
Abstract
This study presents a new bibliometric indicator, the i-score, which is designed to measure the scientific output of individuals or groups. Similar to the Hirsch index (h-index), the i-score uses a single number to assess research performance. However, it goes a step further by considering the geometric area under the publication–citation curve, offering a more refined measurement that addresses the deficiencies of the h-index. Through three empirical studies, this study shows that the i-score offers a more consistent and accurate assessment of research performance by incorporating both productivity and quality.
1. Introduction
The Hirsch index (h-index) [1], introduced by American physicist Jorge E. Hirsch in 2005, is defined as “the number of papers with citation number
On the contrary, the h-index has been widely criticized for its deficiencies and limitations in evaluating research [3–10]. Numerous variations of the h-index have been proposed to overcome these issues, but each typically addresses only one or two flaws.
The purpose of this study is to introduce a new geometric indicator that measures both research productivity and quality, addressing the deficiencies and limitations of the h-index. Like the h-index, the proposed i-score summarizes a researcher’s or group’s scientific output and impact into a single number, which is often preferred by research administrators. Although the deficiencies and limitations of the h-index are well-known, it remains widely used because combining multiple dimensions of research impact into one simple measure is convenient and appealing. The i-score aims to provide the same simplicity while overcoming the h-index’s deficiencies and limitations, making it a more effective tool for research evaluation.
The remaining part of the paper is structured as follows. In the “Literature Review” section, I will review the literature regarding h-index and summarize its main deficiencies and limitations. In the “i-score” section, I will introduce and define a new indicator, i-score, using the geometric area of the rectangle under the publication–citation curve to measure research productivity and quality. In the “Empirical studies” section, I will conduct three empirical studies for the new indicator and present the results. In the “Discussion” section, I will address the limitations of the i-score in research evaluation as well as some possible solutions. Finally, in the “Conclusion” section, I will briefly give my concluding remarks.
2. Literature review
Since 2005, Hirsch’s paper introducing the h-index has been widely cited, leading to numerous related publications. However, the validity and reliability of the h-index have been challenged by bibliometricians and other scholars [2,11–13]. As a result, experts in bibliometrics have recommended against proposing new citation impact indicators unless they clearly demonstrate added value [14].
2.1. Deficiencies and limitations
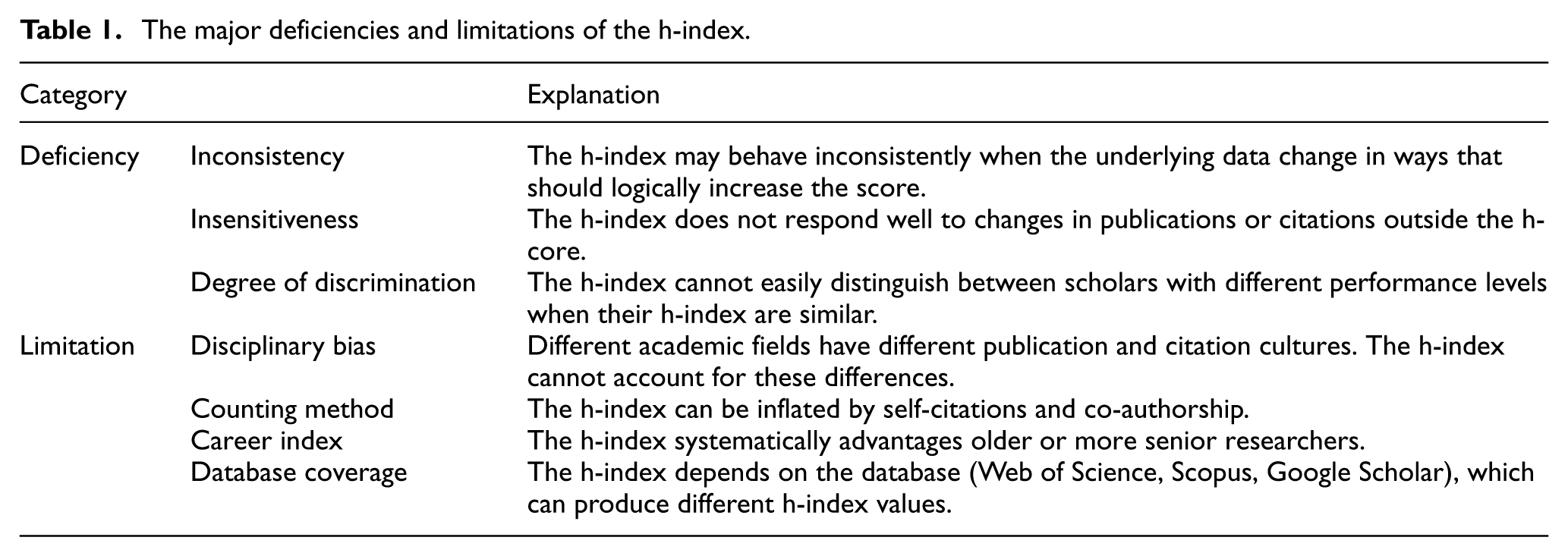
While the h-index effectively balances research productivity and quality, addressing the limitations of some indicators that are overly influenced by a few highly cited papers [11,15], it also has inherent flaws and practical limitations [3–10,16–19] as summarized in Table 1.
The major deficiencies and limitations of the h-index.
Waltman and van Eck [12] point out that the definition of h-index regarding calculating the h-index is arbitrary, considering that the number of citations and the number of publications are two independent entities. They argue that the h-index could be defined as “a scientist has an h-index of h if h of his publications each have at least 2-h citations and his remaining publications each have fewer than 2(h + 1) citations” or “a scientist has an h-index of h if h of his publications each have at least h/2 citations and his remaining publications each have fewer than (h + 1)/2 citations” [12], and such an arbitrary definition may result in inconsistent results when calculating the h.
Previous studies suggest that the h-index is primarily determined by a few highly cited papers that make up the h-core, while it overlooks papers and citations outside of this core [11,13,20,21]. In addition, some researchers argue that the h-index is not effective in distinguishing between scholars with similar research performance [16,22].
The h-index is a commonly used metric for assessing research performance, but it has several well-known limitations when used in research evaluation. It is field-dependent, making cross-disciplinary comparisons challenging [1–4]. In addition, the h-index can be skewed by self-citations [23–25] and co-authorship [3,18], which may artificially inflate its value. The h-index also favours more senior scholars, as it increases with the number of publications and citations over time, and never decreases [2,17,26]. Furthermore, the h-index relies on data from bibliographic databases such as Web of Science and Scopus, which have varying and limited coverage [3,19].
