
Abstract
We are interested in the problem of how to improve estimation in multi-robot information gathering systems by actively controlling the rate of communication between robots. Communication is essential in such systems for decentralized data fusion and decision-making, but wireless networks impose capacity constraints that are frequently overlooked. In order to make efficient use of available capacity, it is necessary to consider a fundamental trade-off between communication cost, computation cost and information value. We introduce a new problem, dynamic information flow, that formalizes this trade-off in terms of decentralized constrained optimization. We propose algorithms that dynamically adjust the data rate of each communication link to maximize an information gain metric subject to constraints on communication and computation resources. The metric is balanced against the communication resources required to transmit data and the computation cost of processing sensor data to form observations. The optimization process selectively routes raw sensor data or processed observation data to zero, one or many robots. Our algorithms therefore allow large systems with many different types of sensors and computational resources to maximize information gain performance while satisfying realistic communication constraints. We also present experimental results with multiple ground robots and multiple sensor types that demonstrate the benefit of dynamic information flow in comparison to simpler bandwidth-limiting methods.
1. Introduction
Decentralized information gathering is an important task where outdoor robots coordinate to build maps, search for targets, track targets and classify objects. Coordination in outdoor systems relies on wireless communication between robots, but existing communication networks are subject to physical limits that are often idealized, over-simplified or ignored (Ghaffarkhah and Mostofi, 2011). We are interested in developing principled algorithms for decentralized information gathering that are designed to respect these limits and to use available communication resources efficiently.
The decentralized information gathering task is where a team of robots actively cooperates to maximize information about a given phenomenon. This task forms the basis of many applications such as cooperative search (Bourgault et al., 2004; Gan and Sukkarieh, 2011; Hollinger and Singh, 2012), target tracking (Chung et al., 2006; Hollinger et al., 2009; Xu et al., 2013b) and environmental monitoring (Golovin et al., 2010; Smith et al., 2011; Delle Fave et al., 2012). Robot teams are useful for information gathering because they can exploit diverse sensing and motion capabilities, access multiple simultaneous viewpoints and cover large areas more rapidly than single-robot systems. Communication is fundamental to the task because robots must share data for estimation and coordinated decision-making.
Communication is not an infinite resource. However, research in multi-robot systems often makes two invalid assumptions that fail to respect the physical limits of real communication networks. The first such assumption is that simultaneous communication between multiple pairs of robots is independent. In most existing wireless networks, bandwidth resources are shared globally and link capacity decreases rapidly as the number of robots increases (Gupta and Kumar, 2000). The second invalid assumption, sometimes called the r-disc model, is that constant bandwidth is available within a given radius about a robot and that zero bandwidth is available otherwise. Real communication links are far more variable (Malmirchegini and Mostofi, 2012). The implications of failing to consider communication limitations are significant and hence communication in realistic environments is currently the topic of considerable research interest (Sadler et al., 2013).
One possible approach to address the issue of communication limits is to simply increase total network bandwidth by using more powerful and sophisticated radio hardware. However, it is always possible to generate a problem instance that exceeds any given resource limit. Sensors such as 3D laser range-finders generate data at a high rate, typically 1.7 million points per second. High-resolution cameras can produce data at even higher rates. Controlling the communication of such data is essential to real-world application of decentralized information gathering systems.
We believe that a better approach is to develop algorithms that make efficient use of the communication resources at hand. We refer to this approach as communication-aware information gathering. The idea is to choose when and how a given pair of robots should communicate based on the information value of the communication and given resource limits. This idea can be viewed as roughly analogous to network flow, where flow represents the data communicated within the system.
The main challenge is that information may be represented at multiple levels of abstraction ranging from raw sensor data to highly compressed forms such as target state observations. Therefore, we must choose not only how to route data but also in what form. This decision must consider computation costs, since data may be processed at various possible locations within a system with varying resource capacity. A given robot may process its sensor data on-board, transmit this data to a powerful off-board processing station or rely on the computation resource of another robot. Manual design of a communication policy in this context is difficult and can result in poor communication efficiency. For example, down-sampling the rate of sensor data transmission may obey bandwidth constraints but can lead to unnecessary degradation in the performance of state estimation algorithms. The design task increases in difficulty for large heterogeneous systems, and any fixed policy would require redesign after any change to the underlying hardware or task. Therefore, the information flow must be adjusted dynamically and autonomously.
In this paper, we formalize the notion of communication-aware information gathering by introducing a novel problem formulation which we call the dynamic information flow (DIF) problem. Given a graph-based representation of a decentralized information gathering system, the objective is to maximize the information value of communication by minimizing a cost-based metric subject to constraints. The graph representation models an information gathering team as a system where data flows along a typical pipeline comprising sensors, perception algorithms, estimation algorithms and control algorithms. These logical elements are connected by communication links with associated costs, and a system may contain many such elements. For example, a single laser sensor may be connected to many other elements implemented on multiple robot platforms.
The DIF problem structure is designed to model trade-offs between information value, communication cost and computation cost at the system level. The information value of sensor observations is not defined globally but instead is defined relative to the belief state of each estimator element. Link costs are abstract costs that model both communication and computation. For example, a given sensor observation may be of high value to an estimator, but obtaining this information may incur a high cost due to the computational demands of a perception algorithm or due to large communication bandwidth requirements. Formulating the problem in this way provides a mechanism to balance these diverse costs against information value in a principled manner.
We define the problem as a family of optimization problems with two concrete variants, min-cost-DIF and threshold-DIF. A solution to the problem is in the form of a set of multicast flow rates that determine which pairs of robots communicate at any given time. In min-cost-DIF, the objective is to minimize the sum of link costs, assuming the relative scale of these costs is known. In threshold-DIF, the relative scale of costs is not assumed to be known and the objective is to find a solution that satisfies a given cost threshold.
The DIF problem formulation provides several significant benefits. Because link costs are abstract and dynamic, the problem admits any realistic communication link model and is not limited to the r-disc assumption. The threshold-DIF variant can model the global bandwidth constraint imposed by common shared-channel communication systems. Modeling system elements logically as a graph where flow rates are dynamically optimized avoids the need to manually pre-determine the information architecture of the system. This property is particularly useful for heterogeneous systems with many types of robots that have a range of sensing and computational resources. Although previous work has explored the problem of controlling communication between estimation and control elements (Semsar-Kazerooni and Khorasani, 2009; Kassir et al., 2012), this paper represents the first comprehensive effort to address communication between sensing and estimation.
We present algorithms and analysis for both problem variants. Our solution to min-cost-DIF is based on an adaptation of multicast routing. We prove that min-cost-DIF can be transformed such that existing multicast routing algorithms may be applied, and we present one such algorithm. Our solution to threshold-DIF is based on an optimization method known as the alternating direction method of multipliers (ADMM) (Boyd et al., 2011). We derive a decentralized version of this algorithm which we call distributed ADMM (DADMM) and show how it can be applied to solve threshold-DIF. We analyze convergence and running time for all algorithms and validate these results through simulations including up to 28 nodes.
We also present experimental results that illustrate the behavior of our algorithms and compare information gain performance with simple bandwidth-limiting methods. The task we consider is to track a moving target using multiple types of sensors. For the case of min-cost-DIF, the experimental system consists of one mobile robot equipped with a camera and one auxiliary static ground station. We also present simulation results for two mobile ground robots. For threshold-DIF, the experimental system consists of two outdoor mobile robots, with and without an auxiliary static camera. One robot is equipped with a 2D laser sensor and the other is equipped with a 3D laser. To further evaluate the performance of our algorithms, we present results from Monte Carlo simulations that demonstrate statistical significance.
Our results show that the DIF algorithms efficiently use available communication bandwidth to increase information gain. We observe that sensor data is either processed on-board or transmitted and processed at the ground station appropriately. We also observe that information from multiple sensor sources is communicated selectively based on sensor utility, available bandwidth and route overlap.
The paper is organized as follows. Section 2 discusses related work in the general area of communication limits in decentralized information gathering systems. The DIF problem and its two variants are defined in Section 3. We present algorithms, analysis and experimental evaluation for the case of min-cost-DIF in Section 4. We then address threshold-DIF in Sections 5 and 6: Section 5 presents our decentralized form of ADMM and Section 6 presents algorithms, analysis and experimental evaluation based on the results from Section 5. Section 7 discusses the method of estimating sensor observation utility that we use in our implementations and Section 8 concludes the paper.
2. Related work
Existing work has studied aspects of communication-aware information gathering from several different perspectives. One idea is to simply ease resource limits by boosting the capacity of wireless networks. Multi-radio multi-channel networks (Wu et al., 2000; Xing et al., 2007) can significantly increase network capacity by using multiple communication channels in parallel. Our previous work has shown that a single channel may be reused in a neighbor-to-neighbor architecture while avoiding mutual interference (Kuo and Fitch, 2014). Whereas the aim of these approaches is to maximize the throughput available from source to destination, this paper takes a complementary view. Instead of transmitting as much data as possible, we attempt to transmit only the most valuable data possible. Thus, data with little information value does not consume communication resources and available bandwidth is used efficiently.
From the perspective of optimal control, the entire problem (including communication decisions) can be modeled as a decentralized partially observable Markov decision process (Dec-POMDP) (Gmytrasiewicz and Durfee, 2001; Goldman and Zilberstein, 2003; Carlin and Zilberstein, 2008; Williamson et al., 2008). Partially observable Markov decision process (POMDPs) are a powerful and general approach but are computationally intractable for large problems due to the ‘curse of dimensionality’. We are interested in problems with many robots and sensors, and we focus on computationally efficient solutions to the more specialized DIF problem.
Related problems in efficient information sharing have been studied in the context of sensor networks. In Kulik et al. (2002) the SPIN routing protocol is introduced as a routing mechanism for sensor networks. Sensor nodes send an advertising message that contains metadata about the sensor information available and potential recipients send requests as required. However, the semantics of the metadata are not specified and are considered application-dependent. In Gupta et al. (2006), a sensor scheduling strategy for multiple sensors is proposed with bounds on the estimation error covariance. The strategy determines the order of sensor selection. Our work presents a general framework which allows for the dynamic selection of subsets of sensors in addition to dynamically selecting the processing platform for the transmitted sensor data.
In the context of target tracking, Chen et al. (2010) propose an algorithm for sensor networks that uses minimal communication by only transmitting relative changes. In our previous work (Xu et al., 2013a), robots learn to predict the observation utility of other robots and adjust inter-robot communication accordingly. These approaches offer promising results for the application of target tracking but do not address information flow for nodes with heterogeneous capabilities and arbitrary utility functions. Our approach seeks to solve the trade-off between communication, computation and sensing in a general, yet computationally efficient, manner.
Another related problem is communication-aware motion planning, where robots choose paths that are advantageous with respect to properties of the communication network, such as connectivity maintenance (Hsieh et al., 2008; Mostofi, 2009; Stachura and Frew, 2011; Lindhé and Johansson, 2013; Twigg et al., 2013; Yan and Mostofi, 2013). Connectivity is important to networked robots, but the problem we propose in this paper has a distinctly different objective. We build on the work in connectivity maintenance and assume that the network is connected. Our focus is on using this connected network efficiently by choosing when data should be transmitted and by choosing the best multicast routing. Instead of planning a path for a robot through its workspace, communication-aware information gathering involves planning a path for information through a network.
A more closely related problem is distributed linear quadratic control (Speyer et al., 2008; Molin and Hirche, 2009; Semsar-Kazerooni and Khorasani, 2009; Kassir et al., 2012), where each controller in a team makes control decisions based on knowledge of the team state vector. The full state vector may not be relevant to a given controller, and so the problem is to identify which state elements should be communicated. Our work again is distinct in that we focus on controlling the flow of observations as opposed to controller state information. Observations may be in the form of raw sensor data or in a processed task-dependent form such as target track estimates. We consider how to best route these observations through the network by balancing the computational effort required to process observations with the cost of communication and the value of this information in its various forms at any given time.
A classic problem in network flow optimization is the minimum cost flow problem (Ahuja et al., 1993). The minimum cost flow problem has known efficient decentralized solutions; however, the DIF problem is more closely related to the multicast network routing problem. This problem is equivalent to the Steiner tree problem on directed graphs which is NP-complete (Ramanathan, 1996). In a special case using network coding, multicast routing can be solved in polynomial time and in a decentralized manner (Cui et al., 2007; Xi and Yeh, 2010). Our algorithms exploit this special case. However, in our implementations we use an approximation that approaches the performance provided by network coding in relatively small networks.
3. Problem formulation
In this section, we define the dynamic information flow problem. We introduce the general problem formulation and then define two important variants; one assumes a priori knowledge of link costs and the other bounds the sum of all link costs by a given global maximum.
3.1. Dynamic information flow
Our goal is to maximize information gain by controlling the flow of information within a decentralized information gathering system subject to communication and processing constraints. Data is continuously produced by sensors and consumed by other elements of the system. We first define a graph structure that models these system elements and the data flow between elements. Given such a model, we then define the dynamic information flow problem in general form.
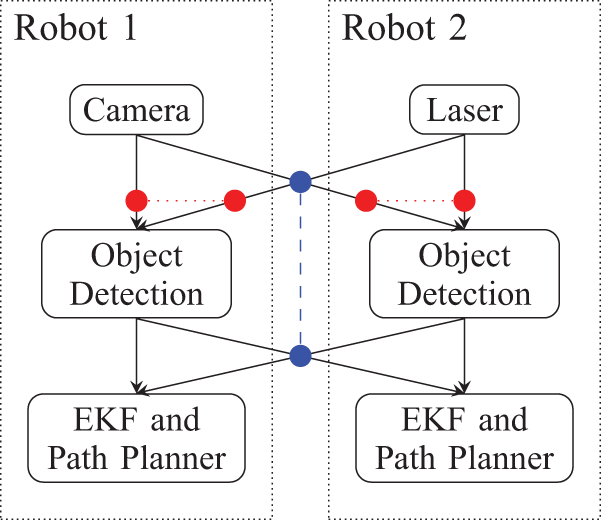
A decentralized information gathering system is a configuration of several elemental components. Sensors are elements that generate sensor data measured by physical sensing devices, such as laser scanners and cameras. Data from such sensors are transformed into observations by applying algorithms such as object detection and classification. Processors are computational elements that perform these processing tasks. Processors may be cascaded if necessary. The observations generated by processors act as input into estimator elements that maintain belief states. For example, an estimator could be an extended Kalman filter (EKF) in the tracking case or an occupancy grid in the mapping case.
Data flows via a communication system from sensors to processors, from processors to other processors and from processors to estimators. The topology of the resulting network is a directed acyclic graph, where information value, communication limits and computation limits induce costs or capacity constraints on the links in the graph. The induced link costs may vary according to the properties of the underlying communication mechanism, which may not be the same for all links. Elements of the system generally are physically distributed among multiple robots or ground stations and therefore communicate using an inter-robot communication system such as a wireless network. It is also possible for multiple elements to reside within a single physical platform and communicate using an intra-robot communication system such as a wired network or in-memory communication.
These system elements can also be viewed in terms of the well-known network flow problem (Ahuja et al., 1993) as follows. The commodity that flows through the network in this case is information in the form of sensor data or processed observations. Sensors correspond to supply nodes, estimators correspond to demand nodes, and processors correspond to intermediate, or transshipment, nodes. Communication links between nodes correspond to arcs or links between nodes of the network.
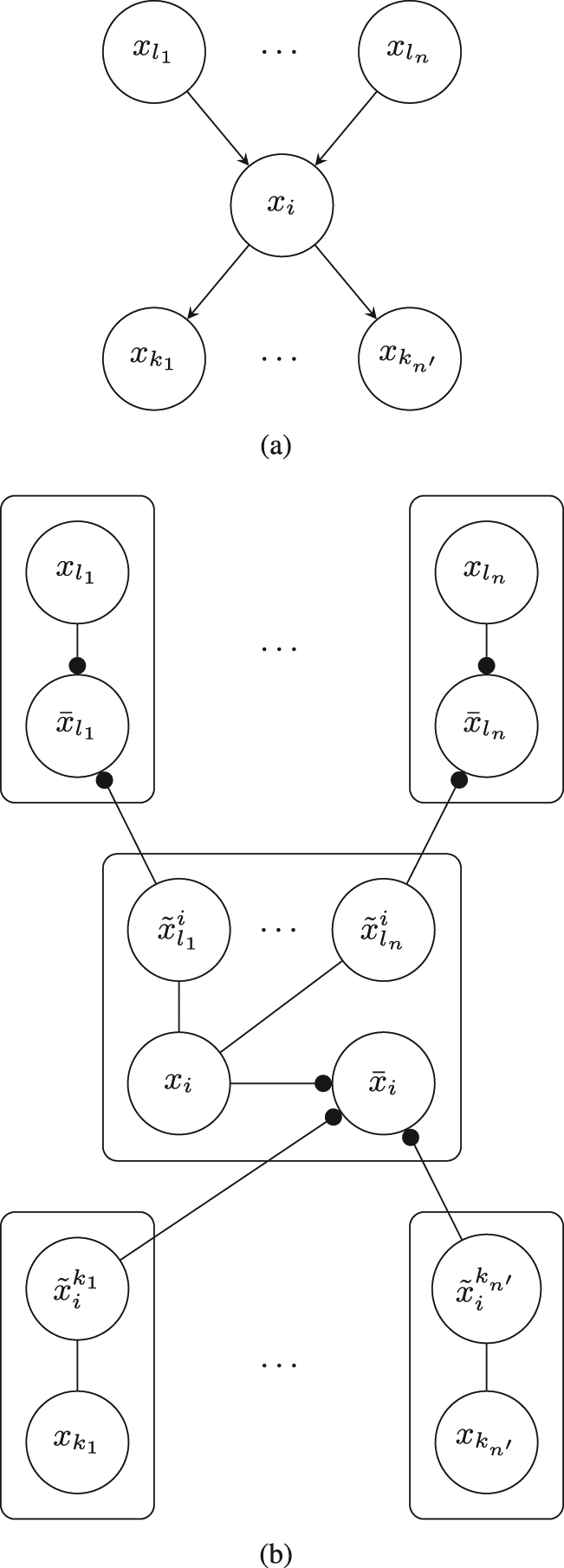
An example diagram of a decentralized information gathering system is shown in Figure 1(a) with the corresponding system topology represented by the directed acyclic graph shown in Figure 1(b). These diagrams could correspond, for example, to the case of two robots tracking a target using different types of sensors and with access to an off-board processing station. For target detection, each robot either processes its raw sensor data on-board or transmits the data to be processed off-board. Moreover, the robots can choose to either share raw sensor data or processed point observations instead.
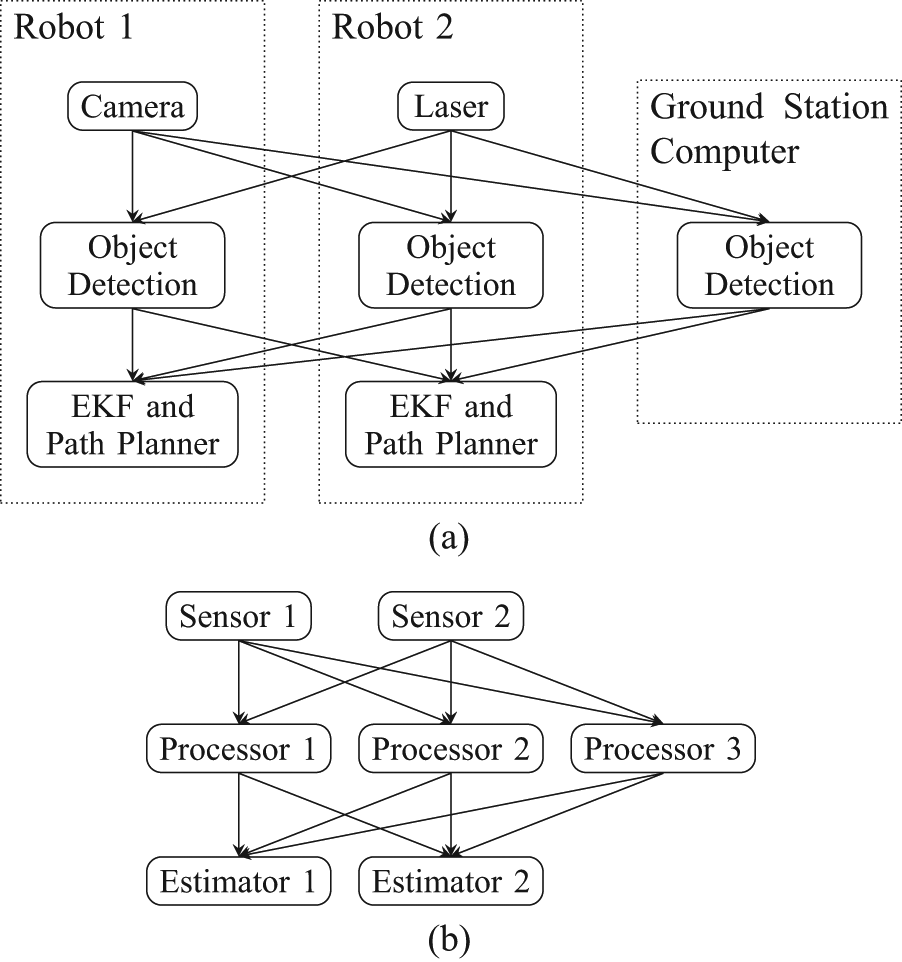
(a) An example of a decentralized information gathering system with two robots and one off-board processor. (b) The corresponding network topology in our dynamic information flow formulation.
Formally, a decentralized information gathering team is represented by a directed acyclic graph (DAG) G = {V, E} where V is the set of vertices (or equivalently, nodes) and E is the set of edges or links. In the graph G, for every i, k ∈ V, if (i, k) ∈ E then we say that k is a child node of i and i is a parent node of k. The set
The set of nodes is partitioned into three mutually exclusive subsets: the set of sensors Vs which act as sources, the set of processor nodes Vp which act as intermediate nodes and the set of estimator nodes Ve which act as destination nodes. Links connect nodes in Vs to nodes in Vp , nodes within Vp and nodes in Vp to nodes in Ve .
Sensor data is multicast from each sensor node m ∈ Vs
to all connected estimator nodes j ∈ Ve
. Sensor m produces data at a fixed rate and this data is consumed by connected estimators at the same rate. To represent this production/consumption rate we introduce the variable
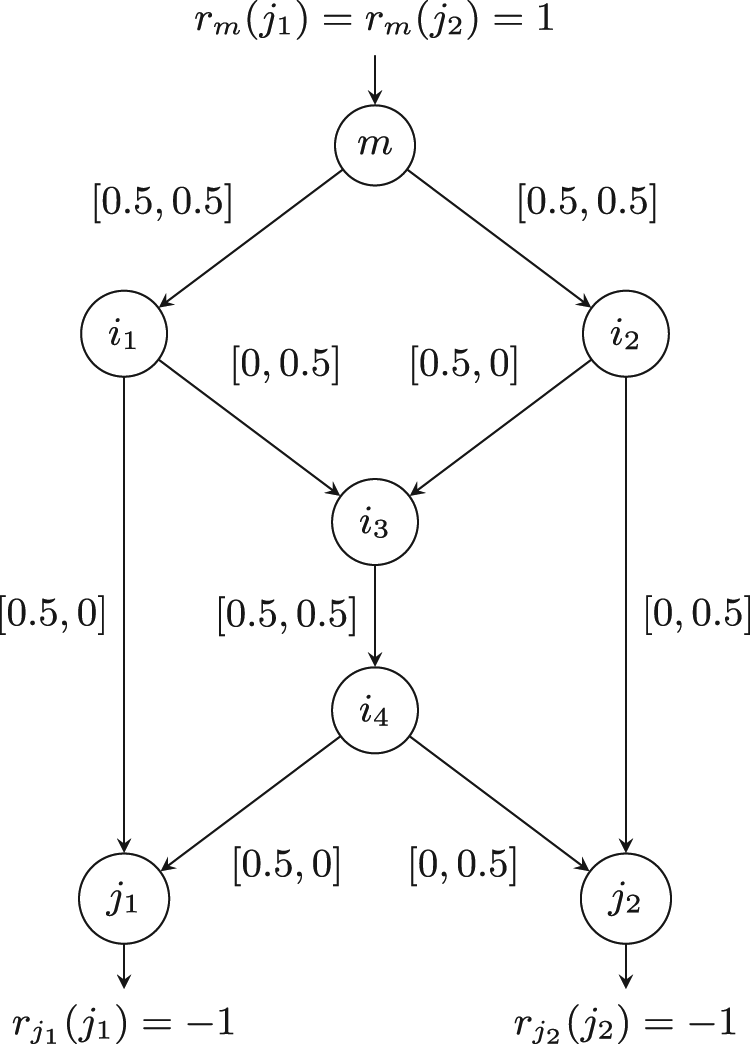
An example routing configuration for the butterfly network. Numbers within brackets are the flow values for each link. The first value corresponds to destination j 1 and the second corresponds to destination j 2.
A set of flow variables
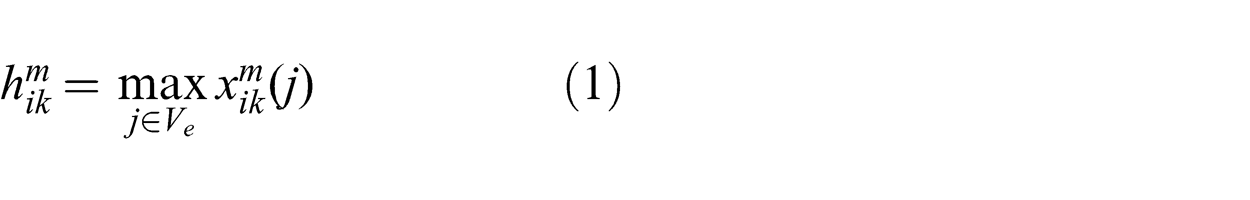
Communication load, computation load and sensor observation utility induce a net link cost of
Sensor observations induce a reward when reaching an estimator. In order to represent this reward, the information value of sensor m to estimator j is subtracted from the cost of each link incident to j.
Because a sensor observation may have little value for a given estimator, the system requires a mechanism by which a sensor can decide not to send any data to a certain destination. We model this option by adding a virtual, zero-cost link directly from each sensor to all connected estimators.
We now define the general dynamic information flow problem as follows. Given link costs
3.2. Min-cost-DIF
We define the first concrete form of the general problem, min-cost-DIF, according to the constrained optimization (2)–(5). Information value, communication and computation resource demand are represented using link costs. This formulation is appropriate for situations where the relative costs between the items are known a priori:

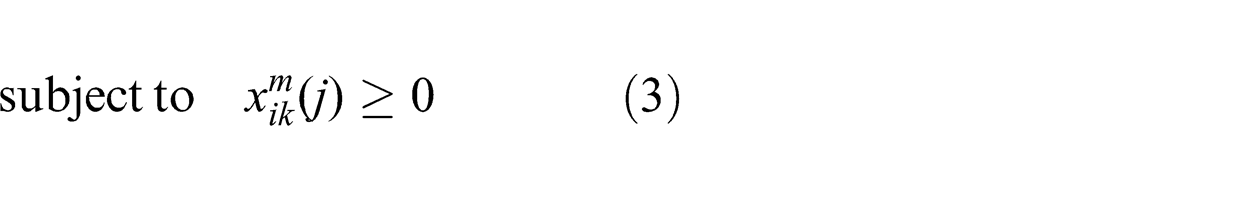

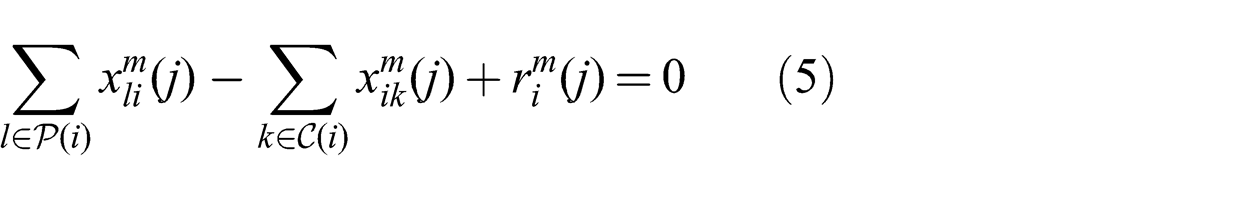
The first constraint (3) ensures that flow is always positive. The second constraint (4) represents the multicast condition and the third constraint (5) ensures that the sum of all inward and outward flow at a node is zero.
In min-cost-DIF, link costs may change over time due to changes in communication and processing costs as well as changes in sensor utility. For example, robots may move closer to or further away from each other, resulting in a change in communication costs. Sensor viewpoint may also change, leading to a change in the value of on-board sensor observations.
3.3. Threshold-DIF
We introduce a second problem variant, threshold-DIF, to represent the case where the correct scale between communication costs, computation costs and information value is not known a priori. In this case, communication bandwidth and processing power are viewed as limited resources. The goal of threshold-DIF is thus to maximize information gain subject to communication bandwidth and processing power constraints.
We augment (2) to (5) to include two additional constraints (6) and (7) and define three additional input parameters,


To motivate constraint (7), consider the decentralized information gathering network diagram in Figure 3 which is a subset of the diagram in Figure 1. If the two robots in this example exclusively use wireless communications to share observations, then all four links that cross the robot boundaries share a common resource (the wireless communication medium). This constraint is indicated in the figure by the dashed link. Moreover, if each robot only uses one computer for all processing requirements then the links from both sensors to each of the object detection modules share another common resource, the on-board processing computer. These constraints are indicated in the figure by dotted links. This class of constraints, which we call inter-link constraints, is represented in (7), where Ks
is a fixed upper bound on resource s and
An example of a system with inter-link constraints. Links tagged with the dashed line share a wireless communication medium, while those tagged with a dotted line share a common processing resource.
For convenience, the main terms used in the DIF problem formulation are listed in Table 1. We note that i, k, m and j all correspond to nodes in the network graph. We use m to denote a source node, j to denote a destination node, i to denote the incumbent node and k to denote the incident node of an edge.
List of symbols.

3.4. Sensor utility
Sensor utility in the DIF formulation is a measure of the relative importance of sensor data with respect to a specific estimator. The importance of sensor data is evaluated based on the improvement it induces in the estimate. Hence, sensor utility depends both on the sensor and on the current state of the estimator. Sensor utility can be computed exactly using the Partially observable Markov decision process (POMDP) formulation of the information gathering problem; however, this is intractable since Dec-POMDPs are nondeterministic exponential time-complete (Bernstein et al., 2002). In Section 4.3, we present a myopic approximation to sensor utility that was used in our experiments. A further discussion of the issue of sensor utility approximation is provided in Section 7.
4. Min-cost-DIF
In this section, we present a message-passing algorithm that solves the min-cost-DIF problem. We introduce a mapping that transforms an instance of min-cost-DIF into an instance of multicast network routing, prove equivalence and show that an algorithm that was originally developed for multicast network routing also finds an optimal solution to min-cost-DIF. We then describe our implementation of this algorithm in the context of min-cost-DIF along with empirical analysis in simulation that evaluates scalability. We also provide experimental demonstrations both in simulation and using a system of one mobile robot and one fixed ground station. Finally, we present results from a Monte Carlo simulation that statistically validates the performance advantage of our method.
4.1. Min-cost-DIF using multicast network routing
An instance of min-cost-DIF can be transformed into an instance of multicast network routing (Cui et al., 2007; Xi and Yeh, 2010) as follows. The flow variable xik (j) is replaced with ti (j)ϕik (j), where ti (j) is the total flow passing through i and destined to j while ϕik (j) is the routing variable for link (i, k); more specifically, it is the fraction of ti (j) that is routed to k.
Following this change of variables, the resulting formulation is given by the optimization problem (8)–(12). Constraint (10) states that the sum of the routing variables for each node is equal to one, while (11) and (12) are equivalent to (4) and (5):


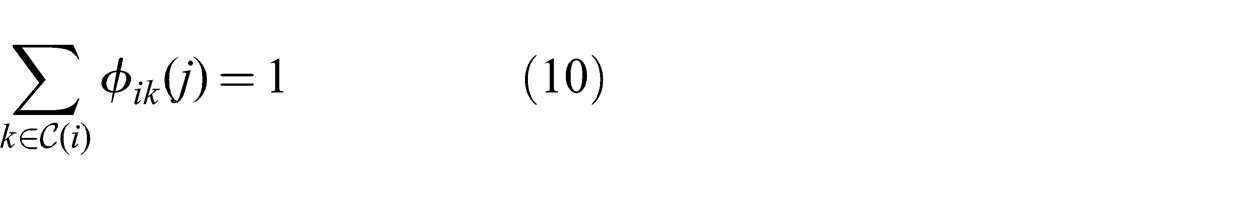
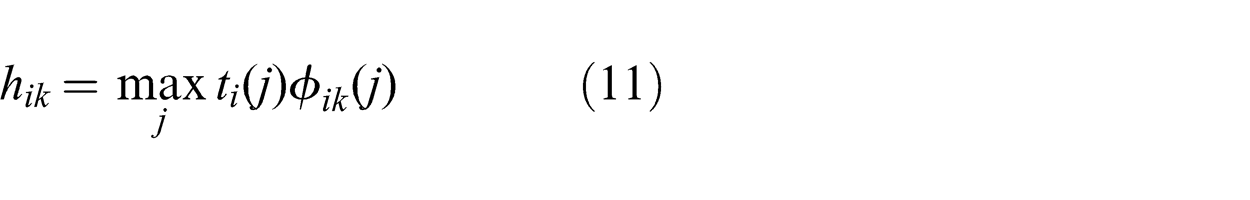
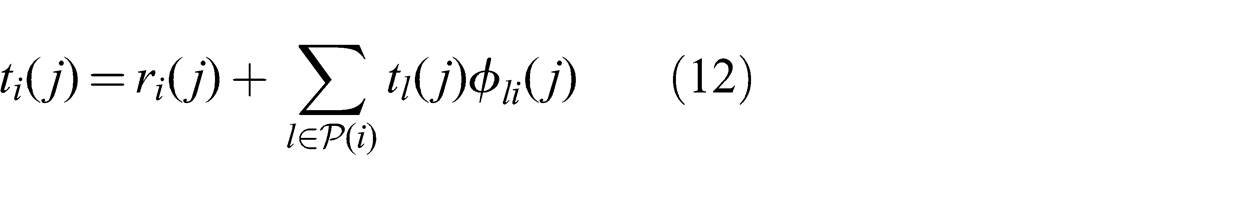
Given this mapping, existing algorithms for multicast network routing can be applied. Here we summarize one such algorithm, originally presented in Cui et al. (2007). The algorithm is based on message passing and relies on obtaining the marginal cost δik (j) for each link. The marginal cost is the rate at which the total cost increases due to a unit increase in flow along that link and is given by (13):

Min-cost-DIF can be solved for each source m independently and in parallel. The full problem can be decomposed into independent sub-problems, one for each source, since the objective is additive and there are no inter-source constraints. This is evident from the problem formulation (2)–(5). Therefore, for simplicity of notation the subscript m is dropped from all variables in this section.
At the start of the algorithm, the routing variables {ϕik
(j)} are initialized arbitrarily such that they obey constraints (9) and (10). The routing variables are then repeatedly updated such that after iteration t the routing variables are set as
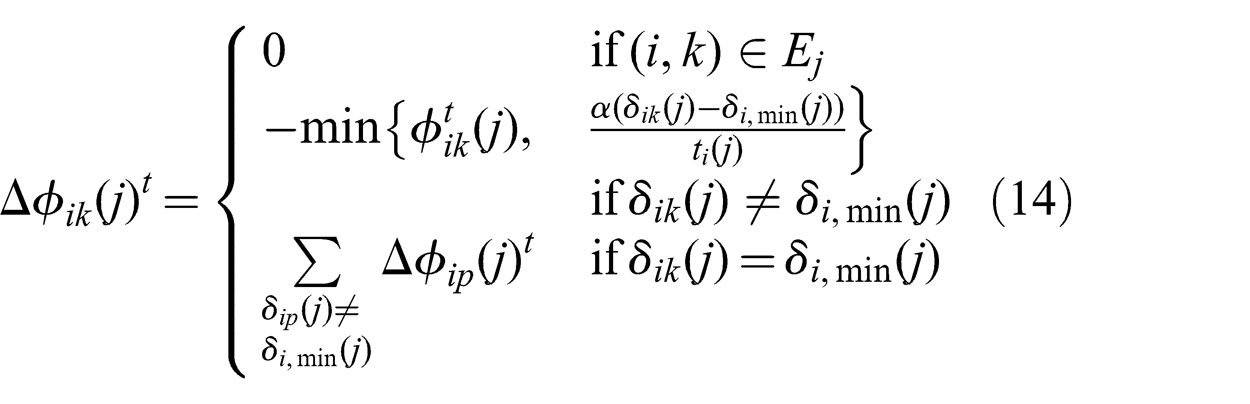
The algorithm runs synchronously. First, the head nodes send messages with their flow contributions to their children. Once a node receives messages from all of its parents, it passes the message to its own children and so forth. The purpose of this downward sweep is to allow nodes to compute the flow of the current routing configuration. The flow values are necessary to compute the marginal costs required in the upward sweep. The downward sweep is followed by an upward sweep during which the marginal costs are computed according to (13) and the routing variables are updated according to (14). The downward and upward sweeps are decentralized, synchronous and are guaranteed to visit every node. Their sequence is dictated by Algorithm 1. The synchronicity property of Algorithm 1 is proved in Lemma 1.

