
Abstract
Research on the causes and consequences of vocal accommodation is accumulating rapidly in social psychology, but important puzzles remain. Recent work has shown that patterns of vocal accommodation among actors engaged in competitive interactions (e.g., debates) are related to audience perceptions of their relative dominance but not prestige. This makes intuitive sense, but it remains unclear how audience perceptions of actors’ relative dominance and/or prestige are impacted in cooperative group interactions and whether and to what extent audience perceptions agree with actors’ own perceptions. Building on past theory and research on vocal accommodation, we address these methodological questions by analyzing data from two experimental studies. Results reveal that for cooperative interactions involving two actors, vocal accommodation is associated with actor and observer perceptions of dominance and prestige, but not to an equal extent. For actors, vocal accommodation is more strongly predictive of their perceptions of each other’s relative prestige. For observers, vocal accommodation is more strongly predictive of their perceptions of actors’ relative dominance. We offer an explanation for the difference and provide directions for future research.
Over the past few decades, evidence has been growing in support of the claim that patterns in vocal adaptation between speakers constitute a nonconscious indicator of the underlying status structure of a group. Social psychological studies examining the relationship between vocal accommodation and small group hierarchies have repeatedly shown that observers who listen to interactions between two speakers tend to rate the actor who demonstrates greater vocal stability as occupying higher status or demonstrating more dominance than the actor who engages in relatively more vocal adjustment to match their interaction partner (Gallagher et al. 2005; Gregory and Webster 1996). Regarding the perceptions of the speakers themselves, Dippong (2020) provided evidence that in dyadic groups, position within the status structure significantly predicts which actor will engage in greater vocal accommodation, with lower status actors demonstrating significantly more vocal adaptation to their partner across relevant vocal frequencies.
Despite evidence linking vocal accommodation to small group status dynamics, there is a need for clarification regarding how structural dimensions map onto vocal dynamics. For one thing, small group hierarchies tend to reflect differences in both power and prestige between group members (Cheng and Tracy 2014; Ridgeway and Berger 1986), and it remains unclear as to whether differences in vocal accommodation reflect structures of prestige, dominance, or a combination of the two. In a recent effort to identify the mechanisms that connect vocal accommodation to small group hierarchies, Kalkhoff, Thye, and Gregory (2017) examined vocal accommodation using a series of televised debates about gun control and found that vocal accommodation predicted audience perceptions of speakers’ dominance but not perceptions of prestige. Thus, in competitive/conflictual settings such as those that Kalkhoff et al. analyzed, it appears that observers perceive vocal adaptation as a process of behavioral dominance and not one of voluntary, prestige-based deference.
While Kalkhoff and colleagues’ (2017) findings are extremely informative, they also point to two additional questions that warrant investigation: How do patterns of vocal accommodation relate to prestige and dominance perceptions in cooperative or collaborative interactions, and how does vocal accommodation relate to the dominance and/or prestige perceptions of group members themselves compared to the perceptions of external observers? These questions are worth pursuing because if vocal accommodation is to be useful as an unobtrusive measure of small group hierarchies (Dippong 2020; Dippong and Kalkhoff 2018), researchers need to be certain of what exactly it measures. Our purpose here, then, is methodological: to clarify how vocal accommodation functions as an indicator of status and power under different structural conditions. Acknowledging that much of the previous research has been somewhat ambiguous concerning the specific structural factors that produce differences in vocal adaptation between speakers, we argue that vocal accommodation, as measured using the Acoustic Analysis Result (AAR), is a nonconscious indicator of the latent power and prestige order of a group and that AAR is agnostic to whether the group hierarchy is rooted primarily in dynamics of dominance or prestige.
In what follows, we present a brief overview of theory and evidence linking vocal accommodation to perceptions of status, prestige, and dominance in small groups. Following our theoretical overview, we present results from two studies examining vocal accommodation in cooperative groups. In Study 1, we manipulated the status structure of dyadic groups and collected self-report ratings of prestige and dominance from both group members. We follow Cheng et al. (2013) in defining dominance as attempts to gain influence or compliance through actual or implied use of force and prestige as influence through the expertise or respect accorded to a group member.
In Study 2, we played audio recordings of the interactions from Study 1 for panels of external raters and collected questionnaire data regarding perceptions of the two speakers. Results from Study 1 provide evidence that vocal accommodation significantly predicts group members’ perceptions of both prestige and dominance, with stronger effects on prestige perceptions. Results from Study 2 also find a significant relationship between vocal accommodation and both types of perceptions, although here we find stronger effects on perceptions of dominance. We also explore whether vocal accommodation mediates the relationship between status and perceptions among observers. We conclude with a discussion of our results, focusing on the contributions of our work and areas for future theoretical development.
Theoretical Overview
Research on interactional synchrony shows that as people interact, they nonconsciously engage in a form of behavioral entrainment whereby their gestures, speech patterns, and other modes of communication synchronize over time (Condon and Sander 1974). Aside from behaviors that are readily visible, people also display a tendency toward synchrony and convergence in their nonverbal behaviors, including synchrony in brain waves (Condon and Ogston 1967; Hoehl, Fairhurst, and Schirmer 2021) and in vocal frequencies (Gregory 1983). Behavioral synchrony conveys a number of interactional benefits, including improved communication and enhanced ability to predict interaction partners’ behaviors (Hoehl et al. 2021) and increased solidarity among group members (Collins 2004; Kalkhoff et al. 2020).
Gregory (1983; Gregory and Hoyt 1982) pioneered sociological models for assessing vocal frequency convergence between interviewers and interviewees using Fast Fourier Transform (FFT). FFT quantifies the vocal signal by plotting the vocal frequencies against the average amplitude of the voice at each frequency for a given segment of speech (Gregory and Kalkhoff 2007). By dividing discussions into multiple temporal segments and examining correlations between vocal frequencies across the full interaction, Gregory (1983) discovered that speakers’ vocal behaviors matched each other’s very closely and created a shared pattern that was distinct to the group.
Subsequent work identified the nonverbal band of the voice, frequencies below 500 Hz, as the primary locus of convergence (Gregory 1990). This band of vocal frequencies constitutes the lower or bass tones of the voice. The nonverbal band conveys no manifest speech content (i.e., intelligible words), although it does convey emotional content and defines tone of voice. Recordings where the nonverbal band is removed still convey the informational message of an utterance, although they sound tinny and devoid of emotion. Conversely, recordings that contain only the nonverbal band sound low and rumbling, as if listening to speech through a wall (Kalkhoff and Gregory 2008). That convergence occurs primarily in the nonverbal frequency band is interesting because the nonverbal frequencies are very difficult to consciously manipulate (Bachorowski 1999). As such, achieving vocal synchrony appears to be a nonconscious interaction process.
Gregory (1994) developed the theoretical model further by bringing accommodation theory to bear on the vocal convergence process. According to accommodation theory, when behavioral convergence occurs between two people, one actor typically puts in more of the effort to achieve synchrony (Giles and Smith 1979). In other words, although both actors contribute to the process of convergence, one person adopts the behaviors and mannerisms of the other to a greater extent. Not surprisingly, when convergence occurs, lower status actors (relative to their interaction partners) tend to adopt the behaviors of higher status actors more so than the reverse (Gallois, Ogay, and Giles 2005). 1 Thus, Gregory (1994) postulated that in converging groups, vocal variability signaled group members’ perceptions of each other’s relative status, with lower status actors demonstrating more variability compared to the relatively stable vocal patterns of their higher status partners.
One of the most common ways that sociologists operationalize vocal accommodation is to use vocal FFT values to calculate a measure known as Acoustic Analysis Result (AAR), which quantifies the relative degree of each actor’s vocal stability or accommodation. Referring to AAR, Kalkhoff et al. (2017:342) noted that it “is useful insofar as it is relatively easily obtained, objectively measured, reliable, and taps into a quantitative property of conversation that seems to occur outside of people’s conscious control.” Results from multiple studies have borne out the prediction that AAR is associated with observers’ perceptions. When listening to recorded interactions, panels of observers typically perceive the more variable actor as lower status or less dominant (Gallaher et al. 2005; Gregory and Webster 1996). 2 Relatedly, there is also evidence that vocal accommodation is related to audience opinions about the winners and losers of political debates (Kalkhoff and Gregory 2008) and even evidence that vocal accommodation can predict the winner of presidential elections (Gregory and Gallagher 2002).