2.2. h-indices
To overcome the limitations of the h-index, more than 50 variants have been proposed and developed, as shown in Table 2. Of these, 18 variants aim to improve the accuracy of the h-core by including more highly cited papers, while 17 focus on adjusting the counting method to account for self-citations and co-authorship. In addition, six variants address disciplinary bias, and eleven consider the academic age of researchers. Eight other variants seek to expand the h-index’s applications. However, only a few variants have addressed issues related to inconsistency and discrimination in the h-index.
List of h-index variants by what they address.
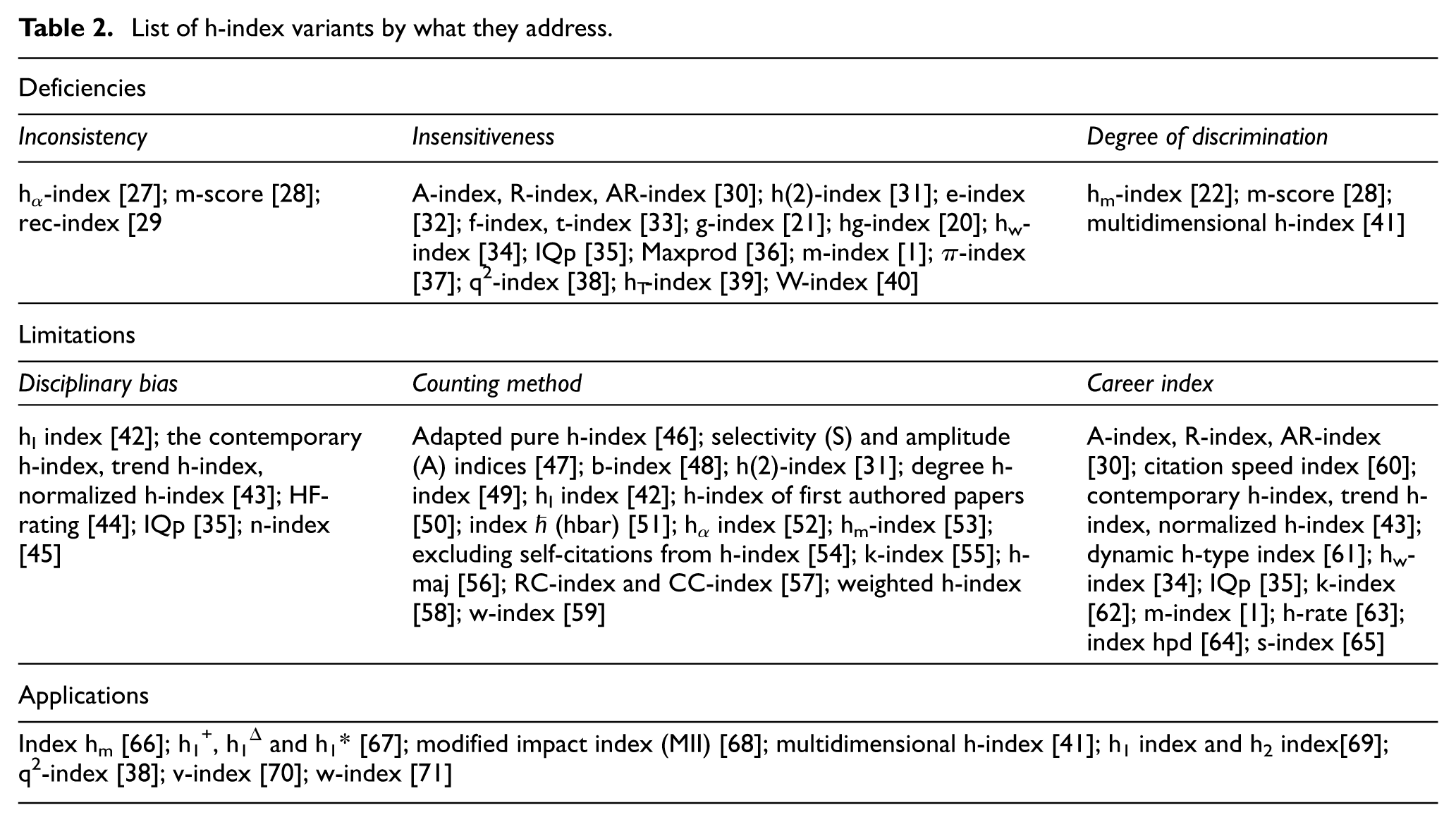
From the perspective of bibliometricians, inconsistency is regarded as a crucial deficiency, as Waltman and van Eck [12] declare that the h-index is not a valid indicator to measure research output. Unfortunately, although the inconsistency is a serious deficiency of h-index weakening the validity and reliability of its measurement, it was less addressed by previous studies and these h-indices.
2.3. Geometric indicators: m-score and rec-index
Shu [28] introduced a new indicator called the m-score, using the geometric area under the publication–citation curve to measure both research productivity and quality. The m-score addresses the inconsistencies of the h-index and offers better discrimination. Building on this idea, Fenner et al. [72] developed another geometric indicator, rec-index, which was defined as the maximum rectangle between the citation vector x and the number of publications. The i-score is an improvement in the rec-index.
Figure 1 illustrates how to use the geometric area under the publication–citation curve to measure research output. For each scholar, we plot their research output on a publication–citation curve, where each point on the curve shows the number of publications (P) that have been cited at least a certain number of times (C). At any given point on the curve, the rectangle CBPO represents the scholar’s research output for having P publications with at least C citations. We can also draw a triangle (2C-2P-O) that is exactly twice the size of the rectangle CBPO. This triangle covers most of the research output but does not include the two tails of the curve, which represent very highly cited or very lowly cited papers. The rec-index [72] identifies the largest rectangle CBPO that can be placed under the publication–citation curve, while the h-index identifies the largest square under the curve, whose area is h 2 .
