
Abstract
Listeners interpret cues in speech processing immediately rather than waiting until the end of a sentence. In particular, prosodic cues in auditory speech processing can aid listeners in building information structure and contrast sets. Native speakers even use this information in combination with syntactic and semantic information to build mental representations predictively. Research on second-language (L2) learners suggests that learners have difficulty integrating linguistic information across various domains, likely subject to L2 proficiency levels. The current study investigated eye-movement behavior of native speakers of English and Chinese learners of English in their use of contrastive intonational cues to restrict the set of upcoming referents in a visual world paradigm. Both native speakers and learners used contrastive pitch accent to restrict the set of referents. Whereas native speakers anticipated the upcoming set of referents, this was less clear in the L2 learners. This suggests that learners are able to integrate information across multiple domains to build information structure in the L2 but may not do so predictively. Prosodic processing was not affected by proficiency or working memory in the L2 speakers.
I Introduction
Speakers use prosody to convey particular meanings by manipulating the duration, loudness, pauses, or stress over particular words or sentences. For example, in We ate Angela’s cake but saved BENjamin’s . . . , the contrastive pitch accent placed on Benjamin’s indicates to the listener that two of the same objects will likely be contrasted (Angela’s cake and Benjamin’s cake). If the word cake receives a contrastive pitch accent instead, as in We ate Angela’s CAKE . . . , now the listener expects that Angela’s cake will be contrasted with another object Angela possesses (as in We ate Angela’s CAKE, but not her ice cream). Note that the initial clauses in both examples contain the same words and structure yet differ in the placement of the contrastive pitch accent. Processing prosody thus is a critical aspect of speech comprehension that informs the listener as to what information is given, new, or focused in a dialogue (Halliday, 1967), facilitating communication between interlocutors.
Despite the importance of prosody for language understanding, it is still unclear how second language (L2) listeners use prosodic cues. Evidence from prior studies suggests that native speakers are able to integrate information from different representational domains, such as prosody and syntax, while reading and listening (Ito and Speer, 2008; Patterson et al., 2017; Sedivy et al., 1995). On the other hand, theories of L2 processing predict difficulties for learners either in the integration of information across various representational domains (Interface Hypothesis; Sorace, 2011) or in complex mapping of information across domains (Patterson et al., 2017). Producing and recognizing L2 prosodic cues is difficult for L2 speakers, especially if prosody differs in form and function between the languages being compared (Mennen and de Leeuw, 2014). In the current study, we used a visual world eye-tracking paradigm (Tanenhaus et al., 1995) to investigate whether L2 learners are able to use contrastive pitch accent to build information structure and, if so, to what extent L2 learners use this prosodic cue predictively, and to what extent this depends on working memory and proficiency. The following sections provide an overview of prior studies investigating anticipatory processing of L1 (first language) and L2 prosody and the potential sources of differences between the two language groups.
1 Anticipatory processing of prosody in native speakers
Intonation can be used as an indication of information structure status, namely whether an element of a sentence has been introduced earlier, is new or is focused (Halliday, 1967). Informational focus is acoustically marked with a wider pitch range, an increased intensity, and increased duration compared to other speech elements that are not in focus (Wagner and Watson, 2010). This makes I gave the APPLE to John a felicitous answer to the question What did you give to John?, in which the direct object is probed; but not to a question in which the apple is given and the indirect object is probed, such as Who did you give the apple to?
Another type of focus is contrastive focus. In English, contrastive focus is marked by a low-falling, then high-rising F0 contour, or L+H* pitch accent (Pierrehumbert and Hirschberg, 1990). Empirical data substantiates the claim that this type of pitch accent is used to denote a new referent, while a deaccented word in a set of referents indicates that the referent has already been mentioned (Terken and Nooteboom, 1987).
The literature suggests that native speakers are able to identify and integrate prosodic information to build information structure in real time (Dimitrova, 2012; Heim and Alter, 2006; Wang et al., 2011). ERP experiments in English (Johnson et al., 2003) and German (Hruska and Alter, 2004) show an increased N400 response at words that should have a focus pitch accent but do not, suggesting that prosody and expectations about focus status may immediately influence processing. Many studies have also looked at focus processing during reading. In these studies, focused target words typically elicit an increased late positive amplitude (e.g. Bornkessel et al., 2003; Cowles et al., 2007), which has been interpreted as reflecting integrative processing. Taken together, ERP evidence from both written and spoken language suggests that focus status influences processes related to both lexico-semantic interpretation and information integration.
Prior work on anticipatory processing of acoustic cues has investigated the role of contrastive pitch accent using a focused referent which is understood with respect to a set of alternatives. Evidence from such research suggests native listeners can use prosodic cues to anticipate upcoming information (Dahan et al., 2002; Ito and Speer, 2008; Nakamura et al., 2012; Sedivy et al., 1995). As an example, using a visual world paradigm, Ito and Speer (2008) had native English speakers decorate a Christmas tree according to spoken instructions. Objects were grouped in the same cell by type, and each object within a cell was a different color. When the L+H* pitch accent was placed on the second adjective, participants made anticipatory looks to the target object. When hearing an infelicitous L+H* contrastive pitch accent on the adjective (e.g. Hang the green ball. Next, hang the BLUE (L+H*) angel), participants produced garden-path fixations, that is, they looked initially to the cell with the same objects as the one previously mentioned. No such effect was found for the more neutral H* pitch accent. Native English listeners were able to use the prosodic cues to make predictions about the upcoming referent and were garden-pathed when the target noun was not the noun they had anticipated.
2 L2 processing of prosody
The literature on L2 learners’ use of L2 prosody shows mixed results. Some studies suggest that learners have problems producing and perceiving prosodic cues, especially if these differ from those prosodic cues in their L1 (Mennen and de Leeuw, 2014). For instance, Akker and Cutler (2003) compared phoneme detection in speakers of Dutch and English, languages that use prosodic cues similarly to inform information structure. Native speakers of both languages were quick to identify target phonemes when the target word was both in semantic focus and contained a predictive prosodic pitch in their respective L1s. However, Dutch L2 learners of English were not able to map pitch accent to semantic information as effectively as native speakers of English. Additionally, ERP studies using written question-answer pairs (Reichle, 2010; Reichle and Birdsong, 2014) reported that low-proficiency English learners of French did not show ERP indices associated with words in contrastive versus informational focus (clefts). High-proficiency learners, on the other hand, did show native-like negativity for contrastive focus, further suggesting that the online perception of information structure is affected by proficiency. Takahashi and colleagues (2018) found in a behavioral task that reaction times for Chinese learners of English were shorter for sentences with felicitous contrastive pitch accent on an adjective as compared to infelicitous sentences (e.g. Click on the scarlet necklace. Now click on the SCARLET (L+H*) mittens). The authors concluded that Chinese speakers were able to effectively use English contrastive prosodic cues likely due to the similarity in pitch contour shape for prosodic focus in English and Mandarin Chinese. The evidence thus far therefore suggests that L2 speakers are sensitive to modulations of L2 prosody but may have difficulty combining this information with other sources, especially when the L2 makes distinctions not present in the L1 and/or when the learner has not reached high proficiency.
3 Predictive processing in L2
As discussed above, native speakers appear to use linguistic cues, including prosody, rapidly to anticipate upcoming information. Research on prediction in L2 learners has yielded mixed results. On the one hand, a number of studies on L2 learners suggests that non-native speakers do not anticipate to the same extent as native speakers, even though they know the specific rules and words used when probed offline (Dussias et al., 2013; Grüter et al., 2012; Grüter and Rohde, 2013; Hopp, 2013; Lew-Williams and Fernald, 2010; Martin et al., 2013). Grüter et al. (2012) found a reduced ability for L2 learners to predict, substantiating this finding by proposing that the association between nouns and gender markers are weaker for L2 learners than for native speakers, affecting their ability to effectively predict in the L2. Namjoshi and Tremblay (2014) investigated English learners of French in an eye-tracking experiment and found that the L2 learners did not use contrastive pitch accent to anticipate upcoming referents using a visual world paradigm. However, neither did native speakers of French in this case.
