
Abstract
Oral narrative assessments are important for diagnosis of language disorders in school-age children so scoring needs to be reliable and consistent. This study explored the impact of training on the variability of story grammar scores in children’s oral narrative assessments scored by multiple raters. Fifty-one speech pathologists and 19 final-year speech pathology students attended training workshops on oral narrative assessment scoring and analysis. Participants scored two oral narratives prompted by two different story stimuli and produced by two children of differing ages. Demographic information, story grammar scores and a confidence survey were collected pre- and post-training. The total story grammar score changed significantly for one of the two oral narratives. A significant effect was observed for rater years of experience and the change in total story grammar scores post training, with undergraduate students showing the greatest change. Two story grammar elements, character and attempt, changed significantly for both stories, with an overall trend of increased element scores post-training. Confidence ratings also increased post-training. Findings indicated that training via an interactive workshop can reduce rater variability when using researcher-developed narrative scoring systems.
I Introduction
The way in which children tell stories (narratives) provides important information about their language and learning ability. Oral narrative assessment accounts for all domains of language, including morphosyntax, semantics and pragmatics (Botting, 2002). As narratives are a regular component of conversation and school activities, they allow language to be assessed in an ecologically valid way within a natural context (Gillam et al., 1999). Narrative assessment can describe developmental changes in children’s language abilities (John et al., 2003; Ukrainetz et al., 2005), and contributes to differential diagnosis of developmental language disorders and learning difficulties (Docking et al., 2016; Miniscalco et al., 2007; King and Palikara, 2018). Oral narrative skills are longitudinal predictors for reading development (Babayiğit et al., 2021). Piasta et al. (2018) suggest early narrative skills provide a foundation for the development of emergent literacy, word reading, and reading comprehension. For these reasons, oral narrative assessment has become an important practice for many disciplines, including speech pathologists and educators (Malec et al., 2017). Moreover, reliable and consistent analysis of oral narratives is essential to support accurate diagnosis and measurement of change in response to therapy.
1 Story grammar
While oral narratives may be analysed across both macrostructural and/or microstructural elements, this study focused on macrostructure. Macrostructure describes a narrative’s overall coherence and story grammar (SG) elements such as characters, setting, initiating events, attempts and consequences (Stein and Glenn, 1979). Microstructure refers to smaller linguistic elements such as sentence length, or grammatical language (Justice et al., 2010). SG assessment results may be interpreted using norms or criterion descriptors and inform diagnosis and goals for education or intervention (Petersen et al., 2008).
The SG approach to the assessment of narrative macrostructure, initially developed by Stein and Glenn (1979), is widespread amongst Western populations (Urbach, 2012). This framework defines stories as the completion of goal-directed behaviours by a protagonist and considers the story setting (place and time), characters and episodes. While elements and their descriptors differ across models developed from this framework, all models agree that stories involve a protagonist in a specific time and place (setting) who is faced with a problem (initiating event). The character responds emotionally (internal response) and thinks of ideas to solve the problem (plan). The character sets their plan into action (attempt) and the outcome (consequence) leads to the resolution of the story and a final concluding statement (resolution and ending) (Urbach, 2012).
While SG may appear clearly defined, its elements can be challenging for narrative assessors to accurately identify when assessing children’s oral narratives. Depending on the child’s ability, SG elements may be omitted or incomplete within the narrative. While it is possible to assess a narrative’s SG on a binary scale of element absence or presence, use of a more descriptive scoring method, such as a rubric, is arguably more informative and holds greater validity (Heilmann et al., 2010a). Rubrics provide descriptive criteria and score ratings for each SG element based on the quality of the element and are used more broadly in educational contexts to facilitate consistent marking criteria across study domains (Jonsson and Svingby, 2007). Assessors must identify and appraise the SG element in question, often relying on brief descriptions in rubrics as a basis for their scores (Heilmann et al., 2010a). Differing interpretation of scoring criteria can lead to greater variability between raters in assessment settings such as clinics or classrooms (Petersen et al., 2008).
2 Reliability of oral narrative assessment tools
Interrater reliability determines whether different raters using the same tool to measure the same variable will reach an appropriately similar score. A tool with high interrater reliability should thus demonstrate low rater variability. Many oral narrative assessment tools report adequate interrater reliability amongst their psychometric properties; however, trained raters are usually used to establish interrater reliability for specific narrative assessment protocols (Gillam et al., 2017; Gillam and Pearson, 2017; Heilmann et al., 2010a; Petersen et al., 2008; Schneider et al., 2005). While appropriate within a research context, this raises issues when viewed from a pragmatic perspective outside the research context.
