
Abstract
An experiment manipulated the relative expertise and status power of dyad task partners, examining how expertise and status power affect language use and if linguistic cues that emerged during the interaction influence a partner's assessment of the speaker's competence. One hundred twenty-eight dyads worked together on a problem-solving task without knowing who had received better quality information beforehand. One hundred twenty-four interactions were transcribed and quantified using both language software and human coders. Members with superior expertise spoke more words and used more tag questions than those with less expertise. The data did not yield support for more politeness in low-status members’ language nor more confidence in high-expertise members’ language. Members who spoke more were perceived as more competent by partners. Members who used more hedges were perceived as more competent and polite. Results identified language features that can be used strategically to exert influence on others and manage impressions.
Status is often structural and formalized in groups and dyads through hierarchy while recognizing expertise is more elusive. People may equate status with expertise, but this can be inaccurate (Hollingshead, 1996). When groups engage in a collective problem-solving task, members engage in a sense-making process to gauge who has more expertise and competence to improve group performance, which in turn affects how much each member contributes during discussion towards the final decision (Bunderson, 2003). These expectations, once formed, bias group members’ evaluations of each other and influence members’ behavior in the group. Performance expectations lead to differences in participation and behavior. There is limited research examining how behavioral cues such as language affect perceptions of expertise above and beyond attribute status cues. By manipulating status power and having participants interact face-to-face, this study examines the relative impact of linguistic features on perceptions of expertise compared to status power cues and other observable cues, thus, responding to a call by Toma and D’Angelo (2015, p. 39) that, “future research should investigate the relative weight of linguistic cues compared with other indicators. Do linguistic cues to expertise override the importance of these other indicators?” Specifically, we manipulate expertise and status power in the lab and examine possible interaction effects, especially when expert and status power mismatch, on how speakers use language and how partners assess each other's competence and politeness.
Expectation States and Language Use
When working towards a collective goal, group members implicitly assess each other's expertise and anticipated contribution to the task and behave accordingly. However, who has more task-relevant expertise than others is not always clear as members may have little information about one another's expertise or have little information about what is required to perform well on the task. Expectation states theory (Berger et al., 1977) explains how members assess one another's expertise and how these performance expectations affect how they behave and influence others. The theory posits that a member with status characteristics, which others believe to be associated with task-relevant expertise, is expected to perform better. Because of this performance expectancy, this member is afforded more opportunities to influence others and contribute to a task. Correll and Ridgeway (2003) state, “performance expectation states shape behavior in a self-fulfilling fashion” (p. 31) and hence reinforces status hierarchies initially determined by the status cues.
Because performance expectations lead to actual influence in the group, correct assessment of members’ expertise is key to group performance. As a sub-theory of expectation states theory, the status characteristics theory (Berger et al., 1972, 1977) identifies status cues that members use to assess expertise. The theory suggests that specific (task-relevant) status cues (e.g., previous experience, qualifications related to the task) have a stronger impact on performance expectations than diffuse cues presumed to be associated with the individual's general capability (e.g., gender, age, hierarchy); however, when specific task-relevant cues are not salient, members search for other cues available to them.
One type of cue is the use of language by members. Ng and Bradac (1993) theorized that one's competence and social position are the main sources of social power and that these sources are reflected in language. Status characteristics theory (Berger et al., 1972; Bunderson & Barton, 2011) proposes that verbally expressed task confidence can be a cue to a member's actual task-relevant expertise. However, little empirical research has examined the utility of linguistic features in assessing member expertise. On the other hand, ample research has found that language use differs by diffuse status cues, such as status power and gender (for a review, see Leaper and Ayres, 2007; van Swol and Kane, 2019). Yet, when expert stance and status power do not match (e.g., lower status member possessing high expertise), it is unclear how expertise and other status characteristics are reflected in language use.
Expertise and Language Use
Task-related expertise, i.e., information valued in a specific problem-solving situation, is a social resource that can grant expert power to one who exclusively possesses it (French & Raven, 1959). A few studies that examined differences between experts and non-experts’ language use found that experts’ language reflects more in-depth thinking and reasoning than non-experts’ language, as indicated by, for example, more use of conjunctions (Kim et al., 2011), lengthy (more than six-letter) words (Toma & D; ngelo, 2015), or language signifying analytical thinking (Newman et al., 2016). Recent research that tested machine learning techniques to identify experts in online platforms found that techniques that look for the complexity of thinking effectively detected experts from non-experts (Horne et al., 2019; Vydiswaran & Reddy, 2019). These techniques also utilized language variables, including word count, articles, lengthy words, cognitive words, and analytical thinking. However, these studies examined experts and non-experts as independent message senders; they were not interacting with one another.
In social influence contexts where the expert differential is structured in the relationship, experts’ language may reflect more than the thinking process and show confidence, resulting from realizing their expert power over others. Newman et al. (2016) found that in non-hierarchical peer consultation relationships, where only a differential level of experiences exists, advisors (experts) used more clout language than advisees (non-experts) across multiple sessions. Confidence is also captured by certainty and decisiveness, as indicated by fewer hedges in the language (Hyland, 1996). Besides, confidence may manifest as more disclosiveness and disinhibition as members with expertise feel more comfortable voicing their ideas. Within the text analysis software LIWC (Linguistic Inquiry and Word Count), authenticity captures the extent to which one speaks in a self-revealing, honest, and open way and a straightforward rather than reserved, guarded, and evasive manner (Jordan et al., 2018; Yuan et al., 2019). Authenticity was previously found to reflect intimacy and how comfortable versus guarded individuals are when expressing their ideas in group settings (Bloomfield et al., 2020). If one believes that they have more expertise than others and therefore have more to contribute, they may disclose more information and do so less cautiously. By contrast, if one believes that they have less expertise than others, they may speak less and in a more guarded manner. Therefore, we hypothesize:
Status Power and Language Use
Formal status power (from here on referred to as status power) is an authorized power to administer rewards and punishments through an appointed role (Yukl & Falbe, 1991). One's formal position is often a more salient status cue than task-relevant expertise because the position is common knowledge to the group, while expertise may not necessarily be. High-status members speak more in group discussion than low-status members (Krifka et al., 2003; Paletz & Schunn, 2011; Sakai & Carpenter, 2011). Research finds that possessing power is correlated with increased confidence in one’s judgment and acting in accordance with one’s conviction (Brinol et al., 2007; See et al., 2011). Thus, when offering suggestions, high-status members may be more likely than low-status members to try to gain compliance from their partner, as indicated by the use of tag questions. Tag questions serve multiple different functions in pragmatics (see Tottie and Hoffmann, 2006 for review). While some tag questions imply the speaker's genuine uncertainty and hesitation (e.g., “Wasn't it?”), others are used to facilitate a response from others (e.g., “Don't you think so?”) (Holmes, 1995). Particularly in the context of giving advice, a tag question after a suggestion is used to mark “agreement as the expected and preferred response” (Hepburn & Potter, 2011, p. 224). Similarly, a study analyzing business meetings found that chairpersons used more tag questions than individuals in a non-leading role (Calnan & Davidson, 1998). While discussing their ideas more than lower-status members, high-status members may want to facilitate an agreeing response, if not already expecting compliance that a tag question following a suggestion implies. It is hypothesized:
The language of individuals with less status power likely reflects defensiveness and politeness. According to politeness theory (Brown & Levinson, 1987), speakers who perceive the other to be more powerful would use more politeness strategies to avoid threatening their face. Previous research found more politeness in low-status speakers’ language, as indicated by indirectness (hedges) (e.g., Kim and Lee, 2017; Morand, 2000), and optimistic sentiment (Danescu-Niculescu-Mizil et al., 2013). Because low-status members are more conscious about how they would be evaluated by others (Keltner et al., 2003), they feel more need to project a positive image by using positive affective language. Previous studies found that when impression management motivations are high, individuals use more positive emotion words, for example, when speakers know each other less well (Reysen et al., 2010; Scholand et al., 2010). Low-status individuals are also concerned about whether they appear competent, especially in mixed-status interactions (Fiske et al., 2015). This tendency is evidenced by the findings that minority group members with task-relevant expertise repeated their unique knowledge significantly more than majority members (Thomas-Hunt et al., 2003) and exerted more influence through reasoned arguments (van Swol & Carlson, 2017). Therefore, we hypothesize:
One of the motivations for this study was to explore linguistic features of the speakers with their expert stance not matching their status power in the relationship (e.g., lower status member possessing high expertise). High-status individuals, even those with low expertise, may demonstrate their power through language because of a strong need to prove the worth expected from them by others (Fast & Chen, 2009). In a similar vein, low-status members with high expertise may still speak politely to enable high-status members to save face. In such cases, an interaction effect may not be observed. Conversely, individuals with low status but high expertise may use language that is similar to that employed by high-status members. For instance, competent subordinates may speak with confidence, as opposed to defensiveness, being certain that their input will make significant contributions (Detert & Burris, 2007). We ask the following research question to unravel how status power and expertise interact to influence language use:
Cues to Assess Member Expertise and Politeness
Past research supported status characteristics theory's prediction that specific task-relevant cues (e.g., job tenure) have a stronger effect than diffuse cues (e.g., gender) in influencing performance expectations, as measured by others’ assessment of member's competence (Bunderson, 2003; Joshi & Knight, 2015; Pugh & Wahrman, 1983). While most of these studies have examined attributes (e.g., gender, ethnicity, education, job tenure) as status characteristics, there is limited research examining how behavioral cues like language use affect expertise assessment above and beyond attributes. Among the few that examined communication behavior as cues in face-to-face interactions, Yuan et al. (2019) found that members with a task-oriented communication style (dominating conversation style) and members who communicate with confidence and minimal tenseness received higher perceived expertise ratings. Similarly, Liao et al. (2018) found a positive association between task-oriented communication and a higher perception of expertise by other members. Conversely, other research finds the effect of one's communication style on their partners’ evaluations was moderated by actual task-related expertise when it is known. For people considered experts, their assertive and confident communication style led to higher ratings of perceived influence; however, for people considered non-experts, a confident communication style backfired (Loyd et al., 2010; Zarnoth & Sniezek, 1997). In an online setting, Toma and D’Angelo (2015) found that lengthier (higher word count) and more psychologically distanced advice messages (fewer I-pronouns, fewer anxiety words) were perceived as more expert. The lengthier the message was, the more likely receivers perceived that they gathered a greater amount of information, and thus, they regarded the sender as an expert.