Alternatively, other studies report that L2 learners can use linguistic information predictively, especially those with greater L2 proficiency (Hopp, 2013). Dussias et al. (2013) also found that only highly proficient English learners of Spanish used determiner information predictively, but not to the same extent as native speakers. Most recently, in Curcic et al. (2019), participants were taught a subset of Fijian nouns, verbs, adjectives, and determiners. The researchers interpreted the eye-tracking data as evidence that overall, learners were able to predict upcoming nouns based on determiner information. Yet, once the learner group was divided into those who were aware of the gender agreement between determiner and noun and those who were not, they found that only learners who claimed they were aware revealed significant anticipatory processing
Clearly prediction is not all or nothing, but affected by various factors (Kaan, 2014). Variation in the ability to predict has not only been attested among L2 speakers (Dussias et al., 2013; Hopp, 2013), but also among native speakers (Borovsky et al., 2012; Federmeier et al., 2002; Hopp, 2013; Huettig and Janse, 2012; Huettig et al., 2011). Previous studies report a relation between the ability to predict, vocabulary knowledge (Borovsky et al., 2012; Federmeier et al., 2002), consistency and speed of lexical access (Hopp, 2013), and working memory (Huettig and Janse, 2012; but see Otten and Van Berkum, 2009). In the current study, we test whether the ability to use prosodic cues predictively is modulated by working memory span or proficiency. If the mechanisms underlying predictive processing are the same in native speakers and L2 learners, one expects that factors that affect predictive processing in L2 speakers will also affect predictive processing in native speakers.
4 Accounting for differences between L1 and L2
Various accounts have been proposed to explain why L2 learners differ from native speakers in some aspects of sentence processing. We will discuss these approaches below and derive predictions as to L2’s ability to integrate information from disparate sources (in this study, syntactic, lexical, and prosodic) to build information structure and do so predictively.
First, according to the Shallow Structure Hypothesis (Clahsen and Felser, 2006), L2 learners do not build complex syntactic structures, but instead rely on contextual and lexical information and processing heuristics to understand sentences. Under this account, it is predicted that L2 learners will not build detailed information structure either and will not combine prosodic cues with other information to inform the information structure.
According to processing-based approaches, L2 learners can fully attain the knowledge of an L2; differences between L2 and native sentence processing can be attributed to a lack of resources in L2 speakers. L2 learners have fewer automatic processing routines and need to suppress their native language, which takes up processing resources. L2 speakers therefore differ from native speakers particularly in more complex processing situations, e.g. when different kinds of information need to be combined (Hopp, 2010; Sorace, 2011), or, in the case of predictive processing, when information needs to be accessed and combined rapidly to form predictions (Grüter and Rohde, 2013).
The Interface Hypothesis specifically posits that L2 learners specifically have difficulty in integrating information across domains when processing sentences (Sorace, 2011). These domains may be lexical, semantic, syntactic, visual, contextual, and most relevant to this article, prosodic in nature. Native speakers are experts at incorporating information from various domains to make meaning, but L2 learners tend to have more difficulties. Sorace and Serratrice (2009) found that for English-Italian bilingual children acquiring language, integrating contextual discourse-pragmatic information with syntax using overt and null subject pronouns resulted in greater difficulty processing sentences than when only coordinating syntactic and semantic information. Furthermore, this ability to integrate discourse-pragmatic information was not affected by structural overlap or lack thereof between the speakers’ two languages, suggesting learners are not able to reach native-like levels of processing when tasked with integrating information across domains even if they can identify the linguistic elements involved.
A slightly different take has been proposed by Patterson et al. (2017). Patterson et al. found that neither the Interface Hypothesis (Sorace, 2011), which predicts difficulty in integration of information across multiple representational domains, nor the Shallow Structure Hypothesis (SSH; Clahsen and Felser, 2006), which posits that learners rely primarily on semantic information over syntactic or prosodic information, could fully account for L2 performance in linguistic processing. Instead, results from their focus study on L2 pronoun resolution suggested that while L2 learners were likely able to combine information across domains when the mapping between them was one-to-one, complex mapping affected the extent to which they were able to successfully do so. In this article, we refer to Patterson et al.’s (2017) discussion of their findings as the complex mapping account. In sum, if one step of the process is broken in L2 processing (recognizing a prosodic cue, knowing its purpose, applying that knowledge to the overall syntactic structure and processing in terms of the affected lexical item), processing will not be native-like.
II The current study
This study focuses on L2 learner use of prosodic and lexico-semantic information (contrastive pitch accent and lexical information) to build information structure and restrict upcoming referents during listening. The questions investigated were as follow:
Do L2 speakers use contrastive pitch accent to build information structure while listening?
Do native speakers and L2 learners use this prosodic information predictively to restrict the set of upcoming referents?
Does each language group use contrastive pitch accent as a function of proficiency and working memory?
We used a paradigm inspired by Ito and Speer (2008) to investigate the use of contrastive pitch accent in native and L2 listeners. A visual world paradigm was used as an indirect measure of speech processing. Two avatars and two objects (two pictures of each object) were displayed on a computer screen while participants listened to short passages. Two context sentences preceded the critical sentence in each passage introducing the objects on the screen as belonging to one of the two avatars. Example critical sentences for each of the four conditions are provided in Table 1.
Example of the four experimental conditions.
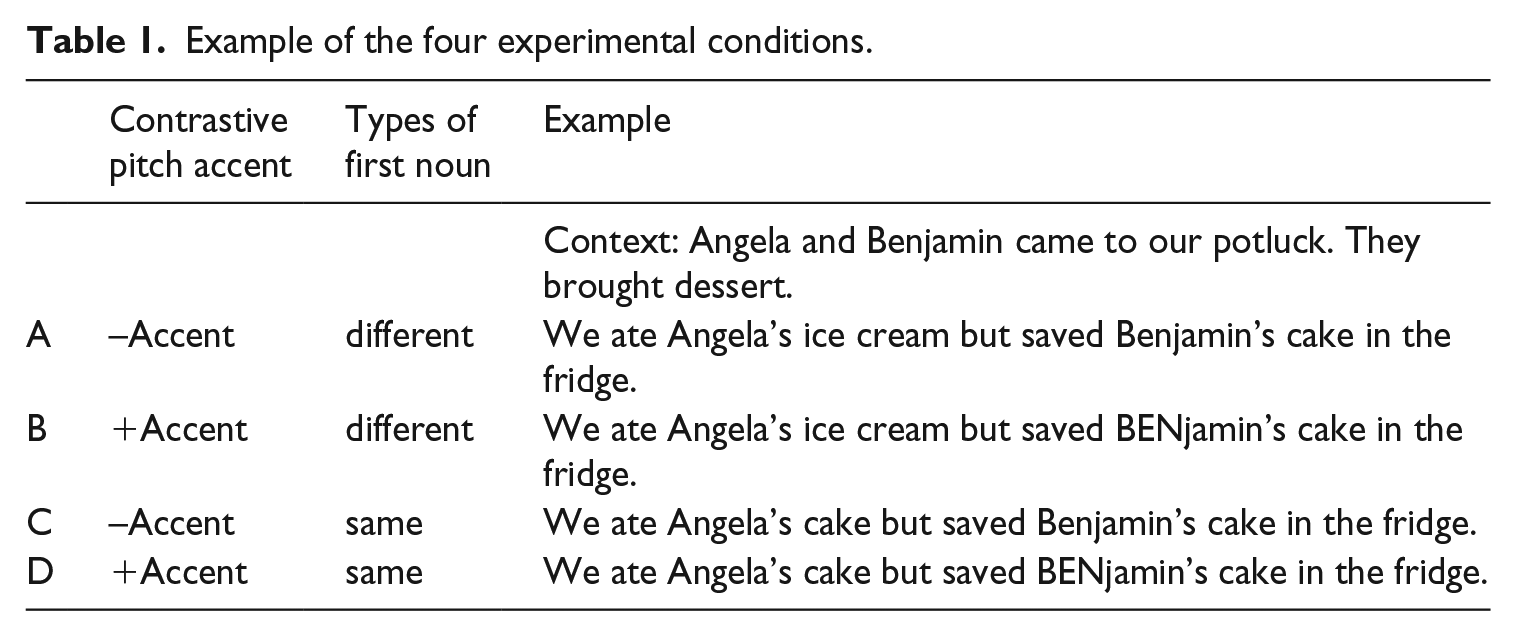
The target proper name (Benjamin) either carried the contrastive pitch accent (+Accent conditions B, D) or carried no contrastive pitch accent (–Accent conditions A, C). Because the contrastive pitch accent signals to a listener that an upcoming referent is similar to one mentioned earlier, condition D (+Accent Same Object) is felicitous while condition B (+Accent Different Object) is not. On the other hand, no contrastive pitch accent is expected when the two mentioned objects are different. Therefore, condition A (–Accent Different Object) is felicitous while condition C (–Accent Same Object) is not as a contrastive pitch accent would be expected on the second proper noun when the two mentioned objects are the same.
