
Abstract
This article provides a review of previous studies that have examined the effects of orthography on establishing contrastive phonological representations in second language acquisition and presents results from an original study on Mandarin speakers’ production of English stops investigating how the presence of orthography affects the production of phonological categories that involve allophony. English voiceless stops are canonically represented as aspirated [ph, th, kh] in word-initial/stressed onset positions but are realized as unaspirated [p, t, k] following /s/ and in unstressed, non-initial onset positions. The results of our imitation experiment showed that Mandarin speakers failed to correctly imitate the unaspirated allophones when presented with written input, and this orthographic effect was stronger with nonwords than with real words. These results are best explained by an orthography effect mediated by phonological awareness and prior linguistic experience.
Keywords
I Introduction
An important aspect of learning a second language (L2) is to learn its phonological system (Broselow and Kang, 2013; Edwards and Zampini, 2008). This includes, but is not limited to, learning contrastive phonemes (Best and Tyler, 2007; Flege, 1987), phonotactic restrictions (Dupoux et al., 1999; Durvasula et al., 2018), stress (Chrabaszcz et al., 2014; Dupoux et al., 2008; Ou, 2020), tonal contrasts (Hao, 2018; Schaefer and Darcy, 2014; Tsukada and Han, 2019), and intonation (Jun and Oh, 2000; Lee et al., 2019; Lu and Kim, 2016; Mennen, 2007). L2 speech characteristics related to these different aspects of learning have been argued to stem from native language (L1) transfer (Gass, 1996; Major, 2008), cross-linguistic markedness (Eckman, 2008), systematic phonetic or phonological differences between the L1 and L2 (Brannen, 2002; Qin and Tremblay, 2014; Young-Scholten, 2004), and perceptual or production mechanisms constrained by the L1 (Boersma, 2009; Boersma et al., 2003). The effect of orthography, however, on L2 speech characteristics has gained attention only recently (Barrios and Hayes-Harb, 2020; Escudero et al., 2014; Hayes-Harb et al., 2010; Lee-Kim, 2021). This article provides a review of previous studies that have examined the effects of orthography on establishing contrastive phonological representations in L2 acquisition and presents results from an original study on Mandarin speakers’ production of English stops investigating how the presence of orthography affects the production of phonological categories that involve allophony.
1 The effect of orthography on L2 acquisition
Previous studies on the influence of orthography on L2 acquisition have reported conflicting results. While some studies have found the effect to be facilitatory (Erdener and Burnham, 2005; Escudero et al., 2008; Hayes-Harb et al., 2010; Showalter and Hayes-Harb, 2013) or inhibitory (Bassetti, 2006, 2007; Showalter, 2018; Young-Scholten and Langer, 2015), others have found a null effect (Showalter and Hayes-Harb, 2015; Simon et al., 2010) or an effect dependent on target contrasts (Escudero and Wanrooij, 2010; Hayes-Harb and Cheng, 2016).
On the one hand, orthography has been shown to assist category formation when learning confusable L2 sounds. For example, in an eye-tracking study, Escudero et al. (2008) trained Dutch speakers to learn English nonwords that contained /ɛ/ and /æ/; one group learned the words by matching their auditory forms to pictures, while a second group was additionally provided with the spelled forms of the words. The pictures were line drawings from the non-object database used in Shatzman and McQueen (2006). Their results showed that the participants who were only presented with auditory input looked equally at the pictures of the words containing both /ɛ/ and /æ/ upon hearing /ɛ/ and /æ/ words (Escudero et al., 2008). Those who were assisted by the presentation of orthography, however, were more accurate in selecting words containing /ɛ/ but were confused upon hearing words containing /æ/. Based on the a priori finding that the /ɛ/–/æ/ pair is ‘perceptually neutralized’ by Dutch listeners (Weber and Cutler, 2004), Escudero et al. (2008) concluded that the written forms provided explicit information for these perceptually confusable sounds and helped lexically encode the nonnative contrast.
On the other hand, orthography may be inhibitory when there is an incongruence between the native and L2 writing systems despite clear phonetic distinction. For example, the same word-initial <s> in orthography corresponds to [z] in German but to [s] in English. The results of a longitudinal study tracking three English speakers learning German showed that, despite rich aural input from their environment and the distinctive nature of /s/ and /z/ in their native language, these speakers still produced German word-initial <s> as [s], suggesting an inhibitory effect from the orthography (Young-Scholten and Langer, 2015). This study indicates that the direct link between L1 and L2 orthography may impede the learning of an existing native contrast (/s/ vs. /z/) in second language acquisition.
Some studies, however, have found a null effect of orthography. For example, using a word-learning paradigm, Showalter and Hayes-Harb (2015) examined English speakers’ learning of the Arabic velar–uvular /k/–/q/ contrast, with or without exposure to the Arabic script or Romanized Arabic. The results showed that the learners who were given written input had no apparent learning advantage over those who were only shown pictures. Similarly, Simon et al. (2010) used a variety of paradigms to test English speakers learning the French high rounded vowel contrast, /u/ and /y/. Their results also showed no effect of orthography on learning the target contrast.
The mixed results from the previous studies have been attributed to several factors. First, an incongruent grapheme–phoneme correspondence between L1 and L2 tends to negatively impact the learning of an L2 contrast, as in Young-Scholten and Langer’s (2015) study on English speakers’ learning of German word-initial <s>. Similarly, Escudero et al. (2014) tested Spanish speakers in learning different Dutch vowel contrasts, some with congruent grapheme–phoneme correspondences between the L1 and L2 and others with incongruent correspondences. The results showed that orthographic input only aided the learning of congruent contrasts and not the incongruent ones. Furthermore, using a familiar L2 writing system that uses incongruent grapheme–phoneme correspondences with the L1 writing system seems to pose even more challenges to the learner than using an unfamiliar L2 writing system (Hayes-Harb and Cheng, 2016; Showalter, 2018). For example, Pinyin (or Hanyu Pinyin), commonly used in China and Singapore, is a Romanization system that shares the same alphabet as English, while Zhuyin (or Bopomofo), widely used in Taiwan, is a semi-syllabary system derived from components of Chinese characters. Hayes-Harb and Cheng (2016) trained English speakers to learn Mandarin words using Pinyin and Zhuyin. These Mandarin words were either grapheme–phoneme congruent (e.g. <nai> for [nai]) or incongruent (e.g. <
Second, the effect of orthography may be modulated by the type of contrast. For example, Escudero and Wanrooij (2010) examined native Spanish speakers’ perception of different vowel pairs (/a–ɑ/, /i–ɪ/, /ɪ–ʏ/, /y–ʏ/, and /i–y/) using auditory and orthography tasks. The auditory task employed an XAB paradigm in which the participants were asked to classify the X vowel as either A or B. In the orthography task, the participants were asked to label each vowel using the Dutch orthographic representation (<aa>, <a>, <ie>, <i>, <uu>, <u>). Based on the accuracy rates from the auditory task, the following difficulty ranking (from most to least difficult) was established: /a–ɑ/ >> /i–ɪ/ >> /ɪ–ʏ/, /y–ʏ/ >> /i–y/. However, the difficulty ranking from the orthography task was reversed: the auditorily most confusable sounds (/a/ and /ɑ/) were more successfully classified in the orthography task than the auditorily most distinct sounds (/y, ʏ, i, ɪ/). The positive orthography effect in the case of the Dutch speakers’ learning the English /ɛ/–/æ/ contrast could also be explained similarly: the auditorily confusable /ɛ/–/æ/ contrast was assisted by the distinct written forms. Showalter and Hayes-Harb (2015: 33) gave a similar account for the lack of an orthography effect in learning the Arabic /k/–/q/ contrast, suggesting that ‘the auditory contrast is so difficult that even when written forms are available, they may simply be unusable.’
Third, the effect of orthography also seems to be moderated by the individual’s level of proficiency in the target L2. While some previous studies used naive learners in their experiments (e.g. Showalter and Hayes-Harb, 2015; Simon et al., 2010), others tested L2 learners of different proficiency levels. For example, Mok et al. (2018) examined Cantonese speakers’ learning of Mandarin tones and showed that the speakers with lower Mandarin proficiency were more affected by orthography than those with higher proficiency. That being said, however, Escudero et al. (2014) did not find any apparent differences between naive listeners and Dutch learners.
Taking all these previous studies into account, the effect of orthography is complex and can be modulated by the familiarity of the mapping (i.e. congruent, incongruent, or entirely unfamiliar), types of contrast (i.e. auditorily confusable or distinct) and L2 proficiency.
