
Abstract
This article explores in depth various sandhi (joining) rules in Kerala’s Malayalam language, which play a vital role in framing of the inflected and agglutinated forms of words and their compounds. It discusses significant progress in a scientific method to generate a specific annotated data set of Malayalam words that would be useful in many Natural Language Processing tasks which involve Malayalam preprocessing. The article discusses the results and issues encountered in developing this word-splitting tool for Malayalam, mainly in the context of improving the alignments between parallel texts that form a core resource in the Machine Translation task.
Keywords
Introduction
Derived from Sanskrit, the technical term sandhi (‘joining’) refers to the modification of the sound of a morpheme, which could be a word or an affix, conditioned by syntactic context. A simple example would be the use in English of ‘an affix’, rather than ‘a affix’. Highly complex sandhi rules exist in the Indo-Aryan and Dravidian languages of South Asia. Kerala’s Dravidian state language Malayalam, which contains many Sanskrit words, uses compound structures which are frequently formed through repeatedly joining suffixes into Malayalam stems, applying complex grammatical rules. This intensively agglutinative nature of Malayalam poses a major challenge in many Natural Language Processing (NLP) tasks that involve preprocessing of Malayalam text.
An earlier study, reporting on a pioneering project aimed at building a morphological processor for Malayalam, indicated the possibility of developing a sandhi processor (Idicula & David, 2007: 185). The word sandhi in Malayalam means ‘joining in a suitable way’ and sandhi rules, as a special category of Malayalam grammar, play a significant role in the process of framing suffix-separated words. When certain syllables are joined using sandhi rules, some insertions and deletions of characters are inevitable. As these rules play such a vital role in framing the inflected and agglutinated forms of words in Malayalam, knowledge about them helps to understand methods of splitting as well as joining words, taking advantage of rules applied both in forward and backward direction.
A rule applied to split a word in Malayalam based on a particular sandhi can be applied in the reverse order to form the same word in the inflected form. The two terms related with aksharam (syllable) in Malayalam are varnavikaaram (change in phonemes) and sandhi. Many changes happen when two varnams (phonetic syllables) are combined. Malayalam grammar teaches that there are two ways by which words are joined, termed as samhitha (സംഹിത) and sandhi (സന്ധി) (Varma, 2006). Samhitha means joining words without bringing in changes in the syllables. Words like വനംകള്ളൻ (vanamkallan) and പനനാര് (pananaru) are two examples of samhitha. Malayalam words like തലക്കനം (thalakkanam) and പനയോല (panayyola) are examples of words joined using sandhi by bringing in changes in the syllable.
Suffix separation plays a vital role in improving the quality of training in the Statistical Machine Translation (SMT) from English into Malayalam (Sebastian & Kumar, 2010). SMT work on highly inflected languages has always promoted morphological analysis of the source language and has shown remarkable improvement when the input to the translational model is subjected to morphological analysis (Goldwater & McClosky, 2005; Lee, 2004). The morphological richness and prominent agglutinative nature of Malayalam make it necessary to retrieve the root word from its inflected form in the training process. Improvement in SMT using a morphological–lexical language model as discussed by Sarikaya and Deng (2007) may be applied in English to Malayalam SMT by embedding the Malayalam corpora with suffix-separated words. A method to convert the Malayalam text into a suffix-separated Malayalam text using the knowledge of sandhi rules defined in Malayalam grammar is presented and discussed in this article.
Usually in machine translation, the words that are joined using sandhi have to be preprocessed to match their English equivalent. This is quite essential in setting the proper alignments between English and Malayalam phrases in the parallel corpus that is subjected to the training process in the translational model (Sebastian et al., 2010). Words like കേരളത്തിൽ (keralathil), കേരളത്തിലും (keralathilum), കേരളത്തിനോട് (keralathinodu) and കേരളത്തിലൂടെ (keralathiloode) are examples of Malayalam words that have to be aligned with various forms of English phrases like ‘in Kerala’, ‘also in Kerala’, ‘to Kerala’ and ‘through Kerala’, respectively. Knowledge of the inflections associated with a Malayalam word and the regular use of suffixes makes it easy to set up an appropriate alignment with its equivalent phrase in the peer English sentence.
Another aspect discussed in this article is a method that helps to develop a data set of Malayalam words annotated with suffix rule category. Data set generation method is designed as a recurrently upgrading process that refines the auto-generated rule sets with the help of manual intervention. A list of suffix words and root words in Malayalam are obtained as byproducts of this process. The data set developed in this way can be subjected to any supervised machine learning model and the sandhi rules associated with new Malayalam words can then be predicted. The scope of this work is spreading in various directions, such as improving ongoing work in NLP applications of Malayalam like machine translation, text summarisation and the development of a morphological analyser (Idicula & David, 2007), as well as developing a full-fledged suffix separator tool for Malayalam language learners.
After this introduction, the article first discusses some existing work in this field and then provides a brief overview of the different classifications of sandhi rules in Malayalam grammar. The methodology comprising of data set generation phase and machine learning phase is then explained, and the rule set identification process for annotating Malayalam words is discussed, before the final section highlights the results obtained, exceptions and observations made in the work, and concludes the study.
Related Research
Much work in the field of morphological analysis in Malayalam has been reported (Idicula & David, 2007) but a mature study on suffix separation has not yet been produced and a full-fledged suffix separator for Malayalam is still an open area of research. Sebastian (2010) attempted to classify the sandhi rules based on the Malayalam syllable preceding the suffix present in the inflected form word, and refers to some earlier studies. A rule-based approach for root word identification is discussed by Subhash et al. (2012). A sandhi splitter using Memory Based Language Processing is presented by Nisha and Reghu Raj (2016). Another rule-based system for splitting compound words in Malayalam is discussed in Nair and Peter (2011), and a sandhi-rule-based compound word generator has been reported by Kleenankandy (2014). All these projects have not been mature enough yet to produce a reliable suffix separator tool in Malayalam. The difficulty and complexities in analysing the sandhi rules of Malayalam grammar and the challenge of generalising them in a machine-acceptable form may be one of the reasons for this. The present article aims to produce an annotated Malayalam data set of sandhi rules through a feedback system that continuously upgrades it and furnishes it as an input to any machine learning algorithm for predicting results of unseen Malayalam words.
Sandhi Rules in Malayalam
As defined in Malayalam grammar, sandhi rules are classified into three classes, based on the following parameters (Aroor, 2015):
Sandhi Class-Type 1: Syllable and its joining position. Sandhi Class-Type 2: Syllable and its type (swaram/vyanjanam). Sandhi Class-Type 3: Syllable and its resulting changes.
The details about these three types of Sandhi Classes are provided in Tables 1–3, respectively. The Sandhi Class-Type 3 is related with Type 2 in various ways. These relations between Type 2 and Type 3 classes are demonstrated in Table 4.
