
Abstract
In response to the rapid proliferation of artificial intelligence (AI), in particular generative AI, research on its application has mushroomed. However, problems arise when AI is taken to be just another IT artifact without fully appreciating what is new and different about it. We take two surprises about AI’s peculiar behavior, found in the public domain, to problematize commonly held understandings of computing. We illustrate how the fact that AI systems exhibit inherent inaccuracies, and AI developers are unable to fully understand their own creations, challenges common expectations. Based on this insight, we put forward the provocative thesis that AI systems are not, in fact, information systems. We derive an ideal type understanding of information systems, as a rhetorical device, and analyze in detail the differences with AI systems. For doing so we focus on AI systems like ChatGPT that derive their core functionality from generative AI models. We show that they differ in principle in how they encode information parametrically rather than explicitly, function probabilistically rather than deterministically, remain static after training rather than maintain currency, are created in a trial-and-error process rather than engineered top down, and present practically as “black boxes” rather than auditable systems. Our analysis contributes a conceptual foundation for understanding AI systems on their own terms, avoiding category errors. This allows positing productive new research questions about AI system use, application, and design that will help the IS discipline maintain relevance, as AI reshapes computing at its core.
Introduction
AI is not a new technology (Crawford, 2021) but the release of ChatGPT in late 2022 catapulted it into mainstream attention. ChatGPT reached 100 million users within just 2 months of launch (Hu, 2023). With it, driven largely by advances in large language models (LLMs), a wider range of generative AI (GenAI) tools saw rapid adoption.
While AI has captured the attention of the public and the IS field alike, the speed of its proliferation is not without problems. In our work with public and professional audiences we regularly encounter problematic misconceptions about the technology. In our work as editors and reviewers, and as keen observers of the IS space, we see too many papers echoing these same misconceptions, while devoting insufficient attention to how AI actually works and how it differs from previous generations of technology (Riemer et al., 2026). This is corroborated by conversations with colleagues in editorial positions. Too often, AI systems are treated as yet another IT artifact without consideration of what makes them different “under the hood.”
In this perspective paper, we assert that the IS discipline must urgently engage with the characteristics and peculiar nature of AI systems at a level not previously necessary. We set out to discuss in detail what makes (generative) AI systems novel and significant, opening a space for new research questions that proceed from, and are connected to, the characteristics of these systems. To this end, we put forward, as a rhetorical device, the thesis that AI systems are not in fact information systems. Through a detailed comparison of AI systems with information systems, we reveal what is different and novel about AI systems and spell out implications for the IS discipline.
For AI systems, we focus on generative AI as the latest and most prominent incarnation. We define AI systems as those that derive their core functionality from a (generative) AI model. These AI models, most notably large language models (LLMs) and multi-modal foundation models, are based on deep learning neural networks pre-trained on large amounts of data. They derive their capabilities from patterns encoded mathematically during training (Riemer and Peter 2024; Schneider et al., 2023). A typical example is ChatGPT, with its plethora of different uses and users. We note that much of our argument might also apply, by extension, to other AI systems based on deep learning architectures, such as predictive models. But we do not include these explicitly.
For information systems, we derive an ideal-type characterization, drawing on Max Weber’s methodological work (Weber, 1904, 1978) and following previous comparative analyses employing ideal types (e.g., Wang et al., 2025). From seminal papers and IS textbooks we distil five foundational characteristics. At their core, information systems are about information, because as sociotechnical systems they fulfil social actors’ “information needs and requirements in regards to specific goals and practices” (Boell and Cecez-Kecmanovic, 2015). We acknowledge that information systems 1 have taken many forms over time, and that many IS scholars might not subscribe fully to this ideal-type understanding. Yet we argue that it remains useful as a device for comparison, precisely because many espoused views of information systems have evolved, in practical and implicit ways, from such foundational understandings.
We begin with two surprising observations about the use and development of AI systems, taken from the public domain. Both are at odds with common expectations about how IT systems work. We use these surprises to problematize 2 widely and implicitly held assumptions about computing—that it is accurate and deterministic—which AI systems, as probabilistic and pattern-predicting systems, are not. What makes these surprises significant is that they reveal how deeply such assumptions are held, and how long they could usefully remain backgrounded as the algorithmic foundations of computing remained stable. This holds both for the general public and for the IS field, where theorizing could proceed without engaging with the basic technical characteristics of computing systems. We assert that, with the proliferation of AI systems, this has changed.
Against this backdrop, we spell out how AI systems work and how they are built, alongside the ideal-type characterization of information systems, to set up a detailed comparison. We then show that AI systems, unlike information systems, (1) cannot in principle store and organize information faithfully or in ways understandable by social actors (Asperti and Tonelli, 2023), (2) are probabilistic and thus in principle unreliable against traditional expectations of accuracy (Biever, 2023; Ullman, 2023), (3) do not update during use because the underlying AI models are pre-trained (Riemer and Peter, 2024), (4) derive their functionality from an emergent trial-and-error process, more akin to craft than top-down engineering (Feuerriegel et al., 2023), and (5) are inscrutable and inauditable, as their core functionality derives from statistical patterns rather than explicit, deterministic procedures (Asatiani, 2020; Schneider et al., 2023). As a result, the capabilities of AI systems are not determined by design—they must be discovered through empirical testing (e.g., Durmus et al., 2024).
We do not imply that information systems in practice always exhibit ideal-type characteristics such as accuracy, reliability, or faithful representation. As sociotechnical systems, many practical factors compromise these ideals: people are involved in data collection and handling, hardware and sensors may lack precision, and software may exhibit errors or levels of complexity that produce unintended consequences. Our point is rather that information systems can in principle strive for and achieve such characteristics, such as when organizations rely on them for auditable record keeping, or when systems such as the aircraft autopilot must operate at high levels of accuracy and reliability, whereas AI systems cannot.
We also acknowledge that AI systems are increasingly infused with traditional computing components to offset AI model characteristics. We will show that this only strengthens our argument about differences between the two systems. These differences matter, particularly as the two increasingly co-exist, interact or become blended within the same organizational environments. For example, as conventional systems components make way for AI ones, their probabilistic nature may change the risk profiles and necessitate new governance approaches. To study such phenomena and derive valid conclusions, the field must proceed from a more explicit understanding of these fundamental differences.
The IS discipline has always adapted to waves of change in its core subject matter. Our analysis stands in the tradition of previous works that sharpened the discipline’s focus to stay relevant, such as calls to refocus on the IT artifact (Benbasat and Zmud, 2003), balance the social and material in our core phenomena (Orlikowski and Scott, 2008), or appreciate ubiquitous (Johnston and Waller, 2009) and everyday computing (Yoo, 2010). The field has long moved beyond its traditional focus on organizational information systems.
Yet, our comparison of AI systems with information systems is not merely another broadening in scope—adding AI to the list of technologies the field engages with—but a call to deepen engagement with assumptions about the underlying technology that could for the longest time usefully remain implicit and backgrounded. This will allow the field to engage with what is peculiar and novel about AI systems, while protecting and clarifying established concepts like “information” and its role in various forms of organizing.
Problematizing common views of computing
Problematization is used to uncover, and make visible for scrutiny, the normally unstated assumptions of phenomena (Alvesson and Kärreman, 2007; Alvesson and Sandberg, 2011). Here, we proceed from two surprising observations, one about the behavior of AI systems in use, a second about how they are built, to foreground and challenge widely held assumptions about computing, and by extension, taken-for-granted assumptions about information systems in IS. We begin with a brief introduction to our approach, then present the two vignettes, and end by discussing what the surprises reveal for framing our subsequent analysis.