2 The effect of orthography on learning phonological alternations
Relatively less research has been devoted to the effect of orthography in relation to the learning of phonological alternations. In a longitudinal study tracking three English speakers learning German, Young-Scholten (2002) observed their acquisition of final devoicing whereby the underlying voicing contrast for obstruents is phonetically neutralized in the word-final position (e.g. the contrast /ʁɑ
Following up on this line of research, Hayes-Harb et al. (2018) conducted a study employing a picture naming task in which a group of English native speakers were asked to learn German-like nonwords with final voiced or voiceless written forms (e.g. <Tro
The aforementioned studies examined whether written forms interfered with the faithful learning of voicing alternations in the word-final position by English speakers whose language also has a voicing contrast. Barrios and Hayes-Harb (2020) further investigated if English speakers could successfully learn the final devoicing process under the mediation of orthography by exposing participants to both suffixed (e.g. /kʁɑ
Along the same line of research, Shea (2017) investigated the effect of orthography in the processing of L2 allophonic alternations, specifically the Spanish voiced stops /b, d, ɡ/ that are realized as approximants [β, ð, ɣ] intervocalically (e.g. [naða] /nada/ ‘nothing’). In a cross-modal priming experiment, English learners of Spanish were asked to make lexical decisions on auditory targets after being presented with written primes. The written primes and audio targets were either identical (e.g. Prime <cabeza> /kabesa/ ‘head’ – Target [kabesa]) or minimal pairs with the auditory target spirantized (e.g. Prime <nada> /nada/ ‘nothing’ – Target [naða]). Compared with a within-model condition (auditory–auditory) and a control group of native Spanish speakers, the English learners’ lexical decisions were faster in the identical condition than in the minimal pair condition, suggesting a direct connection between the written forms <b, d, ɡ> and the canonical representations [b, d, ɡ], but not the variants [β, ð, ɣ].
Using the same priming paradigm to test Mandarin learners of Korean on obstruent–nasal alternations, however, Han and Kim (2022) reported different findings. Korean has a regular phonological process whereby a syllable-final obstruent is nasalized when immediately followed by a nasal (e.g. /kak.mok/ – [kaŋ.mok] ‘stick’). That is, an obstruent and its corresponding nasal are neutralized in the syllable-final position (e.g. neutralization of /k/ and /ŋ/ in /paŋ.mun/ → [paŋ.mun] ‘visit’ and in /pak.mjʌl/ → [paŋ.mjʌl] ‘eradication’. They conducted a similar priming experiment in which the written prime and audio target were either identical (e.g. Prime <식당> /sik.taŋ/ – Target [sik.taŋ] ‘restaurant’) or minimal pairs with the auditory target undergoing nasalization (e.g. Prime <식물> /sik.mul/ – Target [siŋ.mul] ‘plants’). This cross-modal priming condition was compared to a within-modal condition (auditory–auditory), and native Korean speakers were used as a control group. The results showed that lexical decisions were facilitated in both the identical condition and the minimal pair condition, suggesting that there was no interference from the dissociation between the written forms (i.e. the obstruents) and the audio forms (i.e. the nasals). This finding is contrary to those from the previous studies which found evidence of orthography interfering with the learning of phonological alternations.
To summarize so far, orthography has been generally found to impede the correct learning of phonologically alternating sounds. The difference in orthographic representations (e.g. <b> and <p> in German) may create an illusory contrast in the auditory form, interfering with an existing phonological contrast. The same orthographic representations (e.g. <b, d, ɡ> in Spanish) may also impede the learning of allophonic variants. A priming study has alternatively shown no apparent interference from orthography in learning phonological alternations involving Korean obstruents and nasals.
3 English stop allophony
This study also examines a case of phonological alternation. Unlike the studies on German final devoicing and Korean syllable-final obstruent–nasal alternations whereby two graphemes are realized/neutralized as one phonetic form in the word-final position and before a nasal, this study focuses on alternations where different phonetic forms are represented by one single grapheme, a case more similar to the Spanish <b, d, ɡ> where the same graphemes are produced as [β, ð, ɣ] intervocalically and [b, d, ɡ] elsewhere.
There are multiple allophones of English voiceless stops. When /p, t, k/, commonly written as <p, t, k/ch/c/ck>, occur word-initially or in a stressed onset, they are produced as aspirated [ph, th, kh] (e.g.
English voiceless stops allophony.
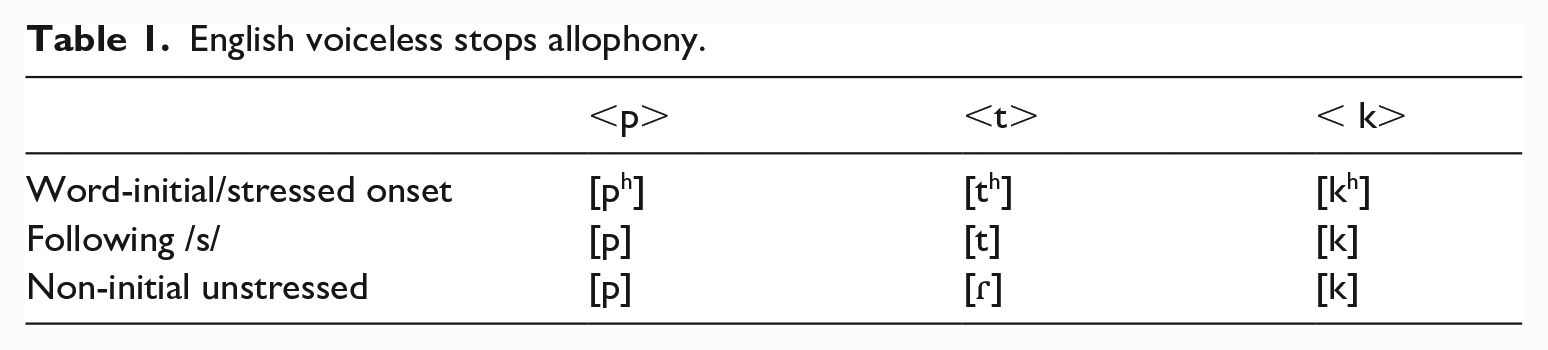
Apart from the canonical aspirated contexts, voiceless stops are unaspirated when they follow /s/, a contextual rule that is oftentimes explicitly taught in classroom settings (Ho, 1987). The non-initial unstressed context, however, depends on a higher-order, prosodic level of knowledge relevant to stress that is rarely noticed nor explicitly taught.
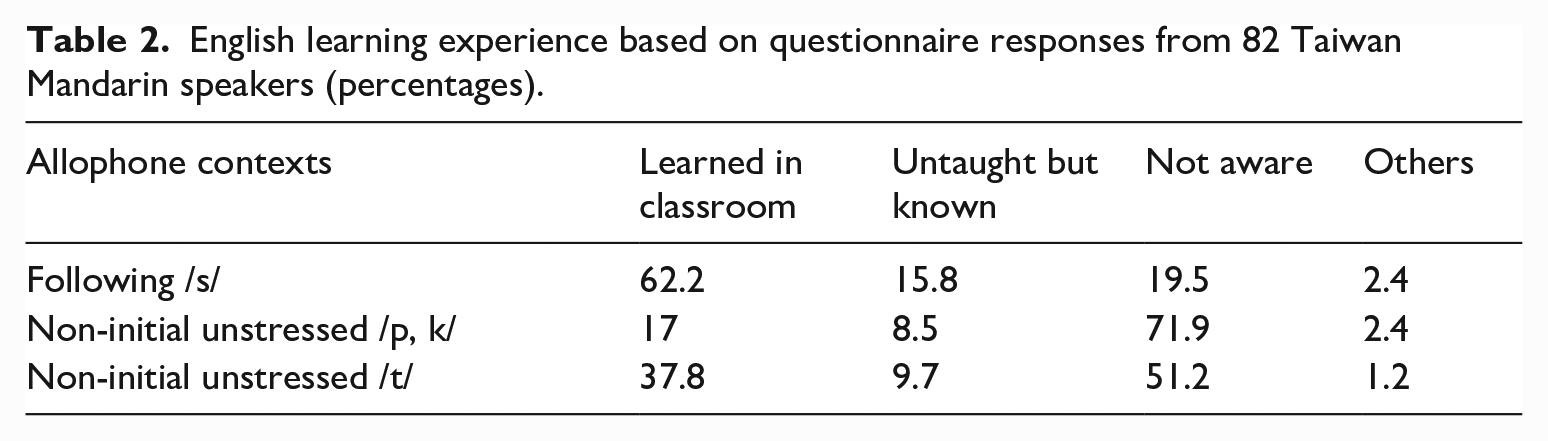
To characterize the English learning experience of Taiwan Mandarin speakers, we asked 82 individuals (61 women, 21 men; aged 19–60 years; M = 33.2) to fill out an online questionnaire; 90.2% of the participants reported that they learned American English while only 7.3% reported that they learned British English. The remaining 2.4% responded that they had learned a mixture of dialects.
The majority of the respondents (62.2%) had been taught in a classroom setting to produce <p, t, k> immediately following <s> as <b, d, ɡ>. Far fewer (19.5%) had not learned this generalization. A small percentage (15.8%) had realized this production difference themselves without being taught; one of these 13 individuals even explicitly responded that <p, t, k> in this context are produced without aspiration. Only two respondents (2.4%) did not remember if they had been taught this generalization. In the non-initial unstressed context, however, only 14 respondents (17%) had learned the generalization before while fewer (8.5%) had realized it themselves. The majority (71.9%) was not aware of this rule. About half of the respondents (51.2%) had not learned to produce non-initial unstressed /t/ differently, while 37.8% had. A smaller percentage (9.7%) were not taught but realized that /t/ in this context is produced differently. Table 2 shows the distribution of the responses.
English learning experience based on questionnaire responses from 82 Taiwan Mandarin speakers (percentages).