The present study tested whether these previously found linguistic cues predict members’ perceptions of their partners’ expertise beyond what they are told in terms of diffuse status cues (e.g., boss/assistant status). To quantify communication behaviors, measurable linguistic variables were obtained. As before, dominance in conversation was operationalized as speaking more words. Since an analytical problem-solving task was used as the group task, a task-oriented communication style was operationalized as language reflecting analytical thinking and offering justifications. A confident style was operationalized as a language with more clout and fewer hedges. Psychologically distanced (guarded) language was captured by language with lower authenticity.
With an explicitly stated diffuse status cue (boss vs. assistant) and high uncertainty about one's partner and the task involved in this study, people may poorly assess each other's expertise. Therefore, an exploratory question raised first was whether a member's actual expertise is associated with how their partner perceives them in terms of such competence.
Subsequently, another research question asks if linguistic cues have any significant effect over other cues to affect partner perceptions. Formally stated:
One reason why possessing actual expertise may not necessarily lead to displaying confidence-laden linguistic cues is due to members’ strategic language choices concerning politeness. Claiming expertise or proposing solutions runs a risk of threatening the other person's face (i.e., desire to appear competent and in control) (Brown & Levinson, 1987; Wilson et al., 1998). However, if experts use politeness markers in language, politeness may obscure expert cues, and their influence may be compromised (Blankenship & Holtgraves, 2005; Leshed et al., 2007). For example, Yuan et al. (2019) found that experts used both more relationship-oriented and less tense language than those with less expertise, which had no impact and a negative impact, respectively, on other members’ assessment of their expertise. Yet, other research on social influence suggests that politeness in language may help the speaker appear more competent (Jenkins & Dragojevic, 2013; Pfafman & McEwan, 2014) or likable (Loyd et al., 2010) and increase speaker influence. Therefore, we examined if politeness language markers (hedges, justifications, and positive emotion words) predict member politeness as perceived by partners and if significant predictors of perceived politeness hurt or help perceived competence given what is found in RQ3.
Method
Participants
Participants (203 females, 53 males; age M = 19.99, SD = 1.28) were from a large, public university in the midwestern United States. They received extra credit in a communication course. The data were collected over the Fall 2018 and Spring 2019 semesters.
Participants ranged from freshmen (18%), sophomores (34.4%), juniors (26.6%), seniors (20.3%), to master's students (0.8%). The majority (78.5%) were domestic students, and 55 (21.50%) were international students (non-U.S. citizens). Of the 128 dyads, there were 80 female-female dyads, 43 female-male dyads, and 5 male-male dyads. To verify that participants were strangers, three items (α = 0.86) asked about the prior experience of knowing, talking to, and doing the class projects together with the partner (1 = never talked, don't know at all, 7 = talked often, know very well). The mean (M = 1.42, SD = 1.14) indicated participants were mostly strangers. Of the 128 recorded interactions, four were lost or damaged and could not be transcribed. The remaining 124 were transcribed verbatim by native English speakers. For analyses including the language variables in the model, N equals 248 individuals from 124 pairs.
Design
Participants were randomly assigned to one of four conditions from a 2 (relative expertise: high/low) × 2 (relative status power: high/low) design. Of the 124 usable transcripts of interactions, 62 were from “Expert Boss & Non-expert Assistant” pairs and 62 from “Non-expert Boss & Expert Assistant pairs.” Therefore, there were 62 individuals for each of the two (relative expertise: high/low) by two (relative status power: high/low) conditions.
Expertise Manipulation. Participants worked in pairs to estimate the average cost of buying baby diapers for the whole of the baby's first year. This topic was chosen to ensure that most undergraduate student participants had little prior knowledge and that expertise manipulation is almost solely achieved by the information given to participants. Participants were instructed to study the information privately before they met to solve the task together. The amount of information was about the same length for the two, but the contents were different. One of them received superior information that is more helpful to estimate the answer correctly (high-expertise condition). High-quality information included more specific numbers to use and pointed to a more practical way of calculation, such as: the average cost will be obtained by the average number of diapers used per year multiplied by the average cost per diaper; parents often change at least ten diapers daily during the baby's first month, but as the baby grows, the numbers decline, etc.
In contrast, the other person (low-expertise condition) received information that included somewhat vague information, such as: the average annual cost will be obtained by averaging the first 12-months diaper costs; in the early days, parents should expect at least five wet diapers every 24 h, etc. See Appendix A for complete information sheets. The experimenter's verbal instructions implied the expertise differential: “You and your partner were given information to help solve the task. It is possible your information may differ, and some information may be more useful towards solving the task than others.” The statement did not give overt cues about how the information differs and who receives which information.
Power Manipulation
Procedure
Two participants arrived at the lab for each scheduled timeslot. Once they signed the consent form, they were told a cover story that the study is about understanding leadership and followership and were given the leadership questionnaire. While participants completed the questionnaire, the experimenter tossed a coin privately and decided on experimental conditions. The experimenter then collected and pretended to grade the questionnaires. Upon announcing the assigned status to each, the experimenter had the assistant sit on a smaller chair and the boss in a bigger office chair in the boss’ room for further instructions. Participants were told about the diaper cost estimation tasks and information distribution. They were also told about the reward: if the team's answer is the closest among all participating teams, the team would win a $100 gift card; the second-best answer would win a $60 gift card; and the third a $40 gift card. It was pointed out that, after completing the task, the boss would report each dyad member's contribution to the experimenter. The experimenter announced that each of them would spend five minutes studying the information sheet in their own room and then interact with each other face-to-face for another 5 min to solve the task together and submit one answer to the experimenter. Importantly, participants were told they could make a note of the given information on scrap paper and refer to the note during the interaction, but they were not allowed to look at the information sheet or show their note to the partner during the interaction.
After instructions, the assistant was escorted to their separate, smaller room. Participants were given their information sheet and were given about five minutes to study the information privately. They were not allowed to use their phones, but calculators and scrap papers were available for their use. After about five minutes, the experimenter asked participants to complete the pre-interaction survey on a research laptop set up in their room. 1 Upon completion, the experimenter had the assistant come to the boss’ room and help the two begin interacting face-to-face to work on the estimation task. The experimenter took the information sheet away from participants, but most participants had their own notes for reference. When the experimenter checked in with participants in five minutes, most asked for a few more minutes. After they came up with a mutually agreed-upon answer, the experimenter took the assistant back to their smaller room. Participants completed the post-interaction survey. The post-interaction survey included manipulation check items and other measures discussed in the next section. Upon the survey’s completion, participants were debriefed that the boss would not actually assess the partner’s contribution, the leadership questionnaire had nothing to do with actual leadership ability, and this study's true purpose was to investigate the effects of status power on communication behavior. The correct answer was not revealed; the winners were notified afterward. Participants were asked to keep information about the study confidential and were dismissed.
Manipulation Check
The status power manipulation was checked by measuring the perceived power difference reported by participants. Two items assessed how higher or lower of status and how much more or less control over the allocation of the reward that their partner seemed to have over themselves (1 = much less/lower than me to 7 = much more/higher than me). The reliability was acceptable (Spearman-Brown = 0.60), and the mean was taken as a composite variable (M = 4.25, SD = 1.02). Assistants (M = 4.86, SD = 0.89) perceived the boss had more power, whereas bosses (M = 3.66, SD = 0.76) perceived the assistant had less power, t(254) = −11.61, Cohen's d = 0.64, p < 0.01.