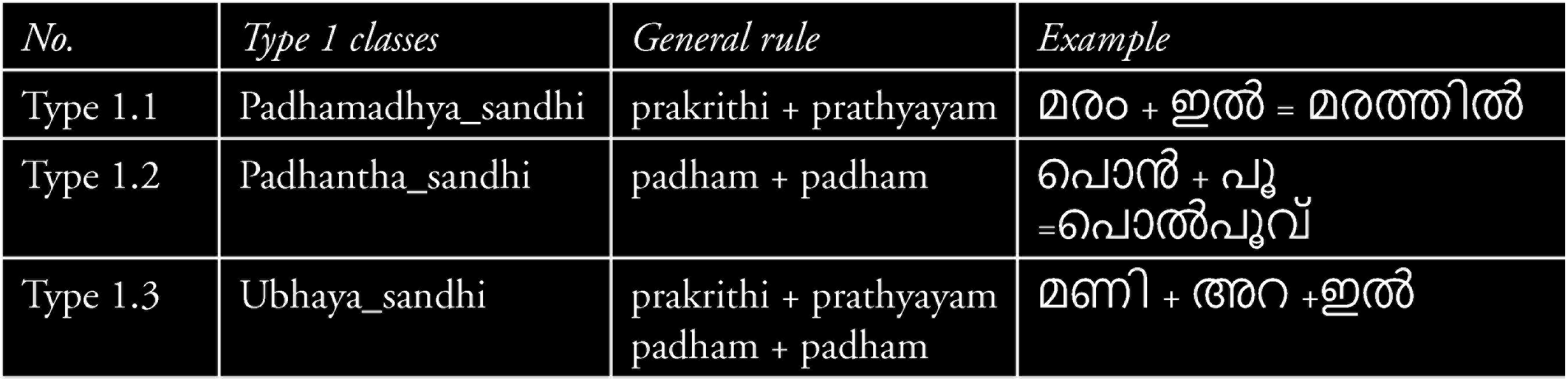
Sandhi Class-Type 1 is a classification based on the position where the fusion happens whether it is in the middle position or at the end, or in both ways. Type 1.1 happens when a meaningful word formed from a group of characters (prakrithi) fuses with a portion that is joined at the end of a word, a suffix (prathyayam). The word padham stands for a word obtained when prakrithi fuses with prathyayam. Sometimes, certain other words or components, termed idanila, may be used to join prakrithi and prathyayam. An example of this combination would be as follows: രാജാവ് (prakrithi) + ഇൻ (idanila) + എ (prathyayam) = രാജാവിനെ (raajaavine), a new word. This word may be used in a sentence like ഞാൻ രാജാവിനെ കണ്ടു (njan raajaavine kandu), which means ‘I saw the king’. The root word രാജാവ് (raajaavu), ‘king’, has to be fused with the suffix ‘ഇൻ ’(in) and ‘എ’(e) to get the correct form of the word രാജാവ് (raajaavu). Type 1.2 happens when a word joins at the end of another word, and Type 1.3 is a result of Types 1.1 and 1.2 appearing in the same word.
The type 2 Sandhi Class is based on the type of syllables that take part in the fusion process. When the word ‘ശരി’ (sheri) joins with the word ‘അല്ല’ (alla), a new word ‘ശരിയല്ല’ (sheriyalla) is formed and is cited as an example of Type 2.1, the swara sandhi in Table 2. The components that take part in this fusion process are ‘രി’ (ri) from the first word and ‘അ’ (a) from the second word. The character ‘രി’ is a combination of ‘ര + ഇ’ (‘ra +i’) and therefore the components that take part in the fusion process are the two swarams ‘ഇ’ (‘i’) and ‘അ’ (‘a’).
Classification Based on Position of Joining
Classification Based on swara_vyjanam Difference
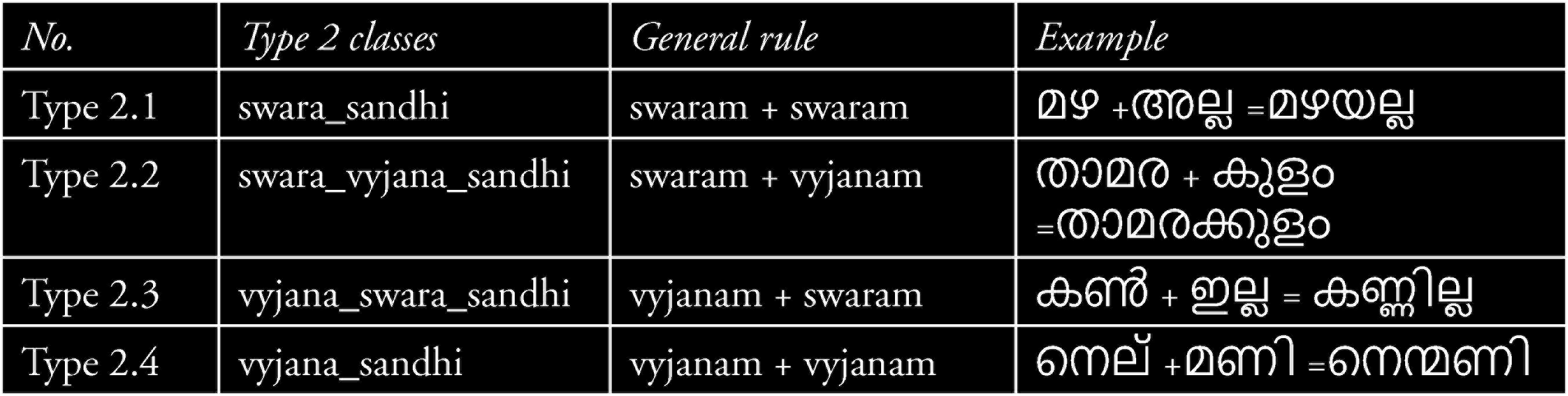
The third classification Type 3 is based on the type of changes happening to the fusing components. The general rules of the four types of sandhi that come under this category are presented in Table 3. Aa and bB denote the two words that take part in the fusion process and ‘a’, ‘b’ and ‘c’ are fusion components that are affected when these words join together. The modified form of ‘a’ and ‘b’ present in the new word formed is denoted as a’ and b’, respectively. Type 3.1 denotes the case where ‘b’ disappears on the fusion of ‘a’ and ‘b’, and a modified form of ‘a’ appears in the form of a’ in the new word. The rule applied on അത് (athu) + അല്ല (alla) = അതല്ല (athalla) given in Table 3 is an example of Type 3.1, where ‘a’ is ‘ത്’ (th) which is obtained by joining ത+◌ ് (tha + virama), ‘b’ is ‘അ’ (a) and a’ in the new word അതല്ല (athalla) is ‘ത’ (tha).
Sandhi rules classified as Type 1, 2 and 3 are not disjoint sets. The different categories of sandhi rules mentioned under these three classes are interrelated. A case of lopa sandhi, that is, Type 3.1 can be further classified as Type 2.1 or Type 2.4 (see Table 3). The relationships that exist between Type 3 and Type 2 classes are presented in Table 4.
