
Abstract
The Journal of Language and Social Psychology has been publishing articles for 30 years. In this article, three different kinds of analyses (viz., content codings, word clouds, and a textual procedure) examining trends over and between the three decades are reported. Drawing on these, future directions for the journal and the field in general are anticipated and proposed.
At this point in time and given the journal’s substantive history, we felt it important to take stock of what patterns and trends that have emerged over the 30-year history of the journal, and with a view to identifying directions for the next decade and beyond. Toward that end, three different kinds of analyses of the past 30 years’ of JLSP’s content were undertaken. In the sections that follow, we present the results and discuss their implications for JLSP and for the field of language and social psychology more broadly.
The Analyses
Analysis I: Article and Author Characteristics
Our first analysis was a traditional content analysis, the goal of which was to determine the demographic characteristics of the journal’s articles and contributors. All articles and research notes that have appeared in JLSP to date (i.e., a complete 30 years) were coded by two trained graduate student coders. This comprised a total of 585 texts. Each volume typically contained four issues, although Volume 1 contained two issues, Volume 8 contained five issues, and several volumes had double issues. The full articles and research notes/short research reports were coded from the electronic archive of issues, available on the SAGE Journals Online website.
Each issue was coded for the number of articles, and each article was coded for the number of authors (per article); the professional affiliation of each author; the geographic affiliation of each author (according to their professional affiliation); the type of article; methodologies and analytic approaches used; the type of sample (where applicable); the number of male, female, and total participants in the study; and the number of studies per article. An inductively derived coding scheme was used, with coders creating additional categories as they encountered new material (e.g., methodology or professional affiliation). To check reliability, coders overlapped on approximately 20% of the data (six issues), and interrater reliability ranged from excellent to acceptable for each of the variables (κ = 1.00 to .74). Questions and discrepancies were resolved through discussion. During and after the coding process, categories were collapsed and consolidated for ease of presentation and comprehension (e.g., 71 specific professional affiliations were ultimately reduced to 30 broader categories). What follows is a descriptive portrait of JLSP across the past 30 years.
As noted above, a total of 585 articles or research notes have appeared in JLSP since its inception. Progressively more articles have been published with each decade: the first 10 years saw 151 articles, the second 201 articles, and last decade 232 articles. Three to 12 articles appeared per publication of JLSP; most publications (here, combined issues are treated as one) contained 4 to 6 articles; articles per publication ranged from 3 to 12.
JLSP’s articles have been predominantly empirical (n = 457; 78%); of these, the lion’s share (n = 390; 85%) have been quantitative empirical articles, whereas a minority (n = 67; 15%) have been qualitative. The remainder of articles have been primarily theoretical or commentary pieces (n = 122; 8.7% of total articles). Finally, a very small minority (n = 6; 0.4% of total) have been focused on the development of a method, scale, or related instrument. 1
Considering these trends over time, quantitative empirical articles consistently comprise roughly two thirds of a given decade’s articles in the JLSP. The first and most recent decades saw similar proportions of theoretical articles (24% and 22% of the total, respectively), whereas the middle decade saw a drop in theoretical articles (to 17%), and a corresponding rise in qualitative empirical articles (14% in the middle decade vs. 8.6% for the first decade and 10.8% for the most recent decade). No methodologically focused articles have been published in the past 10 years.
Regarding empirical articles, most (n = 361; 79%) contained a single study (see Patterson, Giles, & Teske, 2011), but some contained two (n = 71; 16%), three (n = 17; 8%), or more (n = 6; 1%) studies. Roughly half of these studies (53.4%) were based on college samples, whereas just more than a quarter (27.8%) used a noncollege (or partially noncollege) sample. Finally, just more than a fifth of empirical studies were based on texts. The proportion of empirical studies drawing on college samples is relatively constant over time (ranging from 50% to 55%); however, the past 10 years has seen a drop in the proportion of studies using noncollege, human samples (from 33% to 19%) and a corresponding rise in the proportion using text samples (up to 25%, from 12% to 16% in the first two decades of the journal).
