
Abstract
We propose a decentralized variant of Monte Carlo tree search (MCTS) that is suitable for a variety of tasks in multi-robot active perception. Our algorithm allows each robot to optimize its own actions by maintaining a probability distribution over plans in the joint-action space. Robots periodically communicate a compressed form of their search trees, which are used to update the joint distribution using a distributed optimization approach inspired by variational methods. Our method admits any objective function defined over robot action sequences, assumes intermittent communication, is anytime, and is suitable for online replanning. Our algorithm features a new MCTS tree expansion policy that is designed for our planning scenario. We extend the theoretical analysis of standard MCTS to provide guarantees for convergence rates to the optimal payoff sequence. We evaluate the performance of our method for generalized team orienteering and online active object recognition using real data, and show that it compares favorably to centralized MCTS even with severely degraded communication. These examples demonstrate the suitability of our algorithm for real-world active perception with multiple robots.
Keywords
1. Introduction
Information gathering is an important family of problems in robotics that plays a primary role in a wide variety of tasks, including scene understanding (Fäulhammer et al., 2017), manipulation (Kahn et al., 2015), environmental monitoring (Dunbabin and Marques, 2012), and target localization (Cliff et al., 2015). Although the idea of exploiting robot motion to improve the quality of information gathering has been studied for nearly three decades (Bajcsy, 1988; Bajcsy et al., 2017), most real robot systems today (both single and multi-robot) still gather information passively. The motivation for an active approach is that sensor data quality (and, hence, perception quality) relies critically on an appropriate choice of viewpoints (Patten et al., 2016). One way to efficiently achieve an improved set of viewpoints is through teams of robots, where concurrency allows for scaling up the number of observations in time and space. The key challenge, however, is to coordinate the behavior of robots as they actively gather information. Ideally, this coordination should be decentralized so that the system is scalable and robust to failures. This paper presents an online, decentralized planning algorithm for active perception that allows a team of robots to perform complex information gathering tasks using physically feasible sensor and motion models, and reasonable communication assumptions.
Monte Carlo tree search (MCTS) is a promising approach for online planning because it efficiently searches over long planning horizons and is anytime (Browne et al., 2012; Kocsis and Szepesvári, 2006). MCTS is applicable to general problem formulations but can readily incorporate problem-specific heuristics. Recently, MCTS has been successfully applied to robotics scenarios such as active object recognition (Patten et al., 2017), wildlife monitoring (Hefferan et al., 2016), and planetary exploration (Arora et al., 2017). These studies were for single-robot problems, whereas in this paper we propose a new planning algorithm that is a viable solution for all of these scenarios extended to multi-robotteams.
In this paper we propose a new decentralized planning algorithm, Dec-MCTS, that is essentially a novel decentralized variant of MCTS. At a high level, our method alternates between exploring each robot’s individual action space and optimizing a probability distribution over the joint-action space. In any particular round, we first use a new variant of MCTS to find locally favorable sequences of actions for each robot given probabilistic estimates of other robots’ actions that evolve during planning time. The main novelty is our new tree expansion policy, motivated by discounted upper confidence bound (D-UCB) (Garivier and Moulines, 2011), that accounts in general for changing reward distributions.
Then, robots periodically attempt to asynchronously communicate a highly compressed version of their local search trees that, together, correspond to a product distribution approximation. These communicated distributions are used to estimate the underlying joint distribution for the teams’ plan. The estimates are probabilistic, unlike the deterministic representation of joint actions typically used in multi-robot coordination algorithms. Optimizing a product distribution is similar in spirit to the mean-field approximation from variational inference, and also has a natural game-theoretic interpretation (Rezek et al., 2008; Wolpert and Bieniawski, 2004).
Our algorithm is a powerful new method of decentralized coordination for any objective function defined over the robot action sequences. Notably, this implies that our method is suitable for complex perception tasks such as object classification, which is known to be highly dependent on the viewpoint (Patten et al., 2016). Further, communication is assumed to be intermittent, and the amount of data sent over the network is small in comparison with the raw data generated by typical range sensors and cameras. Our method also inherits important properties from MCTS, such as the ability to compute anytime solutions and to incorporate prior knowledge about the environment. Moreover, our method is suitable for online replanning to adapt to changes in the objective function or team behavior.
We provide an extensive theoretical analysis of the algorithm that leverages results from probability theory and game theory. Our main analytical result is to show convergence rates for the expected payoff at the root of the search tree towards the optimal payoff sequence. Thus, the proposed MCTS tree expansion policy balances exploration and exploitation while the reward distributions are changing. This result is proven by extending the MCTS analysis of Kocsis et al. (2006) for the context of switching bandit problems (Garivier and Moulines, 2011). Our second analytical result leverages the work of Wolpert et al. (2006) to show that the product distribution optimization phase locally minimizes the Kullback–Leibler (KL) divergence to the optimal joint probability distribution. Although, given the difficulty of the problem, these results do not directly yield guarantees for global optimality, the analysis provides strong motivation for the use of these components in our algorithm for decentralized, long-horizon planning with general objective function definitions.
We empirically evaluate our algorithm in two scenarios: generalized team orienteering and active object recognition. These experiments are run in simulation, where the robots traverse a probabilistic roadmap (PRM) with a Dubins motion model, and the second scenario uses range sensor data collected a priori by real robots. We show that our decentralized approach performs as well as or better than centralized MCTS even with a significant rate of communication message loss. We also show the benefits of our algorithm in performing long-horizon and online planning.
1.1. Contributions
In this paper we propose a new multi-robot planning algorithm that is decentralized, admits a general class of objective functions, optimizes actions over a long planning horizon, is anytime, robust to communication degradation, and is suitable for online replanning. The algorithm is a novel decentralized variant of MCTS, which features a new tree expansion policy suitable for our context, and combines MCTS with a probabilistic distributed optimization approach inspired by variational methods. We provide a theoretical analysis and empirical results that demonstrate the suitability of our planning algorithm for coordinated information-gathering tasks.
This paper is an extended and revised version of Best et al. (2016) presented at WAFR 2016. The main new contribution is a theoretical analysis of the key MCTS component of our algorithm by relating it to a new multi-armed bandit (MAB) problem. In addition, we provide an extended review of related literature, expanded algorithmic details, a discussion of generalizations for probabilistic objectives, and implementation details.
The remainder of this paper is organized as follows. Section 2 discusses related work in decentralized planning, MCTS, variational methods, and non-myopic planning. Section 3 defines the decentralized planning problem. Section 4 presents our proposed Dec-MCTS algorithm. Section 5 provides a theoretical analysis of Dec-MCTS, with proofs of intermediate results provided in the Appendix. Sections 6 and 7 present an empirical analysis of our algorithm for two example active perception problems. Finally, Section 8 concludes the paper and discusses future work.
2. Related work
2.1. Decentralized information gathering
Information-gathering problems can be viewed as sequential decision processes in which actions are chosen to maximize an objective function. The computational burden of decentralized coordination is typically overcome by using myopic solvers which maximize the objective function over a limited time horizon (Xu et al., 2013; Gan et al., 2014). Unfortunately, the quality of solutions produced by myopic methods can be arbitrarily poor in general. Recently, however, analysis of submodularity (Nemhauser et al., 1978) has shown that myopic methods can achieve near-optimal performance (Krause et al., 2008), which has led to considerable interest in their application to information gathering with multiple robots (Garg and Ayanian, 2014; Hollinger et al., 2009; Patten et al., 2013; Singh et al., 2009). Whereas these greedy methods provide theoretical guarantees, they require a submodular objective function, which is not applicable in all cases. In addition, whereas these methods often guarantee lower bounds on optimality, the solution quality can typically be improved by planning over longer horizons. Similarly, for simplified problems that only require selecting one action per robot rather than sequences of actions, decentralized task allocation approaches are often sufficient (Liu et al., 2015).