Classification Based on How varnam Changes

Methodology of Generating Sandhi Rule Annotated Data Set
The process of generating sandhi rule annotated data set discussed in this section has two phases, namely the Data Set generation phase and the Machine Learning phase. The work flow of the entire process in the Data Set generation phase is illustrated in Figure 1.
Relation between Type 2 and Type 3 sandhi rules

The special characters and numbers present in the Malayalam text are removed through the preprocessing step, and this is then tokenised further to get a bag of Malayalam words. As shown, many words in Malayalam contain suffixes appended with the root word, and this is identified using the Unicode pattern present at the end of the word. Identifying the character (Key Character) that precedes the suffix pattern is important, as it acts as the key factor in selecting the suffix rules present in the suffix rule set. Appropriate rule selection is done based on the key character, and the words are then split into root words and suffixes.
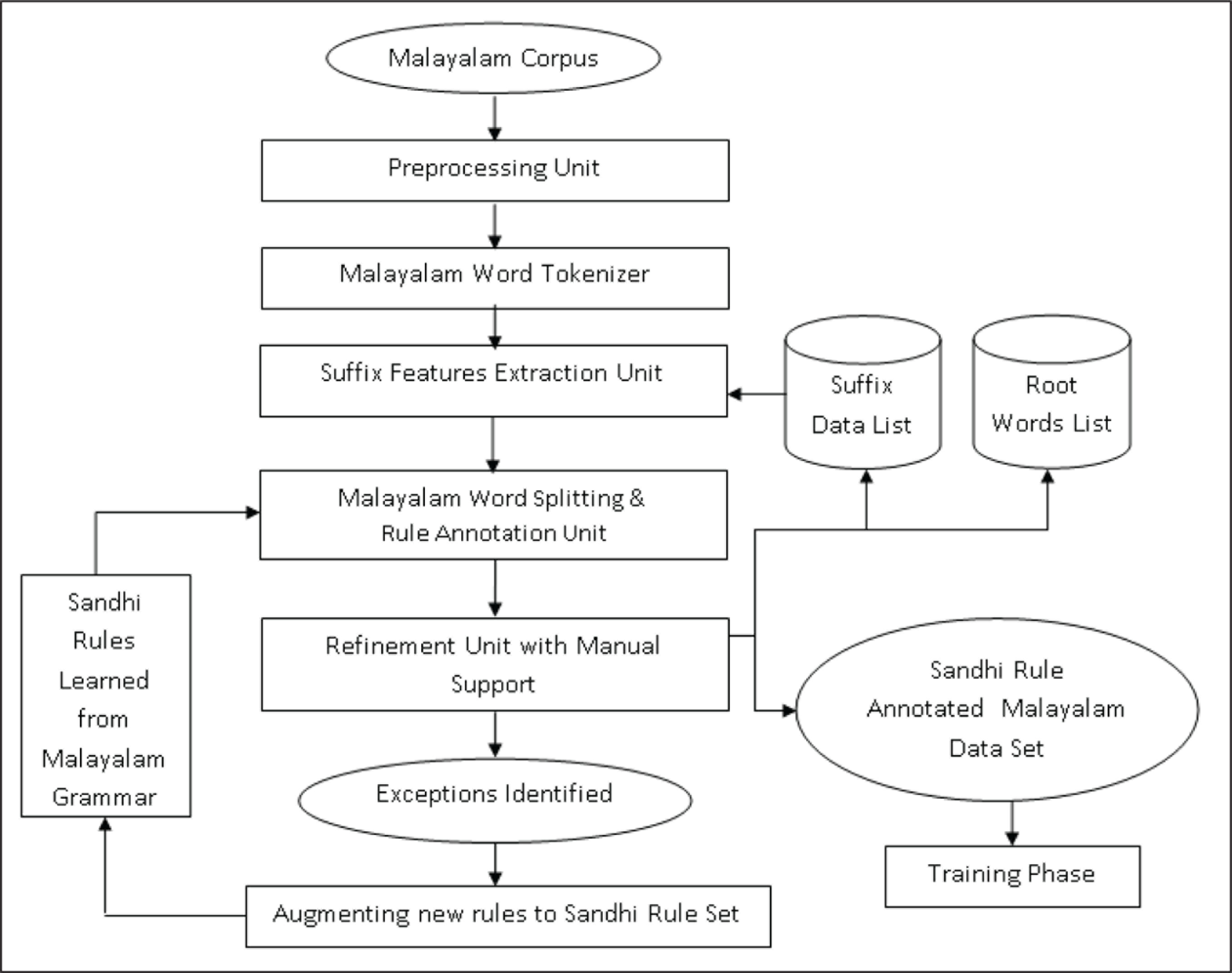
A manual support is taken in the next step to differentiate between good split and bad split. The results are analysed and the sandhi rule set is augmented with a new set of rules to accommodate any exception cases. The good splits are taken for building the annotated data set, where the words and the rules are paired together.
A word in Malayalam is expressed in the form ‘XzY’ where X represents the prefix of the word, Y represents the suffix and z represents the key character that also determines the splitting rule. The general structure of the rule is expressed as follows:
Split Rule: z=x+y on XzY ➔Xx+yY Example: മഴയല്ല (mazhayalla) = മഴ (mazha) + അല്ല (alla)
The tokenised Malayalam text is subjected to the Suffix Pattern and Key_Character identification unit, the key feature in identifying the appropriate word splitting rule for a particular word. Along with this, the nature of the suffix segment present in the word is also considered while fixing the splitting rule. Other features that influence the rule formations are categories of x and y which are the characters that take part in the sandhi fusion process for forming the words XzY. The categories of x and y are determined by analysing the last and first characters of the strings Xx and yY, respectively.
The above-mentioned Malayalam word മഴയല്ല (mazhayalla) on splitting is cited as an example of Type 3.2 class, Aaagama Sandhi (see Table 4). More precisely, it belongs to the S+S category in Type 3.2 class, which means that two swarams take part in the fusion process. Again the characters that fall under swarams are classified as thaalavyam, palatal sounds in Malayalam, and oshttyam, labial sounds in Malayalam (Aroor, 2015). The complete list of the swaram sub-category is given in Table 5.
In Malayalam grammar, the sandhi rules for Type 3.2 are described for various cases and the above example falls under the following rule description:
If S+S:
If x in Xx ϵ set T then value of z is ‘യ’ or
If x in ϵ set O then value of z is ‘വ’
Swaram Sub-class

The swaram ‘അ’ (a) and ‘ആ’ (ā) falls under both categories and therefore there is a chance of generating a wrong word മഴവല്ല (mazhavalla) along with its right form മഴയല്ല (mazhayalla). The formation of such words is handled either by upgrading the rule set by providing the minute details of special cases or by using manual support from a Malayalam expert.
