
Abstract
Background:
Artificial intelligence (AI), particularly generative and large language models, is being used in nursing education, practice, and scholarly writing. Generative AI applications have been specifically examined for their use in conducting literature reviews with evidence supporting reduced production time of scholarly work. However, there has been limited investigation of their levels of accuracy with identifying references for a literature review.
Objective:
The purpose of this study was to compare human-generated citations of literature reviews with AI literature-review generated citations.
Methods:
Using a comparative exploratory design, references from 4 human-written literature reviews, 2 published and 2 unpublished, on 4 different topics, were compared to references derived from 2 AI literature applications, Consensus and Elicit. Three prompting strategies were utilized, including prompts generated using ChatGPT-4. Agreement between the AI and human references was evaluated.
Results:
The percent of agreement between AI and human generated reference lists ranged from 0% to 63.6%. The Consensus application had a greater overall mean rate of match (21.3%) as compared to Elicit (3.7%). The use of a ChatGPT-4 prompt did not significantly impact results, and there were no differences based on published or unpublished literature reviews.
Conclusion:
The 2 literature-based applications examined in this study offered a glimpse of their potential use and limitations. The use of an AI literature review application may support but not replace human work.
Introduction
The use of artificial intelligence (AI), particularly generative AI and large language models (LLMs), has grown by an estimated 540 000% over the last decade. 1 The personal and professional use cases sometimes appear limitless with a staggering 300 million active weekly users according to Reuters (2025). 2 In recent surveys of student and faculty use, an estimated 90% of college-age students report regular use 3 and 94% of faculty working in higher education used AI in the past 6 months. 4
Applications like ChatGPT-4, a commonly used generative AI application, have access to approximately 3000 trillion words, pulling data from various sources such as books, articles, websites, and social media posts. 5 The vast array of retrievable data and sophistication of pattern logic has driven the utilization of LLMs for nursing education, 6 practice, 7 as well as scholarly research and writing support. 8 In a 2024 systematic review of 24 studies of AI use in academic writing and research, the authors concluded that there was a strong potential for the use of AI in idea generation, content structuring, literature synthesis, and data management but recommended further investigation of how the tools can be used to support human work. 9 According to a 2025 scoping review of AI use in nursing education, primary areas of use included content and curricular development, educational support, and simulation training. 6 The authors commented on a lack of rigorous evaluation of AI use in nursing education.
Literature reviews are a common type of scholarly writing conducted by nurse educators and researchers. Writing literature reviews requires a certain level of expertise coupled with methodological soundness. 10 High quality and effective reviews require time and resources, with scoping and systematic reviews estimated to take between 6 to 18 months from initiation to submission for publication.11,12 A primary step of any literature review is to conduct a search of the literature. 13 This is an iterative process where the user starts with search terms, often based on a combination of terms using Boolean operators, and as results are produced, the search is expanded or narrowed, often using filters. A rigorous search of the literature includes multiple bibliographic databases and a trial-and-error approach, with the user considered the content expert to determine when the search is complete.
Generative AI applications now include applications specific for conducting literature reviews, including the step of literature searching. A major advantage of these applications is the significant decrease in time spent, from finding citations to summarizing the findings and writing the final article.14-16 A report published in the United Kingdom cited a 23% reduction in time spent conducting a full literature review, including article scanning, selection of articles, and synthesis, when AI was utilized. 15 Recent literature across diverse fields of study cites mixed results with respect to the quality of literature searches using AI. Kacena et al 16 conducted a study to determine if ChatGPT-4 could assist with writing a credible, peer-reviewed, scientific review article on 3 topics related to musculoskeletal conditions. They found that only 30% of references were accurate. Similarly, Mostafapour et al 14 conducted a literature review on the topic of physician and patient relationships and then conducted that same review using ChatGPT-4. They noted that 24% of the AI-produced references were only somewhat related to the topic and 7.5% were completely irrelevant. The authors also found that when using iterative prompt strategies in ChatGPT, to mirror the human process, the more contextual factors that were asked of ChatGPT-4, the greater the risk for hallucinations, or fake citations.
