
Abstract
This article aims to identify and analyze the knowledge structure and key trends within the field of cognitive technologies, providing insights for researchers and practitioners. Scientometric methods and co-word analysis were employed. In total, 446 articles published in the Web of Science database from 1975 to February 2025 were examined. In total, 1892 keywords were extracted and analyzed using word co-occurrence analysis to identify conceptual clusters and connections between them. The number of publications in cognitive technologies has significantly increased, demonstrating the growing importance of the field. Co-word analysis revealed six main conceptual clusters and 354 connections between them, with a total link strength of 536. These clusters encompass topics such as cognitive technologies, artificial intelligence, machine learning, cognitive computing, deep learning, big data, the Internet of Things, neural networks, natural language processing, and computer vision, highlighting the interdisciplinary nature of the field. Cognitive technologies are strongly interconnected with various scientific and technological domains. This research provides a comprehensive overview of the knowledge map and research trends in this field. The findings can assist researchers in identifying research gaps and future directions, and inform policymakers in making decisions regarding development and investment in cognitive technologies.
Keywords
1. Introduction
In the age of digital transformation, cognitive technologies, as one of the most important scientific and technological drivers, play a significant role in optimizing decision-making processes, human interactions, and improving the efficiency of various systems [1]. These technologies, which include areas such as artificial intelligence (AI), machine learning, cognitive computing, and natural language processing, have experienced tremendous growth in scientific research and industrial applications in recent years. Their importance is evident not only in scientific and technological progress but also in their impact on key areas such as medicine, security, governance, education, industry, and culture [2].
The significant increase in scientific publications in this field indicates the growing interest and attention of researchers in the potential of cognitive technologies. However, understanding the knowledge map, research trends, identifying conceptual clusters, and determining the future directions of this field require the use of accurate analytical methods. Previous studies have also emphasized the importance of this analysis in organizing and guiding scientific research [3].
In this research, the knowledge map of the cognitive technologies field is investigated using word co-occurrence analysis and conceptual mapping. In this regard, first, the theoretical literature of this field, including cognitive sciences and cognitive technologies, is explained; then, the research methodology and data collection method are described, and the word co-occurrence analysis and its steps are presented. In the following, the results of the scientific mapping of this field through cluster analysis, keyword co-occurrence analysis, and concept density analysis are examined. Finally, a summary and conclusion of the research findings and theoretical and practical suggestions will be presented. The findings of this research can help researchers, policymakers, and activists in the field of cognitive technologies to develop more effective strategies for research development, investment, and innovation in this field by gaining a more accurate understanding of scientific trends.
While previous scientometric studies have largely focused on isolated subdomains—such as AI, machine learning, or robotics—this research provides the first integrated conceptual structure of cognitive technologies across major application areas, including health care, industry, business, cybersecurity, education, and smart systems. By mapping these domains collectively, the study offers a holistic knowledge map that reflects the full interdisciplinary nature and scientific evolution of cognitive technologies. To address this gap, this study conducts a scientometric and co-word analysis of 446 publications on cognitive technologies indexed in the Web of Science database. The purpose of this research is to identify the conceptual structure, research trends, and interdisciplinary connections within the field. Based on this objective, the study is guided by the following research questions (RQs):
Research Question 1 (RQ1). What are the main conceptual clusters and thematic areas within the scientific literature on cognitive technologies?
Research Question 2 (RQ2). How have research trends in cognitive technologies evolved?
Research Question 3 (RQ3). Which publications, authors, institutions, and countries have played the most influential roles in this field?
Research Question 4 (RQ4). How are different scientific and applied domains—such as health care, industry, business, cybersecurity, education, and smart systems—connected within the knowledge network of cognitive technologies?
Research Question 5 (RQ5). What research gaps and potential directions for future studies can be identified based on the current knowledge map?
Answering these questions provides a comprehensive and integrated understanding of cognitive technologies as an interdisciplinary research domain and highlights emerging trends that can guide future academic and industrial developments.
2. Theoretical literature
Cognitive technologies, as one of the most important scientific and technological fields in the 21st century, have created new frontiers in information processing, human–machine interaction, and intelligent decision-making. These technologies, which are based on cognitive sciences, AI, and new computing methods, have created transformations in many applied fields. The theoretical study of this field requires accurate knowledge of its definitions, research background, theoretical foundations, and applications. In this section, we first define cognitive sciences and cognitive technologies, identify the types of cognitive technologies and their applications, and then review the theoretical background related to this field.
2.1. Cognitive sciences
Cognitive science is one of the new sciences that, along with nanotechnology, biotechnology, and information technology, form the set of convergent sciences. Cognitive science studies mental processes and complex mechanisms that are behind information processing in the human brain and other creatures. This science seeks to understand how the human mind and other creatures receive, process, store, and retrieve information, and how these processes affect various behaviors and functions. Cognitive science, due to its multidisciplinary nature, benefits from various fields such as psychology, neuroscience, linguistics, AI, and philosophy of mind [4].
The term cognitive science does not refer to the collection of all these disciplines, but rather to their synergy and intersection. In this sense, cognitive science is not a single discipline like each of these disciplines, but rather a united effort between different researchers. The glue that holds the components of cognitive science together is the title of mind and the scientific methods used in this regard. Many research institutes and universities are conducting research in the field of cognitive science and are trying to discover the great secret of man’s greatest asset, the brain and mind, and to recognize its functions as the highest and most complex human capital [5].
Cognitive science is an interdisciplinary field that encompasses several distinct yet interconnected branches, each contributing to a comprehensive understanding of the human mind and its cognitive processes. The following sections elaborate on the principal domains that constitute the foundation of cognitive science [6,7].
Cognitive Psychology represents a fundamental branch of cognitive science, focusing on the investigation of mental processes at the individual level. Cognitive psychologists examine a wide range of processes, including perception, attention, memory, learning, decision-making, reasoning, and problem-solving. The primary objective of this domain is to elucidate how information is processed by the brain and how these cognitive processes influence human behavior. Through experimental methodologies and theoretical frameworks, cognitive psychology provides insights into the internal mechanisms that govern human thought and action.
Neuroscience constitutes another essential pillar of cognitive science, examining the structure and function of the brain and nervous system in relation to cognitive processes. Cognitive neuroscience seeks to identify the neural mechanisms underlying various mental phenomena, such as perception, memory, and decision-making. Advanced neuroimaging techniques, including functional magnetic resonance imaging (fMRI), positron emission tomography (PET), and electroencephalography (EEG), have significantly enhanced our understanding of the neural correlates of cognition. These methodological advances have enabled researchers to establish connections between brain activity and cognitive functions, thereby bridging the gap between neural substrates and mental processes.
Cognitive Linguistics explores the intricate relationship between language and cognition, investigating how language is produced, understood, and processed in the brain. This branch examines various dimensions of language, including grammar (structural organization), semantics (the concepts and meanings associated with words and sentences), and the cognitive mechanisms underlying language comprehension and production. Furthermore, cognitive linguistics investigates how communication through language is established and how linguistic processes influence thinking and decision-making. This domain underscores the fundamental role of language in shaping cognitive experiences and conceptual structures.
