
Abstract
Various approaches have been proposed to learn visuo-motor policies for real-world robotic applications. One solution is first learning in simulation then transferring to the real world. In the transfer, most existing approaches need real-world images with labels. However, the labeling process is often expensive or even impractical in many robotic applications. In this article, we introduce an adversarial discriminative sim-to-real transfer approach to reduce the amount of labeled real data required. The effectiveness of the approach is demonstrated with modular networks in a table-top object-reaching task where a seven-degree-of-freedom arm is controlled in velocity mode to reach a blue cuboid in clutter through visual observations from a monocular RGB camera. The adversarial transfer approach reduced the labeled real data requirement by 50%. Policies can be transferred to real environments with only 93 labeled and 186 unlabeled real images. The transferred visuo-motor policies are robust to novel (not seen in training) objects in clutter and even a moving target, achieving a 97.8% success rate and 1.8 cm control accuracy. Datasets and code are openly available.
Keywords
1. Introduction
The advent of large datasets and sophisticated machine learning models, commonly referred to as deep learning, has in recent years created a trend away from hand-crafted solutions towards more data-driven ones. Learning techniques have shown significant improvements in robustness and performance since early work (Krizhevsky et al., 2012), particularly in the computer vision field.
Traditionally robotic vision-based reaching approaches have been based on crafted controllers that combine (heuristic) motion planners with the use of hand-crafted features to localize the target visually. Recently, learning approaches to tackle this problem have been presented (Bateux et al., 2018; Katyal et al., 2017; Levine et al., 2016b; Sünderhauf et al., 2018; Zhang et al., 2017a,b, 2015); however, a consistent issue faced by most approaches is the reliance on large amounts of data to train these models. Generalization is another challenge: many current systems are brittle when learned models are applied to real robotic configurations or scenarios that differ from those used in training. This leads to the question: How can we better learn and transfer visuo-motor policies on robots for tasks such as reaching?
Various approaches have been proposed to address this problem. Some works tried to directly learn from large-scale real-world datasets (Levine et al., 2016b; Pinto and Gupta, 2016). However, collecting a large amount of real data could be expensive in robotic applications. For example, an “arm farm” with 6–14 physical robots was developed to collect data in parallel for learning robotic grasping (Levine et al., 2016b). Therefore, some methods were proposed to reduce the cost of collecting a large amount of real-world data by using simulated or synthetic data (Bateux et al., 2018; D'Innocente et al., 2017; James et al., 2017; Tobin et al., 2017). Some others tried to make use of both simulated and real data for a more balanced solution (Fitzgerald et al., 2015; Tzeng et al., 2016). A particular approach is modular deep Q-networks for learning a planar reaching task in simulation and then transferring to real environments with a small number of labeled real-world images (Zhang et al., 2017a,b).
In this work, we extend the modular approach (Zhang et al., 2017a) and focus on making use of both simulated and real data to learn robotic skills. In the modular deep Q-networks, labeled real images were previously used for the transfer. Although the amount of data was small, the labeling cost was non-trivial. In comparison, images themselves are cheap for a vision-based robotic system.
Aiming for more data-efficient learning, an adversarial approach similar to generative adversarial nets (GANs) (Goodfellow et al., 2014) was proposed to learn a classifier for grasping using labeled synthetic and unlabeled real data (Bousmalis et al., 2018). Similar approaches were also proposed for other classification tasks, such as adversarial discriminative domain adaptation (ADDA) for handwritten digit recognition (Tzeng et al., 2017) and incremental adversarial domain adaptation for drivable-path segmentation (Wulfmeier et al., 2018). Some works also tried to use adversarial approaches for regression transfer such as domain confusion with weak pairwise constraints for deep visuo-motor representation adaptation (Tzeng et al., 2016).
In this article, we leverage the ADDA idea (which achieved better performance in handwritten digit recognition than domain confusion (Tzeng et al., 2017)) and extend it from classification to regression transfer for learning visuo-motor policies from simulation to the real world. The approach is verified with modular networks in a visually guided table-top object reaching task for a seven-degree-of-freedom (7-DoF) robotic arm (Figure 1). By introducing an adversarial loss, visuo-motor policies can be successfully transferred from simulated (Figure 1(A)) to real (Figure 1(B)) environments with only 93 labeled and 186 unlabeled real images. Benefiting from the modular structure and weighted end-to-end fine-tuning, the learned visuo-motor policies achieved a reaching accuracy of 1.8
Introduction of an adversarial discriminative approach by leveraging the ADDA in a semi-supervised manner for more data-efficient perception transfer from simulation to the real world, achieving a comparable accuracy (2.7
Further verification of modular neural networks (Zhang et al., 2017a) for sim-to-real transfer of visuo-motor policies in a more realistic robotic reaching task: table-top object reaching in clutter using a 7-DoF arm in velocity mode, achieving a 97.8% success rate and 1.8
Investigation of important factors in the adversarial discriminative transfer (ADT) approach with comprehensive comparison experiments and detailed analyses, showing their benefits and limits for future research.
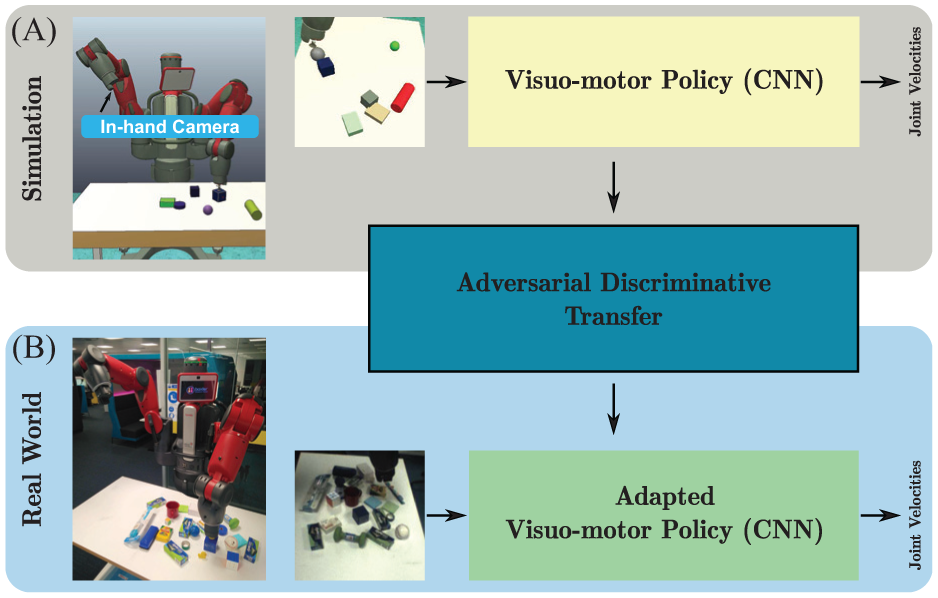
A robot (Baxter) learns visuo-motor policies in simulation (A) to control its left arm (7 DoFs) to reach a target blue cuboid in clutter on a table. Baxter visually observes the table-top environments through the monocular RGB camera in its right hand. An adversarial discriminative approach (see Section 3) is used to transfer visuo-motor policies from simulation to the real world (B). The transfer is semi-supervised so needs very few labeled real images.
2. Related work
Data-driven learning approaches have become popular in computer vision and are starting to replace hand-crafted solutions in robotic applications (Sünderhauf et al., 2018). In particular, there have been growing interest in robotic vision tasks, robotic tasks based directly on real image data, such as object grasping and manipulation (Lenz et al., 2015; Levine et al., 2016b; Pinto and Gupta, 2016). An important factor in data-driven robot learning approaches is large-scale datasets, from either the real world or simulation.
2.1. Learning from real datasets
In the real world, collecting the datasets required for deep learning has been sped up by using many robots operating in parallel (Levine et al., 2016b). With over 800,000 grasp attempts recorded, a deep network was trained to predict the success probability of a sequence of motions aiming at grasping using a 7-DoF robotic manipulator with a two-finger gripper. Combined with a simple derivative-free optimization algorithm the grasping system achieved a success rate of 80%. Another example of dataset collection for grasping is the approach to self-supervised grasp learning in the real world where force sensors were used to autonomously label samples (Pinto and Gupta, 2016). After training with 50,000 real-world trials using a staged learning method, a deep convolutional neural network (CNN) achieved a grasping success rate around 70%.