Narrative assessment tools are designed to assess children in clinical and school education settings and it is therefore the ‘natural setting’ in which they must demonstrate reliability. Assessment tool developers recognize that people rating assessments (‘raters’) may not have access to training and expert support in narrative scoring (Gillam et al., 2017), and have questioned application of reliability data to a natural setting (Justice et al., 2010). Assessment tools validated by trained research staff may report adequate interrater reliability; however, these tools cannot be deemed effective for general use if there is high variability among raters for real-world utility.
3 Training
One solution to high variability is provision of training to raters in natural settings. Multiple studies illustrate the benefits of training in improving agreement in other areas of speech pathology practice including, perceptual voice assessment (Barsties et al., 2017; Brinca et al., 2015; Chan and Yiu, 2002; Eadie and Baylor, 2006; Lee et al., 2009; Schaeffer, 2013; Shewell, 1998), stuttering (Bainbridge et al., 2015; Einarsdóttir and Ingham, 2008), and cleft-palate speech (Chapman et al., 2016). There have also been calls to increase training in narrative assessment for education professionals (Malec et al., 2017).
Only two efficacious oral narrative assessment protocols were identified that offer universally available training programs: the Narrative Assessment Protocol-2 (NAP-2; Bowles et al., 2020) and the Narrative Scoring Scheme (NSS; Heilmann et al., 2010a). The NAP-2 assesses preschool children’s narrative language abilities. Training includes an introduction to terminology, revision of scored transcripts, and practice scoring using exemplars. The NSS (Heilmann et al., 2010a) provides a rubric for rating SG, and normative data within the Systematic Analysis of Language Transcripts (SALT) software (Caygill, 1998; Heilmann et al., 2010a). These two assessment protocols and training packages are designed for self-paced online learning and developed in the United States.
Despite widespread availability to raters, limited research supports real world effectiveness for either assessment tool when used by professionals other than researchers, a limitation recognized by Justice et al. (2010). Similarly, while normative research has established efficacy for NAP-2 and NSS, neither the assessments nor training have been evaluated in natural settings to determine effectiveness (Bowles et al., 2020; Heilmann et al., 2010a). Furthermore, while online training can provide global reach as a vehicle for professional development in assessment protocols, it may be less effective than face to face workshops (Lowman, 2016).
A workshop approach for speech pathologists, used by Lowman (2016), mirrored calibration or moderation methods used in schools and universities to ensure uniform marking of student assessments. Calibration relies on peer discussion of student assessment, with raters evaluating student work then discussing their results until they reach a consensus in scoring interpretation (Gardiner et al., 2020). Calibration training workshops have demonstrated reduction in rater scoring variability for tertiary accounting and business assessments (Gardiner et al., 2020; O’Connell et al., 2016). Improved scoring knowledge and skills have also been associated with greater confidence in use of scoring systems (Alanazi and Nicholson, 2019; Doble et al., 2019; Kamal et al., 2012; O’Connell et al., 2016). Therefore, the use of workshop training which incorporates discussion and calibration for oral narrative assessment may reduce variability in practitioner SG ratings, enhance homogeneity and proficiency, and increase confidence.
The present study investigated whether face to face training workshops, using calibration methods, and a researcher-designed rubric could significantly decrease rater variability in scoring SG of narratives produced by typically developing children. Three specific questions were:
Does workshop training lead to change and reduced variability in SG scoring across speech pathologists?
What is the impact of speech pathologists’ experience on SG scoring in response to workshop training?
Does workshop training improve speech pathologists’ confidence in scoring oral narrative assessment?
II Method
Ethical approval for the study was obtained from the Australian Catholic University Human Research Ethics Committee (2018-270EAP). A quasi-experimental, single group pre-/post-test design was used to explore the research questions.
1 Participants
Fifty-one speech pathologists and 19 fourth year undergraduate speech pathology students participated in the research. Participants were attendees at professional development workshops advertised through professional networks and to final year speech pathology students at Australian Catholic University and participation in the research component was optional. Workshops were conducted in Sydney (n = 18), Melbourne (n = 32), and Brisbane (n = 20) during May 2019. All workshop attendees consented to participate in the research and submitted anonymized response sheets to the researchers. Years of professional experience for the 51 speech pathologists ranged from 0.2 – 38 years (mean = 12.3 years). All speech pathologists worked with a paediatric caseload. One speech pathologist participant submitted pre-training data but did not submit post-training data.
