
Abstract
Generative artificial intelligence is reshaping marketing practice, yet marketing education lacks clarity on which forms of human expertise remain distinctive and assessable when generative systems accelerate production. This study develops a practice-grounded framework of AI-resilient marketing capability through a qualitative investigation of 33 in-depth interviews with practitioners across sectors and levels of AI integration. Rather than testing predefined competency models, the study inductively surfaces how practitioners identify non-delegable human contribution in AI-mediated workflows. Analysis yields the Voice–Judgement–Taste (VJT) framework: voice as expressive authorship that conveys identity and audience relationship; judgement as deciding when AI outputs can be trusted, adapted, or rejected; and taste as evaluating which outputs are worth developing and ensuring coherence across them. Together, these interdependent capabilities explain how professionals manage productivity–authenticity tensions in AI-assisted work. Findings show that human value shifts from producing content to shaping it—for example, revising tone and identity, verifying accuracy and risk, and selecting the most appropriate option from multiple viable outputs. By translating broad graduate attributes into observable practices, the study advances conceptual clarity in marketing education and offers scalable assessment principles for making human contribution visible in AI-rich learning environments.
Introduction
Artificial intelligence (AI) is widely recognised as transforming both marketing practice and marketing education (Grewal et al., 2024). Scholars describe AI integration as “a paradigmatic shift requiring a complete rethinking of how we prepare the next generation of marketing professionals” (Schlegelmilch & Mills, 2025, p. 91), and marketing education has been characterised as designed for the pre-GenAI era yet pressured to serve an AI-centric future (Mehmet et al., 2025). This shift is structural rather than merely technological: AI is reshaping how marketing knowledge is produced, communicated, and evaluated across analytical and creative tasks (Acar, 2024; Grewal et al., 2025). Adoption is accelerating, though unevenly. Universities, to varying extents, are incorporating AI-assisted practices into instruction, assessment, and feedback (Guha et al., 2024; Mehmet et al., 2025), while industry increasingly embeds AI within analytics, targeting, and high-volume creative production (The Chartered Institute of Marketing [CIM], 2024). Although generative AI delivers productivity gains and expanded iteration (Peña et al., 2025), it also introduces risks including stylistic homogenisation, diminished brand distinctiveness, and heightened ethical and reputational exposure when oversight is weak (Acar, 2024; Kim & Koo, 2024). Employers therefore seek graduates who can collaborate with AI while sustaining contextual reasoning, ethical accountability, and brand coherence (Grewal et al., 2025; Mehmet et al., 2025). Yet research offers limited guidance on which forms of human expertise retain distinctive value when generative systems perform substantial production tasks.
Recent work offers programme-level guidance on governance, responsible tool integration, and teaching innovation (Guha et al., 2024; Peña et al., 2025; Richter et al., 2025), yet offers limited specification of assessable human capabilities at the level of disciplinary practice. At a more granular level, extant scholarship commonly identifies creativity, critical thinking, ethical reasoning, and human oversight as key capabilities for AI-rich contexts (Acar, 2024; Grewal et al., 2024; Mehmet et al., 2025). These capabilities are typically organised into broad taxonomies—grouping outcomes as cognitive–analytical skills, socio-ethical capacities, and creative–expressive attributes (Gao & Huber, 2024; Pefanis Schlee & Harich, 2010; Thornhill-Miller et al., 2023)—often under “21st century skills” or future-of-work frameworks (Dumitru & Halpern, 2023; Gao & Huber, 2024; Pefanis Schlee & Harich, 2010). While such classifications signal priority areas, they translate weakly into curriculum and assessment design, offering limited guidance on what observable evidence of student contribution looks like when generative systems perform substantial production tasks in AI-assisted marketing practice. As AI lowers the cost of competent production and blurs authorship, authorisation, and evaluation, more operationalisable, practitioner-anchored constructs with observable indicators are needed to capture how domain expertise is enacted and defended in context (Gonsalves, 2024; Grewal et al., 2024; Thornhill-Miller et al., 2023). More broadly, emerging scholarship cautions that discourse on generative AI in business remains conceptually under-theorised and calls for stronger theoretical grounding beyond speculative or taxonomic responses (Brown et al., 2024). Developing refined, practice-anchored constructs is therefore not only pedagogically necessary but theoretically urgent.
Generative AI also intensifies a productivity–authenticity tension in marketing education. While AI accelerates drafting and ideation (Kim & Koo, 2024; Peña et al., 2025) and can support students’ early-stage analysis (Gonsalves, 2024), research shows that uncritical reliance may displace these processes and narrow stylistic range (Amirjalili et al., 2024; Gonsalves, 2024; Tan et al., 2025). Generative systems therefore risk flattening voice and destabilising authorship across branded, personal, strategic, and multimodal communication contexts. While brand communication research shows that tone, lexical choice, and stylistic patterning shape trust and brand personality (Barcelos et al., 2018; Delin, 2007), writing studies further conceptualise voice as identity, stance, and reader-perceived authorship enacted through textual and multimodal choices (Khuder & Petric, 2026; Tan et al., 2025). These tensions strengthen calls for learning designs that equip graduates with the “requisite AI knowledge and skills” demanded by contemporary practice (Grewal et al., 2024; Guha et al., 2024; Peña et al., 2025; Schlegelmilch & Mills, 2025) while rendering human reasoning and evaluative discernment visible in AI-mediated production (Acar, 2024; Gonsalves, 2024).
To address these challenges, this study adopts an inductive, qualitative theory-building approach grounded in 33 in-depth interviews with marketing practitioners across roles, sectors, and levels of AI adoption. Rather than testing predefined competency models, we draw on practitioner accounts to surface the tacit logics through which professionals articulate and defend forms of human contribution that retain value under AI-mediated production (Whitler, 2022). Through iterative coding, cross-case comparison, and progressive abstraction, these accounts were synthesised into the Voice–Judgement–Taste (VJT) framework.
The study contributes in three ways. First, it empirically develops a practice-grounded conceptualisation of AI-resilient marketing capability, identifying voice, judgement, and taste as distinct yet interdependent domains of human contribution in generative AI environments. Second, it advances conceptual precision in marketing education by reframing graduate capability as integrated expressive authorship, accountable decision authority, and resonance-based evaluative discernment. Third, it translates this framework into pedagogical guidance by specifying observable indicators and assessment approaches capable of rendering these capabilities visible and evaluable in AI-mediated learning contexts. The study addresses three research questions:
Theoretical Background and Conceptual Foundations
Marketing education scholarship conceptualises professional competence as a situated, integrative capability developed through engagement with complex market contexts rather than the accumulation of discrete technical skills (Carson & Gilmore, 2000; Wellman, 2010). Expertise emerges as practitioners synthesise formal knowledge, experiential insight, tacit understanding, and judgement to translate theory into contextually defensible strategic action (Carson & Gilmore, 2000).
Competency-based education extended this perspective by specifying observable graduate attributes aligned with employability and workforce readiness, commonly emphasising communication capability, analytical reasoning, creative problem solving, and decision-making within marketing curricula (Kaufman et al., 2019; Walker et al., 2009; Wellman, 2010). These models improved curriculum transparency and strengthened links between academic preparation and professional expectations (Kaufman et al., 2019). However, these models typically operate at the level of broad capability clusters, identifying desired graduate attributes without specifying how they manifest, integrate, or become assessable in applied marketing practice.
Twenty-first-century and future-of-work frameworks further broadened competency discourse by emphasising adaptive cognitive, social, and creative capacities required in technologically mediated environments (Gao & Huber, 2024; Pefanis Schlee & Harich, 2010; Thornhill-Miller et al., 2023). Creativity, critical thinking, collaboration, and ethical reasoning are positioned as essential for navigating volatility, complexity and technological change (Gao & Huber, 2024; Thornhill-Miller et al., 2023). These frameworks offer important directional guidance, but their breadth reflects their cross-disciplinary ambition: they describe high-level human capacities rather than domain-specific enactments of professional expertise (Kerr & Lloyd, 2008; Thornhill-Miller et al., 2023; Walker et al., 2009). Creativity scholarship illustrates the same instability. Although education research positions creativity as a core graduate capability linked to innovation and adaptive problem solving (Thornhill-Miller et al., 2023; Walker et al., 2009; Wellman, 2010), management education shows substantial variation in how creativity is defined, taught, and assessed across contexts (Kerr & Lloyd, 2008). Table 1 synthesises these competency traditions and highlights a shared challenge: in AI-rich environments, many valued graduate attributes become difficult to attribute, verify, and assess at the level of individual student contribution.