If both native speakers and learners are able to integrate prosodic information in speech processing to aid with construal of information structure and lexico-semantic representations, we expect that participants will look towards the “same” object (i.e. Benjamin’s cake in C, D, and to Benjamin’s ice cream in A, B) relatively more or longer in the +Accent (B, D) than –Accent conditions (A, C). If this is the case, then findings from this study will challenge theories such as the Interface Hypothesis (Sorace, 2011), which would predict learners would not be able to integrate lexico-semantic and prosodic information, or the Shallow Structure Hypothesis (Clahsen and Felser, 2006), which would posit that learners apply less detailed processing of sentences compared to native speakers.
As for predictive ability, the evidence to date lends support to the notion that native speakers will be able to use the contrastive pitch accent to make anticipatory eye-movements toward the same-object referent (more anticipatory looks to Benjamin’s cake in D, and to Benjamin’s ice cream in B versus the –Accent conditions (A and C)). If L2 learners do not use contrastive pitch accent to predict the upcoming referent, they will not show a difference in looks to same-object referent in the +Accent (B, D) versus –Accent condition (A, C) before the target word is presented. The ability to use prosodic information predictively may be related to working memory capacity or English proficiency levels. We expect that those L2 speakers with higher working memory capacity and higher proficiency scores will look more often to the same object in the +Accent conditions and to the different object in the –Accent conditions (Hopp, 2009; Reichle and Birdsong, 2014). If this is borne out, this would contribute evidence that L2 speakers may not be lacking in L2 linguistic knowledge, and that differences in performance between L2 and native speakers are subject to processing resources or other factors (Kaan, 2014), including but not limited to task effects, motivation, or cognitive control.
Another consideration is that differences in predictive processing between native speakers and learners may be partly attributed to the disparity in the way languages encode and use certain information (Dussias et al., 2013; Foucart et al., 2014); we aimed to reduce effects of cross-linguistic differences by using languages wherein contrastive focus is encoded relatively similarly. In Mandarin, as in English, contrastive focus is prosodically cued. This differs from, for example, Spanish, in which focus is typically expressed through word order. It is important to note, however, differences in contrastive focus marked by prosody between English and Mandarin Chinese. While English contrastive focus is marked by an L+H* pitch accent (Pierrehumbert and Hirschberg, 1990; Watson et al., 2008), namely the shape of the fundamental frequency (F0), in Chinese, information structure is denoted by the duration and range of the F0 contour (Chen and Braun, 2006; Jin, 1996). As a tonal language that uses F0 contour to convey semantic information, the shape of a lexical tone must be preserved for word recognition. English and Mandarin Chinese thus do have some inherently different factors that contribute to prosodically marked information structure.
III Method
1 Participants
We recruited 57 participants in the study. Data from five native English speakers and one Chinese learner of English were not recorded successfully due to technical issues in Data Viewer. Two more Chinese participants were omitted from analysis as their familiarity with the nouns used in the study was far lower than in other learners (83% and 73% compared to the 98% average). The remaining participant sample consisted of 27 native speakers 1 of English (4 males; Mage = 20.56, range 18 to 24) and 22 Chinese learners of English (6 males; Mage = 25.09, range 20 to 31) recruited from the University of Florida. On average, the L2 learners began acquiring English acquisition at the age of 8.75 years, with a range of ages 3 to 15 years. Participants completed the MELICET (MELICET; University of Michigan, 2001) and LexTALE English proficiency task (Lemhöfer and Broersma, 2012). The MELICET includes English grammar, cloze, vocabulary, and reading questions. The LexTALE provides a visual lexical decision task intended to measure vocabulary knowledge in advanced learners of English. In this study, we evaluate the composite z-score of results from both the MELICET and the LexTALE as an indicator of proficiency. Finally, participants completed an auditory digit span task in English (forward and backward). The sum total from both the forward and backward digit span tasks is presented below. Table 2 provides an overview of the proficiency and memory data for the two groups.
Mean values (and standard deviations) for behavioral tasks by language group.
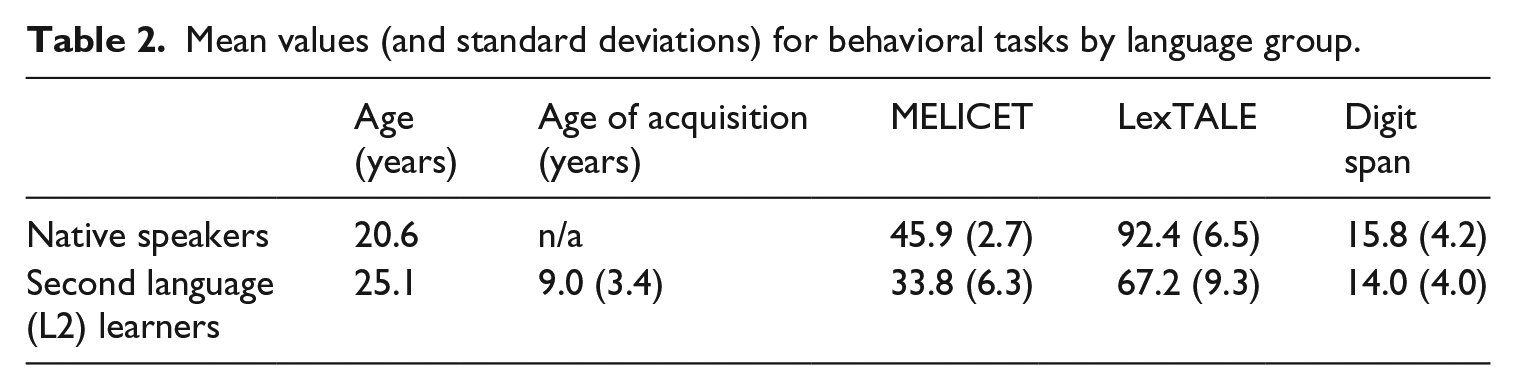
Native speakers were significantly younger than the L2 learners (t(25) = −6.14, p < .001) and scored significantly higher on the MELICET (t(27) = 8.31, p < .001) and LexTALE (t(36) = 10.75, p < .001) than L2 learners. However, the two language groups did not differ in terms of their working memory scores based on the digit span task (t(46) = 1.58, p = 0.12).
Participants either received course credit or monetary compensation ($7.50/hour) for participating. All participants had normal hearing as tested on-site and normal or corrected-to-normal vision. The protocol was approved by the University of Florida Institutional Review Board, and all participants gave written informed consent.
2 Materials
a Experimental passages
We created 32 short passages that served as critical trials and 32 passages that served as filler items. The critical items consisted of three sentences as illustrated in Table 1. The first sentence introduced a male and a female subject using their proper names. Next, situational context was introduced, followed by the target sentence. The target sentence included the two actors and two objects (e.g. We ate Angela’s ice cream but saved Benjamin’s cake in the fridge). The second proper name was always three syllables long with contrastive pitch accent on the first syllable to allow time for effects of contrast to arise before listeners heard the second object.
Four types of fillers were created (eight of each type): passages in which the third sentence used a different connective between clauses than the target trials (e.g. and), passages that used different prosodic cues (e.g. Larry LOVES to paddle down the river, but Maggie thinks this is not very exciting), passages that mention of only one subject in the third sentence (e.g. Margaret found a nice shell and later saw a huge starfish), and passages in which the third sentence begins with a what-clause (e.g. What Lexi really hates are cigarettes, but she does not hate pipes as much). To check that participants were paying attention, comprehension questions followed 16 trials (25%), either critical or filler. Questions targeted the content of the passage and participants gave a ‘yes’ or ‘no’ response using a game controller.
