
Abstract
Human emotions trigger physical reactions of the body that can be interpreted using artificial intelligence (AI) methods. AI-enabled detection mechanisms offer new opportunities to gain deeper understanding of human emotions. AI is already able to recognize basic emotions, such as joy, anger, or fear, but is challenged to detect complex emotions accurately, such as when someone is lying. The human voice conveys a wealth of subconscious information. This research utilizes natural language processing (NLP) to present a novel AI artifact that analyzes solely the human voice to detect whether a person is speaking to their true conviction. This is useful for use cases where it is important for decision makers to know whether a person’s arguments are truthful. A suitable use case could be corporate recruitment, an area where people traditionally lie a lot. The artifact can support human resource (HR) personnel in making better decisions by overcoming their naturally weak ability to detect deception. To suit the sensitive context of recruitment talks, the artifact is designed to protect data privacy, and thus has no speech recognition capabilities and does not store information that identifies the speaker. The model detects deceptive statements with ∼82% accuracy. Integrating the artifact into corporate business processes would enable managers to more accurately detect deceptive behavior of their interview partners. The increasing use of novel AI artifacts to compensate for humans innately weak capabilities to detect other people’s complex emotions will challenge our theoretical conceptualization of organizational decision making in light of emerging human–AI hybrids.
Keywords
Introduction
Artificial intelligence (AI), defined as “the ability of machines to perform human-like cognitive tasks” (Benbya et al., 2020a: p. 9), has made enormous progress over the last years. Previously, AI was primarily used to support decision making by providing novel analytical information resulting from the automated analysis of huge amounts of data. Nowadays, modern technologies enable machines to learn and draw conclusions on a completely new level (Strich et al., 2021). Contemporary research has progressed into complex areas such as analyzing human emotions (Bagozzi et al., 2022) and predicting human behavior. These topics are high on scholars’ as well as practitioners’ agendas (Benbya et al., 2021; Huang and Rust 2024; Storey and Park 2022; Yang et al., 2021).
Corporations are interested in using AI to better understand their customers. They want to serve them better, increase retention (Ganesh et al., 2000), sell more products (Rainsberger 2022), reduce operational costs (Yang et al., 2021), and intensify their relationships with them (Huang and Rust 2024). Being able to automatically detect whether a person is being deceptive is another area of great interest (Suchotzki and Gamer 2024). This knowledge could enhance the capacities of insurance companies to identify false claims when customers report damages, or those of investment bankers to determine whether CEOs are truthfully reporting on the financial position of their company (Yang et al., 2023).
Many human interactions happen when people are not physically in the same room. Phone conversations, voice-assisted interactions over computers (Griffin 2021), and video conferencing are commonplace in business communications. This trend enables AI tools utilizing natural language processing (NLP) to analyze the voice of the speaker without the need for special equipment. For example, call centers could use AI to improve customer interactions by detecting anger or dissatisfaction in the caller’s voice (Sudarsan and Kumar 2019) and providing the handling agent with corresponding recommendations on how best to deal with the detected negative emotions of the caller (Ponomareff 2017). Customers in severe distress may be assigned to faster queues or to agents specifically trained to de-escalate the situation.
AI continues to advance into our everyday lives, more or less obviously and transparently. The societal implications of this advancement are yet not fully understood, and there is no way back (Tiwari 2023). Without doubt, unintended consequences will occur (Nyman et al., 2024) and people will be affected personally (Rainie et al., 2023), which can make many people afraid of AI. However, when corporations are able and willing to minimize the potential negative consequences of AI (Suchotzki and Gamer 2024), it offers a wealth of useful applications that can benefit society at large.
Analyzing the human voice offers unique opportunities because speech carries a lot more information than just the content of the spoken words. Contemporary NLP research is well advanced in detecting basic emotions, including joy, love, surprise, sadness, anger, and fear (Shaver et al., 1987). However, identifying complex emotions like loneliness, guilt, or nervousness still remains a challenge.
A specific area of practical and academic interest is detecting truthfulness, which is common in and key to understanding human interactions. Identifying whether someone is speaking the truth is complex and cannot be reduced to the simple question of whether or not the person is lying, which may be colored by different qualities, such as telling a white lie, not telling the whole truth, or twisting the truth. However, the common characteristic of all forms of deception is that the person aims to convince the audience of a statement that is not in accordance with what they believe to be true.
DePaulo et al. (2003) found initial evidence that the way a person speaks may be a cue to detecting deception, which Yang et al. (2023) findings support. We hypothesize that being dishonest triggers an emotional status that subconsciously affects the voice of the speaker, which AI artifacts can detect. We tested this hypothesis by developing and testing an AI-based artifact that can identify whether a person has deceptive intentions solely from analysis of natural speech.
A common challenge of NLP research is the limited availability of data sets for training purposes. To generate a data set of people’s emotions when giving false statements, we conducted a controlled experiment in a debate club setting and recorded the voices of 92 participants arguing for or against a randomly assigned polarizing topic. We used the dataset to test several AI models, the best of which correctly identified positives (argument represents true conviction) and negatives (argument does not represent true conviction) with 82.4% accuracy.
This artifact was developed to support a practical use case in a human resource management business process, namely determining whether applicants are telling the truth in a job interview/recruitment situation.
Information systems (IS) is an interdisciplinary research field that studies the design, development, use, and management of information technology (IT) and its impact on individuals, organizations, and society. This research contributes to theory in various ways. From a design science perspective, this research advances the automated detection of complex human emotions and explicates design principles to guide the development of related AI artifacts. Our research also advances the adjunct research field of computer science by providing novel insights into the capabilities of AI/NLP and by presenting an AI model that can detect deception in speech more accurately than comparable published models. In the field of psychology, our research contributes to the theoretical discussion of human emotions and especially their measurability, as well as the question of whether ‘lying’ is an emotion.
The artifact developed is not only a technical innovation, but also leads to a conceptual expansion of decision-support logic in a high-stakes environment that traditionally strongly depends on human intuition in decision making. It adds to our understanding of the working relationship between humans and advanced AI artifacts. By enabling humans to incorporate automated emotion detection into complex organizational decisions, this type of artifact paves the way for new types of hybrid organizational decision-making processes, extending our current conceptualization of these matters. Consequently, the emerging human–AI collaboration taxonomies need to be amended to reflect this new option.
The article is structured as recommended by Gregor and Hevner (2013) and follows the steps of the Design Science Research (DSR) process proposed by Peffers et al. (2007): Following this introduction, we identify and motivate the problem to be solved, provide some contextual background and report on related work. Thereafter, we derive objectives for the solution, based on the design requirements and design principles. Subsequently, we describe the experiment to gather the training data and present the design and development of the artifact. Finally, we demonstrate the applicability to practice and evaluate the artifact within the selected use case.
Following the reporting on the technical development, we elaborate on the implications for theory and practice, explicate the limitations of this work, provide avenues for further research, and close the paper with a conclusion.
Problem identification
This research was initially inspired by the case of George Santos, a former elected member of the US Congress, who knowingly provided false statements on his résumé (see, e.g., Kohli 2023). He apparently did not consider it wrong or illegal to provide incorrect information knowingly, defending his actions by saying, “most people stretch the truth on their résumé” (Boyle 2023). Closer investigation shows that this appears to be true: • The reference checking company Checkster reported that 78% of the candidates who applied for a job admitted that they misrepresented themselves on their application (Checkster 2020). • Resumelab stated that 93% of the respondents to their survey said they knew a person who lied on their résumé (Resumelab 2020). • When studying online behavior, Weitzel et al. (2019) found that more than 20% of job seekers provide incorrect information on their social media profiles to attract recruitment companies and almost 40% include untrue specifics related to job advertisements on their online profile.