The mean sample size (per study) was 156 participants; sample sizes ranged from 1 (case studies) to 8,593. Most studies had between 50 and 200 participants (n = 255; 56% of studies), while 20% (n = 92) had between 20 and 50 participants. Studies with between 200 and 500 participants were less common (n = 65; 14%), as were studies with less than 20 participants (n = 28; 6%).
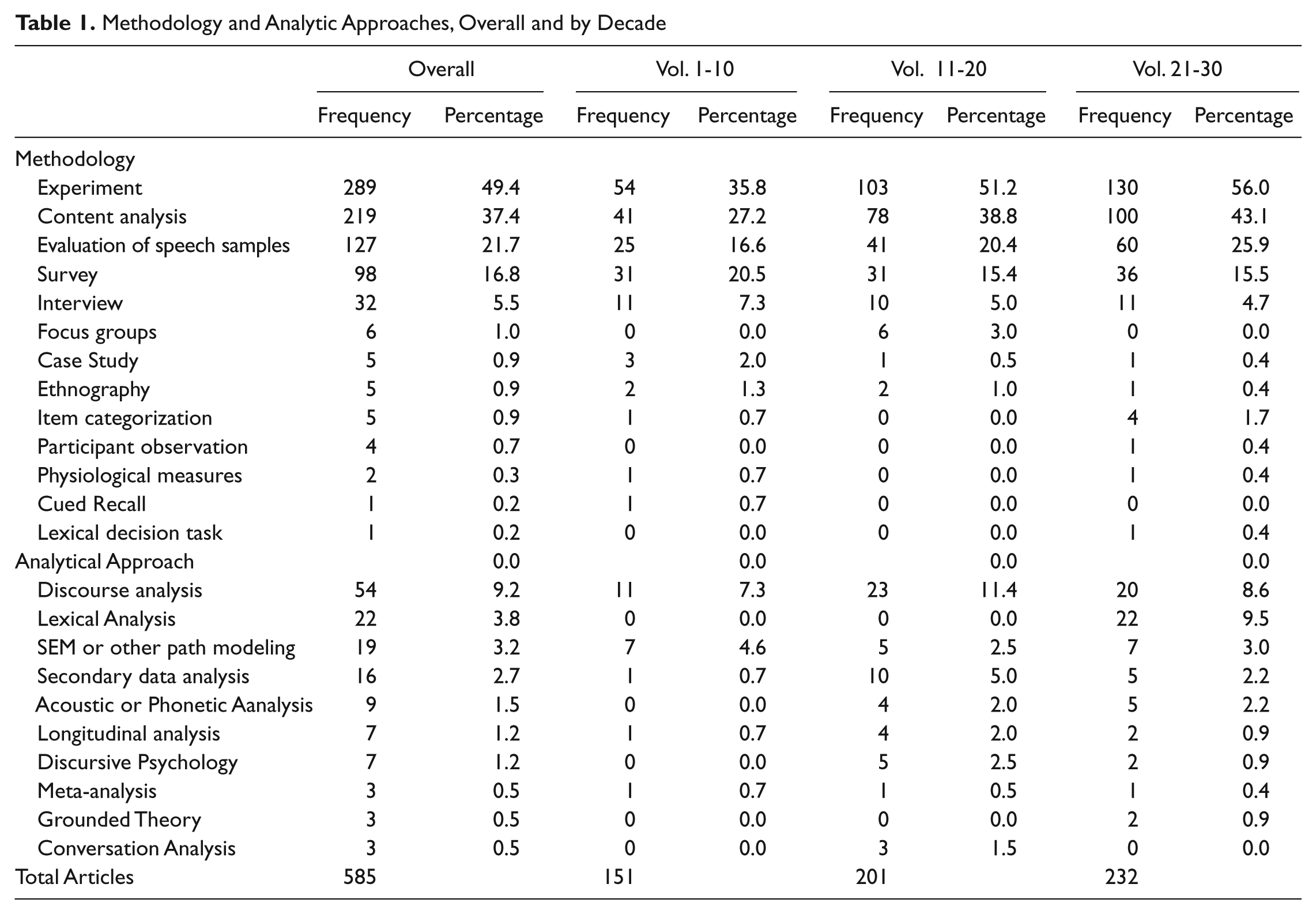
Methodologically, empirical studies used a range of approaches (see Table 1). Articles were coded for all methods and analysis techniques they used; in other words, a single article could have multiple results for methods. Experiments were the most common method used (n = 287; 49% of total articles). Content analysis—which included quantitative coding of behavior, texts, or related data collected from experimental procedures, surveys, interviews, or other means—was the second most frequently used method (n = 219; 37% of total articles). Surveys were much less frequent (n = 98; 17% of total articles), as were interviews (n = 32; 5%). Turning to more specific methodologies and approaches to analysis, evaluation of speech samples (in either written or audio form) was the most common task participants were asked to undertake (n = 126; 22% of total articles). Discourse analysis was the most common qualitative analytic approach (n = 54; 9% of total articles). The relative frequency of each of these approaches—and of the more common methodological approaches more generally—have been relatively stable over time, although the use of both surveys and interviews have been consistently declining. It is also interesting to observe the emergence of lexical analysis—a word-level content analysis typically executed with programs such as Linguistic Inquiry and Word Count (LIWC; see