
Abstract
German has a set of high front rounded vowels, /yː, ʏ/, that are difficult for second language (L2) learners to acquire. They are often misperceived by L2 learners as back vowels. Many models explain the initial perceptual assimilation of L2 segments into first language (L1) segments, but it is unclear how acquisition occurs in the articulatory domain. This study investigates the acoustic-articulatory acquisition of high vowels in German by L1 speakers of Polish. We collected acoustic and ultrasound data for learners at the A-level (beginner), B-level (intermediate), and C-level (advanced) to examine how articulatory acquisition progresses. The findings indicated assimilation of German /yː, ʏ, ʊ/ to Polish /u/ for A-level learners. Differences emerge at the B-level, and at the C-level we observed robust contrasts. The data indicates that L2 segmental acquisition is a long process and that, for perceptually similar segments, L2 learners appear to harvest their L1 articulations and modify them until the contrast is acquired.
I Introduction
Front rounded vowels are typologically rare across the world’s languages. Approximately 6.6% of the world’s languages have some form of front rounded vowel of the 562 languages included in the World atlas of language structures (Maddieson, 2013). The German language has a relatively large vowel inventory of 14 vowels, including front /iː, ɪ, eː, ɛ, yː, ʏ, øː, œ/, central /a, aː/, and back vowels /uː, ʊ, oː, ɔ/, and also features a length distinction between vowels (Kleiner and Knöbl, 2015). The set of German vowels includes high front rounded vowels, /yː, ʏ/, orthographically represented with ü, and mid-front rounded vowels, /øː, œ/, orthographically represented with ö. Polish, on the other hand, has a relatively small vowel inventory, consisting of six vowels, including front /i, ɛ/, central /ɨ, a/, and back /u, ɔ/ vowels, and does not feature either length contrasts or front rounded vowels (Wierzchowska, 1971).
Front rounded vowels pose difficulty for learners as they are often perceived as back vowels. This is especially the case for /yː, ʏ/, which are typically perceived as high back vowels (Desmeules-Trudel and Joanisse, 2020; Mayr and Escudero, 2010). Perceptual difficulties in acquisition may also be related to observed difficulties in the acquisition of pronunciation, as language learners often substitute /y, ø/ for /u/ (Swain, 2008; Wade, 1980).
Front rounded vowels are typically difficult for second language (L2) learners to acquire when their first language (L1) does not have any front rounded vowels (Battye et al., 2000; Flege, 1987; Flege and Hillenbrand, 1984). Their articulation often integrates with the articulation of back rounded vowels, or completely merges with the articulation of back rounded vowels. This effect seems to be modulated by language experience, revealing different patterns based on a learner’s L1 and their L2 (McAllister et al., 2002). The effect can also be observed in perceptual assimilation effects, where it is generally the case that /yː/ tends to be more confusable with /u/ (Lauret, 2007; Mayr and Escudero, 2010) or where /ø/ is more confusable with /u/ (Kamiyama, 2011). The articulation also mirrors the perceptual confusion where, for example, learners who confuse /ø, u/ also produce them with similar acoustic properties (Kamiyama, 2011). Often, learners also produce /y/ as /ju/, suggesting a mismatch between the learners’ perception of the target and the target itself, /y/ (Levy and Law, 2010). To better understand the L2 acquisition of front rounded vowels, we examined Polish learners of German and collected acoustic and ultrasound data for /uː, ʊ, yː, ʏ/. The primary aim of including ultrasound data is to have a direct measure of how articulation is acquired in the L2 context and better understand what strategies learners employ to acquire new articulatory targets. To this end, we are targeting not only the front/back dimensions with /uː, yː, ʏ/, but also the height distinction with /uː, ʊ/. The sets of front and back vowels also have a duration distinction that is of interest. These segments were primarily chosen because of their acoustic similarity to Polish /u/ (i.e. /uː, ʊ/) and because they tend to assimilate to /u/ in L2 acquisition (i.e. /yː, ʏ/).
1.1. Models of L2 acquisition
L1 transfer in articulation is well documented (Flege and Davidian, 1984; Hancin-Bhatt, 1994) and the idea that L1 transfer plays a major role in L2 acquisition is embedded in MacWhinney’s (2005, 2008, 2012) unified connectionist model of L1 and L2 acquisition. This model was developed from the Competition Model (Bates and MacWhinney, 1982; MacWhinney, 1987), which incorporates cue strength, which is directly related to cue validity. What this means is that L1 is transferred to L2 based on its ability to satisfy the need for L1 segmental cues in the L2. The imported aspects of L1 are then strengthened or weakened in the L2 phonology depending on to what degree it leads to errors. In other words, the validity of the L1 cue is assessed in L2 usage and its usage is either strengthened or weakened as a result. In the context of German acquisition, these cues would correspond to different height and front/back dimensions and rounding and their acoustic and articulatory cues. For example, front/back cues need to be adjusted in order for /yː/ to emerge from a more /u/-like articulation. The degree to which this process involves more or significant reweighting plays a role in how difficult segments are to acquire. The unified account expands on the initial insights of the Competition Model by including cue cost and cue support. Cue cost essentially refers to what degree different cues impose cognitive load on the language learner. The higher the cost, the less likely cue validity can or will be assessed and adjusted. Cue support, on the other hand, refers to what aspects of the cue and language usage support the ease of usage and processing. Cues with substantial support in processing and usage are more likely to be appropriately reweighted. In the context of German, cues that carry significant meaning in the language, such as height differences between the front vowels /yː, ʏ/ and front/back differences between /yː, ʏ/ and /uː, ʊ/, are more likely to be acquired. The significant support for those differences underpinned by their ability to carry different meanings strongly encourage the learner to acquire those articulatory contrasts. Under the perspective of the unified account, early L1 transfer is extensive and helps facilitate early fluent speech. However, the early benefits of L1 transfer come at the expense of L1 phonetics/phonology being imported into the L2 system. The initial L1 phonetics/phonology must then be unlearned, resulting in longer acquisition trajectories and accented speech. The formation of L2 categories is thus a lengthy process that emerges from the L1 categories.
The Speech Learning Model (SLM; Flege, 1995) was initially devised to explain why the ability to acquire a language changes (i.e. decreases) over time as well as to deal with age of acquisition effects. Thus, the goal is to understand what impacts an individual’s ultimate attainment of L2 pronunciation. The model postulates that the mechanisms used in L1 acquisition are still active and available for learners throughout their lifespan. The critical aspect of whether a segment will be acquired is whether there is some phonetically discernible difference between the nearest L1 segment and the novel L2 segment. In extreme cases, this can be extremely difficult due to perceptual warping of the phonetic space when it is configured to an L1 (Iverson and Kuhl, 1995; Kuhl, 1991). As such, greater perceptual differences between L1 and L2 segments facilitates the formation of novel categories. Additionally, a single L1 and L2 category may merge when segments are given an equivalence classification. In these cases, a single phonetic category will result from the merging of the L1 and L2 sounds (i.e. diaphones) and articulation will also become merged. Flege (1995) also hypothesizes that speakers’ articulation of L2 segments can differ from the target L1, even at an advanced level, because L2 learners have to mediate contrast between their L1 and the target L2. Flege (1995) bases this hypothesis on observations in the literature that point to the fact that vowels in a language tend to disperse in order to maintain auditory contrast (e.g. Liljencrants and Lindblom, 1972). The reason Flege (1995) incorporates this into the SLM is because he hypothesizes both L1 and L2 share a phonetic space. In terms of German, the general expectation would be that in order to acquire /yː, ʏ, uː, ʊ/, learners would have to attune their perception to detect the differences between the target segments and Polish /u/. Failure to detect differences would result in failure to acquire, while detected differences lead to better discrimination over time and thus better acquisition.
The revised Speech Learning Model (SLM-r; Flege and Bohn, 2021) is an adaptation of the SLM that is primarily designed to account for how phonetic systems reorganize over the lifespan. The core premise of the SLM-r (Flege and Bohn, 2021) is that there is no change in how vowels and consonants are acquired in L1 and L2. Under this model, differences in L1 and L2 learning outcomes arise due to (1) L1 substitution of L2 segments, (2) L1 categories blocking the acquisition of L2 segments, and/or (3) the L2 input differing from the input that L1 learners received. The model also posits that an L2 learner will virtually never produce L2 segments exactly as L1 speakers do because of complex L1 and L2 interactions in the phonetic space (e.g. Flege et al., 2003; Guion, 2003; Kartushina et al., 2016). In short, what the model expects is that the strategies and high cognitive functions utilized in L1 acquisition are the same as that used in L2 acquisition.
The Perceptual Assimilation Model-L2 (PAM-L2; Best and Tyler, 2007) is an extension of the principles of the Perceptual Assimilation Model (PAM; Best, 1995). The model was formulated on comparisons of data from L1 monolinguals and late acquiring L2 learners. The PAM-L2 builds off previous work that demonstrates naïve non-native listeners have difficulty distinguishing some non-native contrasts (e.g. Abramson and Lisker, 1970; Polka, 1992; Strange et al., 2001), while others are discriminated moderately well or with near native-like levels (e.g. Beddor and Strange, 1982; Best et al., 2003; Kochetov, 2004). The relative difficulty a listener has in distinguishing non-native speech is also highly correlated with their L1 (e.g. Best and Strange, 1992; Flege, 1989; Hallé et al., 1999). Best and Tyler (2007) also take note of the fact that listeners are responsive to within category phonetic variations that are not phonologically relevant (i.e. not contrastive, gradient-like perception). Perceptual asymmetries have also been observed for both L1 and non-native listeners, which Best and Tyler (2007) suggest indicates universal rather than experience-tuned biases (Polka and Bohn, 2003).
With respect to how the PAM-L2 views perceptual learning, Best and Tyler (2007) elaborate that non-native speech segments can be either heard as a good or a poor exemplar of an L1 segment (categorized), unlike an L1 segment (uncategorized), or in rare instances, as a non-speech segment (non-assimilated). The type of assimilation (i.e. categorization) can also predict how well listeners discriminate non-native segments. Two-category assimilation, where two non-native segments are categorized as two separate L1 segments, predicts extremely good discrimination; however, with single category assimilation, where two non-native segments are judged to be exemplars of the same L1 segment, poor discrimination is expected. In the context of German, there are multiple categories being categorized as a single Polish phoneme, /u/, making them difficult to acquire. For learning to take place, the PAM-L2 asserts that some perceptible phonetic/phonological deviation from the L1 segment must occur. Specifically, if an L2 segment matches an L1 segment in phonological behavior and phonetic realization with enough similarity, new category formation is assumed to be blocked. However, if the L2 segment deviates in some detectable way by the L2 learner, then learning can occur. Naturally, the greater the deviation from the L1 segment the more likely (and possibly easier) L2 acquisition of a novel category will be. The implication for German is that high front and back vowels will be difficult to acquire. With respect to speech production, the PAM-L2 is a direct realist model of speech perception. That is to say, listeners are attuning themselves to the distal articulatory events that produce the speech signal (e.g. Best, 1994), rather than merely to its acoustic properties. As such, we expect that perceptual discrimination and attunement to different phonetic and phonological aspects of speech segments would correlate to better speech production.
1.2. Ultrasound in L2 research
Ultrasound has been used previously in L2 research (Gick et al., 2008) to examine a wide range of research questions, including covert contrasts (Song and Eckman, 2021), articulatory mapping between L1 and L2 segments (Nance and Kirham, 2024), and articulatory settings for L1 and L2 speakers (Wilson and Gick, 2014). Ultrasound is able to image articulators in real time using ultra-high-frequency sound waves, which originate from a probe that is typically held or mounted below the speaker’s jaw. This visualizes the tongue shape and movement making it an effective method of data collection for the study of both consonants and vowels (Colantoni et al., 2025b). Howson (2023) performed an ultrasound study of L2 acquisition of Lower Sorbian, a moribund language, by L1 German speakers and how acquisition progresses with proficiency. The author found that the A-level (beginner), B-level (intermediate), and C-level (advanced) produced the L2 Lower Sorbian fricatives, /ʂ, ɕ/, with the same contour across speaker groups and with no changes according to proficiency. Howson (2023) suggests that this is because they merged with their German post-alveolar fricative as a result of the difficulties faced by the community while maintaining their heritage language.
Oakley (2023) used ultrasound to examine the acquisition of L2 Mandarin sibilants by L1 English speakers. The author compared L1 English /ʃ/ with Mandarin /ʂ, ɕ/ to determine how speakers acquire novel articulations. The results revealed that even for speakers who did not appear to produce a difference between these segments based on acoustic analysis, their tongue contours differed significantly from each other for each of the English and Mandarin segments. Oakley (2023) concluded that L1 articulatory settings are not mapped onto novel L2 segments and that novel categories are formed by L2 learners.