Efficient non-myopic decentralized coordination algorithms can be designed by exploiting problem-specific characteristics. Market-based methods (Dias et al., 2006) involve each robot negotiating over which tasks it will perform, and are more appropriate for coverage and exploration problems (Zlot et al., 2002). Sadeghi and Smith (2017) applied an auction method with traveling salesman problem (TSP) heuristics to a problem formulated as a generalization of the TSP. Stranders et al. (2009) combined max-sum message passing with branch and bound pruning to find sequences of viewpoints that minimize the entropy of a Gaussian process. Otte and Correll (2013) proposed a distributed rapidly exploring random tree (RRT) algorithm for coordinated path planning with collision avoidance. The authors demonstrated a graceful degradation of performance as communication becomes less reliable, and we observe a similar behavior with our Dec-MCTS algorithm. Corah and Michael (2017) proposed a distributed sequential greedy assignment algorithm for multi-robot exploration, and provided performance guarantees by exploiting a submodularity assumption. Atanasov et al. (2015) propose a decentralized algorithm for tracking targets that have linear Gaussian dynamics, such as for active simultaneous localization and mapping (SLAM). Our proposed algorithm is applicable to a general class of problems since it does not rely on specific assumptions about the problem; however, our approach can readily incorporate problem-specific approximate solutions, such as those above, as heuristics to guide the search.
2.2. Dec-POMDPs
Decentralized active information gathering can be viewed, in general, as a partially observable Markov decision process (POMDP) in decentralized form (Dec-POMDP) (Bernstein et al., 2002; Oliehoek and Amato, 2016). Typically, Dec-POMDP formulations are solved by performing centralized, offline planning over the joint multi-agent policy space, and then these policies are executed online in a decentralized fashion (Amato, 2015; Kumar et al., 2015; Oliehoek and Amato, 2016; Omidshafiei et al., 2017). These centralized, offline planning approaches are impractical in scenarios with large sources of uncertainty, such as when the state of the environment is unknown ahead of time.
In contrast, Spaan et al. (2006) addressed a Dec-POMDP problem setting where both planning and execution are performed in a decentralized manner; we solve our problem in a similar decentralized setting such that computation is performed online and on-board the team of robots. Spaan et al. (2006) proposed a general Dec-POMDP solver where each agent solves a single-agent POMDP, shares information about its own plan, then repeats. At a high level, our algorithm is similar to this general approach, but we differ in how we share information, and we propose solving the single-agent subproblems with an anytime, incremental planner that can account for changing information about the teams’ plan in a principled manner.
While the problem definition we consider in this paper is not formulated as a Dec-POMDP in general form, extended algorithms for the Dec-POMDP case could be designed by using partially observable Monte Carlo planning (POMCP) (Silver and Veness, 2010).
2.3. MCTS
MCTS has recently become popular for online planning in robotics. MCTS has been proposed in many different forms (Browne et al., 2012), but by far the most common is the upper-confidence bounds applied to trees (UCT) algorithm (Kocsis and Szepesvári, 2006; Kocsis et al., 2006). The UCT algorithm performs an asymmetric expansion of a search tree using a best-first policy that generalizes the UCB1 policy for MAB problems (Auer et al., 2002). This expansion policy provides theoretical guarantees for a polynomial bound on regret and therefore is said to balance between exploration and exploitation. Several variants to UCT have been proposed, such as for exploiting smoothness of the reward function (Coquelin and Munos, 2007). A key component of our proposed Dec-MCTS algorithm is a novel UCT variant, D-UCT, that accounts for a changing reward distribution by using a new expansion policy that generalizes the D-UCB policy for switching bandit problems (Garivier and Moulines, 2011). MCTS algorithms have also been extended for problems with partial-observability, such as the POMCP (Silver and Veness, 2010) and DESPOT (Somani et al., 2013) algorithms, and Dec-MCTS could be extended in a similar way. However, MCTS has not yet been extended for decentralized multi-agent planning, which is the focus of this paper.
MCTS is parallelizable (Chaslot et al., 2008), and various techniques have been proposed that split the search tree across multiple processors and combine their results. In the multi-robot case, the joint search tree interleaves actions of individual robots and it remains a challenge to effectively partition this tree. Auger (2011) addressed the related case of multi-player games, where a separate tree is maintained for each player; however, a single simulation traverses all of the trees and therefore this approach would be difficult to decentralize. We propose a similar approach, except that each robot performs independent simulations while sampling from a locally stored probability distribution that represents the other robots’ action sequences.
MCTS has been applied to a wide variety of single-robot tasks, including active object recognition (Lauri et al., 2015; Patten et al., 2017), patrolling environments with adversarial agents (Hefferan et al., 2016; Kartal et al., 2015), information gathering by a glider in thermal wind fields (Nguyen et al., 2015), environment exploration (Corah and Michael, 2017; Lauri and Ritala, 2016), autonomous science by planetary rovers (Arora et al., 2017), active parameter estimation for manipulation (Slade et al., 2017), and monitoring of a spatiotemporal process (Marchant et al., 2014). We propose a decentralized MCTS algorithm that is suitable for multi-robot generalizations of all of these problems. So far, MCTS has been less frequently studied in multi-robot scenarios, though promising ideas have been presented by Kartal et al. (2015) for centralized planning of a team of patrolling robots, and by Corah and Michael (2017) as a single-robot planner within a distributed multi-robot assignment algorithm for the context of exploration and mapping.
2.4. Variational methods for planning
Coordination between robots is achieved in our method by combining MCTS with a framework that optimizes a product distribution over the joint action space in a decentralized manner. Our approach is analogous to the classic mean-field approximation and related variational methods (Koller and Friedman, 2009; Rezek et al., 2008; Yedidia et al., 2005). Other graphical model inference techniques, alternative to variational methods, have motivated related coordination algorithms (Kumar et al., 2015; Regev and Indelman, 2016; Stranders et al., 2009).
Variational methods seek to approximate the underlying global likelihood with a collection of structurally simpler distributions that can be evaluated efficiently and independently. These methods characterize convergence based on the choice of product distribution, and work best when it is possible to strike a balance between the convergence properties of the product distribution and the KL divergence between the product and joint distributions. As discussed in the body of work on probability collectives (PC) (Wolpert and Bieniawski, 2004; Wolpert et al., 2006, 2013), such variational methods can also be viewed under a game-theoretic interpretation, where the goal is to optimize each agent’s action selection based on examples of the global reward/utility function.
PC has been applied to robotics problems, but so far has been limited to selecting a single action from a small action space (Waldock and Nicholson, 2007), rather than planning sequences of actions. An exception to this is the work of Kulkarni and Tai (2010), who combined PC with TSP heuristics to solve the multiple-TSP in a decentralized manner. We propose a similar approach to Kulkarni and Tai (2010), but instead we leverage the long-horizon planning of MCTS to dynamically select an effective and compact sample space of action sequences.