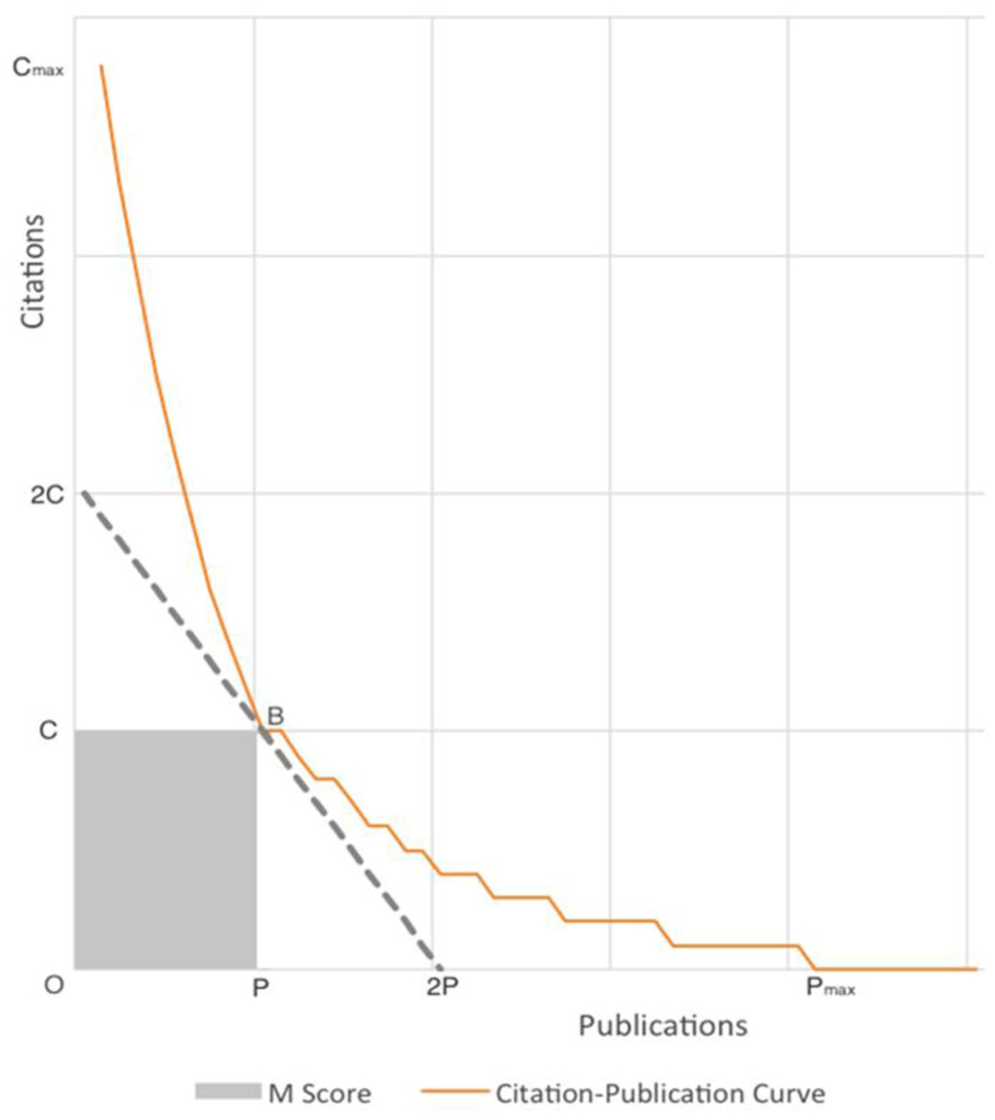
The geometric area under the citation–publication curve.
Measuring research output by using the area of the largest rectangle can avoid some of the problems with the h-index, but it can still be skewed by a few extremely highly cited papers or a large number of lowly cited or uncited papers. To address this issue, Shu [28] used the logarithms of both the number of papers and citations when calculating the m-score, while Harris et al. [29] proposed a two-dimensional bibliometric index (reci, recp) that assesses both the influential and the prolific aspects of a researcher’s output. However, neither method provides a single number, like the h-index, that captures both productivity and quality of research.
3. i-score
In this study, I propose a new geometric indicator called the i-score (impact score) to assess both research productivity and quality. The i-score is based on the same method using geometric area under the publication–citation curve. As shown in Figure 1, for any given point B on this curve, the rectangle CBPO represents the research output of an individual researcher or a group, where the individual/group has P publications that were cited at least C times. Unlike the rec-index proposed by Fenner et al. [72], which uses the area of the largest rectangle CBPO to measure research output, the i-score is calculated as the average area of all rectangles CBPO under the publication–citation curve.
3.1. Definition
The i-score mirrors the rec-index definition in Fenner et al. [72], but instead of taking the maximum rectangle, the i-score takes the average of all rectangles defined at distinct thresholds, providing a more balanced indicator that incorporates the entire citation curve rather than just the single dominating rectangle.
Let the citation curve be the histogram obtained by plotting the number of citations (on the vertical axis) against the ranked publications (on the horizontal axis), with the citation vector x =x1, x2, …, xn sorted in descending order. The rec-index [72] corresponds to the largest rectangle that can fit under the citation curve. The i-score generalizes this by considering all maximal rectangles that appear when the curve is viewed at distinct citation thresholds.
At each threshold C, we construct a rectangle with height C and width P(C), where P(C) is the number of papers with at least C citations. The i-score is then the average area of these rectangles.

where T is the set of distinct citation thresholds.
3.2. Computing of i-score
The computing of i-score is as follows: (1) rank the scholar’s publications in descending order based on the number of citations each has received; (2) identify “P” as the number of publications that have been cited at least “C” times; (3) calculate the value of “rec” as rec = P × C; and (4) finally, the i-score is the average value of these “rec” calculations.