Ultrasound has also been used to assist in the acquisition of L2 segments (Bliss et al., 2018; Bryfonski, 2023; Tsui, 2012). For example, Pillot-Loiseau et al. (2013) compared the articulation of French /y/–/u/ by L1 speakers of Japanese in pre- and post-lesson conditions where ultrasound was used as a method to improve learners’ articulation. They were additionally compared against a control group that did not have ultrasound training. They found that in the post-training condition, speakers showed improvement in their articulation. The Pillot-Loiseau et al., (2013) additionally found that speakers who had undergone training continued to improve the /y/–/u/ contrasts after the sessions were over (i.e. they continued to improve on their own through practice). However, the control group did not improve as time passed. The Pillot-Loiseau et al., (2013) highlight the potential use-case for ultrasound as a method of pronunciation training, especially for difficult contrasts.
II Hypothesis
Our research question is:
How do L2 learners acquire segments that are perceptually difficult to distinguish from L1 segments, such as /ʊ, yː, ʏ/, which tend to be assimilated to /u/?
We used a comparison across language levels, A, B, and C (beginner, intermediate and advanced, respectively), to analyse learning trajectories and to uncover what mechanisms contribute to language acquisition. The models of language presented in this article make overlapping predictions with what we should expect language learners to do when acquiring the articulation of /ʊ, yː, ʏ/. German /uː/ and Polish /u/ differ with respect to length contrasts. The overlapping factor is that we expect to see an assimilation of the L2 segments to an L1 category (Best and Tyler, 2007; Flege, 1995; Flege and Bohn, 2021; MacWhinney, 2005). Polish has a series of 6 monopthongs, /i, ɨ, u, ɛ, a, ɔ/ (Wierzchowska, 1971). German, on the other hand, has a much more dense monophthong inventory consisting of 14 vowels, /iː, yː, uː, ɪ, eː, ʏ, øː, ʊ, oː, ɛ, œ, ɔ, a, aː/. Additionally, unlike Polish, German has a contrast between long and short vowels (e.g. yː, ʏ). In this situation, both the PAM-L2 and the SLM make similar predictions: assimilation of novel L2 German segments into an L1 segment. In terms of the PAM-L2, this is referred to as single category assimilation, where two (or more) segments assimilate to the same L1 segment. Based on previous literature on the assimilation of front vowels (e.g. Desmeules-Trudel and Joanisse, 2020; Lauret, 2007; Mayr and Escudero, 2010), we predict assimilation of the front rounded vowels to Polish /u/. Additionally, German /ʊ/ is acoustically and articulatorily most similar to Polish /u/, so we anticipate that assimilation to Polish /u/ will take place. We predict the acoustic and articulatory configuration for /uː, ʊ, yː, ʏ/ will mirror Polish /u/ in the early stages of acquisition due to L1 assimilation (Best and Tyler, 2007; Flege, 1995; Flege and Bohn, 2021; MacWhinney, 2005) and as learners gain more proficiency, novel segments will emerge gradually by increased separation between the target and /u/. The segments will become more target-like with time as cue re-weighting occurs. We also predict that the acquisition of /yː, ʏ/ will progress more quickly than /uː, ʊ/ because we hypothesize that the front/back distinction is more prominent than the duration/height distinction. Previous research has indicated that L1 phonetic category formation is a slow process (McMurray, 2023; Narayan et al., 2010; Werker and Yeung, 2005), thus we anticipate that L2 phonetic category formation will also be a lengthy process. We predict that learners will not produce segments that have similar perceptual qualities to an L1-segment (i.e. similar to their Polish /u/) until the advanced level, but we do anticipate gradual improvement in articulatory posture for novel segments.
III Methods
3.1. Participants
Seven A-Level (i.e. beginner, 7 female), 8 B-Level (i.e. intermediate, 2 male, 6 female), and 4 C-Level (i.e. advanced, 1 male, 3 female) learners of German, and 8 L1 speakers of German (4 male, 4 female) participated in this study. Polish learners of German were recruited at the Uniwersytet Wrocławski. L1 German speakers were recruited through Humboldt-Universität zu Berlin. Participants were all aged 20–24 years of age and had been studying between 1–6 years at the time of recording (M: 3.84; SD: 1.3). L2 German learners were selected on the basis that they had not learned German at home as a second language and that they had learned it primarily through classroom structure (i.e. foreign language acquisition; FLA). Participants were grouped as either A-, B-, or C-level based on their current enrollment status in a German course. L1 German speakers were all selected on the basis that they had learned German as their primary language at home and spoke primarily German throughout their developmental years. Participants had no self-reported speech or hearing disorders. L2 participants also reported having minimal pronunciation instruction, although they all had strong interest in acquiring L1-like articulation.
3.2. Materials
Stimuli were embedded in a carrier phrase (German: ‘Sag target acht mal’ [‘say target eight times’]; Polish: ‘powiedz target proszę’ [please say target]), to facilitate more natural production. The front and back rounded vowels were produced in minimal pairs to facilitate comparison. The full stimuli set is available in Table 1.
Target words in German and Polish with English translation.

3.3. Procedure
All participants read and signed an ethics form prior to the experiment. Additionally, they completed a questionnaire which provided background information on each participant, such as age, gender, German skill level, and language background (i.e. what other languages had they been exposed to). Participants were also verbally informed of their rights. Participant IDs were assigned to pseudo-anonymize their data using the formula of German level + order the participant took part in the study (e.g. A01 = A-Level learner + first participant of the A-Level to be recorded).
Data for the Polish learners of German were recorded in a quiet room at the Uniwersytet Wrocławski and L1 German participants were recorded in a quiet room at Leibniz-Zentrum Allgemeine Sprachwissenschaft. We recorded ultrasound data using the Micro system from Articulate Assistant Advanced (AAA). The scanner uses a TTL pulse after each frame to synchronize audio automatically and accurately. The probe had a 20 mm radius with a 92-degree field of view. Data were recorded at an average of 80 frames per second. Participants wore the Ultrafit probe stabilization headset to maintain probe location (Spreafico et al., 2018). Acoustics were recorded with a Tascam DR-05 linear PCM recorder at 48,000 Hz.
Stimuli were presented with the AAA software package, which synchronizes audio and ultrasound data and were presented in a pseudorandomized order. Each participant produced 8 repetitions of each target word for a total of 1,296 tokens (8 repetitions × 6 target words × 27 speakers = 1,296). However, mispronunciations or mistakes led to 53 tokens being discarded (~4% of the data).
IV Analysis
In both the acoustic and ultrasound analysis, we use generalized additive mixed models (GAMMs) to analyse time dependent formant patterns and whole tongue contours (Sóskuthy, 2017). As such, we focus on determining where significant effects can be observed by examining the output plots. While the numerical model outputs are important to determine significance, it is crucial to examine the plots to fully understand where each significant effect takes place, either in time for the formant analysis or on which part of the tongue contours for ultrasound.
4.1. Acoustic analysis
Acoustic data were segmented using webMAUS (Schiel, 1999, 2015) and then manual corrections were made and checked by both authors. The onset of the vowel was marked as either the offset of aperiodic noise associated with the fricative, or an increase in intensity and formant structure associated with the offset of the nasal or the bilabial glide. The offset of the vowel is marked as either the onset of aperiodic noise associated with the fricative or the lowering of F2 and F3 associated with the vocalized rhotic. F1, F2, F3, and duration were then extracted using a custom script in Praat (Boersma and Weenink, 2023). Formant Frequencies were extracted using a Burg analysis with a window length of 30 ms. Maximum formant range was set to 5,000 Hz for men and 5,500 Hz for women. Pre-emphasis was set to 50 Hz and a maximum of 5 formants were calculated. Formant measures were extracted at 10 equally spaced intervals over the duration of each target vowel. We normalized the acoustics using the Lobanov method (Lobanov, 1971) and reconverted the z-scores into normalized Hz values to maintain interpretability. To do this, we used the pmax() function in R, using the minimum value for each formant in the unnormalized data as a clamp. For all coding used in the process, see supplemental material. For the normalization process, we included /a, aː/ from each speaker because the Lobanov method is more effective when more of the vocal tract space is used in the normalization process. We performed GAMMs with the mgcv (Wood, 2011) package in R (R Core Team, 2023) to estimate dynamic formant contours for F1, F2, and F3. We split the models into L1 German speakers and L2 German learners because the missing level for Segment: u × L1 resulted in NaN values for some parametric estimates. Each model had fixed effects for Segment (4 levels: /yː, ʏ, ʊ, uː/; 5 levels for L2 German learners: /yː, ʏ, ʊ, uː, u/) and for L2 German learners, Group (3 levels: A-, B-, and C-level learners). Smoothing terms were included for interval number (1–10), the interaction between interval number and Segment, and for L2 German learners, the interaction between interval number, Segment, and Group. We included a random intercept for Participant with a random slope for Environment (i.e. the segments directly adjacent to the vowel). The model formula is presented in (1).
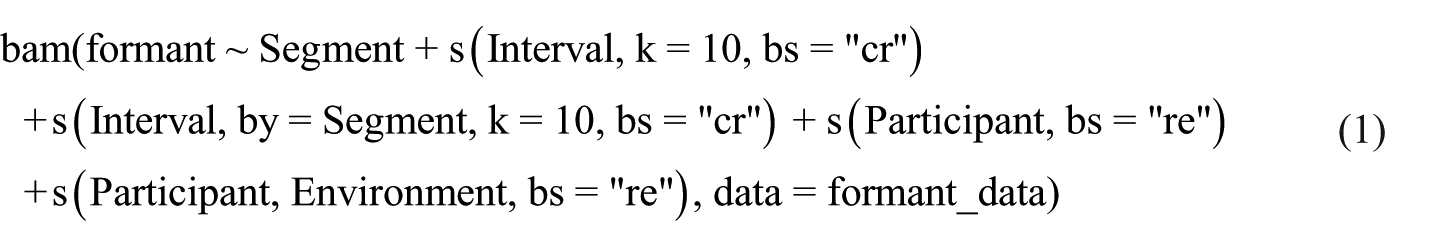
For each GAMM model, we first ran the model as specified above and then calculated the rho value (AR1 correlation parameter) using the start_value_rho function in itsadug (van Rij et al., 2022). The model was recalculated using the rho value and AR.start option to remove autocorrelation from the model. Model estimates were then extracted using itsadug (van Rij et al., 2022) and plotted with ggplot2 (Wickham, 2016). We also plotted difference contours using itsadug (van Rij et al., 2022) and ggplot2 (Wickham, 2016).
Additionally, we performed a linear regression using mixed models in the lme4 package (Bates et al., 2015) for the duration measures. The model included fixed effects for Segment, Group, and the interaction between them. A random intercept by Participant with a random slope by Segment was included in the model. p-values were calculated using the lmerTest package (Kuznetsova et al., 2017) and post-hoc tests were performed with the emmeans package (Lenth, 2023). Results were plotted with ggplot2 (Wickham, 2016).
4.2. Ultrasound analysis
Ultrasound data were segmented in the AAA software (v. 220.5) package using spectrogram and waveform characteristics. The onsets and offsets were set in the same fashion as the acoustic analysis. Tongue contours were then traced using DeepCutLab for Speech (Wrench and Balch-Tomes, 2022), a machine learning algorithm trained on EMA and ultrasound data to identify tongue contours. Tongue contours at the temporal midpoint were extracted for statistical analysis using a Cartesian coordinate system. Coordinates were then normalized using a shift and scale operation. The operation first shifts all x- and y-coordinates so that the minimum value is 0 and then scales the values between 0 (minimum) and 1 (maximum). We did this with the equation found in (2), which was performed for x- and y-coordinates for each speaker individually. The y-coordinates were calculated in the same way except the left side of the equation was original y – min y instead of original x – min x:
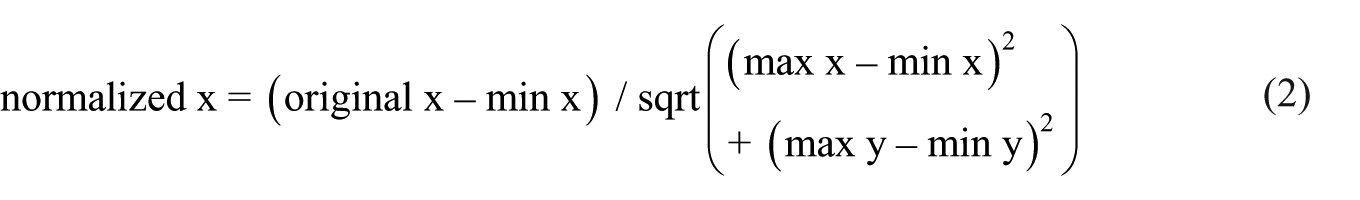
Figure 1 below presents a sample of pre- and post-normalization tongue contours for the production of /ʊ/ by 3 L1 speakers. Pre-normalization is on the left and post-normalization is on the right. Colors represent different repetitions of the same token. The image highlights the importance of normalization because when GAMMs (or other statistical models) are performed and the coordinate space varies from speaker to speaker, it is difficult to properly estimate contours due to different contour values relative to ultrasound position during recording and speaker differences in vocal tract shape and tongue size.