The recruitment manager of an IT company confirmed in an interview with a German national newspaper, “One has to assume that every applicant lies to put her-/himself in a better light. However, there are the irrelevant small cheats and the big lies bordering on fraud” (own translation from German) (Schenz and Zeitung 2018). The manager classified four types of lies to illustrate the spectrum of untruthfulness: • Irrelevant cheats (e.g., made-up hobbies) • Tactical lies (e.g., “business travel is no problem for me”) • Justified lies if the question violates the statutory rights of the interviewee (e.g., “I do not intend to have children”) • Fraud (e.g., forged certificates or providing incorrect marks/grades).
Whereas the smaller cheats are unimportant, the consequences of serious lies can be harsh for the employee and costly (in terms of additional expenses and lost time) for the company. As one of the participants of our focus group stated: “We are in a labor market that favors the applicant, you know, a war for talent. These days, every new employee costs me around 20,000 EUR for headhunters, recruitment camps, onboarding, etc. If we have to terminate employment due to serious lies in the résumé, this money is lost and we need to start the whole process all over again. This is not only a monetary loss, it also costs us months…” (Expert 4).
Recruitment in Germany is traditionally based on the written materials provided by the applicant and one or more personal interviews, sometimes even a professional assessment center (Careerbee 2025). It is uncommon to request or consult personal references, so the recruitment process depends heavily on applicants telling the truth.
What do German job seekers lie about? A recent study (Statista 2022) identified three primary areas: • Exaggerating their responsibilities in the previous job • Listing capabilities they do not have • Lying about their tenure with a previous employer
Surveys show that the number of applicants providing incorrect information to potential employers rose sharply over the last years (Bolden-Barrett, 2017; Resume Templates, 2024). Anecdotal discussion with company representatives confirmed that this issue is in fact a great concern for many companies, specifically when hiring technical personnel. As the CEO of medium-sized software development company put it: “We have big problems, specifically when hiring graduates. The information they provide on their résumés often does not match their real life experiences” (personal communication). This raises the question whether it is possible to automatically detect whether a person is stating the truth before the costly part of the recruitment process, that is, in-person interviews, are conducted.
Research objectives and contextual background
Specification of research objectives
“Everybody lies” is the famous tagline of Dr. Gregory House in the American TV series House, M.D. The series main character refuses to talk to his patients because he does not trust their assertions. Instead, he solely relies on objective measures like laboratory test results. Although the series exaggerates this concept for dramatic purposes, there is a grain of truth in it. Research has found that not telling the truth or making statements that are different than one’s inner belief is frequent in human interactions (Serota et al., 2022). Unfortunately, people are notoriously bad at detecting false statements and are typically able to identify them only half of the time (Bond Jr. and DePaulo 2006; George and Robb 2021). In a large-scale experiment with human participants, Bond Jr. and DePaulo (2006) found that people with no training in detecting false statements were able to correctly identify deception with an average rate of only around 54%. Similar results are presented by Levitan et al. (2020), who developed a game in which participants without training in detecting false statements had to judge whether someone is telling the truth based solely on audio files. The participants detected the accuracy of the recordings 49% of the time, which corresponds to mere chance. More dramatically, in a recruitment context, Suen and Hung (2023) find that interviewers detect false statements less than 20% of the time. These concerning research findings were among the motivations to develop an AI artifact that is able to detect deceptive statements significantly better than people.
Dishonesty: Deception and lies
Deception is defined as the “deliberate attempt to mislead others” (DePaulo et al., 2003: p. 74). This deliberate act includes all forms of intentional dishonesty, but not unintended falsehoods communicated by people who are mistaken (human error), self-deceived (cognitive dissonance), or experience challenges like the Dunning-Kruger effect, according to which people unknowingly overexaggerate their own knowledge and capabilities (Kruger and Dunning 1999).
Research on deception has a long tradition in various areas of scientific research, including psychology, medical research, sociology and organizational sciences. This breadth may be explained by the fact that deception, although usually perceived as negative, is a very common social behavior that the average person performs on a daily basis (DePaulo et al., 2003) As Zuckerman et al. (1981, p. 2) put it: “Lying is a common aspect of interpersonal relationships.”
Research shows that there are various facets of deception, including “real lies, white lies, and gray lies” (Fox 2018). Common across all of the facets, however, is the fact that the speaker is aware of the wrongdoing, which leads to negative emotions like guilt and fear (Ekman 2004; Whissell 2023), that is, the “bad gut feeling” commonly felt when lying.
The role of emotions in deception detection
Not speaking the truth is a highly emotional issue for human beings. Emotions are complex constructs of human feelings (Fox 2018). In broad terms, one could say that “the term ‘emotion’ exemplifies [an] ‘umbrella’ concept that includes affective, cognitive, behavioral, expressive and physiological changes” (Tyng et al., 2017: p. 3). Thus, “an emotion is a complex state that combines feelings, thoughts, and behavior and is people’s psychophysiological reactions to internal or external stimuli” (Zhang et al., 2020: p. 104).
Shu et al. (2018) discuss several models of basic emotions and complex emotions containing mixed facets. These complex emotions remain mysterious and the available concepts remain highly theoretical. Ekman (2004) identifies lying as a complex emotional construct made up of several basic emotions, predominantly fear, guilt, and delight, while DePaulo et al. (2003) found evidence that guilt, shame, and fear are amongst the strongest basic emotions experienced by someone who is lying.
Emotions arise spontaneously rather than through conscious effort (Shu et al., 2018) and result in physiological reactions such as increased heart rate, sweating, and dilation or constriction of blood vessels (i.e., blushing and paling) (Soleymani et al., 2015; Zhang et al., 2020). Such physical reactions, including heartbeat, skin reactions, blood flow, muscle tensions, facial expressions, or changes in voice, can be measured using technical equipment (Shu et al., 2018). The polygraph, or lie detector, measures such bodily reactions (Grubin and Madsen 2005) that people exhibit when they are lying (Proverbio et al., 2013). However, the polygraph use is declining because the results are often inaccurate due to bias, provide incorrect measurements and other deficiencies, such as the need for trained personnel to administer the test and the difficulty of interpreting the results (Katz 1983).
Background on automated detection of emotions
Recognizing emotions with artificial intelligence
Wherever someone experiences measurable physiological reactions, an AI artifact can be developed to interpret those. Research has shown that emotions can be detected through visual and/or auditory modalities (Fox 2018; Pan et al., 2015) and by applying machine learning techniques to the data collected (Yang et al., 2023; Zhang et al., 2020). A popular approach to detecting emotions is by analyzing facial expressions (Adolphs 2002), specifically micro-expressions (Matsumoto and Hwang 2018). For example, Tivatansakul et al. (2014) designed a web-based system that detected six basic emotions based on facial expressions with 86% accuracy. Krishnamurthy et al. (2018) combined video, audio, verbal transcripts, and micro-expression features into a multimodal neural model and report 96% accuracy in detecting deception. They tested their model on the real-life deception detection (RLDD) database (Pérez-Rosas et al., 2015) a publicly available dataset of 121 video clips from courtroom trials. Using the same dataset, Mathur and Matarić (2020) applied unimodal support vector machines along with multimodal fusion methods to identify deceptions in real-life situations and achieved 91% accuracy. Bhamare et al. (2020) used a deep neural network on an undisclosed dataset of 323 interviews. By combining analysis of speech and micro-expressions, they report to detect deception with 98% accuracy. However, their results were highly dependent on the facial features: “When interviewees concealed their eyes with sunglasses, the system failed as was expected” Bhamare et al. (2020, p. 147). Karpova et al. (2020) experimented with 93 volunteers who purposefully lied and tried to hide this from a polytrophic test. Using video analysis and eye-tracking techniques, the authors trained an end-to-end convolutional neural network. Their best model achieved a mean balanced accuracy of 64% in discerning truth from deception. On a dataset with 180 videos from 88 politicians, Kamboj et al. (2021) detected political deception from audio, text and facial features by utilizing a decision tree with an accuracy of up to 69%. Electroencephalogram (EEG) signals also provide the currently best known indications of the emotional state of individuals (Proverbio et al., 2013). Zhang et al. (2020) reported that EEG electrodes applied to the frontal lobe of a subject revealed a classification accuracy of more than 90% across different emotional states. Karnati et al. (2022) built a deep neural network with audio, visual and EEG features on three multimodal datasets. The datasets are publicly available and were technically augmented to provide a larger dataset. Through the combination of three modalities, the authors claim up to 98% emotional state identification accuracy. However, using EEG headgear for signal measurement is inconvenient for the individual and it takes considerable time to correctly measure the multichannel signals, which makes it unsuitable for the common business environment.