For the expertise manipulation check, an independent group of people (N = 66) were recruited to check whether people who received high-quality information (high-expertise condition) would make a significantly more accurate decision than those who received low-quality information (low-expertise condition). The correct answer for the estimation task was $649 (see Appendix B for calculation). Among the responses, six outliers were removed as they were considered clear miscalculations (e.g., $219,000, $20,150). Therefore, 60 cases were used for manipulation check with a range of Min. $291 – Max. $3,066. The means significantly differed by condition, t(58) = 7.38, Cohen's d = 0.69, p < 0.01, such that people who received high-quality information had the mean closer to the correct answer (M = 640.30, SD = 114.62) than those who received low-quality information (M = 877.15, SD = 468.84). Moreover, one-sample t-tests with data from each condition revealed that the mean (M = 877.15) from the low-expertise condition was significantly different from the correct answer, t(28) = 2.62, p = 0.01. In contrast, the mean (M = 640.40) from the high-expertise condition was not significantly different from the correct answer, t(30) = −0.42, p = 0.68. Therefore, the manipulation was successful.
Measures
LIWC-coded Linguistic Cues. Transcripts were cleaned and divided into separate text files for each participant and run through the text analysis software Linguistic Inquiry and Word Count (LIWC; Pennebaker et al., 2015). LIWC counts the number of times specific categories of words appear in the text and yields the relative frequency or the composite score of words from each category. The variables used in this study are word count, clout, authenticity, analytical thinking, and positive emotion words. Word count (WC) is the number of words in the text file, that is, the number of words spoken by the participant. Clout, authenticity, analytical thinking, and emotional tone are summary variables that range from 0 to 100, with higher numbers reflecting more of the characteristic. The developers (Pennebaker et al., 2015) newly added these summary variables to LIWC 2015 and explicated each dimension based on previous research, although the exact algorithms are unavailable due to commercial agreements.
Clout is a measure of the style in which the speaker speaks from a higher status or a superior stance with “a sense of certainty and confidence;” conversely, a lower clout score means the language conveys “a sense of hesitation and doubt” (Jordan et al., 2019, p. 3744). The measure is developed based primarily on Kacewicz et al. (2014) study about language use and social hierarchy, which found higher social status was associated with more we and you-pronouns.
Authenticity measures the extent to which the speaker speaks in an honest, personal, and straightforward style, as opposed to a detached and evasive style (Bloomfield et al., 2020; Xu & Zhang, 2018). For example, authenticity is indicated by more I-pronouns, insight words, and differentiation words; using the metric, Trump’s 2016 debate language was assessed high in authenticity, whereas Clinton's language was low in authenticity (Jordan et al., 2018).
Analytical thinking is a measure of analytical and logical cognitive style as opposed to informal, casual, and narrative thinking style (Jordan et al., 2019). The measure was conceived based on Pennebaker et al. (2014) work that analyzed college admission essays. More analytical thinking is indicated by an increased use of articles and prepositions, whereas more narrative thinking is indicated by more pronouns, auxiliary verbs, conjunctions, and negations.
The other summary variable that LIWC 2015 offers is emotional tone, which indicates whether the speaker's emotional tone is more positive or negative as measured by the proportion of positive and negative emotion words spoken. Given the experimental task, it is unlikely participants would experience or express negative emotions during the interaction. Therefore, positive emotion words were taken as a measure of emotional tone rather than the summary variable. Positive emotion words (posemo) indicate a positive and upbeat speaking style and are represented by a rate, that is, a percentage of this category of words out of the total number of words spoken by the speaker.
Hand-counted Linguistic Features. Two undergraduate student coders, unaware of hypotheses, read the transcripts and coded linguistic features from the text. They counted instances of the speaker's use of the linguistic feature of justifications, hedges, and tag questions. The coders went through sufficient training so that they clearly understood the categories and differentiated between them. Because the counts were continuous variables, the intercoder reliability was assessed with intraclass correlation coefficients (ICCs) using a two-way random-effects model based on absolute agreement. The ICCs indicated good reliability (0.71, 0.91, 0.93, respectively for each linguistic feature). Most discrepancies were resolved by discussion between the two coders, but for the items that they could not agree upon, the researcher resolved the discrepancies.
For justifications, coders counted each time a speaker justifies a suggested option—an idea or course of action—by explaining why it made sense to follow that option. Coders were instructed to look for causation words (i.e., cause, because, since, according to, based on) and instances when the speaker referred to information they took note of or any evidence (e.g., “It says…,” “Based on what I got here…”). When multiple pieces of information (e.g., price of different sizes of diapers) were offered in one sentence after a causation word, coders were instructed to count them only once because the act of justifying one's suggestion was of interest in this study, not the pieces of information.
For hedges, coders counted each time a speaker used a word or a phrase to leave the message ambiguous intentionally. Examples included phrases, e.g., “Maybe we should do…,” “It could (possibly) be,” or words, such as: a little, almost, and stuff, something like that, kind/kind of/sort of, may (not), maybe, might (not), pretty (much), probably.
For tag questions, coders counted each time a speaker adds a small question immediately after a declarative statement or suggestion to solicit agreement. Coders were instructed to look for questions that are tagged at the end of sentences (i. e., “It looks …, doesn't it?” “I think…, don't you agree?” “It should be…, right?” “I think we should….” “Does it make sense?”).
Partner Perceptions Measures. On a scale of 1 (not at all) to 7 (extremely), participants rated member competence, input usefulness, and politeness. Partner competence was measured using four items (i.e., capable, knowledgeable, expert, qualified) (α = 0.86) averaged (M = 5.17, SD = 1.18). To measure perceived usefulness of partner's input, four items (i.e., helpful, valuable, beneficial, useful) were averaged (α = 0.97) (M = 5.33, SD = 1.45). Similarly, four items (i.e., kind, considerate, respectful, well-mannered) were used to measure perceived partner politeness (α = 0.95) (M = 6.28, SD = 0.80).
Other Measures. Participants reported basic demographics, including their gender (female 0, male 1, prefer not to answer 2), international student status (yes/no), and college year (e.g., 1 for freshmen, 5 for master's).
Results
A series of hierarchical linear models (HLM; Raudenbush and Bryk, 2002) were run using jamovi version 1.2 (The jamovi project, 2019) to analyze the data to explicitly model nonindependence resulting from dyadic data (Campbell & Kashy, 2002). The random effect of group (dyad) was taken into account by including the random component in the level-2 model's intercept. Gender, college year, international student status, and the judge role 2 were controlled at level-1 (individual-level) for all dependent variables. Word counts need not be controlled for LIWC variables because percentage scores are calculated proportionally to the speaker's spoken word counts. Only when human-coded variables were included, word count was included in the model to be controlled for. Given the intraclass correlation coefficients (ICC) for word count (0.31) was significant and greater than 0.30 that Kenny (1995) suggests as a biasing factor, the group's average word count was entered in the model as a level-2 predictor whenever word count was included in the model as a level-1 predictor. Word count at level 1 was group-based centered.
Fixed factors were expertise (High/Low-expertise) and status power (High/Low-power). The interaction term (expertise x status) was included in the model only when significant at α = 0.05. HLM deleted cases with missing data list-wise. The HLM results and estimated marginal means by experimental conditions are presented in Tables 1 and 2.
Summary of Hierarchical Linear Modeling (HLM) Analysis Results.
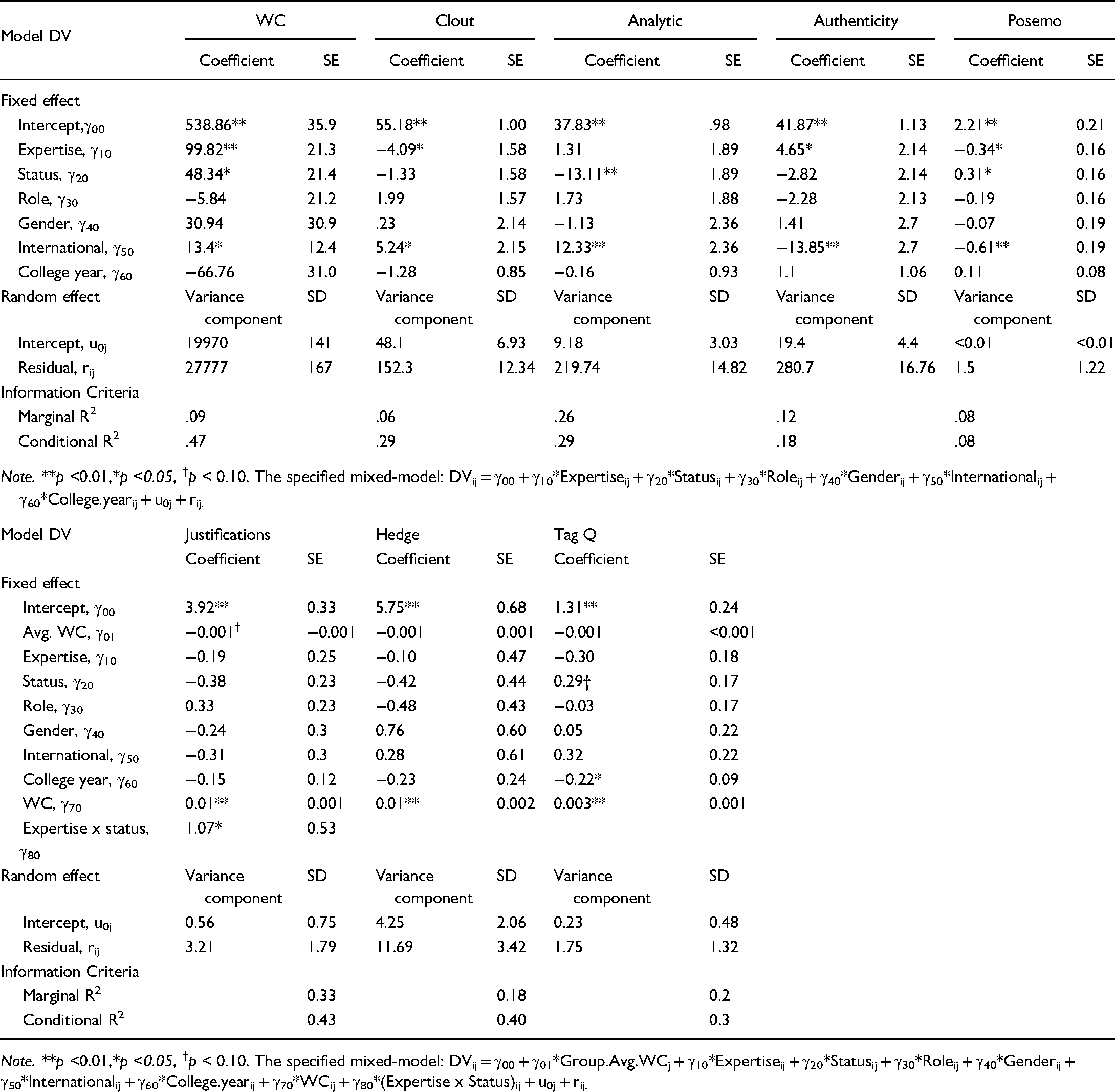
Note. **p <0.01,*p <0.05, †p < 0.10. The specified mixed-model: DVij = γ00 + γ01*Group.Avg.WCj + γ10*Expertiseij + γ20*Statusij + γ30*Roleij + γ40*Genderij + γ50*Internationalij + γ60*College.yearij + γ70*WCij + γ80*(Expertise x Status)ij + u0j + rij.
