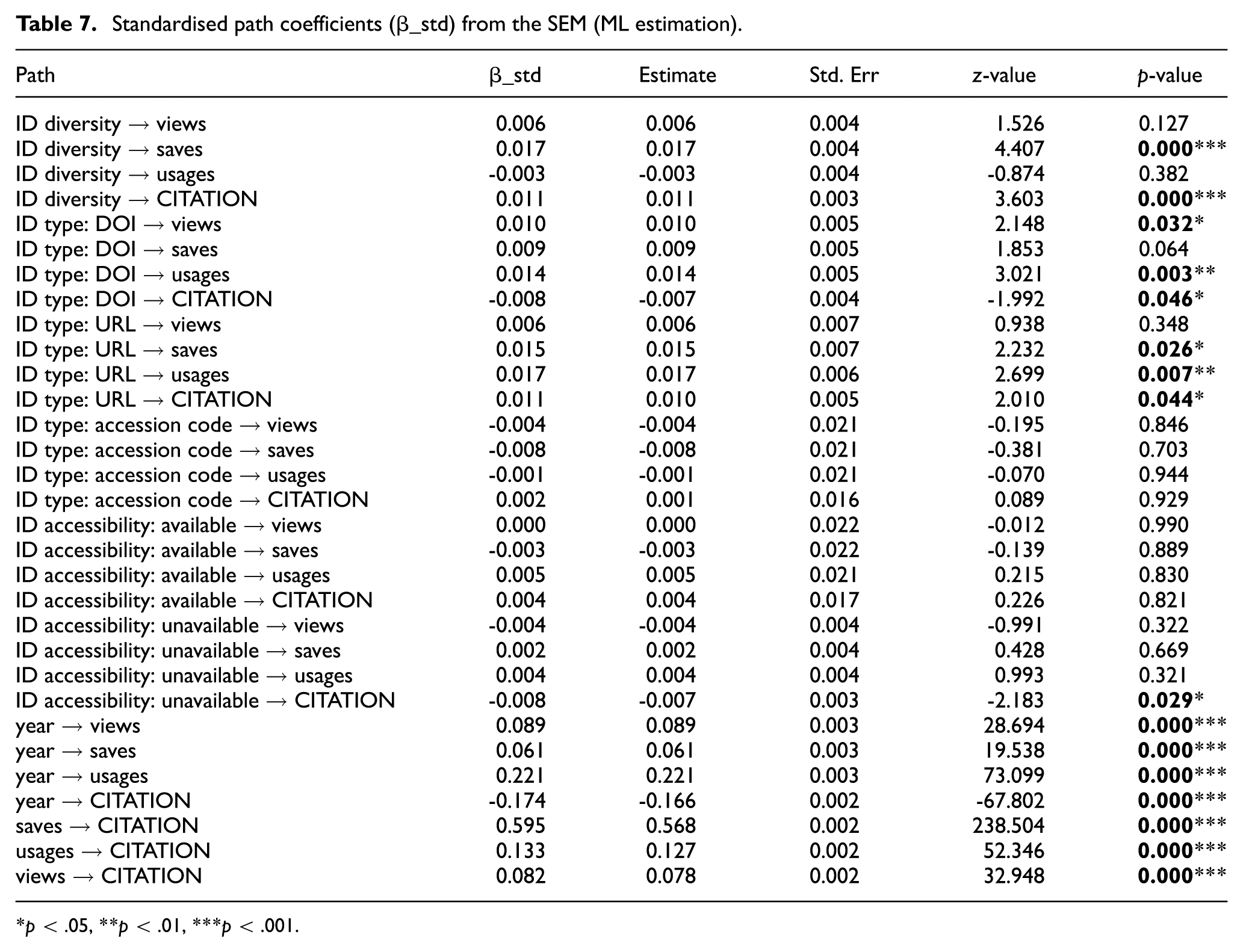
p < .05, **p < .01, ***p < .001.
All of the altmetric indicators considered in this study had positive effects on citations, and their effects were relatively strong. In particular, saves had the largest effect (β = 0.595, p < 0.001), suggesting that saving an article constitutes a major pathway leading to citations.
