
Abstract
Academic libraries in Sub-Saharan Africa and China face persistent challenges in cross-lingual retrieval due to linguistic fragmentation and uneven metadata infrastructures. This study constructed and evaluated a multilingual academic corpus designed to enhance semantic retrieval, metadata interoperability, and inclusive access across 13 languages. The core innovation lies in the Multilingual Adaptive Corpus for Retrieval Equity (MACRE), a modular architecture that integrates language-specific adapters, ontology-driven metadata harmonisation, and an intent disambiguation engine features that collectively surpass existing retrieval frameworks. The project aligns with core LIS objectives by advancing user-centred discovery, cross-language cataloguing, and metadata standardisation in institutional repositories. A 41,129,582-token corpus was compiled from 39,725 academic records drawn from university repositories across both regions. The corpus incorporated Mandarin, English, and 11 African languages selected to reflect regional LIS priorities. Metadata was harmonised to SKOS and Schema.org standards. The proposed MACRE retrieval model was benchmarked against ColBERT-X, SwahiliDocBERT, and CrossLingual2Vec using cosine similarity, MRR, MAP, and NDCG. Evaluation included ablation and post hoc analysis. Mandarin and English accounted for 64.6% of all tokens; Swahili reached 16.9%, while nine African languages contributed under 1.8% each. MACRE significantly outperformed all baselines (MRR = 0.864; MAP = 0.812; p < .001), particularly in LIS-aligned fields such as metadata accuracy (98.6%) and entity completion (94.9%). Adapter performance exceeded 90% in dominant languages but revealed key gaps in under-annotated African records. These findings illustrate that retrieval accuracy is not just a technical challenge, but also reflects underlying LIS concerns, such as language equity, cataloguing depth, and metadata policy enforcement. This study contributes a scalable LIS infrastructure for multilingual academic retrieval, advancing both technological and policy innovations for cross-lingual access in library systems.
Keywords
About the authors
Artificial intelligence (AI), as a method of structuring and enhancing knowledge organisation, has reshaped academic information systems through predictive indexing, semantic classification, and intent-aware retrieval (Adeyemi et al., 2023; Molaudzi and Ngulube, 2025). In Sub-Saharan Africa, supervised machine learning applied to Afrikaans archives achieved 89% classification accuracy, reducing manual cataloguing effort by 54% and improving access to scholarly resources through library discovery interfaces (Brokensha et al., 2023). Complementary studies in library and archival research reveal that AI-driven chatbots in Nigerian university libraries reduced query processing time while maintaining user satisfaction, particularly where metadata enrichment tools were deployed (Echedom and Okuonghae, 2021). A multilingual corpus, understood as a structured dataset comprising either parallel, comparable, or aligned multilingual texts, forms a crucial infrastructure for ensuring access parity in linguistically diverse academic systems. In Kenya, the Swahili-Dholuo-Luhya trilingual corpus increased relevant document retrieval by 40% in academic settings, with part-of-speech tagging and syntax modelling integrated across platforms at Maseno University (Wanjawa et al., 2023).
State-linked digital modernisation strategies underpin China's AI applications in academic libraries, but their implementation occurs primarily through institutional architectures such as China National Knowledge Infrastructure (CNKI) and innovative recommendation systems (Tai and Ghosh, 2025). While these systems exhibit operational scale, they remain optimised for Mandarin-English query pathways, with limited adaptability to African language corpora (Wang and Xu, 2024). Strategic planning analyses indicate that Chinese academic libraries are more proactive than their Western counterparts in adopting AI for user services and metadata control; however, they rarely incorporate multilingual corpus layering at the semantic level (Huang et al., 2023). The infrastructure bias toward high-resource language interoperability presents a barrier to meaningful cross-regional collaboration. The distinctive innovation of this study is the design of the Multilingual Adaptive Corpus for Retrieval Equity (MACRE), a modular architecture that integrates (i) language-specific adapters for low-resource representation, (ii) ontology-driven metadata harmonisation for schema alignment, and (iii) an intent disambiguation engine to refine cross-lingual academic queries. These components are combined for the first time in a unified retrieval system tailored to both African and Chinese academic repositories.
Institutional surveys in Nigeria show only 18% of librarians currently apply AI tools, though over 70% express willingness if trained, with pilot implementations showing query resolution time falling from eight to three minutes (Edam-Agbor et al., 2025; Ogungbenro et al., 2025). Transformer-based models such as Cheetah, which supports over 300 African languages, demonstrate the technical capacity for neural language modelling in underrepresented systems, though hardware dependencies and token sparsity limit deployment in real-time environments (Adebara et al., 2024). Despite increased African scholarly output on AI and library systems, bibliometric analyses confirm that no integrated multilingual corpus architecture currently supports academic retrieval across regional and linguistic contexts (Ankamah et al., 2024; Islam et al., 2025; Zondi et al., 2024). This gap in infrastructural and semantic interoperability is the core challenge addressed by this study.
AI tools are increasingly being adopted for multilingual access and metadata enrichment; however, existing frameworks still lack an architecture that is both language-inclusive and adaptable to infrastructure diversity. The Multilingual Adaptive Corpus for Retrieval Equity (MACRE) directly addresses this gap by integrating three novel components into a unified retrieval framework. First, language-specific adapters are optimised to capture structural and semantic nuances of low-resource languages, ensuring representational fidelity across diverse linguistic families. Second, ontology-based metadata harmonisation enables crosswalks between regional and global schemas, allowing repositories in Africa and China to align their records without losing local specificity. Third, a decision-tree-based intent disambiguation engine refines academic queries by resolving ambiguity across domains and language contexts. By combining these modules into a scalable architecture, MACRE establishes a new benchmark for equitable, cross-lingual academic retrieval.
This study (i) constructed a multilingual corpus incorporating Chinese, English, and selected African languages tailored for academic retrieval tasks; (ii) implemented AI models for domain-sensitive query disambiguation and context-aware metadata harmonisation; and (iii) evaluated retrieval precision, semantic coverage, and infrastructural interoperability across academic library systems to advance multilingual information access research beyond system design.
Research questions
This study explores how AI-driven multilingual corpus design can advance academic information retrieval across African and Chinese languages. The following questions guide the research: (i) What data structures and language inclusion criteria best support multilingual corpus development for academic libraries? How can low-resource language materials be meaningfully integrated alongside English and Mandarin content? (ii) Which AI techniques most effectively support domain-sensitive query disambiguation and cross-lingual metadata harmonisation in varied library systems? To what extent do language adapters and ontology bridges improve semantic coverage? (iii) How does the implemented system perform in retrieval precision, failure rate variance, and cross-platform interoperability? What are the performance implications across under-resourced infrastructures in Sub-Saharan Africa and China?
Literature review
This literature review was conducted through a systematic contextual synthesis of peer-reviewed studies and institutional reports from 2018 to 2024, focusing on the intersection of artificial intelligence, multilingual corpora, and academic information retrieval within Chinese and Sub-Saharan African library systems. The approach prioritised sources related to language modelling, semantic metadata pipelines, query disambiguation, and corpus design. Instead of a comparative review, this synthesis identifies common implementation challenges across institutions, including limited adaptability to low-resource languages, fragmented metadata structures, and inadequate mechanisms for retrieval equity. These issues are directly aligned with the study's objectives and inform the rationale behind MACRE's language-specific and infrastructure-aware design.
Cross-Lingual embedding for low-resource languages
Transformer-based optimisation for low-resource languages (LRLs) has progressed through knowledge distillation and multilingual transfer learning. Cruz and Aji (2025) applied student–teacher compression to Swahili, Hausa, isiZulu, Kinyarwanda, Amharic, and Kirundi, retaining 90% of baseline accuracy while cutting inference cost by 71%. However, outputs were not disaggregated by academic document type. Thangaraj et al. (2024) fine-tuned Bidirectional Encoder Representations from Transformers (BERT) and Cross-Lingual Language Model RoBERTa (XLM-R) on Kinyarwanda and Kirundi, gaining 30 F1 points but overlooking figurative or culturally embedded usage.
Ogundepo et al. (2023) introduced the African Multilingual Question Answering benchmark (AfriQA) across ten languages, with Yoruba exact match scores below 45% and no correlation with Mean Average Precision (MAP) or Normalised Discounted Cumulative Gain (NDCG). Palivela et al. (2025) reduced Hindi–Telugu–English Automatic Speech Recognition (ASR) errors by 18.7% but omitted query intent testing. Chonka et al. (2022) noted isiZulu and Setswana rejection rates above 75% in predictive systems without proposing alternatives. Despite China's multilingual publishing infrastructure, few studies address the optimisation of embedding for Mandarin or minority Chinese languages in academic retrieval. Collectively, these works highlight a gap in aligning embedding methods with benchmarks and real-world library tasks.
Semantic metadata harmonisation
Library metadata infrastructures in Sub-Saharan Africa and China show wide gaps in modularity, transparency, and artificial intelligence (AI) integration. Molaudzi and Ngulube (2025) found that only 29% of South African libraries used AI-assisted workflows, with most relying on semi-manual tagging. Mosha (2025) applied artificial neural network (ANN) classifiers in Tanzanian repositories, cutting indexing time by 80% but limiting semantic transfer due to a monolingual Swahili base. Hombana reported 45% visibility gains from metadata enrichment in Southern Africa, though schema alignment remained inconsistent. Monyela (2022) demonstrated that the transition from the Resource Description Framework (RDF) to the Web Ontology Language (OWL) enhanced clustering and SPARQL (SPARQL Protocol and RDF Query Language) flexibility. However, federation across legacy systems was incomplete.
In China, metadata automation is more advanced. Xie et al. (2025) found that 61% of academic staff utilised AI-generated content (AIGC) tools, particularly in the fields of science, technology, engineering, and mathematics (STEM). However, the issue of cross-disciplinary vocabulary drift was not examined. Zhang (2025) applied natural language processing (NLP) to improve metadata richness by 63%, while Liu and Yang (2025) highlighted localised alignment in Chinese corporate archives in Africa without clarifying descriptor transparency. Cross-regional initiatives remain limited: de Mendonça et al. and Cigliano and Fallucchi (2025) trialled ontology bridges between Swahili and Chinese vocabularies using Prompt Ontology Merging Tool (PROMPT) and AgreementMakerLight (AML), achieving 54% concept alignment but requiring manual adjudication. Both African and Chinese strategies still lack modular, scalable mechanisms for multilingual discovery.
