
Abstract
This study analyzes how ChatGPT characterizes developed and developing countries using a sentiment analysis framework. We selected 10 countries with the highest Human Development Index (HDI) and 10 countries with the lowest. The sentiment analysis provided scores indicating the degree of positivity in the descriptions of these countries provided by ChatGPT. The results revealed that ChatGPT generally expressed positive sentiments about all countries. However, strong evidence emerged showing that countries with high HDI received more positive sentiments compared to those with low HDI. These findings highlight the bias of the model in describing developed versus developing countries. Ultimately, the study highlights the importance of adjusting large language models to ensure fairer representations of countries.
Large language models (LLMs) have transformed the landscape of Natural Language Processing (NLP). The capability of LLMs like ChatGPT in producing high-quality text closely mimicking human language is well documented (Adeshola & Adepoju, 2023; Chukwuere, 2024). Nevertheless, LLMs inadvertently mirror and perpetuate biases present in their training data (Caliskan et al., 2017). While content filtering techniques have been employed to mitigate harmful outputs (Markov et al., 2023), biases can persist within the model itself (Ray, 2023). Deploying biased models in real-world applications can have detrimental consequences, as demonstrated by incidents such as those involving artificial intelligence (AI) healthcare predictions (Obermeyer et al., 2019).
LLMs demonstrate various biases associated with gender (Gross, 2023), language (Georgiou, 2024), religion (Abid et al., 2021), politics (Rozado, 2023), and nationality (Venkit et al., 2023) among others. Zhu et al. (2024) investigated the nationality bias of ChatGPT using a sample of 195 countries, with descriptions provided in both English and Chinese. The authors evaluated the output using vocabulary richness, sentiment, and offensiveness metrics. Evaluations of language have also been conducted by humans and ChatGPT. The findings indicated that although the generated content was largely positive, ChatGPT produced negative content when given prompts with negative connotations. Although the model viewed its output as neutral, it consistently demonstrated self-awareness of nationality bias when evaluated using the same pairwise comparison annotation method employed by human annotators.
The examination of country bias in AI-generated language has received minimal scientific attention. In a relevant study, Boussidan et al. (2024) explored the biases of ChatGPT regarding various countries around the globe. The authors followed a sentiment analysis approach, prompting the model to assign a positivity score to each country. Prompts were provided in four different languages, namely, French, English, Russian, and Arabic. The findings revealed that North American and European countries received higher scores, whereas African countries received the lowest. South American and Asian countries typically fell in the middle range. The results also denoted variations across languages. When prompted in French, African countries, particularly those colonized by France, tended to receive more negative scores. In contrast, when prompted in English, the model assigned positive scores to Commonwealth nations like India and Australia. However, the sentiment analysis in the above study relied on the scores assigned to these countries by ChatGPT, using a scale developed by the authors. The conclusion drawn is that ChatGPT is biased toward specific countries. For instance, Salinas et al. (2023) reported that when prompted to select 20 nationalities, the model chose exclusively from Western countries, omitting African nations.
This study aims to fill a research gap by investigating the sentiments found in ChatGPT-generated language regarding developed versus developing countries. We uniquely employ a sentiment analysis framework, which indicates the sentiment scores of the generated texts about the countries under investigation. These scores were derived from an embedded online dictionary, which assessed the positivity of each word in the generated language. The comparison between developed and developing countries is performed through statistical modeling. Since the LLM is sensitive to biases based on previous research, we hypothesize that developed countries will exhibit higher sentiment scores than developing countries. By analyzing sentiment scores in AI-generated texts, the study aims to reveal potential biases, promoting fairer and more accurate representations. This effort supports ethical AI development, enhances trustworthiness in AI systems, and ensures informed decision-making.