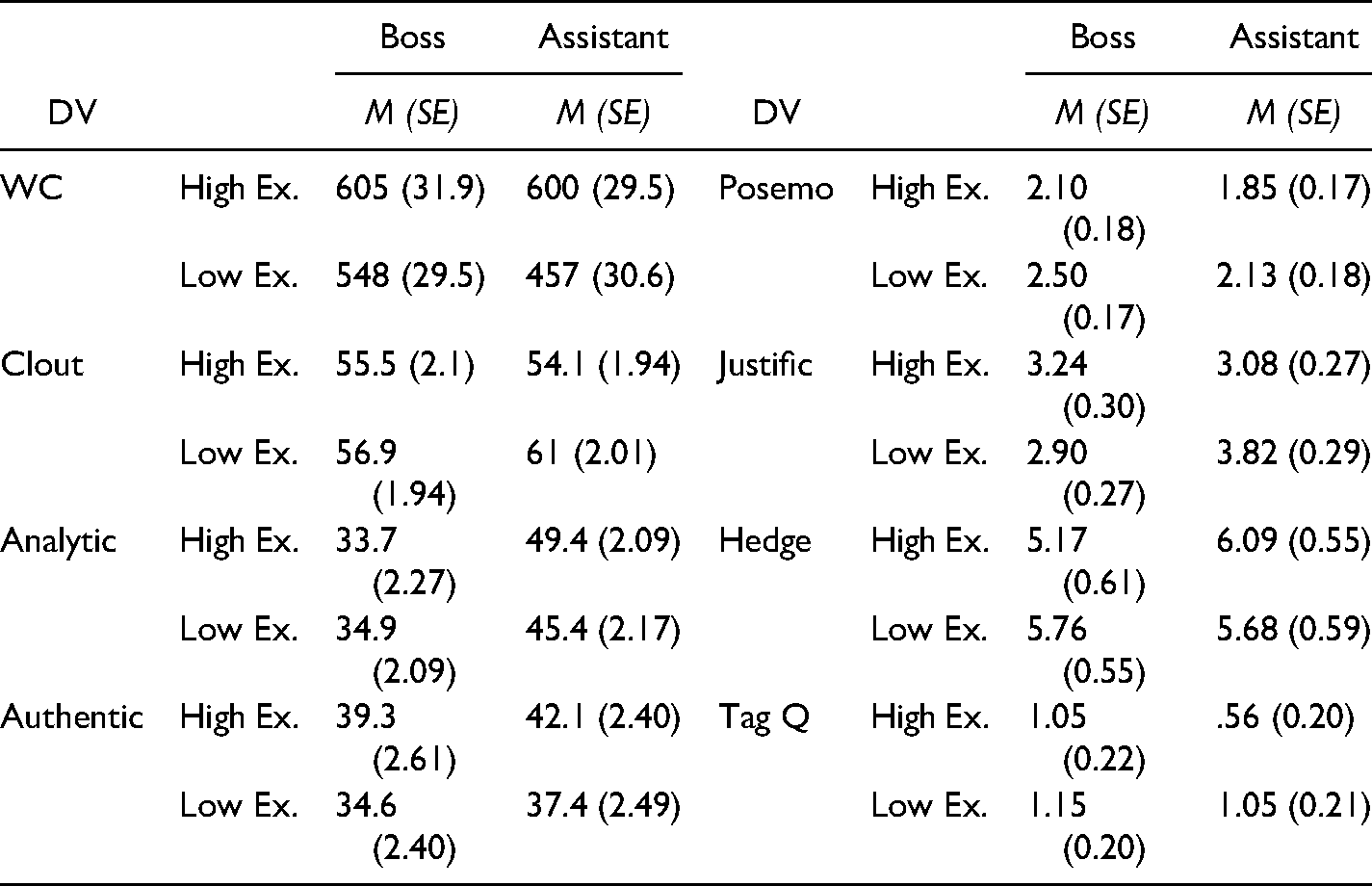
Estimated Marginal Means by Conditions.
The Effects of Expertise and Status Power on Language Use
Results are organized by language measures for the convenience of referring to HLM results in the tables. Reference to corresponding hypotheses and research questions are made in parentheses. Results are summarized in Table 3. The interaction between expertise and status power (RQ1) was noted only when it was found significant in the model, which, in fact, was only for justifications.
Summary of The Effects of Expertise and Status Power on Language Use.
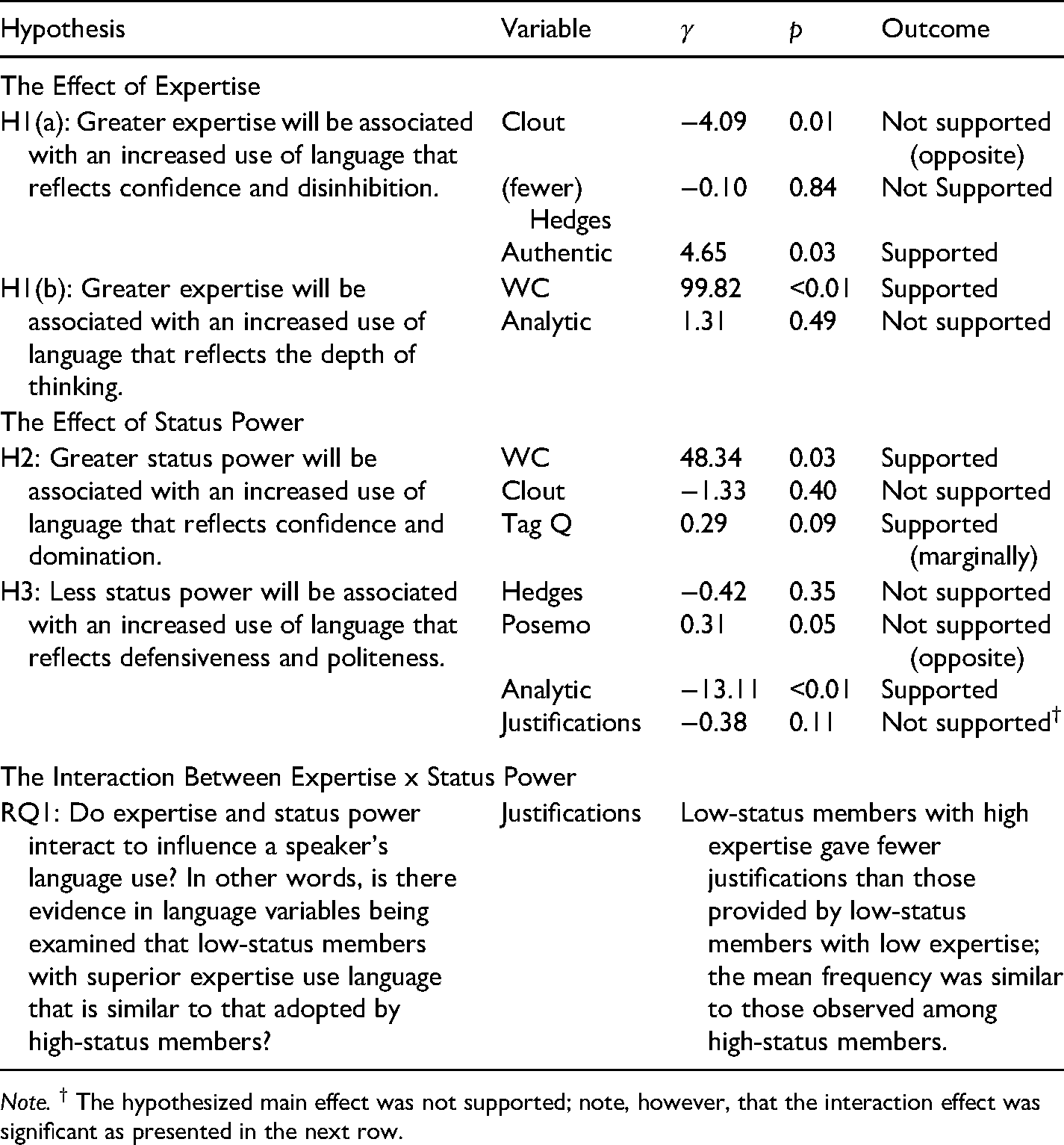
Note. † The hypothesized main effect was not supported; note, however, that the interaction effect was significant as presented in the next row.
