
Abstract
Data science, a dynamic and rapidly growing field with expanding job growth, has wide variations among data science programs and conceptualizations of data scientists’ skills. Consequently, employers face challenges recruiting the right data scientists, due to misalignment between university preparation and industry needs. To explore this further, we present an alternate data science view and use it to investigate knowledge gaps. Text mining of U.S. university syllabi is used to identify knowledge and skills taught by U.S. universities and colleges. These are compared to data science terms and concepts identified in job postings from previous research. We find graduates are better prepared for soft skills, but ill-prepared for technical and analytical skills. The findings are used to discuss how universities and industry can bridge the gaps.
Introduction
Advances in computing power, storage, databases, Internet of Things, mobile devices (Bowers et al., 2018), and cloud technologies exponentially increase the amount of data, spurring new business opportunities. Companies’ attempts to exploit data gave rise to data science (Berman et al., 2018) and analytics (Bowers et al., 2018), which are multi-disciplinary (Cao, 2017b; Stodden, 2020) and evolving fields of study (Seal et al., 2020). Data science utilizes traditional statistics, numerical and textual data mining techniques for discovering new knowledge to support management strategies, decision making, product and service development, and competitive advantage (Radovilsky et al., 2018). It is a high-demand profession with multiple job opportunities (Ramzan et al., 2023). As a discipline, data science has several unresolved questions, such as: how to define it; is it a science; how to make it a science; what is the path to becoming a science; how does data science differ from data analytics, business analytics, and data mining; why do knowledge and skills overlap and sometimes used interchangeably; is it a purely technical discipline; should it include soft skills; What challenges do the prevailing data science view pose; is there an alternate data science view. The latter two questions are within the purview of this research and constitute research gaps in data science literature, which stem from the prevailing data science view.
There are broad, conflicting, and varying data science definitions, and the lack of agreement on the scientific nature of data science requires a well-defined and established definition (Stodden, 2020) to delineate data science topics, methods, theories, hard and soft skills, and techniques to include in courses and programs (Saltz et al., 2018). There are opposing views on whether traditional statistics should be included in data science (Agrawal et al., 2020; Reany, 2014). Differences among subject areas such as data science, data analytics, and business analytics are not well delineated, evident by overlapping knowledge and skills (Radovilsky et al., 2018; Saltz et al., 2018; Stodden et al., 2013), creating confusion and knowledge gaps. There is evidence of knowledge gaps between university preparation and industry needs (Börner et al., 2018). For example, soft skills include communication and presentation of findings and their applications to business decisions. Data scientists who lack these skills are likely to underperform as industry requires data scientists to possess them (Biswal, 2023; Bonesso et al., 2020; Börner et al., 2018; Radovilsky et al., 2018; Reany, 2014). In addition, these knowledge and skills are often neglected by the prevailing view, requiring researchers to identify them. Overlapping knowledge and skills pose challenges on where in the curriculum they belong, how to differentiate between data science subject areas, what to teach, how to design curriculum, processes for adding non-traditional data science skills, and interpreting research results.
We advocate an alternate view of data science that serves as an umbrella for various subject areas, which will be referred to as specializations or branches of data science. It provides several benefits. The first is data science no longer competes with the other specializations, reducing the need to differentiate knowledge and skills unique to it. Second, Reany identified 22 skills of well-rounded data scientists and cast doubt on a single scientist to satisfy them (Reany, 2014) due to different profiles of data scientists (Harlan et al., 2013), including data business people, data creatives, data developers, and researchers, who are “leaders and entrepreneurs”, “artists and hackers”, “programmers and engineers”, and “scientists and statisticians” respectively (Reany, 2014). Reany's skepticism is well-founded, as some view business knowledge to be outside data science, yet useful for business-related problems. Given the fast-evolving field (Seal et al., 2020), adding new knowledge and skills from various specializations, is easily accomplished. A third benefit is data scientists’ profiles are better developed by having a curriculum for each specialization. Fourth, if data science is to assume its rightful place as a science among established sciences, such as physics and chemistry, it requires specializations. These outcomes are unlikely under the prevailing view, which constrains how data science is viewed, how it evolves as a science, how to design curricula to reduce knowledge gaps, and how to conduct research.
Our research objectives are: 1. Articulate the prevailing data science view; 2. Discuss its inherent challenges; 3. Propose an alternate data science view; and 4. Use the alternate view to identify data science knowledge gaps between academia and industry. To pursue these objectives, we advance two research questions:
What is the alternate data science view?
What are data science knowledge gaps between universities and industry?
To address RQ2, we compare 220 data science-related course syllabi from U.S. colleges and universities, to data science terms and concepts identified in prior research (Radovilsky et al., 2018) from data science job postings, using text mining. This eliminates our need to sample job postings. Universities are integral to bridging knowledge gaps (Singh Dubey et al., 2021). Our findings contribute to assessing how effective they are in meeting industry needs and suggesting ways to narrow the gaps. The paper is organized as follows. First, we discuss the prevailing data science view and its inherent challenges. Next, we present an alternate view to address RQ1. We then explain the research method used to analyze course syllabi. This is followed by a discussion on how well universities satisfy industry needs, addressing RQ2. The findings are used to suggest 15 specific recommendations to improve data science by bridging knowledge and skill gaps, moving data science closer to becoming a scientific discipline.
Data science challenges
Prevailing view of data science
Data science is broadly and vaguely defined as the science of data (Bichler et al., 2017), with independent and competing subject areas and definitions used loosely and interchangeably (Stodden, 2020), with multiple interpretations. Data science infancy (Dubey and Gunasekaran, 2015) and constant evolution (Seal et al., 2020), pose challenges for universities and industry. The former struggles with curriculum development (Bowers et al., 2018; Seal et al., 2020), the latter with hiring data scientists with appropriate competencies (Persaud, 2021). It is important universities know what skills and knowledge to include in courses and programs, which departments should offer courses and programs, and how to label them. It is important for industry to identify job postings to fulfil data scientists’ vacancies. Job postings terms and concepts are skills and knowledge industry demands. The challenges of universities to develop data scientists and industry's ability to fulfil vacancies can be traced to narrow definitions (Batistič and van der Laken, 2019), lack of established (Bichler et al., 2017), widely accepted (Saltz et al., 2018), poorly defined, and confusing data science definitions (Nguyen et al., 2020), and lack of consensus among scholars and professionals (Cao, 2017a).
The prevailing view (Figure 1) of data science comprises six inter-related and competing subject areas supposedly with some mutually exclusive knowledge and skills. One can infer from this view that two degrees are needed to specialize in two subject areas, however, some differences are ill-defined as knowledge and skills overlap, causing identical advertised job positions to require different skills (Leon et al., 2018). This is further complicated by courses in one specialization taught by different academic units with different content and emphases. An analytics course in business may be as technical as one in computer science due to similar technologies, algorithms, and course content. It is customary to believe computer science courses are more technical, making it challenging to clearly define technical and analytical differences between them. Patil defines data scientists as possessing “deep” technical skills that are different from business analysts (Patil, 2011). However, it is difficult to assess the depth of knowledge and skills that separate one majoring in business analytics, data analytics, or data science. Furthermore, why should data scientists not possess analytical, communication, and/or business knowledge, and simultaneously, why is it semantically incorrect for business analysts be technical? They do not have to be mutually exclusive and this view is contrary to industry belief that data scientists should possess data reporting, data visualization, business intelligence, decision making, and personal skills (Biswal, 2023; Coursera, 2023).