Early vocal accommodation research (e.g., Gregory and Webster 1996) conceptualizes accommodation as a process of dominance and deference, with dominant actors adjusting their vocal frequencies to match their partners less than their partners adjust to them. As such, the argument goes that higher status actors demonstrate greater vocal dominance. Gallagher et al. (2005) demonstrate that certain structural conditions (i.e., collective task settings) elicit more prestige-based interpretations, although some ambiguity remains as to what specific information is conveyed through vocal accommodation. Just as one can take the advice of a senior colleague either because they value that colleague’s expertise or because that colleague may have a say in promotion or tenure decisions (or some combination of these reasons), vocal accommodation might signal status or power dynamics. If measures of vocal accommodation are to be useful in modeling group hierarchies, it is necessary to assess whether vocal deference signals status/prestige differences, power/dominance differences, or some combination of the two.
Recently, Kalkhoff and colleagues (2017) reported findings that shed light on the differing effects of status and power in shaping patterns of accommodation. By presenting audiences with audio that contained either the full vocal spectrum or audio that had the nonverbal frequencies filtered out and then assessing prestige and dominance perceptions, Kalkhoff et al. (2017) were able to isolate the effects of the nonverbal signal and determine how listeners interpret the information contained within these frequencies. They found that vocal accommodation predicts perceptions of dominance but not prestige. Thus, when considering what information vocal accommodation communicates, at least in competitive debate settings, the answer seems to be that it indicates a dominance process. This makes intuitive sense given the conflictual nature of such interactions. Furthermore, in cases where there is no clear factor differentiating speakers according to relative expertise or respect, then any hierarchy that emerges is likely to be rooted largely in the relative forcefulness of each actor.
Status Beliefs, Dominance Behaviors, and Vocal Accommodation
What, then, about people’s perceptions of dominance and/or prestige that arise in cooperative settings with clear bases of status differentiation? Do observers map patterns of vocal accommodation onto perceptions that reflect the actual underlying basis of the hierarchy (i.e., prestige), or do they perceive all hierarchy as dominance based? And what of the perceptions of interactants themselves? Does vocal accommodation predict their perceptions similarly, or does their position as actors (as opposed to observers) affect how they interpret changes in each other’s nonverbal frequencies?
Regarding the first two questions, Kalkhoff and colleagues (2017) demonstrate that perceptions of dominance uniquely relate to vocal accommodation in competitive groups. Understanding this process further requires analysis of vocal accommodation in a setting with an established status structure where participants are motivated to act cooperatively. Given that much existing work on status processes in small groups emphasizes the role of a collectively focused task context for activating status beliefs, it may be that the effects of any status beliefs that arise in conflictual or debate settings are attenuated by the absence of a shared collective task. Such effects might be stronger in a setting that is known to produce a strong connection between status beliefs and behaviors.
Concerning the latter two questions posed earlier, prior studies have examined either the perceptions of audiences (e.g., Gregory and Webster 1996) or the perceptions of group members (Dippong 2020). Perhaps the most important difference between actors and observers is that actors are trying to make sense of their own behavior, whereas observers are trying to make sense of someone else’s actions (Malle, Knobe, and Nelson 2007). Actors have access to a variety of information that is not accessible to external observers, including an (albeit imperfect) understanding of their own history, motives and intentions, and perceptions of intentionality, which often play a crucial role in shaping how someone understands a given behavior (Malle et al. 2007). To more fully understand how vocal accommodation functions, then, we need to directly compare the perceptions of actors to those of observers.
In small ad hoc task groups, such as those we examine in the present studies, the hierarchies of power and prestige that arise are shaped through two channels: the overt behaviors and status cues that group members emit and the distribution of status characteristics among group members (Webster and Rashotte 2010). 3 Insofar as higher status actors are not precluded from also expressing displays of behavioral dominance (Ridgeway and Berger 1986), the actual power and prestige order that emerges in a group could be based entirely on power differences, entirely on prestige differences, or on some combination of the two. To the extent that dominance is linked to patterns of forceful behavior and prestige is linked to the underlying status structure of a group (Cheng and Tracy 2014), group members’ perceptions should reflect their knowledge of, or position within, the overall hierarchy of power and prestige. Thus, we expect that in cooperative, status-differentiated groups, vocal accommodation will positively predict actor perceptions of dominance and prestige, not simply dominance alone.
Furthermore, because a group’s status structure is built on the overt behavior of interactants (dominance) and on the distribution of differentiating status characteristics (prestige), anyone who has knowledge of the full informational structure should theoretically interpret events accordingly. Often, however, observers viewing an interaction have access only to the overt behavior and limited situational context as a basis for interpreting events (Eisen 1979). Again, when patterns of dominance are readily observable to an audience, this should signal the presence of a power order. Likewise, to the extent that prestige is linked to status structures, observable displays of respect and deference should signal the presence of a prestige order to observers. For observers as well, then, in the cooperative task setting we analyze, vocal accommodation should also be associated with perceptions of both dominance and prestige.
To examine our research questions, we report results from two studies, one collecting data from group members working together on a cooperative decision-making task and one collecting data from panels of observers rating those same group interactions. We estimate mixed-effects models predicting perceptions of prestige and dominance for both actors from vocal accommodation in both sets of data. As an exploratory matter and for reasons discussed in more detail later, we employ generalized structural equation modeling to test whether vocal accommodation mediates the relationship between position within the status hierarchy and observers’ perceptions.
Study 1
We analyze data from a laboratory experiment in which dyadic teams worked together to complete a problem-solving task. Study 1 involved three stages: (1) a manipulation phase in which we employed fictitious ability characteristics to induce status differences between group members, (2) a group interaction phase in which participants worked together in open discussion to solve a problem, and (3) a postinteraction questionnaire phase in which participants answered questions related to their perceptions of each other’s prestige and dominance. To ensure standardization, participants received instructions and completed all tasks through a computer program.
Participants
Data for Study 1 come from a larger project examining various predictors and consequences of vocal accommodation. Our sample consists of 60 students from a large Southeastern university who completed this study in exchange for a $25 cash incentive. 4 Participants completed the study in same-sex dyads, for a total of 30 analytical groups. Within each group, we randomly assigned participants to occupy either a higher status or lower status position. Participants did not meet each other prior to the group task, and their only interaction occurred via audio so that they did not see each other at any point during the study.
Procedures
Volunteers signed up for experimental sessions using an online scheduling platform. We staggered meeting times by several minutes to ensure that group members did not meet inadvertently prior to the study. Upon arriving for the study, participants were seated in private rooms within the lab. Each room contained a desktop PC, headphones, and a high-quality lavalier condenser microphone for collecting audio data. A research assistant obtained informed consent, helped participants clip the condenser microphone in a position that would ensure a strong audio signal, and provided general instructions for the study.
Phase 1: status manipulation
Prior to interacting, participants individually completed a set of pretests of a fictitious newly discovered ability. Groups were assigned to complete either one test (n = 20 groups) or three tests (n = 10 groups) that purportedly measured their ability to intuitively solve novel problems. Two of the tests—contrast sensitivity and meaning insight—have been used extensively in status experiments for several decades. The third test involved a version of the well-known Lost at Sea problem-solving task, modified slightly to allow us to manipulate feedback on test performance. For all three tests, participants were informed that there was a single correct solution and that their score would reflect the number of items or trials that they answered correctly. Depending on the condition to which their group was assigned, participants completed either the Lost at Sea test or all three ability tests. Whether a group completed one or three pretests is related to the broader research project from which we draw these data and has no bearing on the current study. We examined whether taking one test or all three affected outcomes of the analyses we report. We found no significant differences (analyses available from first author).