Competency Frameworks in Marketing and Higher Education: AI-Era Assessment Limitations and Conceptual Extension Through VJT.

Within this lineage, the VJT framework offers a disciplinary refinement of established competency traditions. It specifies how integrative professional expertise is enacted in AI-mediated marketing practice through three interdependent domains of human contribution—expressive authorship (voice), accountable deployment authority (judgement), and evaluative selection under conditions of abundance (taste). By articulating these domains, the framework renders broad graduate attributes conceptually sharper and pedagogically assessable. The empirical analysis that follows examines how practitioners delineate and prioritise these capabilities in contemporary marketing work.
Methodology
This study employed a discovery-oriented qualitative design to examine how marketing practitioners interpret the nature of human contribution within AI-mediated marketing work. Discovery-oriented approaches are particularly suited to surfacing underexamined managerial logics and tacit professional reasoning that may not yet be captured within established theoretical frameworks (Whitler, 2022). Given the rapid diffusion of generative AI and the emergent nature of its organisational implications, an inductive, interpretive design enabled exploration of practitioner sensemaking rather than testing pre-existing competency constructs.
The study is informed by an interpretivist epistemology in which professional capability is understood as socially constructed through practitioner meaning-making and situated practice (Lim, 2025; Ozuem et al., 2022). Within this paradigm, knowledge emerges through iterative engagement between empirical material and researcher interpretation, positioning thematic development as an analytic co-construction rather than objective discovery. Reflexive thematic analysis was therefore selected as the primary analytic framework because it supports inductive theory development while recognising researcher subjectivity as an interpretive resource rather than a methodological limitation (Braun & Clarke, 2019).
Participant Recruitment and Sample Characteristics
To examine practitioner interpretations of AI-mediated marketing capability, 33 in-depth semi-structured interviews were conducted with marketing professionals across the United Kingdom (12), the United States (14), Europe (5), and Asia (2). Interviews were conducted between November 2023 and July 2025 under institutional ethics approvals MRA-23/24-41020 and MRSU-24/25-49961.
Participants were purposively recruited through professional networks and selected based on direct or supervisory involvement in generative AI adoption within marketing workflows. This sampling strategy aligns with qualitative approaches designed to access information-rich cases capable of illuminating emerging professional phenomena (Lim, 2025). Participants represented diverse organisational roles including digital analysts, performance marketers, content strategists, creative directors, consultants, agency founders, automation specialists, and senior marketing leaders. Interviewees reported varied levels of AI integration ranging from exploratory experimentation to daily operational reliance. AI applications discussed included content production, content strategy, campaign development, creative ideation, branding and design, search marketing and SEO, customer insight generation, customer relationship management (CRM), marketing and communication automation, lead generation and customer engagement, marketing research and information gathering, analytics interpretation, performance measurement and attribution, predictive analytics, and strategic marketing decision-making. Referenced tools included ChatGPT, Claude, Copilot, Midjourney, model-integrated content management systems, customer relationship management platforms, and internally developed GPT-based automation tools. This diversity enabled examination of AI-mediated marketing capability across organisational scale, regulatory intensity, industry sector, and creative versus performance-oriented marketing contexts.
Data Collection
Semi-structured interviews were chosen to balance comparability across participants with flexibility to explore emergent practitioner interpretations. Interviews lasted between 50 and 65 min and were conducted in person or via Zoom or Microsoft Teams. All interviews were audio-recorded with participant consent and transcribed using automated transcription software, followed by manual verification to correct transcription errors.
The interview protocol explored three broad domains: (a) practitioner perceptions of AI’s impact on marketing work, (b) perceived changes to skill and capability requirements, and (c) examples of tasks practitioners considered delegable or non-delegable under AI-supported workflows. Questions were intentionally open-ended to allow participants to articulate capability boundaries using their own professional language rather than researcher-imposed terminology. All transcripts were imported into NVivo to support systematic coding and iterative analytic comparison.
Analytical Approach
Phase 1: Inductive Coding and Pattern Identification
Analysis followed Braun and Clarke’s (2019) reflexive thematic analysis framework, combined with inductive theory-building principles from qualitative organisational research (Gioia et al., 2013; Miles et al., 2014). Coding commenced alongside data collection and involved repeated transcript reading to identify practitioner descriptions of capability transformation within AI-mediated marketing work.
Initial coding focused on capturing practitioner language describing human contribution, including references to authorship, identity signalling, decision authority, ethical oversight, evaluation of AI outputs, and responsibility for marketing quality. Codes were intentionally descriptive during early analytic stages to remain close to practitioner meaning-making rather than prematurely abstracting conceptual categories.
Phase 2: Cross-Case Comparison and Capability Clustering
Iterative comparison across transcripts revealed recurring practitioner distinctions between tasks considered automatable and those requiring human oversight. Through cross-case pattern matching (Miles et al., 2014), these practitioner distinctions progressively clustered into three recurrent capability logics:
1. Human authorship, authenticity, stylistic ownership, audience positioning, and, in some cases, brand voice preservation.
2. Decision authority governing AI use, encompassing practitioner emphasis on contextual evaluation, ethical accountability, and responsibility for determining appropriate AI deployment.
3. Discernment of marketing quality and resonance, reflected in repeated practitioner descriptions of selecting, curating, and refining AI-generated outputs.
These clusters recurred across cases and were iteratively stabilised through cross-case comparison, suggesting patterned practitioner sensemaking rather than isolated individual perspectives.
Phase 3: Conceptual Abstraction and Framework Development
Following the identification of capability clusters, analysis progressed to conceptual abstraction consistent with interpretive theory-building approaches (Gioia et al., 2013). Through iterative memo writing, reflexive dialogue between authors, and repeated engagement with transcript data, these clusters were progressively refined into three higher-order constructs: voice, judgement, and taste.
Importantly, these constructs were not predefined analytic categories. Rather, they emerged as higher-order abstractions from recurring practitioner logics concerning expressive authorship, deployment authority over AI use, and evaluative selection among AI-generated alternatives. Voice was conceptualised as expressive authorship through which marketers signal identity, narrative coherence, and relational positioning. Judgement captured practitioner accounts of accountable decision authority, including contextual evaluation, risk assessment, and ethical oversight in AI-mediated workflows. Taste reflected patterned emphasis on evaluative discernment through which marketers select, refine, and differentiate outputs to achieve resonance and cultural relevance.
Consistent with reflexive thematic analysis (Braun & Clarke, 2019), these domains stabilised through iterative movement between data familiarisation, coding, memo writing, and abstraction to ensure interpretive grounding and theoretical coherence. Existing marketing competency and educational capability literatures were engaged only after these constructs had analytically stabilised, serving to position and refine the framework rather than to generate it deductively. Interpretive transparency was further supported through reflexive documentation of analytic decisions and collaborative interrogation of emerging interpretations. Selected illustrative quotations are presented to demonstrate how practitioner discourse informed the development of the final conceptual constructs and to enhance analytic traceability beyond the immediate dataset (see Table 2).
Illustrative Analytic Progression From Practitioner Insights to VJT Constructs.

Reflexivity and Researcher Positionality
Consistent with reflexive thematic analysis, the researchers recognise that thematic interpretation reflects an interaction between practitioner accounts and researcher expertise (Braun & Clarke, 2019). The first and third authors’ prior research on marketing education and AI adoption informed sensitivity to practitioner discussions of capability transformation while necessitating ongoing reflexive attention to interpretive assumptions. This positioning supported theoretically informed sensemaking while maintaining grounding in participant meaning.
Findings
RQ1: Essential Human Capabilities in AI-Mediated Marketing Work
Analysis revealed a recurring practitioner logic regarding meaningful human contribution in AI-mediated marketing work. Across interviews, participants consistently framed three non-delegable capabilities—voice, judgement, and taste—as defining professional responsibility when generative systems accelerate marketing production. These capabilities functioned as interpretive anchors through which practitioners distinguished human expertise from automated output generation.
Voice: Expressive Authorship and Relational Positioning
Practitioners consistently described voice as the most vulnerable dimension of AI-assisted marketing work. While generative tools were widely valued for drafting and structural support, participants emphasised that model outputs frequently lacked intentionality, identity signalling, and relational authenticity.
Liam described an AI rewrite of his self-promotional personal statement as “very formal” and “stiff,” noting that although technically accurate, “it was not me” because it followed “a very particular template.” Maya similarly observed that many AI-generated outputs lack “a touch of human element,” producing multiple texts where “there is no thought behind it.” Warren reinforced this concern, suggesting that AI outputs often feel “a bit too polished and a bit hygienic,” generating patterns that “set off our bullshit detectors” when tone or cultural fit is misaligned.