Artificial Intelligence (AI) represents a computational approach to cognitive science, seeking to develop systems capable of simulating or imitating human cognitive processes through sophisticated algorithms and computational models. This branch is concerned with designing machines that can learn from experience and autonomously solve problems, mirroring human learning mechanisms. The applications of AI span diverse domains, including robotics, recommender systems, medical diagnosis, and autonomous decision-making. By replicating cognitive functions in artificial systems, AI contributes to both the theoretical understanding of cognition and the development of practical technological solutions.
Philosophy of Mind addresses fundamental questions regarding the nature of the mind, consciousness, and their relationship to the brain and body. This philosophical domain grapples with enduring questions such as whether the mind and brain are identical, and how conscious experiences emerge from the physical activities of the brain. These philosophical inquiries explore phenomena that scientific investigation alone cannot definitively resolve, providing conceptual frameworks for understanding the nature of consciousness, intentionality, and mental representation. Philosophy of mind thus plays a crucial role in shaping the theoretical foundations of cognitive science by examining the ontological and epistemological dimensions of mental phenomena.
2.2. Cognitive technologies
Cognitive technologies refer to technologies that utilize the concepts and principles of cognitive sciences to simulate or enhance human mental processes. Cognitive technologies refer to a set of tools, systems, and algorithms that, by utilizing human cognitive models, provide the ability to process, analyze, learn, and make intelligent decisions. These technologies are directly inspired by cognitive sciences, AI, neuroscience, and data science, and their goal is to improve human cognitive performance or create autonomous and interactive systems [8].
Cognitive technologies are one of the most advanced and interdisciplinary fields of modern science, which aim to improve human cognitive abilities or simulate these abilities in machines. These technologies seek to develop tools and systems that, using cognitive knowledge, help humans perform more complex tasks or automate these tasks [9].
Cognitive technologies encompass a range of distinctive characteristics that differentiate them from conventional computational systems. These features collectively define the operational and functional capabilities of cognitive technologies, positioning them as transformative tools in modern scientific and industrial applications.
Intelligence and Learning constitute the foundational attributes of cognitive technologies, wherein sophisticated machine learning algorithms are employed to process large volumes of data and continuously optimize system performance through iterative learning mechanisms. This adaptive capacity enables such technologies to improve their accuracy and efficiency over time without explicit reprogramming.
Adaptability represents another critical feature, referring to the inherent ability of cognitive systems to adjust their behavior and responses in accordance with changing environments, conditions, and user requirements. This flexibility ensures that cognitive technologies remain effective and relevant across diverse and evolving contexts.
Complex Data Processing and Interpretation further characterizes cognitive technologies, which possess the capability to analyze both structured and unstructured data sources simultaneously. This analytical proficiency enables the identification of hidden patterns, correlations, and insights that may not be discernible through traditional analytical approaches.
Dynamic Interaction with the Environment and Users describes the capacity of cognitive systems to establish effective communication and interaction mechanisms with human users and their surrounding physical or digital environments. This interactive capability facilitates seamless collaboration between humans and machines.
Automatic and Intelligent Decision-Making encompasses the ability of cognitive technologies to synthesize available information, evaluate alternative courses of action, and generate optimal decisions autonomously. This feature proves particularly valuable in contexts requiring rapid processing of complex information.
Simulation of Human Cognitive Processes represents perhaps the most distinctive characteristic of cognitive technologies, involving the emulation of human mental functions such as reasoning, problem-solving, information processing, and learning. This simulation enables cognitive systems to address complex challenges in ways that parallel human cognitive approaches [10].
Cognitive technologies have become critical components in many real-world applications. In health care, they support clinical decision-making, medical imaging analysis, and personalized treatment recommendations by interpreting vast amounts of patient data. In business and industry, cognitive systems enable predictive maintenance, intelligent resource allocation, fraud detection, and automated customer service. In education, intelligent tutoring systems analyze learner behavior and adapt content to individual needs. Other domains such as transportation, cybersecurity, and smart cities increasingly rely on cognitive models for real-time perception, pattern recognition, and autonomous decision-making. These diverse applications demonstrate that cognitive technologies are not limited to academic research; instead, they play a crucial role in transforming services, enhancing automation, and improving human–machine collaboration across multiple sectors [11,12].
2.3. Literature review
A substantial body of research has explored the development, adoption, and scientific evolution of cognitive technologies across multiple fields. Early studies focused on AI and expert systems, while more recent work highlights machine learning, deep learning, natural language processing, and cognitive computing as core foundations of modern cognitive systems [13]. Advances in big data, cloud computing, and neuroscience have shifted cognitive technologies toward real-time data processing, autonomous decision-making, and intelligent human–machine interaction [14,15].
The rapid advancement of cognitive technologies has attracted significant scholarly attention across multiple disciplines, prompting numerous studies to investigate their development, applications, and intellectual structure. A growing body of scientometric and bibliometric research has examined the evolution of cognitive technologies, revealing substantial growth in publication output and research collaboration over the past two decades [12,16].
Several studies have explored the application of cognitive technologies in specialized domains. Research in health care has demonstrated the increasing contribution of cognitive computing to diagnostic decision-support systems, medical image interpretation, and personalized treatment planning, with notable improvements in accuracy and efficiency [12,16]. In the business and industrial sectors, scholars have examined the role of cognitive systems in predictive maintenance, intelligent automation, and customer behavior analysis, highlighting their transformative impact on operational processes [17,18]. In addition, investigations into educational applications have focused on intelligent tutoring platforms that utilize learner analytics to deliver adaptive instruction, thereby enhancing learning outcomes [19]. Other domains, including cybersecurity and smart city initiatives, have been scrutinized for their reliance on cognitive computing in real-time pattern recognition, anomaly detection, and autonomous decision-making [20].
Despite the proliferation of domain-specific studies, a comprehensive scientometric analysis mapping the intellectual structure and thematic evolution of cognitive technology research remains limited. Previous studies have primarily focused on individual application areas rather than providing an integrated perspective on the field’s knowledge domain. Consequently, this study addresses this gap by employing co-word analysis to visualize the conceptual relationships and identify the core research themes within the cognitive technology literature.
Several scientometric studies have analyzed scientific production in these areas. Qu et al. [21] mapped global research on cognitive computing and demonstrated rapid growth after 2015, particularly in the United States, China, and Europe. Ajibade et al. [22] identified core research themes such as neural networks, brain–computer interfaces, and cognitive robotics through co-citation analysis. However, most existing studies remain fragmented and domain-specific, focusing on subfields, such as AI, machine learning, or robotics rather than the broader and more interdisciplinary construct of cognitive technologies [23,24].
Despite these advances, existing studies are fragmented and mostly domain-specific. Only a limited number of studies have provided a comprehensive knowledge map of cognitive technologies across all fields. Most scientometric studies either focus on AI or machine learning separately, rather than the broader and more interdisciplinary construct of cognitive technologies. Therefore, a knowledge-mapping analysis using co-word networks can provide a clearer understanding of conceptual clusters, trends, and research gaps. This justifies the importance and novelty of this study.
3. Research methodology
This study adopts a scientometric approach to investigate the intellectual structure and thematic evolution of the cognitive technology knowledge domain. Scientometrics, as a branch of informetrics, encompasses the quantitative analysis of scientific research outputs, including publications, citations, and conceptual relationships within the scholarly literature. This methodological framework enables researchers to systematically examine the development, dynamics, and interconnections within a specific field of study by leveraging large-scale bibliographic data and advanced computational techniques [25].
