
Abstract
Students will speak a second language with an accent if they learn the language after the age of six. It does not matter how motivated and clever they are, the accent will not go away. Only a few gifted students can speak a second language flawlessly. The exact reasons for this phenomenon are unknown. Although a large number of hypotheses have been put forward, the phenomenon is still a puzzle to most language educators. We have conducted some preliminary studies with a computer system to verify some of the hypotheses and determine the relationship between listening abilities and language learning. These efforts will form the basis upon which to obtain a better understanding of the process of learning languages and, over the longer term, to devise better methods for learning languages.
Introduction
With the exception of a few gifted learners, most students have major problems with learning to pronounce words in a foreign language if they begin to learn the language after the age of six (Gilakjani and Ahmadi, 2011). These problems will remain even after many years of dedicated learning and practice. They will speak a second language with an accent for the rest of their life. These problems are not related to the intelligence and motivation of the students, since they do not have similar problems with grammar and vocabulary. Some can read and write as well as, or even better than, native speakers.
On the other hand, there have been some large-scale studies suggesting that younger children do not have an advantage over older students in learning to read and write a second language (McLaughlin, 1992). Pronunciation is the only exception. The exact reasons for this are still unknown, although hypotheses abound. There is still no consensus among language educators today, as it is extremely difficult to prove such hypotheses.
In this paper, we present a computer system that helps students improve their pronunciation of a foreign language. This system provides speech analysis (Figure 2) and facial images (Figures 4 and 5) to students for continuous feedback and guidance. Experiments were conducted to check the effectiveness of our approach. Various hypotheses are presented in the paper and we collected evidence for some hypotheses in our experiments. In the long run, such evidence will be useful for solving this conundrum.
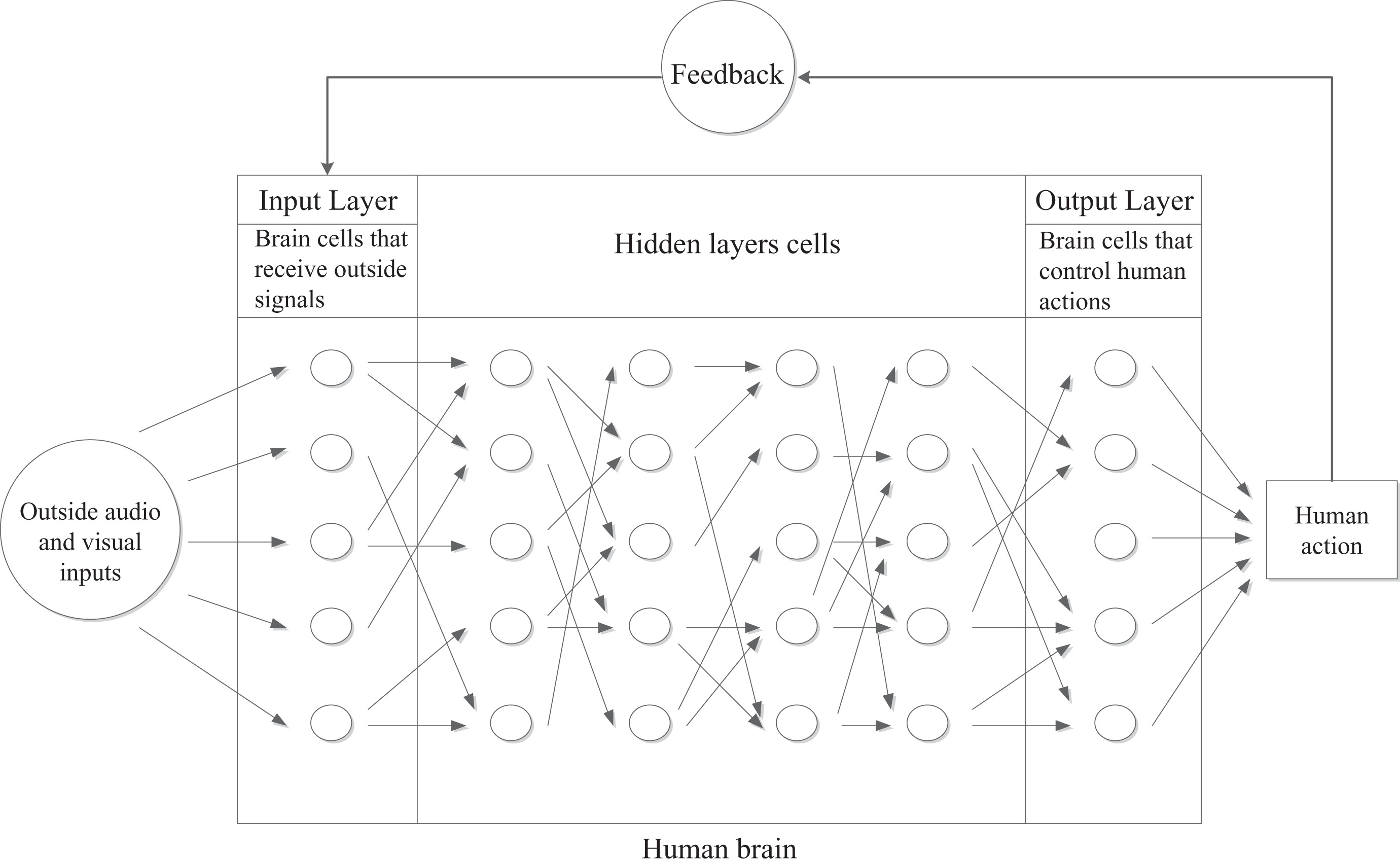
Simplified neural network learning model.
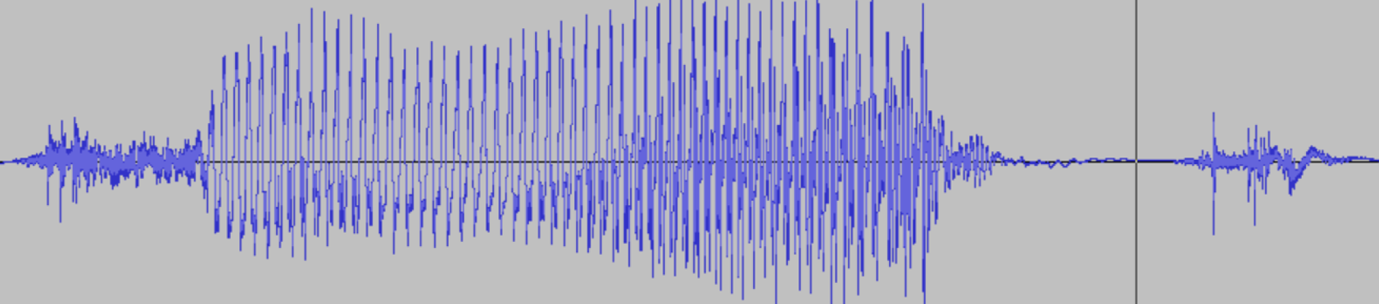
Waveform.
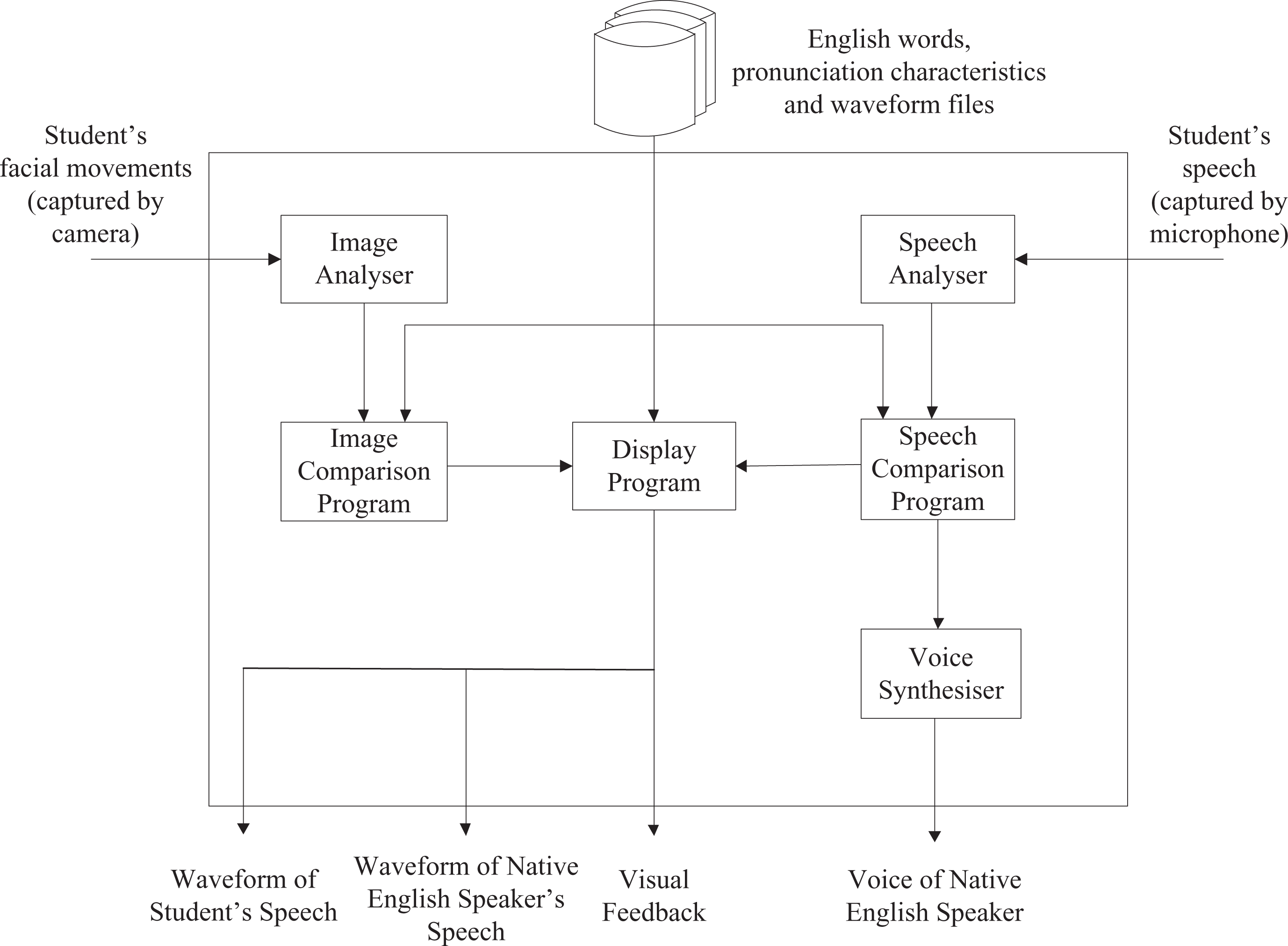
Components of the computer system.

The pronunciation of /ℓ:/ - lip shapes.