Due to possible changes in link costs, this message passing optimization runs continuously throughout system operation. As the system configuration changes, link costs are updated with new values. To ensure convergence, the interval between updates is set to an adequate time period. Further details on the appropriate length of the interval between updates can be found in Section 4.3.
Node i and all of its successors would have performed exactly t − 1 upward updates;
All of its ancestors would have performed exactly t downward updates.
Proof. Suppose one of node i’s successors has performed t′ > t − 1 upward updates. This means that at least one tail node in the successors has performed t′ downward updates. This is impossible because node i has only yet forwarded t − 1 downward messages. Since node i has performed t updates then its ancestors have performed at least t updates. Now, suppose one of node i’s ancestors has performed t″ updates where t″ > t. Then, the head nodes in the ancestry have performed at least t″ updates. This in turn means that they have performed t″ − 1 upward updates which means the tail nodes have performed t″ − 1 > t − 1 updates, which is impossible as just shown. This means that node i has forwarded at least t′ − 1 ≥ t downward updates, which leads to a contradiction.□
Due to observation rewards, negative costs may be assigned to links incident to an estimator j ∈ Ve
. These negative costs are handled within the framework of the multicast network routing algorithm by solving an equivalent problem. A large enough constant
The equivalence of solving the optimization problem (8)–(12) to solving the problem with cost variable c′ ik instead of cik is proved in Theorem 1:
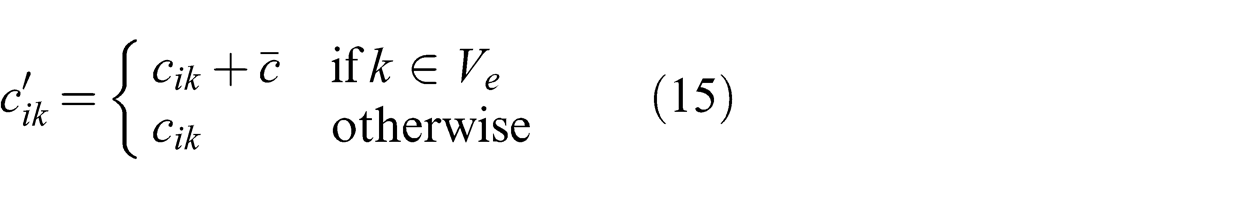
Proof. For every link (i, j) such that j ∈ Ve , constraint (11) turns into the equality relation (16) instead since the only flow that should run along that link is the flow destined to estimator j:
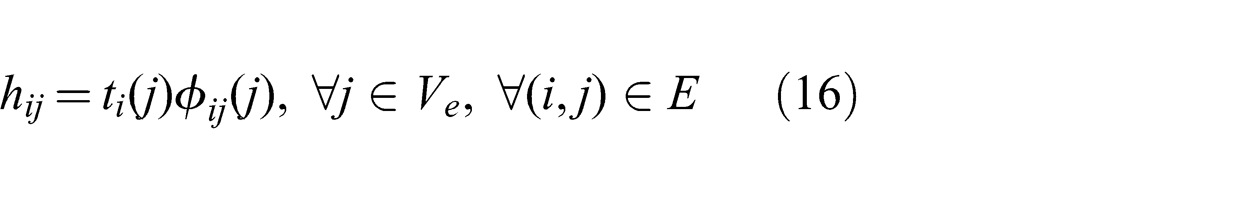
After adding
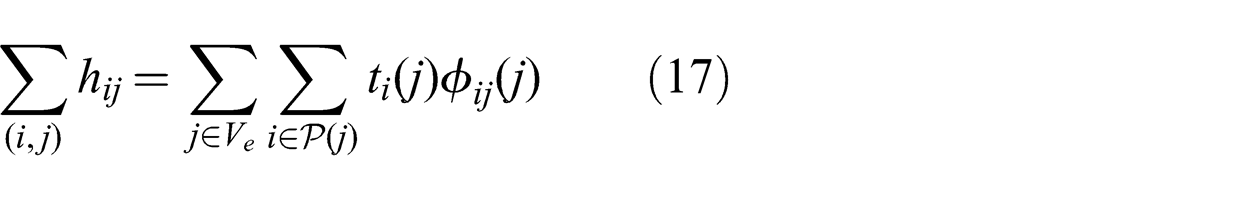
The right-hand side of the equation is equal to the total flow arriving at a destination node summed over all destinations. By definition, this flow is equal to the source flow multiplied by the number of destinations and hence is constant.
4.2. Analysis
Subject to the choice of step size parameter α, the multicast routing algorithm is guaranteed to converge to the global optimum (Cui et al., 2007). Since a DAG contains no loops by definition, no contingencies are required to avoid routing loops. By Theorem 1, a min-cost-DIF instance with negative costs on links to an estimator can still be solved using the multicast routing algorithm by adding a sufficiently large positive constant to all such links.
The running time of multicast network routing with network coding is not explicitly provided in Xi and Yeh (2010) and Cui et al. (2007) but is implied to be polynomial in the size of the network. In practice, we have observed a polynomial rate of increase as a function of network size, as shown in Section 4.3 below.
4.3. Implementation and scalability
Implementing multicast routing for min-cost-DIF involves three main challenges. First, we need to allow all nodes to find the available sources and destinations in a decentralized manner. Second, we need to ensure that the nodes have a suitable mechanism to compute any changing input parameters. Finally, we must choose a suitable multicast policy to implement the chosen flow rates {xik (j)}.
Each node must find the set of sources and destinations to which it is connected in the network. Initially, each node is aware of its direct neighbors only. By performing only one downward sweep and one upward sweep of message passing described in Algorithm 1, each node can obtain the list of sources and destinations to which it is connected. In our implementation, the downward messages contain the set of source identities received so far and the upward messages contain the set of destination identities received so far.
Link costs are continuously computed due to changes in the team configuration throughout the progress of its mission. In our implementation, communication costs are simply set proportional to inter-robot distance. Processing costs are assumed to be constant throughout the system operation. Sensor utility, on the other hand, can be more difficult to compute since each estimator must receive observations from a sensor in order to evaluate this utility. We maintain sensor utility values dynamically though an exploration–exploitation model. Each node obeys the chosen flow rate xik (j) with probability (1−ε) (exploitation) and switches to another randomly selected flow rate with probability ε (exploration). The value of ε is set to a small positive number less than one. More sophisticated alternatives using machine learning methods are possible, such as in Xu et al. (2013a). Section 7 provides further discussion on this issue.
The chosen flow rates {xik (j)} are implemented using a multicast policy that determines how the inward flow of messages at a node is distributed amongst its children. In our problem formulation, we assume that network coding is used. For small-sized networks, network coding can introduce unnecessary complication with little performance advantage in practice (Keshavarz-Haddadt and Riedi, 2008). As an alternative, multicast routing can be implemented without network coding by using randomization. The probability of sending a given inward message along a given outward edge is set proportional to flow variable xik (j). In this case, the average total flow hik through the link for a source flow rate of r is given by (18) instead of the network coding relation given in (1):
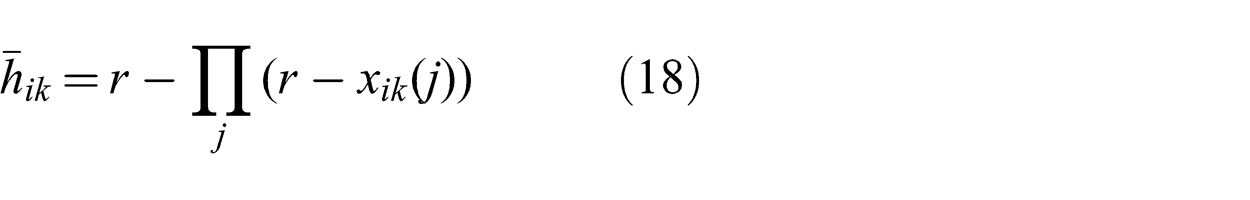
For a given set of flow variables, randomization will result in higher total flow through a link. The extra capacity required in comparison to network coding is given by the relation in (19). From the relation, we deduce that the gap is zero if the maximum flow variable over a link is equal to either zero or the source flow and that the gap is less significant when there are fewer destinations. Therefore, for ease of implementation we use randomization to implement the multicast policy. However, the total flow is still approximated by (1) since (18) otherwise leads to a non-convex problem. We found this approximation to be valid in practice:
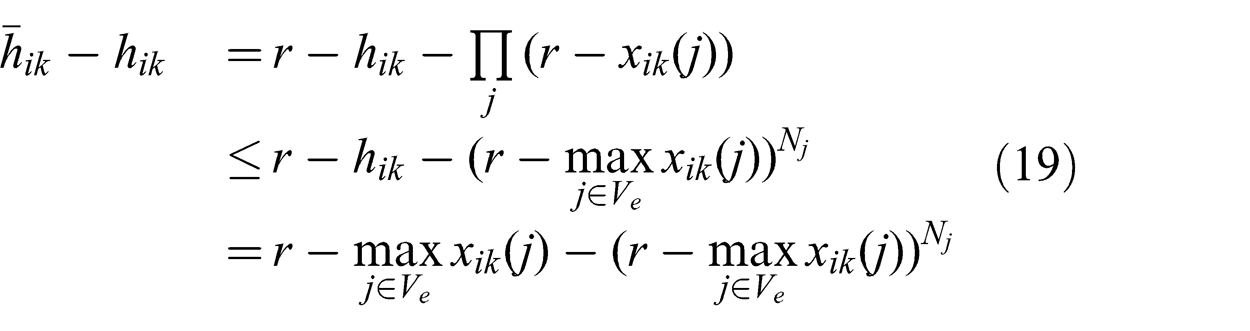
To demonstrate the scalability of the algorithm, we performed an empirical study of the convergence time for a given set of link costs. This study, which gives a convergence time estimate, also gives further insight into the time required between link cost updates.
We evaluated the convergence time in min-cost-DIF through a simulated network using randomized but fixed link costs. Our simulated network includes one sensor and a variable number of processors and estimators where the number of processors is always one more than the number of estimators. Results of the simulation for an increasing number of nodes are shown in Figure 4. The convergence condition is satisfied when the change in the solution variables is below a certain threshold.
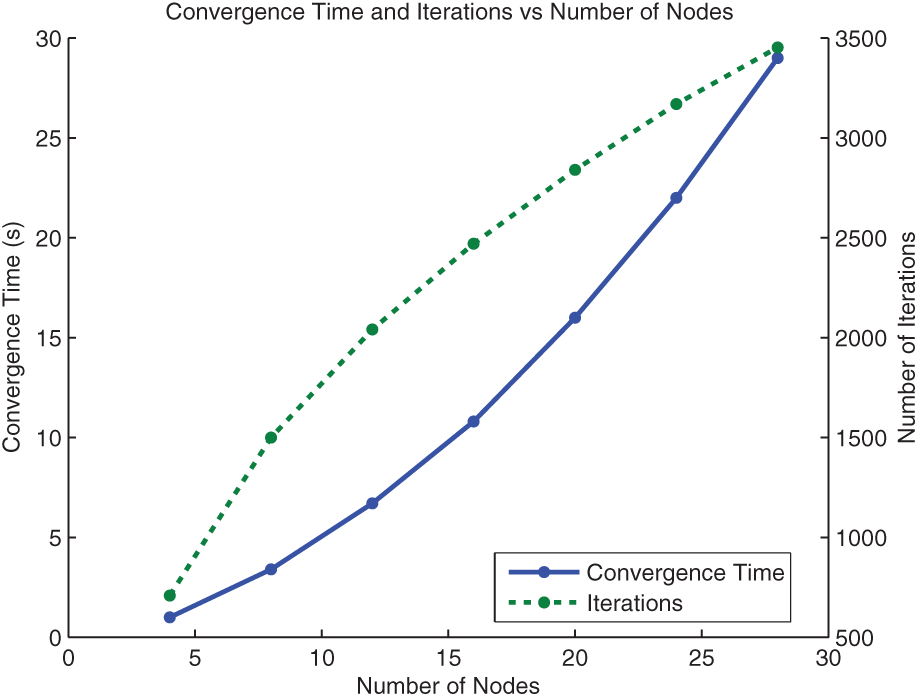
Convergence time and convergence iterations of the message passing optimization as a function of the number of nodes in a simulated network. The simulated network includes one sensor and an increasing number of processors and estimators where the number of processors is always one more than the number of estimators.
Convergence time depends both on the number of iterations required until convergence and the time expended in each iteration. The number of iterations to convergence is hardware-independent and the results shown in Figure 4 indicate that the number of iterations to convergence is a sub-linear function of the network size. The time required for each iteration involves computing routing updates and transmitting the updated values. The time complexity of the routing updates in (13) and (14) is polynomial in the size of the network. Transmission time, on the other hand, is typically linear in the size of the transmitted message which in turn is proportional to the size of the network.
The convergence times shown do not account for communication delay. To estimate such delay in practice, we observed from the experiments shown later in the paper (Sections 6.3 and 6.4) that the time for one iteration over wireless networks is typically less than 100 ms. This value corresponds to networks concurrently being utilized for transmission of sensor data and processed observations. Based on this estimate and the number of iterations at convergence, we can estimate typical values for convergence time for networks from five to ten nodes to be between 50 and 150 s.