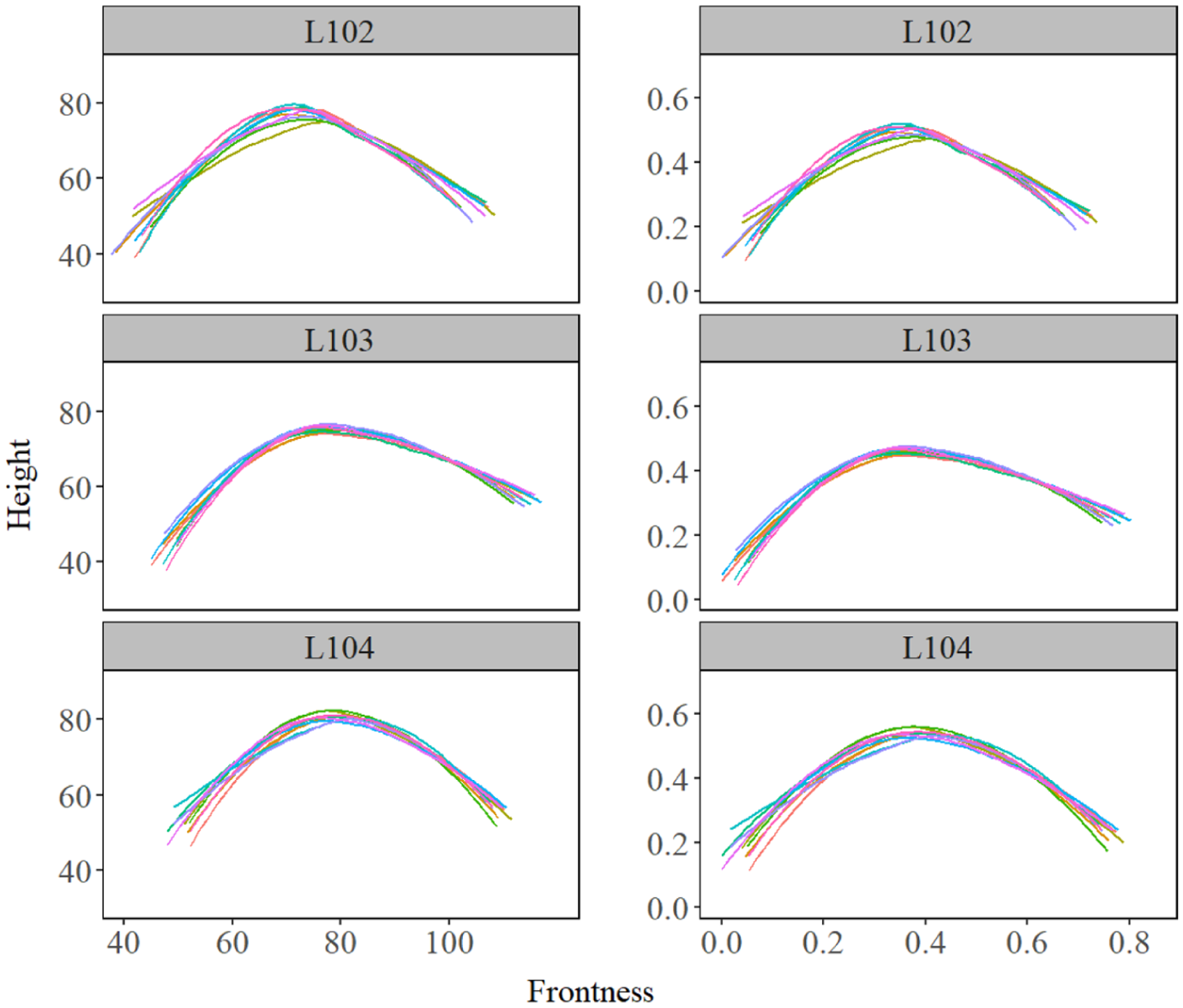
Tongue contours for three first language (L1) speakers pre- (left) and post-normalization (right) for /ʊ/.
Tongue contours were then compared with GAMMs using the mgcv (Wood, 2011) package in R (R Core Team, 2023). As with the acoustic data, it was split into L1 German speakers and L2 German learners because the missing level for Segment: u × L1 resulted in NaN values for some parametric estimates. The GAMMs were fitted with fixed effects for Segment (4 for L1 Germans: /yː, ʏ, ʊ, uː/; 5 levels for L2 German learners: /yː, ʏ, ʊ, uː, u/) and for L2 German learners, Group (3 levels: A-, B-, and C-level learners). Smoothing terms were included for normalized x-coordinate, the interaction between normalized x-coordinate and Segment, and for L2 German Learners, the interaction between the normalized x-coordinate, Segment, and Group. We included a random intercept for Participant with a random slope for Environment (i.e. the segments directly adjacent to the vowel). Knots were set to 7 for each smoothing term and the factor smooths. The model formula used for L1 speakers is presented below in (3) and the formula used for L2 learners is presented in (4).


For the GAMM model, we first ran the model as specified above and then calculated the rho value (AR1 correlation parameter) using the start_value_rho function in itsadug (van Rij et al., 2022). The model was calculated again using the rho value and AR.start option to remove autocorrelation in the model. Model estimates were then extracted using itsadug (van Rij et al., 2022) and plotted with ggplot2 (Wickham, 2016). We additionally plotted difference contours using itsadug (van Rij et al., 2022) and ggplot2 (Wickham, 2016). A brief note on GAMM model estimates: the significant interactions we report can be understood as having a contour that cannot be captured by the simple x-axis smooth (for acoustics s(Interval) and for ultrasound s(X.n)). In order to interpret what the GAMM models reveal about language acquisition the GAMM estimate plots and difference plots are crucial to see where differences in contours exist and what the different contour shapes are.
V Results
The results are divided into two sections: first, we present the results from the acoustic analysis; second, we present the results from the ultrasound analysis.
5.1. Acoustic results
The GAMM estimates in Figure 2 (below) revealed significant differences between each of the segments examined in this study. Visual inspection of the GAMM estimates revealed that F1 was lower for long vowels /uː, yː/, F2 was lower for back vowel, /uː, ʊ/, and F3 was lower for long vowels, /uː, yː/. Table 2 presents key summary statistics. For full statistical printouts, see the R Markdown in supplemental material.
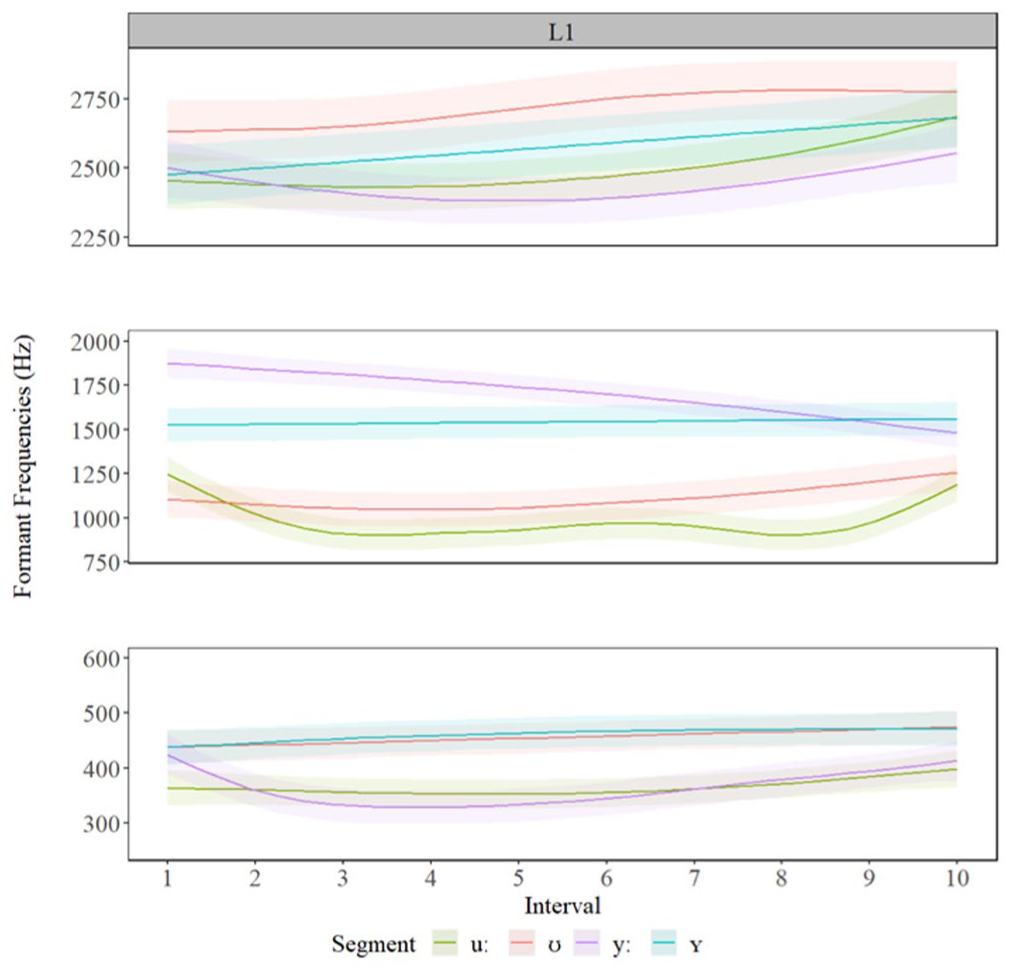
Estimated formant contours for first language (L1) speakers for F1 (bottom panels), F2 (middle panels), and F3 (top panels) for /uː/ (green), /ʊ/ (red), /yː/ (purple), and /ʏ/ (blue).
Key summary statistics for the formant analysis of first language (L1) speakers.
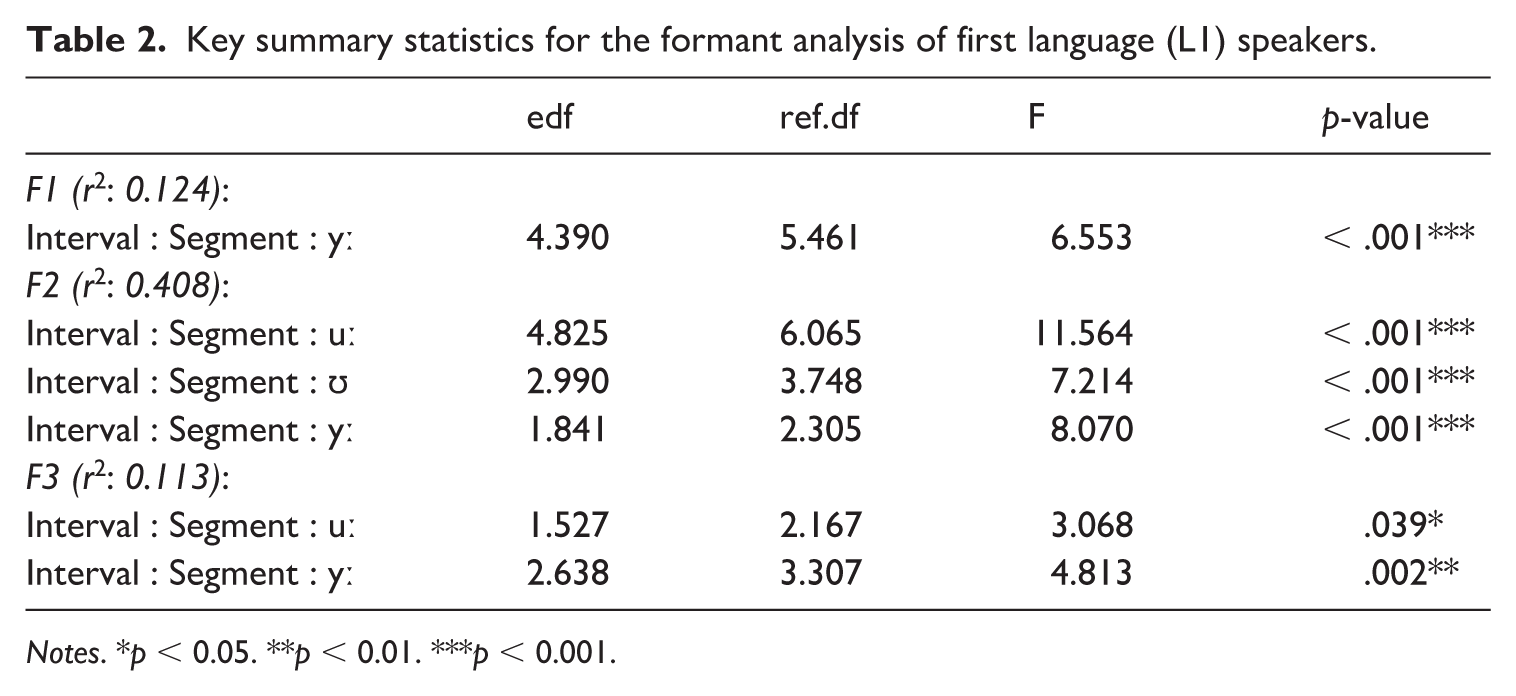
Notes. *p < 0.05. **p < 0.01. ***p < 0.001.
