
Abstract
When planning a cluster randomized trial, evaluators often have access to an enumerated cohort representing the target population of clusters. Practicalities of conducting the trial, such as the need to oversample clusters with certain characteristics in order to improve trial economy or support inferences about subgroups of clusters, may preclude simple random sampling from the cohort into the trial, and thus interfere with the goal of producing generalizable inferences about the target population. We describe a nested trial design where the randomized clusters are embedded within a cohort of trial-eligible clusters from the target population and where clusters are selected for inclusion in the trial with known sampling probabilities that may depend on cluster characteristics (e.g., allowing clusters to be chosen to facilitate trial conduct or to examine hypotheses related to their characteristics). We develop and evaluate methods for analyzing data from this design to generalize causal inferences to the target population underlying the cohort. We present identification and estimation results for the expectation of the average potential outcome and for the average treatment effect, in the entire target population of clusters and in its non-randomized subset. In simulation studies, we show that all the estimators have low bias but markedly different precision. Cluster randomized trials where clusters are selected for inclusion with known sampling probabilities that depend on cluster characteristics, combined with efficient estimation methods, can precisely quantify treatment effects in the target population, while addressing objectives of trial conduct that require oversampling clusters on the basis of their characteristics.
Introduction
When conducting cluster randomized trials evaluators often have access to an enumerated cohort representing the target population of clusters. For example, in the applications motivating our work—cluster randomized trials of vaccine effectiveness in U.S. nursing homes (National Library of Medicine (U.S.), 2013, 2018, 2019)—evaluators can often identify a roster of trial-eligible nursing homes using routinely collected data. Similarly, when conducting educational experiments, administrative data can be used to compile a list of all trial-eligible schools in a state (Tipton, 2013b). When clusters can be selected for participation from an enumerated cohort, the inferential goals of the trial and practicalities related to research economy may conflict with the goal of producing generalizable inferences for the target population underlying the enumerated cohort. For example, evaluators may be interested in oversampling certain groups of clusters to increase the trial’s ability to test hypotheses about heterogeneity of treatment effects (i.e., effect modification or moderation) or to ensure that the trial can produce reasonably precise estimates in cluster subgroups defined by baseline characteristics. Furthermore, some clusters may be oversampled if they have attributes that facilitate the conduct of the trial (e.g., have infrastructure that facilitates data collection), particularly when resources are constrained. In such cases, it is possible to select clusters for participation in the trial using sampling probabilities that depend on baseline characteristics and are under the control of evaluators—and thus, known by design. Such sampling can help achieve the goals of the trial while supporting the generalizability of inferences to the target population.
Most recent work on generalizability methods has focused on individually randomized trials where participants are not representative of the target population, and where evaluators do not have control over an individual’s decision to participate in the trial or access to an enumerated cohort of individuals is not common (Cole & Stuart, 2010; Dahabreh et al., 2019b, 2020; Rudolph & van der Laan, 2017; Westreich et al., 2017). Some work in educational and welfare policy research has discussed generalizability analyses with cluster randomized trial data in settings where cluster participation in the trial was not under evaluator control (e.g., O’Muircheartaigh and Hedges (2014), Tipton (2013a), and Tipton et al. (2017)). Recent work in educational research has mainly considered trials in which clusters are selected for participation by sampling within strata defined by effect modifiers, such that the average treatment effect in the trial may directly generalize to the target population (Tipton, 2013b; Tipton et al., 2014; Tipton & Peck, 2017). This work has mentioned, without providing details, the possibility of using simple weighting (Stuart et al., 2011) or stratification (Tipton, 2013a) estimators to adjust for imbalances between the sampled clusters and the target population (e.g., for effect modifiers that were not stratified on) or when clusters are sampled with unequal probabilities across strata [e.g., to optimally estimate stratum-specific treatment effects (Tipton et al., 2019)].
Prior generalizability work using cluster randomized trial data, whether participation of the clusters in the trial was under the control of evaluators or not, aggregated individual-level information to the cluster level and used weighting or stratification methods to generalize inferences to the target population by estimating average treatment effects, in the target population of clusters (O’Muircheartaigh & Hedges, 2014; Tipton, 2013a, 2013b; Tipton et al., 2017; Tipton et al., 2014; Tipton & Olsen, 2018; Tipton & Peck, 2017; Tipton et al., 2019). These approaches may be inefficient because they ignore information on the relationship of covariates and treatment with the outcome, available from randomized clusters at the end of the trial (but often unavailable from non-randomized clusters). Instead, these approaches use cluster-level baseline covariate information from only non-randomized clusters via the sampling probability (or the probability of trial participation when not under the evaluators’ control). By modeling the relationship of covariates and treatment with the outcome using either individual-level or cluster-level data, efficiency can be improved using an augmented inverse probability weighting estimator, without introducing bias even if the outcome model is misspecified, as long as the sampling probability is correctly specified (when the sampling probability is under investigator control, a model for it can always be correctly specified). Of note, generalizability analyses that use individual-level data require accounting for various forms of within-cluster dependence (Balzer et al., 2019), including causal interference [e.g., due to herd immunity effects (Halloran & Struchiner, 1995)], even if the clusters are assumed to be independent—an issue that is well-appreciated for analyses of cluster randomized trials (Donner & Klar, 2000; Murray et al., 1998).