2.5. Non-myopic, single-robot planning
Long-horizon planning is also beneficial for single-robot information gathering. As discussed in Section 2.3, MCTS approaches have recently gained popularity. Branch and bound tree search (Binney and Sukhatme, 2012; Best and Fitch, 2016) is closely related to MCTS but requires problem-specific bounds with hard guarantees; in contrast, UCT relies on generally applicable probabilistic bounds derived from the Chernoff–Hoeffding inequality. Active perception problems have also been formulated as TSP variants (Best et al., 2018; Charrow, 2015; Yu et al., 2016). A sampling-based planner has been proposed for exploration and inspection tasks (Bircher et al., 2016). Extensions of RRT have been designed for problems where the environment is naturally modeled as a continuous process (Hollinger and Sukhatme, 2014), e.g. Gaussian processes. Hollinger (2015) extends the RRT approach to be more suitable for real-time planning. In exploration scenarios, imitation learning can be used for planning by learning from examples that have assumed full knowledge of the world (Choudhury et al., 2017). For active object recognition, a primary motivating scenario for Dec-MCTS, planning has typically been limited to greedy approaches (Huber et al., 2012; van Hoof et al., 2014; Wu et al., 2015); MCTS approaches are notable exceptions (Lauri et al., 2015; Patten et al., 2017).
3. Problem statement
We consider a team of R robots
The aim is to maximize a global objective function
The problem must be solved in a decentralized and online setting. We assume that robots can communicate during planning time to improve coordination. The communication channel may be unpredictable and intermittent, and all communication is asynchronous. Therefore, each robot will plan based on the information it has available locally. Bandwidth may be constrained and therefore message sizes should remain small, even as the plans grow. Although we do not consider explicitly planning to maintain communication connectivity, this may be encoded in the objective function
4. Dec-MCTS
In this section, we present our Dec-MCTS algorithm as a decentralized solution to the general multi-robot planning problem. We first provide an overview of the algorithm followed by a detailed explanation of all components.
4.1. Algorithm overview
Dec-MCTS runs simultaneously and asynchronously on all robots; we present the algorithm from the perspective of robot r. The algorithm cycles between the three phases illustrated in Figure 1: (1) incrementally grow a search tree using MCTS while taking into account information about the other robots’ plans; (2) update the probability distribution over possible action sequences; and (3) communicate probability distributions with the other robots. These three phases continue regardless of whether or not the communication was successful, until a computation budget is met.
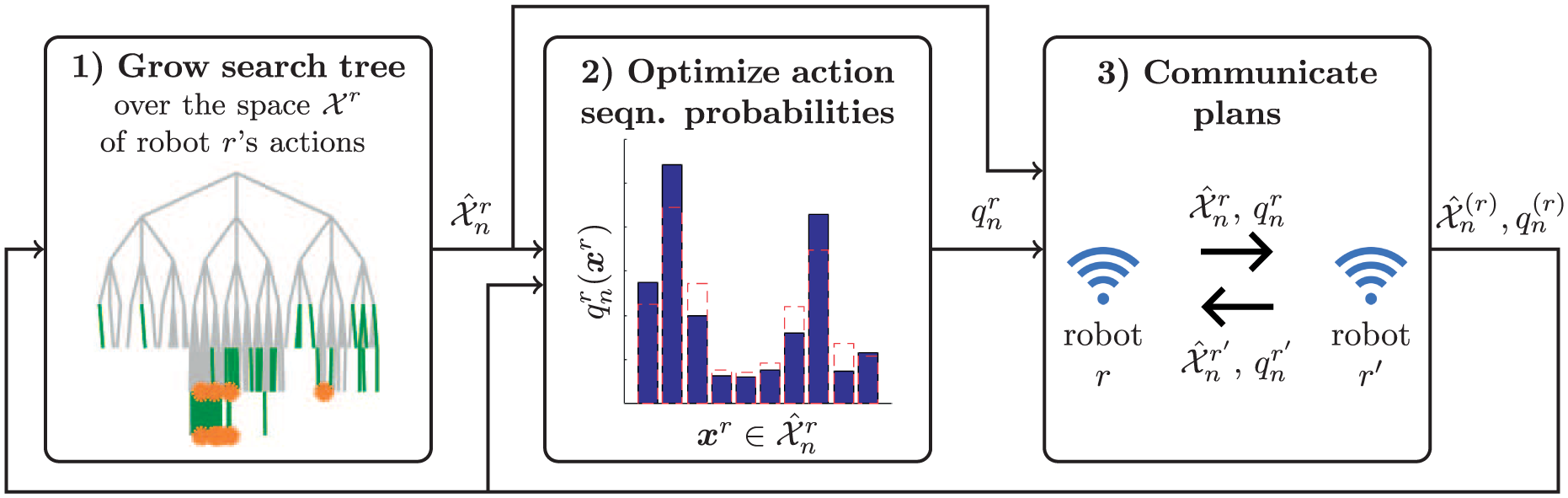
Overview of the algorithm running on-board robot r. (1) The search tree is expanded by adding new actions (green). Periodically, the set of best nodes (orange) is selected as the domain
A key idea of Dec-MCTS is to represent and reason over plans in a probabilistic manner. In particular, robot r ’s current plan is represented by a probability distribution over action sequences. We define a probability mass function
An illustration of the main loop is shown in Figure 1 and pseudocode for the algorithm is provided in Algorithm 1. During the MCTS phase, a search tree

When the computation budget is met, the algorithm returns the action sequence
4.2. Local utility function
The global objective function g is optimized by each robot r using a local utility function
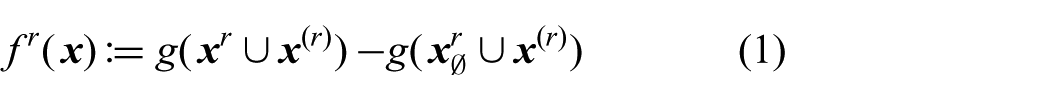
The default sequence
4.3. MCTS with D-UCB
The first phase of the algorithm is the MCTS update shown in Algorithm 2. A single search tree
Standard MCTS incrementally grows a tree by iterating through four phases: selection, expansion, simulation, and backpropagation (Browne et al., 2012). During each iteration t, a new leaf node is added, where each node represents a sequence of actions and contains statistics about the expected reward of all action sequences that begin with this sequence.
The selection phase (Algorithm 2, line 3) selects an expandable node in the tree, where an expandable node is defined as a node that has at least one child that has not yet been visited during the search. In order to find an expandable node, the algorithm begins at the root node i0 of the tree and recursively selects child nodes until an expandable node
In the simulation phase (Algorithm 2, lines 5–7), the expected utility
For our problem, the objective is a function of the action sequence
In the backpropagation phase (Algorithm 2, line 8), the rollout evaluation
4.3.1. D-UCB node selection policy
The node selection policy is used in Algorithm 2, line 3, and dictates the order in which the tree
An established approach for node selection is based on maintaining an upper confidence bound (UCB) on the value of each node. Under this paradigm, at each sample round t, a UCB

This continues recursively until an expandable node is reached.