Emotion detection based on speech analysis
If an intrusive approach like a polygraph or an EEG is not appropriate for the situation and no video recordings sufficiently high in quality to analyze micro-expressions are available, audio analysis is an appropriate alternative, as suggested by Scherer (1995). Early work in this area by Amir and Ron (1998) provided an automated classification algorithm to identify emotions in speech but their work was limited by the technological capabilities at that time. As technology improved, numerous innovative approaches to recognizing emotions based on audio speech analysis have emerged. Zhao et al. (2019), for example, were able to distinguish several basic emotions with a test accuracy of about 96% using speech analysis. This indicates that with increasing computational abilities, analysis of the human voice is a promising route to detect even the complex emotional status of a speaker.
Emotions in spoken language are recognizable based on acoustic features including amplitude, pitch, and formants (Demircan and Kahramanlı 2014; Slimi et al., 2020). A prevalent approach involves the extraction of spectral features, namely the mel-frequency cepstral coefficients (MFCCs) first introduced by Davis and Mermelstein (1980). MFCCs have been shown to be particularly promising and computationally efficient for recognizing patterns in speech (Dave 2013; Fraser et al., 2016; Gupta et al., 2018; Logan 2000). Additionally, they are commonly used in speech emotion recognition (SER) as the basis for analyzing an individual’s emotions (Kishore and Satish 2013; Lalitha et al., 2015; Pakyurek et al., 2020).
Hidden Markov models (HMM) have been used for speech emotion recognition for more than two decades. Utilizing this method, Schuller et al. (2003) identified seven emotional states with 78% accuracy. More recent approaches apply deep learning (DL) methods, including recurrent neural networks (RNNs) (Trigeorgis et al., 2016) and combinations of convolutional neural networks (CNNs) and RNNs (Soleymani et al., 2015; Zhao et al., 2019). Based on log-mel spectrograms, Zhao et al. (2019) identified seven emotional states with an average test accuracy of around 96%. Beyond spectrogram features like MFCCs, some algorithms include contextual features to increase accuracy (Fayek et al., 2017; Trigeorgis et al., 2016). Taking this approach, Fayek et al. (2017) distinguish five emotional states with 65% accuracy. While the SER systems focus on a single person at a time, Majumder et al. (2019) analyze the conversations of a set of individuals and use this data to classify emotions. Their approach can classify six emotions with an average accuracy of 64%.
Automated detection of deception from speech
Although speech-based emotion analyses using MFCCs have great potential to serve as lie detectors (Chamoli et al., 2017), published research on automated detection of deception remains scarce. Several publications present artifacts but do not share sufficient information regarding the data set they used or they use a dataset which did not correctly record the emotion of a lying person because the data collection experiment was set up incorrectly. Fernandes and Ullah (2021), for example, trained several models on various spectral and cepstral features from speech, including MFCC features, and reached an accuracy up to 100%. However, their dataset consists of only one person providing true and false statements at three different times of the day. Nasri et al. (2016) analyzed data of true and false statements expressed by 40 volunteers and reported between 85% and 88% by using 13 MFCC features with a support vector machine. However, the study fails to explain how the participants were encouraged to lie, which makes it difficult to assess the validity of the results.
There are, however, many examples of more robust and better documented studies. Mihalache and Burileanu (2022) utilized neural network architectures for deceptive speech detection. Their model achieved 64% accuracy when tested on the RLDD database. However, the audio recordings in this dataset come from only 56 unique speakers, limiting its diversity. Fu and Lei (2020) proposed a model tested on the Columbia-SRI-Colorado (CSC) corpus. The CSC corpus consists of approximately 7.5 hours of speech data from 32 unique speakers, including 54% deceptive and 46% true speech acts (Hirschberg et al., 2005). Their model achieved 68% accuracy. However, since the CSC corpus is a professional database, it may only partially represent the diversity of real-world speech patterns. Fan et al. (2015) developed a method for detecting deception in spoken Chinese, achieving 64% accuracy on a corpus containing around 9.4 hours of speech data from 30 unique native Chinese speakers, each providing a truthful and deceptive statement. Fu et al. (2023) developed a semi-supervised deception detection algorithm for speech that achieved 69% accuracy. The dataset utilized in the study contains 582 true and 521 deceptive speech samples from 40 speakers (28 males and 12 females). Bareeda et al. (2021) proposed a model that achieved 81% accuracy in detecting lies on the RLDD dataset. The methodology extracts MFCC features and a support vector machine classifier. More recently, Snehalakshmi et al. (2024) presented a platform for lie detection in interviews incorporating a stress measure from MFCC features, deception detection from facial features and a plagiarism checker. With their combined approach, they reached 72.2% accuracy. Because applicants are clearly visible in the videos, they state that “ethical concerns and technology-related issues need to be overcome” in order to apply their solution.
This review of published results shows that a robust algorithm that provides data privacy, uses solely natural speech (i.e., can be used in phone conversations) and delivers consistently high accuracy levels to detect false statements, has not yet been published in publicly available resources.
Objectives for the solution
The DSR method defines steps to ensure rigorously developed generalizable outcomes in the development of artifacts (Hevner et al., 2004). After the problem-centered initiation, that is, motivation of the problem and definition of the research objective, the next step is the objective-centered solution, that is, the definition of measurable objectives and functional and/or non-functional requirements towards the artifact.
Use case
In DSR, use cases are widely used to capture the objective-centered requirements towards an artifact to be developed (Engel et al., 2024). Use cases are a proven and robust tool to ensure all stakeholders involved in the development of the artifact share the same understanding, especially developers and users (Dutoit and Paech 2002). To anchor our research in practice, we chose the corporate recruiting process context. Recruiting is an area where innovative technical tools are often deployed to gain efficiency and raise decision quality (Fleiß et al., 2024) and where AI-enabled tools are increasingly used (Gao et al., 2025; Purohit and Banerjee 2025). The research team used HR textbooks and practitioner-oriented literature (e.g., Bogen and Rieke 2018) to develop the use case.
The company posts a job offering that individuals can apply for using an online tool on the corporate website. The applicants provided the required information in a structured format. The first computational stage in the process is an automated check for defined formalities like minimum GPA, university degree, and years of relevant work experience. Candidates passing this formal check are invited to take a standardized online test focusing on mathematical skills, abstract reasoning, and other skills customized to the respective position. These tests are evaluated automatically and successful candidates are invited to a next stage, which is new.
