
Abstract
Through its specific rhetorical potential that is distinct from verbal text, visual material facilitates and plays a pivotal role in linking novel phenomena to established and taken-for-granted social categories and discourses within the social stock of knowledge. Employing data from the worldwide news coverage of the global financial crisis in the Financial Times between 2008 and 2012, we analyse sensemaking and sensegiving efforts in the business media. We identify a set of specific multimodal compositions that construct and shape a limited number of narratives on the global financial crisis through distinct relationships between visual and verbal text. By outlining how multimodal compositions enhance representation, theorization, resonance, and perceived validity of narratives, we contribute to the phenomenological tradition in institutional organization theory and to research on multimodal meaning construction. We argue that elaborate multimodal compositions of verbal text, images, and other visual artifacts constitute a key resource for sensemaking and, consequently, sensegiving.
Keywords
Introduction
This article explores the role of visual and multimodal text in encapsulating complex and spatially dispersed phenomena in global finance during, and after, 2008 in one distinct event: the global financial crisis (GFC). Such empirical phenomena encompass a plethora of incidents, actors and activities and are, consequently, in need of explanation, simplification and boundary work in order to become collectively comprehensible. The elusive and multifaceted nature of the crisis – complex to such an extent that most of us have struggled to fully grasp and understand it – constitutes considerable challenges to any kind of public debate and discourse. In our research, we draw on emerging literature on the role of visuality and multimodality in the institutionalization of novel ideas in order to explore how the combined use of verbal and visual text facilitates objectification under such extreme conditions.
Conceptually, research on sensemaking and sensegiving (e.g. Brown, Colville, & Pye, 2015; Gioia & Chittipeddi, 1991; Maitlis & Christianson, 2014) provides an excellent starting point for our endeavour. Sensemaking involves bracketing specific instances from the ongoing flow of experiences and encapsulates them in stable social categories, thereby reducing uncertainty (Weick, Sutcliffe, & Obstfeld, 2005). While existing institutional arrangements provide the central ‘building blocks’ for such activity, sensemaking is also a generative process that creates new objects of knowledge, rather than merely perpetuating existing ones (Weber & Glynn, 2006). Sensegiving has been described as intentional attempts to establish dominant ways of understanding previously unintelligible experiences (e.g. Maitlis, 2005). Sensemaking and sensegiving are intertwined processes; both are crucial elements in the early stages of the objectification of novel ideas and innovative practices. In fact, for our purposes, the two cannot be separated. As Rouleau (2005, p. 1415) notes, they are ‘two sides of the same coin – one implies the other and cannot exist without it’.
Our work focuses particularly on a hitherto less explored aspect of constructing meaning – one that Nigam and Ocasio (2010) call ‘environmental sensemaking’. At the centre of such investigation is the question of how actors come to understand a series of experiences as a bounded event that becomes consistently labelled and referred to. We here highlight a rather challenging instance, where phenomena are impenetrable, complex and spatially dispersed, so that audiences will only ever witness parts of them personally (e.g. Fiss & Hirsch, 2005); in addition, such experiences span across multiple discursive communities, which considerably complicates the discursive creation of a commonly shared idea of what is going on (e.g. Jones, Maoret, Massa, & Svejenova, 2012). In such cases, we argue, environmental sensemaking is distributed, yet collective, and sensemaking and sensegiving are co-influential in the attempt to assign meaning to novel phenomena. Actors selectively draw on cues to make sense of incidents, and they engage in sensegiving when they externalize their own sensemaking. These externalizations then provide cues for the sensemaking of others, and so on – which may eventually lead to shared understandings.
Although a fertile stream of research acknowledges the crucial role of discourse in sensemaking and sensegiving (for an overview, see Maitlis & Christianson, 2014), very little is known about the use of discursive resources that go beyond the written and spoken word (Meyer, Höllerer, Jancsary, & van Leeuwen, 2013). Building on existing research on the visual mode of meaning construction, we suggest that the combination of visual and verbal resources is a useful way of bolstering sensemaking and sensegiving efforts that has, so far, been underexplored. In more detail, we aim at enriching literature on sensemaking and sensegiving with a social semiotic perspective (e.g. Kress & van Leeuwen, 2006) and propose a multimodal (e.g. Kress, 2010) approach that acknowledges the specific characteristics of visuals as crucial complements to written text.
Empirically, we focus on the global financial crisis (GFC) as arguably one of the most critical events of modern socio-economic history (Riaz, Buchanan, & Bapuji, 2011). What started with the bursting of the US housing bubble subsequently led to the collapse of stellar institutions in the finance and banking industry, significant downturns in global stock markets, bailouts of several banks by national governments around the globe, and a severe economic recession (Morgan, Froud, Quack, & Schneiberg, 2011). Several aftershocks and the rising debt levels of governments led, among other things, to the European sovereign-debt crisis and speculations regarding an overall failure of the European project (e.g. Featherstone, 2011; Vaara, 2014). While the crisis itself remained intangible and incomprehensible to many, if not most, citizens, its negative consequences for the economy and society alike (for instance, a loss of trust in finance institutions and political leadership, volatile capital markets, increasing inequality in living standards and nascent impoverishment of marginalized societal groups) have proven to be global and enduring.
Not surprisingly, public media discourse dominated the terms in which the issues and incidents attributed to the GFC were discussed, interpreted and framed (regarding the role of public media, see, for instance, Cook, 1998; Gamson, 1992; Schillemans, 2012). Consequently, we explore our conceptual claims by examining efforts at giving sense to the crisis by one of the global authorities in business media with an agenda-setting function: the Financial Times (FT). Extending contemporary approaches to multimodal discourse analysis (e.g. Jancsary, Höllerer, & Meyer, 2016; Machin & Mayr, 2012), we examine sensemaking and sensegiving efforts in all regional editions of the Financial Times e-paper between 2008 and 2012. We identify and develop a typology of distinct roles of visuals within the multimodal compositions that construct and shape central narratives about the GFC. These narratives provide different prisms to understand and make sense of the highly complex and ambiguous empirical phenomena and issues; they define the cast of relevant actors involved, suggest central themes and topics, and arrange them into a temporal structure.
We further integrate our findings by systematizing the role of such multimodal compositions in sensemaking and sensegiving efforts. With this, our article adds to the current literature by elaborating on how visual resources – in combination with verbal text – support representation and theorization, and enhance both the resonance and perceived validity of sensemaking and sensegiving. In addition, by providing insights into the ways in which multimodal compositions embed ideas in broader discourses and institutionalized myths, we also contribute to the phenomenological tradition in institutional organization theory.
The remainder of this article is organized as follows. In the next section, we establish the conceptual foundations of our work by enriching existing research and theory on sensemaking and sensegiving with established insights from visual approaches in organization theory in general, and with a social semiotic perspective on multimodality in particular. Having introduced the GFC as the empirical context and detailing our empirical research design, we present the inductively derived set of multimodal compositions and the central narratives they construct as our core findings. Our discussion then conceptualizes our findings and suggests distinct multimodal extensions of sensemaking and sensegiving mechanisms. We conclude this article by outlining core contributions, as well as boundary conditions of our work.
Theoretical Orientation: Multimodal Sensemaking and Sensegiving
Making sense of novel and complex phenomena
Research on sensemaking (e.g. Brown et al., 2015; Maitlis & Christianson, 2014) explains how elements are selected from the everyday flow of experiences and become encapsulated in abstract social categories when actors are confronted with something unintelligible that they need to understand. Accordingly, making sense of a phenomenon involves ‘labeling and categorizing to stabilize the streaming of experience’ (Weick et al., 2005, p. 411). The existing institutional context both enables and constrains sensemaking (Weber & Glynn, 2006), and sensemaking regularly creates novel typifications and classifications that may alter institutional environments (Weick et al., 2005).