Methodology
Procedure
We used ChatGPT-3.5 to generate the texts. We employed a prompt designed to elicit unbiased thoughts about specific countries. Specifically, we presented the following prompt to ChatGPT: “Please provide us with any thoughts about [name of the country] within 10 sentences.” The sample consisted of 20 countries selected according to their Human Development Index (HDI). HDI is a composite statistic that combines life expectancy, education (measured by both the average years of schooling completed and the expected years of schooling at the start of education), and per capita income. This index categorizes countries into four levels of human development. Higher HDI scores correspond to longer lifespans, higher education levels, and greater gross national income per capita adjusted for purchasing power parity. HDI is employed by the United Nations Development Program's Human Development Report Office to assess and compare the development progress of countries (United Nations Development Programme, 2024).
The selected countries were retrieved from the latest Human Development Report 2023–24 and include data from 2022 (Conceição, 2024). These countries were Switzerland, Norway, Iceland, Hong Kong, Denmark, Sweden, Ireland, Germany, Singapore, and Netherlands as well as Sierra Leone, Burkina Faso, Yemen, Burundi, Mali, Niger, Chad, Central African Republic, South Sudan, and Somalia. The first 10 countries had the highest HDI in the report (0.946–0.967, SD = 0.007), while the other 10 countries had the lowest HDI (0.38–0.424, SD = 0.02).
Analysis
The sentiment analysis was conducted with the use of the SentimentAnalysis package in R (R Core Team, 2024). Sentiments were extracted utilizing the QDAP dictionary from the qdapDictionaries package (Rinker, 2021). The value of particular words ranges from −1 (highly negative) to 1 (highly positive). Scores close to zero indicate neutral sentiment.
We used a Bayesian regression model via the brms package (Bürkner et al., 2024) in R to analyze our data. This is because of its potential to handle small sample data (Georgiou, 2023). The dependent variable included the sentiment SCORE measured between −1 and 1. HDI (low/high) was modeled as the fixed factor, while COUNTRY was treated as a random factor. Weakly informative priors were used, given the lack of predefined assumptions about the data parameters (Georgiou & Giannakou, 2024). These priors followed a student's t-distribution with 3 df, a mean of 0, and an SD of 2.5 (Georgiou & Kaskampa, 2024). The evidence ratio (ER) was used to assess the likelihood of the test hypotheses compared to their alternatives. We adhered to Jeffreys’s (1961) approach, considering an ER of 10 or higher as strong evidence in favor of a hypothesis, and an ER of 0.1 or lower as strong evidence against a hypothesis.
Results
The sentiment analysis indicated positive average sentiment scores (i.e., >0) for all countries under investigation. However, according to the descriptive statistics, the language related to the high HDI group had more positive sentiments compared to the low HDI group. Figure 1 shows the sentiment scores for both high and low HDI countries together with their SDs. The scores ranged between −0.29 and 0.57 for high HDI and −0.5 and 0.5 for low HDI. Figure 2 illustrates the sentiment scores and the SDs for each country with the high and low HDI.