Here, we combine recent advances in the analysis of cluster randomized trials (Balzer et al., 2019; Benitez et al., 2022) and prior work on generalizability analyses for individually randomized trials (Dahabreh et al., 2019b, 2020) to propose augmented weighting estimators for analyzing cluster randomized trials where the evaluators have sampled participating clusters using known sampling probabilities that depend on baseline characteristics. The methods we describe can be used to estimate causal effects in the target population from which participating clusters are sampled, while exploiting individual-level information on the relationship of covariates and treatment with the outcome and allowing for arbitrary within-cluster dependence. We show that knowledge of the sampling probabilities leads to augmented weighting estimators that are robust to misspecification of the outcome model. In addition to robustness, we show that knowledge of the sampling probabilities can be used to develop more efficient estimators of causal estimands that pertain to the non-randomized subset of the target population, but not those that pertain to the entire target population. We evaluate the finite-sample performance of the methods in a simulation study motivated by a cluster randomized trial of vaccine effectiveness in U.S. nursing homes. Our simulations show that the precision of non-augmented weighting estimators can be improved substantially by estimating the sampling and treatment probabilities (even when they are known), rather than using the known probabilities. In contrast, the precision of the augmented weighting estimators is fairly similar whether using the true or estimated probabilities, and superior to non-augmented weighting estimators when the models for estimating the probabilities include covariates in addition to those used in the design (e.g., as may be necessary in trials with modest sample sizes that have baseline imbalances or are not representative of the target population with respect to variables not used in the design).
Study Design, Data, and Causal Quantities of Interest
Study Design and Data
Consider the cluster version of the nested trial design for analyses extending inferences from a individually randomized trial to a target population (Dahabreh et al., 2021): among a cohort of clusters sampled from the target population (e.g., a cohort of trial-eligible clusters), a subset is chosen to participate in a randomized trial with cluster-level treatment assignment. We assume that participation of clusters in the trial is fully under the control of the investigators (e.g., as might be the case for interventions with favorable risk-benefit profiles when all clusters in the enumerated cohort can be potentially included in the trial).
We index clusters in the cohort of trial-eligible clusters by j ∈ {1, …, m}; the jth cluster has sample size N
j
, and we allow the sample size to vary across clusters. Individuals in cluster j are indexed by i ∈ {1, …, N
j
}. We use S
j
for the cluster-level indicator of selection into the trial; S
j
= 1 for randomized clusters and S
j
= 0 for non-randomized clusters. For all clusters, both randomized and non-randomized, we have data on cluster-level covariates, X
j
(i.e., covariates that are constant for all individuals within a given cluster), and a matrix of individual-level covariates,
Selection into the trial depends on sampling probabilities that are chosen by the evaluators and are allowed to depend on covariates (X
j
,
We assume independence across clusters, but we allow for arbitrary dependence among individuals within each cluster [sometimes referred to as a partial interference assumption (Hudgens & Halloran, 2008)]. Such dependence can occur via multiple mechanisms, including (1) shared exposures: individuals share measured and unmeasured cluster-level factors that affect the outcome and response to treatment; (2) contagion: occurrence of the outcome in one individual might affect the outcome of another individual in the same cluster; (3) covariate interference: one individual’s covariates may affect the outcomes of other individuals in the same cluster; or (4) treatment-outcome interference: one individual’s treatment assignment may affect the outcome of other individuals in the same cluster.
We collect data on baseline covariates from the cohort of trial-eligible clusters and view the cohort as a random sample from that target population of clusters. Treatment and outcome data are only needed from clusters participating in the trial; the observed data are independent and identically distributed realizations of the random tuple
Causal Estimands
Let
Following Balzer et al. (2019) and Benitez et al. (2022), our causal quantity of interest is the (cluster-level) expectation of the average potential outcome in the target population of clusters,
Identification
For the Target Population
Identifiability Conditions
The following conditions are sufficient to identify the expectation of the average potential outcome in the target population: A1. Consistency of cluster-level average potential outcomes: if A
j
= a, then
Identification
As shown in Online Appendix A, and similar to work on individually randomized trials (Dahabreh et al., 2019b), under the above conditions, the expectation of the average potential outcome in the target population,
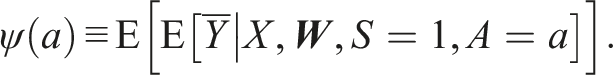
For the Non-randomized Subset of the Target Population
Identifiability Conditions
To identify the expectation of the average potential outcome in the non-randomized subset of the target population, we retain conditions A1 through A4 and replace condition A5 by the following, slightly weaker, condition:
A5*. Positivity of trial participation: Pr [S = 1|X = x,
Identification
As shown in Online Appendix A, and similar to work on individually randomized trials (Dahabreh et al., 2020), under identifiability conditions A1 through A4 and condition A5*, the expectation of the average potential outcome in the non-randomized subset of the target population,
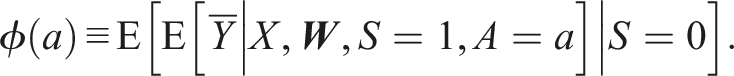
The average treatment effect in the non-randomized subset of the target population can be identified by taking differences between the expectations of the average potential outcomes in the non-randomized subset of the target population under different treatments.