The de facto UCB
Given some discount factor
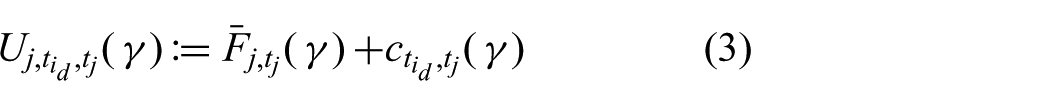
where

and the discounted number of times the parent node has been visited as

Recall that
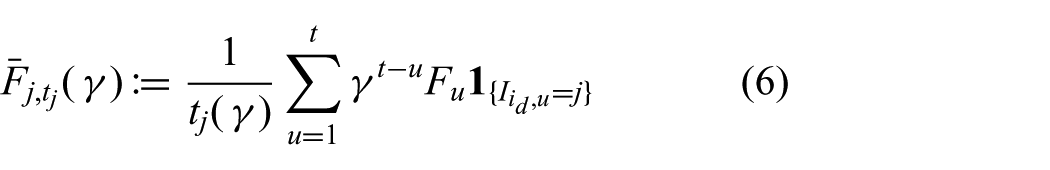
and the discounted exploration bonus is defined as
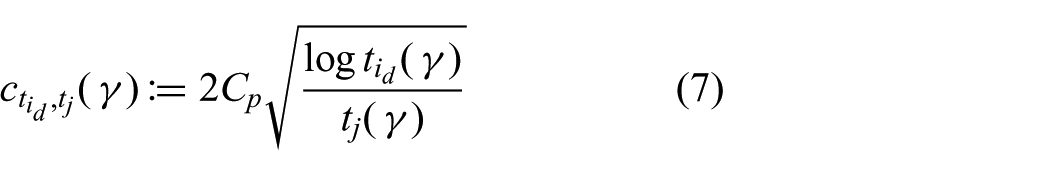
The aim of an online planner, such as Dec-MCTS, is to find the best first action, execute this action, and then replan. Thus, we are interested in the convergence of the root node towards selection of the optimal action. Given the expected upper bound on the number of breakpoints occurring in the subtree rooted at node j, i.e.
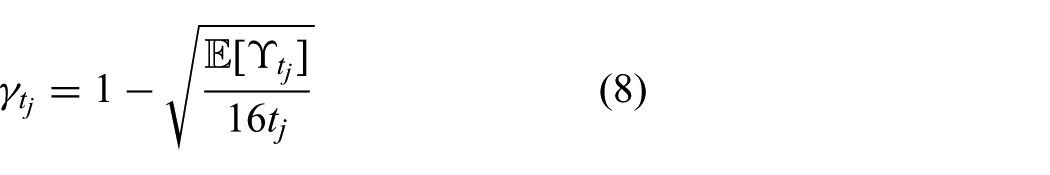
allows us to minimize the time for this convergence. This is analyzed further in Section 5. Having
4.4. Decentralized product distributionoptimization
The second phase of the algorithm updates a probability distribution

One challenge is that the set of possible action sequences
As mentioned in Section 4.1, when the sample spaces
The set
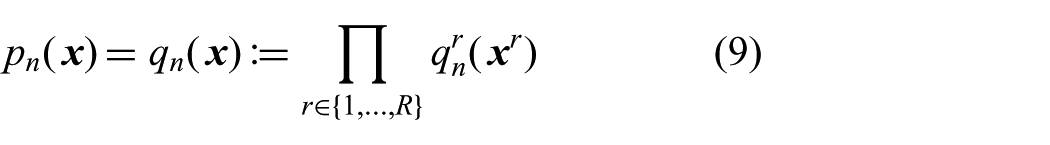
The advantage of defining
Consider the general class of joint probability distributions
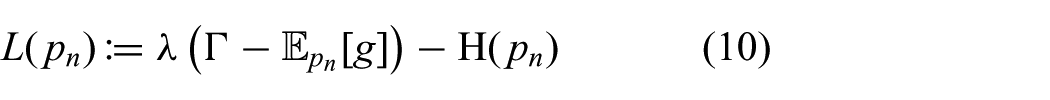
where
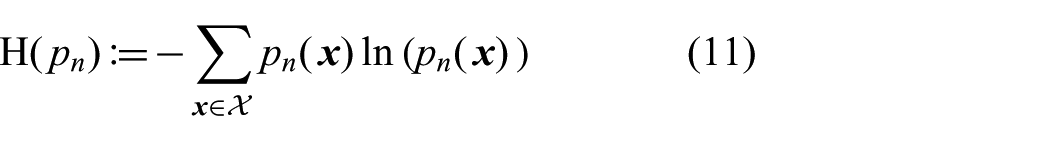
is the Shannon entropy and
For decentralized planning and execution, we are interested in optimizing the product distribution
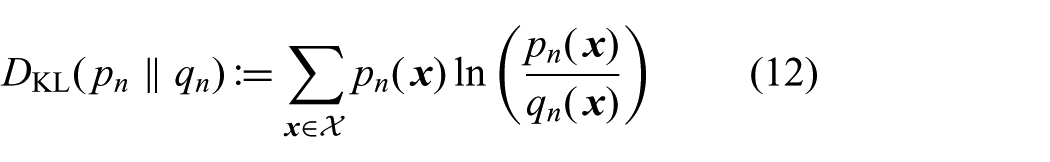
This formulates a descent scheme with the update policy for
Pseudocode for this approach is in Algorithm 3. Each iteration of the loop beginning at line 2 updates the probability
As the Dec-MCTS algorithm progresses, the parameter
4.5. Communication
At each iteration of the inner-loop of Algorithm 1, robot r communicates its current probability distribution
4.6. Online replanning
The best action is selected as the first action in the highest probability action sequence in
4.7. Probabilistic objective functions
So far, we have assumed the objective function g is deterministic for a given set of action sequences
5. Analysis
In this section, we provide a detailed theoretical analysis of Dec-MCTS. The algorithm is an anytime and decentralized approach to multi-robot coordination with two key algorithmic components: (1) the tree search (Section 4.3) is designed to perform long-horizon planning for single-robot action sequences while considering the changing plans of the other robots; and (2) the product distribution optimization (Section 4.4) is designed to directly optimize the joint multi-robot plan while being restricted to a small subset of possible action sequences. While it is difficult to make any strong claims of global optimality in the context of decentralized, long-horizon planning with general objective functions, we focus our analysis on characterizing the convergence properties of these two algorithmic components, then discuss the implications of these results.
In Section 5.1 we begin by presenting and analyzing a special type of MAB problem that is related to tree search. Section 5.2 then presents our main analytical result that the D-UCT algorithm (Algorithm 2) maintains an exploration–exploitation trade-off for child selection while the distributions
5.1. D-UCB applied to bandits
We begin our analysis by studying D-UCB (Garivier and Moulines, 2011) for a specific type of non-stationary, switching bandit problem. The classic MAB problem is that of a gambler deciding which arm to play from a row of slot machines with stationary but unknown reward distributions. As a result, bandits are the canonical model for studying the trade off of acquiring knowledge (“exploration”) and maximizing reward (“exploitation”), or the exploration–exploitation dilemma. In the context of Algorithm 2, the “arm” is analogous to a node selected to expand for a given MCTS rollout. We can therefore leverage the analysis of the MAB for the tree search problem (later in Section 5.2). To achieve this, we modify the assumptions on the type of reward distributions for each arm to those expected at internal nodes of the tree while performing the proposed D-UCT algorithm.
Our analysis follows that of Kocsis et al. (2006); Kocsis and Szepesvári (2006) who analyze the use of UCB1 as the MCTS node selection policy. We mainly reference the technical report by Kocsis et al. (2006) where the proofs for their theorems are given. Specifically, in this section we analyze D-UCB applied to a special type of bandit problem, then in Section 5.2 we exploit this analysis in applying D-UCT to the root node of a tree.
In the remainder of this section, we first provide an upper bound on the number of pulls of any arm that is suboptimal in Lemma 1. Then, Lemma 2 will bound the difference between the optimal payoff and expected total payoff up to some arbitrary time. Lemma 3 then gives concentration bounds of the actual mean about this expected value. We then give the asymptotic probability of the algorithm failing in Lemma 4. The proofs of these lemmas are provided in Appendix A.
