
Abstract
Objective:
To identify any externally validated prognostic model for predicting outcome in unselected populations following acute stroke comprising variables feasible for collection in routine care.
Data sources:
Searches were run in MEDLINE, EMBASE, CINAHL, PsycInfo, AMED and ISI Web of Science with no limits on publication date or language.
Review methods:
Any study describing the development or external validation of a discernible prognostic model to predict any valid outcome following acute stroke was included. Papers were retained if they met pre-specified inclusion criteria identified from previous reviews and pertinent discussion papers. Data extraction focused on methodological quality of model development, generalizability and feasibility of variable collection. Model performance was examined through consideration of external validation studies.
Results:
Seventeen externally validated models were identified from 43 papers fulfilling inclusion criteria. Quality of studies describing model development was variable and model performance in external validation studies was generally poor. Models were generally constructed through secondary use of randomized trial or stroke database data. Prognostic variables broadly encompassed markers of stroke severity, pre-stroke function and comorbidities. One model that fulfilled the review criteria and had extensive external validation in a range of post-stroke populations was identified (the Six Simple Variables model).
Conclusion:
The Six Simple Variables model performed well in six external validation studies, although prediction of outcome in patients with milder strokes was less reliable. Other models identified in this review have been developed using robust methodology but comprise more complex clinical variables which may limit their utility in routine stroke care.
Introduction
Stroke is a heterogeneous clinical syndrome in which the clinical course and outcomes for individual patients are dependent not only on the site and size of the pathological lesion, but on the context of the injury in relation to combinations of mediating factors that are unique to individuals. Pre-stroke function, comorbidities, social, environmental and personal factors are all likely to affect an individual’s functional, cognitive and social outcomes following a stroke and limit the validity of direct comparisons between individuals or populations. If comparisons of individual patient or population outcomes are to be attempted, as may occur for the purposes of audit, observational studies or performance monitoring, it is necessary to control for confounding factors and attempt to statistically homogenize the groups. This process is called case-mix adjustment. Inadequate case-mix adjustment has been highlighted as a major factor limiting between-site comparisons of patient outcome (particularly mortality). 1 However, such comparisons are common. 2 As routine collection of outcomes, specifically patient-reported outcomes, is likely to expand as a mechanism to record patient-centred quality of care,3,4 the need for robust case-mix adjustment models becomes more urgent.
Previous reviews have been undertaken to identify prognostic models specifically in stroke5–12 and have found the models to be generally poor. The review by Counsell et al., published in 2001, 5 identified studies describing models to predict stroke survival, survival in an independent state, or alive and at home. The vast majority of the 83 discrete prognostic models identified demonstrated significant flaws in statistical or internal validities and none was fit for purpose to case-mix adjust in routine clinical care. 5 Other authors have attempted to identify prognostic models which were developed to predict functional outcomes following stroke.6,11 However, these have tended to be limited to prediction of activities of daily living (most commonly the Barthel Index), which has limitations due to its marked and well-documented ceiling effects. 13
Since these reviews were performed, clear evidence demonstrating the benefits of organized specialist multidisciplinary stroke care over general ward care 14 has led to the widespread adoption of this model and fundamental changes to the delivery and monitoring of stroke care across healthcare systems.15–18 It is possible that prognostic factors previously unknown or overlooked are important in determining patient outcomes and these should be modelled explicitly. In addition, increasing scrutiny of the quality of prognostic research19–21 and more sophisticated statistical modelling techniques (e.g. multilevel modelling, latent variable analysis and structural equation modelling) are likely to have altered the type and quality of models to predict outcomes following stroke.
We undertook a systematic review of the literature to ascertain whether any robust, externally validated prognostic model exists to predict outcomes in unselected post-stroke populations comprising variables that are feasible for prospective collection in routine care and observational research.
Methods
Any study or review describing the use of a discernible prognostic or case-mix adjustment models to predict valid and reliable stroke outcomes at a fixed time point following ischaemic or haemorrhagic stroke was considered. Studies referring to ‘adjustment for baseline variables’ were excluded unless a discernible model was further qualified. Studies using cohort data from stroke registers, prospective observational studies performed with the primary objective of model development and studies that described the secondary use of data obtained through randomized controlled trials were all included if there were further studies that validated the models in independent prospective cohorts. Papers describing models which lacked external validation were excluded. Previous systematic reviews were identified and examined to identify any externally validated models that had otherwise been overlooked.