The GAMM estimates in Figure 3 (bottom) revealed there was very little in terms of significant difference between F1 formants at the A- and B-level, but we observed more separation between /ʊ, ʏ/ and /uː, yː/ for C-level. This suggests that height differences between segments are not acquired until a much more advanced proficiency (i.e. C-level) and that it takes a significant amount of acquisition of language skills to differentiate segments such as /yː, ʏ/ (seen in Figure 4) based on height. The GAMM estimates of the F2 results (Figure 3) also revealed for A-level learners, there were differences between Polish /u/ and the target L2 segments, but that the separation between front and back vowels involved a great deal of formant overlap, unlike B-level learners who had more formant separation between the front (higher F2) and back vowels (lower F2). C-level learners had a clear and more defined formant boundary between front and back vowels. The difference plots in Figures 4 to 7 (below) revealed a change in formant frequency along with proficiency during the transition from A-level to C-level involved increased F2 separation between /uː, ʊ/ and /ʏ, yː/. The separation on the F2 continuum suggests a gradual fronting of /ʏ, yː/. F3 revealed a tremendous amount of overlap between all the segments and the distribution of formant frequencies was generally not the same for L2 German learners as it was for L1 German speakers. However, C-level learners did have the correct ‘order’ of L2 German segments: specifically, F3 was highest for /ʊ, ʏ/ and lower for /uː, yː/. However, it should also be noted there was a great deal of overlap in frequencies for the best-fit lines and the confidence intervals of the GAMM plot. Full statistical printouts can be found in supplemental material. Table 3 presents key summary statistics. For full statistical printouts, see the R Markdown in supplemental material.
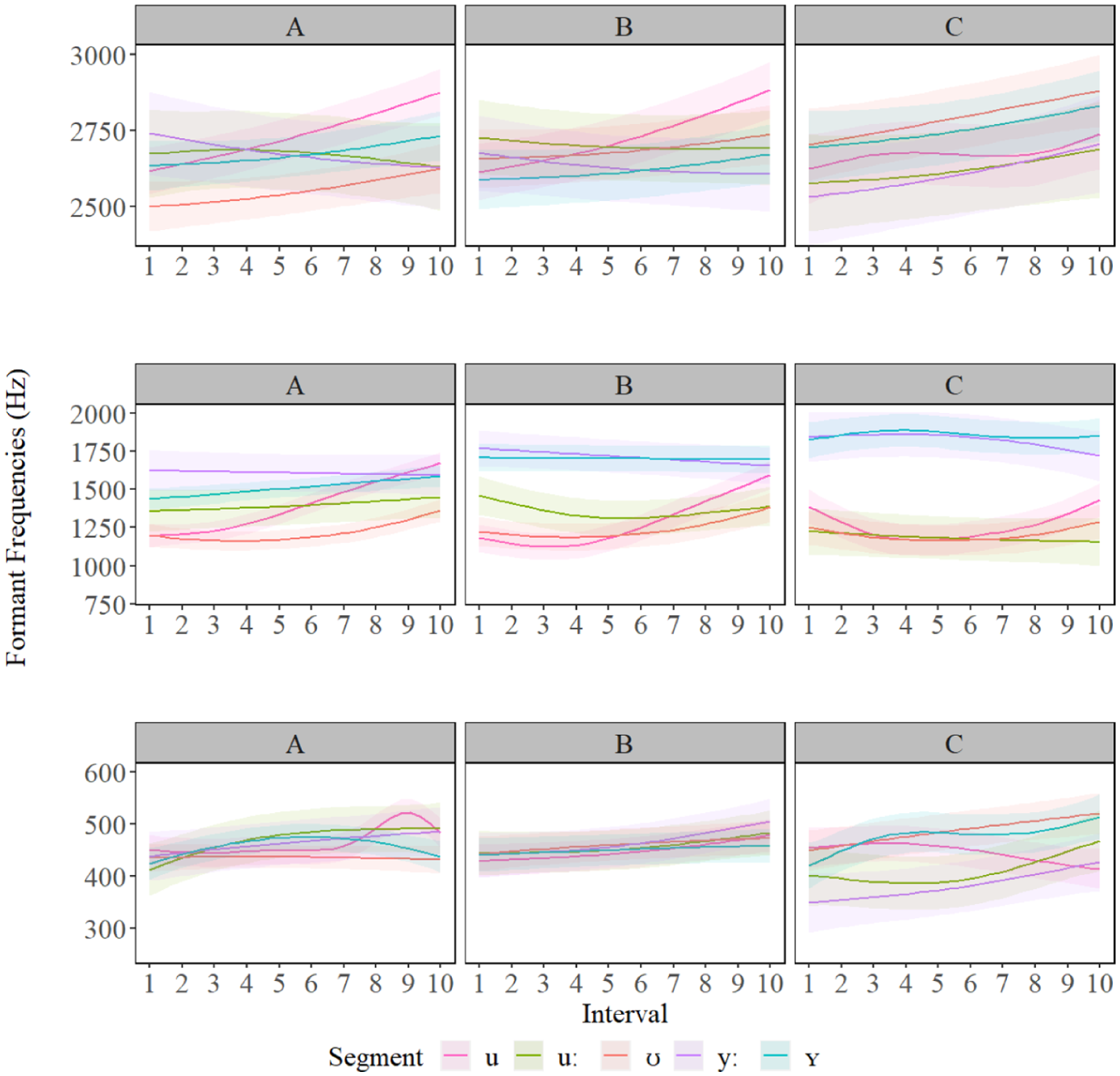
Estimated formant contours for F1 (bottom panels), F2 (middle panels), and F3 (top panels) for /u/ (pink), /uː/ (green), /ʊ/ (red), /yː/ (purple), and /ʏ/ (blue).
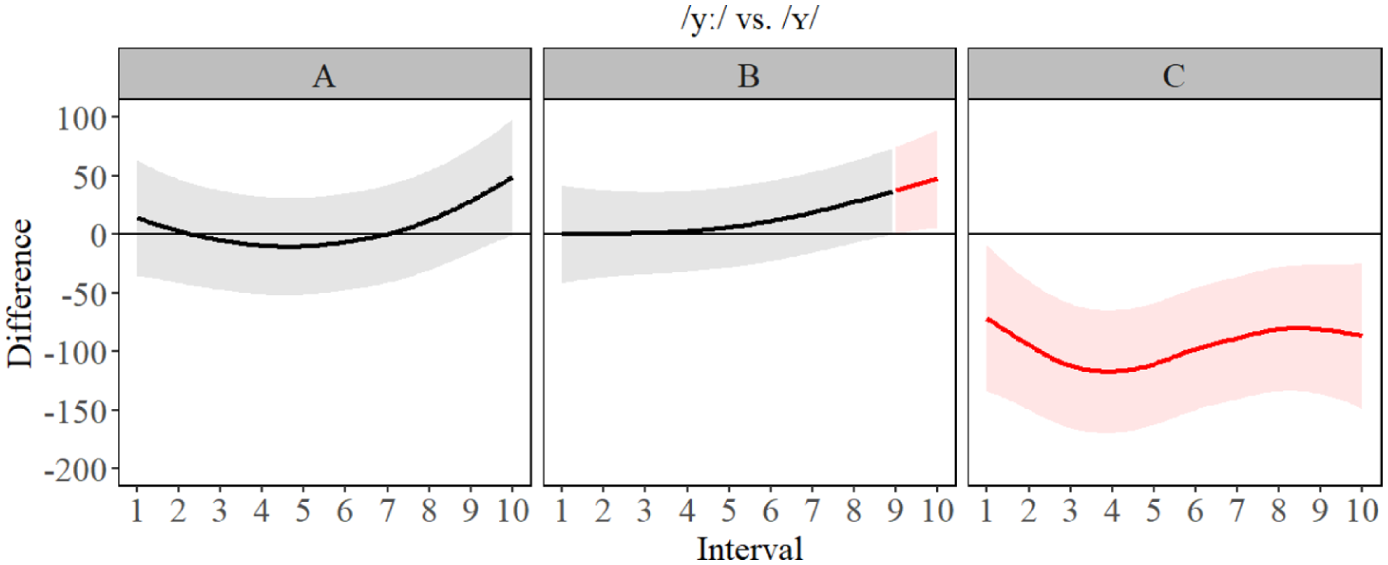
Difference contours for F1 for /yː/ vs. /ʏ/ for A- (left), B- (center), and C-level (right).
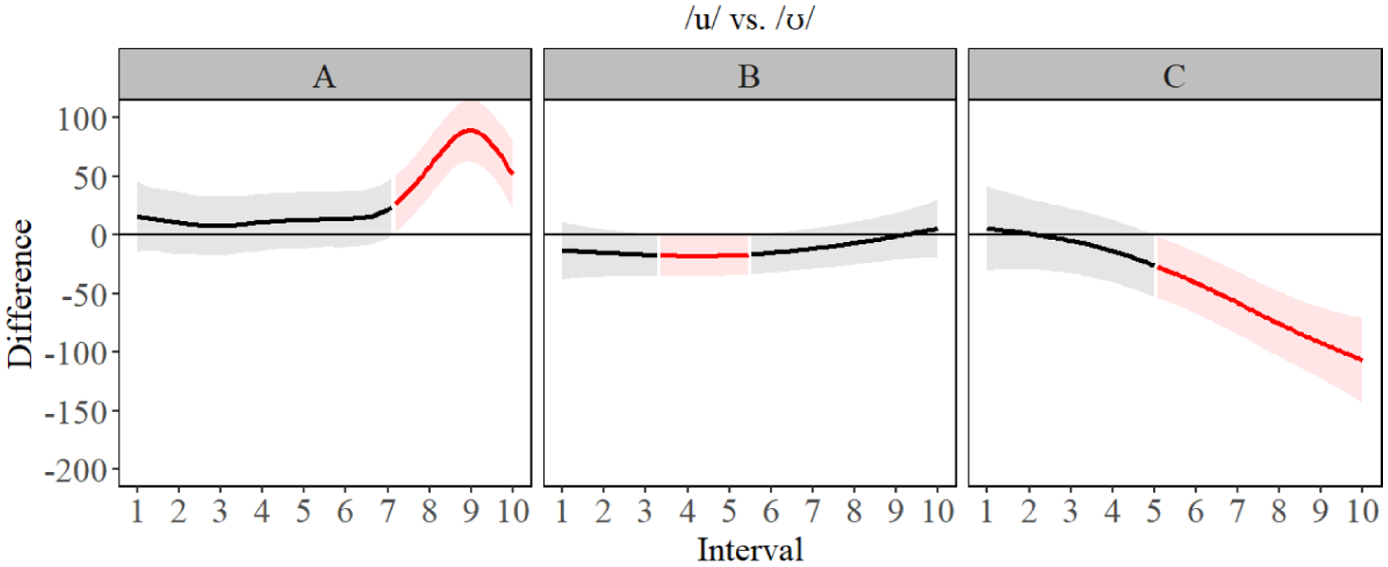
Difference contours for F2 for /uː/ vs. /ʊ/ for A- (left), B- (center), and C-level (right) learners.