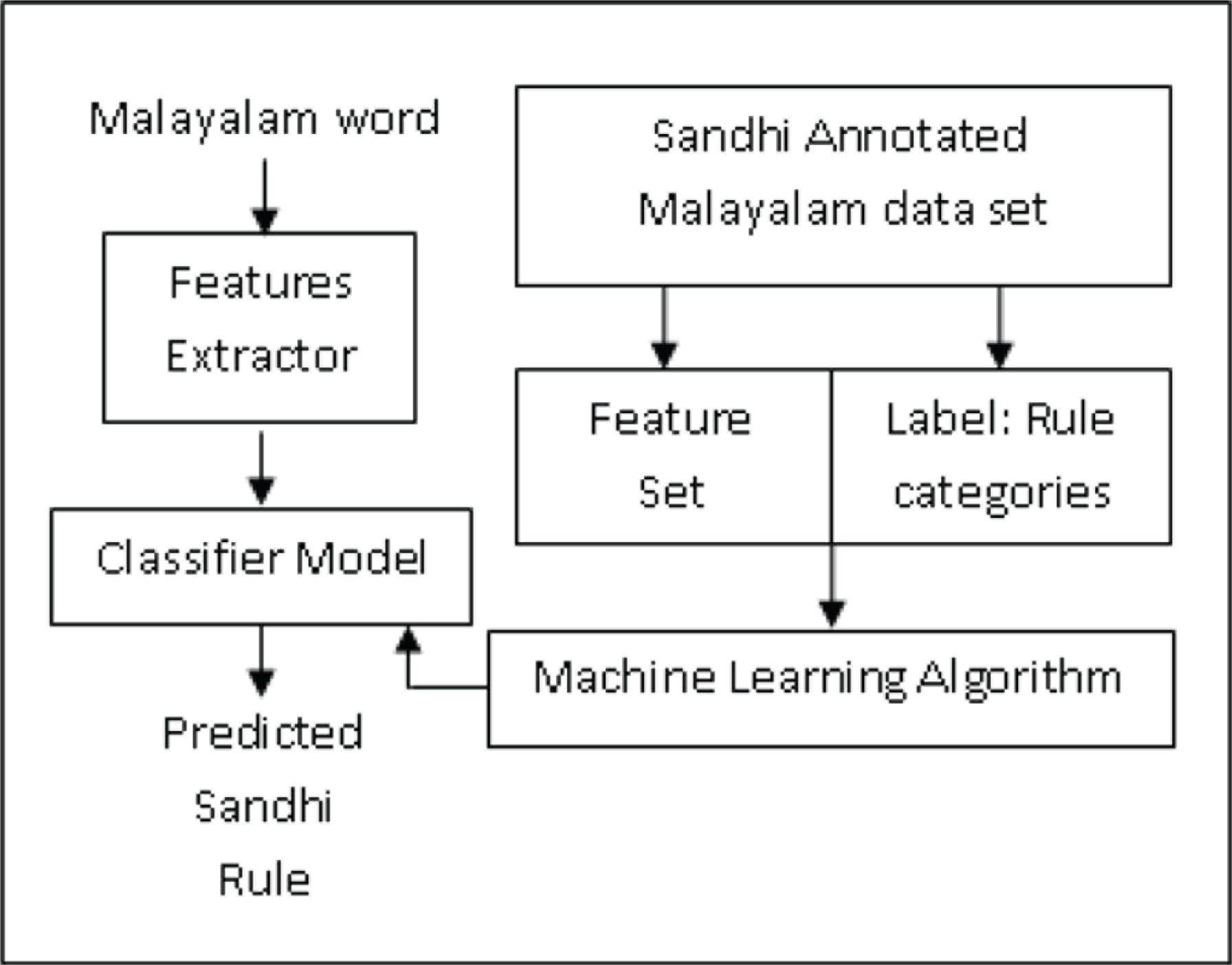
The second phase is the Machine Learning phase, where the features set and labels obtained from the sandhi rules annotated Malayalam data set are now subjected to a machine learning algorithm for building a model. Later in the prediction phase, for an unseen Malayalam word, features are extracted and the feature set generated is subjected to the model for prediction. The supervised classifier used here is the Naïve Baye’s classifier (Murphy, 2006). Figure 2 further is a diagrammatic representation of the machine learning phase.
Rule Set Identification
The Malayalam character set is represented in the UTF-8 format which is a variable width character encoding capable of encoding valid code points in Unicode using one to four 8-bit byte. An understanding of this representation is necessary in building the rule set of the Malayalam word splitter. The identification of the key character plays a vital role in classifying the sandhi rules for the splitting process, as discussed in Sebastian (2010). This earlier work presents a method where suffixes are separated from roots with the help of suffix_keys, suffix _labels and check_letters. In this process of suffix separation, the category of suffix to be separated is identified using the suffix keys. In the example ‘അവള് (aval ) + ഉടെ (ude) = അവളുടെ (avalude)’, the suffix ‘ഉടെ’ (ude) is present in an abbreviated form as ‘◌ുടെ’ which will act as the suffix key for this word. The suffixes can be grouped together based on the vowel sound of the start syllable. The suffixes അല്ലെ (alle) and ആണ് (aanu) start with the same vowel sound ‘അ’(a) and hence are classified into a group with the same suffix-label. Check_letter is that crucial character present in a word that helps to split the word into root and suffix. For example, for words like വാളാണ് (vaalanu), വാളില് (vaalil), and വാളുള്ള (vaalulla), the check _letter is ‘ള’ (ḷa) and the suffix separation rule applied is ‘prev_ള +ള്+ suffix’. The term prev_(x) for a word W denotes a substring that starts from the first syllable of W and ends on the syllable preceding x when scanned from the right hand side of W. In the word ‘കുട്ടിയാണ് ‘(kuttyanu), prev_(യ) denotes the substring ‘കുട്ടി’(kutty). The word structure is thoroughly analysed to identify various check_letters and, based on these check_letters, suffix separation rules are drafted to split the words. Table 6 gives a list of key characters that are useful in the splitting process.
