
Abstract
Detecting deception in interpersonal communication is a pivotal issue in social psychology, with significant implications for court and criminal proceedings. In this study, four experiments were designed to compare the performance of natural language processing (NLP) techniques and human judges in detecting deception from linguistic cues in a dataset of 62 transcriptions of video-taped interviews (32 genuine and 30 deceptive). The results showed that machine-learning algorithms significantly outperform naïve (accuracy = 54.7%) and expert judges (accuracy = 59.4%) when trained on features from the reality monitoring (RM) and cognitive load frameworks (accuracy = 69.4%) or on features automatically extracted through NLP techniques (accuracy = 77.3%) but not when trained on the RM criteria alone. This evidence suggests that NLP algorithms, due to their ability to handle complex patterns of linguistic data, might be useful for better disentangling truthful from deceptive narratives, outperforming traditional theoretical models.
Keywords
Introduction
Detecting deception in interpersonal communication is a pivotal issue in social psychology, with significant implications for criminal investigations and court and criminal proceedings. For example, assessing the credibility of a suspect during interrogation is relevant, as false or distorted information may lead the investigation in the wrong direction. Moreover, in some cases, such as in the Italian court, allegations of sexual harassment are often based on the victims’ declarations, which are treated as evidence and most often without clear and independent evidence of the offence. In such situations, a police officer or a judge is tasked with determining the veracity of the information provided and of the alleged accusation (Oberlader et al., 2021). However, humans exhibit inherent biases when it comes to detecting lies. In the absence of any prior knowledge of the context, human intuitive judgment in deception detection has been proven to be just slightly above the chance level (Bond & DePaulo, 2006; Ekman & O'Sullivan, 1991). Even experts in the field, such as police officers, tend to commit false-negative and false-positive errors (Elaad, 2009; Vrij, 2008). For naïve judges, the truth bias (i.e., the intrinsic human inclination to presume others as honest) has been proposed as one possible explanation for this poor performance (Levine, 2014; Street & Masip, 2015). For expert judges, instead, the debate is still open on whether the problem stems from the identification of the cue (i.e., during the evaluation process) or the difficulty of combining several cues (due to the limited cognitive resources) to then make a straightforward decision (Verschuere et al., 2023).
Recently, researchers have increasingly relied on automated approaches to deception detection based on machine-learning (ML) techniques, i.e., computational methods that enable computer algorithms to identify patterns in data and make predictions based on these patterns (see Constâncio et al., 2023 for a review). One of the most exploited techniques is natural language processing (NLP), a field of artificial intelligence focused on enabling machines to interpret, analyze, and respond to human language. NLP has been applied especially in detecting deception online, such as identifying fake reviews or misinformation (Alonso et al., 2021; Salminen et al., 2022). Typically, NLP-based approaches are heavily data-driven. This means that they rely on extracting features directly from textual data, such as word frequencies, syntactic patterns, and word embeddings (i.e., numerical representations of word co-occurrences), without necessarily incorporating insights from psychological theories that have been used to identify cues of deception in language.
In this context, NLP techniques can be leveraged to transform textual data into numerical features based on theoretical frameworks that will then be used to feed ML models trained to identify subtle verbal indicators in datasets where truthful and deceptive examples are already labeled (i.e., supervised learning). The advantage of this approach is that, after the training is complete, a good ML model can be used to predict whether new statements are likely deceptive or truthful based on learned patterns, and evaluate the efficacy of a specific psychological theory of deception.
Investigating the Veracity of Verbal Content Using Reality Monitoring
Deception may imply reporting fabricated details or intentionally omitting relevant information conveyed in such a way as to seem truthful to the interlocutor (Newman et al., 2003). The Undeutsch hypothesis suggests that deceitful information is qualitatively different in form and content from truthful information (Vrij et al., 2000). Nevertheless, there is no verbal cue that is inherently associated with deception (Vrij, 2008).
Among the several verbal lie detection tools, reality monitoring (RM; Johnson & Raye, 1981) was developed on the basis of evidence from cognitive psychology and currently stands out in the literature for its theoretical robustness, being the most commonly employed approach by researchers. This approach is grounded in the notion that memories of actual experiences exhibit stronger connections to external stimuli than memories of imagined events. Accordingly, memories originating from perceptual experiences should feature contextual, sensory, and affective details, whereas internally generated memories, stemming from thoughts or imagination, should be marked by references to cognitive processes. Eight criteria were outlined to distinguish between these two types of memories, with the presence of cognitive operations being the only lie criterion (Vrij et al., 2007). Research indicates that when scores are combined from these eight criteria, the average accuracy RM rate is comparable to that of other content-based techniques (e.g., the criteria-based content analysis), ranging between 61% and 83%, with an average of 69% (Vrij, 2008). Among the individual criteria, contextual factors, such as temporal and spatial criteria, appear to hold the greatest diagnostic value (Masip et al., 2005).
Systematic reviews (Masip et al., 2005; Vrij, 2005, 2008) and meta-analyses (Amado et al., 2015, 2016; Hauch et al., 2017; Oberlader et al., 2016) have demonstrated that RM exhibits satisfactory inter-rater reliability and empirical validity across diverse study designs and populations, possibly because of its straightforward application (Sporer, 1997; Strömwall et al., 2004; Vrij et al., 2000). Indeed, RM is not time-consuming, involves less subjective decision-making (Oberlader et al., 2016), and holds precise criteria that are easy to operationalize. Despite these findings, caution is advised when using RM due to the lack of an objective decision rule, namely a numerical cutoff for scores that allow the user to classify a narrative as honest or faked (Amado et al., 2015, 2016).
Investigating the Veracity of Verbal Content by Imposing Cognitive Load
In interviews, lie-tellers are known to consume more cognitive resources because they need to fabricate responses that are congruent with other fabricated information while maintaining their credibility during the examination (Vrij et al., 2008). This cognitive load (CL) is often reflected in several indices (e.g., behavioral, physiological, verbal, and neural, among others) that can be leveraged to distinguish truthful from deceptive statements (Vrij et al., 2008).
The “imposing cognitive load approach” (Vrij et al., 2017) takes advantage of this vulnerability in lie-tellers and leverages interviewing strategies that have the effect of further depleting their cognitive resources while keeping the demand manageable for truth-tellers (Walczyk et al., 2013). These strategies may involve asking the examinee to perform a second task during the interview or to continuously switch between two tasks, imposing time restrictions to answer questions, recalling the events in reverse order, or asking the examinee unexpected questions (Vrij et al., 2009; Walczyk et al., 2013).
Among these, the strategy of asking unexpected questions has proved to be effective, reaching accuracy rates from 80% to 95% (Lancaster et al., 2013; Monaro et al., 2017, 2018). It involves the examiner initially asking anticipated questions, i.e., questions that the lie-tellers expect and prepare in advance, and then switching to questions that cannot be foreseen and for which the responses were not prepared. For example, in the context of faked identities, lie-tellers may prepare answers about the name, surname, and date of birth of the stolen identity, but they unlikely prepare the answer for their zodiac sign (Monaro et al., 2017). Responses to unexpected questions in lie-tellers are associated with slower reaction times and a higher number of inconsistencies than truth-tellers (Melis et al., 2024; Monaro et al., 2017). Lie detection approaches based on imposing CL produce higher accuracy rates compared to standard approaches in spotting deception (Vrij et al., 2017).
Investigating the Veracity of Verbal Content Using NLP
The advent of NLP for the analysis of human language has provided new opportunities for the automatic detection of deception (Tomas et al., 2022). These techniques allow to extract features at different levels of granularity: the n-gram model breaks the text into linear sequences of tokens and reveal frequent patterns; part-of-speech (POS) tagging assigns grammatical categories (nouns, verbs, and adjectives) to words, thus informing on shallow syntactic text structure; word/sentence length and number are extracted to evaluate text complexity; the linguistic inquiry and word count (LIWC) categorizes words into psychological, social, and emotional dimensions (e.g., positive/negative affect, social words, etc.) providing the semantic content of the text; named-entity recognition (NER), automatically identifies and categorizes proper nouns (such as names of people, places, and organizations) within texts.
Moreover, these computational techniques can be applied with different methodologies. Data-driven approaches are based on statistical procedures to perform feature extraction and selection. Theory-driven approaches investigate samples of features derived from psychological theoretical models of deception. Last, hybrid models rely on theory to select variables that are restricted to those that are found to be statistically significant.
RM and CL frameworks have been proven suitable for investigation using this computational perspective. Recent studies highlighted how manual coding is not necessarily superior to automated coding of RM (Schutte et al., 2021, preprint; Deeb et al., 2024). In addition, a meta-analysis by Hauch et al. (2015) demonstrated RM effectiveness in detecting verbal deception when using LIWC features. The same meta-analysis also found evidence in favor of the CL theory, showing that lie-tellers produce shorter, less elaborate, and less complex statements (Hauch et al., 2015). These characteristics can be automatically captured in statements through linguistic features such as the number of words, number of sentences, average sentence length, type-token ratio, word length, and use of exclusive words (e.g., but, except, without). Furthermore, a recent study found that verbal cues of CL effectively distinguished truthful from deceptive statements in a mixed dataset that included different contexts of deception (i.e., personal opinions vs. autobiographical memories vs. future intentions), suggesting the potential for these features to serve as more generalizable cues compared to others (Loconte et al., 2023).