Problematizing from surprise
Problematization has a track record in both organization studies and IS, where it has been used to challenge existing assumptions and develop new theory (Alvesson and Kärreman, 2007; Hafermalz et al., 2020; Riemer and Johnston, 2019), derive new research questions (Alvesson and Sandberg, 2011), or more generally allow thinking outside the box (Alvesson and Sandberg, 2011).
Our entry point is surprise. Surprises arise from a mismatch between expectation, informed by background assumptions, and observation (Casati and Pasquinelli, 2007; Maguire et al., 2011). The normal attitude is to set surprises aside as anomalies. But when taken as occasions for deeper inquiry, surprises can be used to make visible the tacit assumptions the surprising observation violated. Here, we take this opportunity. We use the surprising nature of AI systems to reveal and problematize what is commonly taken for granted about how computing works, and by extension, what the IS field understands information systems to be.
Our problematization proceeds dialectically (Hafermalz et al., 2020). After we reveal common-sense assumptions about computing, we explicate in more detail how AI systems are built and how they function. We then explicate what information systems are. This provides the ground for a juxtaposition that distinguishes five fundamental differences, from which we set out to derive implications for the IS discipline.
Surprises: Computers acting weirdly
The following surprises are taken from media reports. Each could be dismissed as unremarkable, as contemporary stories about the oddities of AI systems. Instead, we use them to pause and ask what they reveal about what we commonly and intuitively understand about computing. We deliberately chose practical examples from the public domain because the assumptions that give rise to misconceptions, in both the general public and in IS, are universal and run deeper than the explicit ideal-type conceptions of information systems we will spell out later. They are therefore also much more difficult to unseat.
Surprise 1: AI systems are unpredictable and unreliable
In a widely reported court case (Ea, 2024), Moffatt vs Air Canada, the airline was ordered to pay damages for incorrect information that its customer advice chatbot had provided via its website. A customer, Jake Moffatt, had been informed by the chatbot, wrongly, that he would be reimbursed for travel under the airline’s bereavement policy for up to 90 days after the travel occurred. Moffatt proceeded, but the airline later denied his refund request pointing to its official policy. In the subsequent legal action, Air Canada argued that it should not be held responsible for the “misleading words” of its chatbot. The airline claimed the chatbot should be considered a separate entity accountable for its own actions. The court rejected this, ruling that the chatbot was a component of the airline’s website and therefore the airline’s responsibility. The airline was ordered to compensate Moffatt.
While most media reporting emphasized accountability, for example, that companies cannot dissociate themselves from information disseminated by their AI chatbots, the case itself provides two interesting surprises for our inquiry. First, the surprise by the customer that he received incorrect information on the Air Canada website. Why would the airline’s own computing system provide the wrong information? Second, Air Canada’s attempt to absolve itself from accountability. Why would the airline argue that an AI system is a separate entity, with its own actions and responsibilities? What exactly would make it different?
The court argued that customers are not expected to distinguish between one part of a website that provides accurate, reliable information and another that might not. As tribunal member Christopher Rivers stated: “It should be obvious to Air Canada that it is responsible for all the information on its website. It makes no difference whether the information comes from a static page or a chatbot.” But the outcome clearly shows that there is such a difference in how the AI chatbot provisions information versus the remainder of the website. It is this difference that is at the heart of the surprise.
Surprise 2: Developers do not know what their AI systems can do
It is a well-known characteristic of AI systems like ChatGPT to “make things up” or “hallucinate” (Jones 2025; Mitchell 2023; Sun et al., 2024). In an interview in April 2023 (Pelley 2023), Google CEO Sundar Pichai was asked about this. His response is instructive: There is an aspect of this which we call—all of us in the field call it as a “black box.” You know, you don't fully understand. And you can’t quite tell why it said this, or why it got wrong. We have some ideas, and our ability to understand this gets better over time. But that’s where the state of the art is.
This raises a question that should give us pause. Why would the developers of AI systems not fully understand their own creations? Why do AI companies have to engage in extensive research efforts to ascertain the capabilities of the systems they build? Aren’t they the ones building them? Yet this is precisely what we observe. Companies like Google, OpenAI, and Anthropic engage in elaborate research programs to understand the abilities of their AI models, by undertaking empirical testing and analysis of system behaviors (Wu et al., 2024), running experiments with human subjects to gauge the persuasiveness of AI-generated text (Durmus et al., 2024), and sometimes discovering unexpected capabilities that surprise even their creators (Pandey 2024). An entire industry has sprung up to produce and refine benchmarks and measurement frameworks that help ascertain what AI systems can do (Hendrycks et al., 2021; Wei et al., 2024).
Assumptions revealed by the surprises
How we encounter the world is shaped and structured by our established pre-understandings (Alvesson and Sandberg, 2022). When we encounter something that goes against this pre-understanding it shows up as ‘odd’ or weird, in other words—as a surprise. When the propensity of AI systems to provide incorrect information surprises us, it reveals accuracy as both a tacit assumption and as an obvious hallmark of computing. And when AI developers don’t understand how their own creations work, it reveals that systems are traditionally built top-down, with developers explicating features and procedures to be encoded.
The fact that AI systems break with these assumptions reveals AI as both novel and different, not just in a practical but in a fundamental way. And once these assumptions are made explicit, their foundational hold becomes obvious—of course computing is expected to be accurate; and of course developers are expected to understand what they build and how these systems work.
To appreciate these differences in more detail, we now turn to how AI systems are built and how they work. This will then allow us to further problematize what we take for granted about “information systems.”
Introducing AI systems
Much has been written about the astonishing abilities of generative AI systems, such as their human-likeness (Peter et al., 2025), persuasive (Salvi et al., 2024) and empathetic writing (Welivita and Pu 2024), versatility across tasks (Teubner et al., 2023), and creation of artistic images from text inputs (Ivanenko, 2022). But equally, generative AI has a propensity to “make things up,” what has been termed hallucinations (Alkaissi and McFarlane, 2023; Sun et al., 2024). It also shows an inherent brittleness (Ullman, 2023) and unreliability on knowledge tasks (Biever, 2023). So how do these systems work?
We focus squarely on generative AI, that is on AI systems that have at their core a large language model (Vaswani et al., 2017), or what is now commonly known as a foundation model (Schneider et al., 2023). While the AI system derives its behavior mainly from the AI model (in response to user prompts), this is not to say that AI systems do not also have conventional computing components. Typical examples are OpenAI’s ChatGPT, Google Gemini, and Microsoft Copilot, but also organizational AI systems that utilize open-source models (like Meta’s Llama) to create bespoke solutions with conversational interfaces.
How (generative) AI models are built
AI systems are built around AI models, sometimes also called AI algorithms (Feuerriegel et al., 2023; Riemer and Peter, 2024). These models derive their functionality from training mathematical, probabilistic structures, called artificial neural networks, or deep learning algorithms (Goodfellow et al., 2016). Training uses large amounts of data known to contain relevant patterns; encoding these patterns imbues the resulting model with its abilities.
Deep learning has its roots in image recognition (Deng et al., 2023) and prediction algorithms used in decision-making (Berente et al., 2021). For example, a computer vision model trained on large numbers of photos with corresponding text labels is able to recognize, with some degree of confidence, the same kinds of patterns in photos it has not seen before. More recently, deep learning models have been employed not just for recognition but for generation of new content that embodies similarities to what was encoded from the training data (Bengio et al., 2013; Feuerriegel et al., 2023). Depending on the type of training data, such models can generate text, images, audio, or video (Goodfellow et al., 2016). At a conceptual level these principles are the same for image, video, and text generating models, the latter known as large language models (LLMs).