Sensemaking is most likely to support the objectification of novel ideas when it is a collective, rather than individual, effort. We therefore rely on discursive approaches (e.g. Brown et al., 2015) that focus on the communicative resources of sensemaking and understand the production of texts as basis for institutionalization (e.g. Phillips, Lawrence, & Hardy, 2004). Nigam and Ocasio (2010) use the term ‘environmental sensemaking’ for processes of collective sensemaking regarding events and their social context. Public attention and communication are prerequisites for creating intersubjective understandings of new and complex incidents that are spatially dispersed and take place over longer periods of time (e.g. Fiss & Hirsch, 2005) and for which an established label is not readily available. Such sensemaking is often coordinated and influenced through sensegiving activities (e.g. Gioia & Chittipeddi, 1991; Maitlis, 2005) by central actors who can communicate globally and have agenda-setting capabilities. The news media, in particular, provides salient resources for social meaning construction (Gamson, 1992). It is ‘a sense-maker in that it takes part in developing a meaningful framework for understanding complex phenomena’ and ‘a sense-giver in that it also attempts to influence sense-making and meaning construction among its audiences toward specific definitions of “reality”’ (Hellgren et al., 2002, p. 123). These two roles cannot be clearly separated; they are two sides of the very same coin (Rouleau, 2005). Sensemaking efforts by the media draw on the sensegiving of actors in the field (e.g. how experts explain what is going on) and vice versa (e.g. public figures refer to the sensegiving of the media to legitimize their actions). The news media can therefore be understood as the public arena in which the sensemaking and sensegiving efforts of multiple actors coalesce and are evaluated and balanced according to editorial policies and agendas.
Processes of both sensemaking and sensegiving require certain components and mechanisms which gradually integrate them into the existing discursive and institutional frameworks. First, the event needs to be assigned with a distinct label and a ‘collective public vocabulary’ (Fiss & Hirsch, 2005), which turns a flow of circumstances into words and categories (Weick et al., 2005). A shared label increases attention towards the event, which in turn intensifies sensemaking, and linking a novel label to existing categories specifies its meaning. Exemplars of actors and incidents in the environment ground categories in perceived reality (Nigam & Ocasio, 2010). In sum, these elements provide an answer to the questions: What is going on, how can we talk about it, and what are its boundaries?
Second, categories and examples must be merged into a specific internal structure. Narratives are a central resource for sensemaking (e.g. Vaara, Sonenshein, & Boje, 2016; Vaara & Tienari, 2011), because they assign social roles to actors and imbue links between categories and examples with a temporal structure. Narratives about critical incidents can take on various genres or types (e.g. Boje & Rosile, 2003) that suggest different interpretations and evaluations of what is happening. Relationships between categories and examples (e.g. Loewenstein, Ocasio, & Jones, 2012) also create shared schemas (e.g. Ocasio, Loewenstein, & Nigam, 2015) that establish relations of cause and effect (e.g. Strang & Meyer, 1993). Narratives and schemas, accordingly, answer the questions: What is the story here, and how can we explain what is happening?
Third, and finally, narratives and schemas need to be coherently embedded in specific systems of meaning, such as broader discourses (e.g. Hellgren et al., 2002) or rationalized myths (e.g. Meyer & Rowan, 1977; Zilber, 2006) to become integrated with existing elements of the institutional framework in a meaningful way. While this can be achieved in various ways, research on sensemaking suggests that metaphor (e.g. Cornelissen, 2012; Sillince & Barker, 2012) and metonymy (e.g. Cornelissen, 2008) are particularly useful tools to anchor the unfamiliar in well-established discourses. While metaphor suggests understanding one thing in terms of another (less problematic one), metonymy cues larger bodies of knowledge through part-whole substitution. Together, they answer the question: How does what we experience fit into what we believe to be real and true? Our discursive perspective on sensemaking, accordingly, understands the social categories instantiated in texts as ‘building blocks’ of discourses (see also McKenna & Rooney, 2012), structured and integrated through the narratives and interpretive schemes that link them together.
Visual and multimodal aspects of sensemaking and sensegiving
Most research on sensemaking and sensegiving has focused on written and spoken text (e.g. Maitlis & Christianson, 2014). However, several scholars (e.g. Bell & Davison, 2013; Bell, Warren, & Schroeder, 2014; Höllerer, Daudigeos, & Jancsary, 2018) have argued that purely verbal discourse is both a myth and an analytical fallacy in contemporary society. Rather, discourse encompasses a variety of different ‘modes’ in addition to verbal text – most prominently visual (e.g. images, photographs, graphs, illustrations, or even typography) and material artifacts (e.g. Jones, Meyer, Jancsary, & Höllerer, 2017). It is through the simultaneous presence, interrelationships and mutual influence of multiple modes that meaning construction is achieved (e.g. Zilber, 2018). While some pioneering work has tapped into the potential for embodied (e.g. Cunliffe & Coupland, 2012), material (e.g. Cornelissen, Mantere, & Vaara, 2014), and visual (e.g. Belova, 2006; Cornelissen, Oswick, Thøger Christensen, & Phillips, 2008) sensemaking, little systematic insight on multimodal sensemaking and sensegiving exists to date.
Following Meyer et al. (2013), we suggest that a social semiotic view on multimodality (e.g. Kress, 2010) is a promising way of understanding meaning construction more holistically. Since social semiotics builds on a social constructionist foundation that stresses discourse as a generative force, while allowing for a certain degree of embedded agency, it is strongly compatible with both sensemaking/-giving and discursive approaches in institutional theory. A mode, in this perspective, is defined as a ‘socially shaped and culturally given semiotic resource of making meaning’ (Kress, 2010, p. 79). Modes resemble each other regarding their basic functions (the ‘what’ question): Every mode needs to realize representations of social reality, relations between viewer, content and producer, and internal coherence of texts (e.g. Kress & van Leeuwen, 2006, building on Halliday’s functional linguistics). In contrast, modes differ substantially in the ways in which they address these functions (the ‘how’ question). For instance, visual text provides spatial, holistic and simultaneous representations of social reality, while written and spoken text provides linear, additive and sequential representations (Meyer, Jancsary, Höllerer, & Boxenbaum, 2018). Visual text engages audiences through embodied subjectivities, while verbal text mostly does so through specific pronouns (e.g. Kress & van Leeuwen, 2006). Additionally, the meanings incorporated by verbal text are more arbitrary and conventionalized, while visuals have more potential for iconicity, that is, visual resemblance with material reality (e.g. Rowley-Jolivet, 2004).
Such semiotic ‘distribution of labour’ between modes suggests that sensemaking and sensegiving may flexibly draw from the available pool of resources provided by multiple modes and combine them in a way that is most suited for the specific issue, context and audience(s). Since every mode has distinct ways of supporting the elements and mechanisms outlined above, we need to further unpack their specific sensemaking/-giving potential. Existing literature provides a helpful starting point for further theory development by outlining several characteristics of the visual mode.
First, visuals extend the specific ‘register’ (e.g. Jancsary, Meyer, Höllerer, & Boxenbaum, 2018) of an event in both content and form. Studies utilizing visual cues for eliciting richer accounts from interviewees suggest that visuals enable access to parts of social reality that cannot be expressed in words. Warren (2002) shows how photographs provide ‘sensually complete’ accounts that include aesthetic and affective elements of individual sensemaking. Similarly, Slutskaya, Simpson and Hughes (2012) argue that photographs provide insights into physicality, aesthetics and affect where respondents were not able to express such ideas verbally. Iconic visuals suggest verisimilitude and facticity (e.g. Graves, Flesher, & Jordan, 1996) more plausibly than verbal text. By providing vast amounts of information in a limited space, visuals also communicate attributes of categories more efficiently than written text, for instance in the construction of cultural stereotypes (e.g. Elliott & Stead, 2017; Hardy & Phillips, 1999).
Second, the spatial composition of visuals provides additional means for relating categories and examples to each other. Visuals achieve both narrative and analytical constructions (e.g. Kress & van Leeuwen, 2006), depending on whether their spatial composition implies dynamic or static relations. While verbal text – due to its sequential structuring – is better suited to constructing the temporality of complex narratives, visual text allows for multidimensional spatial models, charts and diagrams which facilitate the construction of causal, hierarchical and attributive relationships (e.g. Meyer et al., 2018). Accordingly, they add a spatial dimension to theorization and narrative that verbal text cannot provide.