2 Narrative samples
Thirteen oral narrative samples were gathered for use within the study from seven children of university speech pathology staff. The children included four boys and three girls between ages 6 and 12 years who had typically developing language. Eight transcripts were selected for use within the study. Longer transcripts were excluded in consideration of time constraints for training purposes.
Narratives were collected and audio-recorded by parents using one or two wordless picture book stimuli: William’s Baby Brother (WBB) and/or Sam’s Skateboard (SS) from the Oral Narrative Assessment Package (ONAP) (McCandlish and Schaefer, 2003). WBB was designed for younger (4–7 years) and SS was designed for older (8–11 years) children. Both stories have three characters and provide potential for complex episodes, with more than one attempt to solve the problem. These story stimuli were selected due to their ease of use, appropriateness to Australian children, and accessibility to participants. The ONAP allowed users the choice of generation or retell. For this study, examiners told the story, then asked comprehension questions and then asked the child to retell the story.
Narratives were transcribed by the researchers, with two used to assess the research outcomes and six others used for training purposes. An additional two artificial narratives based on WBB and SS were generated by the second author to provide exemplars of less complex narratives for training purposes within workshop activities. Thus, a total of 10 transcripts were provided for use in the workshops. An equal number of transcripts from each story, WBB and SS was used for scoring exemplars and practice. The least complex training sample was an isolated description of seven utterances, and the most complex training sample comprised 25 C-units (an independent clause and its modifiers) and had a complication (obstacle to the first attempt to solve the problem). Participants also reviewed the ONAP model scripts for WBB and SS during the workshop.
3 Narrative analysis tool
Analysis checklists in the ONAP were designed to report presence or absence of SG elements with no researched psychometric properties. The SG subscale from the Monitoring Indicators of Scholarly Language (MISL; Gillam et al., 2017) was selected as the analysis tool for this study because it provided a more nuanced rubric. The MISL was designed for use with children’s self-generated narratives and retells in response to varied picture stimuli and for describing stages of developing narrative complexity (from simple descriptions to multiple episodes) as a means of tracking progress. Its psychometric properties were explored using the Aliens story from the Test of Narrative Language (Gillam and Pearson, 2017) and considered acceptable for reliability, validity and responsiveness to therapy. The MISL rubric includes seven SG elements (character, setting, event, response, plan, attempt and conclusion) with four rating levels: Not Present (0), Emerging (1), Mastery (2) and Elaborated Knowledge (3). Definitions for each element are provided in Table 1. Elements rated at the emerging level may include non-specific descriptions or lack clear causal connections. A rating at the mastery level requires evidence of causal connections (e.g. an event motivates a character’s action) while a rating at the elaborated knowledge level requires multiple instances of well-developed elements (e.g. more than one character with proper names). All ratings were summed to create a total SG score for each narrative.
Definitions for Monitoring Indicators of Scholarly Language (MISL) story grammar elements.

Source. Gillam et al., 2017.
4 Training and data collection
Data was collected directly before, and immediately after training on the same day. Three primary data sets were: (1) demographic data for the participants; (2) pre- and post-training SG scores for one WBB and one SS narrative; and (3) pre- and post-training confidence scores.
Pre-training data collection occurred after a 15-minute introduction addressing the purpose of oral narrative assessment and its relevance to language disorder. Participants were informed that the study aimed to investigate whether training can reduce variability in oral narrative analysis, but the nature of variability was not discussed. Assessment and analysis procedures were not addressed during the introduction and participants were invited to score two narrative test samples from a rubric independently without discussion or support.
The narrative test samples were written transcripts of two oral narratives: WBB, a less complex narrative from a younger child (5-years-old, first year of school); and SS, a more complex narrative from an older child (9-years-old, fifth year of school) (see Appendix 1). Child age was not provided to the participants. The SS sample was longer and more linguistically complex with a higher number of C-units (16, cf. 13), mean length of C-units (11.80, cf. 8.00), total number of words (170, cf. 94) and number of different words (88, cf. 48). The SS sample also showed more complexity in SG components. For example, the WBB sample did not include any SG element of Plan, while the SS sample included two C-units describing this element: 5 Sam was trying to think of something to do. 6 Finally, he came up with an idea to sell some of his old toys.