The aforementioned results are impressive but were achieved at high cost in terms of money, space, and time (weeks to months). Aiming for more data-efficient learning, Levine et al. (2016a) introduced a CNN-based policy representation architecture with an added guided policy search (GPS) to learn visuo-motor policies (mapping joint angles and camera images to joint torques) for continuous control, which allows reduction in the number of real-world training examples by converting policy search into supervised learning with trajectory distributions as a bridge. Impressive results were achieved in complex tasks, such as hanging a coat hanger, inserting a block into a toy, and tightening a bottle cap.
2.2. Learning with simulation
Simulation is another resource to reduce the cost of collecting real-world datasets. With domain randomization, policies learned in simulation are robust enough to be directly used on real robots with real RGB cameras observing real scenes in manipulation tasks (James et al., 2017; Tobin et al., 2017). Recently, it has also been proposed to simulate depth images to learn and then directly transfer grasping skills to real-world robotic arms (Viereck et al., 2017).
There are also some negative results, which show that visuo-motor policies learned in a low-fidelity simulator do not transfer directly to real robots with real cameras observing real scenes (Zhang et al., 2015). In fact, very modest image distortions in the simulation environment (small translations, Gaussian noise and scaling of the RGB color channels) caused the performance of the system to fall dramatically. Introducing a real camera observing the game screen was even worse (Tow et al., 2016). However, if adapting with a small number of real images, the visuo-motor policies learned in a low-fidelity simulator can be well transferred to real scenarios for a robotic planar reaching task (Zhang et al., 2017a,b).
2.3. Transfer learning
Transfer learning attempts to develop methods to transfer knowledge between different tasks (scenarios) (Pan and Yang, 2010; Taylor and Stone, 2009). To reduce the amount of data collected in the real world (expensive), transferring skills from simulation to the real world is an attractive alternative. For the case of pre-training in simulation then adapting with very few real-world samples, appropriate transfer learning approaches are required.
To reduce the number of real-world images required for learning visuo-motor policies, a method of adapting visual representations from simulated to real environments was proposed, achieving a success rate of 79.2% in a “hook loop” task, with 10 times fewer real-world images (Tzeng et al., 2016). Another example of vision-based policy transfer is progressive neural networks, which are proposed to improve transfer and avoid catastrophic forgetting when learning complex sequences of tasks (Rusu et al., 2016). Their effectiveness has been validated on reinforcement learning tasks such as Atari and 3D maze game playing as well as simulated robotic manipulation (Rusu et al., 2017).
Similar to GANs (Goodfellow et al., 2014), adversarial approaches were also proposed for domain adaptation in classification contexts such as handwritten digit recognition (Ganin et al., 2016; Ge et al., 2017; Luo et al., 2017; Tzeng et al., 2017), place classification and segmentation (Wulfmeier et al., 2017, 2018), object recognition (Tzeng et al., 2015), and fine-grained recognition (Gebru et al., 2017). An adversarial adaptation approach was also proposed to improve the efficiency of learning a classifier to determine whether a grasp command will be successful or not (Bousmalis et al., 2018). Some works also tried to use adversarial approaches for regression transfer such as a GAN for image style transfer from source to target domains (Bousmalis et al., 2017) and domain confusion for adapting deep visuo-motor representations (Tzeng et al., 2016). These approaches opened a new and attractive direction for more data-efficient learning.
This article mainly extends the ADDA approach (Tzeng et al., 2017) from classification to regression tasks to transfer learned visuo-motor policies from simulated to real-world settings. Unlike the domain confusion method, which leads to representations confusing a discriminator by aiming for a uniform distribution over domain labels (Tzeng et al., 2016, 2015), the ADDA approach encourages a target encoder to have a representation distribution as close as possible to the one from a source encoder, and achieved better performance in handwritten digit recognition (Tzeng et al., 2017).
3. Methodology
In our previous work (Zhang et al., 2017a), a modular structure and its training approach were proposed to transfer visuo-motor policies from simulation to the real world in a low-cost manner. The transfer was achieved by using 1,418 labeled real images to fine-tune a perception module pre-trained in simulation. In this article, we propose a semi-supervised transfer approach to reduce the number of labeled real images required. We call this semi-supervised approach ADT, which mainly benefits from the introduction of an adversarial loss (Tzeng et al., 2017).
3.1. Modular deep networks
Similar to the modular deep Q-network (Zhang et al., 2017a), a modular network architecture (Figure 2) is proposed, which consists of perception and control modules connected by a bottleneck layer. The bottleneck forces the network to learn a low-dimensional representation, not unlike auto-encoders (Hinton and Salakhutdinov, 2006). The difference is that we explicitly equate the bottleneck layer with the object position (
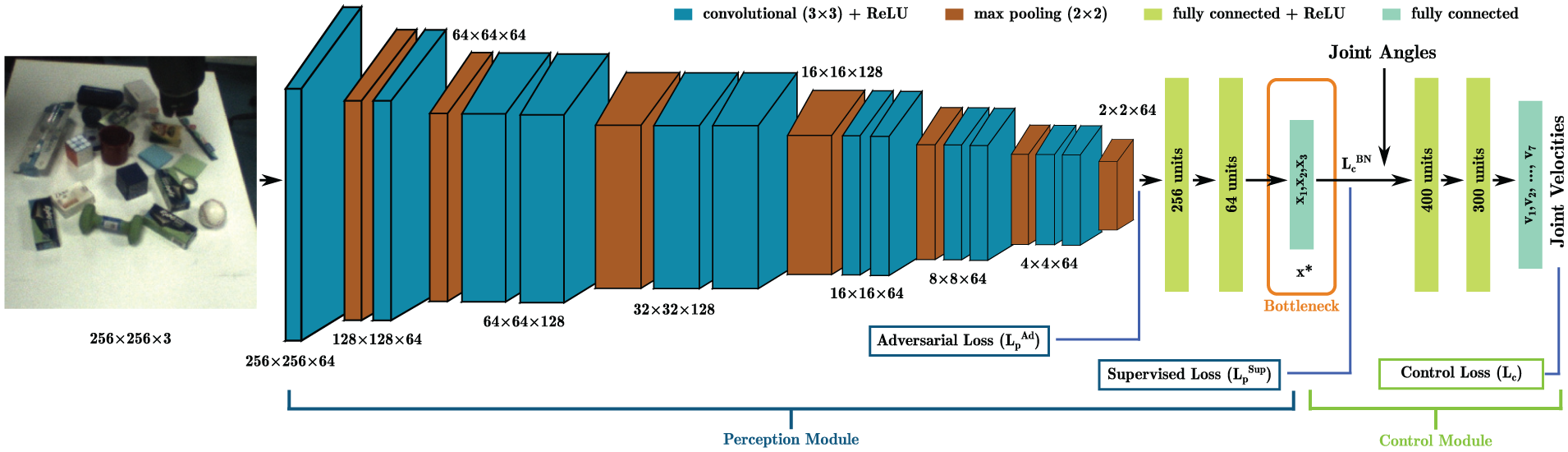
The modular network consisting of perception and control modules, connected by a bottleneck layer representing target object position
With the bottleneck, the perception module learns how to estimate the object position
3.1.1. Training method
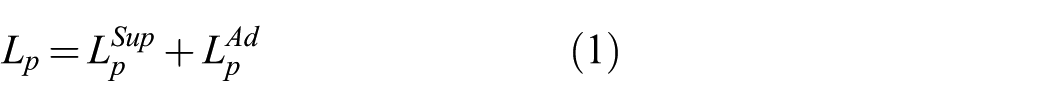
where
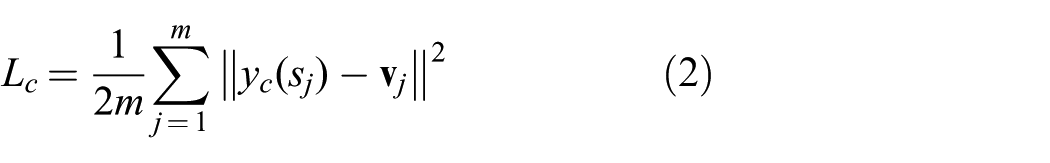
where

where
3.2. ADT
ADT makes use of both adversarial and supervised losses to adapt a perception module with fewer labeled real images. In ADT, the perception module is divided into two parts: encoder and regressor. As shown in Figure 3, the encoder includes all the convolutional layers in a perception module; the regressor represents all the fully connected layers of the perception module.