LLMs like GPT (Generative Pre-trained Transformer) are pre-trained on a massive corpus of text data from various sources to encode statistical “nearness” relationships between words and text fragments, or “tokens” (Radford et al., 2018). This training results in a foundation model (Bommasani et al., 2021; Schneider et al., 2023), which forms the generally task-agnostic basis for LLM-based AI systems (Feuerriegel et al., 2023). While it is technically possible to prompt such a base LLM directly, end users typically interact with AI systems based on post-trained models that behave like a chatbot (Riemer and Peter, 2024).
To create a system like ChatGPT, for example, the foundation model receives further post-training through Reinforcement Learning from Human Feedback (RLHF) (Ziegler et al., 2019). RLHF employs human testers to quality-rank model responses, from which a reward function for reinforcement training is derived. This feedback loop allows the model to further encode human conversational patterns, creating a user experience that provides access to the foundation model’s capabilities via natural language conversation. With additional fine-tuning it is possible to adapt the resulting conversational model for a wide range of bespoke applications (Ziegler et al., 2019). Importantly, all such training occurs before the model is deployed as part of the AI system.
How AI models encode patterns from data
During training, nuanced features inherent in the training data are transformed and encoded into mathematical patterns, mapped as vectors into a high-dimensional, purely probabilistic numerical space, the so-called “latent space” (Asperti and Tonelli, 2023; Kingma and Welling, 2013). Conceptually, this means that no actual text is stored inside a language model, as any textual content becomes encoded purely as numerical relationships with other words.
Training of language models generally involves self-supervision at scale: an initially randomized model is made to predict hidden parts of an input sentence (Mitchell, 2023), successively encoding increasingly complex and abstract features of the training data into the latent space, a process also referred to as “embedding” (Vaswani et al., 2017). It is this latent space, with each layer of the network capturing different levels of abstraction, that is at the heart of generative AI’s ability to generate and combine intricately detailed patterns (LeCun et al., 2015).
One consequence of this mapping and embedding of features of training data onto parameters of the model is that the resulting parametric “representation” in these models cannot in principle be mapped back onto understandable features or aspects of our world, such as labels or attributes (Asperti and Tonelli, 2023). It is this feature that renders these models practically into black boxes in terms of how exactly they “learn” any meaningful features or characteristics from the data, or how these features are brought to bear in a single output (ibid.) 3 .
Additionally, the size of an AI model (the number of nodes and connections in the neural network) influences its performance, its capacity to discern and represent ever more nuanced patterns from training data (Devlin et al., 2019). Subsequent iterations of GPT, such as GPT-2 and GPT-3, improved upon the original version mostly by increasing model size and training on more extensive datasets, rather than through step changes in algorithmic sophistication. This increase in size allowed the models to be used across a much wider range of tasks without task-specific fine-tuning (Brown et al., 2020), exhibiting levels of performance that surprised even their developers (Roberts et al., 2020). It is the size of a model that provides ability, but also renders AI models inscrutable, into de facto black boxes (Castelvecchi, 2016), despite research efforts to locate concepts in sub structures of these networks (Räz, 2023).
Spelling out differences between AI and traditional computing
Having discussed how AI models are built and work, we can now see fundamental differences to traditional computing. First, AI models are built in a semi-automated way, using training algorithms to generate large mathematical structures that encode patterns, from which core functionality derives. This contrasts sharply with traditional programming, whereby “every step of the procedure is explicitly specified by its human designers and written down in a general-purpose programming language” (Kearns and Roth, 2019, 6). As a consequence, the very conception of what an algorithm is changes with AI. AI algorithms are probabilistic and inscrutable, in that computations cannot be traced through a series of deterministic steps (Asatiani, 2020), and their capabilities are often unpredictable (Schneider et al., 2023).
Second, AI models do not merely utilize data in the traditional way, they are foundationally derived from data, without storing it in any conventional sense. The role of data changes from a material operated on by an algorithm to a material from which algorithmic logic is derived. Traditionally, computing rests on a separation between explicit instructions (algorithms) and symbolic materials (data structures) acted on by those instructions (Dourish, 2016). AI collapses this distinction: the conventional separation between functional components that capture what a system does and databases that store the data it uses no longer applies.
Explicating information systems
So far, we have used surprising observations to problematize widely held assumptions about computing, revealing the fundamentally different ways in which AI models are built and function. We now embark to contextualize these insights for the IS discipline through a comparison with information systems, a comparison between a new entity and a well-known one, set up to reveal differences in ways that prove generative for IS research.
But what are information systems? This question has proven surprisingly difficult to answer, for three reasons. First, there is no single agreed-upon definition. Rather, the nature of information systems has been the topic of much debate, resulting in several papers that aim to define or classify them (see below). Second, since its inception in the 1970s the discipline’s understanding of its core entity has evolved considerably, as successive waves of technology added new functionality and pushed computing into all parts of business and society. Finally, it is in the nature of every sufficiently mature field that scholars need no longer explicate first principles, as they have internalized and share commonly accepted understandings of the field’s key concepts (Kuhn, 1970). Foundational characteristics of information systems are rarely discussed in research articles because the medium presumes a readership whose knowledge can be assumed.
How then can we construct an argument about something that remains at once fuzzy and implicit? We find an answer in Max Weber’s notion of the ideal type (Weber, 1904, 1978), a methodological tool for social science analysis. Note that an ideal type (German: Idealtypus) is neither “ideal” in the sense of perfection nor an ethical ideal. It is rather a conceptual tool that accentuates certain features of a phenomenon to facilitate comparison and understanding. Ideal types are by their nature generalizations that reflect a deep structure of thought (McIntosh, 1977). As such they are “pure” models that need not exist in ideal form in reality (though they often do). Social actors do not necessarily think in ideal types, and any given scholar or practitioner will hold a slightly different view, often tacitly, but these views nonetheless are related to, or evolved from, the ideal type (McIntosh, 1977).
Our ideal-type analysis proceeds in three steps: first, we discuss in general the nature of an information system, in particular its relationship to computing, or IT systems; we then home in on the role of “information,” and relatedly the role of information modeling in the development of information systems.
What are information systems?
Selected information systems definitions.

First, it is important to distinguish between computing, information technology, or IT systems on the one hand (Baskerville et al., 2022), and information systems on the other. Both Alter (2008) and Boell and Cecez-Kecmanovic (2015) highlight this as a key sticking point in definitional debates, which center on the relationship between technical and social aspects. Both highlight the difference between IT systems and information systems and follow a sociotechnical interpretation whereby information systems include IT as a technical component but also comprise social actors and their tasks. IT systems are conceived of as technical artefacts for capturing, processing, transmitting, and representing information (Baskerville et al., 2022; Cooper and Zmud, 1990). Information systems, assuming IT systems, “fulfill various actors’ – such as individuals, groups or organizations – information needs and requirements in regards to specific goals and practices.” (Boell and Cecez-Kecmanovic, 2015, 4959). Similarly, Alter (2008) defines an information system as “a work system whose processes and activities are devoted to processing information, that is, capturing, transmitting, storing, retrieving, manipulating, and displaying information.”