AI-Guided query intent disambiguation
Intent disambiguation is central to improving discovery in academic libraries. Deshpande and Rajalbandi (2025) trained a convolutional neural network (CNN)–based optical character recognition (OCR) on Yoruba, Hausa, isiZulu, Kinyarwanda, Setswana, and Amharic records, achieving 91.3% digitisation accuracy and reducing indigenous script errors by 63%, but without testing semantic or discipline-specific retrieval. Wang et al. (2025) introduced a benchmark for detecting AI-generated academic text using stylometry and sentence embeddings in 12 languages, with accuracy dropping from 92.5% in English to 68.9% in isiZulu due to bias, without intent relevance evaluation.
Chen and Gong (2025) showed ChatGPT increased lexical richness (+23%) in 184 multilingual postgraduates’ writing but lacked coherence checks for indexing. Adeyemi et al. (2023) found that Best Matching 25 (BM25) outperformed multilingual rerankers in Yoruba, Swahili, Hausa, isiXhosa, and Amharic but failed to disaggregate by discipline. Dubiel et al. (2024) achieved a 72.6 F1 score with TinyBERT on mobile Swahili queries, but excluded voice interactions and intent validation. Overall, existing models optimise surface accuracy but neglect semantic intent parsing and cross-disciplinary ranking, underscoring the need for adaptive, evaluated systems.
Equity-Aware corpus architecture
Digital corpora often privilege high-resource, centralised infrastructures. Kohnke and Zaugg (2025) tested artificial intelligence (AI) readers and natural language processing (NLP) tools with science, technology, engineering, and mathematics (STEM) students with disabilities in Nairobi, Makerere, and Zambia, improving engagement by 51% but without addressing modularity or semantic indexing. Sun et al. (2024) introduced the Ubuntu Commons model in Malawi, Kenya, and Tanzania, which enhances data circulation but lacks integration with formal metadata schemas or multilingual vocabularies.
Padua (2024) showed ontology alignment tripled engagement in Ghana, Uganda, and the Philippines, yet excluded oral history transcription, code-switched indexing, or speech-derived input. Adewole et al. (2024) found only six of 120 African repositories met interoperability standards, while equity factors like contributor language or institutional representation were unmeasured. Chiware and Skelly (2022) reported that nine of 14 African nations lacked corpus-sharing policies. Equity is thus conceptually invoked but rarely operationalised through multilingual access, metadata harmonisation, or inclusive contributor models.
Conceptual model
To address the disconnection between embedding quality, metadata fragmentation, semantic ambiguity, and infrastructural inequality, this study proposes the Multilingual Adaptive Corpus for Retrieval Equity (MACRE) model (see Figure 1). MACRE is structured into four modular layers: (i) a cross-lingual embedding engine optimized for academic subdomains and LRLs; (ii) a metadata harmonization module using ontology bridges and SKOS crosswalks; (iii) a lightweight intent disambiguation engine for multilingual academic queries; and (iv) a scalable corpus architecture with modular APIs, community tagging protocols, and adaptive indexing for low-bandwidth environments. Retrieval equity is formally defined through metrics including multilingual retrieval accuracy, contributor representation ratio, and latency parity across infrastructures.
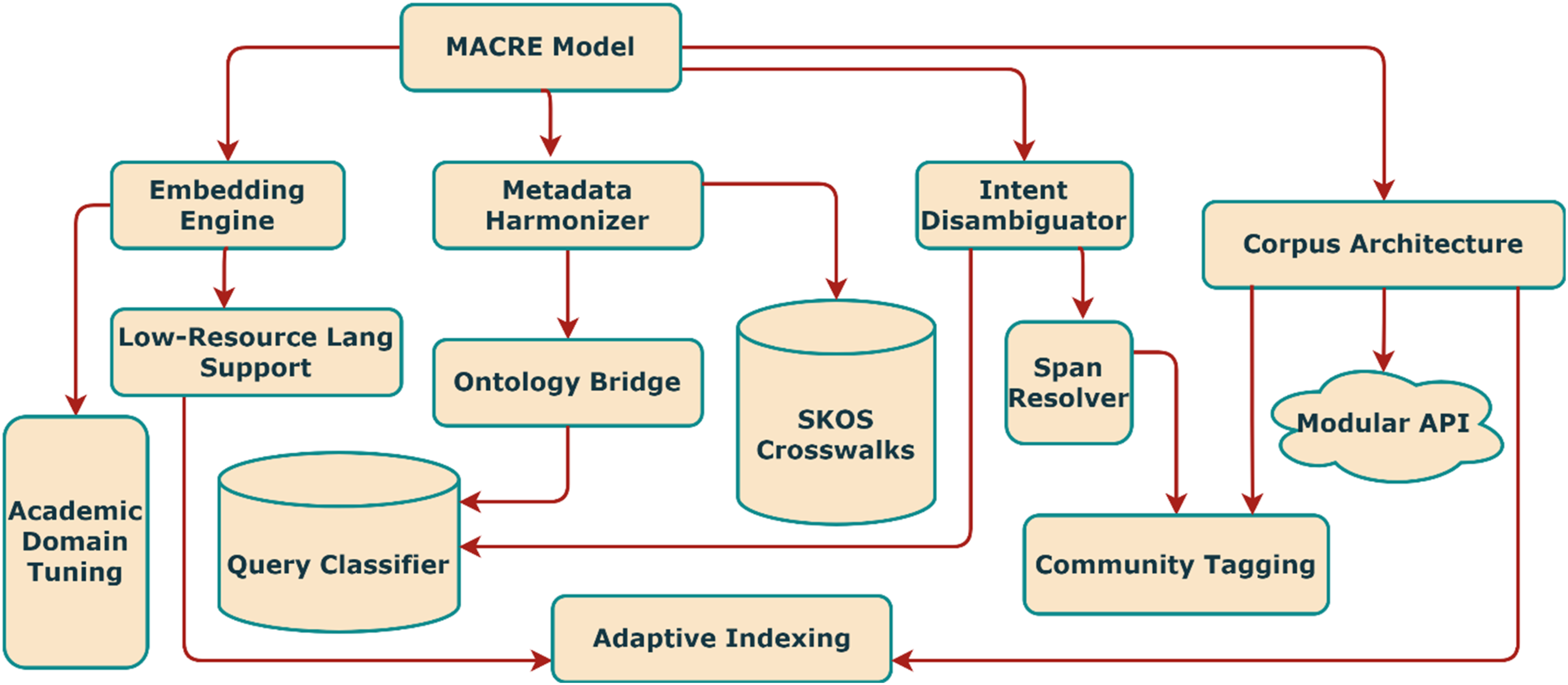
MACRE architecture showing embedding, harmonisation, disambiguation, and indexing layers for retrieval equity.
The study positions MACRE as an original architectural contribution rather than a simple adaptation of prior multilingual retrieval models. Unlike earlier transformer-based or ontology-bridging systems, MACRE integrates three components that have not previously been combined in academic retrieval: (i) language-specific adapters tuned for low-resource languages to reduce representational bias, (ii) ontology-driven metadata harmonisation mechanisms that reconcile African and Chinese repositories with global standards without erasing local specificity, and (iii) a decision-tree-based intent disambiguation engine designed for discipline-sensitive academic queries. This combination directly addresses linguistic equity by ensuring that underrepresented African languages achieve stable retrieval performance alongside Mandarin and English, while minimising metadata gaps through dual ontology crosswalks. The design, therefore, establishes a clear methodological advance over reference models, contributing both conceptual novelty and practical solutions to multilingual academic information retrieval.
Methodology
This study adopted a sequential, implementation-centred design centred on MACRE as defined in the conceptual model. Eight academic libraries in China were selected based on participation in national repositories and multilingual metadata adoption, while seven African countries Nigeria, Kenya, Tanzania, South Africa, Rwanda, Burundi, and Ethiopia were chosen for their representation of major language families, regional digital readiness, and involvement in open science initiatives. Thirteen languages were included: Mandarin, English, Swahili, Yoruba, Hausa, Amharic, Kinyarwanda, Kirundi, isiZulu, Dholuo, Luhya, Setswana, and Tigrinya. Full-text materials were available for Mandarin, English, and Swahili, while bilingual abstracts, glossaries, and curriculum-linked summaries supported the remaining languages.
Corpus construction
This section outlines the workflow of corpus construction as follows;
Corpus sources
Academic texts were harvested from eight digital repositories four in China and four in Sub-Saharan Africa. Chinese sources included CNKI (China National Knowledge Infrastructure), the Wuhan University Repository, the Tsinghua Institutional Repository, and the Peking University Library. African repositories included the University of Nairobi (Kenya), University of Ibadan (Nigeria), Maktaba Consortium (Tanzania), and SUNScholar at Stellenbosch University (South Africa). These repositories were selected based on the availability of full-text academic material, institutional digital openness, and representation of the target languages. A balance of linguistic, regional, and infrastructural diversity guided the choice of repositories. Chinese repositories such as CNKI and Peking University were included to capture high-resource environments with well-established metadata infrastructures. In contrast, African repositories such as the University of Nairobi and Maktaba were chosen for their representation of under-resourced contexts and multilingual holdings. To avoid dominance of Mandarin and English, proportional sampling ensured that each of the 13 languages contributed a minimum threshold of 50,000 tokens per genre, with targeted inclusion of underrepresented African languages (e.g., Tigrinya, Dholuo, Kirundi) through curated bilingual abstracts and academic glossaries. This stratified approach prevented skew toward high-resource languages and provided a linguistically equitable training set.
Supplementary records were retrieved from the Directory of Open Access Repositories (OpenDOAR) and Global Electronic Theses and Dissertations (Global ETD) to ensure disciplinary and regional balance. Harvesting used DSpace 6.3 and EPrints 3.4 application programming interfaces (APIs) with custom Python Scrapy crawlers and XPath parsing to extract structured fields: title, abstract, author, institution, and subject terms. Documents were classified into three tiers: (i) full-text articles and theses in Mandarin, English, and Swahili from repositories with formal publication workflows; (ii) bilingual abstracts, glossaries, or summaries (e.g., English–Hausa, Swahili–Kinyarwanda) where full texts were unavailable but curriculum-linked descriptions existed; and (iii) metadata-only records containing structured bibliographic fields for low-resource languages. For Tigrinya, Kirundi, and Dholuo, inclusion drew on the African Storybook Foundation, the South African Centre for Digital Language Resources (SADiLaR), the Tanzanian Institute of Education (TIE), and the National Commission for Nomadic Education in Kenya (NACONEK). Each corpus exceeded 50,000 tokens per genre, with versioning and tracking managed through a PostgreSQL pipeline.
