
Abstract
In recent years, Open Science (OS) has sparked much discussion among researchers in language testing, as in other fields. While the special issue on OS in language assessment has presented perspectives from various stakeholders, including researchers, testing companies, and universities, it underrepresents the views of government institutions that develop and administer language tests. In this Viewpoint, we discuss the benefits and challenges of OS practices for these institutions, drawing on our experiences at two government institutions in Türkiye. We also offer recommendations for adopting these practices within such contexts. By contributing to ongoing discussions about OS, we hope to promote communication and collaboration among stakeholders to support the effective and responsible implementation of OS practices in language assessment.
Open Science (OS) has gained momentum in recent years in response to challenges posed by traditional models of scientific research and publication. As test developers working at government institutions in Türkiye, we find the special issue on OS in language assessment both timely and relevant. The issue highlights the benefits and challenges of adopting OS practices in language testing across various contexts and stakeholder groups, including researchers, testing companies, and universities; however, it underrepresents the perspectives of government institutions that design and administer language tests, which is the gap we seek to address in this Viewpoint paper.
In her Viewpoint in Language Testing, which served as the focal point for responses from various authors in the issue, Winke (2024) recommends that language testing companies and government agencies adopt more transparent ways to share test data with researchers, highlighting the potential of such data to answer important questions about language learning. Among the responses to Winke (2024), Chapelle and Ockey (2024) offer the strongest critique, describing her vision as “universalist and utopian” and raising concerns about possible unintended consequences of OS practices in language assessment, such as the misuse and misinterpretation of publicly shared test data (p. 882). While we support Winke’s (2024) recommendations for promoting OS in language assessment and recognize the central role governments play in advancing OS to achieve “quality, clarity, and equity” (p. 846), we also acknowledge the validity of the concerns raised by Chapelle and Ockey (2024), among others (e.g., Clark & Bruce, 2024; LaFlair, 2024; Papageorgiou, 2024), as they reflect debates among researchers, administrators, policymakers, and other relevant stakeholders in many contexts, including ours.
Before delving into this paper, it is important to first describe the context in which we work to provide readers with a better understanding of our perspective. The Ministry of National Education and the Center for Assessment, Selection, and Placement are public institutions in Türkiye that undertake a wide range of educational activities, including developing and administering language tests to thousands of test-takers each year in Türkiye. The Ministry’s target population consists of kindergarten to 12th grade (K–12) students, while the Center serves a broader adult population, ranging from university students to academics and government officials. Both institutions collect extensive data from test-takers; however, personal data protection regulations, administrative procedures, and legitimate stakeholder concerns about data privacy, security, and responsible data use limit the implementation of OS practices. This cautious approach stems from the inherent risks of large-scale testing and the potential unintended consequences of OS practices, especially those related to data sharing. In this context, our roles as test developers extend beyond conducting scientific research to managing administrative procedures and providing policymakers with empirical evidence to guide their decision-making processes. In the current paper, we share our perspectives shaped by these multifaceted responsibilities, which may provide insights for others working in similar institutional settings in different countries.
In the remainder of this paper, we discuss the benefits and challenges of OS practices for government institutions and propose recommendations for implementing these practices in such contexts. Our detailed discussion of the challenges should not be viewed as a limitation but as a necessary step toward the responsible and sustainable adoption of OS in these contexts. By contributing to discussions about OS, we hope to encourage communication and collaboration among stakeholders to support the development of practical approaches for OS practices in language tests provided by government institutions.
Benefits of OS practices for government institutions
One of the key benefits of OS lies in its role in building public trust. Since language tests are widely used as “sorting and gatekeeping instruments” for various purposes, including education, employment, and immigration (McNamara & Roever, 2006, p. 3), they often have significant consequences for individuals and societies, which makes accountability to test users crucial (Bachman & Palmer, 2010). By sharing test data and technical reports on test development and validation, institutions involved in language assessment, such as ministries of education, can allow external researchers to examine the validity of the interpretations and uses of their test scores, and this transparency can help build public trust that is grounded in empirical evidence rather than unsubstantiated claims (Winke, 2024).
