
Abstract
According to rational adaptation approaches of language processing, readers adjust their expectations of upcoming information depending on the distributional properties of the preceding language input. However, adaptation to sentence structures has not been systematically attested, especially not in second-language (L2) processing. To further our understanding of adaptive processes, we recorded electroencephalogram (EEG) from L1-Mandarin–L2-English speakers while they read English sentences containing a coordination ambiguity. This ambiguity was always resolved toward a less-preferred clausal coordination in the first half of the study, and towards a noun-phrase coordination in the second half. Group-level results suggest that L2 readers adapted but at a slow rate and a coarse level. Individuals differed in that some changed their processing strategies, and some did not. These findings suggest that adaptation is not a direct function of fine-grained input distributions, and are problematic for the idea that adaptation is important for language learning.
I Introduction
There is ample evidence from language processing and other cognitive science research that humans dynamically adapt their behavior to properties and demands of the situation (Anderson, 1991; Steyer et al., 2015). For instance, listeners can quickly adjust to the particular accent of a talker (Kleinschmidt and Jaeger, 2015). However, evidence for adaptation has not been systematically attested for semantic and syntactic aspects of sentence comprehension (Kaan and Chun, 2018b) and, if effects are observed, it is often unclear what precisely readers or listeners adapt to (Prasad and Linzen, 2021). A current issue in sentence processing research is therefore how and when adaptation occurs and what the underlying mechanisms are.
According to rational adaptation approaches (Kuperberg and Jaeger, 2016), humans keep track of distributional properties of language and the wider context, and adjust their language processing expectations to match what they have been recently exposed to. This is to make language processing as efficient as possible. Thus, language processing is continuously adjusted, with the degree of adjustment depending on the degree of deviance between what is expected and the new input, and on the strength of or confidence in the prior knowledge, among other things (Kuperberg and Jaeger, 2016). An interesting question is whether adaptation is a fine-grained tuning to the proportional distribution of certain properties in the recent input (Delaney-Busch et al., 2019; Ness and Meltzer-Asscher, 2021), or whether it occurs at a coarser level (Nieuwland, 2021a, 2021b). To be more specific, does processing change each time one encounters a certain type of sentence, narrowly keeping track of how often what type of sentence appeared in the recent input? Or does processing change more slowly, without closely tuning to the distribution of sentence types that have been recently seen? Another question is what is adapted to. Observing changes over the course of the study does not imply that (semantic, syntactic) knowledge and expectations are adjusted, but may instead, or in addition, involve, e.g. adjustments of later (repair, updating) processes (Yan and Jaeger, 2020), re-shifting reliance on top-down vs. bottom-up information (Delaney-Busch et al., 2019), or adaptation to the reading task itself (e.g. self-paced reading) rather than to certain linguistic aspects of the stimuli (Prasad and Linzen, 2021).
The debate concerning adaptation has implications for one’s view of language learning. According to rational adaption approaches and other error-based learning approaches (Chang et al., 2006), language learning is a form of adaptation. Listeners and readers make predictions as to upcoming information. If this is not borne out, the deviation between what is predicted and what is actually encountered is used to adjust the knowledge and minimize future prediction errors. Although such an error-based learning mechanism works well in computational models (Chang et al., 2006), it is unclear whether humans learn language in this way (Hopp, 2021; Huettig and Mani, 2016; Kaan, 2015). First, (prediction) errors are not always associated with adaptation (Kaan et al., 2019). Second, learning can take place without prediction and prediction errors. Evidence for the latter is that second-language (L2) learners may not be able to use some aspects of L2 predictively, but do have knowledge of these L2 properties (Huettig and Mani, 2016). On the other hand, some studies do report evidence that language learning is associated with prediction errors (Gambi, 2021; Grüter et al., 2021). Investigating language adaptation in L2 speakers may therefore tell us more about when adaptation takes place at what level and what drives this. This may in turn inform us about the role of prediction and adaptation in language learning.
Reports of adaptation in L2 speakers are inconsistent. Some studies find that L2 speakers can adjust their processing (production and comprehension) after being exposed to many sentences of a particular type, especially if these are infrequent structures in the L2 and/or first language (L1; e.g. Arai, 2016; Foltz, 2021; Hopp, 2020; Hwang, 2021; Kaan and Chun, 2018a; Montero-Melis and Jaeger, 2019). This supports error-based learning approaches, since adjustment is predicted to be larger in response to structures that are initially infrequent and are associated with a larger prediction error (but see Chun, 2018). However, evidence of adaptation in L2 comprehension has not been systematically found (Hopp, 2020). In a self-paced reading study Kaan et al. (2019) tested sentences with and-coordination ambiguities such as The maid folded the blanket and the laundry was put in a big basket. Native English speakers as well as Spanish L2 English speakers showed increased reading times at the disambiguating verb was, suggesting that both groups initially interpreted and as connecting two noun phrases. The native English speakers showed a reduction of this garden-path effect as more sentences had been seen in which and coordinated two clauses. The Spanish L2 English speakers, on the other hand, showed no signs of adaptation. However, these data do not imply that L2 speakers do not or cannot adapt. In addition, the use of self-paced reading may have obscured syntactic adaptation effects, as changes in reading times may in part be driven by adaptation to the self-paced reading task (Prasad and Linzen, 2021). In the current study we therefore used a different method: we recorded event-related potentials (ERPs) while participants read sentences at a fixed, machine-paced rate. We investigated whether L2 speakers of English can change their processing as they encounter more tokens of a particular non-preferred syntactic structure (garden-path), and how this adaptation is manifested (that is, with respect to which components and when in time). Finally, we explored to what extent this is affected by individual differences.
Prior ERP studies investigating adaptation have mostly been conducted in L1 and have typically used semantically (un)related word pairs, or sentences with semantic anomalies or unexpectancies (Brothers et al., 2019; Brown et al., 2000; Delaney-Busch et al., 2019; Lau et al., 2012; Ness and Meltzer-Asscher, 2021; Zhang et al., 2019). These studies mainly targeted the N400 component. The N400 can be interpreted as an index of predictability (but see Federmeier, 2022). One conceptualization of predictive processing is pre-activation of aspects of upcoming information. In this view, the N400 component can be taken to reflect the processing of information that has not yet been activated; the greater the N400 amplitude, the less information has been pre-activated (e.g. Kuperberg et al., 2020). For instance, a particular word (say, cat) can pre-activate a related word (dog). When this related word is subsequently encountered, it takes fewer resources to activate and recognize it (smaller N400 amplitude) than when the word was unrelated to the previous word. Some studies report that the N400 amplitude can be modulated by the proportion of related vs. unrelated word pairs in the immediately preceding context, reflecting trial-to-trial changes in expectations (Delaney-Busch et al., 2019). However, the interpretation of these results as supporting the idea of continuous, fine-grained adaptation has been criticized. A reanalysis of the data (Nieuwland, 2021b) showed that the degree of N400 adaptation was similar across experimental blocks regardless of the proportion of related word pairs. This suggests that readers do not update their processing expectations in detailed ways, but rather coarsely adapt to the task, for instance by becoming better at predicting related words. Other studies failed to find evidence that the N400 changes depending on the number of anomalous sentences encountered previously (Yano et al., 2020), or the proportion of sentences with a semantically unexpected word (Zhang et al., 2019). On the other hand, Brothers et al. (2019) reported a modulation of the N400 depending on whether the talker often produced sentences with unexpected words. This suggests that listeners can track distributional properties for separate talkers (see also Hanulikova et al., 2012; Hopp, 2016; Kroczek and Gunter, 2017). Taken together, current evidence suggests that adaptation to semantic unexpectancies is not very robust or fine-grained, unless there are additional cues (e.g. talker identity) that unexpectancies are likely to occur.