Parallel to these theory-driven approaches, the detection of verbal deception has also been investigated using a data-driven approach. For example, Mihalcea and Strapparava (2009) and Ott et al. (2011) detected deceptive opinions by training a naïve Bayes and a support vector machine (SVM) model on n-grams and a combination of n-grams and LIWC features, respectively. Pérez-Rosas and Mihalcea (2015) investigated an open-domain dataset using n-grams, shallow and deep syntactic features (using POS tagging), semantic features from LIWC, and readability and syntactic complexity metrics. Finally, Kleinberg et al. (2018a, 2018b) employed NER as a proxy for automated scoring of details and verifiable details and accurately classified truthful and deceptive hotel reviews and future intentions.
A recent review of studies from Constâncio et al. (2023) on ML and NLP techniques for lie detection showed that automatic verbal analysis significantly outperformed the chance and human level in a variety of datasets (see Table 1). Furthermore, a short review of the literature on the use of LIWC software for lie detection (Van Der Zee et al., 2022) showed that studies using a data-driven approach reached an accuracy rate ranging from 65% to 74%, whereas studies using a theory-driven approach reached an accuracy rate ranging from 51% to 69%. Studies that employed a hybrid approach, training ML models only on statistically significant theoretical variables, reached an accuracy rate ranging from 50% to 69%. These findings showed that selecting the most appropriate approach is paramount because it may influence ML models’ performance (Van Der Zee et al., 2022).
Studies Employing ML Techniques on Verbal Content for Lie-Detection Tasks Reported in Constâncio et al. (2023).
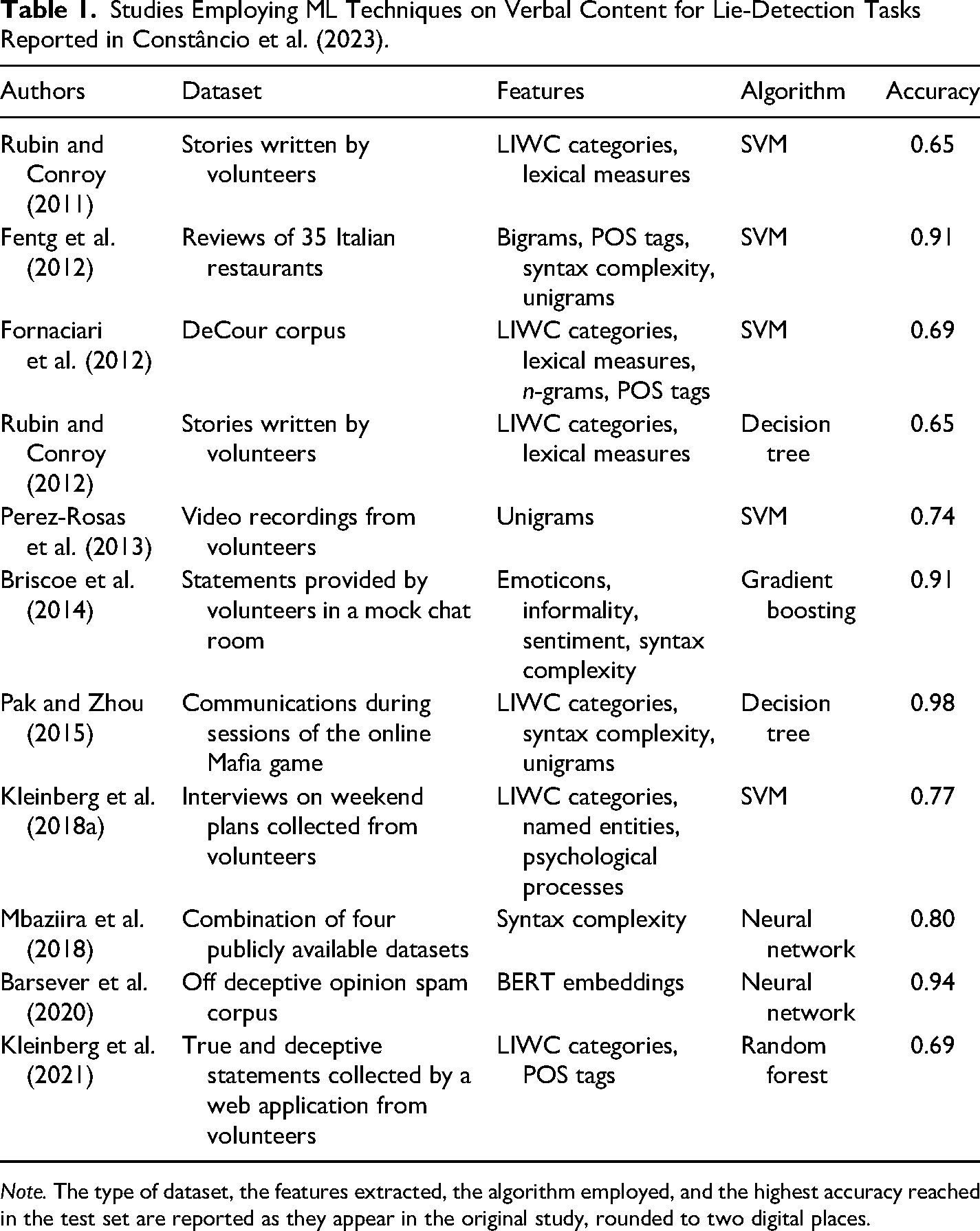
Note. The type of dataset, the features extracted, the algorithm employed, and the highest accuracy reached in the test set are reported as they appear in the original study, rounded to two digital places.
The Current Study
This study examines deception detection through the theoretical lenses of RM and CL in the context of transcripts of interviews with unexpected questions. Through four experiments, this study compared the performances of naïve judges, expert judges trained on RM, and both theory-driven and data-driven ML models in detecting deception, offering critical insights into the relative effectiveness and reliability of each approach.
Specifically, in Experiment 1, we compared the performance of laypeople (i.e., naïve judges) to that of individuals with expertise in the forensic field (i.e., expert judges). Expert judges were trained in the application of RM criteria for lie detection. The main hypothesis (Hypothesis 1a) postulates expert judges achieve higher accuracy than naïve judges because studies have demonstrated RM criteria's effectiveness in distinguishing truth from deception in verbal content (Amado et al., 2016; Gancedo et al., 2021; Vrij, 2008; Vrij et al., 2022).
However, we saw expert judges performing poorly in Experiment 1. Therefore, in Experiment 2, we aimed to investigate the reasons behind this poor performance, trying to disentangle whether it was associated with limitations in the effectiveness of RM when applied to specific datasets or whether the problem relied on experts’ limitations associated with their evaluation and decision-making skills. We employed a computational approach for this purpose. Specifically, four ML models were trained on two sets of RM ratings: those assigned to each transcription by expert judges in Experiment 1 and those provided by leveraging NLP techniques. Three alternative hypotheses were defined for this study:
Hypothesis 2a: Expert judges performed poorly in Experiment 1 because they were poor evaluators. Specifically, expert judges may not effectively assess RM criteria. If this hypothesis is true, a poor performance is expected from ML models trained on expert ratings, similar to that obtained by forensic experts in Experiment 1. Moreover, they are expected to show lower accuracy than those trained on ratings derived through NLP techniques.
Hypothesis 2b: Expert judges performed poorly in Experiment 1 because RM criteria were poorly informative for this type of dataset. If this hypothesis is true, ML models trained on expert and NLP-based ratings of RM are expected to underperform, with an accuracy similar to that obtained by forensic experts in Experiment 1.
Hypothesis 2c: The RM criteria were informative, and expert judges were effective evaluators but may have struggled in effectively combining all the information to derive a final decision. If this hypothesis is true, ML models trained on either expert or NLP-based ratings of RM are expected to outperform the accuracy obtained by expert judges in Experiment 1.
Finally, Experiments 3 and 4 concerned ML models’ performance. Specifically, we examined the effectiveness of theory-driven versus data-driven approaches in feature extraction.
Experiment 3 employed linguistic features from two theoretical frameworks: RM and CL. This procedure was adopted for two reasons: (a) a previous meta-analysis on deception detection indicated that the CL approach yields higher accuracy rates than standard approaches (Vrij et al., 2017); and (b) the dataset under analysis was specifically designed to increase CL in lie-tellers by posing unexpected questions (Monaro et al., 2020).
The first hypothesis for this experiment posits that adding linguistic features associated with the CL framework potentially increases ML models’ accuracy in detecting verbal deception compared to models trained solely on features from RM (Hypothesis 3a).
The second hypothesis postulates that various interview phases (free recall vs. unexpected questions vs. full text) influence ML models’ performance. Specifically, ML models trained on features extracted from unexpected questions (or full text) will yield higher accuracy than those trained on features extracted solely from free speech, based on the assumption that CL features are more prevalent in responses to unexpected questions (Hyp. 3b).
Experiment 4 was designed to explore whether a data-driven approach could surpass the performance of the previous theory-based methods. To this end, NLP techniques to extract a broad set of linguistic features and a data-driven feature selection strategy (Chandril, 2022) were employed to identify a subset of highly informative features. The main hypothesis for this study postulates that a data-driven approach might outperform classical theory-driven approaches, particularly in scenarios in which theory-based methods have already shown limited effectiveness. Specifically, a data-driven method is hypothesized to achieve superior performance by extrapolating rules directly from data rather than relying on general theories (Hypothesis 4a).
