
Abstract
We present new global and local policy search algorithms suitable for problems with policy-dependent cost variance (or risk), a property present in many robot control tasks. These algorithms exploit new techniques in non-parametric heteroscedastic regression to directly model the policy-dependent distribution of cost. For local search, the learned cost model can be used as a critic for performing risk-sensitive gradient descent. Alternatively, decision-theoretic criteria can be applied to globally select policies to balance exploration and exploitation in a principled way, or to perform greedy minimization with respect to various risk-sensitive criteria. This separation of learning and policy selection permits variable risk control, where risk-sensitivity can be flexibly adjusted and appropriate policies can be selected at runtime without relearning. We describe experiments in dynamic stabilization and manipulation with a mobile manipulator that demonstrate learning of flexible, risk-sensitive policies in very few trials.
1. Introduction
Experiments on physical robot systems are typically associated with significant practical costs, such as experimenter time, money, and robot wear and tear. However, such experiments are often necessary to refine controllers that have been hand designed or optimized in simulation. This necessity is a result of the extreme difficulty associated with constructing model systems of sufficiently high fidelity that behaviors translate to hardware without performance loss. For many nonlinear systems, it can even be infeasible to perform simulations or construct a reasonable model (Roberts et al., 2010).
For this reason, model-free policy search methods have become one of the standard tools for constructing controllers for robot systems (Rosenstein and Barto, 2001; Kohl and Stone, 2004; Tedrake et al., 2004; Peters and Schaal, 2006; Lizotte et al., 2007; Kober and Peters, 2009; Kolter and Ng, 2010; Theodorou et al., 2010). These algorithms are designed to minimize the expected value of a noisy cost signal,
For example, imagine a humanoid robot that is capable of several dynamic walking gaits that differ based on their efficiency, speed, and predictability. When operating near a large crater, it might be reasonable to select a more predictable, possibly less energy-efficient gait over a less predictable, higher performance gait. Likewise, when far from a power source with low battery charge, it may be necessary to risk a fast and less predictable policy because alternative gaits have comparatively low probability of achieving the required speed or efficiency. To create flexible systems of this kind, it will be necessary to design optimization processes that produce control policies that differ based on their risk.
Recently there has been increased interest in applying Bayesian optimization algorithms to solve model-free policy search problems (Lizotte et al., 2007; Martinez-Cantin et al., 2007, 2009; Kuindersma et al., 2011; Tesch et al., 2011; Wilson et al., 2011). In contrast to well-studied policy gradient methods (Peters and Schaal, 2006), Bayesian optimization algorithms perform policy search by modeling the distribution of cost in policy parameter space and applying a selection criterion to globally select the next policy. Selection criteria are typically designed to balance exploration and exploitation with the intention of minimizing the total number of policy evaluations. These properties make Bayesian optimization attractive for robotics since cost functions often have multiple local minima and policy evaluations are typically expensive. It is also straightforward to incorporate approximate prior knowledge about the distribution of cost (such as could be obtained from simulation) and enforce hard constraints on the policy parameters.
Previous implementations of Bayesian optimization have assumed that the variance of the cost is the same for all policies in the search space. This is not true in general. In this work, we propose a new type of Bayesian optimization algorithm that relaxes this assumption and efficiently captures both the expected cost and cost variance during the optimization. Specifically, we extend recent work developing a variational Gaussian process (GP) model for problems with input-dependent noise (or heteroscedasticity) (Lázaro-Gredilla and Titsias, 2011) to the optimization case by deriving an expression for expected improvement (EI) (Močckus et al., 1978), a commonly used criterion for selecting the next policy, and incorporating log priors into the optimization to improve numerical performance. We also consider the use of confidence bounds (CBs) to produce runtime changes to risk-sensitivity and derive a generalized expected risk improvement (ERI) criterion that balances exploration and exploitation in risk-sensitive setting. Finally, we consider a simple local search procedure that uses the learned cost model as a critic for performing risk-sensitive stochastic gradient descent (RSSGD). We evaluate these algorithms in dynamic stabilization and manipulation experiments with the uBot-5 mobile manipulator.
2. Background
2.1. Bayesian optimization
Bayesian optimization algorithms are a family of global optimization techniques that are well suited to problems where noisy samples of an objective function are expensive to obtain (Lizotte et al., 2007; Frean and Boyle, 2008; Brochu et al., 2009; Martinez-Cantin et al., 2009; Tesch et al., 2011; Wilson et al., 2011). In describing these algorithms, we use the language of policy search where the inputs are policy parameters and outputs are costs. However, these algorithms are applicable to general stochastic nonlinear optimization problems not related to control (Brochu et al., 2009).
2.1.1. GPs
Most Bayesian optimization implementations represent the prior over cost functions as a GP. A GP is defined as a (possibly infinite) set of random variables, any finite subset of which is jointly Gaussian distributed (Rasmussen and Williams, 2006). In our case the random variable is the cost,
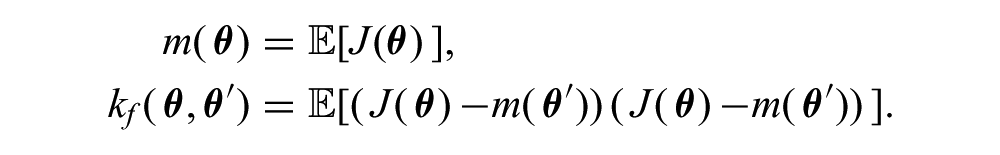
Typically, we set m(
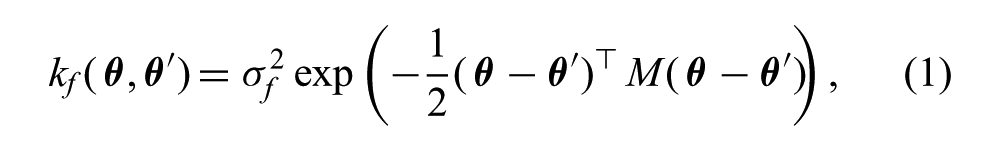
where
Samples of the unknown cost function are typically assumed to have additive independent and identically distributed (i.i.d.) noise,
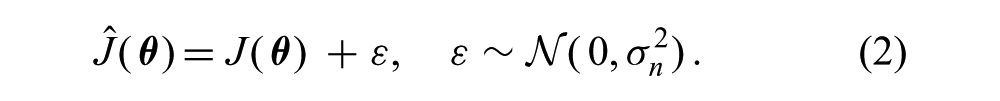
Given the GP prior and data,
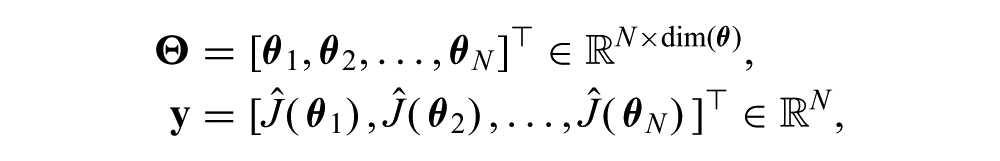
the posterior (predictive), cost distribution can be computed for a policy parameterized by
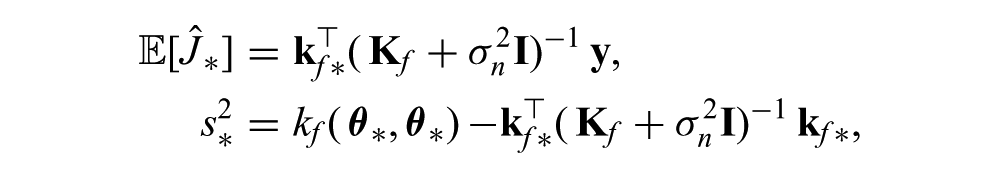
where
If prior information regarding the shape of the cost distribution is available, e.g., from simulation experiments, the mean function and kernel hyperparameters can be set accordingly (Lizotte et al., 2007). However, in many cases such information is not available and model selection must be performed. Typically, when the hyperparameters, Ψ
f
= {σf,
2.1.2. Expected improvement
To select the (N + 1) th policy parameters, an offline optimization of a selection criterion is performed with respect to the posterior cost distribution. A commonly used criterion is EI (Močkus et al., 1978; Brochu et al., 2009). Expected improvement is defined as the expected reduction in cost, or improvement, over the best policy previously evaluated. The improvement of a policy parameter
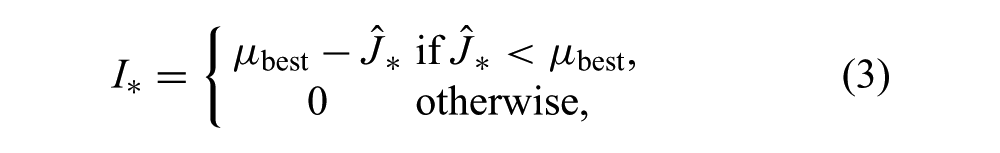
where
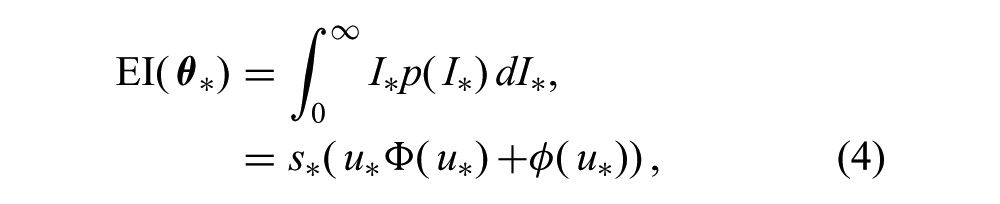
where

From a theoretical perspective, Vazquez and Bect (2010) proved that using EI selection for Bayesian optimization converges for all cost functions in the reproducing kernel Hilbert space of the GP covariance function and almost surely for all functions drawn from the GP prior. However, these results rest on the assumption that the GP hyperparameters remain fixed throughout the optimization. Recently, Bull (2011) proved convergence rates for EI selection with fixed hyperparameters and the case where model selection is performed according to a modified maximum marginal likelihood procedure. The general case of applying Bayesian optimization with maximum marginal likelihood model selection and EI policy selection is not guaranteed to converge to the global optimum.
Although EI is a commonly used selection criterion, a variety of other criteria have been studied. For example, early work by Kushner (1964) considered the probability of improvement as a criterion for selecting the next input. CB criteria (discussed in Section 3.2) have been extensively studied in the context of global optimization (Cox and John, 1992; Srinivas et al., 2010) and economic decision making (Levy and Markowitz, 1979). Recent work (Osborne et al., 2009; Garnett et al., 2010) has considered multi-step lookahead criteria that are less myopic than methods that only consider the next best input. For an excellent tutorial on Bayesian optimization, see Brochu et al. (2009).