Participants were provided with the SG subscale from the MISL narrative rubric (Gillam et al., 2017) and definitions of SG components, but were not provided with exemplars to illustrate scoring application. Participants also completed a demographic questionnaire and a 12-item questionnaire exploring their confidence in administering and scoring oral narrative assessment. Confidence was rated on a Likert scale from 1 (very unsure) to 5 (extremely confident). Consent forms and all data were collected from participants after the pre-training scoring. Participants added a unique identifier code to all documents to enable linking by the authors for analysis.
The second stage involved training in oral narrative assessment. Training was delivered by the second author as a single-day workshop which participants attended at three locations, each containing 4.5 hours of instruction. Content was supported by a PowerPoint and hard copy participant handouts. Formal workshop training commenced with an introduction to oral narrative assessment tools and methods, description of MISL scoring categories and facilitated discussion around areas of confusion or concern. Exemplars of scored narratives were provided and discussed. Participants then practiced scoring oral narrative samples from transcripts individually and in small groups, followed by whole-group discussion of scoring outcomes and considerations. The second author responded to questions or issues arising from practice sessions and presented rationales to assist with scoring dilemmas.
The final stage of data collection occurred immediately post-training. Participants independently scored the same oral narrative assessments as the pre-training stage, without access to their previous scores, and completed the same confidence questionnaire. No discussion or questions were permitted; however, participants were able to refer to handouts as well as their own notes taken during the workshop. Following the post-training data collection, the workshop addressed intervention approaches and resources.