Third, visuals invoke broader discourses and myths through their capacity to bridge disconnected spheres of meaning and integrate them in complex compositions (e.g. Höllerer, Jancsary, Meyer, & Vettori, 2013). They embed novel ideas in shared understandings more subtly than verbal text and help avoid controversy (e.g. McQuarrie & Phillips, 2005). Cornelissen et al. (2008) sketch the idea of visual and multimodal metaphors. They argue that visuals may mark, instantiate and extend verbal metaphors, and therefore make them more potent by reinforcing them in a different mode of understanding. Such work suggests that visuals may help to embed novel ideas more coherently in a specific discourse and facilitate the creation of links between discourses, thereby anchoring a complex event in the existing institutional framework and furthering its objectification.
Apart from these characteristics that are directly relevant for sensemaking, visual text also creates stronger and more immediate attention (e.g. DiFrancesco & Young, 2011), which is considered a prerequisite for triggering sensemaking (e.g. Nigam & Ocasio, 2010). It has also been argued that visual text has almost achieved the status of a global visual language in our contemporary globalized world (e.g. Machin, 2004), which strongly facilitates sensemaking and sensegiving efforts across a variety of discursive and linguistic communities.
Empirical Study: The Global Financial Crisis as Portrayed in Business Media
In order to expand and deepen our understanding of how the interplay between semiotic modes in sensemaking and sensegiving activities is employed, we empirically study such efforts with regard to the complex, ambiguous and spatially dispersed phenomena and experiences that were eventually assembled and objectified into the consistent category of the global financial crisis (GFC). We analyse in more detail the multimodal discourse of the GFC as reflected in one of the most influential and global business media outlets: the Financial Times (FT). From its very first antecedents, the FT has accompanied the crisis with various commentary (for details, see Tett, 2009) and has played a crucial role in terms of both its considerable sensemaking and sensegiving capacity.
Research context: The global financial crisis
Numerous commentators have described the GFC as the most severe synchronized global economic disaster since the Great Depression (e.g. Forbes, Frankel, & Engel, 2012; Lounsbury & Hirsch, 2010; Morgan et al., 2011). Even though it has been suggested that its roots go back to various points in time, its beginning is often put at mid-2007, when the financial market for housing in the US started to face substantial problems (Helleiner & Pagliari, 2010). These early problems – often referred to as the ‘US sub-prime mortgage crisis’ – were mainly generated as a consequence of the bursting of the US housing bubble, which, during 2008, quickly spread around the globe, increasingly gathering momentum, and finally leading to the collapse of several stellar institutions within the finance sector (for a detailed overview, see e.g. Davis, 2010; de Cock, Baker, & Volkmann, 2011; Riaz et al., 2011).
The spectacular bankruptcy of Lehman Brothers, a prominent global financial services firm, had a highly symbolic value and is often referred to as the tipping point that brought in a distinct crisis rhetoric – with today’s financial world commonly being referred to as the ‘post-Lehman world’ (e.g. Lauricella & Gongloff, 2010; Schneider & Douglas, 2013). Several banks and finance institutes shared the fate of Lehman Brothers, being taken over by competitors, or bailed out with public money. It was at this point that commentators started to talk about ‘capitalism in crisis’ (see also Lounsbury & Hirsch, 2010; Morgan et al., 2011). The spread of the financial crisis beyond the US banking system – not only to other sectors, but also to other economies – had a ‘domino effect’ and severely impacted global stock markets and various non-financial sectors such as the global construction and automotive industries (e.g. Sun, Stewart, & Pollard, 2011). While some economies showed signs of considerable stabilization and recovery after 2012, others did not, with one of the most worrying developments being the enduring debt crisis in several Southern European nations. In a similar vein, the World Bank’s Global Economic Prospects (2014) notes that ‘four years after the global financial crisis hit, high-income countries struggle to restructure their economies and regain fiscal sustainability’.
Business media and the Financial Times
Business media have gained a prominent position within society at large (e.g. Kjær, 2010; Kjær & Slaatta, 2007; Tunstall, 1996), and thus constitute a key arena for sensemaking and sensegiving regarding economic and financial issues in particular. The representation of the GFC in the media provides specific social categories (e.g. for actors, incidents, settings and technical issues), models and narratives that give sense to the course of events, and broader discourses and myths, in which such narratives are embedded. Accordingly, business media are of key importance as to how corporations and other socio-economic actors understand and make sense of the world (e.g. Carroll, 2010; Carroll & McCombs, 2003; Vaara, Tienari, & Laurila, 2006). The print media format seems specifically suitable for multimodal analysis: methods for combining photos, illustrations and graphics with written text are particularly salient, since the format of the newspaper article is largely predefined and therefore stable. In addition, in times of crisis, news consumers tend to return to editorial media outlets as these are considered professional and trusted, rather than relying solely on alternative social media sources containing user-generated content and citizen journalism (e.g. Schifferes & Coulter, 2013).
We turn to the Financial Times (FT) as one of the most widely distributed and highly influential business media organizations. In comparison to other outlets, the FT has featured the largest amount of news articles on the GFC (Chalabi, 2010). Founded in 1888, it is currently published in five regional editions – UK, Europe, USA, Asia and the Middle East – and printed in 22 cities around the world. It thus has a global reach and functions as a universal commentator and agenda-setter, with readers encompassing ‘senior business decision-makers, high net worth consumers and influential policymakers’ (Financial Times/AGDA, 2015). Thus, the FT is widely regarded as one of the most prominent daily business newspapers with a worldwide distribution, and it belongs to the exclusive group of print niche media regarded as the ‘the global financial press’ (Samman, 2012).
However, prestige media are not only produced ‘by and for societal elites, aspirants to elite status, and other participants in the cultural mainstream’ (Deephouse & Suchman 2008, p. 56), but also set the agenda for less prominent media outlets with national or regional reach. They shape collective sensemaking more broadly and are central sites for creating, justifying and legitimizing meaning. Accordingly, we suggest that reporting in the FT is a fitting context for examining the sensegiving efforts that eventually led to the objectification of the many ongoing incidents into the distinct event of the GFC (see also de Cock et al., 2011; McKenna & Rooney, 2012).
Sample and data collection
Our observation period starts in 2008 and ends in 2012 (i.e. we sampled media articles over five calendar years). An explorative keyword search beginning in 2006 revealed that the label of ‘global financial crisis’ became dominant only after September 2008 when Lehman Brothers went into a tailspin.
Data was collected by using the advanced full-text search function on the e-paper repository of the FT. 1 By using the e-paper, the original composition of verbal and visual aspects as they appeared in the print version could be retained. We collected all articles that contained one of the following keywords either in the heading or in the lead: ‘global financial crisis’, ‘financial crisis’, or ‘global crisis’. By restricting the keyword search to title and heading, we made sure that the whole article was focused on the GFC (we were not interested in articles that only mentioned it in passing). Consequently, we could be relatively sure that visual content referred to some aspect of the GFC. We decided also to include articles where one or more of these keywords appeared in the page heading (i.e. the entire page was explicitly devoted to a discussion of the GFC). We downloaded – for each hit – the full page (i.e. not just the individual article) to gain a more comprehensive context for analysis. This initial collection yielded 795 pages.
We then reduced our initial sample further. First, we resolved any overlaps between the five editions of the FT, so that every article only appeared in our sample once. This reduced the sample to 409 pages. Most importantly, we also removed articles without multimodal elements – i.e. the combination of verbal text with photographs, images, drawings and/or graphs. After a further, more qualitative assessment as to whether the crisis was the primary focus of the articles, we were left with a total of 229 articles that were subjected to further analysis.
Methodology
We conducted multimodal discourse analysis (e.g. Jancsary et al., 2016; Machin & Mayr, 2012) based on Kress and van Leeuwen’s (2006) social semiotic theory of the visual. Since our research design is qualitative and inductive, we broadly followed the principles of grounded theory (i.e. constant comparative method; e.g. Glaser & Strauss, 1967). We relied on established techniques of hermeneutic analysis (e.g. Jäger & Maier, 2016; Lueger, Sandner, Meyer, & Hammerschmid, 2005) to reconstruct the underlying meanings structures in the data. Our analytical procedure entailed a constant interlocking of cycles of data inclusion, analysis and interpretation, and team interpretation in all phases of the analysis.