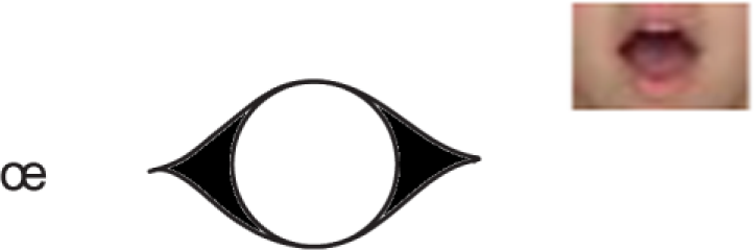
The pronunciation of Cantonese /œ/ - lip shapes.
Background information
Typically, in a conventional language pronunciation class, a teacher reads a word or sentence, and then the students repeat it. The teacher would point out the mistakes of the students. Listening to and correcting the pronunciation of students can be extremely time consuming, especially in the case of large classes. Teachers simply do not have enough time to attend to each student.
With the aid of software packages, students can learn and practice pronunciation and intonation on their own. They can enjoy a private and stress-free learning environment (Busà, 2008). Unfortunately, most packages cannot pinpoint the mistakes that a student has made, because of their limited ability to determine whether or not the user’s pronunciation is accurate. Students cannot themselves identify their mistakes (Zhang et al., 2010). Therefore, a better approach to learning pronunciation is needed (Kim, 2006).
Huang (1983) has stated that vowels are produced by a fixed tongue and lip position. Reveret and Essa (2001) further proposed a set of four facial speech parameters (FSP) to represent the primary visual gestures in speech articulation (Martin et al., 2007). Thus, facial movement is closely related with phonation.