Bibliography is defined as “the quantitative study of published physical units, or bibliographic units, or substitutes for each.” This technique is suitable to help scientists quickly summarize and analyze the development trend and research status in specific subject areas based on a large volume of data. This technique includes quantitative measures and analyses that are applied to bibliographic units such as books, journal articles, and the like, and has become a significant topic due to the growth of knowledge in this field [26].
The selection of scientometric methods for this study is justified by several factors. First, scientometric analysis provides an objective, data-driven foundation for understanding research trends and knowledge structures, thereby reducing potential biases associated with traditional narrative literature reviews. Second, the exponential growth in scientific publications within the cognitive technology domain necessitates the application of computational methods capable of processing and analyzing vast quantities of data efficiently. Third, scientometric techniques facilitate the identification of emerging research themes, influential publications, and collaborative networks that may not be readily apparent through conventional qualitative approaches.
3.1. Co-word analysis as the core methodological tool
The primary analytical technique employed in this study is co-word analysis, also referred to as co-occurrence analysis. Co-word analysis is a content analysis method that examines the frequency with which pairs of keywords or terms appear together within a corpus of scientific documents [26]. This technique is grounded in the theoretical foundations of actor-network theory and social network analysis, which posits that the co-occurrence of concepts within scholarly literature reflects underlying semantic relationships and intellectual connections within the research community [27].
The rationale for selecting co-word analysis as the core methodological tool stems from its unique capabilities in mapping the conceptual structure of scientific fields. Unlike citation-based methods, which primarily capture the historical influence and knowledge flows between publications, co-word analysis directly examines the thematic content of documents by analyzing the relationships between keywords. This approach enables researchers to identify [28] the following:
Major research themes and their relative prominence.
Conceptual relationships between different topics.
Emerging research trends and knowledge gaps.
The intellectual structure of the discipline over time.
Furthermore, keywords serve as concise representations of the core content and main contributions of scholarly articles. As noted in the literature, keywords enable readers to determine the conceptual structure of a discipline without delving into the full text of articles [29]. Consequently, the analysis of keyword co-occurrence patterns provides a reliable and efficient means of understanding the thematic organization of a research field.
3.2. Network visualization techniques
To translate the co-occurrence data into interpretable visual representations, this study employs network visualization techniques. Scientific mapping through visualization has become one of the most significant aspects of contemporary scientometric research, enabling the graphical representation of complex relational data in an accessible and informative format.
Three well-established visualization approaches are utilized in this study [25]:
Distance-based visualization represents the most widely adopted method in scientometric mapping. In this approach, the spatial proximity between nodes (representing keywords or concepts) indicates the strength of their conceptual relationship. Keywords that frequently co-occur are positioned closer together, forming distinct clusters that correspond to major research themes. This method provides an intuitive visual representation of the thematic structure of the field.
Graph-based visualization employs network diagrams to illustrate the connections between nodes through edges or links. The thickness and color of edges may represent the strength of co-occurrence relationships, while node size often reflects the frequency of occurrence. This approach facilitates the identification of central concepts, peripheral topics, and bridging terms that connect different thematic clusters.
Time-based visualization enables the depiction of temporal dynamics within the research field, showing how the prominence of different themes and their interrelationships evolve over time. This approach is particularly valuable for identifying emerging research trends and tracking the historical development of the discipline.
3.3. Research methodology framework
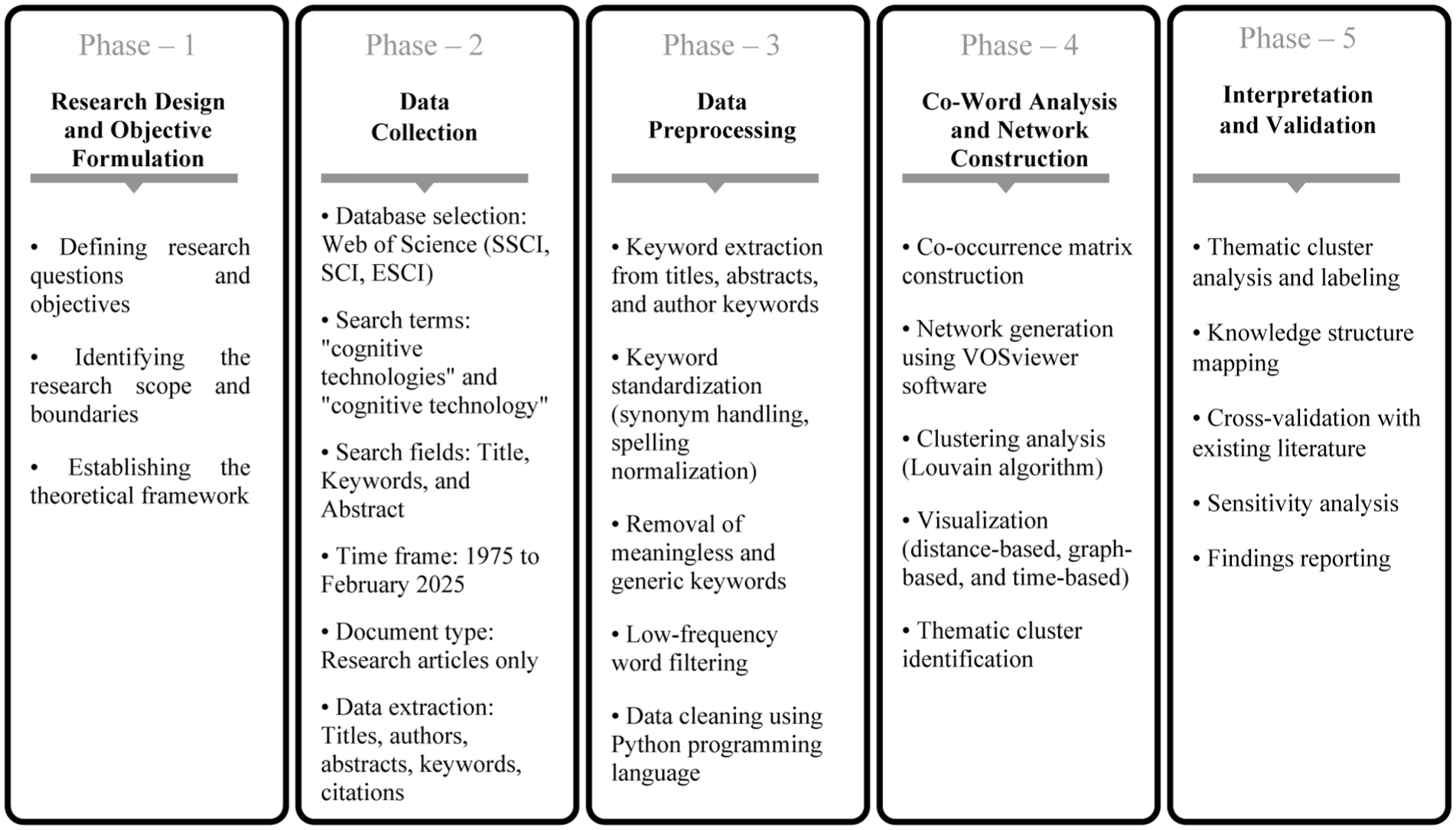
To provide a comprehensive and transparent overview of the research process, this section presents the complete operational workflow of the study in a systematic and sequential manner. Understanding the methodological framework is essential for evaluating the validity and reliability of the findings, as well as ensuring the reproducibility of the research. Figure 1 illustrates the five-phase scientometric workflow adopted in this study, encompassing all stages from research design to interpretation and validation. Each phase represents a distinct yet interconnected component of the research process, collectively forming a coherent and replicable methodological framework.