Gaining public trust through transparency is especially important for high-stakes language tests, where stakeholders must have confidence that scores are valid for their intended purposes. Two examples from Japan highlight the consequences of insufficient public trust in this regard. Although the assessment of speaking was central to reform efforts aimed at improving English language education in Japan, the initiative to administer the English Speaking Achievement Test for junior high school students encountered significant implementation challenges due to public criticism about the necessity and fairness of the test (Allen & Koizumi, 2024). Likewise, a policy proposal by the Ministry of Education, Culture, Sports, Science, and Technology to use four-skill tests administered by external companies as part of the university entrance process was ultimately rejected due to strong public opposition. Key concerns raised by various stakeholders included unequal opportunity to access standardized language tests, especially for students from disadvantaged backgrounds; insufficient guidance on selecting appropriate tests; and difficulties in establishing equivalence across multiple tests mapped to the Common European Framework of Reference for Languages (CEFR) scale (Allen, 2020; Saito et al., 2022). In high-stakes testing, adopting OS practices, such as publishing pilot studies on new tests and sharing test data with external researchers for validation, may help achieve the transparency needed to build public trust. This may, in turn, increase the credibility of institutions, which can support the successful implementation or timely revision of testing programs without much public resistance.
Another key benefit of OS is its potential to help government institutions address practical challenges and develop evidence-based policies. Although these institutions typically have large datasets collected from test-takers, they may lack the resources to analyze them thoroughly or design new tools based on them. By making portions of such datasets accessible to external researchers while safeguarding privacy and security, they can support research on various issues related to operational testing (Isbell & Kremmel, 2024). For example, written or spoken test responses could be utilized to create open-access natural language processing tools to extract linguistic features from texts for automated scoring models. Such tools could benefit both institutions and the broader research community. Research on shared test datasets may also generate empirical evidence to inform language education policies, which can help institutions respond more effectively to local needs and avoid costly policy failures (Organization for Economic Co-operation and Development [OECD], 2020, 2023). To facilitate the incorporation of the generated evidence into policy decisions, institutions might establish intermediary mechanisms like knowledge-brokering bodies in collaboration with universities to translate research findings into actionable insights for policymakers (Wollscheid et al., 2019). In this way, they can effectively use language test data to address practical issues encountered in operational testing and develop policies that meet their local needs.
An additional benefit of OS is its contribution to the visibility of institutions at both national and international levels, which may foster partnerships across organizations. Research shows that open-access publications typically receive higher citation rates (e.g., Neylon et al., 2021) and gain greater visibility beyond academia than closed publications (e.g., Huang et al., 2024), partly due to their rapid dissemination through institutional repositories, academic networking platforms (e.g., ResearchGate), and social media (e.g., X). Institutions that openly share their test development and validation reports, along with accessible resources for target end-users (e.g., teacher guides), can attract attention from a broader audience, including researchers, administrators, policymakers, educators, and the wider public, both domestically and internationally. Furthermore, by providing controlled access to portions of their test datasets, they can support external research that may lead to presentations at prominent conferences and publications in high-impact journals. Such initiatives can enhance institutional recognition and create valuable networking opportunities that pave the way for strategic partnerships with national and international organizations. They may also increase the impact of research by allowing other individuals or organizations involved in language assessment to learn from and build upon the findings of studies on language tests administered by government institutions.
Finally, OS can contribute to institutional capacity building by encouraging the development of new skills, digital infrastructures, and workflow procedures. Implementing OS practices in language assessment requires institutions to build both technical and administrative expertise in various areas, such as data curation, anonymization, and privacy protection; upgrade their existing digital infrastructures to manage research projects according to OS principles; and create workflow procedures for a range of OS-related tasks, such as reviewing data requests, sharing test data, and monitoring compliance with institutional guidelines. Undertaking such capacity-building activities may not only support the sustainable implementation of OS practices but also position institutions as leaders in shaping national and international standards for adopting OS in language assessment, which would ultimately contribute to a cultural shift toward OS (United Nations Educational, Scientific, and Cultural Organization [UNESCO], 2023).