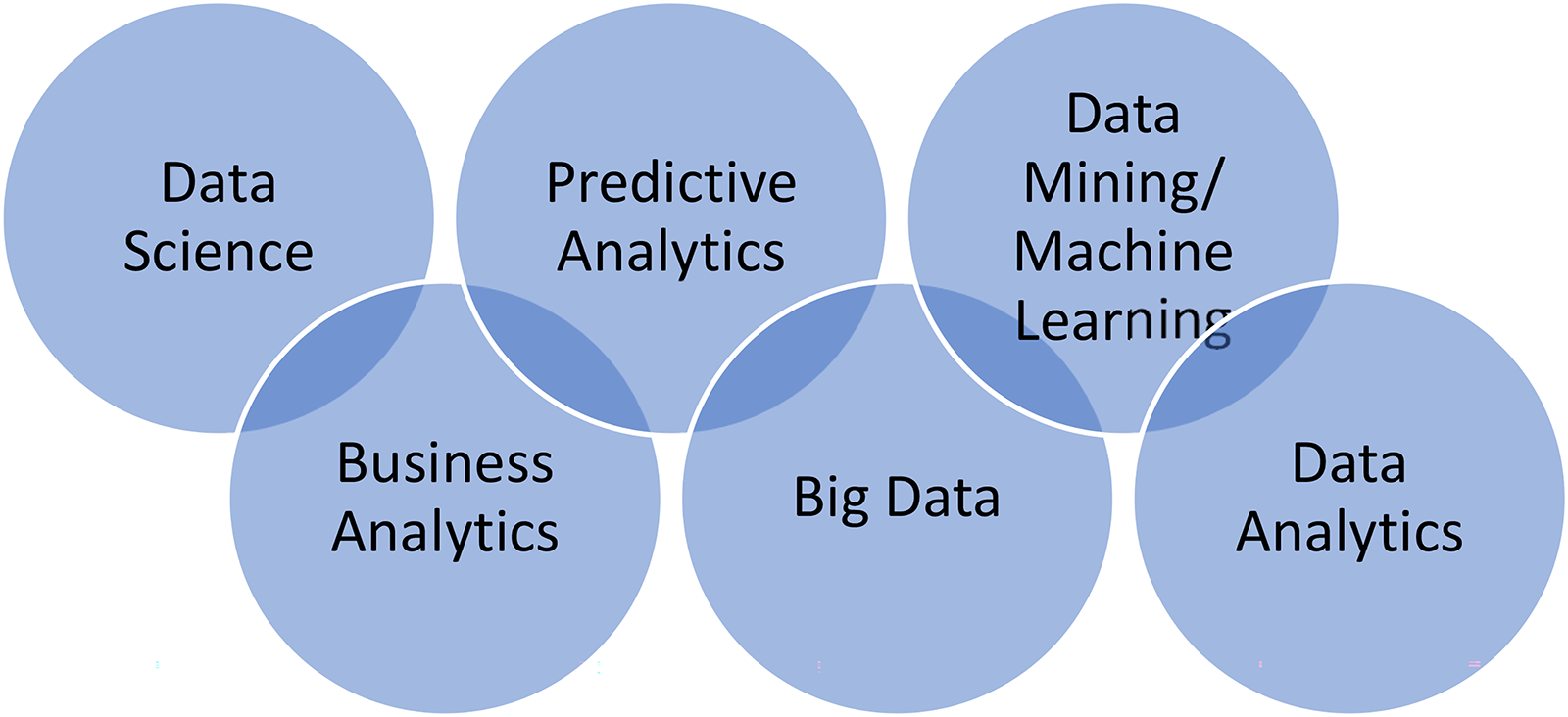
Primary data science subject areas.
The prevailing view manifests confusion regarding curriculum content, scientists’ competencies and expectations, and subject area differences. Under the prevailing view, data science skills differ from big data (Bowers et al., 2018) and business analytics (Persaud, 2021). Columbus suggests data science develops business analysts, yet the prevailing view suggests they are developed by business analytics (Columbus, 2017). Traditional statistics is excluded from data science (Agrawal et al., 2020), making it difficult to develop well-rounded data scientists with no knowledge of statistics and probability. We argue probability knowledge is important to data science, yet we can only find a single specific mention (Coursera, 2023). Nonetheless, Reany among the minority considers statistics a skill in data business, data creative, and data research subject areas of data science (Reany, 2014).
To distinguish between data science and business analytics, Radovilsky, Hedge, Acharya, and Uma argue data analytics covers business-related skills while data science is more technical and both include clustering, while distributed computing and Apache are unique to data science. Presentation and communication are deemed to be part of business analytics only (Radovilsky et al., 2018), however, this is inconsistent with industry demand that data scientists should possess presentation and communication skills (Biswal, 2023; Coursera, 2023). The technology, be it Crystal reports or SharePoint is irrelevant; they are simply presentation technologies that could be used in any specialization. Data science skills for analyzing large amounts of unstructured data are seldom taught in traditional statistics. Statistics and data science cover multiple and logistic regression, but data wrangling techniques in data science are covered in more depth. Linear programming taught in operations is sometimes found in data analytics, but seldom in data science (McAfee et al., 2012).
The preceding discussion raises unanswered questions: 1. Are data scientists developed by computer science only? 2. Can information technology, information systems, and business disciplines develop data scientists? 3. Can data scientists be equally qualified, independent of where they are trained? 4. Should knowledge and skills differ across programs offered by different academic units? 5. Should fundamental technical and analytical differences exist among data analytics, data science, big data analytics, business analytics, and data mining? 6. Should traditional statistics and probability be part of data science core, a specialization, or excluded? These unresolved questions stem from broad, varying, vague, narrow, and conflicting data science definitions (Batistič and van der Laken, 2019; Nguyen et al., 2020; Saltz et al., 2018; Stodden, 2020) that contribute to curriculum, program, subject area inconsistencies, and confusion.
Universities have not been very successful at effectively training data scientists (Stodden, 2020). They lack clear approaches to how, what, and where data science should be taught, but no best practice on delegating teaching responsibilities across academic units exists (Berman et al., 2018). Different data science courses and curricula exist in math, statistics, management, business, marketing, accounting, finance, computer science, operations research, and other departments (Saltz et al., 2018). Similar courses at different universities have different breadth of coverage. A data mining course at a university may cover decision trees, another covers artificial neural networks and support vector machines, that are more challenging to interpret (Du et al., 2020). Data science's inter-disciplinary nature led University of Michigan to create a joint data science program between electrical engineering, computer science, and statistics (Berman et al., 2018). At Stanford, data science is taught in the Statistics program, and University of Southern California, Computer Science. John Hopkins teaches data science in Engineering, while UC Berkeley and Harvard teach it in Information Science and Professional Studies respectively (Stodden, 2020). Decentralization of data science may lead to fragmentation of course content, offerings, and curricula causing data scientists’ competencies to be a function of where they are trained.
These variations spill over to industry and create a shortage of data professionals with technical abilities (El-Deeb, 2022). Companies recognize a need to process and analyze large amounts of data to derive business value (Batistič and van der Laken, 2019), but lack understanding of how to fully exploit data (Barton and Court, 2012). Defining data scientists knowledge, skills, and standards are subjects of intense debate (Harlan et al., 2013), due to misunderstandings about their competencies (Persaud, 2021). These issues are exacerbated by lack of a widely accepted definition and poorly defined scope from academia (Bichler et al., 2017). Consequently, employers struggle to define data scientists’ skills in data science job postings as skills are sometimes inaccurate, vary significantly, and not current to recruit the right candidates (El-Deeb, 2022). Data analytics job postings’ frequent terms are “SQL”, “tools”, “reports”, “business”, “environment”, and “analytics”, while data science terms are “machine learning”, “analytical”, “python”, “Big Data”, “analytics”, and “algorithm”. Data analytics includes business-related skills while data science is more technical (Radovilsky et al., 2018). Nonetheless, data scientists need problem domain knowledge to understand and formulate problems, interpret results, make predictions (Cao, 2017a), visualize and communicate results (Biswal, 2023; Coursera, 2023). Business analysts are also required to use algorithms to solve problems. When specializations are independent or used interchangeably, they pose challenges for employers to recruit the right data scientists. Consequently, a clearly defined scope to improve and manage data science growth is needed to avoid mis-labelling anyone as a data scientist (Miller, 2014).
Alternate view of data science
There are different ways to conceptualize data science as an evolving discipline. The issues discussed earlier are inherent in how data science is viewed. Data science research and university programs define data science as an independent subject area that competes with the remaining five subject areas. This view comes with inherent challenges regarding how to delineate clear differences between them. The primary role of data scientists is to advance technical, analytical, and business knowledge and not be limited to the technical domain. Well-rounded data scientists possess knowledge from multiple subject areas (Reany, 2014), yet some may choose to specialize. It can be argued that the prevailing view constrains our understanding, epistemology, and research.
Data science uses non-traditional statistical, mathematical algorithms including machine learning to analyze data to discover new knowledge, transform data, and make predictions (Agrawal et al., 2020). This requires knowledge in traditional probability and statistics (Coursera, 2023), informatics, computing, communication, management, and sociology to study data (Cao, 2017a), includes data generation, acquisition, management, inference, analysis, and reporting (Stodden, 2020). Data science creates data scientists, data analysts, business analysts, data engineering, and business intelligence jobs which are among the fastest growing jobs (Columbus, 2017) and rated among the best U.S. jobs (Radovilsky et al., 2018). The above statement suggests data science is comprised of multiple specializations, yet the prevailing view portrays it as an independent and competing subject area. To satisfy the demand for data scientists, universities create curricula and academic programs to impart knowledge and skills (Dhar, 2013). North Carolina State University became the first to offer a business analytics graduate program in 2007, and other universities soon followed suit (Cao, 2017a). Today, data science courses and programs are more widespread.