Research methodology framework.
This study employs a scientometric approach utilizing co-word analysis to map the intellectual structure and thematic evolution of the cognitive technology knowledge domain. The research follows a systematic five-phase framework designed to ensure transparency, reproducibility, and scientific rigor. In the first phase, the research objectives and scope are defined based on identified gaps in the existing literature. The second phase involves the systematic collection of bibliographic data from the Web of Science database using a predefined search strategy comprising Boolean operators and specific inclusion criteria. The search was conducted across document titles, keywords, and abstracts using the search terms “cognitive technologies” and “cognitive technology,” limited to research articles published between 1975 and February 2025. In the third phase, the collected data undergo rigorous preprocessing, including keyword extraction, standardization, and normalization, to ensure data quality and consistency. The data cleaning process, conducted using the Python programming language, involved the removal of meaningless keywords, generic terms, ambiguous phrases, and low-frequency words. The fourth phase constitutes the core analytical stage, wherein a co-occurrence matrix is constructed and analyzed using VOSviewer software to generate network visualizations and identify thematic clusters. Finally, the fifth phase involves the interpretation and validation of findings through cross-referencing with existing literature and sensitivity analysis.
To guarantee reproducibility, all methodological parameters are explicitly reported throughout the article. The search query used for data collection is fully documented as follows: TI = (“cognitive technologies” OR “cognitive technology”) OR AB = (“cognitive technologies” OR “cognitive technology”) OR AK = (“cognitive technologies” OR “cognitive technology”), limited to document type “Article” and time range “1975 to February 2025.” The analysis was conducted using VOSviewer software, with clustering parameters set to the default resolution (1.0) and the minimum co-occurrence threshold of five occurrences per keyword. The data preprocessing was performed using the Python programming language with specific cleaning criteria applied for keyword standardization. These specifications enable other researchers to replicate the study using the same or comparable data sets, thereby enhancing the credibility, transparency, and reproducibility of the research findings.
3.4. Word co-occurrence analysis
Word co-occurrence analysis was first introduced by Callon et al. (1983) [30]. They suggested word analysis as a method that can be used to determine and display the relationship between concepts based on textual information [31]. This method has gradually developed and matured with the advancement of subsequent generations and has become the main method of exploring important research points and the evolution of topics [32].
Such advances can be divided into three strategies. The first strategy relates to advances that have focused on keywords. Holmberg and Hellqvist (2009) found that a combination of keywords and their analysis is a productive approach when mapping and comparing research topics in specific fields or disciplines [33]. The second strategy involves advances in similarity measures. Banjade et al. (2015) proposed a method for measuring the semantic similarity of words by combining various techniques, including knowledge-based and corpus-based methods, for similarity search in different dimensions. The third strategy is to improve fusion semantics [34]. Liu et al. presented a semantic-based co-word analysis method that can integrate expert knowledge in word analysis [35].
The word co-occurrence analysis method is based on four main assumptions:
First, each research area can be identified by a list of the most important keywords. Second, keywords are carefully selected by the authors and accurately reflect the content of the article [26]. Third, a keyword or a topic, if it appears frequently in the relevant literature, indicates the research topic because it refines and focuses on the main content of the article. Therefore, if articles have the same keywords, we may consider the two articles as a similar research concept in theory or method. In addition, the more similar the keywords are, the closer the distance is [36]. Fourth, the co-occurrence in different articles indicates the correlation between them. The frequency of simultaneous occurrence of keywords indicates the strength of the relationship between them. Using word analysis, the researcher can quantitatively determine the links between research themes in a scientific field (i.e. the more co-occurrence, the greater this correlation) [29, 37, 38].
The existing literature in a field is the starting point for researchers to build new frameworks and test hypotheses and relationships. The relationships between the structures of literature can also be studied in what is called “science in science,” which refers to a bibliography to show the structure of knowledge in a specific field [28]. In fact, the co-word analysis method is used to discover the intellectual structure in a research field [39]. Co-word analysis not only finds the main keywords for a topic from the perspective of word frequency but also finds the relationship between words, and then combines the methods of keyword co-occurrence analysis and cluster analysis to discover research hotspots and presents the evolution rules of the topic [32].
Bibliographic maps based on word analysis, such as this study, can serve as a predictive tool for researchers to visualize different disciplines and their relationships, and thus identify future trends. The purpose of this technique is to connect the most important concepts by “reducing the distance between descriptors (or keywords) to a set of network diagrams that effectively show the strongest connections between descriptors” [28]. “Bibliography,” based on co-word analysis, can be used as an extraction tool to visualize various relationships, significance, and centrality [40]. The main steps of co-word analysis are shown in Figure 2 [39, 41]:
Step 1: After determining the research field, the necessary research data can be collected. Articles, reference information, and citation times to the article can be extracted from a database.
Step 2: In co-word analysis, different parts of a document, including the title, abstract, and keywords can be used to study the relationship between topics. The frequency of occurrence of keywords indicates the importance and focus of the research. To build the co-word network, all author-provided keywords and keywords plus were extracted from the metadata of the 446 articles. The records were downloaded from the Web of Science Core Collection in BibTeX and CSV formats and processed using VOSviewer and Excel for text cleaning. Duplicate terms, spelling variations (e.g. “deep learning” vs “deep-learning”), plural/singular forms, and nonspecific or irrelevant terms were merged or removed. After this standardization process, a total of 1892 unique keywords remained and were used for co-occurrence analysis and cluster detection.
Step 3: To produce an intuitive analysis of the intellectual structure in a research field, a scientific map is presented to display the topics presented. Concept mapping is prepared based on the domain ontology and the number of times concepts are counted in the target areas (abstracts, keywords, titles, etc.). Each keyword was considered as a node, and the link represents the relationship of the occurrence of keywords. This can also be called a co-word visualization matrix.
Step 4: Visualizing the map and its network features (centrality and density of each cluster) is obtained by analyzing the co-occurrence matrix.

Main steps of co-word analysis.
3.5. Scientific mapping
Scientific mapping or bibliographic mapping is a spatial representation of how structures, disciplines, specialties, and documents or authors are related to each other [42]. This method is used to show and discover hidden key elements (documents, authors, institutions, topics, etc.) in various research fields [3].
Scientific mapping consists of three elements, namely nodes, lines, and clusters. Larger nodes indicate that this node is closely related to other nodes and plays a more important role in the network. The lines between the nodes represent the connection between them. The closer the two nodes are, the more lines there are. These clusters are used to identify different categories of important research points by modular networks. These keywords in a similar cluster are usually strongly related to each other [43].
3.6. Cluster analysis
Cluster analysis and word analysis are effective methods for building relationships and mapping the power between information options in a text unit. This method is widely used in bibliography and provides insight into a large amount of structured text by analyzing key information extracted from the database, such as the number of references, authors, and keywords [40].
Cluster analysis is a widespread method for data mining for the purpose of visualizing and analyzing bibliography. The results of clustering can graphically show the process of merging and clusters [44]. In performing word analysis, we can identify specific patterns of clustering between scientific articles recorded in the current stream. By performing semantic content analysis, it can be observed how prevalent the themes are in each of these clusters. Within the body, certain forms of clustering are observed, especially around dominant keywords. Within those clusters, we can also observe some semantic dependencies [27].