5.1.1. Technical preliminaries
We consider D-UCB applied to a particular type of switching bandit problem. Let
The D-UCB arm selection policy uses the same bound (3) as in Section 4.3.1. Specifically, given a discount factor
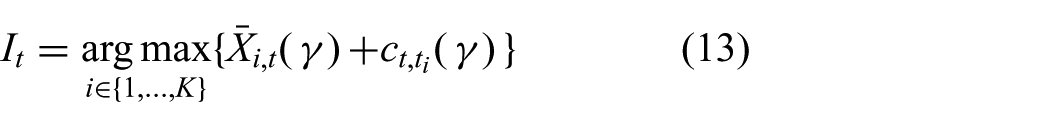
where
As in Kocsis and Szepesvári (2006), we allow the mean value of the payoffs to drift as a function of time; however, these values can also change dramatically at breakpoints. These breakpoints are defined as epochs when a previously suboptimal arm becomes optimal. We denote by
Recall we require a number of assumptions on the reward distributions of each arm so that our analysis for this bandit problem can later be exploited in our analysis for D-UCT. Our first assumption relates to the payoff sequence of each arm.
As mentioned, we allow the expected value for each arm
The number of abrupt changes to
The difference between the expected reward at time t and the limit is termed the drift

Finally, the minimum difference between the expected reward for an optimal arm
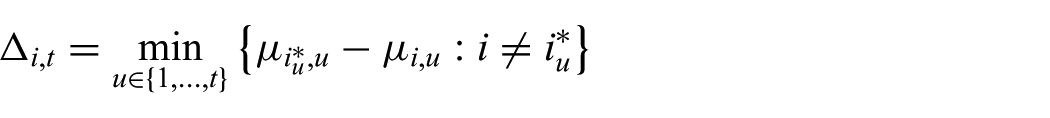
Our last assumption is that we require an index
5.1.2. Theoretical analysis
Given these assumptions, we now begin our analysis of D-UCB for this bandit problem. First, we bound the number of times each suboptimal arm is pulled. Denote by
Let
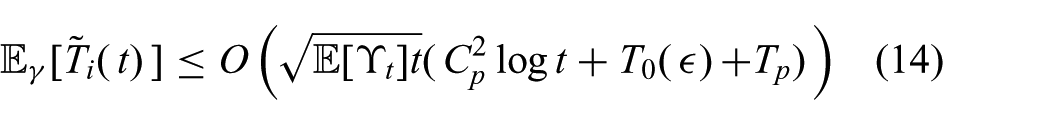
The value of
The following lemma gives convergence of the expected undiscounted payoff

Under the assumptions of Lemma 1,
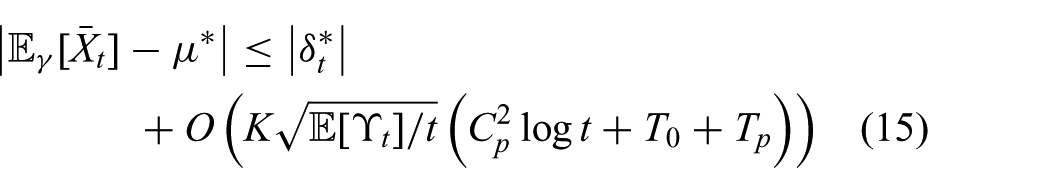
where
From Lemma 2, we have the convergence of the expected payoff
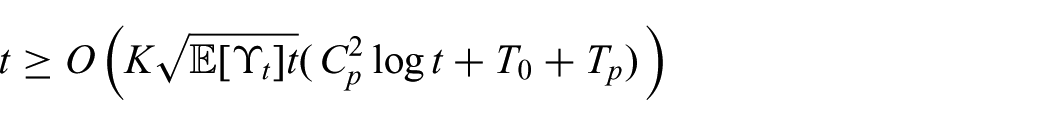
the following bound holds:

Next, we are interested in the probability of the algorithm failing. The proof relies on our assumption that the breakpoint sequence is known monotone and bounded, resulting in D-UCB becoming equivalent to UCB1 for large t.

5.2. D-UCB applied to trees
We now discuss the application of D-UCB as the node selection policy of MCTS. The assumptions we made about the bandit problem in the above section allows us to analyze convergence of the actual to the optimal payoff sequence at the root node after some transitory period.
Recall that the node selection problem at each node in the tree is equivalent to the bandit problem, however with different assumptions on the payoff received. From the perspective of node
The sequence of payoffs generate the stochastic process
Applying the above lemmas to the tree
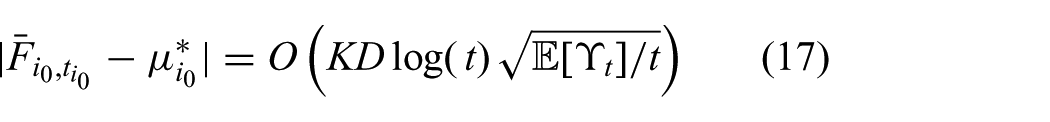
Further, the probability of failure at the root node becomes zero as t grows large.
First, for D=1, running the D-UCB algorithm as the node selection policy is equivalent to running D-UCB on a bandit problem. Thus, the payoffs
Now, consider a tree of depth D and assume the statement holds up to a tree of depth
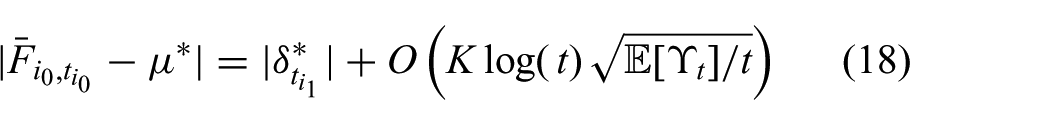
where
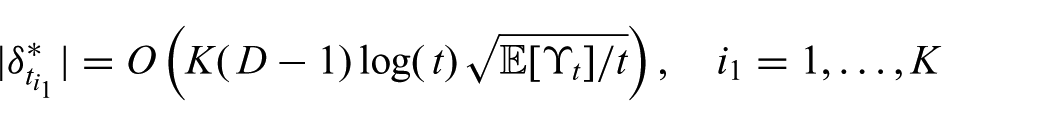
Substituting this result into (18) gives (17). By Assumption 2, the expected number of breakpoints
Remark 1.The results presented here are mainly concerned with the convergence of the bias after some transitory period. For the standard UCT case, Kocsis et al. (2006) assumed the
Remark 2.
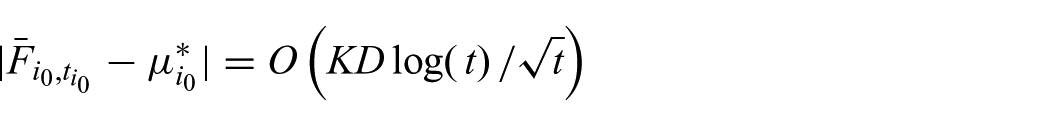
Therefore, D-UCT achieves a polynomial convergence rate, even in problems where the reward distributions are changing abruptly, such as in Dec-MCTS.
5.3. Variational methods by importancesampling
We now consider the effect of contracting the sample space
We justify Proposition 1 as follows. Consider the situation where, at each iteration n, we randomly choose a subset
5.4. Analysis of Dec-MCTS
The analyses above show separately that the tree search of Algorithm 2 balances exploration and exploitation and that, under reasonable assumptions, Algorithm 3 converges to the product distribution that best optimizes the joint action sequence. These results provide strong motivation for the use of these components in the algorithm. However, they do not immediately yield a characterization of optimality for Algorithm 1. To prove convergence rates and global optimality, we would need to characterize the co-dependence between the evolution of the reward distributions
6. Experiments: Generalized teamorienteering
In this section, we evaluate the performance of our algorithm in an abstract multi-robot information gathering problem. An illustration of the problem and an example solution is shown in Figure 2. We empirically show convergence, robustness to intermittent communication and a comparison to a centralized variant of MCTS.