Experiments 1–4 altogether allow us to test a final hypothesis for this study, which posits that theory-driven and data-driven ML approaches are expected to outperform naïve and expert human judges in identifying deception (Hypothesis 4b). This hypothesis stems from ML models’ computational ability to integrate and analyze complex datasets more comprehensively than humans.
Experiment 1: Naïve versus Expert Judges
Methods and Materials
Participants
The sample size was determined through an a priori power analysis using G*Power (Faul et al., 2007). For the sample of naïve judges, the results indicated that a sample size of 42 is sufficiently large to achieve a statistical power (1 − β) = 0.8 in a one-tailed Wilcoxon signed-rank test (one sample case), given a significance level α = 0.05 and a medium effect size (d = 0.4; Bond & DePaulo, 2006). Since we had access to a larger sample size, we collected a significantly higher number of participants, establishing a minimum of 10 judges per statement, replicating the original recruiting and evaluation procedure as in Monaro et al. (2022). Therefore, the sample of naïve judges consisted of 121 Italian-speaking participants (75 females). Age ranged from 18 to 62 years (M = 33.92, SD = 12.40), with years of education ranging from 8 to 21 (M = 15.84, SD = 2.40). Participants were volunteers recruited following a snowball sampling procedure. One participant did not complete the task and was excluded from the analysis.
For the sample of expert judges, the results of the power analysis indicated that a sample size of 23 is sufficiently large to achieve a statistical power (1 − β) = 0.8 in a one-tailed Wilcoxon signed-rank test (one sample case), given a significance level α = 0.05 and a medium effect size (d = 0.55; Gancedo et al., 2021). Since having only 23 participants would result in fewer than two expert judgments per stimulus, we decided to expand the sample size to ensure at least three judges for each statement. Therefore, the sample of expert judges resulted in 36 Italian-speaking participants (27 females). Experts were recruited among psychology students attending the Master's course in forensic psychology and among the authors’ professional network. Participation in the study was on a voluntary basis. Age ranged from 22 to 55 years (M = 30.17, SD = 7.77), with years of education ranging from 13 to 21 (M = 18.86, SD = 2.18). Nineteen experts were psychology students, and 17 were practitioners (i.e., psychologists, psychotherapists, psychiatrists, and lawyers). Experts were also asked to specify their level of expertise in forensic psychology via a multiple-choice question: 11.1% had only completed a course in forensic psychology, 27.8% had undergone additional training in the field, 47.2% held a master's degree in forensic psychology, and the remaining 13.9% were currently employed in the field.
All participants provided their informed consent before starting the experiment. The Board of the School of Psychology, University of Padova, approved the experimental procedure.
Dataset
The dataset consisted of 62 videotaped interviews of Italian participants (43 females, age range 20–29, who voluntarily participated in the study) in a low-stake scenario (recalling a holiday experience). The dataset was collected by Monaro et al. (2020) in a previous study and was analyzed to detect deception through blink rate (Monaro et al., 2020) and facial expressions (Monaro et al., 2022).
The dataset comprised 32 participants allocated to the truthful condition and instructed to describe a real holiday experience that occurred within the preceding 12–18 months. Thirty participants were assigned to the deceptive condition and were required to describe an entirely fabricated holiday. Each videotaped interview comprised three distinct phases:
Baseline, in which the interviewee provided their autobiographical information. Free speech, in which the interviewee freely recalled their holiday experience for approximately two minutes. Unexpected questions, in which the interviewer asked unexpected questions about the holiday experience to increase the interviewee's CL (e.g., “Did a particular event occur during the holiday that made it necessary to revise the initial plans?”).
The average length of the videos was 9.56 min. A more detailed description of the dataset is reported in Monaro et al. (2020) and in the Supplementary Material.
Narratives Transcription Procedure
Interviews were manually transcribed verbatim. Then, a linguistic expert checked and modified raw transcriptions, following the guidelines in CLIPS (Savy, 2006). Adaptations tailored for the present study were made to ensure readability for the readers. Regionalisms were substituted with the standard Italian alternative. Hesitations, false starts, and repetitions were transcribed as accurately as possible. False starts were reported with the symbol +, following Savy (2006): “abbiamo spos+, cioè abbiamo trovato” (“we have mov+, I mean we have found”). Pauses were signaled using punctuation. Sentence boundaries, signaled with a full stop and commas, were inserted using the standard Italian rules for punctuation. Hesitations and laughter were reported using standardized formulas (see Table 1S in Supplementary Material).
RM Scoring
Following Sporer (1997, 2004), the RM framework consisted of eight criteria, as outlined in Table 2. Previous research employed three primary units of measurement to evaluate a statement according to the RM criteria: rating scales, categorical measures (presence vs. absence), and frequency/density counts (see Gancedo et al., 2021 for a meta-analytical review on the use of RM in the forensic context). For this experiment, RM criteria were evaluated using a 7-point rating scale (1 = none, 7 = very much). Previous findings showed that frequency counts may offer better performance and reliability than rating scales (Nahari, 2016). However, rating scales present other advantages: they require less training for human raters, are quick to apply, and provide a clear minimum and maximum score, helping the raters understand whether the obtained score falls within a higher or lower range. This is helpful, especially considering that the RM approach does not rely on a standardized cutoff to finally evaluate an account as truthful or deceptive (Amado et al., 2015, 2016). Moreover, using rating scales (or categorical measures) ensures consistency across all RM criteria. Indeed, when we use relative or absolute frequencies, only five out of eight criteria can be scored by frequency (i.e., perceptual information, spatial information, temporal information, affective information, and cognitive operations) whereas three criteria (i.e., vividness, reconstructability, and realism) are commonly evaluated on a rating or a categorical scale (see Table 2). The formula for calculating the overall RM score is reported in formula (1) (Sporer, 2004). The total RM score ranged from 0 to 48, with higher scores indicating higher narrative genuineness.
List of Reality Monitoring Criteria Adapted From Sporer (2004).
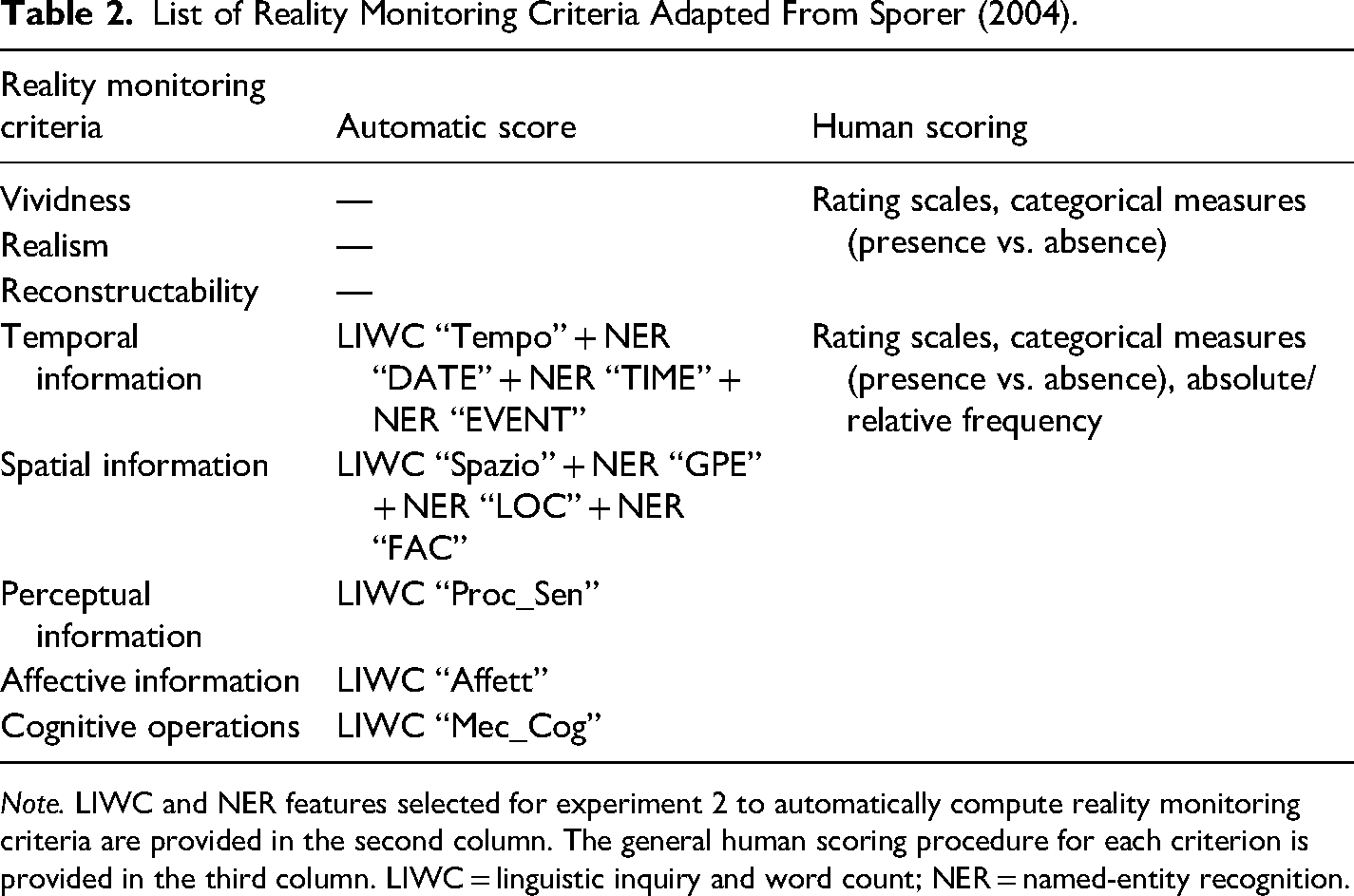
Note. LIWC and NER features selected for experiment 2 to automatically compute reality monitoring criteria are provided in the second column. The general human scoring procedure for each criterion is provided in the third column. LIWC = linguistic inquiry and word count; NER = named-entity recognition.