The 2 previously cited examples represent the use of generative AI applications, such as ChatGPT-4, to conduct literature reviews. More recently, several generative AI literature review-specific applications have emerged. These differ in a variety of ways including the reference databases they have access to, the LLMs they use for their algorithms, the outputs they allow for, and other functions such as filtering options. For example, vended applications like Elicit, Consensus, and Perplexity utilize Semantic Scholar as a primary resource, while others, like Evidence Hunt, utilize PubMed. 17 According to Bolaños et al, 17 the benefit of literature-review-specific AI applications is the use of natural language rather than keyword searching and the incorporation of information from a collection of documents, which creates greater opportunity to reduce inaccuracies and hallucinations.
Apata et al 18 reviewed Consensus and the effectiveness in conducting a literature review, including identifying citations. They found that there is a lack of studies evaluating the search quality of the Consensus application. Bernard et al 19 evaluated if Elicit strengthens a systematic review process by comparing results of an umbrella review on older adult living environments with and without the use of AI support. They found that Elicit missed finding 82% of articles from the original review. The use of Elicit among nursing students has also been explored. 20 In a 2024 study of graduate nursing students (n = 323), students were asked to conduct a search of the literature on their chosen concept using PubMed, Cumulative Index to Nursing and Allied Health Literature (CINAHL), and Elicit. While the accuracy of the 3 applications was not explored, students reflected on their preference and perception of the 3 methods. Preference was similar, with students selecting CINAHL (31.6%) and PubMed (30.7%) just slightly over Elicit (26%). Primary advantages of the Elicit application were the ability to have an abstract produced, user friendliness, and the number of relevant articles retrieved. Primary disadvantages were the infinite number of citations that resulted, limited search filters, and low accuracy/trustworthiness of the sources. The authors recommended the use of AI literature applications in helping students develop relevant terminology and restructure their research queries.
Despite the proliferation of AI applications for scholarly literature searching, there has been limited investigation of their levels of accuracy and overall quality compared to human experts. While AI can work more efficiently, humans must ensure the accuracy, relevance, and comprehensiveness of AI outputs. 8
Purpose
Understanding benefits and limitations of AI literature applications is important as the nursing profession looks to understand and guide the preparation of nurses to responsibly apply AI in education, research, and practice. 21 The purpose of this study was to compare human-generated citations of literature reviews with AI literature-review generated citations.
Methods
A comparative exploratory design was utilized to determine the rate of agreement between AI generated references and human generated references. References derived from 2 different AI literature review platforms, Consensus and Elicit, were compared with references from 4 human completed literature reviews on 4 different topics. Data analyses were conducted in April 2025.
Human Literature Reviews
A total of 4 human-written literature reviews were utilized in this study. A purposeful selection of literature reviews, conducted by a member of the author team of this study, was chosen so that it could be determined if any if the human-generated literature reviews missed any citations that the AI applications found. All authors were nursing faculty engaged in research who had previously published. Four articles, including different types of literature review methods and non-specific nursing areas, were selected to minimize the bias of homogeneity of the citations.