Four lists were constructed. Every participant saw eight sentences from each of the four critical conditions, and no item was presented in more than one version on a list. Information from COCA (The Corpus of Contemporary American English; Davies, 2008) was used to ensure that for each of the four conditions, items were balanced in terms of frequency so that no one condition contained more frequent words than the others in a list. Each list contained all 32 fillers. Critical trials and fillers were pseudorandomized such that two critical trials never appeared twice in a row.
b Auditory stimuli
All audio materials were recorded by a female native speaker of English in a sound-attenuated booth. In order to elicit the auditory materials, the speaker read felicitous sentences out loud in blocks of 20. In the first half of each block, the speaker read only sentences in the –Accent Different object condition (condition A) for 20 trials. After this, the speaker read only the critical sentence in the +Accent Same object condition (condition D). The amplitudes of all the audio recordings were normalized using Praat (version 6.0.36: Boersma and Weenick, 1992–2017). For the –Accent conditions, the pitch contour was realized as L* for the second proper name (e.g. Benjamin) across all trials (see Figure 1), while the pitch contour was L+H* for the +Accent conditions (Figure 2).
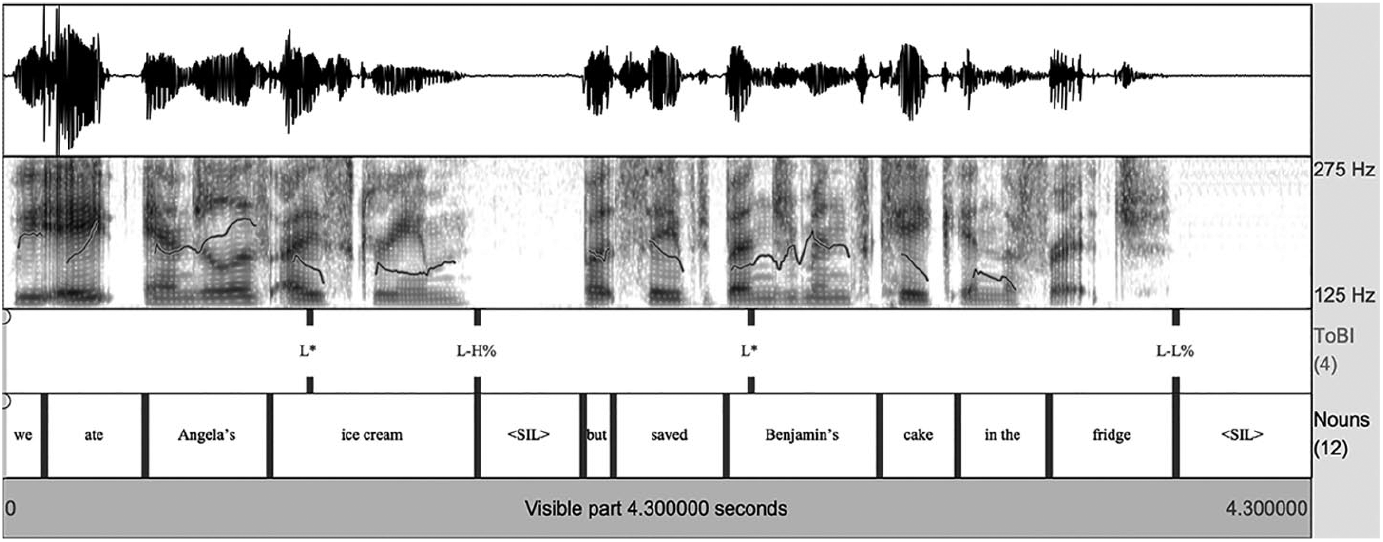
Example ToBI (tone and break indices) transcriptions of target proper name and noun for the –Accent conditions.
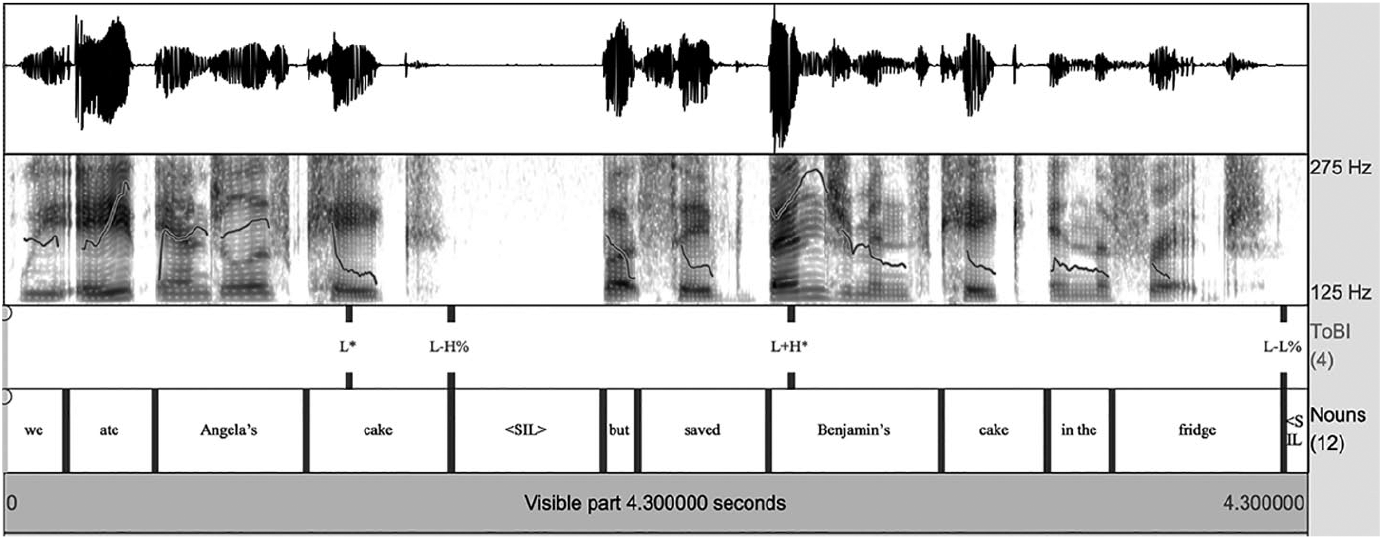
Example ToBI (tone and break indices) transcriptions of target proper name and noun for the +Accent conditions.
Tables 3 and 4 provide the duration, minimum, maximum, and mean F0 for the proper names and nouns in both the –Accent and +Accent conditions for the first and second clause, respectively. No significant differences were found between the first proper names and first nouns for any factors.
Mean duration and F0 information (with standard deviation in parenthesis) for the first proper name (Angela’s) and first noun (ice cream or cake).
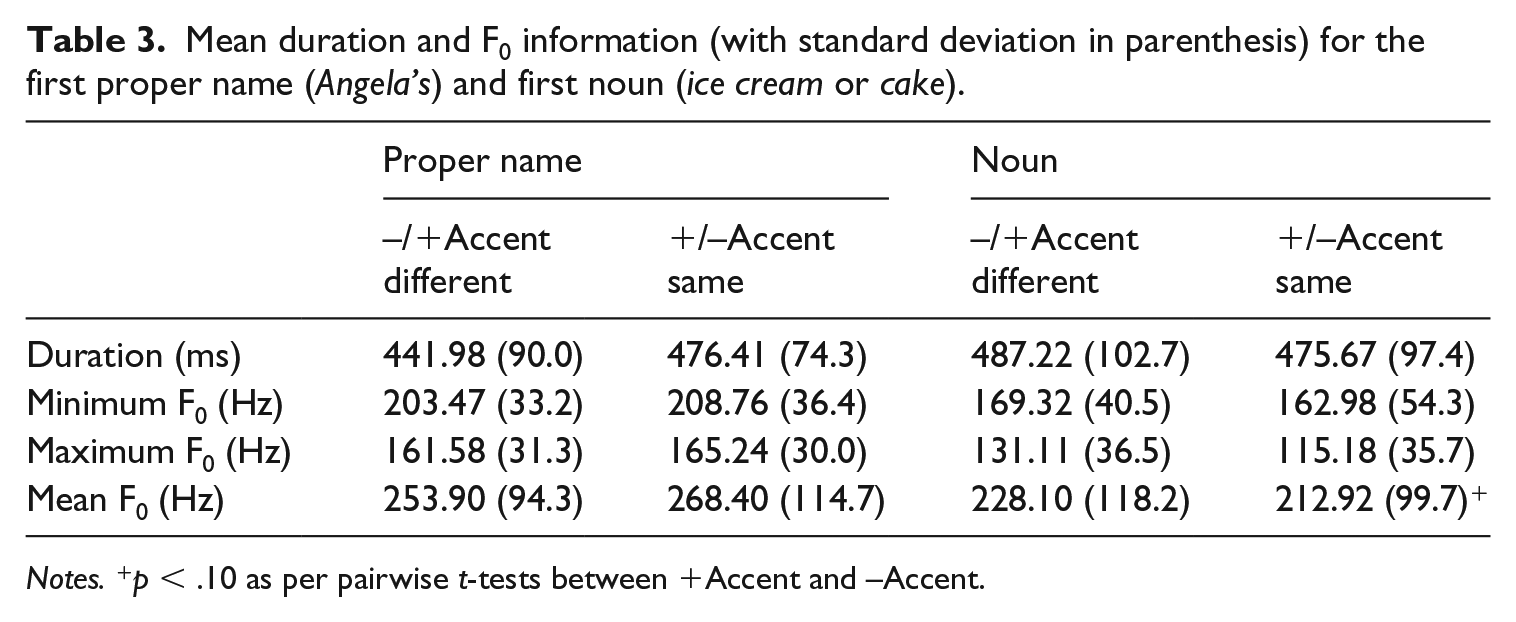
Notes. +p < .10 as per pairwise t-tests between +Accent and –Accent.