Key Character Examples

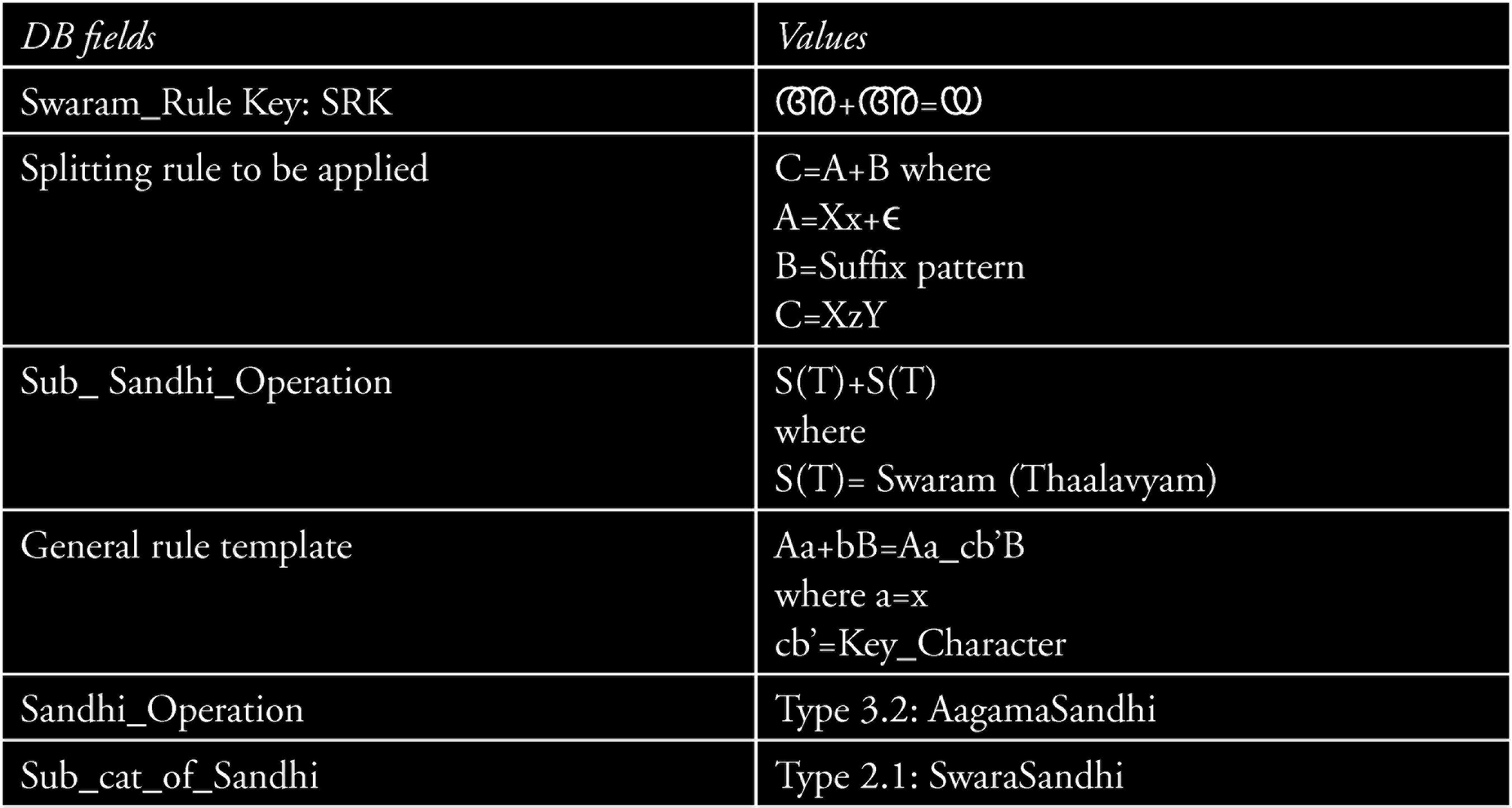
Along with this key character list a database that describes the characteristics of sandhi rules obtained from Malayalam grammar is used for rule identification. The database (DB) has the fields mentioned in Table 7 and the Swaram Rule Key (SRK) is used to identify each field uniquely. The algorithm for rule set identification is discussed further below and examples are given in Table 8 above.
Sandhi Rule Characteristics Learned from Malayalam Grammar
Examples of Feature Set and Rule Identified

Algorithm for Sandhi Rule Set Identification
Input: Malayalam words to split
Output: Sandhi rule categories and Feature Set
Algorithm:
For all sentences in the Malayalam corpus do -
Create a list of Malayalam words (Mal_words_list) after tokenising the sentence and removing numbers and special characters. For all words in Mal_words_list do -
for i= l-1 to 0 and j=0 to length (Key_Charcter list)
check if Key_Character list [j] is equal to XzY[i]
K_char_pos=i XzY_len= length (XzY) break Increment j and decrement i Split the word into prefix_segment, Xx as {XzY[0] to XzY[ K_char_pos -1]} and suffix_segment, yY as { XzY[ K_char_pos ] to XzY[l-1]}
for i=0 to SuffixList SL[n-1]
Calculate the edit distance levy Y,SL[i] between yY and SL[i] find min (levyY,SL[i])and assign Suffix Pattern as SL[i] Split the word Xx and yY into set of character unigrams
Extract the Unicode Label corresponding to end character unigram of Xx and assign to endUL_Xx Extract the Unicode Label corresponding to character next to K_char unigram of yY and assign to next to K_charUL_yY If endUL_Xx and K_charUL_yY are elements of set Upachinnam_UL{}
Map Upachinnam_ULx, y to Swaram_ULx,y Assign x_category as Swaram_ULx and y_category as Swaram_ULy Frame the Swaram_Rule Key by assigning SRK: =join{‘ Swaram_ULx’, ‘+’, ‘Swaram_ULy’, ‘=’, ‘K_char’, ‘next_to_K_char’} Rule_Set_identified:=Splitting_Rule_List[SRK]
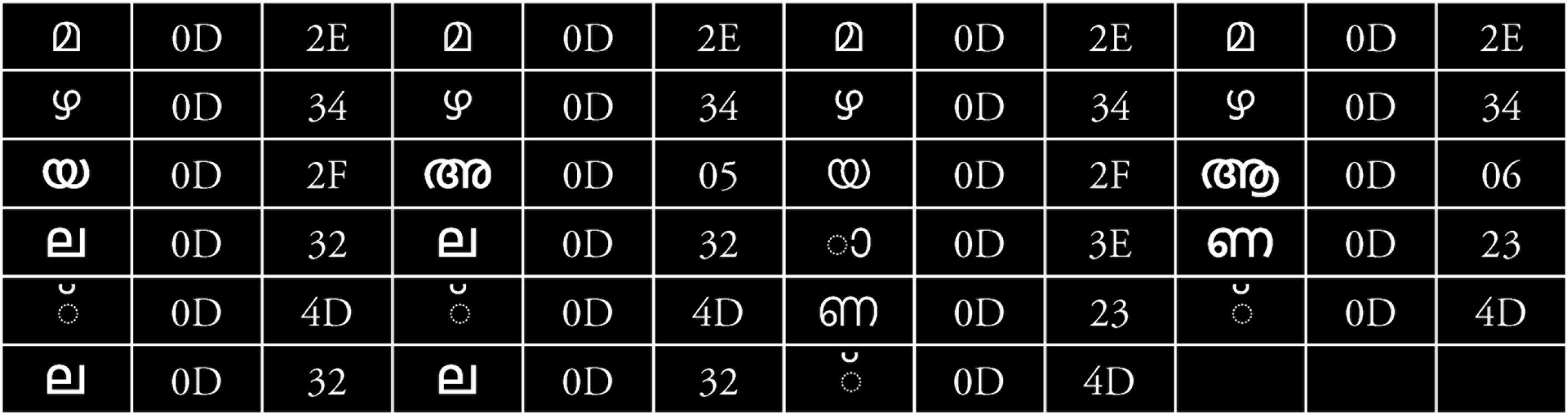
The Malayalam word is split into two segments based on the key character. Basically, the post-segment is termed the suffix segment, and the pre-segment is the prefix segment. Suffix pattern identification needs exploring of the Unicode patterns of various characters in Malayalam (see
But the difference between യല്ല (yalla) and ആണ് (aanu) is greater when compared to the word അല്ല (alla). The highlighted characters in Table 9 show the difference between these words.