2.2. Variational heteroscedastic Gaussian process regression
One limitation of the standard regression model (2) is the assumption of i.i.d. noise over the input space. Many data do not adhere to this simplification and models capable of capturing input-dependent noise (or heteroscedasticity) are required. The heteroscedastic regression model takes the form
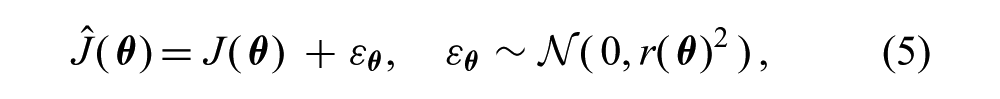
where the noise variance, r(
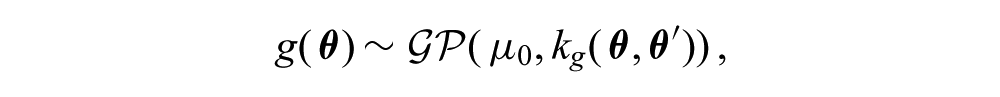
is placed over the unknown log variance function, g(
Stochastic techniques, such as Markov chain Monte Carlo (MCMC) (Goldberg et al., 1998), offer a principled way to deal with intractable probabilistic models. However, these methods tend to be computational demanding. An alternative approach is to analytically define the marginal probability in terms of a variational density, q(⋅). By restricting the class of variational densities by, e.g., assuming q(⋅) is Gaussian or factored in some way, it is often possible to define tractable bounds on the quantity of interest. In the variational heteroscedastic Gaussian process (VHGP) model (Lázaro-Gredilla and Titsias, 2011), a variational lower bound on the marginal log likelihood is used as a tractable surrogate function for optimizing the hyperparameters.
Let
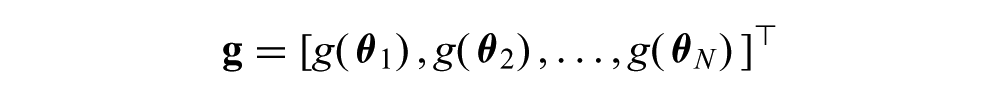
be the vector of unknown log noise variances for the N data points. By defining a normal variational density,
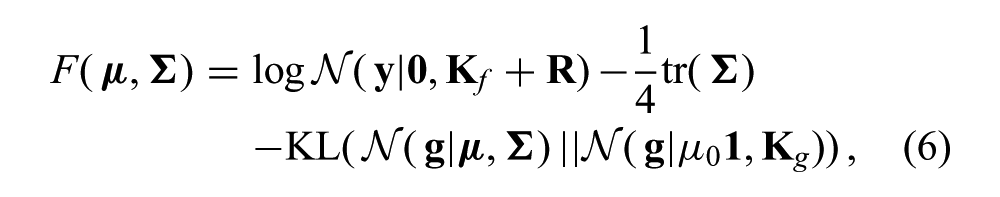
where
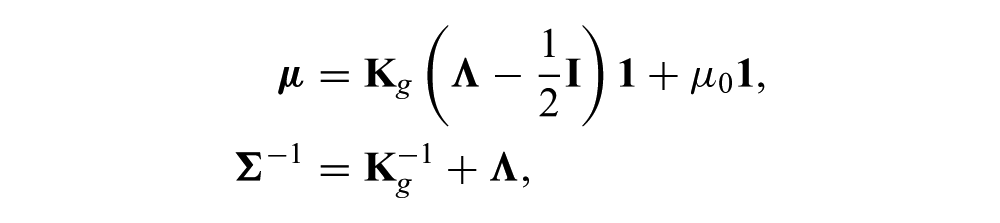
where
The VHGP model yields a non-Gaussian variational predictive density,
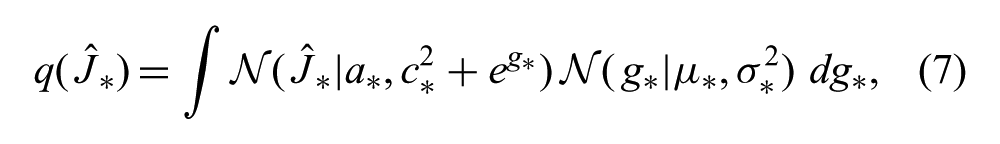
where
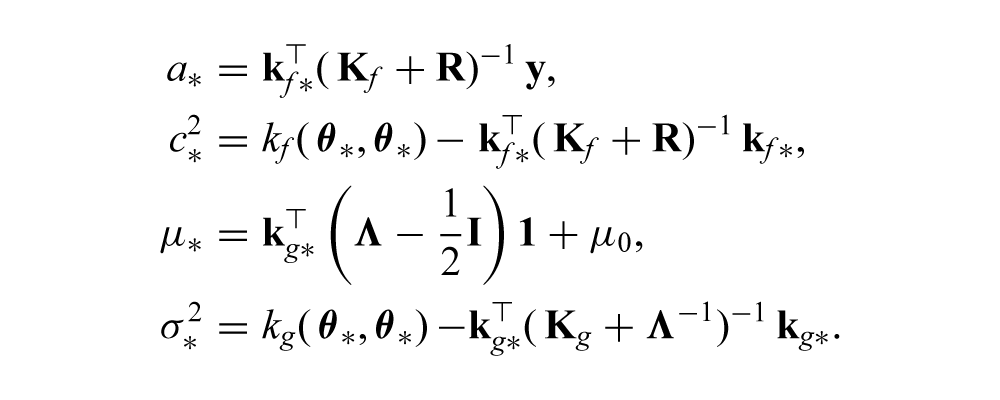
Although this predictive density is intractable, its mean and variance can be calculated in closed form:
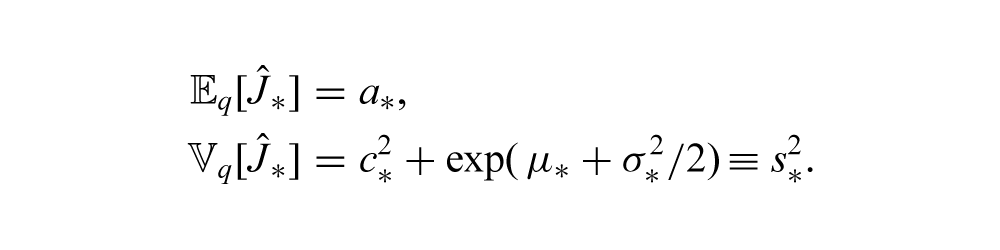
2.2.1. Example
Figure 1(a) shows the result of performing model selection given a GP prior with a squared exponential kernel and unknown constant noise variance on a synthetic heteroscedastic data set. Figure 1(b) shows the result of optimizing the VHGP model on the same data. Model selection was performed using SQP to maximize the marginal log likelihood or, in the case of the VHGP model, the marginal variational bound (6). Owing to the constant noise assumption, the GP model overestimates the cost variance in regions of low variance and underestimates in regions of high variance. In contrast, the VHGP model captures the input-dependent noise structure.
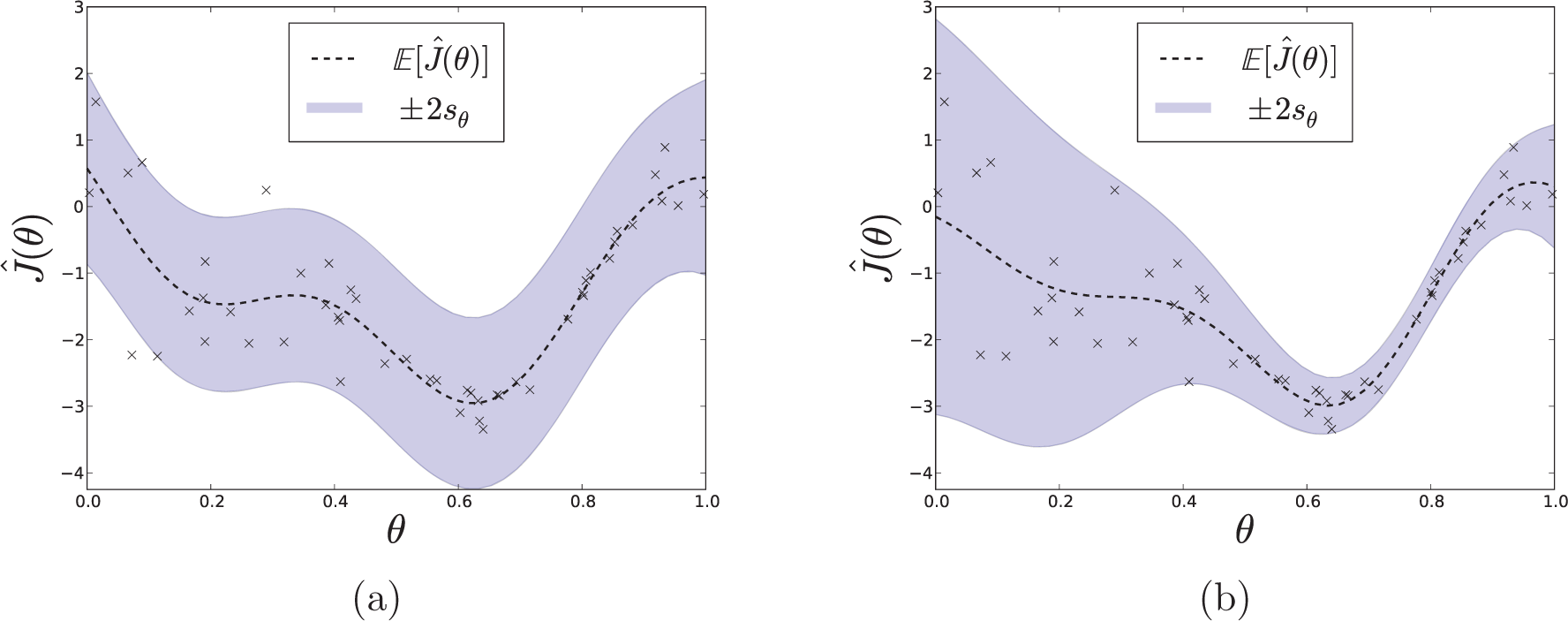
Comparison of fits for the standard GP model (a) and the VHGP model (b) on a synthetic heteroscedastic data set.
3. Variational Bayesian optimization
There are at least two practical motivations for modifying Bayesian optimization to capture policy-dependent cost variance. The first reason is to enable metrics computed on the predictive distribution, such as EI or probability of improvement, to return more meaningful values for the problem under consideration. For example, the GP model in Figure 1 would overestimate the EI for θ = 0.6 and underestimate the EI of θ = 0.2. The second reason is that it creates the opportunity to employ policy selection criteria that take cost variance into account, i.e. that are risk-sensitive.
We extend the VHGP model to the optimization case by deriving the expression for EI and its gradients and show that both can be efficiently approximated to several decimal places using Gauss–Hermite quadrature (as is the case for the predictive distribution itself (Lázaro-Gredilla and Titsias, 2011)). Efficiently computable CB selection criteria are also considered for selecting greedy risk-sensitive policies. A generalization of EI, called ERI, is derived that balances exploration and exploitation in the risk-sensitive case. Finally, to address numerical issues that arise when N is small (i.e. in the early stages of optimization), independent log priors are added to the marginal variational bound and heuristic sampling strategies are identified.