Across accounts, voice was positioned as extending beyond stylistic editing to encompass narrative coherence, audience sensitivity, and embedded brand knowledge. Elliott described remaining “protective” of organisational voice even when working with internal models trained on brand datasets. Practitioners frequently framed AI as providing structural scaffolding, while communicative personality and relational positioning required deliberate human authorship. Voice therefore functioned as expressive authorship through which marketers shape tone, perspective, and audience relationships, signalling identity and relational intent. Participants viewed this capability as particularly fragile under AI-mediated production because it depends on tacit cultural and organisational knowledge that practitioners considered difficult to encode within model training.
Importantly, brand identity was one recurring site where voice became visible, but it did not exhaust how practitioners described the construct. While some participants explicitly linked voice to brand identity, practitioner accounts also revealed broader, non-brand-bound dimensions of voice as human authorship, cognitive engagement, and relational expression. Laura framed voice as organisational authorship, emphasising a “duty. . . to have our own voice rather than be voiced by a computer”. However, other participants positioned voice more generally as human presence and authenticity in communication, noting that “people want to work with people. . . they don’t want to work with. . . computers” and that audiences remain “biased to wanting something that’s created by humans. . . especially. . . as personal as marketing”. Voice was also described as emerging through cognitive and creative processes rather than surface-level stylistic features. Peter explained that relying on AI too early can prevent immersion, as “you never really immerse yourself in the idea” and instead lose “the unique combination. . . and the way my brain works”. Relatedly, participants distinguished human-authored voice from AI outputs characterised as “following formulas”, suggesting that voice involves non-formulaic expression and idea development rather than technical correctness alone. Finally, voice was implicitly linked to audience connection, with marketing described as requiring sensitivity to “how we. . . appeal to human emotions”. Across these accounts, voice extends beyond brand consistency to encompass human-authored expression, idea formation, and audience-oriented communication.
Judgement: Ethical, Contextual, and Strategic Decision Authority
Judgement emerged as the capability practitioners considered most consequential for maintaining professional accountability in AI-mediated workflows. Participants consistently described generative systems as producing outputs that require continuous human interrogation due to hallucinations, bias, and contextual misalignment. As Noah summarised, practitioners must “not take anything literal.”
Practitioner accounts revealed three interconnected dimensions of judgement.
Ethical Judgement
Participants described ethical judgement as recognising when outputs “feel wrong” (Jade) and ensuring accuracy because audiences “can actually pick up that a human’s not written this” (Maya). Practitioners framed ethical evaluation as an anticipatory process involving the detection of misrepresentation, cultural insensitivity, or reputational risk. Importantly, accountability was consistently located with the human decision-maker rather than the system generating content.
Contextual Judgement
Practitioners emphasised the need to localise AI-generated material to audience expectations, organisational norms, and cultural context. Warren noted that generative tools frequently default to an Americanised communication style that does not translate across U.K. marketing environments. Participants described contextual judgement as the ability to interpret situational demands and adapt outputs accordingly, positioning it as a situated interpretive skill rather than a mechanical editing process.
Strategic Judgement
Strategic judgement centred on selecting viable ideas and understanding their organisational consequences. Ruby noted that AI can propose campaign propositions but “cannot decide which aligns with the brand’s goals.” Participants described this capability as linking micro-level content decisions to macro-level brand strategy and long-term market positioning. Emma summarised this responsibility succinctly, warning that “the unexamined output is the enemy.” Together, these dimensions formed an integrated capability through which practitioners retained control over appropriateness and organisational direction. Judgement was therefore framed as deciding whether outputs are accurate, appropriate, and safe to use, enabling marketers to benefit from AI efficiency while maintaining responsibility for final decisions.
Taste: Evaluative Discernment and Distinctiveness
Taste emerged as a subtle yet widely recognised capability through which practitioners differentiated high-quality marketing work from AI-generated volume. Participants frequently described generative outputs as technically competent but aesthetically or emotionally generic.
Jack characterised AI-generated consultancy language as “very generic,” requiring extensive refinement. Peter similarly argued that models “follow formulas” and “do not really speak to us the same way,” maintaining that “a good writer can write something way, way better” than an LLM. Warren emphasised that practitioners must still determine “what is good” and justify why particular outputs warrant development. Chloe captured the directional nature of this capability, observing that “if you do not have taste, the tool drives you instead of the other way around.”
Practitioners operationalised taste through three recurring practices: curation (filtering large volumes of generated options), originality sensing (recognising when outputs feel derivative or emotionally thin), and coherence construction (maintaining consistency across multimodal brand touchpoints). As Warren explained, AI produces scale, but “taste is knowing what’s good, what is worth keeping”—and being able to explain why. Oliver noted that AI outputs often “feel familiar,” whereas taste “pushes past familiar” to identify distinctive possibilities. Grace similarly described taste as what “holds [campaign elements] together, so it feels intentional.” Across interviews, taste was framed as a developmental capability grounded in exposure, critique, and iterative refinement, and as essential for sustaining distinctiveness under AI acceleration. Recent computational work similarly finds substantial divergence in human aesthetic and stylistic preferences when evaluating generated texts, reinforcing sociological accounts of taste as socially organised rather than universally shared (Chung et al., 2025).
Boundary Delineation and Theme Selection
During cross-case comparison, practitioner descriptions repeatedly converged on a deeper organising concern: how responsibility is retained when generative systems can produce plausible marketing outputs at scale. Although interviews surfaced numerous valued professional skills—including creativity, empathy, collaboration, data literacy, and adaptive learning—these capabilities consistently appeared as enabling mechanisms through which practitioners enacted voice, judgement, and taste, rather than as independent domains of human contribution. Creativity, for example, was associated with ideation and exploration, but practitioner discourse more consistently emphasised human involvement in selecting, refining, and validating ideas once generated. Empathy-informed voice through audience-sensitive communication, while complex problem-solving was commonly expressed through judgement as integrating ethical, contextual, and strategic considerations.
Practitioner accounts also indicated that voice and taste were enacted at different points in the workflow. Voice was invoked during the production of communication itself, where practitioners emphasised authorship, expression, and identity. Laura resisted delegating copy generation to AI because she believed “we’ve got a duty as an organization to have our own voice rather than be voiced by a computer,” framing authorship as integral to organisational identity. Peter similarly noted that beginning with AI can disrupt “all of the natural ways in which the piece of writing could have flowed,” locating voice in the shaping of expression rather than post hoc editing. By contrast, taste was more often articulated once outputs already existed and a comparative decision was required. Practitioners described evaluating multiple viable options and advancing those that demonstrated stronger resonance or distinctiveness, particularly in contexts involving audience engagement and emotional appeal. Taken together, these accounts distinguish voice as the shaping of communicative expression and taste as the comparative evaluation of generated alternatives.
Treating voice, judgement, and taste as analytically separable clarifies how these forms of expertise vary in practice. For example, a marketer may demonstrate a distinctive communicative voice by producing engaging, conversational copy aligned with audience expectations yet exercise poor judgement by publishing an AI-generated campaign claim (e.g., product performance or pricing information) without verification, exposing the organisation to factual error or regulatory risk. Conversely, a practitioner may demonstrate sound judgement by carefully fact-checking outputs and rejecting unreliable content, yet produce work that remains generic—for instance, approving safe but templated email copy that lacks differentiation and fails to engage the intended audience. Similarly, a marketer may generate multiple technically acceptable campaign variants but lack the evaluative sensitivity required to identify which option is most distinctive or strategically aligned—for example, selecting a headline that is grammatically correct but indistinguishable from competitors, rather than one that reflects clearer audience insight or brand positioning. These distinctions clarify how human expertise contributes under conditions where generative systems expand the scale and speed of content production. In AI-assisted workflows, the ease of generating plausible outputs can obscure weak judgement (e.g., unverified or non-compliant claims), weak voice (e.g., impersonal or formulaic tone), or weak taste (e.g., failure to differentiate among viable alternatives).