The similarity between the suffix segment and the suffix pattern is determined using the Levenshtein distance (Navarro, 2001), where the edit distance is calculated as the number of characters that need to be substituted, inserted or deleted, to transform a string str1 to str2. The edit distance matrix is built for the available suffixes and it grows as new suffixes are added on to the suffix set. The rows of this matrix are labelled as the suffix segment extracted, using the key character and the columns are labelled as the suffix patterns.
UNICODE Representations of Words yalla, alla and aanu
Mapping of Unicode Labels with swaram_ULs

The Swaram Rule Keys are framed from x_category and y_category swarams which requires knowledge of swarams and their corresponding upachinnams (vowel signs). The list that maps a Unicode label to its corresponding Swaram_UL and Upachinnam_UL is given in Table 10.
Results and Observations
The experiments were conducted on a sample Malayalam corpus, details of which are given in Table 11. The Natural Language Toolkit is chosen as the working platform. Experiments are focused on splitting words that belong to various sandhi categories. This is an ongoing work which follows an incremental approach of upgrading the data set. The results discussed here are mainly targeted at Aagama Sandhi and its sub-categories.
Statistics of Malayalam Corpus

The key_character considered for discussing the results is ‘യ’(ya) and the statistics of words containing it in various portions of a word wi are given in Table 12.
Statistics of ‘യ’ in a Word wi