No restriction was placed on patient age or stroke severity. However, studies describing models developed in populations unlikely to be representative of the wider stroke population (e.g. exclusion of the oldest old or patients at the extremes of stroke severity) were excluded. Studies with a focus on transient ischaemic attack or subarachnoid haemorrhage were not considered in this review.
Information sources
A comprehensive search strategy was generated in collaboration with colleagues at the University of Leeds library. The initial strategy included the stroke terms as used by the Cochrane stroke group, 22 key terms from relevant papers of which we were already aware and discussion between the research team. This strategy was run on the MEDLINE database and reviewed to ascertain whether appropriate papers were being captured. Following this review, the search strategy was amended (Appendix 1 online). The search was then run through MEDLINE, EMBASE, CINAHL, PsycInfo, AMED and ISI Web of Science with no date or language limits on 30 May 2009. Handsearching of references of included studies and previous reviews was performed to identify further potentially relevant citations.
Study selection
Titles were reviewed independently by two researchers (AF and AR) and obviously irrelevant titles excluded. Where there was no consensus, titles were examined by a third reviewer (ET). Titles and abstracts of potentially relevant papers where there was agreement between at least two of the three reviewers were then re-examined by AF and ET and included through consensus. Citations not fulfilling inclusion criteria were discarded (Figure 1).
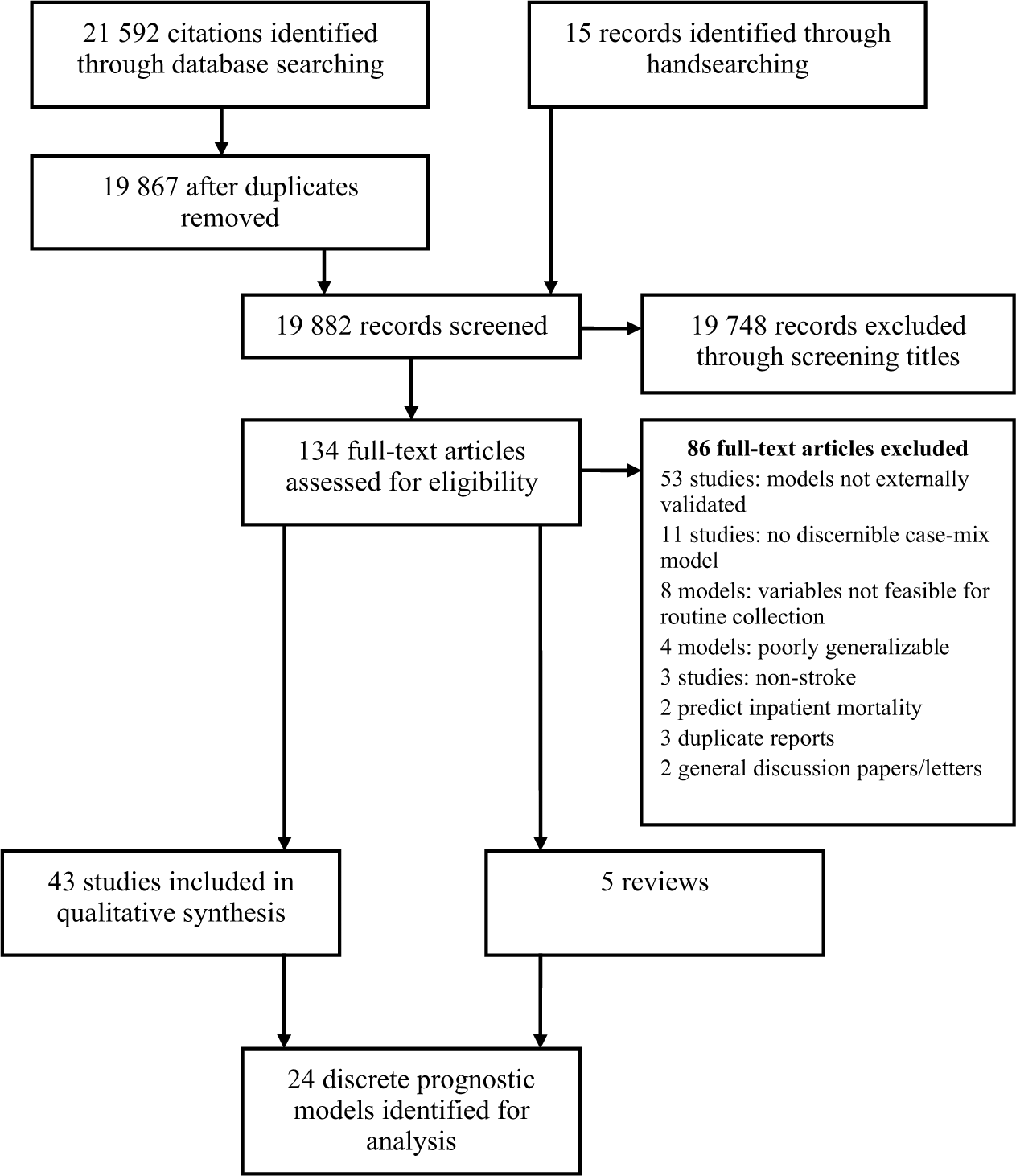
Identification of models for inclusion in review.