Estimation and Inference
For the Target Population
Estimation
We propose the following augmented inverse probability of selection weighting estimator for ψ(a):
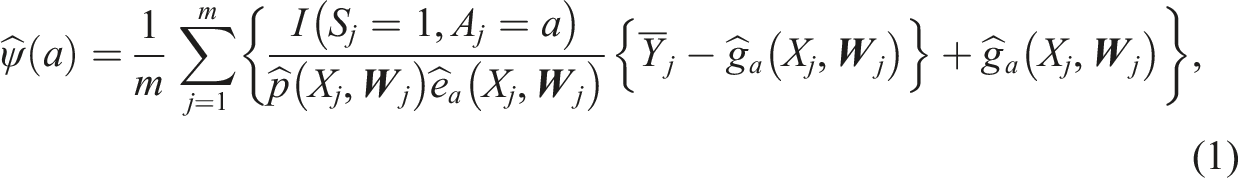
Inference
We estimate the sampling variance of
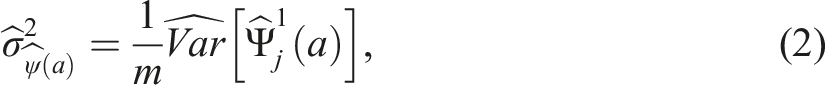
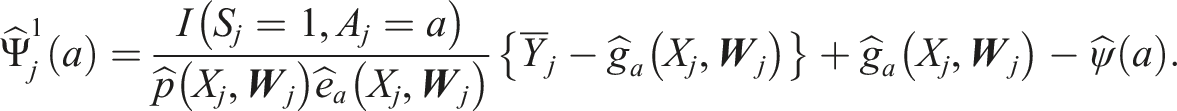
The sampling variance can be used to obtain a (1 − α)% confidence interval as
For the Non-randomized Subset of the Target Population
Estimation
We propose the following augmented inverse odds of selection weighting estimator for ϕ(a):
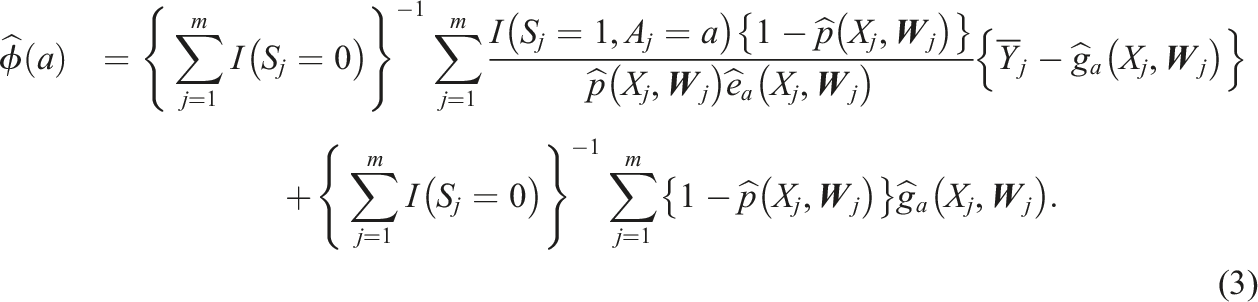
Inference
We estimate the sampling variance of
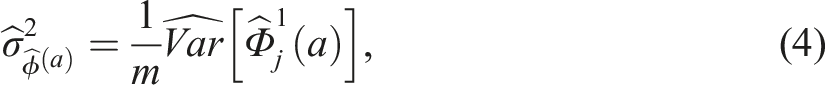
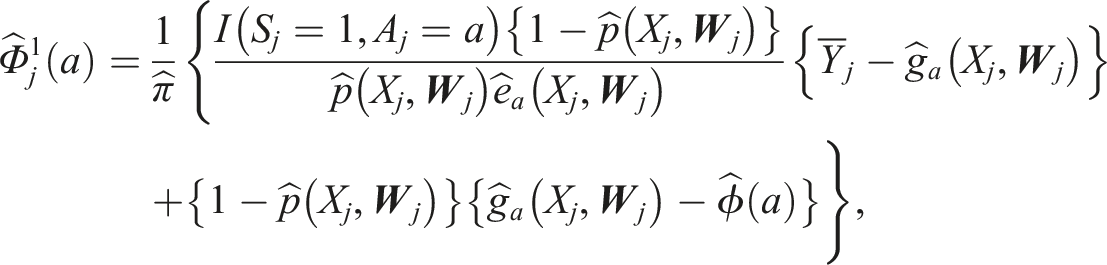
Average Treatment Effects
The expectation of the average treatment effects can be estimated by taking differences between pairs of the estimators of the expectation of the average potential outcome described above. For example, the expectation of the average treatment effect in the entire target population, comparing treatments a and a′, using the augmented weighting estimator in equation (1), can be estimated as
Modeling Participation, Treatment, and Outcomes
As noted above, the sampling probability and the probability of treatment in the trial are both known by design and can be used to estimate the expectation of the average potential outcomes and average treatment effects. Nevertheless, estimating these probabilities using simple parametric models (at the cluster level) can result in more precise estimates (Lunceford & Davidian, 2004; Williamson et al., 2014). We illustrate this behavior of the estimators in the simulation studies presented in the next section.
In contrast, the expectation of the average observed outcome conditional on baseline covariates and treatment in the trial,
When individual-level data is available, the choice of whether to model the outcome at the individual level or cluster level is not obvious. In general, the model of the outcome conditional on covariates and treatment at the individual level will be different than the model of the cluster-level average of the outcome. Furthermore, our ability to specify and estimate either of these models will depend on background knowledge, properties of the data generating mechanism, and data attributes (e.g., sample size and data availability). That said, we note that by using equation (1) or (3), our estimate remains consistent regardless of the specification of the outcome because the sampling probability is known by design and investigators can always correctly specify a model for it.
Simulation Studies
Simulation Study Scenarios for the Outcome Data Generating Mechanism and Outcome Model Specification.