The applicant is asked to have a phone or video call with a company representative. In this conversation—without having time to prepare, which ensures free speech and preempts pre-formulated statements—the applicant is first asked to present the highlights of her/his résumé, to get the applicant talking and counter initial nervousness. After a few minutes, the recruiter then asks the applicant targeted and detailed questions that directly address an area of specific importance for the position, such as how they handled severe team conflicts in the past or how they solved a specific complex technical issue.
During this second phase, the algorithm analyzes the voice of the presenter and informs the company representative when it detects potential deception using a green/red gauge on the screen. Based on this information, the representative can enquire about questionable statements in more detail. Being alerted to potentially deceptive statements enables the representative to garner better information about areas of important for the position and advance people further along the application process more selectively.
Focus group workshop
Description of workshop participants (experts).
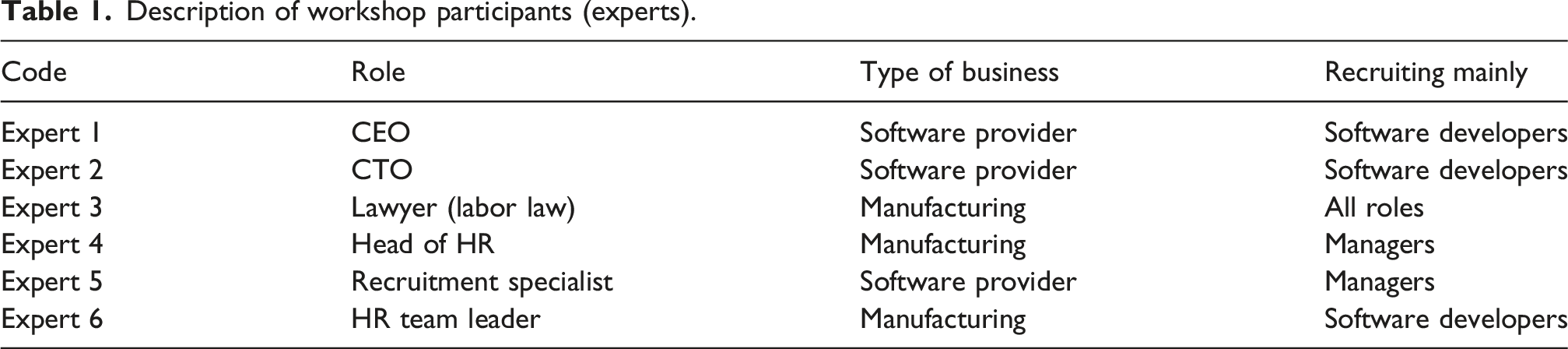
Participants agreed unanimously that such an artifact would enhance their decision quality and save costs by not inviting applicants to physical interviews who lacked key capabilities. The panel confirmed the use case and deemed it feasible, but considered it unsuitable for recruiting senior managers due to the delicate hiring process for top management personnel. Thus, the use case focuses on the recruitment process for IT personnel in junior positions, where the need for personnel and the costs associated with failed hires are high. In addition, extant research shows that people applying for technical positions are specifically prone to make deceptive statements on their job applications (Weiss and Feldman 2006).
All participating companies already use online recruitment instruments, mainly automated checking mechanisms such as filters and minimum criteria hurdles, and automated standardized tests, usually of math, abstract reasoning, and analytical skills. Applicants who pass the automated filters and tests are invited for physical interviews. Our workshop participants no longer use multi-day assessment centers.
Solution requirements
In a moderated discussion, the experts identified their requirements for an artifact that could support their recruitment work. To ensure a broad spectrum of input, the project team provided insights from literature on deceptive behavior in job interviews (e.g., Bill et al., 2020; Bill et al., 2024; Melchers et al., 2020; Renier et al., 2021) and the use of AI tools to detect deception (e.g., Constâncio et al., 2023; Li et al., 2021; Van Den Broek et al., 2021; Vrij et al., 2022; Vrij et al., 2023).
The requirements identified during the discussion were collected and clustered into groups: • • • • • • •
Ethical considerations and data privacy
The workshop participants discussed ethical considerations and data privacy concerns extensively. Every company wants to respect the explicit and implicit data privacy rights of applicants, especially in Germany (Prince and Wallsten 2022). Consequently, the design principles of the proposed artifact comply fully with the European General Data Protection Regulation (GDPR) (EU 2016) and the EU AI Act (EU 2024).
Beyond legal and regulatory compliance, the research team discussed
The artifact is designed to prevent deception, which is unethical behavior. Therefore, a fraudulent person has no legitimate right not to be detected. After all, companies have been using various mechanisms to avoid deception (see, e.g., Vrij 2008), including fraudulent detection in job interviews (Ferran and Storck 1997; Mahbub and Pardede 2018) for decades.
With regard to
Statement of solution objectives
In summary, the artifact needs to fulfill the following objectives which will be the basis for its evaluation (see section 10): (1) No special equipment, (2) Data privacy, (3) Legal and ethical compliance, (4) Free of bias, (5) Decision support only, (6) Superior detection accuracy, (7) Superior performance towards available solutions. Please note that objective 7 was not brought up in the workshop but derives from the DSR method.
Data collection
Publicly available German language datasets are scarce (Xu et al., 2020), and a dataset focusing on deception is not available. Therefore, it was necessary to generate a new dataset to train the algorithm. Due to the sensitive nature of the recruitment use case, it is not possible to gather training data directly in the setting of a recruitment interview. Instead, in a controlled experiment, we collected audio data of verbal representations of opinions from native German speakers arguing for or against their inner conviction, which they identified only after the experiment.
Data collection process
To generate these very specific voice recordings we chose the setting of a debate club. We distributed flyers in local universities, social centers and on various social media channels inviting volunteers to participate in our study, which we referred to simply as “an experiment,” offering each participant a 10€ Amazon voucher as compensation.
The experiment followed typical debate club procedures: The participants were randomly grouped into pairs. Each pair was randomly assigned one of four topics (see 6.3 below), and whether the individual should argue pro or contra. We did not provide the participants with any information about the study’s objective beforehand to avoid possible bias. Notably, none of the participants asked about the underlying intention of the experiment.
The participants had 30 minutes to prepare their arguments and were instructed not to use the internet in their preparation. Participants were permitted to write down bullet point notes but not fully formulated statements. Each participant was then asked to argue their assigned position (pro or contra) on their topic in approximately 2 to 3 minutes of free speech.
After the debate, the research team provided each participant with feedback on their rhetoric performance/argumentation to help them improve their soft skills. Finally, participants were asked to provide suggestions on improving the operational handling of the experiment. No further interaction with the research team occurred to reduce social desirability response bias. Immediately after the feedback discussion, participants received an automated email asking them to complete a brief online survey of basic demographic data and whether they had argued for or against their true conviction about the debate topic. All participants completed the survey fully and within 1 hour of receiving it.
We collected this data in Germany in 2022 and 2023, recording the statements either personally or via videoconference. To ensure data privacy, only the audio was recorded and used. All participants were informed about the data privacy precautions (EU-GDPR compliant) and signed a consent form authorizing the use of the audio recording for research purposes before the experiment started.
Demographics of the participants
We conducted 46 debates, thus collecting 92 audio recordings. Due to audio problems, such as breaks-ups, transmission delays and interference due to bad internet connection, 12 recordings had to be removed, resulting in 80 individual audio files.
The participants included 41 employed non-students, 31 undergraduate and graduate students, and 8 high school students. All debates were conducted in German. 35 were women and 45 were men, and their ages ranged from 16 to 60 years (Ø = 27.15 years; median = 26 years). See Appendix for additional demographic details.