Science is a body of knowledge on a specific subject area. Therefore, data science should be viewed as the collective body of knowledge on data (Miller, 2014) and encompasses knowledge and skills from multiple specializations and disciplines (Bowers et al., 2018; Cao, 2017a; Song and Zhu, 2016; Stodden, 2020) such as data analytics, predictive analytics, data mining, big data analytics, business analytics, predictive analytics, statistics, mathematics, operations research, computer science, information management, and business. It utilizes communication, data generation, acquisition, preparation, management, inference, analysis, modeling, prediction, communication, and reporting skills.
We propose an alternate data science view that accommodates, encompasses, reduces existing challenges, and better positions it as a science. We posit, data science is the umbrella for the five specializations (Figure 2). Reany identifies 22 data scientist skills from the specializations and a single scientist does not specializes in all (Reany, 2014). One can deduce data science, as currently conceived, is not an independent, competing subject area capable of developing well-rounded data scientists. The alternate view (Figure 2) is better positioned to develop data scientists, accommodate new skills and specializations, and reduce existing challenges. For example, traditional probability and statistics can be included as a data science core or specialization.
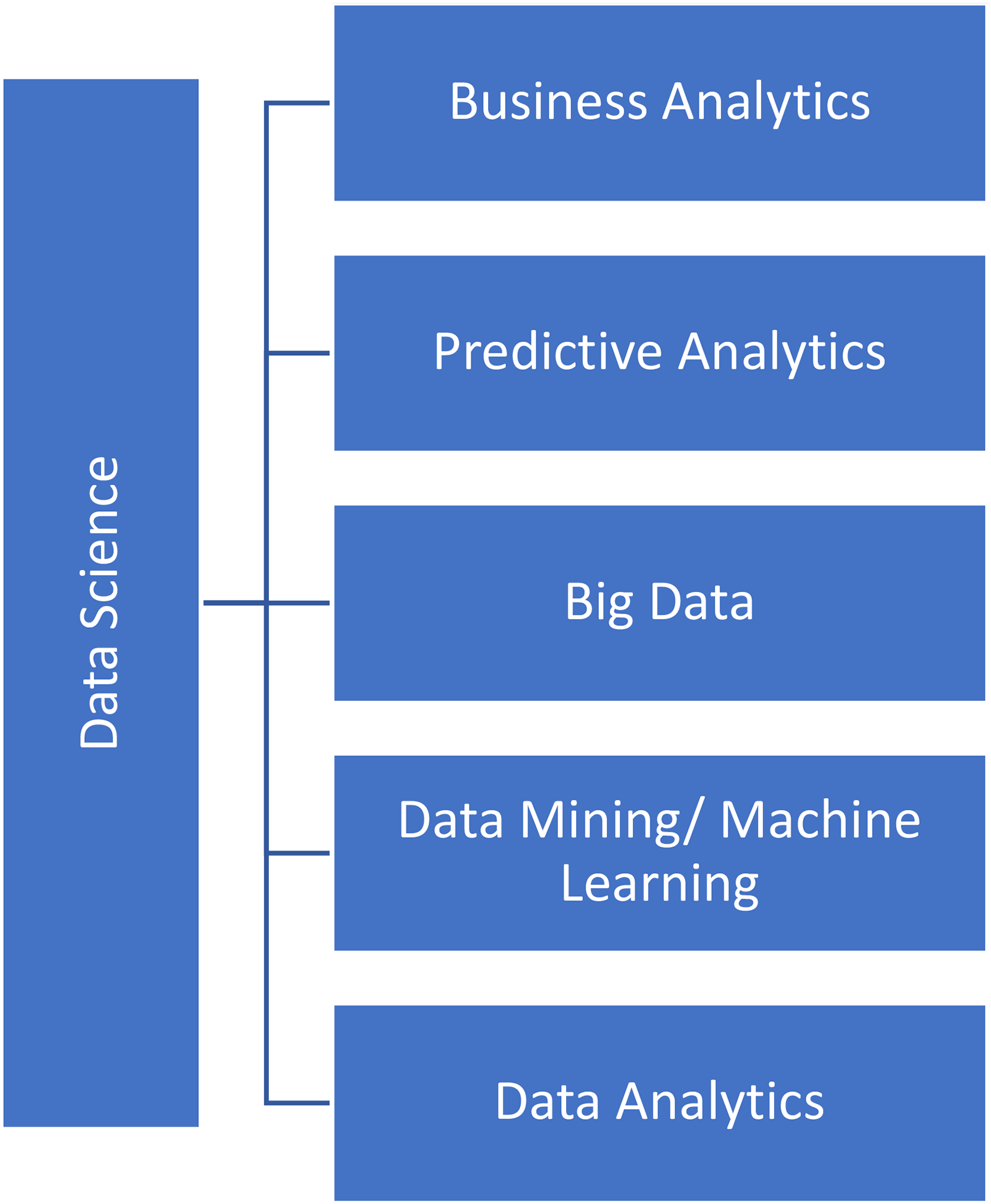
Data science as an umbrella for specializations (branches).
Empirical research method
The alternate view is used to assess whether U.S universities satisfy industry needs by comparing data science university syllabi from U.S. colleges and universities to job postings, an established research approach (Bowers et al., 2018; Sodhi and Son, 2010). Syllabi are artifacts of data science knowledge and skills (Doolittle and Siudzinski, 2010), constituting the supply side of data science, while job postings represent industry demand for knowledge and skills, the demand side of data science (Seal et al., 2020; Sodhi et al., 2008). Figure 3 illustrates the empirical research method used in the analysis.
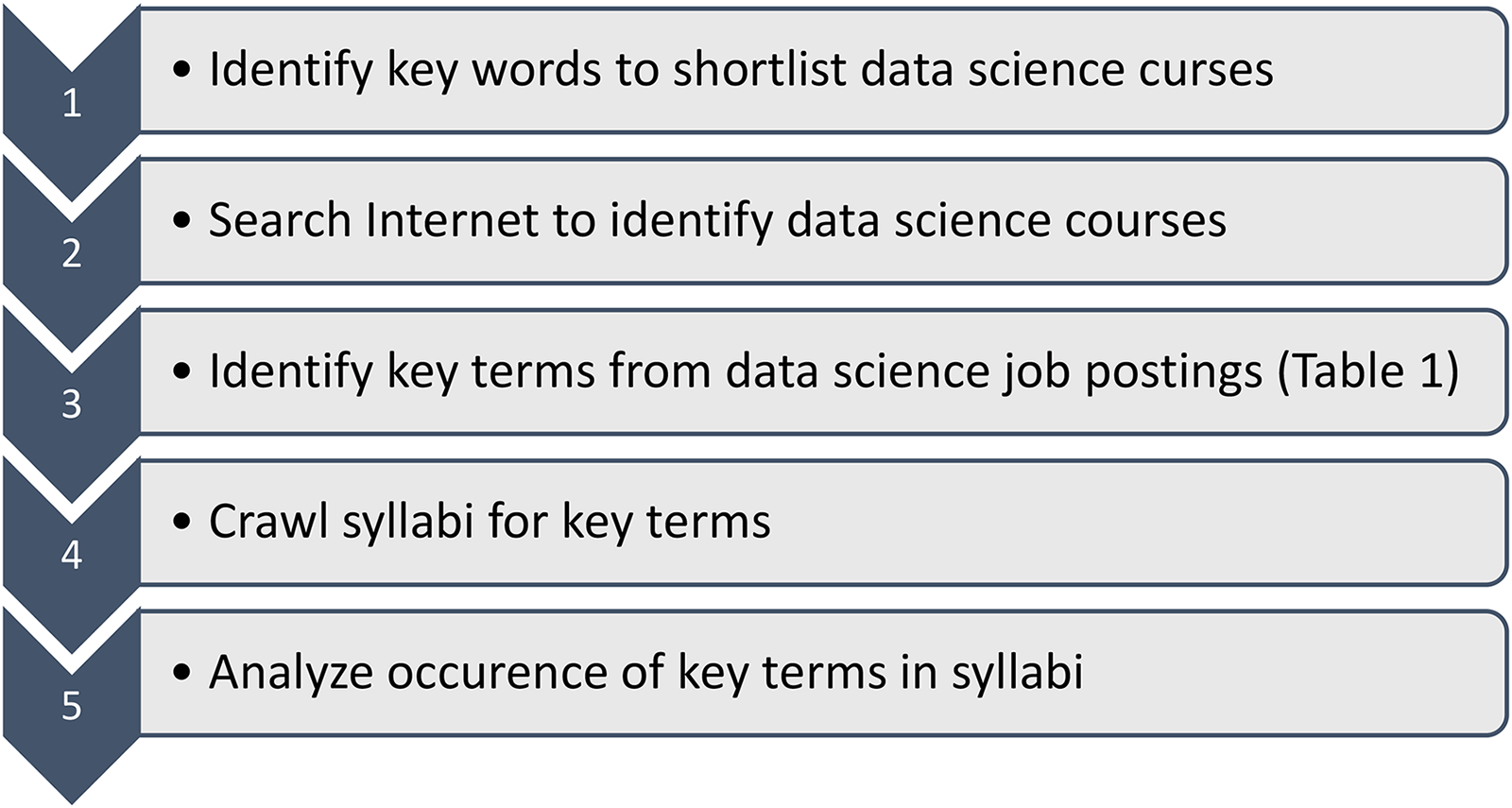
Empirical analysis.