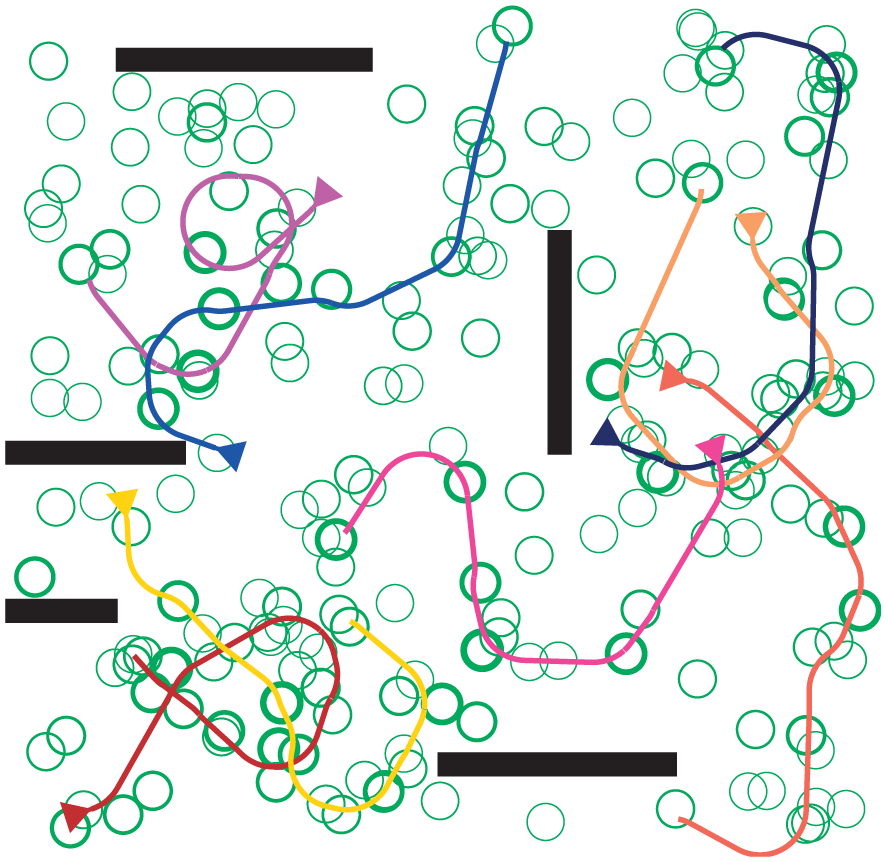
The generalized team orienteering problem. The eight robots (colored paths) aim to collectively visit a maximal number of goal regions (green circles, weighted by importance). The robots follow Dubins paths, are constrained by distance budgets and must avoid obstacles (black).
6.1. Problem statement
The problem is motivated by tasks where a team of Dubins robots maximally observes a set of features of interest in an environment, given a travel budget (Best et al., 2018). Each feature can be viewed from multiple viewpoints and each viewpoint may be within observation range of multiple features. This formulation generalizes the orienteering problem (Vansteenwegen et al., 2011; Gunawan et al., 2016) by combining the set structure of the generalized TSP (Noon and Bean, 1989) with the budget constraints of the orienteering problem with neighborhoods (Faigl et al., 2016) extended for multi-agent scenarios (Best et al., 2018).
Robots navigate within a graph representation of an environment with vertices
For the objective function, we have a collection of sets
6.2. Calculating expectations
The Dec-MCTS algorithm requires computing several expectations that, in general, should be approximated using sampling. However, for this problem definition it is possible to exploit the structure of the objective function to efficiently compute exact expectations. We compute expectations in a similar way to (3) by Best and Fitch (2016):
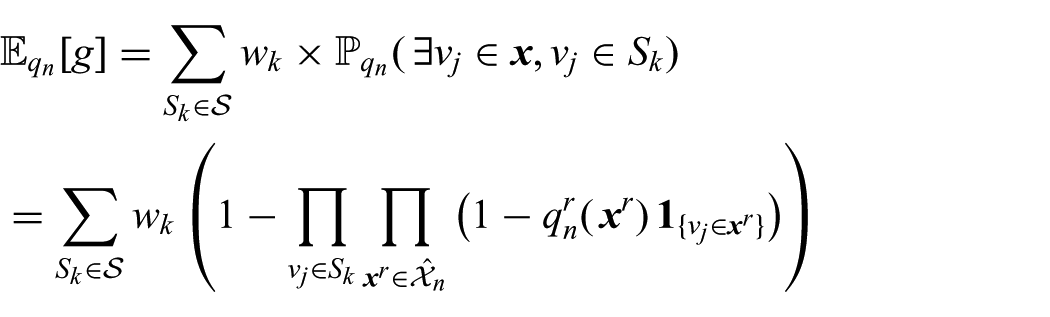
where
6.3. Experiment setup
We compare our algorithm (Dec-MCTS) with centralized MCTS (Cen-MCTS), which consists of a single tree where robot r ’s actions appear at tree depths
Experiments were performed with eight simulated robots running in separate Robot Operating System (ROS) nodes on a quad-core computer with hyperthreading (eight virtual cores). Each random problem instance (Figure 2) consisted of 200 disks with rewards between 1 and 10, 5 obstacles, 4000 graph vertices, and random start verticesfor each robot. Each iteration of Algorithm 1 performs 10 MCTS rollouts and 1 communication broadcast. The set
6.4. Results
The first experiments (Figure 3(a)) show that Dec-MCTS outperforms Cen-MCTS despite the increased difficulty of planning in a decentralized setting. Dec-MCTS achieved a median 7 % reward improvement over Cen-MCTS after 120 s, and a higher reward in 91 % of the environments. Dec-MCTS typically converged after ~60 s. A paired single-tailed t-test supports the hypothesis (
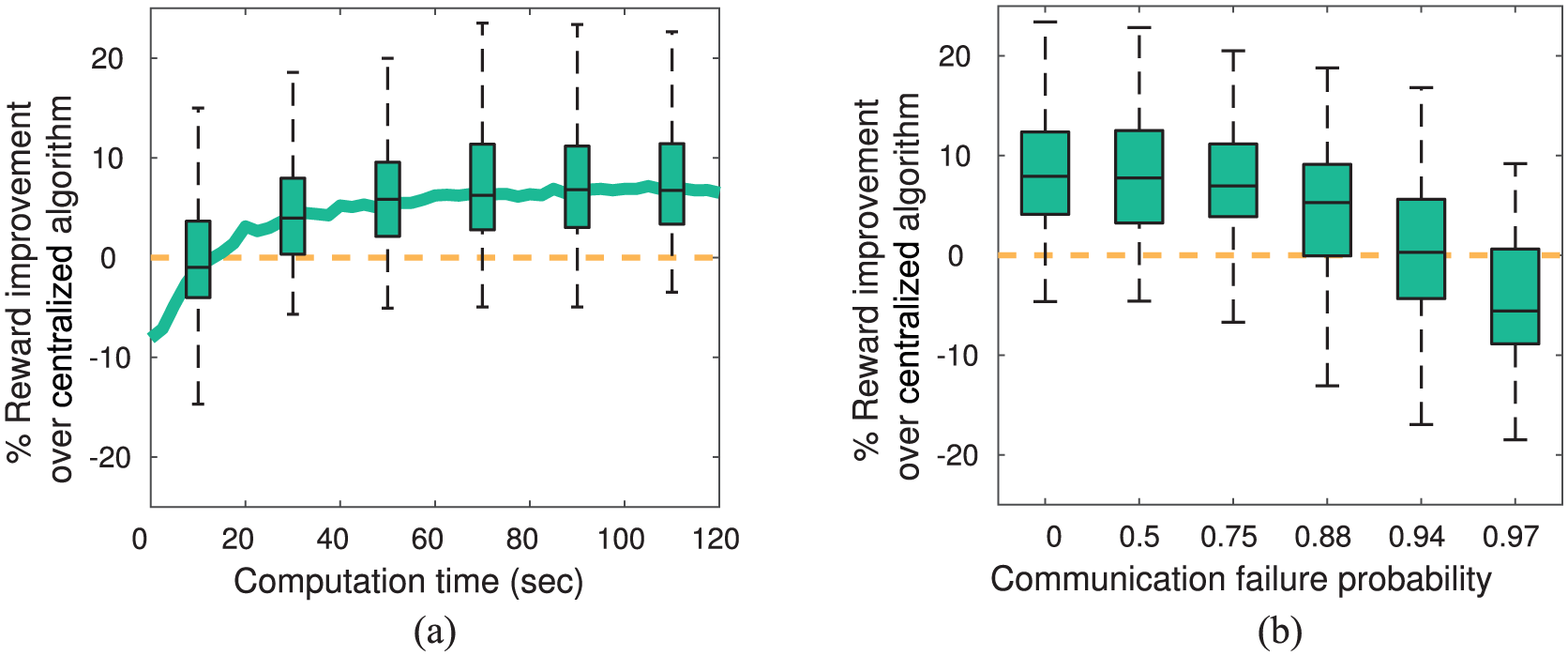
(a) Comparison of Dec-MCTS with varying computation time to Cen-MCTS (120 s). (b) Performance of Dec-MCTS with intermittent communication (60 s computation time). Vertical axes in (a) and (b) show percentage additional reward achieved by Dec-MCTS compared with Cen-MCTS. Error bars show 0, 25, 50, 75, and 100 percentiles (excluding outliers) of 100 random problem instances.