We understand news reporting on the GFC in the FT as a distinct ‘discursive strand’, defined as ‘flows of discourse that centre on a common topic’ (Jäger & Maier, 2016, p. 121) in which verbal and visual elements are interwoven for purposes of sensemaking and sensegiving. At the beginning of our analysis, we artificially separated verbal and visual meanings in order to examine their interplay. We then reassembled them to reconstruct central multimodally composed narrative types. In line with our multi-layered conceptual understanding of sensemaking/-giving, our analysis spans different degrees of abstraction and comprehensiveness. Starting from the narrow construct of verbal and visual ‘grammar’ (e.g. Kress & van Leeuwen, 2006), we first identified individual categories and ‘imageries’ as building blocks for sensemaking and sensegiving. We then focused on the relationships between elements by reconstructing individual discourse fragments 2 on the level of the individual article, and combined these fragments into typified narratives that constitute the primary efforts of giving sense to the complex and ambiguous phenomena that characterize the GFC.
While our analysis proceeded in four distinct steps (see Figure 1), the principles of hermeneutic research demand that individual steps are not always followed in a strictly linear manner. Whenever necessary, going back to previous steps is encouraged to ‘thicken’ interpretation and better grasp the typicality and validity of codes and categories. An exemplary analysis can be found in the appendix.
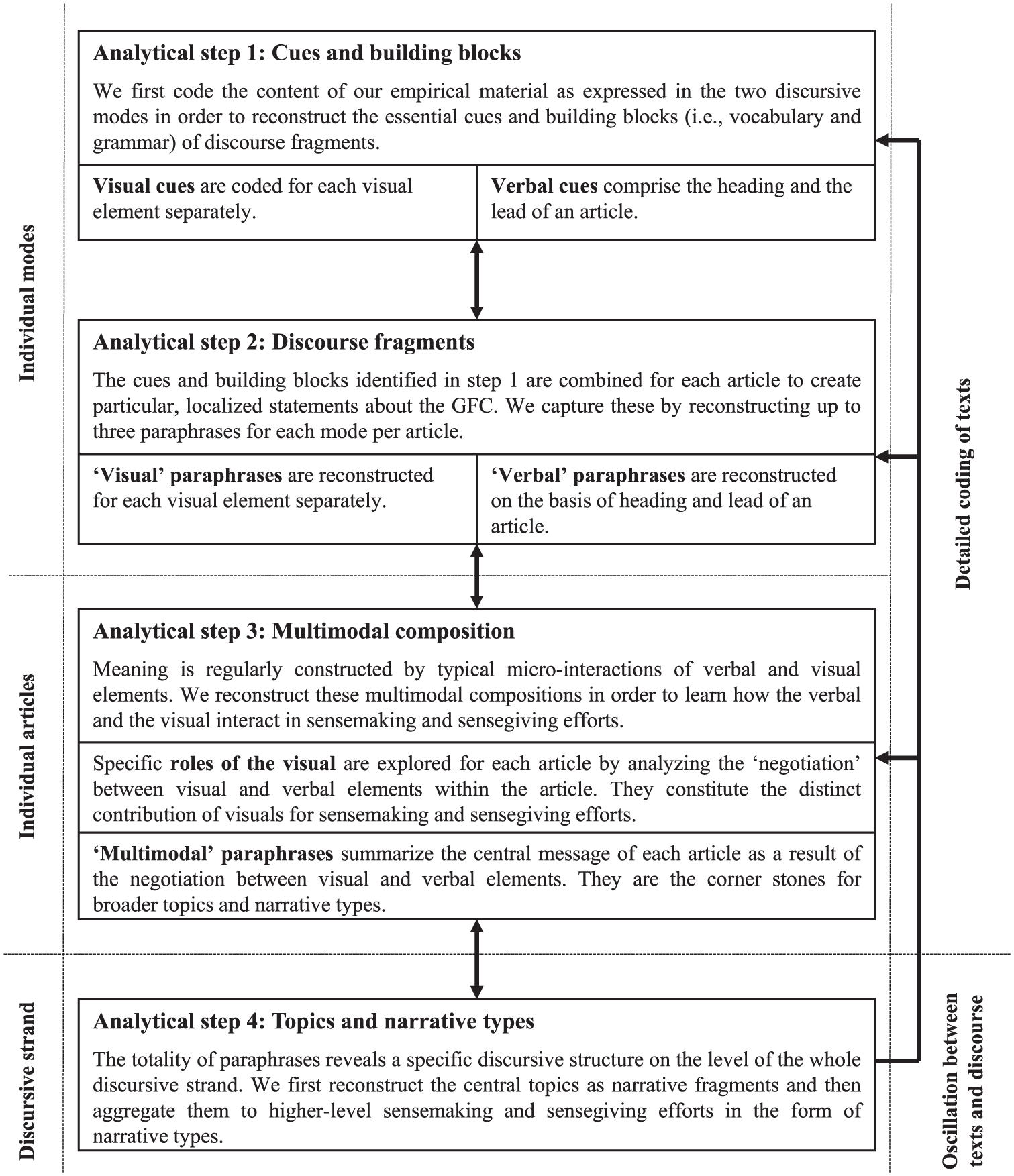
Analytical steps (adapted from Jancsary et al., 2016).
Coding and analysis
In a first step, we coded each individual visual element in detail to reconstruct the particular visual register (e.g. Jancsary et al., 2018) of the GFC. Building on Kress and van Leeuwen’s (2006) visual grammar, we coded for represented social reality (e.g. subjects, objects, actions and settings), ways of relating texts to audiences through distinct viewer positions (e.g. eye contact, perspectival angle, distance), and visual and aesthetic genres (e.g. photographs, paintings or charts). We thereby inductively reconstructed a set of manifest (e.g. cast of actors, incidents, artifacts) and latent (e.g. mood, atmosphere or emotions) categories (for similar coding, see Höllerer et al., 2013). We refrained from analysing, in depth, the full text of the articles, as this would result – for reasons of sheer quantity – in a strong bias towards the verbal. Instead, we reconstructed the core verbal line of argument as represented in heading and lead. First, this enabled us to focus our analysis on the most prominent and most immediate verbal and visual elements of a news article; second, it kept their weight reasonably balanced, allowing for an examination of the central axis of multimodality in this genre.
In a second step, we focused on the relationships between coded elements on the level of the individual article to reconstruct discourse fragments as micro-level instantiations of sensemaking. We applied a modified analytical grid as suggested by Lueger et al. (2005) to contextualize the meaning of individual cues. By systematically answering questions about the sampled images (e.g. ‘What preconditions are necessary for the image to make sense?’, ‘What are the logical consequences if what the image tells us is true?’), we reconstructed up to three paraphrases per image. Taking the perspective of an informed public, the reconstruction of paraphrases was guided by everyday, socially shared knowledge, rather than scientific knowledge. Each paraphrase constituted a rather narrow proposition about different aspects of the GFC. We applied the same procedure for corresponding verbal text in the articles. Our analysis yielded 167 unique paraphrases of visual and 165 unique paraphrases of verbal cues. Exemplary paraphrases included, for instance: ‘The GFC has a direct impact on individuals’, or ‘The GFC creates the need for protection’.
The third step was dedicated to exploring relationships between paraphrases of verbal and visual cues to reconstruct the specific role that visuals take vis-a-vis the verbal in distinct multimodal compositions. For each article, we extensively compared paraphrases of verbal and visual content through team interpretation and interweaved them into one distinct paraphrase of multimodal cues (e.g. ‘In order to protect the general public from the dangers of uncontrolled corporate power and to prevent another financial crisis, the EU proposes novel regulation’). We coded the relationships between modes along the question: ‘What are the distinct contributions of the visual in creating the multimodal paraphrase?’ Codes gradually stabilized across the three dimensions of relationships regarding scope (extend, detail, contrast), layers (emotion, humour, aesthetics, facticity), and form (replication, symbolization, formalization, classification, exemplification) of information.