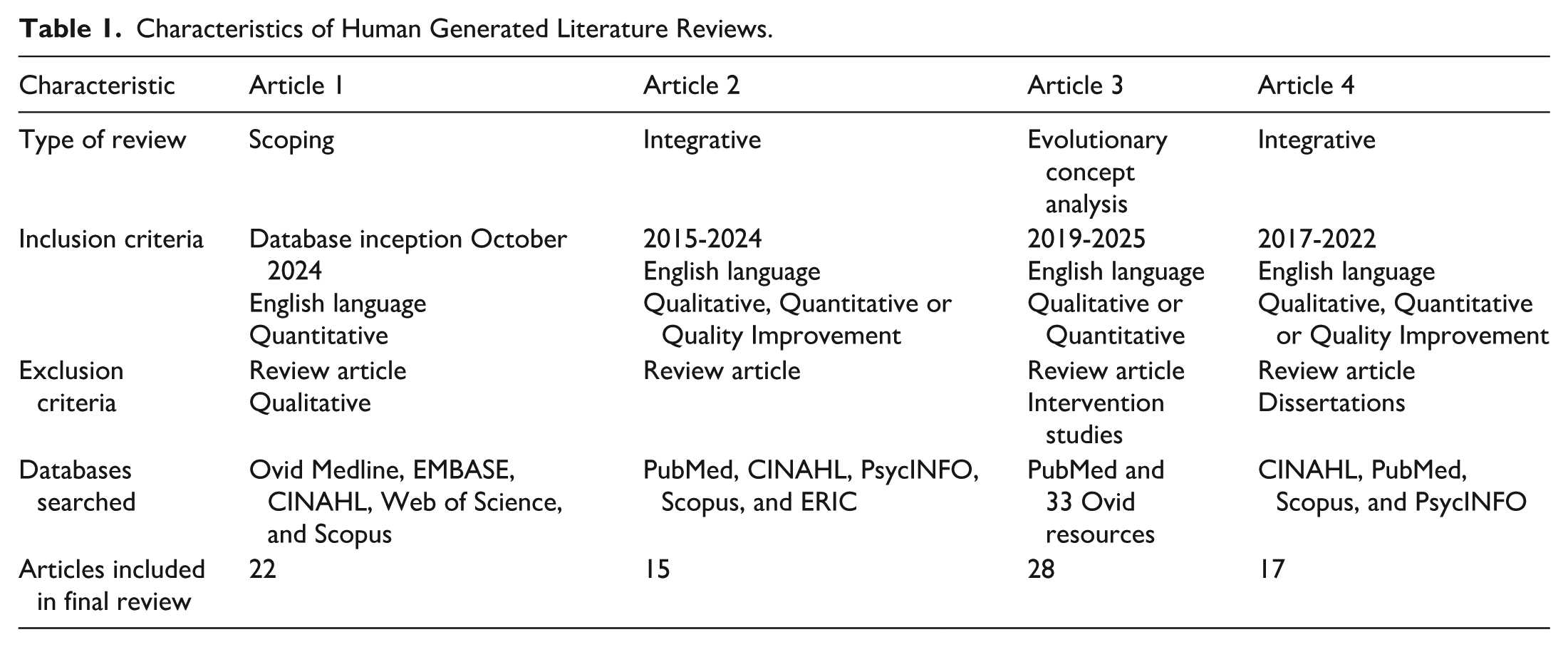
Article 1 was a scoping review that used a wide search of any research-based articles about interruptions and medication administration errors from database inception to 2024. 22 Article 1 was submitted and published in a high-index journal in 2025, following data analysis for this article. Article 2, not yet published, was an integrative review of the use of objective-structured clinical examinations in nurse practitioner students who focused on a 10-year timeframe of research and quality improvement articles. Article 3 was a published 2025 concept analysis of technostress and compassion fatigue in remote healthcare and social service workers since COVID-19. 23 Article 4 was a published integrative review, covering a 5-year timeframe of studies and quality improvement articles on the topic of interruptions and distractions during nurse-to-nurse handoff communication. 24 Further details of the 4 articles are included in Table 1.
Characteristics of Human Generated Literature Reviews.
AI Applications and Prompting Strategies
Consensus and Elicit, two AI literature review applications, were utilized in this study. This decision was based on both applications commonly being cited in the last 2 years specifically as academic research and literature review tools, designed to focus on biomedicine and social sciences. 17 Both applications also draw from the same primary database, with access to Semantic Scholar. Semantic Scholar is considered an original AI library with an index of over 233 million academic articles. Consensus and Elicit, in comparison to Semantic Scholar, are specific for academic research as they include workflow and data extraction functions and pull from Semantic Scholar. We also selected Consensus and Elicit because of free access to both applications, which we felt was important as an aspect of accessibility for faculty and students. It is important to note that at the initial conception of this work, both applications were free; however, when the searches were run in April 2025, Elicit required a fee to download the results so a Plus package was purchased by the author team to perform the analysis. Table 2 gives features of the 2 applications as of April 2025, when the searches were run.