The character ‘യ’ (ya) may be present in a word that need not be split, for example, the word മുയൽ (muyal). Such words lead to a bad split if the position of the character in the word wi is ignored. The statistics of words having ‘യ’ (ya) at various positions in word wi are given in Table 12. Here the position is indicated as pi = -j, where the ‘-’ sign indicates the end of the string and ‘j’ indicates the position from the end of the string. The number of words in the corpus is denoted as N and the interval of position j is calculated by Equation 1 as:
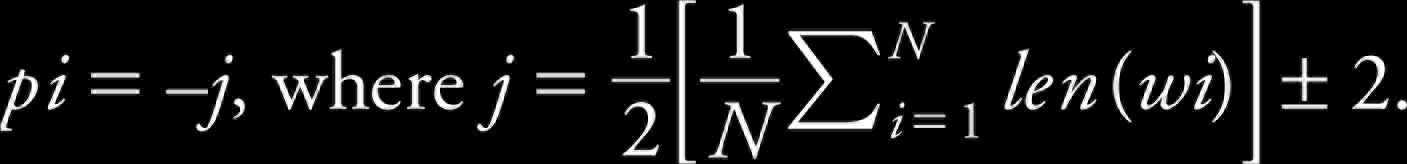
The average length of the words in the Malayalam corpus subjected for experiments is eight, and the pis corresponding to this length is shown in Table 13.
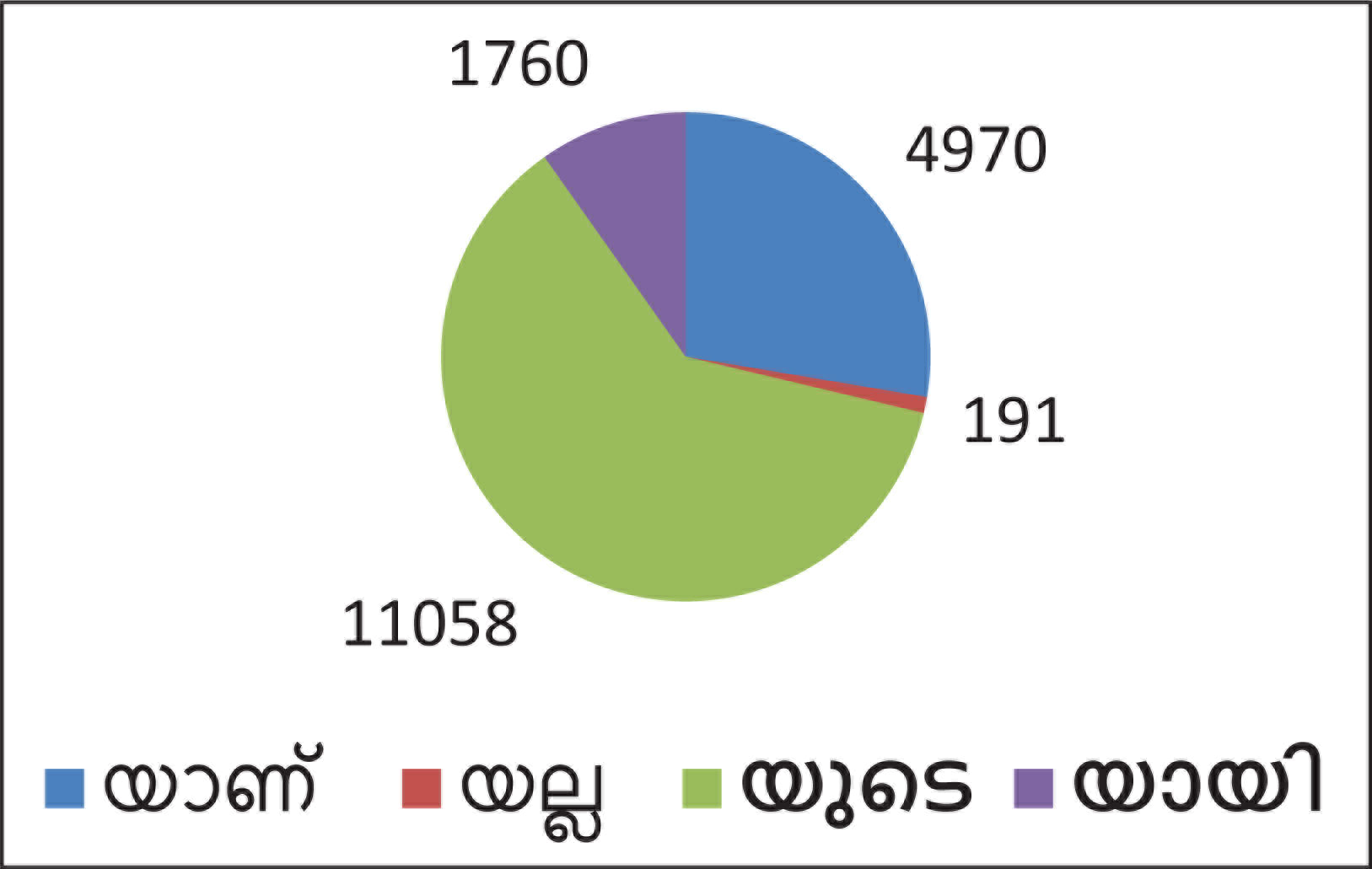
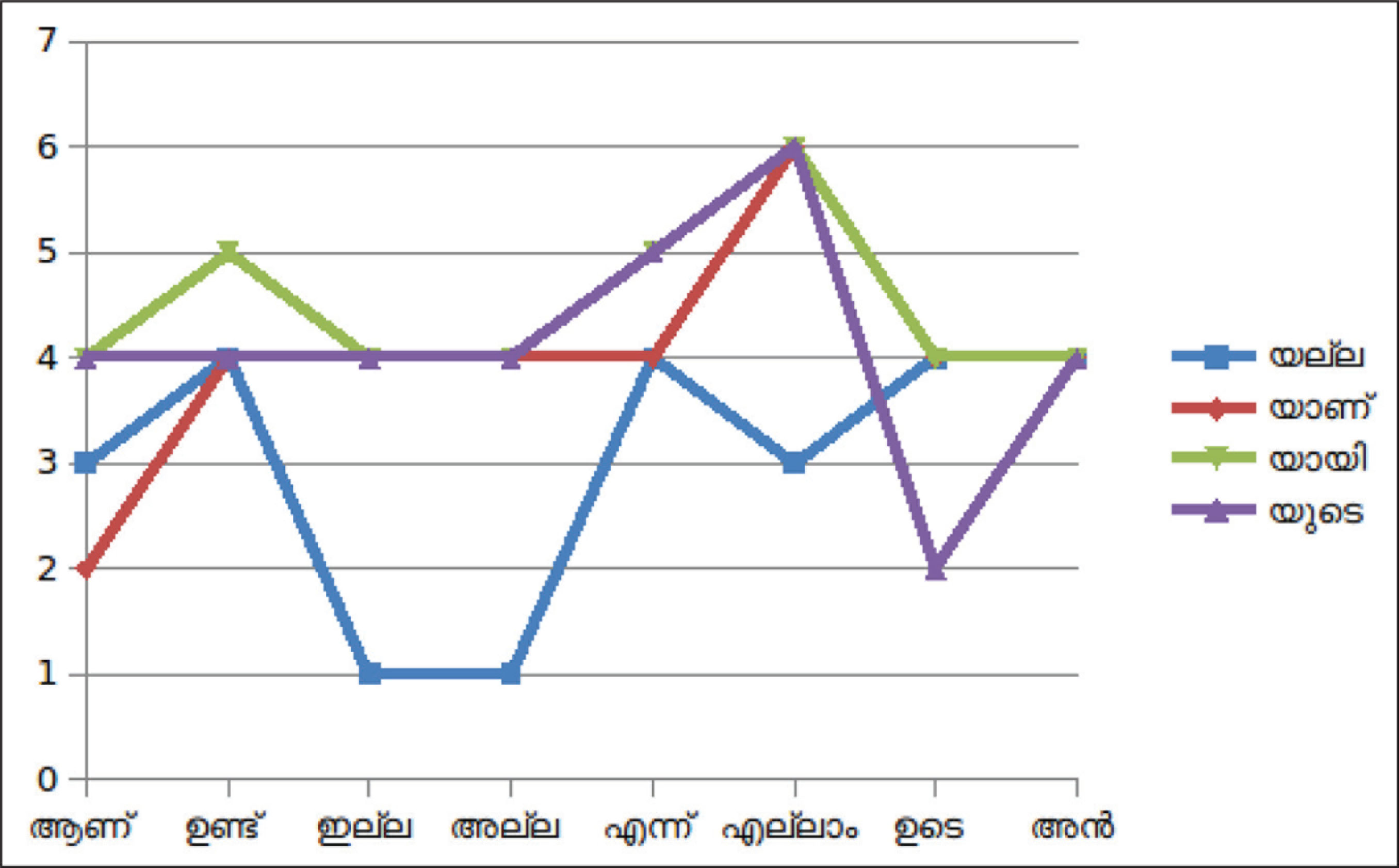
The test samples of suffixes chosen for discussion are യല്ല (yalla), യാണ് (yanu), യായി (yayi) and യുടെ (yude) and the graph provided in Figure 3 plots the count of words in the corpus that contain the test suffixes.
The graphs in Figure 4 indicate the results of the edit distance calculated using the Levenshtein distance equation. A threshold value is set to filter out the bad cases that show a mismatch between the two input strings.
Statistics of ‘യ’ at Position - j

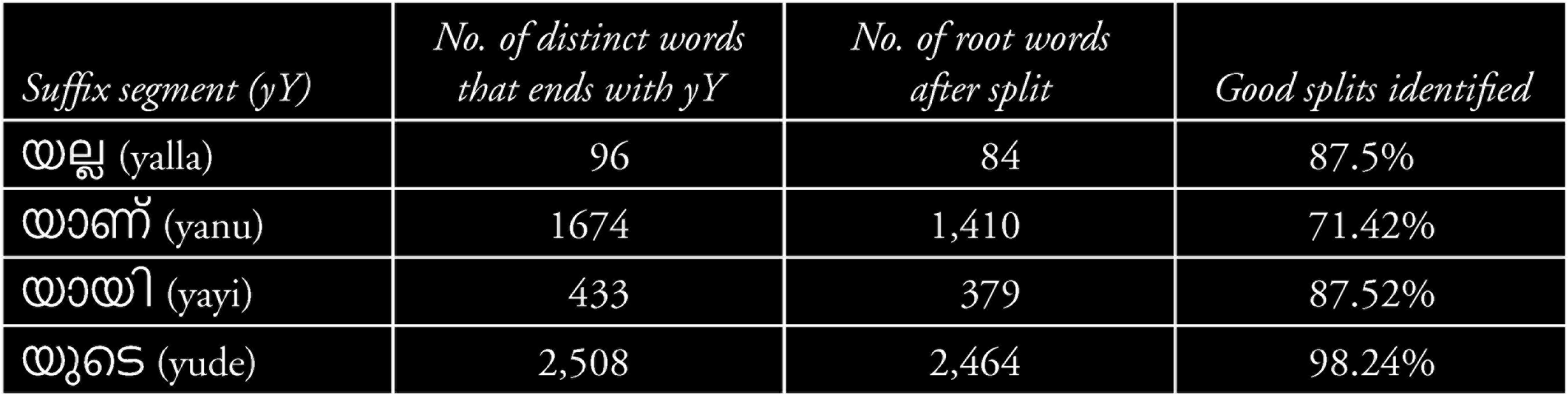
The length of the respective suffix segment is another important feature that affects a valid suffix splitting. Many bad splits are avoided by comparing the length of suffix pattern and suffix segment. To enhance the searching speed in the suffix pattern list, the suffixes are grouped together length-wise and are indexed with their character length. The results obtained were evaluated manually by two human evaluators and an average of their assessment was taken for study. The statistics of word splitter and percentage of good splits obtained are presented in Table 14.
The results in Table 14 show that the percentage of good splits on average is 92.06 per cent. Error analyses on the bad splits were done and the details are shown in Table 15.
