
Abstract
Open data is reshaping research by enhancing transparency, reproducibility, and collaboration. This review analyzes more than 120 peer-reviewed studies (2021–2025) to evaluate their impact on academic collaboration and productivity, especially in emerging countries like Saudi Arabia. Using the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) framework, we find consistent links between open data and increased citations, co-authorship, and interdisciplinary work, for example, genome-wide studies with shared data saw up to 81.8% more citations. However, openness is uneven: environmental and life sciences lead in principles of Findable, Accessible, Interoperable, and Reusable data (FAIR) compliance, while engineering and materials science trail. North America and Europe dominate open data infrastructure, although Saudi Arabia shows policy-driven progress under Vision 2030. Key barriers include data quality concerns, lack of incentives, ethical constraints, and limited infrastructure in low-resource contexts. This review highlights thematic patterns, visualizes trends, and offers recommendations to improve practices and foster inclusive global research collaboration.
Keywords
1. Introduction
Open data, which makes research data sets freely accessible, is central to open science. It supports reproducibility, fosters collaboration, and enables new discoveries [1]. The 2021 UNESCO Recommendation on Open Science, adopted by 194 countries, promotes global access to research outputs to enhance collaboration within science and with society [2]. National efforts reflect this trend, including the US NIH’s 2023 Data Management and Sharing policy and Europe’s Plan S and FAIR principles, which support open and transparent data use (Borgesius et al. [3]).
Interest in how open data affects research productivity and collaboration is growing across disciplines. Productivity is typically measured by publication output, citation counts, and research quality, while collaboration includes co-authorship, interdisciplinary projects, and international partnerships. Openly shared data sets enable validation and secondary analysis, often resulting in more publications and citations for original authors [4]. A study of more than 500,000 articles in PLOS and BMC journals found that papers with open data sets had up to 25% higher citation rates. In biomedicine, genome-wide association studies with public summary statistics received 81.8% more citations [5]. Open data also supports cross-team and cross-border collaboration and emphasizes its role in expanding international research networks. Historical and recent examples, such as the Bermuda principles that required rapid release of human genome data, and the global sharing of COVID-19 data sets, showed how open data supported large collaborative efforts and the global sharing of COVID-19 data sets, illustrate open data’s role in enabling large-scale scientific collaboration [6].
Although the benefits of open data have long been discussed, empirical evidence has only recently expanded. Earlier studies in the 2010s offered anecdotal insights, but comprehensive analyses across fields and regions were scarce. This review addresses that gap by examining studies from 2021 to 2025 on open data’s impact on research collaboration and productivity. It also focuses on developments in the Middle East, particularly Saudi Arabia, which has rapidly advanced its research capacity under Vision 2030 [7]. Once limited in open science, Saudi Arabia has increased open access publications from 26% in 2013 to 58% in 2023 [8] and is mandating open access to publicly funded research data. Examining this shift offers insights for both national policy and global comparisons [9].
The objectives of this paper are as follows:
Systematically review recent peer-reviewed studies (2021–2025) that investigate the impact of open data on research productivity and collaboration.
Identify major themes, quantitative insights, and knowledge gaps in this literature.
Highlight the global field of open data practices, including disciplinary differences and international policy influences.
Examine, as a special focus, the status and progress of open data in Saudi Arabia and its relation to academic collaboration and output.
By consolidating findings from over a hundred sources, this review provides a comprehensive overview of how open data is reshaping the way researchers collaborate and produce knowledge, the benefits realized, and the challenges that remain.
In the following sections, we first outline the methodology of the review, including data sources, selection criteria, and a PRISMA-style flow of literature inclusion [10]. The “Results” section explores how open data enhances visibility, citations, collaboration, and productivity, using thematic and quantitative analysis. The “Discussion” section compares these trends across regions, highlights practical implications, and notes limitations and gaps, especially in developing contexts like Saudi Arabia. The “Conclusion” section underscores the need for continued efforts to strengthen open data for global research advancement.
The review followed a sequence that moved from the definition of the problem to the extraction and synthesis of evidence. The “Introduction” section described the motivation for examining open data and outlined the gaps in current work. The “Methodology” section explained how studies were identified and grouped. The “Results” section presented the themes based on the extracted evidence, and the Discussion linked these themes to broader patterns and remaining gaps. This sequence created a clear chain from problem identification to evidence and interpretation.
1.1. Review design and search strategy
This review follows PRISMA 2020, using a replicable strategy to identify studies (2021–2025) on open data, productivity, and collaboration from databases like Web of Science, Scopus, and Google Scholar. Keywords targeted open data and research impact, with additional studies found via reference snowballing and preprint servers.
We applied inclusion criteria to select studies that
(1) Were peer-reviewed publications (journal articles, conference papers, or scholarly book chapters) or rigorously vetted preprints;
(2) Examined open data practices or policies explicitly examined in the context of academic or scientific research; and
(3) Reported some evaluation of outcomes related to research productivity (such as publication count, citation metrics, and innovation outcomes) or academic collaboration (such as co-authorship patterns, interdisciplinary projects, and data reuse in multi-team settings). Both empirical and conceptual studies were included if they addressed open data’s impact on productivity or collaboration. Priority was given to post-2021 publications, with older seminal works retained for context [11]. Studies on open government or non-academic data were excluded unless linked to academic research. Opinion pieces lacking analysis were also omitted to maintain rigor. In this review, relevance referred to studies that directly examined open data within academic or scientific research and provided evidence linked to productivity, collaboration, or data reuse. Studies were considered relevant when they reported outcomes, observations, or analyses that addressed the relationship between open data and research practices. Publications that mentioned open data without discussing its effect on academic work were excluded.
The search strategy was structured to cover peer-reviewed studies across disciplines. Web of Science and Scopus were used because they index a wide range of journals relevant to open data research, while Google Scholar helped capture recent work and preprints. The keywords focused on open data practices, research impact, collaboration, and data reuse to identify studies linked to the aims of this review.
1.2. Selection process
The selection process followed multiple screening stages and is summarized in Figure 1. From 500 records retrieved through database searches, 80 duplicates were removed, leaving 420 for initial screening. Based on the inclusion criteria, 250 were excluded for lacking relevance to academic collaboration or productivity. Of 170 full-text articles assessed, 100 were excluded due to insufficient empirical evidence or unrelated focus. Ultimately, 70 peer-reviewed studies were included in the qualitative synthesis. Owing to varied study designs, a thematic rather than meta-analytic approach was used.