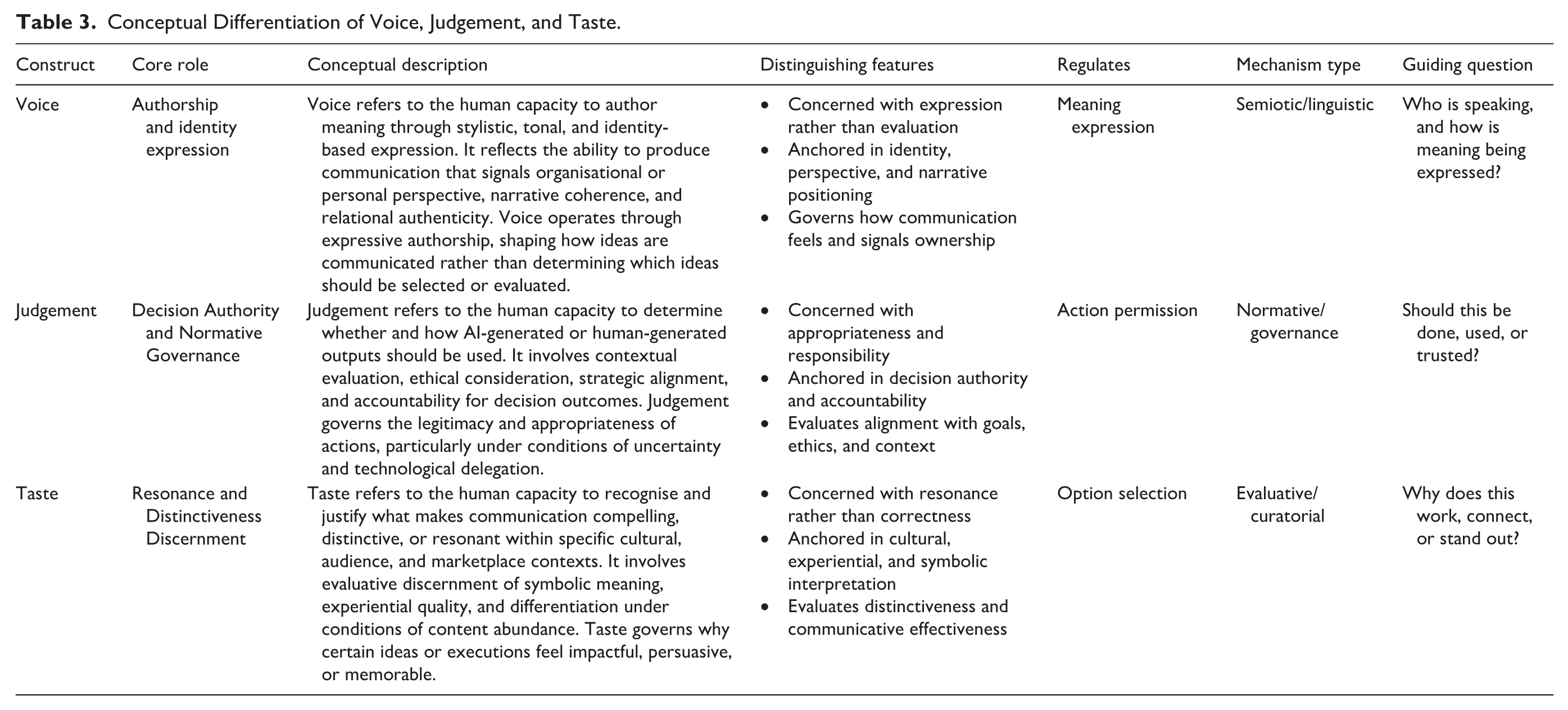
Alternative framings were considered during the analytical process. Practitioner accounts could plausibly have been organised around broad capability taxonomies such as creativity, critical thinking, and ethical reasoning, or around functional marketing stages such as strategy, execution, and evaluation. However, these alternatives proved less explanatory under AI-mediated conditions. Capability taxonomies capture important cognitive attributes but do not differentiate the specific forms of agency practitioners described when working with generative systems. Stage-based models describe sequences of activity but do not explain how responsibility is exercised once AI can generate viable outputs at scale. By contrast, the Voice–Judgement–Taste framework aligns more closely with how practitioners articulated responsibility in practice—through authorship, decision authority, and comparative evaluation. While alternative framings remained analytically viable, the framework was retained as the most explanatory of several plausible interpretations, as it provides the clearest account of how practitioners organise and defend non-delegable human responsibility in AI-accelerated marketing work. Table 3 synthesises these analytical boundaries while preserving their interdependence.
Conceptual Differentiation of Voice, Judgement, and Taste.
RQ2: How Voice, Judgement, and Taste Resolve the Productivity–Authenticity Tension
Across interviews, practitioners described a persistent tension in AI-mediated workflows: generative tools accelerate drafting, restructuring, and ideation, yet outputs often feel generic, culturally misaligned, or inconsistent with brand identity. The central challenge was therefore not whether to use AI, but how to direct its speed without eroding distinctiveness, coherence, and accountability. Rather than abstract capabilities, voice, judgement, and taste functioned as practical mechanisms through which this tension was managed in situ.
Voice functioned as a corrective to the homogenising effects of accelerated production. As generative tools increased output speed, practitioners described a corresponding need to reintroduce authorship and relational intent. AI outputs were frequently treated as provisional drafts requiring human rewriting to restore narrative flow, tone, and identity. Maya identified recurring stylistic markers—caption cadences, stacked emojis, overlong em dashes—that signalled generic authorship and triggered revision. In practice, this often involved rewriting technically correct but overly polished social captions, replacing them with language that reflected brand personality and audience expectations. Under conditions of high productivity, voice therefore operated less at the point of generation and more as a deliberate reassertion of human presence through revision.
Judgement regulated the risks introduced by speed and scale. Practitioners emphasised that increased output volume amplified the likelihood of hallucinations, contextual errors, and misaligned claims, requiring ongoing verification and constraint. Rather than accelerating all tasks, practitioners described selectively slowing workflows where stakes were high. This included fact-checking AI-generated claims, adapting default Americanised phrasing for U.K. audiences, and rejecting outputs that appeared plausible but were strategically misaligned or unverifiable. As Peter noted, beginning with AI-generated drafts can interrupt the organic development of ideas, illustrating how judgement determines when automation enhances productivity and when it constrains strategic clarity or originality. In this sense, judgement functioned as a gating mechanism, deciding when AI outputs could be trusted and when human intervention was required.
Taste operated as the mechanism through which abundance was converted into distinctiveness. Generative systems enabled the rapid production of multiple options, but practitioners consistently emphasised the need to discriminate among them. Faced with numerous acceptable outputs, they described discarding options that felt overly familiar or emotionally flat in favour of those demonstrating stronger resonance. For example, when presented with multiple AI-generated headlines or campaign concepts, practitioners selected those that reflected clearer audience insight or brand positioning. Taste therefore introduced a selective constraint within otherwise expansive generative processes, ensuring that increased productivity did not result in diluted outputs.
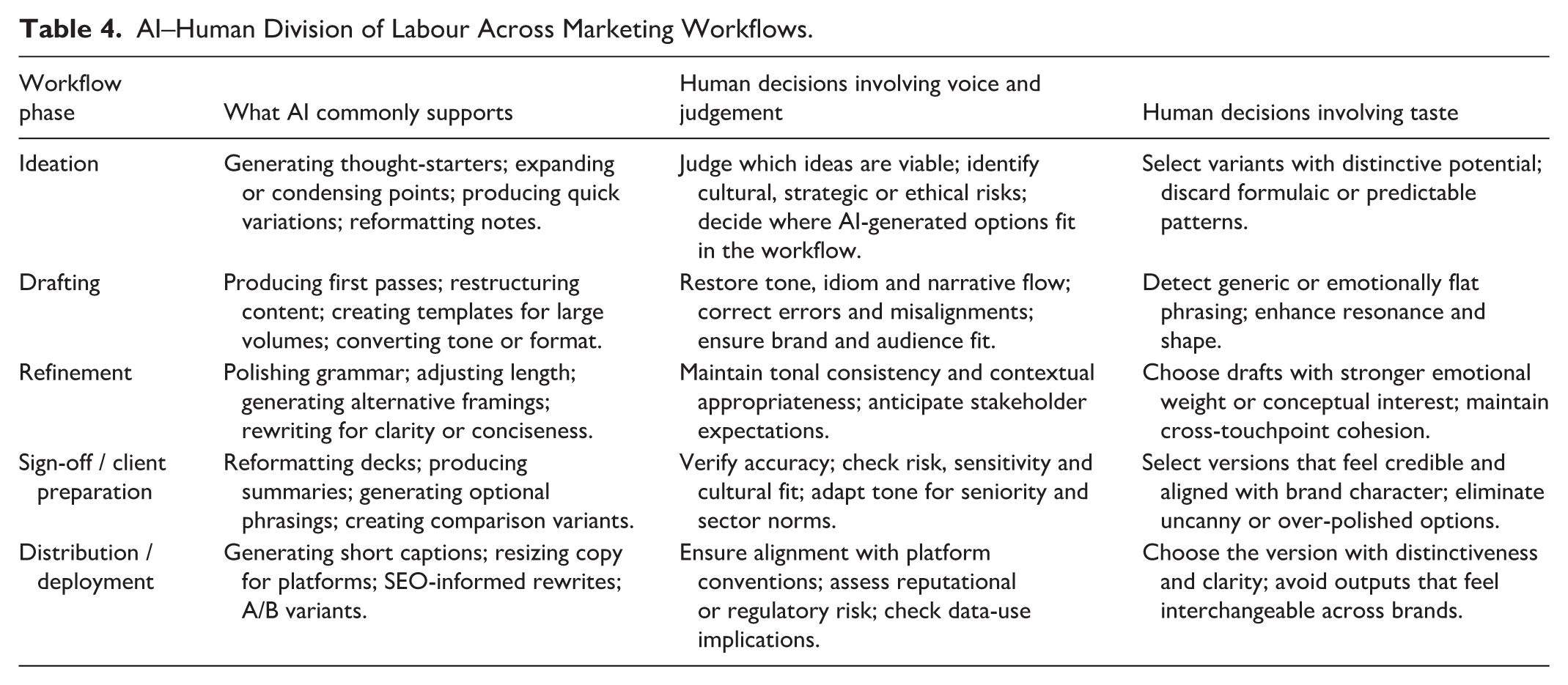
Taken together, these capabilities enabled practitioners to dynamically balance acceleration and control. Rather than treating productivity and authenticity as opposing goals, practitioners used voice, judgement, and taste to determine where speed could be leveraged and where it needed to be constrained. AI reduced procedural friction, but these capabilities reintroduced intentionality at critical points in the workflow—through rewriting, verification, and selection. The framework therefore captures not only what remains human in AI-mediated marketing work but also how practitioners actively regulate the trade-offs introduced by generative systems. Table 4 summarises how this AI–human division of labour unfolds across workflow phases.