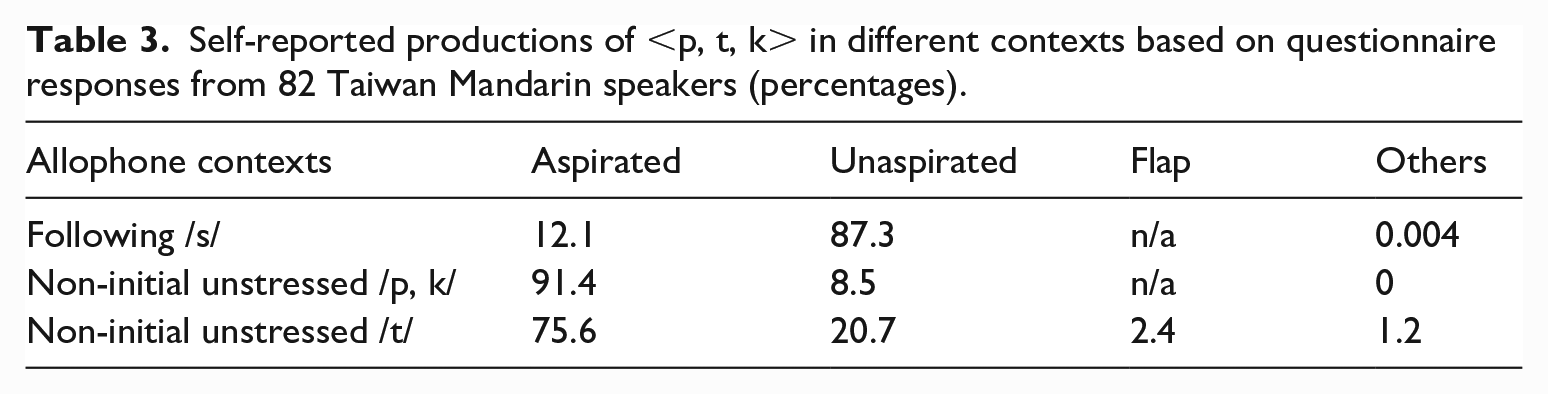
The English learning experience described above was reflected in the self-reported productions of <p, t, k> in different contexts. In the same questionnaire, we asked six open-ended questions (3 places × 2 contexts) about how <p, t, k> was produced immediately following /s/ and in the non-initial unstressed onset position by giving example words (e.g. How do you produce the ‘t’ in ‘store’? How do you produce the ‘c’ in ‘local’?). The participants generally described how they produced these sounds by making reference to a similar sound in other English words (e.g. the ‘t’ in ‘store’ is similar to the ‘d’ in ‘door’) or Mandarin equivalents (e.g. the ‘t’ in ‘store’ is similar to ‘ㄉ’ [t] in Bopomofo). The responses are summarized in Table 3. The majority of the respondents (87.3%) produced <p, t, k> following <s> as unaspirated. The pattern was reversed for <p, k> in the non-initial unstressed position: 91.4% produced these stops as aspirated while only 8.5% produced them as unaspirated. For non-initial unstressed <t>, 75.6% produced it as aspirated, and 20.7% as unaspirated; only 2.4% reported that they produced it as a flap.
Self-reported productions of <p, t, k> in different contexts based on questionnaire responses from 82 Taiwan Mandarin speakers (percentages).
The responses from the questionnaire show that the unaspirated context following /s/ is often explicitly taught in classroom settings and is more easily detected by Mandarin speakers. In contrast, the non-initial unstressed context, which depends on a higher-order, prosodic level of knowledge relevant to stress, was rarely noticed nor was it explicitly taught.
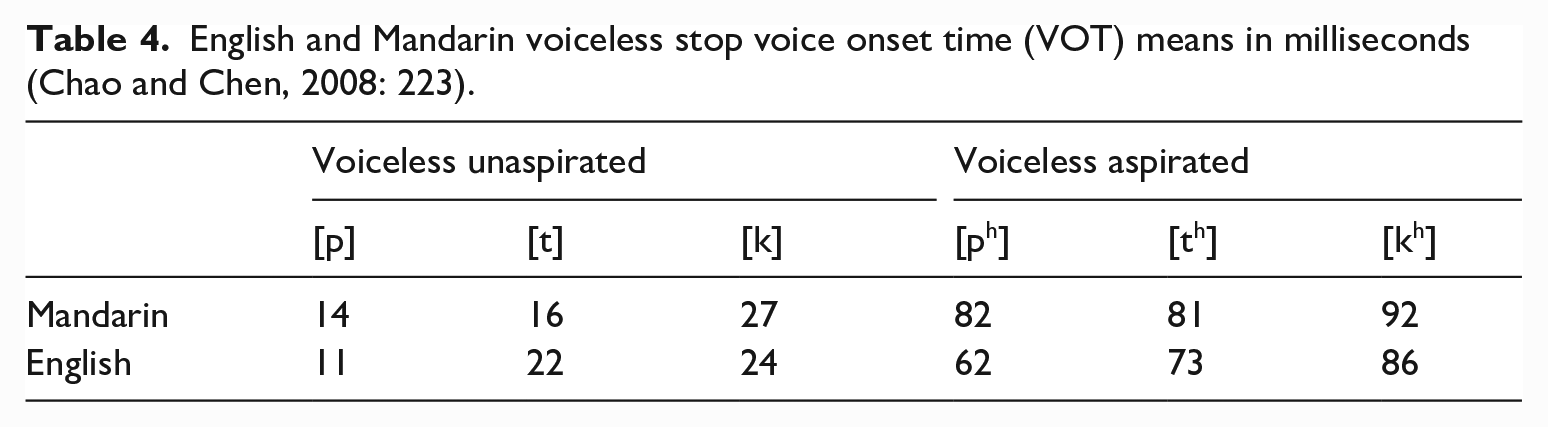
Beyond their L2 learning experience, Mandarin speakers are well acquainted with aspiration contrasts in their own L1. Voice onset time (VOT), the interval between the release of closure and the start of voicing, is often used as a measure for voicing and aspiration (Ladefoged and Johnson, 2010). A positive VOT value indicates voicelessness, whereas a negative value indicates that the segment is voiced. Aspiration is evidenced by a longer positive interval, while shorter positive intervals are observed when there is no aspiration. The mean VOTs generally fall within 11–24 ms for English voiceless unaspirated stops and 62–86 ms for aspirated stops in the word-initial position (e.g. Chao and Chen, 2008; Yang, 2021).
Mandarin Chinese contrasts aspiration (e.g. [pa] ‘father’ vs. [pha] ‘afraid’; [ta] ‘hit’ vs. [tha] ‘tower’; [ka] ‘scratching sound’ vs. [kha] ‘stop’), and the VOT values for unaspirated and aspirated stops fall well within the range of English unaspirated and aspirated stops, as shown in Table 4 (e.g. Chao and Chen, 2008). Yet Mandarin speakers often aspirate English voiceless stops in unaspirated contexts (e.g. Lin, 2007).
English and Mandarin voiceless stop voice onset time (VOT) means in milliseconds (Chao and Chen, 2008: 223).
Using an imitation production experiment, this study examines if Mandarin speakers’ failure to observe English voiceless allophones stems from the fact that these different phonetic forms share the same orthographic representations. We further investigate if the effect of orthography can be mediated by different phonological contexts and lexicality.
II Imitation experiment
Previous studies have shown that when imitating auditory prompts, not all phonetic cues are imitated equally (e.g. Mitterer and Ernestus, 2008; Nielsen, 2011). Phonetic cues are imitated differently according to their relevance in one’s native phonological system (Kim and Clayards, 2019; Kwon, 2019; Lu and Lee-Kim, 2021). Since Mandarin Chinese contrasts aspiration, and the average VOTs of aspirated and unaspirated stops fall well within the range of those in English (Table 4), we expect that VOT cues related to unaspirated and aspirated stops will be successfully imitated by Mandarin speakers. Failing to imitate the aspiration difference when orthography is provided and producing voiceless stops in unaspirated contexts as canonical aspirated stops, however, could be attributed to the inhibitory effect of orthography.
In the imitation experiment, a group of Taiwan Mandarin speakers was asked to imitate English stimuli presented aurally with or without English orthography. We obtained their baseline productions of voiceless stops in different contexts and compared them with the imitated productions. The different contexts included the explicitly taught, segmentally adjacent /s/ context (following /s/) and the higher-order, prosodically driven context (non-initial unstressed). We also included real words as well as nonwords to account for possible frequency effects from existing words since the participants would not have prior exposure to these nonwords. The difference between the baseline productions and imitated productions mediated by the presence or absence of written forms was used to measure the effects of orthography.
If orthography impedes the accurate imitation of English voiceless stops, we expect the following results in the Mandarin speakers’ imitated productions:
1. Canonical aspirated stops will appear in unaspirated contexts, more so for the participants who are exposed to the written forms than those who are not.
2. The orthography effect will be stronger in the higher-order, prosodically driven context compared to the explicitly taught, segmentally adjacent context due to the stronger awareness of the latter context.
3. The orthography effect will be stronger for nonwords than for real words since participants may have prior exposure to the real words and should be less affected by their written forms.
Finally, we made the following prediction for alveolar stops in the unstressed onset context based on the additional flap allophone:
4. Canonical aspirated stops will be observed more frequently when written forms are presented, while other allophones (flaps or unaspirated stops) will be observed more frequently when no written input is given.