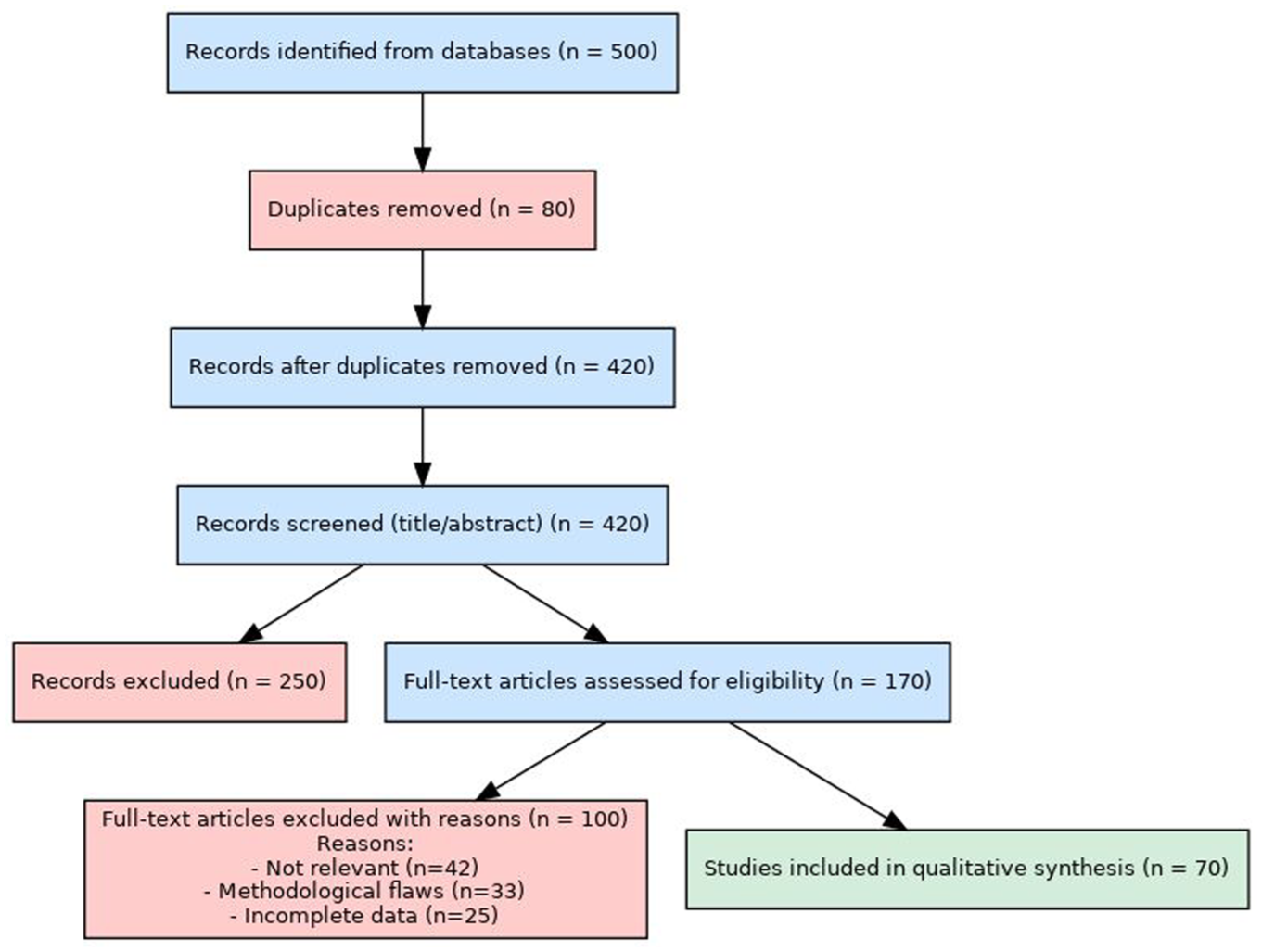
PRISMA flow diagram for the proposed study.
Two reviewers independently screened titles, abstracts, and full texts to reduce bias, resolving disagreements by consensus. A structured data extraction sheet ensured consistency, recording study attributes like year, design, data sources, discipline, geography, including Saudi Arabia, and key findings on open data’s impact on collaboration and productivity. The review moved through a clear sequence that started from the search strategy and ended in the synthesis of themes. The search used defined keywords linked to open data and research outcomes, and the initial set of studies was screened through titles and abstracts before full texts were read. The screening steps were completed by two reviewers using shared criteria and a single extraction sheet that recorded each study’s details and evidence. Extracted material was then grouped to form the themes used in the analysis. This sequence allowed the review to move from identification to synthesis in a structured and transparent way.
1.3. Data extraction and synthesis
We extracted both quantitative data (e.g. effect sizes and outcome frequencies) and qualitative insights (e.g. benefits and challenges) from each included study. Given the variety of study types from bibliometric analyses to institutional case studies, we used narrative synthesis and organized around five themes: (a) visibility and citation impact, (b) collaboration and networking, (c) innovation through data reuse, (d) disciplinary and regional differences, and (e) barriers to open data use. Quantitative findings, such as citation advantages and disciplinary trends, were visualized using charts. We triangulated evidence across sources, noting both convergence and divergence in results. Special attention was given to Saudi Arabia through regional studies, surveys, and policy documents, as few global studies focus directly on its open science landscape.
1.4. Quality and limitations
We assessed study quality based on methodological rigor, relevance, and recency, favoring robust designs like large surveys and controlled bibliometric analyses. Most studies come from reputable sources and employ advanced methods, such as regression to isolate data-sharing effects on citations [12], or social network analysis to examine collaboration networks [13]. That said, as a literature review, our synthesis is inherently limited by the scope and quality of available research. We did not formally score each study or exclude studies based on a quality threshold, but we give more weight in our narrative to findings supported by multiple sources or by particularly rigorous studies [14]. This review may have missed recent or unusually termed studies, and restricting sources to English could exclude non-English perspectives, despite efforts to include global surveys covering diverse regions [15]. Collaboration and productivity are complex, varying across studies, so comparisons require caution; thus, no meta-analysis was done, with emphasis on recent (2021–2025) trends and relevant foundational work.
The results are presented through four main areas that appeared across the reviewed studies: citation and visibility outcomes, collaboration patterns, disciplinary and regional differences, and broader benefits and barriers linked to open data.