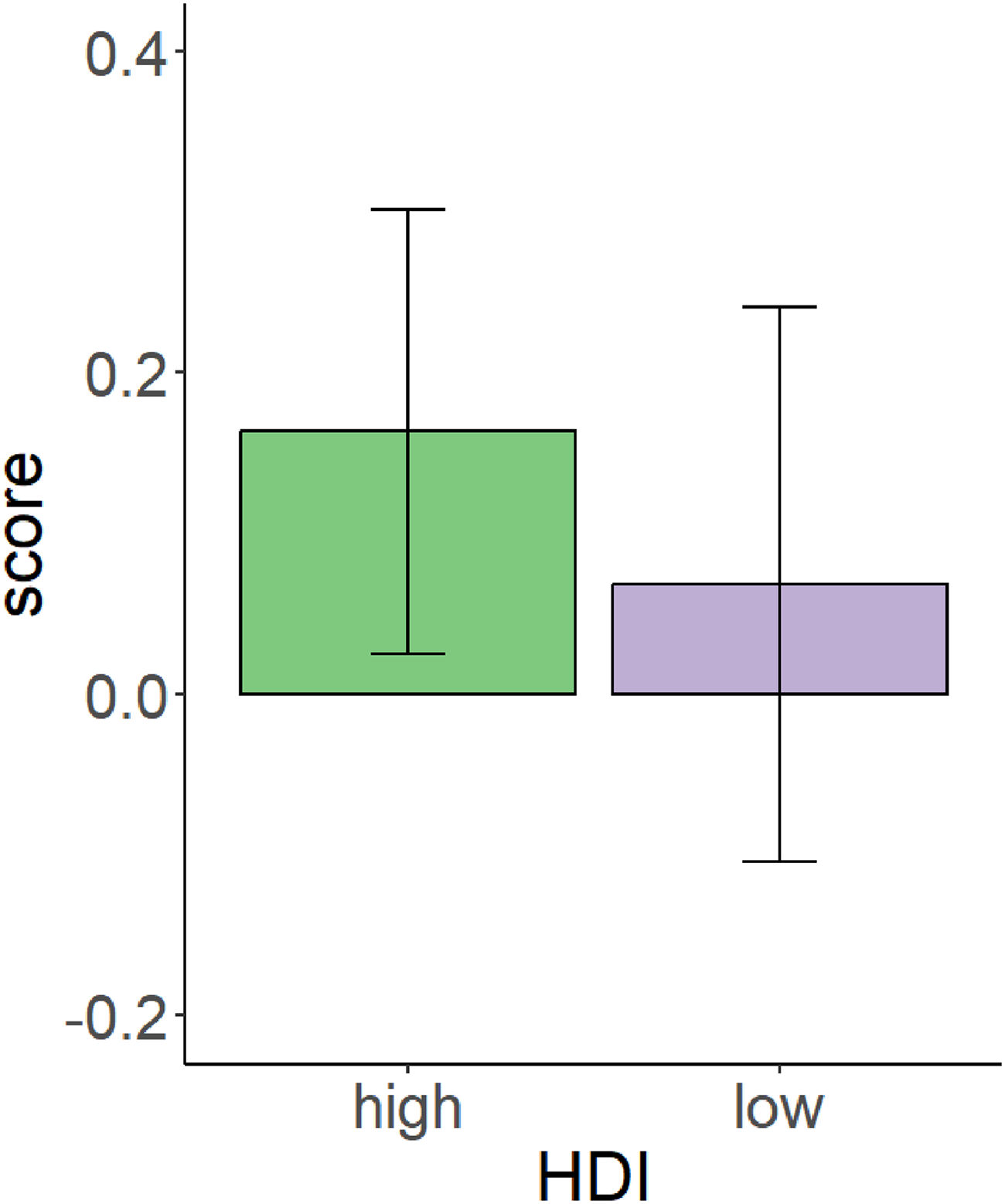
Sentiment scores for countries with high and low HDI.