Building on the resulting 212 paraphrases, the fourth step explored how the discursive strand reveals broader and typified (i.e. detached and generalized from the immediate context of the article) proposals for making sense of the GFC. The whole research team cross-read the final set of paraphrases against the question: ‘How does this help us make sense of the GFC?’ Codes were developed through constant comparison (e.g. Glaser & Strauss, 1967), and started with labels such as ‘victims’, ‘accountability’ or ‘search for solutions’. Refinement in multiple iterative steps of group interpretation resulted in 29 broader topics that were further grouped into a set of eight distinct narrative types. While these narrative types were represented only as fragments (e.g. Vaara et al., 2016) on the level of the article, they revealed intricate forms of sensemaking and sensegiving on the level of the discursive strand. Each of them helps to ‘tame’ the chaotic experiences of the time by bracketing different aspects and bringing them into a comprehensible narrative form, thereby enabling diagnosis and prognosis. The paraphrase mentioned for the third step above, for instance, became part of the topic experts to the rescue. Together with in search of answers and complexity and trade-offs it revealed the narrative type of the ‘heroic quest’.
Finally, and in order to engage with, and extend, existing theory, we discuss below our findings in the light of previous literature on sensemaking and sensegiving. We inquire in more depth into how the multimodal compositions we identified in our empirical material and data create and shape specific narratives – and how this extends our prevailing insights into mechanisms of sensemaking and sensegiving. By aligning our empirical findings with the requirements for sensemaking and sensegiving outlined in the conceptual framing, we suggest that multimodality both enriches the content and bolsters the persuasive appeal of narratives, and therefore supports sensemaking and sensegiving.
Multimodal Composition: Bringing Verbal and Visual Elements Together
The central aim of this article is to take visual and multimodal meaning seriously when studying how sensemaking and sensegiving eventually lead to the objectification of a global event based on a series of spatially and temporally dispersed incidents. Accordingly, we first present findings regarding the interplay between the two semiotic modes as a resource for sensemaking and sensegiving. We then continue to outline the multimodally composed narratives on the GFC that emerge because of such interplay.
Our presentation of this first part of our findings accepts the workings of verbal text as well documented in linguistics, communication studies and discourse analysis, and mainly probes into the various typical ways in which the visual interacts with the verbal. Three aspects of such interaction emerged from our inductive comparative analysis of verbal and visual paraphrases. First, the visual alters the scope of information. Second, the visual adds additional layers of information. Third, and finally, the visual offers alternative forms of presenting information.
Multimodal composition and the scope of information
Adjusting the scope of information through the interplay of visual and verbal text builds on the ability of the visual to condense large amounts of information in limited space and create attention immediately (e.g. Bloch, 1995; Meyer et al., 2018). Consequently, it supports sensegiving and sensemaking by either focusing attention on contextual information or specific details – or, in rare cases, contrasting verbal and visual messages.
Extending the written word means that visualization links elements of the verbal text to broader meaning structures (e.g. myths and discourses) that are otherwise not immediately conceivable (e.g. Lefsrud, Graves, & Phillips, 2018). Such an extension provides a broader symbolic or theoretical backdrop against which specific incidents or actors may be understood. For instance, an article on the financial problems of energy providers is visually illustrated with a set of smoking chimneys. This rather loose connection between the verbal and visual part of the text links financial and environmental issues – and firm performance to broader environmental threats.
Detailing the verbal, on the other hand, entails that visualization focuses attention on a specific aspect or part of the issue that it presents in greater detail. Since these aspects are implied to be more important, or more typical, than others, detailing creates a hierarchy of relevance. Such a technique either makes complex topics more comprehensible through highlighting the most important aspects, or provides visual proof of their existence. A good example from our data is an article on geopolitical shifts due to the crisis. While the verbal text describes upheavals all over the Western world, the visual part is a cartoon of a Chinese manager sitting in front of a safe overflowing with money. Although the overall issue is much more complex, the combination of headline and image suggests a shift of power towards Asia.
Finally, a powerful technique is contrasting verbal and visual elements, which reveals the internal contradictions and complexities of a topic. Contrasting extends, but also subverts, the verbal information in the article, thereby creating completely new meanings. This resembles how irony creates spaces for innovation through questioning established social knowledge (e.g. Sillince & Barker, 2012). Contrasting is a risky technique, since it may trigger additional sensemaking, but may also lead to increased confusion and uncertainty. For instance, a report on a new downturn in markets is accompanied by an image of a politician celebrating in front of fireworks. While highly contradictory at first glance, such contrasting triggers reflection about the decoupling of economic prosperity and political success.
Multimodal composition and layers of information
A second way in which visual text adds resources for sensemaking and sensegiving is by providing additional layers of information to the verbal message. Visuals facilitate making sense of the crisis in emotional, aesthetic and humorous ways. While verbal text is generally able to produce similar effects, this requires more effort, and may also violate the rules of serious business reporting, while visuals are subtler in their transgression of norms (e.g. McQuarrie & Phillips, 2005). Visuals also enhance accounts with claims towards facticity, which verbal text may not achieve at all.
First, visuals are very well suited to conveying and triggering emotions. Two different variants of this technique exist. On the one hand, whenever people are depicted, emotions of participants in the image can be represented through gesture, facial expressions or posture (see e.g. Feng & O’Halloran, 2012). A common example are the frequent images of shocked and crying traders. Such portrayals of emotion have been found to create strong emotional spillovers (e.g. Brantner, Lobinger, & Wetzstein, 2011). On the other hand, images elicit emotions from the audience through specific perspectives, colours and emotional symbolism (e.g. Colombo, Del Bimbo, & Pala, 1999). An article claiming that principles of sustainability will not be abandoned features a photograph of wind turbines against a beautiful and dramatic sunset, thereby enhancing the reassuring verbal message with reinforcing, affective cues.
Second, visuals provide aesthetic cues. In our data, this primarily means the use of artistic photography and drawings, or the reproduction of historical paintings. Aesthetic elements invoke specific regimes of evaluation (Kress & van Leeuwen, 2006). They also create additional attention in business reporting, since they are rather uncommon. For instance, illustrating the efforts of central banks to stanch the effects of the crisis with the painting ‘The Land of Cockaigne’ by Dutch painter Pieter Bruegel alludes to the topic’s sophistication, while using a comic book style image to illustrate uncertainty on the housing market insinuates the more profane nature of such problems.
Third, visualization also adds humour and satire. This may alleviate the gravity of the threat by making light of the rather worrying problems some actors are facing (e.g. Bell, 2012). More often, however, humour is used to exaggerate specific characteristics of incidents and actors. In such cases, it is a way of shielding problematic and potentially offensive statements from criticism. For instance, in the Bruegel painting mentioned above, central banks are portrayed as obese men, gorging on food without investing any effort. This potentially harsh critique is, however, alleviated through the stylized and humorous way in which it is presented.
Fourth, and finally, visualization adds claims towards facticity of information to the written word, underscoring that news reports are not made up, but relate to actual incidents and facts (e.g. Maier, Slovic, & Mayorga, 2016). One way to provide facticity is through naturalistic imagery. For instance, a report claiming that Wall Street managers are being held accountable for their role in the crisis is substantiated by showing these managers sitting in court. Nameplates on the desk clearly identify them as the individuals in question. In a different way, facticity can also be implied through exact measurement, as in the case of a diagram showing decreasing banking performance as empirical proof that the crisis is not yet over.
Multimodal composition and forms of presenting information
The same aspect of social reality can be presented in a variety of ways with different consequences for sensemaking and sensegiving. A person, for instance, can be depicted either as a distinct individual (usually a portrait) or as a specific class of actor (e.g. by focusing on categorical features, such as a stethoscope for a physician). An action or incident can either be depicted naturalistically (e.g. two people talking to each other) or conceptually (e.g. an arrow leading from one box to another). An abstract concept like ‘justice’ can be visualized by a conventionalized symbol (e.g. weighing scales) or a specific example (e.g. an imprisoned criminal). We find a variety of such forms in visual text.
To start with, visualization may aim at simple replication of verbal text. Such visuals are meant to precisely depict parts of the verbal argument, information or subject. In complex issues, such as the GFC, it is not surprising that replication is rare and almost completely restricted to illustrating testimonials of specific people (e.g. experts, leading personae in the field). Also, pure replication is an illusion: there is no literal image in a pure state, and each and every visualization constitutes a distinct perspective (e.g. Kress & van Leeuwen, 2006).