The second experiments analyzed the effect of communication degradation. When the robots did not communicate, the algorithm achieved a median 31 % worse than Cen-MCTS, but with full communication achieved 7 % better than centralized, which shows the robots can successfully cooperate by exploiting the communication channel. Figure 3(b) shows the results for partial communication degradation. When half of the packets are lost, there is no significant degradation of performance. When 97 % of packets are lost the performance is degraded but the algorithm still performs significantly better than with no communication. These results demonstrate the algorithm is robust to unpredictable communication loss.
7. Experiments: Active object recognition
This section describes experiments for online active object recognition, using point cloud data collected from an outdoor mobile robot in an urban scene (Figure 4). We first outline the problem and experiment setup, and then present results that analyze the value of online replanning and compare Dec-MCTS to a greedy planner.

Experiment setup for the point cloud dataset: (a) environment with labeled locations, (b) picnic table (PT), (c) barbecue (BQ), (d) wheelie bin (WB), (e) motorbike (MB), (f) street light (ST), (g) tree (TR), and (h) palm tree (PT).
7.1. Problem setup
A team of robots aim to determine the identity of a set of static objects in an unknown environment. Each robot asynchronously executes the following cycle: (1) plan a path that is expected to improve the perception quality; (2) execute the first planned action; (3) make a point cloud observation using onboard sensors; and then (4) update the belief of the object identities and their poses. Each robot asynchronously performs this cycle until their travel budget is exhausted. The robots have the same Dubins motion model as in Section 6. Each graph edge has an additional constant cost that represents the time required to process an observation and perform replanning. Thus, each robot’s budget is a constraint on the sum of its travel distance and processing time.
We use a perception model for object recognition similar to that proposed in Chapter 7.2 of Patten (2017). The robots maintain a belief of the identity of each observed object, represented as the probability that each object is an instance of a particular object from a given database. The aim is to improve this belief, which is achieved by maximizing the mutual information objective proposed by Patten et al. (2015). The posterior probability distribution for each object after a set of observations is computed recursively using Bayes’ rule. The observation likelihood is calculated by measuring the similarity between the shape of the point cloud with each model instance in the database. Similarity is computed by first aligning the point clouds of a pair of objects using the iterative closest point (ICP) algorithm (Besl and McKay, 1992) and then calculating the symmetric residual error (Douillard et al., 2012). Objects may merge or split after each observation if the segmentation changes. Observations are fused using decentralized data fusion or a central processor and shared between all robots, and thus all robots are assumed to have the same belief of the environment. While planning, the value of future observations are estimated by simulating observations of objects in the database for all possible object identities, weighted by the belief probabilities, and using maximum likelihood estimates for poses.
7.2. Experiment setup
The experiments use a point cloud dataset (Patten et al., 2015) of Velodyne scans of outdoor objects in a
The experiments simulate an online mission where each robot asynchronously alternates between planning and perceiving. Three planners were trialled: our Dec-MCTS algorithm with 120 s replanning after each action, Dec-MCTS without replanning, and a decentralized greedy planner that selects the next action that maximizes the mutual information divided by the edge cost. The recognition score of an executed path was calculated as the belief probability that each object matched the ground-truth object type, averaged over all objects. The planners cannot directly optimize the paths with respect to the recognition score since the ground truth is not known in advance; however, planning with respect to the mutual information objective function is intended to indirectly optimize the recognition score.
7.3. Results
Overall, the results validate the coordination performance of Dec-MCTS. Figure 5(a) shows the recognition score (task performance) over the duration of the mission for 10 trials with 3 robots. The maximum possible recognition score subject to the perception algorithm and dataset was 0.62, which was achieved by visiting every location in the dataset. Dec-MCTS outperformed greedy halfway through the missions since some early greedy decisions and poor coordination reduced the possibility of making subsequent valuable observations. By the end of the missions some greedy plans successfully made valuable observations, but less often than Dec-MCTS. The no-replanning scenario achieved a similar score as the online planner in the first half, showing that the initial plans are robust to changes in the belief. For the second half, replanning improved the recognition score since the belief had changed considerably since the start. This shows that while the generated plans are reasonable for many steps into the future, there is also value in replanning as new information becomes available.