Features of AI Applications.

Abbreviations: AI, artificial intelligence; RCT, randomized control trial.
An initial pilot test of AI-prompting strategies was first conducted using a research topic unrelated to this project. This was done to determine if inclusion and exclusion criteria should be included as part of a prompt or through the AI application filter. Filters available in both AI applications included publication date range, study design, and journal ranking based on an external metric. It was determined that including search filters in a prompt did not produce beneficial results. The authors thus used the filters of publication year and study design in both Consensus and Elicit.
Three separate generative AI-prompting strategies were utilized for each of the review topics to determine how different prompts affected search results, as it has been suggested that the quality of AI responses depend on the quality of the prompt. 25 The authors first independently created a prompt question for the review articles that they were the primary author of (prompt 1). Next, the author team came together, after reading each of the 4 articles, and created a consensus prompt for the literature search (prompt 2). Lastly, ChatGPT-4 was used to create a prompt for each search (prompt 3). To produce a ChatGPT-4 prompt, a standard formula with the following phrase was used: “I am a researcher conducting a literature review using the research question, XXXXX. Generate one prompt that can be used to search in an LLM.” Table 3 includes the prompts and filters applied.
Prompt Strategies and Filters Applied.
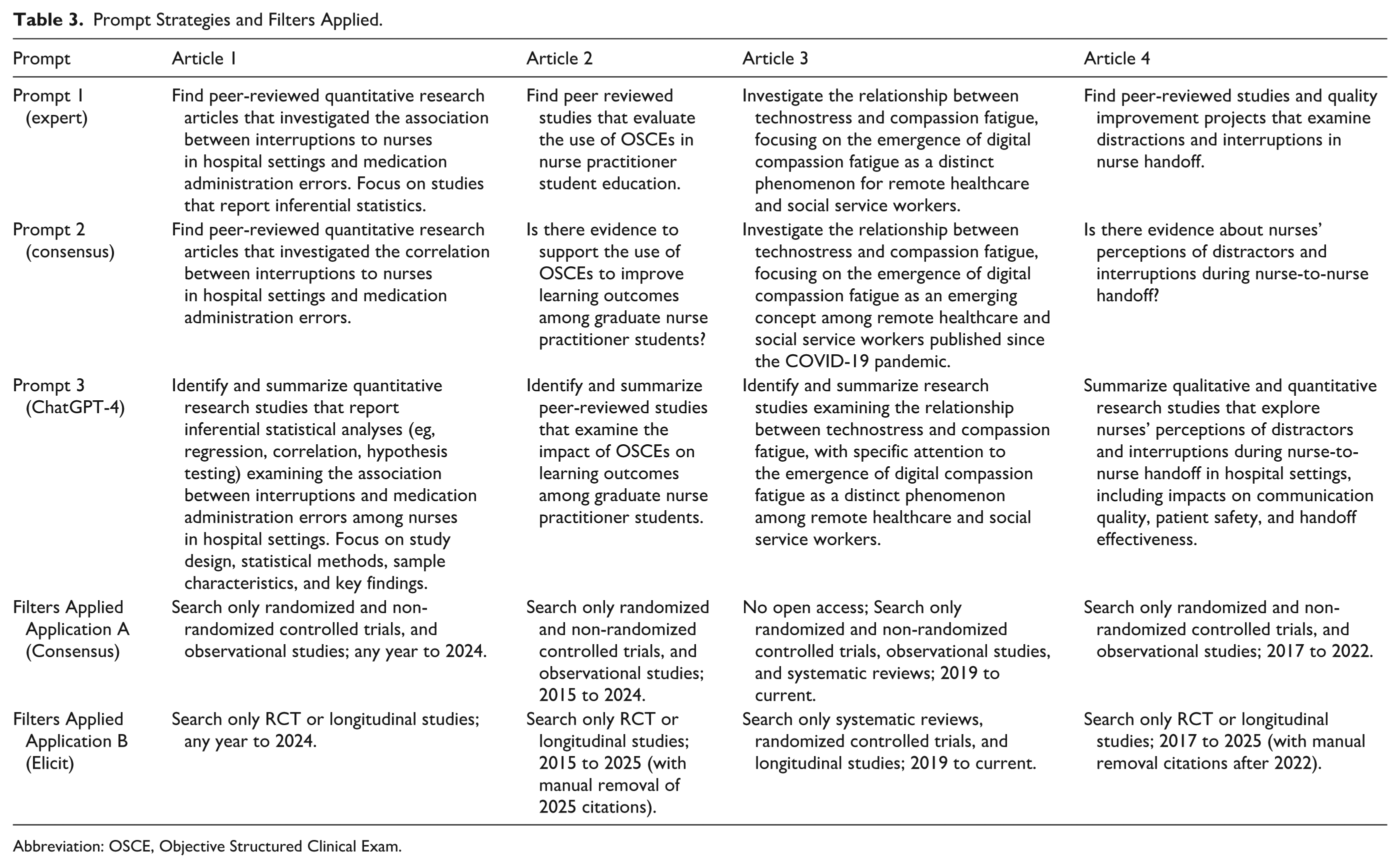
Abbreviation: OSCE, Objective Structured Clinical Exam.