Experimental Procedure
Twelve questionnaires were created on the Qualtrics platform. The transcriptions of the 62 videoclips were randomly distributed among the 12 questionnaires, as in Monaro et al. (2022), to balance the number of truthful and deceptive transcriptions for each questionnaire. Therefore, each questionnaire consisted of five transcriptions, with the exception of only two questionnaires with six transcriptions.
All participants provided informed consent and demographic information before starting the questionnaire. Moreover, expert judges were assessed for their level of expertise in the forensic psychology field. After providing the instructions, the experimenter randomly gave each participant one of the 12 questionnaires.
Specifically, naïve judges were instructed to read each transcript carefully and to rate its credibility on a 10-point scale (1 = totally fabricated, 10 = totally genuine).
Forensic experts were first trained on the use of RM criteria for lie detection through a video lesson, which explained the theoretical background of the RM framework, the operationalization of the eight criteria and how to compute the final RM score; moreover, it provided two practical examples of application of the RM criteria to transcripts. After the training session, the experimenter remained available to reply to any question the experts had related to the RM procedure. Then, they were randomly assigned one of the 12 questionnaires. For each transcription, they were instructed to carefully read the text, evaluate it based on the eight RM criteria, and compute the overall RM score as in formula (1). Based on the final RM score, they were then asked to rate the transcripts’ credibility on a 10-point scale (1 = totally fabricated, 10 = totally genuine). Other measures were also collected for naïve and expert judges but were not included in the analysis (see Supplementary Material for a detailed description).
Results
Accuracy was first computed at the subject level (i.e., number of correct classifications/total number of transcripts) and then averaged among naïve judges and forensic experts. The random baseline was set using the zero rule (see the Supplementary Material for more information). Nonparametric analyses were conducted after we checked whether the distribution of data violated normality assumptions. Data were preprocessed in Python using the Google Colab interface, and statistical analyses (i.e., Wilcoxon signed-rank and Mann–Whitney U tests) were conducted in RStudio.
The results showed that naïve judges and forensic experts obtained an average accuracy slightly above the chance level (accuracyNJ = 54.1 ± 20.1%, accuracyFE = 59.4 ± 19.9%) in identifying lie-tellers and truth-tellers. However, a Wilcoxon signed-rank test revealed that the naïve judges’ performance was not significantly higher than chance level (V = 3831.00, p = .299, rrb = .05, 95% confidence interval [CI] [−.15, .26]). A Wilcoxon signed-rank test also showed that forensic experts’ performance was not significantly higher than chance level (V = 431.00, p = .061, rrb = .294, 95% CI [−0.07, 0.59]). Contrary to expectations, a Mann–Whitney U test showed also that the forensic experts’ average accuracy was not significantly higher than that of naïve judges (U = 2417.5, p = .134, rrb = .12, 95% CI [−0.10, 0.32]), suggesting there is no enough evidence in favor of Hypothesis 1a. In the Supplementary Material, we report the accuracy the naïve judges and forensic experts reached in each experimental condition (truth-tellers vs. lie-tellers).
Experiment 2: ML Models Trained on Expert Versus Computerized RM Scores
Methods and Materials
Text Preprocessing
Before we extracted linguistic features, two raters manually preprocessed each transcription by removing semantic repetitions (“we left at noon… yes at noon”) and false starts (“What I remember uhm… we went to London.”). Using a two-way mixed-effects model for single measures (Shrout & Fleiss, 1979) with JASP software (JASP Team, 2024), the intraclass correlation coefficient (ICC3,1) was found to be .99 (95% CI [0.98, 0.99]) for repetitions and .98 (95% CI [0.96, 0.99]) for false starts, indicating excellent reliability among raters.
NER and features extraction of the CL were computed after this preprocessing step. For the LIWC scoring, an additional preprocessing step was conducted before the computation and consisted of automatic lowercase and tokenization of text using SpaCy and manual adjustment of bigrams (Italian: “non so,” bigram: “nonso,” English: “I don’t know”) and trigrams (Italian: “al di fuori,” trigram: “aldifuori,” English: “outside”). Word stemming was already included in the LIWC dictionary.
Feature Extraction for RM
In this experiment, the RM criteria were automatically computed for each transcription using the LIWC software in combination with the NER technique.
LIWC is the gold standard software for analyzing word usage to identify psychosocial processes (Pennebaker et al., 2001). It calculates the percentage of words in a text corresponding to more than 80 categories related to linguistic and psychosocial dimensions in a validated dictionary (a detailed description of the functioning of LIWC-15 software and categories is reported in Boyd et al., 2022). Using the Italian dictionary (software version LIWC-15), semantic features related to time, space, affect, sensory processes, and cognition were computed to reflect five of the eight RM criteria. The RM criteria of vividness, reconstructability, and realism are subjective scores that do not fit any LIWC categories (see Table 2) and are therefore often excluded for computation.
NER is an NLP technique to identify and extract information (named entities) from texts and classify them into predefined categories, such as people, locations, organizations, and times. Named entities were automatically extracted using SpaCy, a Python library for NLP, on preprocessed text using a transformer-based model for the Italian language, available in Huggingface (ita_nerIta_trf, [https://huggingface.co/bullmount/it_nerIta_trf]). Table 2S in the Supplementary Material lists all entities available in the ita_nerIta_trf model with their descriptions and examples. Figure 1S in the Supplementary Material depicts a common way to represent text with annotated named entities.
Named entities related to “DATE,” “TIME,” and “EVENT” and ‘“GPE”, “LOC,” and “FAC” were added to the LIWC features related to time (Tempo) and space (Spazio), respectively.
This procedure was adopted because the LIWC software was mainly focused on words with a meaning associated with time and space (e.g., adverbs such as “then” and “now” and verbs such as “to go”) without taking into account specific information about space and time (e.g., toponymies, such as “Ibiza,” and terms indicating time, such as “Monday” and “11am”) that were detected using the NER technique.
Table 2 provides a summary of how the RM features using LIWC and NER scores were computed.
ML Models and Training
Logistic regression, SVM, decision tree, and random forest were employed for the computational analysis, conceptualizing the lie detection task as a binary-classification problem. The inclusion of four ML models was intended to ensure that the obtained results were not dependent on the specific model assumptions and were stable across classifiers. The aforementioned models’ performance was evaluated and discussed in terms of accuracy. A random baseline was set using the zero rule. In the Supplementary Material, we provide a brief description of each model and include additional metrics to add interpretations, such as area under the curve (AUC), precision, recall, and F1 score.
A nested cross-validation (NCV) framework was utilized to evaluate ML models’ performance. NCV is a robust method for model evaluation and hyperparameter tuning in ML, especially in scenarios in which unbiased estimation of model performance is required (Muller & Guido, 2016).
This method incorporated two layers: an inner loop for hyperparameter optimization and an outer loop for model performance evaluation. The inner loop, dedicated to hyperparameter optimization, utilized Grid Search for a systematic exploration of hyperparameter space to identify the optimal hyperparameter combination for each model. This process was repeated across the 10 fold of the inner cross-validation (CV), ensuring that the hyperparameter selection was based solely on the training subset and not influenced by the test data. The best hyperparameter combination identified in the inner loop was then used to train the model on the entire training set of the outer loop. The outer loop then assessed the generalizability of the model with a 10-fold CV.
To enhance the performance estimates’ robustness and reliability, the NCV process was repeated with three random seeds to mitigate the effects of random variations in data partitioning, thus providing a robust unbiased estimation of the model's performance. Following this rigorous procedure, the assessment of the model was safeguarded against overfitting and accurately reflected the model's capability to classify truthful and deceptive statements in our dataset.
Procedure
Figure 1 depicts the steps adopted to conduct the computational analyses in this experiment. Specifically, ML models were trained on two sets of ratings. For the first set, the scores the three experts provided in Experiment 1 for the eight RM criteria were averaged for each story. This resulted in a vector of eight scores per story, which was then used to train the ML models with an NCV procedure. For the second set, the RM features were extracted using NLP techniques following the procedure described in section “Feature Extraction for RM.” This resulted in a vector of five scores per story, which was employed to train the ML models with an NCV procedure.