Our computer system will facilitate the teaching and learning of languages by adding visual images of a student’s face and waveforms (Figure 2). The system will not only determine whether or not the student has produced the right sound, but will also present the problem by both displaying the student’s facial movements together with the correct movement on the screen, and by producing the correct human speech (Childers, 2000). With additional graphics and animation, students will be able to understand pronunciation. They will be able to correct their pronunciation and intonation according to the suggestions of the computer. As with other software packages, students can practice and learn pronunciation at their own pace, instead of being tied to the learning speed of their classmates. Furthermore, they can have infinite chances to practice, as there is no limit to how often or how long the system can be used.
Although English is the target language in this project, the software can be modified to support any language. Many students will be able to benefit from this system.
Hypotheses
Students cannot speak a second language perfectly if they learn the language after the age of six (Asher and Garcia, 1969; McLaughlin, 1992: Oyama, 1976). Various hypotheses have been put forward to explain this phenomenon. We briefly present some of them in this section.
Muscle and listening abilities
Some researchers believe that different languages use different parts of those human muscles that control speech. In other words, some parts of our muscles are stronger while other parts are weaker. Only parts of our muscles were trained repeatedly according to the characteristics of the mother language when we were children. We cannot pronounce some sounds of a second language because some parts of our muscles do not have the strength to produce those sounds. That is why we have an accent when we speak a second language. If this hypothesis is true, the situation can be improved if we train the other parts of our muscles.
On the other hand, there is also the belief that listening abilities are mysteriously related to the strength of the muscles. If people have problems in distinguishing a pair of sounds, they should be trained to produce the sounds and strengthen that part of their muscles. After undergoing training, people should be able to distinguish that pair of sounds. One of the objectives of this research is to verify this hypothesis.
Neurobiological-based hypothesis
Lightbown and Spada (1999) stated ‘childhood is the golden age for creating simultaneous bilingual children due to the plasticity and virginity of the child’s brain’. Studies have proven that a neural basis for the articulation of language sounds is completed around age six (Lund, 2003; Lenneberg, 1967). Based on the above explanation and supported by other studies, younger people are believed to have a more flexible brain that is in a better neurophysiological condition than the brains of older people to learn native-like pronunciation.
Stable phonetic categories after the age of five or six
Some other researchers have put forward a different explanation. Flege (1992) believed that the decreasing ability to develop a native-like accent is a consequence of a significant shift in ‘speech processing’ (Bohn and Flege, 1997). A child’s phonetic categories are completed and stabilised at the age of five or six. Building phonetic categories for new sounds would be harder for an adult learner, and therefore producing native-like sounds would also be more difficult.
Sociocultural theory
Some researchers (Tharp and Gallimore, 1988) have argued that learning takes place between a person and their surroundings, including the social, cultural and historical background (Dunegan, 2010: Salomon, 1993; Vygotsky, 1986) . Many other researchers support the sociocultural theory that cognitive development begins as an interaction between humans as well as their social, cultural and historical background (Kublin et al., 1989; Pea, 1993: Wertsch, 1991, 1998). Accent, as defined by Crystal (2003), is ‘the cumulative auditory effect of those features of pronunciation that identify where a person is from, regionally or socially’. The environment is also an important factor in the learning process.
Influence of the native language
Other researchers (Avery and Ehrlich, 1992; Gilakjani and Ahmadi, 2011) believed that native language influences accent development. They claimed that the sound pattern of the learner’s native language is transferred into the foreign or second language. Their claim is supported by various studies (Wenk, 1985; Mochizuki-Sudo and Kiritani, 1991).
How do the deaf learn to speak?
In the past, deaf people could not speak simply because they did not have the ability to listen. Nowadays, some educators have been trying to teach deaf people to communicate using only the spoken language – through lip-reading and voice training (Poe, 2006). Such an approach is supported by many individuals, including those who are deaf (Corbin, 2004; LaQuatra, 2007: The Christian Science Monitor, 1988). There have been many cases of success. This approach works particularly well for those with only mild to moderate hearing loss (Geers and Moog, 1989; Moog and Stein, 2008; Poe, 2006; Stone, 1997).