ERP studies using syntactic errors typically find more robust adaptation effects. These studies typically probe the P600 component. This is a posterior positivity starting from about 500 ms after onset of the word that gives rise to the syntactic error or unexpectancy (e.g. Coulson et al., 1998). ERP studies manipulating the proportion of sentences with syntactic violations report a larger P600 effect for violations when the study has only a small proportion of sentences with violations, but a smaller or even reversed P600 effect with a high proportion of items with violations (Coulson et al., 1998; Gunter et al., 1997; Hahne and Friederici, 1999). In addition, Yano et al. (2020) report that the P600 to violations gets smaller over trials as more sentences with syntactic violations have been seen. The P600 is considered a late component, that is, a component reflecting revision or repair, not initial analysis (Friederici, 1995). According to Kuperberg et al. (2020), this component is elicited by input that cannot be incorporated in the (event-semantic, syntactic, or higher level) representations maintained thus far. The conflict between the new input and extant representations may lead to reanalysis and repair processes. The sensitivity of the P600 to the number of prior syntactic violations encountered suggests that the adaptation is an adaptation of reanalysis and repair. Some studies report an (early) left anterior negativity for syntactic violations which is not modulated by the proportion of violations in the study (Coulson et al., 1998; Gunter et al., 1997; Hahne and Friederici, 1999). This suggests that early syntactic processes do not change, and supports the view that readers do not adapt their initial syntactic expectations, only the way violations are dealt with (for discussion, see Yan and Jaeger, 2020).
II The current study and predictions
The aim of the current ERP study was to test adaptation to sentence structures in L2 readers in order to shed more light on whether L2 learners can adapt and how. In addition, we explored individual differences. The current study differs from prior ERP studies on syntactic adaptation in that we used syntactic garden-paths rather than outright syntactic violations. This was to be more in line with behavioral studies on syntactic adaptation (Fine et al., 2013; Kaan et al., 2019) that investigated adaptation in terms of changing processing preferences, rather than changing expectations of ungrammaticalities. The garden-path structure we used is the and-coordination ambiguity illustrated in Table 1: initially and is interpreted as a noun phrase (NP) coordination, making the following noun phrase (the movie) part of the direct object of the preceding verb. However, at the following verb – made in (1) – this interpretation is no longer possible: and needs to be interpreted as a clausal coordination, with the noun phrase (the movie) being the subject of the second clause. We selected this ambiguity since the dispreference for a clausal ambiguity has been widely attested (Frazier, 1987; Hoeks et al., 2006; Kaan and Swaab, 2003), even in L2 speakers (Kaan et al., 2019). In addition, the ambiguity is not dependent on verb biases, as opposed to other widely used syntactic ambiguities such as reduced relatives, or direct-object / sentential-complement ambiguities (Román et al., 2021), thus removing the need to control for L2 learners’ knowledge of verb biases. Furthermore, this design allowed us to probe changes in processing at word positions that preceded the syntactical disambiguation. Such changes in processing could therefore be attributed to changing expectations of how the sentence would continue rather than to changes in revision processes at the syntactic disambiguation.
Examples of the experimental conditions.
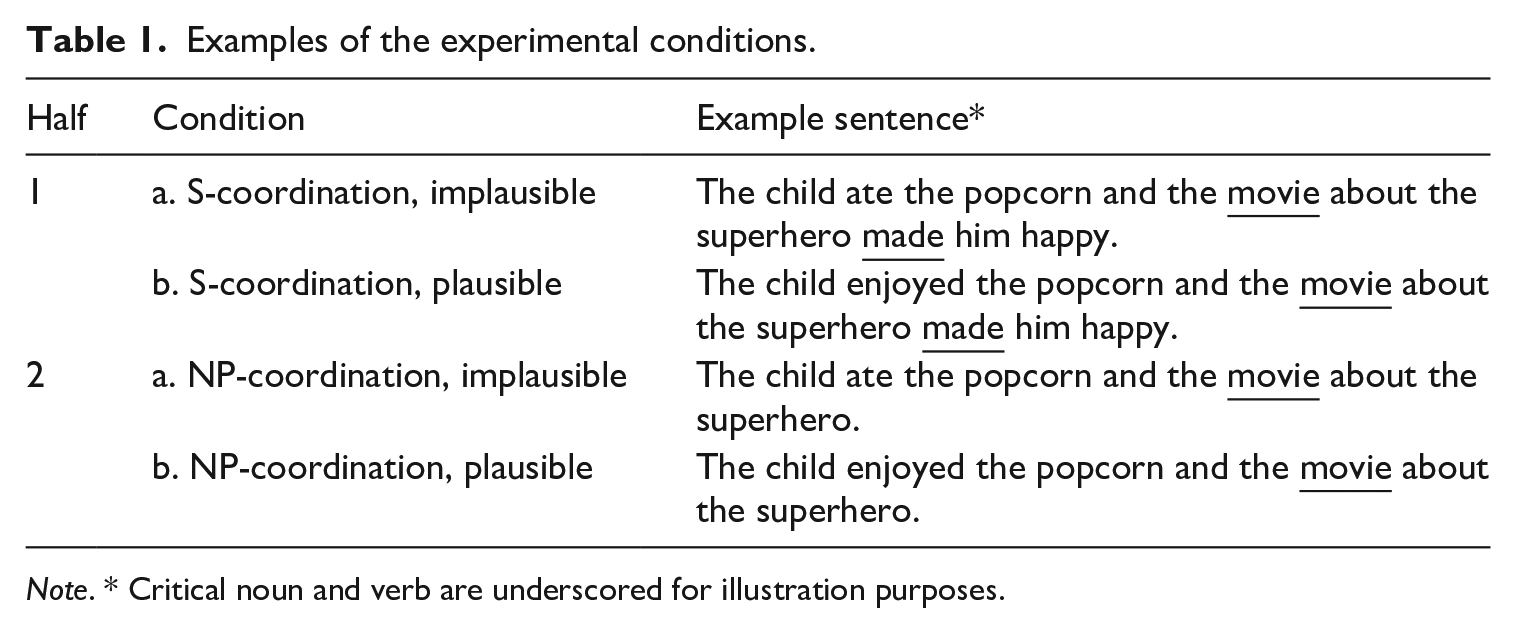
Note. * Critical noun and verb are underscored for illustration purposes.
In the first half of the study, sentences were always of type (1), that is, disambiguated towards a clausal coordination (S-coordination) at the verb in the second clause. In the second half of the study, the sentences stopped after the noun phrase after and, hence enforcing an NP-coordination (2). In half of the experimental sentences across the study, the noun after and was implausible given the preceding verb; e.g. ate . . . the
First, we looked at changes in the ERPs at the noun following and (henceforth the ‘critical noun’). Based on prior research (e.g. Kaan and Swaab, 2003), we expected that readers would initially interpret and as a NP-coordination. At the start of the study we therefore expected an N400 anomaly response for the critical noun that was implausible (1a) vs. plausible (1b) object of the preceding verb. In addition to the N400, we also probed later positivities (P600 and frontal positivity), since these components have been observed following, or instead of, N400 effects (e.g. Kuperberg et al., 2020). If L2 learners adapt to the recent context in a fine-grained way and start expecting an S-coordination, plausibility effects would become smaller in the first half as more S-coordinations have been seen; in the second half (NP-coordinations), the N400/P600/frontal positivity plausibility effect was expected to become larger again as readers adapt to NP-coordinations and again start interpreting the critical noun as belonging to the preceding verb. A second possibility is that adaptation occurs, but at a coarser level. For instance, readers may adapt to the implausibilities, but do not necessarily change their expectations of the upcoming structure as a function of the recent context. This could result in an overall decrease in size of the plausibility effects in the ERPs. A third possible outcome is that no adaptation takes place and the size of the ERP plausibility effects remains stable over the course of the study (Yano et al., 2020; Zhang et al., 2019). This would mean that the L2 readers keep interpreting the noun as a direct object of the preceding verb, regardless of exposure to S-coordinations or the number of implausible continuations.