Challenges of OS practices for government institutions
The most significant challenge of adopting OS practices for government institutions is data sharing. Even releasing a small portion of test data requires careful consideration of practical difficulties such as obtaining informed consent and anonymizing data; ethical concerns about personal privacy; potential risks of data misuse, misinterpretation, and manipulation; and unintended consequences of public scrutiny.
A prerequisite for data sharing is to obtain informed consent from test-takers (or their legal guardians if they are under a certain age), raters, and test administrators for the use of their data for research purposes. All the key principles of research integrity (e.g., All European Academies, 2023; Universities UK, 2019; U.S. Department of Health and Human Services, 2024) rightly emphasize the need to respect the persons involved in research and the protection of their rights and well-being. However, in large-scale testing, especially in K–12 contexts, obtaining consent from test-takers or their parents is not always straightforward. Research indicates that active parental consent, which requires parents to provide explicit permission via a signed form, often results in substantially lower research participation rates than passive parental consent (i.e., opt-out), in which parents are informed about a study and asked to contact the research team should they not want their child to participate (e.g., Courser et al., 2009; Liu et al., 2017). In contexts where passive consent is not permitted due to child protection laws and regulations, institutions must work closely with schools, teachers, and administrators to secure parental consent, which requires human resources, organizational coordination, and stakeholder communication (Waechter et al., 2023).
In some cases, test-takers or their parents may decline the use of their test data for research purposes. To address this issue, institutions may mandate informed consent as a condition for taking language tests, which may raise ethical concerns about test-takers’ rights and autonomy. Alternatively, they may limit research to the data gathered from test-takers who provide informed consent, which risks creating datasets that may not fully represent the entire test-taker population. While such sampling bias occurs in most studies in the field of applied linguistics (Andringa & Godfroid, 2020), it could limit the generalizability of the findings of studies conducted on large-scale language tests, making their implications less applicable to the broader population. An educational example is the OECD’s Programme for International Student Assessment (PISA), in which exclusions and non-responses within countries limit the representativeness of the sample, thereby undermining the ability of the assessment to make fair international comparisons (e.g., Borger et al., 2024).
Once informed consent is obtained, institutions must implement various anonymization strategies on language test datasets to comply with personal data protection laws and regulations. Examples of such strategies include deleting variables containing confidential information, replacing personal identifiers with placeholder values, and recoding certain variables into broader categories. Most of these strategies can be readily applied to structured datasets, such as test scores or questionnaire responses, through data management systems; however, different strategies are needed to anonymize unstructured datasets, such as writing and speaking task responses. This type of data cannot be easily anonymized because it should first be reviewed by humans or processed by computer algorithms to detect and remove the linguistic content containing personally identifiable information. Next, computational tools should be run on the data to mask biometric traits (Weitzenboeck et al., 2022). For example, in the video recordings of speaking task responses, test-takers’ faces could be automatically blurred using masking tools (e.g., Owoyele et al., 2022). Likewise, in audio-recorded task responses, test-takers’ voices could be anonymized using voice conversion techniques, which are developed to modify a speaker’s acoustic properties to resemble those of a target speaker while preserving the linguistic content of their speech (e.g., Yoo et al., 2020). Handwritten responses to writing tasks could also be converted into digital text via optical character recognition technology. While such anonymization strategies facilitate the protection of test-taker privacy, they are all resource-intensive for government institutions, which raises the question of who would bear the costs—taxpayers, testing agencies, or researchers seeking access to the data. If public funding is used, institutions must ensure that data-sharing practices serve the public good to maintain financial accountability.