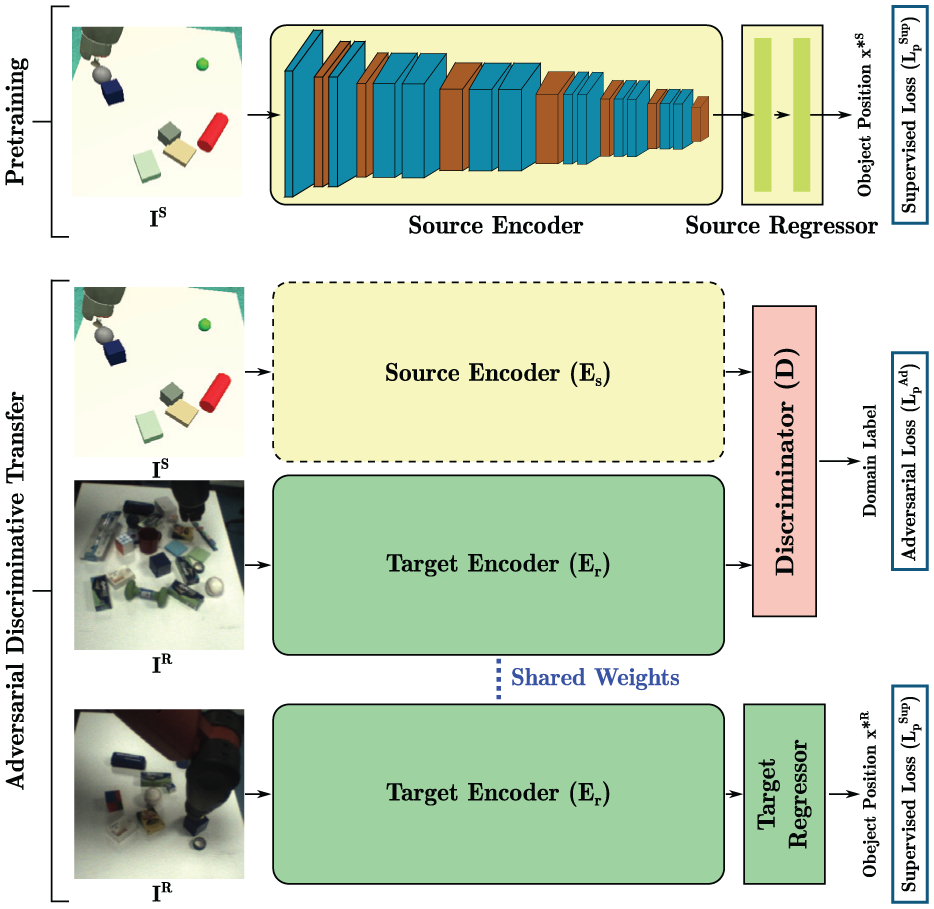
In ADT, the perception module is divided into two parts: encoder and regressor. The encoder includes all the convolutional layers; the regressor represents all the remaining fully connected layers. We first pre-train a perception module (source encoder + source regressor) with
A perception module (source encoder + source regressor) is first pre-trained with simulated images (
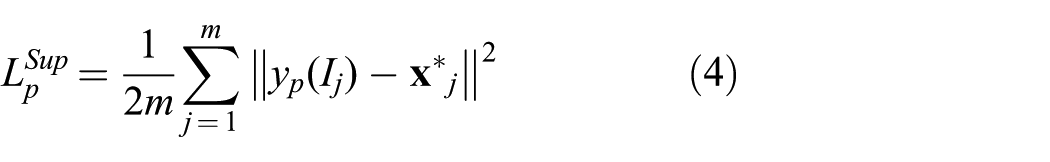
where
The source encoder is then locked and used as a reference in the ADT to train a target encoder with both simulated (

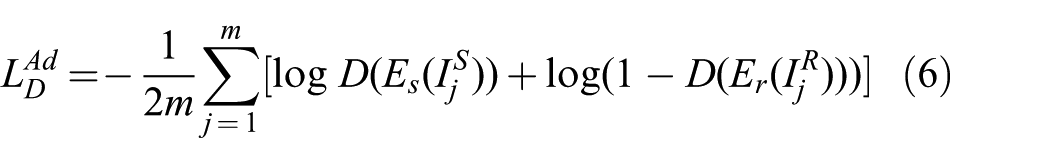
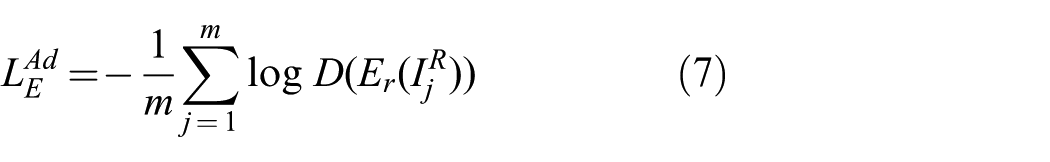
where
Experimental results in Section 5.2 show that a single adversarial loss (
Experimental results also show that maintaining
the value of
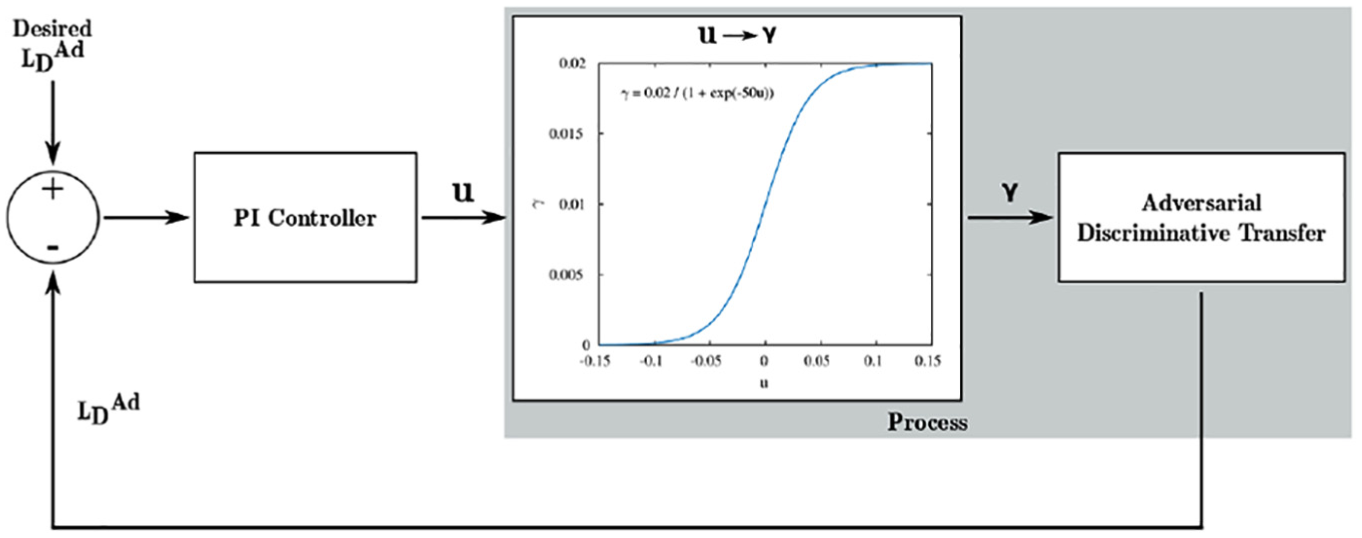
A PI controller is used to control
Our tuned coefficients for proportional and integral gains are
4. Benchmark: robotic reaching
We use a canonical target reaching task as a benchmark to evaluate the effectiveness of the proposed approach. The task is defined as controlling a robot arm so that its end-effector position
4.1. Task setup
The real-world task employs a Baxter robot’s left arm (7 DoFs) to reach a blue cuboid in clutter. All objects are arbitrarily placed in the operational area (50
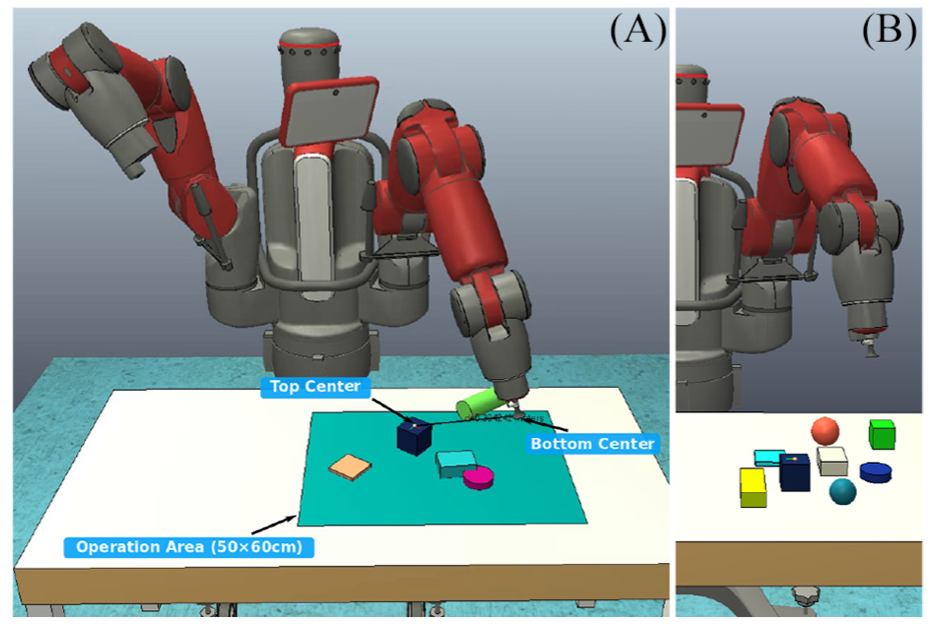
A Baxter robot controls its left arm in velocity mode to reach a blue cuboid (
4.2. Network architecture
In this work, we used a network with the architecture shown in Figure 2. The perception module has an architecture customized from VGG16 (Simonyan and Zisserman, 2015). The customization mainly includes reducing the number of convolutional layers in each group (between two max pooling layers) and changing the number of feature maps in each convolutional layer for lower computational cost but without losing performance for the benchmark task. It consists of 12 convolutional layers with 3×3 filters and seven 2×2 max pooling layers, followed by three fully connected layers. The twelve convolutional layers and two hidden fully connected layers use rectified linear unit (ReLU) activation. Simulated or real RGB images are cropped and down-sampled to
The control module consists of 3 fully connected layers, with 400 and 300 units in the 2 hidden layers (with ReLU activation), respectively. Input to the control module is the scene configuration
The discriminator network consists of 3 fully connected layers with 256 units in each of its 2 hidden layers (also with ReLU activation). Input to the discriminator is an encoded feature vector with a dimension of 256, either from the source encoder or target encoder. The output layer has two units (two classes: simulated or real) with softmax activation. The discriminator is also randomly initialized.
4.3. Datasets collection
Perception datasets contain a number of image–position (I–
number of distractor objects in clutter, random in
shape of distractor objects in clutter, random in nine primitive shapes with different geometries (five cuboids, two spheres, two cylinders);
pose of distractor objects, random position in the operational area and random orientation about the vertical axis;
color of distractor objects, random RGB values;
left arm configuration, random in joint space, excluding those with self-collision;
color of the table, floor, robot body, and target cuboid, random changes based on reference colors (
camera pose, random changes of the right arm joint configuration relative to reference angles (
camera field of view (FoV), random changes based on a reference FoV (
table pose, random changes based on a reference position (