5 Analysis
Descriptive statistics were used to explore changes in SG scoring pre- and post-training for WBB and SS. A paired samples t-test determined if any significant change had occurred in total SG scores. A repeated measures ANOVA determined if there was an interaction effect between experience and total SG scores pre- and post-training. Years of professional experience was categorized into three subgroups that provided viable participant numbers for analysis: students and less than one year (n = 24), one to 10 years (n = 21), and more than 10 years (n = 24). The Wilcoxon signed-rank test was used to determine if any significant change had occurred in ratings of individual SG elements pre- and post-training and to compare Likert scale ratings pre- and post-training for rater confidence on aspects of assessment and analysis.
III Results
1 Narrative scores and variability
Descriptive statistics for both WBB and SS pre- and post-training total SG scores are shown in Table 2. Changes in range and standard deviations demonstrated a reduction in variability for WBB post-training, but not for SS. A paired samples t-test indicated a significant increase in total scores for WBB pre- and post-training (t(69)= −3.42, p = .001, d = 0.48) but no significant change in total scores for SS pre-and post-training (t(69)= −0.68, p = .50, d = 0.10).
Descriptive statistics for Monitoring Indicators of Scholarly Language (MISL) total scores pre- and post-training.

Descriptive statistics and Wilcoxon signed-rank test results for the WBB and SS SG element scores are shown in Table 3. Both stories showed significantly increased scores for the elements Character and Attempt. The score for SS Consequence also significantly increased. Scores significantly decreased for WBB Plan and SS Setting.
Monitoring Indicators of Scholarly Language (MISL) element scores pre- and post-training for William’s Baby Brother (WBB) and Sam’s Skateboard (SS).