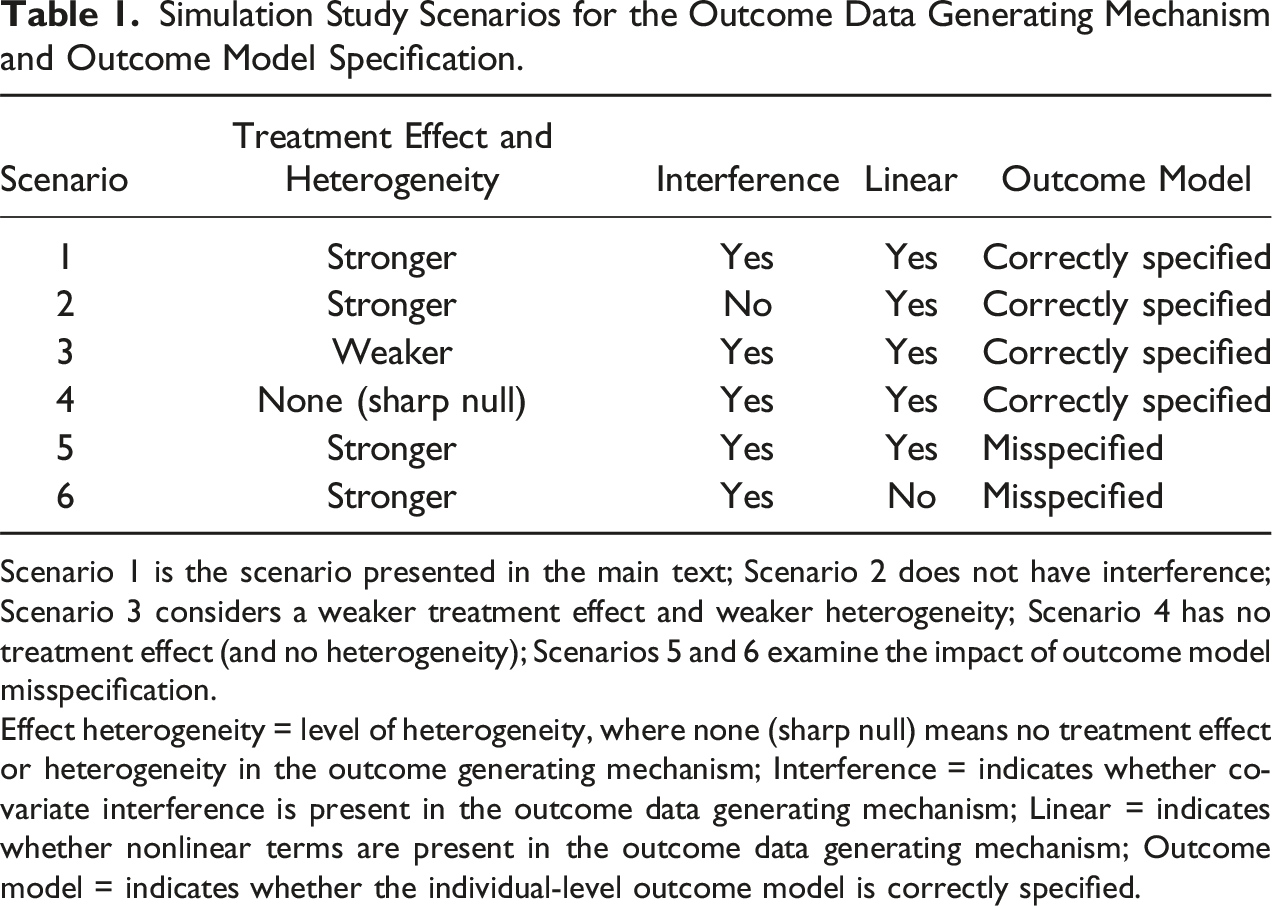
Scenario 1 is the scenario presented in the main text; Scenario 2 does not have interference; Scenario 3 considers a weaker treatment effect and weaker heterogeneity; Scenario 4 has no treatment effect (and no heterogeneity); Scenarios 5 and 6 examine the impact of outcome model misspecification.
Effect heterogeneity = level of heterogeneity, where none (sharp null) means no treatment effect or heterogeneity in the outcome generating mechanism; Interference = indicates whether covariate interference is present in the outcome data generating mechanism; Linear = indicates whether nonlinear terms are present in the outcome data generating mechanism; Outcome model = indicates whether the individual-level outcome model is correctly specified.
Baseline Data Generation
We generated a sample of m = 5000 trial-eligible clusters from the target population. Each cluster had a sample size N j , j = 1, …, m, randomly drawn from a Poisson distribution with mean parameter of 100. Thus, the number of individuals in each cluster varied, but on average, there were approximately 100 individuals per cluster, which is similar to the sample sizes in the trials we used to motivate the simulation.
We generated a binary cluster-level covariate, X
j
, with a Bernoulli distribution with parameter Pr [X
j
= 1] = 0.05. In each cluster, we generated individual-level covariates, by generating two column vectors of
Selecting the Clusters in the Randomized Trial With Known Sampling Probabilities
We simulated trials with different cluster sample sizes: 50, 100, or 200 clusters. We sampled clusters from a cohort of 5000 trial-eligible clusters into the randomized trial so that Pr [X j = 1|S j = 1] = 0.5; that is to say, we wanted the clusters enrolled in the trial to be (approximately) equally split between the two possible levels of the cluster-level covariate X j . To accomplish this, we had to oversample clusters with X j = 1 and undersample clusters with X j = 0.