All searches were conducted during the same week in April 2025 to ensure consistency in the search process given that the AI application search capabilities, data access, and underlying models are noted to change regularly. Each author independently ran the 3 prompts related to their review topic in sequential order through the 2 AI applications. The first generation of 10 citations and a sequential generation of outputs up to a total of 100 citations were downloaded for analysis. This approach was utilized as both AI applications indicated that they generate the most relevant citations in order of fit. All citations were downloaded into an excel spreadsheet for review. Once downloaded, the citations from the matched human-written article were entered into the same Excel file so that a simple sorting function could be used to make a comparison. The primary author had access to all searches to assess the accuracy of the comparison.
Data Analysis
A matrix of the 4 articles across the 3 prompts as well as the search returns for the first 10 and 100 citations, across both AI applications, were used to complete the analysis. Forty-eight individual searches were conducted across a total of 1320 citations. For each search, the percent of agreement was calculated using the number of matched AI-derived references and the human-derived references included in each review. A simple percent match was calculated using the equation of number of AI references in agreement divided by the total studies included in the human searched literature review.
To determine if the AI applications discovered any articles that the human searches did not identify, each author manually reviewed the AI reference lists related to their review topic. If an AI-derived reference appeared to fit the inclusion criteria of the completed review article, the author screened the article abstract and full text to decide fit. Presentation and discussion to the entire author group then occurred to make a final determination of fit.