Mean duration and F0 information (with standard deviation in parenthesis) for the second proper name (Benjamin’s) and second noun (cake).
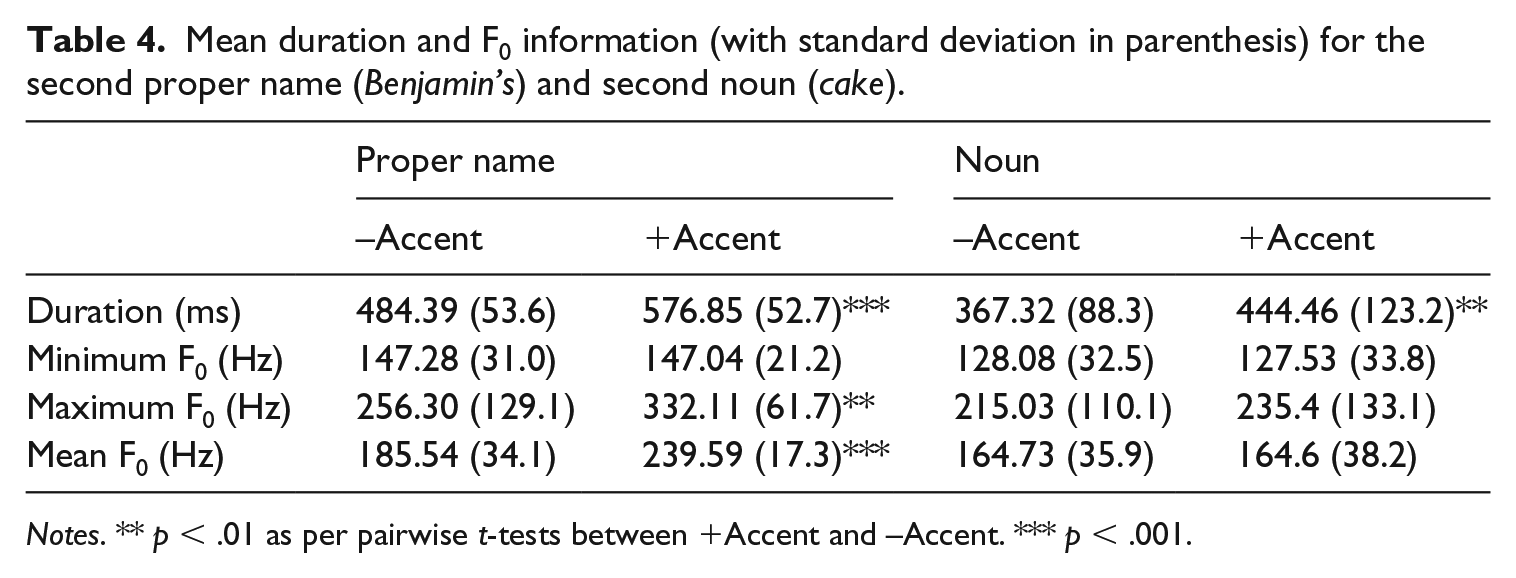
Notes. ** p < .01 as per pairwise t-tests between +Accent and –Accent. *** p < .001.
For the second proper noun, items carrying a contrastive pitch accent had significantly longer duration (t(62) = −6.85, p < .001) and higher maximum F0 values (t(62) = −2.95, p < .01) as well as higher mean F0 values (t(62) = −7.87, p < .001) than non-accented items, as depicted in Table 4. The second nouns only differed in duration, wherein those in the +Accent conditions were longer than those in the –Accent conditions (t(62) = −2.88, p < 0.01).
Next, all recordings were spliced at the silence immediately following the final consonant in the conjunction but in the target sentence. Following this, the audio recordings were cross-spliced to create the infelicitous conditions (conditions B and C). Time stamps were set for the onset of the second proper name and the second noun in the target sentence.
c Visual display
Two avatars were presented in the order they were introduced from left to right. Avatars were depictions of a male and female, and both of their names were printed (in size 20 Arial font) underneath the respective picture to help the listeners link the names to the avatars. For critical items, 64 unique avatars were created (32 male and 32 female). The avatars were presented on the top third of the screen with a height of 190 pixels. Four objects then appeared underneath the avatars 5 seconds before onset of the second proper name. The objects corresponded to the two possessed items mentioned in the target sentence as indicated by a vertical line down the middle of the display. As such, underneath each avatar the same two objects were presented. In the case of the example in Table 1, a picture of ice cream and cake appeared under each avatar. The position of the target item (middle or bottom of the screen with width of 180 pixels) was counterbalanced across lists. Together, 128 unique pictures were used (64 critical trials and 64 fillers trials), and two of each object was used in each trial, as in Figure 3, for a total of 256 color pictures from an open source collection of clipart. AOI (areas of interest) were defined for the target object, the competitor, and the two other items (those images underneath the first proper name presented in the critical sentence).

Example of a visual display in one trial of the eye-tracking experiment.
3 Procedure
Participants were seated in front of a computer screen and fitted with an SR EyeLink II head mounted eye-tracker. Next, the location of gaze fixations was calibrated. A set of instructions appeared on the screen, and participants advanced through the trials using a controller. Participants listened to the passages through headphones. A central fixation point appeared on the screen for 500 ms at the start of each trial. Participants saw five practice trials at the beginning of the experiment, two of which were followed by questions. Participants responded to comprehension questions by pressing one of two shoulder buttons on the controller. After all questions were answered, participants began the experiment. Upon completion, participants were administered a digit forward and digit backward task in English, followed by the LexTALE test (Lemhöfer and Broersma, 2012), the Michigan English Language Institute College English Test (MELICET; University of Michigan, 2001), the LEAP-Questionnaire (Marian et al., 2007), and a noun familiarity test. In the latter task, participants were presented the names of the avatars and nouns that were used in the eye-tracking portion and were prompted to rate their familiarity with each name and object on a Likert scale from 1 (very unfamiliar) to 7 (very familiar). The experiment took about 1 hour per participant for native speakers of English and 1.5 hours for Chinese learners of English.
4 Analysis
Eye fixation data were analysed using linear mixed-effects models with the lmer function (lme4 version 1.1.10; Bates et al., 2015) and lmerTEST package (version 2.0-33, Kuznetsova et al., 2016) in R version 3.4.2 (R Core Team, 2017). Mixed-effects models allow for the evaluation of empirical data for groups of different sample sizes, and trial and subject as random effects (Baayen, 2008). The dependent variable for the eye-tracking data was the natural log gaze probability ratio of looks to the same object versus looks to the different object beneath the avatar representing the second proper noun (e.g. Benjamin) (
We analysed data separately for the two language groups. The fixed effects in the models constructed for analysis of each language group were contrastive pitch accent (negative for –Accent, positive for +Accent), target object type (negative for different and positive for the same target object from the first object mentioned), working memory (based on the sum total of the forward and backward digit span task scores), and proficiency (calculated as the composite z-score of each participant’s LexTALE and MELICET score after the scores were found to correlate). Values for each factor were centered around the mean. The mixed-effects models were run for the five time bins. The final model structure was: log gaze ~ Accent + Target Object + WM + Proficiency + Accent:Target + Accent:WM + Target:WM + Accent:Proficiency + Target:Proficiency + Accent:Target:WM + Accent:Target:Proficiency + (1 | Subject) + (1 | Trial ID).