Topics
We deliberately chose highly polarizing topics for the discussions: • • • •
These polarizing topics were selected to increase the likelihood that participants would have a clear and unambiguous opinion. According to participants’ responses to the email questionnaire, the speakers’ true convictions were aligned with the research team’s expectations: none of the participants stated a true conviction in favor of reintroducing the death penalty, introducing cost-covering tuition fees, legalizing hard drugs or banning restaurant chains that serve unhealthy fast food. However, social desirability response bias may have influenced these stated convictions.
Allocation of topics and assigned pro/contra positions.
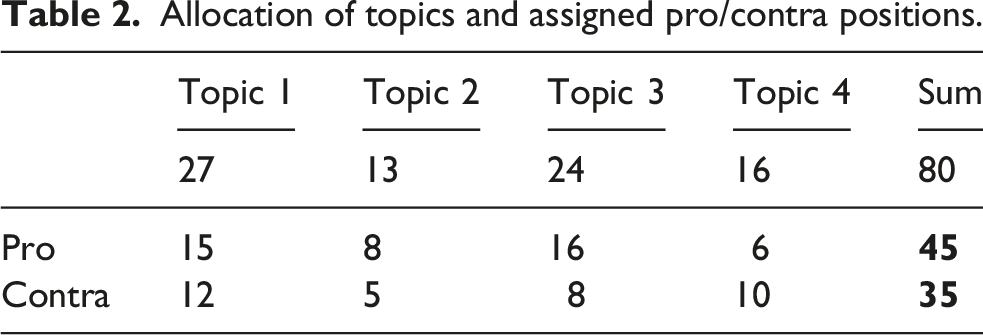
Inner conviction of the participants per topic.

Development of the AI model
Feature descriptions
Based on the literature on emotion detection and automatic deception detection from speech, we pre-selected audio features that were used successfully in published studies. To train the models to classify true conviction, first the mel-frequency cepstral coefficients (MFCCs) (Davis and Mermelstein 1980) were extracted from the audio recordings. The MFCCs were derived from a time-frequency representation of the audio signal with the frequencies from 500 to 6000 Hz on a mel scale. Using MFCCs has two advantages: (1) it provides computational efficiency for recognizing patterns in speech (Dave 2013; Fraser et al., 2016; Gupta et al., 2018; Logan 2000), and (2) it generates strong results for audio files of inferior quality (Tivatansakul et al., 2014). In the next step, additional audio features were extracted, including the zero-crossing rate (ZCR), which is used to differentiate between voiced and unvoiced speech segments. ZCR reflects the number of times the signal crosses the zero axis in a given time window (Shete et al., 2014). In speech signals, voiced segments are characterized by periodic waveforms produced by the vibration of vocal cords. These waveforms result in a relatively low ZCR. In contrast, unvoiced segments, for example, those produced by airflow noise, are characterized by random and non-periodic waveforms, which result in a comparatively high ZCR (Bachu et al., 2010). Next, the spectral roll-off (McFee et al., 2015) was extracted from the audio files, which provides information about the spectral energy distribution in speech. It is used to characterize the timbre of speech tones, with brighter tones yielding higher values (Giannakopoulos et al., 2006). A further extracted feature includes statistics of the initial peaks of the sounds done during the recorded speeches. This way, variations in speech pauses can be detected. As basis-emotion recognition systems also consider pitch features, we furthermore extracted chromagrams corresponding to the twelve tone chromatic pitch classes (McFee et al., 2015). Finally, the fundamental frequency, which represents the lowest frequency in a periodic waveform, was assessed. It is a key characteristic of the speaker’s voice and can provide important information about the speaker’s emotional state (Hirst and De Looze 2021).
AI model training
The training procedure follows the approach of a support vector machine (SVM) (Hearst et al., 1998). An SVM classifier puts a separating hyperplane into a space so data points of one class are on one side of the hyperplane and the data points of the other class on the other side. SVM was chosen for three reasons: (1) The available dataset is relatively small and SVMs with its maximum-margin hyperplanes are better suited to achieve good results here; (2) SVMs are robust against noise and outliers, which frequently occur in audio data; and (3) SVMs can handle nonlinearly separable data, which is often the case in audio processing (Boateng and Kowatsch 2020). Additionally, SVM models are relatively easy to interpret and understand, which makes it easier to understand why a particular decision was made and identify improvement areas.
The following hyperparameters were applied to the training of the SVM. The radial basis function (RBF) (Hearst et al., 1998) kernel was used to implement the SVM for binary audio classification. The RBF kernel is a popular choice for nonlinear classification problems because it can map input data into high-dimensional feature spaces where linear classifiers can effectively separate the data, which allows the SVM to capture complex relationships between input variables and output class labels. The RBF kernel uses a radial basis function to measure the similarity between input data, and the kernel width hyperparameter, gamma, controls how far the influences of training examples reach. When training the SVM, the regularization hyperparameter C is essential in controlling the tradeoff between overfitting and underfitting. A higher value of C leads to a narrow margin, which may result in overfitting, and vice versa. As an overfitted model would memorize the training data and, thus, perform poorly on the test data, we want to avoid it. Hence, different values for the hyperparameters were tested to determine the optimal performance for the binary audio classification task.
Results
This section presents the average performance of the trained models. All performance metrics were derived through k-fold cross validation (Stone 1974) with specifically five folds and 25 repeats. For every repeat, the dataset was randomized and equally divided into five folds. According to the general procedure, one fold was kept for the test and the other four for the training of the model. Then, the folds were rotated until every fold has been once used for the test. This was then repeated 25 times. As an SVM does not do automatic feature selection, an appropriate choice of features is needed. Hence, the models were initially tested using 40 MFCC features, and in a second step with a reduced set of only 13 MFCC features. After careful analysis of the initial set of results, the MFCC features were further reduced to three features which generated the best results. This reduced set of MFCCs was then enriched by complementing values from ZCR, spectral roll-off, chromagrams, variations in speech pauses, and fundamental frequency to further improve the performance.
Thus, the results regarding all SVM architectures differing in C and gamma hyperparameters are presented. This emphasizes and highlights the final model’s importance as part of a dynamic process of model comparison. For every feature set combination, multiple SVM hyperparameter combinations were evaluated, which resulted in more than 100 models each. For ease of reference, only the five best performing models for each feature set are presented.
Performance metrics
The following performance metrics are applied to measure each model’s efficiency and reliability: (1) (2) (3) (4)
These metrics alone are not sufficient to fully validate the results. For example, a high TP rate can be achieved when there is an extreme imbalance in the ratio between recordings of people whose convictions were not represented and speech data of people whose convictions were represented. To avoid this issue, a balanced ratio of input data is required, as well as a weighted consideration of the TP and TN rates (Aldwairi et al., 2018).
To compare the models’ performance, we applied the following metrics (Saxe and Hillary, 2018).
Model set 1: 40 MFCC features
Models using 40 MFCC features.

The non-impressive results show that utilizing many MFCC features does not produce satisfactory predictive performance.
Model set 2: 13 MFCC features
Models using 13 MFCC features.

Model set 3: Three MFCC features + acoustic features
Models using three MFCC and nine additional acoustic features.

Bias of the artifact
The AI artifact was trained using data generated from volunteers who participated in a debate club experiment. Although the demographics of the participants (see Section 6.2) indicate a heterogeneous mix, testing the artifact for potential bias poses an important task in developing AI models (Renier et al., 2021). The following tests were conducted to test for bias in the training data set:
Age and gender
To test the algorithm for bias towards age and gender, subsets of data for control groups with participants of different age and gender were constructed and tested. The relationships of the labels predicted by the algorithm and the given information for age/gender were tested using the chi-square test (David Freedman 2007). No significant relation was found. The test for bias in this context is particularly important as a recent study indicates that many recognition methods are prone to assign a lie to a female person (Mambreyan et al., 2022).