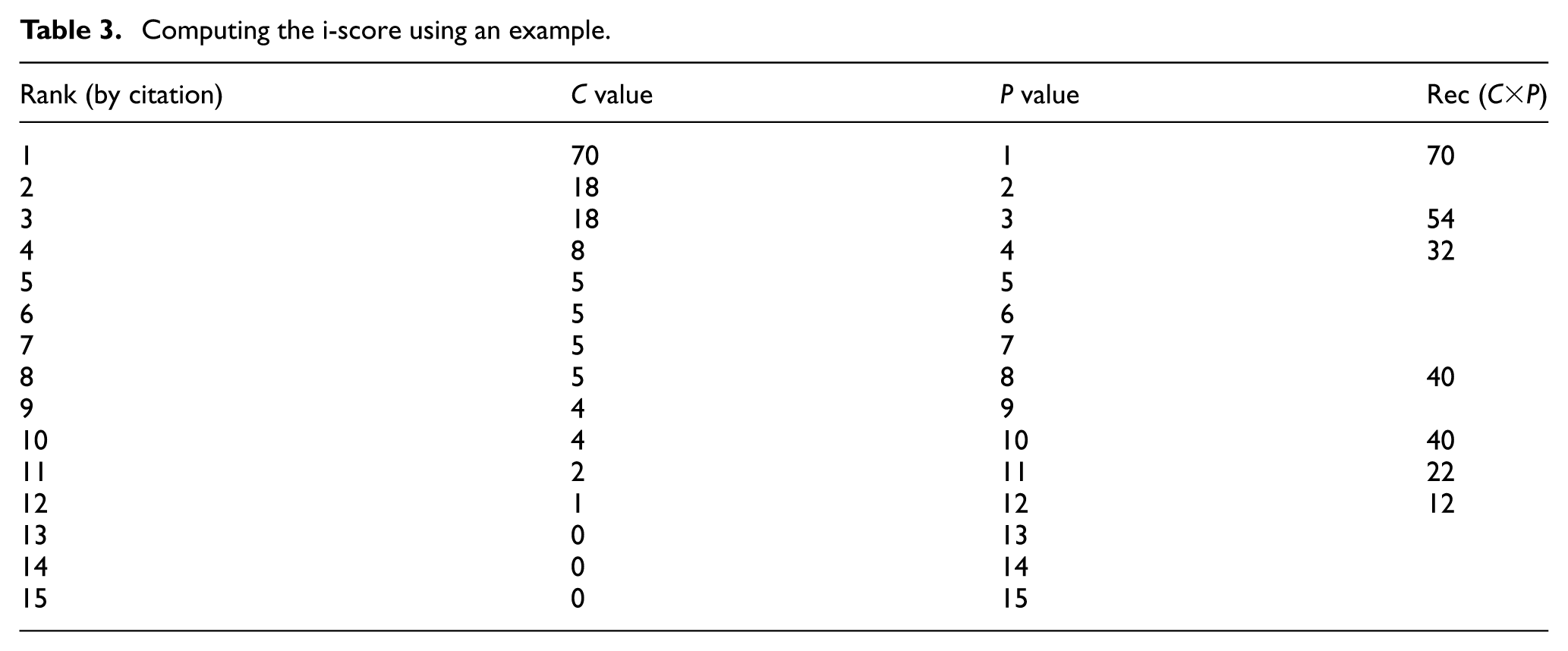
As demonstrated in Table 3 and Figure 2, a scholar published 15 papers, of which 12 were cited between 1 and 70 times each. To compute the i-score, we follow the four-step procedure mentioned above.
Step 1. Construct the ranked list.
Each paper is ordered from the most cited to the least cited. In this case, the most cited paper received 70 citations, the second and third papers each received 18 citations, the fourth received 8 citations, and so on, until the twelfth paper received 1 citation. The last three papers received 0 citations.
Step 2. Transform into a cumulative publication–citation distribution.
For each distinct citation threshold “C,” we count the number of papers “P” that have at least C citations. This produces points on the publication–citation curve (Figure 2), illustrating that:
1 paper was cited at least 70 times,
3 papers were cited at least 18 times,
4 papers were cited at least 8 times,
8 papers were cited at least 5 times,
10 papers were cited at least 4 times,
11 papers were cited at least 2 times
12 papers were cited at least 1 time.
Step 3. Compute rec values.
Each rec value is calculated as the product of “C” (the citation threshold) and “P” (the number of papers meeting that threshold). Only the points where a change occurs in the cumulative curve are included, so we obtain the following seven rec values: 70, 54, 32, 40, 40, 22, and 12.
Step 4. Average the rec values.
The i-score is defined as the mean of these rec values
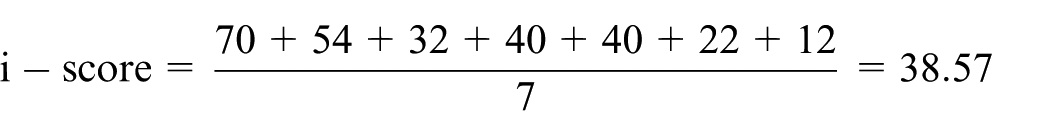
Computing the i-score using an example.
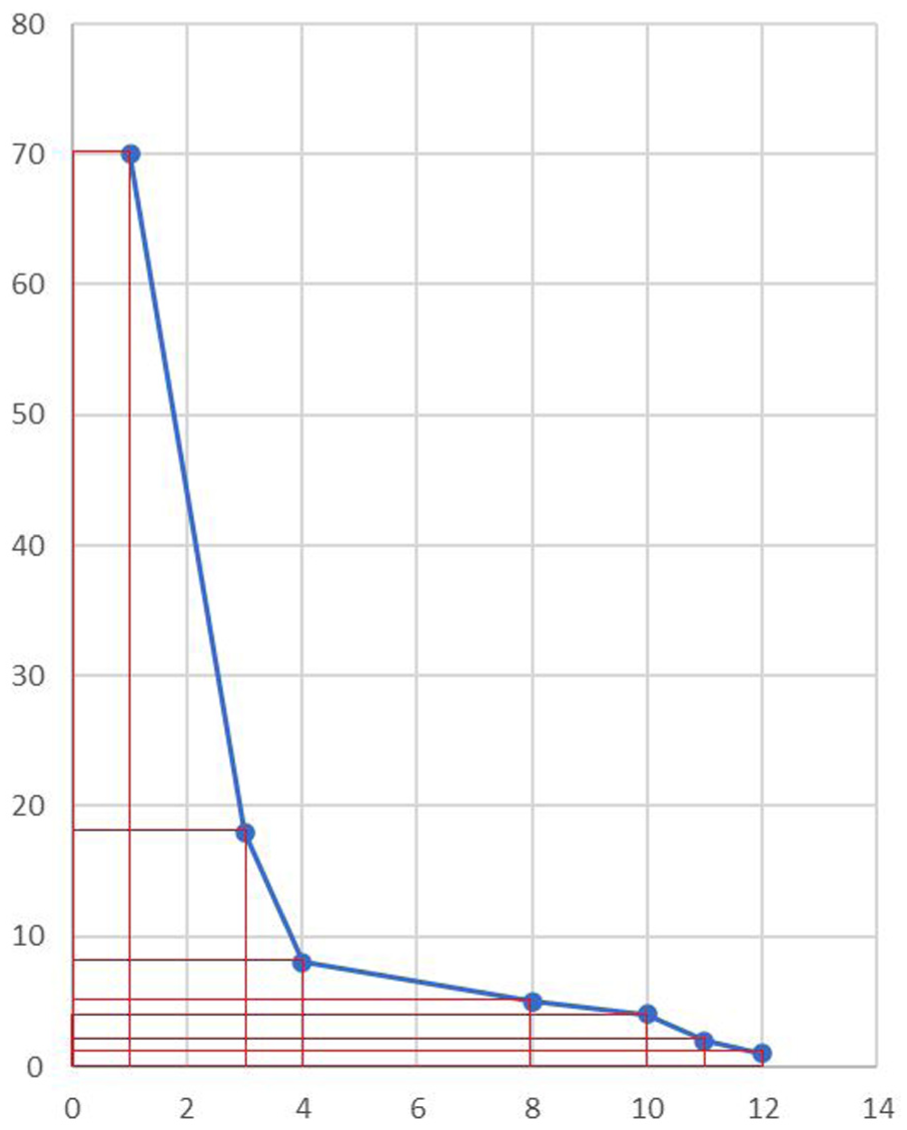
Calculating the i-score by a sample citation–publication curve.