It was tested whether the number of words spoken (word count) varies by individual's expertise and status power. ICC was 0.31, indicating that group differences accounted for 31% of the variance in word counts. A likelihood ratio test (LRT) comparing models with and without the random intercept indicated group-level variance was significantly different from zero (LRT χ2 (1) = 12.40, p <. 01). This must be due to the amount of time spent on discussion varied by each dyad despite the experimenter’s effort to keep it at about five to seven minutes. Comparison of high-expertise to low-expertise members found that high-expertise members spoke a significantly greater number of words than low-expertise members (γ10 = 99.82, SE = 21.30, p < 0.01) (H1-WC supported). Status power was a significant predictor (γ20 = 48.34, SE = 21.40, p = 0.03); high-status members spoke more words than low-status (H2-WC supported). See Table 2 for means.
It was tested whether differences in the use of clout language were accounted for by the individual's expertise and status power. ICC for clout was 0.19, indicating group differences accounted for 19% of the variance in clout. This group-level variance was significantly different from zero (LRT χ2 (1) = 4.46, p <. 01). Comparison of high-expertise to low-expertise members found low-expertise members used a significantly higher percentage of clout than high-expertise members (γ10 = −4.09, SE = 1.58, p = 0.01), which was the opposite of the hypothesis (H1-clout not supported). Status power was not a significant predictor of clout language (γ20 = −1.33, SE = 1.58, p = 0.40) (H2-clout not supported).
For analytical language (ICC < 0.01, LRT χ2 (1) < 0.01, p = . 99), expertise was not a significant predictor (γ10 = 1.31, SE = 1.89, p = 0.49) (H1-analytic not supported). Analytical language differed by status; the comparison of high and low-status members revealed that the latter used a significantly higher percentage of analytical language than that employed by the former (γ20 = −13.11, SE = 1.89, p < 0.01) (H3-analytic supported).
For authenticity (ICC = .05, LRT χ2 (1) = 0.27, p = . 60), expertise was a significant predictor of authenticity in language (γ10 = 4.65, SE = 2.14, p = 0.03); low-expertise members used a significantly lower percentage of authenticity than high-expertise members (H1-authenticity supported).
For positive emotion words (ICC < 0.01, LRT χ2 (1) < 0.01, p = .99) and tag questions (ICC = .12, LRT χ2 (1) = 1.73, p = 0.19), it was tested whether differences were accounted for by status power. Status power was a significant predictor of positive emotion words (γ20 = 0.31, SE = 0.16, p = 0.05), but in the opposite direction than hypothesized. High-status members used a significantly higher percentage of positive emotion words than low-status (H3-positive emotions not supported). For tag questions, high-status members used more tag questions than low-status members, although the difference was marginal (γ20 = 0.29, SE = 0.17, p = 0.09) (H2-tag supported).
For justifications (ICC = .12, LRT χ2 (1) = 1.77, p = 0.18), the interaction between expertise and status power was significant (γ30 = 1.07, SE = 0.53, p = 0.046), answering RQ1. The comparison of estimated marginal means suggested that with low-expertise, low-status members (M = 3.82, SE = 0.29) provided more justifications than high-status members (M = 2.90, SE = 0.27). With high expertise, however, the difference between members of low (M = 3.08, SE = 0.27) and high statuses (M = 3.24, SE = 0.30) was not significant. That is, low-status members with high expertise gave fewer justifications than those presented under low expertise, with these individuals behaving similarly to high-status members (RQ1). Main effects of expertise (γ10 = −0.19, SE = 0.25, p = 0.44) and status power (γ20 = −0.38, SE = 0.23, p = . 11) were not significant (H3-justifications not supported).
For hedges, ICC was 0.23, indicating group differences accounted for 23% of variance in hedges. The group-level variance was significantly different from zero (LRT χ2 (1) = 7.05, p = .01). The main effects of expertise (γ10 = −0.10, SE = 0.47, p = 0.84) and status power (γ20 = −0.42, SE = 0.45, p = 0.35) were not significant (H1 & H3-hedges not supported).
Effects of Status Cues on Partner Perceptions
It was examined which status cues predict task partner’s perceptions of member competence, input usefulness, and member politeness, respectively. Of particular interest was the exploration of which linguistic cues significantly predict a partner's perception, even in the presence of other cues (RQ2 and RQ3). To answer RQ2, the expertise and diffuse cues were entered in the model first. Then, linguistic cues were added to the model. For better model fit and simplicity, only linguistic cues found significant (p < 0.05) or marginally significant (p <0.10) were kept in the model and reported in the following. For the inquiry about mediation (RQ3c), only the word count was tested as a potential mediator of the effect of expertise on a partner's assessment of competence and usefulness of input, as word count was the only linguistic cue with the hypothesized association between member expertise and the partner perceptions found significant.
Partner Competence. Table 4 summarizes the results from HLM models examining predictors of partner competence perceptions. For perception of partner competence (ICC = 0.01, LRT χ2 (1) = 0.02, p = 0.88), the interaction between expertise and status power was significant (γ30 = 0.66, SE = 0.29, p = 0.03) (conditional R2 = 0.12). Comparison of the estimated marginal means in four (2 × 2) conditions (Figure 1) showed that, when high-status members had low expertise (M = 4.74, SE = 0.16), they were evaluated as less capable by their partners, compared to the other conditions. Therefore, the association between members’ actual expertise and a partner’s assessment of their competence was not so clear as high-status members were punished by violated competence expectations (RQ2a). All other diffuse cues were not significant.
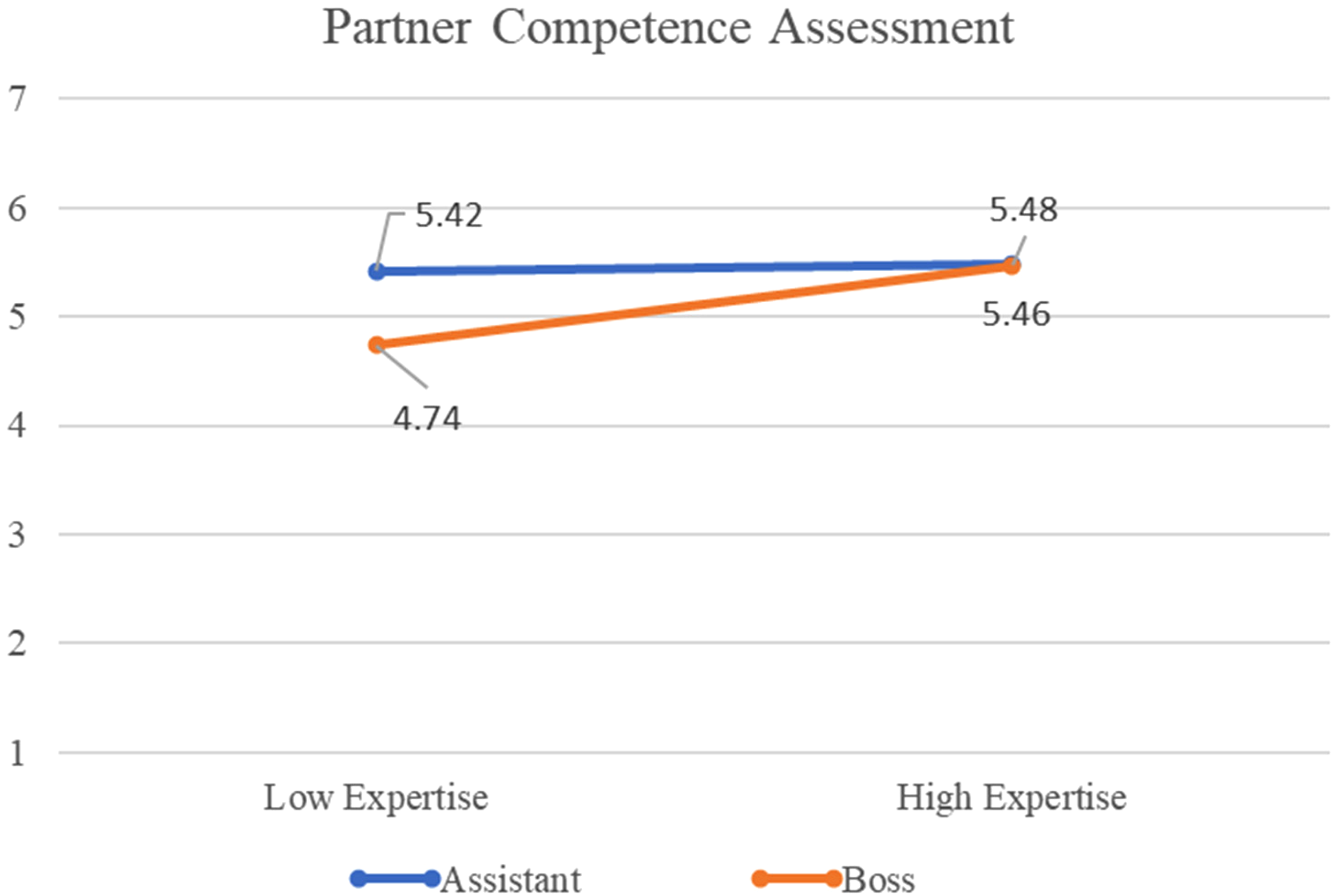
Estimated marginal means of partner competence by conditions.