Tausczik & Pennebaker, 2010)—in the past 10 years as an increasingly common tool for quantitatively analyzing language use. Other innovative software options, such as Leximancer (Cretchley, Rooney, & Gallois, 2010), are becoming increasingly available and being adopted to good effect. Indeed, it is very likely that such procedures may change the empirical landscape of articles published in the JLSP by the time of the 40th anniversary of the journal (see Gallois, Cretchley, & Watson, 2012).
Methodology and Analytic Approaches, Overall and by Decade
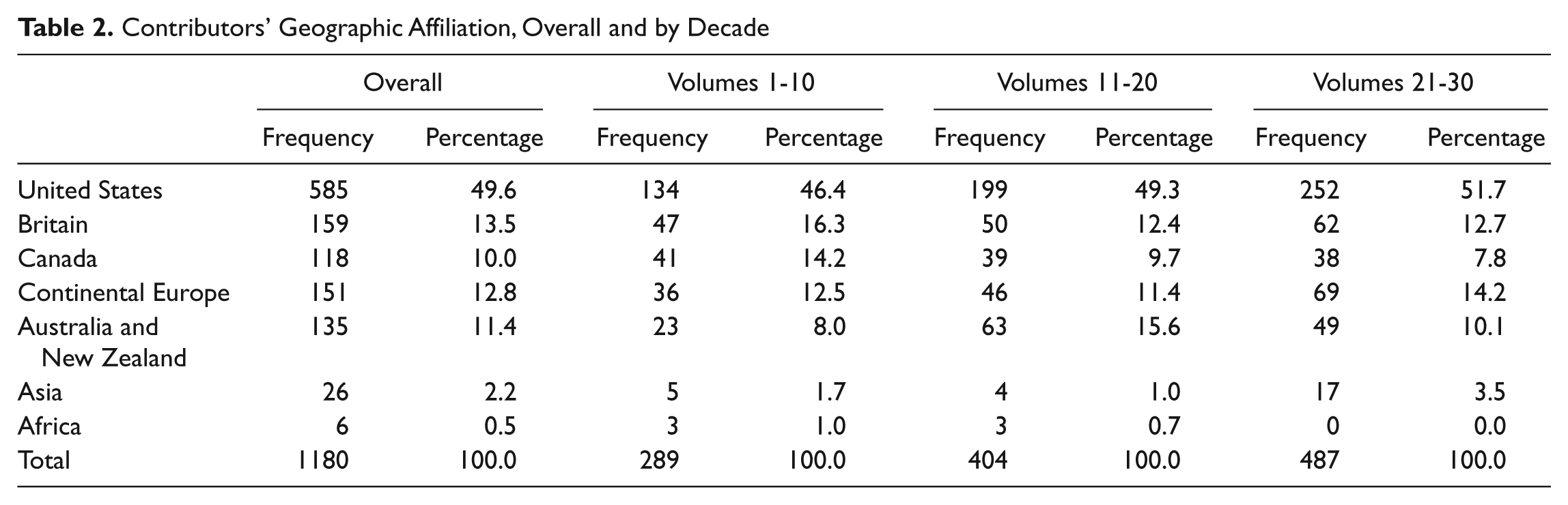
Of the 1,180 (nonunique) contributors to the journal over the past 30 years, a majority have institutional affiliations within the United States, with relatively equal (but significantly fewer) contributions from Britain and continental Europe (see Table 2). That said, this does not mean that studies analyzing non-English language are not submitted regularly, and it is estimated that around 50% of papers submitted have authors with affiliations outside North America. Perhaps not surprisingly given the name of the journal, the majority of authors have derive from either psychology (n = 429; 44%) or communication (n = 295; 30.3%) departments; the rest represent a range of disciplines from linguistics to business to health and professional affiliations from private enterprise to government offices and agencies to nonprofits. The top 10 professional affiliations for contributors, both total and by decades, are presented in Table 3. The most published authors in the journal were Cindy Gallois and Peter Bull, with 15 each. They were followed by authors with 5 or more items and included, with frontrunners Richard Clément and Sik Hung Ng, Bob Gardner, Angie Williams, Mike Hogg, and Jim Bradac.