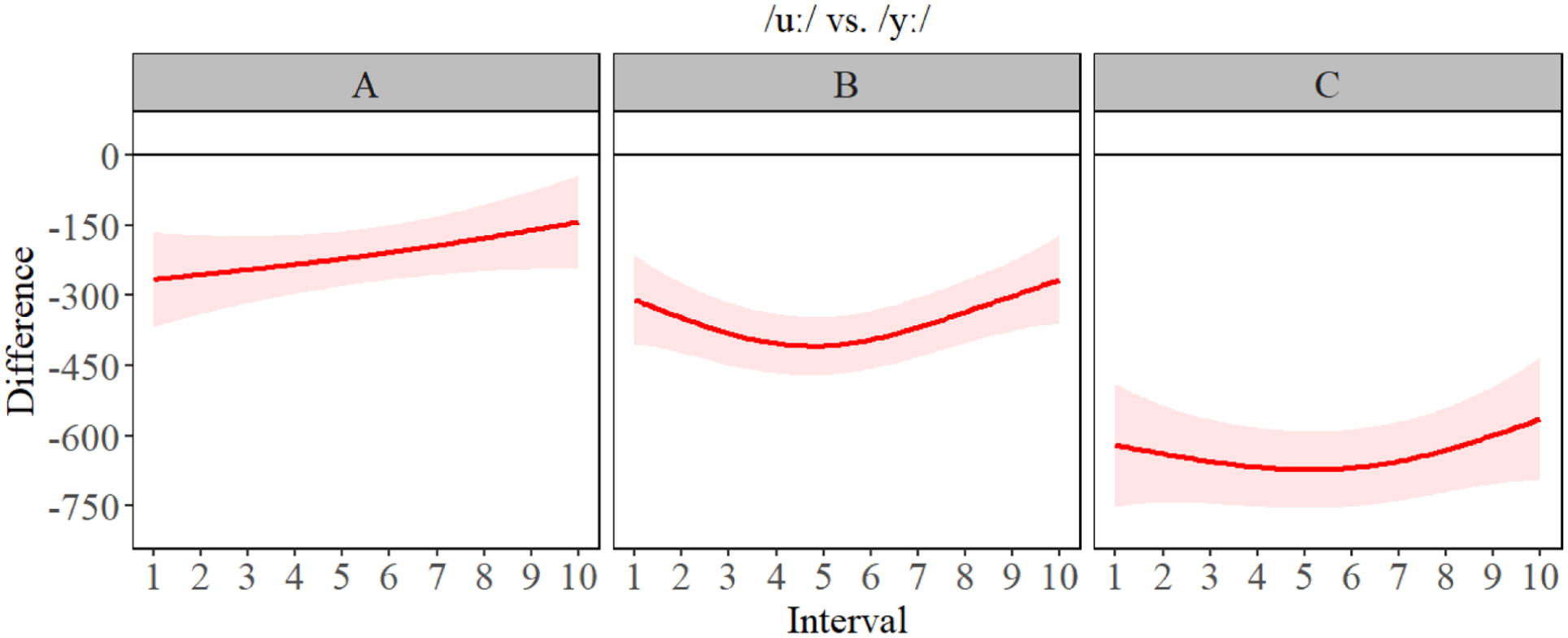
Difference contours for F2 for /uː/ vs. /ʏ/ for A- (left), B- (center), and C-level (right) learners.
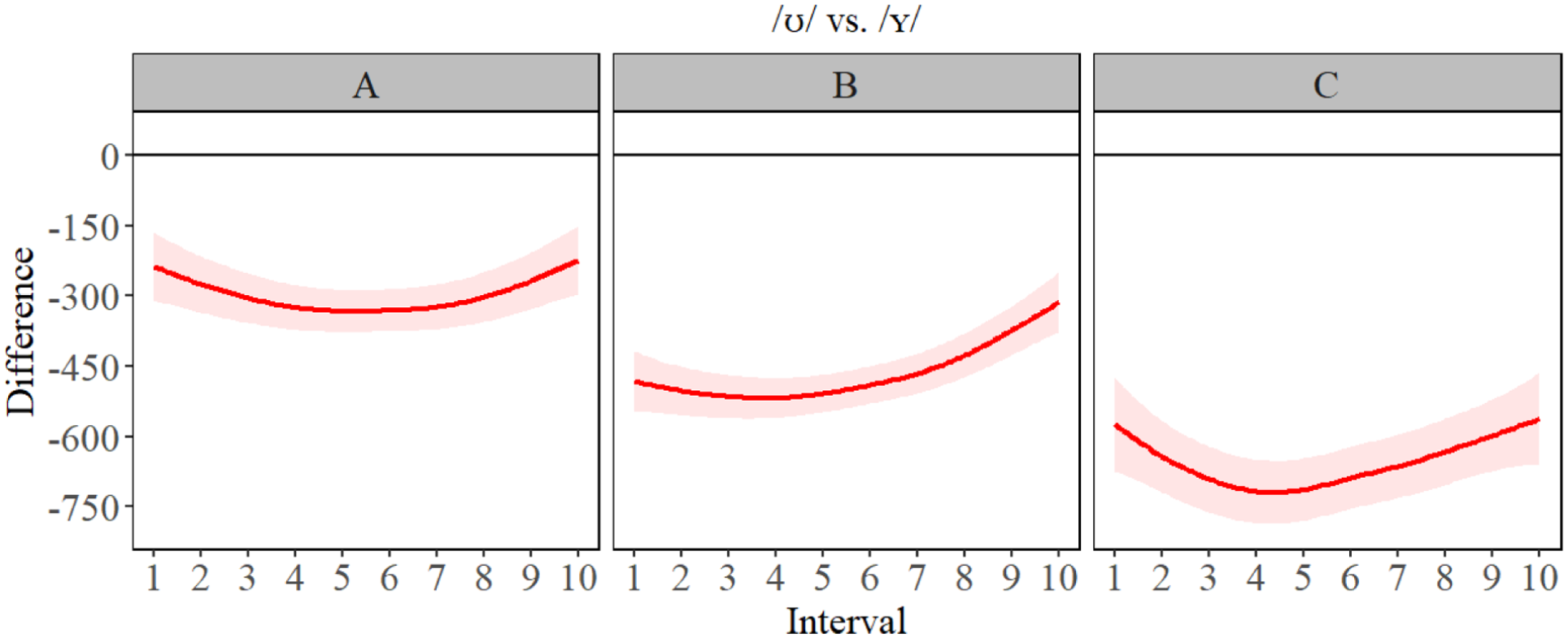
Difference contours for F2 for /ʊ/ vs. /ʏ/ for A- (left), B- (center), and C-level (right) learners.
Key summary statistics for the formant analysis of L2 learners.
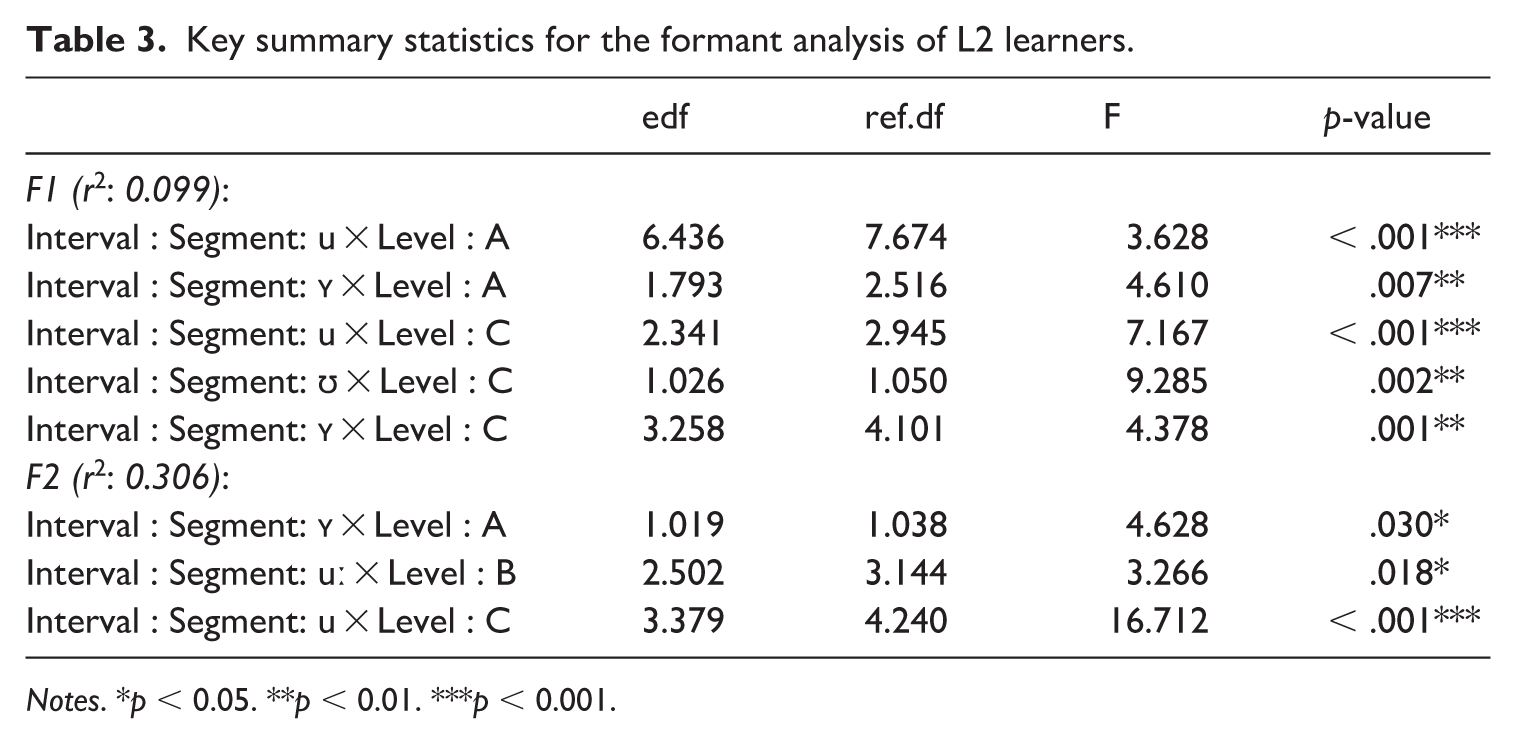
Notes. *p < 0.05. **p < 0.01. ***p < 0.001.
The analysis of duration revealed a significant effect of Segment [F(4, 21) = 33.42, p < .001], Level [F(3, 22) = 4.54, p = .013], and Segment × Level [F(11, 24) = 10.05, p < .001]. The adjusted R2 for the model was 0.650. Figure 8 presents a violin plot of the duration results. The crucial post-hoc comparisons revealed no significant differences in durations for all A-level segments (p > .05). B-level learners crucially revealed a significant difference between /yː/ (M: 0.128, SD: 0.036) and /ʏ/ (M: 0.098; SD: 0.028; p = .042). C-level learners revealed significant differences between both long and short pairs: /uː/ (M: 0.178; SD: 0.056) and /ʊ/ (M: 0.1; SD: 0.035; p < .001), /yː/ (M: 0.205; SD: 0.058) and /ʏ/ (M: 0.105; SD: 0.037; p < .001), and Polish /u/ (M: 0.09; SD: 0.028) and /uː/ (p = .002). L1 speakers also predictably revealed a significant difference between long and short pairs: /uː/ (M: 0.135, SD: 0.030) and /ʊ/ (M: 0.079; SD: 0.025; p < .001), and /yː/ (M: 0.119; SD: 0.027) and /ʏ/ (M: 0.079; SD: 0.028; p = .003). Additionally, A- and B-level learners showed no significant differences in duration when the same segments were compared against L1 speakers (p > .05). However, C-level learners did show a longer duration for /yː/ (p = .039) than L1 speakers. Figure 8 presents violin plots of the duration results. For a full statistical printout of the linear model, see the R Markdown in supplemental material.

Violin plots for duration for A- (top-left), B- (top-right), and C-level (bottom-left) learners, and L1 speakers (bottom-right) for /u/ (pink), /uː/ (green), /ʊ/ (red), /yː/ (purple), and /ʏ/ (blue).
5.2. Ultrasound results
The GAMM estimates shown in Figure 9 indicated differences for L1 speakers in constriction location for /yː, ʏ/ when compared to /uː, ʊ/, and differences in height for the long vowels, /uː, yː/, when compared to the short vowels, /ʊ, ʏ/. Table 4 presents key summary statistics. For full statistical printouts, see supplemental material.