Simulated and real images for training perception modules. Simulated images were collected from a V-REP simulator using domain randomization (Tobin et al., 2017). Real images were collected for perception adaptation on a real Baxter (Figure 1(B)).
All the above randomization is distributed uniformly. The reference colors, FoV, and table pose were tuned manually to approximate the real scene. The reference joint angles of the right arm (i.e., camera pose) were tuned in the real world, making sure the in-hand camera can see the entire operational area. The parameters for the randomized factors based on references were manually tuned to simulate possible variations in the real scene.
The real images shown in Figure 6 were collected in the real world on a Baxter robot (Figure 1(B)) with random objects and left arm configurations. There are 11 real distractor objects in total. The ground-truth position of the target blue cuboid was collected by putting the end-effector bottom center on the cuboid top center and recording the left arm configuration (target configuration
More formally, we use
In training, to increase the training data diversity, data augmentation is done on the fly for both simulated and real images by varying image brightness (
Control datasets contain a number of scene configuration–velocity (
Control datasets were purely collected in simulation using V-REP, represented as
For comparison experiments in Section 5, we collected 11 perception (3 labeled simulated, 4 labeled real, and 4 unlabeled real) and 3 control datasets, as listed in Table 1. The datasets and code are available at https://github.com/Fanleyrobot/ADT.
Collected datasets.

5. Experiments and results
We first evaluated the performance of supervised perception adaptation as a baseline. The performance of the proposed approach was then evaluated in three aspects: adversarial discriminative perception adaptation performance, control module performance, and hand–eye coordination. The important factors in ADT were also investigated with detailed comparison experiments. All the evaluations were conducted in the real world using the following metrics.
Perception error: the Euclidean distance between the estimated and ground-truth object positions.
Control error: the Euclidean distance between the target cuboid top center and end-effector bottom center (“Top Center” and “Bottom Center” in Figure 5(A)).
Success rate: the percentage of successful reaching among all trials, where a reach is deemed successful if the final Euclidean distance between the target and end-effector (after the robot stops or its time is out) is smaller than 4.6
5.1. Supervised perception adaptation
Supervised adaptation is a commonly used approach in deep learning for knowledge transfer between different domains. Here, we used its performance as a baseline to compare with the proposed ADT approach. To investigate the influence of the numbers of simulated and real images on adapted perception accuracy, we evaluated 15 different perception modules. They were trained with different combinations of labeled images:
the number of labeled simulated images is from 0 to 3,000 (i.e.,
the number of labeled real images is from 0 to 279 (i.e.,
As introduced in Section 3.1.1, all 15 perception modules were first trained using simulated images then adapted with real images, but only using the supervised loss
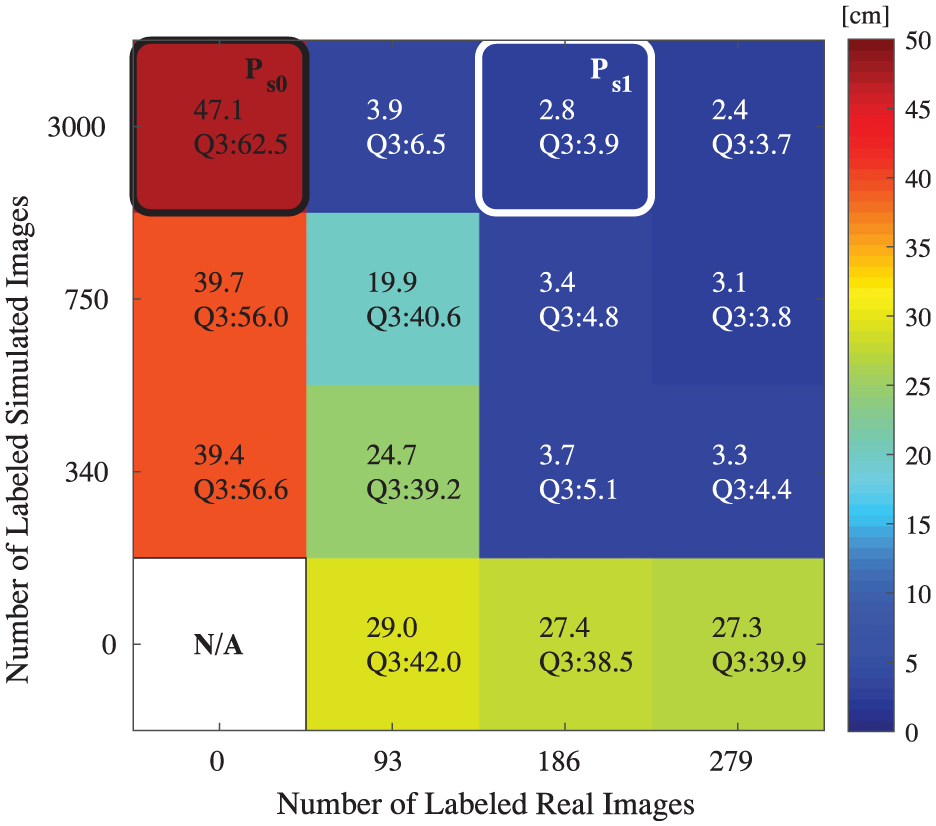
Object position estimation error map for supervised adaptation. The numbers in the map show the median and third quartile (Q3) of the Euclidean distances between predicted and ground-truth positions. “N/A” means no result for that case.