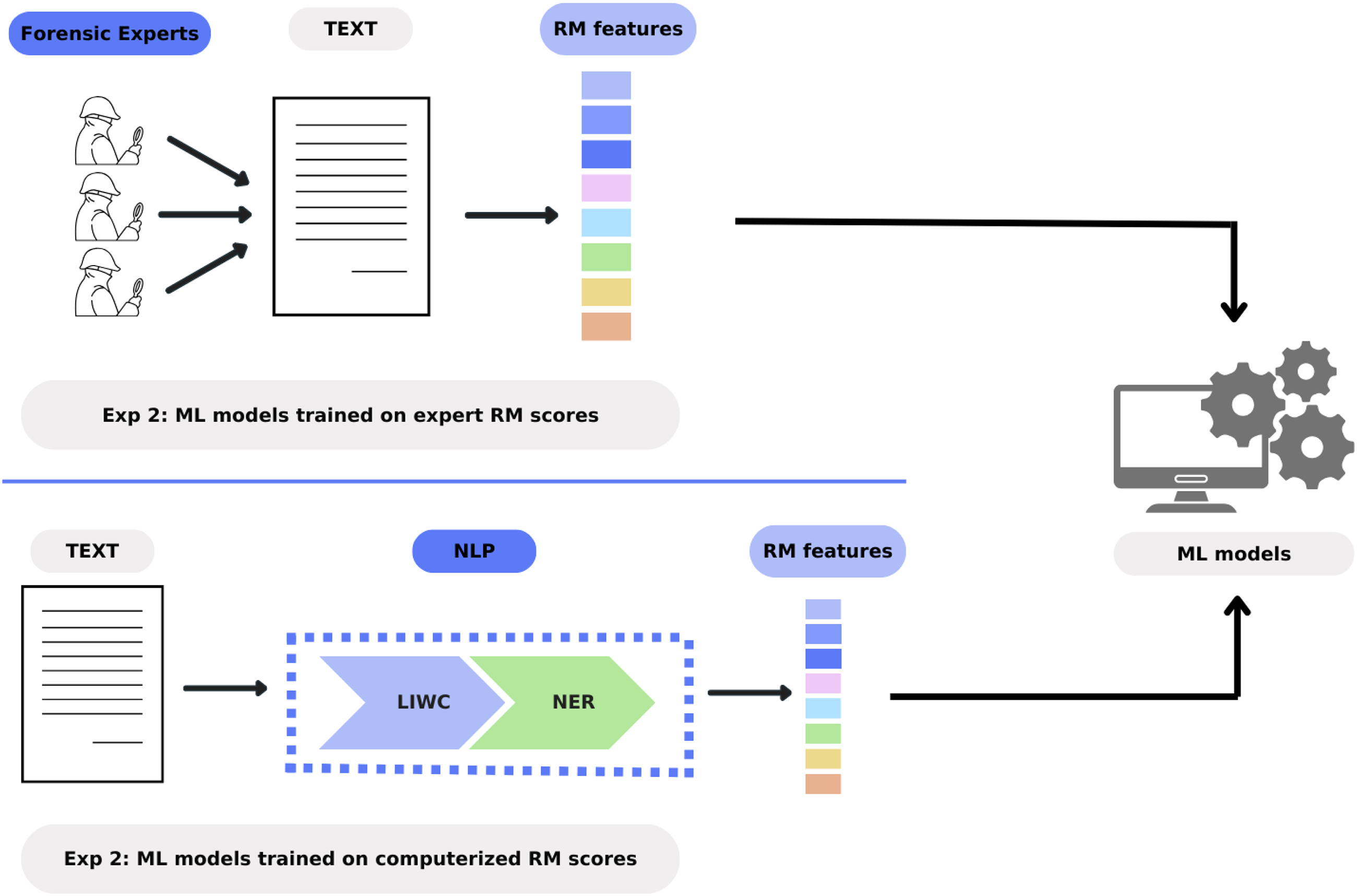
Procedure employed in Experiment 2 to obtain two sets of features to train ML models.
Results
Table 3 provides the results of Experiment 2. Table 3S (in the Supplementary Material) reports the average performance and standard deviation in terms of accuracy, AUC, precision, recall, and F1 score obtained from the four ML models when they are trained on expert ratings of RM and computerized RM applied to full text.
ML Models’ Performance is Reported in Terms of Average Accuracy in the 10-Fold Nested Cross Validation.
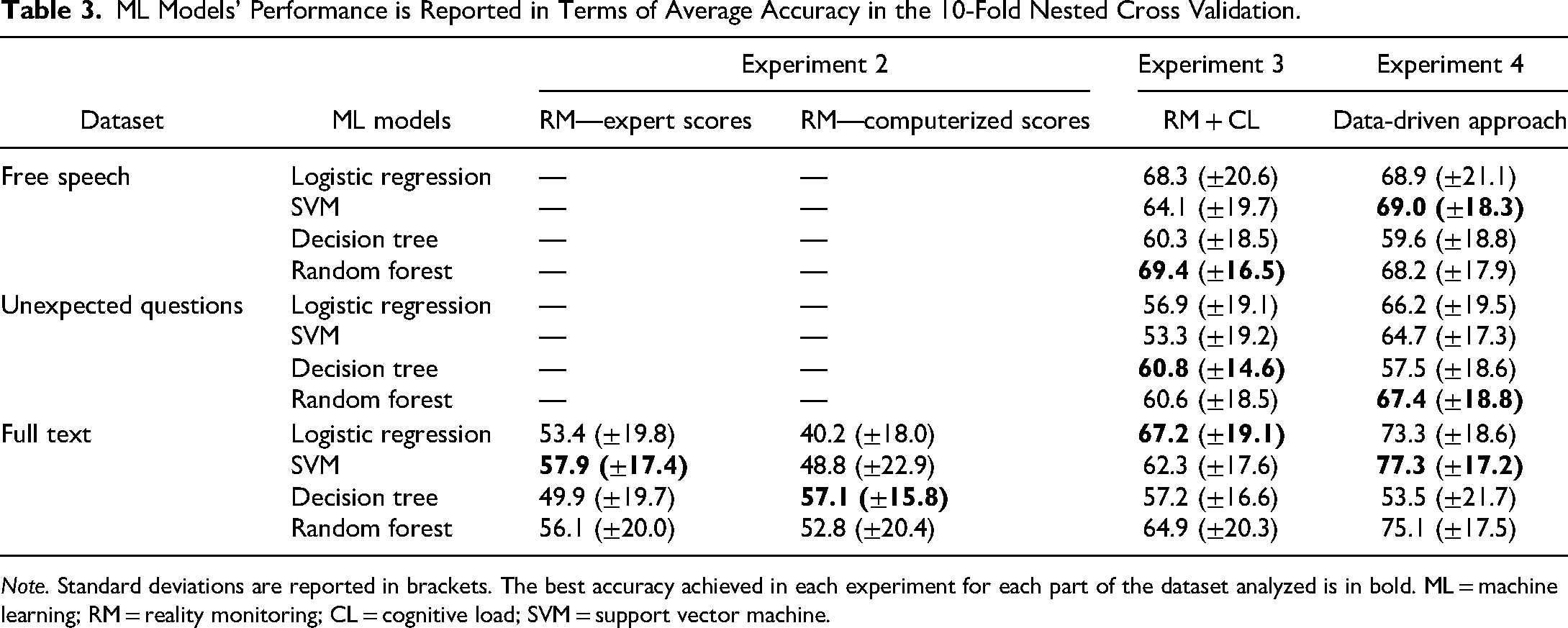
Note. Standard deviations are reported in brackets. The best accuracy achieved in each experiment for each part of the dataset analyzed is in bold. ML = machine learning; RM = reality monitoring; CL = cognitive load; SVM = support vector machine.
When we used expert ratings of RM, the SVM and random forest models produced the highest average accuracy, 57.9% (±17.4) and 56.1% (±20.0), respectively. However, these performances were only slightly above chance level. Similarly, when we used computerized RM scores, the decision tree model exhibited the highest average accuracy, 57.1% (±15.8), but also this performance was just slightly above chance level. A Kruskal–Wallis test showed that the average accuracy of forensic experts from Experiment 1 was not significantly different from those of the best ML models trained with expert and computerized RM scores in Experiment 2 (H(2) = 0.006, p = .997, η2(H) = 0, 95% CI [0, 0.05]). These findings support the second hypothesis (Hypothesis 2b), namely that expert judges performed poorly in the lie detection task because the RM criteria were poorly informative for this type of dataset.