Second, we looked at the ERPs at the disambiguating verb – made in (1a) and (1b) – in the first half of the study (S-coordinations). We expected readers to initially interpret and as an NP-coordination. They would then need to revise this interpretation when encountering the disambiguating verb in the second clause. This revision would be reflected in the P600 amplitude. Revision or re-ranking processes at the disambiguating verb (made) are harder when the noun is a plausible object of the preceding verb (1b) than when it is an implausible object of the preceding verb (1a). This is because implausibility serves as an additional support for an analysis in which and connects two clauses structure, or because reanalysis is easier when semantic cues support the intended structure and bias away from the unintended one (Garnsey et al., 1997; Román et al., 2021). At the disambiguating verb in the first half of the study we therefore expected L2 speakers to show a larger P600 for the conditions in which the NP is a plausible (1b) than when it is an implausible object (1a). Syntactic anomalies and unexpectancies have also been associated with N400 effects, in particular in L2 speakers (Guo et al., 2009). We therefore also probed this effect, as well as the late frontal positivity sometimes observed for semantic manipulations (Kuperberg et al., 2020). If L2 readers adapt to S-coordinations over the course of the first half, and start expecting that and combines two clauses rather than two noun phrases, we expected that (1) the P600 at the disambiguating verb would decrease in amplitude overall; and (2) the plausibility effect in N400/P600/late frontal positivity at the disambiguating verb would become smaller as more S-coordinations have been seen. This is because readers would start interpreting and as an S-coordination, and the following noun as the subject of the next verb. The plausibility of the noun with the preceding verb is then no longer relevant.
Finally, since some effects may be obscured in group-level analyses (Grey, 2023; Tanner and Van Hell, 2014), we explored variations among individuals in their responses to the critical noun and disambiguating verb, and how these relate to proficiency.
III Methods
1 Participants
We registered our protocol and analysis at https://osf.io/8g5sd/registrations. Due to the Covid-19 pandemic and financial constraints we had to stop data collection at 48 participants. Eleven data sets were excluded from the data analyses reported below because of preregistered exclusion criteria: low accuracy on the comprehension questions (less than 75% correct, 5 participants), not meeting the LexTale criterion (one participant, see below); excessive blinking (3) or an excessive amount of other artifacts yielding fewer than 20 clean trials per condition (2). Participants included in the data set were 37 native speakers of Mandarin Chinese, recruited mainly from Nanjing Normal University and other universities in the Nanjing area (8 men, 29 women, ages 19–25 years, mean age 22.4 years). Inclusion criteria were that participants had learned English at school at or after the age of 6 years, had passed the TEM8 (test for English majors level 8), and scored at least 60 on the English LexTale task conducted in a separate session before the electroencephalogram (EEG) study. 1 Furthermore, participants were right-handed, neurologically healthy, had no history of brain damage or disease, mental illness, or any history of reading- or learning-related problems, had normal or corrected-to-normal vision, and had not taken any recreational drugs before the study (based on self-report). Language background information is summarized in Table 2.
Participant language background information: Means with ranges in parentheses.
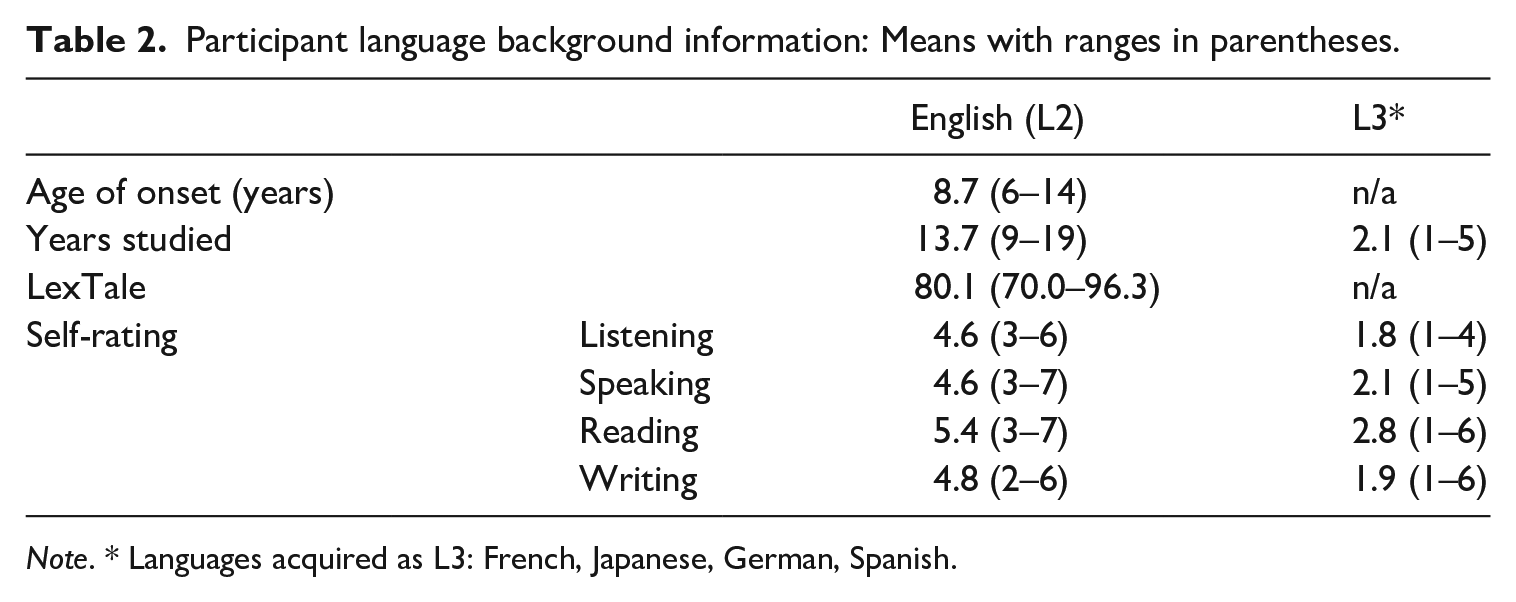
Note. * Languages acquired as L3: French, Japanese, German, Spanish.
2 Materials
Experimental materials consist of 160 item sets of the type illustrated in Table 1. Sentences in all conditions contained the conjunct and which was preceded and followed by a noun phrase. The noun phrase following and was either a plausible object of the preceding verb – enjoyed . . . the movie, (1b)/(2b) – or was implausible as the object of the first verb; ate . . . the movie (1a)/(2a). The noun after and was always followed by at least two words. This was to avoid disambiguation by punctuation at or right after the critical noun. In conditions (1a) and (1b) (first half of the study) the sentence was disambiguated towards an S-coordination at the inflected verb (made). At least three words followed the disambiguating verb. In conditions (2a) and (2b), which were presented in the second half of the study, and connected two noun phrases. Sentences started out the same as in (1a) and (1b), except that they ended before the critical verb.
To check that the critical noun was implausible in the NP-coordination implausible condition, and plausible in the NP-coordination plausible condition, we conducted a plausibility rating. A second norming study collected measures of association between the nouns on either side of and. Both studies were conducted over Mechanical Turk. Details are given on https://osf.io/8g5sd/. On the basis of the norming studies, we selected the 160 item sets to be used in the main experiment. These 160 quadruplets were divided into four item groups that were matched on the plausibility ratings for the plausible and implausible versions, noun association ratings, length and frequency of the noun after and, the length and frequency of the disambiguating verb in the S-coordination conditions, and the length and frequency of the sentence-final word in the NP-coordination conditions. Frequency was the log transformed lemma frequency per million extracted from the British National Corpus (BNC Consortium, 2007) using the NIM search engine (Guasch et al., 2013). Four participant lists were then created by Latin squaring the four item groups. Each participant list contained 40 items for each of the four conditions, no item was repeated within a list, and each item was presented in all conditions across the experiment as a whole.
An additional 56 plausible filler sentences were included (same for each list) to add variation and to reduce the expectation of implausibilities. These distractor items did not have any coordinating structures and were on average of the same length as the experimental items (example: The train departed from the station that was on the north side of town). Each participant thus saw a total of 216 items (40 for each of the four experimental conditions, plus 56 filler items), of which 80 (37%) had an implausible relation between a noun and a preceding verb. Fifty-four of the 216 trials (25%) were followed by a yes/no comprehension question to encourage the participant to keep paying attention. Questions mainly probed the first clause, and never probed the resolution of the ambiguity of and (examples: The man lifted the refrigerator and the table in the kitchen. Question: Was the man in the living room? (No); The teacher distributed the homework and pencils with pink erasers. Question: Did the students receive something to write with? (Yes)). The complete set of materials is available at https://osf.io/8g5sd/.