Data extraction
Data extraction was performed in duplicate by two independent researchers (ET and RL). Further examination of models was only performed if there was evidence that they had been externally validated in independent populations.23,24
Quality of the prognostic studies was considered against criteria used by Counsell et al. 5 in their 2001 review of prognostic models in stroke and a framework to assess model internal validity and potential biases as described by Hayden et al. 20 Independent statistical appraisal of model development methodology and performance was performed by TM using criteria selected from those suggested by Counsell et al. 5
Details regarding the name of the case-mix model, author, model variables, reference population (inception cohort and study exclusion criteria), prospective or retrospective data collection, losses to follow-up, outcome measures (and time point of measurement), sample size, external validation of model and feasibility of collection of independent variables were extracted if available. Studies describing the development of models and subsequent validation studies were then grouped together.
Data items: model characteristics
Case-mix adjustment or prognostic models containing independent variables which were considered neither clinically relevant nor feasible for routine collection in non-specialist settings (e.g. magnetic resonance imaging or invasive imaging) were excluded. Models developed on study populations with an inception cohort (time from stroke onset to data collection) of greater than two weeks were also excluded. Models where outcomes were not assessed at a fixed time point following stroke onset were excluded.
Adequate sample size for model development was assumed if the ‘events per variable (EPV)’ was greater than ten for dichotomous outcomes. 25 The EPV is calculated by dividing the number of discrete outcome events (e.g. number of deaths) by the number of independent (including dummy) variables in the model. For a dichotomous dependent variable, the lower frequency outcome from the pair is used to calculate EPV. 25 Models developed through adoption of a valid method of variable selection (clinical reasoning and forwards or backwards stepwise selection for logistic regression modelling) were retained. Models were excluded if there was no specific consideration of multicollinearity and interaction terms, 26 or if linearity assumptions were not tested or addressed if not met.
Summary measures
Measures of model performance were extracted from external validation studies of identified models and comprise measures of discriminatory function (e.g. c statistic), sensitivity/specificity analysis, the coefficient for multiple determination (R squared statistic) and calibration in external datasets.
Risk of bias
Potential sources of bias from individual studies (retrospective secondary use of data from randomized controlled trials (RCTs) or stroke registers, selected populations that may limit generalizability or overfitting of models) are highlighted and discussed qualitatively. Quantitative assessment of bias has not been performed. Comparisons of models based on performance are limited by disparate measures of performance, data sources and variable methodological quality of external validation studies.
Presentation of results
Quantitative synthesis has not been possible in this review; models are presented in tabular form with their relative performance against each of the quality and statistical criteria outlined. The variables included in each of the models are also provided when they have been reported in the original studies.
Results
The initial search identified 21 592 titles. Removal of duplicates reduced this to 19 867. Screening of titles and abstracts led to two independent reviewers agreeing to the retention of 176 citations. In 487 citations where consensus between these two reviewers was not met, the opinion of a further independent reviewer (ET) was sought with the retention of a further 183 citations. Following discussion (AF and ET), 119 papers were examined in full text. A further 15 potentially relevant citations were identified through handsearching of the reference lists of these papers (ET). In addition, five review articles were retained to identify any models that may have been overlooked.5–9 Examination of previous reviews did not identify any additional externally validated models fulfilling inclusion criteria and comprising variables that were feasible for collection in routine care. A total of 43 papers were retained for data extraction including three discussion papers (Figure 1).