For each test, participants received fabricated feedback regarding their own performance and their partner’s performance. Participants randomly assigned to the higher status position received feedback that they scored in the superior range on the test(s) they completed and that their partner scored in the fair range. Participants assigned to the lower status position received feedback that they scored in the fair range on the test(s) and that their partner scored in the superior range. These ability tests provide a basis to induce believable status differences based on artificial characteristics. By manipulating the status structure using artificial characteristics instead of overt characteristics like race or gender, we eliminate the possibility that participants might draw on previously formed beliefs that could attenuate the intended status structure while ensuring that participants could not share information that inadvertently undermines the manipulation during open interaction. Extensive research on small group status structures supports the use of artificial status characteristics (see e.g., Dippong, Kalkhoff, and Johnsen 2017; Webster 1977).
Phase 2: open interaction
Following the status manipulation, participants completed a well-known group problem-solving task known as Lost on the Moon. This task is similar to the Lost at Sea task that participants completed as part of the Phase 1 status manipulation (mentioned previously). Here, however, participants did not simply complete the task on their own and receive contrived feedback for the status manipulation. Instead, participants completed the Lost on the Moon task with a partner to create a cooperative task-based interaction that would allow us to measure vocal accommodation and participant perceptions of their own and their partner’s dominance and prestige.
Lost on the Moon presents participants with a fictitious survival task in which they must make decisions regarding how to prioritize supplies to maximize chances of survival while awaiting rescue (for a description of the Lost on the Moon task, see Cheng et al. 2013). Participants individually ranked the supply items and then worked together to form a final group decision. Group members communicated over Skype Voice (audio channel only) such that they were able to hear each other’s voices but not see each other. Groups were given up to 15 minutes to discuss the task and compile a final decision. To collect vocal data, we digitally recorded group interactions using high-quality microphones and Audacity software. Each participant’s voice was recorded to a unique channel, allowing us to isolate each person’s speech and eliminate cross talk in the recordings.
Phase 3: questionnaire
After completing the group interaction phase, participants completed a questionnaire that contained items to assess perceptions of each other’s prestige and dominance. These scales were developed and validated by Cheng and colleagues (2013) and have subsequently been used to measure perceptions based on vocal accommodation. Participants rated themselves and their partner on eight items assessing dominance perceptions and nine items measuring prestige perceptions. The questionnaire also contained manipulation check items to assess the successful instantiation of the intended status order.
Variables
Our analyses center on two dependent variables: dominance perceptions and prestige perceptions. Both sets of perceptions were measured separately for self and partner using a 7-point likert type scale with responses ranging from 1 (strongly disagree) to 7 (strongly agree). Items assessing dominance perceptions included, for example, “Some people who interact with him (her) are probably afraid of him (her)” and “He (she) seems willing to use aggressive tactics to get his (her) way.” Prestige perceptions were measured using such items as “His (her) unique talents and abilities are probably recognized by others” and “He (she) seems like a person who would be held in high esteem by others” (for the full list of questions, see Cheng et al. 2013, online supplement). We calculated participant scores for both scales by taking the mean of the scale items. In our analyses, we model self-perceptions and partner perceptions as repeated measures. Our measures of prestige and dominance demonstrated good alpha reliability. For prestige perceptions, alpha reliability is .825 for higher status actors and .844 for lower status actors. For dominance perceptions, alpha reliability is .805 for higher status actors and .860 for lower status actors.
Independent variable
Our independent variable is participants’ AAR scores, which reflect vocal accommodation or vocal stability. In short, AAR summarizes the extent to which speakers adjust their paraverbal frequencies to match their interaction partner, averaged across the duration of the interaction. This involves dividing each actor’s recorded speech into distinct temporal segments. In the case of the current study, we follow prior research that used three segments corresponding roughly to the beginning, middle, and end of conversation. These speech segments are FFT transformed using SpectraPlus software to generate quantitative indicators of vocal behavior and then compared between group members (for a full description of procedures for calculating AAR, see Kalkhoff et al. 2017, online supplement). 5 High AAR values reflect less vocal adjustment toward a discussion partner, and relatively lower AAR values indicate increased vocal accommodation.
Control variables
Following previous research on vocal accommodation, our models control for a variety of factors related to the overall speech and group members’ characteristics. In terms of speech characteristics, we control for two variables that previous research has linked to perceptions of status: actors’ overall vocal pitch (derived from an analysis using SpectraPlus) and each actor’s total speaking time. Regarding demographic characteristics, we control for participant ethnicity (1 = white), participant age, biological sex (1 = female), and academic level (1 = freshman).
Results
Of the 30 groups we analyzed in Study 1, 18 were female dyadic groups, and 12 were male groups. Participants’ mean age was 20.65 years and ranged from 18 to 31 years. Furthermore, 36.67 percent of the sample self-identified as white, and 36.67 percent reported that they were currently freshmen. Table 1 presents descriptive statistics for dependent and independent variables and for key control variables. As we expected, higher and lower status participants differed significantly regarding AAR values, prestige perceptions, and speaking time. Contrary to expectations, group members did not significantly differ in dominance perceptions or vocal pitch. 6
Study 1 Descriptive Statistics (N = 60)
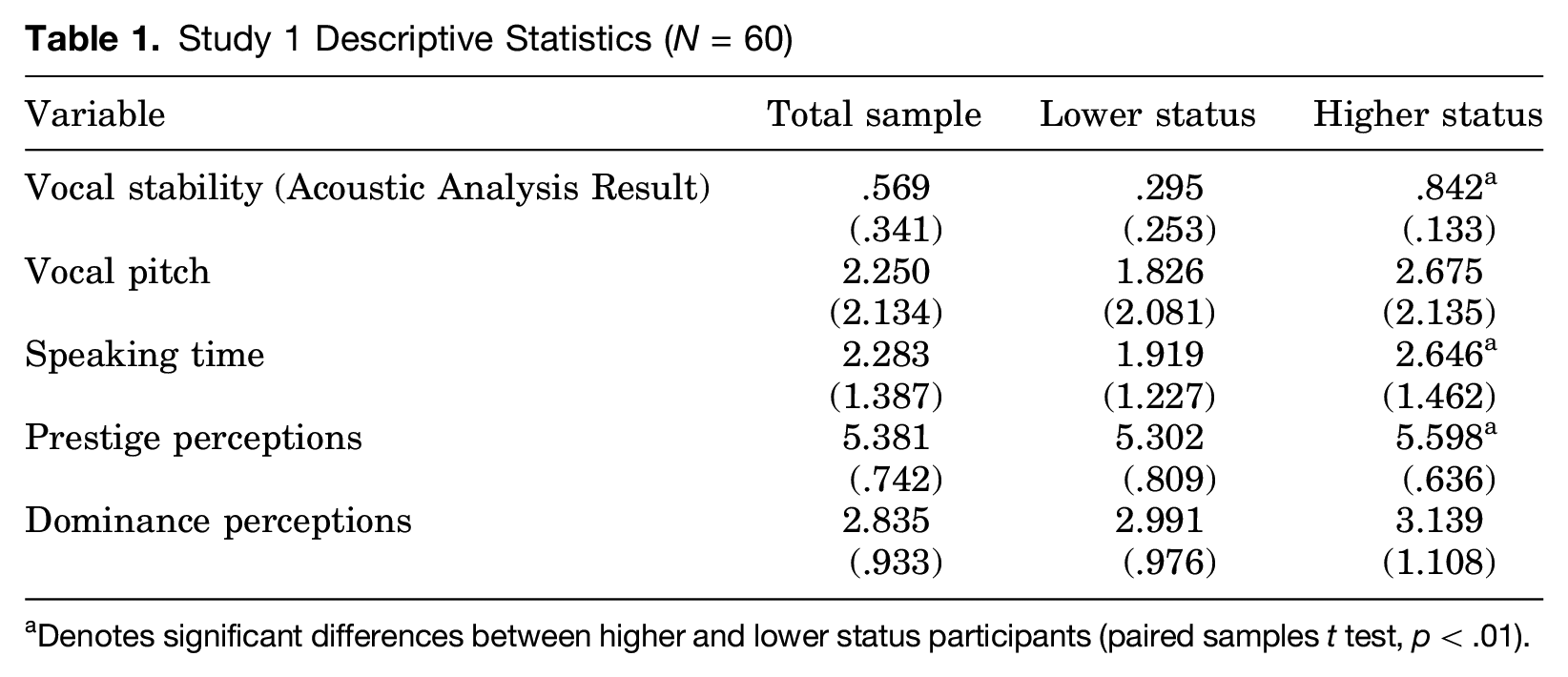
Denotes significant differences between higher and lower status participants (paired samples t test, p < .01).