The order of the sentences and fillers was pseudo-randomized such that no more than two items of the same condition followed each other, and such that sentences with S-coordinations – as in (1a), (1b) – were presented only in the first half of the study, and NP coordinations – as in (2a), (2b) – in the second half. Items were presented in nine runs of 24 trials each. The order of runs within each half of the study was randomized per participant. Participants were not instructed about sentence types and were not made aware that the type of sentences changed midway through run 5.
3 Procedure
In the EEG study, participants were fitted with an electrode cap. They were seated in a chair in a sound-attenuating room, 60–65 cm away from a computer monitor. Sentences were presented word by word on the monitor, white letters on a black background, Courier New font, 22 points. The size of the visual angle for a seven-letter word was about 33 degrees.
Trials started with a fixation cross presented for 800 ms. Each word was presented for 300 ms separated by a 350 ms blank screen. The last word of a sentence was followed by a blank screen of 1,250 ms. Some sentences were followed by a comprehension question, presented in its entirety with the answers ‘no’ and ‘yes’ presented on the left and right side of the screen below the question. Participants indicated their answer by pushing ‘f’ and ‘j’ on a keyboard for ‘no’ and ‘yes’ respectively. Trials were separated by the message ‘Press for next’. Participants pushed the spacebar on the keyboard to start the next trial.
Participants were told to read the sentences silently and attentively and to refrain from moving and blinking until they saw a question or the press for next message. Participants first saw a practice run of eight sentences with three comprehension questions.
4 EEG recording and preprocessing
EEG was recorded from 30 scalp electrodes (actiCAP), placed according to the 10–20 system (FP1/2, Fz/3/4/7/8, FC1/2/5/6, FT9/10, Cz/3/4, T7/8. CP1/2/5/6, Pz/3/4/7/8, Oz/1/2), using a Brain Amp amplifier (Brain Products, GmbH Germany). Eye movements and blinks were monitored with bipolar electrodes next to the left and right eye as well as below and above the right eye. EEG and EOG (electro-oculograpm) were recorded with a sampling rate of 500 Hz with a high pass hardware filter of 0.016 Hz and a notch filter of 50 Hz. An electrode on the nose tip served as reference. Impedance was kept below 5 kOhm.
5 Analysis
EEG data was preprocessed using EEG lab (Delorme and Makeig, 2004) with the ERP lab plug-in (Lopez-Calderon and Luck, 2014). EEG was re-referenced off-line to the average of the left and right mastoids. Eye movement artifacts were corrected using independent components analysis (ICA, Jung et al., 2000). First, segments of EEG with extreme noise were manually removed; these were typically segments between sentences and at the beginning and end of a run. We then performed ICA on the remaining continuous data from the scalp electrodes using runica in EEGLab, based on the infomax ICA algorithm (Bell and Sejnowski, 1995). Components corresponding to horizontal and vertical eye-movements were identified through IClabel (Pion-Tonachini et al., 2019) and manually confirmed (1–3 components per participant). These components were then used to adjust scalp electrode data. After eye-movement correction, we additionally automatically rejected segments containing a voltage difference of over 75 μV in a time window of 200 ms (50 ms steps). Bad channels were identified by visual inspection and interpolated via spherical interpolation. Data loss was about 6–9%, equally distributed over the conditions for the positions probed [average number of trials remaining out of 40 for the disambiguating verb: 36.9 (1a); 36.4 (1b); for the critical noun: 37.2 (1a); 37.4 (1b); 37.6 (2a); 37.6 (2b)].
For the ERP analysis, the EEG data was filtered with a 0.1–30 Hz band-pass filter. Epochs were defined from −200 ms to 1,000 ms relative to the onset of the noun after and in all experimental sentences, and the second clause verb in conditions (1a) and (1b). Data were baseline-corrected relative to a 200 ms interval preceding the onset of the critical words.
The N400 was quantified as the mean amplitude between 300 and 550 ms after word onset across the following electrodes: FC1, FC2, C3, Cz, C4, CP1, CP2. These sites were selected in order to capture the typical broad, central distribution of the N400. The selected latency is longer than traditionally used for native speakers (300–500 ms), but is based in Guo et al. (2009), and meant to capture potential longer N400 latencies that have been observed in L2 speakers (Ardal et al., 1990; Dallas et al., 2013; Weber-Fox and Neville, 1996). The P600 and late frontal positivity was quantified as the mean amplitude between 550 and 900 ms after stimulus onset. Some prior studies on native English speakers (e.g. Kaan et al., 2020) use 500–900 ms as the interval for late positivities. However, since we defined the N400 as 300–550 ms, we used a 550–900 ms interval so as not to have the windows overlap. For the P600, we averaged the amplitude across electrodes CP1, CP2, CP5, CP6, Pz, P3 and P4, corresponding to the typical central-parietal and parietal distribution of the P600 (e.g. Coulson et al., 1998). To probe the frontal positivity we investigated the mean amplitude between 550 and 900 msec across bilateral frontal and frontal-central sites (Fz, F3, F4, FC1, FC2). Since we were also interested in how the components changed over the course of the study, we did not average the ERP across trials in the analysis.
Separate linear mixed effect models were used to assess the N400, P600 and frontal positivity as defined above at the critical noun and the verb (R version 4.1.2, R Core Team, 2019; lme4 package version 1.1-29, Bates et al., 2015b). For the analysis of the ERPs to the critical noun we used Plausibility (deviation coded: implausible as −0.5; plausible as 0.5), Half (deviation coded: first half as −0.5, second as 0.5) and their interactions as fixed effects in the model. Participant and Item ID were included as random intercepts. We started with a model in which Plausibility, Half, and their interaction were included as by-participant random slopes and Plausibility as a by-item random slope. When the model did not converge or produced singularity issues, random effects were eliminated starting with factors that had the smallest variance (Bates et al., 2015a). Finally, to assess changes over time within each Half, we ran separate models for each half with Plausibility and Trial position relative to other experimental trials within the half (Trial position, centered) as predictors.
For ERPs at the verb in the first half (S-coordinations) we estimated a model with Plausibility (deviation coded: implausible as −0.5; plausible as 0.5), Trial position (centered), and their interactions as fixed effects. Participant and Item ID were included as random intercepts. As in the noun model we started with a maximal random effects model, and reduced it when needed.
Using the lmerTest (Kuznetsova et al., 2017), p-values were obtained. Model descriptions and complete model outcomes are in the supplementary materials provided on https://osf.io/8g5sd/. Exploratory analyses are described below.
IV Results
1 Comprehension questions
Comprehension questions were responded to correctly 87.4% (SD 6.7%) of the time on average, suggesting participants understood the sentences and were paying attention. Questions following the NP-coordinations (second half) were responded to more accurately [Mean accuracy (SD), implausible 89.5% (9.1); plausible 87.8 % (8.1)] than questions following S-coordinations (first half) [implausible: 83.8 % (12.3); plausible 82.7% (11.9)]. A generalized linear mixed effects model with Plausibility, Half and their interaction as fixed effects, by-participant and by-item intercepts, and Half as a by- participant random slope showed improved performance in the second compared to the first half [b = 0.53, 95% CI [0.15, 0.91], SE = 0.20, z = 2.71, p < 0.01]. The increase in accuracy may be due to the NP-coordinations being syntactically less complex than S-coordinations. To see whether performance over the course of the study changed regardless of syntactic construction, we assessed accuracy on questions following distractor items only, since the same types of distractor items were used in both halves. Comparing accuracy for questions following distractor items in the first vs. last four runs, performance was numerically better later in the study. This suggests that the difference in performance on comprehension questions between the halves is not due to the change in complexity of the sentences, and that participants were still paying attention in the second part of the study [Mean accuracy (SD), first four runs: 85.7 % (11.7), last four runs: 97.3 % (6.2); b = 1.60, 95% CI [−0.18,3.39], SE = 0.91, z = 1.76, p = 0.08].