Experiment 3: Theory-Driven Approach Combining RM and CL
Methods and Materials
Feature Extraction for CL
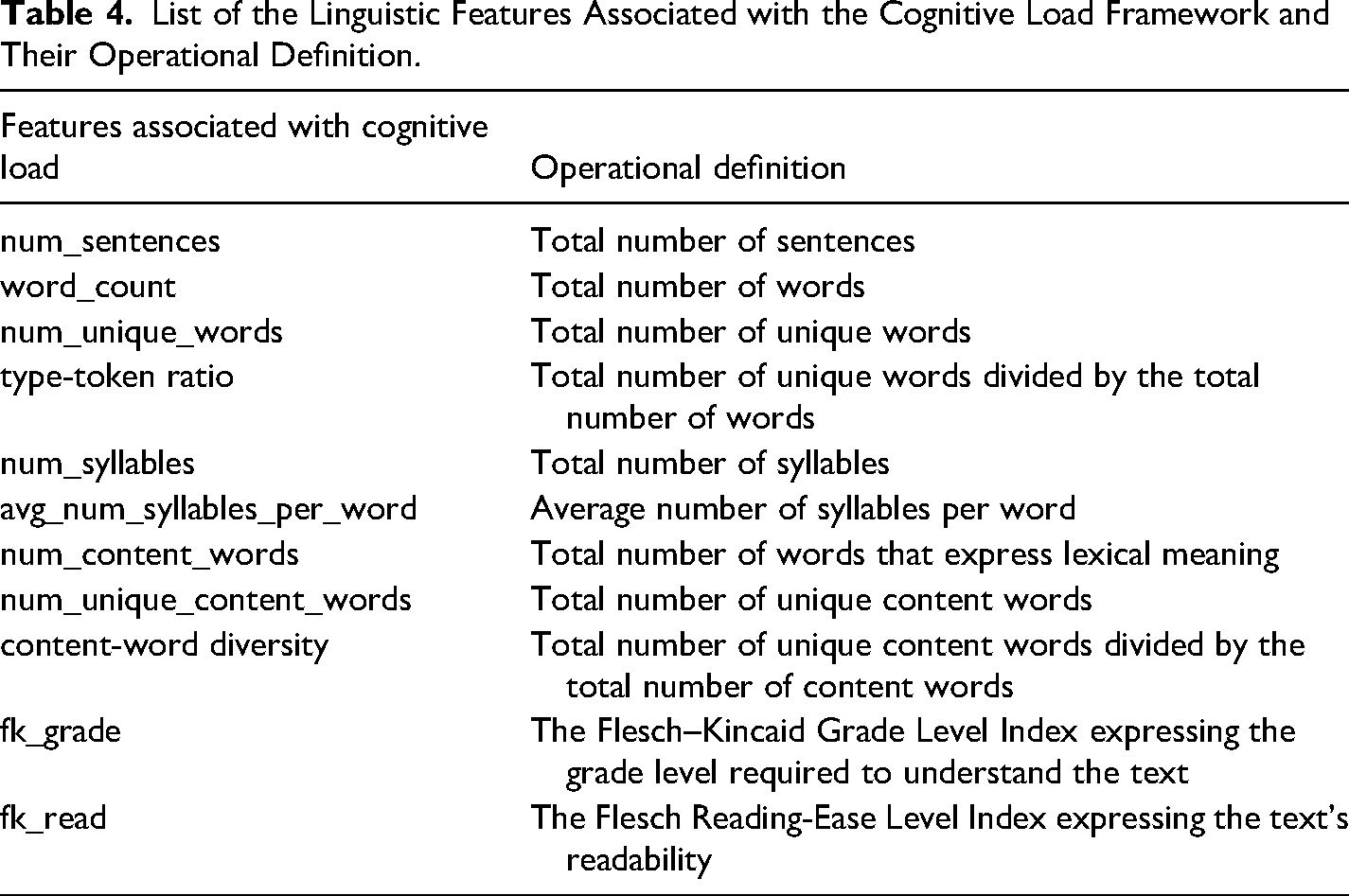
Previous research employed statistics regarding the text's length, readability, and complexity to extract linguistic features associated with CL in deception studies (Hauch et al., 2015; Pérez-Rosas & Mihalcea, 2015; Sarzynska-Wawer et al., 2023; Solà-Sales et al., 2023; Zhou et al., 2004). Statistics associated with CL were automatically computed on preprocessed text using the Python library TEXTSTAT and are reported in Table 4.
List of the Linguistic Features Associated with the Cognitive Load Framework and Their Operational Definition.
Procedure
Figure 2 depicts the procedure adopted for the computational analyses in Experiments 3 and 4. Specifically, the dataset was first split into three sections: (a) Free Speech, which contained the transcription of the free recall of the holiday; (b) Unexpected Questions, which contained the responses to unexpected questions; and (c) Full Text, intended as the combination of text from the Free Speech and Unexpected Questions sections. Then, linguistic features associated with RM and CL were automatically extracted following the procedure defined in sections “Feature Extraction for RM” and “Feature Extraction for CL.” Subsequently, the same ML models and NCV procedure employed in Experiment 2 were applied to each section of the dataset.
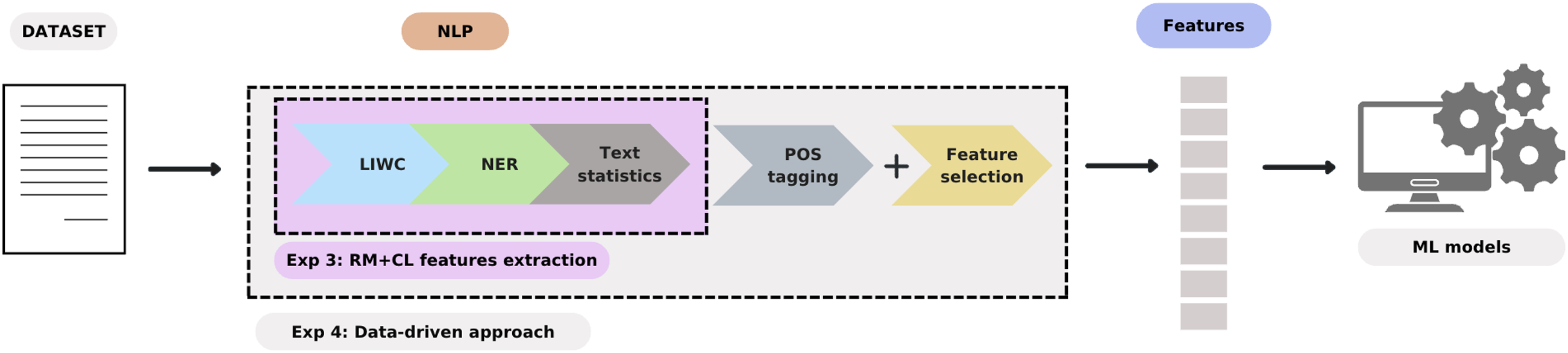
Procedures employed in Experiments 3 and 4 to create a set of linguistic features to feed ML models.
Results
Table 3 reports the results from this experiment (see also Table 4S in the Supplementary Material). Considering the four ML models trained on linguistic features extracted from the Full Text dataset – using the RM and CL frameworks – we observed a general increase in the obtained predictive performance. In fact, after combining features from two theoretical frameworks, we reached an accuracy of 69.4% (±16.5), with an improvement of up to 9.3% over models trained solely on expert or computerized RM scores. The results show that the inclusion of linguistic features associated with the CL framework resulted in enhanced accuracy of ML models in detecting verbal deception compared to models trained solely on features from RM, confirming our hypothesis (Hypothesis 3a).
Additionally, features from RM and CL were specifically extracted from statements in the Free Speech, Unexpected Questions, and Full Text sections to investigate their potential informative and predictive role. Findings comparing the performance obtained from ML models trained on each section showed that linguistic features from the Free Speech section significantly contributed to an increase in overall accuracy across the four models. Contrary to our expectations (Hyp. 3b), linguistic features from the Unexpected Questions section yielded lower accuracy rates, similar to those achieved by models trained exclusively on expert and computerized RM scores. Interestingly, when we leveraged the Full Text section for feature extraction, there was a slight decline in performance, with the highest average accuracy recorded at 67.2% (±19.1).
Experiment 4: Data-Driven Approach Using NLP Features
Methods and Materials
Feature Extraction and Selection
This experiment involved the extraction of a comprehensive set of 128 linguistic features, using a combination of NLP techniques on preprocessed texts. The Python library TEXTSTAT was employed to compute 11 basic textual features related to the text's length, readability, and complexity, as in Experiment 3. The LIWC software was employed to extract 85 psychological, linguistic, and affective dimensions from texts. The Python SpaCy library was employed to extract 15 named entities (with the NER technique) and 17 grammatical and syntactical parts of speech (with the POS-tagging technique) in the text.
Using the scikit-learn library in Python, the original set of 128 features was narrowed down to a more manageable and informative set of 20 features that best captured the nuances of the textual data, following these steps:
Removing POS features unrelated with the purpose of the task, such as the number of spaces (using spacebar; SPACE), punctuation usage (PUNCT), the number of symbols (SYM), and other noncanonical POS tags (X); those features were more related to the transcription process than to telling a truthful or a deceptive story and could represent a confounder if included in the analysis. Removing duplicates, such as the numerical features in LIWC and POS tagging that were already detected with the NER technique and the LIWC “Non_flu” category, which was a duplicate of the POS tag “INTJ.” Removing LIWC linguistic features overlapping with the grammatical and syntactic features extracted with the POS-tagging technique given that the latter is more efficient and complete in extracting these features than the LIWC software. Feature-engineering a new variable named “fillers” by summing filler words and nonfluencies, typical of hesitation and oral speech patterns, extracted with the LIWC software and the POS tagging. Specifically, the LIWC “riempiti” category was added to the POS tag “INTJ.” Removal of features that showed more than 60% of zero values across the dataset. Selection of the best 20 features after testing for mutual information, which measures the linear and nonlinear dependency between random variables, ensuring that each selected feature contributed significantly to the predictive models (Ross, 2014). This selection process was performed using the function sklearn.feature_selection.SelectKBest (Pedregosa et al., 2011).
Procedure
Figure 2 depicts the procedure adopted for the computational analyses in Experiments 3 and 4. As in Experiment 3, the dataset was first divided into three sections (i.e., Free Speech vs. Unexpected Questions vs. Full Text). Then, following the feature-extraction and -selection process described in the previous section, four ML models were trained using an NCV procedure on the best 20 linguistic features from each section of the dataset. The ML models and the NCV procedure are described in section above called “ML Models and Training.”