Contributors’ Geographic Affiliation, Overall and by Decade
Top 10 Contributor Professional Affiliations, Overall and by Decade
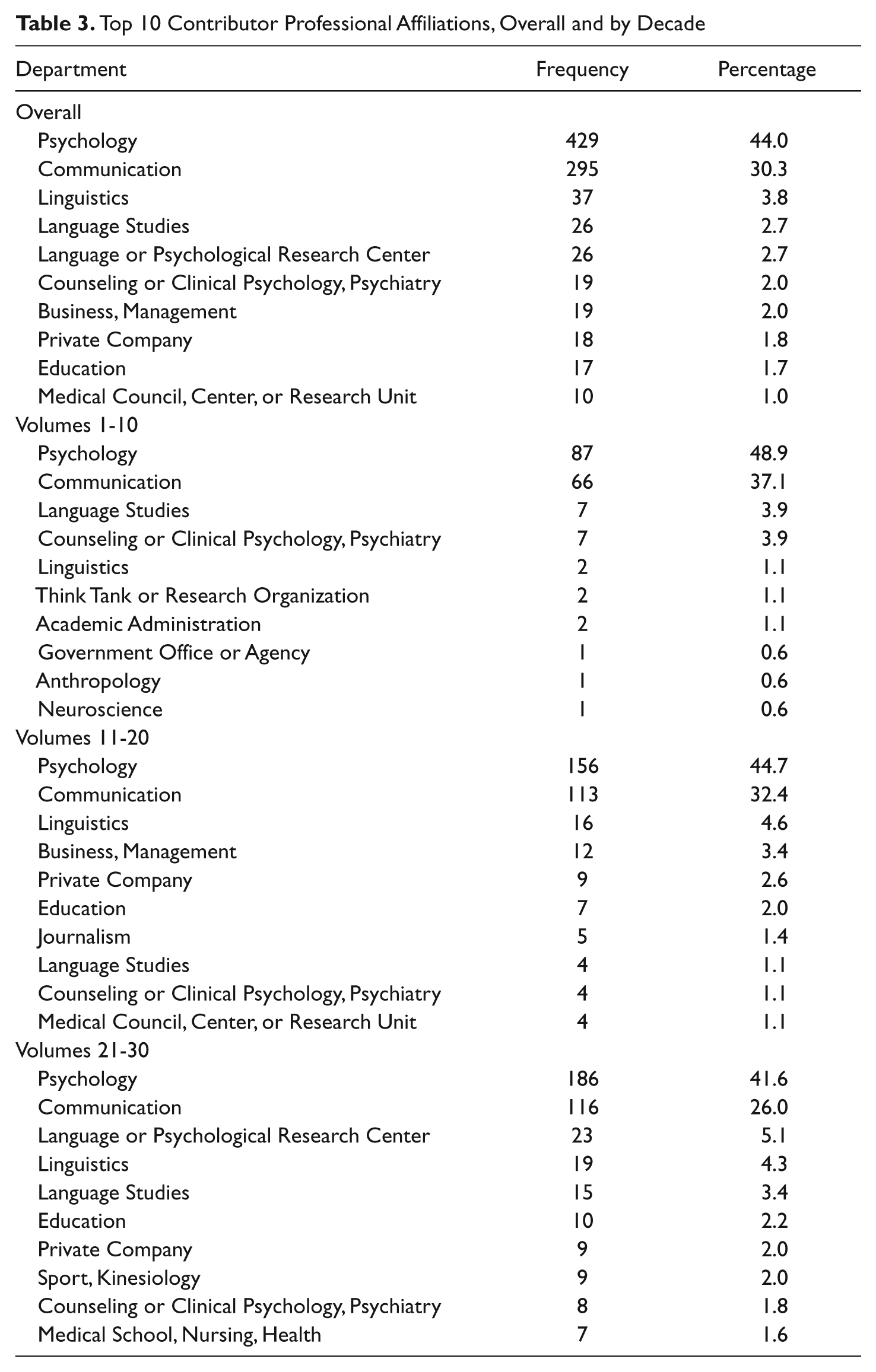
Over time, the relative contributions of these geographic areas have shifted some: Although Americans are always the primary contributors, their relative contribution has grown from 46% in the journal’s first decade to 52% in the most recent decade. Canada’s relative contributions have dropped considerably, from 14% in JLSP’s first 10 years to 8% in most recent years. Britain’s relative contributions have also decreased over time, dropping from 16% in the first decade to 13% in the third. Finally, there has been an overall increase in contributions over time from Australia and New Zealand, as well as Asia (see Table 2). These contributions have also been coming from an increasingly broad range of departments (although it should be noted that authors’ professional affiliations have been more clearly and consistently indicated in later years of the journal; several of the early volumes do not list all authors’ affiliations). Although psychology and communication consistently dominate professional affiliations (of those that were listed) across time, more recent years have seen an increase in the number of business and management department affiliations, language or psychological institutes, and private companies, and a corresponding decrease in contributions from communication and psychology vis-à-vis articles from other disciplinary bases (see Table 3).