Nervosity
To rule out that the artifact is measuring the speaker’s nervosity instead of deception, an experiment was conducted to collect and analyze speech data in moments when the participants were highly nervous. The level of nervosity did not significantly affect the level of accuracy of the detection of deception (Jechle et al., 2026).
Professionals
When presenting the artifact in meetings with companies, a limited number of test recordings from practitioners were collected. These professionals were people working for several years in their respective roles and thus not directly comparable to the general population. It turned out that the detection accuracy is even slightly higher than in the general population groups. However, the number of participants is too small to make a solid statement, so this remains anecdotal evidence.
In the light of these tests, it can be concluded that the model indeed measures whether a speaker speaks in accordance with her/his inner conviction and no bias of age, gender or occupation was detected.
Demonstration of the artifact
Perceived usefulness of the artifact
To demonstrate the usefulness of the developed artifact, the HR professionals who provided feedback in the initial workshop were consulted again. The capabilities of the artifact were demonstrated and potential practical applications and hindering issues were discussed. In summary, all experts agreed that the artifact is useful. The more applications a company receives, the more likely they are to apply AI algorithms to help with the recruitment process.
Although the feedback was very positive, some issues were also mentioned. • For more technical positions, like, for example, software developers, an experts said they would need to have specifically designed very deep/detailed test cases to see “whether the person really has the capabilities they claim to have” (Expert 6). • Those companies who require their employees to have specific certifications (like SCRUM Master, PRINCE2, etc.) said it would be good have these certificates automatically checked to reduce the manual effort. The rationale is that people do not submit forged certifications if they know an AI algorithm will evaluate them.
However, although both points are relevant in a recruiting context, they are not within the scope of the proposed artifact.
One of the practitioners consulted, a lawyer specialized in labor law (Expert 3), also commented on the legal implications. He stated that he sees no legal roadblocks for deploying such an AI artifact if the applicant informed about the deployment of mathematical/statistical analysis of their voice transparently and ahead of time, and a clause is added to the data privacy agreement that is part of every interaction with applicants. He expressed hope that widespread deployment of such algorithms could reduce the number of applications containing false statements. He also suggested that adapting the recruitment process in this way may need the approval of the works council.
Design principles
The aim of the DSR method is to ensure that the findings will not only apply to one specific situation but also have a certain level of generalizability. Developing artifacts that benefit IS researchers and generate value for practitioners—one of the core missions of IS research (Iivari 2020)—requires design principles to be identified, developed, and communicated (Gregor and Hevner 2013). Design principles are “prescriptive statements that indicate how to do something to achieve a goal” (Gregor et al., 2020) and collectively advance the body of knowledge of our discipline by serving as guiding principles for future developments (Nguyen et al., 2021).
The design principles presented in the following are based on the solution requirements elicited in the focus group workshop (see Section 5.2). These were challenged by the project team during the development phase of the artifact and discussed and finalized with the experts during the demonstration of the artifact.
The AI artifact itself is a neutral technology which cannot abide by ethical and legal guidelines and regulations. The responsibility to use the artifact in a legal and ethical manner remains with the user. However, the artifact is designed to ensure data privacy in the sense that it has a minimal data design (i.e., only requests the data it really needs) and does not need to store collected data. This makes it technically possible to operate within the limits of the EU-GDPR. Still, the responsibility to obtain consent before the interview remains with the user—which is already current standard practice in the corporate environments. From an ethical perspective, the artifact is not designed to make a decision, but rather only to provide an assessment. The actual decision remains with the human being. This is also underscored by clearly communicating the ∼20% margin of error in assessments. Here again, it remains the responsibility of the user to inform the interviewee transparently and ahead of time and offer the option to opt out without consequences. Finally, the requirement to perform better than a human being was not listed as a design principle because it is an innately indispensable functional requirement, a conditio sine qua non, that is, if the AI artifact does not perform better than HR professionals, it will not be used anyway.
Design principles.

Summary of demonstration
In conclusion, the HR professionals were all interested in the technology and see potential to use it in their own recruitment process to help the recruiters to sort out deceptive applications early in the process. The experts were satisfied with the accuracy of the artifact and did not identify any major hindering barriers. The feedback received from the demonstrations was used to formulate generalizable design principles.
Consequently, the demonstration phase was concluded successfully by confirming the usefulness of the artifact to solve the stated solution objective in the selected use case.
Evaluation of the artifact
The next step following its demonstration is the evaluation of the artifact (Peffers et al., 2007). As discussed by Gregor and Hevner (2013), not every artifact can be evaluated in its envisioned setting. In those cases, a
Formally, an artifact needs to be evaluated in terms of achieving its development objectives (Hevner et al., 2004) which were stated in Section 5.5. All seven stated objectives were met by the artifact:
Comparison to published research.
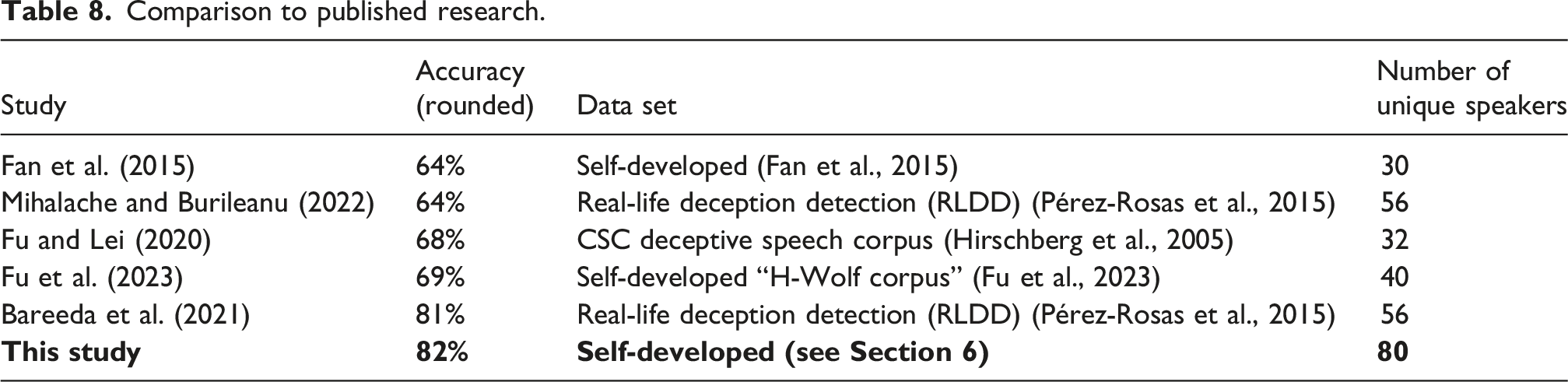
The artifact presented in this study is compared to other artifacts in terms of detection accuracy and breadth of the dataset. Only published studies of comparable scope (detection of deception) and methodological approach (analysis of human voice) were selected for comparison.
As can be seen from the table, the presented artifact provides the highest accuracy of all models. The work of Bareeda et al. (2021) provides a very close accuracy, however, the reliance on a single feature type (MFCC) limits its robustness. The artifact presented here not only utilizes a larger and more heterogeneous dataset, it also complements the analysis of the spectral characteristics (MFCCs) with acoustic features, which provides are more robust algorithm.
The combination of spectral and acoustic features, a diverse dataset, and the application of 25 repeated five-fold cross validation, enhances the model’s robustness and applicability to real-world scenarios. The achieved accuracy slightly surpasses the best performing model from reference studies.