Results
Data-Driven Approach
The data-driven approach demonstrated an overall improvement in performance compared to Experiment 3 (Table 3; see also Table 5S in Supplementary Material), providing evidence in support of the superior performance of data-driven approaches compared to theory-driven approaches (Hypothesis 4a). Specifically, the Full Text section showed a significant leap in accuracy, particularly with the SVM, which reached the highest accuracy (77.3 ± 17.2%). The Unexpected Questions section, despite being the section with the lower performance, showed a noticeable improvement in accuracy, with the random forest model performing, the best, at 67.4% (±18.8). In the Free Speech section, the SVM achieved the highest accuracy, 69.0% (±18.3), but it did not surpass the performance of the best model trained with RM and CL in the same section.
Comparing Accuracy Among Experiments
Figure 3 presents the accuracy achieved by human judges and the best ML models in each experiment. A Kruskal–Wallis test revealed a statistically significant difference in the average accuracy scores across experiments (H(5) = 39.21, p < .01, η2(H) = 0.13, 95% CI [0.07, 0.24]). Dunn's post-hoc tests with false-discovery rate correction were applied to assess differences between pairs of conditions. Notably, the average accuracy of the best ML model trained on RM and CL features was significantly higher than the average accuracy achieved by naïve judges (z = 3.92, p < .01) and forensic experts (z = 2.39, p = 0.017) in Experiment 1. Similarly, the average accuracy of the best ML model trained on features extracted with a data-driven approach was found to be significantly higher than the average accuracy reached by naïve judges (z = 5.47, p < .001) and forensic experts (z = 3.67, p < .01) in Experiment 1. Table 6S of the Supplementary Material presents also the remaining post-hoc comparisons. These findings support our last hypothesis, proving that theory-driven and data-driven approaches leveraging ML and NLP techniques are more effective in detecting verbal deception than human judges (Hypothesis 4b).
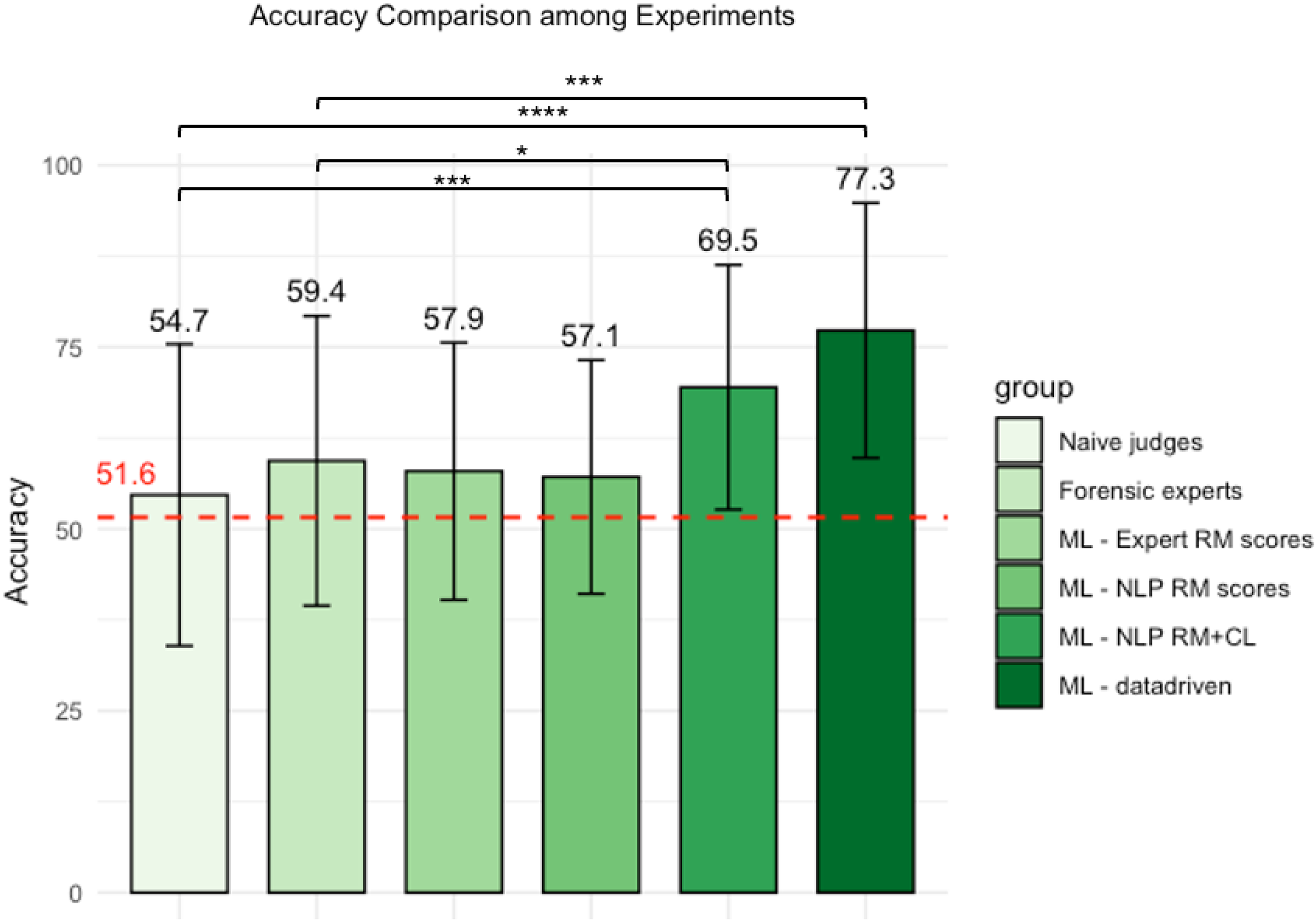
Bar plot of the average accuracy (and standard deviation) obtained from the four experiments.
General Discussion
This series of studies contributes to deception detection research by examining the theoretical frameworks of RM and CL through computational methods, advancing our understanding of how these frameworks function in the analysis of deceptive language. In addition, through four experiments, we assessed the effectiveness of human (naïve vs. experts) and ML-based (theory-driven vs. data-driven) approaches in deception detection when applied to a dataset of interviews with unexpected questions.
In the first experiment, we tested the RM framework by comparing the performance of naive and expert judges, with the latter trained specifically in RM criteria. Neither naïve judges nor forensic experts surpassed the chance level (accuracyNJ = 54.1 ± 20.1%, accuracyFE = 59.4 ± 19.9%). Additionally, the average accuracy of forensic experts was not significantly higher than that of naïve judges. Although this result was expected for naïve judges and aligns with previous studies (Bond & DePaulo, 2006; Curci et al., 2019; DePaulo et al., 2003; Pérez-Rosas & Mihalcea, 2015), it was contrary to expectations for forensic experts (Hypothesis 1a). In fact, previous research proved the effectiveness of RM criteria in verbal-deception detection, reaching approximately 70% accuracy (Amado et al., 2016; Gancedo et al., 2021; Vrij, 2008; Vrij et al., 2022). Additionally, a meta-analysis of studies showed that the average accuracy that we can obtain after following different cues is 67% (Hartwig & Bond, 2014).
To address the reasons behind this poor performance of experts in experiment 1, we introduced a second experiment that leverages computational techniques and ML models. ML models were trained on two sets of ratings, those given by expert judges using the RM criteria (i.e., expert ratings) in Experiment 1 and those obtained by computerized methods using NLP techniques for RM (i.e., computerized ratings), to determine whether naïve experts’ poor performance was due to an inaccurate assessment of RM criteria, a lack of informativeness of those criteria for this dataset, or a decision-making problem in combining all the information. Our findings showed that the average accuracy of forensic experts was not significantly higher than those of the best ML models trained on experts (accuracy = 57.9 ± 17.4%) or computerized ratings of RM (accuracy = 57.1 ± 15.8%), supporting the hypothesis that RM criteria might be poorly informative for the dataset under analysis, regardless of whether they were evaluated by forensic experts or derived from computational methods (Hypothesis 2b).
The results of Experiments 1 and 2, collectively, challenged the presumed robustness of RM in deception detection and raises questions about its sensitivity across different datasets and contexts.
Furthermore, these results challenge the efficacy of computational approaches built on theoretical frameworks that ultimately exhibit limited effectiveness, as demonstrated in this case with the RM.
Considering these premises, we tested in a third experiment whether the combination of multiple theoretical frameworks, specifically the RM and CL frameworks, could enhance ML models’ accuracy in detecting verbal deception (Hyp. 3a). The results from Experiment 3 demonstrated that the combination of features from two theoretical frameworks resulted in an accuracy of 69.4% (±16.5), with an improvement of 9.3% compared to models trained solely on expert or computerized RM scores. Furthermore, the average accuracy of the ML model trained on RM and CL features was significantly higher than the average accuracy that naïve and expert judges achieved in Experiment 1. This finding may be attributed to the fact that the dataset under analysis was specifically designed to increase CL in lie-tellers by posing unexpected questions (Monaro et al., 2020, 2022) and to the inherently higher accuracy of the CL approach (Vrij et al., 2017). Alternatively, the simple inclusion of a higher number of relevant features might have led to this higher accuracy.