Hierarchical Linear Modeling (HLM) Analysis Results for Partner Competence.
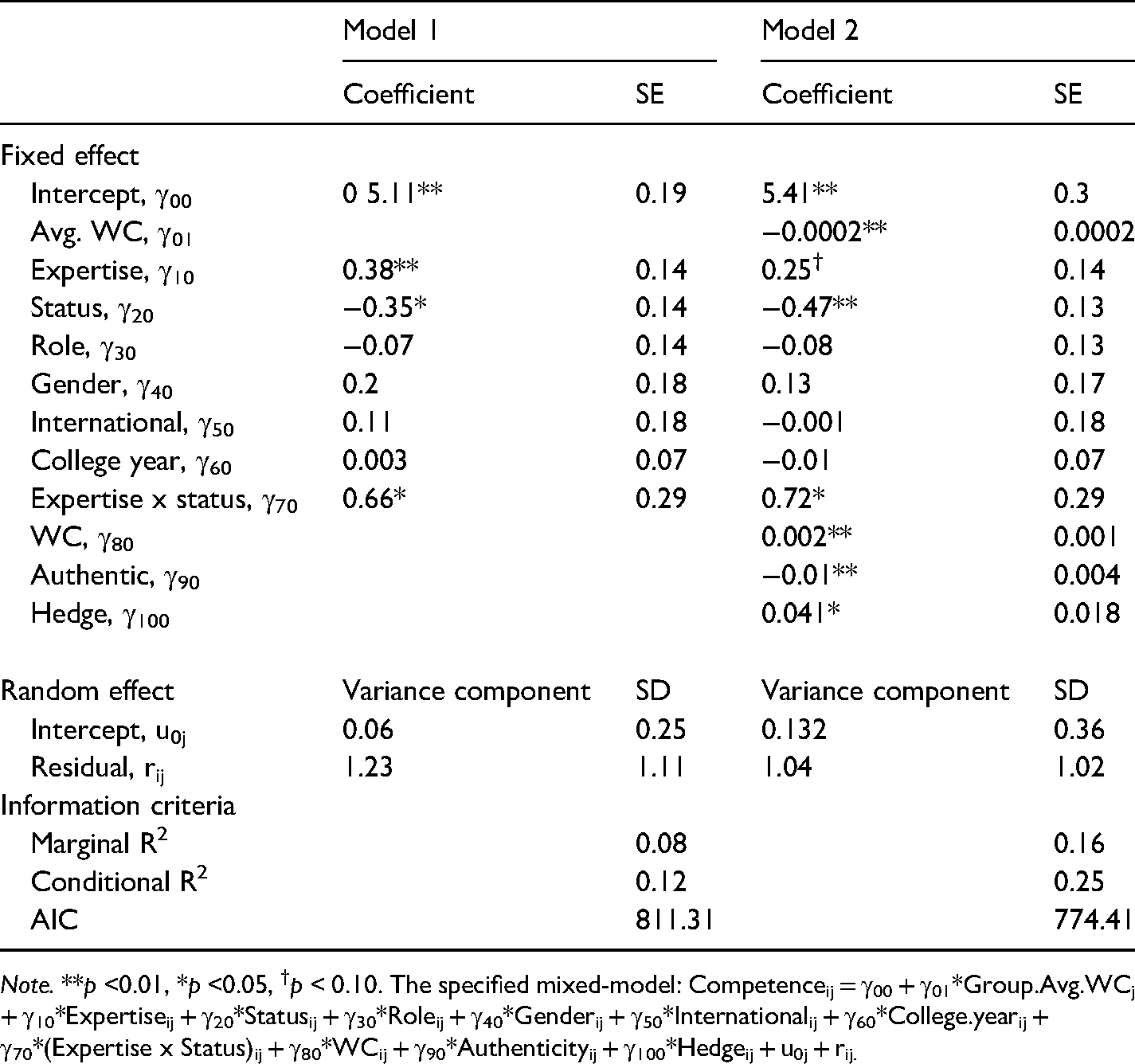
Note. **p <0.01, *p <0.05, †p < 0.10. The specified mixed-model: Competenceij = γ00 + γ01*Group.Avg.WCj + γ10*Expertiseij + γ20*Statusij + γ30*Roleij + γ40*Genderij + γ50*Internationalij + γ60*College.yearij + γ70*(Expertise x Status)ij + γ80*WCij + γ90*Authenticityij + γ100*Hedgeij + u0j + rij.
Linguistic cues explained additional variance in partner competence ratings (conditional R2 = 0.25). Word count (γ80 = 0.002, SE = 0.001, p < 0.01), authenticity (γ90 = −0.01, SE = 0.004, p < 0.01), and hedges (γ100 = 0.04, SE = 0.02, p = .02) had a significant impact on partner's perception of the member's competence (RQ3). With more authenticity in language, the member was perceived to be less capable. An increased use of hedges was associated with higher competence evaluations by partners, which was counter-intuitive. Members who spoke more words were perceived as more capable; to put the effect size into perspective, 100 more words spoken was associated with a 0.2 increase in the competence rating.
To examine the mediating role of word count between member expertise and partner’s perception of the member competence, MLMED macro for multilevel mediation testing in SPSS (Rockwood & Hayes, 2017) was used. The random intercept was included for word count, the mediator. The level-1 mediating effect (within-indirect effect) of expertise on partner perception through word count was found significant, b = 0.21, SE = 0.07, p = 0.01, CI at 95% = [0.08, 0.37], with bootstrap sample size of 10,000. The results indicated that word count served as a correct linguistic cue to member expertise in that members with superior expertise spoke more words, which in turn drove their partners to assess them as competent. No other linguistic cues mediated the hypothesized effect of expertise.
The Usefulness of Member Input. Table 5 summarizes the results from HLM models examining predictors of perceptions of the partner input (ICC < 0.01, LRT χ2 (1) < 0.01, p = 0.99). Both expert (γ10 = 1.15, SE = 0.16, p < 0.01) and status power (γ20 = −0.36, SE = 0.16, p = .03) were significant predictors (conditional R2 = 0.19). Low-expertise members evaluated input from their high-expertise partner to be more useful than high-expertise members evaluating input from their low-expertise partner. High-status members evaluated input from their low-status partner to be more useful than low-status members evaluating input from their high-status partner. All other diffuse cues were not significant. Comparison of the relative magnitudes of coefficients suggested that member expertise was more strongly associated with partner's perception of input usefulness than status power (RQ2b).
Hierarchical Linear Modeling (HLM) Analysis Results for Partner Input.