This empirical analysis indicates that the running time of our algorithm is polynomial in the size of the network for typical problem instances of interest. We observed that the number of iterations required until convergence is sub-linear in the number of nodes, and the time complexity of each iteration is polynomial in the number of nodes. In practice, we found iteration times to be dominated by communication delay resulting in the convergence time indicated above. We envisage that this period can be reduced by employing various quality-of-service protocols, yet this solution is deferred to future work.
Based on the above analysis, we can now specify nominal values for the interval between link cost updates. The frequency of link cost updates is set such that the multicast routing algorithm has sufficient time to converge. In our implementation, we chose fixed values between 50 and 150 s. However, we note that while the optimization algorithm is iterating, a valid routing is available and information can continuously flow through the network. The frequency of link cost updates determines how reactive the algorithm is to changes in estimated sensor utility, and thus the importance of a higher update frequency would be to handle situations where sensor utility changes rapidly. We leave consideration of this case to future work.
4.4. Two-robot simulation
We evaluated our solution approach to min-cost-DIF in simulation for the case of two mobile robots tracking a moving target. The implementation is decentralized with nodes running in separate processes. The aim of this simulation is to demonstrate the multicast behavior of dynamic information flow and to show the improvement in information gain realized in the min-cost-DIF setting in comparison to a control condition with uniform-rate communication.
The simulation setup is shown in Figure 5. Two mobile robots are assigned to separate workspaces. The first robot has a 360° field-of-view sensor and the second robot has a 180° field-of-view sensor. The sensors are bearing-only sensors, forcing cooperation between the robots. A moving target tracked by the robots moves in a circular pattern within a square region of interest outside the robots’ workspaces.
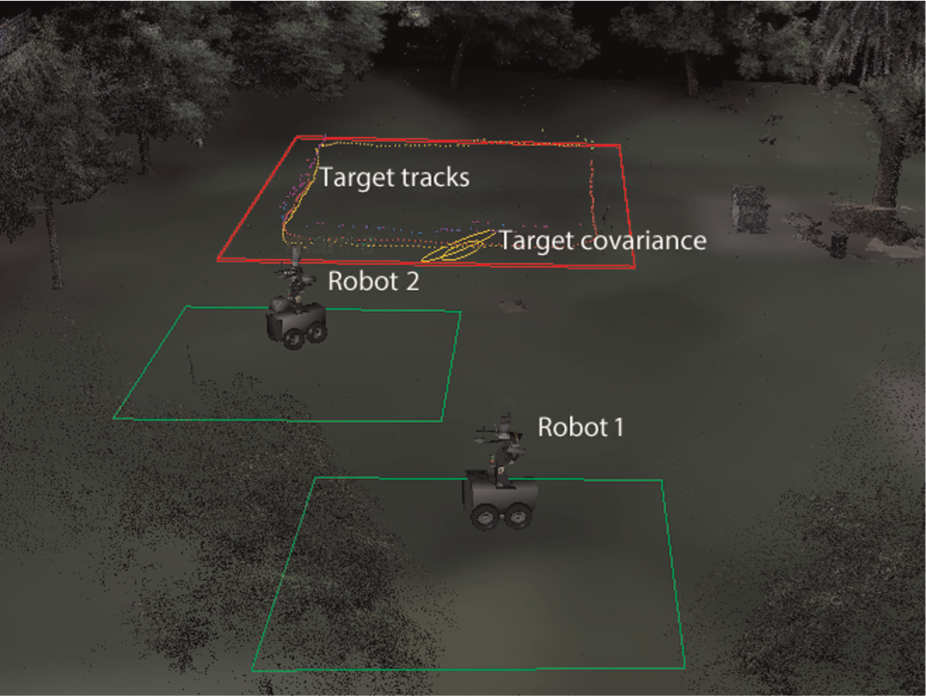
Demonstration setting of the two-robot simulation and experiment. Robots 1 and 2 are shown with their boundaries. Sample target tracks are shown making a square pattern inside the region of interest.
The network diagram of the system is shown in Figure 6. The object detection routine on each robot imposes a processing cost. Due to the multicast property, the processing cost of each processing module is distributed among the receiving estimators. Therefore, if the estimators collectively evaluate an observation utility greater than the processing cost, then the sensor raw data should be processed and sent forward. Virtual links, not shown in the figure, allow for the no-send policy. The cost of the links incident onto the estimators is adjusted throughout the simulation by the robots’ sensor utility evaluations.
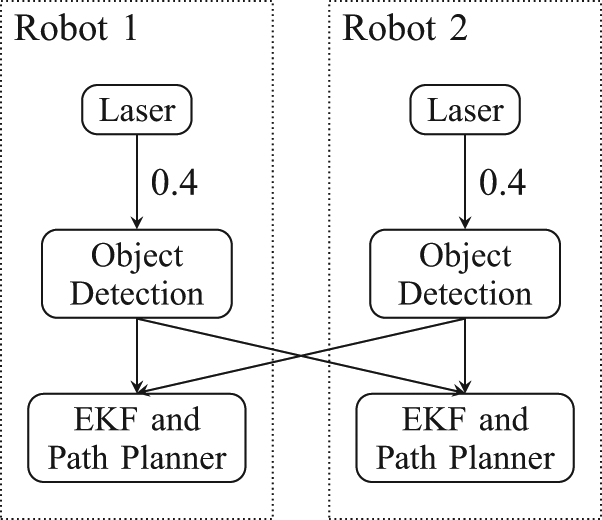
The min-cost-DIF network diagram for the two-robot simulation. Virtual links are omitted for clarity.
To validate the performance of the algorithm, a control test was also run. In the control test, the sensor rates were reduced to the same average rate used in the dynamic case.
The information for each of the robots’ estimate over time is shown in Figure 7 and the corresponding average bars are shown in Figure 8. In Figure 7(a), the information in Robot 1’s estimate was higher on average for the dynamic flow case. In contrast to the down-sampled case, the dynamic flow case boosted inter-robot flow when required preventing long periods of poor information gathering performance. The advantage of the dynamic flow case can also be seen more clearly in Figure 8(a). The dynamic case for Robot 2 exhibits some lag in information gathering performance but it eventually outperformed the down-sampled case as shown in Figure 7(b). This is also confirmed in Figure 8(b).
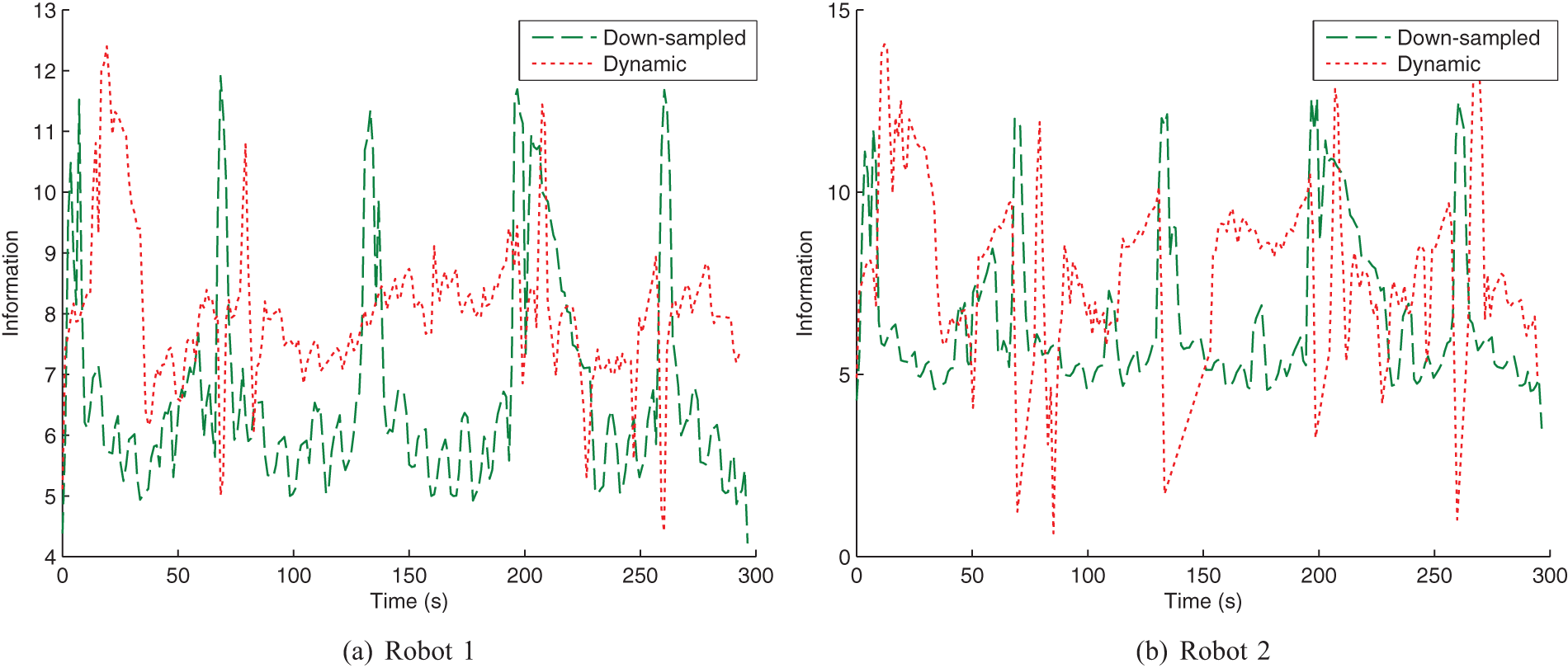
Information value (negative entropy) of the robots’ target estimate over time for the two-robot simulation. The plots are shown for two communication methods, down-sampled and dynamic, with both requiring the same amount of computation on average.
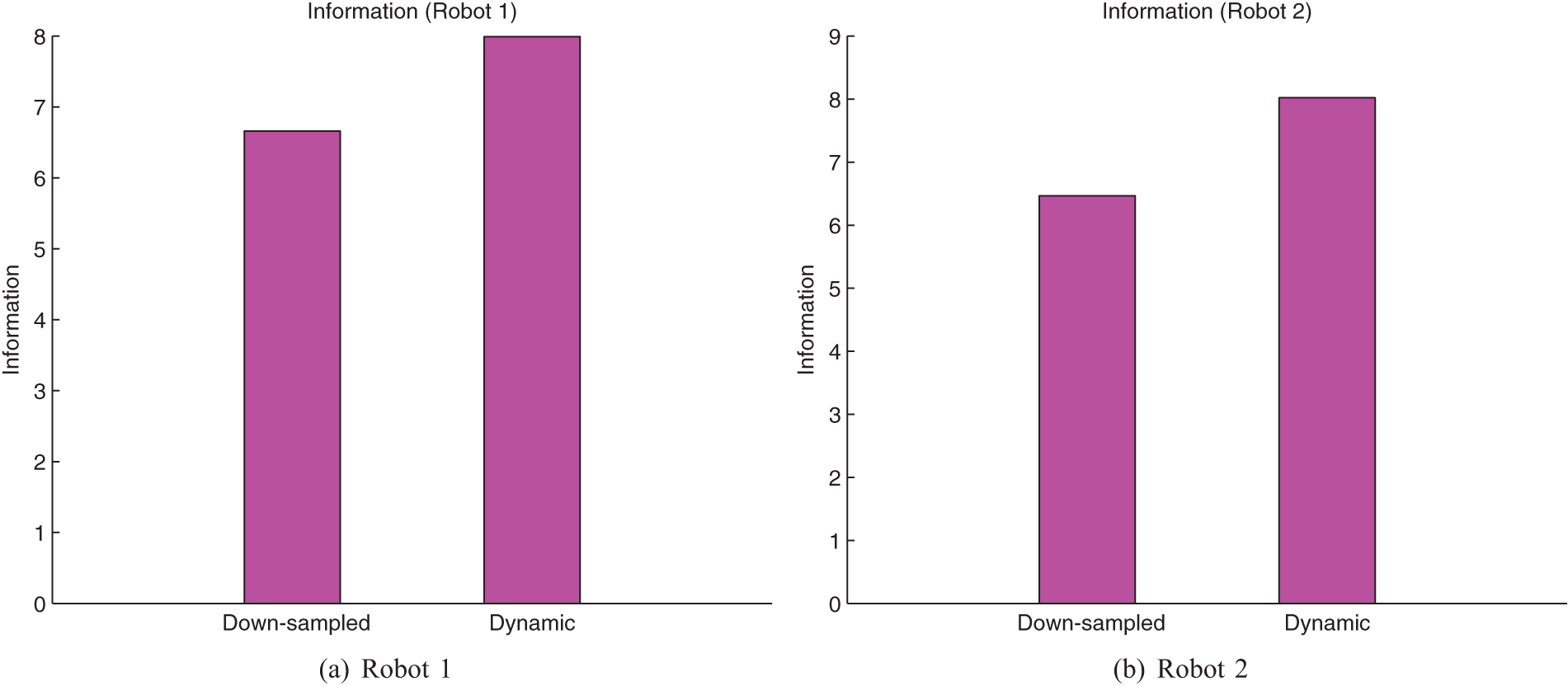
Time averages of the plots in Figure 7 shown in bar format. The improvement for the dynamic case over down-sampling is clearly observed.
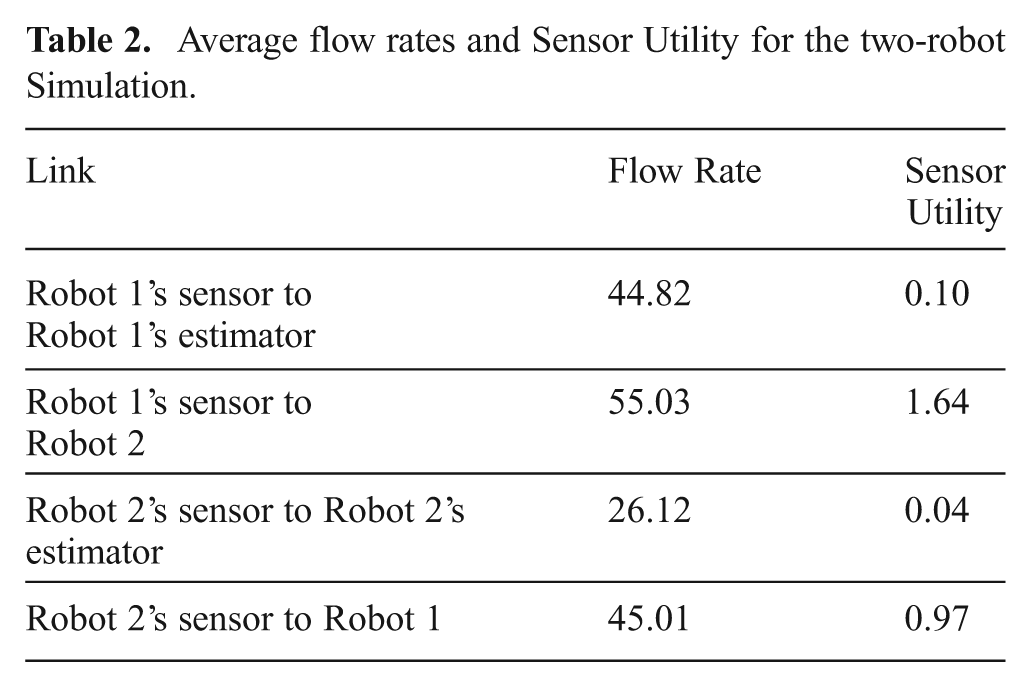
The policies and estimated sensor utilities for the dynamic flow case are plotted against time in Figure 9 with the corresponding averages shown in Table 2. The plots show consistency between sensor utility and flow. In particular, the oblique parts of the flow curve correspond to time periods where a robot would receive sensor observations freely due to raw data already being processed for the other robot. This free reception of data is a feature of multicast routing.
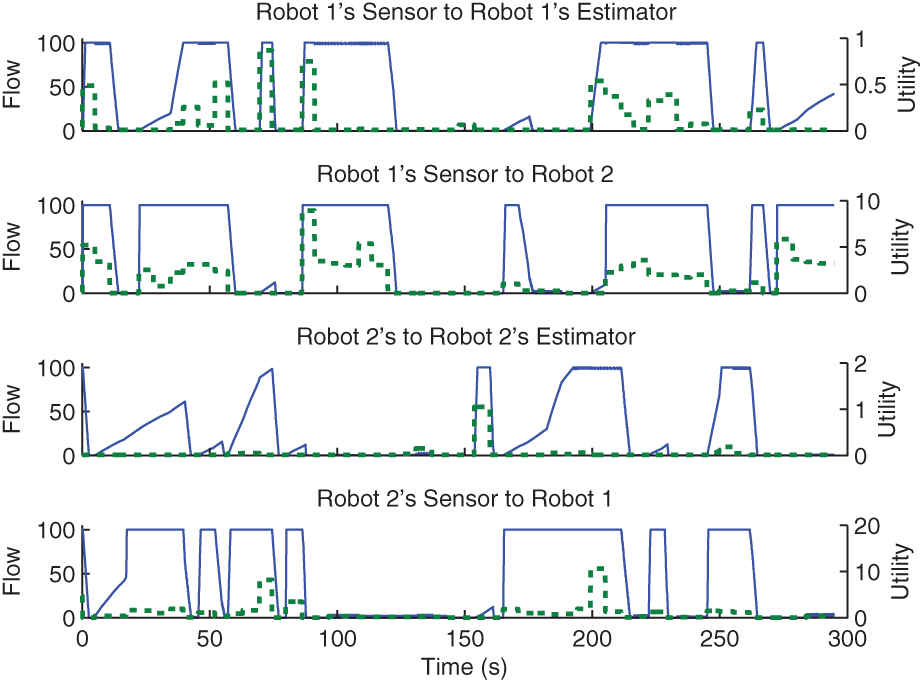
Flow rates and sensor utility for the two-robot simulation. Flow rates are shown in solid lines while the evaluated sensor utility is shown in dashed lines.
Average flow rates and Sensor Utility for the two-robot Simulation.
As noted in Section 4.3, discrete flow decisions minimize the error from our maximum flow approximation of the total flow in each link. As seen in Figure 9, with the exception of transient periods, the flow variables were mainly either 0 or 100.
4.5. Robot and ground station simulation
We also evaluated the case of one mobile robot and one ground station. The main purpose of this simulation is to show the generality of the dynamic information flow approach. The simulation was run using ROS and Gazebo.
The setting includes one Pioneer 2DX robot model with an on-board camera and one off-board processing station. The robot’s on-board processing is computationally expensive, however, it has wireless access to the off-board processing station. The demonstration process is as follows. The robot begins near the processing station. It then proceeds to gain information about a moving target.
The network diagram of the demonstration is depicted in Figure 10. Subject to communication cost, which is set proportional to distance, the robot’s decision is expected to vary between on-board and off-board processing. The maximum flow assumption is valid for this scenario since there is only one destination node.
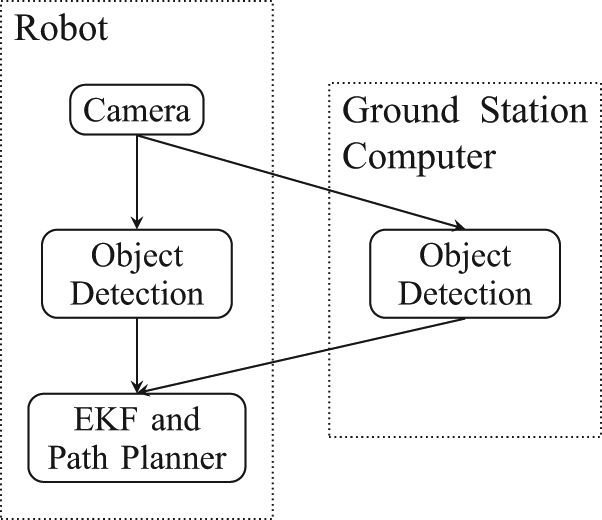
The min-cost-DIF diagram of the robot and ground station demonstration scenario.
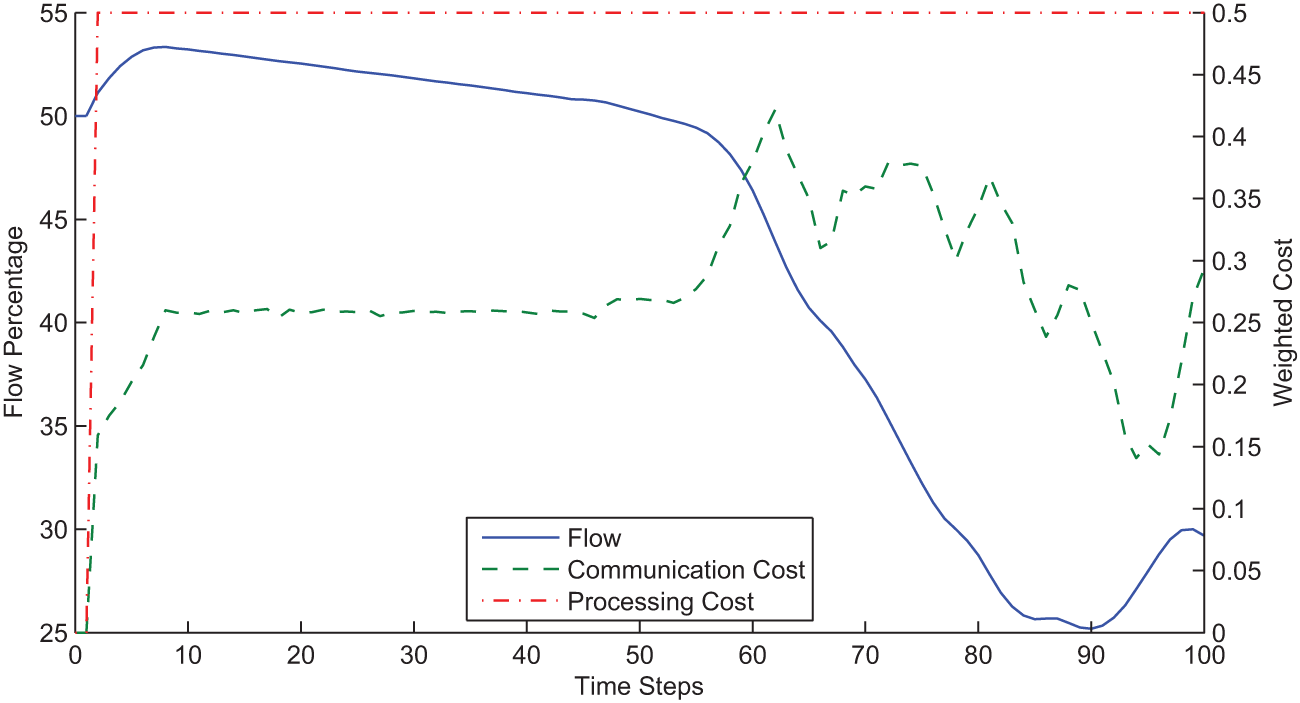
Figure 11 shows the flow between the robot and the ground station, the communication cost and the robot’s processing cost over time. The processing cost is assumed to be fixed over time as shown in the figure. The communication cost varies based on the distance between the robot and the ground station and the flow is adjusted accordingly. In Figure 11, at around time step 50, communication cost outweighs the cost of on-board processing. This leads to a switch from off-board processing to on-board processing. It should be noted that the communication cost displayed in the plot is only for transmission from the sensor to the processor. When compared with on-board processing cost, the total communication cost is doubled. The results of this simulation show the generality of the dynamic flow formulation. Even though the expected behavior here is as expected, the aim is to show that this behavior was achieved within the min-cost-DIF framework without modification.
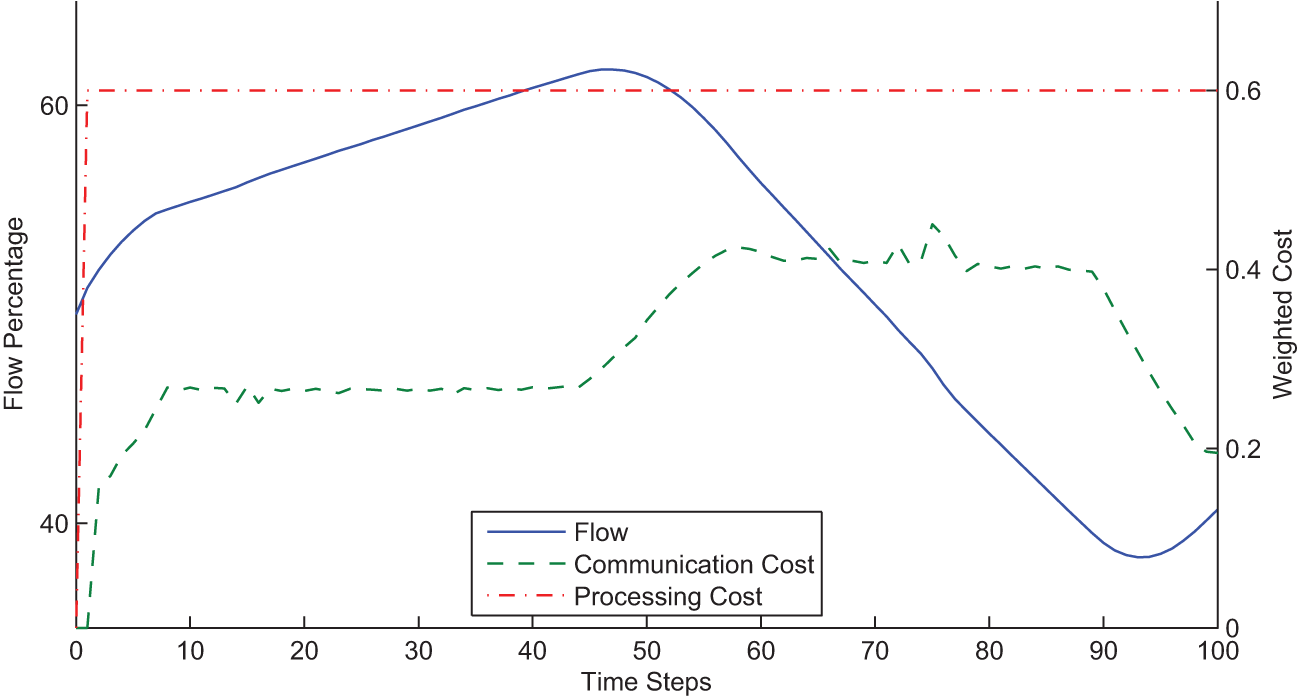
Flow, communication cost and processing cost of the link from the sensor to the ground station processor for the one robot/one ground station simulation.
4.6. Robot and ground station experiment
We also performed an experiment in hardware for the one robot/one ground station case. A Pioneer 3DX robot equipped with an on-board computer using an Intel Atom processor N270 1.6 GHz was used. The robot is equipped with a SICK LMS291 2D lidar used exclusively for localization. The robot uses an on-board webcam as a 2D bearing-only sensor to track a moving target. With the exception of the off-board processing ground station, all processes were executed on-board the robot including localization, image processing (when required), estimation, decision-making and the information flow control algorithm.
The change in flow, communication cost and processing cost over time is shown in Figure 12. These results are consistent with the simulation results for the analogous case. We observe that the robot initially chooses to send images to be processed off-board by the ground station. The ground station performs object detection and sends point observations back to the robot. As the robot moved away to track the target, the communication cost increased and thus the robot chose to perform processing on-board. A snapshot of the moment when the robot decided to switch to on-board processing is shown in Figure 13.
Experimental results for the one robot/one ground station case.