2 ERPs at the noun after ‘and’
ERPs for the noun after and (the critical noun) in the two halves are displayed in Figure 1. The conditions in which the critical noun was implausible given the preceding verb showed a larger N400 vs. the conditions in which the noun was plausible [b = 0.38, 95% CI [0.07, 0.70], SE = 0.16, t = 2.41, p < 0.05]. This was marginally modulated by Half [Interaction of Plausibility and Half: b = −0.59, 95% CI [−1.22, 0.03], SE = 0.32, t = −1.86, p = 0.06]. The negativity for the implausible condition lasted throughout the time window and sites defined for the P600, and was modulated by Half as well: posterior electrodes (550–900 ms) showed a significant interaction of Plausibility and Half [b = −0.65, 95% CI [−1.21, −0.08], SE = 0.29, t = −2.24, p < 0.05]. Analysis of frontal effects in the 550–900 ms window showed no significant effects.
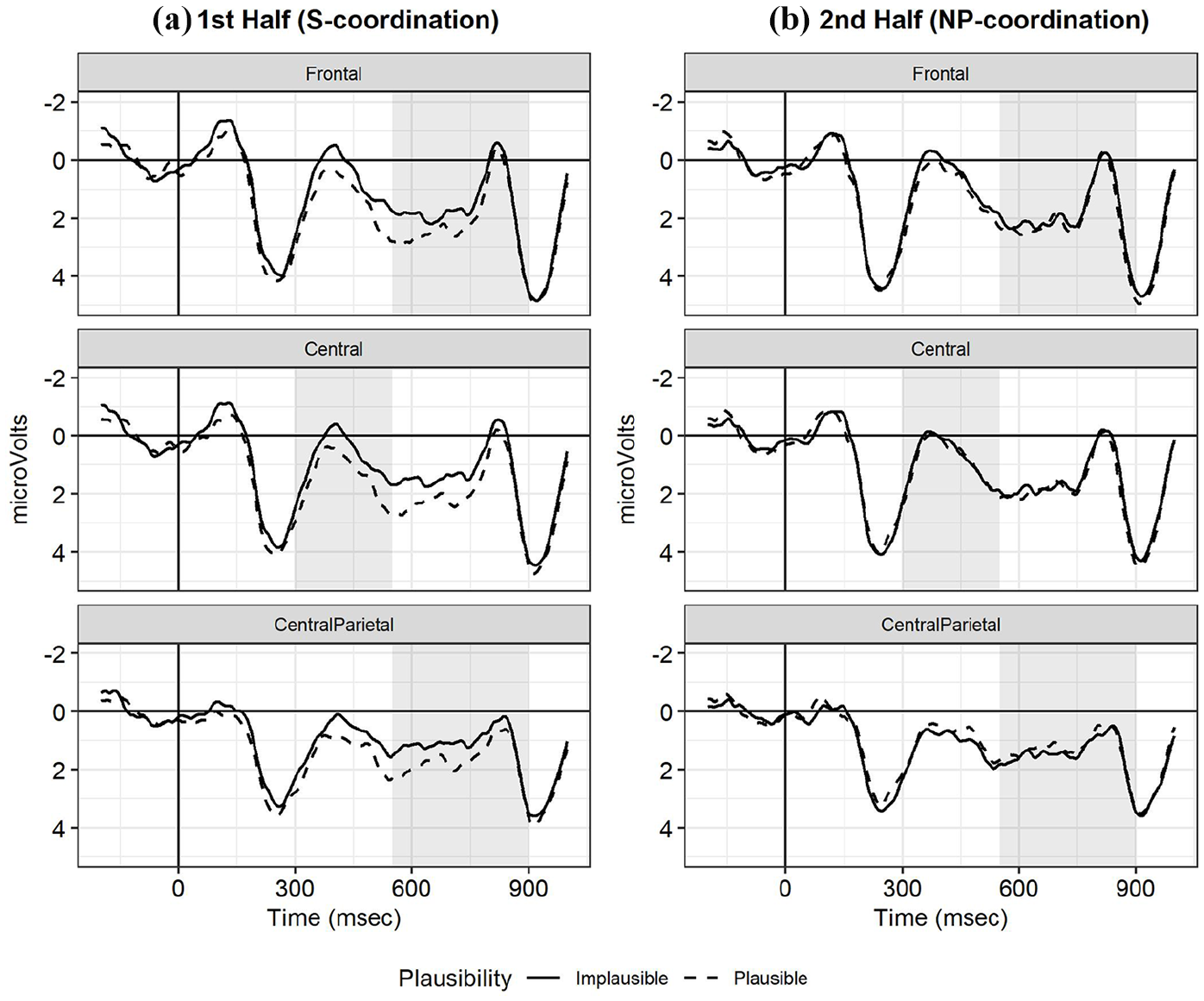
Event-related potentials (ERPs) at the critical noun for central, central-parietal and frontal regions. (a) S-coordinations (first half); (b) NP-coordinations (second half).
To resolve the interaction between Plausibility and Half, we recoded Half such that either the first or the second half served as reference level (Schad et al., 2012). The effects of Plausibility were seen only for the first half [reference level corresponding to the first half, N400: b = 0.69, 95% CI [0.23, 1.14], SE = 0.23, t = 2.95, p < 0.01; 550–900 ms central-posterior sites: b = 0.53, 95% CI [0.13, 0.95], SE = 0.21, t = 2.60, p < 0.01; second half: N400: b = 0.09, 95% CI [−0.33, 0.52], SE = 0.22, t = 0.43, p = 0.67; 550–900 ms central-posterior sites: b = −0.11, 95% CI [−0.50, 0.28], SE = 0.20, t = −0.56, p = 0.58]. 2
To assess changes in the ERPs for the noun after and within each half, we conducted analyses on the halves separately using Plausibility, Trial position (centered within the half) and their interaction as fixed-effects. No interaction between Plausibility and Trial position was seen for any of the effects investigated. Overall, ERPs between 300–550 ms and 550–900 ms after noun onset became overall more positive over the course of the first half as more experimental trials had been seen (see Figure 2a, for 300–500 ms) [300–550 ms: b = 0.01, 95% CI [0.00, 0.02], SE = 0.01, t = 2.09, p < 0.05; 550–900 ms, central-parietal: b = 0.01, 95% CI [0.00, 0.02], SE = 0.00, t = 2.95, p < 0.01; 550–900 ms, frontal: b = 0.02, 95% CI[ 0.01,0.03], SE = 0.01, t = 3.81, p < 0.001].