Manipulation checks
To verify that we instantiated cooperative, collective motivations, group members responded to two questions assessing level of perceived cooperation and competitiveness with their partners. Responses for both questions ranged from 1 = not at all to 5 = very much. For cooperation, the mean score was 4.617, and this was significantly higher than the midpoint (one-sample t = 21.41, df = 59, p < .001). For competitiveness, the mean score was 2.483, and this was significantly lower than the scale midpoint (one-sample t = −3.259, df = 59, p < .002). Overall, then, cooperation between group members was high, and competition was low.
Main analyses
Table 2 presents regression analyses predicting prestige perceptions from vocal accommodation scores, with actors nested within discussion groups and separate perceptions for self and partner nested within individual actors. As can be seen in Model 1 of Table 2, AAR is a positive and significant predictor of prestige perceptions: group members rate individuals who demonstrate less vocal accommodation as being more prestigious. Model 2 introduces vocal control variables for speaking time and vocal pitch. Neither of these controls exerts a significant influence on perceptions of prestige, and the effect of AAR remains significant. With the introduction of demographic controls in Model 3, the effect of AAR is clear and stable.
Mixed Models Predicting Actors’ Prestige Perceptions from Vocal Stability: Study 1 (N = 60)
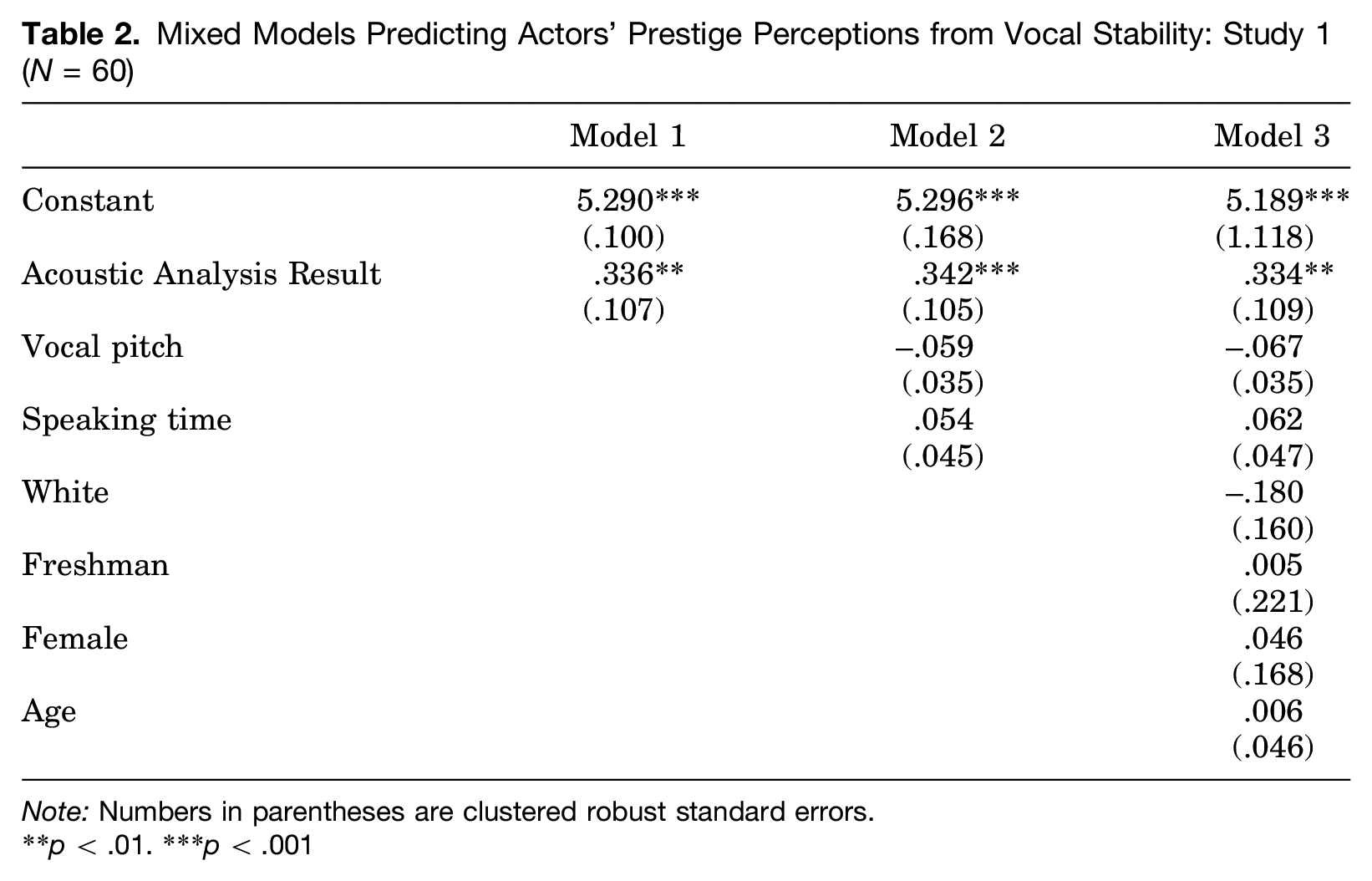
Note: Numbers in parentheses are clustered robust standard errors.
p < .01. ***p < .001
In Table 3, we look at the effects of AAR on self-reported perceptions of dominance. The results are similar to those we observed for prestige in that AAR significantly predicts perceptions across all models. Despite the fact that t tests did not show significant differences in dominance perceptions between actors assigned to lower and higher status positions, AAR is nonetheless associated with the dominance ratings that participants provided for self and partner. Again, control variables have no significant effect and do not alter the relationship between AAR and perceptions. It is worth noting that while AAR significantly predicts perceptions of dominance and prestige, the relationship between AAR and dominance is substantially weaker than between AAR and prestige. From this, we can conclude that our status manipulation generated a power and prestige order that was based primarily in status differences, although actors did consciously perceive some dominance-related behaviors.