Snapshot from the one robot/one ground station experiment. The image shows the robot having moved away to follow the target. At this distance, the robot prefers to perform processing on-board.
4.7. Monte Carlo simulation
We performed a Monte Carlo simulation for the experimental setting of Section 4.4 comparing the down-sampled and the dynamic communication cases. The aim of the simulation is to analyze the statistical significance of the performance advantage introduced by our solution to min-cost-DIF.
Each method was tested in 20 randomly initialized trials running for 1 min each. The down-sampling rate was chosen to match the average rate resulting from the dynamic case.
The results of the Monte Carlo simulation are shown in Figure 14 in box-plot format. The results shown assume each trial as one sample. Dynamic communication clearly outperforms down-sampling. A Welch’s t-test for statistical significance resulted in a p-value of less than 0.001.
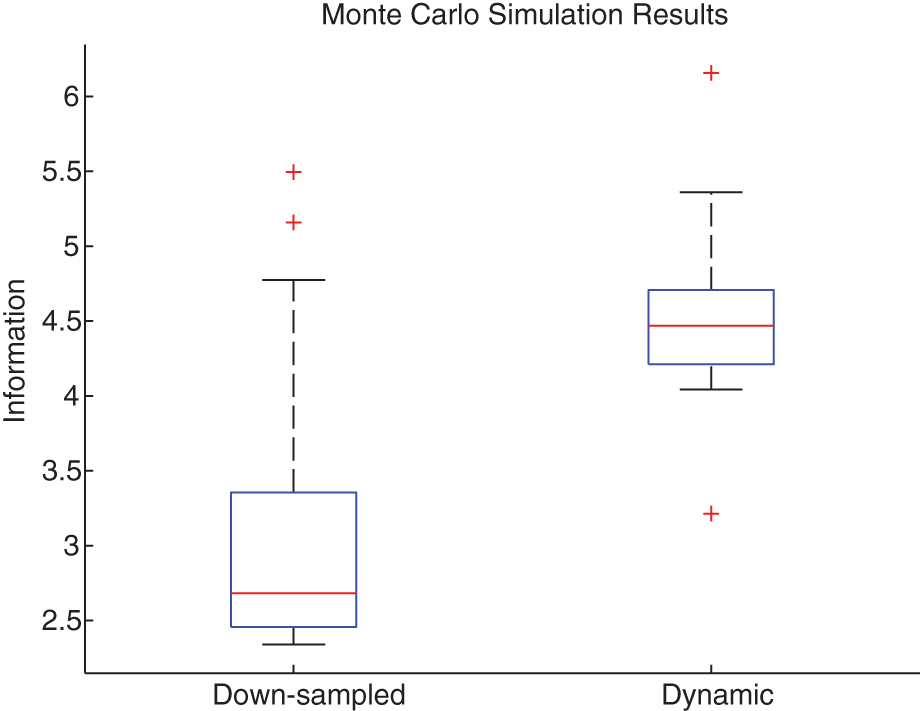
Monte Carlo simulation results comparing down-sampling with dynamic information flow. Each method was tested on the two-robot scenario for 20 trials running for 1 min each. In the results depicted, a trial acts as one sample. The box extents represent the first and third quartiles, while the whiskers represent the extrema. The median is represented by the horizontal line inside the box.
5. Distributed optimization for threshold-DIF
In this section we introduce a distributed optimization method that will form the basis of our solution to threshold-DIF. The method is a distributed version of ADMM which we call DADMM. The DADMM method solves distributed non-smooth constrained convex optimization problems with a DAG structure. Threshold-DIF is a distributed optimization problem since its objective is a sum of local objectives and it only has neighbor-to-neighbor constraints. It is non-smooth due to the linear objective, and it has the structure of a DAG by definition.
We begin with a brief introduction to ADMM. Then, DADMM is presented along with complexity analysis. We then present the mapping from threshold-DIF to DADMM later in Section 6.
5.1 ADMM
For convenience, we provide a brief summary of ADMM. A detailed description can be found in Boyd et al. (2011).
ADMM solves optimization problems of the form given by (20). The objective is assumed to be a sum of two proper convex functions f 1 and f 2 where the first is a function of the vector z 1 and the other is a function of the vector z 2. We refer to z 1 as the primary vector variable and to z 2 as the secondary vector variable. The Lagrangian of the problem is shown in (21):
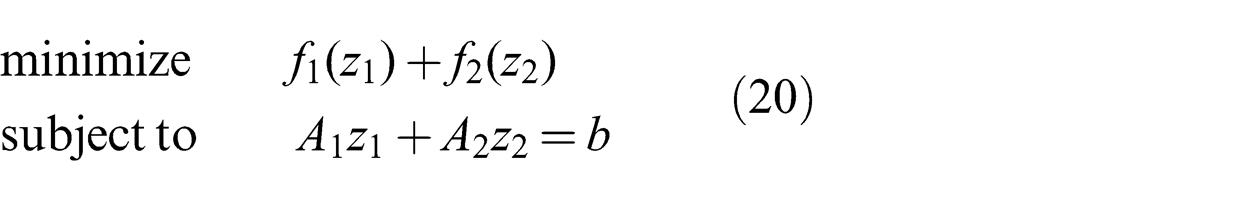
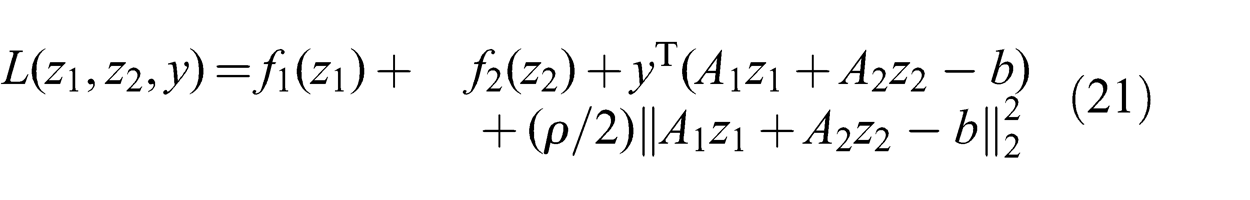
ADMM is summarized in (22). Each iteration involves three updates. The primary update minimizes the Lagrangian about z 1, the secondary update minimizes the Lagrangian about z 2 and the third updates the Lagrangian variable y. Convergence is shown in Boyd et al. (2011):
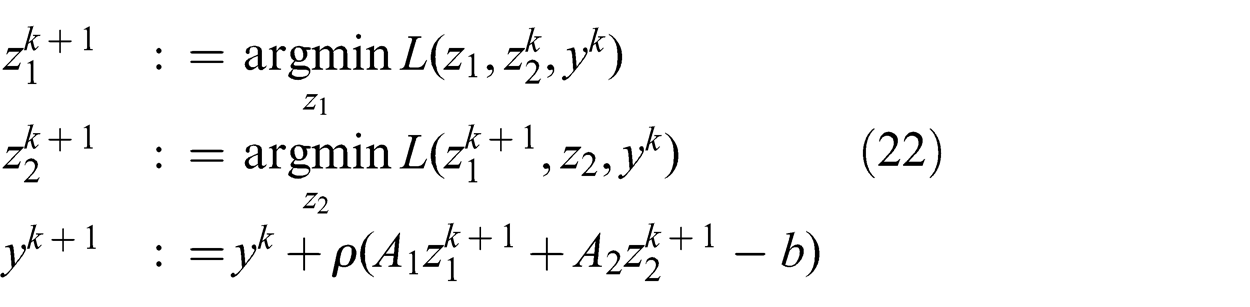
5.2 Problem formulation
The general form of optimization problems that can be solved by DADMM is described as follows. Consider the DAG G = {V, E} defined in Section 3. Attach to each node i ∈ V a vector variable xi
and a proper convex function fi
(xi
), which is not necessarily smooth. Node i can have constraints with its parents as per (24) where gi
is an affine function. The notation xU
where U = {i
1,…,in
}