Using the natural log gaze probability of looks to the same object versus different object as the dependent variable, we aimed to directly assess the effect of contrastive pitch accent for native speakers and learners. We included working memory and proficiency to investigate whether these factors played a role in processing of contrastive pitch accent. Models with a more complex random effect structure failed to converge. We did not include interactions between working memory and proficiency as we made no predictions with regard to those effects.
IV Results
In an effort to reduce the likelihood that participants were using segmental information from the target noun and because one of the aims was to determine whether prosodic information was used predictively, we limited the length of the time bins analysed to 200 ms, as it takes 200 ms to 300 ms for listeners to plan and launch saccades to a target (Hallett, 1986; Viviani, 1990). Figures 4 and 5 show the log gaze probability ratio of looks to the same object by condition for English and Chinese speakers from 400 ms before to 600 ms after the second noun onset (e.g. cake) divided into five time bins of 200 ms each. The onset of the second noun (e.g. cake) occurs at 0 ms. The filled shapes represent the –Accent conditions and the open shapes represent the +Accent conditions. The Different conditions are marked by triangles and the Same conditions by circles. The felicitous conditions are the filled triangles (–Accent Different) and the open circles (+Accent Same).
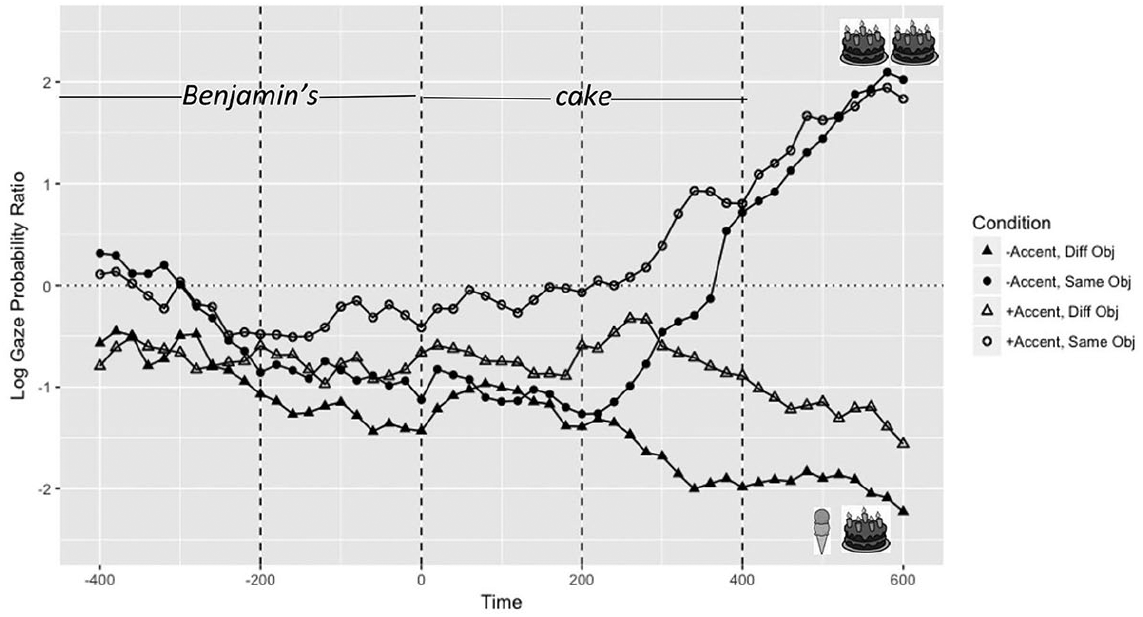
Log gaze probability ratio of looks to same vs. different objects (see main text) for the time range starting –400 ms before the second noun (cake) onset to 600 ms afterwards: Native speakers.

Log gaze probability ratio of looks to same vs. different objects (see main text) for the time range starting –400 ms before the second noun (cake) onset to 600 ms afterwards: L2 learners.
As evidenced from Figures 4 and 5, listeners in both language groups preferred looking at objects that have not been mentioned: logit values tend to be lower than 0 preceding the onset of the second noun in all conditions, regardless of the presence or absence of the contrastive pitch accent over the second proper name. That is, participants were more likely to fixate on the cake when they heard ice cream in the first clause of the critical sentence and more likely to fixate on ice cream when they heard cake in the first clause. Eventually, these looks were modulated by contrastive pitch accent in the +Accent conditions. Below we break down results by language group. 2 Additionally, we assessed performance on the comprehension questions. An analysis revealed that L1 speakers (90.24% accuracy) performed better than L2 learners (80.99% accuracy) in responding to these questions (t = −3.2016, df = 40.085, p = 0.002). 3
1 Native speakers
Results for native speakers are presented in Table 5. In Time Bins 1 through 4 (–400 ms to 400 ms after noun onset), the intercept was significantly smaller than 0, revealing that participants preferred to look at the different object versus the same object before and after the onset of the critical noun, which is also reflected in the top panel of Figure 4. In Time Bins 3 (0 ms to 200 ms) and 4 (200 ms to 400 ms), the effect of Accent was significant (Time Bin 3: β = −0.47, SE = 0.19, t = 2.51; Time Bin 4: β = −0.65, SE = 0.19, t = 3.38). That is, speakers looked more to the same object in +Accent conditions from 0 ms to 400 ms: in the corresponding time bins, the logit proportions of looks to the same object in the +Accent conditions (unfilled shapes, conditions B and D in Figure 4) are larger than those in the –Accent conditions. Also, Time Bin 3 reveals that Proficiency was a main effect (β = −0.23, SE = 0.10, t = −2.34), indicating that native speakers with higher proficiency scores looked more to the different object than the same object.
Results from mixed-effects models for native speakers of English for five separate time bins.
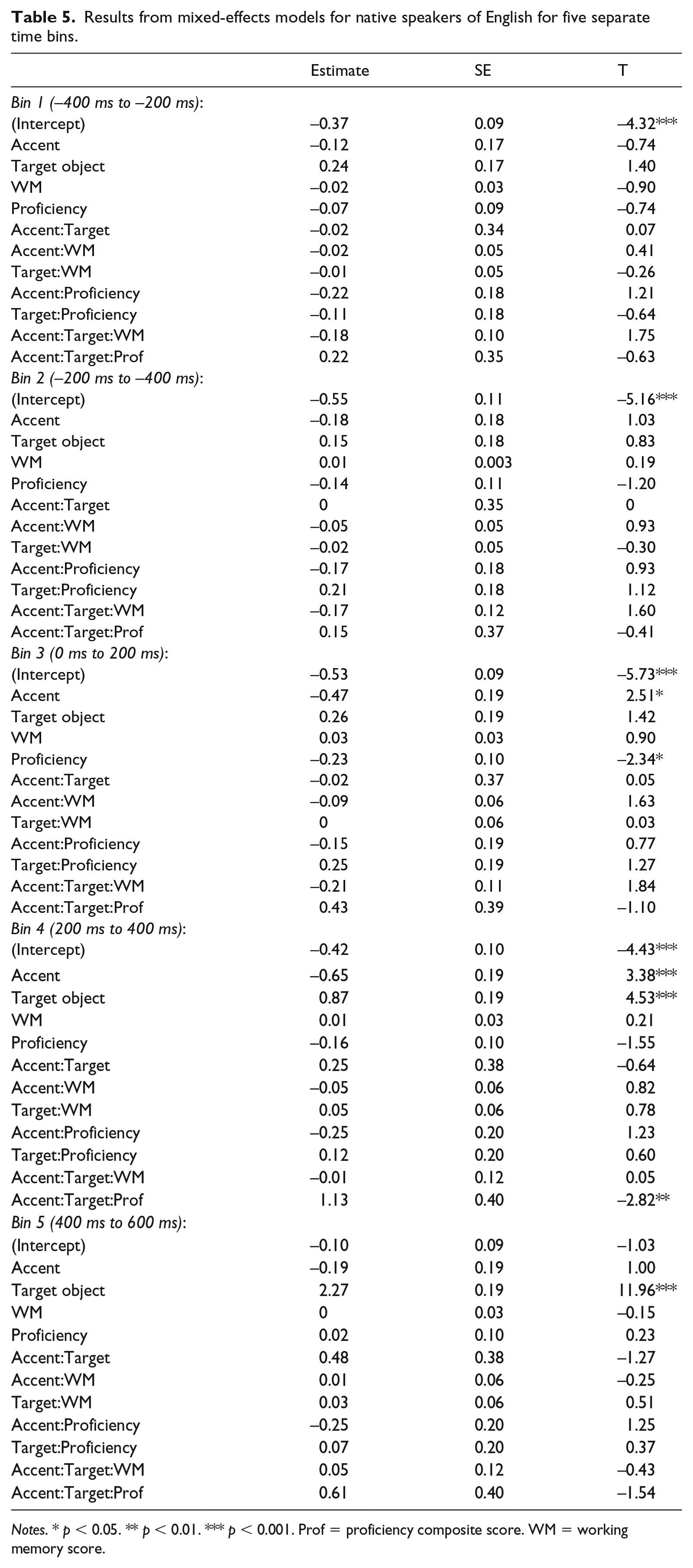
Notes. * p < 0.05. ** p < 0.01. *** p < 0.001. Prof = proficiency composite score. WM = working memory score.