Second, understandings of information systems have evolved over time. Baskerville et al. (2022), investigating practitioner views, distinguish between a “classic view” and a more recent, more widely held “nexus view.” The classic view corresponds to organizations employing discrete IT systems to fulfil the information needs of their actors. The nexus view reflects an evolved technology landscape in which organizations deal with IT at a higher level of abstraction, “stitching together information (not just data) obtained from various platforms into packages of information that are in a form that is useful to the organization” (Baskerville et al., 2022: 394). With the proliferation of SaaS, hosted solutions, and cloud systems, few organizations, practitioners and scholars would still subscribe to the classic view as the most useful picture. Yet the nexus view evolved from and subsumes the classic view, which remains the one found in most introductory textbooks (see Table 1). For our ideal-type comparison, the classic view will allow making a foundational argument that applies to the nexus view by extension (we return to the nexus view later).
Finally, information systems are about information. This seems as trivial as it is obvious, but it is the core tenet at the heart of common definitions (see Table 1) and central to our argument. It is shared by both the classic and nexus views. We adopt the widely held view that data is a more technical term than information: computing systems keep data in databases, which becomes information when useful for a social actor (Lamb and Kling, 2003).
The role of information
While approaches to characterizing information systems differ in how social aspects are accounted for, all revolve around information. The field has seen several attempts to conceptualizing information (Boell, 2017; McKinney and Yoos, 2010; Mingers, 1996); we adopt Boell’s (2017) seminal classification, which distinguishes four different views: • The physical view embodies an abstract understanding of information, as a quality residing in the physical world, a mere material to be stored, computed, and transmitted, which corresponds to Shannon’s well-known conception (McKinney and Yoos, 2010). • The objective view stresses the significance of information, as signs that represent something for someone. It regards “information as contained in signs in an observer-independent way” (Boell, 2017, 6), as “objective facts.” Unlike the physical view, this allows distinguishing information from data, as something meaningful. • The subjective view follows the sign understanding but stresses the difference between the existence of signs and the specific meaning that signs represent to an individual, as information. • The sociocultural view extends the sign understanding to the social context and stresses that information is typically not idiosyncratically individual, but rather shared by social groups, because meaning is embedded in sociocultural interactions or a shared life-world.
What unites objective, subjective, and sociocultural views is a representational understanding of information, in the sense that information draws on signs, whereby signs refer to—or “signify”—something, like an entity or aspect of the world that is meaningful to individuals or groups; note that such aspects can be both physical or digital.
This view finds its most explicit, ideal-typical, expression in representation theory (Burton-Jones et al., 2017), which theorizes information, and information systems, as mediators between (social) actors and their worlds, and how information systems (as sociotechnical systems) are designed and developed to capture and organize information (Wand and Weber, 1995). Following this view, “the essential purpose of information systems is to provide representations of individuals’ or groups’ perceptions of real-world phenomena” (Burton-Jones et al., 2017, 1308), to keep abreast of (events in) the world through representation rather than direct observation (Burton-Jones and Grange, 2013).
Strong expressions of this view posit that relevant aspects, entities, relations, activities, procedures be “re-presented” faithfully, that is, accurately and completely (Burton-Jones et al., 2017), and that the information system aims to “maintain an up-to-date faithful representation if it is to remain useful.” (ibid, p. 1310). The modeling of information, often termed conceptual modeling (Wand and Weber, 2002), is then an important cornerstone of how information systems are designed and developed.
Information modeling as the basis for information systems design
According to representation theory (RT), the purpose of an information system is to embody in its “deep structure” the scripts that describe the phenomena it seeks to represent (Burton-Jones et al., 2017). Scripts are the key constructs generated, refined, and transformed during the development process until they become computer code executable by a machine. They find expression in conceptual models that explicitly capture the constructs and conditions necessary for the information system to create and maintain representations.
In practice, this takes the form of conceptual modeling techniques used in the specification phase of IS design, such as entity-relationship diagrams (ERDs) for information modeling (Chen, 1976) and business process modeling notation (BPMN) for process modeling (Dumas et al., 2013), practically supported by a range of dedicated software tools (Riemer et al., 2011). These “models help designers to understand the static and dynamic aspects of a to-be-designed information system (…) and make their domain understanding explicit” (Malinova and Mendling, 2021: 2101). Data models serve as explicit representations of how IT systems store and distribute data about aspects of the world; process models capture the procedural logic by which IT systems transform and distribute information for social actors.
Ideal-type conceptualization of information systems
We can now explicate the characteristics of an ideal-type information system. We note again that deriving this ideal type is not to claim it represents how most practitioners or scholars view information systems today. Rather, our claim is that it captures a foundational archetype, more akin to a genus, that underpins the multitude of concrete understandings found today, which evolved from these foundational characteristics. The ideal type is close to what appears in many IS textbooks still in use (e.g., Laudon and Laudon, 2020; Piccoli and Pigni, 2018; Galliers and Leidner, 2009; see also Table 1). We use it as a canvas against which fundamental differences with AI systems can be revealed and discussed, and distinguish five foundational characteristics: • Information organization: Information systems capture and organize information for social actors by representing relevant aspects of the physical or digital world, in principle faithfully and accurately. • Information provision: Information systems manipulate, transform, and provide information in principle deterministically and reliably, serving the purposes of social actors. • Currency over time: Information systems maintain faithful representations over time as relevant aspects of the world continue to change. • Explicit design: Information systems are designed using conceptual explication (e.g., modeling techniques) that makes aspects of the world explicit as the basis for implementation. • Comprehensible systems structure: The decomposition of information systems into subcomponents is in principle comprehensible and auditable, resting on a foundational distinction between data (information) and functional logic (system behavior).
Analysis: How AI systems are different to information systems
We have outlined how AI systems are built and how they work, and derived an ideal-type understanding of information systems. Using the five ideal-type characteristics, we now juxtapose the two to show in detail how they differ. Our claim that AI systems are not information systems does not imply that AI falls outside the scope of the IS discipline (quite the opposite). But it captures the ways in which AI systems are different from what we are accustomed to, and that these differences matter when studying them.
Recall that we take AI systems to be those that derive their main capabilities from a generative, foundation or large language, model. ChatGPT serves as an ideal-typical example, as a sociotechnical system including users and their tasks—without user intent expressed in prompts the system will exhibit no behavior at all. Where information systems have conventional IT systems at their core (Baskerville et al., 2022), AI systems have an AI model at theirs.
How do AI systems organize information?
AI systems deal with “information” very differently from information systems. Only on an abstract, physical (Boell 2017) or token view (McKinney and Yoos 2010) could AI systems be said to store and organize information, namely according to the principles of their deep learning architecture. Conceptually, however, this way of encoding information is fundamentally different from how information systems organize information in our ideal-type understanding.
Sociotechnical approaches, as captured in the sign view or more narrowly in representation theory, take information to be something understandable by social actors with respect to aspects of their worlds. Practically, a piece of information pertaining to a business transaction, stored and processed by a conventional IT system, can in principle be retrieved faithfully in exactly that form later. This is a key constitutive feature of information systems and should appear obvious. Yet by contrast, information “stored” in the latent space of an AI model amounts to a form of information transformation or compression (Asperti and Tonelli, 2023). It is a constitutive feature of this process that information encoded from training data cannot reliably be reconstructed and mapped back from the latent space to real-world concepts (ibid.).