3.1. Expected improvement
Recall from Section 2.1.2 that the EI is defined as the expected reduction in cost, or improvement, over the average cost of the best policy previously evaluated. The probability of the policy parameters,
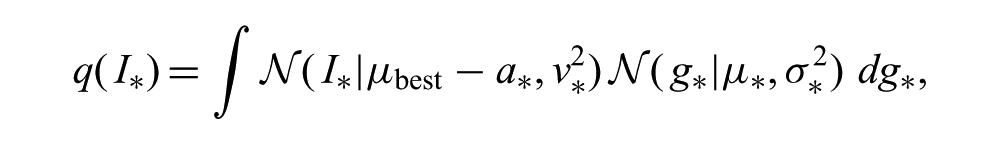
where
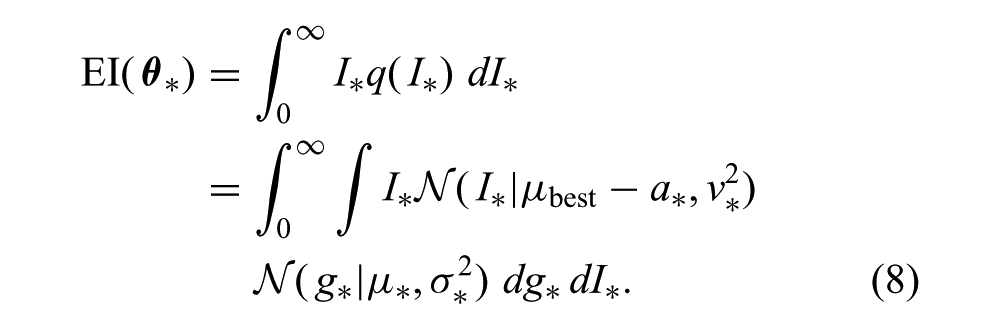
To get (8) into a more convenient form, we can define
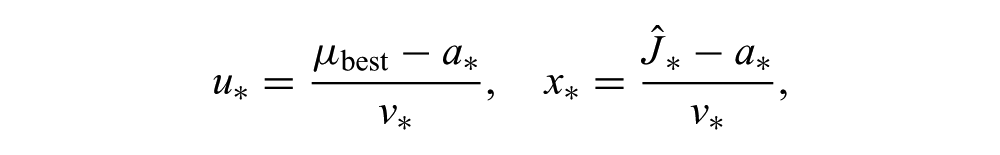
and rewrite the expression for improvement (3) as
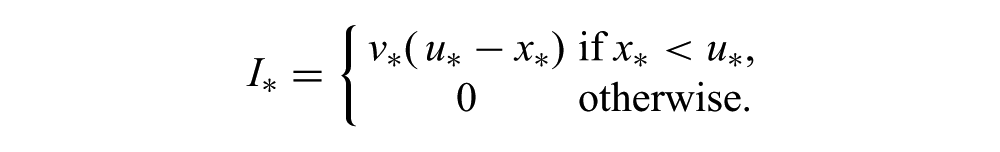
By using this alternative form of improvement and changing the order of integration, we have
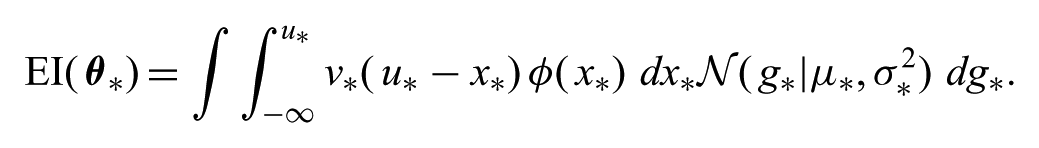
where ɸ(⋅) is the PDF of the normal distribution. Letting f(x*) = v*(u*−x*) and integrating
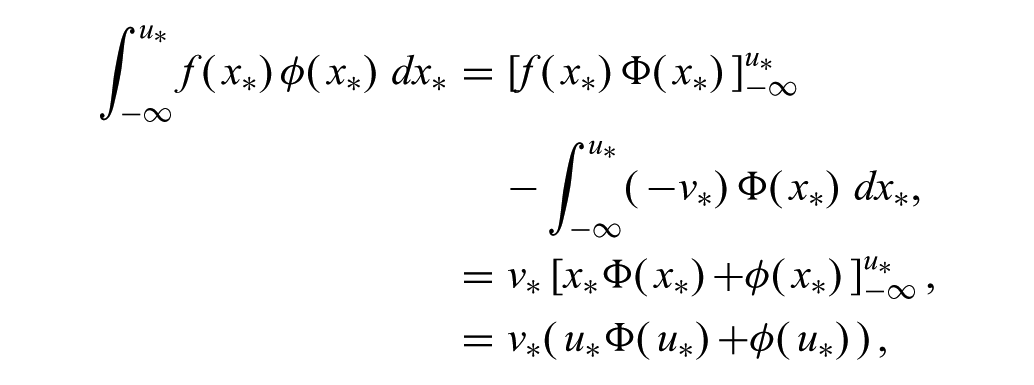
where we have used the facts that
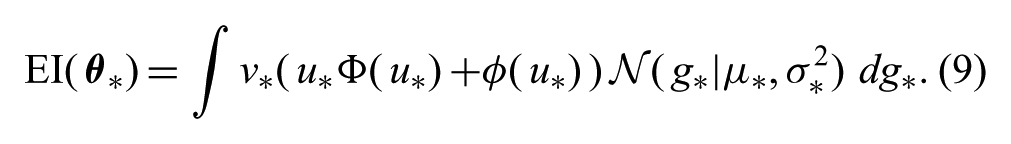
Although this expression is not analytically tractable, it can be efficiently approximated using Gauss–Hermite quadrature (Abramowitz and Stegun, 1972). This can be made clear by setting
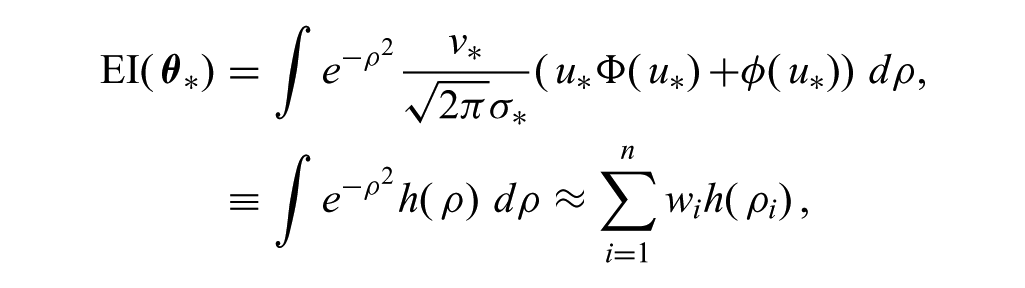
where n is the number of sample points, ρi are the roots of the Hermite polynomial,
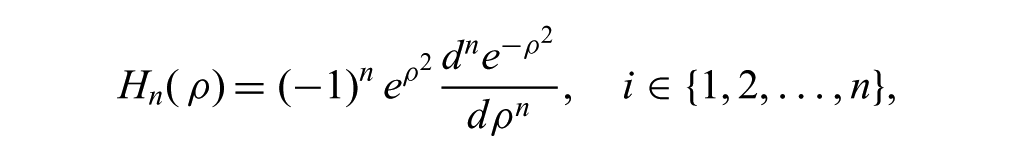
and the weights are computed as
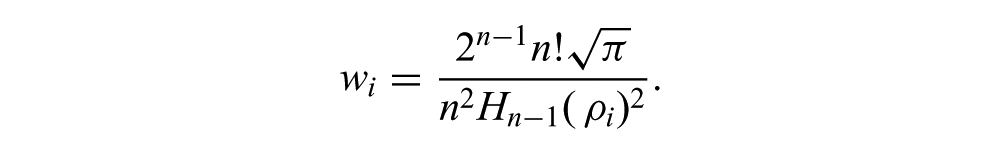
In practice, a variety of tools are available for efficiently computing both wi and ρ i for a given n. In all of our experiments, n = 45.
Similarly, the gradient ∂EI (
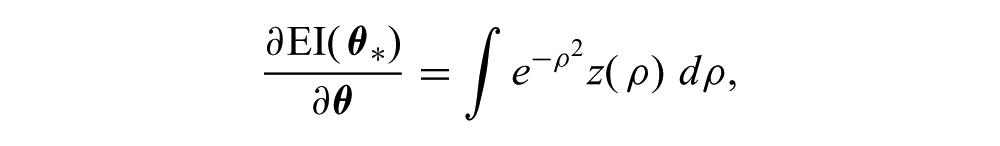
where
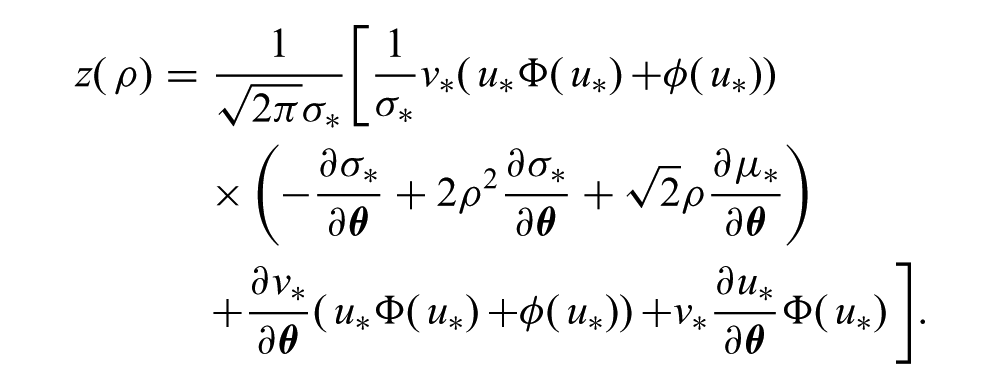
As in the standard Bayesian optimization setting, one can easily incorporate an exploration parameter, ξ, by setting u* = (μbest −a* + ξ)/v*, and maximize EI using standard nonlinear optimization algorithms. Since flat regions and multiple local maxima may be present, it is common practice to perform random restarts during EI optimization to avoid low-quality solutions. In our experiments, we used the NLOPT (Johnson, 2011) implementation of SQP with 25 random restarts to optimize EI.
3.2. Confidence bound selection
In order to exploit cost variance information for policy selection, we must consider selection criteria that flexibly take cost variance into account. Although EI performs well during learning by balancing exploration and exploitation, it falls short in this regard since it always favors high variance (or uncertainty) among solutions with equivalent expected cost. In contrast, CB selection criteria allow one to directly specify the sensitivity to cost variance.
The family of CB selection criteria have the general form
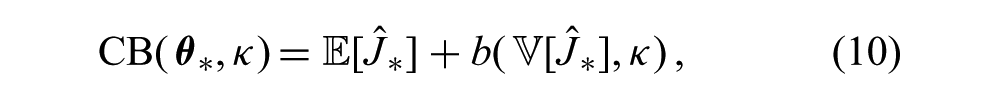
where b(⋅,⋅) is a function of the cost variance and a constant risk factor, κ, that controls the system’s sensitivity to risk. Such criteria have been extensively studied in the context of statistical global optimization (Cox and John, 1992; Srinivas et al., 2010) and economic decision making (Levy and Markowitz, 1979). Favorable regret bounds for sampling with CB criteria with
Interestingly, CB criteria have a strong connection to the exponential utility functions of risk-sensitive optimal control (Whittle, 1981, 1990). For example, consider the risk-sensitive optimal control objective function,
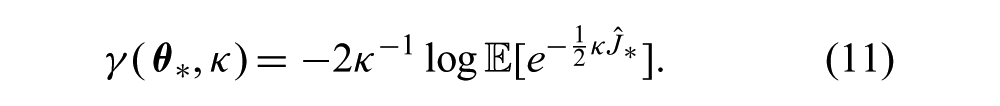
By taking the second-order Taylor expansion of (11) about
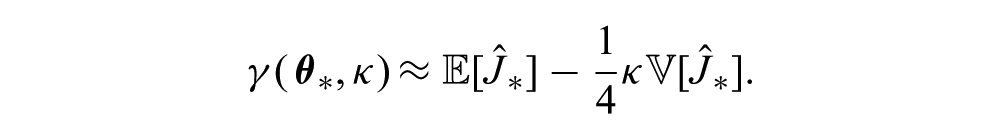
Thus, policies selected according to a CB criterion with
In practice, one typically sets
3.3. Expected risk improvement
The primary advantage CB criteria offer is the ability to flexibly specify sensitivity to risk. However, CB criteria are greedy with respect to risk-sensitive objectives and therefore do not have the same exploratory quality as EI does for expected cost minimization. It is therefore natural to consider whether the EI criterion could be extended to perform risk-sensitive policy selection in a way that balances exploration and exploitation.