Step 1: We identified key words – “data science”, “data analytics”, “Big Data”, “predictive analytics”, “data mining”, “data analysis”, and “business analytics” – to shortlist data science-related courses under the alternate view, whereby data science is the umbrella for the five specializations or branches. Each course falls within one of five specializations and is independent of programs. Therefore, an undergraduate data science course is treated no differently than a graduate course, and there is no need to distinguish courses from specific programs. Identifying knowledge gaps in undergraduate or graduate programs requires a different assessment where courses are selected based on programs. The alternate view is markedly different from conventional wisdom on data science; hence this study is exploratory in nature.
Step 2: Between fall 2017 and spring of 2019, we searched the internet for syllabi using the key words from Step 1. Key words were selected based on their relevance to a specialization or branch of data science under the alternate view. We collected 220 university syllabi in total. Not all university syllabi are posted online, and limited resources prevented us from obtaining an exhaustive sample. This limitation is discussed in the Conclusion, Limitations, and Future Research section.
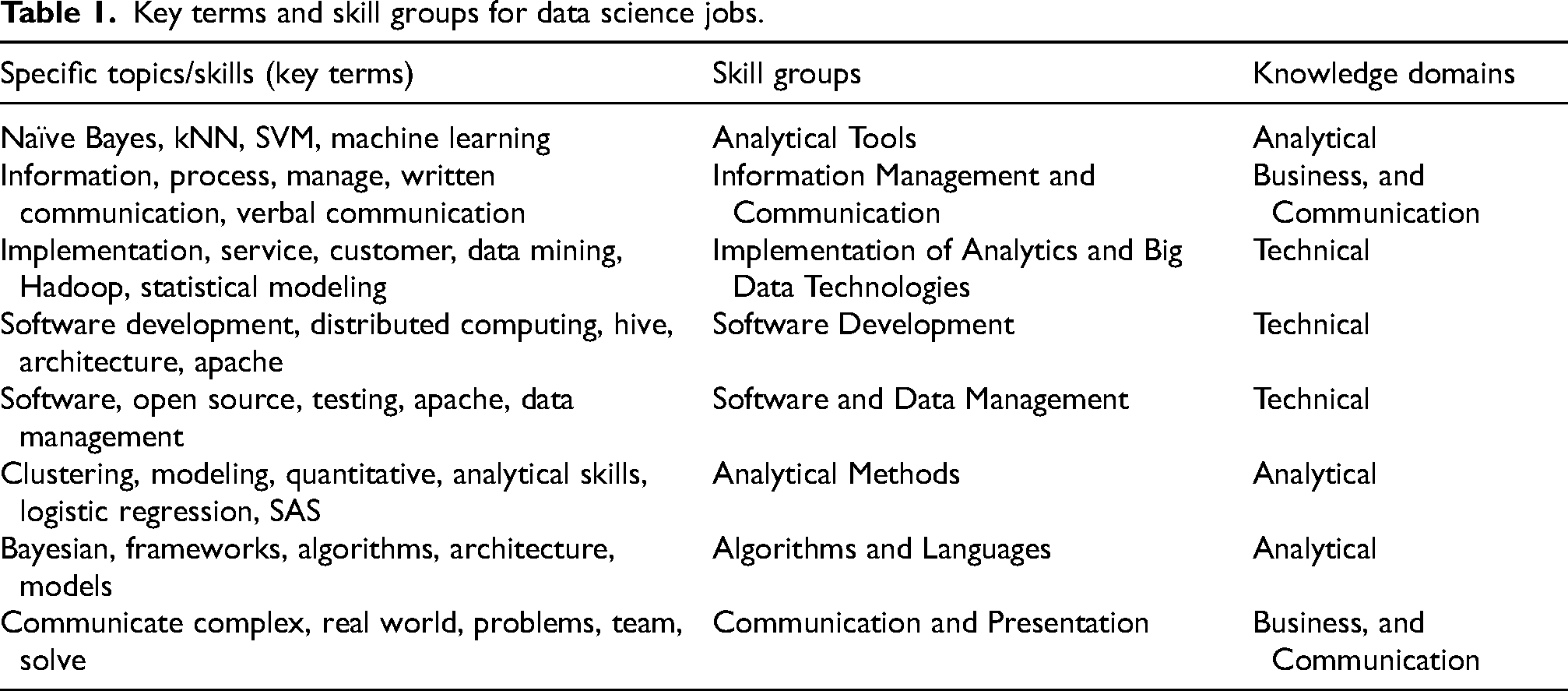
Step 3: We refer to results from Radovilsky, Hedge, Acharya, and Uma's study to create a list of data science terms from job postings in 2017 (Table 1). Terms represent data scientists’ knowledge and skills employers demand (Radovilsky et al., 2018). They are organized into eight skill groups: Analytical Tools, Information Management and Communication, Implementation of Analytics and Big Data Technologies, Software Development, Software and Data Management, Analytical Methods, Algorithms and Languages, Communication and Presentation, identified using factor analysis, based on proximity to each other (Radovilsky et al., 2018). Skill groups were aggregated into four knowledge domains, Technical, Analytical, Business, and Communication (Radovilsky et al., 2018). The first three are based on Cegieelski and Jones-Farmer's definitions of data science professions (Radovilsky et al., 2018). The technical domain includes applications such as SAS and Tableau, languages (such as Python, R, and SQL), and infrastructure (Hive and Hadoop), analytical includes problem-solving skills and predictive analysis, and business includes project and client management (Cegielski and Jones-Farmer, 2016). Communication includes written and verbal presentation skills (Radovilsky et al., 2018) required for data science jobs (Börner et al., 2018). These domains reflect the scope and cross-disciplinary nature of data science.
Key terms and skill groups for data science jobs.
Step 4: We used text mining to crawl the downloaded syllabi for key data science terms (Table 1). A syllabus with terms “SVM” and “kNN” indicates they are covered. For each key term, we computed the corresponding raw term frequencies (TF) across the corpus as well as the document frequencies (DF) of syllabi that contain each key term. TF is the number of times a key term appears across all syllabi, and DF the number of syllabi containing a key term. The former indicates breadth of coverage, the latter indicates depth. While term-frequency-inverse-document-frequency (TF-IDF) is sometimes used in text mining to represent the importance of key words and phrases across documents, it does not adequately represent breadth and depth of coverage.
Step 5: We analyzed the occurrences of key terms from Table 1 by computing raw TF and DF scores, which are then aggregated by skill groups and knowledge domains. For example, the TF for Analytics Groups is the sum of all raw TF scores for each of its key terms. Higher scores indicate broader coverage.
Text mining results from course syllabi
Table 2 shows a breakdown of syllabi by department. There are roughly similar numbers across departments. The “Others” category includes departments like public health. This is not surprising as data science-related skills are taught across disciplines (Stodden, 2020).
Summary of course syllabi by department.

Results indicate depth coverage is uneven and some skills are not covered (Figure 4). For example, the Information Management and Communication skill group has the best depth of coverage with 372 occurrences and includes “verbal communication” which is not covered. “Information”, “process”, and “manage” (279, 75, 17 respectively) account for 371 occurrences. Software development has the least depth of coverage with 6 and includes “hive”, “distributed computing” and “apache” which are not covered. The skill groups Implementation of Analytics and Big Data Technologies, and Analytical Methods include all key terms, yet coverage is uneven. The former has better depth of coverage with 336 key term occurrences, and the latter has 258. “Statistical modeling”, a topic in Implementation of Analytics and Big Data Technologies, and “analytical skills” from Analytical Methods, have 5 occurrences each.