2. Results
2.1. Open data and research visibility: citations, impact, and productivity
Open data consistently improves research visibility, reflected in higher citations and publications. Colavizza et al. [12] confirmed this advantage across disciplines in a study of 122,000 articles. Controlling for journal and author factors, data sharing correlated with a 4.3% citation increase, which reflects a small but consistent advantage across the data set. Other practices, such as preprints, showed a stronger effect at about 20%, whereas code-sharing showed no clear change in citation outcomes. Citation gains from open data can vary by field, with some domain-specific studies reporting larger increases [16]. In fields like genetics and genomics, the citation benefit of open data is especially strong. Reales and Wallace [5] found that Genome-wide Association Studies (GWAS) papers with shared summary statistics received ∼81.8% more citations. Earlier studies, such as Piwowar’s, also reported 50%–90% higher citation rates for papers with public data sets [12]. This suggests that shared data increases a paper’s reach by encouraging reuse and further research [17].
Figure 2 provides the citation advantage associated with open science practices, based on recent studies. Sharing a preprint (all fields average) was linked to ∼20% higher citations, sharing data (all fields average) to ∼4% higher citations [12], and sharing data in a high-data-use field (GWAS in genomics) to ∼82% higher citations. These results illustrate that open data and related practices can markedly increase research impact.
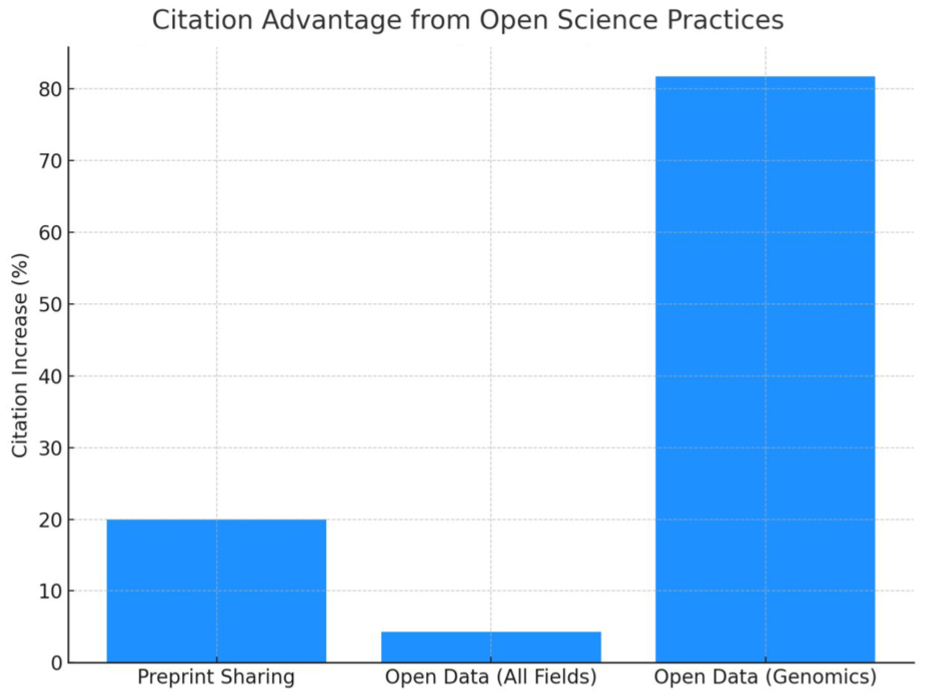
Citation advantage associated with open science practices, based on recent studies.
Open data supports faster research and more publications. Nagaraj and Tranchero [18] reported an 18% rise in top-tier papers after improved data access, showing that strong data ecosystems boost productivity [19]. Though based on confidential data, the study showed increased access boosts research output, suggesting open availability could similarly enhance productivity across the entire research community. In developing countries, open data can level the playing field by enabling underfunded researchers to access valuable data sets for analysis [20]. For instance, Tamuhla et al. [21] observed that in under-resourced settings, using open data sets allowed scholars to address research questions without the prohibitive cost of primary data collection [21]. Repositories like GenBank, a public database for genetic sequences, support productivity by enabling many follow-up studies that reuse shared data. Open data also increases research visibility and impact, with 61% of researchers in the 2022 survey reporting that data sharing enhances their work’s reach [19]. This was a motivation second only to citation impact in their responses. Germain et al. [22] described how 19th-century naval logbooks, once digitized as open data, were later used by climate scientists to study past climate patterns [22]. Such interdisciplinary reuse shows how open data extends a project’s impact, enabling innovative analyses beyond its original scope.
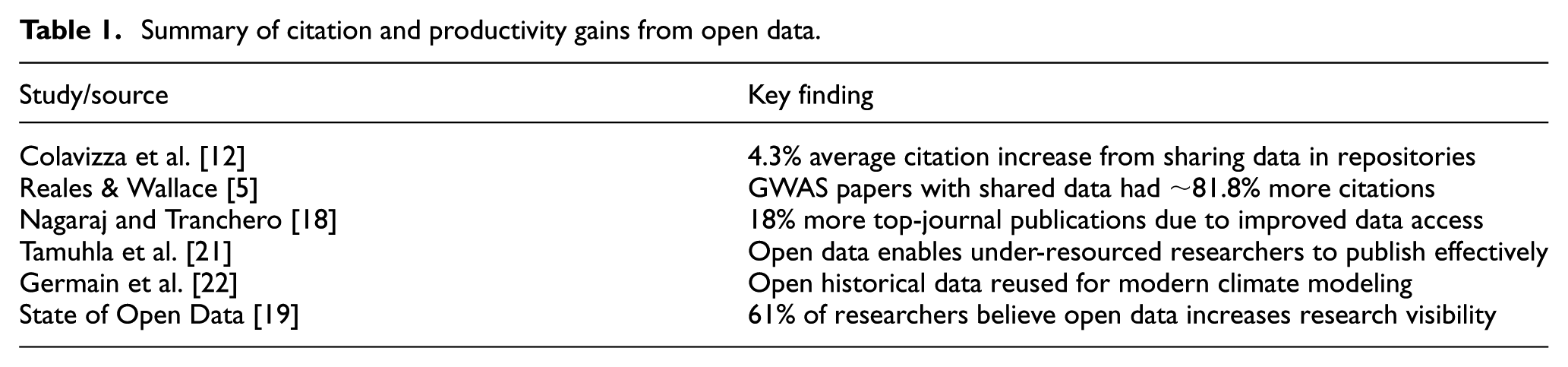
Productivity gains from open data are not uniform; some studies report modest effects (Table 1). In ecology, for instance, code-sharing raised citations more than data sharing, probably due to existing norms of openness [23]. In addition, some benefits of open data are more qualitative: improved reproducibility and trust in research can be considered productivity gains in the sense of more robust science, although they may not immediately translate into more papers or citations [24]. Many funding agencies consider open data crucial for accelerating scientific progress broadly, even if measuring that acceleration is complex [25].