4. Empirical studies
To validate the new indicator, three empirical studies were conducted. The first study addressed the inconsistency in the h-index identified by Waltman and van Eck [12]. The second study compared the i-score with the h-index, m-score, and rec-index using the same data set reported by Cronin and Meho [73]. The third study analysed the correlation between the i-score and other bibliometric indicators using a large data set.
4.1. Inconsistency test
Waltman and van Eck [12] argue that the arbitrary calculation of the h-index can lead to inconsistent results, as demonstrated through three examples. These examples were also used in this study to validate the m-score, rec-index, and i-score, all of which are based on the geometric area under the publication–citation curve.
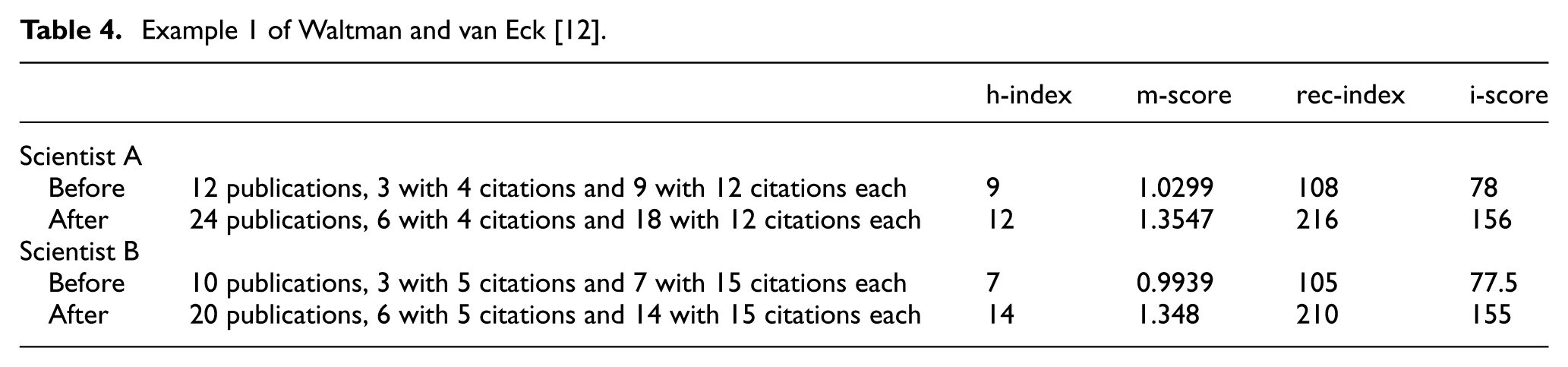
In the first example, Waltman and van Eck [12] point out that the h-index can violate the principle that the ranking of two scientists should remain consistent when their relative performance is the same. As shown in Table 4, when Scientists A and B both double their research output, Scientist A’s h-index increases from 9 to 12, while Scientist B’s h-index jumps from 7 to 14. As a result, their rankings shift, even though their relative performance remains the same. On the contrary, the m-score, rec-index, and i-score all maintain consistent rankings. Scientist A’s m-score, rec-index, and i-score increase from 1.0299 to 1.3547, 108 to 216, and 78 to 156, respectively, while Scientist B’s scores rise from 0.9939 to 1.348, 105 to 210, and 77.5 to 155, respectively, preserving the original ranking between the two scientists.
Example 1 of Waltman and van Eck [12].
In the second example, Waltman and van Eck [12] observe that the h-index can violate the principle that the ranking of two scientists should remain consistent when they add the same research record. For instance, when Scientists X and Y each add the same number of publications and citations within the same timeframe (as shown in Table 5), Scientist X’s h-index remains at 5, while Scientist Y’s h-index jumps from 4 to 6. This change alters their rankings despite their identical contributions. The m-score and rec-index also show similar inconsistencies. For example, Scientist X’s m-score and rec-index increase from 0.4886 to 0.5907 and from 25 to 35, respectively, while Scientist Y’s m-score and rec-index rise from 0.4685 to 0.6055 and from 24 to 36. On the contrary, the i-score provides consistent rankings – Scientist X’s i-score increases from 19.5 to 21.7, and Scientist Y’s rises from 22.5 to 24.3, keeping Scientist Y ranked higher than Scientist X both before and after the addition of the new research records.
Example 2 of Waltman and van Eck [12].

In the third example, Waltman and van Eck [12] demonstrate that the h-index fails to uphold the principle that the ranking of two groups should align with the rankings of their individual members. As illustrated in Table 6, Group A has a lower h-index than Group B, despite its members having higher h-indices than those in Group B. On the contrary, when using the m-score, rec-index, and i-score, the group rankings are consistent with the rankings of their individual members. Specifically, since the m-score, rec-index, and i-scores of Scientists X1 and X2 are higher than those of Scientists Y1 and Y2, Group A’s overall m-score, rec-index, and i-score are also higher than those of Group B.
Example 3 of Waltman and van Eck [12].

According to Waltman and van Eck [12], the arbitrary nature of the h-index—where h publications are cited at least h times—can lead to inconsistencies. On the contrary, m-score, rec-index, and the i-score, which reflect the geometric area under the publication–citation curve, provide a more reliable measure. While m-score and rec-index may still show some inconsistencies, the i-score consistently avoids this issue.
4.2. Comparison test
An additional empirical study was conducted to compare the i-score with the h-index, m-score, and rec-index in ranking 31 influential information scientists, originally reported by Cronin and Meho [73]. The findings reveal that indicators like the m-score, rec-index, and i-score, which use the geometric area under the publication–citation curve, can differentiate scholars with similar research performance, whereas the h-index cannot.