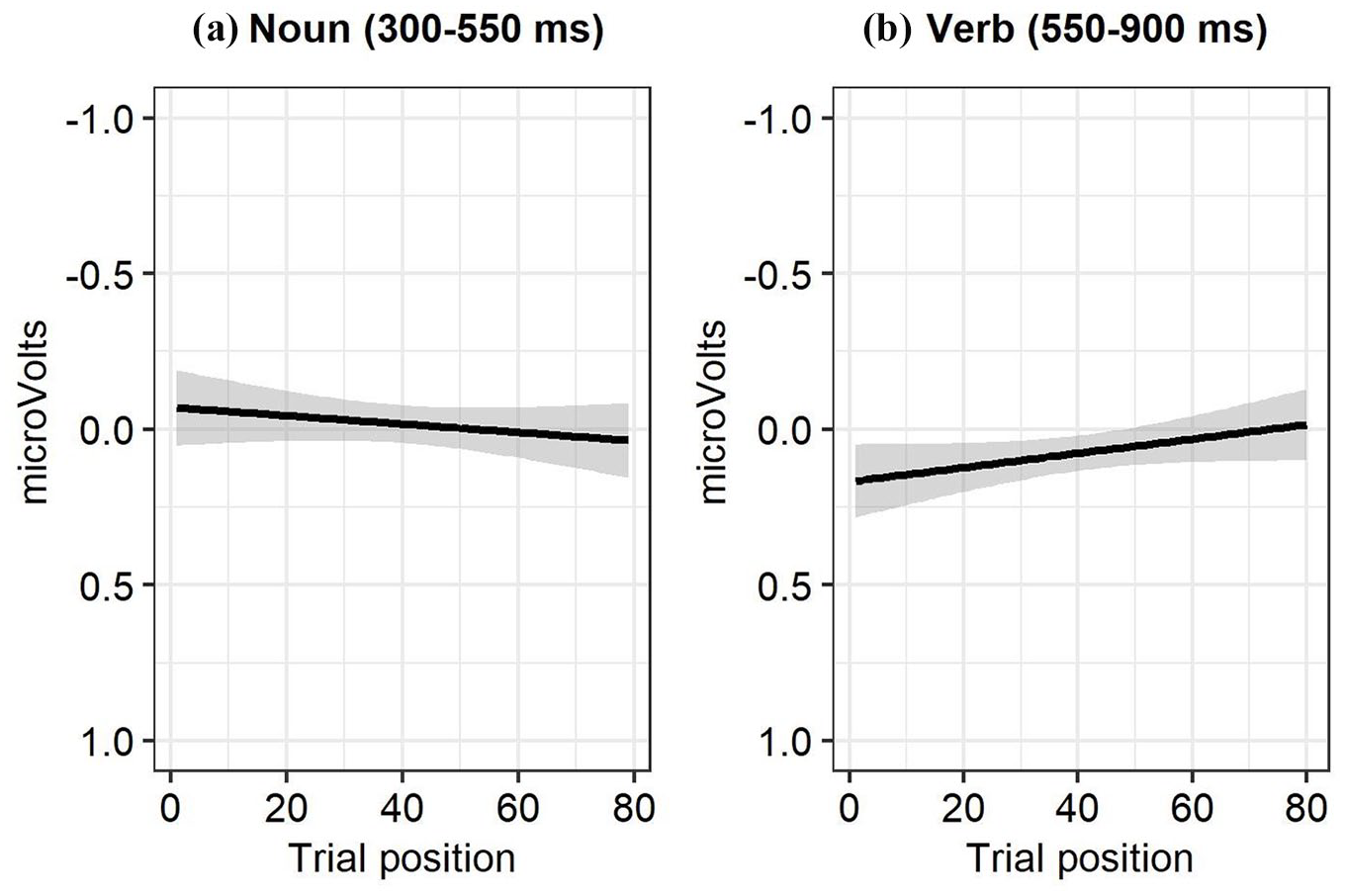
Effects of Trial position on amplitude over the first half. (a) Critical noun amplitude 300–550 ms, central electrodes. (b) Disambiguating verb, amplitude 550–900 ms central-parietal electrodes.
3 ERPs at the verb (S-coordinations, first half)
Figure 3 shows the ERPs at the disambiguating verb for the conditions in which the noun after and is implausible (1a) vs. plausible relative to the first verb (1b). No significant effects involving plausibility were observed in any of the effects and time windows probed. Amplitudes in all three time windows became less positive (more negative) over the course of the half (for the 550–900 ms window at central-parietal sites, see Figure 2b) [effect of TrialPosition: 300–550 ms central sites: b = 0.01, 95% CI [0.00,0.02], SE = 0.00, t = 1.99, p < 0.05; 550–900 ms central-posterior: b = −0.02, 95% CI [−0.03,−0.01], SE = 0.01, t = −4.45, p < 0.001; frontal: b = −0.02, 95% CI [−0.04,−0.01], SE = 0.01, t = −3.74, p < 0.001]. 3
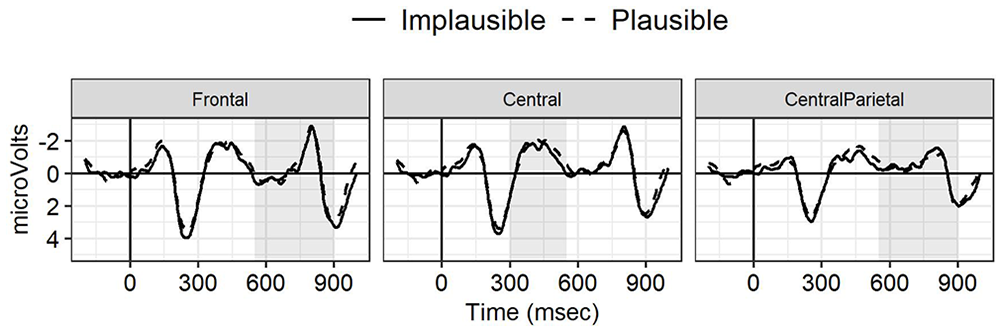
ERPs to the disambiguating verb in the S-coordinations (first half) for central, central-parietal and frontal regions used in the analysis.
4 Interim summary
In the first half of the study (S-coordinations) our L2 speakers as a group showed a long-lasting N400 effect for the critical noun (noun after and) when this noun was implausible vs. plausible given the preceding verb. However, this effect could not be seen in the second half (NP-coordinations). We lack evidence that our readers gradually adjusted their processing of plausibility at the noun within each half, however. ERPs at the disambiguating verb (S-coordinations, first half) did not show any effects of plausibility. ERPs for this verb became overall less positive as more S-coordinations had been seen. This effect was not seen for the critical noun, which instead showed an increased positivity over the course of the first half. This suggests that the negative trend in the ERPs is specific to the verb and may be related to a decrease in processing difficulty at the verb. These results suggest that our L2 readers adapted to the materials in some respect: the reduced N400 plausibility effect in the second half can be interpreted as readers getting used to nouns being anomalous given the preceding verb; the reduced positivity at the verb over the course of the first half suggests that revision became easier for the readers as more S-coordinations had been seen. Our present data however do not provide any evidence that our L2 readers as a group started to expect S-coordinations over the course of the first half.
5 Exploratory analyses of individual differences and proficiency
Group-wise analyses can be confounded by individual differences. A secondary aim of this study, which we did not pre-register, was to explore individual differences in adaptation by looking at differences in ERP responses to the verb and the critical noun. Prior studies have shown that some individuals predominantly elicit N400 effects, some elicit P600 effects (e.g. Bian et al., 2021; Bice and Kroll, 2021; Grey, 2023; Tanner and Van Hell, 2014). This variation has been found for syntactic as well as semantic violations, and may be related to proficiency and language dominance, among many other factors (Bice and Kroll, 2021; Grey, 2023). To explore differences among our participants’ responses to the critical noun and the disambiguating verb, we calculated the response dominance index (RDI; Tanner and Van Hell, 2014). The RDI is an index of whether the individual response is more dominant in terms of an N400 or a P600. We obtained the RDI by subtracting the magnitude of the N400 effect aggregated over trials (plausible minus implausible conditions, 300–550 ms, central electrodes) from the magnitude of the P600 effect (implausible minus plausible, 550–900 ms, central-parietal electrodes) and dividing this difference by the square root of 2 (for scatter plots, see supplementary materials).
a Response dominance index at the noun
For the critical noun in the first half (S-coordinations), most participants showed predominantly an N400 for the implausible vs. plausible condition (23 out of 37). Responses for the second half (NP-coordination) were more varied, with some participants (n = 20) showing a negativity and some (n = 17) a positivity for the implausible vs. plausible condition. 4 The absence of a plausibility effect for the NP-coordinations (second half) in the group-analysis may therefore have been obscured by these individual differences. These observations also suggest that individuals differed in how they adapted their processing. Separate analyses for those who showed a positive RDI in the NP-coordinations (second half), that is, who predominantly showed a positive response for the implausible condition in the second Half, showed a significant Plausibility by Half effect [b = −1.28, 95% CI [−2.16,−0.40], SE = 0.45, t = −2.86, p < 0.01], confirming that the positivity for the implausible vs. plausible conditions was larger in the second half than the first half for this subgroup. In addition, the positive effect for the implausible vs. plausible conditions became larger over the course of the second half in this group [b = −0.03, 95% CI [−0.06,−0.00], SE = 0.01, t = −2.00, p < 0.05]. In contrast, those with a negative RDI (predominantly negative response) in the second half, showed no significant effects involving Half, or Trial position within Half. They only showed a main effect of Plausibility with the implausible conditions eliciting a larger N400 relative to the plausible conditions (see Figure 4) [b = 0.89, 95% CI [0.48,1.29], SE = 0.21, t = 4.30, p < 0.001].