Statistics of Word Splits
Error Analysis
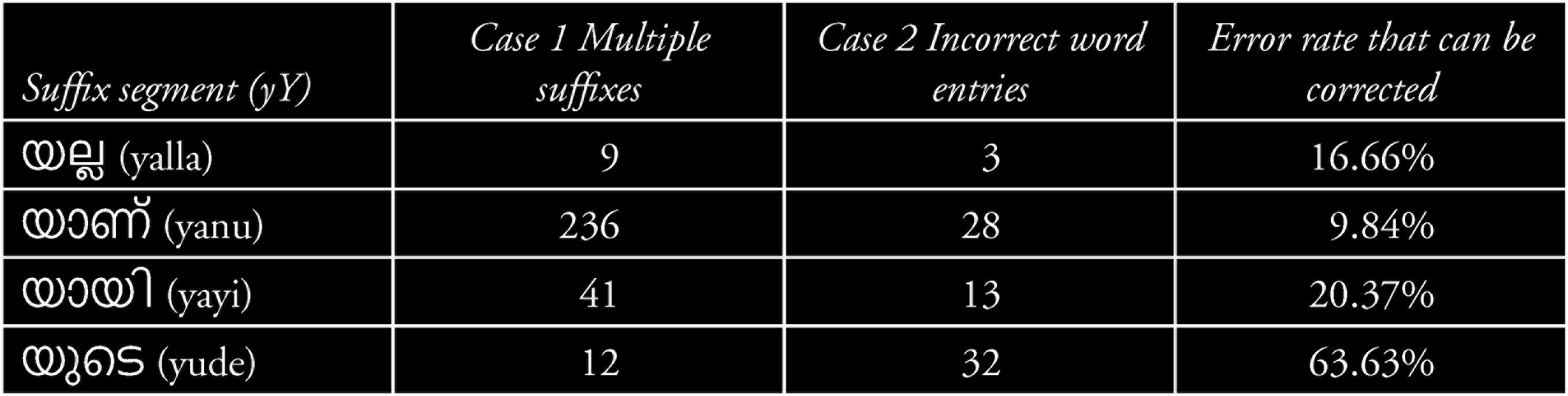
An analysis of the bad splits was done to identify the exception cases and to improve the results obtained. An instance of a bad split is considered to be one among the following three cases:
Case 1: Multiple Suffix Words
A word of multiple suffixes where the root word after initial splitting has to be subjected to suffix splitting again.
The example is as follows: അറിവുള്ളവളായി (arivullavalayi) = അറിവ് (arivu) + ഉള്ള (ulla) + അൾ (al) + ആയി (aayi). The example given above will result in the following forms after splitting:
Output: അറിവുള്ളവള (arivulaa) + ആയി (aayi). Expected output: അറിവുള്ളവൾ (arivullaval) + ആയി(aayi).
Root words that are obtained from Multiple Suffix Words (MSWs) after the word split suffer from an incorrect word ending, which does not give them an entry into the root list. These root words need to be manually corrected and are subjected to word splitting again. The words that have multiple suffixes are separated using pis with greater count. MSWs are formed in three ways with sandhi rules defined on
A padham (whole word) joining with suffixes alone. A padham joining with another padham. A padham joining with another padham and suffixes.
Multiple suffixes depending on the suffix type are handled separately and they are subjected to word split processes in a repeated manner. Addressing the issues that are encountered while further splitting multiple suffixes in a word is beyond the scope of this article.
Case 2: Wrong Entry Words (WEW)
These are words that are not a correct Malayalam word, which has resulted due to a wrong entry made while building the corpus. An example would be ക്തിയുടെ=ക്തി+ഉടെ (kthiyude = kthi + ude). The correct Malayalam is ശക്തിയുടെ (shakthiyude), while ക്തിയുടെ (kthiyude) is an incomplete form of the word ശക്തിയുടെ (shakthiyude), which may have occurred in the corpus due to a typographical error.
This case of a wrong word entry in the corpus can be removed if the corpus is cleaned. The error rate attributed from this case is something that can be corrected by manually editing the incorrect word in the corpus. Since these words are instances of good splits, but result in an incomplete root word, manual correction made in the corpus is a suitable solution to remove these words from the bad split category. The percentage of error rate that may be corrected by this method is shown in Table 15.
Case 3: Non-Split Words
These are words which are a correct Malayalam word that has a valid meaning and need not be subjected to the word splitter.
Example: അനുയായി (anuyayi).
Output: അനുയായി = അനു (anu) + ആയി (aayi).
The clear meaning of this word is ‘follower’, and hence it need not be split. But due to a bad split, a root word അനു (anu) is obtained, which is a meaningless Malayalam word.
Non-split word (NSW) results are real examples of bad splits, which result in a meaningless root word in Malayalam. The presence of such words in the corpus is very rare, and hence they can be included in a NSW category for future reference and may be extracted from the corpus before the word splitting process is initiated.
There are extensions possible for this method in the case of upasargams, another category of sandhi. This is another category of sandhi rule that is similar to the ones mentioned in Sandhi Class-Type 1.1. In Type 1.1, the inflections are joined at the end, but there are also cases where portions of words are joined in the beginning of a word (upasargams) to form a new meaningful word (Aroor, 2015). For example, സു (upasargam) + ദിനം (day) = സുദിനം (good day). The method discussed here can be used for splitting the prefixes as well. A collection of words that belong to upasargams are needed for this process and the word splitting task then has to take place in the beginning of a word.
Conclusions
Linguistic work of the present kind offers a valuable contribution to knowledge. The educational challenges of regional and local language diversities are undeniable, and any technological advances in facilitating language acquisition and multi-lingual competence are an important aspect of South Asian Studies. Malayalam is not just a local language, or the state language of Kerala, but has also become a global language after widespread migration of millions of users of this language. This study on sandhi rules in Malayalam and their classification in the article confirms that the detailed knowledge of sandhi rules is valuable and can be utilised in computer-assisted learning programmes to frame sandhi rule sets. These help in generating a sandhi rule annotated data set for Malayalam, which could be used as a resource in the preprocessing phase of various NLP tasks of Malayalam which requires morphological analysis.
A method that extracts features from a Malayalam word which helps in automatically selecting the appropriate rule from the sandhi rule database leading to the annotation process was also discussed in this article. Non-availability of annotated standard corpora and natural language preprocessing tools is one of the reasons for the lack of fully fledged NLP systems in Malayalam. This is a viable method to achieve sandhi annotated corpora using a supervised machine learning model. The refined data set was subjected to a machine learning algorithm that develops a model for predicting the sandhi rules for an unseen Malayalam word. The annotated data set is recurrently being upgraded and this work is heading in the direction of meeting the requirements of a sophisticated suffix separator tool for Malayalam.
Footnotes
Acknowledgements
The Malayalam text used for experiments is taken from the English–Malayalam corpus used in the Shared Task and Workshop on Machine Translation in Indian Languages (MTIL-2017), conducted at CEN, Amrita Vishwa Vidyapeetham, Coimbatore jointly with LDC-IL-CIIL, Mysore.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.