A growing body of research investigates both technically and conceptually how information is encoded in the latent space of deep learning models. For example, researchers measure the “information capacity” of language models (Morris et al., 2025) or examine how and where particular concepts might be located in the latent space (Räz, 2023), seeking to improve interpretability and explainability. Both are in principle lacking in any deep learning network of sufficient size (Castelvecchi, 2016). The very existence of this research underlines our point: the way these systems handle information is fundamentally different from how information systems do. Dedicated research is therefore needed to make these differences accessible to more conventional understandings.
We conclude that, where information systems are in principle able to represent and store information about aspects of the world reliably, accurately, and faithfully (even when this falls short in practice as data quality is often lacking), and in ways understandable by relevant social actors, AI systems are not. This is not to say that AI systems cannot in practice prove more useful for “informing” than conventional systems. The ability to store and reproduce information faithfully is no guarantee of veracity, as the old adage “garbage in, garbage out” reminds us. A social media system might store and reproduce user content faithfully, yet a generative AI system like ChatGPT could still prove a better source of “collective intelligence” if the base quality of information in social media is low. Our argument is that any analysis of such practical differences must proceed from an understanding of the difference in nature between the two types of systems.
How do AI systems provision information?
In line with the different way AI systems “store” information, their provision of information is equally different, as a function of how information is encoded in the AI model. Any response by an AI model, for example, when a user seeks to “retrieve” information, is a probabilistic output based on encoded patterns in the latent space. LLMs “are trained to predict the next word in a string, given the preceding words,” drawn from a probability distribution of all possible words (Chatterji et al., 2025).
The probabilistic nature of AI model outputs is at the heart of the widely discussed phenomenon of “hallucinations”: the propensity of these systems to generate plausible-sounding yet incorrect information (Huang et al., 2023; Xu et al., 2025). Hallucinations are often seen as one of AI’s central challenges (Verspoor, 2024) and are commonly understood as outputs that deviate from verifiable facts or contradict established knowledge (Zhang et al., 2023). While frequently discussed as “failures,” hallucinations are widely recognized as an inherent feature or at least an “unavoidable aspect” of these systems (Xu et al., 2025). In fact, according to OpenAI’s own research, hallucination rates for their newer, more powerful models were getting worse, not better (Metz and Weise, 2025).
For our argument, hallucinations are a symptom of the fundamentally different way AI systems deal with information compared to information systems. Where information systems in principle provision information reliably and deterministically, in that users can retrieve exactly what was stored, AI systems do so probabilistically, with no built-in mechanism for guaranteeing accuracy. The way hallucinations are commonly regarded as a “failure” is itself evidence of how AI system behavior is implicitly judged against learned expectations of accuracy and consistency associated with ideal-typical information systems (Gustavsson and Ljungberg, 2021).
Several techniques have emerged to alleviate hallucinations and improve accuracy. The most prominent is retrieval augmented generation (RAG) (Holstein et al., 2025; Li et al., 2024b), which connects the AI model at the core of the system with additional data via vector databases (Jing et al., 2024) or live search indexes (Memon and West, 2024). In RAG systems, documents are typically “vectorized”: their information content is encoded into a high-dimensional numerical space similar to how LLMs are built to make them accessible for response generation. This reduces hallucinations but cannot fully suppress them, as responses are still generated by the core AI model (Li et al., 2024b).
These efforts to alleviate “shortcomings” underline our point about fundamental differences. While it may be practically possible to suppress inaccuracies in particular AI systems to negligible levels in practice, the fundamental differences matter precisely because such measures must be taken, and accuracy remains a significant technical challenge. AI systems are fundamentally different in how they provision information, with direct implications for information accuracy and reliability.
How do AI systems maintain information currency over time?
Deep-learning-based AI models are pre-trained (the “P” in “GPT”). Informational content is encoded during training, when the model is built. Once training concludes and the model is deployed, there is no capacity for updating the model further. Contrary to frequent claims that “AI learns” (e.g., Berente et al., 2021), the latest generation of deep-learning-based AI models do not update during runtime or learn from user interactions continuously (Riemer and Peter, 2025). This is why AI systems like ChatGPT often provision outdated information about current events.
This contrasts markedly with the capacity of information systems to maintain currency in their representation of evolving phenomena. Again, several techniques have emerged to alleviate this limitation. Memory features record and retain up-to-date information about the user, such as a history of prior prompts. AI systems are also connected to traditional IT components, such as search engines or RAG systems, to retrieve and present more current information. While these improve information currency, AI models still lack the ability to update information or correct mistakes. Recent research has further shown that these systems struggle with content outside their training distribution; the BBC found that AI systems introduce factual inaccuracies when summarizing news content in more than half of test cases, because the base information in the model is not current with newer developments (Rahman-Jones, 2025).
Again, the mere existence of these mitigating techniques employing traditional computing components reinforces our point about fundamental differences. AI models underpinning AI systems, unlike the IT systems (databases) underpinning information systems, are unable to keep track of changing information over time.
How are AI systems built?
AI systems development contrasts markedly with IS design. In information systems development, social actors’ understanding of phenomena is typically captured in conceptual models. These models can then serve as the basis for translating those understandings into an IT system (“models provide traceability from requirements to implementation decisions.” Malinova and Mendling, 2021: 2102).
With AI, there is no data model or procedural model to be “implemented” (Cantwell Smith 2019). As our second surprise showed, even AI engineers understand what they do as more akin to a craft than traditional software engineering. AI systems are built iteratively through trial and error, mirroring how AI algorithms “learn” their patterns. What a particular AI model is capable of doing then becomes an empirical question, investigated through extensive testing and benchmarking after a round of training has concluded (Hendrycks et al., 2021).
A growing body of research develops techniques to improve both the pre-training of the foundation model and the fine-tuning that occurs in post-training. Most notable are experiments with new ways of defining good responses for reinforcement learning from human feedback, such as checklists (Viswanathan et al., 2025), synthetic examples (Ye et al., 2024), or structured rubrics (Gunjal et al., 2025). In each case, the existence of such research speaks to AI development as an iterative process of tinkering, whereby different techniques are tried and their effects on honing model behavior measured against benchmarks. This stands in stark contrast to traditional information systems design, where system behavior is largely a product of explicitly designed data structures and functional procedures that reflect what stakeholders want the system to do.
How can AI systems be audited?
It is widely acknowledged that AI of any kind is inscrutable (Berente et al., 2021) and lacks explainability (Bedué and Fritzsche, 2022; Jackson and Panteli, 2024). This is all the more true for AI systems that derive their core capabilities from a foundation model, where it is generally impossible to know which training data features become associated with particular outputs (Asperti and Tonelli, 2023; Castelvecchi, 2016). Crucially, the traditional distinction between data and functionality dissipates in these systems, because system behavior is derived from data itself during training. What the system can do (e.g., assist in various writing tasks) and what the system “knows” (e.g., the informational content encoded in the model) both derive from the same training process.
By contrast, information systems maintain a distinction in principle between data structures—what kind of information the system can deal with and keep track of—and procedures—the ways in which such data is manipulated and transformed. Because both are the product of explicit design, system behavior is also in principle deterministic and auditable. Information systems can further be decomposed analytically into various social and technical components responsible for different functions or behaviors.
It is certainly true that there are practical limits to how information systems can be decomposed or audited, given that they often become impractically large and complex, and given the human element in shaping system behavior. Nonetheless, such decomposition is possible in principle and often necessary, for example, where information systems are employed for record keeping. AI foundation models, by contrast, are practically inauditable, given how information is encoded and their probabilistic nature.
Selected ideal-typical characteristics of information systems, compared to AI systems.

Discussion: Implications and new questions for IS
AI systems are not information systems. That was our thesis. We asked, should we care? The answer is both yes and no.