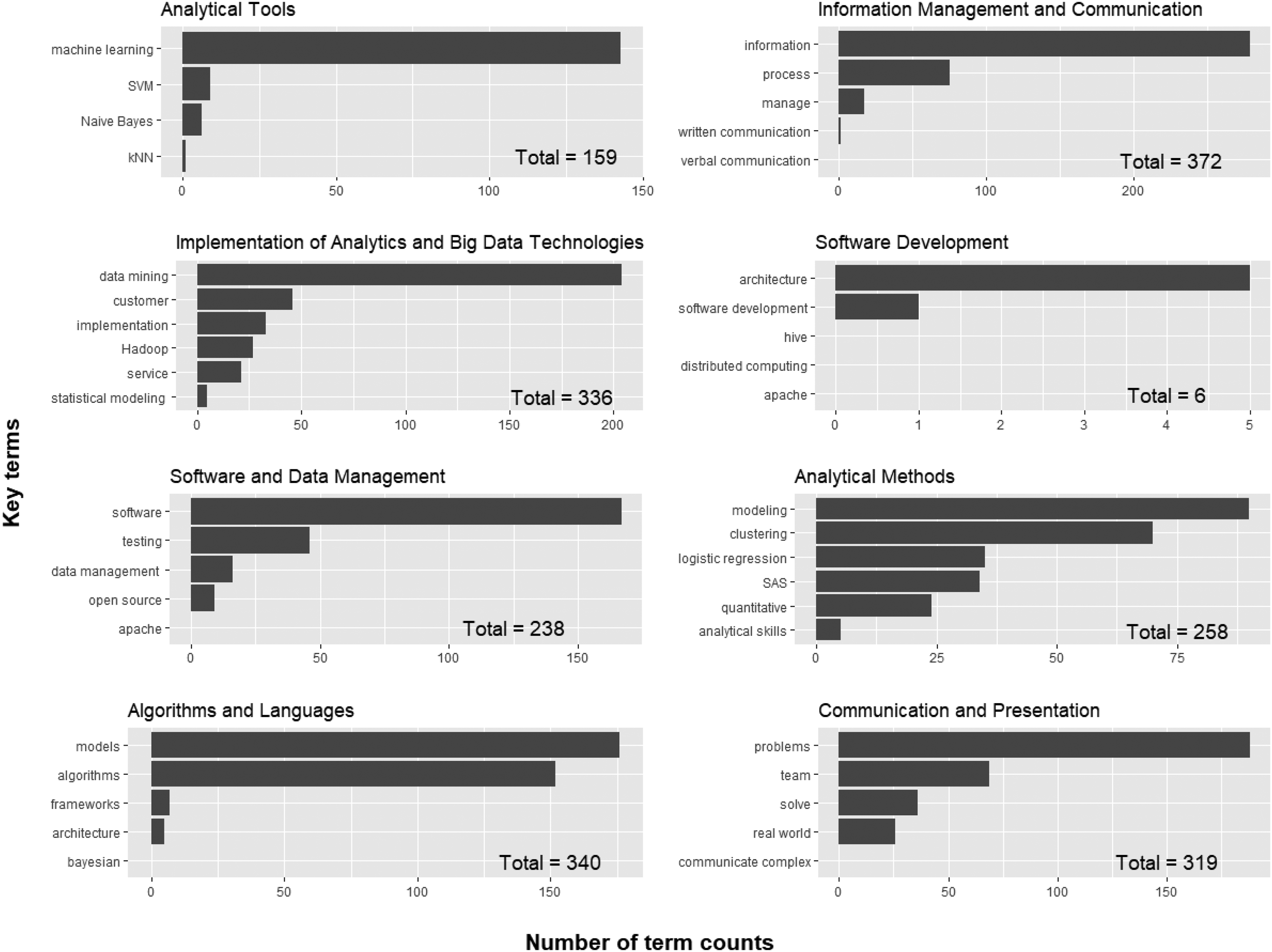
Depth of data science knowledge and skills coverage.
Document frequencies (DF) represent the number of syllabi that include a key term and represents skill group breath of coverage across all syllabi (Figure 5). The higher the aggregated DF, the more courses that cover each key term. The results show Information Communication and Management has the best coverage with 198 out of 220 syllabi with at least 1 key term in the skill group. However, “written communication” and “verbal communication” collectively, are covered in 1 syllabus, “written communication,” in 1 syllabus, “verbal communication,” in 0. Communication and Presentation skill group is a close second with 173 key terms even though “communicate complex” does not appear in any syllabus. Software Development has the lowest breadth of coverage, with 5 syllabi containing key terms where “Apache”, “hive” and “distributed computing” are not covered.
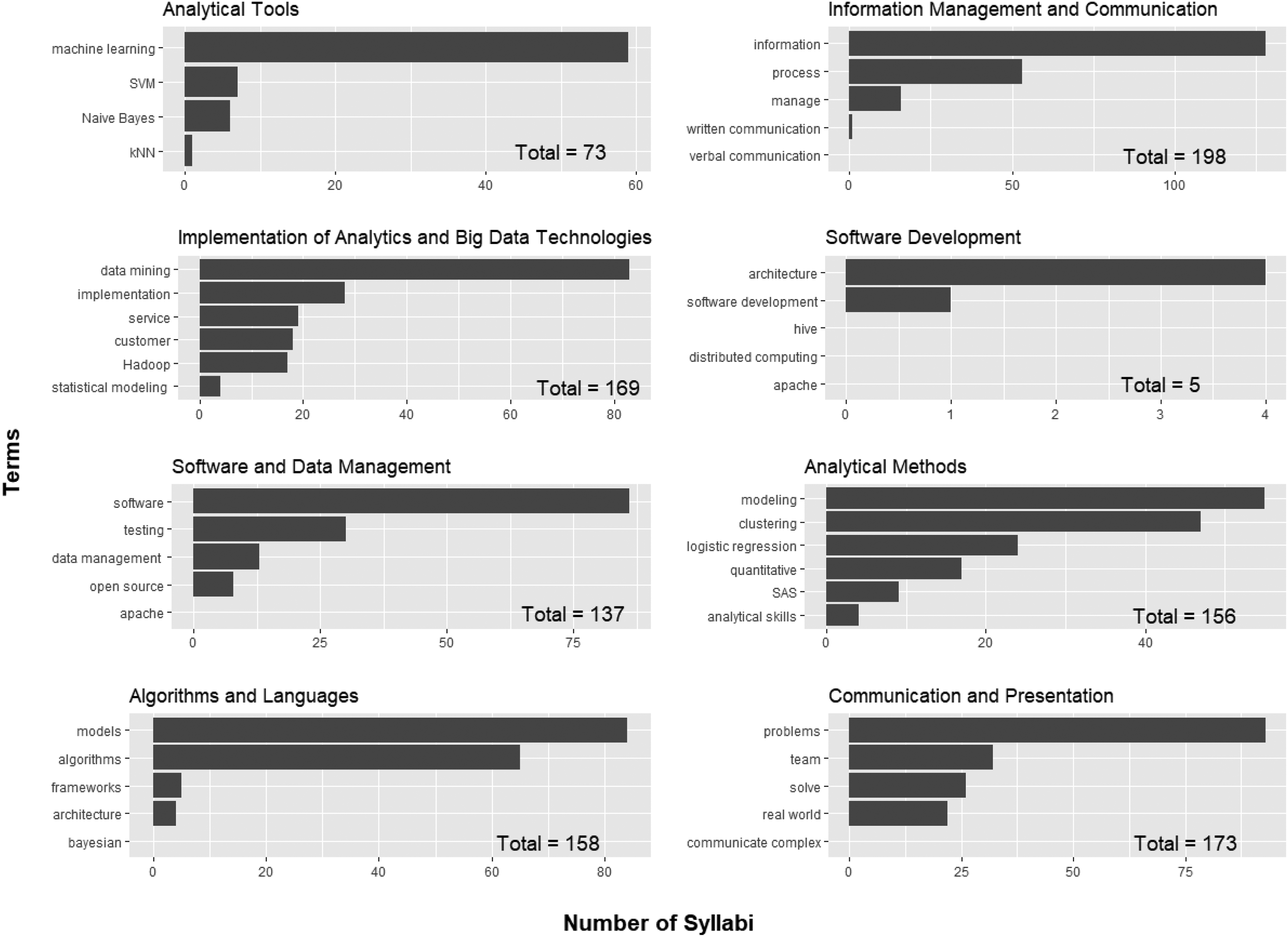
Breadth of data science knowledge and skills coverage.
Algorithms and Languages and Analytical Methods have a total of 158 and 156 syllabi respectively containing key terms. The former does not have uniform coverage across its key terms. “Models” and “algorithms” appear in 84 and 65 syllabi respectively. However, “frameworks,” “architecture,” and “Bayesian” appear in 5, 4, and 0 syllabi respectively. Analytical Methods coverage is more even, with “SAS” and “analytical skills” appearing in 9 and 4 syllabi respectively.
Are universities meeting industry needs?