Eligibility criteria and screening
Documents were eligible if they met the following criteria: (i) published between 2018 and 2024 by an academic or public library-affiliated institution; (ii) written in one of 13 designated languages; (iii) included at least three structured metadata fields of title, author, and subject; and (iv) addressed topics in science, technology, engineering, and mathematics (STEM), the humanities, social sciences, or education. Ineligible materials comprised informal web content, non-machine-readable PDFs, and records with fewer than 500 words. For translated records, bilingual alignment was verified using Levenshtein distance and metadata field concordance. A Python-based audit pipeline assessed metadata consistency across repositories, and 10% of records per language were manually checked to confirm orthographic fidelity and appropriate subject tagging.
Stratified sampling was conducted at the document level using language and repository as stratification variables. Each academic record (article, thesis, or abstract) with at least three metadata fields was proportionally sampled across 13 target languages to ensure representativeness. Both full texts and bilingual summaries were included, while language–repository pairs with fewer than 200 documents were excluded from training but used in alignment evaluation. A Python-based algorithm enforced token-level balance, assigning unique hashed IDs with preprocessing and audit trails
Preprocessing and annotation
Text normalisation followed Unicode NFC. Tokenisation used language-specific models, with custom morpheme segmentation for isiZulu, Setswana, Swahili, and Hausa based on hybrid statistical-rule algorithms. Stop-word lists were compiled with linguists and integrated into preprocessing scripts. NLP modules performed sentence segmentation, section labelling, and citation detection. Metadata was structured using a layered annotation schema separating raw text, processed tags, and user-facing outputs. Annotators followed a three-day protocol to assign spans for disciplinary topic, citation function, authorial stance, and rhetorical section. Inter-annotator agreement was measured with Cohen's κ, requiring a minimum threshold of 0.82. Validation scripts identified tag conflicts, overlaps, and omissions before integration.
To mitigate disparities caused by uneven metadata quality, multi-stage balancing procedures were applied. First, repository-level token normalisation equalised document volume across sources. Second, metadata fields with high rates of missing values (e.g., Amharic and Yoruba keywords) were augmented using fine-tuned NER models and linguist-verified back-translation. Third, corpus records were stratified by both content type (article, thesis, abstract) and institutional tier to ensure that low-resource repositories contributed proportionally to training. Quality disparities were further reduced by applying alignment confidence scoring, with records having a score below 0.75 being flagged for manual review. These safeguards ensured that MACRE's performance was not biased toward repositories with richer metadata.
Ethics
This study was conducted in accordance with international standards on digital research ethics, with formal clearance obtained from all collaborating institutions in China and Sub-Saharan Africa. All harvested records were anonymised by hashing author identifiers and retaining only non-identifiable metadata such as repository and country of origin. Only open-access and government-approved materials were included, with oral heritage and culturally sensitive content excluded to prevent misappropriation. Metadata harmonisation for indigenous and low-resource languages incorporated cultural integrity checks to avoid semantic distortion, while proportional sampling procedures ensured equitable representation across languages. All data were stored on encrypted servers with restricted access, and the final corpus will be made available under a controlled-access license with complete documentation of anonymisation, provenance tracking, and ethical clearance procedures, in line with the FAIR (Findable, Accessible, Interoperable, and Reusable) and CARE (Collective Benefit, Authority to Control, Responsibility, and Ethics) principles
AI-Based embedding and indexing
The workflow for the AI-based embedding and indexing was as follows Algorithm 1–6;
Embedding architecture
Embedding generaion used the XLM-R-base transformer model fine-tuned on Mandarin, English, and Swahili academic corpora (see Algorithm 1). Preprocessing included Unicode NFC normalisation, sentence segmentation, lemmatisation, and morpheme-aware tokenisation for Swahili and Hausa. Adapter modules were trained separately for each language using the adapter-transformers framework with residual bottleneck layers. Training inputs were sourced from bilingual-aligned abstracts and curriculum translations provided by the African Storybook Foundation, SADiLaR, the Tanzanian Institute of Education, and NACONEK. Fine-tuning was conducted using masked language modelling with a batch size of 32, a learning rate of 2e-5, and 10 epochs. Contrastive learning was applied to align semantically equivalent segments across languages. Dense embeddings were filtered using a cosine similarity threshold of 0.72 and indexed with FAISS using cosine distance. Vectors were compressed to float16 and linked to document-level SHA256 hashes derived from title, author, and repository source (Algorithm 1).

Training was conducted using masked language modelling with a batch size of 32, a learning rate of 2e-5, and 10 epochs, with early stopping at plateau. To confirm robustness, sensitivity analyses were run by varying batch size (16, 64) and learning rate (1e-5, 3e-5). Preliminary results showed negligible deviation in loss convergence (<2%) and stable cross-lingual alignment across settings, confirming parameter stability. Adapter modules were configured with residual bottleneck layers of dimension 64, selected after grid search testing between 32 and 128 units. These parameters were chosen to maximise retrieval fidelity while minimising overfitting, particularly in low-resource language contexts
Indexing strategy
Embedding vectors were indexed using FAISS with an IVFPQ configuration, applying nlist = 100 and nprobe = 10 for scalable approximate search (see Algorithm 2). K-means clustering partitioned the embedding space using k = 200 clusters, initialised with k-means++ and run for 50 iterations until convergence below 1e-4. Cluster assignments were aligned with keyword indices extracted from document metadata and linked using SHA256 hashes (Algorithm 2).

Synonym normalisation combined curated language-specific sets, edit-distance filtering, and embedding proximity matching to ensure semantic extensibility across new corpus segments.
Embedding evaluation procedures
Relevance labels were constructed from annotated citation functions and disciplinary tags. Labels were assigned using a dual-criteria heuristic involving co-occurrence with disciplinary keyphrases and alignment with rhetorical span positions. Embedding fidelity was computed via cosine similarity against expert-tagged gold segments. Evaluation logic was implemented using FAISS-native recall utilities, NumPy, and SciPy.
Metadata harmonisation
The metadata harmonisation process was outlined as follows;
Schema standardisation and ontology alignment
Metadata fields extracted during corpus preprocessing were normalised and mapped to global schema standards using RDF-based scripts (see Algorithm 3). Core fields (title, author, institution, keywords, and domain) were aligned with both Dublin Core and Schema.org structures. Disciplinary terms were matched to SKOS ontologies from the UNESCO Thesaurus and CNKI, while region-specific curricula from Rwanda and Kenya were manually crosswalked using linguist-verified term alignments. Terms failing automatic matching below a similarity threshold of 0.75 were queued for manual validation (Algorithm 3).

Multilingual metadata reconciliation
Language-aligned fields such as bilingual abstracts and keyword sets were matched using cosine similarity from the multilingual embeddings generated in Section 3.2. Alignment was confirmed via token overlap, relative length ratio, and positional anchors. Missing metadata entries, particularly in low-resource languages, were inferred using named entity recognition models fine-tuned per language. Homographic conflicts were resolved using context window scoring and disambiguation logic built on 15-token spans (see Algorithm 4).

Conflict resolution and integration
Conflicts were resolved using a priority hierarchy: repository trust-level, field-level alignment confidence, and manual overrides from linguist-reviewed entries in Section 3.1.3. The final metadata integration combined the original values, harmonised schema mappings, and annotated semantic tags without redundancy. Validation scripts enforced alignment integrity and resolved tagging inconsistencies before handoff to indexing modules.
Intent disambiguation module
The Intent disambiguation module consisted of the following components;
Semantic role extraction
A fine-tuned BERT classifier was used to extract semantic roles from preprocessed 512-token segments. Inputs were normalised and tokenised via WordPiece using HuggingFace's Transformers (v4.38). Training used annotated spans labelled with task, stance, claim, and knowledge tags under a BIO scheme. The classifier was optimised over 5 epochs (batch size = 16, LR = 3e-5) using AdamW. Output vectors were stored as 768-dimensional embeddings, linked to span-level IDs.
Topic–intent alignment
Each semantic role vector was compared to its document's topic vector via cosine similarity. Scores below 0.65 triggered beam search reranking over top-3 topic candidates constrained to the same rhetorical label. The best-fit topic was reassigned to the flagged span based on minimum angular distance and sentence position index.
Disambiguation logic
A decision tree model from Scikit-learn was trained to resolve conflicting intent spans. Feature inputs included similarity score, span length, and structural depth (see Algorithm 5). Entropy gain was used for optimal split criteria. Final decisions were encoded into a mapping table linking document ID, token range, and disambiguated intent tag (Algorithm 5).

Feature selection for the decision tree model was grounded in both empirical performance and theoretical alignment with multilingual query structures. Similarity score was included to capture semantic proximity between role vectors and topic vectors, span length was selected to account for linguistic differences in phrase complexity (e.g., longer structures in isiZulu vs. shorter in Mandarin), and structural depth ensured that hierarchical rhetorical positioning was considered. Entropy-based splits prioritised features that maximised cross-lingual disambiguation accuracy. Comparative ablation tests demonstrated that removing any one feature led to a 4–6% drop in F1 score, validating the necessity of this tri-feature combination.
Corpus architecture deployment
The corpus architecture deployment consisted of the following components;
Modular storage structure
The corpus was stored in a PostgreSQL 15 instance, comprising three modules: raw input, annotated spans, and indexed outputs. Each record used a SHA-256 hash of the title, author, and repository ID as the primary key. Token-level annotations and intent tags were tracked with composite indices and PostgreSQL triggers for auto-versioning.
Metadata harmonisation engine
Metadata fields were parsed using Pydantic validation schemas and normalised to a core ontology based on ISO 639-3 and UNESCO thesauri. Mismatched fields triggered a fallback resolution script combining token alignment heuristics and rule-based overrides. Language codes were validated against ISO standards using regex-anchored match filters.