Twenty-one discrete prognostic or case-mix adjustment models were identified predicting mortality, dependency and functional outcomes following stroke. In addition, two studies described the use of three existing impairment scales to predict post-stroke outcome (Table 1). These were the National Institute of Health Stroke Severity score (NIHSS), the Canadian Neurological Score (CNS) and the Middle Cerebral Artery Neurological Score (MCANS) also known as the Orgogozo score.27,28 Of the 21 models identified, four29–32 had been validated by the authors using a ‘split sample technique’. Here the model is developed using data from a proportion of the sample (training set) and validated on the remainder (validation or test set). This represents a form of internal (not external) validation 23 and these models were not considered further.
Twenty-one models and three existing scoring systems identified through review process
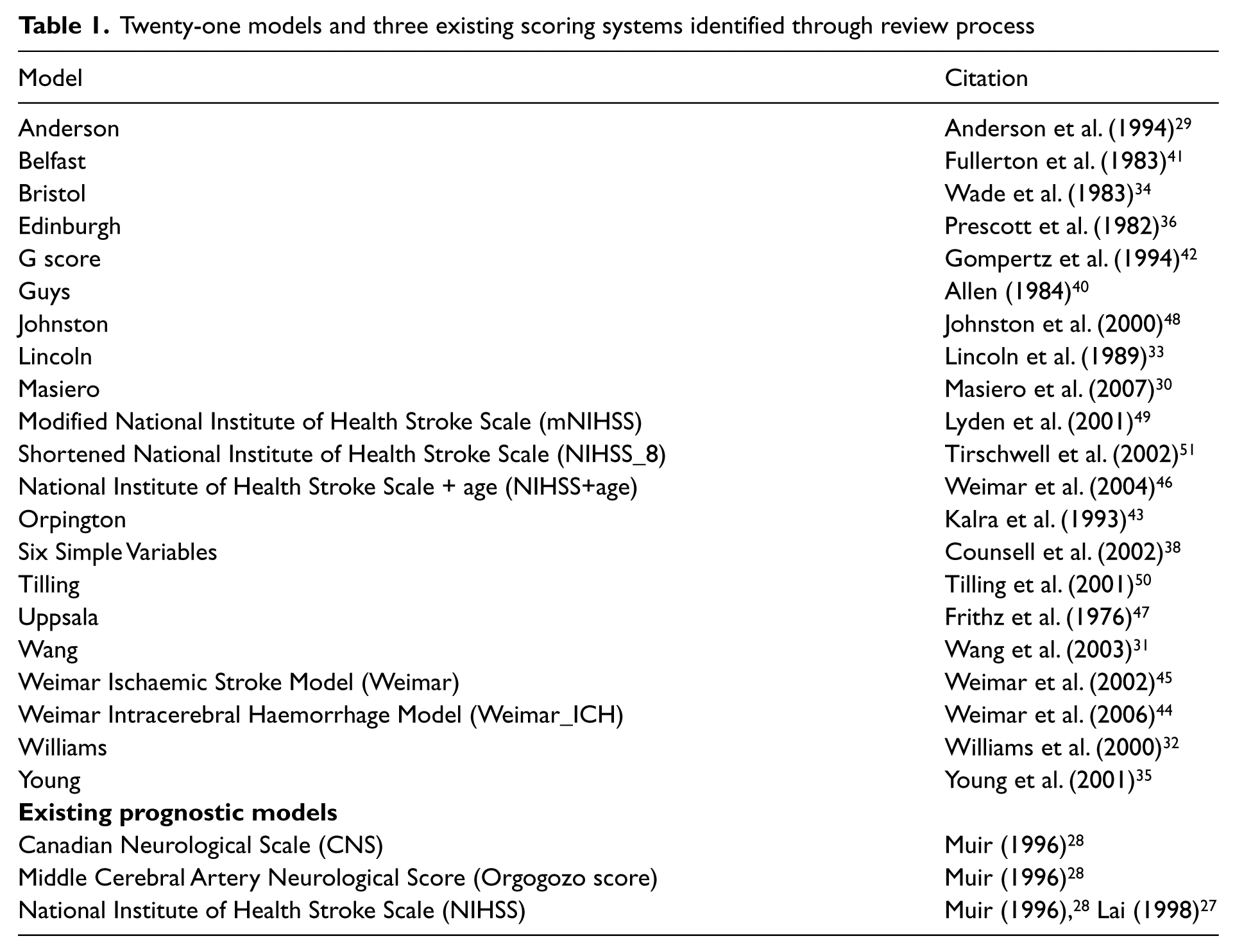
Data extraction was performed from papers describing development and validation of 17 prognostic models. Detailed tables examining studies describing development and validation of individual models are available from the authors. Table 2 offers a summary of the key features of each externally validated model.