Table 7 illustrates that the h-index struggles to distinguish between scholars with similar performance, as it results in ties for certain h-index values: 27, 23, 22, 17, 13, 12, 10, and 4. Two scholars had the same h-index for 5 out of these 7 values, 3 scholars tied for 22, and four scholars tied for 12. This lack of differentiation can be addressed by using indicators based on the geometric area under the publication–citation curve, which provides unique rankings for all scholars. For instance, Bates, White, and Dillon all share an h-index of 22, despite having different research outputs with 66, 69, and 90 publications, and 2742, 3150, and 2155 citations, respectively. However, when assessed using the m-score, rec-index, and i-score, their research outcomes yield distinct values: m-scores of 1.9947, 1.9466, and 1.9057; rec-indexes of 880, 1242, and 856; and i-scores of 449.57, 449.12, and 354.49, respectively.
Comparison of the h-index, m-score, rec-index, and i-score, along with their rankings (in brackets) for 31 information scientists.
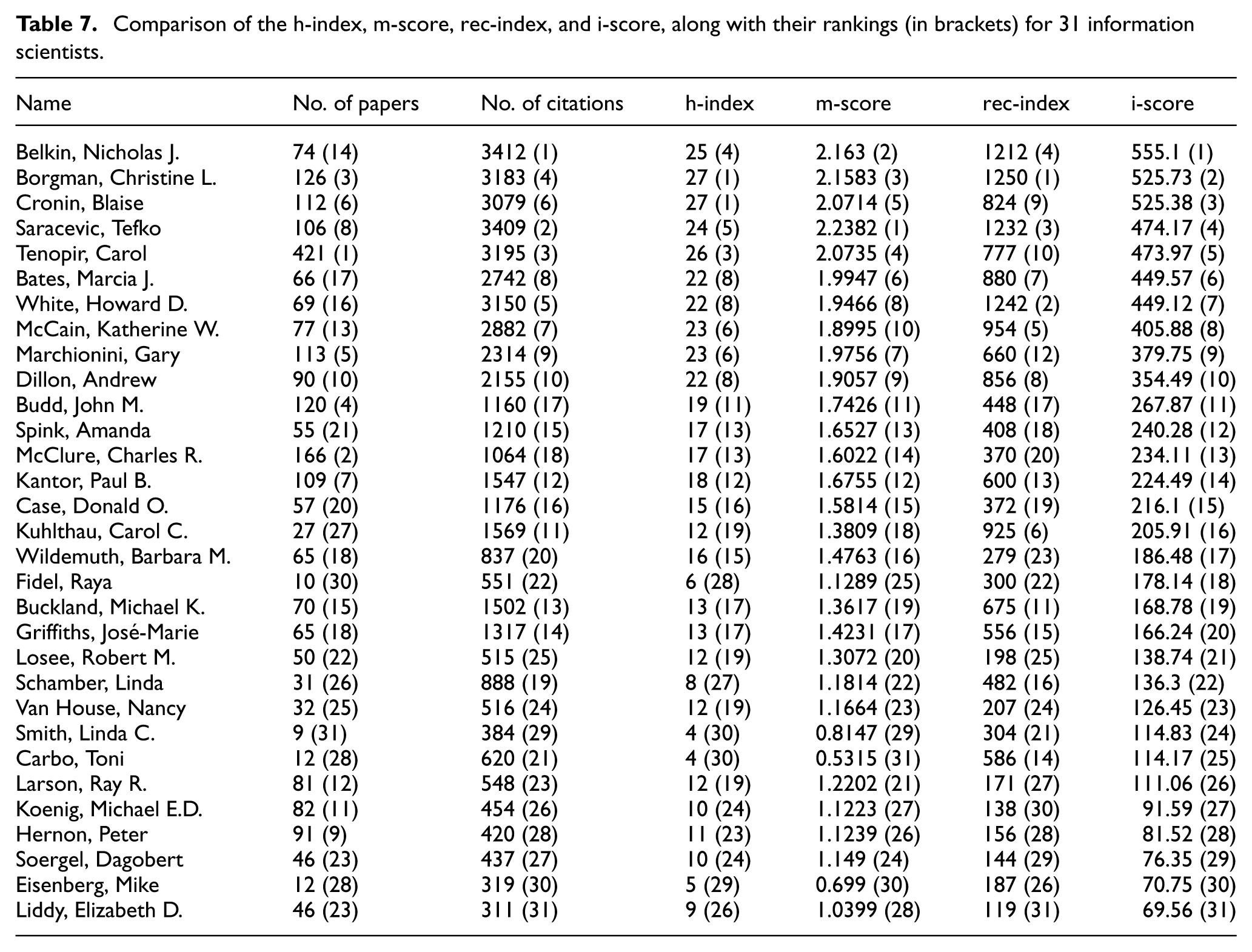
These indicators, based on the area under the publication–citations curve, are influenced by a set of highly cited papers. For example, although Hernon has more publications (91 vs. 10) and a higher h-index (11 vs. 6) than Fidel, his m-score (1.1239 vs. 1.1289), rec-index (156 vs. 300), and i-score (81.52 vs. 178.14) are all lower than Fidel’s. Fidel’s advantage comes from her four highly cited papers, which received 233, 117, 80, and 75 citations, respectively, despite only having six papers cited at least 6 times. On the contrary, Hernon’s most cited paper received only 53 citations, even though he has 11 papers cited at least 11 times. Another example is Schamber, who was ranked 27th by h-index (8). She received 888 citations for her 31 papers, including three that were cited more than 100 times (293, 241, and 158 citations). As a result, her ranking improves to 22nd by m-score and i-score and 16th by rec-index.
Of the three indicators that use the area under the publication–citation curve, the rec-index can be skewed by a small number of highly cited papers, which produce the largest area under the publication–citation curve. In contrast, the m-score and i-score, which use logarithms or averages of these areas, respectively, help to minimize the influence of outliers. For example, although White has fewer publications (69 vs. 74) and fewer citations (3150 vs. 3412) than Belkin, White’s rec-index is higher (1242 vs. 1212). However, his m-score (1.9466 vs. 2.163) and i-score (449.12 vs. 555.1) are both lower than Belkin’s. This inconsistency arises because White’s two most highly cited papers have received 726 and 621 citations, respectively, creating a larger area under his publication–citation curve. While Belkin has more papers (11 vs. 7) with 100 or more citations than White, his two most cited papers received only 671 and 466 citations. Belkin’s rec-index of 1212 comes from 15 papers that were cited at least 15 times, which is lower than White’s rec-index, driven by just two papers with more than 621 citations each.