Even though the effect sizes were small, the ID characteristics that had direct effects on citations were ID diversity (β = 0.011, p < 0.001), the number of DOIs (β = –0.008, p < 0.05), the number of URLs (β = 0.011, p < 0.05) and the number of inaccessible IDs (β = –0.008, p < 0.05). While the number of DOIs was found to exert positive effects on views and usages among the altmetric indicators, its direct effect on citations was very small but statistically significant in a negative direction. Although the numbers of accessible or inaccessible IDs did not affect altmetric indicators, the number of inaccessible IDs showed a weak but negative effect on citations. The number of accession codes and the number of accessible IDs did not have direct effects on either altmetric indicators or citations.
The control variable year in the research model was found to affect all indicators, namely views (β = 0.089, p < 0.001), saves (β = 0.061, p < 0.001), usages (β = 0.221, p < 0.001) and citations (β = –0.174, p < 0.001). More recent articles exhibited higher levels of altmetric activity, while the number of citations showed a decreasing trend despite being adjusted to average counts by year of publication, similar to the other indicators. This result suggests that recently published articles have not yet accumulated sufficient citations.
Table 8 presents the direct, indirect and total effects between each predictor and citations in the research model, reported as standardised coefficients. Considering the non-normality of the data set, significance and CIs were tested using 5,000 bootstrap resamples.
Observed and bootstrap estimates of direct and indirect effects.
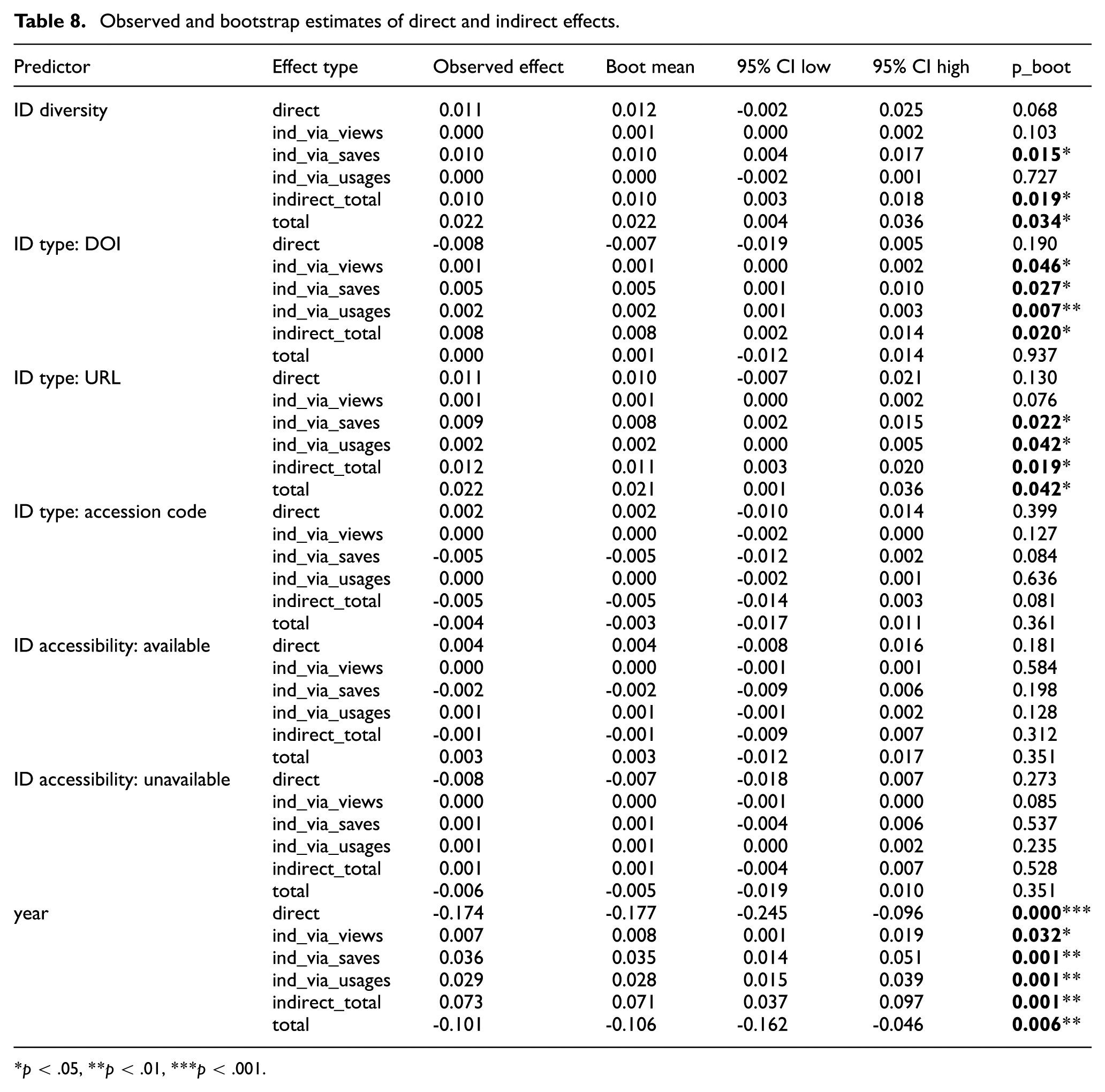
p < .05, **p < .01, ***p < .001.