For Bernoulli-type sampling of clusters from the target population sample, we used the sampling probability given by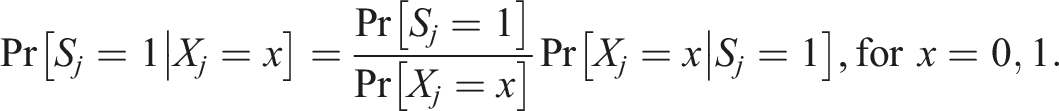
For example, suppose that the targeted trial sample size was 50 clusters, the target population sample was 5000 clusters, and the desired proportion of clusters with X
j
= 1 in the trial was 0.5. Then, among clusters with X
j
= 1, we set the known-by-design sampling probability to
Treatment and Outcome Generation
Treatment A
j
was randomized at the cluster level, following a Bernoulli distribution with parameter Pr[A
j
= 1|S
j
= 1] = 0.5. For each individual i in cluster j, we calculated the linear predictor
Estimators
We considered estimation of the expectation of average potential outcomes and the average treatment effects in the entire target population and its non-randomized subset. When estimating quantities in the entire target population, we applied the augmented inverse probability weighting estimator in equation (1) with the outcome-model fit using cluster-level information (AIPW1) or individual-level information (AIPW2). We also considered the following non-augmented inverse probability weighting estimator (IPW):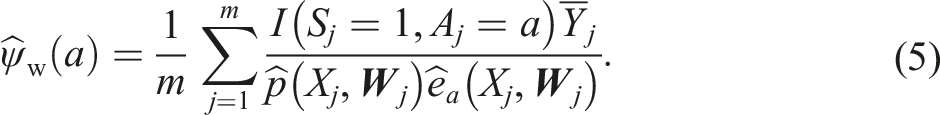
This estimator can be viewed as a special case of
When estimating quantities in the non-randomized subset of the target population, we used the augmented inverse odds weighting estimator in equation (3) with the outcome-model fit using only cluster-level information (AIOW1) or both cluster- and individual-level information (AIOW2). We compared these estimators against the following non-augmented inverse odds weighting estimator (IOW):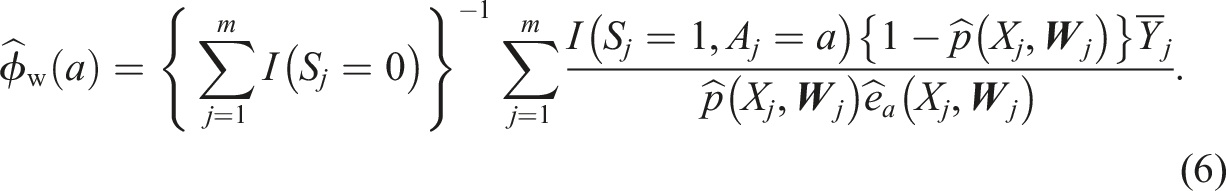
Similar to the inverse probability weighting estimator above,
We note in passing that the augmented inverse probability weighting estimator (using the known-by-design or estimated probabilities) is asymptotically at least as efficient as the non-augmented inverse probability weighting estimator using the known-by-design probabilities, when the outcome model is correctly specified (see Online Appendix D). Finally, we compared all these estimators against a trial-only estimator, which is estimated by averaging the individual-level outcomes in each cluster and then taking the average of these averages over the clusters participating in the trial.
Model Specification
For all estimators, we considered three possible versions for the sampling probability and probability of treatment in the trial: one where the known-by-design probabilities were used, one where both probabilities were estimated with a simple logistic regression model at the cluster level (conditional only on the cluster-level variable, X
j
, that determined the sampling probabilities), and one where both probabilities were estimated with a more complex logistic regression model at the cluster level (on the cluster-level variable, X
j
, that determined the sampling probabilities and cluster-level averages of the individual-level covariates,
For estimators that involve outcome modeling (i.e., AIPW and AIOW), we either modeled the outcome using cluster-level data (AIPW1 and AIOW1) or individual-level data (AIPW2 and AIOW2). When modeling using cluster-level data, we used a linear regression model for the cluster-specific average outcome, conditional on X
j
and the cluster-level averages of
Performance Assessment
We evaluated the performance of the estimators over 2000 simulation runs, in terms of bias and average standard deviation. We compared the estimated average standard deviation of the estimators (over the simulation runs) against (1) the average of the influence curve-based standard deviations, and (2) the average of a standard deviation estimated using a clustered bootstrap procedure that resamples with replacement from all the clusters (Field & Welsh, 2007), with 500 bootstrap samples in each of the simulation runs. We also compared the coverage of the augmented weighting estimators when using the influence curve-based standard deviation versus the standard deviation estimated using the clustered bootstrap procedure. To facilitate numerical comparisons, we multiplied the simulation estimates of the bias and average standard deviation by the square root of the target cluster sample size,
Additional Simulation Scenarios (Scenarios 2 Through 6)
Here, we briefly summarize the additional scenarios we examined in the simulation study (see also Table 1 for a summary of the different scenarios and Online Appendix F for additional details regarding the specification of models for data generation and for analyzing the data as needed for different estimators). Briefly, in Scenario 2, we modified Scenario 1 to generate data in the absence of interference; in Scenario 3, we considered weaker treatment effects and heterogeneity; and in Scenario 4, we generated data under the sharp null hypothesis of no treatment effect (and no effect heterogeneity). In Scenarios 5 and 6, we examined the impact of different kinds of misspecification of the outcome model. In Scenario 5, we generated data using the same approach as in Scenario 1, but when modeling the outcome at the individual level, we omitted
Results for Scenario 1
Scaled Bias of Estimators for Quantities in the Target Population.