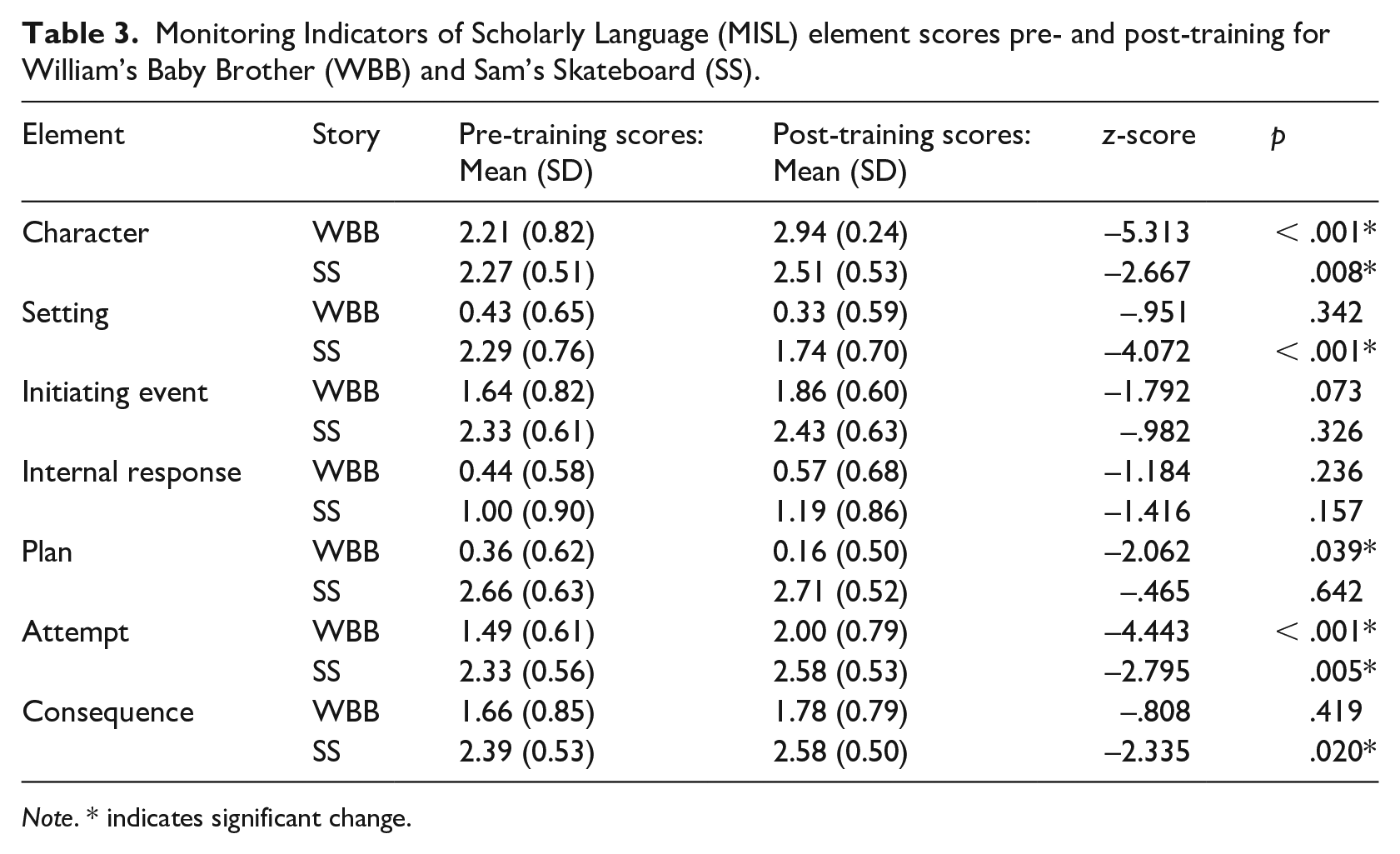
Note. * indicates significant change.
2 Professional experience and confidence
ANOVA identified a significant interaction between years of experience and WBB total SG score change pre- and post-training (F(2, 66) = 3.43, p = .038,
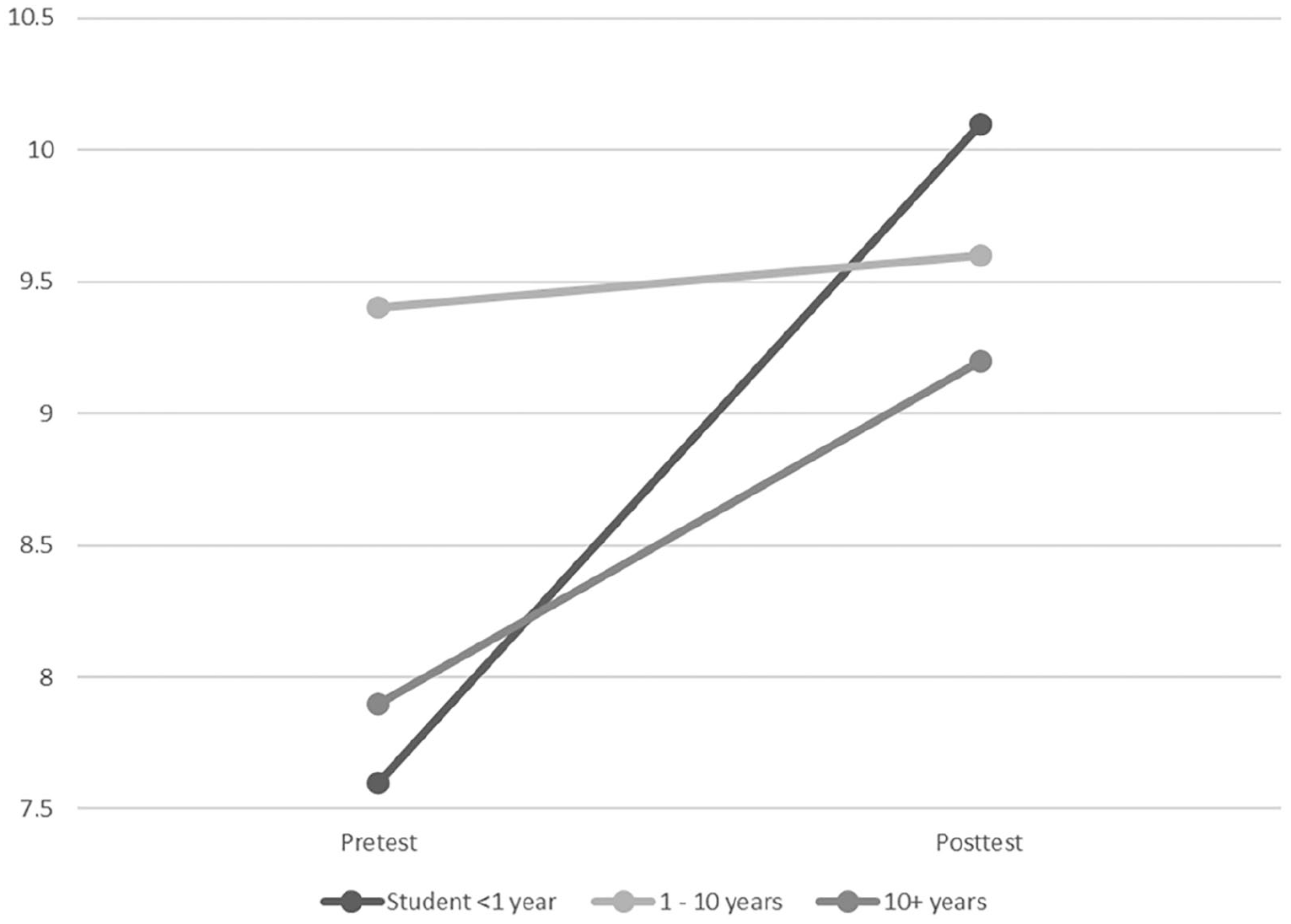
Total scores for William’s Baby Brother (WBB) pre- and post- training by years of experience.
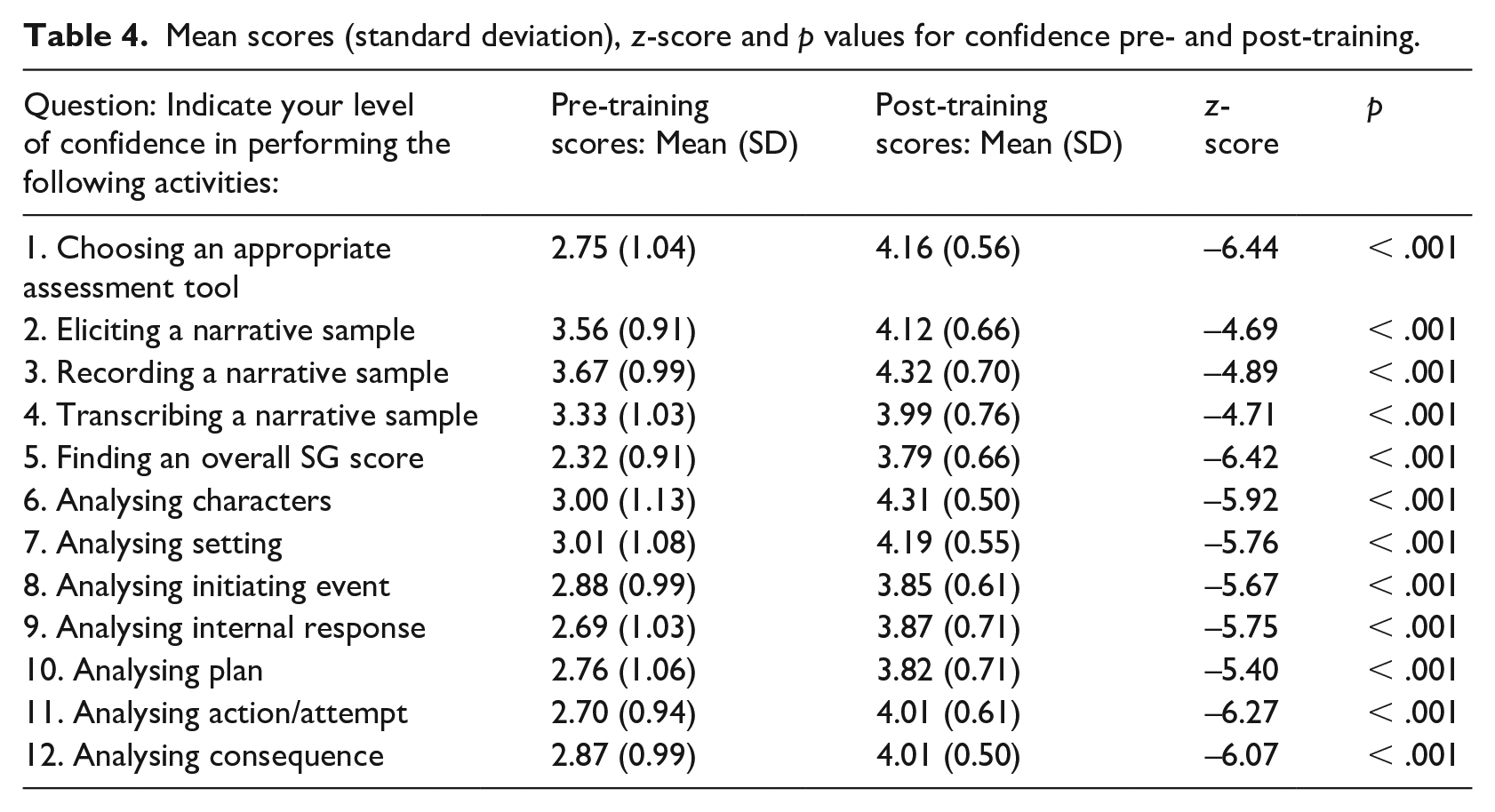
Mean scores (standard deviation), z-score and p values for confidence pre- and post-training.
IV Discussion
The present study examined whether provision of workshop training would impact variability of oral narrative assessment scoring. It also questioned whether experience influenced response to training, and whether practitioner confidence was impacted by training. The results showed significantly diminished variability for one story sample, and no change for the other. An overall trend for decreased variability was seen for individual SG elements. In the story which showed significant change, an interaction between years of experience and response to training was noted with students and new graduates showing the greatest change in scores compared to more experienced participants. Confidence in all areas of oral narrative assessment improved following training.
1 The impact of training on score variability
Results indicate that training has some benefit on reducing rater variability in oral narrative scoring, and guided examples related to target stories with accompanying discussion are likely to lead to greater consensus in interpretation of story element definitions. One possible reason why WBB showed reduced variability in total score after training and SS did not, is the influence of story complexity. SS was a story from an older child and showed more complexity than WBB, as illustrated by more and longer utterances, more diverse vocabulary, and higher MISL scores. Previous research comparing ratings of narrative