From Figure 7, we can see that the perception modules trained with only simulated (the left-most column) or real images (the bottom row) have very large errors. For the modules trained with both simulated and real images, increasing the number of either simulated or real images helped reduce the error. Fine-tuning (adaptation) with as few as 93 real images can make a perception module work in the real world with a median error of 3.9
To study how much the on-the-fly data-augmentation method (Section 4.3) can help improve the perception accuracy, we trained a perception module using 3,000 simulated and 186 real images without data augmentation. It achieved a median error of 3.1
5.2. ADT
In this section, we evaluated the perception modules trained by the proposed ADT approach using the same test set. 16 modules were trained using ADT to investigate how the amount of labeled and unlabeled real images influences the adaptation performance. They were adapted with different combinations of real images:
the number of labeled real images from 0 to 186 (i.e.,
the number of unlabeled real images from 0 to 279 (i.e.,
All 16 perception modules were adapted using the adversarial loss (Equation (5)) from the same module
In the transfer phase, we used a constant learning rate of 0.001 and a mini-batch size of 32. In particular, 32 simulated (from
Figure 8 shows the performance of the perception modules adapted with different numbers of unlabeled and labeled real images. The bottom row shows the results for the modules adapted without unlabeled real images, i.e., supervised adaptation (three of them have appeared in the top row of Figure 7, except the one adapted with 48 labeled real images). The results for the cases without labeled real images (i.e., unsupervised adaptation,
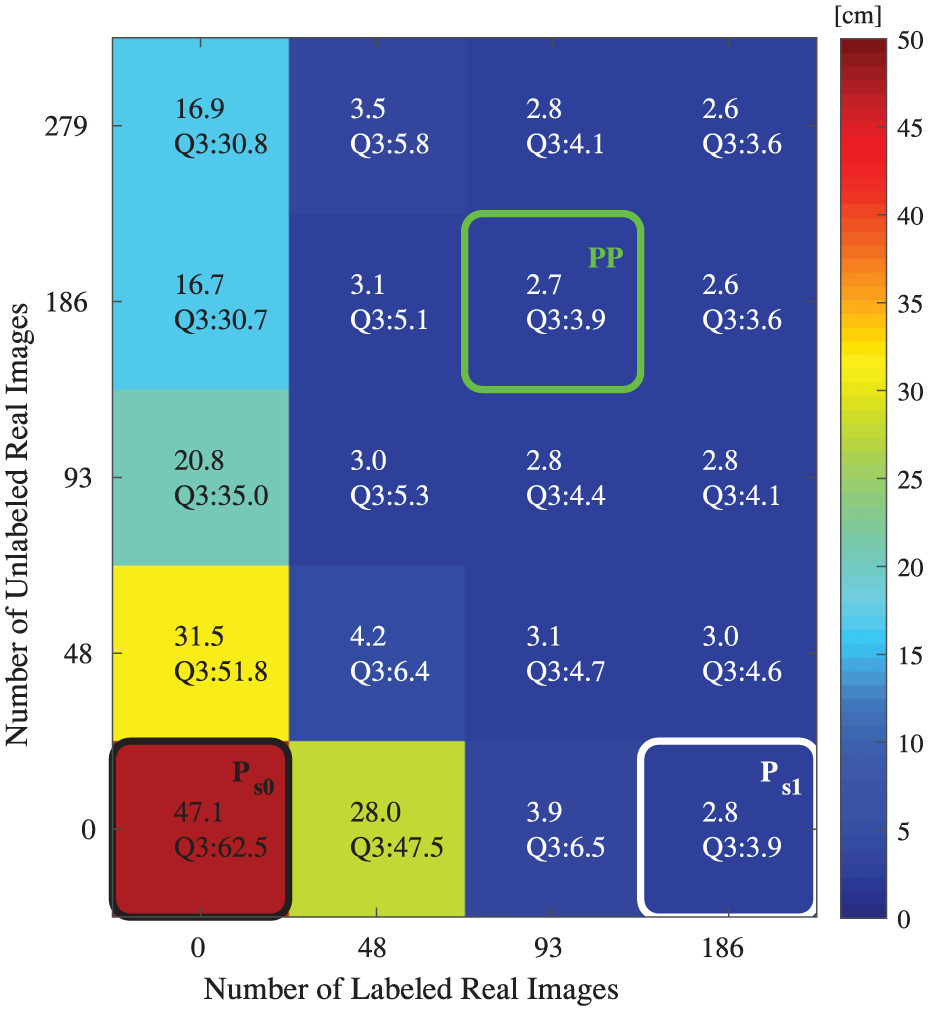
Object position estimation error map for the ADT approach. The x-axis shows the number of labeled real images used; the y-axis shows the number of unlabeled real images. Note: the bottom row shows the cases without unlabeled real images (i.e., supervised adaptation, effectively the top row in Figure 7); but different from Figure 7, the cases with 48 rather than 279 labeled real images were evaluated here to better observe how the ADT approach would work with fewer annotated real images.
The other results are for the cases with both labeled and unlabeled real images (i.e., semi-supervised adaptation). We can see that the modules adapted with more labeled images have smaller errors, but the improvement is non-obvious after more than 93 labeled samples. Similarly, more unlabeled real images also resulted in smaller errors. However, performance became worse if the number of unlabeled images was more than twice the number of labeled samples (e.g., the modules adapted with 48 labeled and more than 93 unlabeled real images, as well as the module adapted with 93 labeled and 279 unlabeled samples) or fewer than half the number (e.g., the modules adapted with 186 labeled and 48 unlabeled real images). This might be because large differences between unlabeled and labeled data make their distributions differ a lot, which then result in worse adaptation. More investigation is necessary in the future to make better use of unlabeled real data, enabling performance improvement for the cases with two times more unlabeled data than labeled ones.
The best performance was achieved by the modules adapted with 186 labeled and 186 or 279 unlabeled real images. However, trading off the accuracy and the number of labeled real images (expensive), the module adapted with 93 labeled and 186 unlabeled real images is the best one, labeled as
By comparing the bottom row (supervised adaptation) with the other rows (ADT), we can see that the benefit of the adversarial loss was significant, particularly for the cases with very few labeled samples, e.g., the modules adapted with 48 labeled real images (more than 85% improvement, perception errors reduced from 28.0
5.3. Important factors in ADT
To further investigate the effectiveness and robustness of the proposed ADT approach, we conducted some comparison experiments in four different aspects.
How robust is ADT to different random seeds in training?
How effective is the PI controller?
How does the desired discriminative loss for the PI controller affect the adaptation performance?
How does the capacity of a discriminator network affect the adaptation performance?