Mixed Models Predicting Actors’ Dominance Perceptions from Vocal Stability: Study 1 (N = 60)
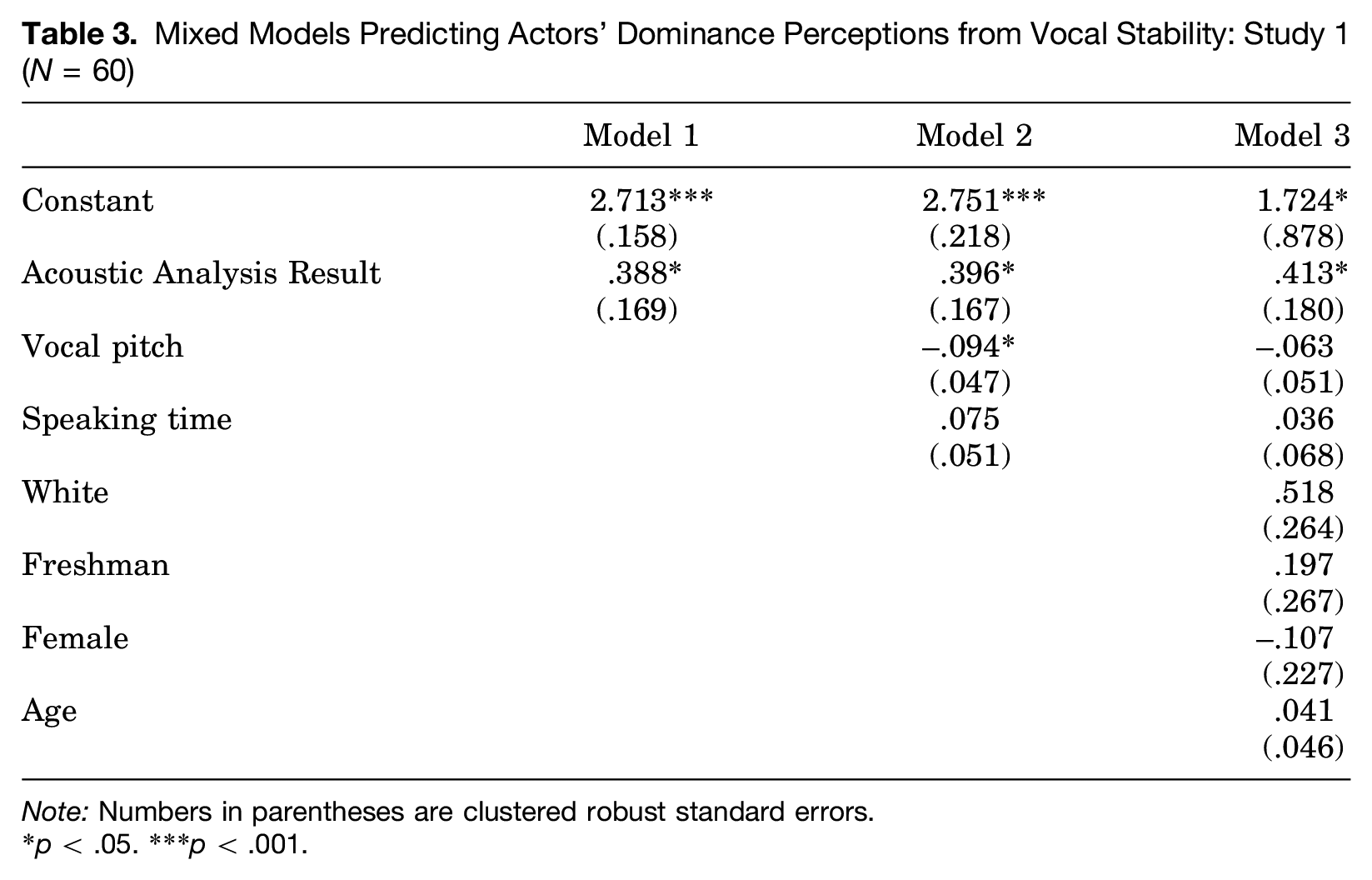
Note: Numbers in parentheses are clustered robust standard errors.
p < .05. ***p < .001.
Summary
Based on results from experimental problem-solving groups, we find evidence that in cooperative task groups, vocal accommodation significantly predicts group members’ perceptions of each other’s relative prestige and dominance, net of a range of vocal and demographic characteristics. Overall, these results bolster confidence in previous theory and experimental research (Dippong 2020; Dippong and Kalkhoff 2018) that has suggested that AAR can be useful as an unobtrusive approach to measuring and modeling status differences in small groups. Specifically, we find that AAR not only aligns with the basic structure of the group but is also predictive of the social and behavioral factors that underlie small group hierarchies.
Whereas prior work has found that among observers of group interactions, AAR is significantly associated with dominance and not prestige in competitive settings (Kalkhoff et al. 2017), we find that AAR is significantly associated with group members’ dominance perceptions and prestige perceptions in cooperative settings. In our second study, we seek to replicate and expand on prior studies by collecting data from panels of observers who listened to the interactions from our experimental groups. Unlike prior studies that have analyzed data from either actors (e.g., Dippong 2020; Moore, Dippong, and Rejtig 2019) or observers (e.g. Gallagher et al. 2005), by collecting data from a set of groups and from observers of those same groups, we can directly compare their perceptions and how they relate to vocal accommodation.
Study 2
Most existing work examining how vocal accommodation operates in small groups has employed a particular methodology that involves collecting evaluations from panels of observers. To assess how observers and actors differ in how they perceive group interactions based on vocal accommodation and to allow for a clearer comparison between our results and prior studies, we conducted a second study that replicates the well-established audience rating design. Using the vocal recordings collected for Study 1, we played these discussions to panels of observers and asked them to rate the actors in the recording using the same prestige and dominance measures that the actors used to rate themselves.
Participants
A total of 180 student volunteers completed Study 2 in exchange for a $25 cash incentive. Because we conducted Study 2 at the same university as Study 1, participants who completed Study 1 were ineligible to participate in the second study. We administered Study 2 in sessions consisting of one to six participants. To maximize our total number of observations, each participant listened to two different recordings during their session. We collected ratings from 12 separate observers for each of the actors in all of the 30 groups in Study 1, producing 720 observations.
Procedures
When arriving at our lab, participants were assigned to seats around a conference table, and at each seat, they found a pair of headphones connected to a central listening terminal. After providing informed consent, participants were informed that they would be listening to recordings of interactions between two people who were trying to make a decision together. To help participants understand the decision-making task, a research assistant briefly explained the nature of the Lost on the Moon activity. We informed participants that following each recording, they would complete a questionnaire assessing their perceptions of the people they just heard.
Following the instruction phase and after answering any questions the volunteers had, the research assistant instructed the participants to put on their headphones. Headphones were kept at a constant volume across sessions, and no participants reported difficulty hearing. To provide participants with a visual cue to help them differentiate between speakers, a monitor at the head of the table displayed slides indicating which actor was speaking (e.g., when Actor A was speaking, the monitor displayed the words “Actor A” and changed with each speaking turn).
Next, participants privately completed a questionnaire that included the same measures of prestige and dominance that we used in Study 1, although slightly reworded to fit the context of an observed interaction. The whole process was then repeated with a second recording and second questionnaire. Following the second questionnaire, research assistants interviewed the participants to assess suspicion regarding the purpose of the study. Then the volunteers were paid and excused. In all, sessions for Study 2 lasted an average of approximately 45 minutes.
Variables
Our analyses employ the same variables as in Study 1. We have two dependent variables: observers’ ratings of speakers’ dominance and of speakers’ prestige. We measured these using the same items as we used to measure actors’ perceptions in Study 1. Observer ratings of prestige and dominance demonstrated good to excellent alpha reliability. For prestige perceptions, alpha reliability is .898 for higher status actors and .906 for lower status actors. For dominance perceptions, alpha reliability is .960 for higher status actors and .948 for lower status actors.
Our focal independent variable is the AAR scores derived from the Study 1 recordings. We include the same control variables (speaking time, vocal pitch, demographic characteristics of the speaker). For Study 2, we also include controls for the demographic characteristics of the observer. Our analyses follow the same overall strategy employed in Study 1, with ratings nested within individual observers and accounting for the nesting of individuals in panels that participated in the same study session.
It is important to note that observers were naïve regarding the manipulated status structure of the groups to which they listened. To ensure that participants did not inadvertently draw status-related inferences from irrelevant cues, we counterbalanced the labels/names (Actor A or Actor B) given to the higher status and lower status interactants. We also counterbalanced the ordering in which the recordings were presented. Thus, any perceptions of the speakers’ characteristics can be attributed to the features of the observed interaction.