Nevertheless, some debates have arisen about the usefulness of this approach compared with the use of sign language (Baker, 2004; Myers, n.d.; Ray, 2010). Supporters of sign language argue that sign language is the natural way for deaf people to learn to communicate, and that sign language encourages a sense of pride. As a result, a new method for teaching deaf people to communicate has emerged.
The new method, referred to in some publications as ‘bilingualism’ (Center for Sign Linguistic and Deaf Studies, 2013), gives deaf people an opportunity to develop their voice as much as possible, with sign language being used for support (Poe, 2006; Grosjean, 2010; Plaza-Pust, 2008; Humphries et al., 2012). The Chinese University of Hong Kong has been conducting a deaf education programme using bilingualism since 2006. The programme has been successful and is well received by the school authorities and parents.
The teaching and learning processes for deaf students are more difficult and time consuming than those for normal students. Although there have been cases of failure (Spradley and Spradley, 2002), some deaf people have been able to learn to speak with a reasonable level of accuracy, given a proper level of support.
The computer system will also benefit hearing impaired individuals. It will act as a learning tool for the hearing impaired as it can display their facial movements on the screen and provide them with instant visual feedback. They will be able watch the differences in the patterns on the screen and learn to speak on their own.
Our approach
Exactly how the human brain learns and works is still unknown. However, many scientists use the neural network model to explain learning and other human behaviours (Hotz, 2013). Some computer scientists have used these neural network theories to build computers that learn by themselves.
Each individual has a large number of brain cells (Azevedo et al., 2009). Many studies have come to the conclusion that intelligent and highly educated people do not have more brain cells than average people. Thus, we believe that knowledge is not stored in the cells themselves.
On the other hand, intelligent people have more links between cells than other people. In other words, each human cell is connected to many other cells. A cell receives signals from other cells while it simultaneously sends signals to other cells. The number of connections differs for each cell. The signals are irregular and not uniform in strength. In the learning process (Figure 1), the visual and audio signals will be inputted to the first layer of cells. Different signals will be sent to the hidden layers of cells. The hidden layer of cells will send the signals to the output layer of cells. The output layer of cells will control the human’s actions. The results of the human’s actions will be fed back to the input layer of cells. The input layer of cells will compare these with the desired results. The input layer of cells and hidden layers of cells will modify the number and strength of the connections between cells. The output layer will produce another action. This process will continue until we get the desired results. The number of connections and strengths of the signals will change in each round.
For example, a child learns how to ride a bicycle by watching how another person rides. He tries to ride the bicycle and will fall in the first few hours. His brain cells will adjust the number of connections that they have and the strength of their input and output signals.
Because infants are curious, they pay a lot of attention to details of the outside world. For example, babies stare at strangers’ faces in lifts. However, their level of curiosity will decrease as they grow older. They probably pay less attention to details of facial movements if they learn pronunciation at older ages. Thus, the human brain cells are not getting enough inputs to create proper connections.
Our computer system provides students with continuous speech analysis and facial images. It is hoped that these kinds of stimulation will be able to provide inputs and improve the connections between brain cells. We asked students to pronounce vowels and consonants, even though they might have problems distinguishing them at first. These exercises strengthen the muscles that control the features of speech.
Overview of the computer system
Our computer system will capture facial movements and sounds from the students. Human speech is a series of pressure changes in the medium (air) between the sound source and the listener. Speech signals can be assimilated by a computer and then represented in a waveform pattern as shown in Figure 2. We can identify the pronunciation and intonation by analysing the waveform pattern. The objectives are to provide constant feedback and guidance to students.
The design (Figure 3) includes the following programs:
Image Analyser – The analyser captures the facial movements when a student pronounces a word. Speech Analyser – The analyser captures human speech and transforms it into waveform patterns that can be easily seen and integrated on a typical computer video monitor. Image Comparison Program – This program compares a student’s facial movements with the correct movements stored in the computer system. Speech Comparison Program – This program compares a student’s speech with the correct one stored in the computer system. Voice Synthesiser – The voice synthesiser tells the student (using human speech) whether or not the word was pronounced correctly. If the student makes a mistake, the computer will produce the correct speech so that the student can listen to it and try again. Display program – This program tells the student how to correct the problem by displaying his/her facial movements (along with the correct movements) together with the waveforms on the screen. The student can identify his/her mistakes and repeat the exercise until he/she can pronounce the words correctly.