Performance of identified models against quality criteria
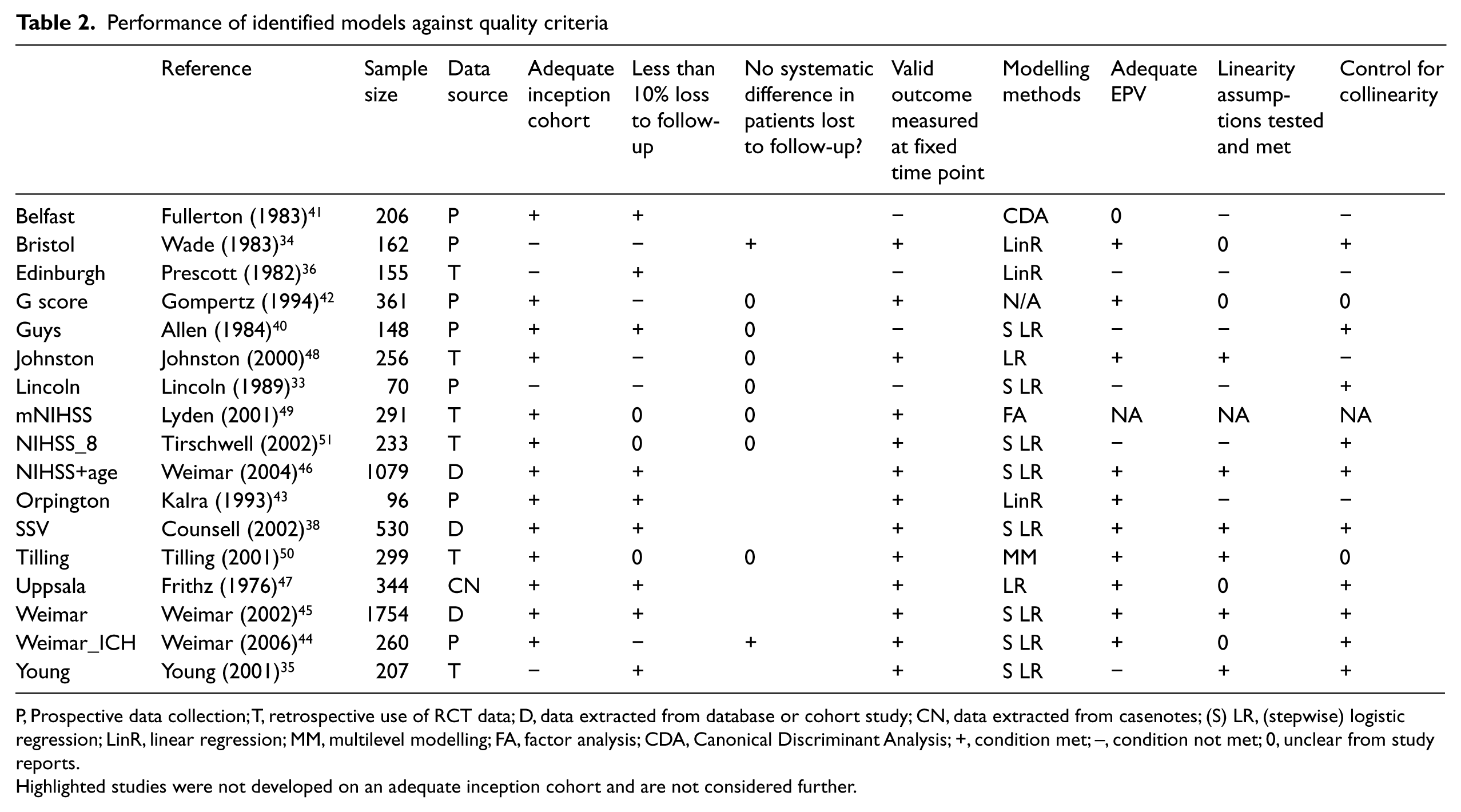
P, Prospective data collection; T, retrospective use of RCT data; D, data extracted from database or cohort study; CN, data extracted from casenotes; (S) LR, (stepwise) logistic regression; LinR, linear regression; MM, multilevel modelling; FA, factor analysis; CDA, Canonical Discriminant Analysis; +, condition met; –, condition not met; 0, unclear from study reports.