Results
From the initial 180 respondents, we dropped six individuals from our analyses due to missing data on key measures, leaving us with 174 observers and 696 observations. Observer age ranged from 18 to 30 years old, with a mean of 20.13 years. Concerning race and ethnicity, 54.6 percent reported their racial category as non-Hispanic white, 10.9 percent self-reported as Hispanic, 18.4 percent identified as black or African American, 7.5 percent listed their race as Asian, and 8.6 percent reported other or multiple racial categories. In terms of academic standing, 37.9 percent were freshmen, 20.7 percent were sophomores, 17.2 percent reported being juniors, 19 percent were seniors, and 5.2 percent listed their standing as “other.” Table 4 shows observers’ overall ratings of speakers’ prestige and dominance and ratings separated by speaker status.
Study 2 Descriptive Statistics (N = 174)
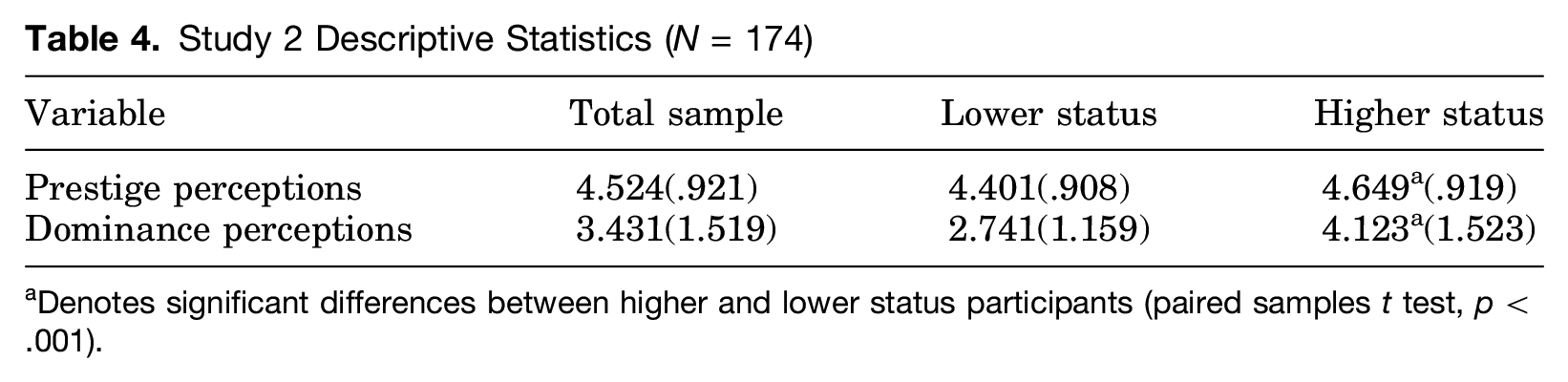
Denotes significant differences between higher and lower status participants (paired samples t test, p < .001).
To ensure that presentation order did not bias observer perceptions, we assessed whether ratings differed by the order in which we presented the groups. For three of the four ratings, we observed no significant differences based on whether the recording was played first or second. For dominance ratings of lower status actors, however, speakers in the second recording presented were rated as slightly more dominant than those in the first recording (mean rating of 2.89 vs. 2.59; t = 2.495; p = .013). The counterbalanced order of presentation ensures that this difference does not systematically affect ratings of any particular subset of groups. 7
The most noteworthy aspect of observer ratings in Table 4 is that perceptions of dominance differ between higher and lower status speakers much more widely than perceptions of prestige and that for both dimensions, the differences between higher and lower status speakers is statistically significant. Recall that in Study 1, group members did not rate each other’s dominance differently based on status position. This provides the first piece of evidence that observers interpret the interactional dynamics of a group somewhat differently than the group members themselves.
Looking at the relationship between AAR and observers’ prestige perceptions in Table 5, we see in Model 1 that AAR has a small but significant effect on prestige ratings. This effect holds up when accounting for other vocal characteristics in Model 2 and demographic characteristics in Model 3. The cooperative, status-based nature of the interaction in which AAR arose mapped onto the perceptions of observers. From this, we can conclude that when group members are differentiated according to prestige, AAR will predict how prestigious they appear to observers. And when group members are differentiated entirely by dominance (i.e., Kalkhoff et al. 2017), then AAR is related entirely to perceptions of dominance.
Mixed Models Predicting Observers’ Prestige Perceptions from Vocal Stability: Study 2 (N = 174)
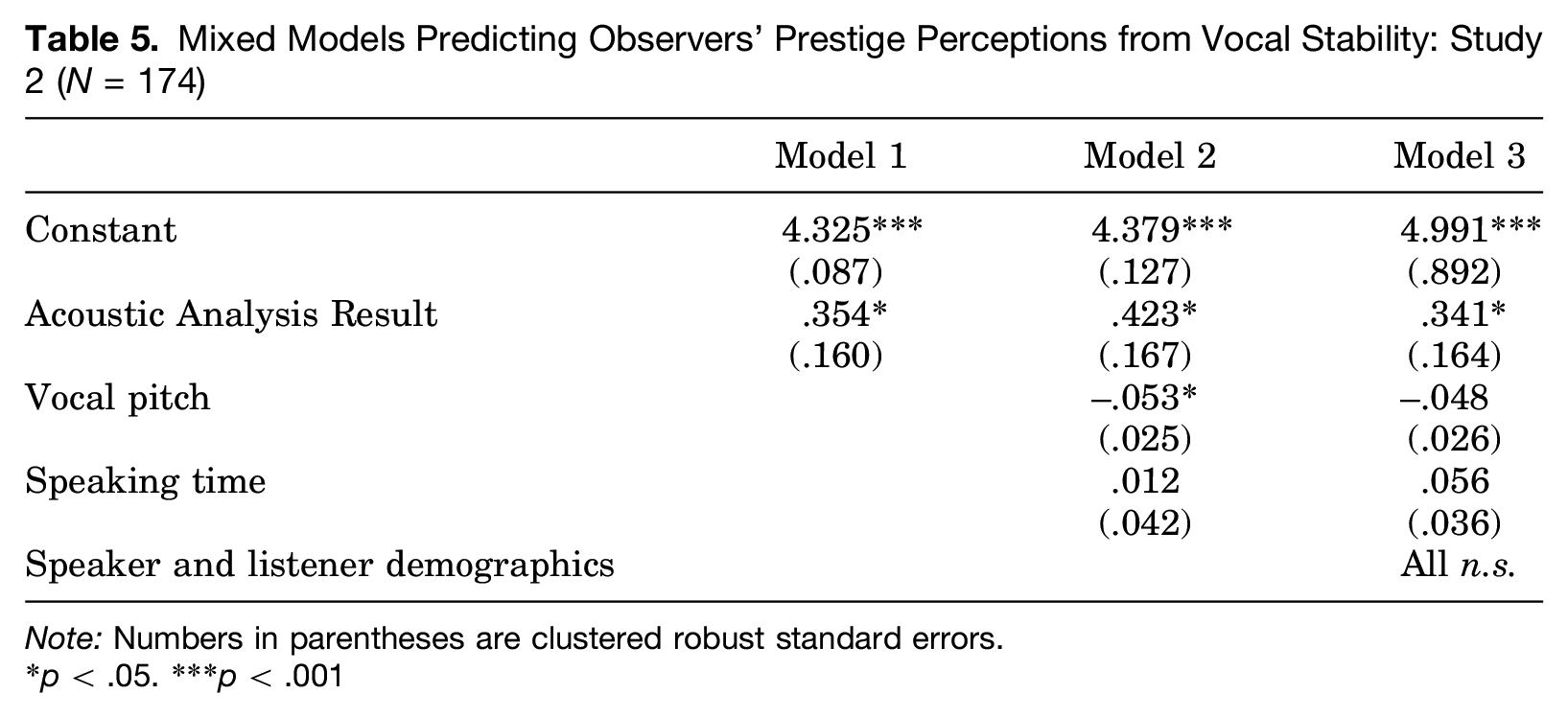
Note: Numbers in parentheses are clustered robust standard errors.
p < .05. ***p < .001
Finally, in Model 1 of Table 6, we see that AAR is a significant predictor of dominance ratings as well. This finding holds up with the introduction of vocal characteristics in Model 2 and demographic variables in Model 3. Interestingly, and contrary to the results of Study 1, AAR is more strongly related to observers’ dominance perceptions than to their prestige perceptions. This is likely because observers were naïve to the status structure while actors were not. Although status differences did influence how observers perceived the speakers, they interpreted interactional dynamics primarily through the lens of dominance. It is possible that the effects of AAR on dominance might have been weaker had the observers been apprised of the status structure, but that would not alter the overall picture these data provide.