Beyond practical difficulties, sharing language test data raises ethical concerns about personal privacy. To protect personal privacy, institutions must comply with national laws (e.g., Turkish Personal Data Protection Law, 2016) and international regulations (e.g., EU General Data Protection Regulation, 2016). While such legislation provides guidelines for collecting, using, storing, and disposing of personal information, it does not adequately address the complexities of sharing this information for OS purposes. Language test data often include spoken, written, and even multimodal performance samples, which can be used to infer various types of personal information, such as personality traits, emotions, and socioeconomic status, through advanced data analysis methods (e.g., Kröger et al., 2020, 2022; Moreno et al., 2021). For instance, in an experimental study, El Bahri et al. (2024) analyzed the written texts produced by students in social media-based learning environments using a set of artificial intelligence (AI)-based personality detection tools. Personality traits identified by these tools based on the use of specific words and phrases in the texts were compared to the findings of the Big Five Personality Test administered to the same group of students. Results revealed that the personality traits of most students were accurately identified from their written texts through the AI-based tools. Beccaro et al. (2024) also analyzed the audio recordings of oral exam responses collected from university students enrolled in an Electric Circuits course to investigate the students’ emotional states during oral exams. Using a transfer learning method for speech emotion recognition, they developed a model to classify student emotions into four categories (angry, happy, sad, and neutral) by leveraging a pre-trained HuBERT model and an InceptionTime network. Experimental results indicated that the model achieved an accuracy rate of approximately 90% in detecting the students’ emotions from their speech. These studies suggest the feasibility of inferring various personal characteristics from assessment data, which raises significant privacy concerns, especially when such inferences are made without informed consent.
Without additional personal information, such as biodata, the inferences drawn from language test data may be insufficient to identify individual test-takers in large-scale testing contexts. Nevertheless, they can still be used to profile test-takers through data mining techniques, and such profiles may be exploited for commercial and political purposes. For instance, companies could create consumer profiles for targeted advertising across various industries by analyzing the use of specific words or phrases associated with certain behaviors or preferences in written or spoken task responses. In language tests designed for refugees or immigrants, test-takers could reveal their attitudes toward the host country in their responses, and this information could be used to construct political narratives that depict immigrants as threats to social harmony or as contributors to perceived challenges in different areas, including education, healthcare, employment, and security, in the country. Thus, sharing language test data with a third party entails a substantial risk of test-taker profiling, which may result in misuse of data for unintended purposes. This risk is especially concerning for vulnerable groups, such as refugees, persons with disabilities, and children from minority groups, who are more likely to experience discrimination and stigmatization than the general population due to their marginalized or disadvantaged status in society (e.g., European Network Against Racism [ENAR], 2016; United Nations Children’s Fund [UNICEF], 2022; (United Nations, Department of Economic and Social Affairs 2024) U.S. Department of Education, Office for Civil Rights, 2024).
In addition to data misuse, institutions releasing certain parts of data from language tests may have to deal with the consequences of data misinterpretation. As Chapelle and Ockey (2024) underscore, such institutions typically remove or limit contextual details of the data to maintain test-taker confidentiality, which could result in misinterpretation in secondary research. For example, suppose that the writing section of a computer-delivered language test was piloted with a group of 12th-grade students, most of whom had low keyboarding skills. A secondary researcher using this dataset without knowing this detail might misinterpret the low performance of the students as evidence of poor writing ability among all 12th-grade students, which could fuel public criticism about language curricula or instructional methods. The risk of misinterpretation may also arise from the use of data mining on language test data. As Chapelle and Ockey caution, this method can “yield boundless meaningless statistical differences and relationships” (p. 884), which might obscure rather than enhance our understanding of language assessment. Moreover, when applied to incomplete datasets, data mining may produce misleading results about specific products and services, such as language test preparation courses, which could lead stakeholders to make flawed decisions.
Another risk associated with data sharing involves the manipulation of test data for ideological, commercial, or academic purposes (Clark & Bruce, 2024). For instance, unethical researchers may distort or selectively present the test data to deliberately portray certain types of high schools as less successful in language education than others nationwide. Such manipulation could be used to advance specific agendas, such as promoting certain educational policies or discrediting particular schools or regions. When institutions cannot respond to such false claims, possibly due to the inherent difficulty of detecting manipulation in large datasets, the resulting misinformation could undermine public trust and contribute to political crises. In the long term, the consequences of such misinformation may damage the reputations of institutions and increase public skepticism, making it hard to implement necessary reforms.