AI–Human Division of Labour Across Marketing Workflows.
RQ3: Designing Curricula and Assessment to Surface, Develop, and Evaluate Voice, Judgement, and Taste
Practitioners consistently redirected attention from artefact production to how AI-generated outputs are selected, justified, and revised. In AI-mediated environments, meaningful human contribution becomes most visible in this interpretive work—such as revising tone, checking accuracy, and explaining why one option is chosen over another. This reflects a shift in assessment logic from evaluating what students produce to evaluating how they think, decide, and justify under conditions where production itself can be delegated to AI. Assessment therefore needs to capture both output quality and the reasoning through which those outputs are shaped and defended, a challenge underscored by prior research on the difficulty of reliably evaluating stylistic and aesthetic qualities in AI-generated texts (Tan et al., 2025; Tardy, 2012).
What to Assess: From Outputs to Defensible Processes
Rather than evaluating artefacts in isolation, practitioners described three observable dimensions of contribution:
Voice: whether linguistic, narrative, and, where relevant, multimodal choices establish a clear and coherent authorial stance, identity, and audience relationship, which may include but is not limited to specified brand identity (Tan et al., 2025).
Judgement: whether decisions demonstrate contextual awareness by checking accuracy, identifying risks, adapting outputs to the audience and organisational context, and justifying whether content should be used.
Taste: whether students can explain why one option is stronger than others and ensure consistency and coherence across outputs and touchpoints.
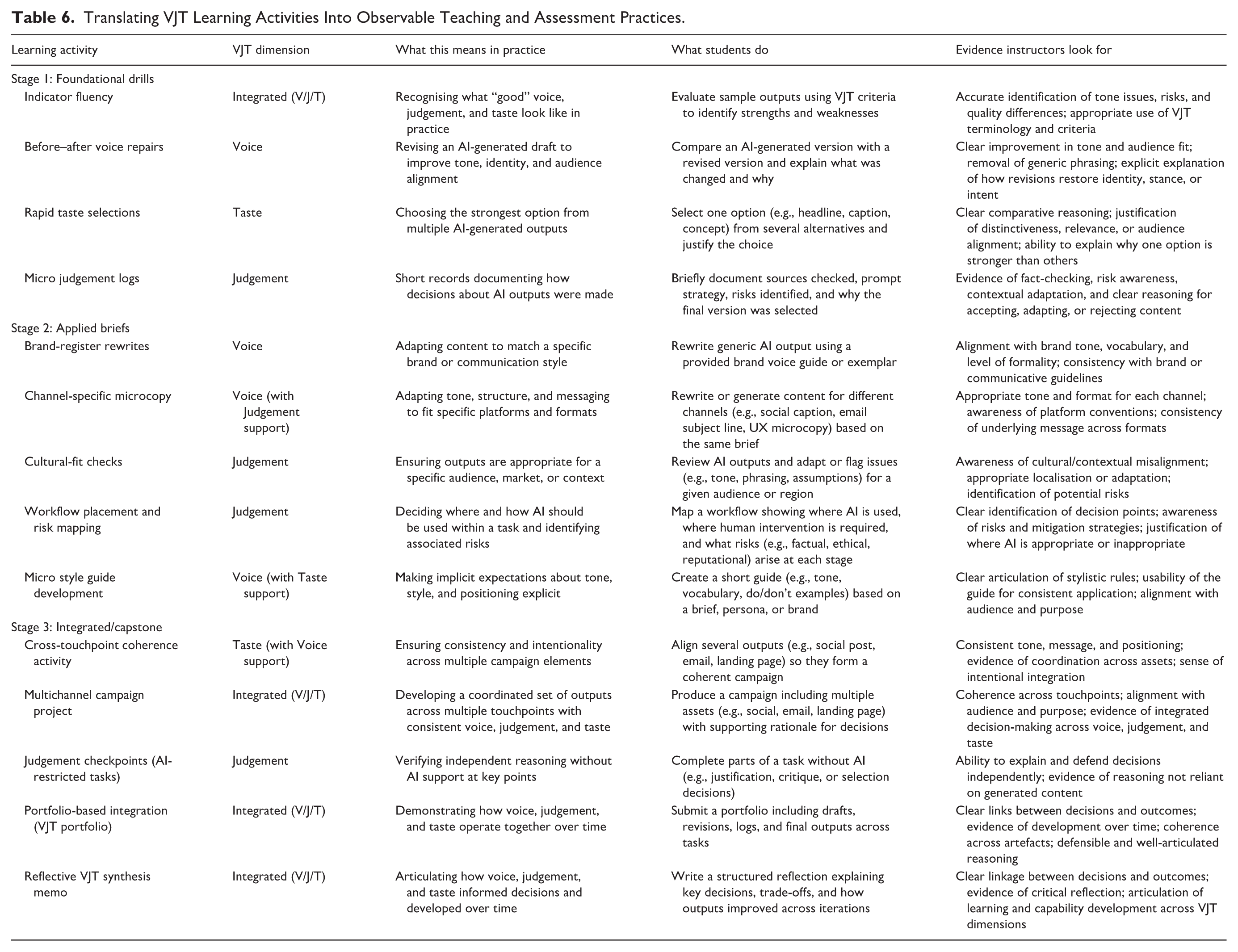
Table 5 translates these dimensions into rubric-ready indicators to support calibration and reliability. Table 6 then translates these indicators into concrete learning activities and assessment tasks, showing how voice, judgement, and taste can be made observable and evaluable in practice.
VJT Definitions and Indicators.

Translating VJT Learning Activities Into Observable Teaching and Assessment Practices.
Surfacing Voice: Assessing Expressive Authorship
Practitioners positioned voice as most visible in revision rather than initial drafting. While AI may accelerate production, identity becomes legible through deliberate human re-authoring (Tan et al., 2025). Instructionally, this translates into compact evidence bundles—an AI draft, a tracked human revision, and a concise rationale linking specific linguistic, narrative, and, where relevant, multimodal choices to a declared authorial stance, persona, strategic position, campaign voice, or organisational identity.
In practice, participants described making voice explicit through conventions and reverse-engineering exercises. Liam described teaching junior marketers’ narrative stance as role encoding—“blog articles are written in the first person, biographies in the third”—and emphasised shaping reader movement as a “journey” rather than presenting “lots and lots of facts.” Others described training junior marketers to analyse communicative exemplars for characteristic syntax, idioms, humour registers, visual cues, and formality thresholds, then reapply these patterns when revising AI drafts. In brand-based tasks, this may involve tone-of-voice guides and brand assets; in non-brand tasks, it may involve declared audience, genre, persona, or strategic intent. Jack framed this as “eradicating” generic phrasing to restore organisational specificity.