1 Participants
Forty participants were recruited (21 women, 18 men, 1 nonbinary; aged 20–36 years; M = 23.65) at National Yang Ming Chiao Tung University to participate in this experiment. All participants reported Mandarin as their first language, and their mean self-rated English speaking ability was 4.38 (SD = 1.11) on a 7-point scale, with 1 indicating poor and 7 proficient. Their mean onset age of English learning was 6.15 years (SD = 2.26), and their mean length of English learning was 16.73 years (SD = 4.04). In Taiwan, English exposure could start as early as Grade 3 in elementary school. None of the participants had lived abroad for more than six months, so all the participants had learned English in the school setting, similar to the learning experience described in the questionnaire responses reported in Section I.3. The majority of the participants (36 out of the 40) reported that they only used English in English-related classes; 3 also used English at work; only 1 used English more broadly with friends. None reported any hearing deficiencies. All participants were compensated monetarily for their time.
2 Design and materials
A total of 288 monosyllabic/disyllabic stimuli were compiled, half being real words and the other half nonwords (see Appendix 1 in supplemental material). The real words were commonly used English words taken from the ‘senior high school English word-list’ created by the College Entrance Examination Center in Taiwan (https://www.ceec.edu.tw) with the exception of four proper nouns; the nonwords were selected or modified from the ARC Nonword Database (Rastle et al., 2002). Both the real word and nonword lists included 24 items with voiceless stops following /s/ (
Sample stimuli of the imitation experiment.
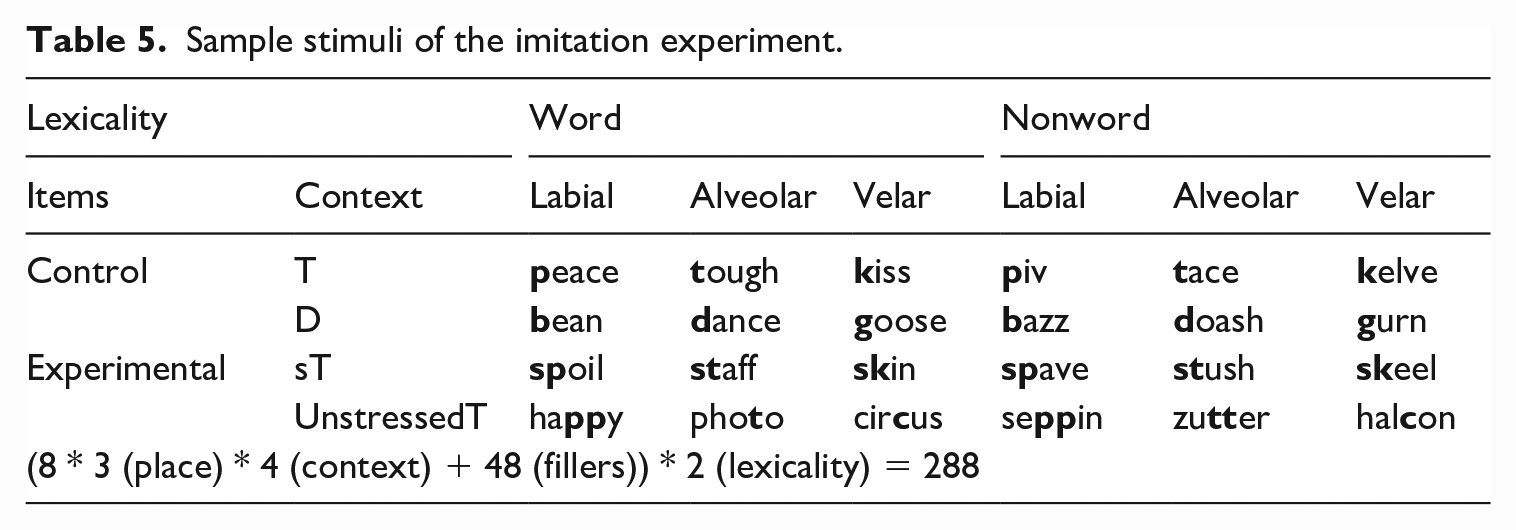
The stimuli were recorded in isolation by a male native speaker of North American English in which the unstressed, non-initial alveolar stop is produced as a flap (e.g. [ˈfoʊ
The Voice onset times (VOTs) of the recorded stimuli.
The results of a two-way ANOVA using the aov() function and corresponding post-hoc tests using TukeyHSD() function in R showed significant
3 Procedure
The 40 participants were randomly assigned to the
For the nonword and real word sessions, the participants were instructed to listen to the 288 items randomly presented to them and to repeat them as closely as possible. For the participants who were assigned to the
III Results
1 Baseline production
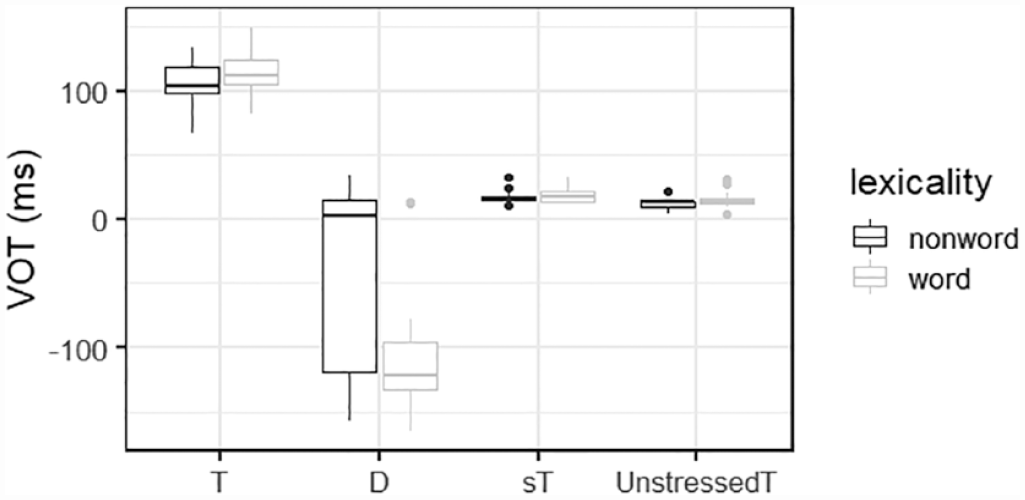
We first examined the results from the baseline productions to compare with those of the imitated speech of the participants in the
Voice onset times (VOTs) of the participants’ baseline productions as a function of group (audio vs. mixed) and context (T, D, sT, and UnstressedT).
The y-axis represents the participants’ VOT values, and the x-axis represents the four different contexts. The results from the
To confirm that the baseline productions were comparable between the
Summary of fixed effects for the baseline production.
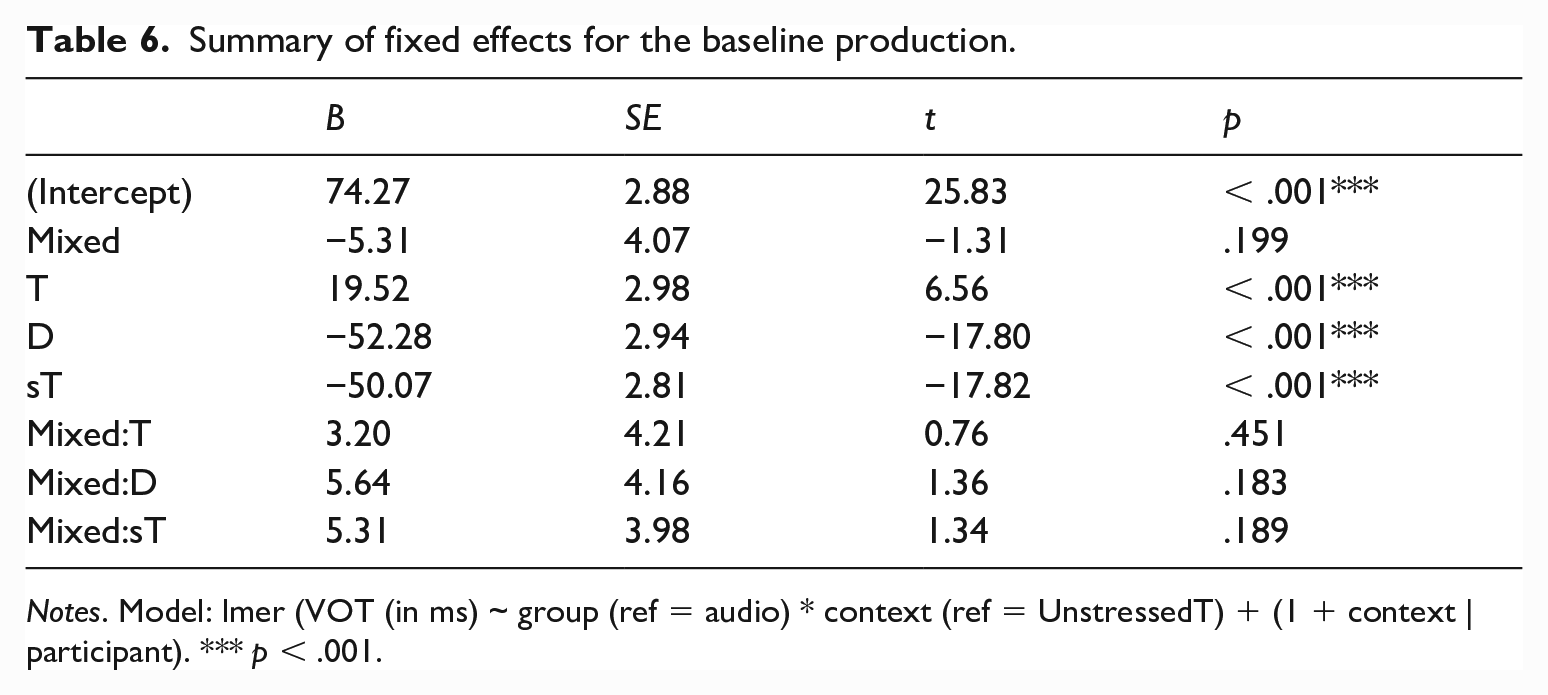
Notes. Model: lmer (VOT (in ms) ~ group (ref = audio) * context (ref = UnstressedT) + (1 + context | participant). *** p < .001.