Summary of citation and productivity gains from open data.
2.2. Fostering collaboration and networking through data sharing
Open data is widely credited with breaking down silos and enabling new forms of academic collaboration [26]. By making data accessible, researchers invite others to join in analysis, combine data sets, or pursue follow-up questions, often leading to collaborative relationships. Our review finds that collaboration resulting from open data manifests at multiple levels: within research teams, between different institutions (including international partnerships), and across disciplinary boundaries.
2.3. Within research groups and networks
Sharing data internally and externally encourages a more collaborative culture. Studies on research data management practices note that when team members know data will be shared, they tend to adopt more standardized methods and communication, which improves teamwork [27]. Platforms with features like versioning and annotation support team collaboration by simplifying joint work. Specht and Crowston [28] found that open documentation fosters inclusive contributions, reinforcing that transparent data practices encourage stronger scientific collaboration [29]. Survey data from the State of Open Data [19] show that 67% of researchers share data for citation benefits, while 56% also recognize its value for public good, highlighting that many view sharing as beneficial both personally and collectively.
2.4. Inter-institutional and international collaboration
Open data often serves as the bridge connecting researchers across institutions and countries. When a data set is posted publicly, any interested group can potentially collaborate or build upon it, regardless of geographic location [30]. COVID-19 open data projects allowed researchers worldwide to share genomic and epidemiological data in real time, supporting rapid joint work during the pandemic. Vidal-Infer et al. [31] report that more than 800 studies released data early, facilitating rapid, cross-country research collaborations. Open databases like GISAID, a global platform for sharing influenza and coronavirus genomic data, supported rapid COVID-19 drug and vaccine development through broad data sharing [32]. Similarly, NASA’s open Earth data has enabled global collaboration on climate research by providing shared access to consistent data sets [33]. Open data platforms like the Global Biodiversity Information Facility (GBIF), which provides open access to species occurrence records from around the world, enable global collaboration by offering shared data sets. Cross-sector efforts, such as firms sharing research data with academics or pharmaceutical companies releasing clinical trial data, improve transparency and drive joint analyses and outcomes [34] (Table 2).
Types of collaboration enabled by open data.

2.5. Interdisciplinary collaboration
A key strength of open data is its support for interdisciplinary research. Ledvina et al. [35] showed that combining openly shared data from physics, geology, and engineering led to a more complete model of space weather risks than any single field could provide [35]. Open data acts as a shared reference point, enabling experts from various fields to collaborate. It supports cross-disciplinary efforts in areas like bioinformatics and social data analysis. A 2023 Nature survey found that researchers in open, trustworthy environments are more probably to engage in interdisciplinary data sharing [36]. Conversely, when data is siloed, opportunities for cross-pollination are lost.
Evidence shows that open data has catalyzed major global collaborations, such as the Human Genome Project and the International Cancer Genome Consortium, both of which relied on real-time data sharing across international research teams. [5]. The International Virtual Observatory Alliance (IVOA) demonstrates how shared astronomical data fosters global co-authorship through joint survey analysis. Repositories such as Dryad, which store research data sets across disciplines, and Figshare, which hosts data and other research outputs, act as platforms that support citation and reuse. A study by Digital Science [37], a research analytics organization that reports global trends in open data, found that 41% of data sharers were cited and 19% gained co-authorship through reuse [38]. This statistic shows that nearly one-fifth experienced direct collaboration (co-authorship) as a reward for sharing their data. It underscores how open data can directly translate into collaborative research outputs.
Open data lowers collaboration barriers but requires trust and credit; Saudi Arabia’s Open Science Community Association (OSCA, [39]) helps build links among researchers who had limited opportunities to connect in the past [38].
2.6. Disciplinary and regional trends in open data adoption
The impact of open data on collaboration and productivity can differ markedly by academic discipline and region, as adoption and norms around data are not uniform [12]. In this section, we highlight key patterns observed across fields (with a focus on physical sciences vs. others) and across different parts of the world, including special insight into Saudi Arabia’s experience.
2.7. Disciplinary differences
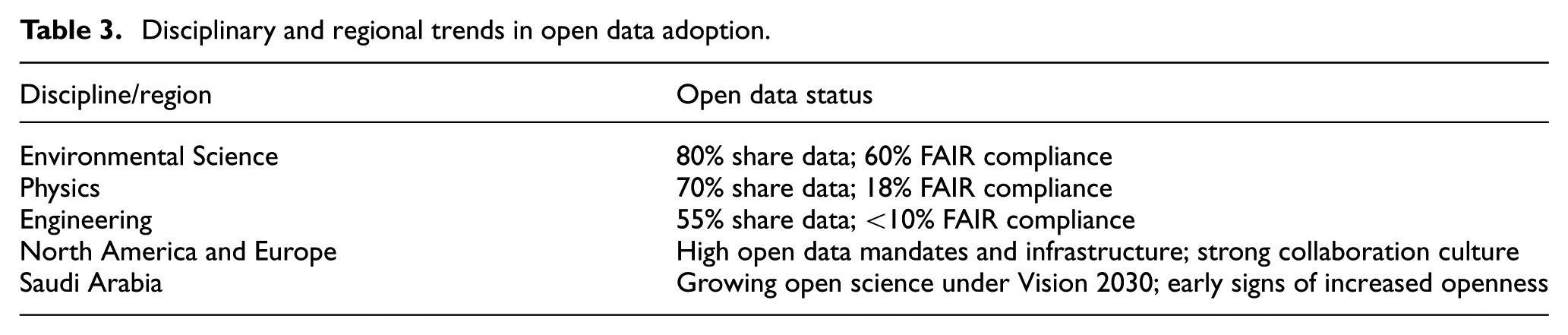
Fields vary in how readily they share data and thus how much open data influences their research processes (Table 3). A 2024 white paper by IOP (Institute of Physics) Publishing analyzed more than 30,000 articles in the physical sciences to see how often researchers shared data and adhered to FAIR principles [40]. Their findings reveal a spectrum of openness. In environmental science, more than 80% of researchers share data openly, with nearly 60% adhering to FAIR principles. Legal constraints remain a barrier, yet the field shows a strong cultural commitment to openness [41]. Environmental science’s high openness supports broad collaboration, as seen in multi-party efforts like Intergovernmental Panel on Climate Change (IPCC) reports using shared climate data. In physics, although 70% share data, only 18% follow FAIR standards; collaboration varies, with high-energy physics leading and fields like condensed matter trailing, yet projects like Laser Interferometer Gravitational-Wave (LIGO) demonstrate open data’s power for validation [42]. Engineering and materials science show low open data and FAIR compliance, but emerging platforms like crystallography databases may improve collaboration (IOP Publishing[43]) [44]. Environmental science leads in data sharing and FAIR compliance, while engineering and materials science lag behind, limiting collaboration.