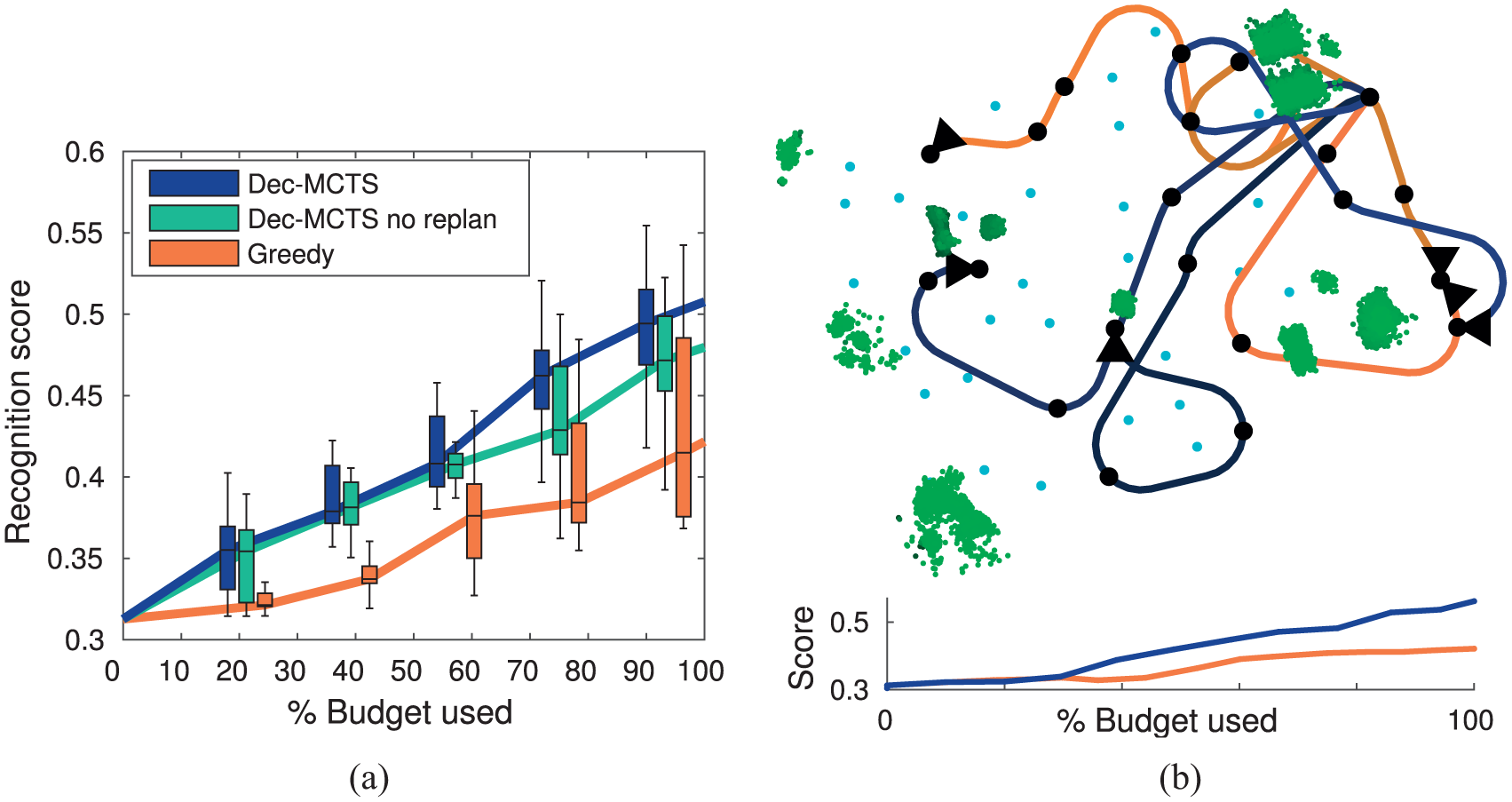
(a) Task performance over mission duration for 10 trials (maximum possible score is 0.62). (b) Overlay of two example missions with three robots. Blue paths denote online Dec-MCTS (score 0.53). Orange paths denote greedy policy (score 0.42). Objects are green point clouds where shading indicates height. Robots observe at black dots in direction of travel. Start location top right.
Figure 5(b) shows two example missions using online Dec-MCTS (blue) and greedy (orange) planners, and their score over the mission duration. Greedy stayed closer to the start location to improve the recognition of nearby objects, and consequently observed objects on the left less often; reaching this part of the environment would require making high-cost/low-immediate-value actions. On the other hand, Dec-MCTS achieved a higher score since the longer planning horizon enabled finding the high value observations on the left, and was better able to coordinate to jointly observe most of the environment.
8. Conclusion and future work
We have presented a new algorithm for decentralized coordination that is suitable for a general class of problems. Our results demonstrate that the performance (i.e. solution quality) of our approach is as good as or better than its centralized counterpart in real-world applications, and that it effectively optimizes over sequences in the joint-action space even with intermittent communication. A key conceptual feature of our approach is its generality in representing joint action sequences probabilistically rather than deterministically. Dec-MCTS has the ability to efficiently plan over long planning horizons, computes anytime solutions, allows incorporating prior knowledge, and provides convergence rate guarantees.
The problem formulation considered in this paper is general in that we are interested in planning sequences of actions to optimize a joint objective function, without requiring assumptions such as submodularity. A straightforward extension to our approach would be to adapt the algorithm to address the Dec-POMDP formulation. This could be achieved by generalizing the MCTS component of our algorithm to POMCP (Silver and Veness, 2010) while still using our proposed D-UCT tree expansion policy. A difficulty would be to efficiently find good-quality solutions while also considering probabilistic transition models and having the search tree branch for both actions and observations.
Our experiments demonstrate that Dec-MCTS achieves reasonable performance even when the communication becomes less reliable. While these results show a robustness to communication loss, they also indicate that some of the communication messages are not entirely necessary. An interesting avenue for future work would be to develop a communication-planning algorithm that selects when to communicate and who to communicate to while running Dec-MCTS in scenarios with limited communication bandwidth. A possible approach could be a dynamic programming formulation for planning communication to maintain coordination in a similar way to how Ondruska et al. (2015) planned the use of navigation hardware to maintain localization accuracy. Other communication-planning formulations that may be useful here include those of Kassir et al. (2015) and Lindhé and Johansson (2013). A key difficulty is to develop a measure of information value of a communication message in the context of improving planning performance. Along this line of inquiry, Cliff et al. (2017) introduced measures for quantifying the dynamics of inter-agent dependencies in a team that is optimizing a collective goal. We have begun exploring these ideas for communication planning in Best et al. (2018).
Another interesting line of inquiry is to incorporate coalition forming into our approach. As formulated, static coalitions of agents can be formed by generalizing the product distributions in our framework to be partial joint distributions. The product distribution described in Section 4.4 would be defined over groups of robots rather than individuals. Each group acts jointly, with a single distribution modeling the joint actions of its members, and coordination between groups is conducted as in our algorithm. Just as our approach corresponds to mean-field methods, this approach maps nicely to generalized mean field inference (Xing et al., 2004) or region-based variational methods (Yedidia et al., 2005), and guarantees from these approaches may be applicable. It would also be interesting to study dynamic coalition forming, where the mapping between agents and robots is allowed to change, and to develop convergence guarantees for this case. A key challenge would be to determine which robots’ plans are more tightly coupled and, therefore, would benefit from planning within a coalition.
It would be interesting to apply the same general framework to multi-agent scenarios where standard algorithms already exist for associated single-agent scenarios. Problem-specific single-agent planning algorithms could replace the MCTS component of Dec-MCTS, while still performing the distributed product distribution optimization phase, in order to provide stronger theoretical guarantees or algorithmic efficiency for special cases. Scenarios where this could be applicable include multi-robot mission monitoring (Best et al., 2017), persistent monitoring (Alamdari et al., 2014), cooperative wildlife localization (Cliff et al., 2015), TSP variants (Best et al., 2018), collision avoidance (Otte and Correll, 2013), and dynamic coverage problems (Hönig and Ayanian, 2016). It would also be worth investigating other MCTS variants, e.g. BRUE (Feldman and Domshlak, 2014), as an alternative to UCT.
Footnotes
Appendix A: Proofs
Appendix B: Technical results
Fix an arbitrary
Then for t such that
We show that
Using the inequality
Using the Hoeffding–Azuma inequality, the first term can be bounded by
for
By Lemma 13 of Kocsis et al. (2006), this term is bounded by
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Australian Research Council’s Discovery Project funding scheme (No. DP140104203), the Australian Centre for Field Robotics, the New South Wales State Government, the Faculty of Engineering and Information Technologies, The University of Sydney, under the Faculty Research Cluster Program, and The University of Sydney’s International Research Collaboration Award.