Several practitioners cautioned that beginning with AI can shortcut immersion in idea development, reinforcing the need for structured revision practices that foreground identity restoration and intentional stance-taking. Collectively, these approaches position voice as observable alignment between communicative choices and a declared identity, stance, and audience relationship (Tan et al., 2025), consistent with research conceptualising voice as self-representation constructed through textual and contextual cues (Tardy, 2012).
Making Judgement Auditable: Evaluating Decision Authority
Judgement was framed as accountable deployment authority: when outputs can be generated instantly, professional responsibility rests on whether someone can defend their use. Practitioners emphasised active interrogation and contextual verification, highlighting hallucinations and contextual misalignment as routine risks. Warren described reviewing materials assembled through “Google and AI and YouTube,” requiring students to explain the reasoning behind their inclusion, while Elliott resisted what he termed a “spinner in 10 seconds,” warning against organisational pressure to treat instant output as publication-ready.
To make judgement assessable, participants advocated lightweight documentation rather than exhaustive process capture. A concise judgement log—recording sources consulted, prompt strategy, verification steps, risks identified, and rationale for final selection—was commonly described as sufficient. As Jonathan put it, AI is “amplified intelligence” that “still needs to be guarded by humans.” In curricular terms, evaluation therefore extends beyond output quality to the defensibility of deployment decisions under AI acceleration.
Cultivating and Operationalising Taste: Criteria-Based Selection Under Abundance
As discussed in RQ1, practitioners described taste as structured evaluative selection under conditions of output abundance, enacted through curation, originality sensing, and coherence construction. Practitioners emphasised the need to externalise tacit quality expectations into explicit criteria. Warren described building a “codified system of goodness versus badness,” while Chloe warned that without developed taste, practitioners risk allowing the tool to dictate decisions rather than directing it themselves.
Instructionally, this suggests designing studio-style tasks in which students generate variants, apply articulated quality criteria, justify comparative selection decisions, and synthesise a coherent execution. The assessable unit is the reasoning underpinning selection as well as the quality of the chosen output.
Ethical and Cultural Fit as Routine Checks
Across interviews, voice, judgement, and taste were linked to reputational exposure and trust. Assessment criteria therefore extend beyond creative quality to include cultural sensitivity, regulatory awareness, and anticipatory risk evaluation. Embedding these checks within routine coursework aligns evaluation with professional accountability expectations. At the same time, briefs and brand guidelines are themselves culturally situated artefacts rather than neutral evaluation anchors. Research on taste and valuation shows that evaluative criteria are embedded within socially organised systems of meaning that shape how quality and appropriateness are recognised and legitimised (Arsel & Bean, 2013; Smith Maguire, 2018; Warde, 2014). In diverse classrooms, instructors may therefore need to surface these assumptions and encourage discussion of how expectations vary across audiences, markets, and communicative traditions.
Workflow-Aligned Learning Progression and Implementation Constraints
Interviewees proposed a staged, learn-by-doing progression that develops voice, judgement, and taste through iterative practice while maintaining manageable evidence requirements. Figure 1 translates these practitioner insights into a curriculum model that progressively increases contextual complexity and accountability. Stage 1 develops indicator fluency through low-stakes drills that isolate core VJT practices (voice revision, judgement logging, and basic taste comparisons). Stage 2 introduces applied client-style briefs in which students must justify decisions within defined brand and audience constraints, making judgement and taste criteria explicit and documented. Stage 3 shifts the emphasis from task execution to accountable integration: students produce a portfolio demonstrating cross-touchpoint coherence while defending how voice, judgement, and taste informed campaign-level decisions. The progression therefore moves from skill recognition, to situated application, to integrated professional accountability, enabling instructors to scaffold increasingly defensible decision-making under AI-assisted production.
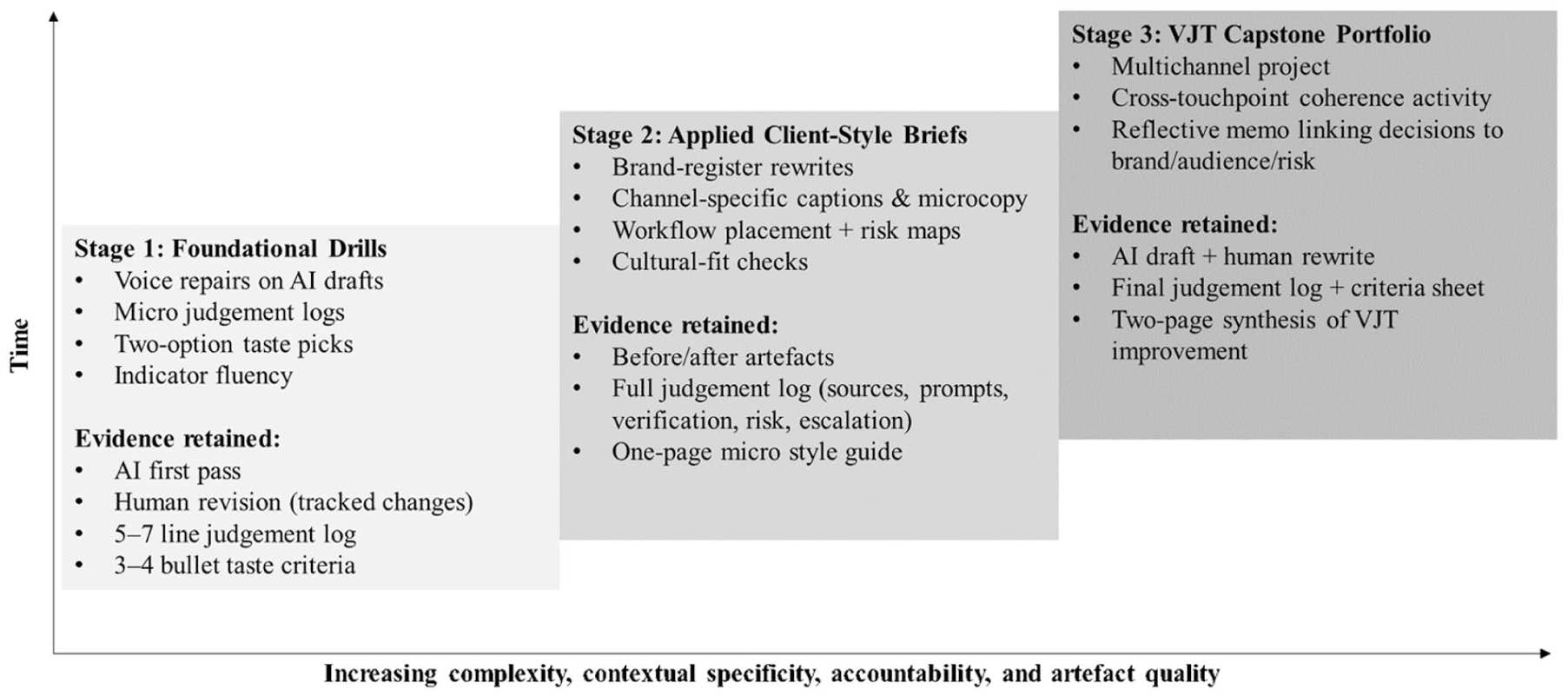
Practitioner-informed curriculum progression for developing voice, judgement, and taste in AI-mediated marketing work.
Practitioners cautioned against over-engineered documentation that attempts to capture every procedural step. As Warren observed, “stage one, stage two, stage three. . . doesn’t scale,” reinforcing a preference for concise rationales that surface decision logic without imposing unsustainable grading burdens. Participants also distinguished between surfacing capability and manufacturing dispositions: as Noah noted, curiosity “has to come from the self,” suggesting assessment should evidence inquiry-in-action rather than attempt to grade personality traits.
To address integrity risks in AI-assisted coursework, practitioners recommended periodic AI-restricted checkpoints. As Eve described, examinations show that “it’s just you and a piece of paper,” functioning as complementary verification of independent reasoning alongside AI-permitted process evidence. Together, these design principles frame VJT as a scalable assessment architecture aligned with professional expectations of defensible judgement and discernment.