Our findings corroborate the literature positing misalignments between university course offerings and industry demand (Börner et al., 2018). These are depth and breadth of knowledge gaps coverage between skills taught in courses and required by industry. We illustrate this by computing the aggregated TF (x-axis) and DF (y-axes) for each skill group to identify depth and breadth of data science coverage (Figure 6). Median TF (288.5) and DF (155) are chosen as benchmarks because they are less prone to outliers, especially given the sample size. Results indicate three skill groups – Information Management and Communication, Communication and Presentation, and Implementation of Analytics and Big Data technologies – are above the median depth and breadth of coverage. Information Management and Communication has the best depth of coverage with (TF = 372), followed by Implementation of Analytics and Big Data Technologies (TF = 336), Algorithms and Languages (TF = 335), and Communication and Presentation (TF = 319). The Business and Communication knowledge domain includes the first and fourth skill groups.
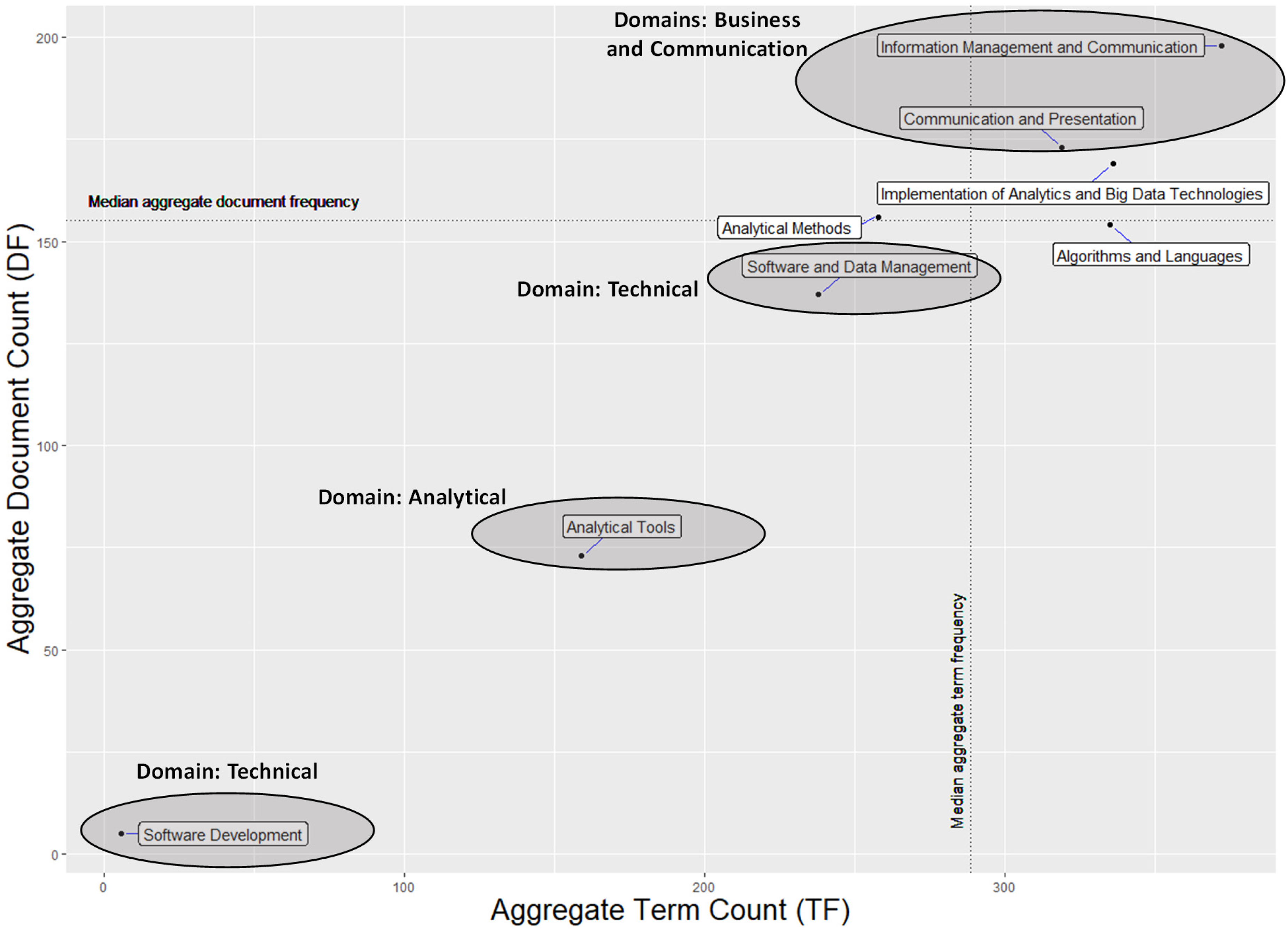
Breadth and depth of coverage of data science knowledge and skills.
Implementation of Analytics and Big Data Technologies and Algorithms and Languages are skill groups in the technical and analytical domains with above median depth of coverage. Overall, except for Information Management and Communication, skills in the remaining three groups have similar depth of coverage based on their TF scores. Topics in these four groups are covered in depth and skill groups - software development, analytical tools, software and data management, and analytical methods – are below the median depth of coverage. Software Development has the lowest depth of coverage (TF = 6), a marked difference from the other seven groups. Analytical Tools is the next lowest (TF = 159), followed by Software and Data Management (TF = 238). Analytical Methods is close to the median (TF = 258). In general, skill groups in the technical and analytical specializations, are insufficiently covered.
Business and communication specialization has the best breadth of coverage with Information Management and Communication (DF = 198) and Communication and Presentation (DF = 173). Next is Implementation of Analytics and Big Data Technologies (DF = 169) from the technical specialization, Analytical Methods is slightly above the median (DF = 156), and Algorithms and Languages slightly below (DF = 154). The remaining three skill groups - Software Development, Analytical Tools, and Software and Data Management - are at the bottom (DF = 5, 73, and 137 respectively). Similarly, Software Development has the lowest breadth of coverage, and skills in the technical and analytical specializations are not widely covered.
Next, we discuss the breadth and depth of skills from the four knowledge domains to assess how universities are doing. They do a good job teaching soft skills in business and communication. Topics in skill groups - Information Management and Communication, and Communication and Presentation - are taught in-depth (high TF) and covered in many courses (high DF). The technology industry faces a university-industry knowledge gap in leadership and interpersonal skills (Börner et al., 2018; Singh Dubey et al., 2021), but universities cover Information Management and Communication from business and communication specialization and Implementation of Analytics and Big Data Technologies from the technical domain well.
Technical and analytical domains’ shortcomings stem from lack of depth and breadth. Our findings suggest Analytical Tools and Software Development are areas universities can significantly improve. Analytical Tools include machine learning algorithms including Naïve Bayes, kNN, support vector machines, and Software Development includes distributed computing and architecture (Radovilsky et al., 2018). There is a shortfall of technically-skilled graduates (El-Deeb, 2022), so Software Development will expectedly experience labor shortage (Breaux and Moritz, 2021). Both skill groups can benefit from significant expansions of depth and breadth of coverage. Analytical Methods are above the median breadth of coverage but could benefit from more depth of coverage. Clustering and logistic regression courses (Radovilsky et al., 2018) can be more extensively taught. Algorithms and Languages have good depth of coverage but below the median breadth of coverage, pointing to opportunities to add topics like Bayesian probabilities. Both skill groups from analytical, and Software and Data Management stand to benefit from better depth and breadth of coverage.
Software Development is noticeably poorly covered and with the worst depth and breadth of coverage. Its key terms showed up sufficiently in job postings to warrant inclusion as a data science skill group (Radovilsky et al., 2018), but appeared 6 times in 5 out of 220 syllabi. As an outlier, it raises questions about its inclusion in data science because it is traditionally taught in computer science. “Software” and “software development” show up in Software Development, and Software and Data Management respectively (Table 1). Hence, a case can be made for its inclusion in Algorithms and Languages. These suggest employers expect data scientists to have software development skills, but universities deem otherwise or have yet to adapt. This is symptomatic of the absence of a clear data science definition and scope.
Improving data science
We addressed RQ1 by proposing the alternate view of data science as the umbrella for complementary data science specializations, as opposed to mutually exclusive and competing. The alternate view enables assessment of misalignments or knowledge gaps between academia and industry, from a different data science perspective. This wider view accommodates varying conceptualizations that allow universities to better satisfy industry demand, by creating specializations. Pertaining to RQ2, despite evidence of soft skills knowledge gaps in general (Börner et al., 2018; Singh Dubey et al., 2021), our results show data science does a good job developing data scientists with such knowledge and skills. One explanation is the alternate view allows for a broader data science perspective. The prevailing view adopts a narrower perspective where data science is technical in nature and excludes soft skills. This is contrary to industry demand for data scientists to possess a wider repertoire of skills, including soft skills (Biswal, 2023; Radovilsky et al., 2018; Reany, 2014). The argument is akin to the birth of the information systems discipline when practitioners are expected to have technology, business, and interpersonal skills, among others (Lee et al., 1995).