Symbolization of verbal discourse is primarily realized as metaphors, transferring the meaning of a source domain to a target domain (e.g. Cornelissen, 2012; for metaphors of the GFC, see, for instance, Tourish & Hargie, 2012). This embeds an object in a distinct system of meaning, thereby creating novel opportunities for sensemaking and knowledge creation (e.g. Biscaro & Comacchio, 2017). Visuals have their own way of realizing metaphors (e.g. Feng & O’Halloran, 2013). For instance, a person in a corporate setting taking an escalator downwards symbolizes the verbal message that high-ranking managers are facing pay cuts and job loss. The image of a broken shield firmly establishes loss of protection as a result of the G20 not being able to agree on financial regulation. Symbolization is a means of meaning extension and often involves emotion, humour or aesthetics.
Visualization also provides formalization, that is, conceptualization and measurement of verbal arguments. Formalization aims at explaining and theorizing (e.g. Strang & Meyer, 1993) an issue by relating elements of a narrative to each other conceptually. For instance, in an article on the failure of a bank, a timeline contextualizes the incident by linking the most important milestones to each other. Formalization also means operationalization and quantification. The graph showing decreasing bank performance mentioned earlier is a fitting example. Since formalization links the specific to the general, it constitutes an extension of meaning. It also strongly claims facticity.
Classification means that visualization presents particularly salient categories as representative of a specific verbal message. A common way in which such classification is used in our data is as metonymy – the representation of a whole by its parts (e.g. Cornelissen, 2008). The caricature of rich Asian businessmen signifying the growing economic power of Asian countries is a good example. In another article, a courtroom setting metonymically refers to the justice system as a whole. Classification is a particularly strong technique for detailing verbal text. In order to clarify the status of a depiction as a category rather than representation, aesthetic styles, humour or emotions are often added to stress or even exaggerate features.
In comparison to both representation and classification, exemplification shows distinct and concrete elements of a news story (i.e. category members rather than abstract categories). It provides further details about parts of the verbal text by materialization instead of typification (e.g. Meyer et al., 2018). For instance, in an article about growing problems in the Ukraine, a photograph shows a discussion between the prime minister and the president as one concrete instance of ongoing crisis talks. Exemplification is meant to define a particular person or incident as part of the overall topic. It is predominantly achieved through naturalistic depiction to increase perceived facticity.
Narratives of the Global Financial Crisis in the Financial Times
Within the highly institutionalized sphere of media reporting (e.g. Benson, 2006; Cook, 1998), newsworthy incidents are assigned specific meaning(s) as they become contextualized, framed and encapsulated in broader ideas through narrativization. In the case of complex and multifaceted events like the GFC, one can expect various layers of meaning to proliferate under the same label. Narratives provide simplification and increase comprehensibility to enable a new label’s further spread, and, finally, objectification. We present, in Table 1, the eight narrative types that represent the sensemaking and sensegiving efforts within our empirical sample. While visuals do not construct any narrative type by themselves, they support, complement and extend them in the ways outlined above. We summarize each narrative type in an ideal-typical statement and then present its dominant visuals.
Narrative types within the discursive strand of the global financial crisis.

Although our data does not allow for a more systematic analysis of the position of these narrative types in broader discourses, we can still appreciate how they link the originally unintelligible incidents constituting the GFC to established myths (e.g. Meyer & Rowan, 1977; Zilber, 2006) and discourses within the shared stock of knowledge. The narrative structure of sensemaking and sensegiving efforts frames the GFC as a crisis event with a beginning, a projected end, a set of stages and a cast of actors being involved in a variety of episodes (e.g. critical event, silver linings, self-healing, it’s not over yet). Further, such change is embedded in a myth of evolution and adaptation, implying a ‘survival of the fittest’ (e.g. tales of survival, test of mettle, the world has changed, new opportunities, resilient capitalism). Such evolutionary imagery is complemented by an allusion to the myth that all change is painful (e.g. meet the victims, social unrest) and fights for resources are inevitable (e.g. political shifts, political controversies, international discord). The narratives also reify social elites (e.g. experts to the rescue, in search of answers, political heroes) and stress individualism and individual responsibility (e.g. meet the victims, identify the culprits, test of mettle) while sometimes referencing collectivist ideas, albeit less heroically (e.g. we are in this together, global threat). In summary, the discursive strand of the GFC firmly places the event in a shared symbolic universe that explains it (partially by invoking ‘the devil we know’).
Discussion
How does visual text contribute to encapsulating complex, spatially dispersed phenomena in a shared label representing an externally bounded, yet internally differentiated event which eventually becomes widely perceived and experienced as social fact? Our findings have shown that sensemaking and sensegiving efforts within the FT involve a variety of multimodal compositions that, together, create eight narrative types outlining and bounding the GFC. In this section, we discuss our findings in light of their relevance for sensemaking and sensegiving theory. In linking our empirical insights back to our conceptual framework, we suggest that multimodal compositions affect both the narratives as well as their persuasive appeal.
Figure 2 provides a schematic overview of how multimodal compositions may affect sensemaking and sensegiving efforts on two dimensions. Dividing the circle into an upper and a lower part shows how visuals – in their relationships to verbal text – enrich the content of narratives through theorization or representation (see Nigam & Ocasio, 2010). Dividing it into a left-hand and right-hand part, in contrast, shows how interactions of visuals with verbal text bolster the persuasive appeal of narratives through enhancing their perceived validity or resonance. Despite such analytical differentiation of mechanisms, Figure 2 should not be misunderstood: In practice, multimodal texts may realize multiple mechanisms simultaneously, depending on which strengths and communicative potentials of the visual mode are particularly salient for a certain narrative. Our example in the appendix, for instance, combines a variety of mechanisms as discussed in detail below.
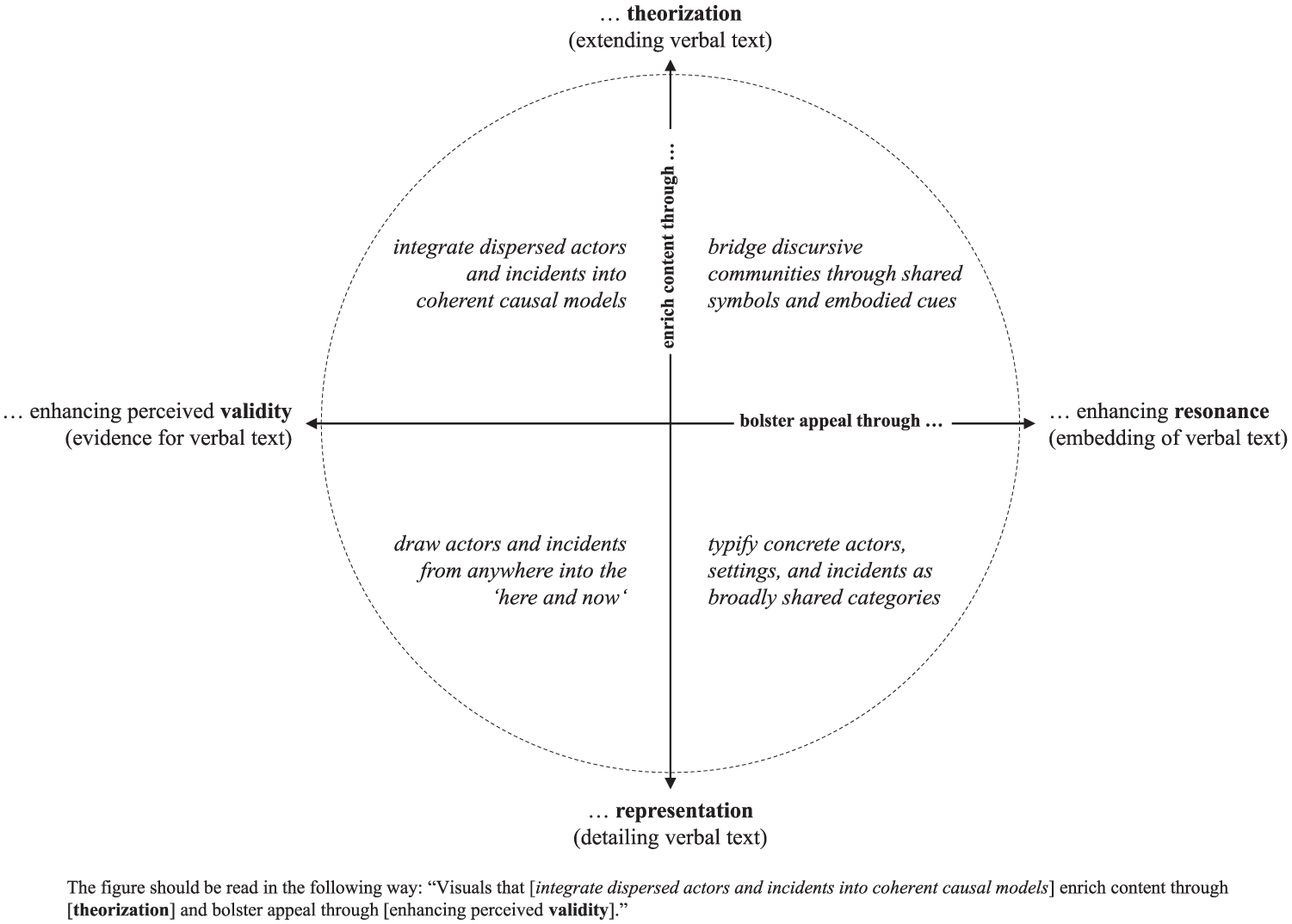
Mechanisms of multimodal sensemaking and sensegiving.