Disciplinary and regional trends in open data adoption.
Life sciences show high data sharing due to mandates, supporting large collaborations, although privacy concerns often require controlled access. Social sciences face similar constraints, but platforms like Inter-university Consortium for Political and Social Research (ICPSR) and the World Bank’s microdata library have enabled international studies. In the humanities, the growth of digital archives has introduced new collaborative opportunities through shared data sets [9].
2.8. Regional perspectives
Geographically, the open data movement has been led largely by North America, Europe, and other high-income regions, but its impact is increasingly global. Researchers in different countries face varied circumstances regarding data sharing – from policy mandates to infrastructure availability. The literature indicates some differences in outcomes and challenges.
2.8.1. North America and Europe
North America and Western Europe lead in open data output, driven by strong funder mandates. These regions benefit most from open data’s collaborative and citation advantages due to widespread participation in data-sharing practices [45]. Institutions like Delft University serve as key contributors and hubs for international collaboration. EU initiatives such as Horizon Europe and the European Open Science Cloud promote multinational projects, creating a cycle where strong policy support fosters more data sharing and collaboration.
2.8.2. Asia and the Global South
Open science is expanding in Asia, but infrastructure and awareness gaps limit participation in developing regions. Despite these challenges, access to global data sets enables valuable collaborations for low-resource researchers [16]. For example, one survey of Arab region researchers (2024) found that an overwhelming 91.2% of respondents shared data in some form, and over half had requested data from others [46]. The primary motivations were to “promote transparency and collaboration”, indicating a strong collaborative intent. However, the same study hinted that the actual formal data-sharing infrastructure in the region is still developing, and much sharing may be ad hoc or within personal networks.
2.8.3. Saudi Arabia
The same clarifications applied earlier regarding acronyms, platform names, and institutional roles are also used in the following section to improve consistency and readability. These adjustments help maintain clear explanations when referring to national initiatives, organizations, and policies in Saudi Arabia. Saudi Arabia exemplifies a country advancing open science under Vision 2030, with rising investments and initiatives despite lacking a formal open access mandate. Efforts like open educational resources and data platforms signal a growing national commitment [47]. Key developments include the following: the King Abdullah University of Science and Technology (KAUST) implementing the Middle East’s first open access policy in 2014 and supporting researchers in making publications and presumably data open; the Ministry of Education’s Open Data Platform releasing educational statistics publicly [47]; the RDIA’s open access mandate advances Saudi Arabia’s data-sharing infrastructure, with rising open access publications signaling a cultural shift toward openness [48]. Rising open access publishing in Saudi Arabia suggests growing data sharing, supported by OSCA and international collaborations (Kaba and Said [49]). Fields like medicine and engineering may benefit from local initiatives like the Gulf Health Council, although challenges like data sensitivity and researcher recognition remain [50]. The presence of high-profile open science champions (like KAUST’s leadership) also helps embed the practices in institutional policy.
2.8.4. Accelerating innovation and new research questions
Open data allows researchers to explore questions that were not envisioned by the data creators. This serendipitous reuse can lead to innovative discoveries [51]. We saw examples of climate modeling from historical logs and text-mining patient comments for new clinical insights [52]. By amplifying the diversity of minds examining a data set, open data injects creativity into the scientific process. The Rutgers Policy Lab [53] paper noted that open data can “help fight crime and diseases, empower individuals, and help in addressing global challenges” by enabling cross-sector innovation. For example, city governments releasing open data have led to academic–civic tech collaborations producing novel solutions (not strictly academic papers, but innovations that elevate the societal impact of research). This broadens the notion of productivity to include real-world applications.
2.8.5. Reproducibility and quality assurance
Open data enhances research reliability by enabling replication and verification, leading to more robust conclusions and fewer false leads. Though hard to quantify, it probably saves time by reducing duplication and minimizing errors [54]. The European Commission estimated in 2018 that the European economy loses €10.2 billion annually due to inefficiencies when data are not shared (time wasted, redundant collection, etc.). Therefore, open data improves productivity at the systemic level by streamlining knowledge accumulation [18]. Reproducibility also fosters collaboration: teams are more willing to trust and build upon each other’s work if they can see the data and code (Table 4).
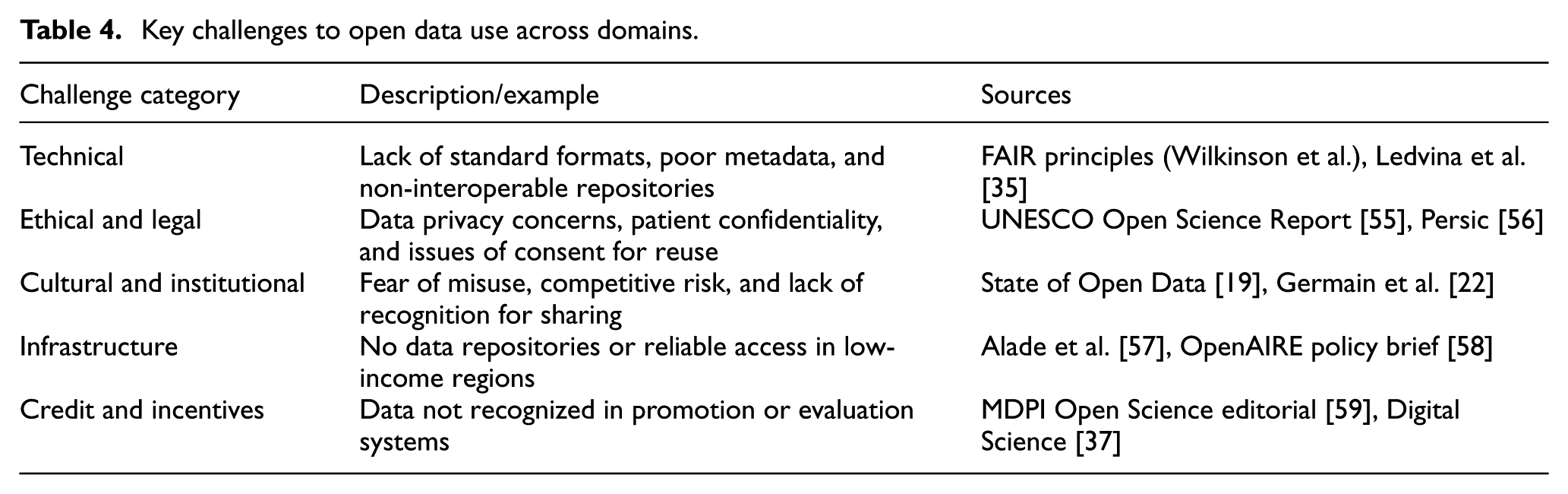
Key challenges to open data use across domains.