Schonlau et al. (1998) considered a generalization of EI where the improvement for
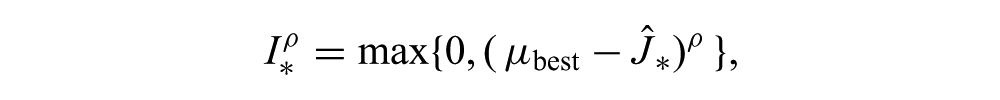
where ρ is an integer-valued parameter that affects the relative importance of large, low-probability improvements and small, high-probability improvements. Interestingly, the authors showed that for ρ = 2,
To address this problem, we propose an ERI criterion. In this case, the risk improvement for the policy parameters
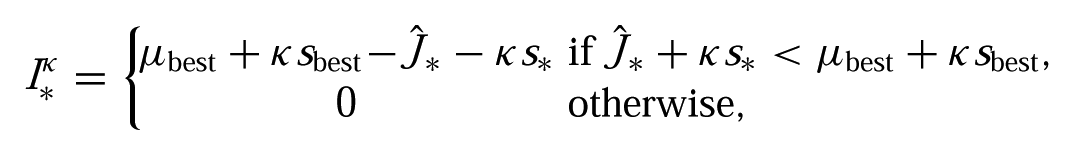
where
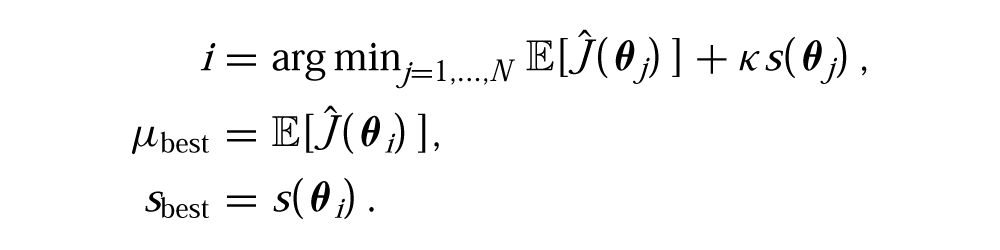
Intuitively, the risk improvement captures the reduction in the value of the risk-sensitive objective,
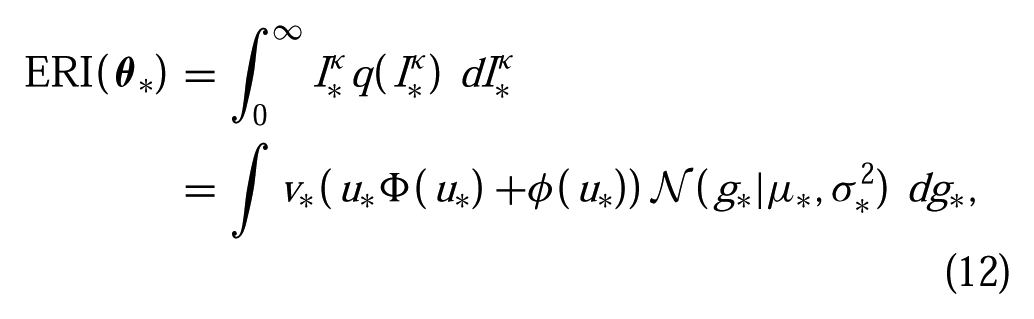
where u* = (μbest − a* +κ(sbest − s*))/v*. Thus, ERI can be viewed as a straightforward generalization of EI, where ERI = EI if κ = 0.
3.4. Coping with small sample sizes
3.4.1. Log hyperpriors
Numerical precision problems are commonly experienced when performing model selection (which requires kernel matrix inversions and determinant calculations) using small amounts of data. To help improve numerical stability in the VHGP model when N is small, we augment F(
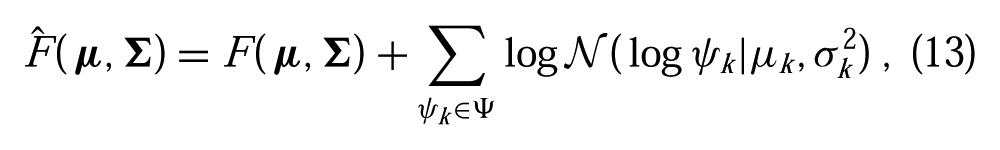
where Ψ = Ψ f ∪ Ψ g is the set of all hyperparameters. Lizotte et al. (2011) showed that empirical performance can be improved in the standard Bayesian optimization setting by incorporating log-normal hyperpriors into the model selection procedure. In practice, these priors can be quite vague and thus do not require significant experimenter insight. For example, in our experiments with variational Bayesian optimization (VBO), we set the log prior on length scales so that the width of the 95% confidence region is at least 20 times the actual policy parameter ranges.
As is the case with standard marginal likelihood maximization,
3.4.2. Sampling
It is well known that selecting policies based on distributions fit using very little data can lead to myopic sampling and premature convergence (Jones, 2001). For example, if one were unlucky enough to sample only the peaks of a periodic cost function, there would be good reason to infer that all policies have approximately equivalent cost. Incorporating external randomization is one way to help alleviate this problem. For example, it is common to obtain a random sample of N0 initial policies prior to performing optimization. Sampling according to EI with probability 1−∊ and randomly otherwise can also perform well empirically. In the standard Bayesian optimization setting with model selection, ∊-random EI selection has been shown to yield near-optimal global convergence rates (Bull, 2011).
Randomized CB selection with, e.g.,
The VBO algorithm is shown in Algorithm 2.

4. Local search
Like most standard Bayesian optimization implementations, no general global convergence guarantees exist for VBO. In addition, performing global selection of policy parameters can produce large jumps in policy space between trials, which can be undesirable in some physical systems. A straightforward way to address this latter concern is to restrict the parameter range to the local neighborhood of the nominal policy parameters. However, adding constraints in this way does not improve the convergence properties of the algorithm.
Gradient-based policy search methods make small, incremental changes to the policy parameters and typically have demonstrable local convergence properties under mild assumptions (Bertsekas and Tsitsiklis, 2000). Thus, in addition to using the learned cost model to perform global policy selection, we consider its use as a local critic for performing risk-sensitive gradient descent. It is straightforward to show that, under certain assumptions, the generalized RSSGD update follows the direction of the gradient of a CB objective. In addition, when a minimum variance baseline is used, the algorithm can be viewed as taking local steps in the direction of the risk improvement (Section 3.3) over the current policy parameters. This creates the opportunity to flexibly interweave risk-sensitive gradient descent and local VBO to, e.g., select local greedy policies or to change risk-sensitivity on-the-fly.
4.1. RSSGD
Stochastic gradient descent methods have had significant practical applicability to solving robot control problems in the expected cost setting (Kohl and Stone, 2004; Tedrake et al., 2004; Roberts and Tedrake, 2009), so we focus on extending this approach to the risk-sensitive case. The stochastic gradient descent algorithm, also called the weight perturbation algorithm (Jabri and Flower, 1992), is a simple method for descending the gradient of a noisy objective function. The algorithm proceeds as follows. Starting with parameters,
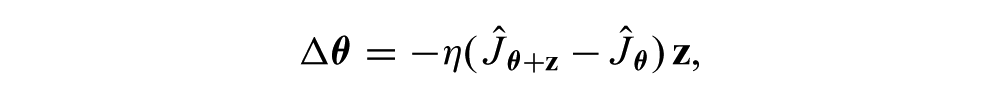
and η is a step size parameter. Intuitively, this rule updates the parameters in the direction of
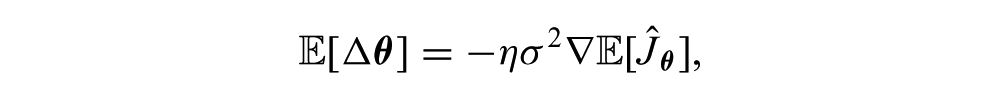
where
In contrast, consider the RSSGD update
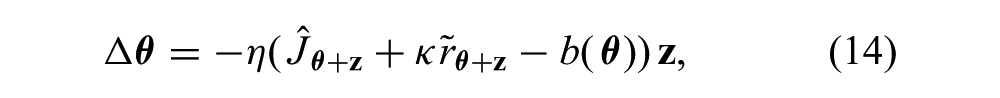
where
Substituting (5) into (14) and taking the first-order Taylor expansion at
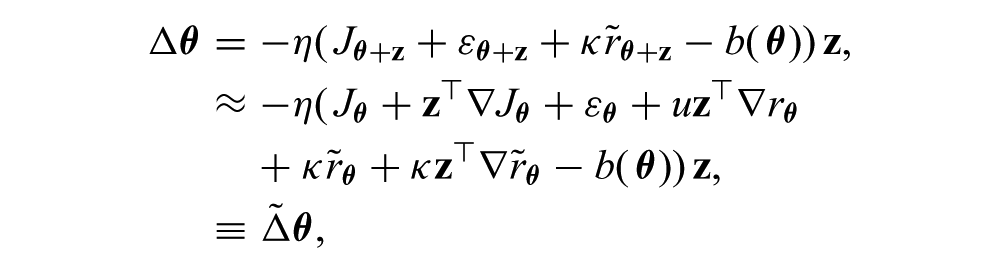
where
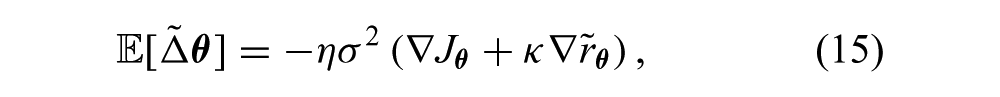
where the expectation is taken with respect to
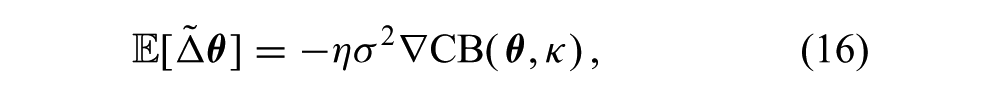
a scaled unbiased estimate of the gradient of the CB objective, CB (
4.1.1. Natural gradient
From (16) it is clear that the unbiasedness of the update is also dependent on the isotropy of the sampling distribution,
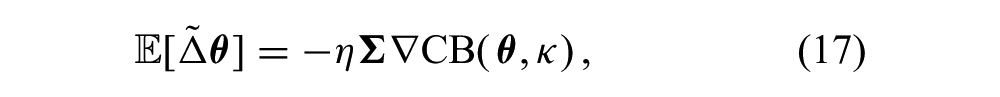
but it is still in the direction of the natural gradient (Amari, 1998). To see this, recall that for probabilistically sampled policies, the natural gradient is defined as
4.1.2. Baseline selection
The expected update (15) is unaffected by the choice of the baseline function, b(
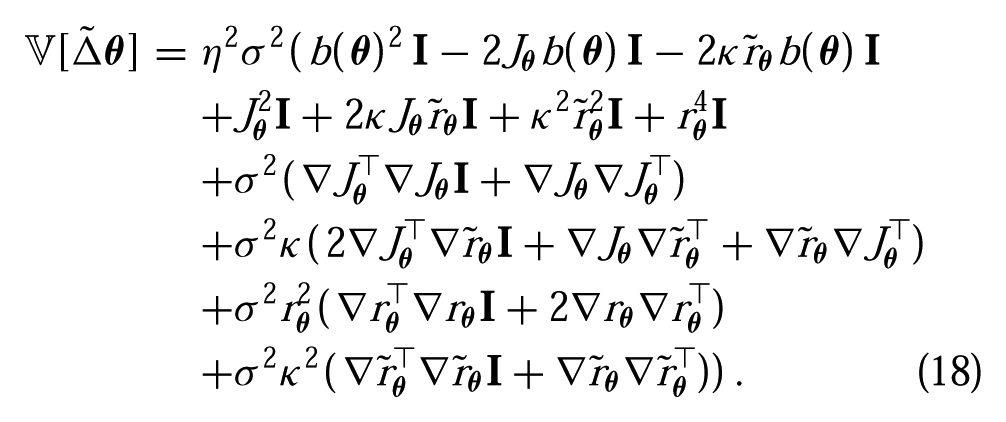
It is straightforward to show that the baseline that minimizes (18) is
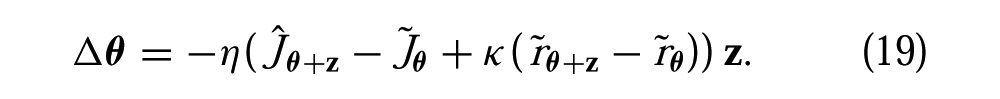
Intuitively, Equation (19) reduces to the classical stochastic gradient descent update when either the system has a neutral attitude toward risk (κ = 0) or when the estimate of the cost standard deviation is locally constant:
In implementation, it can be helpful to divide the step size by

As in VBO, the critic is updated after each policy evaluation by recomputing the predictive cost distribution. However, in this case model selection and prediction are performed using only observations near the current parameterization,
5. Experiments
In Sections 5.1 and 5.2 we illustrate the VBO algorithm using simple synthetic domains. In Section 5.3, we apply VBO to a impact recovery task with the uBot-5 mobile manipulator. Finally, in Section 5.4, we apply the RSSGD algorithm in a dynamic heavy lifting task with the uBot-5.