Data science jobs include data scientists, data analysts, business analysts, data engineers, and business intelligence developers (Columbus, 2017), requiring wide ranging skills across data scientists’ profiles, making it difficult to develop well-rounded data scientists (Reany, 2014). For data science to serve as an umbrella, it should include eight skill groups from job postings (Radovilsky et al., 2018). Skill groups Analytical Tools and Software Development with noticeably low depth and breadth of coverage, require attention. The latter explains the lack of appropriately skilled data scientists to fulfil industry needs (El-Deeb, 2022), should be of concern to universities instrumental in bridging knowledge gaps (Singh Dubey et al., 2021). Intellectual content should be established in data science to be considered a full-fledged field (Stodden, 2020). It starts with a common data science view derived from the skill groups (Radovilsky et al., 2018) to better define courses, curricula, programs, and specializations. This presents a clearer vision of how, what, and where to teach data science courses, in the absence of a universal model (Berman et al., 2018). The alternate view enables data science, an inter-disciplinary field (Cao, 2017a) with specializations, to better determine academic homes. For example, computer science curricula can focus on data analytics with technical emphases. Business programs can create a variety of specializations with business and analytical emphases, while communications studies focus on visual/communications. Universities can further avail themselves of opportunities for cross discipline approaches among computer science, business, information systems, and communication studies. These simplify educational choices for aspiring data scientists, minimize knowledge gaps, improve curricula, and better support hiring efforts. Data science can also be housed in a multi-disciplinary department, similar to Columbia University and University of Virginia (Stodden, 2020), leveraging expertise from various specializations and knowledge domains. When data science is taught in business programs, electives in software development may come from computer science, and communication and presentation from communication studies. Because data science is dynamic and changes rapidly (Columbus, 2017), universities should expect curricula changes to the core and specializations. We now discuss four improvements to data science as a discipline, based on our findings.
Complementary specializations (branches) of data science
The alternate view presents a different lens to conceptualize data science to improve curriculum design, student preparation, data science specializations, knowledge gaps, employment, and research. We recommend Figure 2 as the umbrella for data science specializations. It eliminates data science as an independent, mutually exclusive, and competing subject area. It further reduces confusion between data science specializations and reduce the need to identify unique data science key terms unique to all five branches. We further recommend including traditional statistics in analytics courses (Klimberg and McCullough, 2013), or as a specialization. Lastly, we recommend including it as part of data science core and as a specialization comprising probability, linear regression, multiple regression, inferential statistics, among others. This ensures students not specializing in traditional statistics, including transmuters (Ramzan et al., 2021, 2023), have some exposure to it. Transmuters are individuals who want to change professions. The two studies conducted in Pakistan, identify transmuters came from varying backgrounds including engineering, computer science, physics, statistics, business, physics, mathematics, and medical (Ramzan et al., 2021, 2023). Universities can create cross-disciplinary programs for transmuters: One for transmuters from technical backgrounds such as engineering, statistics, and physics, and another for non-technical transmuters from business, social studies, or communication studies. Furthermore, there are four different profiles of data scientists – Data Business, Data Creatives, Data Developers, and Data Researchers – with overlapping and unique skillsets (Reany, 2014). Complementary branches of data science allow universities to develop specific data scientists’ profiles, using specializations to complement varying backgrounds.
Create curricula and programs for specializations
Identifying core knowledge is a subject of intense debate (Radovilsky et al., 2018). The existence of knowledge gaps suggests a need for a core derived from multiple skill groups, to develop well-rounded data scientists (Reany, 2014). The alternate view plays an important role by presenting a different perspective to improve data science curriculum design. For example, studies show business and communication skills not widely covered in graduate business analytics programs (Bowers et al., 2018), but our findings suggest otherwise. We recommend courses on business and communications skills to explain, present research findings, and use visualization tools. One explanation for lack of coverage is the narrow prevailing view excludes them from data science (Bowers et al., 2018) and emphasizes technical and analytical, inconsistent with Reany's view (Reany, 2014). The alternate view includes specializations not currently in existence and represent a diverse data science landscape. Our findings further suggest data science cuts across specializations, despite belief that business and communication skills are only included in business analytics. Business and communication skills are in demand (Van Loon, 2024), hence data scientists should be exposed to them because business knowledge appears in 30 percent of job ads (Bowers et al., 2018), regardless of specialization. Furthermore, data scientists should be prepared for various roles in their career. To accomplish this and meet industry demand, universities can create cross-disciplinary programs among computer science, business, and communication studies.
A core provides foundational knowledge and skills for specializations. Figure 6 lists three knowledge domains – technical, analytical, and business and communication – not commonly found in the purely technical prevailing view. Hence, we recommend data science curriculum include all knowledge domains. For example, computer science can focus on technical areas because their currculula use technical resources such as Apache, Hadoop, hive architecture, special hardware and software. Information systems, operations research, and technical business disciplines can focus on analytical areas using tools such as SPSS Modeler, SAS Miner, Tableau, SQL, Python and R to formulate problems, analyze, and interpret data. Lastly, Liberal Arts and non-technical disciplines can focus on presentation, visualization, and communication.
Bridge knowledge gaps for specific skill groups
Our findings identify data science skill gaps. Our approach is predicated on maintaining high breadth and depth of course coverage in Information and Communication Management, Implementation of Analytics and Big Data Technologies, and Communication and Presentation, despite studies showing a lack of Big Data skills (Dubey and Gunasekaran, 2015; Miller, 2014). Above median results (Figure 6) may be unsustainable, as syllabi are a snapshot in time and subject to change. The remaining five skill groups, which are part of technical and analytical knowledge domains, require upskilling in depth and breadth of coverage.
We propose 12 concrete recommendations to bridge these gaps. 1. Increase course offerings in the skill groups, Analytical Tools, Software Development, Software and Data Management, Analytical Methods, and Algorithms and Languages. 2. Increase depth of coverage in individual courses to address the lack of depth in Analytical Tools, Software Development, Software and Data Management, and Analytical Methods. 3. Provide in-house professional development opportunities for faculty to stay current and competent in teaching knowledge and skills demanded by industry such as Analytical Tools, Information Management and Communication, Implementation of Analytics and Big Data, Software Development, Software and Data Management, Analytical Methods, and Algorithms and Languages. 4. Support cross-disciplinary data science scholarships for Analytical Tools, Implementation of Analytics and Big Data, Software Development, Software and Data Management, Analytical Methods, and Algorithms and Languages. 5. Include industry collaboration projects in courses to improve content in Analytical Tools, Implementation of Analytics and Big Data, Software Development, Software and Data Management, Analytical Methods, and Algorithms and Languages skill groups. 6. Increase coverage of ethics in Information Management and Communication, and Communication and Presentation. 7. Increase coverage on regulatory practices related to Information Management and Communication, and Communication and Presentation. 8. Create a common foundation course or core that includes all eight skill groups: Analytical Tools, Information Management and Communication, Implementation of Analytics and Big Data Technologies, Software Development, Software and Data Management, Analytical Methods, Algorithms and Languages, and Communication and Presentation. This provides exposure to verbal and written communications, distributed computing, Bayesian, and Apache that are insufficiently covered. Furthermore, software development, frameworks, architecture, and statistical modeling are seldom covered. 9. Create specializations to increase software development, analytical tools and methods, software and data management, and algorithms and languages depth of coverage, which are below the median (Figure 6). Analytical tools and methods should be included in the analytical knowledge domain, while software development, algorithms and languages, and data management belong in the technical domain. A general finding is technical and analytical knowledge domains suffer from a lack of breadth and depth of coverage, and can benefit from a data science core and specializations. This finding validates the shortage of data scientists with technical skills (El-Deeb, 2022). Software Development depth and breadth of coverage were the lowest and its inclusion is debatable as data scientists may not consider it data science. 10. Procure real data for faculty and students to use in data science classes, assignments, projects, and research. The data should be sufficiently diverse to enable faculty and students to acquire new skills across multiple knowledge domains. 11. Provide sabbatical leave for faculty to acquire additional knowledge and skills, consistent with faculty teaching and research interests. 12. Industry and universities should provide software for classes and research projects. Table 3 comprises a summary of these recommendations.
Summary of curriculum recommendations for data science skill groups.