As only a finite number of constructs could be expeditiously coded, articles were not coded for theoretical underpinnings; this was deemed unmanageably difficult to code on this occasion. A mere mention of a theory does not mean it guided the study’s design, and correspondingly, some studies had clear theoretical underpinnings not explicitly mentioned. We did, however, examine all titles across the 30 years as well keywords when they were introduced into the journal (in 2003). Interestingly, named theories were only infrequently afforded such status in these ways—the overwhelming majority of keywords referenced social constructs, methods, and processes—and about a dozen theories or models appear only very occasionally (e.g., action assembly, luring communication, and intergroup contact). Those that emerged most often were, arguably, communication accommodation and social identity theories as well as second language acquisition and linguistic category models. Obviously more systematic, comprehensive, and reliable codings could be engaged in the future (see Rice & Fuller, in press). However, given specific theories’ lack of visible presence in titles and keywords as well as the subordinate roles of generic “theory” and “model” in the overall front cover word cloud (see below), it might be prudent, in the future, to encourage state-of-the-art overviews and critiques of major theories, particularly those crafted that appeal to applied content areas.
Overall, the most striking feature of this analysis is the journal’s stability over time: while there have been some changes (e.g., relative contributions from different professional and geographic areas) over the past 30 years, much has remained quite consistent. Although many kinds of analyses regarding topic areas studied and/or bibliometric analyses of citations (see Rice, Chapin, Pressman, Park, & Funkhouser, 1996) could have been engaged, for parsimony, we invested in two other different analyses that could provide insight into the journal’s emphases over the years.