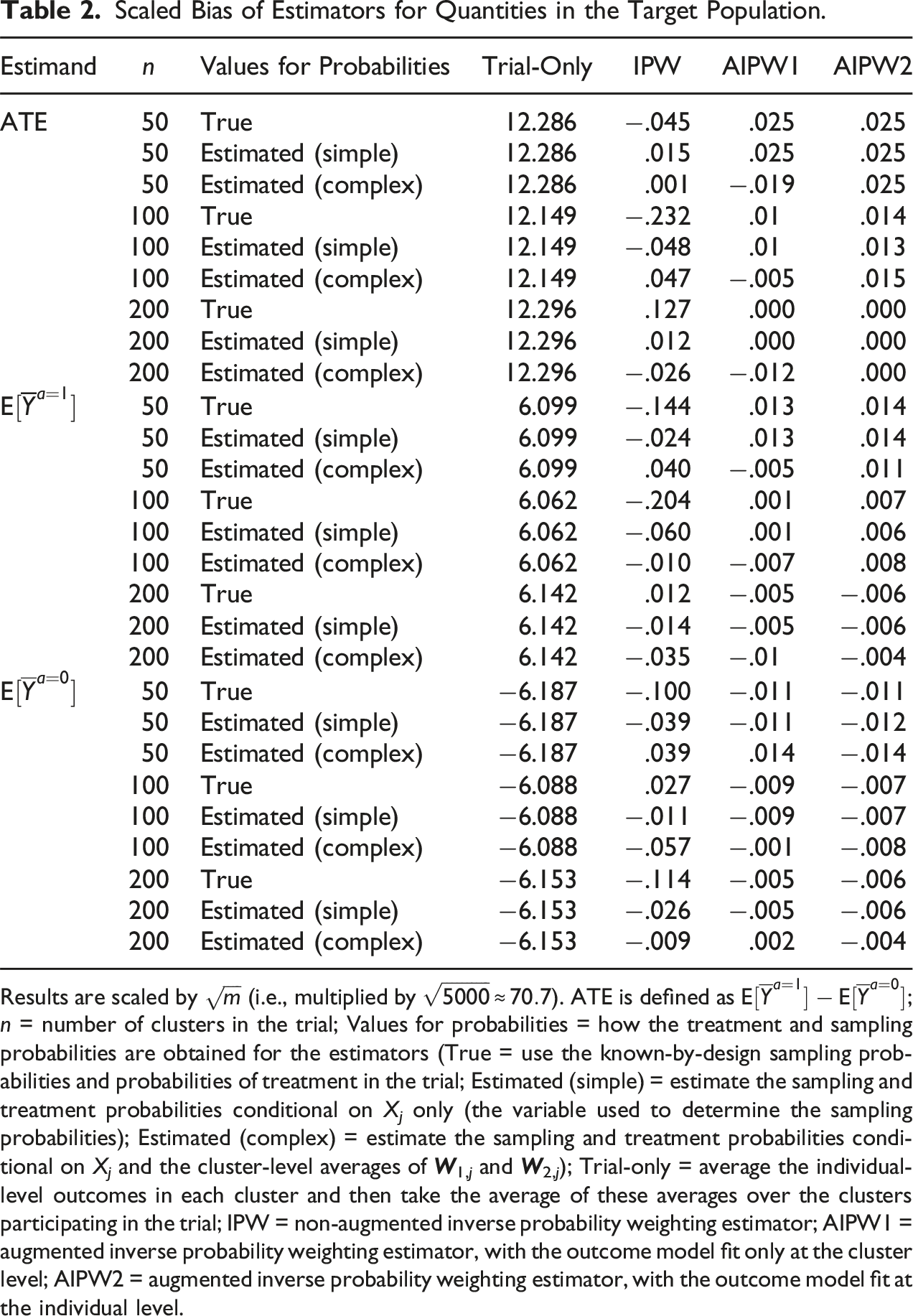
Results are scaled by
Scaled Standard Deviation of Estimators for Quantities in the Target Population.
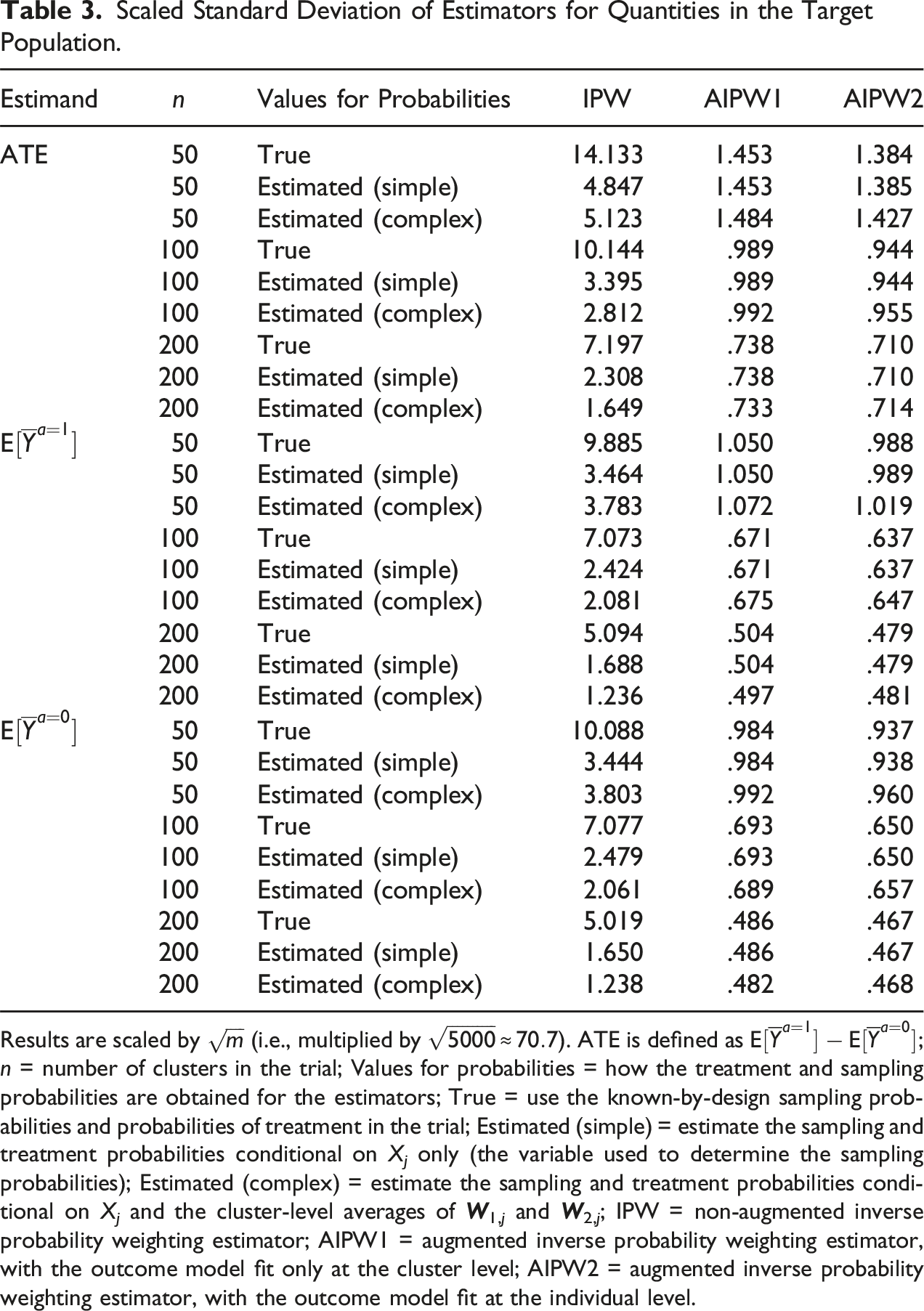
Results are scaled by
Coverage and Scaled Average of Standard Errors of the Augmented Weighting Estimators for Quantities in the Target Population.