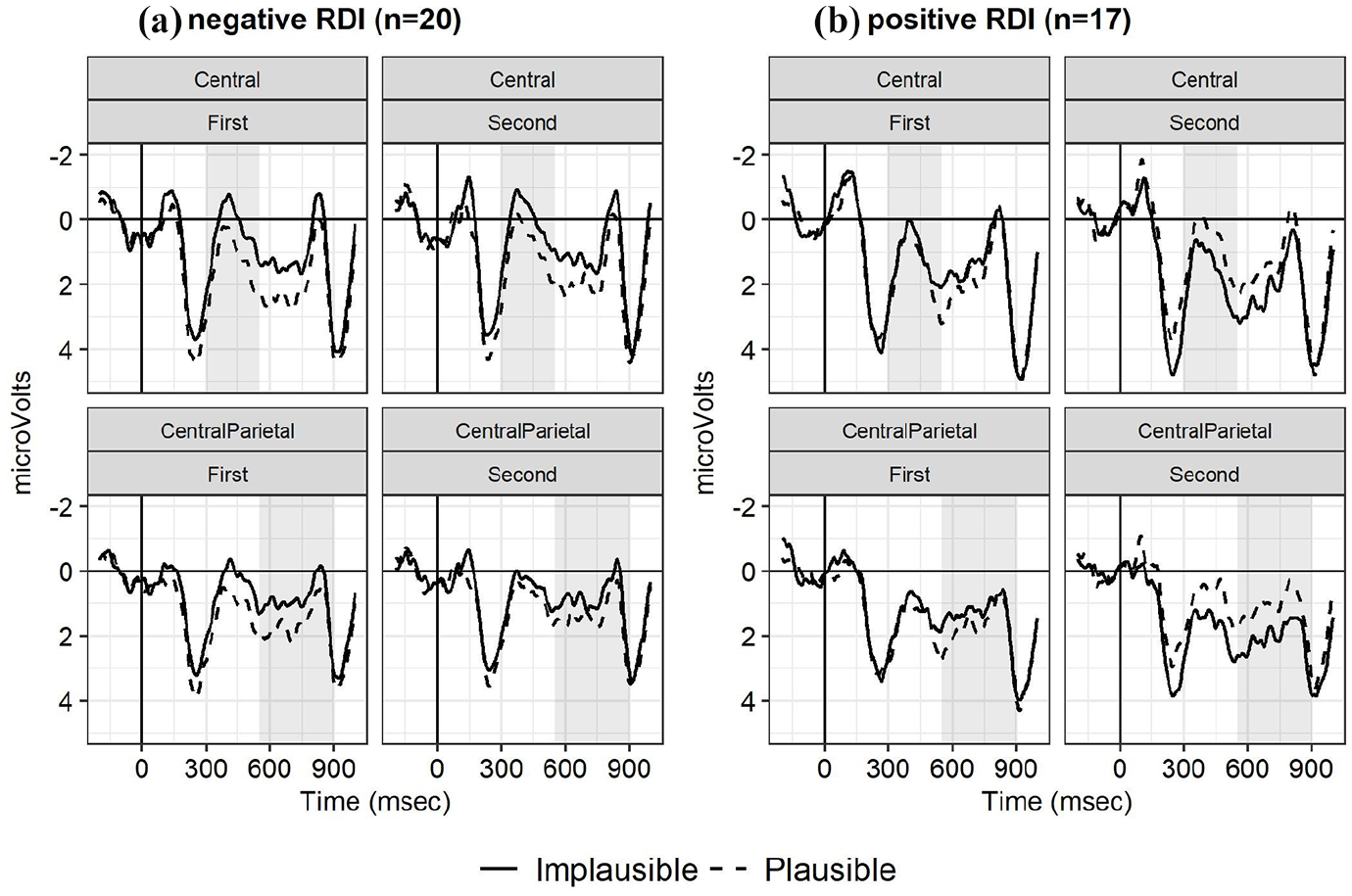
ERPs to critical noun in the first and second half for central and central-parietal electrodes. (a) Those with predominantly negative responses in the second half (negative RDI, n = 20); (b) Those with predominantly positive responses in the second half (positive RDI, n = 17).
To assess whether the individual differences were related to proficiency, we correlated the RDI with the English LexTale scores. LexTale scores ranged from 70 to 96.25 in our sample, and correlated with self-rated proficiency measures (averaged over modality) [Pearson’s r = 0.35; t(35) = 2.23, p < 0.05]. The size of the N400 effect correlated with the LexTale score: the smaller the LexTale score, the larger the N400 effect (amplitude of plausible minus implausible) in the first Half [Pearson’s r = 0.37; t(35) = −2.36, p < 0.05] and second Half [Pearson’s r = −0.34; t(35) = −2.18, p < 0.05]. The RDI in the second Half weakly correlated with LexTale: those with a lower LexTale scores showed a stronger dominance for an N400 response (smaller RDI) [Pearson’s r = 0.32, t(35) = 2.01, p = 0.05]. The degree of change in RDI between the halves was not associated with LexTale score [Pearson’s r = 0.04, t(35) = 0.28, p = 0.78 ]. The source underlying the RDI variation among participants may therefore be in part proficiency-related but remains to be further explored.
b Response dominance index at the verb
Our participants showed substantial variability in their responses at the disambiguating verb (S-coordinations, first half), with some showing predominantly a negative response (negative RDI, n = 15) and some a positive response for the implausible conditions (n = 19), and some having an RDI of around zero (n = 3). Only very few participants (n = 3) showed the expected effect of a larger P600 for the plausible vs. implausible conditions (negative P600 magnitude) rather than an N400 for the implausible vs. plausible (positive N400 magnitude). The RDI at the verb did not correlate with LexTale score [Pearson’s r = −0.06; t(35) = −0.33, p = 0.75].
V Discussion
1 Interpretation of the results
The aim of the study was to investigate whether and how L2 readers adapt to sentence structures in the preceding experimental context. We presented L1 Mandarin L2 English speakers with coordination ambiguities, which were always resolved towards (less preferred) S-coordinations in the first half of the study, and towards (more preferred) NP-coordinations in the second half. Adaptation was probed by means of manipulating the plausibility between the noun after the coordination (and) and the preceding verb. If readers adapted to the syntactic coordination in a fine-grained way, they would no longer expect the noun after and to be the direct object of the preceding verb in the first half of the study (S-coordination), but should expect this again in the second half (NP-coordination). We expected the plausibility effects at the noun to change accordingly. In addition, we expected the plausibility effect at the disambiguating verb, as well as the P600 to the verb in general, to diminish over the course of the first half (S-coordinations).
These expectations were only partially borne out. At the group level, learners showed an N400 plausibility effect at the noun after and in the first half (S-coordinations), but not in the second half (NP-coordinations). No plausibility effects were seen at the disambiguating verb in the first half (S-coordinations). However, ERPs to this verb became overall less positive as more S-coordinations had been seen, suggesting a decrease in processing effort.
Exploratory analyses at the individual level showed larger individual differences at the critical noun in the second half (NP-coordinations) than in the first half (S-coordinations), which suggests that individuals differed in their adaptation. Whereas most participants showed an N400 plausibility effect at the critical noun in the first half (S-coordinations), individual responses became more varied in the second half (NP-coordinations), with some remaining to show a negative response for the implausible condition, and some a positive response. The absence of a group-level plausibility effect at the noun in the second half was therefore due to variation among our participants, and cannot be ascribed to our readers becoming less sensitive to the anomalies. Those with a smaller LexTale score predominantly showed a negative response, which was also larger in amplitude. The degree of change in response dominance between the two halves was, however, not associated with proficiency. Finally, we found a substantial individual variation in participants’ plausibility effects at the disambiguating verb. Since this could not be associated with proficiency, we will not further discuss the plausibility effects at the verb.
Our data suggest that our L2 readers adapted to the sentences in our study, but not in a fine-grained way, and not all in the same way. Our participants initially took the noun phrase after and as semantically belonging to the preceding verb and noun, leading to an N400 effect when the noun was implausible given the verb. We have no evidence that this changed as more S-coordinations had been seen, or that our readers started to anticipate S-coordinations over the course of the first half. We did observe that the ERPs at the verb became less positive overall as the first half progressed. Assuming that garden-pathing and syntactic revision are associated with an increased positivity, the smaller positivity may indicate that readers had less difficulties revising the structure over the course of the first half. Our observations therefore suggest that adaptation is not fine-grained: it is not a quick adjustment of processing response to properties of the immediately preceding stimuli. It also does not affect all levels of processing in the same way: revision processes at the verb may be affected sooner than semantic processes at the critical noun.