Yes, because we have revealed fundamental differences between the two. Against an ideal-type understanding of information systems, we might well conclude that AI systems are not information systems, at least conceptually. When the technology du jour does not fit the characteristics that traditionally defined the entity that gave the IS discipline its name, we should pause and ask what this means.
No, because we do not want to imply that AI systems are out of scope for IS. First, AI systems like ChatGPT are obviously widely used to “inform.” According to a recent study by OpenAI, “seeking information” represents 24% of all ChatGPT use instances and was the fastest growing category in the year prior (Chatterji et al., 2025). Second, our collective understanding of what information systems are, and thus what falls within the scope of IS, has evolved significantly over the past decades.
At the same time, many of the assumptions about computing that found explicit expression in our ideal-type characterization have become backgrounded over time. As each iteration of technology builds on prior ones, the actual functioning of technology can usefully remain implicit and black-boxed, so long as systems behave according to learned expectations. This is visible in how practical understandings of information systems have moved from the classic view, which is close to our ideal type, to a higher-level nexus view concerned with combining and configuring information services, rather than creating and maintaining particular information systems as our ideal type describes.
AI systems present a fundamental break with these established understandings. They function and behave differently, and this matters both for individual users and for IS practitioners making decisions about their information systems environments. When systems are probabilistic instead of deterministic, when they make unusual “mistakes,” a deeper engagement with their characteristics becomes necessary. By extension, these differences present novel opportunities for IS researchers.
In the following sections we discuss implications for individual systems acceptance and use, for organizational applications, and for how the discipline understands systems design and development. It is beyond the scope of this perspective paper to treat these implications comprehensively or to unpack them across the breadth of topics of interest to IS scholars. We provide selected ideas by way of example and pose initial questions, acknowledging that the implications are broader and will require further work. We summarize the discussion in Table 3.
Implications for systems acceptance and use
IS research on the adoption and use of AI systems has mushroomed recently, focused mostly on systems like ChatGPT in work and organizations (e.g., Li et al., 2024a; Retkowsky et al., 2023; Von Brackel-Schmidt et al., 2025), spanning areas such as creative (Benbya et al., 2024) and knowledge work (Retkowsky et al., 2023), leadership support (Höhener, 2025), and search and information retrieval (Schuetzler et al., 2024; Wang, 2024).
AI systems are increasingly displacing search engines (Wang, 2024) and online forums (Xue et al., 2023). Programmers now frequently use ChatGPT instead of searching or interacting on forums like Stack Overflow (ibid.). Statements such as “ChatGPT is capable of catering to users’ information search needs, similar to traditional search engines such as Google, Baidu, and Yahoo” (Wang, 2024: 1) speak directly to this substitution effect.
Yet, while differences between AI systems and traditional information systems are sometimes acknowledged, for example, “a language model’s main purpose is to generate text, not to provide accurate information” (Schuetzler et al., 2024: 7504), and issues with inaccuracies or hallucinations are noted as “limitations,” conceptual differences are often glossed over. Many papers refrain from discussing technical foundations or characteristics of AI systems at all, beyond general statements about functional capabilities. As a result, AI systems are often treated as information systems without examining what might be different (e.g., Meservy et al., 2024; Wang, 2024).
It is not surprising that users make no categorical distinction between AI systems and information systems, as they may use one like the other. But as IS scholars we should keep foundational differences firmly in sight. When users are surprised by inaccuracies and “hallucinations,” we must theorize from a well-grounded understanding of AI systems characteristics. The differences between systems that provide faithful accounts, for example, Stack Overflow categorizing user-generated solutions to frequent coding problems, and systems like ChatGPT generating solutions from encoded patterns, matter. The latter may well prove more useful, but such conclusions should be the result of empirical questions that proceeds from, and incorporate, differences in systems characteristics.
These differences will also matter for acceptance and trust. Users unaware of how AI systems work may hold unrealistic expectations and be surprised when outputs are unreliable, leading to distrust (Colville and Ostern, 2024). Workers could feel uneasy due to the “uncontrollability” of AI, and its lack of understandability and explainability (Bedué and Fritzsche, 2022; Jackson and Panteli, 2024). At the same time, users report transparency and reliability as important antecedents to trusting AI systems (Glikson and Woolley, 2020). Yet as we have shown, deep learning AI systems lack these traits at a fundamental level compared to traditional systems. This mismatch opens important avenues for research that thematizes both user expectations grounded in conventional understandings and actual AI systems characteristics.
Conceptual distinctions between AI systems and information systems also have the potential to advance research into algorithm aversion (Dietvorst et al., 2015); the study of why individuals often react adversely to algorithmic decisions compared to human ones (Jussupow et al., 2024). This field has yielded conflicting results, as humans sometimes prefer and sometimes reject algorithmic decisions. We suggest it might benefit from a fuller discussion of differences in the kinds of algorithms used. It will likely matter, at least in some situations, whether the algorithm is deterministic and rule-based or probabilistic and inscrutable.
We offer the following research questions as a starting point: • Do users unaware of AI systems characteristics hold different expectations about accuracy and reliability than those with AI literacy? • Does the nature of the system make a difference when users receive “surprising outputs”? • How do users construct their views about AI systems when experiencing inaccuracies, in the absence of AI literacy? • What is the effect of using various kinds of AI systems for informing practices, compared to traditional information systems? • Does knowing about the nature of the algorithm (deterministic vs probabilistic) influence algorithm aversion? If so, in what ways?
Organizational application and management
The Air Canada case highlights the risks of integrating AI systems into a traditional information systems landscape without due consideration of their differences. As new techniques emerge for embedding AI foundation models into information systems environments, new questions arise for systems management, risk, governance, and user expectations.
The nexus view of information systems shows that for many IS practitioners the components they configure are already black-boxed to some extent. This works well as long as those components behave in predictable and well-understood ways. But what happens when AI systems enter the fray? When information provisioning becomes probabilistic rather than deterministic?
Before the recent wave of generative AI, organizational AI was mostly confined to tightly bounded functional capabilities such as image recognition, pattern classification, or predictive decision support (Berente et al., 2021). Now AI models are making inroads into the information systems landscape more broadly, taking over entire processes or tasks traditionally carried out by deterministic systems. Making the differences in systems characteristics explicit thus becomes more pressing.
For example, conversational AI components are used to make information in databases or document repositories accessible via natural-language chat interfaces, often using retrieval augmented generation (RAG) (Holstein et al., 2025; Li et al., 2024b). While RAG is associated with “reducing hallucinations” compared to standalone AI systems (Li et al., 2024b), it compromises significantly on accuracy and reliability compared to traditional systems, given that outputs are still generated probabilistically.
Such inaccuracies will be further amplified when AI models carry out complex, multi-step processes, as seen in recent approaches to “agentic AI” (Purdy, 2024). Small inaccuracies or hallucinations may propagate and compound across a series of inference steps. Employing such components within a traditional information systems environment will likely require combination with strict, rule-based frameworks like robotic process automation (RPA) (Ribeiro et al., 2021; Syed et al., 2020). And what happens when probabilistic, agentic systems operate inside systems of record, such as accounting systems? Will this not compromise the reliability and accuracy required for operational compliance?