In these comparison experiments, all perception modules were trained using the same conditions for
5.3.1 Robustness to different random seeds
To evaluate the robustness of the proposed ADT approach, five perception modules were trained using different random seeds, i.e., seeds 1 to 5. Seed 1 is the one used for
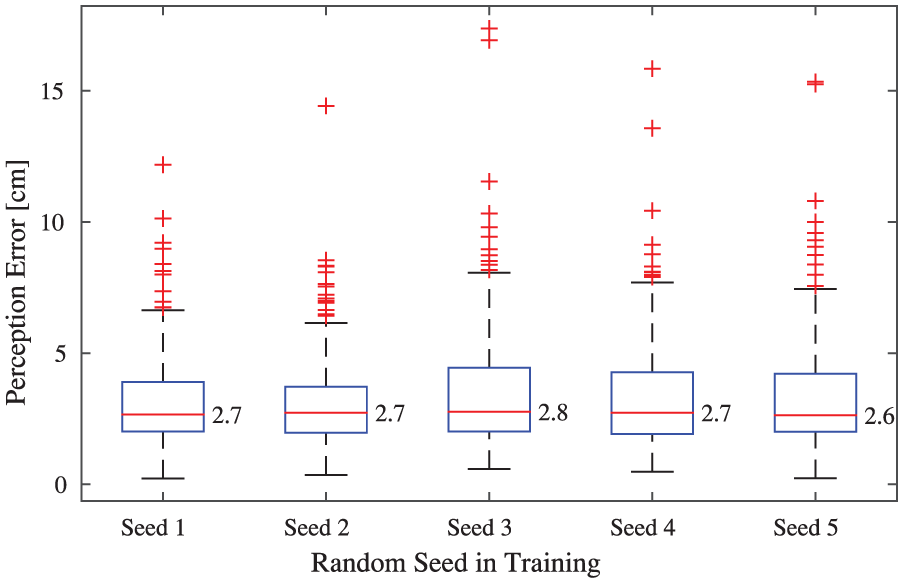
Box-plots of the Euclidean distances between predicted and ground-truth positions for perception modules adapted using the ADT approach with different random seeds. The crosses represent outliers, the numbers show the medians. The outliers are those ≥Q3+w(Q3-Q1) or ≤Q1-w(Q3-Q1), where Q1 and Q3 are the first and third quartiles;
5.3.2. Effectiveness of the PI controller
To see the benefit of the PI controller, a module was adapted using the adversarial discriminative loss but without the PI controller, i.e.,
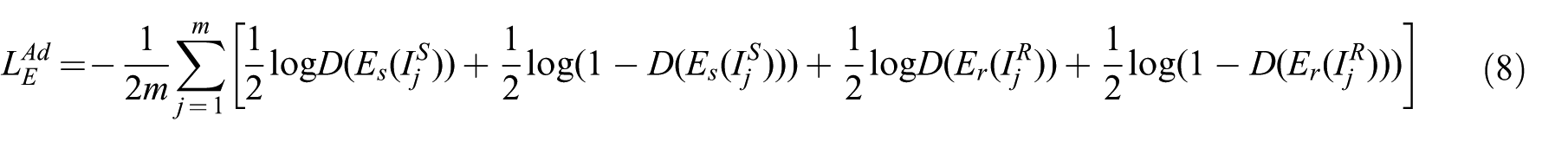
of which the weights in source and target encoders were shared, i.e.,
Figure 10 compares the results, from which we can see that the domain confusion approach (DCT) has much larger errors than ADT, either with or without the PI controller. The approaches with the PI controller achieved better performances than those without. In particular, ADT has a 13% smaller median perception error than ADT without PI; DCT’s median error is 35% smaller than that of DCT without PI. These results show that the PI controller did help improve the adaptation no matter using an adversarial discriminative loss or domain confusion loss.
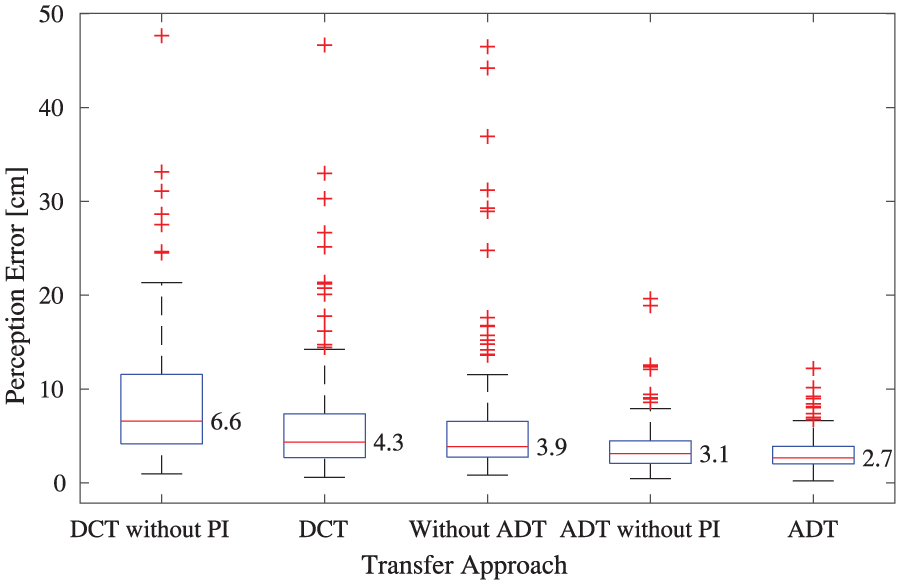
Box-plots for perception modules adapted using different adversarial losses with/without the PI controller. DCT denotes a perception module adapted using the domain confusion approach where Equation (7) was replaced by Equation (8). Without ADT represents a perception module adapted without any adversarial loss, i.e., supervised adaptation (the top-second-left in Figure 7).
From the comparison with the approach adapted without any adversarial loss (Without ADT), we can see that DCT has even larger errors than Without ADT, while ADT’s errors are smaller. This indicates that the adversarial discriminative loss worked better than the domain confusion loss for our case. Note that the results of the DCT approaches in Figure 10 are those under the same condition as the ADT ones for fair comparison; broader qualitative experiments indicate that the domain confusion loss can bring some performance improvement (slightly better than supervised adaptation), but it was less significant than the adversarial discriminative loss.
5.3.3. Appropriate desired
for the PI controller
To investigate how the desired discriminative loss
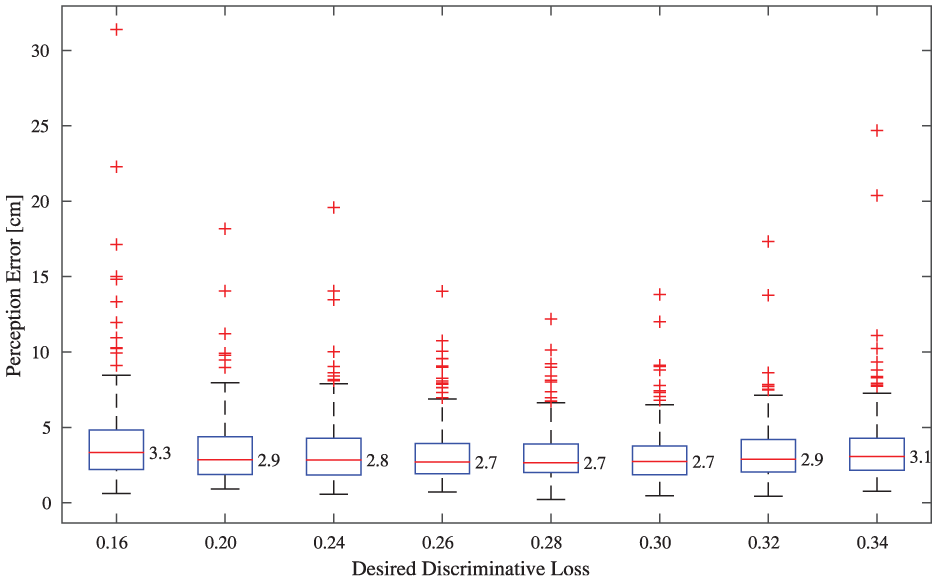
Box-plots for perception modules adapted using the ADT approach with different desired discriminative losses for the PI controller.