In summary, the evaluation of the artifact is positive. It is achieving its stated objectives, applicability to the presented use case, and is technically superior towards the comparable published artifacts.
Contribution to theory and practice
Our findings contribute to theory from two main perspectives: (1) for design science researchers, our work presents a
Contribution to design science research
AI-enabled information systems to detect complex emotions
Innovative AI artifacts are becoming ever more integral to the business/IT-landscape in contemporary businesses. As interactions between AI agents and people continues to increase in breadth and depth (Bagozzi et al., 2022; Huang and Rust 2024), it becomes ever more important for the AI agent to emotionally understand the human agent. The automated detection of individuals’ complex emotions can enable researchers to deeper understand human behavior, specifically in emotionally stressful situations. This tool would help researchers to automatically detect individuals’ personality traits (Yang et al., 2022), understand the implications of using social media on personal well-being (Krasnova et al., 2015), or analyze rational and irrational behavior in algorithmic decision acceptance (Burton et al., 2020).
As the human–computer interface evolves rapidly from keyboard to voice (see, e.g., Phillips (2021)) our research opens up useful application to study numerous aspects of human behavior. One could also see various applications into the field of intelligence augmentation, the combination of artificial and human intelligence, as proposed by Jain et al. (2021). Another area closely connected to our research is honesty in the digital age (Cohn et al., 2022), the phenomenon that humans behave differently in digital environments than in the real world. Cohn et al. (2022) find that individuals cheat about three times more when they interact with a machine than when they interact with a person. For example, Ananthakrishnan et al. (2020) shed light on the issue of fraudulent reviews and Moravec et al. (2022) discuss the phenomenon of fake news. In a nutshell, individuals tend to be less truthful if no other person is present.
There is a long history of using technical support to analyze human behavior and, specifically, deceptive actions in IS Research. Almost 50 years ago, Jenkins and Johnson (1977) published their research into the relevance of body language to information analysts, Weinmann et al. (2022) later analyzed computer mouse movements to predict fraudulent insurance claims, and Yang et al. (2023) analyze multiple aspects of the human voice to assess the trustworthiness of managers on conference calls.
Although our work is focused on deceptive intentions, it shows that this class of algorithms is able to detect a variety of emotional states like stress, uncertainty, and fear. Thus, our findings support the research strand on automated detection of complex human emotions with high accuracy from speech. We presented evidence that the defining voice features essential to the speaker’s convictions are contained within the verbal statements’ spectral representation and that an SVM architecture previously used in basic emotion detection and speech recognition can also be applied to derive the complex emotions a lying person experiences. Thus, our findings provide researchers with a solid base to research the detection of other complex emotions using an SVM with a distinct set of MFCCs. Furthermore, as the model works without semantic understanding or conversion into text, it enables researchers working in jurisdictions with strict data privacy laws to extend their research and could pave the way for research in sensitive areas such as hospitals or psychiatric institutions.
Design principles to guide the development of artifacts to detect complex emotions
Designing an innovative IT-artifact to be deployed in a highly sensitive corporate business process poses multiple unique challenges. In the development process of the artifact presented, four design principles were derived, tested, and confirmed following a rigorous DSR methodology.
Design principles provide prescriptive knowledge that bridges the gap between theoretical considerations and practical knowledge in artifact design. They encapsulate what should be built and how, grounded in theoretical and/or empirical insights, and enable the systematic creation and evaluation of digital solutions (Gregor et al., 2020). Consequently, design principles act as prescriptive statements, offering actionable guidance on developing artifacts to achieve their previously specified objectives (Hevner et al., 2004). The explication of these principles contributes to theory by formalizing design knowledge from tacit experiential learning into structural components which support the efforts developers of non-identity-based AI-enabled artifacts which detect complex emotions from voice-based interactions. By outlining mechanisms and rationales, they translate abstract theories and unstructured insights into reproducible procedures for system design and implementation. Consequently, the stated design principles generalize lessons learned from the specific instance of this research project into generalized reusable constructs, thus supporting theoretical generalization for IS design theory.
Contribution to behavioral research
This novel AI-enabled artifact enhances organizational decision making by enabling experts and managers to overcome a typical human deficiency: our weak ability to detect deception. The following arguments draw upon extant research examining the emergent, multifaceted collaboration of human actors and AI systems (Baptista et al., 2020; Benbya et al., 2020b; Rai et al., 2019). The aim is to understand how novel AI tools can potentially affect organizational decision making in high-stakes contexts. In this vein, we seek to advance a more nuanced understanding of how AI-enabled technologies are being used to reconfigure organizational work practices and the implications for actors whose roles and activities are thereby transformed.
Effects of novel AI-enabled artifacts on organizational decision making
The strong growth of AI-enabled tools to support organizational decision making changes the dynamics and correspondingly challenges our understanding of the theoretical foundations of these processes. Contemporary research has a strong focus on identifying implications and providing corresponding frameworks to structure the new landscape of decision support systems (see, e.g., Fabri et al., 2023; Jöhnk et al., 2020; Pathirannehelage et al., 2024).
In organizational decision making, managers traditionally rely on both intuitive gut feelings (Hayashi 2001) and analytical practices when processing information (Dane et al., 2012). Advanced AI-enabled tools, such as the one presented here, combine both of these formerly segregated practices. The AI can analytically process much more information than a human being and now can additionally replace the intuitive gut feeling by an objectivized measurement of complex emotions. Whereas humans are notoriously bad at detecting deception, the AI-enabled artifact is able to unveil hidden information and implicit cues, thus enabling decision making beyond the traditional reliance on explicit statements. Consequently, innovative AI tools now allow decision makers to access this layer of implicit information embedded in the way something is said, by assessing paralinguistic cues.
In human interactions there is always a nonverbal layer involved in communication. Oral communication is richer and more complex than just the words spoken, and the subtle cues within natural language carries significant weight regarding a speaker’s confidence, sincerity, and even deceptive intentions. Using AI tools to analyze complex emotions allow decision makers to interpret this information more accurately, rather than simply taking the words at their face value or relying on their gut feelings. The ability to assess nonverbal cues will change organizational decision making and theories regarding decision support systems significantly, as foreseen by Grover et al. (2018) and others.
The trend towards the formation of hybrids, which combine human and AI capabilities (Fabri et al., 2023) can be seen in multiple organizational areas, like in hybrid software engineering (Abrahão et al., 2025), or the formation of hybrid team structures (Bayrak et al., 2021). In decision making, the boundary between analytical and intuitive practices has started to vanish. In individual decision making, hybrid approaches have gained traction quickly, for example, in the field of medicine (Reverberi et al., 2022). In organizational decision making, the diffusion of the new capabilities takes longer, mainly due to the complexity of the environment. Raisch and Fomina (2025) present a model of hybrid organizational decision making in a common management area and identify time and knowledge as main drivers, meaning that hybrid decision making enables management to include more information in their decisions and save time to come to a conclusion. Carter and Wynne (2024) discuss the effect a non-human collaborator has on team decision making in an organizational context.
There is currently little research available about hybrid organizational decision making in high stakes areas, like human resources. Contemporary behavioral research is mainly concerned with the ethical implications (see, e.g., Bankins 2021) and design science focusses on providing design principles for the development of such systems (see, e.g., Storey et al., 2024). The integration of advanced AI capabilities, such as detecting emotions, into hybrid organizational decision making remains largely unexplored in academic publications. The research presented enables other researchers to explore this route because there is now an AI-enabled artifact available, embedded in a practically relevant use case, that closes this gap.