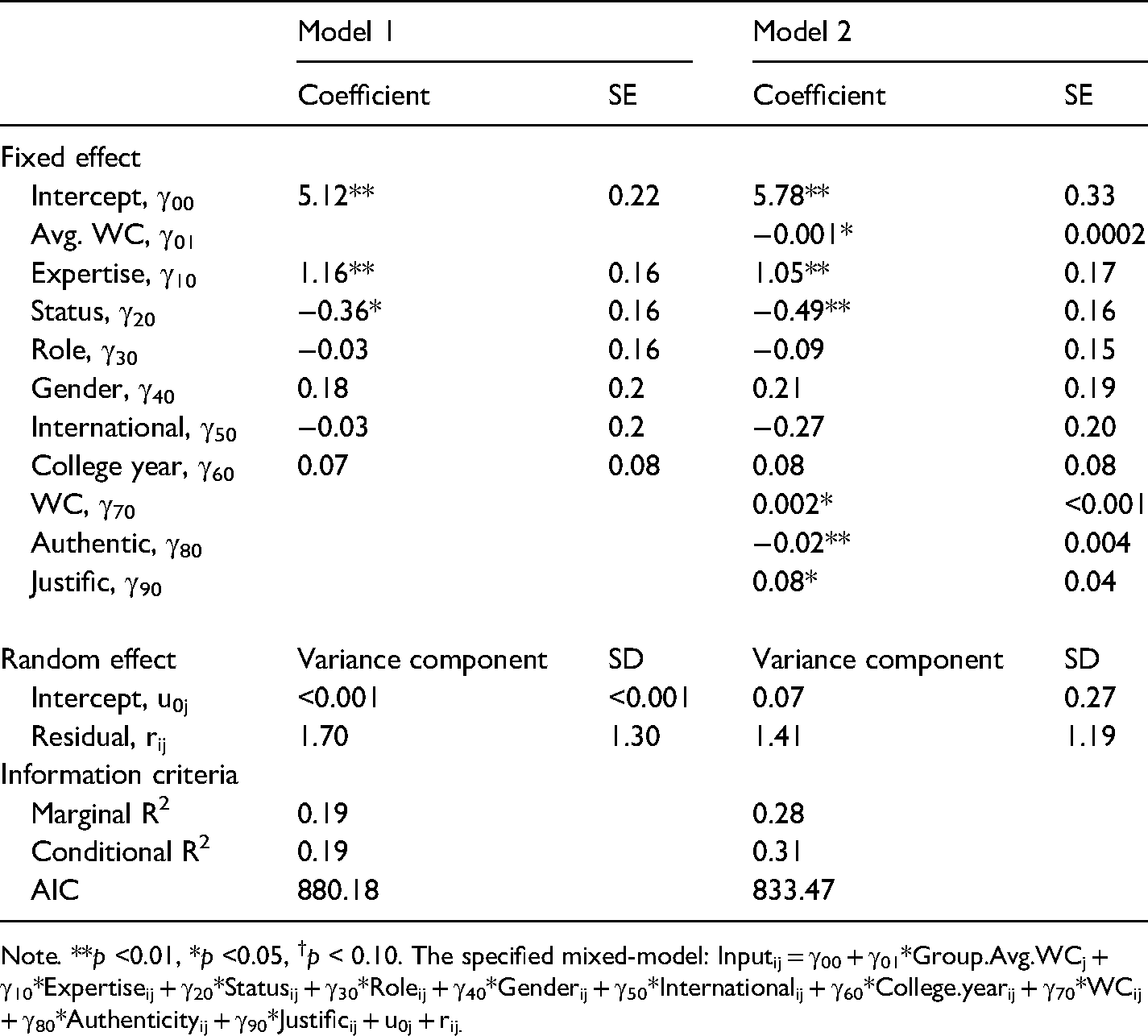
Note. **p <0.01, *p <0.05, †p < 0.10. The specified mixed-model: Inputij = γ00 + γ01*Group.Avg.WCj + γ10*Expertiseij + γ20*Statusij + γ30*Roleij + γ40*Genderij + γ50*Internationalij + γ60*College.yearij + γ70*WCij + γ80*Authenticityij + γ90*Justificij + u0j + rij.
When significant linguistic cues were added, conditional R2 increased to 0.31. Word count (γ70 = 0.002, SE = 0.001, p < 0.01), authenticity (γ80 = −0.02, SE = 0.004, p < 0.01), and justifications (γ90 = 0.08, SE = 0.04, p = .04) had a significant impact on partner's perception of input usefulness (RQ3). With less authenticity in language, a member's input was viewed as more useful by their partner, which is consistent with the result for competence perceptions. With the increased use of justifications and spoken words, input was perceived as more useful. To put the effect size into perspective, speaking 100 more words was associated with a 0.2 increase in the input usefulness rating.
When tested using MLMED macro, the level-1 mediating effect (within-indirect effect) of expertise on partner perception through word count was found significant, b = 0.20, SE = 0.09, p = 0.02, CI at 95% = [0.05, 0.38], with bootstrap sample size of 10,000. The results indicated that word count served as a correct linguistic cue to member expertise in that members with superior expertise spoke more words, which in turn drove their partners to assess their input as useful. No other linguistic cues mediated the hypothesized effect of expertise.
Partner Politeness. Table 6 summarizes the results from HLM models examining predictors of perceptions of partner politeness. For partner politeness perceptions, ICC was 0.26, suggesting group-level variance was significantly different from zero (LRT χ2 (1) = 9.26, p <. 01). Among the diffuse cues, only gender (γ40 = −0.39, SE = 0.12, p < 0.01) was a significant predictor; females were perceived as more polite than males by their partners. When significant linguistic cues were added, conditional R2 has improved from 0.31 to 0.38. Positive emotion words (γ80 = 0.08, SE = 0.04, p = 0.03), hedges (γ90 = 0.02, SE = 0.01, p = 0.045), and justifications (γ100 = 0.05, SE = 0.02, p = 0.052) were associated with partner's perception of member politeness, although the impact of justifications was marginal (RQ4a). With more positive emotion words, hedges, and justifications in language, a member was perceived as more polite by their partner. Comparison of these predictors to the findings for RQ3 suggests that the use of justifications and hedges were, in fact, positively associated with the partners’ perception of member competence and their input, respectively. Positive emotion words were not associated with the partner’s perception of member competence nor the usefulness of their input. Therefore, it can be concluded that the use of politeness language did not hurt how the member is evaluated on the competence dimensions (RQ4b).
Hierarchical Linear Modeling (HLM) Analysis Results for Partner Politeness.
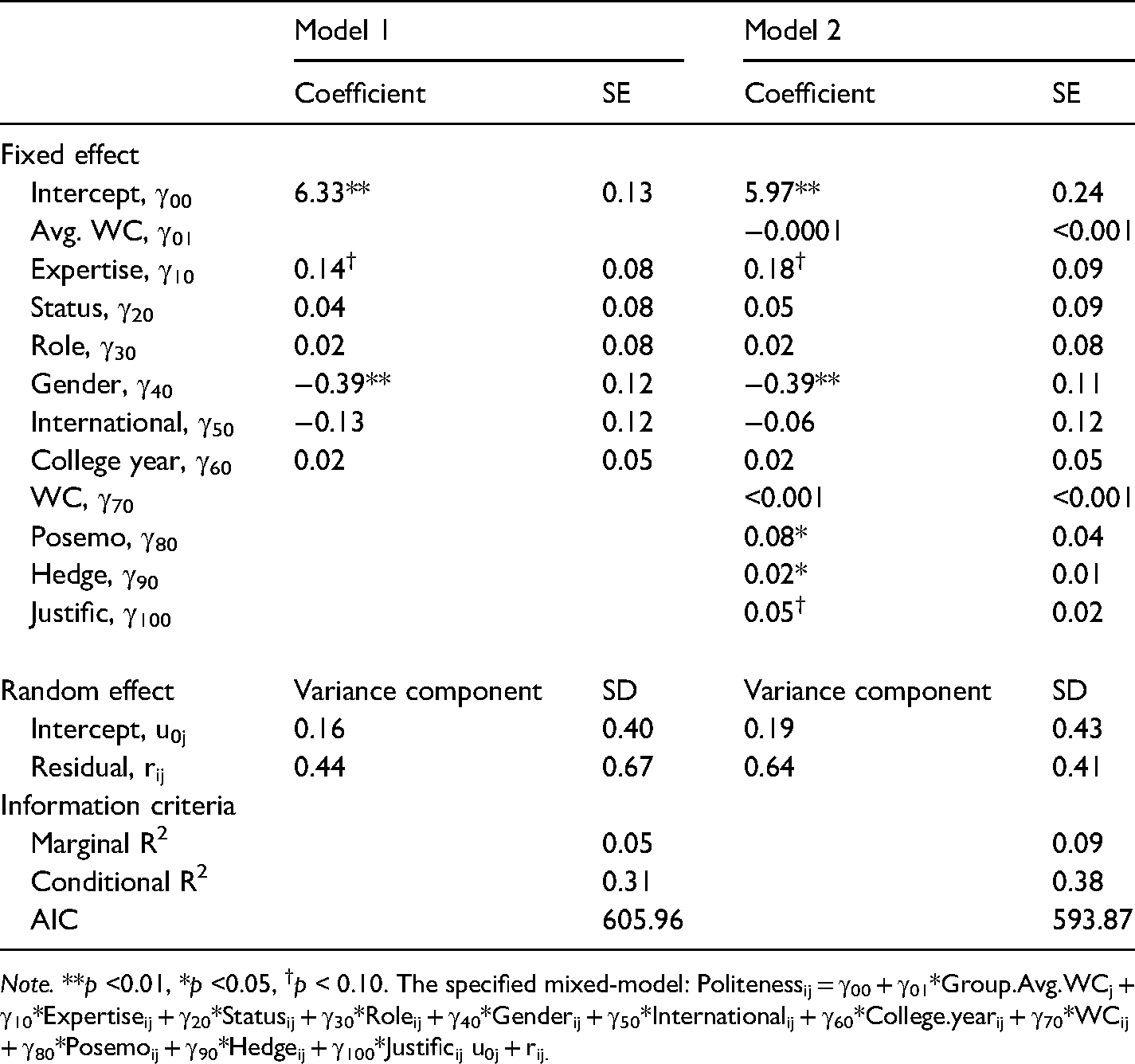
Note. **p <0.01, *p <0.05, †p < 0.10. The specified mixed-model: Politenessij = γ00 + γ01*Group.Avg.WCj + γ10*Expertiseij + γ20*Statusij + γ30*Roleij + γ40*Genderij + γ50*Internationalij + γ60*College.yearij + γ70*WCij + γ80*Posemoij + γ90*Hedgeij + γ100*Justificij u0j + rij.