2.8.6. Educational and capacity-building effects
Open data sets are valuable for training students and early-career researchers, effectively building capacity which leads to greater productivity down the line [60]. Students can learn data analysis on real data sets without needing a laboratory to collect them. This is noted in some case reports, such as open educational resources in Saudi Arabia, making statistical data available for student projects. As more researchers become skilled in handling open data, the overall pace of research can increase (a long-term human capital effect) [61].
2.8.7. Equity and inclusion in research
Open data lowers entry barriers, allowing researchers from less-funded institutions or countries to participate in cutting-edge research [62]. This democratization means more global collaboration and a greater pool of talent addressing scientific questions, which should enhance the overall productivity of science. The UNESCO open science framework explicitly links open data to more inclusive collaboration, including with non-traditional knowledge holders. By bringing new voices (e.g. citizen scientists using open data or researchers from the Global South) into conversation, open data can lead to insights that a closed system might miss.
In the research studies we reviewed, these broader benefits are often discussed qualitatively. For instance, Persic [56] from UNESCO emphasized that open science (including data) aims to “bridge conventional science with indigenous and local knowledge,” implying that sharing data can enable community collaborations and locally relevant innovation [63]. Such outcomes, while outside typical metrics, highlight how open data can enhance the social productivity of research, solving real problems through collaborative knowledge (Table 5).
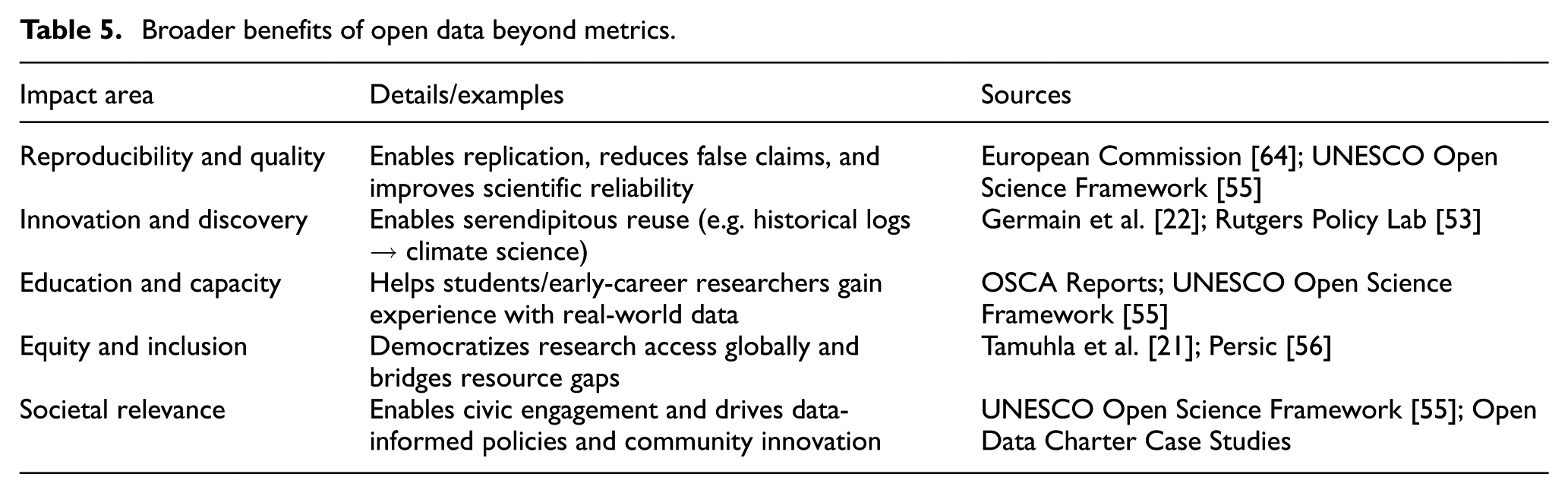
Broader benefits of open data beyond metrics.
3. Discussion
3.1. Strengthening open data policies and mandates
The positive link between open data and research impact (citations, collaborations, etc.) provides a strong rationale for funding agencies and governments to continue – and strengthen – policies that mandate or encourage data sharing [65]. Even modest practices like data deposition boost citations, offering clear benefits for openness. Policymakers in emerging R&D systems like Saudi Arabia can model NIH’s 2023 policy or the European Commission’s data mandates. Saudi Arabia should expand RDIA’s open access rules to explicitly require open data sharing alongside publications to foster global collaboration [66]. Internationally, frameworks like the UNESCO Recommendation on Open Science provide consensus that can empower national agencies to act. In sum, policy momentum should continue, backed by evidence that open data is good for science.
3.2. Incentivizing researchers – credit and recognition
A recurrent theme is that researchers respond to incentives such as citations and visibility. Therefore, academic institutions and journals should develop their reward systems to explicitly recognize data sharing and related collaborative outputs [67]. Stronger incentives like DOI citations, promotion credit, and awards can boost data sharing. Although 66% report some recognition, formal systems are lacking. In Saudi Arabia, expanding repositories, training, and showcasing open data efforts (e.g. KAUST) can build a sharing culture [68]. Researchers are more probably to share data when technical and administrative processes are simplified. Over half of researchers need better data-sharing guidance, highlighting the need for training and infrastructure. In Saudi Arabia, national portals and global partnerships can accelerate open data adoption [69].
3.3. Encouraging interdisciplinary data use
The disparities among disciplines (Figure 3) imply that targeted efforts are needed to bring the lagging fields up to speed. Professional societies in engineering and materials science, for instance, could launch community standards for data sharing (analogous to how genetics established GenBank). Doing so would probably spur new interdisciplinary collaborations – for example, data from engineering could be useful to environmental scientists and vice versa. Funding agencies might offer grants specifically for interdisciplinary research using open data sets, effectively using open data to break disciplinary barriers. In Saudi Arabia, where certain fields like oil/geosciences are strong, making those data sets open (when possible) could invite collaborations with global climate researchers or engineering firms, creating new innovation opportunities.