Enriching the content of narrative types
Collective sensemaking and sensegiving need to achieve a publicly shared system of categories (e.g. Fiss & Hirsch, 2005), on the one hand, and to link categories internally to schemata and narratives (e.g. Ocasio et al., 2015; Vaara et al., 2016) and externally to existing discourses and myths (e.g. Hellgren et al., 2002; Zilber, 2006), on the other. Drawing on Nigam and Ocasio’s (2010) concept of environmental sensemaking through representation and theorization, we elaborate how multimodality shapes and extends the potential of texts to achieve these requirements.
Representation, that is, the use of exemplars and specific features of an issue or field as resources for sensemaking (Nigam & Ocasio, 2010), is supported by visuals that detail the meaning of the verbal narrative. Linking novel phenomena to categories and examples (e.g. Loewenstein et al., 2012), as well as imagery (Höllerer et al., 2013) makes them more concrete and palpable than verbal text could ever achieve alone. Exemplification addresses the core challenge of distributed sensemaking that global events ‘may not be experienced equally or directly encountered by those who interpret and act upon them’ (Fiss & Hirsch, 2005, p. 29). Naturalistic photographs draw concrete and contextualized actors and incidents into the ‘here and now’. It is in this way that the facticity of claims is enhanced, which may be further supported by emotions displayed by the people depicted. Classification typifies concrete actors, settings and incidents as broadly shared categories, often metonymically (e.g. Sillince & Barker, 2012), to facilitate a shift from vague to clear, and to subsume whole ideas into single, memorable images. Visual classifications abstract from the intricacies of concrete social reality, for instance, by removing background and setting, and by adding or exaggerating typical features of a category (e.g. typical dress, mimicry, body stance or props; see, for instance, Hardy & Phillips, 1999). Such abstraction can be further complemented by adding emotion, humour or aesthetics. Exemplification and classification often go hand in hand in visuals (e.g. Meyer et al., 2018), which requires verbal text to tell recipients whether a visual is meant to concretize or abstract. In the appendix, the caption reveals that the person depicted on the bottom left is a specific actor, while the person in the top right visual remains undefined (as a proxy for the ‘typical citizen’).
Theorization refers to the creation of abstract models defining relations between categories and the rationalities guiding these relations (Nigam & Ocasio, 2010; see also Strang & Meyer, 1993). It is supported by multimodal compositions extending the meaning of the verbal elements. Formalization integrates dispersed actors and incidents into coherent causal models (e.g. diagrams and charts) based on aggregated data. Visuals display complex relationships and vast amounts of data in a way that can be processed rapidly (e.g. Kress & van Leeuwen, 2006; Rowley-Jolivet, 2004). Maps, charts and infographics are much better suited to integrate spatially and temporally dispersed incidents into a single event than verbal text, and endow claims with a certain facticity. Symbolization employs metaphor and analogy as central vehicles for sensemaking (e.g. Cornelissen, 2012; Etzion & Ferraro, 2010). Visual metaphor bridges discursive communities through shared symbols and embodied cues (for instance, lightning to evoke forces of nature). These general visual cues, Machin (2004) argues, have become an almost globally comprehensible visual language, often drawing on emotion, aesthetics and humour to exaggerate the message and draw viewers into the visual. Such extension – and sometimes contrast – of verbal elements addresses both an event’s internal structure (relationships between elements) and its relationship to broader myths and discourses. Additionally, it supports linking events to myths through bridging divergent discourses and spheres of meaning (e.g. Höllerer et al., 2013). Referring to the appendix, the top right image is an example of symbolization that links the looming crisis to overbearing corporate power and uncertain weather, while the graphs below constitute an attempt at formalization.
Bolstering the persuasive appeal of narrative types
Our findings reveal that multimodal compositions not only affect the content of narratives, but may also provide additional resources to increase the persuasive appeal of sensemaking and sensegiving efforts. While we do not claim that multimodal text is necessarily more successful than purely verbal variants, we suggest that multimodality extends the repertoire of text producers. Especially in cases of spatially dispersed incidents that necessitate sensemaking across a variety of discursive communities, making narratives resonate and be perceived as valid is a major effort.
Resonance of new and complex issues is increased by embedding the unknown in familiar contexts. This entails the evocation of broadly shared categories (classification) and discourses (symbolization), but also transcending strictly cognitive understanding by adding emotional cues, aesthetics and humour. These provide a ‘feeling’ for a complex event (e.g. Should I feel threatened or reassured?) and serve as cues for action. This finding ties in with more embodied approaches, claiming that sensemaking is more than just information processing, and draws on intuitive and embodied feelings (e.g. Cunliffe & Coupland, 2012; see also Maitlis & Christianson, 2014). Visuals enable sensegiving to add such cues through their ability to communicate emotions, aesthetics and embodied subjectivities (e.g. Belova, 2006). The top right photograph in the appendix illustrates all these elements excellently: typified imagery is combined with strong symbols and a general atmosphere of gloom.
Validity (i.e. correspondence to the ‘real world’) of sensemaking and sensegiving efforts becomes an issue when narratives are comprehensible but their truth value is questionable. The perception of validity requires that claims are supported with unproblematic ‘facts’. In contrast to resonance, therefore, validity is strengthened through adding claims towards facticity, which may also involve reducing emotion, aesthetics and humour (except for emotions expressed by participants in the image, which may enhance facticity). Visuals claim validity either by providing exemplification through ‘objective’ naturalistic representation (e.g. Graves et al., 1996), or through the graphical presentation of empirical data (formalization). In the appendix, validity claims are bolstered, on the one hand, through ‘giving a face’ to the European Union, and through visualizing data on the capital ratios of banks.
Contribution and Conclusion
Our study has considerable implications for research on sensemaking and sensegiving. Specific characteristics of the visual mode (i.e. iconicity, facticity, multidimensionality, or embodied positioning) are crucial in efforts to encapsulate complex experiences into a shared label that represents an externally bounded, yet internally differentiated event and in enhancing both the perceived validity and resonance of sensegiving efforts. Accordingly, we further unpack existing insights on environmental sensemaking (Nigam & Ocasio, 2010) by showing how different communicative resources are combined to achieve it, and also broaden it by discussing how multimodality not only enriches the content, but also bolsters the persuasive appeal of sensemaking and sensegiving efforts. This emphasizes the practical value of the semiotic division of labour (e.g. Elliott & Stead, 2017; Meyer et al., 2013). As a consequence, research that ignores visuals or treats them analogically to verbal text may run the risk of missing large parts of what is actually going on. Our findings add to existing work that has acknowledged the existence of multiple modes in, and of, sensemaking (e.g. Cornelissen et al., 2008, 2014) by providing a more systematic account on how different modes contribute to narrative sensemaking and sensegiving (e.g. Vaara & Tienari, 2011). A better understanding of the contribution of visuals in their interaction with verbal text also extends research that has focused on visual narratives in collective sensemaking (e.g. Bell, 2012). In our study, visuals are employed to complement verbal text through unique features and affordances (Meyer et al., 2018) that the verbal mode cannot achieve on its own: creating an impression of ‘face validity’, bringing the ‘there and then’ into the ‘here and now’, simulating embodied subjectivities, and creating multidimensional accounts and models. Future research could take our insights further by studying, for instance, the success of multimodally composed narratives in sensemaking and sensegiving in comparison to purely verbal narratives. Additionally, our study suggests that visuals inhabit a middle-ground position between more cognitively based sensemaking relying on verbal text and ‘embodied and sensual sensemaking’ (e.g. Cunliffe & Coupland, 2012) based on material reality. While visual artifacts are texts – frozen in time and space – that need to be decoded cognitively, they can transport sensual, aesthetic and affective impressions through suggesting distinct subjectivities (e.g. Kress & van Leeuwen, 2006). More research is therefore needed to explore how visuals may mediate between knowing and feeling in sensemaking and sensegiving efforts.