Analysis II: Topical Content in Word Clouds
The first of these analyses visually represents the topical content of the JLSP with “word clouds” created using the online Java applet Wordle (http://www.wordle.net). From a given text input, this applet creates visual clusters of the words found in the text, with relative word size proportional to that word’s relative frequency in the text (e.g., if one word is twice as big as another, this indicates that it occurs twice as often). Common words (such as “the,” “a,” “and,” etc.) are removed by the program and not included in the visual output. (Orientation is purely artistic, and can be manipulated according to taste.) The titles and abstracts of all the articles in the JLSP, first overall (see front cover of this Anniversary Issue for this representation) and then split by decade (for comparison purposes), were used as text input (see Figures 1-3). The overall word cloud on the issue cover features “language,” “linguistic,” “communication,” “social,” “intergroup,” the combination of which reflects the distinctiveness of the social psychology of language vis-à-vis other language science and communication subdisciplines and journals. Complementarily, Leximancer analyses of JLSP articles across the same 30 years innovatively conducted by Julia Cretchley and Cindy Gallois (see also Cretchley et al., 2010) show that our discipline—at least as represented in this journal—is one that has, and currently does, invest mainly in studies of adult English-language production that relate to group, as well as theoretically oriented intergroup, processes.

Word cloud for Volumes 1-10 (first decade)

Word cloud for Volumes 11-20 (second decade).

Word cloud for Volumes 21-30 (third decade)
As might be expected, several words appeared prominently across all decades: language, study, participants, communication, results, social, research. Interestingly, while “language,” “English,” and “speech” figure prominently in the first decade (Figure 1), they decline in relevance over the next decade and are replaced by an increasing focus on “communication” as well as “context” (Figures 2 and 3). In the second and third decades, “intergroup” consumes attention as does “gender” and “women.” Interestingly, “media,” “political,” and “health” feature in the latter decades, and apart from “applause,” nonverbal behaviors are conspicuous by their absence across the word clouds as are, perhaps surprisingly, concepts such as “workplace,” “culture,” “ethnic,” or even “intercultural.”
Analysis III: Topical Content in Text Analysis