As expected, by Time Bins 4 (200 ms to 400 ms) and 5 (400 ms to 600 ms), native speakers looked more to the same object when it was the target object, and to the different object when this was the target (Effect of Target Object type). Finally, a three-way interaction of Accent, Target Object type and Proficiency was found in Time Bin 4 (β = 1.13, SE = 0.40, t = −2.82). This significant interaction revealed that looks to the same object decreased as proficiency increased when the target was a different object in –Accent conditions. Those with lower proficiency scores looked to the same and different object roughly equally for the –Accent conditions. There was no effect of Working Memory in any time bin.
As reflected by the significant effect of Accent in Time Bins 3 and 4, and as demonstrated by the upper panel in Figure 4, native speakers looked more often to the same object in both of the +Accent conditions compared to the –Accent conditions. This effect started prior to 200 ms, which is too soon to be driven by the target noun, and hence is indicative of predictive use of the prosodic cues.
2 L2 learners
The same model as that used for native English speakers was constructed for Chinese learners of English. The results are presented in Table 6. Similar to native speakers, Time Bins 1 (–400 ms to –200 ms) to 4 (200 ms to 400 ms) revealed that Chinese learners also preferred to look at the different object as compared to the same object (intercept significantly smaller than 0). We found a significant interaction of Accent, Target Object and Proficiency in Time Bin 1 (β = −1.03, SE = 0.47, t = 2.19). However, since the target object has not been presented at this point, we interpret this effect as spurious and will not further discuss this. In Time Bin 3 (0 ms to 200 ms), the effect of Accent was marginally significant (β = −0.35, SE = 0.19, t = 1.80). In Time Bin 4, Accent is a main effect (β = −0.43, SE = 0.21, t = 2.03), revealing that Chinese learners looked more often to the same object versus the different object in the +Accent conditions. In Time Bin 5, learners looked more to the same object when it was the target object, as expected (β = 1.33, SE = 0.21, t = 6.31). Furthermore, the interaction between Target Object and Proficiency suggests that learners with higher proficiency had a larger Target Object effect, with more gazes to the same object when the target object was the same as the one mentioned previously, and fewer when the target object was different (β = 0.77, SE = 0.31, t = 2.49). Working memory did not have any effect.
Results from mixed-effects models for Chinese learners of English for five separate time bins.
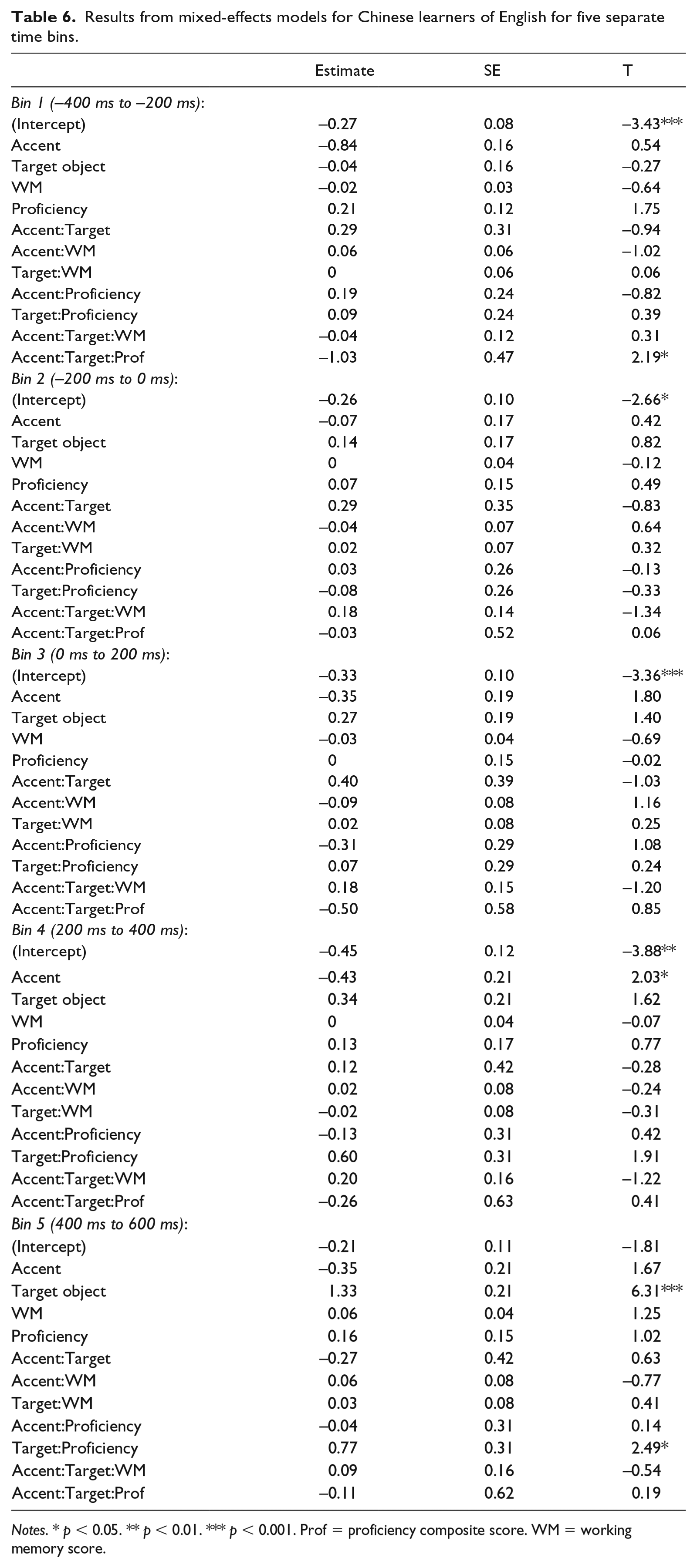
Notes. * p < 0.05. ** p < 0.01. *** p < 0.001. Prof = proficiency composite score. WM = working memory score.
In sum, like the native speakers, learners showed more looks to the same object in the +Accent conditions than in the –Accent conditions. However, this effect become significant somewhat later than in the native English group.
3 Summary of the results
Both native speakers and L2 learners revealed a different-object bias as indicated by the significant negative intercepts in bins 1 through 4. However, contrastive pitch accent modulated this preference: when the proper name was accented, native speakers started to look more at objects that were the same as the object mentioned before (i.e. ice cream in condition B, cake in condition D). This effect of Accent was significant in the predictive time window, before 200 ms. L2 learners showed a similar effect but somewhat later than the native speakers. Furthermore, native speakers had increased looks to the different object immediately following the onset of the noun in the –Accent condition as proficiency increased. On the other hand, more proficient L2 speakers looked more to the target object in the final time bin.
V Discussion
In this study, we investigated whether L2 learners can use contrastive prosodic cues to build information structure and do so predictively. Furthermore, we investigated to what extent this effect was modulated by working memory capacity or proficiency. Results suggest that L2 speakers can use prosodic information to build information structure during listening, but we do not have strong evidence that they can predictively restrict the set of upcoming referents on the basis of prosody or that proficiency or working memory scores affected the use of the contrastive pitch accent to predict or process the subsequent noun phrase. In addition, we found a large bias for Different objects in both L2 and native speakers. These effects are discussed in detail below.