Highlighted studies were not developed on an adequate inception cohort and are not considered further.
Three models (Lincoln, Bristol and Young models)33–35 were developed on cohorts where the collection of model variables were collected on admission to (or discharge from) a rehabilitation facility and therefore the inception cohort (time from stroke event to assessment) was not uniform. Measurement of variables for the development of the Edinburgh model was at four weeks from admission to the acute hospital 36 and this is likely to limit the usefulness of this model in the acute stroke setting.
Of the remaining 13 models, inception cohorts for model development were less than two weeks. The Six Simple Variables model was developed using data from the Oxford Community Stroke Project (OCSP) cohort.37,38 Within the original OCSP cohort about three-quarters of assessments were performed within two weeks of the stroke event (median time to assessment 4 days), 37 however the Six Simple Variables model was developed using data on assessments performed up to 30 days following stroke. The proportion of assessments performed after 14 days was small and their inclusion is unlikely to limit the usefulness of the Six Simple Variables as a model.
Models should ideally be developed from prospective data collected according to a protocol with the express purpose of model development. 39 There were three main sources of data used for model development and validation: prospective data collection for the purposes of model development, retrospective use of data collected within stroke registers, and the secondary use of data from previously conducted randomized controlled trials.
Five of the 13 remaining studies described data collection with an a priori intention of developing a prognostic model (Belfast, G score, Guys, Orpington, Weimar_ICH).40–44 These tended to be small studies (sample size 96–361, median 206). The G score 42 and Weimar_ICH 44 models both reported loss to follow-up of greater than 10%, but the characteristics of non-responders as compared to patients with complete outcomes data was only considered (and found to be non-significant) by Weimar et al. 44
Two of the studies described models derived from data held within a large stroke database (Weimar and NIHSS+age)45,46 and one model (Six Simple Variables) was derived from existing data from prospective cohort studies. 38 The Uppsala model was developed through extracting data from patient case-notes. 47
Four remaining models used data from previously conducted RCTs (Johnston, mNIHSS, NIHSS_8, Tilling).48–51 These model development studies all excluded participants where outcomes data were not available at at least one time point. One of these studies (Johnston 48 ) reported the numbers of patients excluded through incomplete outcomes data, but none compared the characteristics of patients excluded through missing data with the model development study population or reported the approach to missing outcomes data adopted in these trials (Table 2). Exclusion of patients with incomplete data (or those lost to follow-up) through secondary use of data (from RCTs, databases or previously conduced cohort studies) may introduce the the risk of systematic bias. Moreover, inclusion or exclusion criteria of RCTs (e.g. exclusion of patients unable to transfer from bed to chair 50 or exclusion of patients with contraindications to thrombolysis 51 ) may affect the ability of models developed from trial data to predict outcomes in the groups that were excluded from the training dataset. If validation studies were also performed in selected populations, the performance of models in empirical populations may remain untested and uncertain.
Modelling methodology
The case-mix adjustment models identified in this review are based largely on logistic regression modelling techniques to predict dichotomized outcomes (Table 2). The Tilling model was developed through multilevel modelling which allows consideration of the hierarchical structure of data to predict individual patient recovery trajectories (Barthel Index) over time. 50 Seven of the 13 models were developed to predict dichotomized continuous (or ordinal) dependent variables (Johnston, G score, Weimar_ICH, Weimar, NIHSS+age, NIHSS_8, mNIHSS).42,44–46,48,49,51 Dichotomizing continuous variables into two extremes results in loss of information 52 and prevents the prediction of more complex outcomes. However, treating an ordinal variable (such as the Barthel Index) as interval data may fail to account for non-linear relationships between the independent and dependent variables unless this is addressed specifically. The Orpington model was developed through linear regression modelling with no report of specific consideration as to whether or not linearity assumptions were met. 43
Of the 13 remaining models, two (Guys, NIHSS_8)40,51 had an EPV of less than 10 during model development. One further study (Belfast model) reported insufficient information to determine if an EPV of 10 had been achieved. 41 If the number of observed outcome events (or whichever outcome is fewer for dichotomous dependent variables) is less than 10, the model coefficients are likely to be unstable and the model unreliable. 25 This may be reflected in the relatively poor sensitivity 53 and specificity42,53 of the Guys model in external validation studies (Table 3).