Cluster analysis is a multivariate statistical analysis method for the quantitative classification of several samples. The basic analytical approach of this method is to construct a similarity matrix based on statistics that can show the distance of samples or indices from multiple observations, and then divide the observations into several clusters based on the measured distances, to understand the structure and characteristics of those observations [45].
Clusters are determined using the association strength method. Total link strength is defined as the number of links that a node shares with all other nodes in the network. Concepts that belong to a cluster are displayed with the same color. They often co-occur more than clusters outside of themselves [27].
Each topic can be described by two methods: centrality and density [46]. The centrality index is one of the important indicators in the analysis of the word co-occurrence network. This index refers to the position of specific nodes within the network, and the value of each node is obtained by counting the number of its neighbors. The number of neighbors is obtained based on the links that connect to that node. In a word co-occurrence network, the higher the degree of centrality of a word, the more network connections it has and the more influential it is. Centrality measures the interaction of a network with other networks. On the contrary, density measures the internal strength of the network [47].
3.7. Software used
After collecting information from the Web of Science database, the data were cleaned using Python software, and meaningless and irrelevant data were removed. Then, the data were analyzed using similarity visualization by text mining and text visualization technique VOSviewer (Center for Science and Technology Studies, Leiden University, Netherlands). VOSviewer provides distance-based visualizations of bibliographic networks. VOSviewer also has some special text-mining features. In addition to drawing the map, this software identifies the clustering of concepts with specific colors. The number of clusters is determined by a clarity parameter, and the parameter with higher clarity is representative of a greater number of clusters. VOSviewer automatically links cognitive technology terms together using a default clustering algorithm [48].
In a bibliographic network, there are often many differences between nodes in the number of their relationships with other nodes. In the analysis of bibliographic networks, the user usually has to normalize the differences between the nodes. VOSviewer applies the normalization of the connection strength by default [25]. After importing the data into the VOSviewer software, the social network analysis of authors and high-frequency cognitive technology terms, and the distribution of high-frequency cognitive technology terms are displayed by VOSviewer with two-dimensional maps. Also, Excel software was used to analyze and create charts of the bibliographic information of each publication, including author, country, and year of publication.
4. Data collection
The information for this analysis was collected from the Web of Science database, which is the most important, authoritative, and extensive bibliographic database in the fields related to social sciences [47]. The statistical population of this study includes all indexed publications related to the field of cognitive technologies with a structured search of document keywords, titles, and abstracts from 1975 to February 2025 (the past 50 years). The keywords “cognitive technologies” and “cognitive technology” were entered in the advanced search section, and the titles, authors, journal lists, and other required bibliographic information of the articles were saved using the considered filters. Table 1 shows the search protocol.
Search protocol in the Web of Science database.

In terms of input and output, co-word analysis is performed using a set of documents that represent the terminological information contained therein and related to them. These terms are often introduced as keywords [38]. It should be noted that to improve the quality of the data, meaningless, general keywords, ambiguous phrases, and low-frequency words are removed so that the features of the original words are more distinct and visible. The data cleaning stage has been done using the Python programming language. The cleaned data included accurate and relevant information related to the field of cognitive technologies that could help to better understand the trends and key topics of this field.
5. Analysis of findings
Using the protocol in Table 1, research documents published in the cognitive technologies research area were identified, with the most important keywords being: “Cognitive technologies, Artificial intelligence, Machine learning, Cognitive computing, Deep learning, Big data, Internet of Things, Neural networks, Natural language processing, Computer vision.”
Also, using the protocol in Table 1, a search from 1975 to February 2025 yielded a total of 446 documents, the frequency distribution of which is shown in Figure 3.
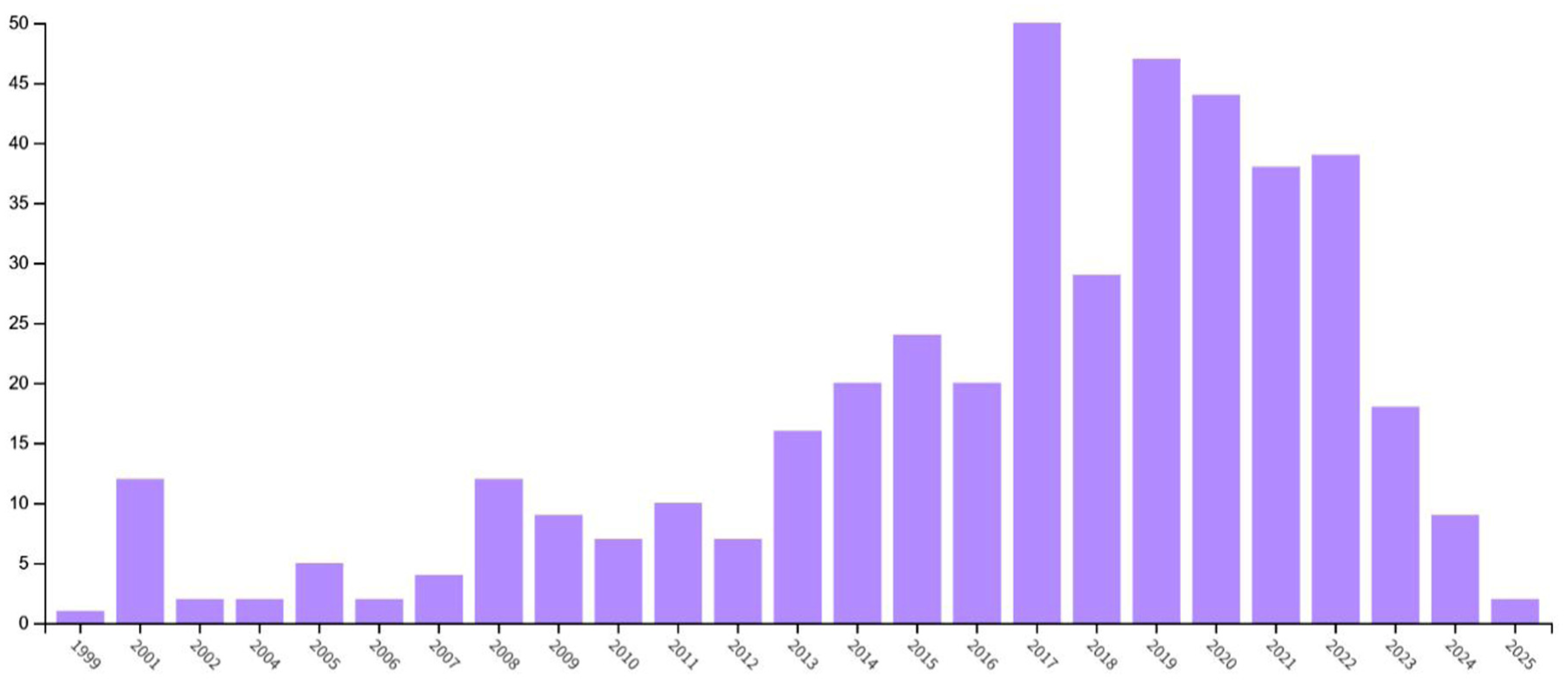
Total publications until February 2025.