4.3. Correlation test
The last empirical study compared the i-score with other common bibliometric indicators used to assess research productivity and quality, focusing on their correlations. The analysis included researchers who had a unique author ID from Scopus, along with their publication records. Data were retrieved from Scopus in March 2023, and we collected all publications and citations recorded up to February 2023. To reduce the impact of outliers, only authors with at least 30 publications were considered. In total, data from 1,059,309 authors, as well as their following bibliometric indicators, were analysed. Both Pearson and Spearman correlation tests were conducted to evaluate the relationships among these indicators.
Total number of publications (TP)
Total number of citations received (TC)
The h-index (h)
The citation rate (CR)
Citation distribution index (CDI)
The i-score (i)
The CR is the average number of citations a researcher’s publications receive over the whole period. The CDI, previously referred to as the “Relative Integration Score”) measures the overall shape of a citation distribution by using the relative citation levels of papers across all 10 deciles. A higher CDI means that an entity has fewer papers in the low-citation deciles or more papers in the high-citation deciles. By definition, the world average CDI is 0. In theory, CDI scores range from −50 (if all papers fall into the lowest citation decile) to +50 (if all papers fall into the highest decile) [74].
As shown in Table 8, the i-score demonstrates strong linear relationships with two fundamental indicators of research output: TP and TC. Its Pearson correlations with TP (0.8090) and TC (0.9225) are both higher than those of the h-index, which reports values of 0.7609 and 0.8207, respectively. These results indicate that the i-score increases in a stable and predictable manner as researchers produce more work and accumulate more citations. In other words, the i-score reflects both research productivity and cumulative citation impact more closely than the h-index.
Pearson correlation coefficient among bibliometric indicators.
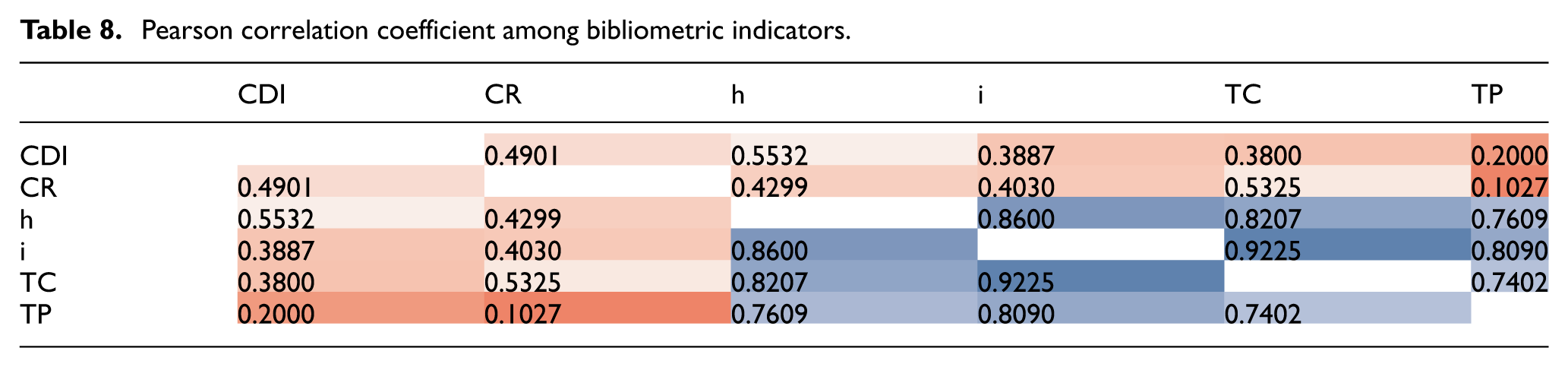
In contrast, the i-score shows weaker correlations with relative-impact indicators such as CR and the CDI. This pattern is expected. Measures of relative impact divide citations by the number of publications; thus, researchers with many publications may achieve a strong overall impact (high TC) but moderate relative citation levels. The i-score follows this logic as it is designed to capture the cumulative contribution of a researcher’s full publication and citation record, not relative citation efficiency. Therefore, its weaker correlations with CR and CDI do not indicate inconsistency; rather, they reflect the different conceptual focus of the indicator.
Table 9 presents the Spearman correlations among the same set of indicators. Here, the i-score continues to align closely with the rankings produced by established metrics. Its rank correlations with CDI (0.6711), CR (0.7983), and especially TC (0.9679) are all higher than the corresponding Pearson correlations in Table 8. This pattern indicates that while these measures capture different aspects of research performance, the i-score produces researcher rankings that are broadly consistent with widely used bibliometric indicators.
Spearman correlation coefficient among bibliometric indicators.

The only exception occurs with the TP, where the i-score shows a lower Spearman correlation (0.5914) than that of the h-index (0.6592). This can be explained by how both the data and the h-index behave. As many researchers have the same number of publications, this creates many ties in the rankings. The h-index, due to its well-known insensitivity, varies less and ends up matching the tied publication ranks more closely, resulting in a higher Spearman correlation with TP. In contrast, the i-score incorporates citation distribution and responds to meaningful citation growth, producing more differentiated rankings among researchers with identical publication counts. This leads to a weaker Spearman correlation, which is an expected and theoretically consistent outcome given its design as a more sensitive and discriminating performance indicator.
Overall, the results from Tables 8 and 9 show that the i-score behaves in a stable way with respect to core dimensions of productivity and cumulative impact. Importantly, the fact that the h-index also shows strong correlations does not weaken the reliability of the i-score. Rather, it indicates that the i-score aligns with well-established measures while offering a more balanced and nuanced representation of a researcher’s overall contribution. These properties collectively support the conclusion that the i-score is a dependable and informative indicator of research performance.
5. Discussion
While the i-score addresses key shortcomings of the h-index, such as inconsistency, insensitiveness, and the degree of discrimination, it shares similar limitations with the h-index. These include counting methods (size dependence), disciplinary bias (field dependence), career index (age dependence), and database coverage. Such limitations are common to bibliometric indicators based on publication and citation data and, therefore, cannot be fully eliminated. However, the geometric design of the i-score allows these limitations to be addressed through explicit mitigation strategies without redefining the indicator itself.
5.1. Counting (size dependence)
As co-authorship becomes more common, accurately measuring each co-author’s contribution presents a significant challenge in bibliometric analysis [75]. Size dependence occurs when researchers with many publications or those involved in large collaborative teams obtain systematically higher indicator values. Because the i-score is constructed using publication counts and citation frequencies based on full counting, it is affected by this issue. Nevertheless, several practical strategies can be applied to reduce size-related inflation.