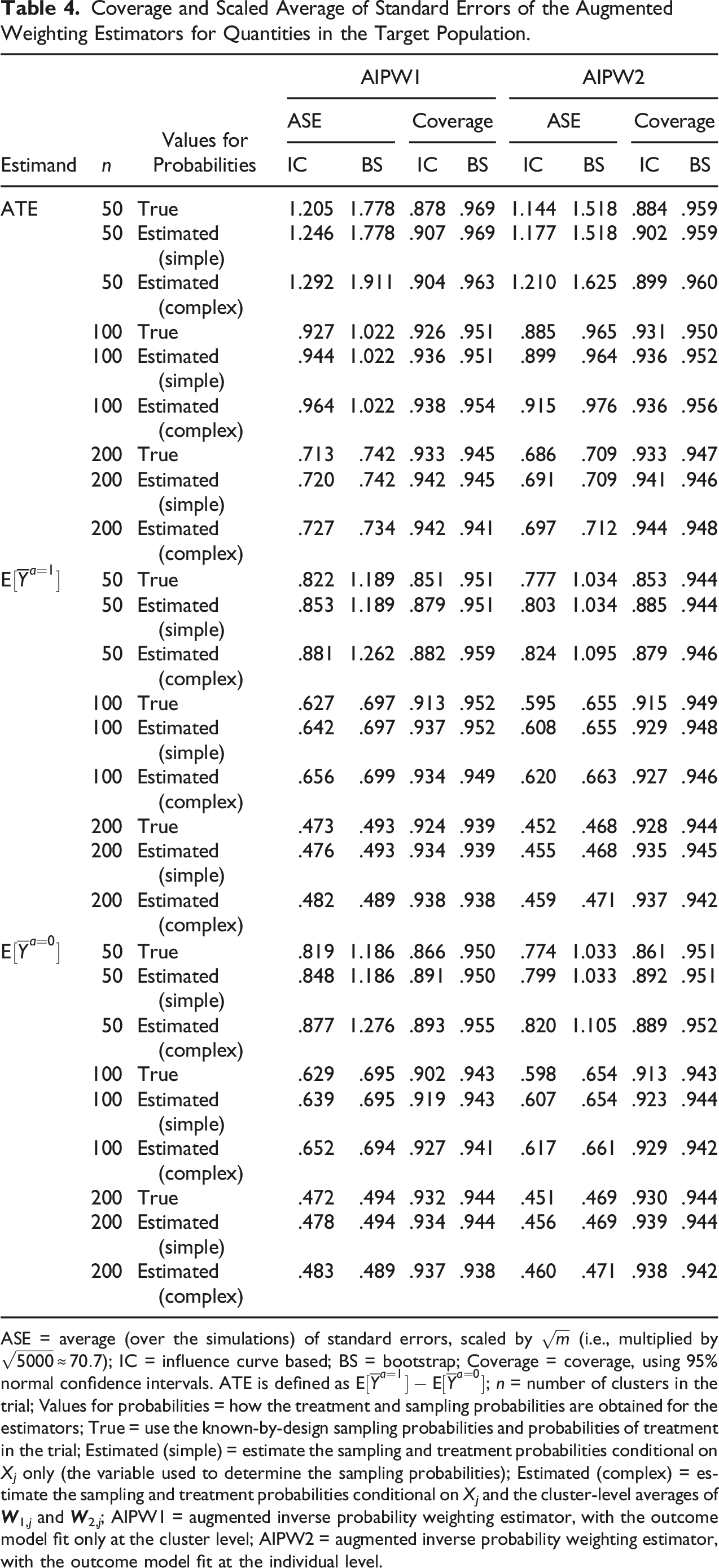
ASE = average (over the simulations) of standard errors, scaled by
Results for Additional Simulation Scenarios (2 Through 6)
We report detailed results for these scenarios in Appendices G through K. Regardless of the magnitude of the treatment effect and the amount of heterogeneity, in Scenarios 2 and 3, the trial-only estimator was biased (except when there no heterogeneity of treatment effects), while the other estimators (IPW, AIPW1, and AIPW2) remained unbiased. Scenario 4, produced similar results for the IPW, AIPW1, and AIPW2 estimators (in this scenario, the trial-only estimator was also unbiased for the average treatment effect in the target population, but remained biased for expectations of the average potential outcome). In these scenarios, as in Scenario 1, the AIPW estimators had smaller standard deviation than IPW. In Scenarios 5 and 6, where we examined the impact of misspecifying the outcome model, the AIPW estimators had little bias because regardless of the specification of the outcome model, the probability of participation was either the true one (known by design) or estimated using a correctly specified model (i.e., the simulations reflect the robustness property of the AIPW estimator).