Summary of external validation studies for identified models with adequate inception cohorts

Variables included in each of the models are presented in Table 4. These variables fit into three broad categories; markers of stroke severity, pre-stroke function and comorbidities. All of the models contain a marker of post-stroke motor function and most feature age and conscious level.
Variables included in individual models (only models with adequate inception cohorts are listed)

Variable selection was often performed through entering variables reaching statistical significance in univariate analysis into multivariable models. This data-driven approach risks inclusion of variables which are of statistical, but questionable clinical significance (for example the inclusion of non-specific ECG changes as a predictor in the Belfast model 41 ). Multiple univariate analyses may also identify or disregard correlations through the role of chance. 54 Forwards or backwards stepwise variable selection was common in model development (Guys, NIHSS_8, NIHSS+age, Six Simple Variables, Weimar, Weimar_ICH)38,40,44–46,51 and helps to circumvent problems with collinearity as the effect on model residuals of inclusion and exclusion of combinations of individual variables is considered in turn.
Model performance was quantified through presentation of the c statistic (a measure of the ability of a model to discriminate correctly between two incongruous outcome pairs) 55 or sensitivity and specificity. In the Orpington model development study, the amount of variation in Barthel Index explained with the Orpington model was presented as the R-squared statistic. 43
Table 3 presents data on the performance of the models in the external validation studies identified in this review.
Factors potentially limiting feasibility of variable selection
National clinical audits conducted in a number of countries have revealed variable access to stroke unit care. In the recent Royal College of Physicians National Sentinel Stroke Clinical Audit (2010) of England, Wales and Northern Ireland, 88% of included patients spent some of their inpatient stay on a specialist stroke unit. 56 National audits in New Zealand and Australia performed in 2009 57 and Scotland in 2011 58 revealed that 52%, 74% and 82% respectively of included patients spent time on a stroke unit (these figures exclude patients admitted to hospitals without a stroke unit). These audits occurred at different times and the expectation is that access to specialized stroke unit care will continue to improve over time, however, the general point remains that specialist stroke unit care is not currently universally achieved.
The feasibility of collecting variables within individual models is dependent on the setting and the skills and experience of those performing assessment. The availability of staff trained to perform complex clinical assessments (e.g. the NIHSS) may currently limit the use of some models to specialist settings. In addition, data collection is resource dependent. In funded research projects feasibility of assessments is likely to differ from that of routine clinical care. Eight of all the 24 models and prognostic scores identified in this review require complex clinical assessments for completion (Johnson, Lincoln, NIHSS, Weimar, Weimar_ICH models, Belfast, NIHSS+age, Uppsala, mNIHSS)28,33,41,44–49 and are therefore unlikely to be feasible for collection in non-specialist settings. In addition, three of these models require collection of variables within 6 hours of the stroke event (Johnston, NIHSS+age and Weimar_ICH models).44,46,48 Feasibility of hyperacute data collection in this way may limit the use of these models to patients admitted directly to the specialist stroke setting.
Discussion
There are currently no universally accepted criteria to assess the quality of prognostic studies used to develop case-mix adjustment models.19,21,54 However, there is both generic and disease specific literature that has identified key clinical and statistical criteria that should be considered in model development and assessment.5,6,19,20,26,39,54,59–61 The 21 models considered in this review have been considered against many of these criteria.
There are methodological weaknesses in the development and validation of many of the models considered in this review, and clinical feasibility of collection of complex variables may limit the use of some of the models in the routine care setting.
The extent to which models have been validated in independent cohorts also varied and this will affect the confidence with which these models may be used in settings other than those in which the validation studies were performed. Most (11) models were validated in just one external validation study, and these were often performed by the authors of the instrument. Further validation of these models may have been performed in studies that have not been identified in this review.
The Weimar models to predict dichotomized Barthel Index at 100 days following ischaemic stroke 45 and the NIHSS+age 46 are well-developed models, but their performance in independent cohorts has been variable and this may restrict their usefulness as case-mix adjustment models. In addition, the variables to construct these models incorporate the NIHSS which requires specific training to administer.