The statistical model showed no difference between the
For the production of voiceless alveolar stops in the
Actual and predicted counts of flap, aspirated and unaspirated tokens in producing alveolar stops in the UnstressedT context by the participants in the audio and mixed groups.
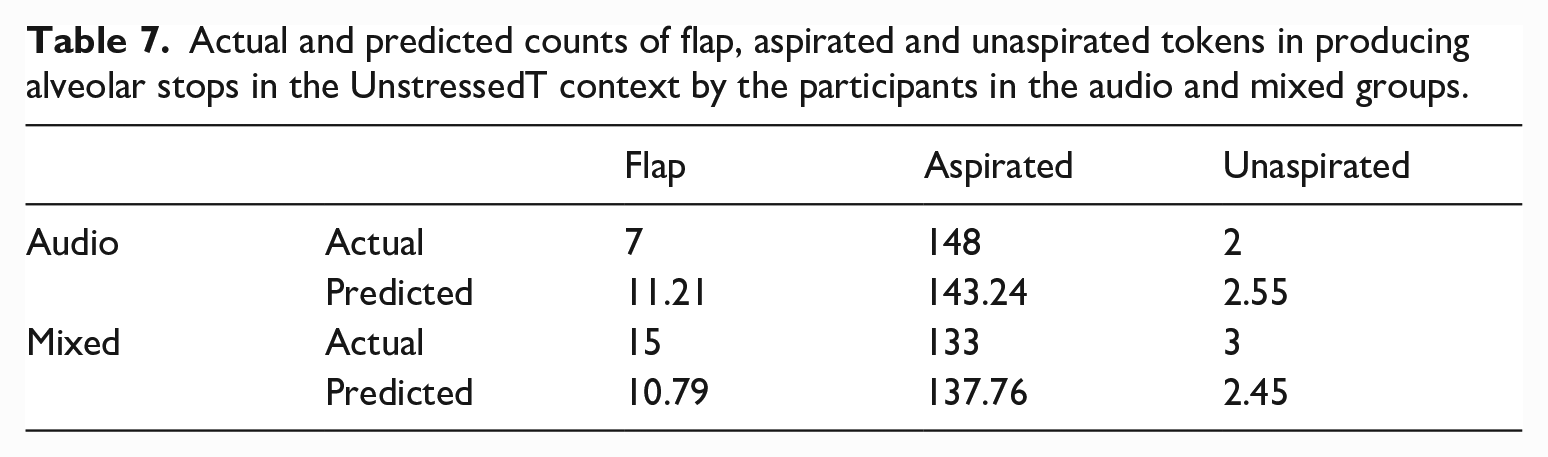
Taken together, the results from the baseline productions revealed that aspirated stops were frequently observed in the
2 Imitated production
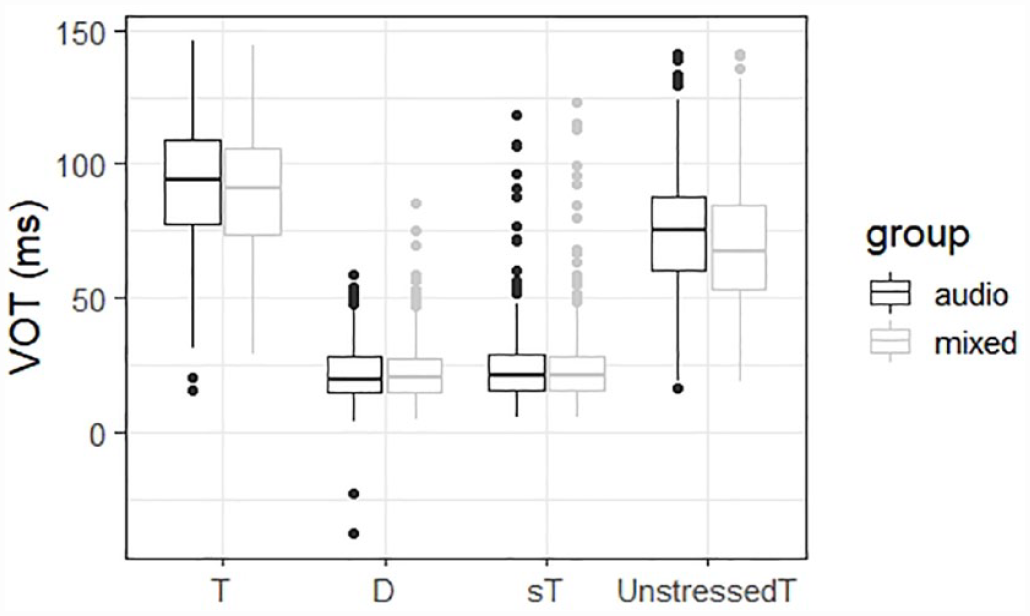
Out of the 7,680 tokens (8 items × 3 places × 4 contexts × 2 lexicality × 2 groups × 20 participants), 352 tokens that were produced as flaps were set aside for further analysis. We also excluded 105 tokens that were missing or mispronounced, and 172 tokens with VOTs that were 2.5 standard deviations away from the mean (exclusion rate: 3.6%). We provide an analysis on flaps later in this section. The VOT values of the remaining tokens in the imitated productions are shown in Figure 3.
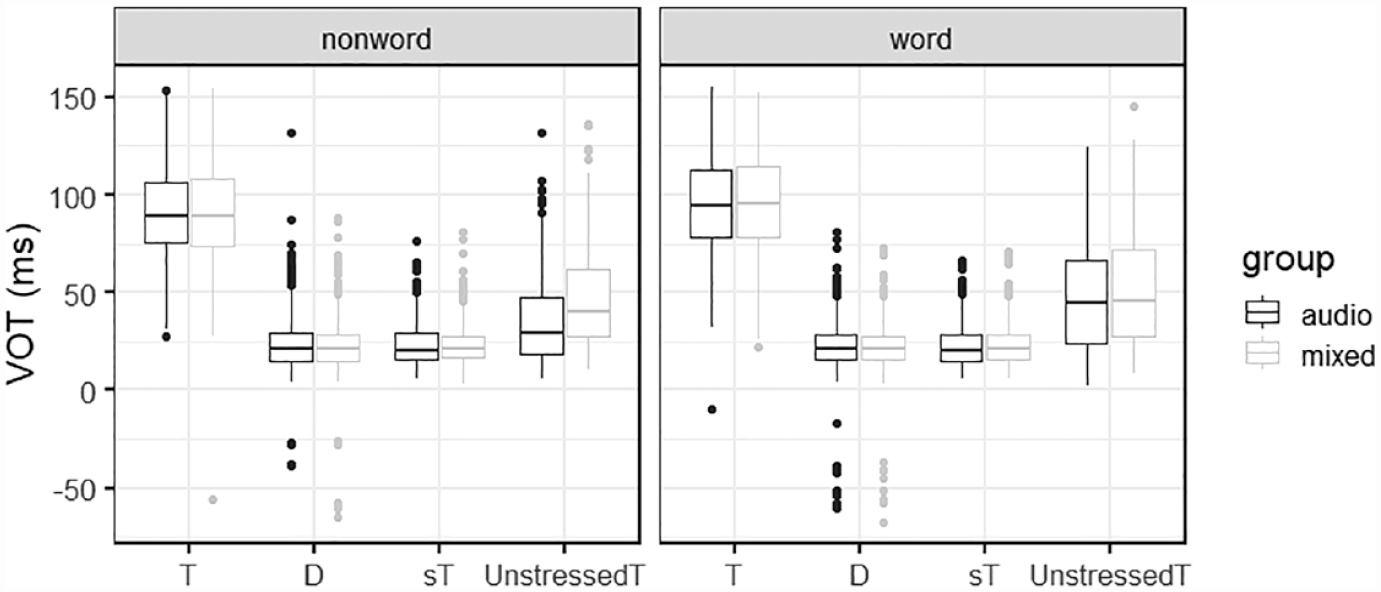
The participants’ voice onset times (VOTs) (ms) of the imitated productions as a function of context (T, D, sT, UnstressedT) and group (audio vs. mixed) paneled by lexicality (nonword vs. word).