The findings show that the number of articles has increased from one article in 1975 to more than 40 articles in recent years, demonstrating very steep growth. The findings indicate that a total of 66 countries have publications in the field of cognitive technologies, with Russia (99 documents), the United States (79 documents), China (45 documents), the United Kingdom (25 documents), and Italy (22 documents) recording the highest number of publications in this field.
A total of 5314 citations have been made to articles in this field. Considering that the frequency of citations to highly cited articles can objectively reflect the impact of articles in academic exchanges, highly cited articles have recently become a standard for evaluating the level of scientific research internationally [49]. Considering this, the citation rate in the field of cognitive technologies has grown significantly since 1975. The number of articles and the total number of citations in this field and its related fields from 2020 to 2024 have reached more than four times their level compared with the previous 40 years, indicating the growing importance of this research field.
5.1. Analysis of keyword frequency
This section discusses the high-frequency keywords in the field of cognitive technologies. A total of 10 main keywords representing the main characteristics and dimensions of the topic and case study in the research field were identified for sample domain analysis. The extracted keywords include a combination of terms related to cognitive technologies, but some of them appear repeatedly, in uppercase, or with different synonyms. In the next step, these keywords were cleaned. This cleaning included the following:
Converting all words to lowercase (for uniformity).
Removing general and meaningless keywords (such as “model” or “systems”).
Combining synonymous keywords (such as “artificial intelligence” and “ARTIFICIAL-INTELLIGENCE”).
After cleaning the data, the 10 words with the highest link, occurrence, and frequency were identified, which are shown in Table 2.
Categorization of keywords in the research field.
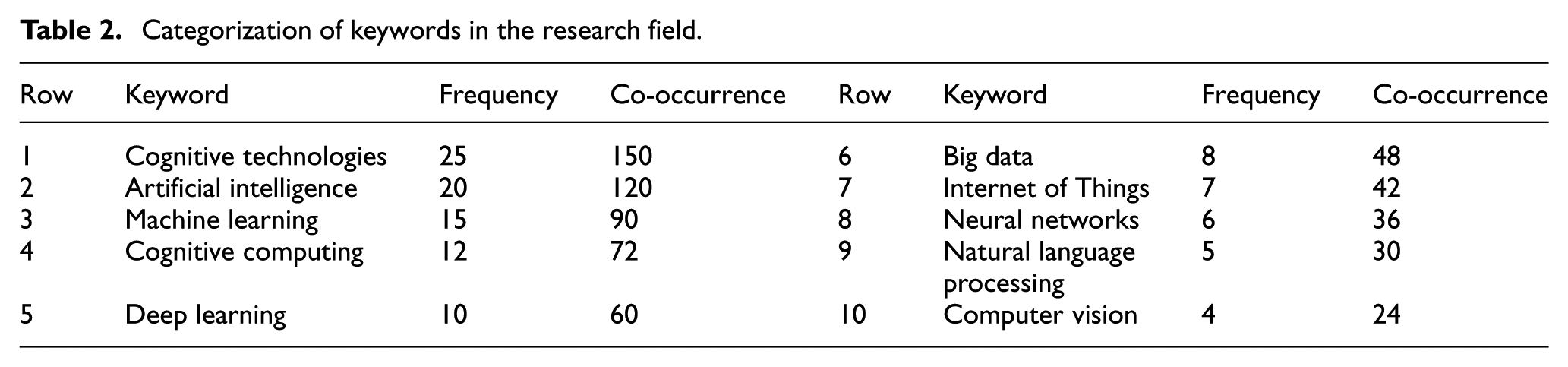
Based on the data in Table 2, it can be concluded that these 10 words have the most importance in the scientific map of the research and have many nodes and links connected to them. According to the information obtained, cognitive technologies with 150 co-occurrences and 25 frequencies have the most co-occurrences in the network and are identified as the most central and dense words, and AI with 120 co-occurrences and 20 frequencies is in the second rank, and machine learning with 90 co-occurrences and 15 frequencies was identified as the third most central and dense rank. Ten of the most important research areas identified in the research topic are also in accordance with Figure 4.

The most important research areas identified.
5.2. Cluster analysis
Based on the findings, the conceptual clusters of the words are shown in Table 3.
Conceptual clusters of words.
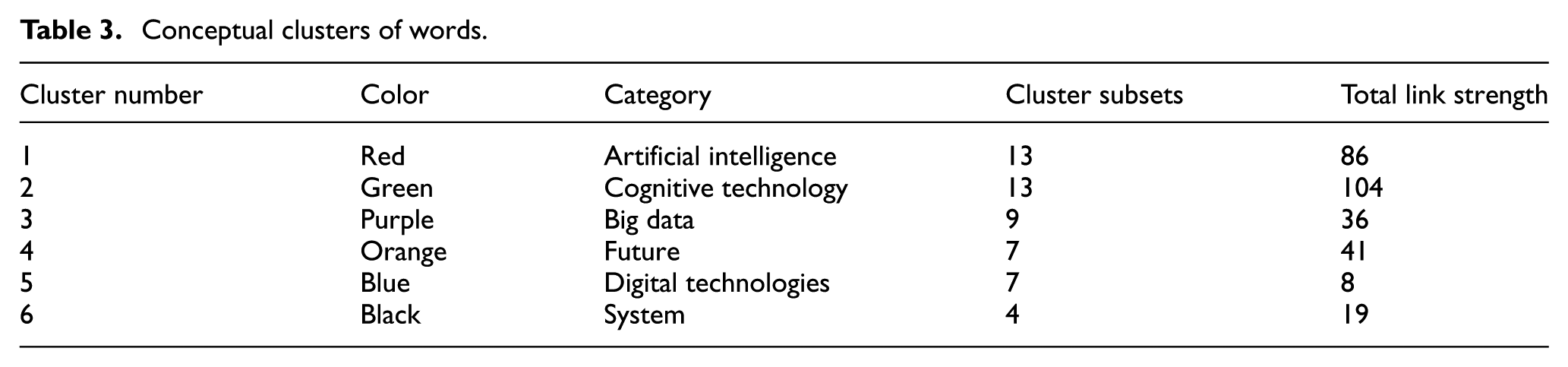
The first cluster (red) is related to the AI category, which, with 13 subsets, has the most items in the entire network. The second cluster (green) is related to cognitive technologies with 13 items, which, considering that it has the most occurrences and links in the network, is considered the most important cluster. By examining all six clusters and their sub-clusters, 354 links with a total link strength of 536 were identified. The number of clusters, links, and the amount of dispersion of concepts at the map level indicate a relatively good concentration, and this indicates that researchers have been able to work in a focused and in-depth manner on the categories of this field. Figure 5 shows how clustering is done in the field of cognitive technologies in the form of a word co-occurrence map.