5.3.4. Appropriate discriminator networks
To study how discriminator network architecture could affect the adaptation performance, we adapted eight perception modules with different discriminator networks as follows (numbers in brackets represent the number of units in each layer):
Net 1, 2 hidden layers,
Net 2, 2 hidden layers,
Net 3, 2 hidden layers,
Net 4, 2 hidden layers with units
Net 5, 2 hidden layers,
Net 6, 3 hidden layers,
Net 7, 4 hidden layers,
Net 8, 5 hidden layers,
Figure 12 shows the errors of the eight perception modules. We can see that Nets 3–8 have similar perception errors with a median error of either 2.6 or 2.7
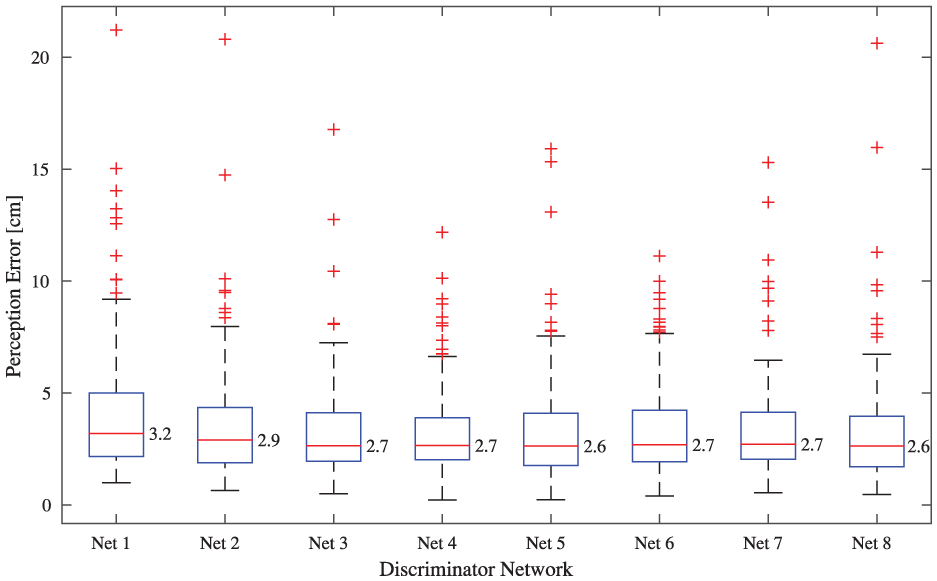
Box-plots for perception modules adapted using the ADT approach with different discriminator network architectures.
5.4. Control module performance
To investigate how many trajectories are sufficient for training a control module, we evaluated three control modules trained with different control datasets which have varying numbers of trajectories: 118, 333, and 2,964 (i.e.,
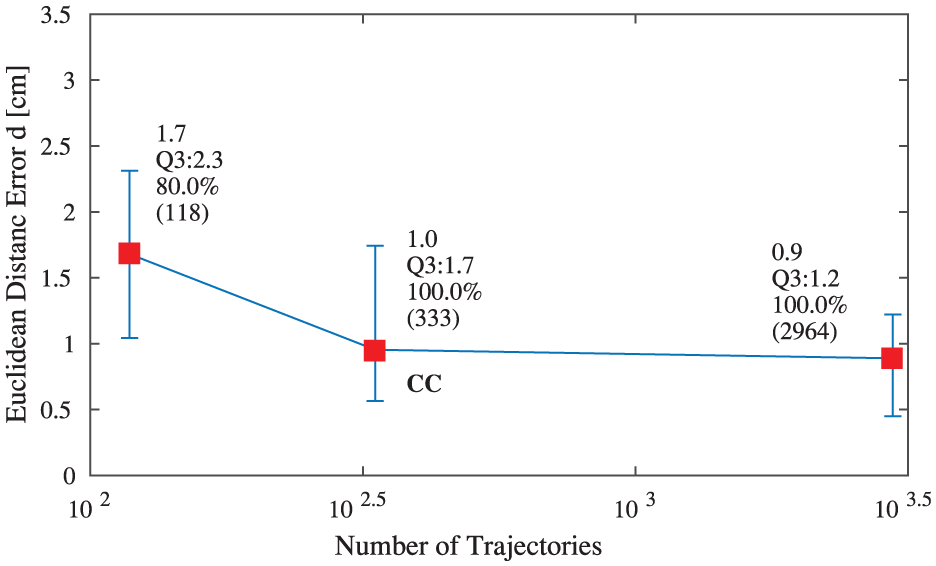
Control performance curve that shows the median (red square), first quartile (Q1, lower bar), and third quartile (Q3, upper bar) of the Euclidean distances between the target and end-effector. Three control modules were evaluated in 45 real trials. They were trained with different numbers of simulated trajectories (the numbers in brackets). Their success rates are also listed.
From Figure 13, we can see that a control module trained with more trajectories is able to achieve a better control performance in terms of both control error and success rate. The control module trained with 118 trajectories has a success rate of 80%; the other two are 100%. It also has a much larger control error than the other two. This indicates that 118 trajectories are too few to obtain a good control module. The module trained with 2,964 trajectories achieved a slightly smaller control error (0.9
As a comparison, we also evaluated the pseudo-inverse method (which was used to collect trajectory samples) in the real world, using joint angles and target position (not images) as inputs. It has a median control error of 0.2cm (Q3: 0.5 cm), which is smaller than the three trained control modules. However, the control error of
5.5 Hand–eye coordination
To further improve hand–eye coordination, we proposed an end-to-end fine-tuning approach using weighted losses. To evaluate the effectiveness of the approach, we compare five combined networks and a baseline.
The detailed end-to-end fine-tuning settings for
End-to-end fine-tuning settings.
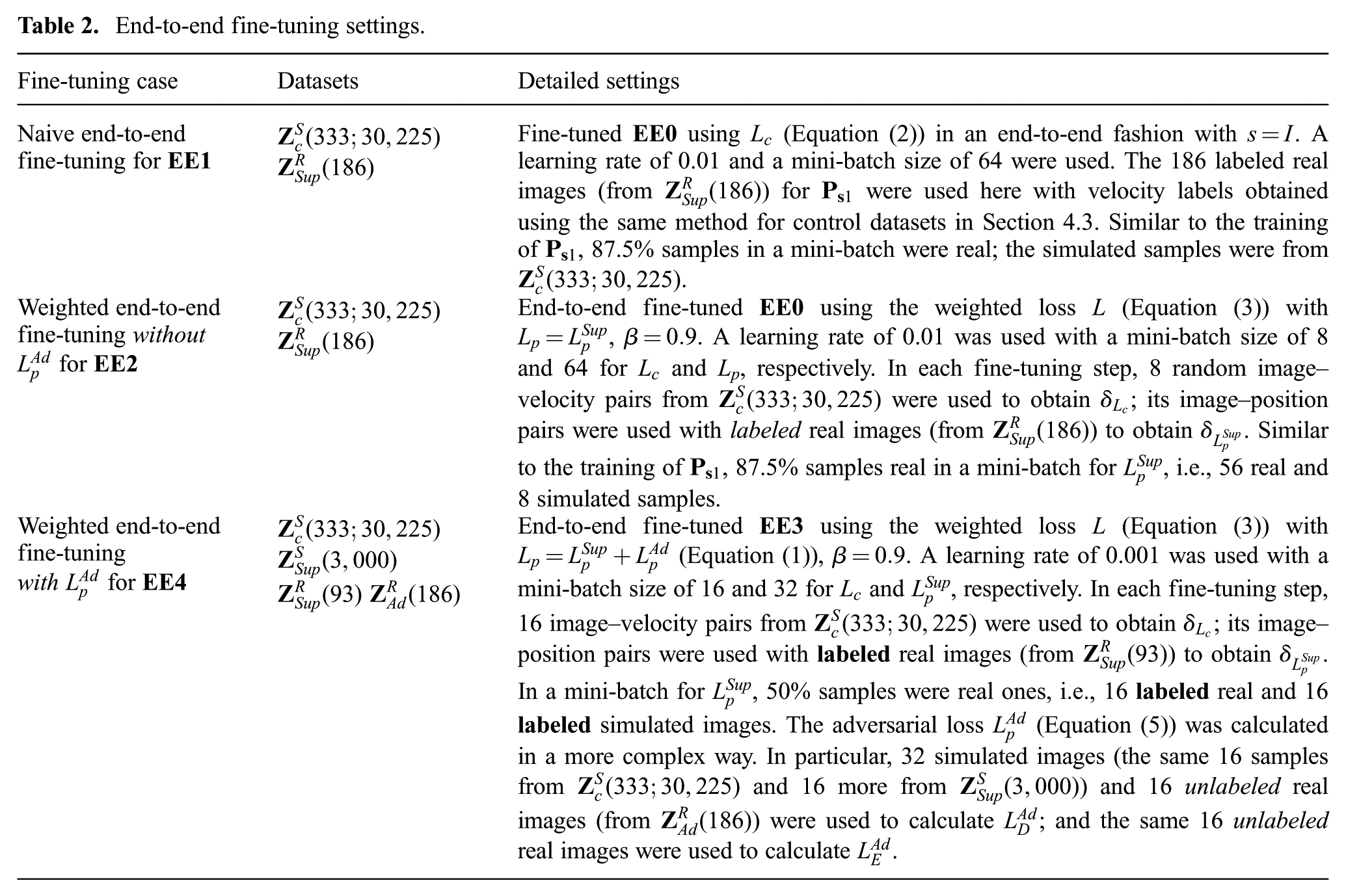
In the fine-tuning for
The baseline and combined networks were first evaluated in the real world without distractor objects on the table (Figure 14(A)), then the case with novel distractor objects in clutter (Figure 14(B)). In the case of Figure 14(B), 6 novel distractor objects (not seen in training) and 3 more white board eraser boxes (only the single box case was seen in training) were used in addition to those 11 distractor objects appeared in training. The metrics of control error (e) and success rate (

Real-world test cases for measuring end-to-end performance: (A) reaching the blue cuboid without distractor objects; (B) reaching with seen and novel (not seen in training) objects as distractors; (C) reaching with occlusion(s); (D) reaching when the target is moving.