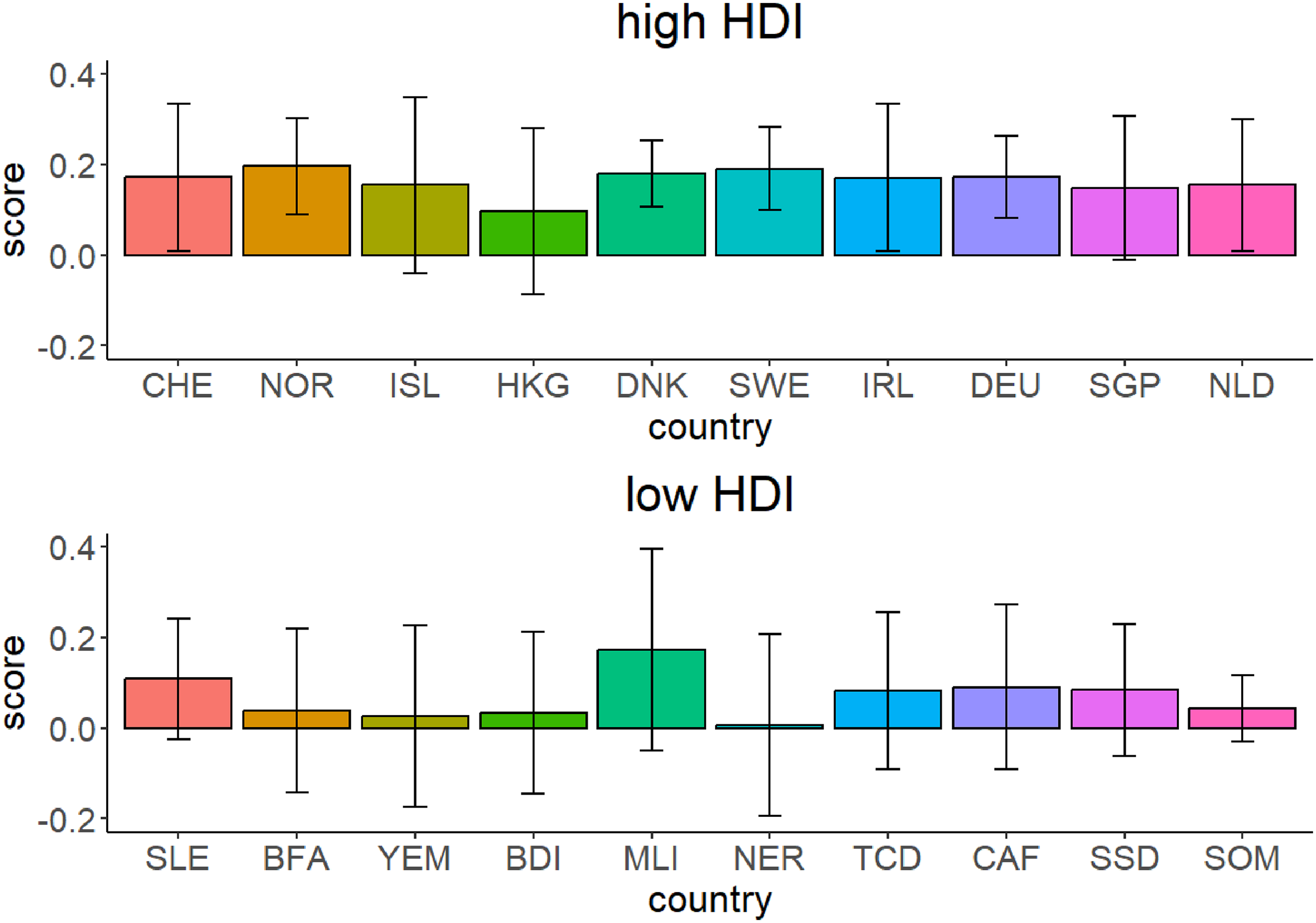
Sentiment scores for each country with high and low HDI.
We utilized a Bayesian regression model to assess whether ChatGPT exhibited sentiment differences between countries with high HDI and those with low HDI. According to the analysis, the credible interval (CI) for high HDI suggests that there is a 95% probability that the true value of the sentiment score lies between 0.13 and 0.20. As the values do not cross zero, there is strong evidence that the true value of high HDI was greater than zero, indicating in this case positive sentiments for these countries. Similarly, the CI for low HDI indicates a 95% probability that the true value of the parameter lies between 0.04 and 0.10. This provides strong evidence that the low HDI is significantly greater than zero, implying that these countries are associated with positive sentiments. Subsequent hypothesis testing exhibited strong evidence (ER = 3,900, PP = 1.00) that the high HDI countries exhibited higher sentiment scores than the low HDI countries. Table 1 shows the results of the Bayesian analysis and hypothesis testing.