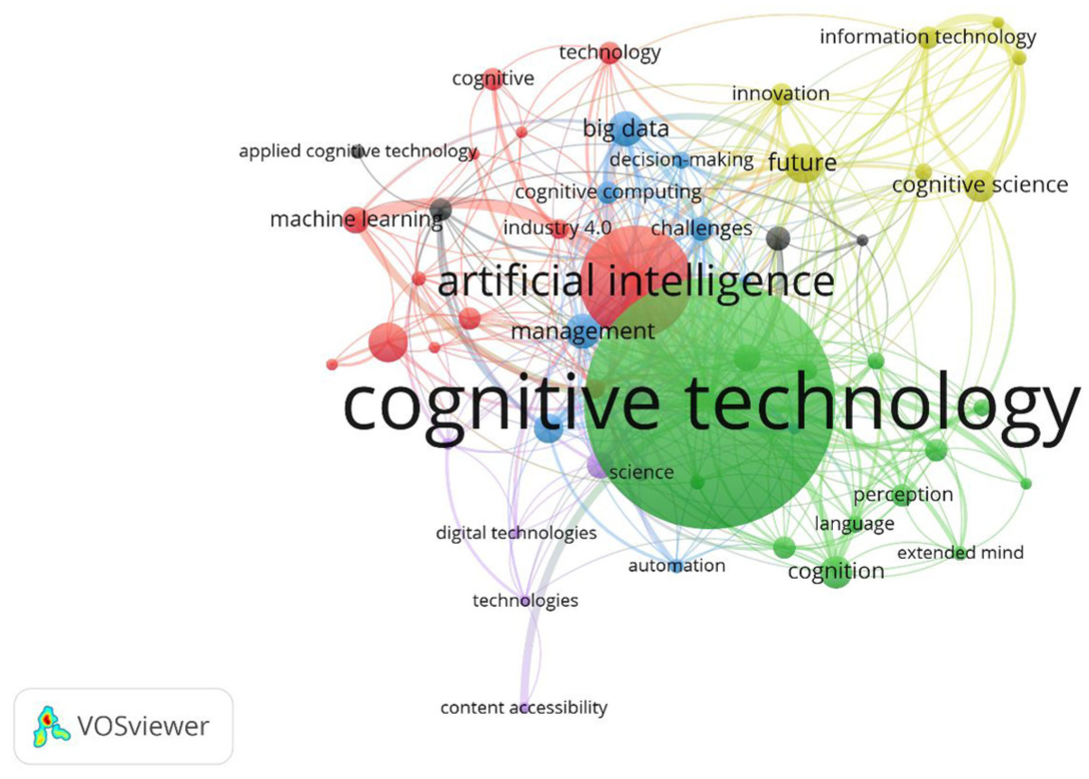
Word co-occurrence map in the field of cognitive technologies during the years 1975–2020.
In this map, the nodes that have more centrality and density are shown as larger circles. The colors indicate the thematic clusters, and the size of the nodes and their labels indicate the weight of that concept, or in other words, the number of repetitions or co-occurrences of that topic [47]. With this explanation, the topics of cognitive technology, AI, big data, future, digital technologies, and systems are considered the main concepts of the clusters. Considering that the size of the circles indicates the amount of knowledge available about each concept, the topic of cognitive technologies has the largest node and label, has the most links, and shows that most publications have been in this field.
Since the distance between concepts at the map level indicates the relationship between concepts, the two nodes of cognitive technologies and AI are the largest and closest nodes to each other, which shows that these topics have a very close relationship with each other and play more important roles in the word co-occurrence network and have more influence, importance, and centrality in the network. In other words, this means that in the existing texts, attention has been paid to their effects on each other. On the contrary, when the long distance of the topic of cognitive technologies from Agriculture or the Internet of Things is seen, it means that less attention has been paid to the effects of these concepts on each other in the existing literature.
Therefore, the large node “cognitive technology” shows that this concept is the core and most frequently used term in the analyzed data. Also, the nodes around “cognitive technology” show the concepts related to it. For example, “artificial intelligence,”“machine learning,”“deep learning,”“big data,” and “cognitive computing” are among the important concepts related to cognitive technologies.
5.3. Analysis of keyword co-occurrence
Keyword co-occurrence analysis is used to show the evolution of different topics over time. In this analysis, different colors show topics according to the frequency of appearance, which facilitates the understanding of topics that are currently specific and those that have been neglected. However, co-occurrence analysis is limited due to the small number of years it covers [38]. The distribution of terms in the research area based on the average time of their appearance is shown in Figure 6.
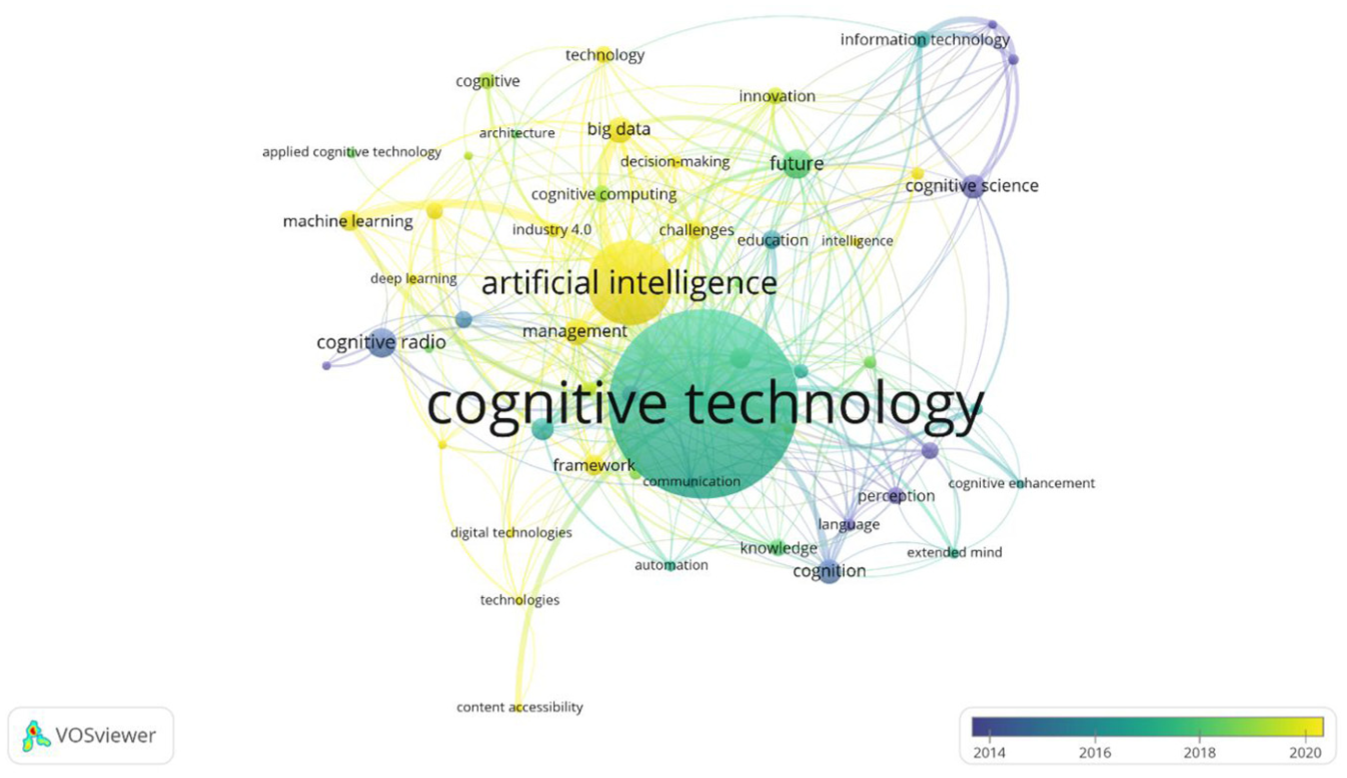
Keyword co-occurrence map in the field of cognitive technologies over the past years.