We did find evidence of adaptation between the halves as the structure changed from S-coordination to NP-coordinations, but this was subject to individual differences. Some participants remained to show a negativity at the noun for the implausible for the plausible conditions in the second half, suggesting they did not drastically change their processing strategy in the context of the new structures (NP-coordinations) or as a function of the number of anomalies encountered. Some participants, on the other hand, started to apply a different strategy in the second half and showed a positive response to the anomaly, which became larger over the course of the second half. A speculative interpretation is that this subset of participants shifted from relying on a semantic strategy to a syntactic strategy, perhaps revising the syntactic representation at the critical noun in expectation of an S-coordination. An alternative interpretation is that they started to anticipate that the sentence would end after the noun phrase and that the implausible condition would be syntactically incorrect since it would be missing a verb. The latter explanation is in line with this group showing an increased positivity at the noun for the implausible vs. plausible conditions over the course of the second half: as more NP-coordinations were seen, their expectations became stronger that no finite verb would follow, and hence that the critical noun in the implausible conditions could not be syntactically licensed.
We could not relate the amount of change in ERP responses between the halves to proficiency, but lower scores on the LexTale correlated with more negative-dominant ERP responses. The size of the N400 plausibility effect was also larger for those who scored lower on the LexTale. This suggest that these learners relied more on lexical association and the semantic context than high-scoring participants. Similar effects have been observed in eye-tracking-during-reading studies, where lower-proficiency L2 readers showed larger lexical surprisal effects than higher-proficiency readers (Mor and Prior, 2021; but see Whitford and Titone, 2017). This has been ascribed to lower-proficiency participants relying more on semantic context to compensate for weaker lexical representations (Mor and Prior, 2021). Prior ERP research has also shown that lower-proficiency learners, or L2 learners who provide less accurate grammaticality judgments, are more likely to show N400 rather than P600 effects for syntactic violations (Bice and Kroll, 2021; McLaughlin et al., 2010; Tanner et al., 2013). This also has been attributed to lower-proficiency learners using lexical-semantic routes rather than syntactic routes (but see Grey, 2023).
Why did some participants change their strategy and others not? Some studies have found that once-established strategies are hard to change (e.g. Arnon and Ramscar, 2012; Vogels et al., 2020), and that changes of strategy, or at least inhibition of pre-potent strategies, require cognitive resources (Dave et al., 2021). Changing strategies and picking up changes in the distributional properties of the input may be especially hard for some L2 speakers due to lower lexical proficiency and the lack of resources (Foltz, 2021). Readers with larger working memory spans have been reported to have larger ‘pre-updating’ P600 effects reflecting the prediction and integrating of upcoming information in highly constraining contexts (Ness and Meltzer-Asscher, 2018). Furthermore, self-paced reading data suggest that high-memory span readers can use plausibility information to resolve syntactic ambiguities (Long and Prat, 2008). Those who showed the largest change in ERPs between the halves in our study may therefore also have had more cognitive resources than those who did not. We did not collect any cognitive control or working memory measures, so are unable to further test this.
It is still unclear whether the observed changes in processing reflect adaptation to the S-coordinations, or whether these arise from adaptation to semantic anomalies regardless of the syntactic structure. In order to test this, one needs a control group who is exposed to NP-coordinations only. However, in support of adaptation to some aspect of the structure, ERPs to the disambiguating verb became less positive as more S-coordinations had been seen, which we interpreted as syntactic revision becoming easier. Second, prior studies investigating adaptation to semantic anomalies in sentences tend not to find any adaptation effects for the N400 (Yano et al., 2020; Zhang et al., 2019), and none have reported an increased posterior positivity for the implausible conditions. None of these studies manipulated the syntactic constructions of the items with the semantic anomalies. This suggests that at least some aspects of our syntactic manipulation may have facilitated adaptation in the current study.
2 Theoretical implications
This study investigated adaptation to sentence structures in L2 speakers in order to shed more light on what is adapted to during sentence processing and what factors influence this. Our results suggest that our L2 speakers did adapt, but that this adaptation occurred rather slowly (we could not detect changes in the first half), and was subject to individual variation, with some participants shifting to a syntactic strategy, and some participants not visibly changing their processing. These findings are problematic for the idea that readers immediately change their processing based on fine-gained distributional properties of the preceding context. Instead, adaptation may occur at a much more global level, if at all, based on characteristics of the individual. This individual variation can be captured by the notion of utility in prediction and adaptation (Kaan and Grüter, 2021; Kuperberg and Jaeger, 2016): the language user adjusts their prediction and adaptation to maximize processing efficiency. Especially for the learners in our study who scored lower on the LexTale test, maximum processing efficiency was reached by relying on the relation between the critical noun and the preceding context, and mainly adhering to this strategy regardless of the syntactic structure, perhaps due to the lack of resources. For our more proficient participants (and, speculatively, participants with more cognitive resources), it was more efficient to rely more on syntactic cues and eventually analyse the implausible critical noun as an NP missing a verb. Future research should further explore the relation between proficiency, cognitive resources and reliance on certain cues (for a Bayesian modeling approach, see, for example, Yadav et al., 2022).
Our findings are also problematic for the view that prediction and adaptation are the main mechanisms underlying language learning, in particular the learning of syntactic structures. In this view, listeners and readers make predictions as to upcoming information, and adjust their knowledge and processing if the prediction is not borne out. The plausibility effects in our study suggest that our readers predicted at some level, but we were not able to detect adaptation effects in the first half of the study, and only about half of our participants changed their processing in the second half. This suggests that prediction errors do not straightforwardly induce a change of processing expectations. It is therefore hard to maintain that adaptation during comprehension is a primary mechanism underlying the learning of syntactic structures. Note that also in the monolingual literature, syntactic adaptation has not been systematically observed (Kaan and Chun, 2018b). Why is syntactic adaptation so hard? Even if the learner makes predictions as to syntactic structures, syntactic prediction errors (garden-paths) may not be informative as to the intended target structure (Kaan et al., 2019). In order for the error to be informative and lead to adaptation to the target syntactic structure, the learner would also need to know what the source of the error is and what the intended structure is, and would need to have the resources to keep track of changes in distributions and to adapt. Even though priming and active prediction may help in the acquisition of some syntactic structures (Grüter et al., 2021; Jackson and Ruf, 2016), it is still unclear whether this helps the learning of more complex structures.
3 Limitations
The current experiment has various shortcomings. First, our data collection was limited and our analysis based on a much smaller set of data than we preregistered. Most importantly, as mentioned above, we did not have a control group in which only sentences of one type (NP-coordinations) were presented, or a group in which the NP-coordinations were presented before S-coordinations. It therefore remains unclear whether the changes in processing observed in our study are due to the use of S-coordinations and adaptation to those specific syntactic structures, or whether our participants got used to the noun after and often not making sense given the preceding verb. Third, we did not test the participants in their L1, so cannot tell to what extent and how they adapt to similar constructions in Mandarin Chinese and to what extent our findings are specific to Mandarin speakers reading L2 English. We also did not compare our L2 group with a group of L1 English speakers processing the same sentences. However, it is currently debated what the value is of comparing L2 speakers with a native speaker group (Freunberger et al., 2022). Instead, we explored variation within our L2 group to help identify factors that may drive adaptation. We found individual variation in ERP responses to the critical noun, especially in the second half of the study, with participants with lower lexical proficiency showing a more predominant negative response in both halves. However, the degree of change in ERP responses between the halves was not reliably associated with proficiency measures. More research needs to be conducted what drives individual differences in adaptation.
Footnotes
Acknowledgements
The authors like to thank Yucheng Liu, Eleonora Mocevic, Sophia Paulitz and Megan Nakamura for materials construction and testing, and Tianyue Wang and Yushuang Bi for data collection.
Data availability
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was in part supported by The Key Projects of Philosophy and Social Science Research for Colleges and Universities in Jiangsu Province (2022SJZD123). EK is in part supported by NSF BCS-2017251.
Supplemental material
Supplemental material for this article is available online.