1 Different object bias
Both speaker groups investigated revealed a strong bias towards new objects. That is, speakers tended to look at the new object (as opposed to the already mentioned object) after having heard the first possessed noun. We postulate that the nature of the materials constructed resulted in this type of behavior. All critical sentences used the coordinator but (e.g. We ate Angela’s cake but saved Benjamin’s cake in the fridge). Recall that in building the materials, the recordings of the felicitous conditions (A and D) were cross-spliced after the silence in the conjunction but. The presence of this coordinator may have indicated to the listener that a contrast was upcoming, resulting in more looks to the new object prior to the listener hearing the second proper name. However, regardless of the different-object bias, in the +Accent conditions, native speakers started to look more to the same object after hearing the second proper name produced with an L+H* pitch accent but before they could have heard the target referent, indicating that they adjusted their predictions (cf. Ito and Speer, 2008).
2 The use of prosody by L2 speakers
The first aim of the study was to explore whether the contrastive pitch accent L+H* facilitates looks to particular referents for L2 speakers. Starting at 200 ms to 300 ms after the onset of the critical noun, Chinese learners of English looked more to the same object in +Accent than in the –Accent conditions. These findings reveal that learners were able to incorporate prosodic information to interpret linguistic information in this online study. Our results are in contrast with Namjoshi and Tremblay (2014)’s observations that English L2 learners of French were not able to integrate contrastive pitch accent and syntactic information. Our study differs in the timing of avatar presentation and layout of the visual display. In Namjoshi and Tremblay (2014), each image of the noun used was accompanied with an image of the possessor (an avatar). In our design, we presented the avatars and their names at the beginning of each experimental trial. A line down the middle of the display separated the two avatars and their possessions, making it easier for participants to determine which avatar had what. Participants in our study could therefore focus more on information in the speech stream, allowing them to map prosodic information to lexico-semantic information and information structure with greater ease.
We find that L2 learners are indeed able to integrate prosodic and lexico-semantic information quite similarly to native speakers, albeit with difference in timing (see next section). This challenges the Interface Hypothesis (Sorace, 2011), which predicts difficulty in L2 processing when integrating linguistic cues across different domains. The Shallow Structure Hypothesis (Clahsen and Felser, 2006) cannot explain these results in full since this approach posits learners predominantly rely on semantic information, suggesting they are less likely to interpret and incorporate prosodic information in speech processing. Instead, the complex mapping account (Patterson et al., 2017) and more general processing accounts (Hopp, 2013; Kaan, 2014) allow for the effective mapping of semantic and prosodic information to elicit sentence meaning, although this mapping requires more time and perhaps more effort on the part of the learners as compared to native speakers. Additional evidence in favor of the processing and complex mappings account is provided by an ERP study conducted by Lee et al. (2019). Lee et al. used participants drawn from the same L2 population and used the same materials as in the current study but found qualitative differences in brain responses between native and L2 speakers. Specifically, native speakers showed an increased N400 effect at the noun following the proper noun in the +Accent Different versus +Accent Same conditions, whereas the L2 speakers showed an N400 effect only in the –Accent Different conditions. According to Lee et al. (2019), these results suggests that L2 speakers used the prosodic cues differently from native speakers. In particular, the pitch accent may have facilitated lexical access in the L2 speakers, so the lack of accent and use of a non-repeated noun in the –Accent Different conditions may have elicited an increased negativity. Note that in the ERP study, no visual display was used. This could have made it harder to access the lexical items and restrict the set of referents, making the task more effortful and mapping of the prosody and lexico-semantic information more complex than in the present study. This supports the view that L2 processing can be similar to native speakers’ when the task is simple, as in the current study, but can be qualitatively different when the task is more complex.
3 Anticipatory processing of L2 prosody
Regarding anticipatory effects of the contrastive pitch accent, our results replicated those of previous studies on native speakers (e.g. Ito and Speer, 2008) supporting the view that native speakers make predictions based on cues provided by contrastive pitch accents. On the other hand, our learner data do not provide strong enough evidence that L2 learners used the contrastive prosodic cue predictively, or at least reliably so.
The delayed effect of Accent in the L2 speakers can be attributed to several factors, which are not mutually exclusive. First, the reduced ability to predictively use prosody to build information structure for learners, or to do so consistently, may also be attributed to the slight differences between marking of contrastive focus in English and Mandarin. As discussed in the introduction, empirical data suggest that in Mandarin, information structure is conveyed by the range of F0 contours rather than the shape of the pitch contours (Chen and Braun, 2006; Jin, 1996). As a tonal language that uses F0 contour to convey semantic information, the shape of a lexical tone must be preserved for word recognition. It is thus possible that even though learners are able to integrate the information sources across domains, they may not use all potential sources of information to anticipate referents because of the complexity involved and may rely on lexical and semantic information primarily and later integrate prosodic information (Clahsen and Felser, 2006; Kaan, 2014; Dussias et al., 2013; Hopp, 2013; Martin et al., 2013).
Alternatively, learners may be able to use prosodic information predictively if given enough time as processing is generally slower for learners compared to native speakers, especially if it requires the integration of information from various domains, and thus, the experimental paradigm used in this study may have not captured this phenomenon. Supporting evidence for our L2 speakers being overall slower to process the sentences is that the Target Object effect (which is dependent on the actual target word) is significant only 400 ms after the onset of the target word, whereas native speakers show this effect already 200 ms to 300 ms after onset of the word. A follow-up eye-tracking study including a set of materials that separates the proper noun from the possessed noun using an adjective (e.g. but saved Benjamin’s tasty cake . . .) would grant a clearer understanding of whether learners use contrastive pitch accent effectively to predict an upcoming referent.
Finally, we acknowledge that the apparent qualitative similarity in eye movements between the native and L2 groups does not mean that native and L2 speakers interpreted the contrastive pitch accent in the same way, or dealt with the infelicitous use of prosody in the same way. Different interpretational processes may also give rise to timing differences. Follow-up studies which do not include infelicitous sentences and which more explicitly probe the meaning of the sentence are needed to investigate this issue.
4 Effects of working memory and proficiency
Finally, we had posited that L2 proficiency and working memory span would affect learners’ ability to use prosodic information predictively during sentence comprehension. We did not find effects of working memory in either native speakers or learners. Using a forward and backward digit span task may not have been appropriate for our purposes, or may not have given us a wide enough range of scores. Instead, a Listening Span Task (Daneman and Carpenter, 1980) may have been more appropriate for testing working memory in relation to auditory sentence processing.
Proficiency did have an effect in some time windows, but these effects are hard to interpret. L2 speakers who were more proficient showed more looks to the target in bin 5. This suggest that these speakers were faster in recognizing the target word. We did not find any effects of proficiency on the L2 use of prosody, however. Unexpectedly, we did find that native speakers with higher English proficiency scores looked more at different objects from 0 ms to 200 ms after target noun onset and looked more at target objects in the –Accent Different condition between 200 ms to 400 ms after target noun onset. We speculatively interpret this as more proficient native speakers using the lack of accent more effectively as a cue signaling a different object.
VI Conclusions
Our findings show that L2 speakers are able to integrate prosodic and lexico-semantic information to build information structure. We, however, do not have strong evidence that learners do so predictively, or that this is affected by proficiency or working memory capacity. Our findings stand in contrast to other studies conducted to date that report that L2 learners have problems using prosodic information. Our results therefore challenge the Interface Hypothesis (Sorace, 2011). They provide support for approaches according to which L2 speakers can map information across representational domains, at least when the mapping is simple (Patterson et al., 2017) and not many resources are required (Hopp, 2013). Although further research is needed, our observations suggest that L2 learners can learn to successfully use L2 prosody if the task is relatively easy and involves a restricted number of referents. As prosody is not a topic commonly taught in the second-language classroom and is notoriously difficult for L2 speakers to acquire (Mennen and de Leeuw, 2014), these insights can help L2 curricula by designing simple scenarios in which prosody can be incorporated and by introducing more complex mappings and more complex situations step-by-step.
Footnotes
Acknowledgements
The authors thank Naomi Braun, Ethan Kutlu, and Julia Barrow for their assistance in constructing materials, and to Lisha Yang, Aleuna Lee, and Souad Kheder for running participants.
Authors’ Note
Michelle Perdomo is now affiliated with Vanderbilt University, TN, USA.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.