The VOTs of the UnstressedT stimuli in the imitated productions were much shorter than those in the baseline productions (Mbaseline = 71.65 ms; Mimitation = 45.01 ms). The number of aspirated stops in the
We then compare the degree of imitation mediated by the presence or absence of orthography. We assessed the degree of imitation for each trial using the following formula (Babel, 2012; Kim and Clayards, 2019; Walker and Campbell-Kibler, 2015):
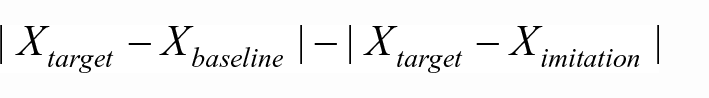
The resulting values reflect the number of units (i.e. milliseconds) that the participants moved their production towards the target and away from their own baseline. A number close to 0 indicates limited imitation while a positive or a negative value shows convergence towards or divergence from the target speech, respectively. The baseline measures for each participant’s voiceless stop productions in the
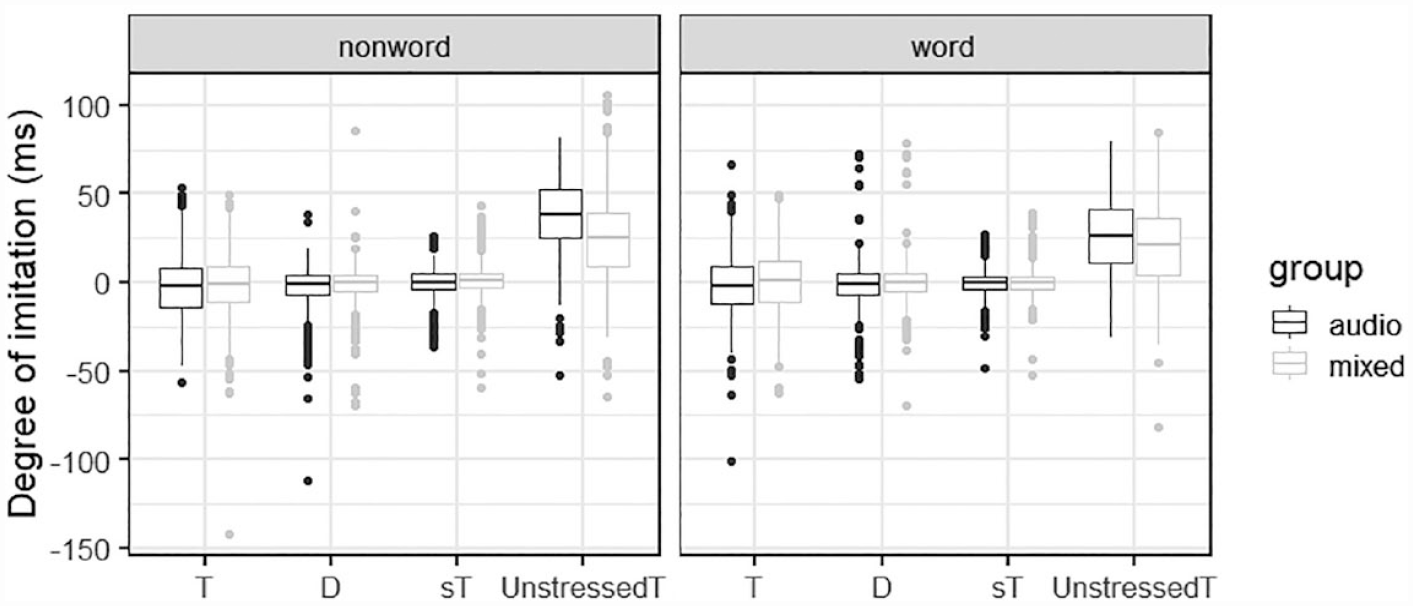
The participants’ degree of imitation in voice onset time (VOT) (ms) as a function of context (T, D, sT, UnstressedT) and group (audio vs. mixed) paneled by lexicality (nonword vs. word).
The y-axis represents the degree of imitation (the difference in ms between the baseline and imitated productions); the x-axis is the four contexts. The results of the
Summary of fixed effects for the imitated production.
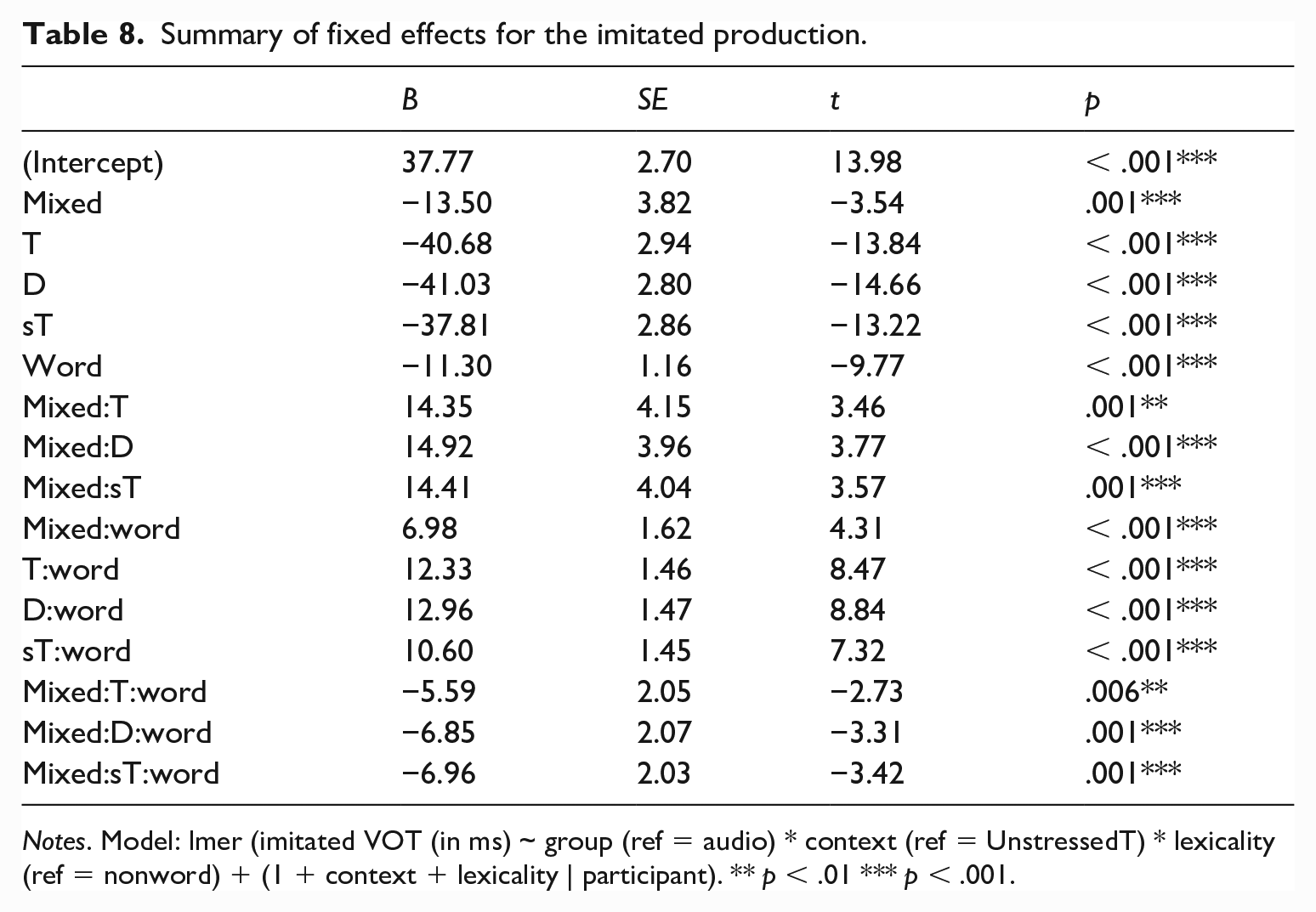
Notes. Model: lmer (imitated VOT (in ms) ~ group (ref = audio) * context (ref = UnstressedT) * lexicality (ref = nonword) + (1 + context + lexicality | participant). ** p < .01 *** p < .001.