Finally, to explore the content of JLSP articles further, a text analysis of the titles and abstracts of each decade’s articles was undertaken using Crawdad (Corman & Dooley, 2006). Crawdad performs a centering resonance analysis on inputted text, modeling the text as a network of words using computational linguistics algorithms. It then determines a word’s influence on the basis of its position in the network. Words that are influential are those that contribute to coherence in the text. Influence is moderately correlated with word frequency, but the two are distinct.
Table 4 presents the top 10 most influential words and word pairs for each decade of JLSP. Word pair influence is calculated by multiplying the influence of each word in the word pair and then multiplying that by the number of co-occurrences of the words in the pair.
Top 10 Most Influential Word and Word Pairs, by Decade
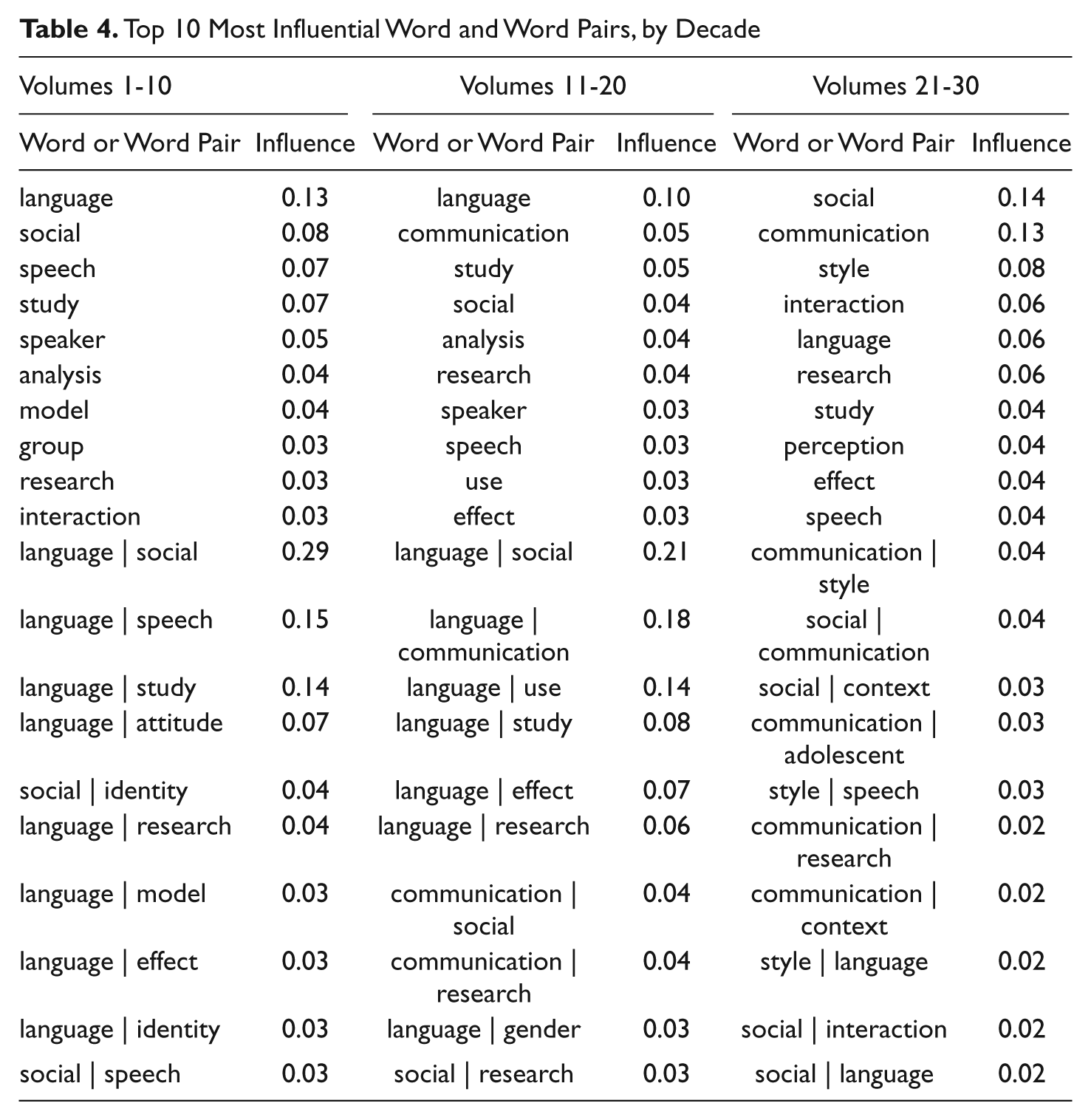
Interestingly, the word “language” is influential in the first two decades, but only moderately so in the most recent decade. In contrast and again somewhat in tandem with Analysis II findings, “communication” appears not at all in the first decade, then rises in influence across the latter two decades. “Social,” too, rises in prominence considerably in the most recent decade, being the most influential word in the titles and abstracts of the past 10 years, and appearing in 4 of the 10 most influential word pairs. Generally, the influential terms in the first decade suggest what might be considered “classic” language and social psychology research: “social identity,” “language attitudes,” “language use,” “language model(s),” and “language effects.” The most recent decade’s terms, in contrast, suggest a move toward a broader conceptualization of language and social psychology, with attention to additional variables: “context,” “perceptions,” “interaction,” and “style” (again, with the increased influence of “social”).
With respect to influence, it is also interesting to note that middle decade has lower influence coefficients for single words, whereas the third does for pairs. This suggests somewhat different network characteristics of the two. The middle decade’s centering resonance analysis network for Volumes 11 to 20 was characterized by lower density and focus (.004 and .098, respectively) than either the first or final 10 volumes (Volumes 1-10: density = .005, focus = .128; Volumes 21-30: density = .008 and focus = .137).
Looking Ahead
Given where the JLSP has been, and where it is now, we believe it is well positioned to continue making important contributions to our understanding of the social psychological aspects of language and language use. No doubt many of the journal’s mainstays over the past 30 years—social identity, language attitudes, intergroup communication, and so on—will continue to feature prominently in the journal. But new developments in how we use language, and how researchers study language, may result in some shifting of content and methodology in JLSP going forward.