Our study also contributes to literature on the discursive construction of institutions. Phillips et al. (2004) suggest that sensemaking and sensegiving are starting points for institutional processes, leading to the construction of texts that become embedded in discourses on producing and sustaining institutions. Although sensemaking is already embedded in a world of texts, discourses and institutions (e.g. Weber & Glynn, 2006), our study confirms that linking texts to broader discourses is an important aspect of sensemaking and sensegiving. Our findings, therefore, have implications for the emergence and institutionalization of novel categories. Munir and Phillips (2005), for instance, identify four prerequisites for institutionalizing a new category: embedding it in existing discourses, suggesting new subject positions, creating new discourses and changing existing discourses. Despite the ‘visual’ nature of their subject matter (i.e. snapshot photography), they remain surprisingly silent about the specific role of visualization. Our study shows that visual cues are vital in the narrative emergence of novel institutions (e.g. Zilber, 2006) and suggests that visual forms of interdiscursivity are an important aspect of the objectification of novel ideas. Research (e.g. Navis & Glynn, 2010) has shown that initial efforts in category emergence are directed towards claiming similarity between members, whereas differentiation between members becomes more salient later. Our findings suggest that visuals play a role both in legitimizing broader categories and in detailing their internal differentiation.
As with any research, our study has certain limitations that, at the same time, open up avenues for future research. A central limitation of this study is its restricted focus on one genre of print media. Samman (2012) shows that even within the business press, the treatment of the GFC varies substantially. Other genres, therefore, may reveal additional forms of sensemaking/-giving for different audiences. Future research might look, for instance, at tabloid formats that are likely to rely more strongly on emotional and attention-grabbing forms of visualization. Today’s digitalized media landscape also underlines the need for research that goes beyond traditional print media: new online media are reorganizing the communication landscape and changing conditions for the use of visuals (see e.g. Leonard, 2014; for the GFC and social media, see Baden & Springer, 2014). The digitalization of media production and consumption also allows for more active audiences – a development that offers great opportunities for scholarly work with an interest in understanding how audiences participate in the (co-)production and consumption of ideas, for instance in various social media such as Twitter and Facebook. In terms of methods, we encourage more detailed hermeneutic analyses focusing on the interaction of verbal and visual modes on both the manifest and latent levels of meaning construction. Semiotic approaches like that of Unsworth and Cléirigh (2011) show that such interaction is a complex matter. In addition to reconstructing typical compositions, more detailed engagement with multimodal registers (e.g. Jancsary et al., 2018) may be fruitful. Finally, future research might also aim at contrasting our findings with other topics and issues, thereby exploring whether the type of issue has a systematic effect on its multimodal construction. Corporate scandals (e.g. Rhodes, 2016) or new forms of organizing in the sharing economy (e.g. Kornberger, Leixnering, Meyer, & Höllerer, 2017) require distributed sensemaking just as much as broader societal issues such as climate change (e.g. Lefsrud & Meyer, 2012) or the global trend towards nationalist populist movements.
Footnotes
Appendix
The title of the article at hand claims that the ‘EU leads the field with plan on bank capital’, and the article lead specifies that ‘implementing rules aimed at averting another financial crisis will not be a painless process’. It is followed by a reference to the author Nikki Tait. In the first, larger photograph, we see a single adult person of unclear gender and ethnicity holding an umbrella. In the background, we observe commercial buildings, probably financial institutions (as indicated also by the caption). Two dynamics are implied: the person is walking past, and it is raining (although the rain is not clearly visible and only implied by the open umbrella). The setting is urban, the distance is social (i.e. showing the entire person). In terms of perspective, the frog’s eye view puts the viewer in a less powerful position; power is most clearly assigned to the bank buildings. The lighting is rather dark. The darkness and the rain imply an emotional effect of feeling uncomfortable, the overall atmosphere is inhospitable, almost threatening. The image alludes to an economic value sphere (the bank buildings) and more social values (protection). The second, much smaller image has a more restricted visual code. It shows a single white male adult with no additional props or objects. The only dynamic is an implied adjustment of his glasses. The shot is intimate and at eye level, implying an offer of identification, but there is no eye contact. Instead, the gaze of the man seems to be towards the first image above. The portrait expresses thoughtfulness and focus, and an atmosphere of seriousness. The third visual element – an infographic – consists of diagrams showing capital ratios and requirements as well as their developments. Their colour scheme is aligned with the other two visuals, creating a clear relationship between them.
The visual content of the first image was summarized by three paraphrases: (1) The GFC has a direct impact on individuals; (2) the GFC creates the need for protection; and (3) the GFC is linked to abstract corporate power. The second image generated by two additional paraphrases: (4) The GFC creates a need for determination and/or action; and (5) the GFC creates a need for expertise and/or focus. Finally, the verbal part (title and lead) was expressed through two more paraphrases: (6) The GFC creates a need for regulation; and (7) the GFC leads to a painful process of change. 3
The first, larger photograph realizes the content of the article in a primarily symbolic way. Regulation is depicted as the umbrella, a very different but more easily comprehensible tool of protection. The public is symbolized by the blurry figure below the umbrella, while the dangers of the financial sector are included through the towering buildings in the background. The umbrella is clearly positioned in between the buildings and the person. These symbols realize a metaphorical take of the story that simplifies it and makes it more comprehensible. Additionally, the photograph elicits emotion and adds aesthetic aspects to the story that the verbal ignores. Both title and lead – with the exemption of the suggestion that the process will not be painless – avoid emotional language, but remain rather technical and neutral. The photograph contrasts this mood. In this way, the visual design of the first photograph extends the meaning of the verbal. The second, smaller photograph has a very different relationship to the verbal. It exemplifies the verbal by using Michel Barnier as a cue for the European Union. In this sense, it personalizes an institutional actor by giving it a face (and factual existence). Instead of extending the meaning of the verbal, it details and specifies it, thereby increasing the article’s credibility. Through facial expression, it also subtly represents emotion. The third visual element, finally, formalizes, or operationalizes the content of the verbal. It shows precisely what such regulation would be concerned with. This adds another layer of facticity to the article. It also extends the verbal aspects of the article through referring to a theory in which capital ratios are important for sound banking. Together, the composition of the multimodal text shows a certain division of labour. The larger image catches attention, elicits emotion and immediately communicates the central aspect of the article (i.e. protection from danger). The other two visuals specify this initial claim and anchor it more strongly in perceived reality and the scientific world. Combining our interpretations of the three visual elements and the verbal text, we therefore formulate the multimodally derived paraphrase of the article as follows: In order to protect the general public from the dangers of uncontrolled corporate power and to prevent another financial crisis, the EU proposes novel regulation.
When abstracting the multimodally derived paraphrase from its immediate context, we reveal a more general suggestion that experts are responsible for the protection of the general public by keeping the dangers of the financial market at bay. There is also a clear claim that such protection is possible, and that further crises can be avoided. Together with similar articles, our example contributes to a storyline of expert solutions to the GFC [experts to the rescue]. The notion of the expert is visible in various aspects of meaning construction within the article, from the way in which the portrait is designed (e.g. suit, glasses, visionary gaze) to the inclusion of the graphs that refer to expert discourse. After analysing the complete sample, experts to the rescue was clustered with the complementary storylines in search of answers and complexity and trade-offs to reconstruct the narrative type of the ‘heroic quest’.
Funding
The authors gratefully acknowledge financial support from the UNSW Sydney Business School, as well as from the Austrian Science Fund (FWF): I 635-G17.