First, size effects associated with large collaborative teams can be reduced by restricting the input data to publications in which the researcher holds a key authorship role, such as first author or corresponding author. This approach focuses the indicator on contributions that more directly reflect leadership or significant contributions in research. Second, fractional counting of publications and citations can be applied during data preparation, where credit is divided among co-authors before constructing the publication–citation curve. For example, if a paper is assigned a weight of 1/5 under fractional counting, it is counted as 1/5 of a publication rather than one full publication when calculating P. Likewise, each citation is counted as 1/5 of a citation when calculating C. Third, size effects can also be reduced by normalizing the i-score by publication volume, for example by dividing the raw i-score by a function of the TP.
5.2. Disciplinary bias (field dependence)
A well-known limitation of all citation-based indicators is their sensitivity to disciplinary differences. Publishing and citation practices vary widely across fields: some disciplines are characterized by rapid publication cycles, large collaborative teams, and high-citation density (e.g. biomedicine and physics), while others produce fewer outputs, have slower citation accrual, and lower citation density (e.g. humanities and mathematics) [75–77]. When raw publication and citation counts are used, the i-score is field-dependent, and direct comparisons across disciplines are, therefore, inappropriate. This limitation reflects structural differences in scholarly communication systems rather than a weakness specific to the i-score.
Field effects can be reduced by normalizing the i-score within each discipline. This can be performed by replacing raw publication and citation counts with field-normalized publication and citation scores before constructing the publication–citation curve. For example, consider two disciplines, A and B. The average number of publications per author and the average number of citations per paper are both 5 in discipline A, while the average number of publications per author is 20 and the average number of citations per paper is 25 in discipline B. If we set the average number of publications and the average number of citations in each discipline to a score of 100, each paper receives a publication score of 20, and each citation receives a citation score of 20 in discipline A while each paper receives a publication score of 5, and each citation receives a citation score of 4 in discipline B. By using these publication scores and citation scores to calculate P and C, differences in publication volume and citation frequency between disciplines A and B are reduced. Alternatively, i-scores can also be rescaled relative to discipline averages to obtain a field-normalized i-score. These approaches allow cross-disciplinary comparisons while preserving the geometric meaning of the indicator.
5.3. Career index (age dependence)
Another limitation common to citation-based indicators is their dependence on career length. Because both publications and citations accumulate over time, senior researchers will almost always have higher i-scores than early-career researchers, independent of relative research quality or influence. This makes direct comparisons across career stages problematic.
To address this, bibliometric studies often restrict the analysis to specific time windows, such as a 5- or 10-year publication window. These adjustments can also be applied to the i-score, thereby allowing a more balanced evaluation of scholars at different career stages. Age-related effects can also be reduced by introducing temporal weighting. In this approach, recent publications and citations are given more weight, while older ones receive progressively lower weight before constructing the publication–citation curve. This allows the i-score to better reflect recent research activity while still considering past contributions.
5.4. Database coverage
According to Okubo [75], bibliometric studies usually begin by selecting the databases that best represent the target population. The validity of the i-score, like that of any bibliometric indicators, is constrained by the coverage of the database used. Different bibliometric databases, such as Web of Science, Scopus, and Google Scholar, differ substantially in scope, indexing techniques, and coverage. As a result, the same researcher may have different i-scores depending on the database chosen. This variation complicates comparisons across institutions or countries that rely on different data sources.
To ensure a fair and consistent comparison, it is recommended that evaluators specify the database used and apply the i-score within the same data set. However, even with consistency, the problem of incomplete or uneven coverage persists as fields such as computer science (conference papers) or the humanities (books and monographs) may be systematically underrepresented. Therefore, while the i-score can provide meaningful insights within a given data set, it cannot fully overcome the biases introduced by database limitations.
5.5. Extreme cases
Extreme cases, such as researchers with one very highly cited paper or many marginally cited publications, present challenges for many bibliometric indicators because they reduce discriminatory power. The h-index, which is based on the h-core of the publication–citation curve, tends to undervalue researchers with a small number of extremely highly cited publications or many uncited works. In contrast, indicators based on areas under the publication–citation curve (e.g. the i-score, rec-index, and m-score) may be influenced by such extreme cases.
Because the i-score uses an intermediate approach by averaging the areas of all rectangles under the publication–citation curve, the influence of extreme cases is reduced. Some additional adjustments can further limit their impact. For example, upper bounds can be applied to publication or citation thresholds, or diminishing weights can be assigned to rectangles with very high publication or citation counts. These adjustments preserve the basic structure of the i-score while reducing sensitivity to extreme values.
5.6. Implications
The mitigation strategies discussed above clarify the intended role of the i-score in research evaluation and help explain its contribution compared with existing indicators, especially the h-index. Although the i-score shares several structural limitations with other citation-based measures, its geometric design allows these limitations to be addressed in a systematic and transparent way. By using information from the entire publication–citation curve, the i-score provides better discrimination and avoids some formal problems of the h-index, while remaining adaptable to different evaluation contexts. In addition, the use of normalized or fractional-weighted values instead of raw publication or citation counts offers more opportunities to reduce size, field, and age effects. In contrast, the h-index relies on a single threshold and is, therefore, less flexible for normalization by authorship role, discipline, or time.
For these reasons, the i-score should not be viewed as a replacement for the h-index, but as a complementary indicator. When used with appropriate normalization and together with other quantitative and qualitative measures, the i-score can provide a more detailed and balanced representation of research output and impact than the h-index alone.
6. Conclusion
This study introduces the i-score, a new geometric indicator inspired by Hirsch’s concept of using a single number to measure research output. Unlike the h-index, the i-score utilizes the area under the publication–citation curve to provide a more nuanced measurement. Initial tests demonstrate that the i-score overcomes key deficiencies of the h-index, such as inconsistency, insensitivity, and lack of discrimination, by offering a more consistent and accurate assessment that considers both productivity and quality. In the final test, the i-score is compared with other bibliometric indicators using a larger data set, further validating its accuracy and reliability.
The study reveals that the i-score provides deeper insights into the relationship between research productivity and quality compared with the h-index and other geometric indicators like the m-score and rec-index, which are more limited in this regard. This research makes a valuable contribution to bibliometric evaluation, and future studies are encouraged to further validate the i-score and explore its potential applications. Also, future research could further examine and validate the mitigation strategies discussed in this study. Empirical tests could explore how authorship-based counting, field normalization, and temporal weighting affect the i-score and its sensitivity to size, disciplinary, and age-related effects. Applying these strategies across different data sets, disciplines, and career stages would help assess their effectiveness and clarify the conditions under which the i-score provides the most reliable evaluation results.
Footnotes
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study is supported by the National Science Foundation of China (# 72274048).
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.