Aside from the aforementioned practical issues, ethical concerns, and potential risks associated with data sharing, institutions may face the consequences of increased public scrutiny, particularly when the results of studies are unexpected or negative. While openness and transparency can help build public trust, they may also lead to public criticism through various channels, including social media. For instance, if the findings of an OS study indicate lower-than-expected language test performance in specific geographical regions, they may trigger a public backlash, with criticism of local schools, teaching quality, or policy decisions. Such cases may discourage institutions from sharing test data and taking necessary actions due to concerns about negative public perception or political repercussions.
Toward an OS environment for government institutions
To effectively implement OS practices in language assessment, we propose creating an OS environment for ministries of education, national testing bodies, and other relevant institutions, drawing from key factors identified by the UNESCO (2023) for promoting a cultural shift to OS. This environment comprises four components: policy development, digital infrastructure, capacity-building, and monitoring and evaluation. Policy development involves creating policies to implement OS practices in language assessment by adapting existing national and international policies to the specific needs of the field. Digital infrastructure focuses on designing secure and accessible systems that support the management of language assessment research. Capacity-building includes identifying the OS-related knowledge and skills necessary for key stakeholders and providing them with relevant training. Monitoring and evaluation encompasses tracking both the intended and unintended consequences of OS practices in language assessment, addressing legal and ethical issues, and offering recommendations for improvement.
Regarding policy development, although national (e.g., Office of the Chief Science Advisor of Canada, 2020), supranational (e.g., European Commission, n.d.), and international (e.g., UNESCO, 2021) OS policies that can be applied to different fields of science have been formulated, there remains a need to adapt such policies to the discipline-specific features of language assessment—a field driven not only by academic priorities but also by commercial and political interests. In order to support OS practices in the field, these policies should address key concerns among stakeholders (e.g., Clark & Bruce, 2024; Gebril & Bali, 2024; Papageorgiou, 2024), such as safeguarding test-takers’ confidentiality when sharing their performance samples, minimizing the potential misuse of shared test data, and regulating the use of such data for commercial purposes. They could also include mechanisms to encourage the adoption of OS practices by government institutions (Winke, 2024). For instance, language test accreditation systems such as Q-MARK by the Association of Language Testers in Europe (ALTE, n.d.) could feature OS practices as part of their quality standards. This system includes 18 quality standards for the design and validation of language tests; however, none of these standards explicitly address OS-related practices. Thus, an additional standard might require applicant institutions to share part of their assessment data with external researchers for validation studies and publish their test development and validation reports to provide stakeholders with concrete evidence for the validity of the interpretations and uses of their test scores. Professional organizations like ALTE, the International Language Testing Association (ILTA), and the European Association for Language Testing and Assessment (EALTA) could develop such policies in collaboration with government institutions, universities, testing companies, and non-governmental organizations to ensure their widespread adoption.
Robust digital infrastructures should also be built to manage language assessment research projects in alignment with OS principles. Several institutions have established such infrastructures to make their educational datasets available to external researchers for reanalysis or secondary use. Notable examples include data access programs implemented by the Department for Education in the United Kingdom (Government Digital Service, n.d.), the Institute for Educational Quality Improvement (n.d.), the Australian Curriculum, Assessment, and Reporting Authority (n.d.), the Canadian Research Data Center Network (n.d.), and the Michigan Education Research Institute (n.d.). In most of these programs, access to educational test datasets is granted through an application process, which reflects the need to balance transparency with data protection. By contrast, international organizations like the OECD and the International Association for the Evaluation of Educational Achievement (IEA) provide public access to datasets from large-scale international tests, such as PISA, Trends in International Mathematics and Science Study (TIMSS), and Progress in International Reading Literacy Study (PIRLS). While open-access datasets may not be feasible for most institutions due to concerns discussed earlier in this paper, the core elements of these national and international initiatives might be incorporated into institutional research management systems to enable controlled access to language test data, as illustrated in Figure 1. In the figure, OS-related elements are presented in bold, while examples of standard processes are shown in italics.