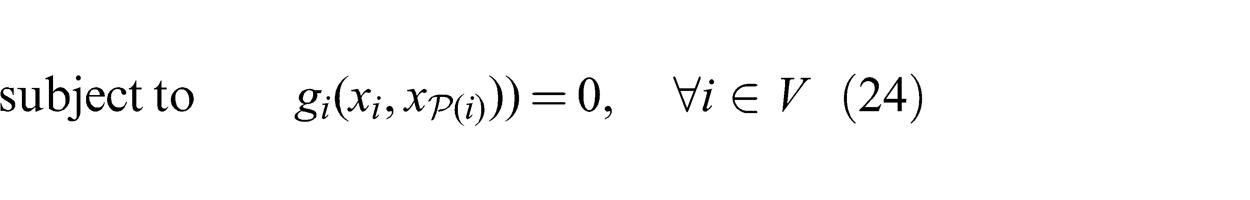
5.3 Inequality constraints
The standard form of ADMM does not include inequality constraints. Therefore, we have only included equality constraints gi
in the problem definition. This is a non-restrictive assumption since by adding extra variables, inequality constraints can be transformed into equality constraints as we will show. Suppose that instead of gi
we have a function

By adding a slack variable pi , this inequality constraint becomes an equality constraint plus a non-negative constraint on pi as shown in (26). The slack variable pi can be viewed as a variable belonging to a virtual parent node whose objective is an indicator function that is zero when pi is non-negative and infinity otherwise:
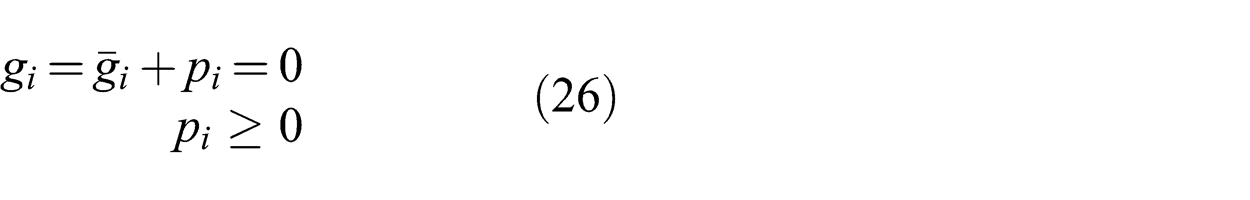
In DADMM, pi can be optimized independently. The solution of the optimization over pi is given by (27):

5.4 DADMM
DADMM consists of a preliminary decentralization step followed by the main optimization process. The decentralization step is only performed once during which the optimization problem is modified, through the addition of variables and constraints, such that it only requires neighbor-to-neighbor communication. In the optimization process, message passing and optimization updates run in a sequence that enforces decentralization while retaining equivalence to centralized ADMM.
The decentralization step modifies constraints (24). For every vector xi
where i ∈ V, a mirror vector

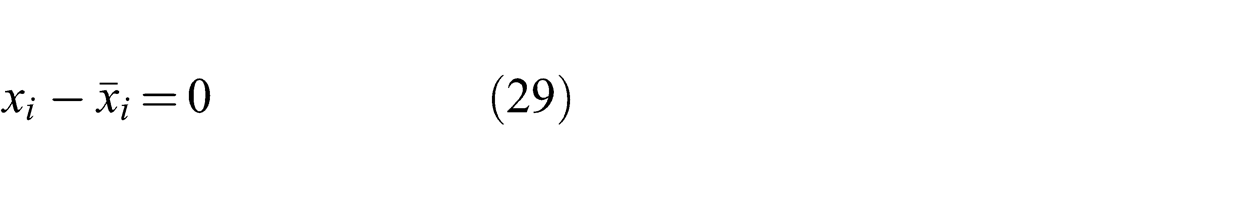
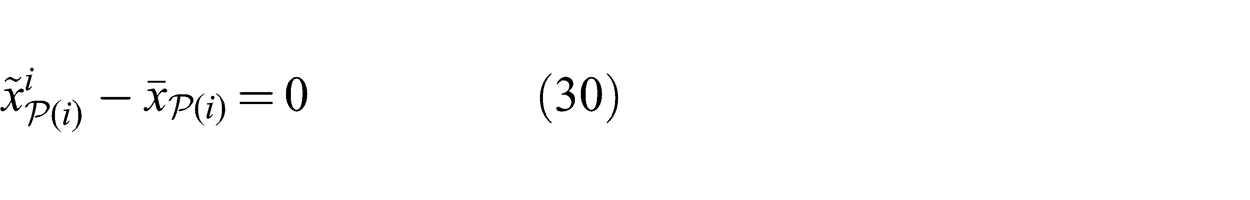
The new constraints are assigned the following Lagrangian multiplier vectors. The Lagrangian multiplier λi
is associated with constraint (28), μi
is associated with constraint (29) and
All the above constraints and variables except
Decentralization step of DADMM. In (a), node i is shown with its parents and children in a DAG. It is assumed that node i has constraints that include all of its parents. By transforming the network into that of (b), each of node i’s parents only needs to communicate with node i given that they are not coupled elsewhere.
From the ADMM perspective, the sets of vector variables xi
and
The main optimization process consists of message passing and optimization updates defined in a sequential and decentralized manner that is equivalent to the centralized version (22). The process begins with the head nodes and then proceeds to traverse the graph according to Algorithm 1. Algorithm 1 refers to two types of updates and two types of messages, upward and downward. We will now proceed to define what takes place during each update and what each message contains.
At the outset, each node i ∈ V is initialized with1
xi
,
The decentralized nature of the process is evident from the definition of the updates at the node level. We need to show that the process is in fact equivalent to performing the centralized version of ADMM on the entire system. A proof of this equivalence is provided in Theorem 2 following Lemma 2.
Proof. From Lemma 1, we know that if node i has just performed the tth update then it has performed t − 1 upward updates. Now, suppose that the next update is the (t + 1)th downward update. This is impossible because according to Lemma 1, node i would have performed t upward updates. The second part of the statement can be proved through a similar argument.
Proof. The proof is by induction. Before the start of the algorithm, the variables of node i are set to1
xi
,
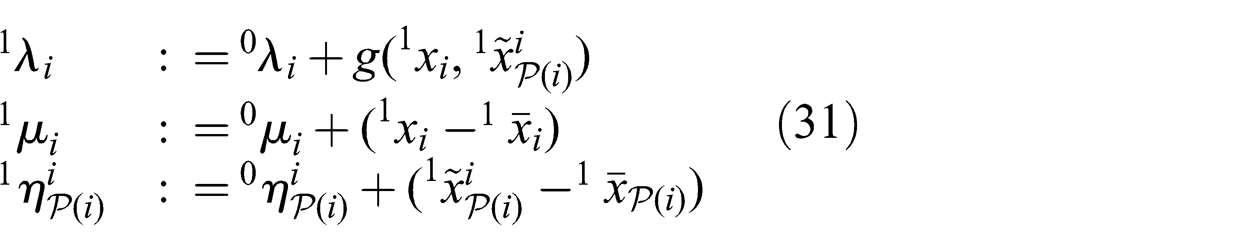
Assume that after node i’s (t − 1)th Lagrangian update, all variables belong to the ADMM update at t′ = t − 1. We now prove the statement for t′ = t. After the (t − 1)th Lagrangian variable update, node i directly updates its primary variables according to (32):
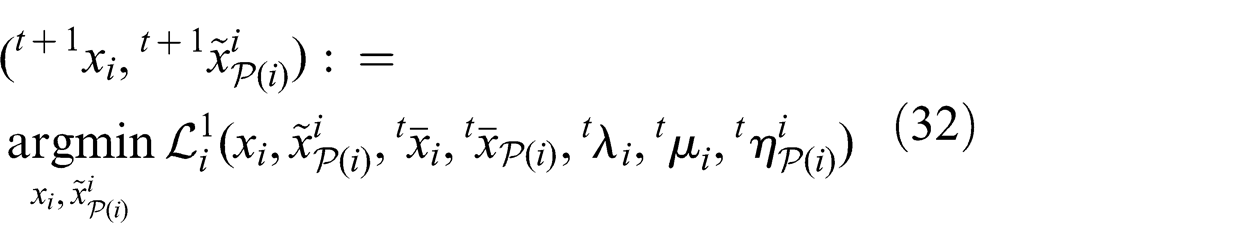
According to Lemma 2, the downward update is followed by an upward update. In the upward update, node i would have received
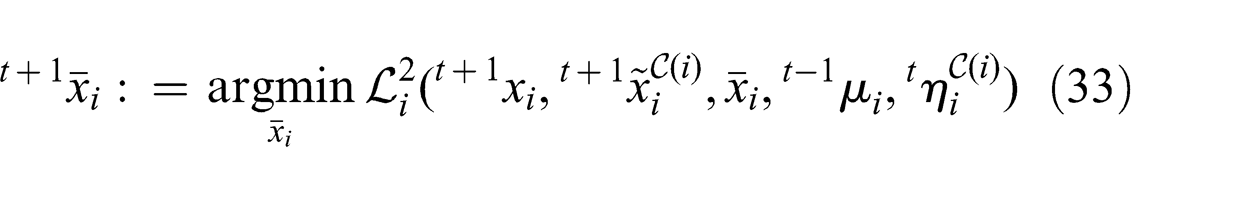
The minimization over
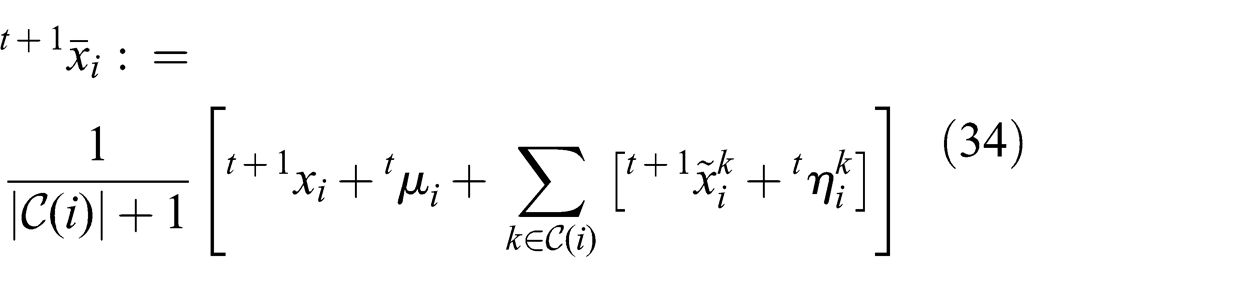
Finally, from Lemma 2, we have given that the upward update is followed by downward update t + 1 during which the Lagrangian variables are updated in an analogous manner to (31) to obtain
t+1
λi
,
t+1
μi
and
5.5. Analysis
In this section, we analyze the computational complexity of one iteration of DADMM. Analysis of the full problem depends on its convergence rate, which we consider for the special case of threshold-DIF in Section 6.
First, we define the following terms:

The worst-case complexity of one iteration of DADMM is given by Theorem 3.
Proof. Each ADMM iteration consists of three updates: the primary update, secondary update and the Lagrangian update. Since the algorithm is decentralized and synchronous, its running time is dominated by the time to update a single node multiplied by the depth of G.
We now develop an upper bound on the computation performed by an arbitrary node i. The primary update involves solving
The secondary update computes an average over xi
and
The Lagrangian update involves an evaluation of all constraints given by equations (28), (29) and (30). The evaluation of each element of gi
involves at most ni
+ n′
i
variables. The evaluation of the other constraints involves two variables each. Therefore, the time complexity of the Lagrangian update is
The total time complexity is the sum of these three updates. Thus, we have
We now restate the bound as a function of n
max,
6. Threshold-DIF
In this section, we show how DADMM can be applied to the threshold-DIF problem. The mapping from threshold-DIF to the general problem formulation of DADMM is presented in detail. A detailed complexity analysis of DADMM in terms of the threshold-DIF problem size is provided. We present several experimental results in simulation, including a 15-node example and a Monte Carlo simulation, and results from an experimental system with two outdoor ground robots and a stationary camera.
6.1. Threshold-DIF using DADMM
The threshold-DIF problem can be solved using DADMM. However, we first must reformulate constraints (4) and (7) such that they are compatible with the DADMM framework.
The maximum function in (4) is replaced by the set of inequalities (39). The maximum function is non-smooth and cannot be optimized in one step. With the set of inequalities in (39), the objective and all equality and inequality constraints of the optimization become linear as required by DADMM.
The set of inequalities in (39) is equivalent to the maximum relation in (4) as long as one of the constraints is active. One constraint will always be active for

The inter-link constraint (7) is replaced by (42) where
After transforming the constraints, we obtain the problem (37)–(42) shown below:


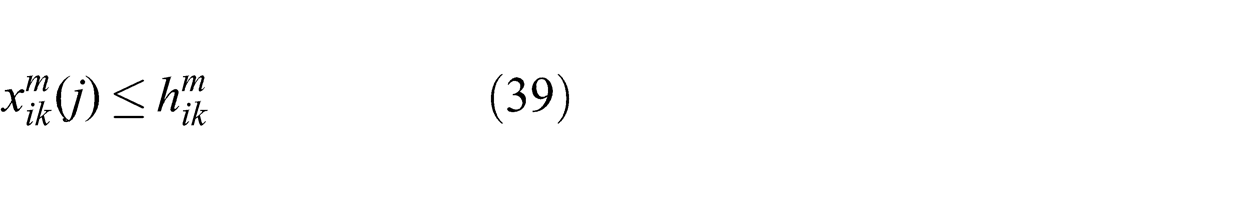
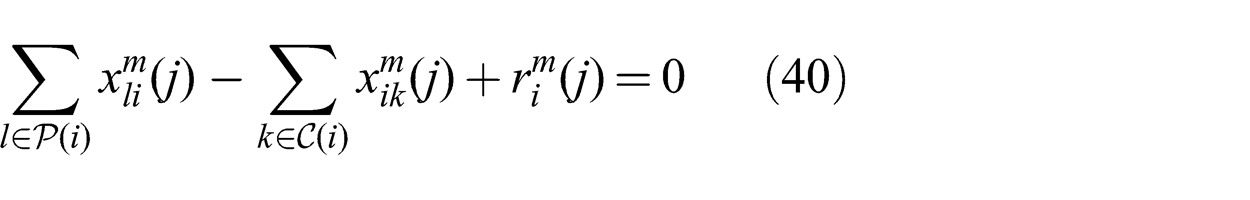

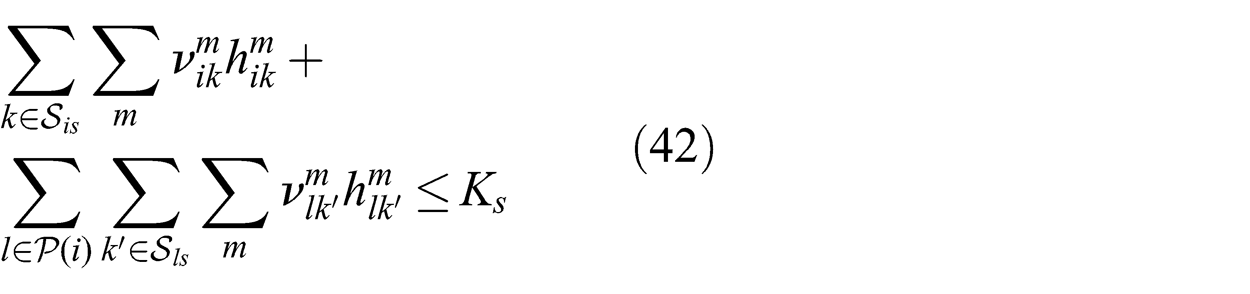
To solve threshold-DIF, all that is required at this stage is that the threshold-DIF variables and constraints be mapped to the variables of the distributed optimization problem (23)–(24). This can be done as follows. The sets of variables
DADMM runs continuously throughout system operation. As the system configuration changes, link costs and weights are updated with new values. To ensure convergence, the interval between updates is set to an adequate time period. In practice, this interval was found to be of similar length to that of min-cost-DIF in Section 4.3.
6.2. Analysis
In this section, we provide time complexity analysis of DADMM when applied to threshold-DIF. The complexity is expressed in terms of the size of the threshold-DIF input parameters.
Complexity analysis is provided for the entire optimization process including the number of iterations required for convergence. We first determine the complexity of one iteration following directly from Theorem 3. We then find a bound on the number of iterations based on the algorithm’s convergence rate.
The complexity of a DADMM iteration was determined in Section 5.2. The complexity of one iteration in terms of threshold-DIF problem specification can be determined by substituting the appropriate values for n
max and
Nm : number of sources in the network;
Nj : number of destinations in the network;
Ns : number of inter-link constraints.
The maximum number of primary variables n max is proportional to the maximum number of routing variables which, in turn, is proportional to the number of sources multiplied by the number of destinations multiplied by the number of children. The number of children is bounded from above by the number of nodes. Therefore, n max is bounded such that n max ≤ NmNj |V|.
The maximum number of constraints
Substituting the obtained bounds into the result of Lemma 3, the complexity of one iteration of DADMM for threshold-DIF becomes
To determine the complexity of the whole optimization process, the convergence rate is required. A convergence rate in an ergodic sense is established in He and Yuan (2012) with relatively mild assumptions.
The result is restated here after establishing the appropriate notation. Define the primal vector of the kth iteration as
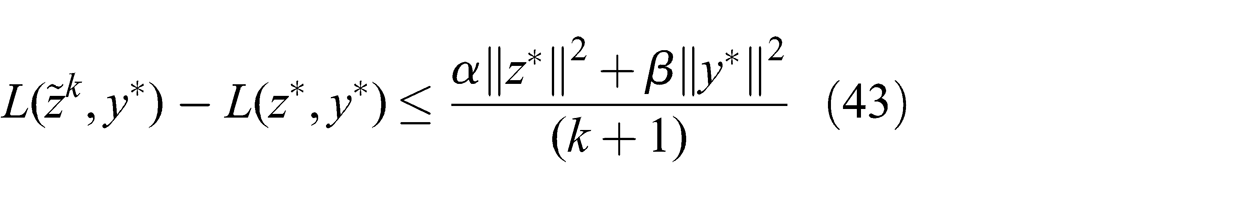
From (43), it is clear that in order to obtain a bound on the convergence rate, we need to find an upper bound on the squared norm of the primal and dual optimal vectors. The absolute value of the elements in the primal vector have an upper bound uz which follows from the problem definition in Section 6.1. Hence, an upper bound on the norm of the primal vector is given by (44):