Discussion
Our findings seek to answer three questions. The first question is regarding how status differences (an assigned diffuse characteristic) and expertise differences (an initially unknown task-relevant expertise) are manifested in language use. Members with higher status power spoke more and used more tag questions; however, they did not use more clout language. Our data did not yield support for more politeness markers, such as hedges and positive emotion words, in lower status members’ language. Low-status members’ language did show evidence of engaging in more analytical thinking. There was a trend—albeit non-significant—that low-status members offered more justifications than higher-status members to support their ideas. Still, this effect was moderated by member expertise, such that low-status/low expertise members offered more justifications than low status/high expertise or high-status members. Overall, the findings yield little support for politeness theory. Rather, the findings are consistent with Fiske et al. (2015) contention that people with lower social status tend to “talk up” to appear competent, whereas those with higher social status tend to “talk down” to appear warm. They reasoned, “low-status people would be more worried about whether they are seen as competent, downplaying concerns about their apparent warmth … high-status people want to be liked, but low-status people want to be respected” (p. 841). Therefore, members may have used “compensatory self-presentation strategies” (p. 842) as captured by the more positive emotional tone in high-status members’ language and more analytical thinking in low-status members’ language. In this sense, the use of a tag question along with a suggestion could be a strategic choice made by high-status members as a mechanism to elicit agreement from a lower status member politely while keeping the leading role in the conversation (Calnan & Davidson, 1998; Hepburn & Potter, 2011).
Possessing superior expertise in the dyad was associated with more words spoken, whereas less expertise was associated with less authenticity and more clout language. We found no evidence that members with superior expertise used language laden with confidence. Rather, experts in our study spoke in a more straightforward and personal manner (more authenticity). Consistent with the aforementioned notion of compensatory self-presentation (Fiske et al., 2015), members with superior expertise may have tried to avoid speaking from a superior stance, which resulted in less clout in their language and as many hedges as their low-expertise partner.
The second question asks how expertise, status power, and linguistic cues collectively affect the task partner's perceptions of member competence and input usefulness and whether any linguistic cues mediate between actual expertise and partner perceptions. The results revealed several linguistic cues that explain partner perceptions above and beyond what is explained by status, expertise, and other diffuse cues. Our data find support for the theory of status characteristics, such that task-relevant expertise influenced partner perceptions more than diffuse characteristics or linguistic cues. Members were generally capable of correctly assessing each other's expertise and not distracted by diffuse cues (e.g., gender, college years), as evidenced by strong associations between actual expertise and partner perceptions of member competence and input usefulness. A member's higher status power cue did not help them appear more competent but rather hurt their competence rating when the expectation for competence was violated. Such evidence of the general capability of correct expertise judgment is consistent with prior research (e.g., Hollingshead et al., 2011; Toma and D’Angelo, 2015; Yuan et al., 2013).
With more words spoken and more justifications given, a member was perceived as more competent and providing more useful input. Among the language cues, only the word count was found to mediate between a member's actual expertise and their partner's perceptions of expertise. Members with superior expertise spoke more words, and more words were associated with higher member competence and input usefulness as assessed by their task partner. Although a word count is a reliable indicator of a member's actual expertise, authenticity—without consideration of other status and linguistic cues—might be a misleading cue for judging member expertise. Reduced authenticity (i.e., a more distant and guarded manner) was associated with a partner's perception of increased competence and higher input usefulness, although the effect size was smaller than that of expertise and status power. This particular finding is consistent with Toma and D’Angelo’s report (2015) that online advice messages with few I-pronouns, which signal low authenticity and a psychologically distanced style, are perceived as reflecting expertise. They found I-pronouns did not help correctly distinguish between advice from experts and that from laypeople.
The third question is what linguistic cues affect the task partner's perceptions of member politeness and whether these linguistic cues differ from those that affect perceptions of member competence and input usefulness. Contrary to the belief that polite language may compromise appearing competent, using more hedges was associated with perceptions of higher competence as well as politeness. This finding is unexpected but deemed to be consistent with previous research that found more use of hedges in academic manuscripts predicted more favorable evaluations because reviewers found the text to be written more carefully (Bajwa et al., 2019). Notably, Yuan et al. (2019) found that the relationship-oriented communication style, indicated by being respectful and mindful of protecting the relationship, can be an indicator of expertise as it was used more by experts than non-experts. Although our study does not find hedges being used more by high-expertise participants, clout was found much less in the language of high-expertise members. Thus, it remains for future research to test whether any politeness marker can be a reliable cue to actual expertise or a misleading cue. Besides hedges, the increased use of justifications was positively associated with a partner's perception of input usefulness as well as a member's politeness. Note that justifications were unrelated to a member's actual expertise. Nevertheless, the effectiveness of justifications in both appealing to the usefulness of ideas and appearing polite could explain why low-status members with low expertise used more justifications than high-status members or low-status members with high expertise. They might have done so strategically to manage impressions.
Members using more positive emotion words were perceived as more polite by their partners. Although not hypothesized, when positive emotion words were tested as a mediator of the effect of status power on partner perception of member politeness, it was a marginally significant mediator (the within-indirect effect b = 0.05, SE = 0.03, p = 0.08, CI at 95% = [0.005, 0.12]). That is, high-status members used words that reflected positive emotions, and an increased use of such words predicted the partner's increased perception of member politeness. This is evidence that high-status members’ compensatory self-presentation strategy (Fiske et al., 2015) to appear polite effectively conveyed the impression that they intended to make on their partner. Despite the additional variance explained by linguistic cues, it should be noted again that gender (a diffuse cue) had a more sizable effect than linguistic cues on the partners’ perceptions of member politeness.
In summary, the findings support expectations states theory's contention that the performance expectations formed based on the member’s attributes—both the member expertise and the status power—shape the member's conversational behavior regarding how much they dominated the conversation (words spoken). The results, however, point to a need to extend the theory to account for members behaving in a way that fulfills an impression management goal beyond simply the influence goal of meeting performance expectations. This study further extends the theory of status characteristics (Bunderson & Barton, 2011) by demonstrating the utility of word count as a behavioral cue to assess member competence while suggesting a caveat against potentially misleading linguistic cues. A recently proposed input-process-output model of group interaction (van Swol & Kane, 2019) has suggested how the inputs of status and expertise differences affect language during discussion and how group processes develop beyond the initial inputs. Previous research examining language use in groups and dyads has often not examined manipulated variables (van Swol & Kane, 2019). This study was an innovative endeavor to manipulate the input of expertise and status power and examine the effects on language. Our findings revealed that the assigned status differences, as well as the initially unknown expertise differences, did manifest in the members’ language use and that those cues that emerged later during the interaction (i.e., linguistic cues) additionally shaped partner perceptions.
Limitations
The experimental procedure that manipulated status and expertise allowed conclusions about the relationship between the status characteristics and language use. However, the study is not without the limitations of experimental studies previously noted by researchers (Schaerer et al., 2018). Assigning a high or low-power role to participants inadvertently “activat[es] the schemas … as to how powerful and powerless individuals ought to behave [that] can lead to fundamentally different outcomes than the actual experience of high and low power” (p. 198). In other words, role-playing participants might not have internalized power nor were experiencing it like those actually in a relationship (e.g., superior-subordinate). For example, the expectation of playing the boss role might have instead pressured student participants to be cautious about what they say to win the partner’s favor. Another limitation is that it is unclear at which point during the interaction the participants discovered their expertise differential and ascribed an expert status to the one who possessed superior information. Thus, the language of expert participants could not be attributed solely to their expert status. Depending on when the expert status emerged, some structural factors related to the given information (e.g., numbers) may have influenced the experts’ language more than their expert status.
Conclusion
This study found that member expertise and status power were associated with more words spoken during a collective problem-solving task. Low-status members used language that reflected more analytical thinking than that used by high-status partners. They also offered more justifications for their ideas when they had less expertise than when they had superior expertise. The findings regarding partner perceptions suggest that speaking more in conversation is a reliable cue to members’ actual expertise. However, attributions of expertise based on clout language and (fewer) politeness markers may be misleading. Expert members should speak more words and offer more justifications in a cautious and polite manner, instead of in a self-revealing manner, to signal their expert stance in collective problem-solving groups, especially when their expertise is initially unknown to others.
Footnotes
Acknowledgments
The authors like to thank research assistants who worked for the Communication, Advice, and Social Influence lab at University of Wisconsin-Madison in the 2018 and 2019 academic years for administering the lab experiment and transcribing and coding the language data.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This research was supported in part by the Dissertation Research Grants from the Department of Communication Arts at the University of Wisconsin-Madison.
1.
The pre-interaction survey asked participants to type in their initial estimate and indicate how confident they are about their initial estimate. These responses were not used in this study.
2.
One of the participants in the dyad was assigned the role of judge, which essentially means the person who submitted the group's final answer to the experimenter. The role was a fixed factor, but was not of interest in this study, thus, treated as a control variable in the analyses.