Additional evidence for a data science life cycle
Continuous evolution of data science (Seal et al., 2020) comes with narrow (Batistič and van der Laken, 2019) and varying definitions (Stodden, 2020), ill-defined scope, changing technologies, and unclear industry expectations. Its multi-disciplinary nature (Stodden et al., 2013) requires a coherent scope to develop as a discipline (Stodden, 2020). Its multi-disciplinary nature (Stodden, 2020), lack of agreement (Bichler et al., 2017), complexity and content pose challenges on how to conceptualize it as a science and manage knowledge gaps. The first recommendation stems from our findings which validate the need for a life cycle, as a support mechanism for universities (Stodden, 2020). The alternate view in conjunction with a life cycle accommodates new specializations and topics currently outside the prevailing view. Ethics, governance, probability and statistics can be included in the core or specializations. Furthermore, the life cycle acts as a vehicle to guard against silo academic programs and encourage cross-disciplinary knowledge sharing, teaching, and research, nudging data science towards a scientific discipline. Our findings suggest the evolution and longevity of data science (Seal et al., 2020) warrants a keen understanding of industry needs and collaboration to develop core knowledge and specialization skills. Therefore, collaboration between academia and industry is highly recommended. The inability of data science to produce well-rounded data scientists (Reany, 2014) and our discovery of knowledge gaps further validates the need for a core and specializations. This is compounded as analytics skills differ by industry sector (Bowers et al., 2018). Hence, the third recommendation is tailoring analytical skills to specific industries. Analytic skills in manufacturing/engineering are different from business due to domain knowledge, company, and industry challenges. The life cycle is strengthened when companies provide internships, technology, data, faculty sabbaticals, funding, and projects. For example, manufacturing companies can help accounting and finance students develop domain knowledge, visualizations skills using Tableau, and analysis skills using SAS Miner. The life cycle can be a catalyst for bridging knowledge gaps and fostering collaboration, judging from past examples between IBM and Columbia University Scientific Computing Lab (IBM, n.d.), IBM and Watson School of Engineering, and IBM Institute for Business Value and MIT Sloan Review (LaValle et al., 2010).
Discussion, limitations, and future research
The prevailing view of data science comes with inherent challenges that constrain course, program, and curriculum design, thereby impeding student preparedness for industry (Biswal, 2023; Leon et al., 2018). It assumes mutually exclusive skills, but our findings suggest several skills are relevant across specializations, making the case for cross-discipline education. There is a lack of specializations in data science, resulting in unclear career paths and knowledge gaps (Bowers et al., 2018; Seal et al., 2020). Some findings contradict past research (Bowers et al., 2018; Leon et al., 2018; Seal et al., 2020), and suggest the data science landscape looks different when viewed through different lens. A shortage of data scientists with technical abilities (El-Deeb, 2022) is supported by our findings. In addition, earlier limitations of the prevailing view support the alternate view of data science as the umbrella for complementary specializations that enable clearer data science perspectives on what to include, how to develop more rounded data scientists, and how to make it a scientific discipline. The life cycle enables universities and industry to bridge gaps and better manage data science growth using a broader, cross-disciplinary, more unified, and flexible view.
Cross-disciplinary data science integration increases collaboration to address the growing complexity of business, industry, political, and environmental challenges. The International Association of Business Analytics Certifications suggests integrating academic disciplines to improve collaboration, reduce silos, and improve innovation (International Association of Business Analytics Certification, 2023). Academic and professional disciplines tend to erect boundaries that hinder the free exchange of ideas and a wider problem-solving view. Integration is enabled by advances in technology, acting as a common thread to bind experts from different fields, encouraging insights, skills, and perspectives to solve complex and pressing challenges of climate change, healthcare, hunger, and technological innovation. For example, communication straddles fields such as psychology, philosophy, and human-computer interaction that are applied to communication. Integration across subfields increases creativity, innovation, and growth (Tenenboim-Weinblatt and Lee, 2020). Pioneers in anthropology (Borofsky, 2002) and sociology (Leahey and Moody, 2014) support integration, lending support to a wider alternate data science view, better suited for complex problems.
This research makes eight contributions. 1. Most importantly the alternate view is better suited to aid and manage data science growth, evolution as a science, and cross-disciplinary integration. 2. The alternate view enables data science specializations that are unlikely to exist under the prevailing view, and seldom discussed. 3. The view encompasses four knowledge domains: technical, analytical, business, and communication that cut across specializations. 4. The presence of knowledge gaps suggests a need for a data science core and specializations to develop well-rounded data scientists. 5. Our findings identify knowledge gaps, some of which differ from previous findings, due to the broader, alternate view of data science used in this investigation. 6. The alternate view reduces data science challenges inherent in the prevailing view, paving a path for a smoother future. 7. It reduces the need to distinguish courses between graduate or undergraduate programs in each of the five specializations, as knowledge gaps are assessed based on courses, independent of programs. The assumption is a graduate or undergraduate course teaches similar skills, despite differences in rigor. For example, a graduate course in regression may cover log-linear models, but not its undergraduate counterpart. But all students possess knowledge and skills on regression analysis. 8. Lastly, the 12 data science recommendations move it closer to becoming a science.
Every research project has limitations. Consequently, this exploratory research has its fair share, due to its nature. The research objective presents an alternate view for investigating knowledge gaps using university syllabi from U.S. universities and colleges. It was not intended to corroborate industry experts’ opinions with syllabi knowledge gaps results. Such a project requires a much larger scope and sample size; particularly for a global investigation that necessitates resources few faculty possess such as, multilingual expertise, multiple language interpretation and translation, and global reach. It is a research project better suited for international organizations such as the United Nations or World Bank.
The first limitation relates to expert opinion where future research can investigate university preparation using a comparative investigative approach, where experts weigh in on syllabi knowledge gaps to assess how well students are meeting industry needs. This is an important study, but beyond our research objective and scope. Second, the sample is not exhaustive due to its exploratory nature and limited resources at our disposal, such as gaining access to university syllabi not posted online or in different laguages. The sample can be larger, but 220 syllabi are sufficient for an exploratory study. Third, this study can be expanded to include non-U.S. universities. However, because U.S. universities command a significant role in the growth of data science, our research findings have global implications, albeit with caution (Donoho, 2017). U.S. education is a leader and benchmark for other institutions, as the first business analytics graduate program was created by North Carolina State University in 2007 (Cao, 2017a). A global study should include data science key terms, knowledge, and skills taught by non-U.S. universities and demanded by non-U.S. employers. Given the global leadership of U.S. education, we recommend expanding the U.S study sample size before embarking on a global study. The sample size should be increased for a global comparative analysis and the identification of knowledge gaps by country, to investigate geographical differences. This is a major undertaking with inherent challenges not easily overcome: 1. University syllabi in many countries are not written in English and require translation; 2. There are epistemological challenges as equivalency between key terms may not exist; 3. Text mining requires precision to match key search terms and presents a major challenge for non-equivalent key terms; 4. Acquiring a representative global sample is a massive resource undertaking for any faculty member; 5. In underdeveloped and developing countries, syllabi are not often available online. Fourth, data science is a new and evolving discipline. Any sample syllabus used to investigate an evolving discipline, is a snapshot in time as the target does not sit still. A larger sample will address the currency of data science. Fifth, some findings are not corroborated by the literature due to differences between the prevailing and alternate view. We recommend adopting the alternate view with larger local and international samples, to confirm or refute our findings. Sixth, verbal, written communication and other skills may be expected but not explicitly stated in job ads. Because text mining relies on key terms, there is no room for reading between the lines. Furthermore, academia reacts to industry needs; hence, implicit skills are difficult to identify making investigation more challenging. Applying the alternate view to future research can resolve these issues. As part of the data science life cycle, future research can adopt the alternate view to establish new topics to complement, revise, create or improve data science specializations. Seventh, data science terms used in this research are based a prior study (Radovilsky et al., 2018). For consistency, we refrained from expanding (adding synonyms) or altering terms. For example, Naïve Bayes and Bayesian are part of the same methodology but not completely identical. Excluding either one affects the results when one course uses either one of the terms. Hence, we included them separately to be consistent (Radovilsky et al., 2018). With additional resources, future studies may solicit input from employers or industry experts to identify skills and knowledge excluded from Radovilsky et al. (2018), thus, strengthening the analysis. Our data collection period of 2017–2019 coincides with the job postings key words and phrases research by Radovilsky et al. (2018). As data science continues to evolve (Seal et al., 2020), future studies can explore new job postings terms and current syllabi in accordance with data science life cycle (Stodden, 2020) for updates. Finally, syllabi used in this research are from U.S. colleges and universities which may restrict generalizability, which can be overcome in future studies by including non-U.S. universities and colleges and job postings from various countries.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.