Because CL features were more prevalent in responses to unexpected questions, we hypothesized that ML models trained on features extracted from Unexpected Questions would yield higher accuracy than those trained on features extracted from Free Speech (Hypothesis 3b). Contrary to this hypothesis, the results indicated that linguistic features derived from the Free Speech dataset significantly contributed to an increase in overall accuracy across all models. Linguistic features derived from the Unexpected Questions dataset yielded lower accuracy, similar to that achieved by models trained exclusively on expert and computerized RM scores. Notably, when we employed the Full Text dataset for feature extraction, performance slightly declined, with the highest average accuracy recorded at 67.2% (±19.1). One possible interpretation of this result is that the extraction of linguistic markers useful for the detection of deceptive narratives is more effective with longer texts, as in the Free Speech and Full Text datasets.
Finally, when NLP techniques are used, various methodologies are available for extracting features from textual data, such as theory-driven, data-driven, and hybrid approaches (Van Der Zee et al., 2022). Although in forensic contexts hybrid models should be preferred to data-driven models given that data-driven models may be effective at predicting but ineffective at explaining, studies have proven a lower effectiveness of hybrid approaches compared to data-driven models (Van Der Zee et al., 2022). Therefore, in the fourth experiment, we investigated the performance of a data-driven approach in this lie detection task and compared the results with those of previous experiments. Specifically, comparisons from Experiments 3 and 4 allow us to examine the effectiveness of theory-driven versus data-driven approaches. NLP techniques were employed to extract a broad set of linguistic features, and a data-driven feature-selection strategy (Chandril, 2022) was employed to identify a subset of highly informative features.
The results from Experiment 3 showed that training ML models on combined linguistic features from two deception frameworks (i.e., RM and CL) yielded higher but moderate accuracy (best_accuracyfreespeech = 69.4 ± 16.5%). However, in Experiment 4, there was a significant leap, particularly with the SVM, which reached the highest accuracy (best_accuracyfulltext = 77.3 ± 17.2%). This performance was also significantly better than that of naïve judges and forensic experts (Experiment 1). These findings underline the efficacy of a data-driven approach in discerning patterns in comprehensive textual data compared to theory-driven approaches that combined linguistic features derived from the RM alone or in combination with the CL framework. We confirmed our hypothesis that a data-driven approach may be particularly relevant in contexts in which theory-based methods have demonstrated limited effectiveness (Hypothesis 4a). Indeed, while previous studies have shown that RM typically achieves around 70% accuracy in distinguishing truth from deception (Vrij, 2008), it yielded lower accuracy in our study (from around 57% to 59%). In contrast, our data-driven NLP approach surpassed the expected 70% accuracy, suggesting that it could serve as a reliable alternative in cases where traditional and theory-based methods, like RM, fall short.
Most importantly, the results from Experiments 1–4 suggest that training ML models on features extracted using NLP techniques may represent a more advantageous approach in detecting deception from narratives, overcoming the modest accuracy achieved by naïve and expert judges because of their ability to handle complex patterns of language data (Hypothesis 4b). Moreover, they could help identify which linguistic features are more informative to derive a final decision.
Limitations and Future Perspectives
Although this study's results highlight significant advancements in the field of deception detection with the comparison of human judgments to computational predictions, several limitations must be acknowledged to properly contextualize the results and guide future research.
First, the reliance on a relatively small dataset significantly constrains the findings’ generalizability. The dataset, comprising only 62 narratives and solely in Italian, limits our ability to confidently extend these results to broader and more heterogeneous contexts. Future studies replicating our experiments using larger and more varied datasets in different languages would enhance our findings’ robustness and potentially reveal cultural and linguistic nuances in deception detection. Additionally, the dataset under analysis was designed to collect outright false statements. However, a more frequent and ecological form of deception is constituted by embedded lies (Caso et al., 2023; Verigin et al., 2019), where people interwire truth and lies together. As a consequence, the detection rates found in our series of studies may be even lower when considering this type of deception.
Second, forensic experts assessed the RM criteria on a 7-point scale to judge the narratives’ veracity. However, other approaches are available in the literature. For example, one approach involves evaluating the absence and presence of each criterion on a 3-point scale (0 = absent, 1 = partially present, 2 = totally present), and another counts the frequency of details for at least five of the eight criteria. This study's results provide insights limited to the qualitative assessment of RM criteria on a 7-point scale and may not be generalizable to methodologies utilizing frequency of details. Future research could employ a different approach for RM assessment, for instance, by taking into account the frequency of details.
Third, by focusing exclusively on specific deception cues, such as those provided by the RM criteria, people may overlook other potentially informative cues. For instance, details’ verifiability plays a crucial role in deception detection. The verifiability approach suggests that truth-tellers provide details that are more verifiable and a higher proportion of verifiable details (Nahari et al., 2014; Palena et al., 2021; Verschuere et al., 2021). Accordingly, a recent study showed that asking judges to assess narratives for their verifiability rather than their veracity yields higher accuracy, up to 70% (Verschuere et al., 2023). In our study, forensic experts may have underperformed relative to ML models because they employed an ineffective heuristic, as also evidenced by the results from Experiment 2, which demonstrated the RM's limited informativeness in assessing our dataset's veracity. Our research can therefore be extended by asking forensic experts to use different deception cues, such as assessing details’ verifiability and using criteria-based content analysis (Steller & Koehnken, 1989).
Lastly, we found that a data-driven approach yielded the highest accuracy when testing the models using NCV. However, it is essential to recognize the limitations of these results, especially considering the potential impact of error rates in forensic contexts. Although our model achieved a significant improvement, the approximate 30% error rate remains a concern, particularly given the serious implications of misclassification in legal settings where credibility assessments can influence case outcomes. These findings underline the need for continued research and refinement of NLP and ML methods to improve reliability in high-stakes applications. Indeed, there is substantial room to explore more sophisticated ML approaches in future studies. For example, techniques such as word embeddings offer a promising avenue for future research. Word embeddings provide a way to capture semantic relationships between words by representing them in a high-dimensional space (Lai et al., 2016), thereby uncovering subtle linguistic patterns associated with deceptive speech that traditional models do not capture. Moreover, using neural-network architectures, such as long short-term memory networks and transformers, would allow future research to process sequential data more effectively, potentially achieving higher accuracy in models trained on textual data. Finally, fine-tuning large language models has also been proven to be effective in detecting deception in raw texts (Loconte et al., 2023).
However, a significant limitation of data-driven approaches is their lack of explainability, which is particularly relevant in forensic settings, in which understanding the rationale behind an algorithm's decision is as crucial as the decision itself. Although data-driven methods can efficiently identify patterns, make predictions, and sometimes explain which specific linguistic features contributed to those predictions, these outputs often are not easy to interpret. This opacity makes it challenging to align these findings with general theories of memory and deception, which is necessary for forensic credibility. Ensuring that computational techniques not only predict but also explain their predictions in terms that relate to established psychological theories will be essential for their acceptance and ethical application in legal contexts.
Overall, these future perspectives suggest a trajectory toward more integrated and sophisticated systems that leverage a combination of theoretical insights and cutting-edge ML techniques. By broadening the theoretical frameworks and enhancing the computational methods used in deception detection, researchers can provide more accurate, reliable, and explainable tools for forensic and other critical applications. This progression promises not only to advance the understanding of deception but also to enhance practical lie detection capabilities in real-world settings.
Conclusion
To conclude, experimental results from four experiments provided theoretical and practical considerations for advancing verbal deception detection research.
From a theoretical perspective, the exploration of multiple theoretical frameworks, such as RM and CL, through computational methods, has demonstrated the potential to enhance accuracy in identifying deceptive narratives and calls for the fusion of more diverse theoretical perspectives to offer more robust tools for deception detection, especially when one framework alone falls short. From a practical perspective, the integration of computational methods in deception detection holds significant implications in forensic contexts when credibility assessment is required in criminal proceedings. Potentially, computational methods may aid forensic experts when they perform only slightly above chance level, even after being trained on well-established frameworks.
However, the ethical implications of deploying computational methods in such sensitive settings are significant. Ethical considerations must include discussions on the transparency of the algorithms used (Von Eschenbach, 2021; Zerilli et al., 2019), the potential for overreliance on automated systems without adequate human oversight, and the need for ongoing evaluation of these systems’ efficacy and fairness, especially when they influence judicial outcomes. Although our results were modest in Experiment 3 compared to those of Experiment 4, we highlight the importance of employing hybrid approaches that combine data-driven and theory-driven methodologies. Such approaches would provide a more explainable model, which is crucial in forensic contexts in which the reasoning behind decisions must be transparent and justifiable.
The results of this series of studies suggest the need for future studies aimed at integrating advanced computational techniques into the field of lie detection as well as providing transparent algorithms for the interpretation of the results in the forensic context.
Supplemental Material
sj-docx-1-jls-10.1177_0261927X251316883 - Supplemental material for Detecting Deception Through Linguistic Cues: From Reality Monitoring to Natural Language Processing
Supplemental material, sj-docx-1-jls-10.1177_0261927X251316883 for Detecting Deception Through Linguistic Cues: From Reality Monitoring to Natural Language Processing by Riccardo Loconte, Chiara Battaglini, Stéphanie Maldera, Pietro Pietrini, Giuseppe Sartori, Nicolò Navarin and Merylin Monaro in Journal of Language and Social Psychology
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.