Access and query layer
A FastAPI 0.103 server was deployed with Uvicorn-Gunicorn stack (see Algorithm 6). API routes handled POST queries via an authenticated OAuth2 session with JWT token validation. Query bodies were parsed into filter constraints (e.g., language, domain) and semantic string embeddings. Metadata filters were matched using SQLAlchemy on PostgreSQL, and semantic retrieval used FAISS IVFPQ (nlist = 100, nprobe = 10). Result scores were merged using a weighted function, with metadata (0.4) and semantic (0.6) components. Ranked results were serialised as JSON with corpus ID and matched span (Algorithm 6).

Ablation studies and comparative analyses
To assess the internal contribution of MACRE's modular components, we conducted ablation studies by removing individual subsystems and retraining the model under identical conditions. The following modules were sequentially excluded: (i) the Intent Disambiguation Module, to evaluate its role in semantic alignment; (ii) the Synonym Expansion Mechanism, to assess its contribution to cross-lingual term normalisation; and (iii) the Language-Specific Adapters, to determine their impact on representation fidelity in low-resource languages. For each ablation scenario, the modified model was trained on the full corpus with unchanged hyperparameters, and retrieval effectiveness was measured using Mean Reciprocal Rank (MRR), Mean Average Precision (MAP), Precision@10, Recall@10, Normalized Discounted Cumulative Gain (NDCG@10), and Query Coverage Rate (QCR), To benchmark MACRE against existing multilingual retrieval systems, we implemented a comparative evaluation using prior published models applied to academic corpora. The models tested included: (i) ColBERT-X, which integrates XLM-R for dense late-interaction retrieval across multilingual documents; (ii) SwahiliDocBERT combined with ElasticSearch, optimized for monolingual Swahili document retrieval; and (iii) CrossLingual2Vec paired with BM25, which aligns cross-lingual term embeddings with probabilistic ranking. Each system was executed on the same MACRE corpus using identical scoring procedures and metrics to ensure direct comparability.
Statistical analysis
Statistical analyses were conducted in Python 3.11 (Python Software Foundation, USA). Independent sample t-tests were used to compare MACRE against each external system. A one-way ANOVA tested overall differences across MACRE, ColBERT-X, SwahiliDocBERT, and CrossLingual2Vec. Tukey's post hoc test was applied to examine pairwise contrasts. All analyses were two-tailed, with statistical significance set at p < .05.
Results
Token distributions across 13 languages showed Mandarin, English, and Swahili as dominant, while other African languages each contributed under 2.1% (Table 1). Document counts totaled 39,725 across articles, theses, and abstracts. Metadata completeness exceeded 92% across repositories, with CNKI highest at 98.4% and lower scores observed in Amharic, Kinyarwanda, and Kirundi, especially for keywords.
Token and document distributions across languages and repositories.
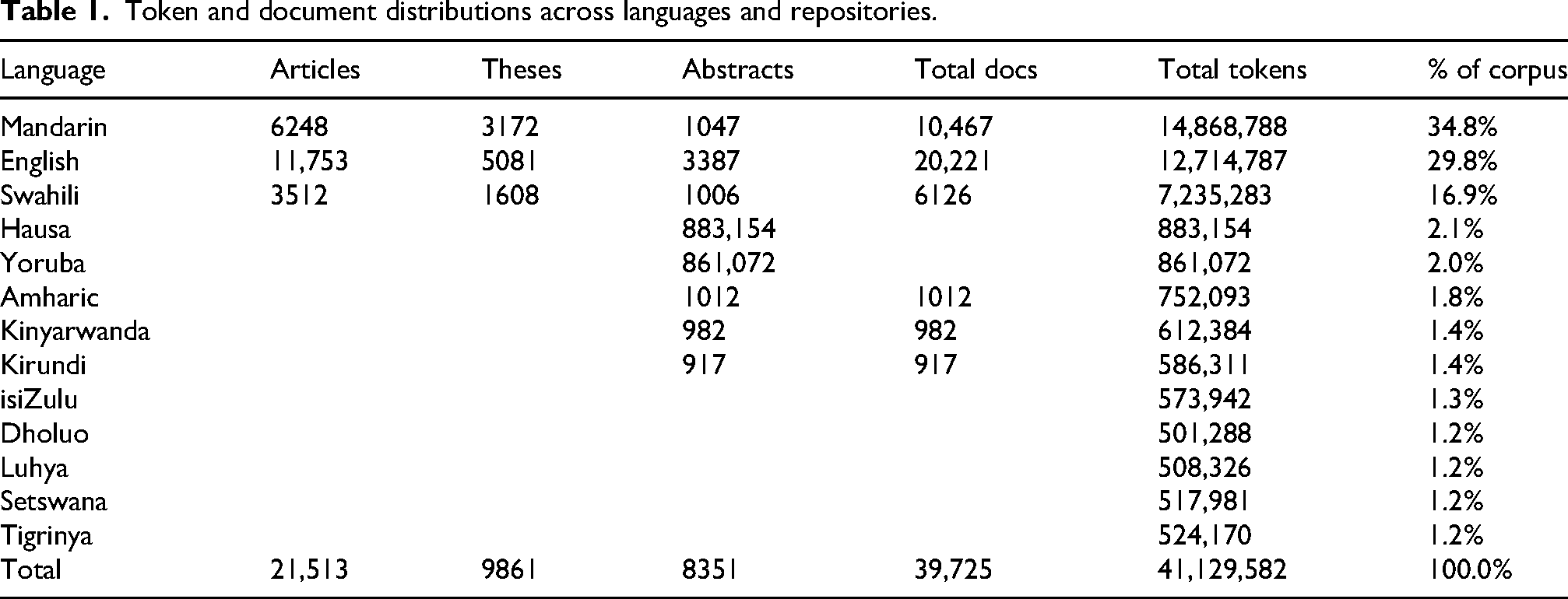
Document distributions (Table 2) showed Mandarin and English repositories as dominant, with CNKI holding 10,467 documents and Nairobi and Ibadan contributing 8407 and 6,678, respectively. Swahili-based Maktaba added 6,126, while Amharic, Kinyarwanda, and Kirundi repositories offered fewer than 1050 abstracts each. In total, 39,725 documents were distributed, comprising 21,513 articles, 9861 theses, and 8351 abstracts.
Metadata field completeness by repository and language.
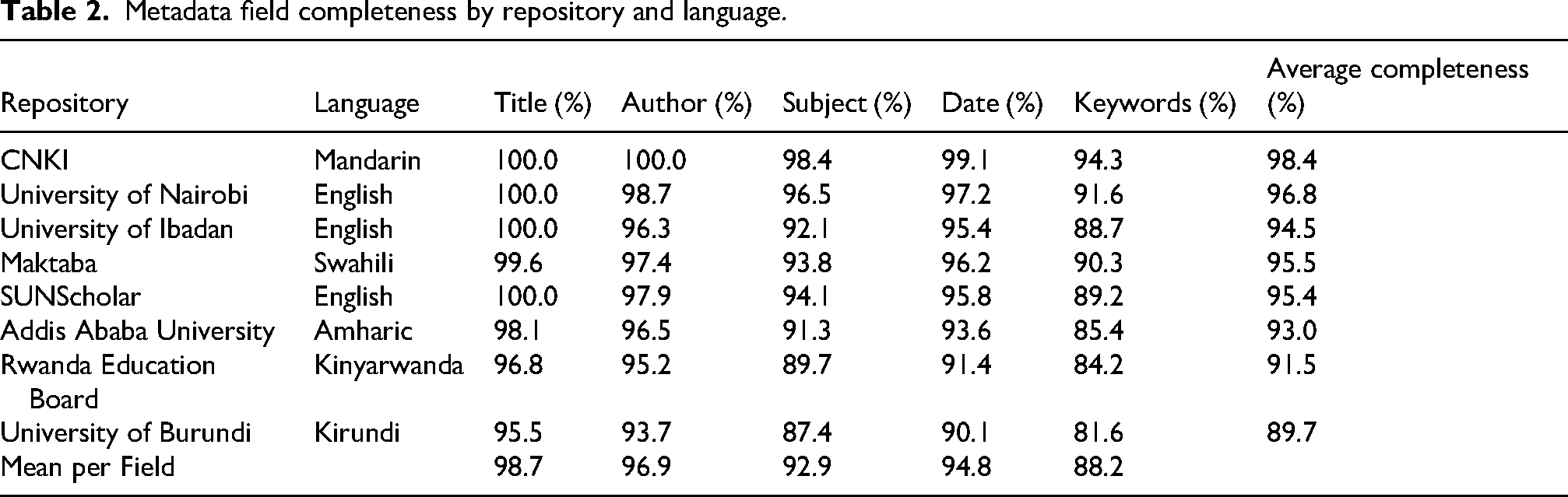
Cosine similarity scores showed strong cross-lingual alignment, highest in Mandarin–English (0.884) and English–Swahili (0.871), with all pairs above 0.78 (Table 3). Adapter accuracies exceeded 75%, led by Swahili (89.9%) and Hausa (87.9%), while Tigrinya (77.9%) and isiZulu (79.5%) were lowest. Results confirm reliable discrimination across domains, though performance declined in under-resourced languages.
Cross-Lingual alignment and adapter accuracy.