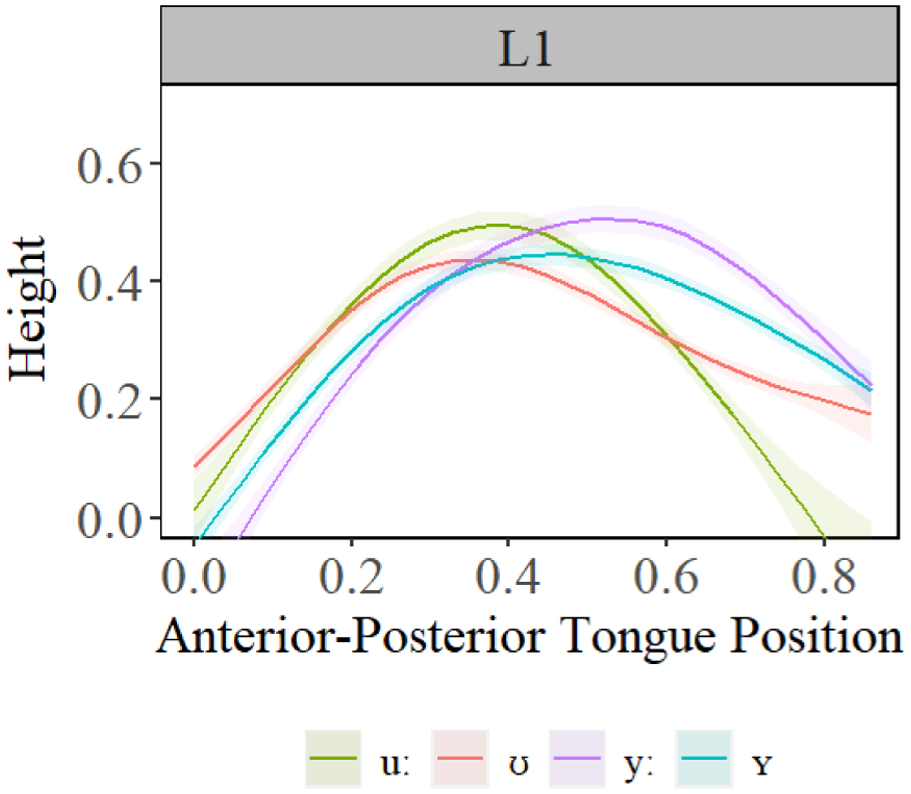
GAMM model predicted tongue contours for /uː/ (green), /ʊ/ (red), /yː/ (purple), and /ʏ/ (blue) for first language (L1) German speakers.
Key summary statistics for the ultrasound analysis of L1 speakers.
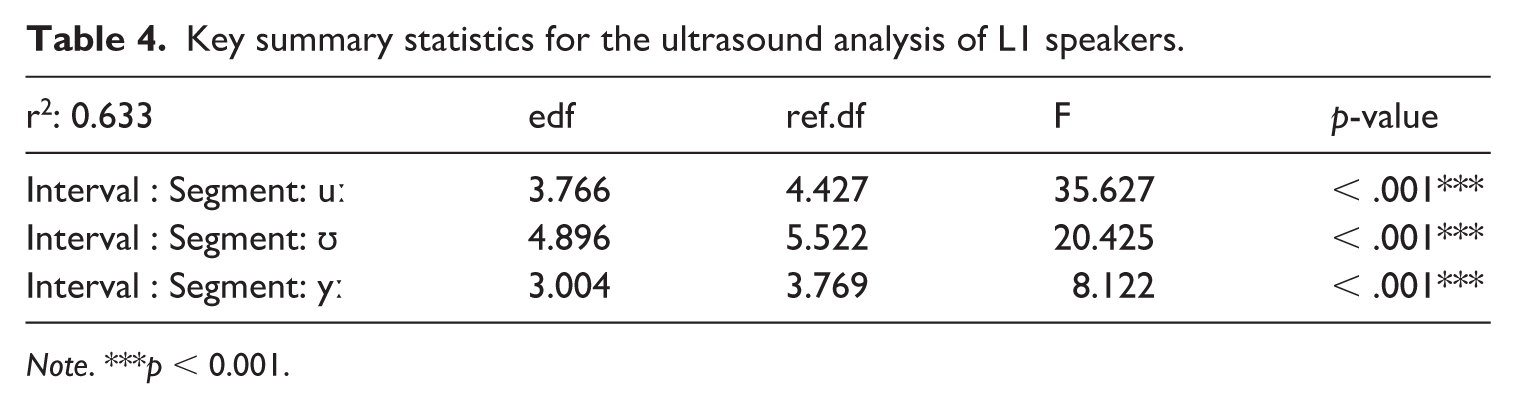
Note. ***p < 0.001.
The GAMM estimates shown in Figure 10 revealed that for A-level learners, there was slight fronting for all segments compared to /u/, and slightly more raising of the anterior tongue body/blade for /yː, ʏ/, compared to other segments. B-level learners had slightly more fronting for /yː, ʏ/, compared to other segments, but no significant difference in tongue contour for those two segments. All segments differed significantly from Polish /u/ on the front/back dimensions and/or height, seen best in Figures 11 to 14. We observed that differences between Polish /u/ and German /uː/ diminish with language level. C-level learners had only a small difference in the most anterior portion of the tongue for /u, uː/, seen best in Figure 11. C-level learners, however, did have significant difference in constriction location and degree between all segments, indicating robust contrasts between L2 German segments. The general observation we had for language acquisition was that constrictions made at a different place, i.e. /yː, ʏ/ vs. /u/, are acquired more quickly than height, especially in the case where two novel L2 segments are contrasted primarily by height (e.g. /yː, ʏ/). In those cases, only the C-level learners presented robust contrasts, suggesting that acquisition of complex contrasts takes a significant amount of time. Table 5 presents the key summary statistics. For full statistical printouts, see supplemental material.
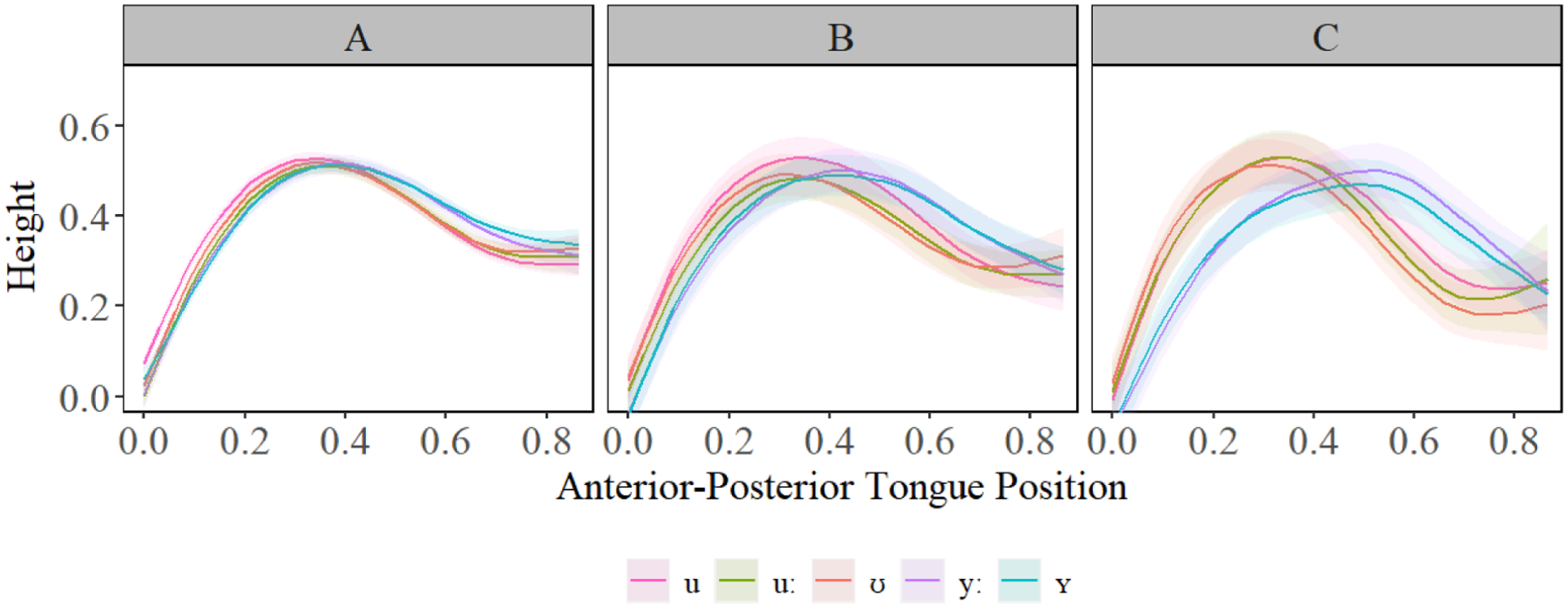
Generalized additive mixed model (GAMM) predicted tongue contours for /u/ (pink), /uː/ (green), /ʊ/ (red), /yː/ (purple), and /ʏ/ (blue), for A- (left), B- (center), and C-level (right) second language (L2) German learners.
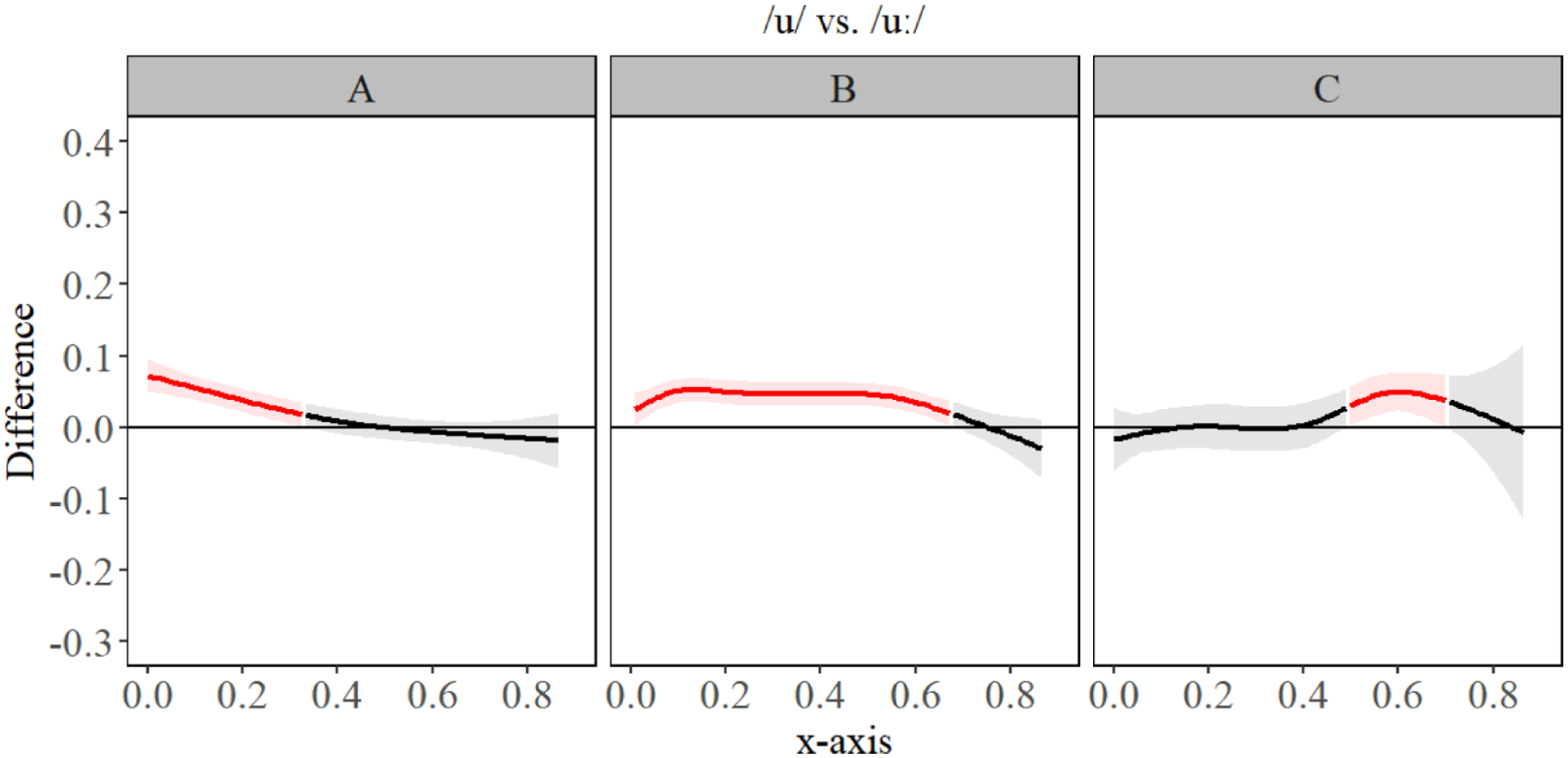
Generalized additive mixed model (GAMM) difference contours for /u/ and /uː/ for A- (left), B- (center), and C-level (right) second language (L2) German learners.