Discussion
Generative AI is reshaping how marketing artefacts are produced and where professional value resides— shifting value away from production itself towards the regulation and justification of outputs. Positioned within ongoing debates on market-relevant marketing education, this shift exposes a growing disconnect between rapidly evolving AI-enabled practice and relatively static competency models in higher education. As marketing becomes increasingly AI-assisted, digital-first, and resource-constrained, the definition of market-relevant skills is being reconfigured—not as stable sets of attributes, but as situated forms of human contribution that emerge in relation to technological capability. In this context, the Voice–Judgement–Taste framework identifies three non-delegable capabilities—voice, judgement, and taste—that practitioners treat as decisive when generative tools accelerate production yet obscure responsibility for marketing action. Rather than relying on broad exhortations to teach “creativity,” “critical thinking,” or “ethics” (Acar, 2024; Grewal et al., 2024; Thornhill-Miller et al., 2023), the framework specifies how these capabilities are enacted in practice as observable, assessable forms of professional judgement and differentiation under conditions of technological abundance. In doing so, it offers a more precise basis for identifying and evaluating market-relevant skills, while also responding to calls for stronger theoretical grounding in generative AI scholarship that caution against speculative or taxonomic treatments that outpace conceptual precision (Brown et al., 2024). Although developed in the context of marketing, this shift in how human contribution is defined under AI-mediated production has wider relevance for professional education, where similar tensions between automation, accountability, and evaluative judgement are emerging. It highlights a shared challenge for educators and curriculum designers: how to design learning and assessment that make these forms of human judgement, authorship, and decision-making visible and defensible in AI-assisted work. The VJT framework therefore constitutes a practice-grounded process theory of human agency under AI-mediated production: as generative systems expand output capacity, expertise shifts from content creation to the regulation of authorship, authorisation, and selection.
VJT as Layered Regulation of Marketing Action
Generative systems can approximate voice, judgement, and taste at the level of artefacts: they can mimic brand registers, generate plausible rationales, and rank options using learned preferences. VJT does not contest this surface competence. Instead, it names the accountable regulation of marketing action under conditions where authorship and responsibility are contested. Voice concerns the authorised stance a communicator adopts towards an audience, encompassing more than stylistic patterning (Khuder & Petric, 2026). While this often includes the stance a brand adopts, it is not limited to brand expression. It also encompasses how communicators position themselves in relation to audiences, purposes, and contexts more broadly, reflecting voice as a socially and rhetorically constructed form of self-representation rather than a fixed stylistic property, with interpretation shaped through interaction between writer, text, and reader. Judgement concerns ownership of risk, verification, and sign-off—for example, checking claims, adapting outputs to context, and deciding whether content is safe to publish. Even when an AI output resembles these qualities, practitioners remain responsible for whether it is true, appropriate, and strategically legitimate—and for being able to justify that decision in context. Although the present framework is historically situated within the current phase of generative AI adoption, more agentic systems would likely intensify rather than eliminate the need for human responsibility over authorship, authorisation, and evaluative legitimacy.
VJT conceptualises marketing expertise as three interlocking ways marketers guide and control their work—through authorship (voice), decision-making (judgement), and selection (taste). Voice governs expressive authorship: how identity, intent, and relational stance are realised in communication. This aligns with brand communication research showing that tone, lexico-syntax, and narrative patterning shape perceived authenticity and trust (Barcelos et al., 2018; Delin, 2007), as well as with work conceptualising voice as cognitively constructed, socially negotiated, and textually enacted (Khuder & Petric, 2026). Judgement regulates deployment authority by determining whether marketing action is ethically, contextually, and strategically acceptable, aligning with evidence that AI-mediated expertise is exercised through decisions about trusting, adapting, rejecting, and owning outputs (Walton et al., 2025), and with competency scholarship distinguishing decision authority under uncertainty from technical execution, particularly where accountable sign-off depends on contextual interpretation (Carson & Gilmore, 2000; López Jiménez & Ouariachi, 2021). Taste regulates differentiation once acceptability is established, guiding selection and refinement among viable alternatives and aligning with accounts that distinguish standard attainment from phronetic judgement concerned with value, orientation, and action under uncertainty (Dunne, 2015). Treating these capabilities as analytically separable is educationally valuable because they vary independently in practice—strong voice with weak taste (distinctive yet incoherent), sound judgement with flat voice (safe yet generic), or strong taste with poor judgement (appealing yet inappropriate; Kaufman et al., 2019; Kerr & Lloyd, 2008). VJT therefore clarifies how human expertise governs AI-mediated marketing action by positioning voice as identity realisation, judgement as deployment authorisation, and taste as value-directed selection and refinement.
Taste as Socially Organised Discernment Under Abundance
Taste warrants particular emphasis because AI makes production abundance the default condition. Cultural and valuation scholarship conceptualises taste as a practised capacity for comparing, justifying, and coordinating selections using shared evaluative conventions and “devices” that make choice manageable, often operating below conscious deliberation while legitimising distinctions and hierarchies of value (Smith Maguire, 2018; Warde, 2014). In this sense, taste is a relational and contextual competence developed through participation in evaluative practices rather than a matter of individual preference alone. Under such conditions, taste becomes most visible when multiple plausible alternatives must be comparatively evaluated. Generative AI intensifies this requirement by expanding the volume of technically competent yet weakly differentiated outputs—for example, choosing between several grammatically correct headlines that meet baseline quality but differ in tone, specificity, and audience resonance. Here, taste determines whether a safe but interchangeable option is selected or a more distinctive and contextually aligned alternative is advanced.
This distinction matters because marketing scholarship often treats taste as a proxy for “quality” or cultural superiority (Arsel & Bean, 2013), whereas valuation research conceptualises judgement as layered: baseline quality establishes acceptability, while evaluative practices differentiate among alternatives that already meet that threshold (Smith Maguire, 2018; Warde, 2014). It is this second layer—selection among acceptable alternatives—that concentrates substantial AI-era marketing value and remains under-theorised within marketing education discourse.
Practitioner accounts show that this form of discernment is enacted through the articulation of evaluative criteria, distinctiveness thresholds, and coherence checks that make selection decisions explicit and defensible. This renders taste assessable as comparative selection and refinement across viable options, rather than as isolated aesthetic preference. Its relevance is most pronounced in brand-sensitive, regulated, and client-facing communication contexts where tone missteps, weak rationale, or incoherent execution carry reputational or legal risk, and less central in low-risk, high-volume production where stylistic discretion is limited.
These boundary conditions carry two curricular implications. First, students’ professional readiness depends not only on technical proficiency but on character-centred communication capacities—such as responsibility, clarity of intent, and the ability to exercise independent judgement within ambiguous situations—particularly where AI can obscure accountability or mask weak reasoning (Cardon, Fleischmann, Logemann, et al., 2024). Second, AI’s speed and fluency can create a false sense of adequacy, compressing the cognitive space through which originality and ethical discernment develop and potentially standardising outputs around dominant or biased patterns (McAlister et al., 2023). VJT-intensive instruction therefore matters most where human intentionality, contextual nuance, and defensible reasoning cannot be reduced to automated patterning.
Assessment: Governing Interpretation Rather Than Pretending to Eliminate It
VJT’s assessment contribution lies in making judgement governable, rather than attempting to eliminate it from grading. Performance-based assessment routinely faces reliability and fairness challenges when evaluating higher-order capability (Kerr & Lloyd, 2008; Walker et al., 2009), and these challenges are not unique to “taste”; critical thinking and ethical reasoning similarly require interpretive evaluation rather than objective measurement (Fawns et al., 2026; Saxton et al., 2012).
Rather than eliminating judgement, AI-rich contexts make it more central: assessment must now capture outcomes and the reasoning processes through which those outcomes are selected, justified, and made accountable. The core design question is whether a programme can establish clear links between the task, the student’s work, and how it is graded, while making the basis of evaluative judgement explicit and defensible, and supporting consistent interpretation through shared criteria and calibration (Fawns et al., 2026; Mancar & Gülleroğlu, 2022). Tan et al.’s (2025) study on multimodal writing highlights this point; the authors found weak agreement among trained raters on what counts as strong voice (Kendall’s W ≈ .27), with dispersion in which cues raters emphasise (stance, genre expectations, use of AI-generated visuals). This cautions against assuming that a single static rubric can fully capture voice without rater preparation and task-specific context setting, and it supports VJT’s move to anchor voice in observable indicators such as brand register fit, narrative stance, idiom control, and coherence, while recognising interpretive pluralism across genres, modalities, and cultures (Barcelos et al., 2018; Tan et al., 2025).
Reliability, then, depends on aligned interpretation. Constructs such as voice are inherently interpretive and may be evaluated differently by trained readers unless evaluative criteria are made explicit and calibrated. Agreement on voice and taste can be strengthened when anchor exemplars and decision rules are explicit and when brief calibration cycles include discussion of borderline cases (Mancar & Gülleroğlu, 2022; Saxton et al., 2012). Given the modest baseline agreement observed in GenAI-mediated voice rating (Kendall’s W ≈ .27; Tan et al., 2025), programmes should set reliability targets that meaningfully exceed this level rather than accepting it as inevitable (Field, 2005). Because Kendall’s W does not have universally fixed interpretive thresholds, values around .40–.60 are commonly treated as indicating moderate agreement in education and behavioural research. Calibration procedures should therefore aim for at least moderate inter-rater agreement—practically, a target of approximately Kendall’s W ≥ .50 in rubric-based assessment contexts. In practice, this means: (a) setting an a priori expectation of at least moderate agreement appropriate to the stakes, (b) verifying it through routine moderation, and (c) monitoring inter-rater consistency each term—treating reliability as a programme-level quality practice rather than a one-off statistic.