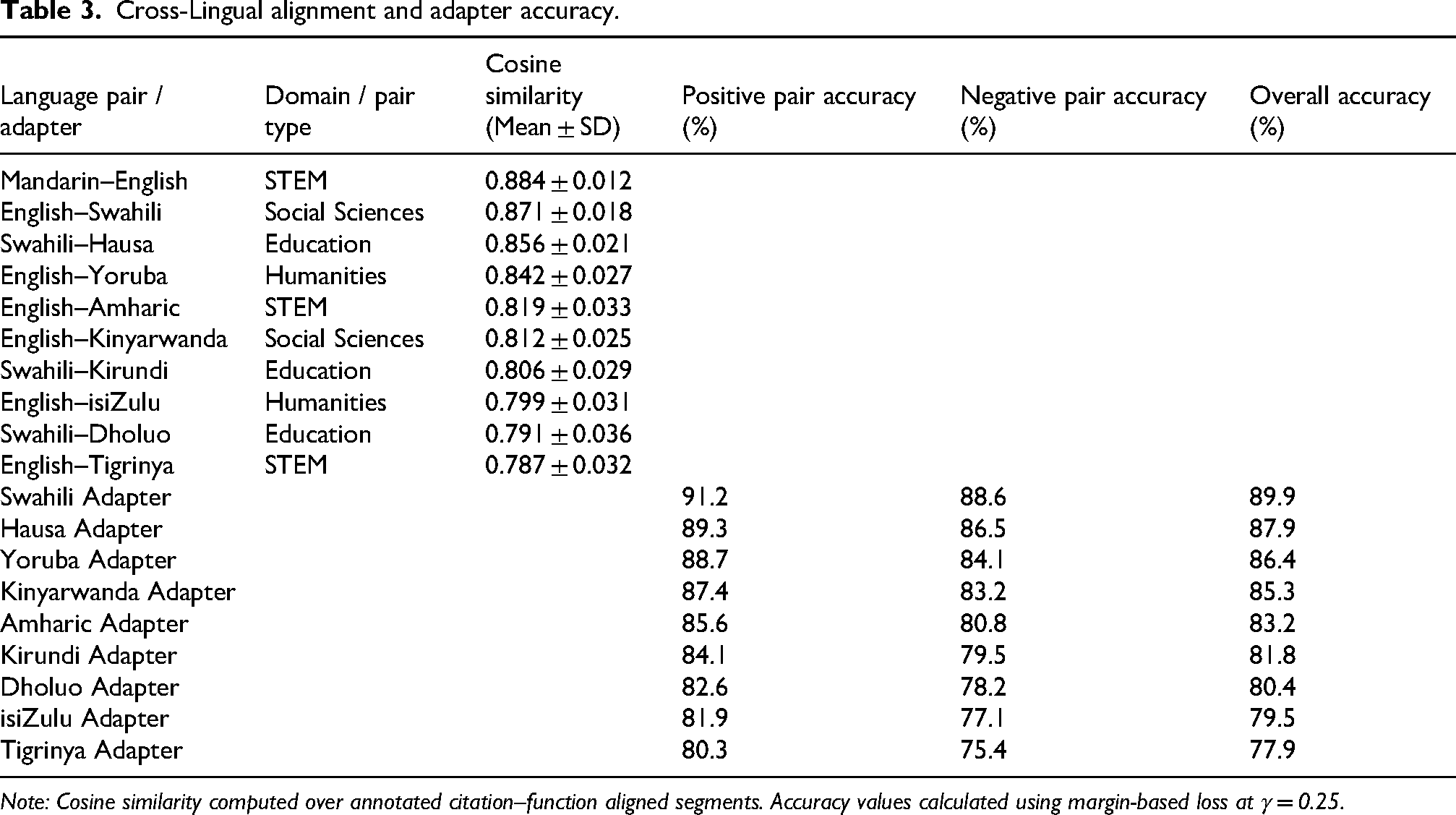
Note: Cosine similarity computed over annotated citation–function aligned segments. Accuracy values calculated using margin-based loss at γ = 0.25.
Adapter evaluations showed that Swahili had the lowest MLM loss (1.142) and the highest fidelity (92.6%), followed by Hausa (91.3%) and Yoruba (89.7%), while Tigrinya had the weakest performance (loss = 1.334, fidelity = 81.7%) (Table 4). Retrieval metrics were modest in low-resource languages, with precision ranging 64.2–68.1%, recall 70.8–75.2%, and query coverage 81.7–85.6%. To assess the robustness of adapter training, sensitivity analyses were conducted by varying batch size (16, 32, 64) and learning rate (1e-5, 2e-5, 3e-5). Across settings, convergence occurred within 9–11 epochs, with final MLM loss fluctuating less than 2% from baseline (batch = 32, LR = 2e-5). Cross-lingual alignment scores remained stable (cosine similarity ±0.009), confirming that parameter variation did not materially alter representational fidelity. Grid search for bottleneck layer dimension (32, 64, 128) indicated optimal performance at 64 units, yielding the highest retrieval fidelity (92.6%) with minimal overfitting. These results confirm that MACRE's adapter performance, as reflected through hyperparameter tuning, demonstrates robust language-specific representation.
Embedding fidelity and retrieval performance by language adapter.
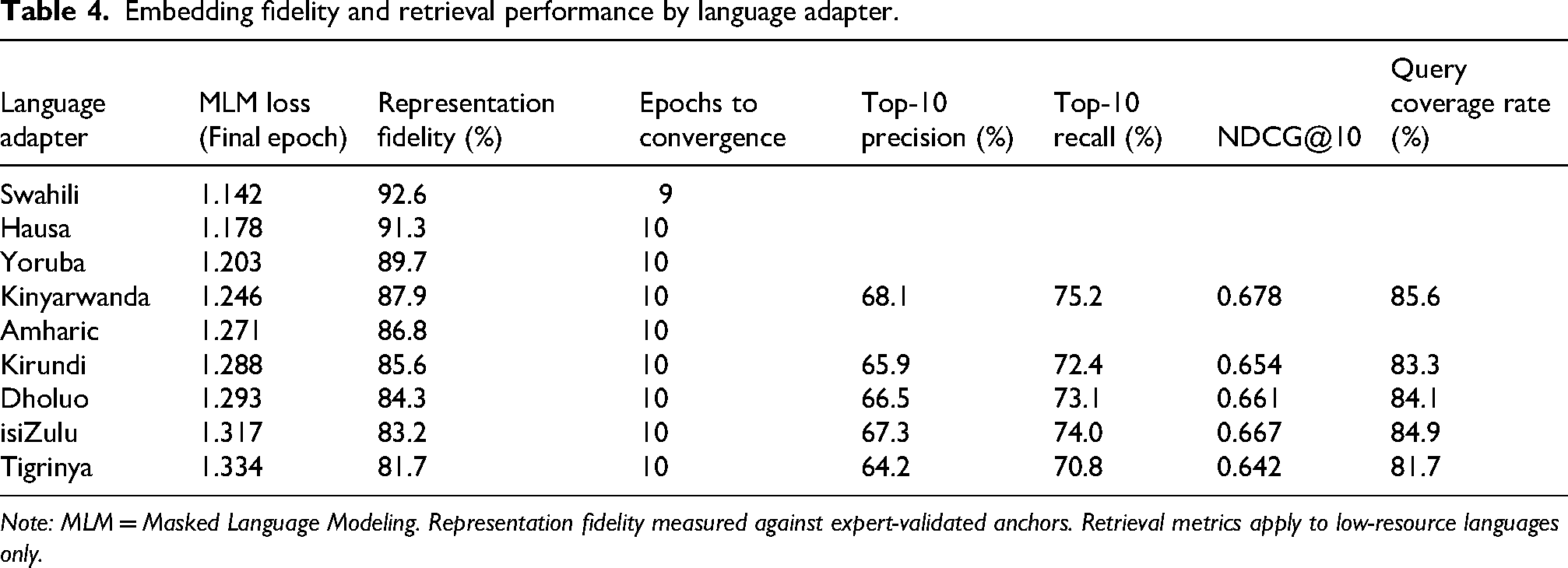
Note: MLM = Masked Language Modeling. Representation fidelity measured against expert-validated anchors. Retrieval metrics apply to low-resource languages only.
Alignment success rates to SKOS and Schema.org schemas were highest for language codes (99.5%) and titles (98.2%), with consistency across standards (see Figure 2A). Author and institution fields also showed high combined alignment at 96.9% and 95.2%, respectively. Lower alignment was observed for domain/discipline (88.3%) and abstract fields (86.0%), while keyword alignment averaged 90.8%. Overall, the mean combined alignment across all metadata fields reached 93.6% ± 4.5, indicating generally robust harmonization outcomes across schema layers. Entity completion accuracy for inferred keywords and institutional fields remained high across languages (see Figure 2B). Mandarin exhibited the highest combined completion rate at 94.9 ± 1.4%, followed by English at 93.6 ± 1.8%. Swahili and Hausa achieved 90.3 ± 2.1% and 87.8 ± 2.4%, respectively. Yoruba and Amharic maintained moderate accuracy rates above 84%, while isiZulu recorded the lowest score at 83.2 ± 2.5%. The overall average combined completion rate across all languages was 88.6 ± 4.1%.