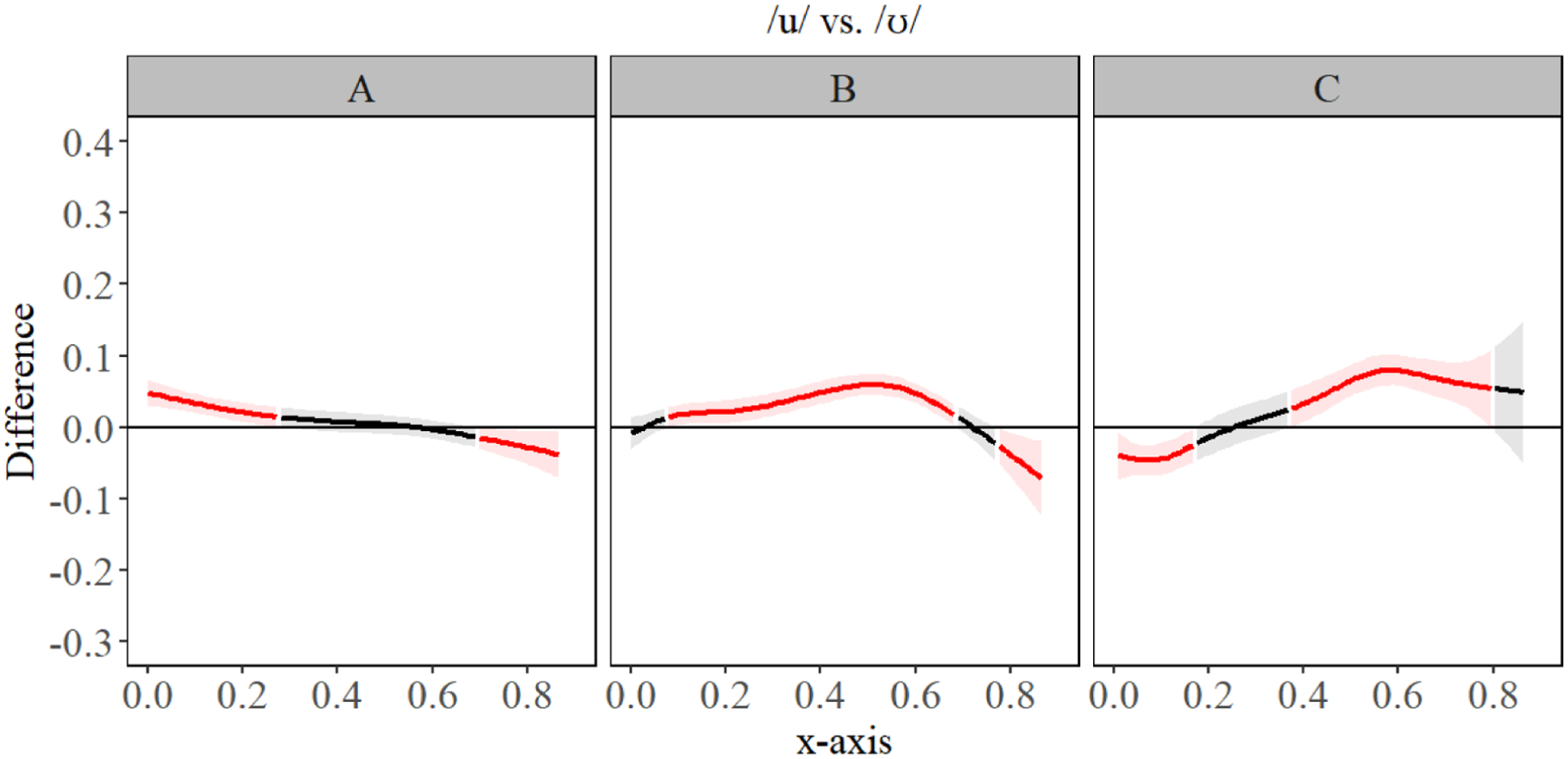
Generalized additive mixed model (GAMM) difference contours for /u/ and /ʊ/ for A- (left), B- (center), and C-level (right) second language (L2) German learners.
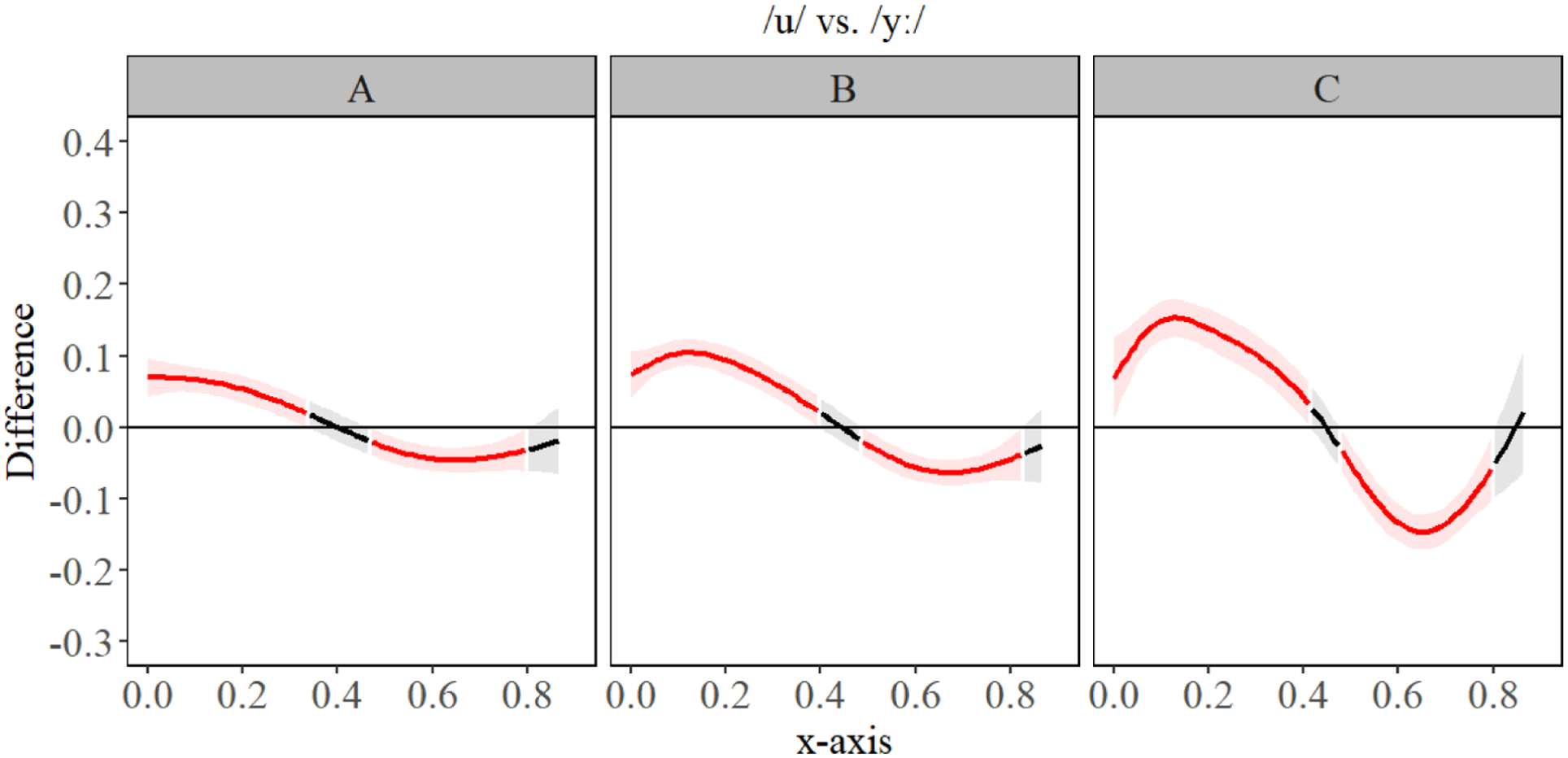
Generalized additive mixed model (GAMM) difference contours for /u/ and /yː/ for A- (left), B- (center), and C-level (right) second language (L2) German learners.
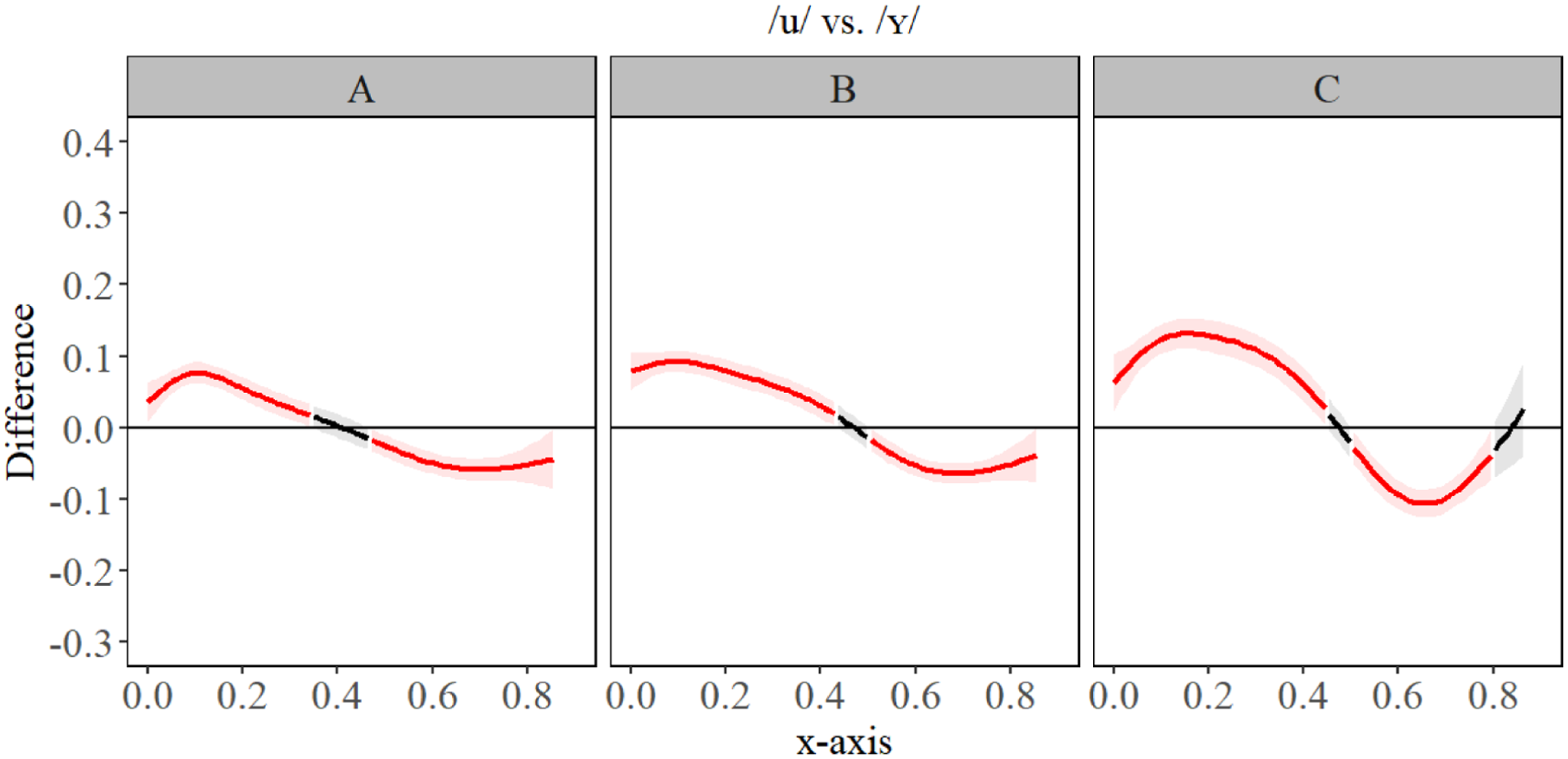
Generalized additive mixed model (GAMM) difference contours for /u/ and /ʏ/ for A- (left), B- (center), and C-level (right) second language (L2) German learners.