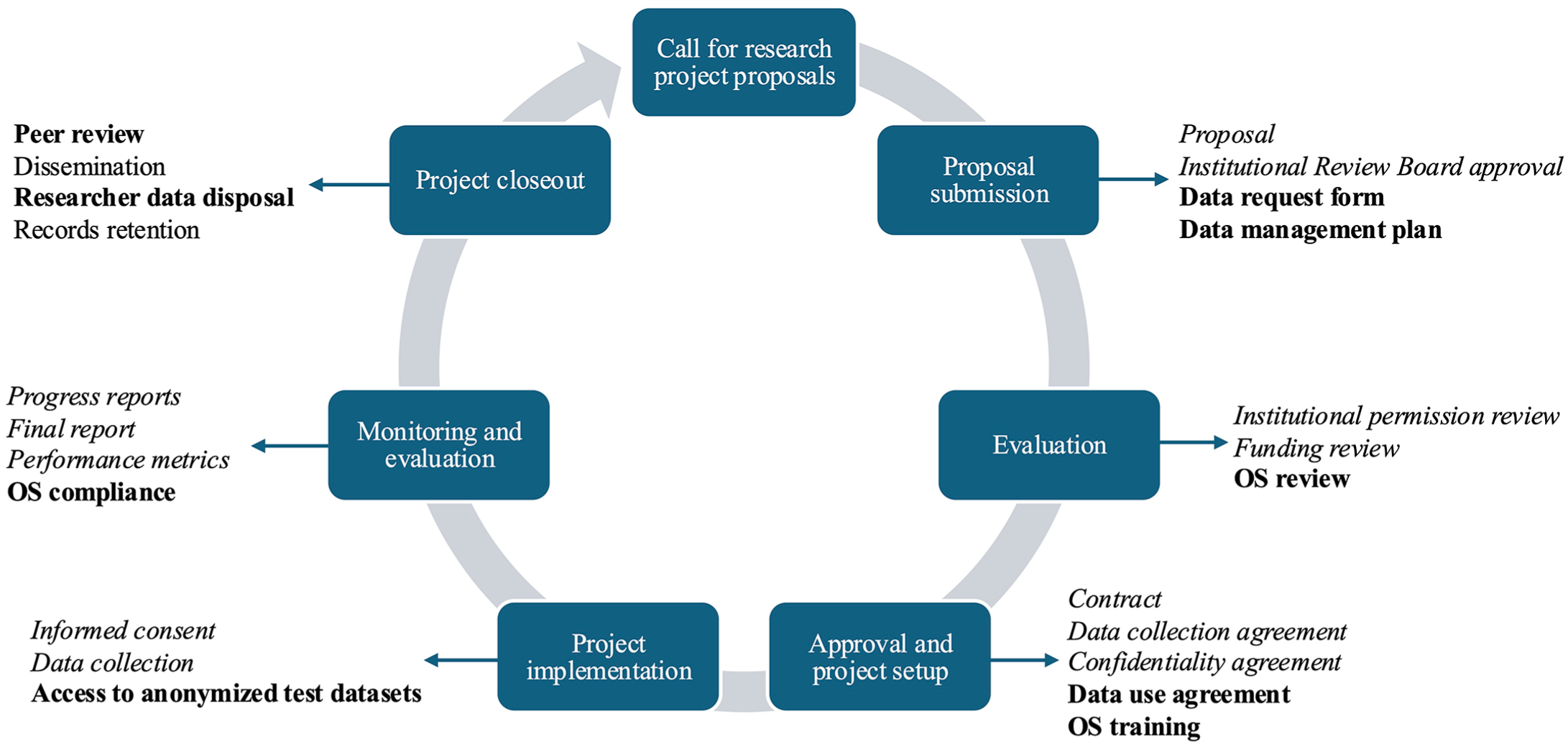
Research project management system with OS-related elements for government institutions.