quality found agreement was highest at the ‘polar extremes’ of the rating scale (Streit Olness et al., 2005). It is possible that, since SS was a more complex and developed story, it was clearer for all raters, regardless of experience, to identify strengths and score consistently. Conversely, training to assess a less sophisticated narrative had a greater impact on consensus, highlighting the importance of including narratives of varying complexity in training.
Another potential factor is that speech pathologists marking a less mature story may mark it lower to ensure the child’s difficulties are noted, and to leave room for improvement over treatment. However, mean scores for both WBB and SS increased, despite discussion during the workshop guiding raters to mark a story lower if they were unsure about whether the criteria were sufficiently reached. Noting this instruction, the increase in scores may indicate that uncertainty in scoring was minimized following training.
Observations of variability were less consistent for individual SG elements. Overall, 71% of SG element scores showed a decrease in standard deviation following training, indicating a trend towards lower variability, with half of these also showing a significant increase in scores. This is likely due to discussion and use of exemplars during training, which clarified definitions of key concepts within the rubric. For example, discussion about proper names occurred, with participants debating whether ‘Mum’ was a proper name in WBB. It was decided that this was a proper noun in the context of the narrative, as most children only call their mother ‘Mum’. The significant increase in score and decrease in standard deviation for Character in WBB reflected this understanding following training. Participants also debated whether Mum and ‘the shopkeeper’ could be considered main characters in SS. Discussion about how to score attempts for WBB required clarification about the problem and goal (to pacify the baby).