Difficult vowels and consonants for Hong Kong students
In this section, we use the pronunciation symbols of the International Phonetic Alphabet (IPA) in our discussion.
There are many dialects in China. Over 90% of the population (DeWolf, 2010) in Hong Kong speaks Cantonese. Huang (1973) listed a number of common English errors made by Cantonese speakers.
For example, the English sound /ℓ:/ (as in her) is absent in Cantonese. Hong Kong students usually map the pronunciation of the English sound /ℓ:/ from the Cantonese sound /œ/. For example, they may pronounce ‘her’ as the Chinese word ‘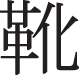 ’, which means ‘boot’.
’, which means ‘boot’.
The lip shapes and tongue positions of the two sounds are different, as shown in Figures 4 and 5. When one says ‘her’, it is necessary to keep the lips flat and close together, not rounded. Moreover, /ℓ:/ (as in her) is also a longer sound than /œ/.
A few more examples are given below: /θ/ (as in thin) replaced by /f/ (fin). Beginning /n/, /l/ and /r/ are not distinguished. Beginning /v/ (as in vest) replaced by /w/ (west). Final /z/ (as in graze) replaced by /s/ (grace). Final /b/ (as in cab) and /p/ (cap) not pronounced clearly or confused with each other. Final /k/ (as in back) and /g/ (bag) not pronounced clearly or confused with each other. Silent letter ‘h’ wrongly (as in honest) pronounced as /h/.
Phases of the experiments
Phase 1 – Identifying difficult vowels and consonants
Students were invited to take a preliminary test. The sounds of pairs of words were played by a computer system. All of these words contained vowels and consonants that would be difficult for Hong Kong students to pronounce. The students were asked to select the answer from a pair of words. The error rates were recorded and analysed. These rates enabled us to identify the vowels and consonants that each individual found to be difficult. Phase 2 – Using the computer systems
Students pronounced the words with which they had problems, as identified by our system. The computer displayed the waveform (as in Figure 2) and their facial expressions on the screen. The waveform and the correct facial movement of a native speaker were also displayed on the screen for comparison. Phase 3 – Evaluating the improvement
After about 10 weeks of training, students were asked to take the listening test again. The error rates were recorded and analysed. The results of this phase were compared with those in phase 1.
Results and future research
Fifty-two students participated in this project. In the very beginning, they took a listening test. We played the sound of a word and asked them to identify the word from a pair of words. Their errors were recorded. These tests were recorded and analysed to determine each individual’s weaknesses.
We provided a brief face-to-face lecture to students about pronunciation theories (as discussed in the previous section). We taught them the proper positions of the tongue and lips. Training exercises with our computer system were provided to students according to their individual errors. The system provides constant visual feedback and guidance in these exercises. At the end of this project, the students were asked to take another test. The post-test has similar contents of the pre-test. These tests were developed by members in our research team. Each test consists of 100 pairs of words. These tests were designed according to the vowels and consonants (Huang, 1983) that the students had difficulties in Hong Kong. These words are very common in daily usages. Students above form 4 level in secondary school should have the knowledge of these words.