Conceptualizing the interworking of humans and AI artifacts
Another interesting lens for analysis is the embedding of advanced AI-enabled artifacts into business processes and the resulting consequences for the actors involved. The integration of AI artifacts into processes and the corresponding impact is one of the most dynamic contemporary research areas in IS research. Fabri et al. (2023), for example, provide a taxonomy of human–AI hybrids to analyze the interworking relationship of AI capabilities that are deployed in various use cases. We applied that taxonomy to position our work and identified the need to extend the application of the taxonomy by defining a new archetype.
The AI artifact presented in this paper would qualify as human agency, where the human agent uses the AI capabilities to enhance their work quality. The human agents (recruitment personnel) use the human cognitive function of perceiving to have the artifact provide an opinion on the trustworthiness of the statement of the applicant. In this human to AI interaction the human agents keep full control over the decision and use the information provided by the artifact as one input factor (amongst others) to verify/challenge their opinion, that is, the artifact facilitates the decision process. We classified the human focus as sensemaking because the recruiters need to critically evaluate the artifact’s assessment and use their own judgment to derive the final decision.
However, from a functional perspective the setting described above calls for a new archetype, contextually situated between Archetype 3: Sequential Augmentation (Superpower-Giving AI) and Archetype 4: Sequential Co-Evolution (Assembly Line AI) as suggested by Fabri et al. (2023, p. 635). The new Archetype 3a: Singular Interaction Support (Advisor AI) is distinct from Archetype 3, as the AI performs tasks the human agent is not able to do (additional skill), can be used flexibly (either in sequence or multiple times in different steps during the process), and has a solely supporting role among many input factors. In an analogy to enterprise architecture management, this would compare to a web service in a service-oriented architecture: The AI artifact can be called upon either at a predefined step in the process (as suggested in the use case in this paper), or it can be utilized multiple times at different steps during the process, depending on the specific contextual situation. In any case, the role of the AI artifact remains solely supportive, providing advice to the human agents. Thus, its role is less prominent than Archetype 3, Superpower-giving AI. The new Archetype 3a is much more like a piece in the puzzle, offering advice and a second opinion, but not the stronger guidance of the example of risk assessments in court cited by Fabri et al. (2023) to describe Archetype 3.
The theoretical foundation for this proposed new archetype is that most existing models of human–AI collaboration models focus on AI’s capabilities to process more information in a shorter time than people can (Raisch and Fomina 2025; Trunk et al., 2020; Wen et al., 2025). However, the advanced AI capabilities of emotion recognition—which amalgamate with the human capacities—are not yet adequately reflected in the corresponding theoretical models.
Popular theoretical lenses in human–AI collaboration models are shared cognitive theories like shared mental models (SMM) or transactive memory models (TMM). They assume that collaborators function as distributed memory networks, where participants know “who knows what,” allowing cognition to be shared across agents rather than stored in one place. AI-enabled artifacts with the capability for automated emotion recognition fit into such shared cognitive theories, but with a different focus. The human capabilities are extended into a different sphere, the recognition of complex emotions with greater accuracy than before. This offers new opportunities to make better decisions that surpass the current conceptualization of AI to analyze more information in a shorter time. The user of the artifact gains an additional skill, the objective interpretation of a complex emotion, which enables them to make a better decision because the intuitive part of decision making is enhanced by a neutral and more accurate AI-enabled analysis. Such AI-assisted intuitive judgment could be categorized as cognitive augmentation because the AI artifact augments the cognitive capabilities of decision makers, when called upon, and thus helps them improve the quality of their organizational decision making.
An important capability of the presented artifact is that operates independent of the content of utterances, thereby responding to legitimate concerns about privacy and ethical data use. This manifests a new paradigm of privacy-preserving cognitive augmentation and presents a new theoretical lens for further development of human–AI collaboration models.
Contribution to practice
Applicants providing false statements on their résumés seem to be the rule rather than the exception (Schenz and Zeitung 2018). This was confirmed in our expert workshops: “We often have the problem, especially when recruiting for junior positions, that the capabilities stated in the CV do not match the experiences the applicants actually have” (Expert 4). This poses serious issues in terms of money and time lost: “We recruit people on a global basis, mainly in southern and eastern Europe, but also from India and Asia. Flying those people in for face-to-face interviews is costly, let alone the time it takes our staff to conduct the interviews. We estimate that each of these interviews costs us between €5,000 and €10,000” (Expert 1). Having an automated mechanism to reduce the number of interviewees who advance to the live interview stage of the recruitment process by providing false statements has great practical value.
Another area of potential application of the artifact presented is in the service industry. GDV, the German insurance association, estimates the damage from insurance fraud at 6 bn EUR annually (GDV 2024). GDV has determined that ten percent of insurance claims has a fraudulent component and around 5% of customers of member insurance companies have submitted at least one fraudulent claim (GDV 2020; GDV 2024). Applying AI techniques to detect whether a caller is speaking to her/his conviction when making a claim may not completely solve these issues, but it could help alert the claim agent to the need for more intensive questioning and give the caller the opportunity to correct their statements and avoid submitting a fraudulent claim.
It is an open secret that customers’ statements at helpdesks or the customer service desk do not always fully reflect the truth (Alton 2017). It would save time and resources if an algorithm could detect whether the customer truly rebooted their computer before they called the helpdesk, or whether the customer is being knowingly deceitful about a product malfunction. Such an algorithm could also help verify whether and when a product was really sent to the support team, resulting in productivity gains and a reduction of operational losses.
There are many potential applications in medical and therapeutic fields. Mobile assisted living systems help vulnerable patients manage their daily lives independently. An AI algorithm inquiring how much they drank during the day or whether they took their medication correctly could enhance these systems because patients often do not answer these questions truthfully (Fainzang 2002). The algorithm could identify answers that do not reflect the person’s convictions and trigger human intervention from a designated caregiver to ensure the well-being of the patient. Psychotherapists could employ such an algorithm to see whether the patient is speaking to her/his convictions and physicians could apply the algorithm to improve anamnesis and the resulting diagnosis, especially with regard to socially difficult topics such as sexually transmitted diseases, drug use, or drinking and eating habits (Palmieri and Stern 2009). Naturally, these applications require transparent disclosure to the patient and adherence to corresponding data privacy regulations.
Limitations and further research
The main
Our findings offer a strong basis for
Conclusion
This paper presents a novel AI artifact that detects deceit among speakers by analyzing the acoustic and spectral features of their natural speech, but without voice recognition. We trained the AI model on a specifically generated German language dataset consisting of 80 audio files recorded in the experimental setting of a debate club. Out of the models evaluated, the best version detected deception with 82.4% accuracy. Our results demonstrate how support vector machines can be applied to perform acoustic speech analysis to detect whether or not a person is speaking to their true convictions.
An AI artifact that detects deception using only human voice characteristics, without voice recognition, pushes IS theory beyond traditional data processing and management. It forces a deeper engagement with the complexities of human communication, the implications for organizational decision making using AI artifacts in sensitive contexts, and the design of systems that can extract meaningful, non-identifying insights from rich, real-time data (Blohm et al., 2025). The application of such a novel AI artifact into organizational decision making enables managers to make better decisions by overcoming humans’ natural weak ability to detect deceptive intentions of other people accurately. Such artifacts advance the concept of human–AI hybrids, a re-conceptualization of organizational decision making concepts and an extension of the current taxonomies for human–AI collaboration.
Additionally, the presented AI artifact demonstrates that semantic understanding of a conversation is not necessary to detect complex human emotions. Our research shows that analyzing the spectral features of the human voice is sufficient to achieve accurate results. As the old saying goes: “It’s not what you say, but how you say it.”
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors would like to thank the Technology Transfer Center, Günzburg, Germany for funding parts of the data collection for this study.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.