According to Figure 6, the order of publications initially appears in purple for earlier years (2014–2016), and then, newer publications in recent years (2018–2020) appear in yellow or red. In 2014, the most common terms were cognitive sciences, radio cognition, and perception. Approaching 2020, the words AI, machine learning, big data, and cognitive computing have been the most common terms.
According to the keyword co-occurrence map, the following conclusions can be drawn:
Movement toward applied areas of cognitive sciences: Researchers’ studies have shifted from examining the theoretical foundations of cognitive sciences to the applied areas of cognitive sciences.
AI and machine learning: As seen in the map, AI, and especially machine learning and deep learning, plays a very important role in research related to cognitive technologies. This indicates that recent advances in AI and machine learning have had a significant impact on the development of cognitive technologies.
Cognitive sciences: The close connection between cognitive technologies and cognitive sciences is also evident in the map. This shows that a deeper understanding of human cognitive processes plays an important role in the development of cognitive technologies.
Big data and Industry 4.0: The presence of words such as “big data” and “industry 4.0” in the map shows that cognitive technologies are entering areas such as big data analysis and smart industry, and can play a key role in these areas.
Challenges and Future: The existence of words such as “challenges” and “future” shows that, in addition to the progress made, there are many challenges in the path of developing cognitive technologies, and researchers are examining and addressing these challenges.
5.4. Analysis of keyword density
To find keyword analysis and dynamic changes in research hotspots, high-frequency words were obtained using the density map of VOSviewer software. In the data pool, 1892 keywords were found. In the co-word analysis, the co-occurrence threshold for keywords is determined. In this research, the minimum co-occurrence for each keyword is considered 5 times. Obviously, small areas whose words have not achieved the co-occurrence threshold are removed from the analysis results. Considering the above co-occurrence threshold for the words under study, the software identified 53 words in the studied documents, and the density map of these words was drawn, which is shown in Figure 7.

The density of words used by authors in the field of cognitive technologies during the years 1975–2025 (threshold = 5).
Each colored point shows the density of terms at that point. By default, the colors range from blue to green and from yellow to red. As the number of terms around a point increases and the weight of neighboring terms becomes larger, the color of the points will be from yellow to red. On the contrary, with fewer terms at a point and less weight of neighboring terms, the colors are closer to blue [25]. Points that are yellow and orange indicate concepts and terms that have the most repetition and focus in the texts related to cognitive technologies. For example, concepts such as “cognitive technology,”“artificial intelligence,” and “big data” are located at these points and are of high importance. According to Figure 7, the keyword “cognitive technologies” is yellow and has the highest frequency (occurrence = 100), after which “artificial intelligence” (occurrence = 45), “future” (occurrence = 16), “big data” (occurrence = 14) are located, which shows the amount of knowledge in these categories and indicates that more publications have been presented in these areas.
6. Conclusion
The results of this research showed that cognitive technologies have had significant growth in scientific production in recent years and have become one of the key interdisciplinary fields. The analysis of 446 scientific publications and the extraction of 1892 keywords show that the main axes of research in this field include AI, machine learning, cognitive computing, deep learning, big data, the Internet of Things, neural networks, natural language processing, and computer vision. The study of word co-occurrence led to the identification of six conceptual clusters and 354 connections between them, with a total link strength of 536, which indicates strong connections and thematic convergence in this field.
The upward trend of scientific publications in the field of cognitive technologies indicates the increasing attention of researchers to these technologies and their applications in solving complex scientific and operational challenges. The analysis of the data in this research showed that the term “cognitive technology” has appeared as a central node in the co-word network and has had the most links with other concepts. Also, its close relationship with “artificial intelligence,”“machine learning,” and “deep learning” shows that cognitive technologies are highly dependent on advances in AI. The prominent presence of “big data” also indicates the key role of data analysis in the development of these technologies.
In addition, the clustering of research concepts showed that cognitive technologies are not only growing scientifically but also have found widespread applications in industrial and social fields. The presence of concepts such as “Industry 4.0” and “smart cities” indicates the movement of these technologies toward practical applications and their role in the development of intelligent systems.
From a future research perspective, this study shows that new research paths are being formed. Identifying research gaps and focusing on the development of new models, optimizing algorithms, and interdisciplinary applications can help advance this field. Using advanced analytical methods in future studies can provide a more accurate understanding of emerging trends and facilitate the development of scientific and industrial strategies.
Finally, the findings of this research can be a valuable basis for researchers, policymakers, and activists in this field to have a better understanding of scientific trends and to have better planning for the development of research and innovations related to cognitive technologies. The dynamism of this field shows that in the future, we will see more developments in this field that will have profound effects on science, industry, and society. Considering the presented materials, the following theoretical and practical suggestions can help to improve scientific understanding, develop practical applications, and increase the effectiveness of cognitive technologies in various fields.
Theoretical suggestions
Developing Theoretical Frameworks for Cognitive Technologies: Given the interdisciplinary nature of this field, it is suggested that new conceptual models and theoretical frameworks be presented to better understand the interaction between the components of cognitive technologies and other sciences.
Using Topic Modeling Algorithm: Future studies can apply advanced text-mining techniques such as topic modeling (e.g. Latent Dirichlet Allocation (LDA) or Bidirectional Encoder Representations from Transformers (BERT)) to analyze article abstracts or full texts and extract latent thematic structures. Integrating both co-word network analysis and topic modeling in future work would allow researchers to compare network-based conceptual clusters with statistically generated latent topics, offering a more comprehensive and multi-layered understanding of the cognitive technologies’ knowledge structure.
Investigating the Impacts of Cognitive Sciences on the Development of Intelligent Technologies: Conducting studies that examine the role of cognitive sciences, cognitive psychology, and neuroscience in the advancement of cognitive technologies can provide a deeper understanding of how these technologies work.
Analyzing Future Trends of Cognitive Technologies: Future research can, by utilizing future studies’ methods, identify the paths of growth and development of cognitive technologies and examine their effects in various fields.
Investigating the Relationship between Cognitive Technologies and Ethics and Governance: Considering the social and ethical consequences of these technologies, studying governance frameworks, policymaking, and regulation can be effective in better management of this area.
Interdisciplinary Studies: It is suggested that future research examine the synergy of cognitive technologies with other scientific fields such as medicine, management, social sciences, and engineering to discover new applications of these technologies.
Practical suggestions
Creating Specialized Databases and Platforms: Creating a comprehensive database of articles, research, and applications of cognitive technologies can help researchers identify scientific trends and examine research gaps.
Investing in Interdisciplinary Research: Supporting research projects that examine the relationship between cognitive technologies and other scientific fields can help develop knowledge in this area.
Applying Cognitive Technologies in Key Sectors of Society: It is suggested that governments and industrial organizations use these technologies in areas such as health, security, education, and smart governance to increase the productivity and efficiency of systems.
Holding Specialized Conferences and Workshops: Holding scientific and specialized conferences with a focus on cognitive technologies can help exchange knowledge and form scientific networks between researchers and industry.
Creating Supportive Policies for the Development of Cognitive Technologies: Developing supportive policies, granting financial facilities, and creating special research centers can help the growth and development of these technologies at the national and international levels.
Developing Practical Solutions Based on Cognitive Technologies: Industrial and governmental organizations can use cognitive methods to optimize decision-making, analyze data, and improve services.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.