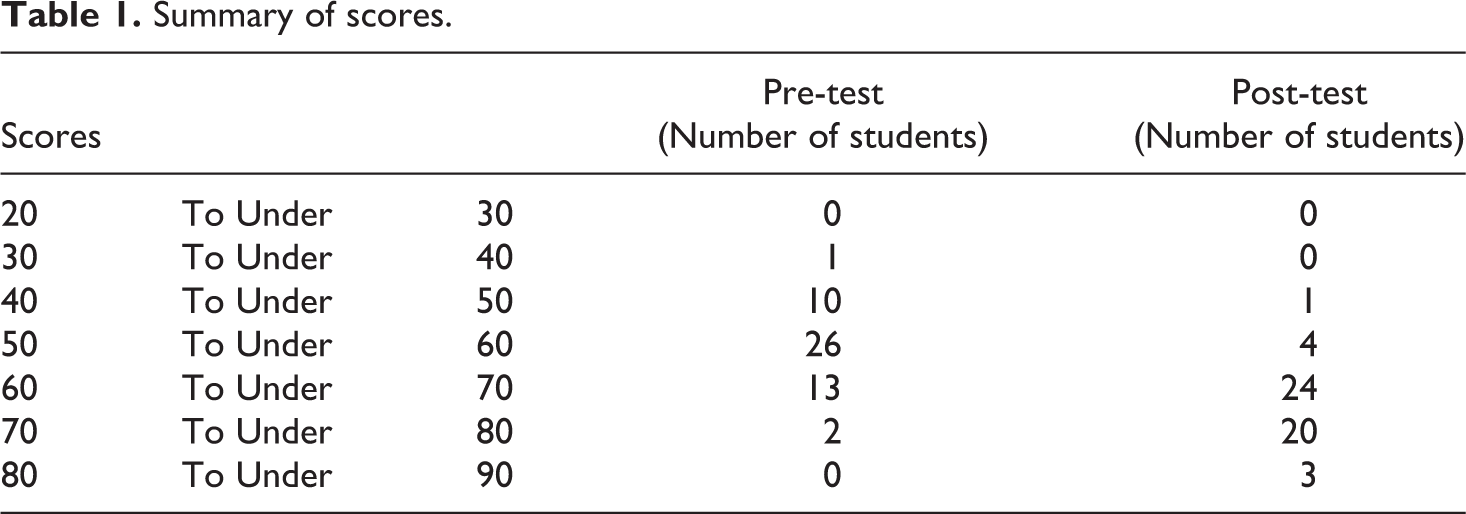
The results are summarized and presented in Table 1 and Figure 6. Ninety per cent of the students who took the second test were able to achieve improvements of more than 15% in identifying the right words and sounds in the listening tests. Their pronunciation skills also improved, although it was more difficult for us to quantify these improvements. The results provide further evidences that there are strong correlation between listening capacities and pronunciation skills (Abdolmanafi-Rokni, 2013; Shimamume and Smith, 1995).
Summary of scores.
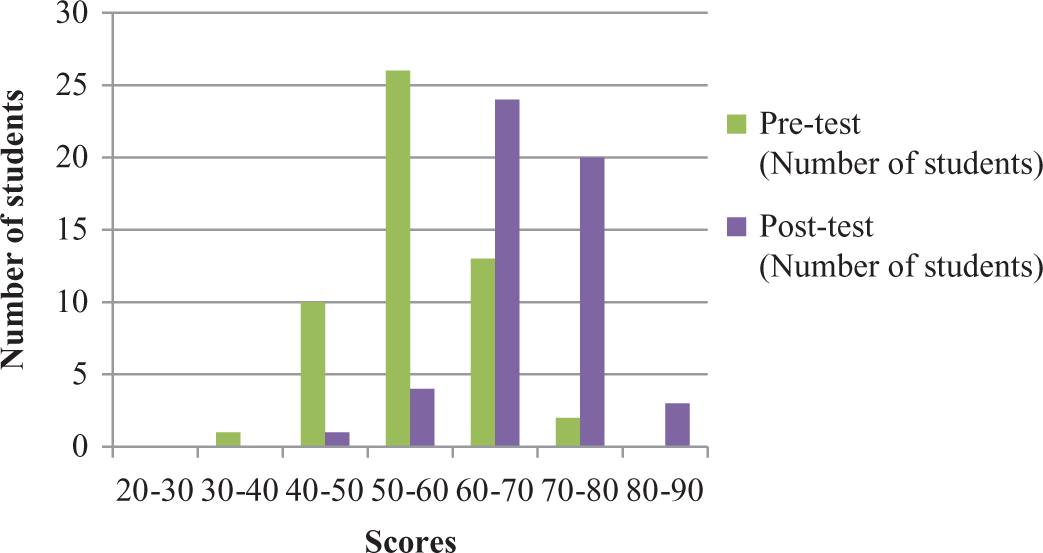
Comparison of scores.
The results are exciting, as the duration of our project was quite short. They prove the feasibility of using speech analysis and visual images to improve the learning process. Although, theoretically, the same result can be obtained with a patient and dedicated language teacher, our approach is more cost effective. It will be worthwhile in the future to carry out more studies involving more students, and involving longer periods. That will enable us to obtain a better understanding of the learning process and fine-tune our system. With proper modifications, our system will also be a useful tool for teaching deaf students to talk.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the grants of Lingnan University, Hong Kong.