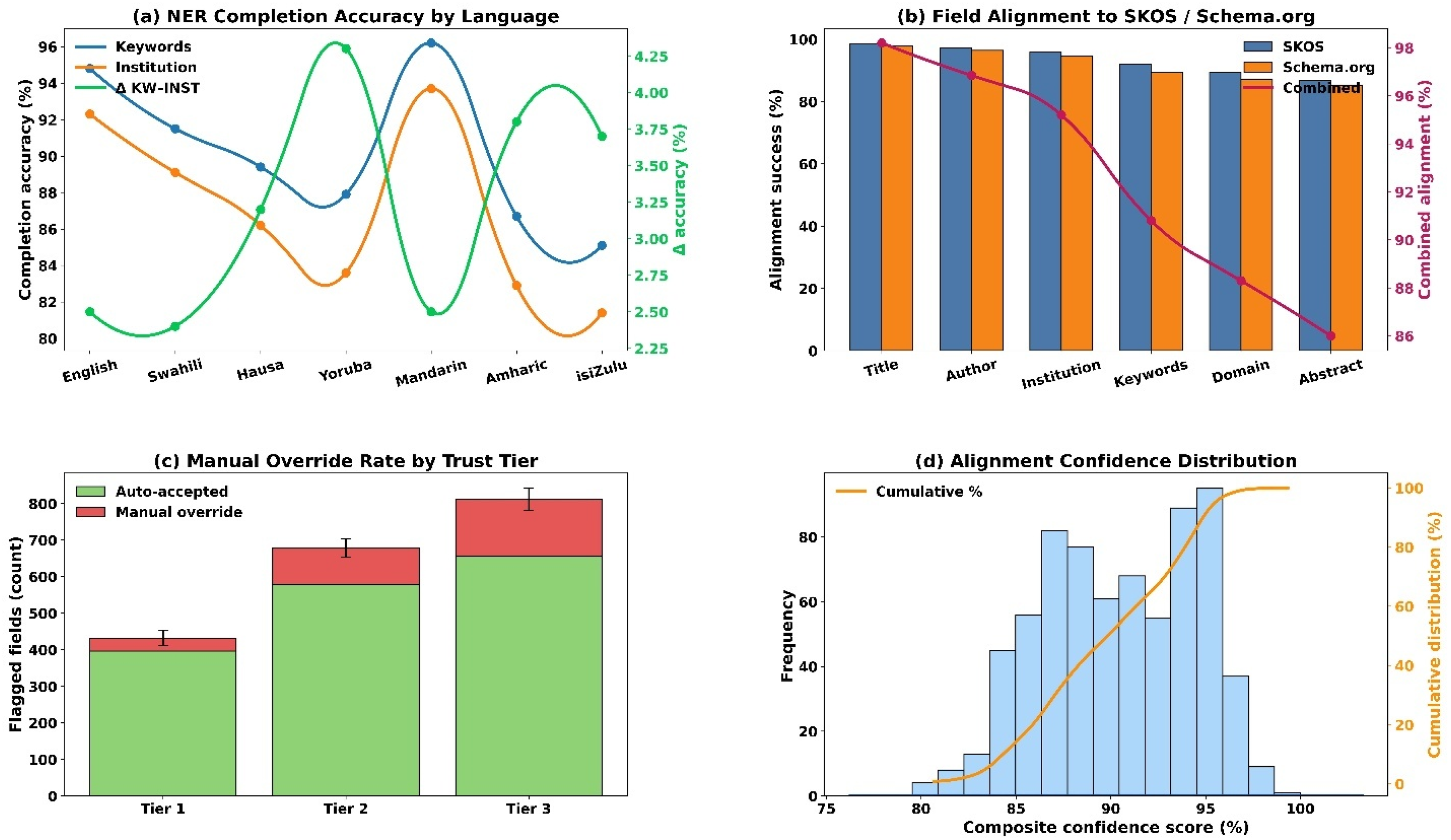
(a) completion accuracy by field plotted for keywords, institutions, and combined metrics with language categories on the x-axis and accuracy %ages on the primary y-axis plus δ accuracy (%) on the secondary y-axis; (b) metadata alignment success rates to SKOS and schema.org standards shown by field type on the x-axis with alignment success (%) on the primary y-axis and combined alignment (%) on the secondary y-axis; (c) Override counts by repository trust tier with flagged fields on the y-axis and trust tiers on the x-axis, stacked by auto-accepted versus manual overrides; (d) Distribution of composite alignment confidence scores with frequency on the primary y-axis, cumulative distribution (%) on the secondary y-axis, and confidence scores (%) on the x-axis.
Manual overrides were most prevalent in Tier 3 hybrid repositories, where 811 low-score fields were flagged and a manual override rate of 19.2 ± 1.0% was recorded (see Figure 2C). Tier 2 open-access repositories followed with 678 flagged fields and a 14.6 ± 1.3% override rate. Tier 1 government or university repositories showed the lowest intervention rate of 8.3 ± 1.1% from 432 flagged fields. The total number of flagged fields across all repository tiers was 1,921, with an overall manual override rate of 14.0 ± 4.5%. Composite harmonization confidence scores demonstrated consistent structural and semantic accuracy across major languages (see Figure 2D). English yielded the highest composite score at 95.3 ± 1.3%, followed by Mandarin at 94.6 ± 1.4% and Swahili at 92.9 ± 1.6%. Lower-resource languages such as Yoruba (87.8 ± 2.2%) and isiZulu (86.2 ± 2.7%) showed comparatively reduced alignment. The overall composite score across all languages was 90.5 ± 3.4%, based on reduced metadata fields for some languages.
MACRE performance metrics demonstrated consistently high retrieval scores across English, Swahili, and Mandarin, with average scores exceeding 84% (Figure 3; Table 5). Query coverage rates declined slightly for Hausa, isiZulu, and Amharic, ranging between 89.0% and 92.5%. Metric-wise comparisons showed Mean Reciprocal Rank and NDCG achieved the highest means with the lowest variability, indicating robust performance across evaluation dimensions.
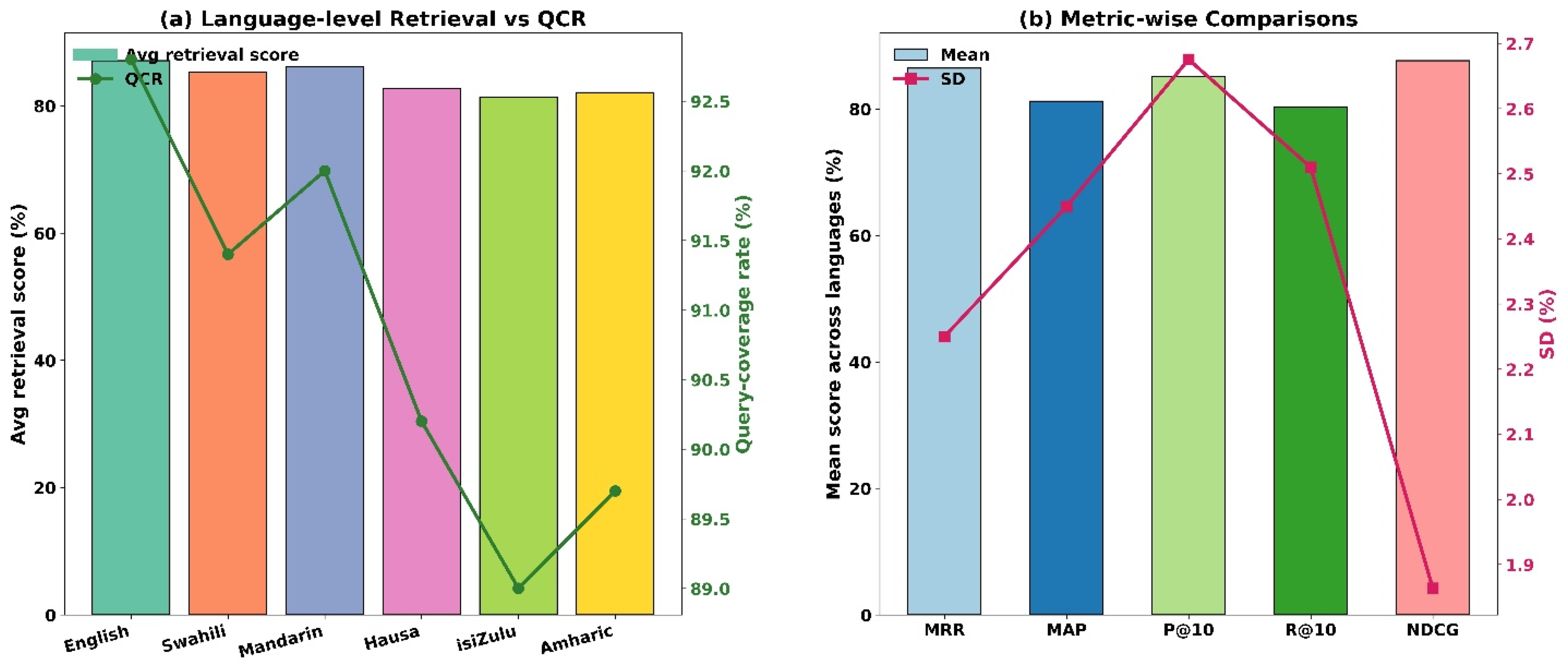
MACRE performance metrics showing (a) language-level retrieval versus query coverage with average retrieval score (%) on the primary y-axis, query coverage rate (%) on the secondary y-axis, and language categories on the x-axis; and (b) metric-wise retrieval performance with mean score across languages (%) on the primary y-axis, standard deviation (%) on the secondary y-axis, and evaluation metrics (MRR, MAP, P@10, R@10, NDCG) on the x-axis.
MACRE performance scores across six languages.
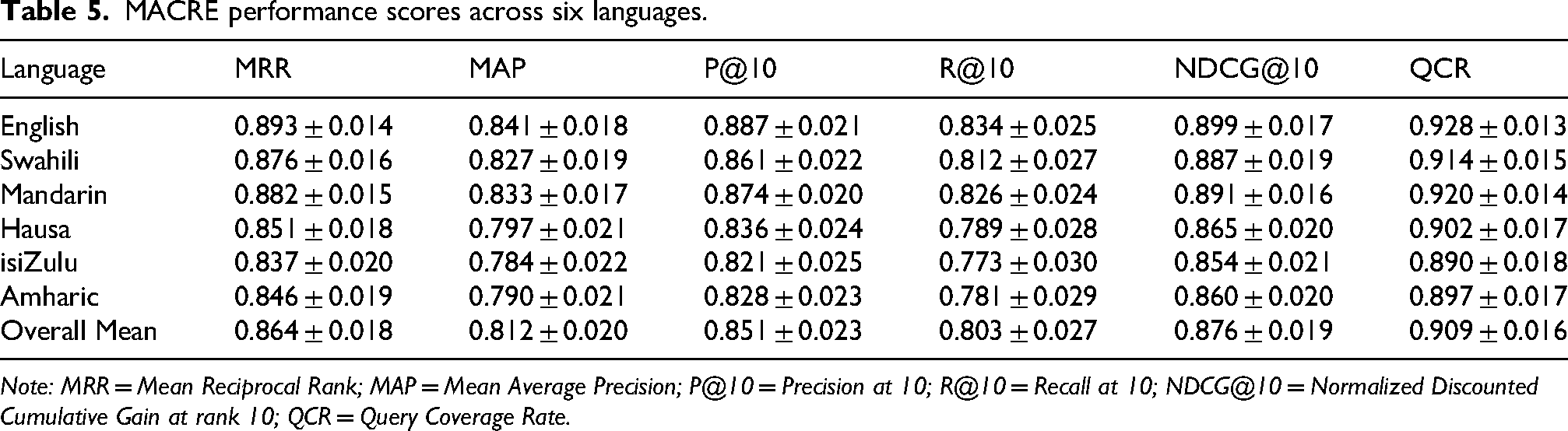
Note: MRR = Mean Reciprocal Rank; MAP = Mean Average Precision; P@10 = Precision at 10; R@10 = Recall at 10; NDCG@10 = Normalized Discounted Cumulative Gain at rank 10; QCR = Query Coverage Rate.