5.1. Synthetic data
As an illustrative example, in Figure 2 we compare the performance of VBO to standard Bayesian optimization in a simple one-dimensional noisy optimization task. For this task, the true underlying cost distribution (Figure 2(a)) has two global minima (in the expected cost sense) with different cost variances. Both algorithms begin with the same N0 = 10 random samples and perform 10 iterations of EI selection (ξ = 1.0, ∊ = 0.25). In Figure 2(b), we see that Bayesian optimization succeeds in identifying the regions of low cost, but it cannot capture the policy-dependent variance characteristics.
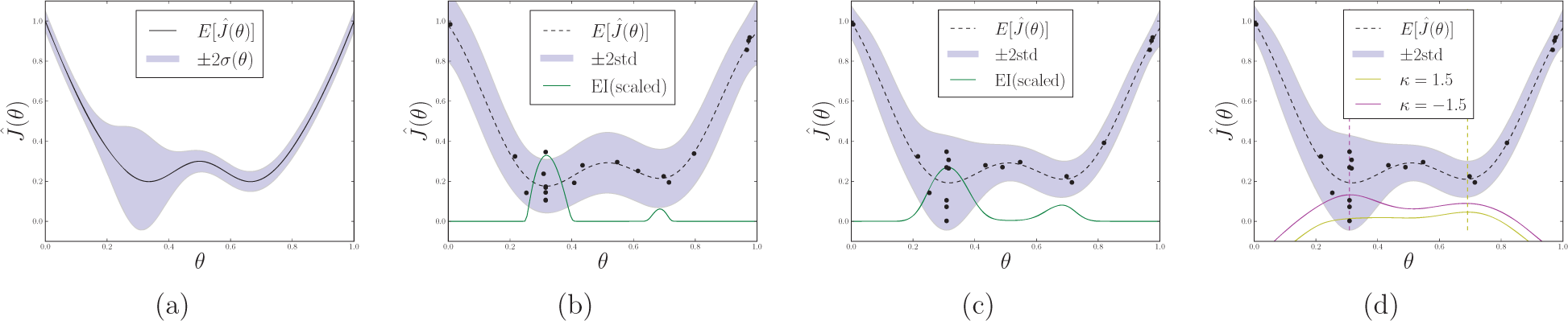
(a) An example unknown noise distribution with two equivalent expected cost minima with different cost variance. (b) The distribution learned after 10 iterations of Bayesian optimization with EI selection and (c) after 10 iterations of VBO with EI selection (using the same initial N0 = 10 random samples for both cases). Bayesian optimization succeeded in identifying the minima, but it cannot distinguish between high- and low-variance solutions. (d) CB selection criteria are applied to select risk-seeking and risk-averse policy parameters (indicated by the vertical dotted lines) given the distribution learned using VBO.
In contrast, VBO reliably identifies the minima and approximates the local variance characteristics. Figure 2(d) shows the result of applying two different CB selection criteria to vary risk-sensitivity. In this case, −CB (
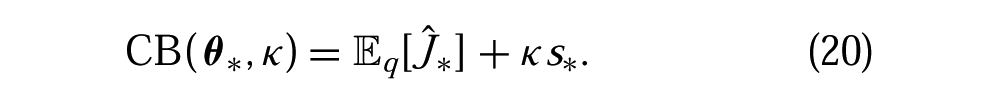
Risk factors κ = −1.5 and κ = 1.5 were used to select a risk-seeking and risk-averse policy parameters, respectively.
5.2. Noisy pendulum
As another simple example, we considered a swing-up task for a noisy pendulum system. In this task, the maximum torque output of the pendulum actuator is unknown and is drawn from a normal distribution at the beginning of each episode. As a rough physical analogy, this might be understood as fluctuations in motor performance that are caused by unmeasured changes in temperature. The policy space consisted of “bang–bang” policies in which the maximum torque is applied in the positive or negative direction, with switching times specified by two parameters, 0 ≤ t1, t2 ≤ 1.5 s. Thus,
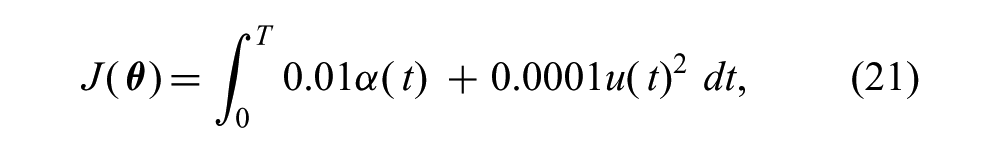
where 0 ≤ α (t) ≤ π is the pendulum angle measured from upright vertical, T = 3.5 s, and u(t) = τmax if 0 ≤ t ≤ θ1, u(t) = −τmax if θ1 < t ≤ θ1 +θ2, and u(t) = τmax if θ1 +θ2 < t ≤ T. The system always started in the downward vertical position with zero initial velocity and the episode terminated if the pendulum came within 0.1 rad of the upright vertical position. The parameters of the system were l = 1.0 m, m = 1.0 kg, and
The cost function (21) suggests that policies that reach vertical as quickly as possible (i.e. using the fewest swings) are preferred. However, the success of an aggressive policy depends on the torque generating capability of the pendulum. With a noisy actuator, it is reasonable to expect aggressive policies to have higher variance. An approximation of the cost distribution obtained via discretization (N = 40,000) is shown in Figure 3(a). It is clear from this figure that regions around policies that attempt two-swing solutions (
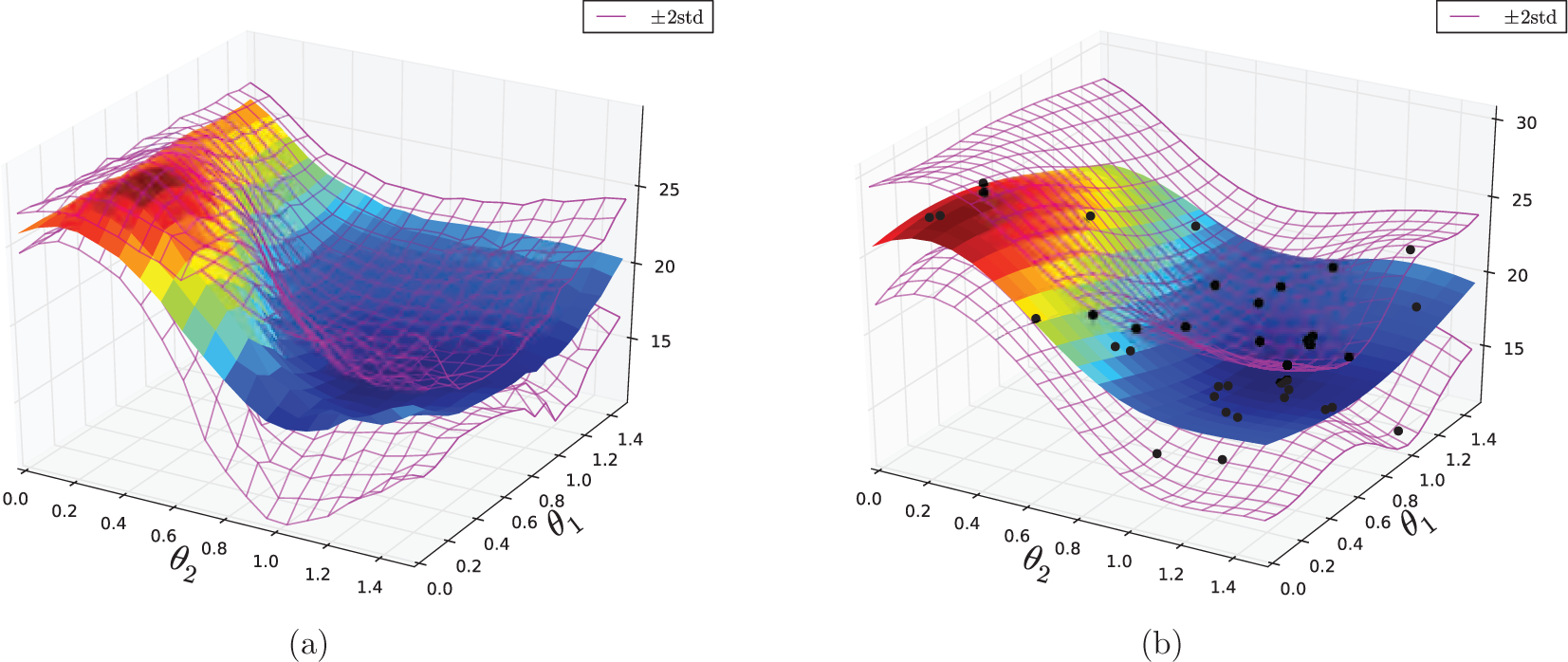
(a) The cost distribution for the simulated noisy pendulum system obtained by a 20 × 20 discretization of the policy space. Each policy was evaluated 100 times to estimate the mean and variance (N = 40,000). (b) Estimated cost distribution after 25 iterations of VBO with 15 initial random samples (N = 40). Owing to the sample bias that results from EI selection, the optimization algorithm tends to focus modeling effort in regions of low cost.