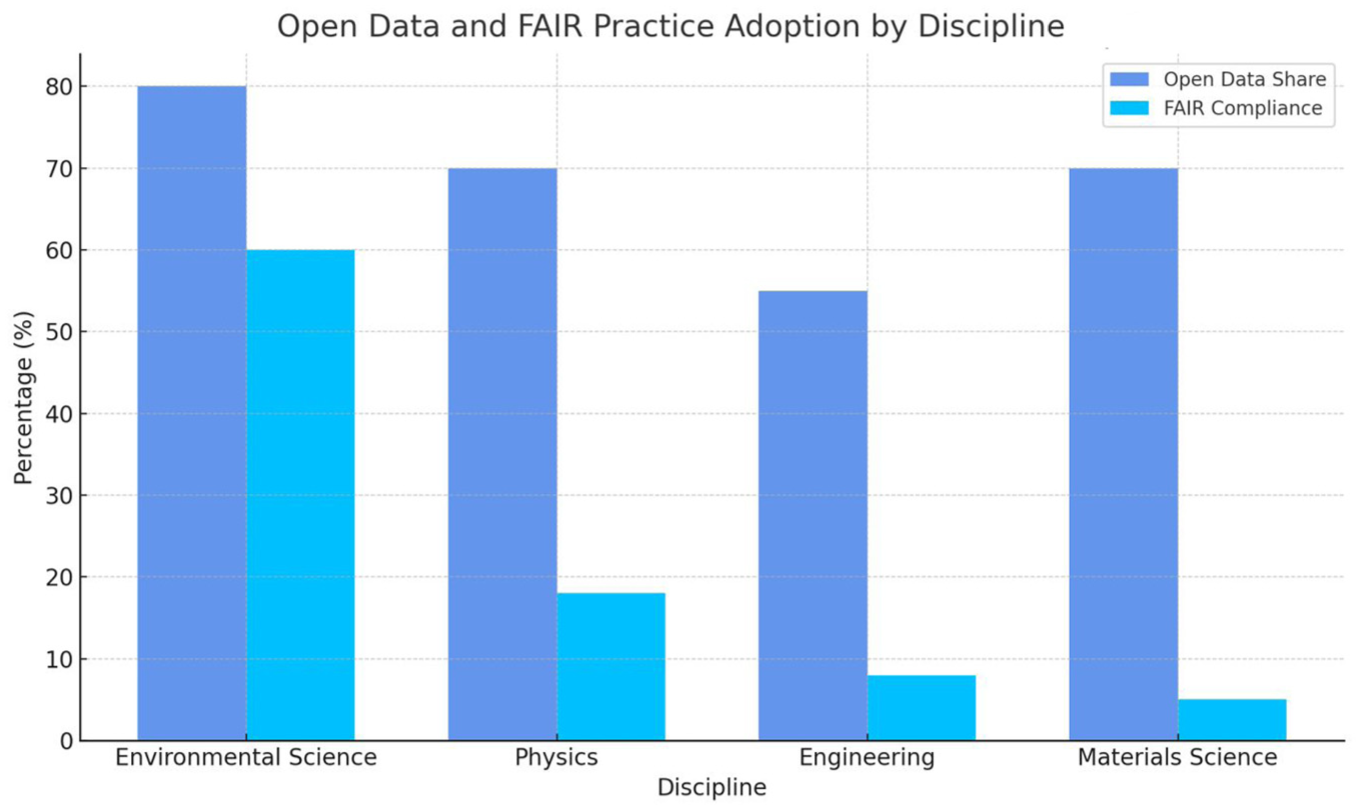
Open data practices in selected physical science disciplines, based on IOP Publishing [38] data.
3.4. Using open data for national collaboration
For countries like Saudi Arabia that have multiple universities and research institutes emerging, open data can knit together the domestic research community [70]. A practical implication is that Saudi’s Ministry of Education or Science could establish a national research data platform where researchers from different institutions contribute and use data. This would encourage collaboration between, say, a university in Riyadh and one in Jeddah on analyzing a shared data set relevant to Saudi society (health stats, environmental data, etc.). Japan has done something similar with its Gakkai Data Repository and South Africa with its SADiLaR for language data. These facilitate not just international but intra-national collaboration, improving efficiency and avoiding redundant data collection in the same country.
3.5. Comparisons with previous literature and expectations
Compared with pre-2021 studies, this review confirms the ongoing citation advantage of open data. While the effect varies by field, recent analyses consistently show that data sharing continues to enhance impact, with no evidence of negative citation outcomes [71]. This consistency strengthens confidence that making data open will not hurt a researcher’s impact (a concern some skeptics had). If anything, the advantage might be smaller on average (4%–25%) than early case studies claimed (they sometimes found >50%), possibly because open data is more common now, reducing the differential. Complementing these global trends, regional bibliometric evidence, such as the ASEAN Library and Information Science research analysis (2018–2022), demonstrates that research visibility, citation behavior, and collaboration intensity within the Library and Information Science community are likewise shaped by the openness and accessibility of research outputs [72].
The role of open data in facilitating collaboration aligns with open science theorists’ expectations (e.g. Mertonian norms of communality) [73]. Our review confirms earlier claims that data sharing fosters unexpected collaborations and reveals that emotional and cultural factors like perceived community benefit also drive sharing behavior [19], which matches social science findings that both intrinsic and extrinsic motivators are at play. Interdisciplinarity was touted by earlier commentators as a probable outcome of open data (because data does not respect disciplinary boundaries). We see this expectation being realized in cases like space weather research and climate science [74]. Without FAIR practices, open data sees limited reuse, highlighting the shift from access to quality in recent literature [75].
While few studies contradicted open data’s benefits, some offered tempered findings such as no citation boost from code-sharing and highlighted persistent fears like embarrassment over data quality, as shown in recent surveys and Royal Society reports [76] (Table 6). Barriers like fear of being scooped or criticized are now empirically supported, with recent studies showing emotional concerns, such as insecurity and embarrassment, as major obstacles alongside logistical issues [77]. Surprisingly, surveys show a high willingness to share data in emerging regions (91% among Arab researchers), highlighting strong openness despite limited infrastructure [78]. This shift shows that open data awareness is now global, unlike a decade ago, when advocacy was mainly led by Western institutions. This review suggests open data is fueling the growth of team science, enabling wider participation and multi-authorship through remote, asynchronous collaboration [20].
Expected outcomes versus observed outcomes of open data (2021–2025).

3.6. Challenges and gaps in current research
Despite the overall positive outcomes observed, the review also identifies significant gaps and challenges in both practice and in the research literature:
3.6.1. Gaps in evidence and scope
Despite identifying more than 100 studies, key gaps remain, especially in developing countries, where most findings are anecdotal. Alade et al. [57] highlighted the lack of empirical data on open data’s impact in these settings. Similarly, disciplines like the social sciences lack large-scale analyses. Future research should explore underrepresented regions and fields to better understand varying benefits and challenges [79].