We now seek a bound for the squared norm of the dual vector ‖y*‖2. To simplify the analysis, we note that the centralized ADMM version of the threshold-DIF problem has the form of the optimization problem defined in (45) where the indicator function I
≥0 is defined in (46) below. The set
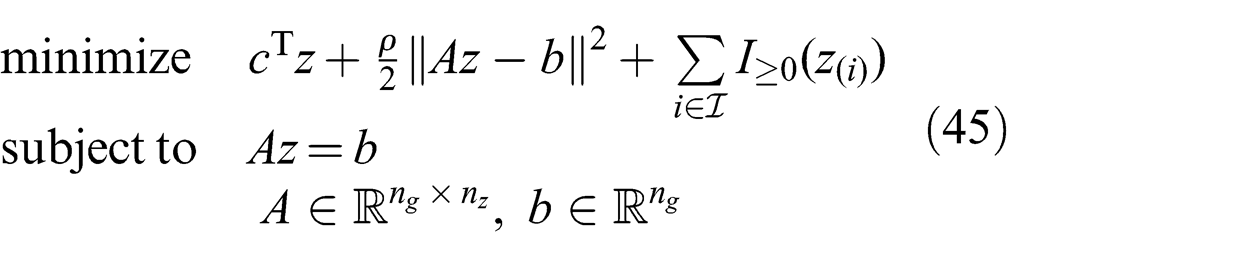

An upper bound on ‖y*‖2 can be obtained from the following lemma.
Proof. At optimality, we have Az − b = 0 and zero belongs to the subdifferential of the Lagrangian as shown in (47). The ith element of the vector


The subgradient ∂I
≥0 evaluated at 0 is an unbounded set and therefore cannot be used to directly bound y*. However, the optimality condition (47) has nz
rows while y* has dimension ng
. Furthermore, the maximum number of active inequality constraints, that is, constraints where
To this end, we need to make sure that the matrix
Therefore, the optimality condition (47) can be restated as (49) where

From (49), we obtain (50) where
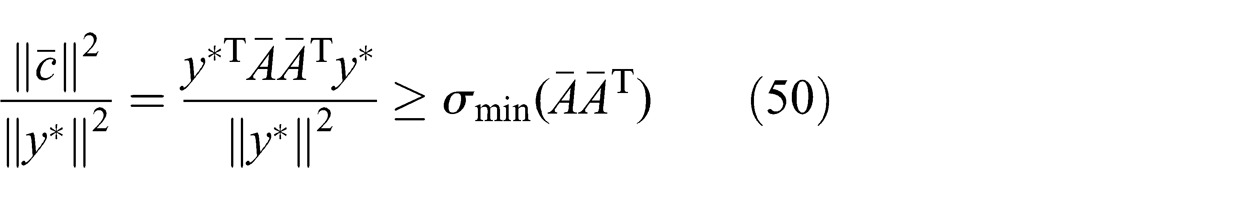
The proof is established by setting
We assume that all elements in c are upper-bounded by a constant value uc . This is a reasonable assumption since c represents the link cost vector and only the relative cost is of importance. Consequently, from Lemma 3, we have the upper bound given in (51) for the squared norm of the dual vector:
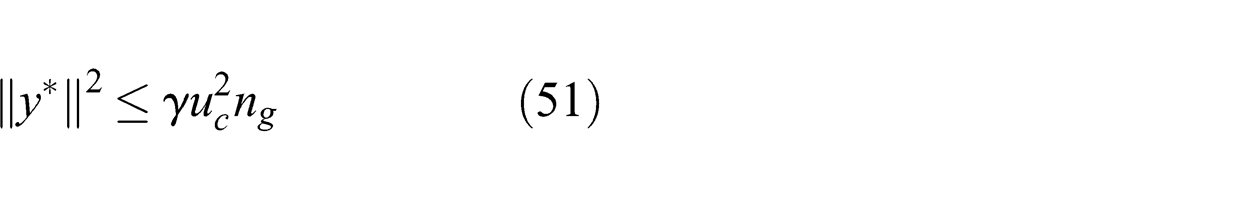
We can now state the main complexity result given by Theorem 4. The complexity is polynomial as expected since the problem is convex and the number of variables is polynomial in the number of nodes.
Proof. Bounds (44) and (51) mean that the left-hand side of (43) is bounded by a constant weighted sum of nz
and ng
. Therefore, an upper bound on the number of iterations k required to produce an error ε is given as
Note that the number of primary variables nz
is bounded by
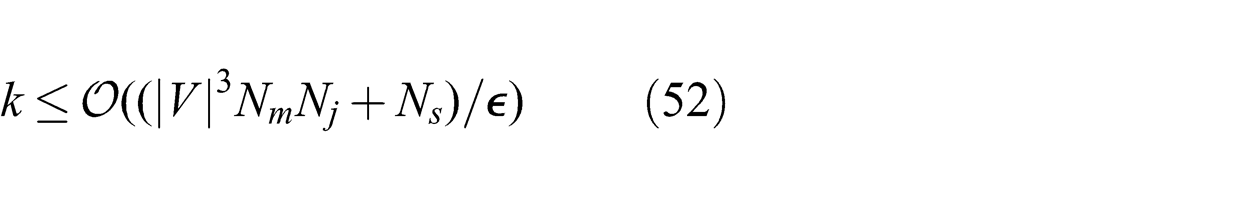
The complexity of the whole optimization process is obtained by multiplying the number of iterations by the complexity of each iteration. Thus, for an ε-optimal solution, DADMM for threshold-DIF runs in
6.3. Two-robot experiment
We implemented our approach and performed an experiment where two mobile robots communicate to track a moving target. The aim of this experiment is to show the information gain advantage of dynamic information flow in the case of limited inter-robot communication bandwidth.
6.3.1. Experimental setup:
The experimental system consists of two modified Segway RMP 400 robots. An image of the robots is shown in Figure 16. The first robot is equipped with a Velodyne 3D Lidar with a 360° field of view. The second robot is equipped with a 2D SICK LMS291 horizontally mounted laser scanner with a 180° field of view. Although these sensors provide range as well as bearing, they were treated as bearing-only sensors to force cooperation between the robots. Each robot is also equipped with a server-class computer with an eight-core processor. For localization, the two robots rely on high-accuracy inertial measurement unit (IMU) and differential global positioning system (DGPS) modules.

The Segway RMP 400 robots used in the experiments.
An image of the experimental setting is shown in Figure 17. The two robots were placed in two separate areas with virtually bounded geographical regions to avoid collision. Target tracking was limited to a geographically bounded region of interest and for the purpose of the demonstration, tracking was limited to one target performing circular patterns.

The outdoor experimental setup, with robots visible outside the tracking region of interest. The border of the tracking region is designated by solid lines.
The network diagram for this demonstration is shown in Figure 18. It is assumed that maximum communication bandwidth is limited and does not allow both robots to send sensor data at the full rate. We also assume that communication throughput decreases with inter-robot distance. Therefore, the robots are required to share the available bandwidth. The bandwidth sharing constraint is indicated by the dashed lines drawn between the two inter-robot links. Virtual links, not shown in the figure, allow for the no-send decision. It is expected that through dynamic information flow the bandwidth will be shared efficiently with respect to sensor utility. The maximum flow assumption is valid in this scenario since no processing costs are assigned.
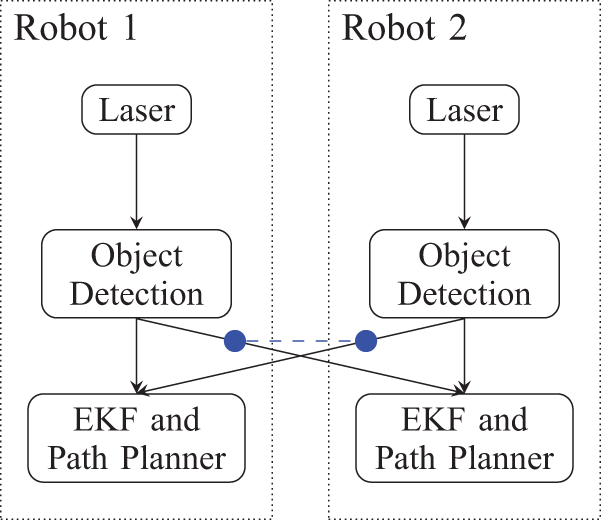
The threshold-DIF diagram for the two-robot scenario. Virtual links are omitted for clarity.
To validate the performance of dynamic information flow, two control tests were run for the purpose of comparison. The first control test allows unconstrained communication between all nodes and shall be referred to as the unconstrained case. This test mainly acts as a benchmark since it violates bandwidth constraints. The second control test involves a reduced communication rate that obeys bandwidth bounds. This test shall be referred to as the down-sampled case.
6.3.2. Results:
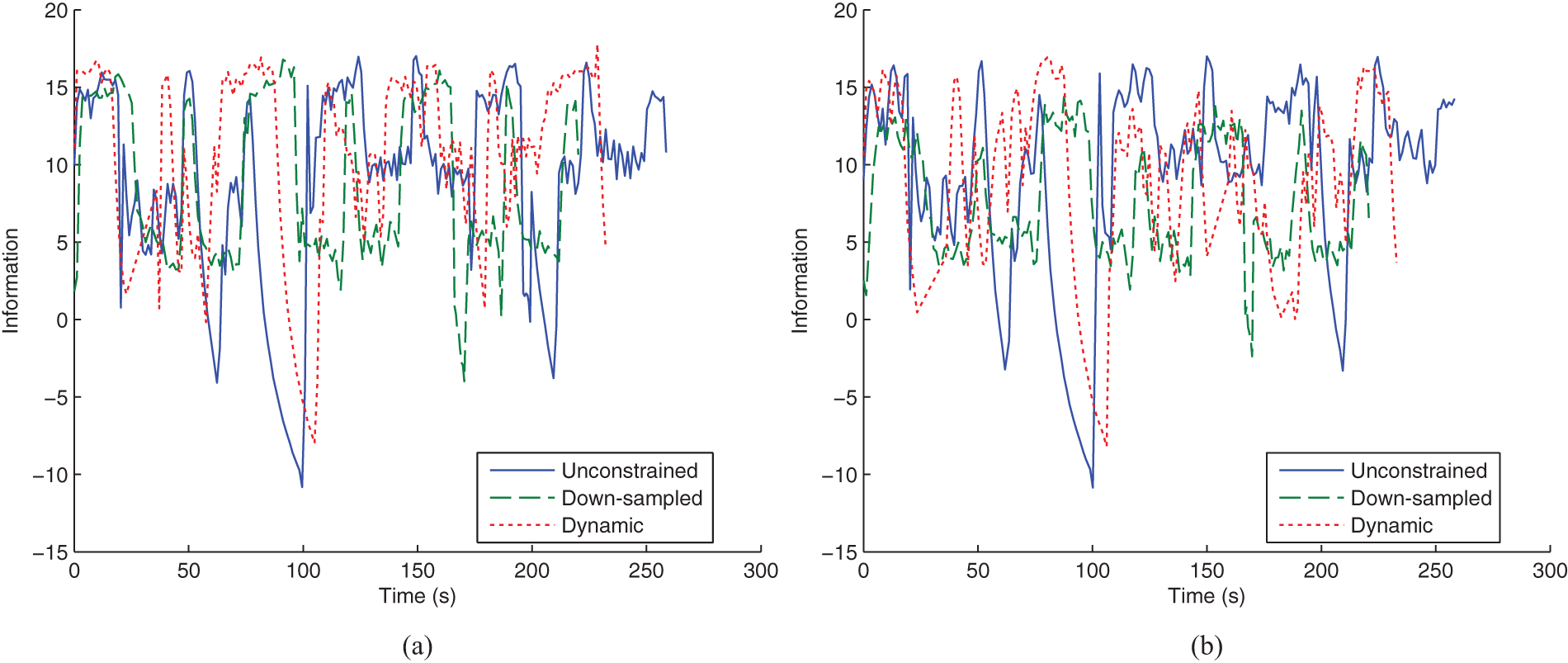
The information value for the robots’ target estimates over time is shown in Figure 19 with the corresponding average bars shown in Figure 20. In both figures, we observe minimal difference in information value across the three communication methods for Robot 1. Because Robot 1 has a 360° field-of-view sensor, the target is always visible and therefore tracking does not depend on observations received from Robot 2. However, we do observe a difference in information value for Robot 2. Figure 20(b) shows that the down-sampled method results in reduced information gathering performance when compared to our method. This effect is also evident in Figure 19(b) where there is a clear decline in information for the down-sampled case at times 20 s and 60 s. This decline occurs because the target drops outside the robot’s sensor field-of-view. Dynamic flow ensured that information was directed from Robot 1 to Robot 2, but down-sampling naively shared the communication medium.
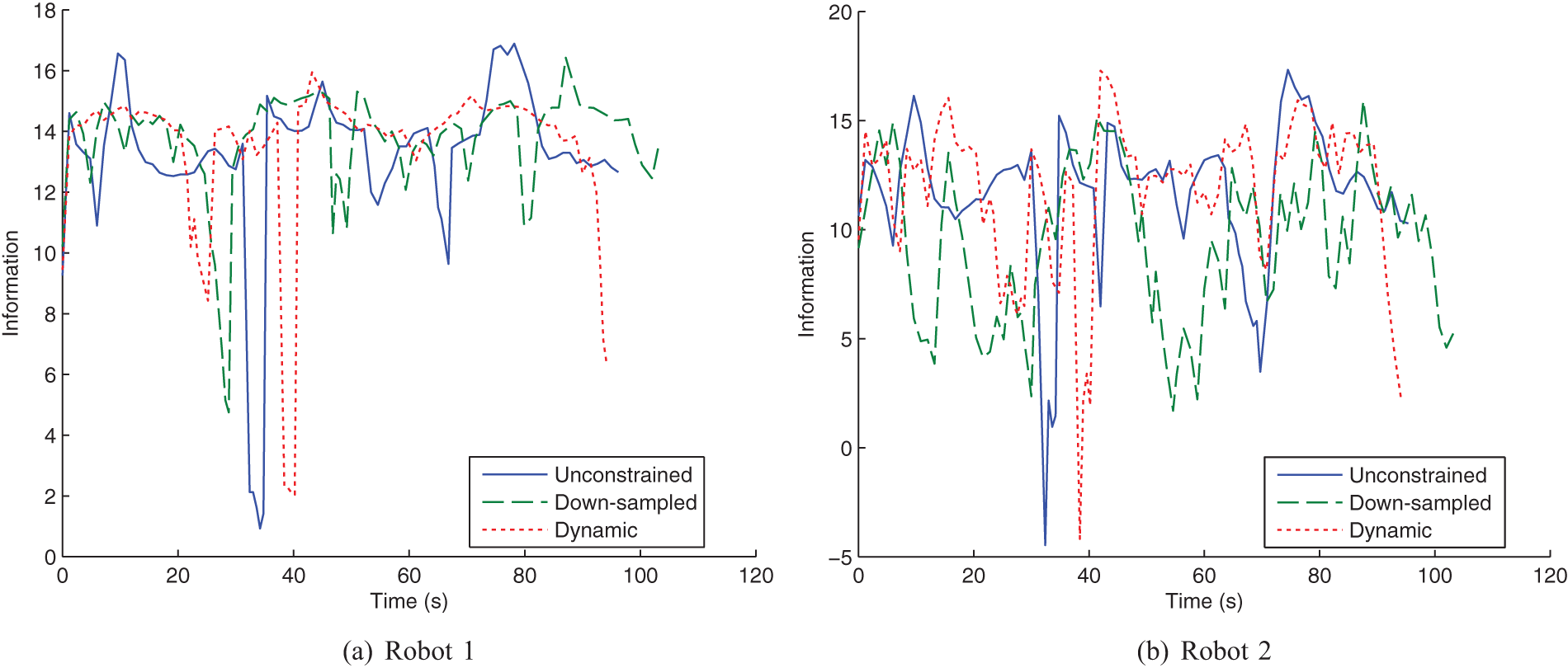
The information value (negative entropy) of the robots’ target estimate for the two-robot hardware experiment. Plots shown are for all three communication methods: unconstrained, down-sampled and dynamic. The sudden drops in information are due to target loss.
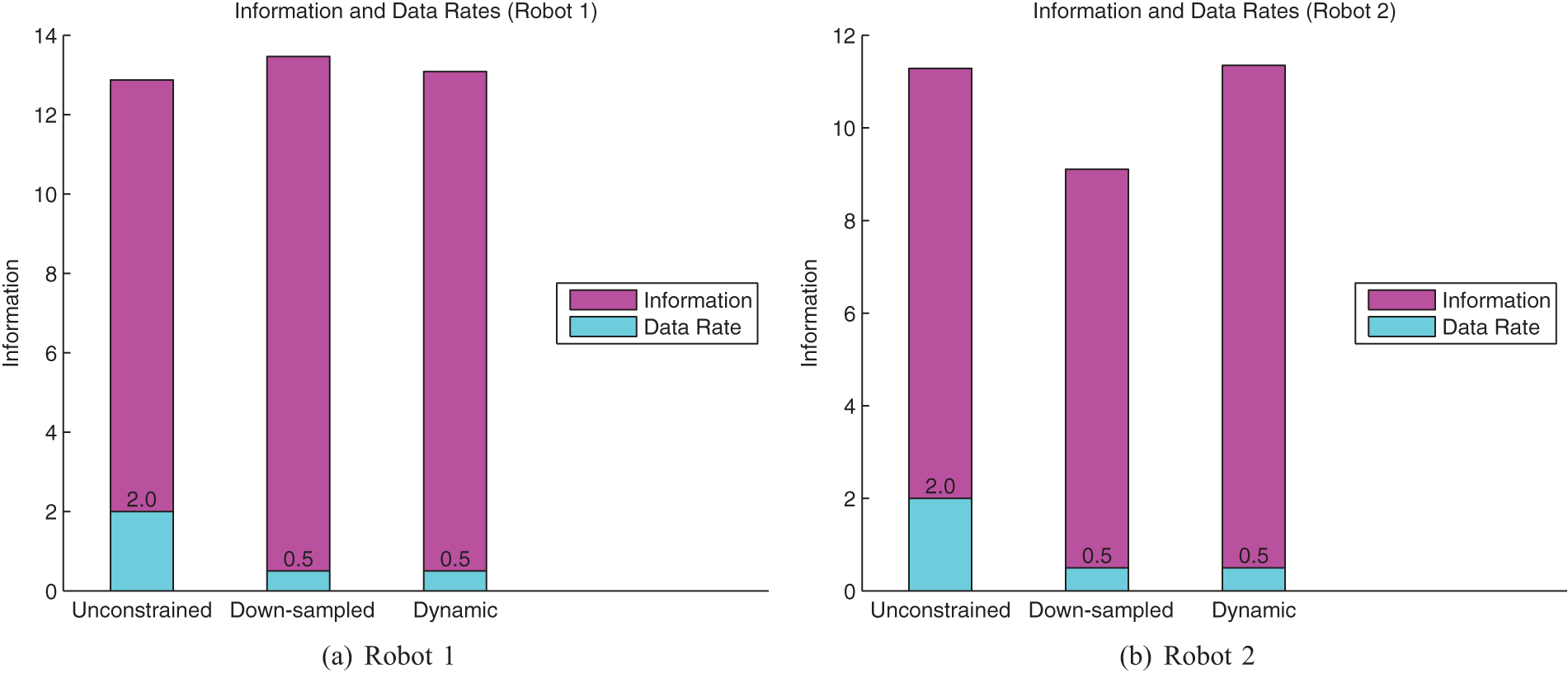
Time averages of the plots in Figure 19 shown in bar format. Data rates are shown superimposed. The dynamic case shows a clear improvement in information gain in comparison to down-sampling for Robot 2.
The advantage of dynamic information flow is further confirmed in Figure 21. The bottom two plots show the approximate sensor observation utilities and data flow between robots over time for the dynamic flow case. The flow from Robot 1 to Robot 2 dominates bandwidth usage when the target is not in Robot 2’s sensor field-of-view. However, at times 40 s and 80 s, the flow was directed from Robot 2 to Robot 1 because the target was closer to Robot 2. The top plot shows the distance between the robots over time. At the average inter-robot distance, the available bandwidth is limited to approximately half of the maximum bandwidth. As expected, the sum of the information flows obeys this reduced capacity. The flow rate and sensor utility averages are shown in Table 3.
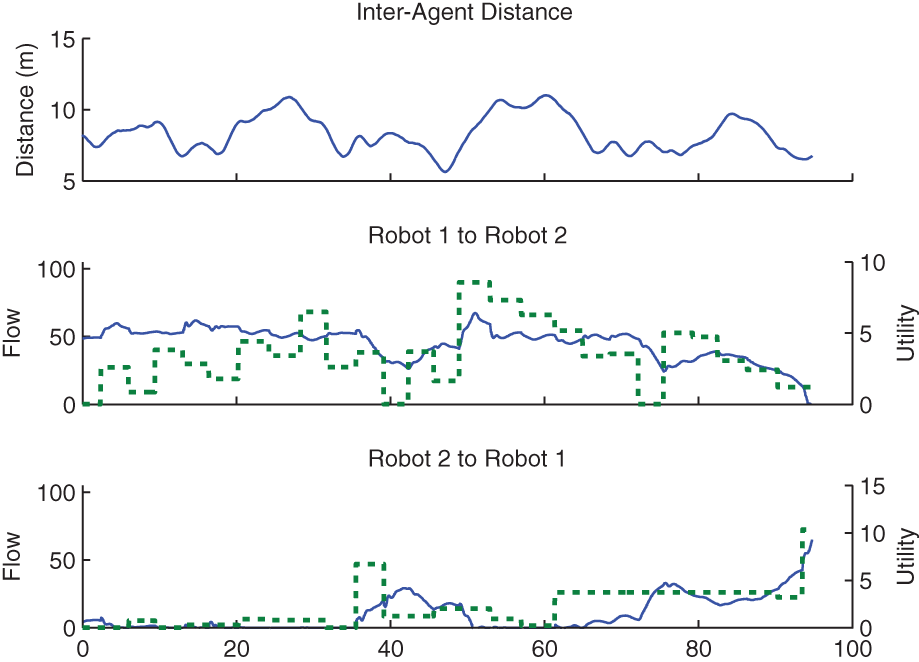
Inter-robot flow rates and sensor utility over time for the dynamic flow case of the two-robot experiment. In the first plot, the inter-robot distance is shown. In the lower plots, flow rate is shown as solid lines and sensor utility is shown as dotted lines. Flow rate varies with utility and available bandwidth varies with inter-robot distance.
Average flow rates and Sensor Utility for the two-robot Experiment.