Figure 3(b) shows the results of 25 iterations of VBO using EI selection (N0 = 15, ξ = 1.0, ∊ = 0.2) in the noisy pendulum task. After N = 40 total evaluations, the expected cost and cost variance are sensibly represented in regions of low cost. Figure 4 illustrates the behavior of two policies selected by minimizing the CB criterion (20) on the learned distribution with κ = ±2.0. The risk-seeking policy (
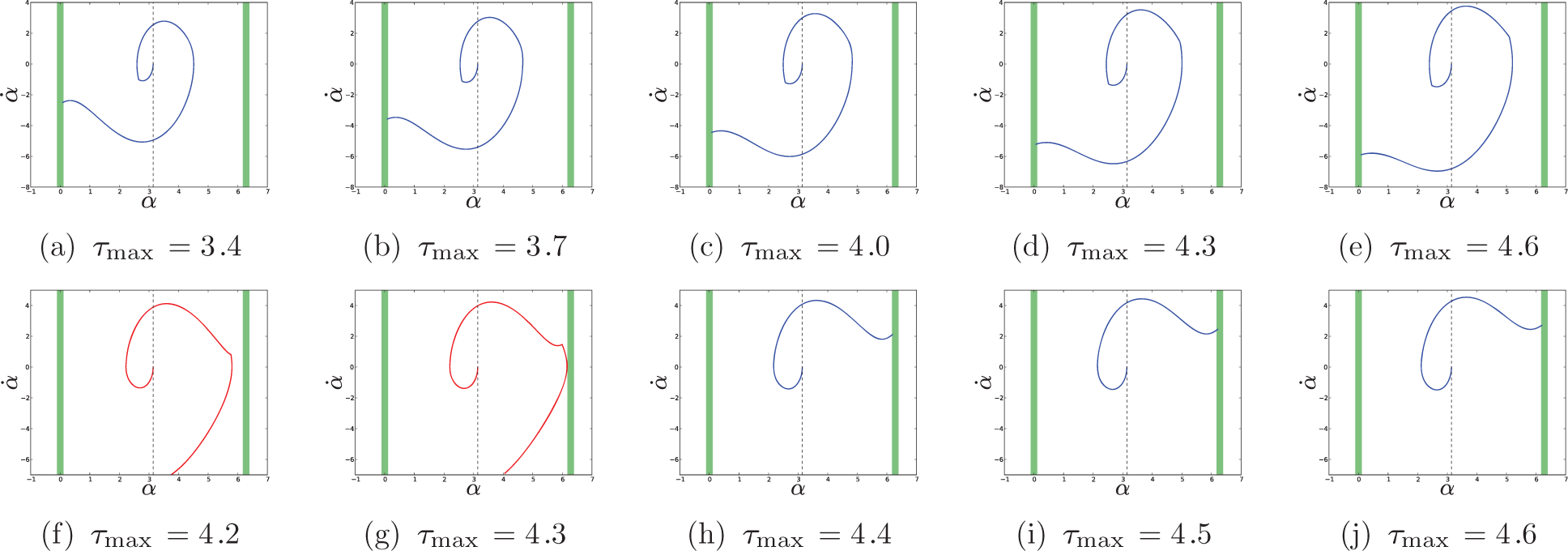
Performance of risk-averse (a)–(e) and risk-seeking (f)–(j) policies as the maximum pendulum torque is varied. Shown are phase plots with the goal regions shaded in green. The risk-averse policy always used three swings and consistently reached the vertical position before the end of the episode. The risk-seeking policy used longer swing durations, attempting to reach the vertical position in only two swings. However, this strategy only pays off when the unobserved maximum actuator torque is large.
It is often easy to understand the utility of risk-averse and risk-neutral policies, but the motivation for selecting risk-seeking policies might be less clear. The above result suggests one possibility: the acquisition of specialized, high-performance policies. For example, in some cases risk-seeking policies could be chosen in an attempt to identify observable initial conditions that lead to rare low-cost events. Subsequent optimizations might then be performed to direct the system to these initial conditions. One could also imagine situations when the context demands performance that lower risk policies are very unlikely to generate. For example, if the minimum time to goal was reduced so that only two swing policies had a reasonable chance of succeeding. In such instances it may be desirable to select higher-risk policies, even if the probability of succeeding is quite low.
5.3. Balance recovery with the uBot-5
The uBot-5 (Figure 5) is an 11-degree-of-freedom (11-DoF) mobile manipulator developed at the University of Massachusetts Amherst (Kuindersma et al., 2009; Deegan, 2010). The uBot-5 has two 4-DoF arms, a rotating trunk, and two wheels in a differential drive configuration. The robot stands approximately 60 cm from the ground and has a total mass of 19 kg. The robot’s torso is roughly similar to an adult human in terms of geometry and scale, but instead of legs, it has two wheels attached at the hip. The robot balances using a linear-quadratic regulator (LQR) with feedback from an onboard inertial measurement unit (IMU) to stabilize around the vertical fixed point. The LQR controller has proved to be very robust throughout 5 years of frequent usage and it remains fixed in our experiments.

The uBot-5 demonstrating a whole-body pushing behavior.
In our previous experiments (Kuindersma et al., 2011), the energetic and stabilizing effects of rapid arm motions on the LQR stabilized system were evaluated in the context of recovery from impact perturbations. One observation made was that high-energy impacts caused a subset of possible recovery policies to have high cost variance: successfully stabilizing in some trials, while failing to stabilize in others. We extended these experiments by considering larger impact perturbations, increasing the set of arm initial conditions, and defining a policy space that permits more flexible, asymmetric arm motions (Kuindersma et al., 2012b).
The robot was placed in a balancing configuration with its upper torso aligned with a 3.3 kg mass suspended from the ceiling (Figure 6). The mass was pulled away from the robot to a fixed angle and released, producing a controlled impact between the swinging mass and the robot. The pendulum momentum prior to impact was 9.9 ± 0.8 Ns and the resulting impact force was approximately equal to the robot’s total mass in Earth’s gravity. The robot was consistently unable to recover from this perturbation using only the wheel LQR (see the rightmost column of Figure 7). The robot was attached to the ceiling with a loose-fitting safety rig designed to prevent the robot from falling completely to the ground, while not affecting policy performance.
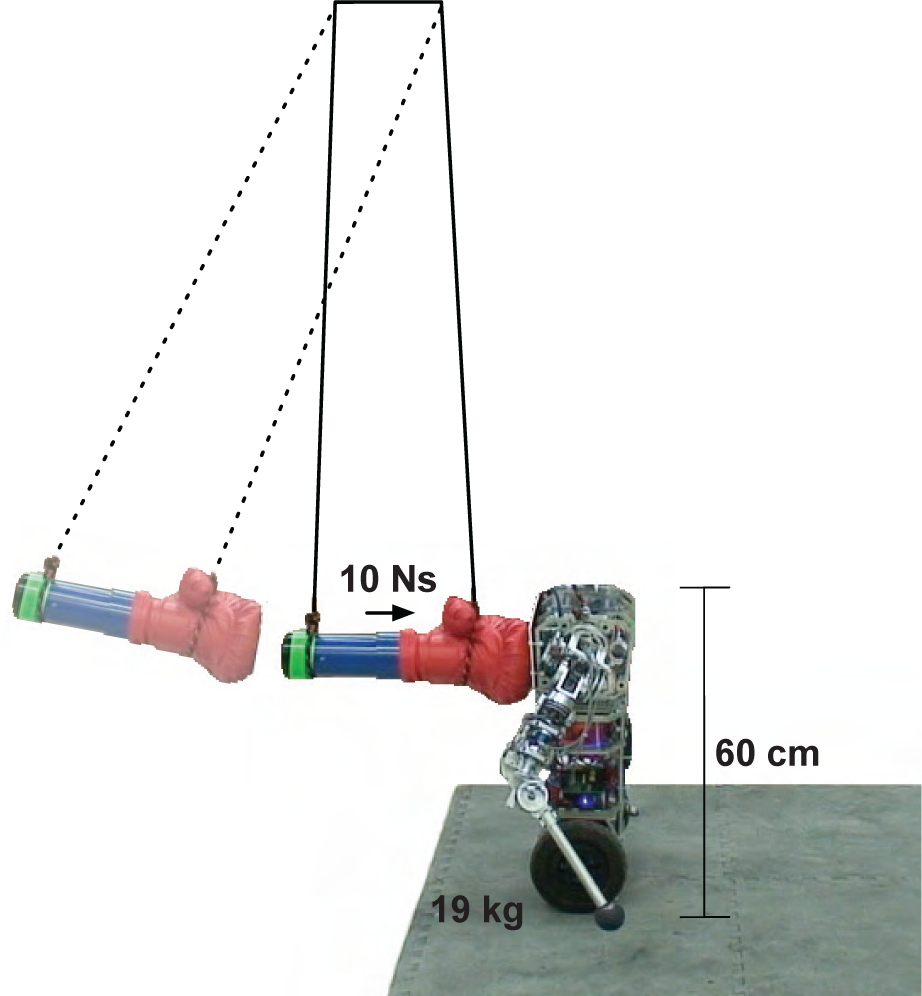
The uBot-5 situated in the impact pendulum apparatus.
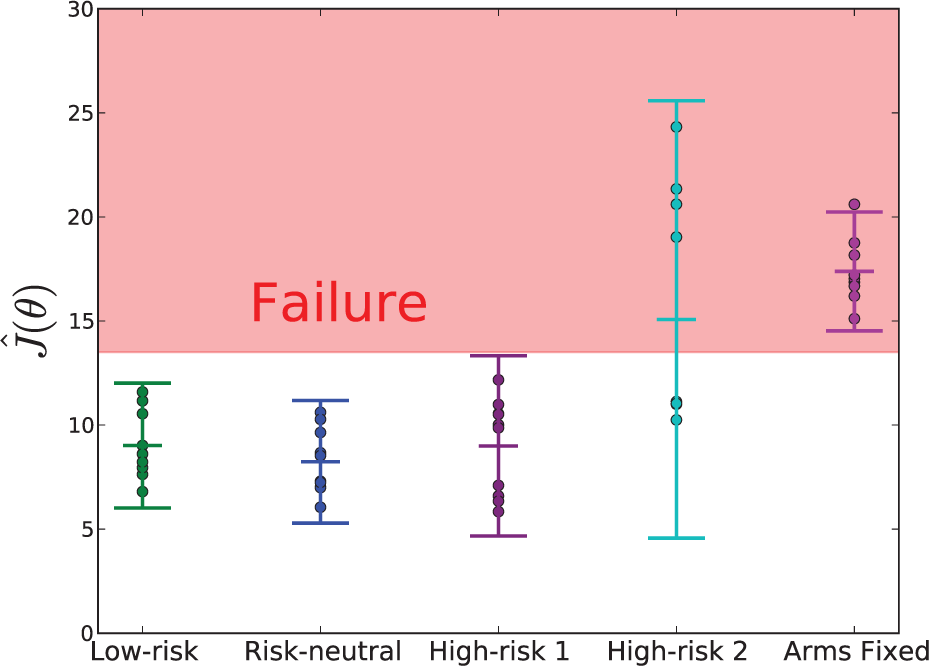
Data collected over 10 trials using policies identified as risk-averse, risk-neutral, and risk-seeking after performing VBO. The policies were selected using CB criteria with κ = 2, κ = 0, κ = −1.5, and κ = −2, from left to right. The sample means and two times sample standard deviations are shown. The shaded region contains all trials that resulted in failure to stabilize. Ten trials with a fixed-arm policy are plotted on the far right to serve as a baseline level of performance for this impact magnitude.
This problem is well suited for model-free policy optimization since there are several physical properties, such as joint friction, wheel backlash, and tire slippage, that make the system difficult to model accurately. In addition, although the underlying state and action spaces are high-dimensional (22 and 8, respectively), low-dimensional policy spaces that contain high-quality solutions are relatively straightforward to identify.