When organizational information systems are augmented or replaced by AI systems, it raises questions not only of trustworthiness for users (Colville and Ostern, 2024) but also of risk and liability for decision-makers (Baxter and Schlesinger, 2023; Jöhnk et al., 2021), especially in high-stakes, regulated domains such as medical, financial, or legal advice. For IS researchers, “accuracy” and “reliability” will now need to be treated as independent variables in studying systems success. These issues compound the already widely discussed matters of bias and fairness, which stem from how AI functionality is derived from data (Van Giffen and Ludwig, 2023), and the inscrutability and lack of explainability of AI systems (Bedué and Fritzsche, 2022; Jackson and Panteli, 2024), given that outputs are generated via inference rather than clearly specified rules.
While earlier work expressed hope that new approaches to AI might improve explainability (e.g., Benbya et al., 2020), recent systems based on deep learning and foundation models do not afford practical explainability. Calls for IT departments to “find ways to untangle the computations and mathematics at play” (Someh et al., 2022) or “to implement additional measures of explainability” (Väyrynen et al., 2025) will fall flat. Similarly, it is unhelpful to put forward “ethical AI” principles demanding explainability, transparency, or accountability (e.g., Jovanovic and Campbell, 2022; Rana et al., 2024; Wahde and Virgolin, 2021) from a technology that lacks these features foundationally. Rather, organizational decision-makers, board members, policymakers, and IS researchers should acknowledge that foundational systems characteristics challenge established governance practices (Schneider et al., 2023) and explore new ways to manage risks.
For decision-makers and corporate boards, this means becoming acquainted with the foundational characteristics, systemic differences, and inherent risks of AI systems (Van Giffen and Ludwig, 2023) and integrating these into IS strategy rather than treating them as separate matters (e.g., Kučević, 2025). Empirical research might investigate how organizations deal with emerging liability risks from AI systems (Jöhnk et al., 2021), such as by crafting “human in the loop” configurations (Grønsund and Aanestad, 2020) for mission-critical processes.
Without a sound conceptual understanding of AI systems characteristics, practitioners and IS researchers alike risk making a category error when integrating AI systems into information systems environments. Organizations risk “polluting” carefully built information and knowledge management environments that traditionally assured reliable record keeping, as AI systems have been characterized as “mis- or disinformation” (Sun et al., 2024) or even “bullshitting” systems (Hicks et al., 2024). For IS researchers, this tension opens timely research questions: • What is the trade-off in risk and reward of replacing traditional information-delivery systems with conversational systems using AI models and RAG components? • How are AI systems components best embedded into information systems to manage reliability and inaccuracy risks, for example, through human-in-the-loop configurations? • How can LLM-based inference in agentic AI systems be integrated with rule-based process controls to balance performance and reliability? • How can measures of accuracy and reliability be integrated into systems management? What are appropriate metrics? • How can a lack of explainability be mitigated in both internal and stakeholder-facing use? • What upskilling is needed across organizations for responsible application of AI systems within traditional information systems environments?
Systems design and development
As we have shown, AI systems not only function differently, they are also built differently. AI requires both entirely different design principles and new approaches for integrating it into traditional systems environments. While some initial IS work has addressed the former (e.g., Abbasi et al., 2024; Pathirannehelage et al., 2024), and much is being written outside the discipline on the technical development of AI systems, the latter opens a particularly important area of study for IS. How will the very different capabilities and characteristics of these two approaches be combined into coherent systems environments, making use of new AI capabilities while preserving the integrity of information systems.
Design principles for AI systems will revolve around their very different data requirements, the need to adapt pre-trained models to changing requirements, and the difficulties of interpreting and justifying outputs. AI systems design requires new data management and curation practices (Mikalef and Gupta, 2021), given the fundamentally different role of data in building AI systems (Jarrahi and Glaser, 2025) and the importance of data quality in curating training datasets (Asatiani et al., 2020).
Integrating AI development into the broader canon of IS design (science) approaches will require reconciling very different design philosophies (Abbasi et al., 2024). As we have shown, AI model training is much less linear and top-down, and much more experimental than traditional approaches. This turns the design of AI systems, and their integration as conversational engines or data analysis components into information systems environments, into an empirical research problem, whereby developers must test model behavior to reveal capabilities and understand risks (Ni et al., 2025).
Main issues raised by different characteristics of AI systems vis-à-vis information systems.
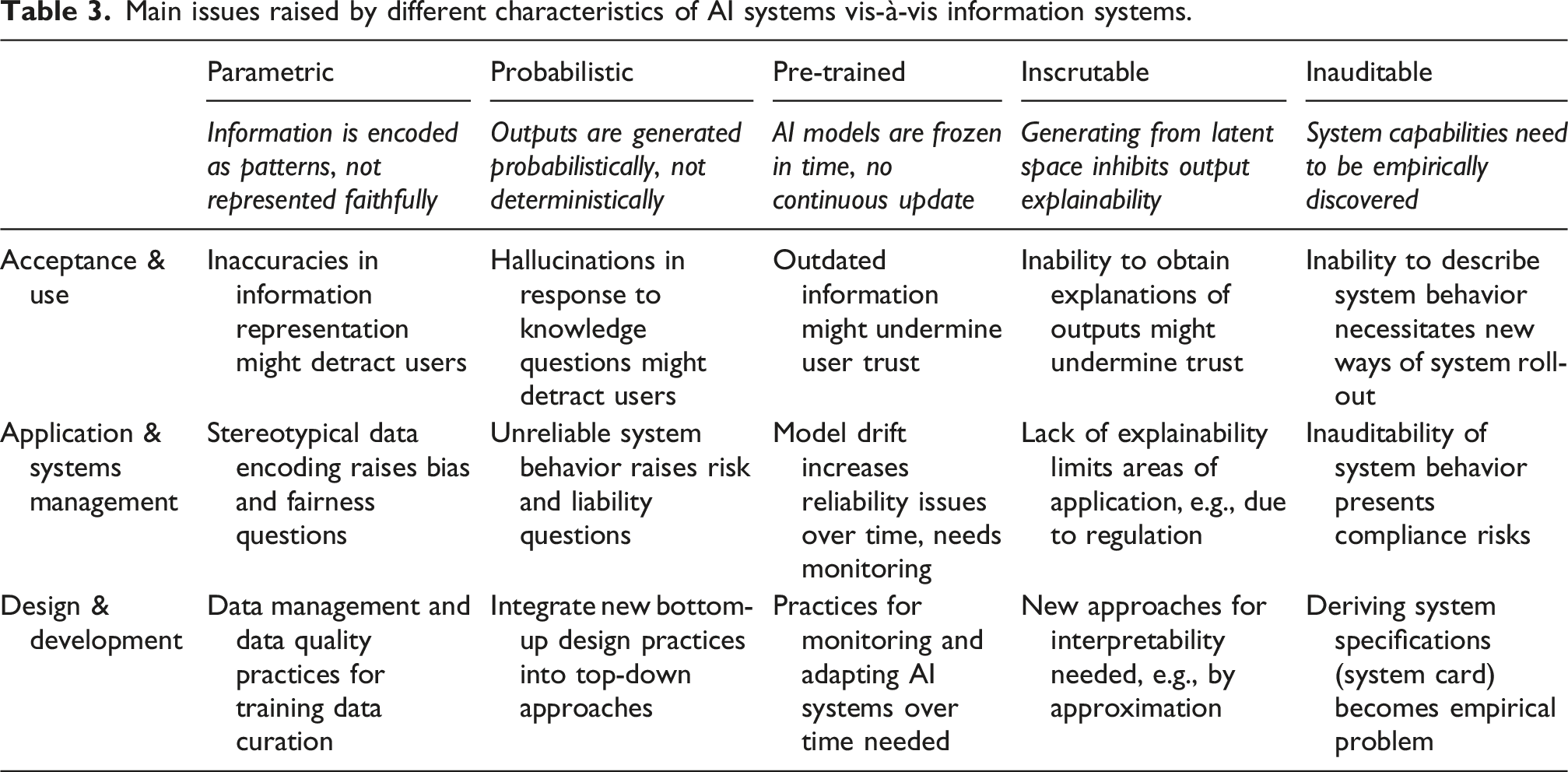
The following presents a list of potential new research questions: • How can data quality practices for training data curation be integrated into traditional data management? • How are AI components best represented in traditional systems modeling approaches? • What would an approach for RAG data modeling look like, particularly one that integrates RAG with traditional database applications? • What do best-practice approaches for ascertaining and certifying foundation model capabilities look like? • What does a pragmatic integration of top-down with bottom-up development look like? • How will AI-assisted coding be integrated with traditional IS design practices? • How do we account for new reliability and accuracy requirements in traditional modeling approaches?