Mixed Models Predicting Observers’ Dominance Perceptions from Vocal Stability: Study 2 (N = 174)
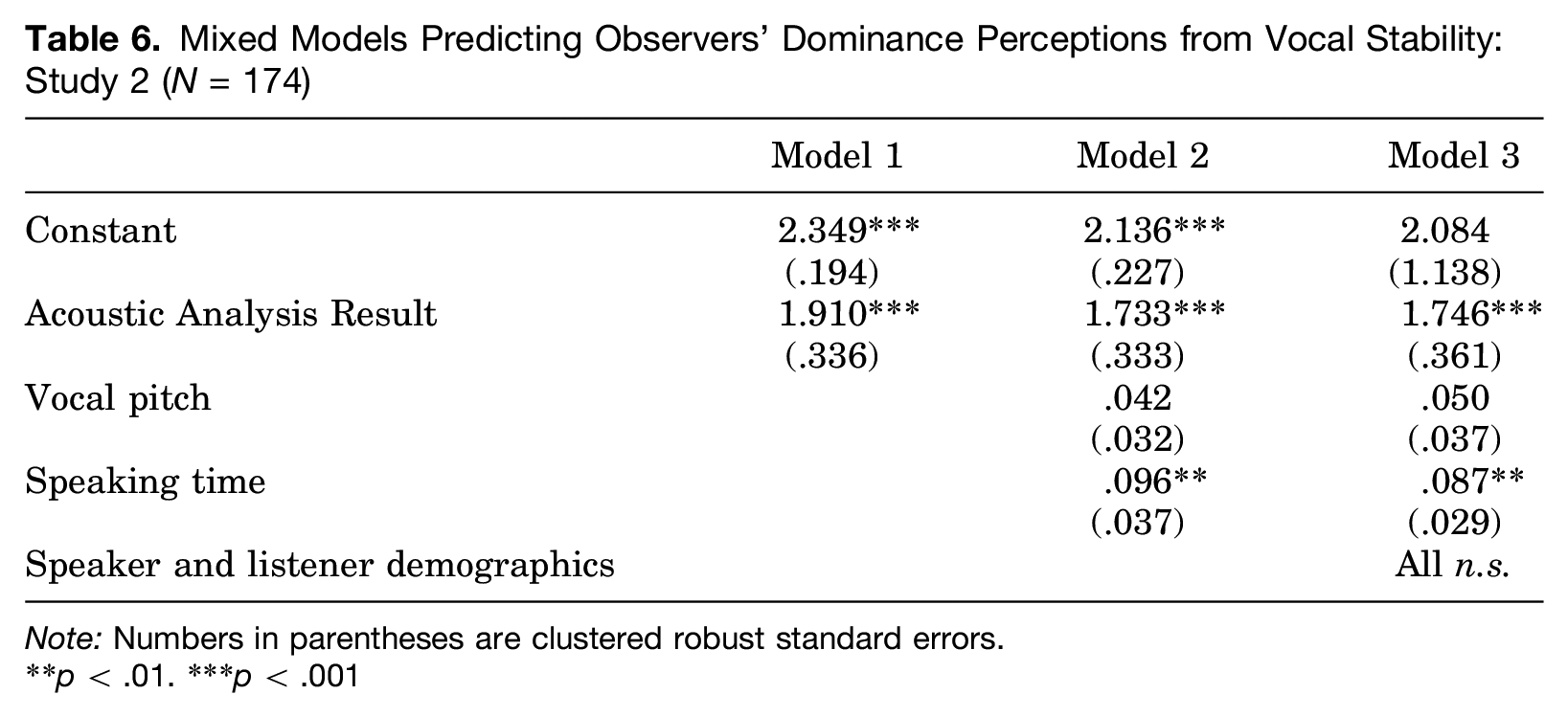
Note: Numbers in parentheses are clustered robust standard errors.
p < .01. ***p < .001
Comparing Models for Actors and Observers
Because we have identical statistical models drawn from two separate samples, we are able to examine how the relationship between AAR and perceptions differed between our samples. Using z tests to compare regression coefficients (Paternoster et al. 1998), we find that although AAR predicts perceptions of dominance for both samples, the relevant regression coefficient is significantly larger among observers (z = −3.92, p < .001). 8 This is probably at least partially due to the fact that observers reported much higher dominance scores overall (t = 3.458, p < .001). Compared to group members, observers overestimate the degree of dominance within the group, with relatively weak effects for prestige perceptions. Regression coefficients for the effects of AAR on prestige perceptions were not statistically different between actors and observers.
Exploratory analyses
To further examine how vocal accommodation relates to perceptions of prestige and dominance, we employed generalized structural equation modeling (GSEM) to test whether AAR mediates the relationship between status and perceptions among observers. 9 We use GSEM instead of standard structural equation modeling because we have nested data and GSEM allows for multilevel models. Our models predict AAR from the manipulated status structure of the group (1 = higher status), controlling for the nesting of observations within groups. We then predict perceptions from both status and AAR. Our model employs bootstrapped standard errors (5,000 replications).
GSEM analyses reveal significant effects for dominance perceptions but not for prestige perceptions. As can be seen in Figure 1, the path from AAR to dominance perceptions is significant, and mediation analyses verify the presence of significant indirect effects (z = 3.59, p < .001). While the direct effect of status on dominance remains significant (b = .742, p < .001), AAR mediates a significant portion of the effects of status on perceptions. With the inclusion of the direct effects of status, the path between AAR and prestige perceptions is not significant, and mediation analyses confirm that AAR does not mediate any significant part of the relationship between status and prestige ratings. When group hierarchies are organized primarily according to status differences, the direct effects of status overpower the effects of AAR on prestige perceptions. Theoretically, this makes sense because status and prestige are very closely connected concepts. When it comes to dominance perceptions, AAR may contribute unique information by filling in the gap between the group status structure and behavioral displays of dominance.
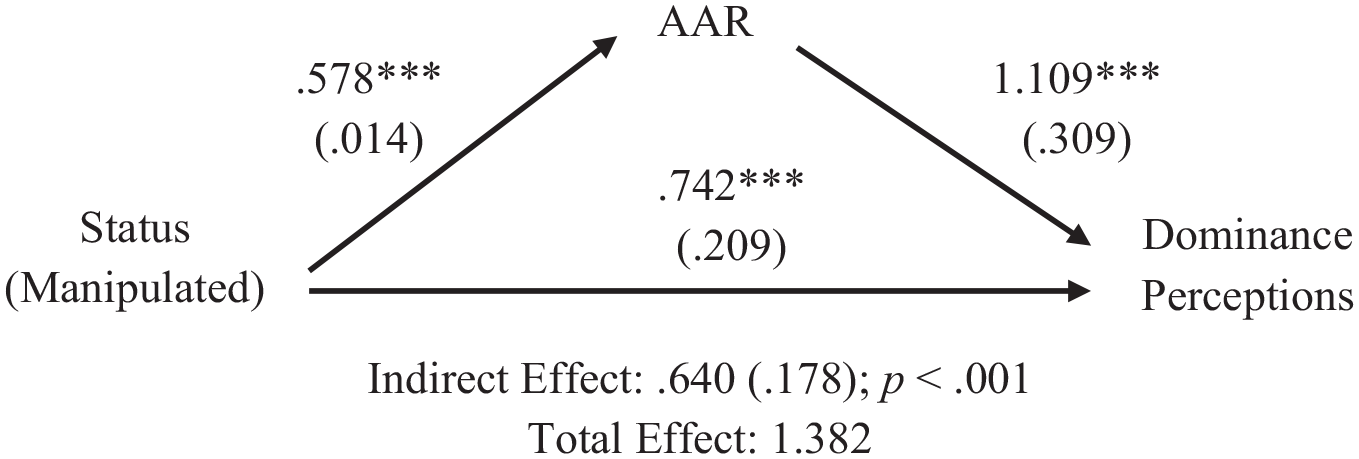
Generalized Structural Equation Modeling Model and Path Coefficients Testing Mediation
Summary
Findings from Study 2 suggest that observers of the cooperative groups in our study interpreted vocal accommodation as a process of both dominance and prestige. This finding is similar to what we obtained for group members themselves. There are theoretically interesting differences between Studies 1 and 2 as well. Most notably, for actors/interactants in Study 1, the effects of AAR on perceptions were stronger for prestige and relatively weak for dominance. For observers in Study 2, though, we find the exact opposite—stronger effects on dominance perceptions and weaker effects for prestige.