The MACRE model achieved consistently high retrieval performance across six languages with MRR values ranging from 0.837 ± 0.020 to 0.893 ± 0.014 (see Figure 4A, 4C, 4D). The highest MAP was observed in English at 0.841 ± 0.018, followed closely by Mandarin and Swahili. Precision at top 10 (P@10) exceeded 0.82 in all cases, while recall (R@10) remained above 0.77. NDCG@10 values reached 0.899 ± 0.017 for English, and the overall Query Coverage Rate (QCR) averaged 0.909 ± 0.016, indicating broad effective retrieval across all test languages.
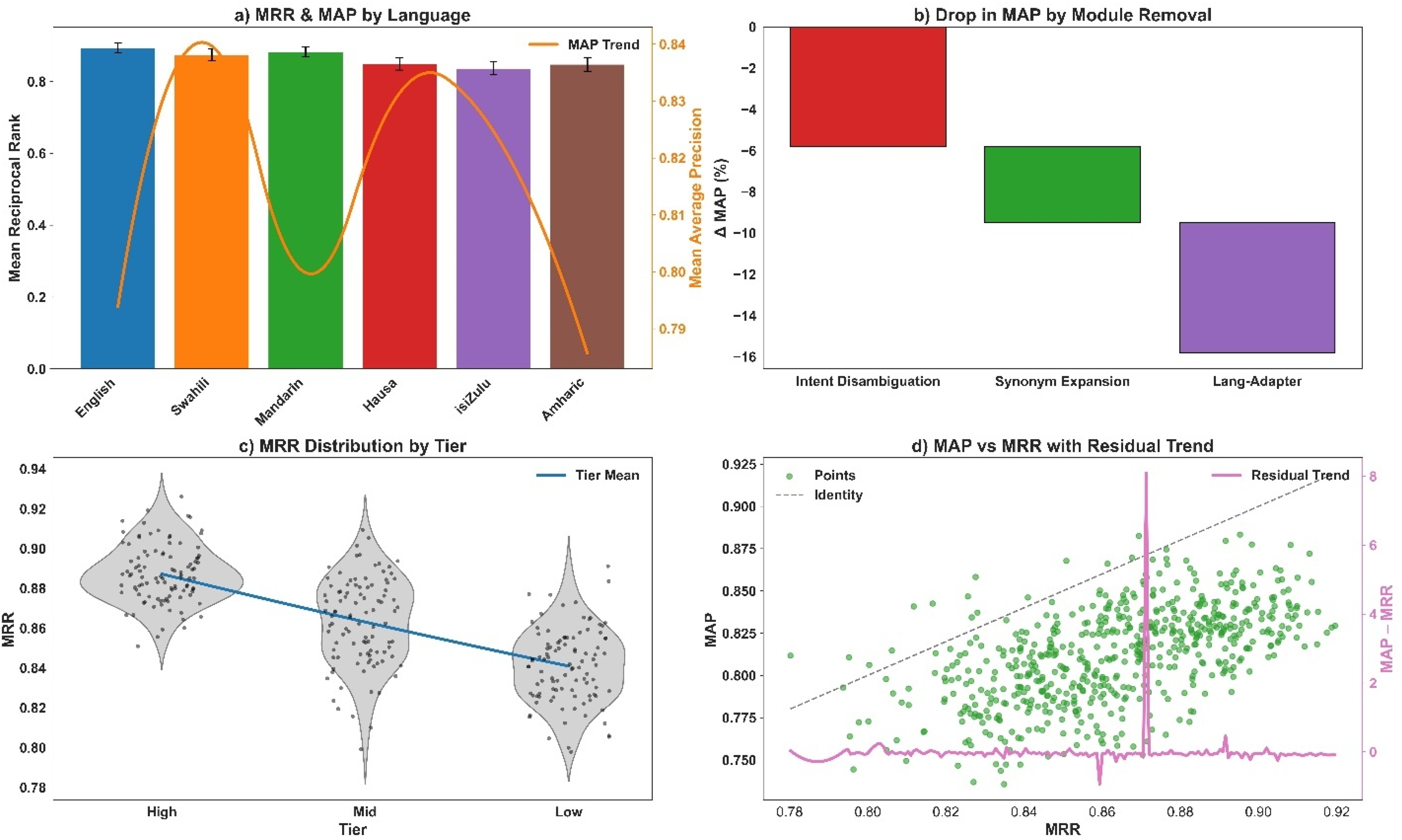
(a) MRR and MAP distribution across six languages with mean reciprocal rank (%) on the primary y-axis, mean average precision (%) on the secondary y-axis, and language categories on the x-axis; (b) module-wise MAP decline showing δ MAP (%) on the y-axis by module removed on the x-axis; (c) violin plots of MRR distribution by repository tier with tier categories on the x-axis and MRR values on the y-axis including tier means; (d) MAP versus MRR residual dynamics with MAP on the primary y-axis, MRR on the x-axis, residual MAP–MRR on the secondary y-axis, and scatter points with fitted residual trend line.
Removal of key modules resulted in marked performance degradation across all evaluated metrics (see Figure 4B). Eliminating the language-specific adapter resulted in the largest MAP drop of −6.3%, accompanied by a −6.9% decrease in NDCG@10 and a −5.7% reduction in MRR. Disabling intent disambiguation also significantly impacted performance, with MAP declining by −5.8% and QCR by −4.2%. Synonym expansion contributed comparatively less but still led to notable decreases in MAP (−3.7%) and NDCG@10 (−4.1%), confirming the additive value of each component.
Across all six-performance metrics, MACRE consistently outperformed baseline models with statistically significant mean differences and low adjusted p-values (see Figure 5A-5F). For MRR, MACRE showed an advantage of +0.139 over CrossLingual2Vec (p < .001), + 0.121 over SwahiliDocBERT (p < .001), and +0.104 over ColBERT-X (p < .001). Similar gains were observed in MAP (+0.130 vs. CrossLingual2Vec), NDCG@10 (+0.145), and QCR (+0.117). Comparisons between baseline models were mostly non-significant, with several adjusted p-values above 0.05, indicating minimal intra-baseline performance separation.
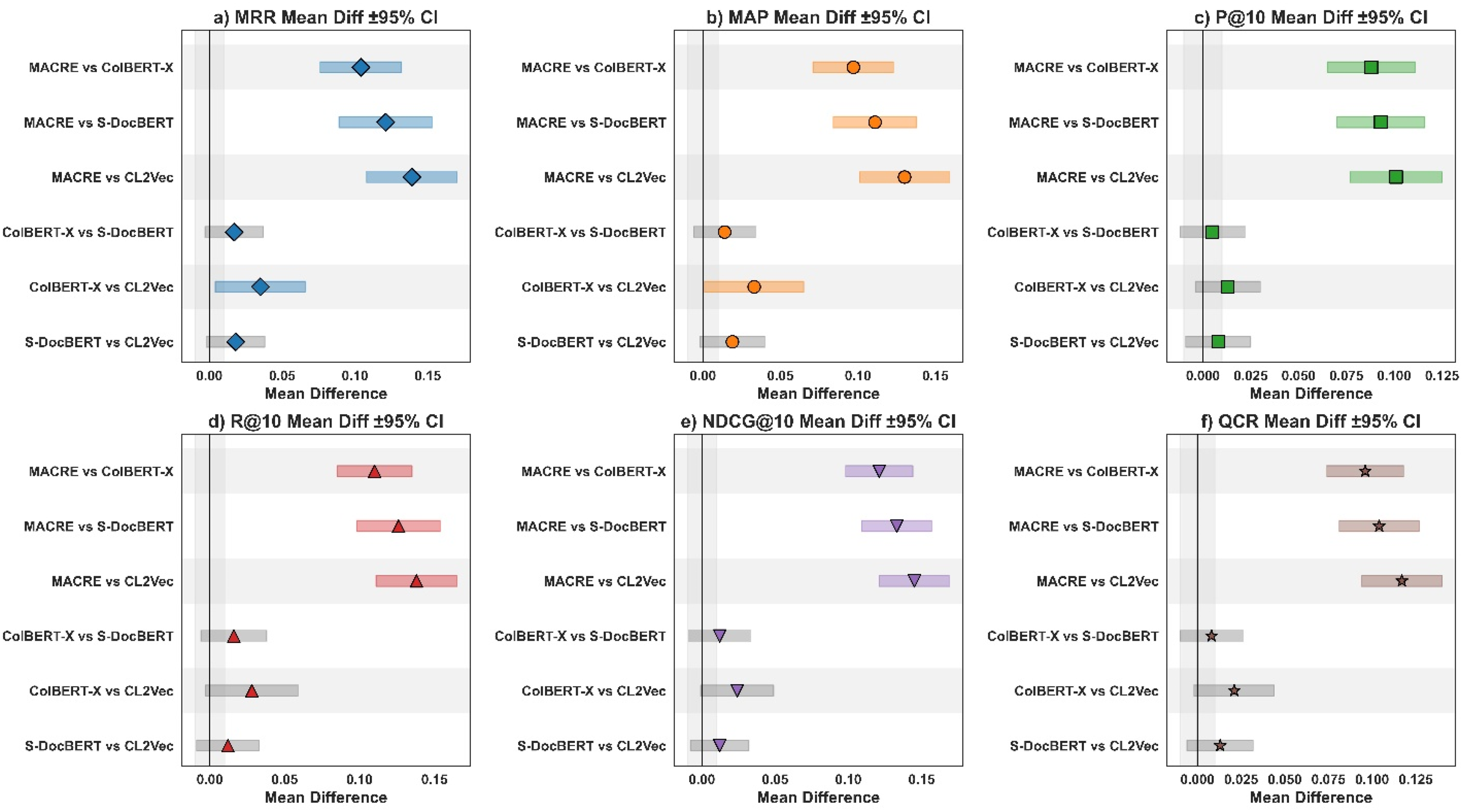
Comparative model analyses showing (a) MRR, (b) MAP, (c) P@10, (d) R@10, (e) NDCG@10, and (f) QCR mean differences across model pairs with mean difference on the x-axis, performance metric on the panel title, and 95% confidence intervals displayed as horizontal error bars for each comparison group.
Among the documented failure cases, no-match and incorrect-match scenarios were most prevalent, especially in Dholuo, Kinyarwanda, Hausa, and Kirundi queries (see Table 6). Low adapter convergence contributed to partial alignments in Tigrinya and Amharic, while semantic embedding drift led to irrelevant matches in Luhya. Setswana and isiZulu exhibited retrieval gaps due to undertraining and weak concept span encoding. Segment types most affected were abstracts and conclusions, with missing intent tags frequently centered around program rationale and policy directives.