The bigger picture: Implications for the IS discipline at large
Since its emergence in the early 1980s (Keen, 1980), the IS discipline has tracked shifts in computing from insular, desktop-bound systems to networked (McCauley, 1983), Internet (Braa and Sørensen, 1998), and mobile computing (Varshney, 1999). Information systems have outgrown organizational boundaries to become inter-organizational (Klein, 1996) and then ubiquitous (Johnston and Waller, 2009). The discipline’s focus widened from representational notions of information for individual organizational purposes, embodied in the classic view (Baskerville et al., 2022), to a configurational view whereby information is provisioned by various services, as embodied in the nexus view (ibid.), to broader “digital” understandings whereby information mediates everyday experiences, captured in the term “experiential computing” (Yoo, 2010).
Each widening in scope has brought new opportunities, challenges, and research questions. The emergence of AI might appear no different in that respect. Yet our analysis shows that it is different at a foundational level. The previous evolutionary waves were underpinned by the same procedural, deterministic approach to computing and the same explicit understanding of information. AI systems, as probabilistic computing with parametric encoding of information content, are different in this foundational sense.
It has long been argued that the discipline must engage more directly with the “IT artifact,” the technologies underpinning the sociotechnical phenomena of interest to IS scholars (e.g., Orlikowski and Iacono, 2001), and that IS research lacks “deeper engagement” with the nature of computing (Akhlaghpour et al., 2013). One might counter that when technological foundations are stable and well understood, and this understanding is widely shared among practitioners and scholars, much can remain unspoken and backgrounded. Research can proceed efficiently based on shared assumptions (Kuhn, 1970).
Yet when foundations shift profoundly, explicit attention is required and previously unnoticed assumptions become problematic, as our surprising observations illustrate. Without such attention and a recasting of foundational assumptions, the field risks making a category error in its understanding of AI systems. On the one hand, AI systems are too often taken to be unproblematically just another kind of information system, or the distinction goes unthematized entirely. On the other hand, the void in conceptual understanding is often filled with unhelpful anthropomorphic analogies that cast AI in terms of human capabilities. We encounter too many examples of both in our own editorial work (Riemer et al., 2026).
When AI goes unthematized as a technology, it tends to be treated merely in terms of user perceptions, even when studies investigate the fit between technology and task (e.g., Huy et al., 2024; Parthiban and Adil, 2024). Or it is discussed as just another kind of IT system, such as when we read that users use “ChatGPT to fulfill their information retrieval needs,” (Wang, 2024), or that LLMs “offer unique information retrieval and synthesis capabilities” (Meservy et al., 2024). We put forward our analysis to arrive at a more nuanced understanding that helps see differences and new questions. It is one thing to acknowledge that users may treat AI simply as a search system, and another entirely to base one’s own research conceptualizations on such understandings.
The same applies to the second category error. AI companies may describe their creations in anthropomorphic terms (e.g., OpenAI, 2024), and users may fall for the anthropomorphic seduction of conversational interfaces (Peter et al., 2025), but IS as a field should not. Despite its framing as artificial “intelligence” and the human-like feel of such technologies in interaction (Shanahan et al., 2023), we must not lose sight of AI’s nature as a particular kind of computing system. Otherwise, espoused understandings slip into misleading or outright incorrect anthropomorphic analogies.
We already frequently see studies on generative AI that talk about “AI’s capacity to learn and adapt dynamically” (Wang, 2024), AI’s “capacity to improve through experience” (Höhener, 2025), “AI’s continuous learning and adapting” (Mohanty and Grundstrom, 2025), or that “GAI models simulate how we think by relying on algorithms that ‘learn’ with each use” (Sabherwal and Grover, 2024), all assertions that are demonstrably incorrect against our analysis. Or AI is thematized as a “proactive social actor” (Ran et al., 2025) or “co-equal collaborator” (Saller et al., 2026), giving rise to terms such as machine behaviorism (Ni et al., 2025), human-AI collaboration (e.g., Ran et al., 2025; Von Brackel-Schmidt 2025), or human-AI teams (Müller et al., 2026), whereby AI is treated more akin to a team member rather than a computing system. Attributing intent, autonomy, and the capacity to learn to a system that derives its core functionality from a stateless, pre-trained mathematical model deserves at least explicit engagement with its technical characteristics—even when users might treat AI as a human-like actor.
Our intent here was not to critique existing work in detail, but to lay out the novel characteristics of AI systems. We argue that doing so will help position the IS discipline as an influential voice in AI research, filling a gap between highly technical work in AI development and higher-level studies of AI use effects. The intersection of social and technical understandings of systems is where the IS discipline has its strengths. We put forward our insights to strengthen the “techno-conceptual” aspects of studying the use, organizational application, and design of AI systems as part of a broader IS research agenda.
Spelling out conceptual differences is also necessary to protect, rather than water down, established understandings of what counts as “information” and the role of information systems in “informing” practices. Without conceptual boundaries and explicit discussion of differences, the field risks vacating hard-won theoretical ground.
Conclusion
We put forward the thesis that AI systems are not information systems. Starting from surprising observations about AI use and development, we problematized commonly held assumptions about computing. Our comparison of AI systems with ideal-typical characteristics of information systems revealed fundamental differences across several dimensions: how they treat information, represent phenomena, maintain currency over time, and how they are built. AI breaks with conventional understandings of information systems in profound ways.
But the significance of this finding extends beyond the analytical comparison itself. The IS discipline adapted successfully to networked, mobile, and ubiquitous computing without having to revisit foundational assumptions, because the computational substrate underpinning these changes remained stable at base. Now, AI disrupts this stability. The question, then, is not whether IS can study AI systems—it obviously can (and should)—but whether it can do so well enough using inherited conceptual foundations. We posit that, without new conceptual foundations, the discipline risks theorizing the behavior, implications, and organizational integration of AI systems from assumptions that do not hold for this novel technology it seeks to explain.
At the same time, there is a productive tension that should not be resolved prematurely. The arrival of systems that do not deal in information in any traditional sense could paradoxically be the most important thing to happen to the discipline’s understanding of information itself. AI forces us to articulate what we have long taken for granted about computing, information, and information systems. The question for the IS community is whether it treats this as an invitation to sharpen its core constructs, that is, defining with greater precision what its established concepts mean in contrast to what AI systems are, or to broaden them, developing new conceptual vocabulary adequate to the novel characteristics of AI. We suggest that both responses are legitimate, and that the debate between them will prove generative for the discipline’s continued relevance as AI reshapes computing at its core.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.