Real-world end-to-end control performance.
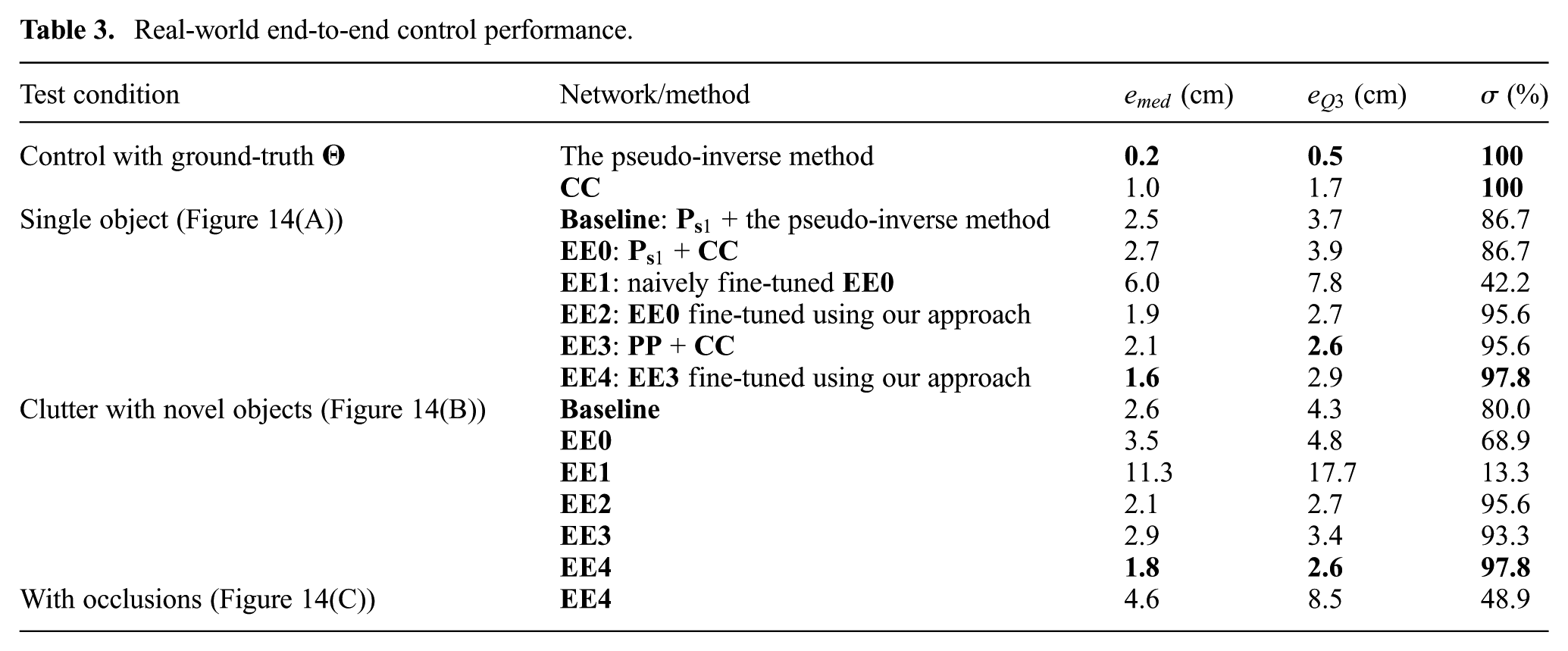
From Table 3, we can observe similar trends in the results for the cases of Figure 14(A) and (B). In comparison, the baseline and combined networks have larger errors in the case with distractor objects (more realistic). In particular,
In contrast,
A similar performance drop can also be observed from the results of
After weighted end-to-end fine-tuning, both
In addition,
To further evaluate the performance of
6. Discussion
The results described previously lead us to the following observations.
6.1. Effectiveness of ADT
The significant reduction (50%) in the required number of labeled real images for sim-to-real transfer of visuo-motor policies shows the effectiveness of the ADT. The PI controller and discriminator network architecture both play important roles in the approach. An acceptable transfer accuracy (3.0cm) can be achieved with as few as 48 labeled real images, which is promising for robotic applications where labeling data is expensive or impractical.
However, the approach in its current version can only effectively use a number of unlabeled real images no more than two times the number of labeled ones. This precludes using very few labeled and many unlabeled real images to further reduce the cost. More investigation is necessary to tackle this problem, enabling a few shots transfer of visuo-motor policies from simulation to the real world.
6.2. Value of a modular structure and end-to-end fine-tuning
The significant performance improvement of
The modular approach can also be used in more general ways. Although we explicitly equated the bottleneck layer with the target object position in this work, the bottleneck in general could be any explicit or latent low-dimensional features (as in an auto-encoder). The perception and control modules can also be trained with other methods such as unsupervised learning and reinforcement learning. The effectiveness of the modular approach for reinforcement learning (DQN) has been validated in a planar reaching task (Zhang et al., 2017a,b).
6.3. Domain randomization and adaptation
In Section 5.1, the perception module trained with 3,000 simulated images (
Nevertheless, with the ADT approach, the adaptation with just a few labeled real images (as few as 48) is able to transfer a network from simulation to the real world, and needs fewer simulated images than pure domain randomization approaches (James et al., 2017; Tobin et al., 2017). The combination of domain randomization and adaptation is promising for more efficient deep neural network transfer.
7. Conclusion
In this article, we have proposed an ADT approach for cheaper transfer of visuo-motor policies from simulation to the real world. Its feasibility was demonstrated with a modular approach in the task of reaching a table-top object amongst clutter with a 7-DoF robotic arm in velocity mode. Our adversarial transfer approach reduced the labeled real data requirement by 50%. Successful transfer was achieved with only 93 labeled and 186 unlabeled real images. By using weighted losses to fine-tune a combined network in an end-to-end fashion, its reaching accuracy was improved significantly (37.9% better than that before fine-tuning), achieving a success rate of 97.8% with a median control error of 1.8cm. The learned policies are robust to novel distractor objects in clutter and even a moving target. The ADT along with the modular approach is promising for more efficient sim-to-real transfer of visuo-motor policies.
The datasets and code are available at https://github.com/Fanleyrobot/ADT.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was conducted by the Australian Research Council Centre of Excellence for Robotic Vision (project number CE140100016). This research has also been supported by the Australian Research Council’s Linkage Infrastructure, Equipment and Facilities scheme (project number LE160100090). Additional computational resources and services were provided by the HPC and Research Support Group at QUT.