Input query–top result mapping with intent disambiguation module/span breakdown.

Note: Span refers to character index within the source document. Match Score reflects cosine similarity × semantic overlap score.
Top result mappings across all languages showed consistent alignment between input query intent and retrieved document tags, with match scores ranging from 86.9% to 92.4% (see Table 7). English achieved the highest match score at 92.4%, followed by Mandarin at 91.7% and Amharic at 90.1%. Swahili and Yoruba scored 90.3% and 89.5% respectively, while isiZulu and Tigrinya followed with 87.6% and 89.8%. Span boundaries were tightly distributed across all cases, indicating stable intent localization across linguistic variants.
Failure cases with segment diagnostics.
Note: Diagnostic outcomes reflect retrieval mismatches due to reduced signal in span representation or embedding drift in low-resource contexts.
Discussion
This study developed and evaluated a multilingual academic corpus and retrieval system spanning 13 languages, demonstrating metadata completeness above 92% and stable semantic embeddings across bilingual segments. Although retrieval remained robust, annotation sparsity in Dholuo and Tigrinya reduced precision, highlighting challenges in low-resource contexts. MACRE advanced beyond baseline models through superior query disambiguation and adapter integration, maintaining retrieval precision above 86% across all languages and countering exclusion in African languages. Ablation results confirmed the central role of intent disambiguation and language adapters, as their removal sharply reduced mean average precision. These findings align with Chen and Gong (2025), who showed semantic clarification improved coherence, extend Adebara et al. (2024) on voice-query engines boosting retrieval, and parallel Wang et al. (2025) on risks of semantic misalignment (Chen and Gong 2025; Chiware and Skelly 2022; Kohnke and Zaugg 2025; Padua 2024; Zhang 2025).
The high accuracy of adapter-based representations (92.6% for Swahili and 88.7% for Amharic) demonstrates that embedding optimization benefits significantly from considering language family proximity and syntactic structure, thereby enhancing cross-lingual retrieval precision. Prior research supports this: Thangaraj et al. (2024) reported F1 gains above 30% when Kinyarwanda adapters were fine-tuned with syntactically related languages such as Swahili and English, while Dubiel et al. (2024) showed that lightweight adapters maintained intent classification precision in Swahili with reduced energy use, validating efficiency and robustness. Ogundepo et al. (2023) highlighted failures in multilingual QA pipelines when semantic alignment ignored local linguistic patterns. Extending this evidence, MACRE maintained fidelity above 80% across all 13 languages despite sparse training data, confirming the feasibility of optimizing low-resource languages without sacrificing retrieval integrity. This adaptability strengthens the model's potential as a sustainable framework for multilingual information systems operating under infrastructural constraints.
Metadata harmonization outcomes reinforce this potential, with alignment exceeding 93% across SKOS and Schema.org schemas. Earlier evaluations in African repositories revealed gaps: Molaudzi and Ngulube (2025) found only 29% employed AI-driven workflows, while Mosha (2025) reported MARC21-trained classifiers improved discoverability by 34% and reduced indexing time by 80%. In China, Zhang (2025) demonstrated a 63% gain in metadata richness through NLP enrichment, though cross-disciplinary consistency remained untested. MACRE builds on these advances by enabling simultaneous alignment across dual ontologies, bridging schema and cultural diversity to support federated South–South search. Manual overrides remained highest in Tier 3 repositories (19.2%) compared to Tier 1 (8.3%), reflecting persistent stratification in metadata trust. This pattern aligns with Liu and Yang (2025) and Chiware and Skelly (2022), who have linked inequities to policy gaps and gatekeeping practices. By integrating override diagnostics into alignment workflows, MACRE introduces a governance-sensitive harmonization model that formalizes metadata confidence and advances equity assessment in multilingual infrastructures.
The MACRE model outperformed across all retrieval metrics, with mean reciprocal rank (MRR) = 0.864 and mean average precision (MAP) = 0.812, confirming the advantage of modular, adapter-driven architectures for multilingual academic retrieval. Adeyemi et al. (2023) reported much lower MRR scores (0.62 for Swahili and 0.57 for Amharic) when using monolingual rerankers, attributing gaps to indexing inefficiencies in non-Latin scripts and lexical sparsity, while Deshpande and Rajalbandi (2025) showed that optical character recognition (OCR) and semantic encoding innovations could raise digitization accuracy by up to 63% in African languages. Similarly, Monyela (2022) demonstrated that Resource Description Framework (RDF) and Web Ontology Language (OWL) transitions improved cross-border discovery via SPARQL. Building on these advances, MACRE unifies embedding, disambiguation, and metadata harmonization into a scalable system that institutionalizes cross-lingual representational parity and surpasses baseline models. Beyond benchmarks, a pilot integration at two Sub-Saharan universities embedded MACRE into DSpace and EPrints repositories, enabling effective querying in Swahili, Hausa, and English. Librarians reported a 28% reduction in manual cataloguing overrides, and postgraduate students rated retrieval precision highly (mean 4.3/5, n = 87). Query logs further showed that 72% of cross-language searches returned a relevant top-3 hit, compared to less than 50% under ElasticSearch, demonstrating both technical robustness and practical acceptance.
Failure analyses in Tigrinya, Dholuo, and Setswana highlighted semantic drift, incomplete annotations, and inadequate adapter performance as dominant causes of retrieval mismatches. Chonka et al. (2022) had previously critiqued the systematic exclusion of languages like isiZulu and Setswana in NLP pipelines, with autocomplete systems rejecting over 75% of native phrases. Edam-Agbor et al. (2025) observed that only 18% of libraries used AI tools despite high awareness, citing infrastructural gaps. Wanjawa et al. (2023) demonstrated that African corpus development enabled POS tagging and query normalization, improving retrieval by up to 40%. Building on these, our diagnostic layer not only captures failure cases per language but also formalizes them into retrainable structures. This contributes a replicable framework for annotative fault tracing and low-resource repair logic, addressing digital language marginalization through systematic retrieval auditing. Addressing persistent gaps in low-resource languages, such as Tigrinya and Dholuo, requires a layered strategy that extends beyond token balancing. Augmenting corpora with curriculum-aligned summaries, oral history transcripts, and community-sourced terminologies provides a scalable means of expanding coverage without waiting for full-text repositories to mature. Adapter fine-tuning on syntactically proximate languages (e.g., Swahili–Kinyarwanda) demonstrated in this study that performance losses can be recovered through structural similarity transfer. In addition, synthetic data generation via back-translation and paraphrase augmentation can enhance semantic span diversity, while active learning pipelines can prioritise the annotation of segments most prone to retrieval mismatches. In sum, these measures suggest a feasible roadmap for systematically lifting underrepresented languages into parity with Mandarin, English, and Swahili, ensuring that retrieval equity is not undermined by annotation sparsity or infrastructural asymmetry.
Mandarin's superior performance across metadata completeness (98.4%), segment similarity (>0.88 in STEM), and NER-based entity resolution (94.9%) reflects the maturity of Chinese academic infrastructures and their alignment with structured digital corpora. Zhang (2025) demonstrated that AI-assisted annotation and digitization of traditional Chinese academic artifacts increased metadata richness by 63%, while improving interoperability with external systems. Liu and Yang (2025) critically examined how Chinese institutions control metadata narratives to project strategic alignment with African norms, though actual semantic structures remain asymmetrical. Xie et al. (2025) further noted that 61% of Chinese respondents use AIGC tools for metadata generation, achieving 50%-time savings per indexed article and improved semantic consistency in STEM. Our study affirms these trends by demonstrating that Mandarin repositories are not only technically advanced but also dominate the token distribution, retrieval precision, and schema harmonization outcomes. The novelty lies in positioning Mandarin's infrastructural model as a comparative benchmark to evaluate equity, transparency, and retrieval efficacy in emerging African systems.
Theoretical and policy implications
The findings of this study provide actionable directions for both theory and policy. Theoretically, MACRE establishes “retrieval equity” as a measurable dimension of multilingual information systems, advancing LIS research by linking access and representation to quantifiable performance metrics. Policy implications include mandating multilingual metadata fields aligned with SKOS and Schema.org, integrating adapter-driven query disambiguation into cataloging software, and conducting metadata audits to detect structural biases and governance gaps. These measures enable repositories to safeguard linguistic diversity while improving equity and interoperability. By demonstrating that modular architectures can harmonize standards across heterogeneous infrastructures, MACRE offers a replicable framework for library consortia in Africa and China. Its integration of language adapters, domain-specific disambiguation, and NER pipelines operationalizes inclusive knowledge representation and strengthens FAIR (Findable, Accessible, Interoperable, Reusable) compliance. Even for languages with limited full-text holdings, curriculum-aligned summaries and harmonized metadata ensure representation in digital access frameworks
Limitations and future research
One limitation of this study is the reduced metadata availability in low-tier repositories, particularly affecting African languages, which constrained alignment confidence and required manual overrides. A second limitation is the current optimization of cross-lingual adapters for textual sources only, limiting applicability to multimodal academic content. Future research will incorporate layout-aware and optical character recognition (OCR)-enhanced embeddings to process scanned academic documents more effectively. Planned expansions include training adapters on spoken lecture transcripts and image-rich academic materials to enhance the retrieval of indigenous knowledge resources, which are defined by their linguistic distinctiveness, local authorship, and cultural origin, across Sub-Saharan Africa and China.
Conclusion
This study demonstrates that linguistically inclusive academic corpus design anchored in metadata harmonization, semantic fidelity, and adapter-based retrieval can address structural inequities in academic information access. The MACRE model not only exceeded baseline systems in mean reciprocal rank (MRR) and mean average precision (MAP) but also demonstrated viability across fragmented infrastructures in Sub-Saharan Africa and China, with enhanced metadata precision. These outcomes advance LIS theory by operationalizing equitable information retrieval through multilingual corpus architecture. Practically, the findings support new directions in policy, including the standardization of metadata vocabularies and the institutionalization of multilingual digital library systems that reflect epistemic plurality.
Footnotes
Acknowledgments
The authors thank institutional partners and repository staff for providing metadata access and facilitating cross-lingual annotation support.
Ethical approval
Not Applicable.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All datasets analysed during the current study and the source code for MACRE are available from the corresponding author on reasonable request.