The analysis of the effects of ID diversity on citation showed no significant direct effect but a statistically significant indirect effect mediated by saves (β = 0.010, p = 0.015). Overall, ID diversity had a significant positive total effect on citations (β = 0.022, p = 0.034). However, unlike the ML estimation results, which indicated that ID diversity had an effect on citations, the bootstrap CIs showed that the direct path was not statistically significant. This discrepancy may be attributed to the non-normality of the data, which could have led to an underestimation of standard errors. Therefore, this study follows the results derived from the bootstrap CIs.
In the ML estimation, the number of DOI-type IDs appeared to have a direct negative effect on citations, but the bootstrap CIs indicated that this effect was not significant. Instead, the number of DOI-type IDs influenced citations indirectly through views (β = 0.001, p = 0.046), saves (β = 0.002, p = 0.027) and usages (β = 0.004, p = 0.007). Although the effect sizes were small, the indirect total effect (β = 0.008, p = 0.020) was statistically significant, suggesting that the number of DOI-type IDs affects citations through mediation by altmetric indicators.
For the number of URL-type IDs, the ML estimation suggested a direct positive effect on citations, but the bootstrap CIs indicated that this effect was not statistically significant. Nevertheless, the total effect (β = 0.022, p = 0.042) was statistically significant, showing that the number of URL-type IDs has an overall influence on citations. Among the altmetric indicators, the indirect effect mediated by views was not significant, whereas those mediated by saves (β = 0.008, p = 0.032) and usages (β = 0.002, p = 0.042) were significant. The indirect total effect was also statistically significant (β = 0.012, p = 0.019), indicating that the number of URL-type IDs affects citations primarily through mediation by saves and usages.
For id type_Accession Code and id accessibility_available, which were not statistically significant in the ML estimation, the bootstrap CIs also confirmed that these effects were not significant. While the ML estimation suggested that id accessibility_unavailable had a direct negative effect on citations, the bootstrap CIs indicated that this direct path was not statistically significant. Thus, id accessibility_unavailable was also found to have no statistically significant effect on citations.
For the control variable year, all indirect effects mediated through altmetric indicators as well as the total indirect effect were found to have statistically significant positive relationships. However, the direct path from year to citations showed a strong negative effect (β = −0.177, p < 0.001), and consequently, the total effect – combining both direct and indirect effects – was found to be a statistically significant negative influence.
4.3. Hypothesis testing and model modification
4.3.1. Hypothesis testing
Based on the path coefficient analysis, the results of hypothesis testing are summarised in Table 9 and Appendix 1. To test H1, the effects of ID diversity, the number of DOI-, URL- and accession code-type research data IDs, as well as the numbers of accessible and inaccessible research data IDs, on views, saves and usages were examined. The sub-hypotheses that ID diversity affects saves, the number of DOI-type research data IDs affects views and usages, and the number of URL-type research data IDs affects saves and usages were supported, and all of these relationships were positive. In contrast, the number of accession code-type research data IDs and the numbers of accessible or inaccessible research data IDs did not show statistically significant effects on any altmetric indicators and were therefore rejected. Consequently, H1 was partially supported, with some sub-hypotheses accepted and others rejected.
Results of hypothesis testing (partial).