The parameterized policy controlled each arm joint according to an exponential trajectory, τi(t) = e−λit, where 0 ≤ τi (t) ≤ 1 is the commanded DC motor power for joint i at time t. The λ parameters were paired for the shoulder/elbow pitch and the shoulder roll/yaw joints. This pairing allowed the magnitude of dorsal and lateral arm motions to be independently specified. The pitch (dorsal) motions were specified separately for each arm and the lateral motions were mirrored, which reduced the number of policy parameters to three. The range of each λi was constrained: 1 ≤ λi ≤ 15. At time t, if
The cost function was designed to encourage energy-efficient solutions that successfully stabilized the system:
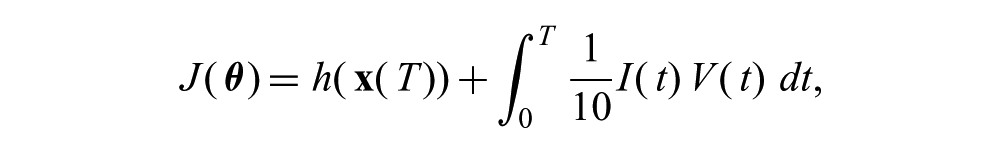
where I(t) and V (t) are the total absolute motor current and voltage at time t, respectively, T = 3.5 s, and h(
After training, we evaluated four policies with different risk-sensitivities selected by minimizing the CB criterion (20) with κ = 2, κ = 0, κ = −1.5, and κ = −2. Each selected policy was evaluated 10 times and the results are shown in Figure 7. The sample statistics confirm the algorithmic predictions about the relative riskiness of each policy. In this case, the risk-averse and risk-neutral policies were very similar (no statistically significant difference between the mean or variance), while the two risk-seeking policies had higher variance (for κ = −2, the differences in both the sample mean and variance were statistically significant).
For κ = −2, the selected policy produced an upward laterally directed arm motion that failed approximately 50% of the time. In this case, the standard deviation of cost was sufficiently large that the second term in CB objective (20) dominated, producing a policy with high variance and poor average performance. A slightly less risk-seeking selection (κ = −1.5) yielded a policy with conservative low-energy arm movements that was more sensitive to initial conditions than the lower risk policies. This exertion of minimal effort could be viewed as a kind of gamble on initial conditions. Figure 8 shows example runs of the risk-averse and risk-seeking policies.

Time series (time between frames is 0.24 seconds) showing (a) a trial executing the low-risk policy and (b) two trials executing the high-risk policy. Both policies were selected using CB criteria on the learned cost distribution. The low-risk policy produced an asymmetric dorsally directed arm motion with reliable recovery performance. The high-risk policy produced an upward laterally directed arm motion that failed approximately 50% of the time.
5.4. Dynamic heavy lifting
We evaluated the RSSGD algorithm in the dynamic control task of lifting a 1 kg, partially filled laundry detergent bottle from the ground to a height of 120 cm using the uBot-5 (Kuindersma et al., 2012a). This problem is challenging for several reasons. First, the bottle is heavy, so most arm trajectories from the starting configuration to the goal will not succeed because of the limited torque generating capabilities of the arm motors. Second, the upper body motions act as disturbances to the LQR. Thus, violent lifting trajectories will cause the robot to destabilize and fall. Finally, the bottle itself has significant dynamics because the heavy liquid sloshes as the bottle moves. Since the robot had only a simple claw gripper and we made no modifications to the bottle, the bottle moved freely in the hand, which had a significant effect on the stabilized system.
The policy was represented as a cubic spline trajectory in the right arm joint space with seven open parameters to be optimized by the algorithm. The parameters included four shoulder and elbow waypoint positions and three time parameters. The start and end configurations were fixed. Joint velocities at the waypoints were computed using the tangent method (Craig, 2005). The initial policy was a hand-crafted smooth and short duration motion to the goal configuration. Our ability to provide a good initial guess for the policy parameters makes local search with RSSGD more attractive. However, with the bottle in hand, this policy succeeded only a small fraction of the time, with most trials resulting in a failure to lift the bottle above the shoulder.
The cost function was defined as
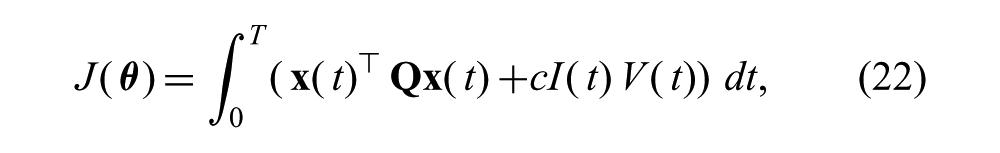
where
5.4.1. Risk-neutral learning
In the first experiment, we ran RSSGD with κ = 0 to perform a risk-neutral gradient descent. The VHGP model was used to locally construct the critic and model selection was performed using SQP. A total of 30 trials (less than 2.5 minutes of total experience) were performed and a reliable, low-cost policy was learned. The robot failed to recover balance in 3 of the 30 trials. In these cases, the emergency stop was activated and the robot was manually reset. Figure 9 illustrates the reduction in cost via empirical measurements taken at fixed intervals during learning.
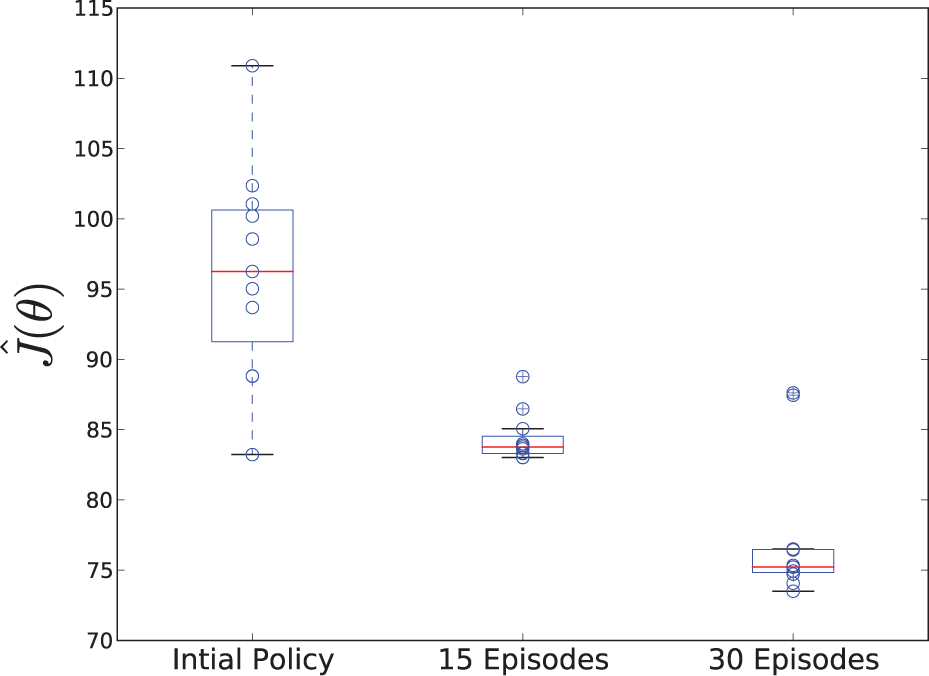
Data collected from 10 test trials executing the initial lifting policy and the policy after 15 and 30 episodes of learning.
Interestingly, the learned policy exploits the dynamics of the liquid in the bottle by timing the motion such that the shifting bottle contents coordinate with the LQR controller to correct the angular displacement of the body. This dynamic interaction would be very difficult to capture in a system model. Incidentally, this serves as a good example of the value of policy search techniques: by virtue of ignoring the dynamics, they are in some sense insensitive to the complexity of the dynamics (Roberts and Tedrake, 2009). Figure 10(a) shows an example run of the learned policy.

(a) The learned risk-neutral policy exploits the dynamics of the container to reliably perform the lifting task. (b) With no additional learning trials, a risk-averse policy is selected offline that reliably reduces translation. The total time duration of each of the above sequences is approximately 3 seconds.
5.4.2. Variable risk control
In the process of learning a low average-cost policy, a model of the local cost distribution was repeatedly computed. The next experiments examined the effect of performing offline policy selection using the estimate of the local cost distribution around the learned policy. In particular, we considered two hypothetical changes in operating context: when the robot’s workspace is reduced, requiring that the policy have a small footprint with high certainty, and when the battery charge is very low, requiring that the policy uses very little energy with high certainty. Offline CB policy selection and subsequent risk-averse gradient descent was performed for each case and the resulting policies were compared empirically.
Context changes were represented by a reweighting of cost function terms. For example, to capture the low-battery-charge context, the relative weight of the motor power term in (22) was increased:
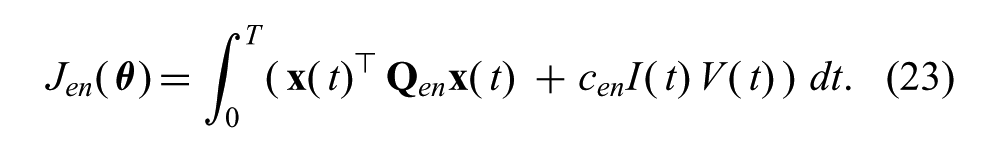
The VHGP model was used to approximate the transformed cost distribution,
Both risk-neutral (κ = 0) and risk-averse (κ = 2) offline policy selections were performed for each case. In addition, five episodes of risk-averse (κ = 2) gradient descent were performed starting from the offline selected risk-averse policy. Each policy was executed five times and the results were compared empirically. Figure 11(a) shows the results from the translation aversion experiments. The risk-neutral offline policy had significantly lower average (transformed) cost and lower variance than the original learned policy. The risk-averse offline policy also has significantly lower average cost than the prior learned policy, but its average cost was slightly (not statistically significantly) higher than the offline risk-neutral policy. However, the offline risk-averse policy had significantly lower variance than the risk-neutral offline policy. An example run of the offline risk-averse policy is shown in Figure 10(b). Finally, the policy learned after five episodes of risk-averse gradient descent starting from the offline selected policy led to another significant reduction in expected cost while maintaining similarly low variance.