6.4. Three-sensor-node experiment
We also evaluated our approach in a more complex scenario. This scenario involves the two robots from the previous experiment with the addition of a stationary camera. The aim of this three-sensor-node scenario is to show the generality of our method and to emphasize the multicast behavior of dynamic information flow.
6.4.1. Experimental setup:
In this scenario, the two robots are aided in tracking by a Prosilica GC2450 camera acting as a bearing-only sensor. The camera is positioned outside the tracking region of interest opposite the robots. The camera sends raw images to Robot 2 which processes the images and shares the observations with Robot 1. Hence, wireless communication is required for three links: 1) the link from the camera to Robot 2, 2) the link from Robot 1 to Robot 2 and 3) the link from Robot 2 to Robot 1. In the experiment, the robots remained stationary. This does not affect the results of the demonstration since separation distance is ignored in this scenario. Simulation results with moving robots in a similar setup are shown later in Section 6.5.
The network diagram is shown in Figure 22. The experiment assumes that available bandwidth is sufficient for the two mobile robots to share observations. However, if images are received from the static camera then the wireless network becomes congested. The camera provides accurate tracking when the target is in its proximity and inside its field-of-view. Dynamic flow is expected to allow images to be sent from the camera in such a situation. The extra flow from the camera has to be accompanied by a simultaneous reduction of flow in the other links sharing the medium.
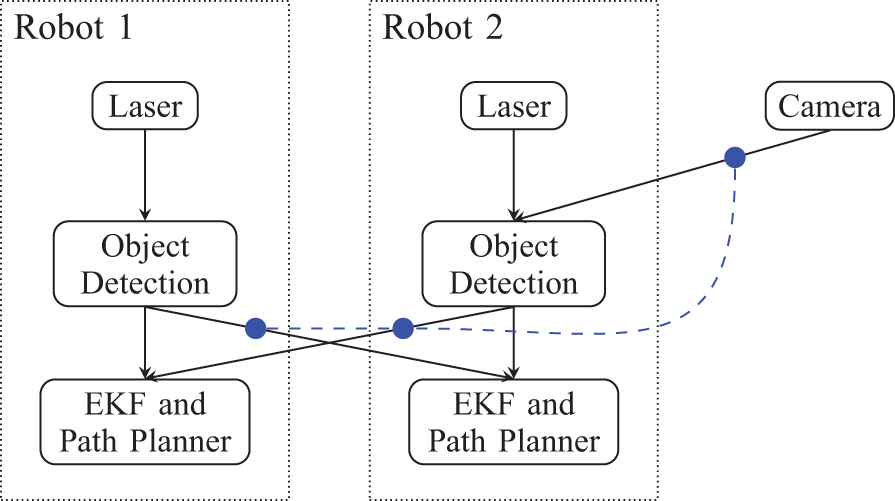
The threshold-DIF diagram for the three-sensor-node scenario. Virtual links are omitted for clarity.
All three communication methods were tested. In the unconstrained communication case, images from the camera were sent to Robot 2 for processing and caused congestion in the wireless network. The bandwidth limits on the wireless network effectively reduced the image transfer rate and consequently diminished the advantage of the unconstrained case.
6.4.2. Results:
The information value for each of the robots’ estimates is plotted over time in Figure 24 with the corresponding average bars shown in Figure 25. The figures show that the dynamic case outperforms down-sampling for both robots. They also show better performance for the dynamic case in comparison to the unconstrained case for Robot 1, since the unconstrained case would have failed to produce the desired communication due to infrastructure bandwidth limitations. The results for Robot 2 show similar performance between the dynamic case and the unconstrained case.
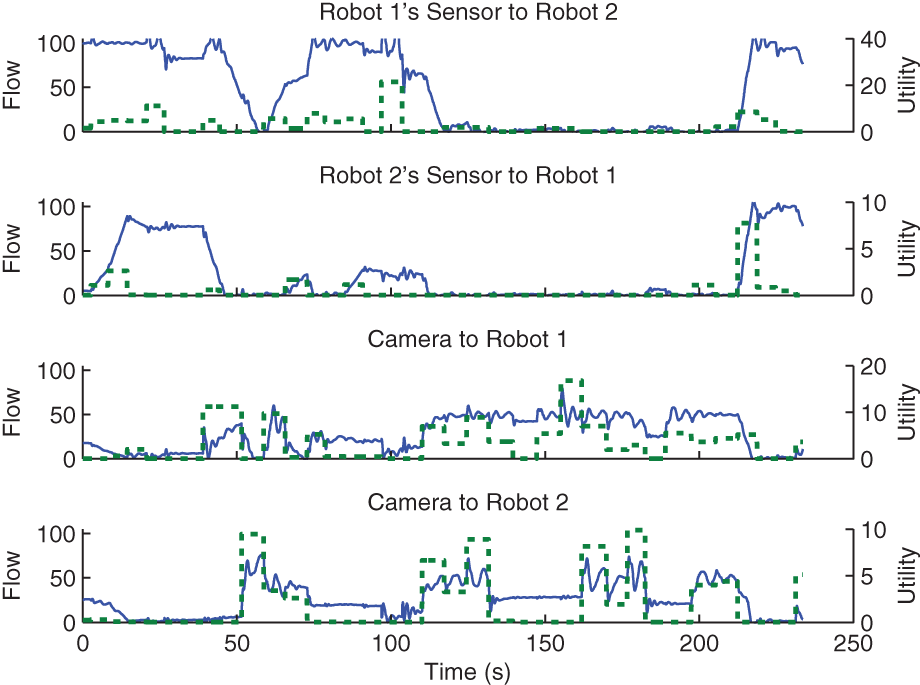
Inter-robot information flow and sensor utility over time for the dynamic flow case of the three-sensor-node experiment. Flow rates are shown in solid lines; sensor utility is shown in dashed lines. Based on the bandwidth constraints and the camera’s data rate, 50 is the maximum flow available for the data sourced from the camera. At approximately 120 s, communication from the camera interrupts communication between robots due to the increased utility of camera observations.
The information value (negative entropy) of the robots’ target estimate for the three-sensor-node experiment. Plots are shown for all three communication methods: unconstrained, down-sampled and dynamic.
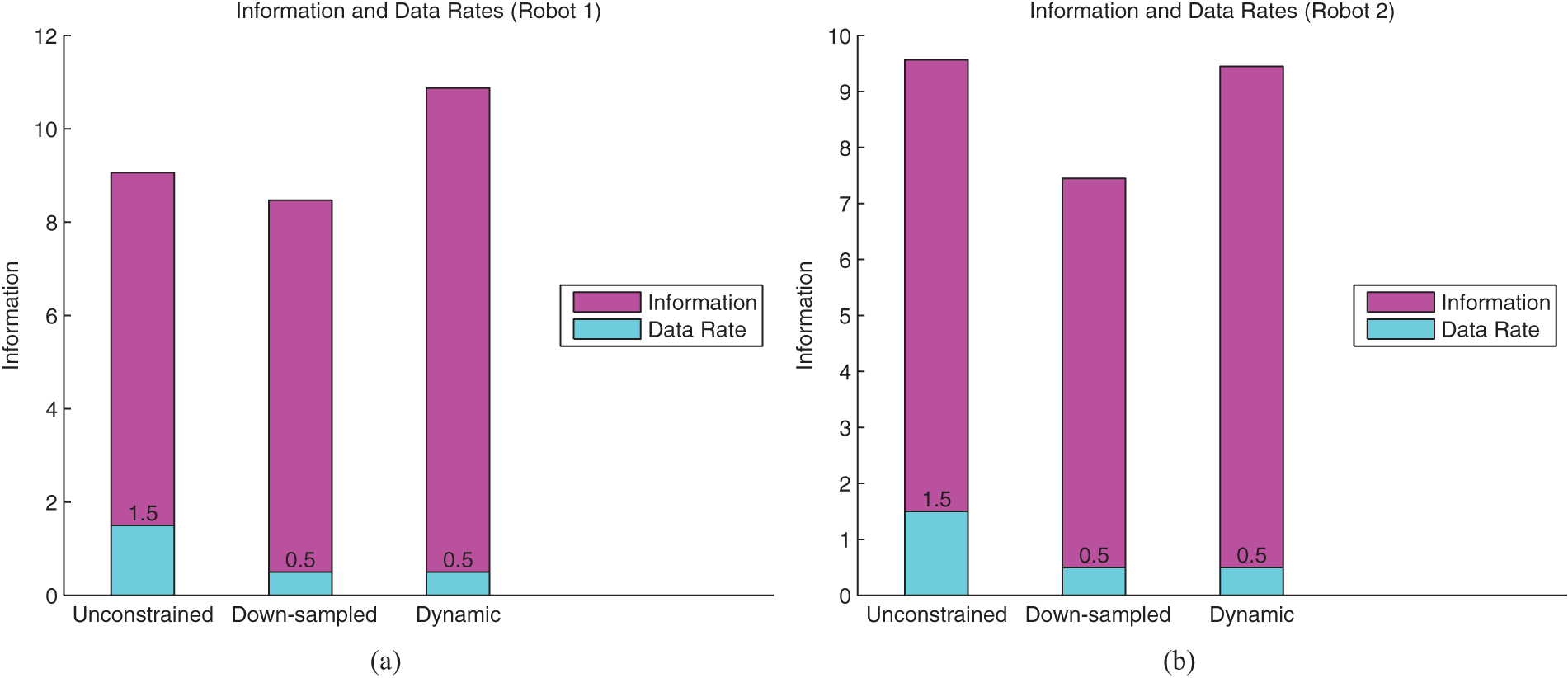
Time averages of the plots in Figure 24 shown in bar format. Data rates are shown superimposed. The dynamic information flow case has high average information gain performance with low average data rate.
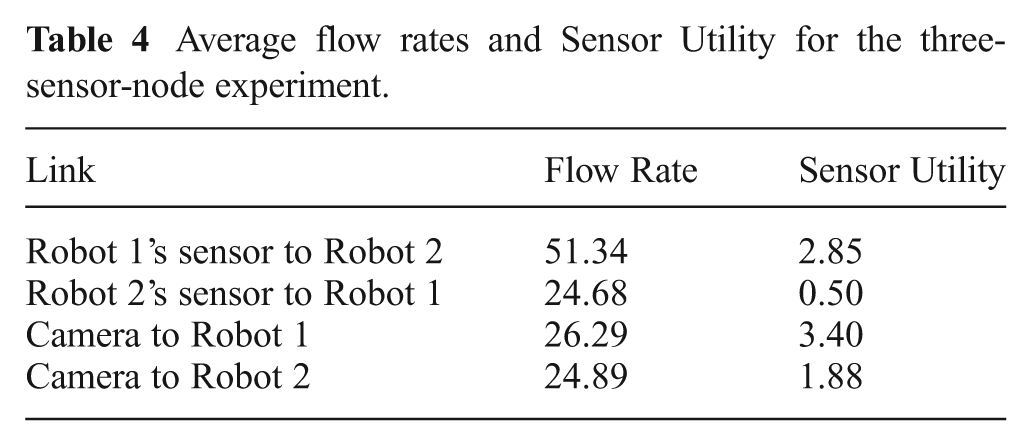
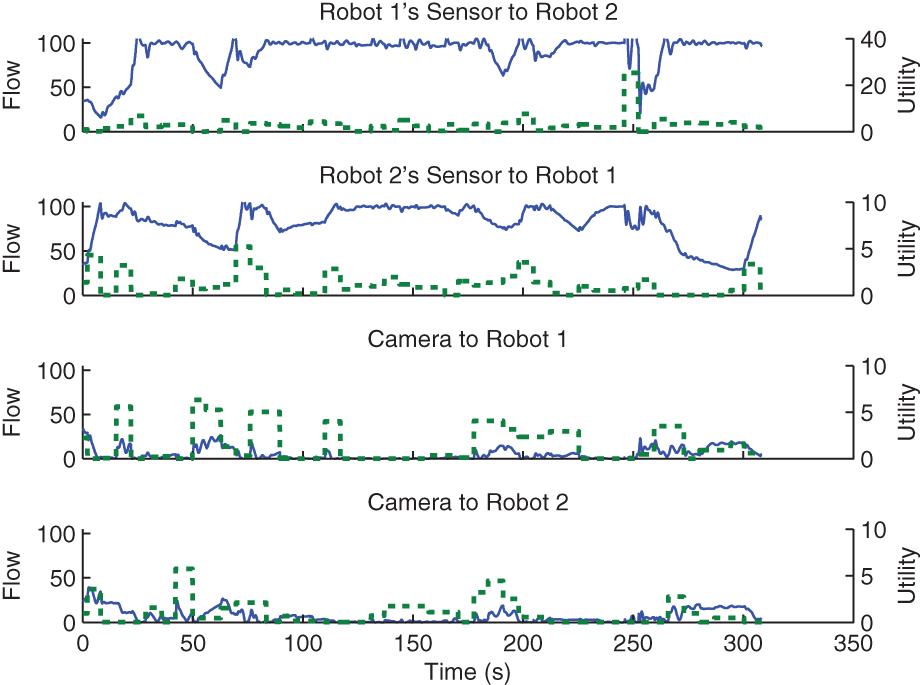
One of the main objectives of this experiment is to highlight the multicast behavior. Multicast behavior can be observed by analyzing the bottom two plots of Figure 23. At times 80 s, 150 s and 190 s, the flow from the camera to Robot 2 retains a high value even though the camera utility for Robot 2 is low during those times. Robot 2 receives these observations without inducing additional cost since observations destined to Robot 1 are processed on-board Robot 2. Robot 1 receives these observations due to their high utility for Robot 1 but these observations must be processed on-board Robot 2 according to the system architecture. Multicast routing ensures that such flow does not get tallied twice. The top two plots confirm that the system obeys the bandwidth limits as the drop in flow takes place concurrently with the rise in flow from the camera. It should be noted that the maximum possible flow from the off-board stationary camera is only 50 units according to bandwidth bounds. The flow rate and sensor utility averages are shown in Table 4.
Average flow rates and Sensor Utility for the three-sensor-node experiment.
These results also validate the maximum flow approximation of total flow. The flow in each of the inter-robot links shown in the top two plots in Figure 23 holds data to only one destination. Therefore, there is no error arising from the maximum flow approximation for those links. The link from the camera holds data destined to both robots. At instances when the camera link is at zero or at maximum flow, there is no loss due to the maximum flow approximation. Also, the number of destinations in this case is two and hence the loss calculated from (19) is at most 25% of maximum flow for all other instances.
6.5. Three-sensor-node simulation
We repeated the experiment presented in Section 6.5 in simulation. Here, we allow robots to move in order to improve tracking performance.
6.5.1. Experimental setup:
The experimental setting is similar to that of Section 6.4. Sensor output was only simulated through point observations. Therefore, no raw images were involved and the raw-data communication rate was fictitious. In a similar manner to the hardware case, communication is required for the links between the robots as well as the link from the camera.
The network diagram for this experiment is the same as shown earlier in Figure 22. Through dynamic information flow, the camera is expected to selectively interrupt communication between the two robots in order to send its images based on the benefit of its observations as evaluated by the robots.
The simulation was run for all three communication methods. The unconstrained communication method is naturally expected to produce higher information gain since the bandwidth bounds are not enforced due to the fictitious data rates.
6.5.2. Results:
The bottom two plots shown in Figure 26 highlight an aspect of multicast behavior different to that highlighted by the hardware analogue of this simulation. When only one robot evaluates a higher utility for camera observations, such as at times 120 s, 150 s and 220 s, no significant change in flow is observed. However, when both robots evaluate an improvement in the utility, the increase in the flow from the camera can be clearly seen.
Information flow and sensor utility for the three-sensor-node simulation. Flow rates and sensor utility are represented as in Figure 23. The maximum flow rate available for the data sourced from the camera is assumed to be 50. Flow rates vary with sensor utility.
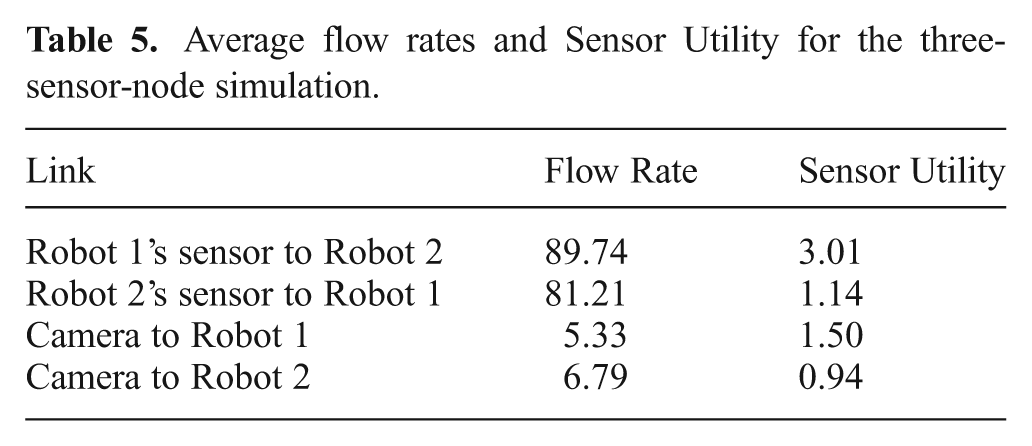
The information value of the robots’ target estimates over time is shown in Figure 27 with the corresponding average bars shown in Figure 28. As expected, unconstrained communication results in higher information on average. However, this communication setting violates the bandwidth bounds. Nevertheless, Figure 28 shows that the dynamic case outperforms the down-sampled case for both robots. Figure 27 shows that the dynamic case dominates the down-sampled case at time 70 s, between times 150 s and 200 s and between times 250 s and 300 s. Observations were received from the camera at these times for the dynamic flow case (as can be seen in Figure 26). These times correspond to the configuration where the target enters the camera’s field of view and becomes closer to the camera than the mobile robots. The flow rate and sensor utility averages are shown in Table 5.
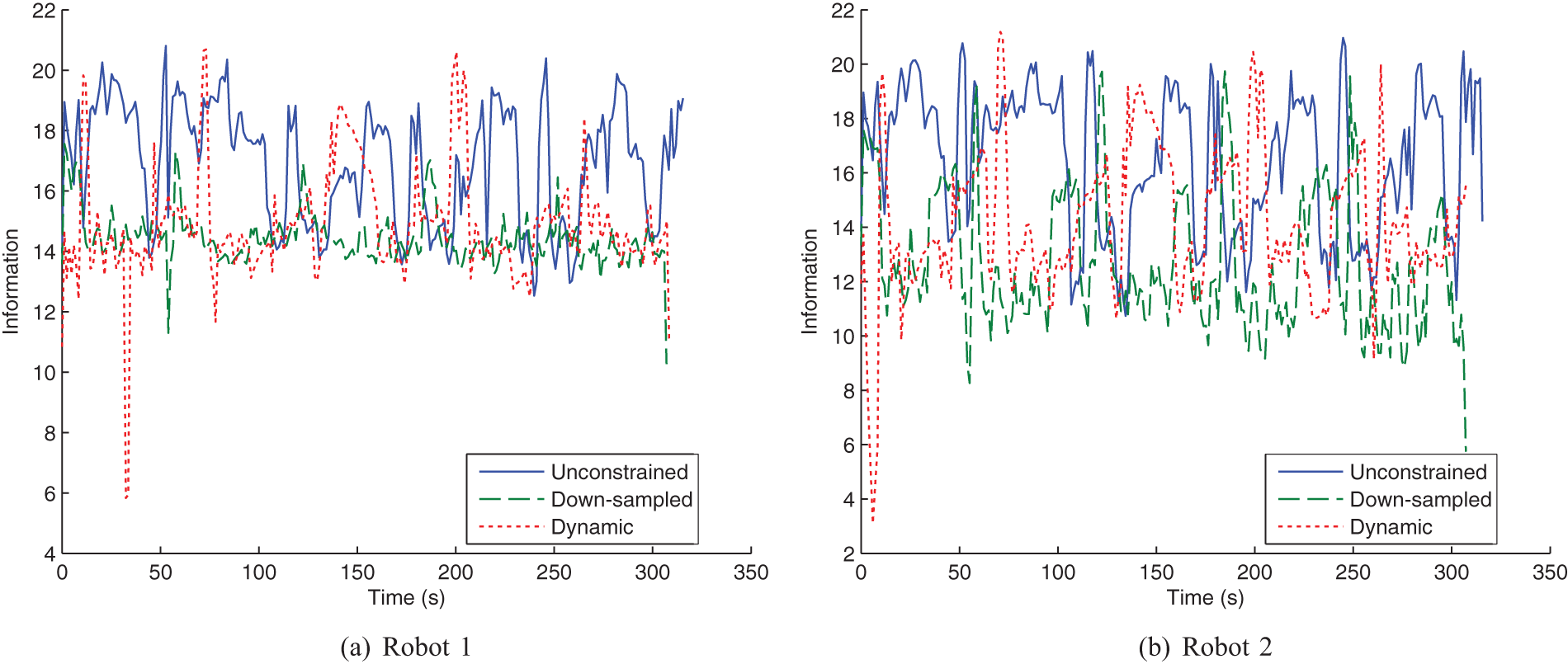
The information value (negative entropy) of the robots’ target estimate for the three-sensor-node simulation. Plots are shown for all three communication methods: unconstrained, down-sampled and dynamic.
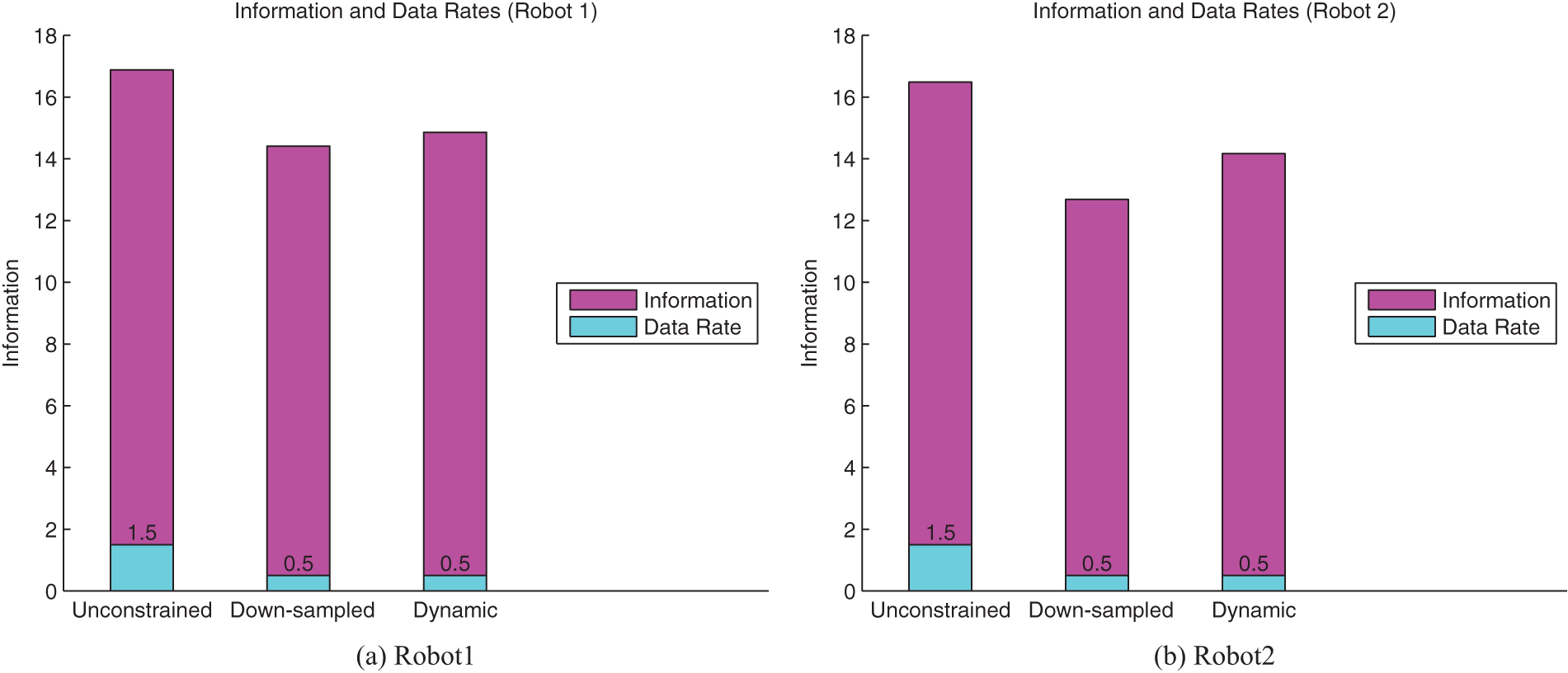
Time averages of the plots in Figure 27 shown in bar format. The data rates are shown superimposed. The improvement for Robot 2 achieved by dynamic communication over down-sampling using the same communication rates is clearly observed. The unconstrained method violates the bandwidth constraints and is only included as a benchmark.
Average flow rates and Sensor Utility for the three-sensor-node simulation.
Similar to the hardware case, we note there is no error arising from the maximum flow assumption in the links between the two robots. The loss occurring in the link from the camera is negligible.
6.6. Multiple-node simulation
We demonstrated our decentralized algorithm on a simulated 15-node threshold-DIF network. The purpose of the simulation is to demonstrate our approach for a problem that is not amenable to manually designed communication protocols.
The simulated network comprises five agents each equipped with a sensor, a processor and an estimator. The network has a fully connected topology such that each sensor is connected to all processors and each processor is connected to all estimators. The agents are spatially distributed evenly in a linear manner. Each sensor is assumed to produce data at a rate of 100 units. A global communication constraint of 500 units was applied. In addition, a per-link capacity constraint of 200 units was applied to each processor–estimator link. Sensor utilities were externally randomized and provided to the estimators.
Figure 29 displays, in chronological order, the routing state of the network at various time instances throughout the simulation. Each column represents one agent equipped with a sensor, processor and estimator. This configuration is a matter of choice rather than a restriction of the algorithm. The links shown in the figure represent those that carried more than 10 units of data during the simulation. The figure demonstrates the shift of flow from one part of the network to another as the sensor utilities change. More importantly, the routing states shown would be difficult to determine based merely on intuition.
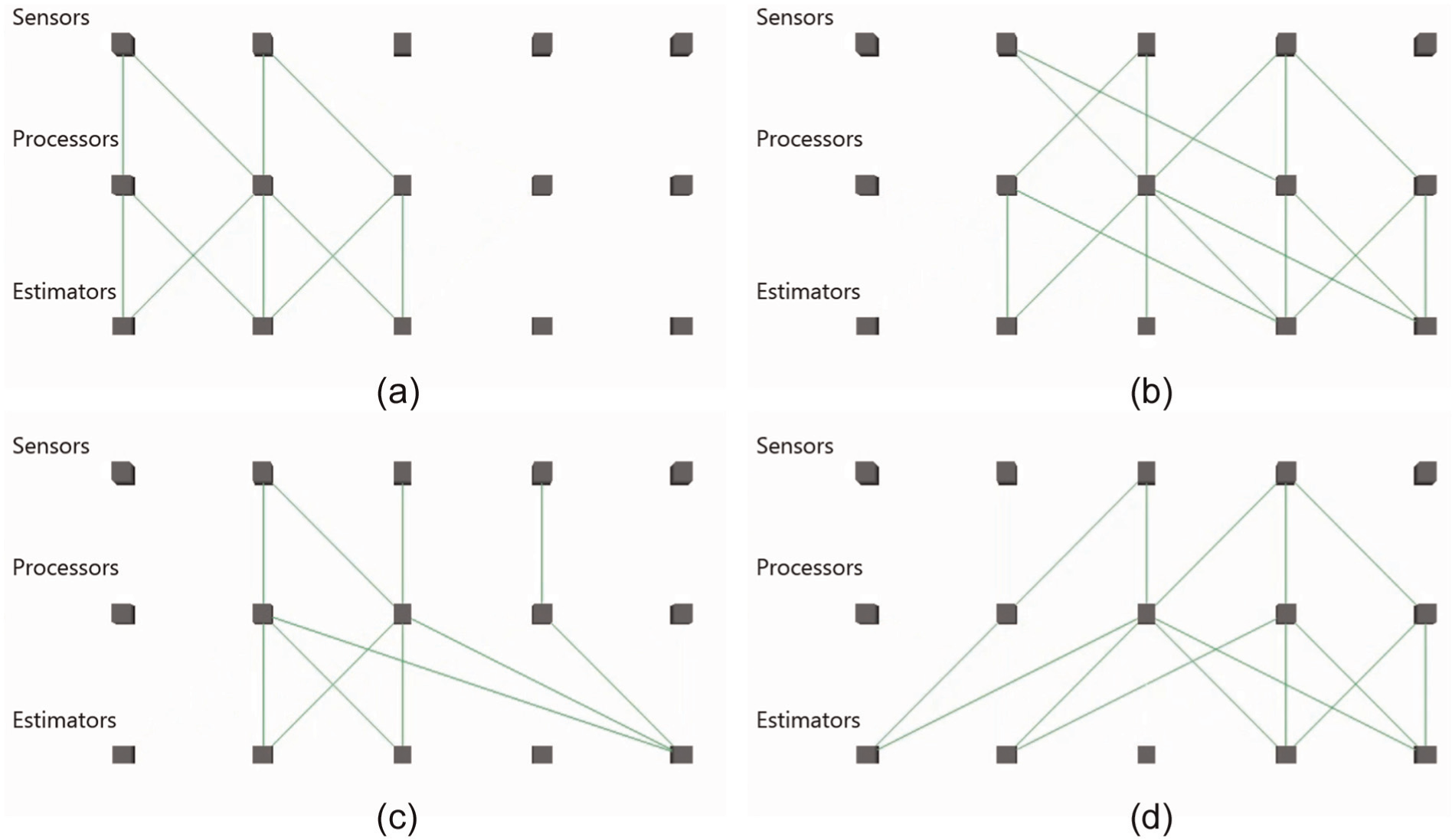
Routing state of multiple-node simulation at various times depicting active wireless links. Each column represents one agent equipped with a sensor, processor and estimator. Active links are represented by green lines. A link is considered active if it holds more than 10 units of data flow.
6.7. Monte Carlo simulation
To validate the performance of dynamic information in comparison to down-sampling, we conducted a Monte Carlo simulation for the experimental setting of Section 6.3. The aim of the simulation is to analyze the statistical significance of performance improvement due to our solution to threshold-cost-DIF.
The results of the Monte Carlo simulation are shown in Figure 30 in box-plot format. For each communication method, we ran 20 randomly initialized trials running for 1 min each. The results shown assume each trial as one sample. Dynamic communication outperforms down-sampling with p-value of less than 0.03 based on Welch’s t-test.
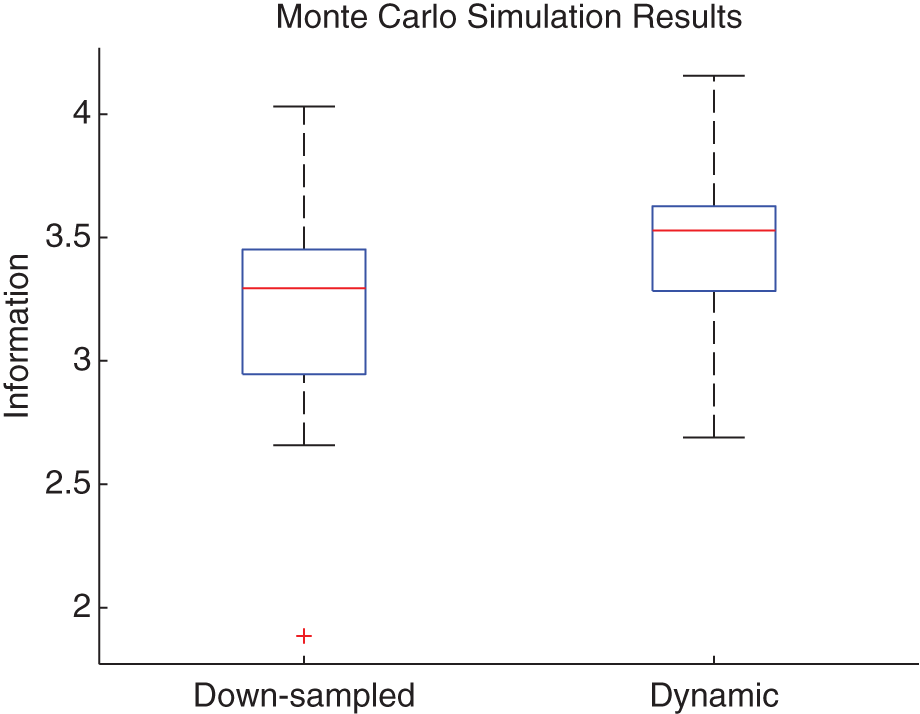
Monte Carlo simulation results comparing down-sampling with dynamic information flow. Each method was tested on the two-robot scenario for 20 trials running for 1 min each. In the results depicted, a trial acts as one sample. The box extents represent the first and third quartiles, while the whiskers represent the extrema. The median is represented by the horizontal line inside the box.
7. Discussion of sensor utility estimation
An essential component in addressing dynamic information flow is the estimation of sensor utility. In this section, we discuss our implementation of sensor utility estimation, its limitations and possibilities for improvement.
In our implementation, an estimator approximates sensor utility by evaluating the most recent sensor observation received. The value of the observation is computed as the reduction in entropy realized by fusing the observation into the estimator. This approach is advantageous due to the simplicity of implementation. Entropy reduction can be computed efficiently without additional data storage. The disadvantage of this approximation is that it is myopic; it only reflects the instantaneous effect of a sensor observation on the information gathering performance of a single robot. Myopic approximations such as this are commonly used since the long-term value of a sensor observation can be difficult to compute in the general case (Williamson et al., 2009). Alternatively, robots could learn the utility of an observation from other robots, as in Xu et al. (2013a). This approach is suited to homogeneous systems with sufficient capacity for the extra computational overhead necessitated by the learning process.
For non-myopic sensor utility estimation, the value of a shared observation should be evaluated according to that observation’s impact on the actions of other robots. Consider the following example where two moving robots track two moving targets. Suppose that the targets are far apart and each robot is only tracking one target. The observation from the first robot still induces an information gain in the second robot’s estimator in this case. However, the observation is of little value to the second robot because this additional information does not affect the second robot’s choice of viewpoint in the immediate future. The second robot can always receive the latest target estimate, which is an accumulation of past observations, from the first robot when needed. Therefore, in a non-myopic approach the value of an observation should not be based purely on information gain but rather on its effect on decision-making. Non-myopic estimation can improve the performance of DIF algorithms but is beyond the scope of the paper.
The submodularity of mutual information has been recently used to provide near-optimal solutions to the sensor selection problem (Golovin and Krause, 2011). However, the submodularity property does not hold for information gathering tasks with dynamic environments (Williams, 2007), which is the case of interest in this paper.
8. Conclusions and future work
We have introduced the dynamic information flow problem and defined two variants, min-cost-DIF and threshold-DIF. We proposed an efficient decentralized solution for each variant that allows heterogeneous decentralized information gathering teams to dynamically decide when and where sensor information should be transmitted. We expect this work to be of value in a broad range of application areas in and beyond robotics. For example, agriculture and environmental monitoring robotics involves problems in coordination and estimation for multiple robots with high-data-rate sensors that would benefit from efficient use of limited communication bandwidth. Our work can also be beneficial to automated personnel and equipment tracking systems in geographically large areas such as ports and mines.
In min-cost-DIF, robots determine flow rates based on information value, communication costs and computation costs. Our solution to min-cost-DIF was adapted from recent results in multicast routing, which we extended to allow for negative link costs that represent sensor utility. This solution was demonstrated in simulation for a system of two mobile robots and was also demonstrated experimentally and in simulation for the case of one mobile robot with access to an off-board processing station. The scalability of our solution was empirically evaluated in a simulation with up to 28 nodes.
In threshold-DIF, flow rates are optimized based on the value of information while obeying local computation limits and global communication limits. Our solution to threshold-DIF is based on a distributed version of ADMM that requires neighbor-to-neighbor communication only. We proved that the convergence time of our solution is polynomial in the size of the network. The benefits of this solution were demonstrated in simulation and hardware demonstrations with two mobile robots and two robots plus a stationary camera.
Our results have shown empirically that judicious adjustment of flow rates can improve information gathering performance. We focused on experimental systems with high-data-rate sensors that can easily overwhelm a standard wireless network. We have begun to explore scalability to larger networks in simulation, but the general issue of scalability and performance in large real-world networks (greater than 10 nodes) is an important area of future work.
Another interesting avenue to pursue is to consider further variants of the general DIF problem. For example, we would like to extend the cases considered in this paper, which address sensor-to-estimator communication, to include estimator-to-controller communication. This extension would introduce a new DIF variant for unified communication-aware information gathering and is of particular importance to applications that involve large amounts of data exchange for both estimation and control. The challenges of communication efficiency for control have traditionally been studied in the context of team decision theory in terms of information structure optimization (Ho, 1980). The difficulty of information structure optimization would complicate its integration with DIF, mainly due to the non-linearity of the control objective as a function of communication decisions. However, if communication costs are readily specified, as assumed in the case of min-cost-DIF, then the integration of our previous communication-efficient control method (Kassir et al., 2012), which also takes communication costs as input, can be made possible. This integration would require simplifying assumptions such as the separation between estimation and control, for example.
The performance of our solutions to DIF could be further improved through an accurate non-myopic sensor utility estimate. A possible solution to non-myopic sensor utility estimation might include employing machine learning techniques that learn the sensor utility as a function of the platform state. It is also interesting to consider cases where sensor utility estimates change rapidly, and to explore the sensitivity of DIF algorithms to such high frequency changes.
Another desirable future advancement would be to extend our current distributed solution to threshold-DIF to obtain an any-time feasible solution. Any-time feasibility might be achieved through the adaptation of feasibility projection methods from optimization theory.
In our current implementation, the identities of the nodes in the network need to be globally known. We envisage that this is not a necessary requirement and can be replaced by an automated discovery process. Nodes can advertise their types and then run a handshaking procedure with appropriate nodes before establishing connections.
Footnotes
Acknowledgements
We would like to thank Professor Stephen Boyd for his helpful advice on ADMM. We would also like to thank James Underwood, Zhe Xu, Suchet Bargoti, Joseph Nguyen, Marcos Castro, Tim Patten and Mark Calleija for their help in conducting the experiments.
Funding
This work is supported in part by the Australian Centre for Field Robotics and the New South Wales State Government.