Results of the Bayesian Analysis and Hypothesis Testing.
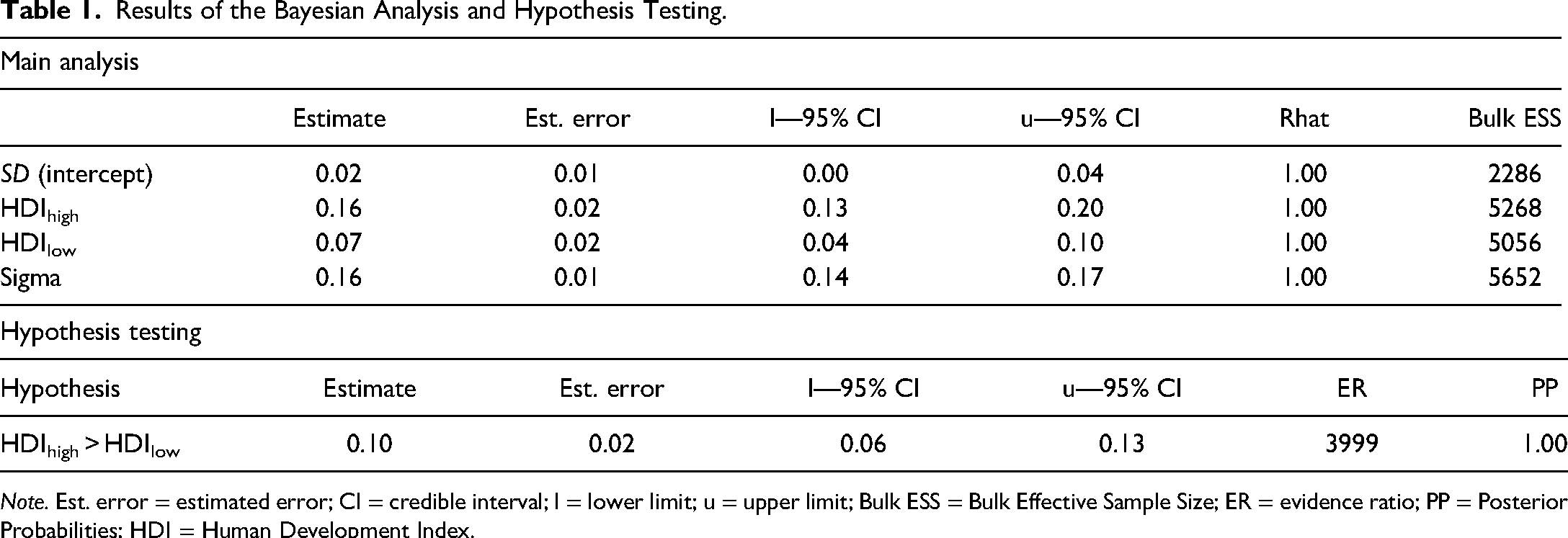
Note. Est. error = estimated error; CI = credible interval; l = lower limit; u = upper limit; Bulk ESS = Bulk Effective Sample Size; ER = evidence ratio; PP = Posterior Probabilities; HDI = Human Development Index.
Discussion
The study examined the language used by ChatGPT to describe developed and developing countries by employing a sentiment analysis framework. We utilized prompts to direct ChatGPT in generating discourses pertaining to selected developed and developing countries; these countries were divided based on their HDI scores. We subsequently elicited the sentiment scores for these texts using sentiment analysis in R. Comparisons between high HDI and low HDI countries were conducted using a Bayesian regression model.
The results demonstrated positive sentiments on average for both high and low HDI countries and each of the 20 countries added to the analysis. This is consistent with the findings of Zhu et al. (2024), who reported the generation of positive content by ChatGPT for various nationalities around the world. Thus, the model avoids using negative language for the description of these countries. However, the Bayesian regression analysis confirmed our initial hypothesis, since the language used by ChatGPT for the description of each country encompassed more positive sentiments for countries with high HDI than countries with low HDI. The former group included mostly European nations, while the latter group mainly included African countries. These results corroborate earlier findings. For instance, Boussidan et al. (2024) found that ChatGPT attributed higher positivity ratings to North American and European countries, while African countries received lower ratings.