Fairness is equally standards-based. Because voice and taste are culturally embedded and genre- and channel-sensitive, fairness depends on alignment to the specified brief, audience, and brand register rather than conformity to a single prose canon (Barcelos et al., 2018; Tan et al., 2025). In moderation, the key question is not “Do I like this?” but “Does it meet the stated criteria for this register and audience, and can the student defend that alignment with evidence from the text and the brief?” Calibration should therefore use anchor exemplars and decision rules that help raters distinguish brand-register misalignment from legitimate stylistic diversity, and explicitly surface where implicit beliefs about authenticity and authorship may be shaping scores (Luo & Dawson, 2025). Framed this way, VJT treats evaluation as an accountable application of shared standards to contextually situated work.
While practitioners strongly endorsed judgement logs, revision comparisons, and VJT portfolios as ways to surface human reasoning, scalability remains a constraint. Detailed auditing of AI interaction processes can increase marking workload in high-enrolment modules, so process artefacts are likely to be most sustainable when sampled, staged, or concentrated in synoptic and capstone assessment (Bearman et al., 2024). A related challenge is the emerging “AI-on-AI” problem: students may use generative tools to produce reflective rationales, blurring where the student’s work ends and the AI’s begins and complicating claims about authorship and judgement visibility (Khlaif et al., 2025). However, emerging assessment scholarship suggests that the response is not to abandon reflective artefacts, but to design them around iterative comparison, evidence referencing, and multi-decision justification tasks that are difficult to fabricate retrospectively (Bearman et al., 2024). Scalable implementation may also require distributed evaluation models that combine calibrated peer review, guided self-assessment, and mixed AI-permitted and AI-restricted tasks to preserve evidentiary integrity while sustaining workload and institutional quality assurance (Ilieva et al., 2025).
Curriculum Architecture: Sequencing Evidence and Accountability
Finally, VJT implies a curriculum architecture that mirrors how capability is built and evidenced in practice. We propose sequencing VJT learning along two axes—time and increasing complexity/accountability—so that students first gain fluency with indicators and then demonstrate transfer under higher-stakes constraints. Over short horizons, instruction can begin with low-stakes drills that isolate evidence (e.g., before–after voice repairs comparing AI-generated and human-revised versions, micro judgement logs documenting accept/reject decisions, rapid taste selections between multiple viable outputs), then move to situated briefs requiring cultural-fit checks, risk identification, and justified placement decisions. Over longer horizons, cohorts encounter increasing contextual specificity (multichannel campaigns, regulated sectors, diverse audiences) and clearer expectations for demonstrating decision-making (e.g., reasoning logs, cross-touchpoint coherence, and brand-aligned voice revision), culminating in a capstone portfolio that brings together artefacts showing how decisions were made (e.g., AI first pass, human rewrite, judgement log, criteria or style guide) to demonstrate transfer across media and contexts (Grewal et al., 2024; Mehmet et al., 2025). Figure 1 captures this progression by showing how VJT becomes more demanding as contexts become more specific and accountability increases. In an era where production is cheap, marketing expertise is increasingly evidenced through the human capacity to shape identity (voice), decide what should be used (judgement), and determine what is worth developing (taste), and to make those decisions clear enough to teach, assess, and defend.
Although much of our empirical illustration and discussion centres on writing, the interviews suggest that the underlying constructs may have relevance beyond textual work. Voice appears to surface in motion-graphics captions, UX microcopy, and narrative choices in short-form video, where audiences read identity cues in ways that parallel textual interpretation (Tan et al., 2025). Judgement similarly shapes data-story trade-offs in dashboards and ad reporting, including decisions about context, confidence, and risk signalling in regulated sectors (Gonsalves, 2024; Grewal et al., 2025). Taste may also inform cohesion across multi-asset campaigns, from image selection and colour systems to the cadence of social sequences and landing-page emphasis, echoing creative-industry accounts that position taste as central to modern direction role (Cillo & Rubera, 2025; Rowe, 2025).
Future Research
Our discovery-oriented, reflexive thematic analysis surfaces practice-proximate constructs and observable indicators; the next step is to test the robustness, portability, and consequences of VJT for learning and labour-market outcomes. The assessment architecture presented here should therefore be understood as a proposed and illustrative design whose scalability, marking workload implications, and inter-rater consistency require empirical testing through pilot implementations and programme-level evaluation. Future work should also examine whether voice indicators travel across brand-based, student-authored, professional, and multimodal tasks, given evidence that voice is interpreted variably in AI-assisted multimodal texts.
First, measurement research should establish construct validity and scoring reliability for VJT across genres (e.g., email, social, long-form, UX microcopy) and modalities (text, image–text, short video). Building on Tan et al. (2025), rater-calibration experiments can compare generic versus genre-anchored training and report effects on inter-rater agreement (e.g., κ, Kendall’s W), while parallel studies test whether judgement logs improve process validity by predicting expert ratings of appropriateness, accuracy, and ethical fit.
Second, pedagogical intervention trials are needed to evaluate whether VJT-centred designs outperform tool-centric training on practice-relevant outcomes (Mehmet et al., 2025; Richter et al., 2025). Course-embedded experiments could manipulate instructional sequencing (e.g., voice-first versus idea-first), AI guardrails (e.g., required first-pass submission), and feedback regimes (e.g., rubric-only versus rubric plus judgement-log commentary). Key outcomes include VJT rubric scores, error rates, cultural-fit violations, and time-to-competence.
Third, longitudinal portfolio and employability studies can test whether VJT evidence predicts workplace-relevant performance better than generic AI/tool badges. Tracking VJT portfolios from capstone into early employment would allow linking artefact quality (e.g., before/after deltas, rationale quality, cross-touchpoint coherence) to internship conversion, early performance signals, and supervisor ratings (Cardon, Fleischmann, Aritz, et al., 2024; Honea et al., 2017).
Fourth, cross-cultural and contextual generalisation deserves direct attention. Practitioners flagged cultural drift (e.g., Americanised default tone in U.K. contexts); comparative studies should test cultural calibration protocols for voice and taste across markets and examine remediation strategies when model registers misalign with local norms (Barcelos et al., 2018). Building on arguments for context-rich assessment design in the AI era (Gonsalves, 2025), research should also test whether contextualised briefs (e.g., regulated-industry scenarios, culturally specific campaigns, multi-asset brand systems) yield more reliable and discriminating VJT scores than decontextualised tasks.
Finally, VJT should be extended beyond writing into multimodal and creative-direction workflows by operationalising taste for visual systems (palette, typography, composition) and voice for motion-graphic captions and narrative arcs, and testing whether cross-touchpoint coherence predicts campaign-level outcomes more strongly than single-asset quality (Cillo & Rubera, 2025; Rowe, 2025). Complementary studies should link VJT performance to consumer outcomes (trust, perceived authenticity, affect) and examine rater cognition and expertise development, including how indicator weighting varies by genre familiarity and how much training is needed to stabilise scoring without suppressing legitimate variation.
Footnotes
Acknowledgements
The authors thank the many marketing practitioners who participated in this research for generously sharing their time and insights. We are grateful to Lauren Cummings-Stanislaus and other organisational gatekeepers who facilitated access to participants. We additionally acknowledge representatives from organisations including the Digital Marketing Institute, Monks, Bett–Hyve Group, United Airlines, Deloitte, Oracle, Bristol Myers Squibb and Cushman & Wakefield, among others, for their collegial engagement with the research and their support for ongoing dialogue around its implications. This study draws in part on Savannah Van Vuren’s MSc dissertation in Digital Marketing, supervised by the first author. We further thank Anne Foy at the Academy of Marketing for administrative support during the conduct of the funded project.
Ethical Considerations
Approval to conduct this study was obtained from the King’s College London Research Ethics Committee (MRA-23/24-41020) and (MRSU-24/25-49961).
Consent to Participate
Prior to participation, all participants received an information sheet outlining the purpose of the study, what participation involved, and their rights as participants. Written informed consent was obtained from all participants prior to interview, and participation was voluntary.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Academy of Marketing through an Academy of Marketing Pedagogic Research Grant (Funding ID: AM-PEDAGOGY-2023-03).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated and/or analysed during the current study are available from the corresponding author on reasonable request.