Discussion
We described a nested cluster randomized trial design where clusters are selected for inclusion in the trial with known sampling probabilities that may depend on baseline covariates, and proposed robust augmented weighting estimators for this design. The robustness of the proposed estimators stems from the fact that the sampling probability and the probability of treatment in the trial are known by design, and thus, models for them can always be correctly specified. Our estimators give evaluators the option of exploiting individual-level data on the relationship between covariates, treatment and outcomes, to further increase efficiency, while accounting for within-cluster dependence, including various forms of interference. We showed that, for causal estimands that pertain to the non-randomized subset of the target population, knowledge of the sampling probabilities can be used to develop augmented weighting estimators that are more efficient compared to augmented weighting estimators when the sampling probabilities are unknown. This improvement is not available for estimands that pertain to the entire target population because their efficient influence function is the same, whether the sampling probabilities are known or unknown.
Our proof-of-concept simulations, motivated by large cluster randomized trials of vaccine effectiveness (National Library of Medicine (U.S.), 2013, 2018, 2019), show that the augmented weighting estimators perform well in finite samples and better than previously described non-augmented weighting estimators. The augmented weighting estimators had about the same performance whether the true or estimated sampling and treatment probabilities were used, even in small trials. In contrast, our simulation results suggest that estimating the known-by-design sampling and treatment probabilities when using the non-augmented weighting estimators can substantially improve precision, but the improvement is often not enough to reach the precision of the augmented weighting estimators. In the simulation, the standard deviation estimated using a clustered bootstrap procedure worked well for inference with the augmented weighting estimators and the influence curve-based standard deviation (which is computationally faster) also performed well in larger cluster trial sizes. Even though the clustered bootstrap procedure we used worked well in our simulations, there are many options for bootstrapping clustered data (Davison & Hinkley, 1997; Field & Welsh, 2007) and comparisons among them might be useful, particularly for studies with a smaller number of clusters.
Prior work on designing a cluster randomized trial to support generalizable inferences has focused on sampling clusters such that crude (unadjusted) analyses of the trial data can estimate treatment effects in the target population (Tipton, 2013b; Tipton et al., 2014; Tipton & Peck, 2017). Such “representative” sampling using a constant sampling probability across strata defined by effect modifiers puts a premium on being able to use relatively simple statistical analyses but cannot accommodate other practical aspects of trial conduct, such as the need for rapid recruitment of clusters, the recruitment of clusters with established research infrastructure, or the desire for efficient estimation within subgroups of clusters defined by covariates. When representative sampling does not result in good balance between the trial and the target population, this prior work has mentioned the possibility of using simple weighting or stratification methods, without providing evidence of good performance. Our proposed design essentially works in the opposite direction, by acknowledging that evaluators often have to select clusters for participation conditional on baseline covariates, while still wanting to draw generalizable inferences—an instance of experimental design with multiple objectives (Sverdlov & Rosenberger, 2013; Sverdlov et al., 2020; Woodcock & LaVange, 2017). For example, our approach can support trials designed to test hypotheses in subgroups of clusters, by oversampling clusters with certain characteristics, and uses the known-by-design sampling probabilities to produce inferences that apply to the target population.
Our proposed design and analysis methods should be useful when practicalities of trial conduct (e.g., efficient recruitment) or the trial’s inferential goals require oversampling clusters with certain characteristics. They can form the basis for explicit approaches to the planning of future cluster randomized trials (Copas & Hooper, 2021; Raudenbush, 1997) via formal optimization procedures for trading-off competing research objectives. Such optimization efforts are motivated by the desire to use the most efficient experimental designs that are feasible; thus, they should routinely be paired with efficient estimation approaches, such as those that we have proposed.
In most cases, evaluators will choose sampling probabilities that depend on a low dimensional set of discrete covariates (e.g., those deemed as the most likely and strong effect modifiers for the treatment effects of interest). That said, our methods can also accommodate more complex sampling schemes. For example, when evaluators would like to sample clusters based on multiple covariates [as may be the case in large cluster randomized trials that motivate our work (National Library of Medicine (U.S.), 2013, 2018, 2019)], a risk or effect score, or other dimensionality reduction approach, could be used to create a lower dimensional variable that can then be used to determine the sampling probabilities.
Throughout, we assumed that the evaluators have complete control over cluster participation in the trial. Nevertheless, the methods can be easily extended to allow for the possibility that selected clusters may decline participation in the trial. When sampled clusters can decline participation, additional causal assumptions regarding the exchangeability of clusters that agree to participate with those that do not, among the sampled clusters, will be needed (this is analogous to recent results for individually randomized trials (Dahabreh et al., 2019c). Furthermore, the model for the probability of participation among sampled clusters will need to be correctly specified on the basis of background knowledge, because participation among the sampled clusters will not be under the control of the evaluators.
In summary, cluster randomized trials where clusters are selected for inclusion with known sampling probabilities that may depend on cluster characteristics, combined with efficient estimation methods, can lead to substantial improvements in the precision of the estimated effect in the target population, while also addressing competing objectives of trial conduct.
Supplemental Material
Supplemental Material - Cluster Randomized Trials Designed to Support Generalizable Inferences
Supplemental Material for Cluster Randomized Trials Designed to Support Generalizable Inferences Sarah E. Robertson, Jon A. Steingrimsson, and Issa J. Dahabreh in Evaluation Review.
Footnotes
Declaration of Conflict Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Dr Dahabreh is the principal investigator of a research agreement between Harvard University and Sanofi on transportability methods for individually randomized trials, unrelated to this manuscript; Dr Dahabreh also reports consulting fees from Moderna for work unrelated to this manuscript. The other authors report no potential conflicts of interest.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by National Library of Medicine (NLM) Award R01LM013616 and Patient-Centered Outcomes Research Institute (PCORI) awards ME-1502-27794 and ME-2019C3-17875. The content of this paper is solely the responsibility of the authors and does not necessarily represent the official views of the NLM, PCORI, the PCORI Board of Governors, or the PCORI Methodology Committee.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.