The fitted model showed that participants’ imitations were significantly better in the reference
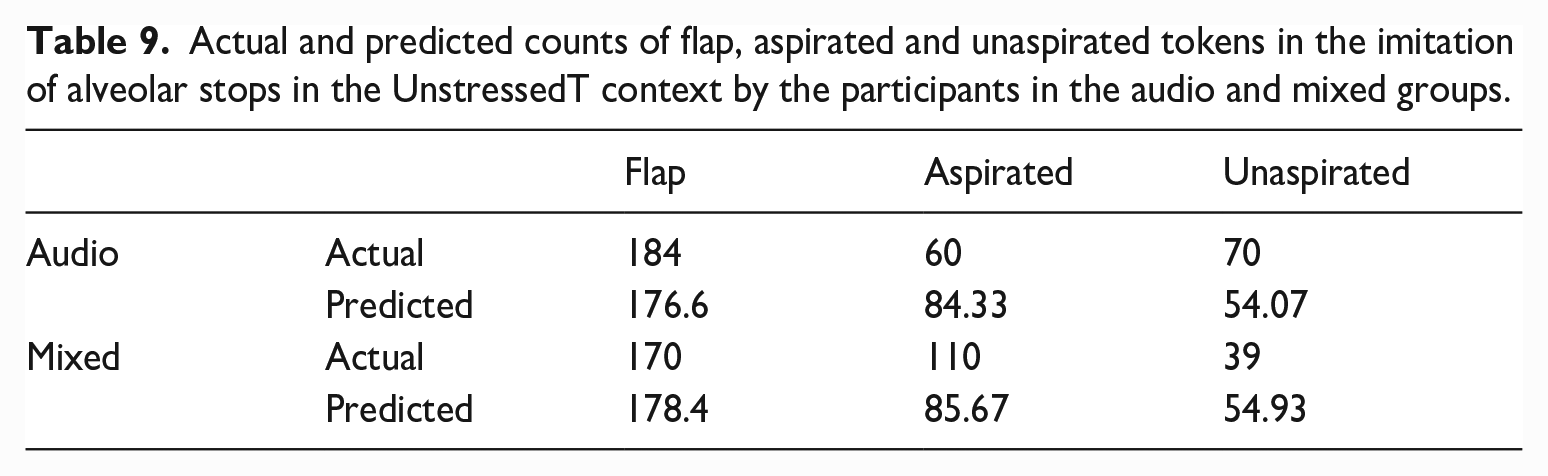
We then analysed the imitated patterns for the non-initial alveolar tokens in the
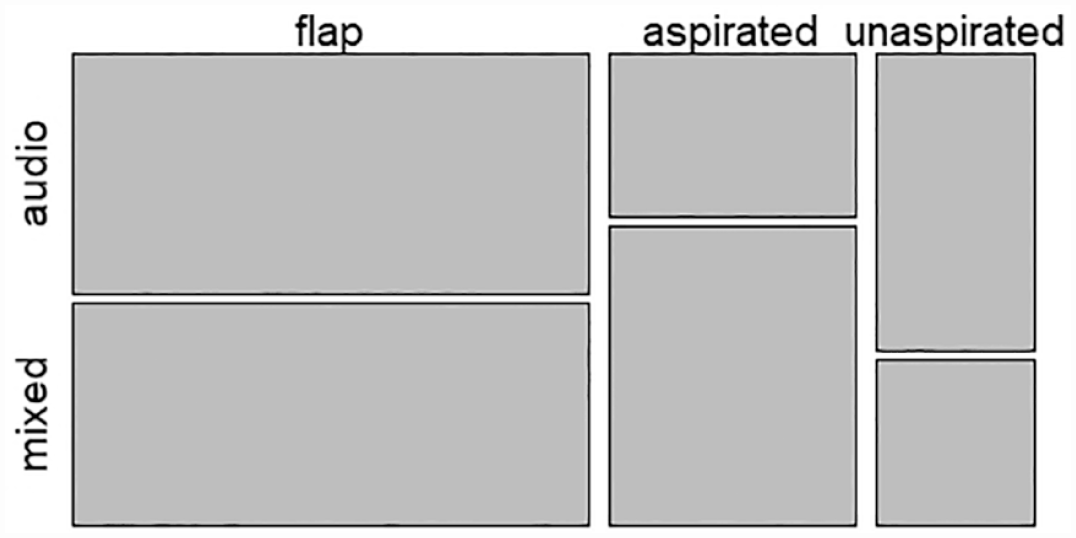
A mosaic plot for the distribution of flaps, aspirated and unaspirated tokens in imitating alveolar stops in the UnstressedT context in the audio and mixed groups.
Actual and predicted counts of flap, aspirated and unaspirated tokens in the imitation of alveolar stops in the UnstressedT context by the participants in the audio and mixed groups.
For each group, we further divided the tokens according to
Actual and predicted counts of flap, aspirated and unaspirated tokens in imitating alveolar stops in the UnstressedT context according to lexicality by the participants in the audio and mixed groups.
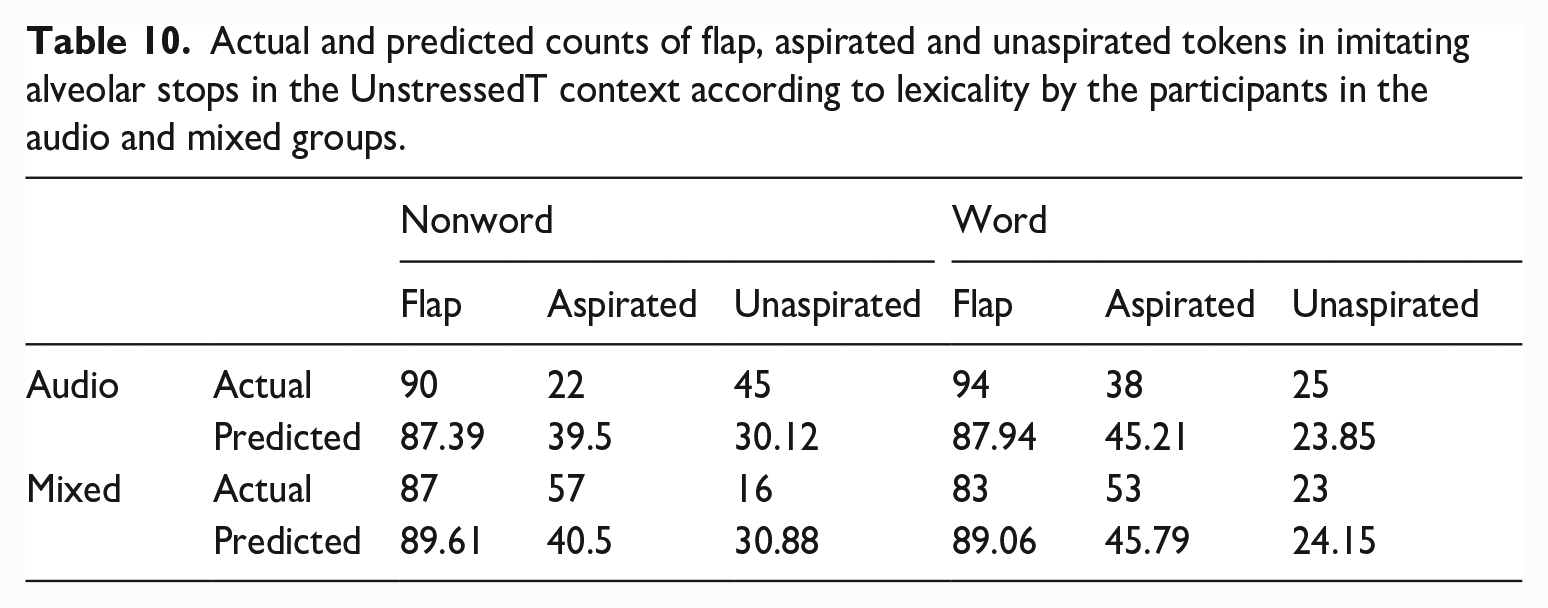
To summarize, compared with the baseline productions in which no group difference was observed, the different degrees of imitation in the imitated productions based on whether the written forms were provided or not indicated an orthography effect. In the imitated productions, canonical aspirated stops were less frequently observed in the
IV General discussion
This study examined an L2 learning scenario related to phonological alternations mediated by orthography. English voiceless stops, usually represented with <p, t, k> in writing, are realized as various allophones in different contexts: (1) as unaspirated [p, t, k] when they occur after /s/, or (2) as unaspirated [p, k] or flap [ɾ] when they occur in an unstressed non-initial onset. Mandarin speakers, however, often produce the English voiceless stops in these contexts as the canonical aspirated stops [ph, th, kh] that are associated with the stressed or word-initial onset position. We thus hypothesized that the failure to produce voiceless stop allophones, especially the unaspirated stops that exist as contrastive phonemes in Mandarin, stems from the incongruent correspondence of one grapheme to multiple phonetic forms (Table 1). We designed an imitation experiment in which one group of Mandarin participants was exposed to only aural input while the other was presented with both aural and written forms. The main findings from this experiment are as follows:
Canonical aspirated stops were more frequently found in the UnstressedT context when the participants were exposed to the written forms than when they were not, as indicated by the stronger degree of imitation in the
Canonical aspirated stops were more frequently found in the higher-order, prosodically driven unaspirated context than the explicitly taught, segmentally adjacent context, as suggested by the stronger degree of imitation in the
Different effects of orthography on nonwords and real words only appear in the
For unstressed, non-initial alveolar stimuli, similar
These results contribute to the previous discussions on the effect of orthography by showing that incongruent correspondences between the written forms and phonetic forms indeed impede the accurate learning of an L2, despite there being a clear phonetic contrast in the L1 (here, aspirated vs. unaspirated stops). However, unlike the previous studies that showed L2 learners may perceive an illusory contrast in the auditory input according to the contrast represented by written forms (e.g. the same phonetic form [p] corresponding to two written forms <p> and in German), the results of the present study further demonstrate a failure to notice a phonetic contrast when the written forms do not present a corresponding one. The written forms of <p, t, k> in English are strongly connected with the canonical productions of aspirated [ph, th, kh] that are found in the word-initial and stressed positions (Whalen et al., 1997), and this canonicity seems to level the acoustic differences of other allophones that could be easily noticed by Mandarin L2 learners.