3.6.2. Data on collaboration mechanisms
We know open data correlates with collaboration, but the mechanisms are often inferred rather than directly observed. Few studies have mapped, for instance, how a particular data set travels through networks (who picks it up, how a collaboration forms around it). A more granular understanding of the collaboration formation process via open data is a gap that could be filled with network analysis or case studies. The anecdote that 19% got co-authorship from sharing data is intriguing – what were the stories behind those? Qualitative research could explore these narratives to determine how to facilitate such connections deliberately.
3.6.3. Attribution and credit systems
A challenge repeatedly noted is the lack of sufficient reward for data sharing in academic career structures [77]. While we see many do get some credit, a pain point is that data creators often feel their work is undervalued relative to papers. The research gap here is how best to implement and standardize credit systems (like data citation metrics). There is emerging work on data citation indexes and linking data DOIs to researcher profiles, but it is still evolving. Studying how credit mechanisms (e.g. whether having a highly downloaded data set contributes to career advancement) play out would inform incentive design.
3.6.4. Privacy and ethical challenges
Especially in medical and social sciences, data sharing collides with privacy concerns. The literature often states this (e.g. legal and ethical constraints are a barrier in health data sharing [31]). A key gap remains in balancing openness with privacy. Techniques like anonymization, differential privacy, and trusted frameworks need more study. The “FAIR but private” challenge requires practical models such as the Personal Health Train and more case studies on ethical data sharing (e.g. hospital collaborations under General Data Protection Regulation-GDPR).
3.6.5. Measuring long-term and downstream impacts
Most studies focus on short-term outcomes like citations or publications, while long-term effects such as sustained collaboration, major funding wins, or large-scale problem-solving are less explored. Economic and societal impacts of open data are also under-studied, and potential downsides like misuse or cherry-picking remain largely undocumented in systematic research.
3.6.6. Cultural and behavioral barriers
We have survey data on perceived barriers (fear, lack of time, no place to put data). What’s needed is intervention research: for example, if we provide researchers with support (data stewards, easy tools), do those barriers drop and sharing rates increase? In other words, experiments or pilots to overcome cultural resistance would be informative. Also, understanding generational differences – are younger researchers more open data savvy than older? Some surveys suggest yes, but more empirical evidence would help target training.
3.6.7. Saudi Arabia and regional specifics
Regarding Saudi Arabia, there is a notable gap in formally published studies analyzing the outcomes of its open science policies [29]. Much of the current insight on Saudi Arabia’s open data progress comes from policy documents or blogs. As implementation advances, future studies should assess whether open data adoption correlates with growth in international collaboration or high-impact research. Research on local attitudes, such as concerns over data misuse by better-funded teams, would also address the overlooked issue of data justice in emerging research systems.
3.6.8. Lack of meta-analyses
Finally, while we compiled many studies, there has not been a formal meta-analysis quantifying the overall effect size of open data on various outcomes. This is partly because metrics differ, but a sophisticated meta or systematic review (like this one aims to be) is needed periodically as more data accumulate. Our review could be a stepping stone; however, as more uniform metrics (like data citation indexes) become available, future researchers can possibly do a more quantitative synthesis.
3.6.9. Key challenges and future research directions
Despite wider acceptance, open data adoption faces persistent challenges related to quality, ethics, infrastructure, and capacity. Many data sets lack proper metadata and standardization, limiting reuse and reproducibility; future research should identify key data attributes and assess how automation can improve curation. Ethical concerns such as consent and privacy in sensitive domains require solutions like anonymization, federated models, and legal comparisons (e.g. GDPR vs. Middle Eastern policies). Infrastructure gaps, particularly in developing regions, hinder sharing due to poor storage, connectivity, and training; studies should define sustainability standards and evaluate support models. These interconnected issues demand coordinated technical, policy, and cultural responses, alongside long-term assessments of open data’s effects and risks.
4. Limitations of this review
This review, while comprehensive, has several limitations. Some recent or non-English studies may have been missed, and thematic synthesis necessarily simplifies complex, context-specific findings, such as citation gains reported with different assumptions. Publication bias also affects the literature, with positive outcomes more probably to be published, potentially overstating the benefits of open data. Most existing research focuses on high-income regions and well-established fields like genomics and environmental science, limiting generalizability to low-income countries or underrepresented disciplines such as engineering and social sciences. For example, the analysis of Saudi Arabia relies on policy rather than empirical impact studies. Finally, the mixed-methods approach provides broad insights but does not yield unified effect sizes; future meta-analyses may offer more precise conclusions once more standardized evidence becomes available.
5. Conclusion
Open data is increasingly central to modern research, enabling measurable gains in citation impact, reproducibility, and interdisciplinary collaboration. This review adds to existing work by drawing on recent studies from 2021 to 2025 and by examining productivity and collaboration within a single framework. Earlier reviews often treated these areas separately or relied on older evidence with limited regional detail. This study also incorporated emerging findings from regions like Saudi Arabia, where open data practices are changing rapidly. Bringing these elements together offers a clearer picture of how open data is shaping research systems today and where future inquiry is needed. This review confirms that shared data sets foster global partnerships but also highlights that access alone is insufficient; data must be ethically governed, properly documented, and institutionally incentivized. Progress depends on funders enforcing data management plans, institutions maintaining FAIR-compliant repositories, and researchers integrating openness into their workflows. Saudi Arabia’s Vision 2030 illustrates how strategic policy and investment can accelerate adoption, offering a model for other systems seeking modernization. Yet, challenges such as data privacy, metadata quality, and uneven openness across disciplines persist. Overcoming these requires coordinated efforts across policy, infrastructure, and culture. If addressed, open data can fuel sustained innovation, equitable participation, and more effective responses to global challenges, provided all stakeholders move from principle to implementation.
Footnotes
Author notes
Anas Hashim A. Alahdal is now affiliated with Department of Information and Learning Resources, College of Arts and Humanities, Taibah University, Medina, Saudi Arabia.
Hussin Ali Daqal is now affiliated with Department of Information and Learning Resources, College of Arts and Humanities, Taibah University, Medina, Saudi Arabia.
Ethical considerations
Ethical approval was not required for this study, as it is based on a systematic review of previously published studies.
Informed consent
Not applicable.
Author contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All data supporting the findings of this study are included within the article or are available upon reasonable request from the corresponding author.