Key summary statistics for the ultrasound analysis of L2 learners.
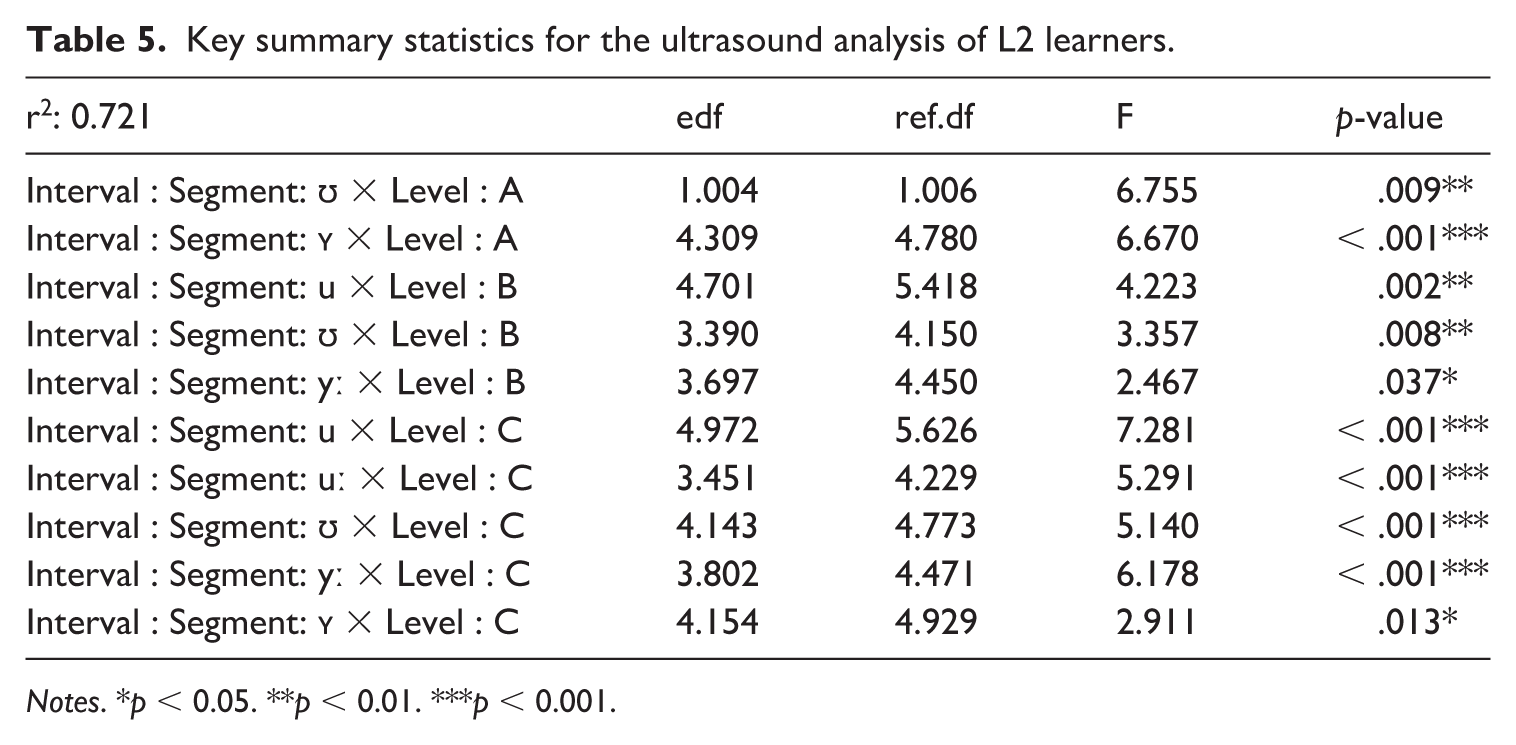
Notes. *p < 0.05. **p < 0.01. ***p < 0.001.
VI Discussion
We performed an acoustic-articulatory study to examine the acquisition of front rounded vowels by L2 Polish learners. We found that there are strongly overlapping acoustic and articulatory patterns for /uː, ʊ, yː, ʏ/ with /u/ in A-level learners. The acoustics for /yː, ʏ/ gradually emerged with experience, becoming more L1-like as proficiency increased. This was especially true for F1 and F2. The changes in F1 implicated a lengthy process for acquiring height differences between /uː, yː/ and /ʊ, ʏ/, which was confirmed by the ultrasound analysis. The articulatory implications of the F2 results were confirmed with ultrasound data that revealed /yː, ʏ/ undergo gradual fronting with improved proficiency. Additionally, there was a gradual shift in F1, F2, and F3 that suggested some lip rounding as acquired by the C-level. Specifically, we observed a decrease in F1 and F3, with some apparent reduction in F2, which suggests there could be more lip-rounding/protrusion (Al-Tamimi, 2017) when looking at differences between C-level and A- and B-levels. We additionally observed lowering in F2 over time for /uː/ from the A- to C-level, suggesting a gradual backing (Fant, 1975) of the German phoneme, compared to the L1 Polish segment, /u/. This indicates that learners picked up on subtle acoustic differences between these segments and acquired novel articulatory patterns for /uː/. The ultrasound results also revealed that the articulation likewise proceeded as a gradual fronting from an /u/-like to front rounded vowel. Gradual fronting of the front vowel correlated strongly with increase in F2 and height differences between front vowels also correlated to decrease in F1. Vowel duration also gradually improved in the correct direction, with A-level learners producing no durational distinctions, and gradual acquisition of appropriate distinctions between long and short vowels. It should be noted that although ultimate attainment was high, learners never achieved acoustics or articulation that mirrored L1 speakers exactly. Age of acquisition effects are often not observed in phonetic acquisition (e.g. Bongaerts et al., 1997; Olson and Samuels, 1973; Snow and Hoefnagel-Höhle, 1977), although they may have played a role in the differences observed here. However, we suggest that differences in acquisition are due to interactions between L1 and L2 in the acoustic-phonetic space. The needs of the system to maintain contrast between segments in an already crowded space may lead to differences in acquisition for L2 segments when compared to L1 segments.
Although the language was acquired in a foreign language context (i.e. outside a country that speaks it as their L1 and in the classroom) and participants reported little or no phonetic/pronunciation training, durational, place, and height differences were acquired (to varying degrees of L1-likeness). This implies that language learning mechanisms are still available to learners even above the age of 20 years of age. This is not compatible with theories like the Critical Period Hypothesis (Lenneberg, 1967) that suggest that L1 mechanisms ‘shut off’ after a certain period of time and that L1 and L2 acquisition are fundamentally different (Bley-Vroman, 1989, 2009). On the other hand, theories like the SLM (Flege, 1995) that posit language learning mechanisms are available throughout a learner’s life are supported here.
The significant finding of our study is that learners use their L1 articulatory patterns during L2 acquisition. Previous findings that suggested they are not (e.g. Oakley, 2023) did not examine learners at all levels; therefore, it was not as apparent that derivatives of the L1 patterns emerge early in acquisition and then progress as proficiency increases to more target-like articulations. This finding is in line with the Unified Model (MacWhinney, 2005, 2008, 2012) that posits significant L1 transfer in the articulatory domain. Segments that are perceived in the initial state as similar to L1 segments thus harvest those articulatory patterns and are then modified as the learner’s L2 abilities increase. The process is lengthy and requires significant improvement in skill level. Categories do appear to form early (Casillas, 2020), likely before the B-level is achieved. Nevertheless, it takes a significant improvement in proficiency for them to fully develop, likely beyond the C-level. This was supported by small but significant differences in formant values and articulatory postures even at the A-level. Those differences strengthened as proficiency increased in the direction of more target-like articulation. This should not be overwhelmingly surprising in this context due to the fact that L1 category formation is slow (McMurray, 2023; Narayan et al., 2010; Werker and Yeung, 2005) and front rounded vowels are acquired late in the L1 context (Major, 1987). Thus, these findings support the concept that cues are continually reweighted in the acquisition process (MacWhinney, 2005, 2008, 2012) and as a result articulation gradually changes with proficiency in line with the reweighting of cue importance.
The observed differences in end-state acquisition (i.e. C-level) also did not match that of the L1 speakers. Whether or not the ultimate achievement possible would mirror L1 articulation more closely is not ascertainable from this dataset. However, the fact that end-state differences between L1 and L2 speakers of German should not be wholly surprising. Such findings have been observed in previous studies. For example, previous findings (e.g. Colantoni et al., 2025a) also found that while allophonic differences in English-/l/ are acquired by L2 learners, complex acoustic and articulatory differences emerge and appear to be dependent on L1 language. This makes sense if in fact the L1 and L2 phonetic space is shared (Flege, 1995), then mediation and contrast between L1 and L2 segments needs to be maintained. Therefore, in order to maintain vowel dispersion (e.g. Liljencrants and Lindblom, 1972) in the acoustic-articulatory space, inhibition or promotion of L1-like segments is expected to be observed. In this study, it could be the case that acoustic dispersion between the L1 and L2 segments has been achieved in an optimized way for Polish learners of German at the C-level when the system has to account for both L1 and L2 segments. Under this interpretation, differences in L2 learners at an advanced level and L1 German speakers are more a function of cue balancing and distribution that is required to mediate contrast between all the segments in the speakers' acoustic-articulatory space.
Additionally, Flege and Bohn (2021) suggest that substitution may be another reason that acquisition of novel segments does not occur. In the data, we found that at the A-level, L2 German learners demonstrated only small deviations from Polish /u/ with respect to the acoustics and articulation of the target L2 German vowels. This implicates that irrespective of the height or constriction location of the L2 segments, L2 learners appear to begin with the same acoustic-articulatory configuration, /u/. However, in this article we also found that early substitution facilitates speech and additionally facilitates learning of L2 segments. The early substitution facilitates speech with lower degrees of effort for speakers, while also facilitating later learning through continued exposure to L1 stimuli and continued refinement of the target segments. This facilitation is observed in our study where learning progressed from A to C levels. For both Flege (1995) and Best and Tyler (2007), this implies that there is some acoustic-perceptual difference between the L1 and L2 segments being acquired, no matter how small. Thus, the data heavily implies that even small differences in F1 and F2, and the larger differences in F3 between /uː/ and /ʊ/ were discernible to the learners even at an early stage. Although, it should be noted that it appears height contrasts, when they are small, are much harder for L2 learners to acquire than front/back contrasts. This can be observed in the data where F1 is completely overlapping at the B-level, but clear front/back contrasts emerged at the C-level. The ultrasound additionally suggests little if any difference in height for the A- and B-level learners. Nevertheless, fine grained acoustic-articulatory differences between segments emerge with high proficiency, even for segments that exhibit only a slight difference in height. This is best observed in the data with the emergent differences between /uː, ʊ/ and /yː, ʏ/. Flege and Bohn (2021) also posit that L1 segments can block L2 acquisition. While the data presented here does not negate this claim, it does present a case that even segments with only small acoustic-phonetic differences can be acquired by L2 learners, even without significant instruction. While some L1 segments may block L2 acquisition as Flege and Bohn (2021) suggest, the overall trend presented here is that L2 segments emerge from categories that the learner acquired in their L1, even when the difference between L1 and L2 segments is relatively small, as we observed with German /uː/ and Polish /u/. Early substitution may be utilized as a strategy on the path to acquisition. L1 segments that are similar to L2 segments are used by learners in order to produce comprehensible speech early in the acquisition process. As the learner becomes more proficient, they make consistent adjustments to their articulation to produce a more target-like articulation. In other words, our data suggests that L1 similarity can provide a starting point for acquisition insofar as there is some acoustic-perceptual dissimilarity that the learner can discern in order to facilitate acquisition. Thus, language learners, even at an older age, appear to be relatively well equipped to acquire even small acoustic-articulatory differences.
However, we acknowledge that there are also limitations to this study. Specifically, the sample does represent an imbalance between male (n = 3) and female (n = 16) for L2 learners and that the overall sample size for the C-level learners (n = 4) is smaller than that of A- (n = 7) and B-level (n = 8) learners. Therefore, our conclusions should be taken in context.
Footnotes
Acknowledgements
We would like to thank Dr. Dorota Klimek-Jankowska and Uniwersytet Wrocławski for providing space to record data and for assisting in finding participants for our study. We would also like to thank our participants for taking the time to participate in our study.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project has received funding from the European Union’s Horizon 2020 research and innovation program under the Marie Skłodowska-Curie grant agreement number 101018840.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.