Our findings echo those reported by Shea (2017) who observed that English learners of Spanish failed to connect allophonic variants [β, ð, ɣ] to the written forms <b, d, ɡ>, and only the canonical forms [b, d, ɡ] enjoyed a facilitatory effect. Using imitation instead of Shea’s priming paradigm, this study additionally showed that the written forms obscured the correct imitation of variants, and the effect was mediated by lexicality and the awareness of the variant contexts. Note that, with the exception of [ð], the English speakers did not have the allophonic variants in their native sound inventory; however, /ph, th, kh/ and /p, t, k/ exist as contrastive phonemes in Mandarin. Our results showed that the orthographic effect is strong enough to dampen a native contrast, especially for nonwords.
Our results, however, were inconsistent with those reported by Han and Kim (2022), who showed Korean obstruent/nasal phonologically conditioned variants primed equally well with or without written forms. Since our study and Han and Kim’s (2022) employed different experimental paradigms and types of contrasts, direct comparisons cannot be easily made and should be interpreted with caution. We speculate that this alternation case is conditioned by segmental adjacency (i.e. a syllable-final obstruent is nasalized when immediately followed by a nasal; e.g. /kak.mok/ – [kaŋ.mok] ‘stick’) and the target contrast is salient (obstruent vs. nasals). This could be a similar case to our
Curious readers may notice that /k/ can be written more variably than /p, t/ and may wonder if the orthography effect might have been of a different magnitude with the velar than with non-velar stimuli and when the written form was <k> than when it was less canonically represented as <ch/c/ck>. Since our stimuli did include these different written forms, we were able to examine this question in the
Average degrees of imitation (standard deviations in parentheses) as a function of place of articulation in the UnstressedT context.
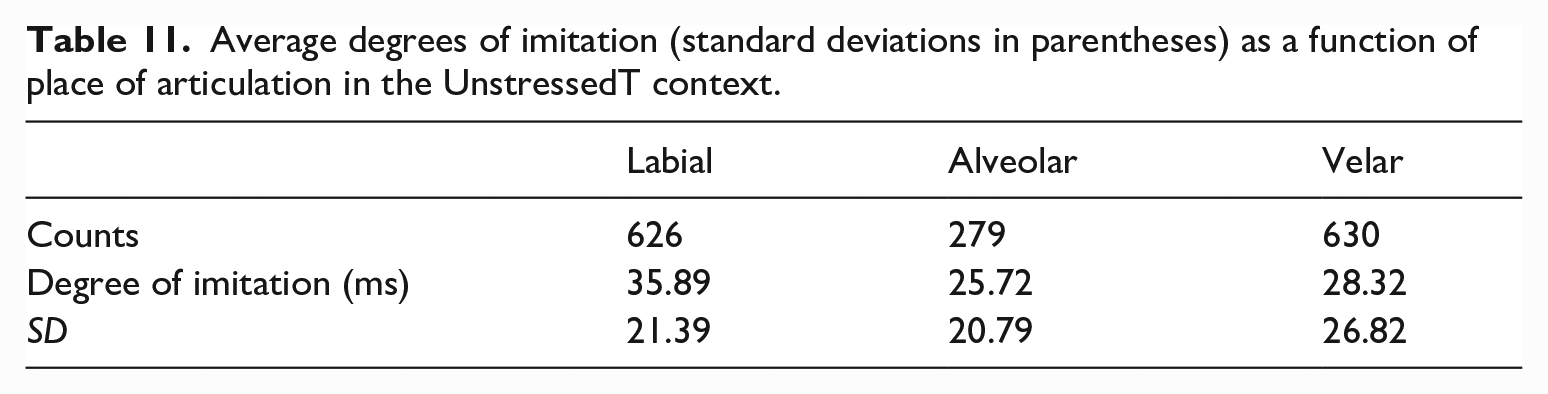
Based on the results, the degree of imitation for the velar stimuli was between that for the labial and alveolar stimuli. We then examined if different degrees of imitation could be observed across different written forms that represent /k/, as shown in Table 12.
Average degrees of imitation for the dorsal stimuli according to different written forms in the UnstressedT context.
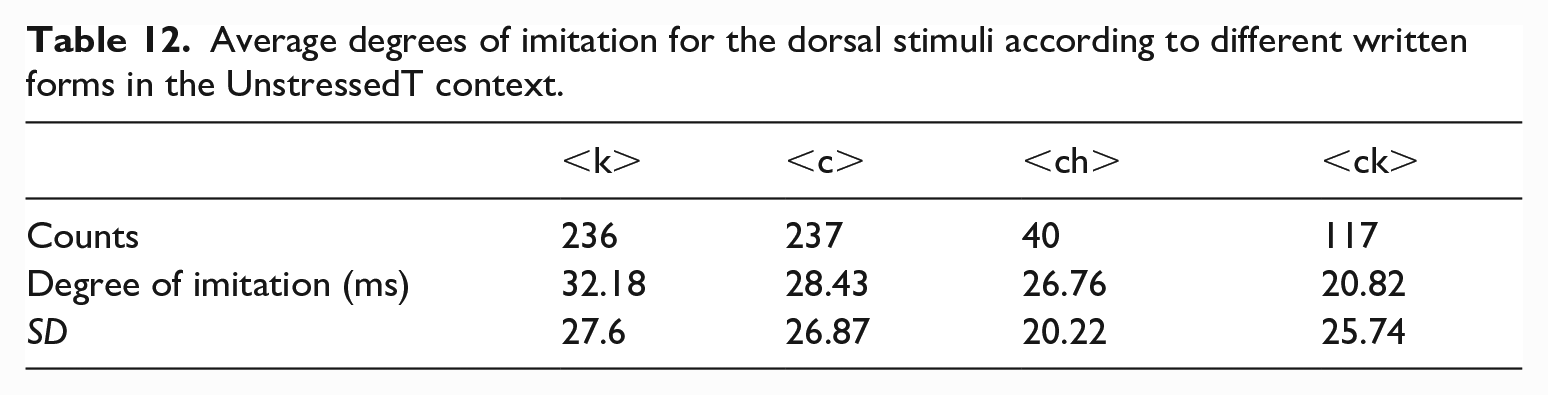
We indeed observed a higher average degree of imitation associated with <k> than with the other three written forms. However, due to the large standard deviation and the unbalanced counts in the stimuli, further research is needed to establish if different written forms indeed elicit orthography effects of varying magnitudes.
Our results also established differential mediation of orthography in various unaspirated contexts. The stops in the segmentally adjacent
Furthermore, the effect of orthography was observed more strongly with nonwords than real words, presumably due to the well-established connections between the lexical representations and phonetic forms for the real words from existing exemplars. This implies that with more exposure to L2 vocabulary, the effect of orthography should decrease. To examine this possible effect, we obtained the word frequencies of the real word stimuli from Leech and Rayson (2014) (see Appendix 1 in supplemental material) and correlated them with the degrees of imitation. Though slight, we did find a significant negative correlation between the log-transformed word frequency and the degree of imitation (p < .001, r = −0.09). This direction of research is also left for the future, perhaps for a study that only includes real words with various word frequencies to investigate if L2 learners’ experience mediates the effect of orthography.
One limitation of this study concerning the different orthographic effects in real words and nonwords, however, needs to be pointed out. We included the baseline session, in which written forms of the real word stimuli, but not the nonword stimuli, were presented to the participants; one may thus wonder if this could have reduced the degree of imitation for the real words in the audio group. As previous studies have shown a lasting effect from exposure to spelling (e.g. Bürki et al., 2012), the baseline session may have created a ‘mixed’ condition for the real words by exposing the participants to the written forms. If the real words in the baseline session were presented in another form (e.g. picture naming to bypass any possible mediation of orthography), we might have expected a similar degree of imitation in real words and nonwords in the audio group. This, however, did not obscure the observed effects of group (i.e. orthographic) and context (i.e. phonological awareness), which were the most important findings of this study. We leave the use of picture naming in employing imitation paradigm in examining L2 orthography effect to future studies.
Finally, the participants we recruited were Taiwan Mandarin speakers who use a non-alphabetic system (see Section I.1) and traditional Chinese characters to write their L1. Apart from the studies that showed L2 orthography affecting the phonological categorization of nonnative sounds, different L1 orthographic systems (e.g. non-alphabetical Zhuyin vs. alphabetical Pinyin systems) have been shown to also affect how sounds are processed (e.g. Lin and Lin, 2010). The orthography effect in learning English stops could thus be stronger for Mandarin speakers who use Pinyin, an alphabetic system like English. A future study could compare the degrees of orthographic mediation in L2 learning by L1 speakers using different L1 orthographies.
Supplemental Material
sj-docx-1-slr-10.1177_02676583231169127 – Supplemental material for The effect of orthography in Mandarin speakers’ production of English voiceless stops
Supplemental material, sj-docx-1-slr-10.1177_02676583231169127 for The effect of orthography in Mandarin speakers’ production of English voiceless stops by Yu-An Lu and Cheng-Huan Lee in Second Language Research
Footnotes
Acknowledgements
We extend our gratitude to Sang-Im Lee-Kim and Tsung-Ying Chen, as well as the attendees of the Seoul International Conference on Speech Sciences 2019 and the reviewers and editors of Second Language Research, for providing us with valuable comments and insights. We would also like to thank Chih-Chao Chang, Yung-Hsin Hsiao, Shao-Jie Jin, Meng-Hsuan Lin and Shih-Ching Yu for collecting and processing the data. Any remaining errors are ours.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Ministry of Science and Technology of Taiwan Grant (MOST110-2628-H-A49-001-MY2) to Yu-An Lu.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.