To test H2, the effects of the altmetric indicators used in this study – views, saves and usages – on citations were examined. The results showed that all three indicators had positive effects on citations. As all sub-hypotheses were supported, H2 was accepted.
To test H3, it was examined whether ID diversity, the number of DOI-, URL- and accession code-type research data IDs and the numbers of accessible and inaccessible research data IDs had direct effects on citations. While the ML analysis suggested that some characteristics of research data identifiers directly affected citations, the bootstrap results indicated that none of these characteristics had a significant direct effect on citations. Since this study gives priority to bootstrap results over ML results due to the characteristics of the sample, all sub-hypotheses were rejected, and H3 was therefore not supported.
To test H4, it was examined whether ID diversity, the number of DOI-, URL- and accession code-type research data IDs and the numbers of accessible and inaccessible research data IDs indirectly affected citations through the three altmetric indicators adopted in this study (views, saves and usages). The results showed that ID diversity had a positive indirect effect on citations mediated by saves, and the number of URL-type research data IDs had positive indirect effects mediated by both saves and usages. The number of DOI-type research data IDs had positive indirect effects on citations through all three altmetric indicators. Interestingly, although the number of DOI-type research data IDs did not have a statistically significant direct effect on saves, it still influenced citations through this mediation path. In contrast, the number of accession code-type research data IDs and the numbers of accessible and inaccessible research data IDs did not exhibit any indirect effects on citations through altmetric indicators. Since only 6 of the 18 sub-hypotheses were supported, H4 was partially accepted.
4.3.2. Final model
Figure 3 presents the final structural equation model of this study. Statistically nonsignificant variables and paths were excluded, while the effects of the control variable were retained. The path from ID type: DOI to Saves was not statistically significant; however, since it functioned as a mediating path, it was included in the model as a dotted line. The results confirmed that research data ID characteristics did not have direct effects on citations, but instead exerted positive indirect effects through the short-term diffusion indicators – saves, views and usages.
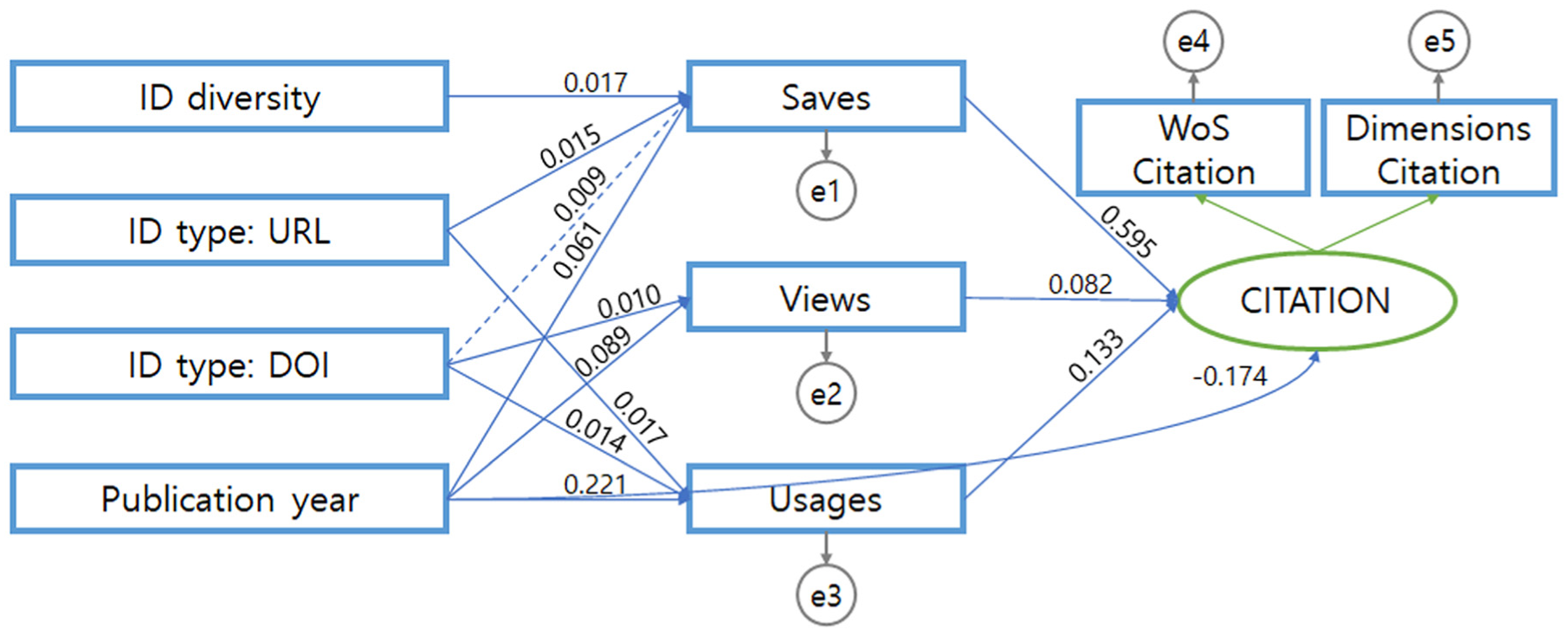
Final SEM results of the effects of ID characteristics on citation via altmetrics.