Ethical Considerations
Ethical approval was not required as this study did not involve human participants or human data.
Results
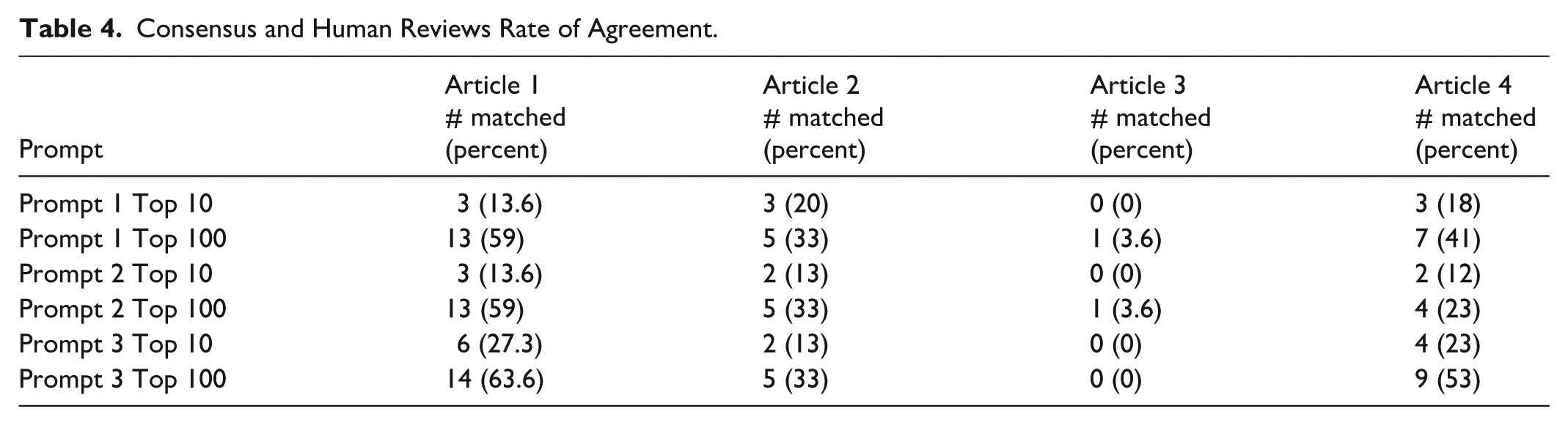
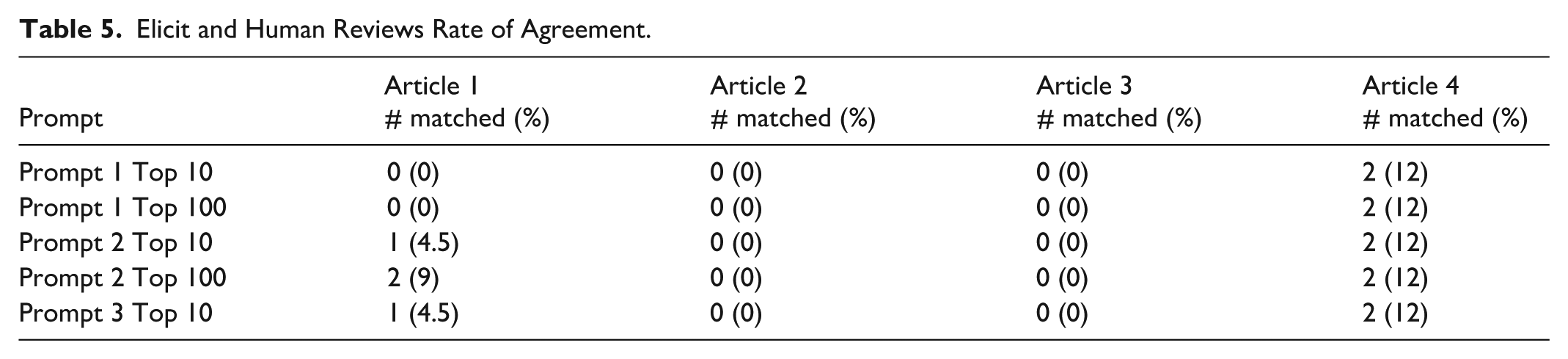
The top 10 and top 100 results across the 2 literature review AI applications were examined. Across all 3 prompts and both AI applications, the overall agreement with the 4 human-searched references ranged from 0% to 63.6% as shown in Tables 4 and 5. The Consensus application had a greater overall mean agreement rate to human searching (21.3%) as compared to the Elicit application (3.7%). Agreement improved from the 10 results to the top 100.
Consensus and Human Reviews Rate of Agreement.
Elicit and Human Reviews Rate of Agreement.
Results by Review Article and Prompts
Articles 1 and 2 were unpublished when data analysis occurred in April 2025. The Consensus application reached an agreement rate threshold of 63.6% for article 1 and 33% for article 2, across the 3 prompt strategies. Articles 3 and 4 were published in indexed journals at the time the AI platforms were searched. Article 3 had very low agreement rates (range 0%-3.6%) across the prompts and both applications. Article 4 had an agreement rate up to 53% in Consensus and 12% in Elicit. The agreement rate for Elicit between published and unpublished articles varied, but was consistently low.
In comparing the 3 prompting strategies, the ChatGPT-4 prompt (prompt 3) performed as well or slightly better in Consensus. Elicit had an equally poor performance across the 3 prompts (see Tables 4 and 5).
New AI References Identified
The Consensus application identified 1 reference not identified in the human search for article 3 that was a fit with inclusion criteria for the article. No new references for articles 1, 2, or 4 were identified in either AI platform.