Our exploratory analyses reveal that AAR mediates the relationship between status and dominance perceptions but not the relationship status and prestige perceptions. It is important to note, however, that the ability of AAR to predict prestige perceptions obviously lies in AAR’s relationship to status. The fact that AAR does not contribute any unique information to the relationship between status and prestige perceptions does not necessarily undermine the usefulness of AAR as a measure of power and prestige. When the exact power and prestige order is known, modeling the status structure directly is preferable to using a secondary indicator like AAR. But when the status structure is not known, AAR performs well as an indicator of the power and prestige order.
Discussion
Across two studies, we have shown that vocal accommodation, as measured by AAR, is useful for measuring and modeling the structure of small groups. Our measure of vocal accommodation predicted both the prestige perceptions and the dominance perceptions that group members reported and those that panels of observers reported. Although actors and observers differed in how they responded to vocal accommodation—with AAR more closely related to prestige for actors and to dominance for observers—they clearly agreed that higher AAR scores are characteristic of actors at the top of the hierarchy and that relatively lower scores indicate a lower position. Based on the broad agreement between actors and observers regarding the direction of the relationship between vocal accommodation and position within the group hierarchy, we can be even more confident that studies that have relied exclusively on audience ratings and perceptions were indeed tapping into interactional dynamics that also held meaning for the speakers themselves.
As we have stated in this article, it is our position that AAR functions as an indicator of the latent power and prestige order of a group irrespective of whether power or prestige is the primary basis of differentiation. Our results from cooperative, status-differentiated groups, coupled with Kalkhoff et al.’s (2017) results from competitive groups, bolsters our claim. In groups that are differentiated primarily by prestige, AAR predicts such differences. When group members form a hierarchy around displays of dominance, AAR is sensitive to that as well. Our results also provide evidence that if a group hierarchy contains elements of both status and dominance, AAR will reflect that mix of elements.
At this point, it is worth discussing the difference between vocal accommodation as an outcome of group structures and as a predictor of people’s behaviors or perceptions. In Study 1, we manipulated the status structure of our groups, and we observed that lower status actors engaged in more vocal accommodation. Regardless, then, of how different sets of actors perceive interaction partners, the systematic differences between actors’ AAR scores are attributable directly to the manipulated status structure of the group. That is, the status structures that we created produced the differences in vocal accommodation that we observed. This is obviously a separate matter from what behaviors AAR is able to predict and how it functions as a mediating variable between status and other outcomes. Just as, for example, educational attainment can be seen as an outcome of relevant family background factors or as a predictor of other life outcomes, AAR is useful as both an outcome of structural conditions and as a predictor of other group behaviors.
The evidence indicating that AAR is an outcome of group status structures is compelling. The list of behaviors that AAR can predict is growing but is quite incomplete. Current outcomes connected to vocal accommodation consist mostly of self-report measures of different types of perceptions. Our results show that even when groups reflect a clear status ordering, AAR may not predict certain status-related outcomes, such as perceptions of prestige, and this may depend on whose perceptions are being measured. Accordingly, social psychologists who are interested in using vocal accommodation to test their theoretical arguments need to be aware that the AAR measure performs differently when applied to group-level phenomena (e.g., status and power structures) compared to individual-level outcomes (e.g., perceptions).
The research we report here points to at least three areas for further theoretical development. First, we have argued that observers’ lack of firsthand knowledge of the status structure of the group played a role in how they formed impressions of speakers. The current study is limited in that actors were aware of the status structure of the group, while observers were not. This mechanism can be tested by comparing the perceptions of observers with knowledge of the status hierarchy to those without any such knowledge. Second, we have focused entirely on groups where speakers vocally converged. Work within accommodation theory (Gallois, Ogay, and Giles 2005) suggests that behavioral divergence can also reveal important information about the structure of an interaction. More empirical work is needed to assess how different patterns of convergence and/or divergence produce different perceptions. It is unclear at this point whether there exists any particular threshold of convergence that changes how actors interpret vocal dynamics. Further work can help expand the list of group outcomes that AAR predicts. One potentially fruitful way forward would be to connect vocal accommodation to status-related work in the expectation states tradition, which specifies a number of clear group outcomes related to position within the status structure, including opportunities to contribute to the task, expectations for competence, and level of influence over group outcomes (Berger et al. 1977). Lastly, more work is needed to understand how vocal accommodation operates in groups larger than dyads and in settings with more complex status structures.
Conclusion
Overall, the research we present contributes to social psychological knowledge on status, power, and the causes and consequences of vocal accommodation. Evidence suggests that AAR is a reliable, nonconscious indicator of an underlying power and prestige order. Vocal adaptation analysis appears to be a fruitful methodological tool that social scientists can utilize to get beneath an individual’s self-presentation motives and to assess a group’s status and dominance structure. Tools like AAR hold the potential to build consensus and create rapid streams of discovery within the social sciences and promote the development of sociology as a “high-consensus, rapid discovery science” (Collins 1994).
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported here was funded in whole under award W911NF-17-1-0008 from the U.S. Army Research Office/Army Research Laboratory. The views expressed are those of the author and should not be attributed to the Army Research Office/Army Research Laboratory.
1
Speakers’ behaviors can also diverge, which occurs typically when individuals are motivated to disassociate from their interaction partners (Gallois, Ogay, and Giles 2005). In the present studies, we focus entirely on groups that converge vocally, leaving the question of how status operates in diverging groups for future research.
2
3
We do not intend the present studies to serve as an explicit test of status characteristics theory (SCT). The experimental setting we employ falls squarely within SCT’s scope (collective task setting), and as such, we expect that the status processes we examine will reflect the theoretical mechanisms outlined in SCT.
4
In total, 65 dyads participated in the larger study from which we draw these data. Of those initial groups, 30 dyads were randomly selected to receive ratings from panels of observers (see Study 2). The characteristics of the sample we present here do not differ significantly from those of the larger pool of groups from which they were drawn (analyses available from first author).
5
Prior to calculating AAR, we examined the raw Fast Fourier Transform (FFT) values to ensure that all groups demonstrated convergence (as opposed to divergence). Following Gregory (1983) and ![]() , we inspected correlations between actors’ FFT values (within each temporal segment and averaged across all three segments) and treat positive correlations as indication of convergence.
, we inspected correlations between actors’ FFT values (within each temporal segment and averaged across all three segments) and treat positive correlations as indication of convergence.
7
We also tested to see if the labels used (Actor A vs. Actor B) had any effect on ratings. There were no significant differences based on actor label.
8
Comparing coefficients from Model 3 in Table 4 and Model 3 in ![]() .
.
9
We present results from mediation models for observers only. We were unable to estimate accurate generalized structural equation modeling models for the perceptions of actors due to collinearity issues between our predictor (status) and mediator (AAR) variables. Specifically, in mediation analyses, collinearity between predictor and mediator produces imprecise estimates of indirect effects (Loeys, Moerkerke, and Vansteelandt 2015).