5. Conclusion and implications
As part of efforts to clarify the relationship between open science policies and the diffusion of research outputs, this study examined the extent to which research data identifiers specified in DAS affect research diffusion. In particular, it investigated whether identifier characteristics – such as diversity, type-specific counts and accessibility – contribute to long-term diffusion, measured by citations, through short-term diffusion indicators including saves, shares and views.
The results revealed that among the characteristics of research data identifiers specified in DAS, ID diversity, the number of URL-type IDs and the number of DOI-type IDs influenced citations indirectly through altmetric indicators. Although accession codes appeared more frequently than DOIs, they did not exert either direct or indirect effects on citations. Similarly, the number of accessible or inaccessible IDs did not show any statistically significant relationship with citations. However, the positive effects observed for ID diversity, URL-type IDs and DOI-type IDs were all very weak in magnitude. The control variable, publication year, exhibited positive relationships with all altmetric indicators but a negative direct effect on citations, which can be attributed to the fact that, while short-term diffusion measures such as saves, views and usages occur immediately after publication, the accumulation of citations requires more time.
ID diversity influenced citations only through saves among the three altmetric indicators examined in this study. The number of URL-type IDs affected citations through both saves and usages, while the number of DOI-type IDs influenced citations through all three altmetrics. Notably, although the direct path from DOI to saves was not statistically significant, the mediation path through saves had a significant effect on citations. Among the three altmetric indicators, saves mediated the effects of ID diversity, URLs and DOIs; usages mediated the effects of URLs and DOIs; and views mediated the effect of DOIs only. These findings suggest that saves, as a short-term diffusion indicator, play a particularly important role in shaping long-term research diffusion as measured by citations.
While previous studies have analysed citation patterns by DAS type [15,23] or examined the influence of altmetrics on citations [25,27,28], no research has specifically investigated how the manner in which research data are presented in DAS relates to altmetrics and, in turn, to citations. Therefore, this study is significant in that it provides a more detailed and nuanced examination of how research data contribute to the diffusion of scholarly outputs. This study also demonstrates that disclosing research data, preparing DAS and providing accessible identifiers can have a tangible impact on research diffusion as measured by citations. These findings may help dispel doubts regarding the effectiveness of data disclosure and DAS preparation relative to the time and cost required. By fostering greater awareness within the scholarly community about the value of research data sharing and DAS, this study is expected to contribute to the development of a more active environment for research data sharing.
This study has a limitation in that the analysis was conducted on a single journal, PLOS ONE, and did not consider the various characteristics of research data identifiers. In addition, even though the analysis targeted a multidisciplinary journal, altmetrics and citations may still be affected by the specific disciplinary domains of individual articles, which were not sufficiently taken into account. Future research will comprehensively examine other journals that provide DAS to broaden the range of sample data and identify differences across academic disciplines. Furthermore, future studies will consider not only the diverse characteristics of research data identifiers but also factors such as public interest in research topics and the quality of the provided research data.
Footnotes
Appendix
Results of hypothesis testing.