Discussion
There has been limited investigation of the accuracy and overall quality of AI applications compared to humans for literature identification. This study provides insights into the performance of 2 AI literature review applications compared with human literature searches. The findings can be used to guide nurse educators, researchers, and practitioners who are considering using AI to search for literature.
Low agreement between references from human-written literature reviews and AI applications was found. A primary reason is likely the limitations on data that AI applications have access to. For example, both Elicit and Consensus have access to Semantic Scholar, which has partnerships with academic publishers and academic journals, including PubMed. 26 However, AI applications can only access full-text downloads of articles that are open access and often cannot get access to databases that require commercial licenses or paywalls. In this study, Consensus had a higher rate of agreement with the 4 original human literature reviews compared to Elicit. At the time of data collection, the Consensus application cited having access to 200 million articles from the Semantic Scholar database as compared to Elicit, which reported access to 25 million academic articles from Semantic Scholar. As of March 2026, Consensus reported access to over 250 million articles with additional article access to OpenAlex and a crawl of the scholarly web. Elicit reported access to 138 million articles and access to OpenAlex, indicating a rapid increase in access for both applications. Thus is it likely that if the same study methods were applied in March 2026, that results might differ.
In 2017, PubMed deployed a new relevance sort option (labeled as Best Match) to improve searches with a more relevant sort order of references displayed by topic. In this study, the researchers similarly thought that the top 10 results for each AI application would return the most relevant sets of references. 27 This was not supported, as shown by the low number of matches in the top 10 results from both applications. This is one example of how traditional literature searching, a learned skill, may not translate directly with AI search applications and thus, nurses need to understand uses and limitations of AI. It has been suggested that the extent of a human’s AI knowledge has a potential influence on the results of an AI search process. Karcena et al 16 reported that a researcher with more advanced AI knowledge may be more efficient and effective in guiding a generative AI application and altering search settings to produce more relevant results. Improving knowledge of how to create and use AI prompts can result in improved outputs, as prompting is a learnable skill. 28
The American Association of Colleges of Nursing (AACN) is integrating AI as a component of foundational informatics competencies (domain 8), 21 and the 2026 American Academy of Nursing position statement on AI in healthcare endorses AI as a transformative force that requires nurses to be equipped with AI literacy. 29 The N.U.R.S.E.S framework, which stands for Navigate AI basics, Utilize AI strategically, Recognize AI pitfalls, Skills support, Ethics in action, and Shape the future, supports AI literacy across all levels of nursing. 30 With the anticipation of nurses integrating AI in their work as educators, researchers, or clinicians, nursing faculty, who report limited knowledge and skill with AI use, 31 will need to quickly become proficient to role model AI competency.
Limitations
The study included a small sample of literature review applications (n = 2) and review articles (n = 4), thus limiting generalizability. The choice of 2 AI applications was purposeful as Consensus and Elicit were common AI literature review tools at the time of data extraction, both having been in existence for several years at the time of our search, and noted for their access to biomedical and social science data. Since our search, additional applications like Paperguide and Research Rabbit have been released and the features of Consensus and Elicit have expanded. The rapid growth of these applications makes it a challenge to do widespread comparisons. Comparing outcomes of 4 articles is acknowledged as a limitation. Most generative AI applications like those examined in this study are heavily reliant on the prompt utilized, especially in a single-turn prompt application. Expanded experimentation with different prompts and filtering strategies may have yielded improved results. Lastly, these types of applications evolve quickly with updated models, filtering options, and other system enhancements that could significantly improve performance over time.
Conclusion
Literature review applications like those examined in this study may be suitable to support human literature work but should not replace human work. If AI is used for a literature search, the use or more than one AI application is recommended, as different applications examine and access varied datasets, and vary in functional options (eg, filters) and underlying algorithms.
Footnotes
Ethical Considerations
Ethical approval was not required as this study did not involve human participants or human data.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
AI Use
AI applications were used in the data collection for this article as described. AI was not used for any of the writing or conceptualization of the article.