As displayed in Figure 1, external researchers would first submit proposals in response to institutional calls to tender for research or implementation projects. Each proposal, accompanied by an Institutional Review Board approval (if needed), data request form, and data management plan, would undergo an evaluation process, including an OS review. This review would focus on the feasibility of granting access to the requested data, the suitability of the proposed data management plan, and the contribution of the proposed research to the institutional research agenda. Upon approval, researchers would complete mandatory OS training tailored to the risk level of the data they will access. A tiered training approach could be adopted to distinguish between low-risk (e.g., anonymized test scores), medium-risk (e.g., audio-recorded performance samples), and high-risk (e.g., video-recorded performance samples) test data. Developed by government institutions or affiliated bodies, this training could address key topics for responsible data use, including agreements, security and privacy protocols, and transparency requirements. After signing data use agreements, researchers would gain secure access to anonymized datasets. Monitoring and evaluation would be undertaken throughout the project to track progress and monitor compliance with OS guidelines. Before dissemination, research reports would undergo peer review, during which institutions would consult other researchers to assess the accuracy of data analysis, the appropriateness of interpretations, and compliance with data use conditions. After approval, the reports would be shared in various formats (e.g., public summary), and researchers would be required to destroy the data according to institutional guidelines.
For the successful implementation of OS policies and digital infrastructures developed for language assessment research, it is crucial to invest in capacity-building programs tailored to the needs of different stakeholders. While a wide range of OS teaching and learning resources have been developed through capacity-building initiatives in various parts of the world (see Open Science Capacity Building Index; UNESCO, n.d.), these resources are often dispersed and generic, which may limit their usefulness for field-specific training programs. Therefore, there is a need to create an OS literacy framework to define the knowledge and skills needed by different groups engaged in language assessment research. Based on such a framework, training programs could be designed or adapted to address the specific needs of each group. For example, administrative staff could be trained to manage OS workflows specific to language tests in their institutions, while IT personnel could learn how to anonymize test data to share it with external researchers. Internal researchers could receive training on evaluating the results of data analyses using real-life examples from language tests. Targeted awareness-raising activities could help policymakers better understand the importance of using evidence derived from OS practices when developing language assessment policies. Collaborations with universities, research agencies, and non-governmental organizations may also contribute to these efforts, promoting a culture of shared responsibility and continuous learning among stakeholders.
Aside from capacity-building programs, monitoring and evaluation activities should be conducted to evaluate the intended and unintended consequences of OS practices adopted for language assessment at an institutional level, address legal and ethical issues, and identify areas for improvement. While global initiatives have proposed various indicators or metrics to assess changes and measure progress in the implementation of OS practices (e.g., UNESCO, 2023; World Wide Web Foundation, 2017), institutions should identify indicators that align with their strategic goals and contextual needs to use their resources effectively. These indicators should not only focus on the outputs of the OS practices, such as the number of test datasets shared, but also address OS policies, processes, outcomes, and societal impacts (UNESCO, 2023). Using such indicators in evaluation studies may help identify best practices in implementing OS at the institutional level and inform the development of new monitoring tools. It is important to note that although evaluation studies play a critical role in understanding the impact of OS practices, they should not be relied upon as the primary mechanism for detecting misuse or legal breaches. Instead, these studies should complement formal oversight mechanisms specifically responsible for identifying and addressing legal and ethical issues, including unauthorized data access, misuse, or falsification. Through the combination of evaluation studies and formal oversight, institutions can better uphold legal and ethical standards, optimize their investments in OS practices, and mitigate potential unintended consequences of these practices.
Conclusion
Undoubtedly, the debate over OS practices in language assessment will continue in the coming years. In this Viewpoint, we have sought to contribute to this debate as test developers working at two government institutions involved in large-scale language testing in Türkiye. While our context is specific, we hope that our experiences and reflections may resonate with others working in similar institutional settings around the world. We believe that OS has great potential to bridge the gap between research, policy, and practice in language assessment. Thus, rather than being deterred by the complexities involved in OS practices, we should seek alternative ways for the responsible and effective implementation of these practices in language assessment.
Footnotes
Acknowledgements
The authors are grateful to the Editor, Professor Talia Isaacs, for her invitation to contribute this Viewpoint and for her insightful comments and suggestions on an earlier version of this manuscript. Any remaining errors are solely our own.
Author contributions
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The first and second authors are employed by the Ministry of National Education and the Center for Assessment, Selection, and Placement in Türkiye, respectively. In their roles, they manage internally and externally funded research projects, contribute to decisions regarding the publication of language test development and validation reports, and participate in the creation and dissemination of datasets for use by external researchers. The views expressed in this paper reflect their personal perspectives and experiences, not those of relevant institutions.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.