The Six Simple Variables models are robust in terms of model development and have been extensively externally validated in six independent post-stroke populations including community- and hospital-based cohorts,38,62–67 and with both prospective and retrospective data extraction. The inter-rater reliability of the collection of Six Simple Variables variables has also been shown to be acceptable. 68 The Six Simple Variables model may be used to predict 30-day mortality and six-month independent survival with c statistics (a measure of the ability of a model to correctly predict good over poor outcome) consistently greater than 0.75. Model performance where variables are collected hyperacutely (within 6 hours of the event) has been shown to be reasonable (c statistic >0.8065 66 ), although the models perform less well in milder strokes. 66 Calibration of models (correct prediction of outcome in independent populations) is generally good, although the Six Simple Variables model tended to make over pessimistic predictions of survival and living at home 63 or independent survival 65 in moderate to severe strokes. However, it is in these patients that particular uncertainty may exist as regards prognosis and where prognostic models may be most useful. It has been suggested that the Six Simple Variables model can be used for stratifying patients for RCTs and for the adjustment of observational cohorts,38,63,65 although the models are not sufficiently robust for predicting outcomes in individual patients following stroke.38,65 Prognostic scoring systems developed from population level data should only be used as a guide to predict outcome in individuals as they fail to account for factors such as the recovery trajectory. The multilevel modelling approach using repeated measures of function as adopted by Tilling et al. may address some of these issues. 69 It should also be considered that there are many markers of recovery that are more likely to be of interest to individual patients and their carers as post-stroke outcomes than the hard endpoints of death and dependency. 38 These may include markers of physical or social functioning, mood or quality of life. However, the prediction of these outcomes is further complicated by the complex nature of these endpoints.
This review provides a systematic overview of available externally validated prognostic models in stroke, updating previous reviews5,6 to include more recent models and modelling methodologies. This review was based on a comprehensive and replicable search strategy producing a vast amount of literature for consideration. Despite this process, it is possible that relevant citations describing model development or validation of existing models have been overlooked. In addition, models that are yet to be externally validated and may yet prove to be good predictors of patient outcome have been excluded from the review. Information regarding modelling techniques may not have been reported in detail in individual studies, and where this detail was lacking we have not attempted to obtain this information directly from authors. It is therefore possible that further robust models may have been excluded. Apparently poor performance of individual models in independent populations may reflect the methodology of external validation studies. It has not been possible to offer a quantitative summary of the performance of individual models in external populations due to the heterogeneity of external validation studies. Instead, validation studies have been presented individually to allow comparative assessment of their methodological quality and generalizability.
Conclusions
This review has identified that the Six Simple Variables model demonstrates statistical robustness, good discriminatory function in external validation studies and comprises variables that are clinically feasible to collect at ward level by non-specialist staff. However, the Six Simple Variables model predicts the hard endpoints of death or dependency which do not capture the nuances of complex rehabilitation outcomes or patient-reported outcomes that are likely to be of more interest to patients and their carers following stroke (e.g. reintegration or social functioning).
Alternative modelling approaches for case-mix adjustment, such as latent class analysis, 70 structural equation modelling or decision trees, may allow exploration of the heterogeneity in the recovery of individuals following stroke where allowing for the interrelationships among prognostic factors may improve existing models. Further work is needed to explore the feasibility and utility of these alternative modelling approaches to adjust for case-mix in large unselected populations of patients admitted to hospital with acute stroke.
Clinical messages
Many existing prognostic models in stroke require complex assessments that may limit their feasibility for use in routine stroke care.
The Six Simple Variables prognostic model is feasible to collect in routine settings, statistically robust and extensively externally validated in post stroke populations.
Many existing prognostic models in stroke (including the Six Simple Variables model) predict mortality or dependency. These endpoints may be of less interest to individual patients and their carers than more complex rehabilitation outcomes.
Footnotes
Acknowledgements
With thanks to Deirdre Andre at the University of Leeds Library for assistance with developing the search strategy, Anita Rajendram (University of Leeds) for initial screening of citations, and Ruth Lambley (Academic Unit of Elderly Care and Rehabilitation, University of Leeds) for assistance with data extraction.
Conflict of interest
None declared.
Funding
We are pleased to acknowledge funding from the National Institute for Health Research (NIHR) Collaborations for Leadership in Applied Health Research and Care (CLAHRC) at Leeds, York and Bradford. The views and opinions expressed in this paper are those of the authors and not necessarily those of the NHS, the NIHR or the Department of Health.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.