| Hypothesis | Sub-hypothesis | Result |
|---|---|---|
| H1. The characteristics of research data IDs have a significant effect on altmetric indicators. | Partially supported | |
| H1a-1. Research data ID diversity affects views. | Not supported | |
| H1a-2. Research data ID diversity affects saves. | Supported | |
| H1a-3. Research data ID diversity affects usages. | Not supported | |
| H1b-1. The number of DOI-type research data IDs affects views. | Supported | |
| H1b-2. The number of DOI-type research data IDs affects saves. | Not supported | |
| H1b-3. The number of DOI-type research data IDs affects usages. | Supported | |
| H1c-1. The number of URL-type research data IDs affects views. | Not supported | |
| H1c-2. The number of URL-type research data IDs affects saves. | Supported | |
| H1c-3. The number of URL-type research data IDs affects usages. | Supported | |
| H1d-1. The number of accession code-type research data IDs affects views. | Not supported | |
| H1d-2. The number of accession code-type research data IDs affects saves. | Not supported | |
| H1d-3. The number of accession code-type research data IDs affects usages. | Not supported | |
| H1e-1. The number of accessible research data IDs affects views. | Not supported | |
| H1e-2. The number of accessible research data IDs affects saves. | Not supported | |
| H1e-3. The number of accessible research data IDs affects usages. | Not supported | |
| H1f-1. The number of inaccessible research data IDs affects views. | Not supported | |
| H1f-2. The number of inaccessible research data IDs affects saves. | Not supported | |
| H1f-3. The number of inaccessible research data IDs affects usages. | Not supported | |
| H2. Altmetric indicators have a significant effect on citations. | Supported | |
| H2a. The views indicator affects citations. | Supported | |
| H2b. The saves indicator affects citations. | Supported | |
| H2c. The usage indicator affects citations. | Supported | |
| H3. The characteristics of research data IDs have a direct effect on citations. | Not supported | |
| H3a. Research data ID diversity affects citations. | Not supported | |
| H3b. The number of DOI-type research data IDs affects citations. | Not supported | |
| H3c. The number of URL-type research data IDs affects citations. | Not supported | |
| H3d. The number of accession code-type research data IDs affects citations. | Not supported | |
| H3e. The number of accessible research data IDs affects citations. | Not supported | |
| H3f. The number of inaccessible research data IDs affects citations. | Not supported | |
| H4. The characteristics of research data IDs have an indirect effect on citations through altmetric indicators. | Partially supported | |
| H4a-1. Research data ID diversity indirectly affects citations mediated by views. | Not supported | |
| H4a-2. Research data ID diversity indirectly affects citations mediated by saves. | Supported | |
| H4a-3. Research data ID diversity indirectly affects citations mediated by usages. | Not supported | |
| H4b-1. The number of DOI-type research data IDs indirectly affects citations mediated by views. | Supported | |
| H4b-2. The number of DOI-type research data IDs indirectly affects citations mediated by saves. | Supported | |
| H4b-3. The number of DOI-type research data IDs indirectly affects citations mediated by usages. | Supported | |
| H4c-1. The number of URL-type research data IDs indirectly affects citations mediated by views. | Not supported | |
| H4c-2. The number of URL-type research data IDs indirectly affects citations mediated by saves. | Supported | |
| H4c-3. The number of URL-type research data IDs indirectly affects citations mediated by usages. | Supported | |
| H4d-1. The number of accession code-type research data IDs indirectly affects citations mediated by views. | Not supported | |
| H4d-2. The number of accession code-type research data IDs indirectly affects citations mediated by saves. | Not supported | |
| H4d-3. The number of accession code-type research data IDs indirectly affects citations mediated by usages. | Not supported | |
| H4e-1. The number of accessible research data IDs indirectly affects citations mediated by views. | Not supported | |
| H4e-2. The number of accessible research data IDs indirectly affects citations mediated by saves. | Not supported | |
| H4e-3. The number of accessible research data IDs indirectly affects citations mediated by usages. | Not supported | |
| H4f-1. The number of inaccessible research data IDs indirectly affects citations mediated by views. | Not supported | |
| H4f-2. The number of inaccessible research data IDs indirectly affects citations mediated by saves. | Not supported | |
| H4f-3. The number of inaccessible research data IDs indirectly affects citations mediated by usages. | Not supported | |
Acknowledgements
The views expressed in this article are those of the author and do not necessarily reflect the official position of the affiliated institution.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author received no financial support for the research, authorship and/or publication of this article.