For SS, discussion about how to score attempts focused on identifying the complication which increased the attempt score (didn’t have enough money). Discussion about the consequence score focused on identifying multiple occurrences (getting $10 for selling old toys, and $5 for mowing the lawn). It is also possible that the workshop process and focus on SG elements helped participants to assess these independently of influencing factors, such as the microstructural complexity of the narrative sample. This may explain the significant decrease in scores and standard deviation for setting in SS. In the test sample, the setting was expressed thus: 1 One day Sam was walking around the city when he saw a big garage sale sign. 2 Sam walked to the behind of the house and found an old box with a skateboard in it.
Although the setting was expressed in complex language, it did not meet the MISL criteria of “reference to place denoted using proper name, or reference to specific time” required to be classed as elaborated knowledge.
2 The impact of years of experience
Training was most beneficial for participants with the least experience, who also had the largest change in total scores following training, resulting in a more homogenous post-training result overall. This is consistent with findings across other areas of speech pathology showing inexperienced raters made greater improvements than more experienced raters following training (Silbergleit et al., 2018). It is also consistent with the notion that interrater reliability of narrative assessment tools will improve as raters gain experience (Gillam et al., 2017).
Some change, although not significant, was seen for raters with more than 10 years of experience, suggesting variability may increase over time. This may relate to the phenomenon of ‘coder drift’, which describes variability of ratings increasing over time due to a lack of calibration (Syed and Nelson, 2015). These results indicate that training is most beneficial to students and early career practitioners, yet also supports more experienced practitioners.
3 The impact of training on confidence
A significant increase in confidence after training was likely due to opportunities presented for asking questions, comparing responses and consolidating understanding throughout the collaborative workshop. In this flexible training, participants were able to air specific concerns and clarify individual aspects of scoring. The improvement in confidence is consistent with other studies in the speech pathology field (Alanazi and Nicholson, 2019; Doble et al., 2019; Kamal et al., 2012).
In the education sector, Millet (2018) suggested that low confidence in assessment grading leads to increased variability between raters. Calibration studies have reflected that increase in confidence following workshops may contribute to reduced variability, with the potential for variability to continue to decrease as confidence in the scoring process increases (O’Connell et al., 2016). In the current study, while confidence increased and overall variability diminished for total scores, confidence in scoring individual story elements did not always lead to a reduction in variability for the same story elements. Hence, confidence in rating did not guarantee homogeneity of scoring.
4 Limitations
While several narrative exemplars were provided during the training workshops, only two stories were analysed by participants for pre- and post- testing, which limited data available for analysis as well as training experience. Inclusion of stories from children with language disorders may have provided a more thorough training for participants, providing opportunities to contrast narratives of varying quality and practice differential scoring. The stories in both research analysis and training were retells of the same two narratives, limiting exposure of participants to stories gathered using different protocols and procedures. Follow-up was beyond the scope of the study and could have provided insight into the long-term outcomes of training. Furthermore, only brief demographic data was gathered. A more extensive review of participant experience with oral narrative scoring may have been informative.
5 Implications for practice and future research
The outcomes of this study indicate workshop training involving group discussion and exemplars, facilitated by a trainer with expertise in narrative assessment, is beneficial when applied to oral narrative assessment scoring. Collaborative training processes may contribute to increased confidence in the delivery of narrative assessments, and greater consistency of narrative assessment, thereby increasing the validity and effectiveness of narrative assessment in natural contexts.
Further research into the long-term effects of training would be beneficial in evaluating the efficacy of workshop training as well as providing recommendations for the frequency of training to maintain skills and confidence. In speech pathology, increased validity of scoring is essential to consistent practice when assessing children for involvement in language or narrative intervention groups, or on handover to another practitioner. As a diverse range of professions utilize oral narrative assessment procedures, further investigation into the application of this training across professions, particular the education sector, would also be beneficial (Malec et al., 2017).
V Conclusions
The findings of this study suggest that interactive workshop training led by an experienced professional is an effective tool for decreasing variability of speech pathologist scores in oral narrative assessment. While likely to be of most benefit to early career professionals, workshops which involve peer discussion and calibration is beneficial in increasing participant confidence and skills regardless of years of experience. Further investigation into areas of disagreement between raters, particularly after training, would assist in improvements to both assessment protocols and training packages. Workplaces may consider implementing workshop training amongst their teams to facilitate reduced variability in scoring and increase practitioner confidence.
Footnotes
Appendix 1. Transcripts used for pre- and post- scoring
Acknowledgements
This study was undertaken as part of a Bachelor of Speech Pathology (Honours) awarded by Australian Catholic University. Appreciation is extended to Dr Michael Steele for statistical support, participating speech pathologists and to the parents and children who provided oral narrative samples.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.