The effects of one methodological development can already be seen in the pages of JLSP. Over the past decade, there have been several studies using some type of computerized corpus analysis, primarily at the lexical level. The most well-known technique in this regard is the LIWC program (Tausczik & Pennebaker, 2010). The use of these types of programs should continue, especially as computerized corpus analyses become easier and more useful. Perhaps more important, as language becomes increasingly digitized, the size, range, and nature of the samples that can be analyzed in this way will increase dramatically. Examples of this trend can be seen in the attempts to examine the linguistic manifestation of culture through the computerized analysis of Google’s digitized book project (Culturomics: Michel et al., 2011), as well as the analyses of emotion words (or Gross National Happiness index) on Facebook (Kramer, 2010). Although computerized corpus analyses should continue to be popular, a major challenge will be to move beyond the simple decontextualized lexical level and incorporate a consideration of context and structure. Some progress has been made in this regard (see Oberlander & Gill, 2006), but much more is needed. A further challenge will be to use computerized corpus analyses as a means of theory testing rather than in an inductive manner only.
The ways in which people communicate—and use language—have been changing in fairly dramatic ways over the past several decades. When JLSP began there was no World Wide Web, no text messaging, no Facebook or Twitter, and so on. The development and rapid adoption of these technologies is both a challenge and an opportunity for language and social psychology researchers. These technologies are deeply social and their use raises a host of fundamental questions deserving of systematic study. In what ways, if any, have these platforms altered communication processes? For example, claims have been made in the popular press that some of these platforms—texting in particular—are altering language in less than desirable ways. Are they? We actually know relatively little about the nature of language use in these domains (although, see Crystal, 2008), an issue clearly worthy of future empirical examination. And there are a host of related questions deserving of research as well. For example, in what way, if at all, do some of the fundamental processes involved in face-to-face language use (e.g., face-management, accommodation, alignment, etc.) operate in mediated environments? And what, if any, new and perhaps unique social processes underlie language use in these new domains?
The development of new communication technologies is not limited to human–human language use but includes also the use of natural language for communicating with nonhuman entities (computers and robots). The increasing availability and sophistication of online bots, coupled with high-profile events such as IBM’s Watson winning on Jeopardy, point to the increasing importance of this type of language use. Like computer-mediated communication, this represents both a challenge and an opportunity. The challenge is to articulate clearly the social psychological principles involved in language use (with humans and nonhumans); the opportunity is a chance to test these principles by building and examining the viability of natural language systems.
The field of language and social psychology is closely aligned (and overlaps considerably) with the field of pragmatics. One major difference, though, has been the traditional emphasis in the former on the use of experimental procedures (approximately 50% of the articles in JLSP include at least one experiment). This is changing, though, as there has been increasing experimental activity in the field of pragmatics recently (e.g., Novek & Sperber, 2004), some of it involving the use of imaging techniques (Van Berkum, 2009). It is likely that this approach will continue to grow and some of this research should find its way to the pages of JLSP. In addition, social psychology and language researchers have much to offer experimental pragmatics by providing a much-needed social psychological perspective for this work.
Moving to focal social issues that might be important targets for future language and sociopsychological study, it is difficult propose compelling ones without betraying personal and/or ideological biases. In a modest attempt to circumvent this, a web source for same was located (http://en.wikipedia.org/wiki/Social_issues). This lists 60+ “social issues . . ., which directly or indirectly affect a person or many members of a society and are considered to be problems, controversies related to moral values, or both.” From this catalogue, the following parsimonious number of (possibly Western biased) items were selected as societally pressing candidates for serious study. Interestingly, the journal and, for the most part, the field have not yet engaged these social issues in any way programmatically. They are censorship, civil rights, corruption, divorce, environmental degradation, human trafficking, homelessness, poverty, safety, suicide, and war.
To use language is to engage in a social process, a process that both reflects and creates the social order and hence a process with multiple social implications. This is true regardless of whether one is using language face-to-face or in a mediated environment, whether it is synchronous or asynchronous, and so on. There is no doubt that new ways of using language will continue to be developed, as will new ways of exploring the new (and old) uses to which language is put. Because of the inevitable social nature of language, the JLSP should continue to be a highly relevant resource and outlet for research on language use.
Footnotes
Acknowledgements
We are grateful to Bernadette Watson, Maggie Pitts, and Cindy Gallois for their cogent observations of the analyses in this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.