Overall, ChatGPT presents with biases by distinguishing between developed and developing countries as seen in the sentiment analysis. This can significantly amplify racial and ethnic biases and stereotypes (Choudhary, 2024). By consistently using more positive language to describe developed countries and less positive language to describe developing ones, ChatGPT may perpetuate perceptions of superiority or inferiority based on national economic status. This could lead to the reinforcement of existing inequalities between more developed and less developed countries, influencing societal attitudes and potentially impacting policy decisions and resource allocation.
There is further evidence in the literature for social injustice stemming from AI algorithms. For example, the Optum algorithm in the health system of the U.S. labeled Black patients as less ill compared to White patients, even in cases where people from both racial groups were equally ill (Obermeyer et al., 2019). Such inequities be caused by algorithmic structure bias, insufficient data collected from particular groups, the use of algorithms that reflect or replicate biased human decision-making, and the reluctance of powerful institutions holding large datasets to reduce inequities, among others (Moore, 2022). Another source of inequities may be the lack of diversity among the computer scientists involved in developing AI systems (Hussain et al., 2015). More specifically, individuals from low socioeconomic status minority groups are significantly underrepresented in the high-tech workforce. A more diverse workforce could enhance AI products, as individuals from various social groups may better recognize how algorithms may or may not accurately represent their own communities. In addition, computer scientists and engineers often lack training in comprehending the various aspects of human data and their connections to systems of inequality (Joyce et al., 2018). Such training would be beneficial by fostering a more holistic approach to technology development, ensuring that algorithms and systems are designed with an awareness of societal impacts, biases, and disparities. This, in turn, can lead to more ethical and equitable outcomes, as well as technologies that better serve diverse populations. It is worth noting that the responsibility for the behavior or output of an AI system should not solely rest with the programmers who create it. Instead, society at large plays a crucial role in shaping the data and context from which the AI learns. This advocates for a broader understanding of accountability in AI development, highlighting the need for societal responsibility in shaping the data that informs AI systems to ensure they operate ethically (Ferrara, 2024).
The results of this study are relevant to the intersection of linguistics and psychology because they demonstrate how LLMs, such as ChatGPT, can reflect and potentially reinforce biases in the way countries are described based on their developmental status. From a linguistics perspective, the study sheds light on the language choices and sentiment patterns embedded in the model's descriptions, which may align with global power dynamics or stereotypes about developed and developing nations. This relates to how language can shape perceptions and reinforce societal hierarchies. This process involved tokenizing sentences into individual words and assigning sentiment scores using predefined dictionaries. Each word was evaluated based on its polarity (positive or negative) and intensity (the strength of the sentiment within those categories), providing a detailed sentiment analysis. From a psychological perspective, the findings touch on how exposure to biased language through AI can influence people's attitudes, beliefs, and perceptions about countries and their populations. This suggests that models like ChatGPT may unintentionally contribute to shaping biases or implicit attitudes through the way they frame information, which is a core concern in psychology. The present study highlights the need to address biases not only in the technical development of models but also in how they impact psychological constructs like perception, stereotyping, and social judgment.
Conclusions
A significant differentiation between developed and developing countries was observed in the language of ChatGPT on the basis of a sentiment analysis. These tentative findings could be important for AI developers who may consider adjusting the algorithm accordingly to reduce socially biased language in LLMs like ChatGPT. Future research can include a larger pool of countries and use additional metrics to investigate the language of the model. Furthermore, future work can examine the sociocultural impacts of biased AI-generated content on global perceptions and interactions.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by the Phonetic Lab of the University of Nicosia.