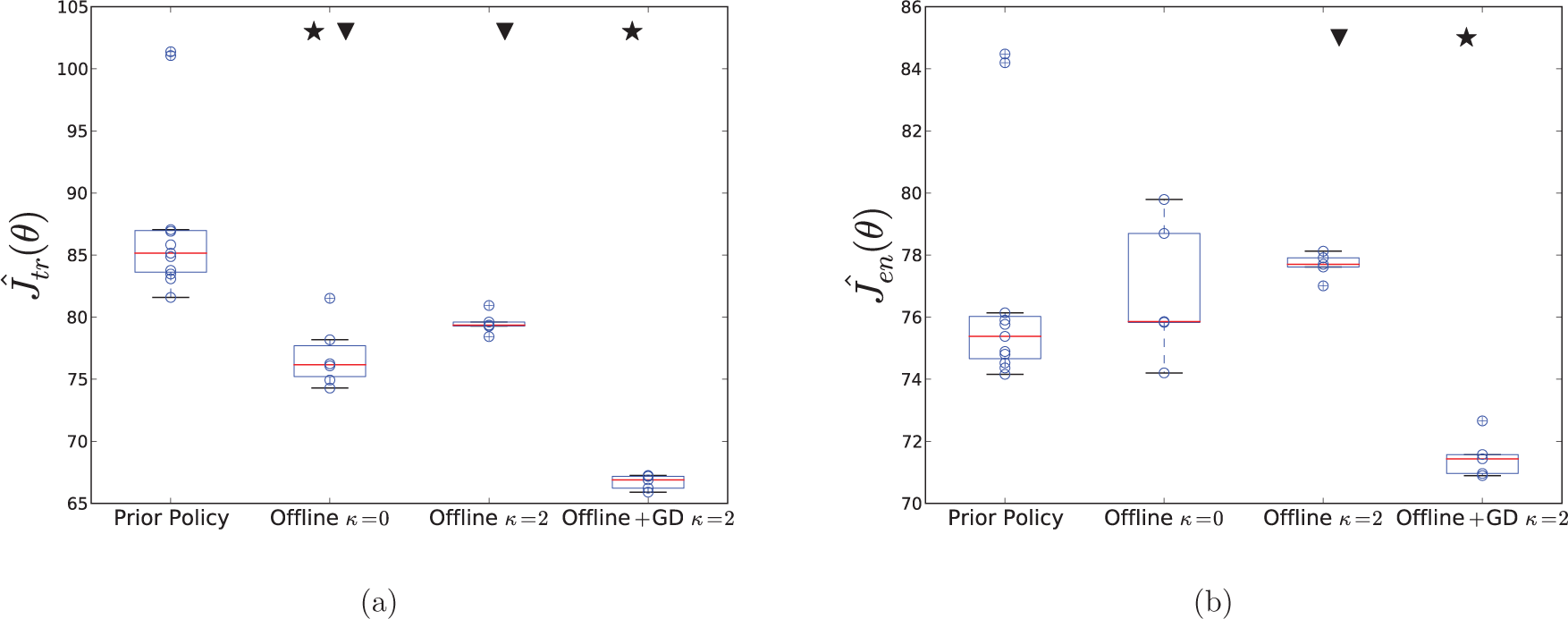
Data from test runs of the prior learned policy, the offline selected risk-neutral and risk-averse policies, and the policy after five episodes of risk-averse gradient descent starting from the risk-averse offline policy: (a) translation aversion; (b) energy aversion. A star at the top of a column signifies a statistically significant reduction in the mean compared with the previous column (Behrens–Fisher, p < 0.01) and a triangle signifies a significant reduction in the variance (F-test, p < 0.03).
For the energy-averse case, the offline risk-neutral policy had no statistically significant difference in sample average or variance compared with the prior learned policy. The risk-averse policy had slightly (not statistically significantly) higher average cost than both the original learned policy and the offline risk-neutral policy, but it had significantly lower variance. The policy learned after five episodes of risk-averse gradient descent had significantly lower average cost than the offline risk-averse while maintaining similar variance (see Figure 11(b)). The statistical significance results given in Figure 11 are strongly in line with our qualitative assessment of the data. However, we should take care to consider these in light of the small sample sizes available, which constrain our ability to verify their underlying assumptions.
6. Related work
Several successful applications of Bayesian optimization to robot control tasks exist in the literature. Lizotte et al. (2007) applied Bayesian optimization to discover an Aibo gait that surpassed the state-of-the-art in a comparatively small number of trials. Tesch et al. (2011) used Bayesian optimization to optimize snake robot gaits in several environmental contexts. Martinez-Cantin et al. (2009) describe an application to online sensing and path planning for mobile robots in uncertain environments. Recently, Kormushev and Caldwell (2012) proposed a particle filter approach for performing direct policy search that is closely related to Bayesian optimization techniques.
A variety of algorithms have been designed to find optimal policies with respect to risk-sensitive criteria. Early work in risk-sensitive control was aimed at extending dynamic programming methods to optimize exponential objective functions. This work included algorithms for solving discrete Markov decision processes (MDPs) (Howard and Matheson, 1972) and linear-quadratic-Gaussian problems (Jacobson, 1973; Whittle, 1981). Borkar derived a variant of the Q-learning algorithm for finite MDPs with exponential utility (Borkar, 2002). Heger (1994) derived a worst-case Q-learning algorithm based on a minimax criterion. For continuous problems, van den Broek et al. (2010) generalized path integral methods from stochastic optimal control to the risk-sensitive case.
Other work has approached the problem of risk-sensitive control with methods other than exponential objective functions. For example, several authors have developed algorithms in discrete model-free RL setting for learning conditional return distributions (Dearden et al., 1998; Morimura et al., 2010a, b), which can be combined with policy selection criteria that take return variance into account. The algorithms discussed in this paper are related to this line of work, but they are more directly applicable to systems with continuous state and action spaces. The recent work of Tamar et al. (2012) describes likelihood-ratio policy gradient algorithms appropriate for different types of risk-sensitive criteria. The simulation-based algorithm in their work is closely related to the RSSGD update rule. However, rather than learning a non-parametric cost model, their algorithm uses a two-timescale approach to obtain incremental unbiased estimates of the cost mean and variance. In some cases, this unbiasedness might be more important than the sample efficiency that cost-model-based approaches can offer.
Policy gradient approaches that are designed to learn dynamic transition models, such as PILCO (Deisenroth and Rasmussen, 2011), can also be used to capture uncertainty in the cost distribution (Deisenroth, 2010). These approaches are capable of handling high-dimensional policy spaces, whereas the approaches described in this work are only appropriate for low-dimensional policy spaces. However, to achieve this scalability, certain smoothness assumptions must be made about the system dynamics. Furthermore, performing offline optimizations to change risk-sensitivity would be significantly more computationally intensive than the approach presented here.
Mihatsch and Neuneier (2002) developed risk-sensitive variants of TD(0) and Q-learning by allowing the step size in the value function update to be a function of the sign of the temporal difference error. For example, by making the step size for positive errors slightly larger than the step size for negative errors, the value of a particular state and action will tend to be optimistic, yielding a risk-seeking system. Recently, this algorithm was found to be consistent with behavioral and neurological measurements taken while humans learned a decision task involving risky outcomes (Niv et al., 2012), suggesting that some form of risk-sensitive TD may be present in the brain.
The connection between these types of methods and biological learning and control processes is an active area of research in the biological sciences. For example, some neuroscience researchers have identified separate neural encodings for expected cost and cost variance that appear to be involved in risk-sensitive decision making (Tobler et al., 2007; Preuschoff et al., 2008). Recent motor control experiments suggest that humans select motor strategies in a risk-sensitive way (Wu et al., 2009; Nagengast et al., 2010a, 2011). For example, Nagengast et al. (2010a) show that control gains selected by human subjects in a noisy control task are consistent with risk-averse optimal control solutions. There is also an extensive literature on risk-sensitive foraging behaviors in a wide variety of species (Kacelnik and Bateson, 1996; Bateson, 2002; Niv et al., 2002).
7. Discussion and future work
In many real-world control problems, it can be advantageous to adjust risk-sensitivity based on runtime context. For example, systems whose environments change in ways that make failures more or less costly (such as operating around catastrophic obstacles or in a safety harness) or when the context demands that the system seek low-probability high-performance events. Perhaps not surprisingly, this variable risk property has been observed in a variety of animal species, from simple motor tasks in humans to foraging birds and bees (Bateson, 2002; Braun et al., 2011).
However, most methods for learning policies by interaction focus on the risk-neutral minimization of expected cost. Extending Bayesian optimization methods to capture policy-dependent cost variance creates the opportunity to select policies with different risk-sensitivity. Furthermore, the ability to efficiently vary risk-sensitivity offers an advantage over existing model-free risk-sensitive control techniques that require separate optimizations and additional policy executions to produce policies with different risk.
The variable risk property was illustrated in experiments applying VBO to the problem of impact stabilization. After a short period of learning, an empirical comparison of policies selected with different CB criteria confirmed the algorithmic predictions about the relative riskiness of each policy. However, how to set the system’s risk-sensitivity for a particular task remains an important open problem. In particular, we saw that when variance is very large for some policies, risk-seeking optimizations must be done carefully to avoid selecting policies with high variance and poor average performance. Other risk-sensitive policy selection criteria may be less susceptible to such phenomena.
Several properties of VBO should be considered when determining its suitability for a particular problem. First, although the computational complexity is the same as Bayesian optimization,
Another important consideration is the choice of kernel functions in the GP priors. In this work, we used the anisotropic squared exponential kernel to encode our prior assumptions regarding the smoothness and regularity of the underlying cost function. However, for many problems the underlying cost function is not smooth or regular; it contains flat regions and sharp discontinuities that can be difficult to represent. An interesting direction for future work is the use kernel functions with local support. Kernels that are not invariant to shifts in policy space will be necessary to capture cost surfaces that, e.g., contain both flat regions and regions with large changes in cost. Methods for capturing multimodality of the cost distribution are also important to consider, especially in domains where unobservable differences in initial conditions can lead to qualitatively different outcomes.
One straightforward way to extend VBO would be to consider different policy selection criteria. In particular, multi-step methods that select a sequence of n policy parameters could be valuable in systems with fixed experimental budgets. Osborne et al. have proposed a multi-step criterion in the standard Bayesian optimization setting that has produced promising results (Osborne et al., 2009; Garnett et al., 2010). Other risk-sensitive global optimization algorithms could also be conceived by using other methods to build the heteroscedastic cost model (Tibshirani and Hastie, 1987; Snelson and Ghahramani, 2006; Kersting et al., 2010; Wilson and Ghahramani, 2011). It would be worthwhile to investigate whether these methods are more appropriate for particular problem domains.
The VBO and RSSGD algorithms are connected by their use of a learned heteroscedastic cost model to perform policy search. VBO uses this model to globally select policies, whereas RSSGD uses it as a local critic to descend the gradient of a risk-sensitive objective. Both algorithms have the advantage of being independent of the dynamics, dimensionality, and cost function structure, and the disadvantage of their performance being dependent on the dimensionality of the policy parameter space. We considered the possibility of interweaving gradient descent with local offline policy selection in dynamic lifting experiments with the uBot-5. First, a policy was learned that exploited the system dynamics to produce an efficient and reliable lifting strategy. Then, starting from this learned policy, new local cost models were fit and used to select translation-averse and energy-averse policies. It is noteworthy that this kind of flexibility is possible after so few trials, especially given the generality of the optimization procedure. However, a limitation of the implementation described is that generalization to different objects or lifting scenarios would require separate optimizations. The extent to which more sophisticated closed-loop or model-based policy representations could support generalization is an interesting open question.
The use of the cost model in the RSSGD algorithm is somewhat restricted and there are several possibilities for improvements. For example, some work has shown that adjusting the covariance of the perturbation distribution while learning can produce better performance (Roberts and Tedrake, 2009). This idea is related to the covariance matrix adaptation that is done in some cost weighted averaging methods (Stulp and Sigaud, 2012). An interesting direction for future work would be to use the learned local model to adjust the sampling distribution by, e.g., scaling the perturbation covariance by the optimized length-scale hyperparameters of the VHGP model. In this way, parameters would be perturbed based on the inferred relative sensitivity of the cost to changes in each parameter value. Methods for using gradient estimates from the local critic to update the policy parameters or, conversely, using gradient observations to update the critic could also be explored.
8. Conclusion
Varying risk-sensitivity based on the runtime context is a potentially powerful way to generate flexible control in robot systems. We considered this problem in the context of model-free policy search, where risk-sensitive parameterized policies can be selected based on a learned cost distribution. Our experimental results suggest that VBO and RSSGD are efficient and plausible methods for achieving variable risk control.
Footnotes
Notes
Funding
Scott Kuindersma was supported by a NASA GSRP Fellowship from Johnson Space Center. Roderic Grupen was supported by the ONR (MURI award N00014-07-1-0749). Andrew Barto was supported by the AFOSR (grant number FA9550-08-1-0418).